00:54 Einführung
02:25 Über die Natur des Fortschritts
05:26 Der bisherige Verlauf
06:10 Einige quantitative Prinzipien: beobachtende Prinzipien
07:27 “Die Nadel im Heuhaufen” durch Entropie lösen
14:58 SC-Populationen sind Zipf-verteilt
22:41 Kleine Zahlen dominieren bei SC-Entscheidungen
29:44 Muster sind überall in SC
36:11 Einige quantitative Prinzipien: Optimierungsprinzipien
37:20 5 bis 10 Runden sind erforderlich, um jedes SC-Problem zu beheben
44:44 Gealterte SCs sind unidirektional quasi-optimal
49:06 Lokale SC-Optimierungen verlagern nur Probleme
52:56 Bessere Probleme schlagen bessere Lösungen
01:00:08 Fazit
01:02:24 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Während Supply Chains nicht durch definitive quantitative Gesetze charakterisiert werden können - im Gegensatz zur Elektromagnetismus - können dennoch allgemeine quantitative Prinzipien beobachtet werden. Mit ‘allgemein’ meinen wir, dass sie auf (fast) alle Supply Chains anwendbar sind. Die Aufdeckung solcher Prinzipien ist von großem Interesse, da sie zur Entwicklung von numerischen Rezepten zur vorhersagenden Optimierung von Supply Chains verwendet werden können, aber auch dazu dienen können, diese numerischen Rezepte insgesamt leistungsfähiger zu machen. Wir überprüfen zwei kurze Listen von Prinzipien: einige beobachtende Prinzipien und einige Optimierungsprinzipien.
Vollständiges Transkript

Hallo zusammen, herzlich willkommen zu dieser Reihe von Vorlesungen über Supply Chains. Ich bin Joannes Vermorel und heute werde ich ein paar “Quantitative Prinzipien für Supply Chains” präsentieren. Für diejenigen von Ihnen, die die Vorlesung live auf YouTube verfolgen, können Sie Ihre Fragen jederzeit über den YouTube-Chat stellen. Ich werde Ihre Fragen während der Vorlesungen jedoch nicht lesen. Am Ende der Vorlesung werde ich auf den Chat zurückkommen und versuchen, zumindest die meisten Fragen zu beantworten.
Quantitative Prinzipien sind von großem Interesse, weil sie in Supply Chains, wie wir während der ersten Vorlesungen gesehen haben, die Beherrschung der Optionen beinhalten. Die meisten dieser Optionen sind quantitativer Natur. Sie müssen entscheiden, wie viel Sie kaufen, wie viel Sie produzieren, wie viel Inventar Sie bewegen und möglicherweise den Preispunkt - ob Sie den Preispunkt nach oben oder unten bewegen möchten. Ein quantitatives Prinzip, das Verbesserungen in den numerischen Rezepten für Supply Chains vorantreiben kann, ist von großem Interesse.
Wenn ich jedoch die meisten Supply Chain-Experten oder -Autoritäten heutzutage nach ihren Kernquantitativen Prinzipien für Supply Chains fragen würde, vermute ich, dass ich häufig eine Antwort in Form einer Reihe von Techniken für eine bessere Zeitreihen-Prognose oder etwas Ähnlichem erhalten würde. Meine persönliche Reaktion ist, dass dies zwar interessant und relevant ist, aber auch den Kern verfehlt. Ich glaube, das Missverständnis liegt im Wesentlichen in der Natur des Fortschritts selbst - was ist Fortschritt und wie kann man so etwas wie Fortschritt in Bezug auf Supply Chains umsetzen? Lassen Sie mich mit einem anschaulichen Beispiel beginnen.

Vor sechstausend Jahren wurde das Rad erfunden und sechstausend Jahre später wurde der Rollkoffer erfunden. Die Erfindung stammt aus dem Jahr 1949, wie durch dieses Patent veranschaulicht. Als der Rollkoffer erfunden wurde, hatten wir bereits die Atomkraft genutzt und sogar die ersten Atombomben gezündet.
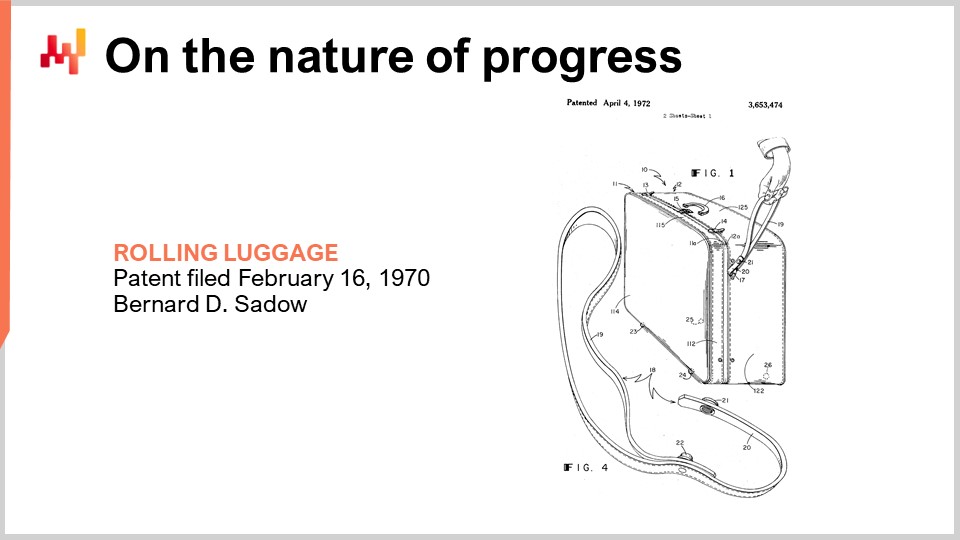
20 Jahre später, im Jahr 1969, schickte die Menschheit die ersten Menschen auf den Mond. Im nächsten Jahr wurde der Rollkoffer mit einem etwas besseren Griff verbessert, der wie eine Leine aussieht, wie durch dieses Patent veranschaulicht. Es ist immer noch nicht sehr gut.

Dann, 20 Jahre später, hatten wir bereits das GPS-System, das seit fast einem Jahrzehnt Zivilisten dient, und der richtige Griff für den Rollkoffer wurde endlich erfunden.
Hier gibt es mindestens zwei interessante Lektionen. Erstens gibt es keine offensichtliche Zeitrichtung, was den Fortschritt betrifft. Fortschritt geschieht auf chaotische, nicht-lineare Weise und es ist sehr schwer einzuschätzen, welcher Fortschritt in einem Bereich basierend auf dem geschieht, was in anderen Bereichen passiert. Dies ist ein Element, das wir heute im Hinterkopf behalten müssen.
Das zweite ist, dass Fortschritt nicht mit Raffinesse verwechselt werden sollte. Etwas kann weit überlegen sein, aber auch viel einfacher. Wenn ich das Beispiel des Koffers nehme, sieht das Design, sobald man es gesehen hat, völlig offensichtlich und selbstverständlich aus. Aber war es ein leichtes Problem zu lösen? Ich würde sagen, absolut nicht. Der einfache Beweis dafür, dass Supply Chain Management ein schwieriges Problem war, ist, dass es einer fortgeschrittenen Industriezivilisation etwas mehr als vier Jahrzehnte dauerte, um dieses Problem anzugehen. Fortschritt ist trügerisch in dem Sinne, dass er sich nicht an die Regel der Raffinesse hält. Es ist sehr schwer zu identifizieren, wie die Welt vor dem Fortschritt aussah, weil sich die Sichtweise der Welt buchstäblich ändert, während er stattfindet.

Nun zurück zu unserer Diskussion über die Supply Chain. Dies ist die sechste und letzte Vorlesung in diesem Prolog. Es gibt einen umfassenden Plan, den Sie online auf der Lokad-Website über die gesamte Serie von Supply Chain-Vorlesungen einsehen können. Vor zwei Wochen habe ich die Trends des 20. Jahrhunderts für Supply Chains vorgestellt und dabei eine rein qualitative Perspektive auf das Problem eingenommen. Heute nehme ich den gegenteiligen Ansatz an und betrachte dieses Set von Problemen aus einer ziemlich quantitativen Perspektive als Gegenstück.

Heute werden wir eine Reihe von Prinzipien überprüfen. Mit Prinzip meine ich etwas, das zur Verbesserung des Designs von numerischen Rezepten im Allgemeinen für alle Supply Chains verwendet werden kann. Wir haben hier den Anspruch der Generalisierung, und es ist ziemlich schwierig, Dinge zu finden, die für alle Supply Chains und alle numerischen Methoden zur Verbesserung von ihnen von höchster Relevanz sind. Wir werden zwei Kurzlisten von Prinzipien überprüfen: Beobachtungsprinzipien und Optimierungsprinzipien.
Beobachtungsprinzipien gelten dafür, wie Sie quantitativ Wissen und Informationen über Supply Chains gewinnen können. Optimierungsprinzipien beziehen sich darauf, wie Sie handeln, sobald Sie qualitatives Wissen über Ihre Supply Chain erlangt haben, insbesondere wie Sie diese Prinzipien nutzen können, um Ihre Optimierungsprozesse zu verbessern.
Fangen wir damit an, eine Supply Chain zu beobachten. Es verwirrt mich, wenn Leute über Supply Chains sprechen, als könnten sie sie direkt mit ihren eigenen Augen beobachten. Für mich ist dies eine sehr verzerrte Wahrnehmung der Realität von Supply Chains. Supply Chains können nicht direkt menschlich beobachtet werden, zumindest nicht aus quantitativer Sicht. Dies liegt daran, dass Supply Chains von Design her geografisch verteilt sind und potenziell Tausende von SKUs und Zehntausende von Einheiten umfassen. Mit Ihren menschlichen Augen könnten Sie nur die Supply Chain beobachten, wie sie heute ist und nicht, wie sie in der Vergangenheit war. Sie können sich nicht mehr als ein paar Zahlen oder einen winzigen Bruchteil der mit Ihrer Supply Chain verbundenen Zahlen merken.
Wenn Sie eine Supply Chain beobachten möchten, werden Sie solche Beobachtungen indirekt über Unternehmenssoftware durchführen. Dies ist eine sehr spezifische Art, Supply Chains zu betrachten. Alle quantitativen Beobachtungen, die über Supply Chains gemacht werden können, erfolgen über dieses spezifische Medium: Unternehmenssoftware.
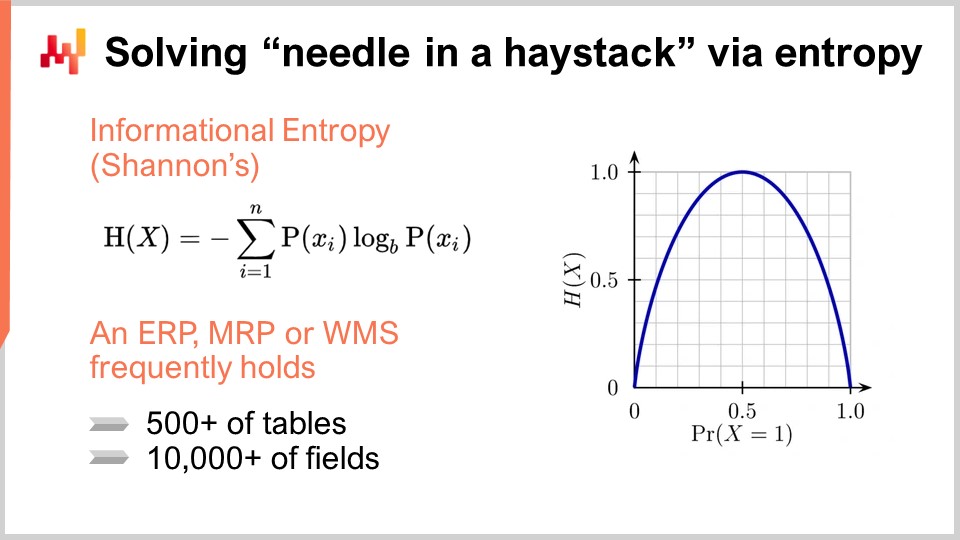
Charakterisieren wir eine typische Unternehmenssoftware. Sie wird eine Datenbank enthalten, da die überwiegende Mehrheit solcher Software so konzipiert ist. Die Software wird voraussichtlich etwa 500 Tabellen und 10.000 Felder enthalten (ein Feld ist im Wesentlichen eine Spalte in einer Tabelle). Als Einstiegspunkt haben wir ein System, das potenziell eine enorme Menge an Informationen enthält. In den meisten Situationen ist jedoch nur ein winziger Bruchteil dieser Softwarekomplexität tatsächlich relevant für die interessierende Supply Chain.
Softwareanbieter entwerfen Unternehmenssoftware unter Berücksichtigung sehr unterschiedlicher Situationen. Wenn man sich einen bestimmten Kunden ansieht, ist die Wahrscheinlichkeit groß, dass nur ein winziger Bruchteil der Fähigkeiten der Software tatsächlich genutzt wird. Das bedeutet, dass es zwar theoretisch 10.000 Felder gibt, die erkundet werden können, aber in der Realität verwenden Unternehmen nur einen kleinen Bruchteil dieser Felder.
Die Herausforderung besteht darin, die relevanten Informationen von den nicht vorhandenen oder irrelevanten Daten zu sortieren. Wir können Supply Chains nur über Unternehmenssoftware beobachten, und es können mehr als eine Softwarekomponente beteiligt sein. In einigen Fällen wurde ein Feld nie verwendet und die Daten sind konstant und enthalten nur Nullen oder Nullwerte. In dieser Situation ist es einfach, das Feld zu eliminieren, da es keine Informationen enthält. In der Praxis können jedoch nur etwa 10% der Felder mithilfe dieser Methode eliminiert werden, da im Laufe der Jahre viele Funktionen in der Software verwendet wurden, auch wenn dies nur zufällig geschah.
Um Felder zu identifizieren, die noch nie sinnvoll genutzt wurden, können wir ein Werkzeug namens informationstheoretische Entropie verwenden. Für diejenigen, die mit Shannons Informationstheorie nicht vertraut sind, mag der Begriff einschüchternd wirken, aber er ist tatsächlich einfacher, als er erscheint. Informationstheoretische Entropie quantifiziert die Menge an Informationen in einem Signal, wobei ein Signal als eine Sequenz von Symbolen definiert ist. Wenn wir zum Beispiel ein Feld haben, das nur zwei Arten von Werten enthält, wahr oder falsch, und die Spalte zufällig zwischen diesen Werten oszilliert, enthält die Spalte viele Daten. Wenn jedoch nur eine Zeile von einer Million wahr ist und alle anderen Zeilen falsch sind, enthält das Feld in der Datenbank so gut wie keine Informationen.
Informationstheoretische Entropie ist sehr interessant, weil sie es Ihnen ermöglicht, die Menge an Informationen in jedem Feld Ihrer Datenbank in Bits zu quantifizieren. Durch eine Analyse können Sie diese Felder von den reichsten bis zu den ärmsten in Bezug auf Informationen einstufen und solche eliminieren, die kaum relevante Informationen für die Optimierung der Supply Chain enthalten. Informationstheoretische Entropie mag anfangs kompliziert erscheinen, ist aber nicht schwer zu verstehen.

Zum Beispiel haben wir informationstheoretische Entropie als Aggregator in einer domänenspezifischen Programmiersprache implementiert. Indem wir eine Tabelle nehmen, wie z.B. Daten aus einer Flachdatei namens data.csv mit drei Spalten, können wir die Zusammenfassung anzeigen, wie viel Entropie in jeder Spalte vorhanden ist. Dieser Prozess ermöglicht es Ihnen leicht festzustellen, welche Felder die geringste Menge an Informationen enthalten und sie zu eliminieren. Mit der Entropie als Leitfaden können Sie schnell ein Projekt starten, anstatt Jahre damit zu verbringen.
Im nächsten Schritt machen wir unsere ersten Beobachtungen über Supply Chains und überlegen, was zu erwarten ist. In den Naturwissenschaften ist die Standarderwartung eine Normalverteilung, auch bekannt als glockenförmige Kurven oder Gaußsche Verteilungen. Zum Beispiel wird die Körpergröße eines 20-jährigen männlichen Menschen oder sein Gewicht eine Normalverteilung haben. In der Welt der Lebewesen folgen viele Messungen diesem Muster. Wenn es jedoch um die Supply Chain geht, ist dies nicht der Fall. Es gibt praktisch nichts Interessantes, das in Supply Chains normalverteilt ist.
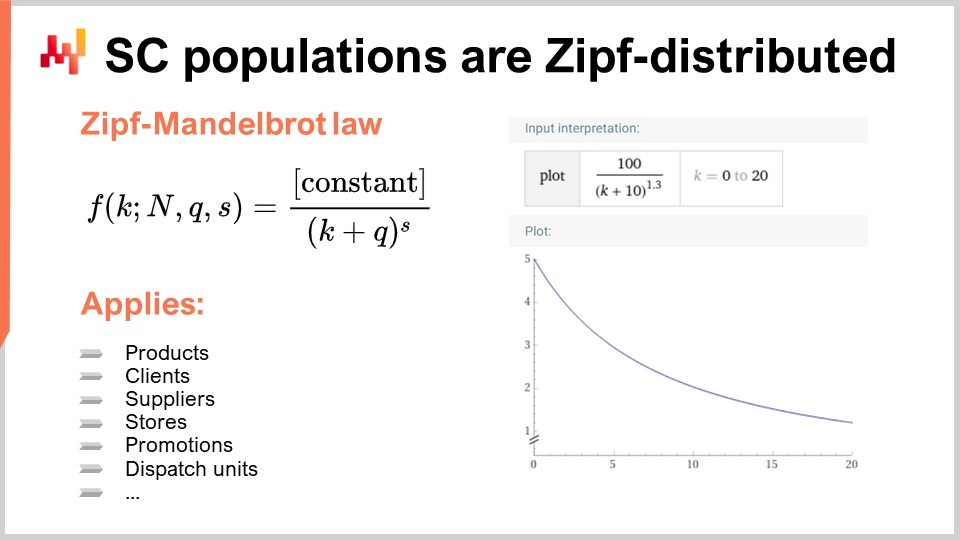
Stattdessen sind nahezu alle interessanten Verteilungen in Supply Chains zipf-verteilt. Die Zipf-Verteilung wird in der gegebenen Formel veranschaulicht. Um dieses Konzept zu verstehen, betrachten Sie eine Population von Produkten, wobei das Interesse die Verkaufsmenge für jedes Produkt ist. Sie würden die Produkte nach der höchsten bis zur niedrigsten Verkaufsmenge über einen bestimmten Zeitraum, wie z.B. ein Jahr, sortieren. Die Frage ist dann, ob es ein Modell gibt, das die Form der Kurve vorhersagt und bei gegebener Rangfolge die erwartete Verkaufsmenge liefert. Genau darum geht es bei der Zipf-Verteilung. Hier steht f für die Form eines Zipf-Mandelbrot-Gesetzes und k bezieht sich auf das k-te größte Element. Es gibt zwei Parameter, q und s, die im Wesentlichen erlernt werden, ähnlich wie Sie mu (den Mittelwert) und sigma (die Varianz) für eine Normalverteilung haben. Diese Parameter können verwendet werden, um die Verteilung an eine interessierende Population anzupassen. Das Zipf-Mandelbrot-Gesetz umfasst diese Parameter.
Es ist wichtig zu beachten, dass nahezu jede Population von Interesse in der Supply Chain einer Zipf-Verteilung folgt. Dies gilt für Produkte, Kunden, Lieferanten, Promotions und sogar Versandeinheiten. Die Zipf-Verteilung ist im Wesentlichen eine Abstammung des Pareto-Prinzips, aber sie ist besser handhabbar und meiner Meinung nach interessanter, da sie ein explizites Modell dafür liefert, was für jede interessierende Population in der Supply Chain zu erwarten ist. Wenn Sie auf eine Population stoßen, die nicht zipf-verteilt ist, ist es wahrscheinlicher, dass es ein Problem mit den Daten gibt, anstatt eine wahre Abweichung vom Prinzip.

Um das Konzept der Zipf-Verteilung in der realen Welt zu nutzen, können Sie Envision verwenden. Wenn wir uns diesen Code-Schnipsel ansehen, werden Sie feststellen, dass es nur wenige Zeilen Code benötigt, um dieses Modell auf einen realen Datensatz anzuwenden. Hier gehe ich davon aus, dass es eine Population von Interesse in einer Flachdatei namens “data.csv” gibt, wobei eine Spalte die Menge repräsentiert. Normalerweise hätten Sie eine Produktkennung und die Menge. In Zeile 4 berechne ich die Ränge unter Verwendung des Rangaggregators und sortiere gegen die Menge. Dann gebe ich zwischen den Zeilen 6 bis 11 einen differentiable programming Block ein, der durch Autodev explizit gemacht wird, wo ich drei skalare Parameter deklariere: c, q und s, genau wie in der Formel auf der linken Seite des Bildschirms. Dann berechne ich die Vorhersagen des Zipf-Modells und verwende einen mittleren quadratischen Fehler zwischen der beobachteten Menge und der Vorhersage des Modells. Sie können die Zipf-Verteilung buchstäblich mit nur wenigen Zeilen Code regressieren. Auch wenn es sich anspruchsvoll anhört, ist es mit den richtigen Werkzeugen ziemlich einfach.

Dies bringt mich zu einem weiteren beobachtenden Aspekt von Lieferketten: Die Zahlen, die Sie auf jeder Ebene der Lieferkette erwarten würden, sind klein, normalerweise weniger als 20. Sie haben nicht nur wenige Beobachtungen, sondern die Zahlen, die Sie beobachten, sind auch klein. Natürlich hängt dieses Prinzip von den verwendeten Einheiten ab, aber wenn ich von “Zahlen” spreche, meine ich diejenigen, die aus Sicht der Lieferkette einen kanonischen Sinn ergeben, nämlich das, was Sie beobachten und optimieren möchten.
Der Grund, warum wir nur kleine Zahlen haben, liegt an den Skaleneffekten. Nehmen wir T-Shirts in einem Geschäft als Beispiel. Das Geschäft könnte Tausende von T-Shirts auf Lager haben, was wie eine große Zahl erscheint, aber in Wirklichkeit haben sie Hunderte von verschiedenen Arten von T-Shirts mit Variationen in Größe, Farbe und Design. Wenn Sie sich die T-Shirts auf der Granularitätsebene ansehen, die aus Sicht der Lieferkette relevant ist, nämlich die SKU, wird das Geschäft nicht Tausende von Einheiten von T-Shirts für eine bestimmte SKU haben; stattdessen haben sie nur eine Handvoll.
Wenn Sie eine größere Anzahl von T-Shirts haben, werden Sie nicht Tausende von T-Shirts herumliegen haben, da dies in Bezug auf die Verarbeitung und Bewegung ein Albtraum wäre. Stattdessen verpacken Sie diese T-Shirts in praktische Boxen, was genau das ist, was in der Praxis passiert. Wenn Sie ein Verteilungszentrum haben, das viele T-Shirts bearbeitet, weil Sie sie an Geschäfte versenden, dann ist die Wahrscheinlichkeit groß, dass diese T-Shirts tatsächlich in Boxen sind. Sie könnten sogar eine Box haben, die eine vollständige Auswahl an T-Shirts mit verschiedenen Größen und Farben enthält, was die Verarbeitung entlang der Kette erleichtert. Wenn Sie viele Boxen herumliegen haben, werden Sie nicht Tausende von solchen Boxen haben. Stattdessen werden Sie, wenn Sie Dutzende von Boxen haben, sie ordentlich auf Paletten organisieren. Eine Palette kann mehrere Dutzend Boxen aufnehmen. Wenn Sie viele Paletten haben, werden Sie sie nicht als einzelne Paletten organisieren; höchstwahrscheinlich werden Sie sie als Container organisieren. Und wenn Sie viele Container haben, werden Sie ein Frachtschiff oder etwas Ähnliches verwenden.
Mein Punkt ist, dass es in der Lieferkette immer eine kleine Zahl ist, die wirklich relevant ist, wenn es um Zahlen geht. Diese Situation kann nicht dadurch vermieden werden, dass man einfach auf eine höhere aggregierte Ebene wechselt, denn wenn man auf eine höhere Aggregationsebene wechselt, tritt eine Art Skaleneffekt auf und man möchte einen Batching-Mechanismus einführen, um die Betriebskosten zu senken. Dies geschieht mehrmals, sodass es unabhängig von der betrachteten Skala, ob es sich um das Endprodukt handelt, das in einem Geschäft pro Einheit verkauft wird, oder um ein massenproduziertes Produkt, immer um kleine Zahlen geht.
Selbst wenn Sie eine Fabrik haben, die Millionen von T-Shirts produziert, ist die Wahrscheinlichkeit groß, dass Sie riesige Chargen haben und die Zahlen, die für Sie interessant sind, nicht die Anzahl der T-Shirts sind, sondern die Anzahl der Chargen, die eine viel kleinere Zahl sein wird.
Worauf will ich mit diesem Prinzip hinaus? Zunächst einmal müssen Sie sich ansehen, wie die meisten Methoden in wissenschaftlicher Berechnung oder Statistik aussehen. Es stellt sich heraus, dass in den meisten anderen Bereichen, die nicht mit der Lieferkette zusammenhängen, das Gegenteil vorherrscht: große Anzahl von Beobachtungen und große Anzahl, bei denen Präzision wichtig ist. In der Lieferkette hingegen sind die Zahlen klein und diskret.
Mein Vorschlag ist, dass wir Werkzeuge benötigen, die auf diesem Prinzip basieren und die Tatsache tiefgreifend berücksichtigen und akzeptieren, dass wir kleine Zahlen anstelle von großen Zahlen haben werden. Wenn Sie Werkzeuge haben, die nur mit dem Gesetz der großen Zahlen im Hinterkopf entwickelt wurden, entweder aufgrund vieler Beobachtungen oder aufgrund großer Zahlen selbst, haben Sie eine völlige Fehlanpassung, wenn es um die Lieferkette geht.
Übrigens hat dies tiefgreifende Auswirkungen auf die Software. Wenn Sie kleine Zahlen haben, gibt es viele Möglichkeiten, wie die Softwareebenen von dieser Beobachtung profitieren können. Wenn Sie sich zum Beispiel den Datensatz der Transaktionszeilen für einen Hypermarkt ansehen, werden Sie feststellen, dass basierend auf meiner Erfahrung und Beobachtung 80% der Zeilen eine Menge haben, die genau eins ist und an einen Endkunden in einem Hypermarkt verkauft wird. Benötigen Sie also 64 Bits an Informationen, um diese Informationen darzustellen? Nein, das ist eine völlige Verschwendung von Speicherplatz und Verarbeitungszeit. Die Annahme dieses Konzepts kann zu einem operativen Gewinn von einer oder zwei Größenordnungen führen. Dies ist kein Wunschdenken; es gibt echte operative Gewinne. Sie könnten denken, dass Computer heutzutage sehr leistungsstark sind, und das sind sie auch, aber wenn Sie mehr Rechenleistung zur Verfügung haben, können Sie fortschrittlichere Algorithmen haben, die Dinge tun, die noch besser für Ihre Lieferkette sind. Es ist sinnlos, diese Rechenleistung zu verschwenden, nur weil Sie ein Paradigma haben, das große Zahlen erwartet, wenn kleine Zahlen vorherrschen.
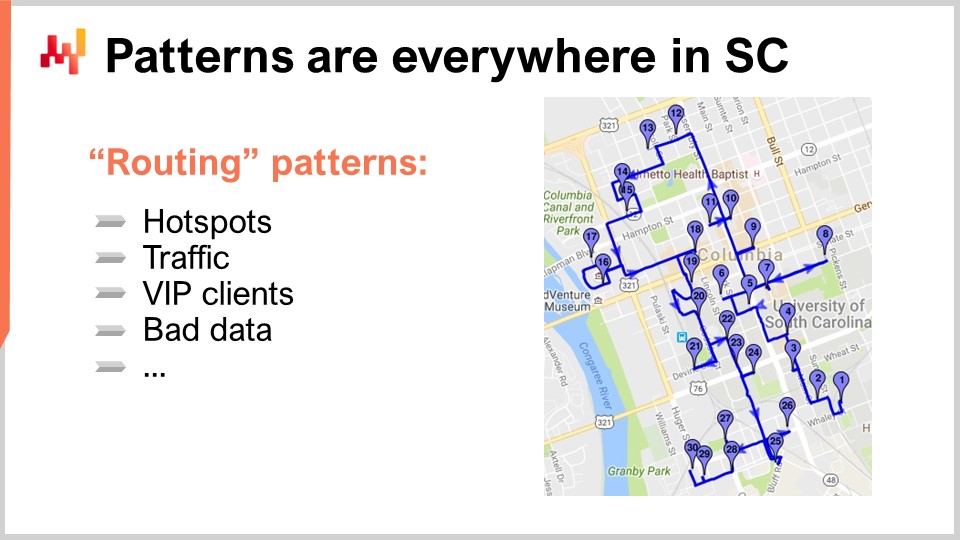
Das bringt mich zu meinem letzten Beobachtungsprinzip für heute: Muster sind überall in der Lieferkette vorhanden. Um dies zu verstehen, werfen wir einen Blick auf ein klassisches Problem der Lieferkette, bei dem Muster normalerweise als nicht vorhanden angesehen werden: Routenoptimierung. Das klassische Problem der Routenoptimierung umfasst eine Liste von Lieferungen, die gemacht werden müssen. Sie können Lieferungen auf einer Karte platzieren und möchten die Route finden, die die Transportzeit minimiert. Sie möchten eine Route festlegen, die durch jeden einzelnen Lieferpunkt führt und gleichzeitig die Gesamttransportzeit minimiert. Auf den ersten Blick scheint dieses Problem ein völlig geometrisches Problem zu sein, bei dem keine Muster in seiner Lösung vorhanden sind.
Ich behaupte jedoch, dass diese Perspektive völlig falsch ist. Wenn Sie das Problem aus dieser Perspektive angehen, betrachten Sie das mathematische Problem, nicht das Problem der Lieferkette. Lieferketten sind wiederholte Spiele, bei denen Probleme sich wiederholt manifestieren. Wenn Sie im Geschäft der Organisation von Lieferungen tätig sind, ist die Wahrscheinlichkeit groß, dass Sie jeden Tag Lieferungen durchführen. Es geht nicht nur um eine Route; es ist buchstäblich eine Route pro Tag, zumindest.
Darüber hinaus haben Sie wahrscheinlich eine ganze Flotte von Fahrzeugen und Fahrern, wenn Sie im Geschäft der Lieferungen tätig sind. Das Problem besteht nicht nur darin, eine Route zu optimieren; es geht darum, eine ganze Flotte zu optimieren, und dieses Spiel wiederholt sich jeden Tag. Dort treten alle Muster auf.
Zunächst sind die Punkte nicht zufällig auf der Karte verteilt. Sie haben Hotspots oder geografische Gebiete mit einer hohen Dichte an Lieferungen. Sie können Adressen haben, die fast jeden Tag Lieferungen erhalten, wie zum Beispiel der Hauptsitz eines großen Unternehmens in einer großen Stadt. Wenn Sie ein großes E-Commerce-Unternehmen sind, liefern Sie wahrscheinlich jeden Geschäftstag Pakete an diese Adresse. Diese Hotspots sind nicht unveränderlich; sie haben ihre Saisonalität. Einige Viertel können im Sommer oder Winter sehr ruhig sein. Es gibt Muster, und wenn Sie das Spiel der Routenoptimierung sehr gut spielen wollen, müssen Sie nicht nur berücksichtigen, wo diese Hotspots auftreten werden, sondern auch wie sie sich im Laufe des Jahres verschieben werden. Außerdem müssen Sie den Verkehr berücksichtigen. Sie sollten nicht nur über die geometrische Entfernung nachdenken, da der Verkehr zeitabhängig ist. Wenn ein Fahrer zu einem bestimmten Zeitpunkt während des Tages startet, ändert sich der Verkehr, während er seine Route fortsetzt. Um dieses Spiel gut zu spielen, müssen Sie Verkehrsmuster berücksichtigen, die sich ändern und im Voraus zuverlässig vorhergesagt werden können. Zum Beispiel ist um 9:00 Uhr und 18:00 Uhr in Paris die gesamte Stadt komplett verstopft, und Sie müssen kein Experte in der Prognose sein, um das zu wissen.
Es gibt auch Dinge, die vor Ort passieren, wie Unfälle, die die üblichen Verkehrsmuster stören. Wenn wir Lieferungen aus mathematischer Sicht betrachten, nehmen wir an, dass alle Lieferpunkte gleich sind, aber das sind sie nicht. Sie könnten VIP-Kunden haben oder spezifische Adressen, an denen Sie die Hälfte Ihrer Lieferung abgeben müssen. Diese wichtigen Meilensteine in Ihrer Route müssen bei der effektiven Routenoptimierung berücksichtigt werden.
Sie müssen auch den Kontext beachten, und es ist üblich, unvollständige Daten über die Welt zu haben. Wenn zum Beispiel eine Brücke geschlossen ist und die Software nichts davon weiß, besteht das Problem nicht darin, dass die Brücke beim ersten Mal geschlossen war, sondern dass die Software nie aus dem Problem lernt und immer eine Route vorschlägt, die optimal sein soll, aber letztendlich unsinnig ist. Die Menschen kämpfen dann gegen das System, was aus Sicht der Lieferkette keine gute praktische Lösung für die Routenoptimierung ist.
Der Punkt ist, dass es in Lieferketten-Situationen überall viele Muster gibt. Wir müssen darauf achten, uns nicht von eleganten mathematischen Strukturen ablenken zu lassen und uns daran erinnern, dass diese Überlegungen auch für die Zeitreihenprognose gelten. Ich habe das Problem der Routenoptimierung als Beispiel genommen, weil es in diesem Fall deutlicher war.
Zusammenfassend müssen wir die Lieferkette aus allen beobachtbaren Dimensionen betrachten, nicht nur aus den offensichtlichen oder wo sich die Lösung auf elegante Weise präsentiert.

Dies bringt mich zu den zweiten Grundsätzen, wie wir unsere Lieferkette betrachten sollten. Bisher haben wir vier Grundsätze gesehen, wie wir unsere Lieferkette betrachten sollten: indirekte Beobachtung, Unternehmenssoftware, das Durcheinander sortieren, um zu bestimmen, was relevant ist und was nicht, und Entropie. Wir haben festgestellt, dass Verteilungen oft dem Zipf’schen Gesetz folgen, und selbst mit kleinen Zahlen können wir Muster erkennen. Die Frage ist nun, wie handeln wir? Mathematisch gesehen führen wir bei der Entscheidung für den besten Handlungsweg eine Optimierung irgendeiner Art durch, was die quantitative Perspektive ist.

Das erste, was zu beachten ist, ist, dass sobald wir eine Optimierungslogik für Lieferketten in der Produktion haben, Probleme auftreten werden, wie z.B. Fehler. Unternehmenssoftware ist ein sehr komplexes Biest und oft voller Fehler. Wenn Sie Ihre eigene Optimierungslogik für Ihre Lieferkette erstellen, wird es viele Probleme geben. Wenn jedoch ein Stück Logik gut genug ist, um in die Produktion zu gelangen, sind die Probleme, mit denen wir jetzt konfrontiert sind, wahrscheinlich Randfälle. Wenn es kein Randfall wäre und die Software oder Logik jedes Mal fehlerhaft wäre, würde sie niemals den Weg in die Produktion finden.
Die Idee dieses Prinzips ist, dass es fünf bis zehn Runden dauert, um ein Problem zu beheben. Wenn ich von fünf bis zehn Runden spreche, meine ich, dass Sie auf ein Problem stoßen, es betrachten, die Ursache verstehen und dann versuchen, eine Lösung anzuwenden. Aber die meiste Zeit wird die Lösung das Problem nicht lösen. Sie werden feststellen, dass sich ein Problem im Inneren des Problems verbirgt oder dass das Problem, das Sie zu beheben dachten, nicht die eigentliche Ursache war oder dass die Situation eine breitere Klasse von Problemen aufgedeckt hat. Sie haben möglicherweise eine kleine Instanz einer breiteren Klasse von Problemen behoben, aber es treten weiterhin andere Probleme auf, die Varianten desjenigen sind, von dem Sie dachten, es gelöst zu haben.
Lieferketten sind komplexe, sich ständig verändernde Biester, die in der realen Welt operieren, was es schwierig macht, ein Design zu haben, das gegen alle Situationen richtig ist. In den meisten Fällen versuchen Sie, ein Problem nach bestem Wissen und Gewissen zu beheben, und dann müssen Sie Ihre überarbeitete Logik auf die Erfahrungen der realen Welt testen, um zu sehen, ob sie funktioniert oder nicht. Sie müssen iterieren, um das Problem zu beheben. Mit dem Prinzip, dass es zwischen fünf und zehn Iterationen dauert, um ein Problem zu beheben, ergeben sich tiefgreifende Auswirkungen auf die Geschwindigkeit der Anpassungen und die Häufigkeit, mit der Sie Ihre Logik für die Optimierung der Lieferkette aktualisieren oder neu berechnen. Wenn Sie zum Beispiel eine Logik haben, die eine vierteljährliche Prognose für die nächsten zwei Jahre erstellt und diese Logik nur einmal pro Quartal ausführen, dauert es zwischen einem und zwei Jahren, um Probleme mit dieser Prognoselogik zu beheben, was eine unglaublich lange Zeit ist.
Selbst wenn Sie eine Logik haben, die jeden Monat ausgeführt wird, wie im Fall eines S&OP (Sales and Operations Planning)-Prozesses, könnte es immer noch bis zu einem Jahr dauern, um ein Problem zu beheben. Deshalb ist es wichtig, die Häufigkeit der Ausführung Ihrer Logik zur Optimierung der Lieferkette zu erhöhen. Bei Lokad zum Beispiel läuft jede Logik täglich, auch für Prognosen für die nächsten fünf Jahre. Diese Prognosen werden täglich aktualisiert, auch wenn sie sich von einem Tag zum nächsten nicht viel ändern. Das Ziel ist nicht, statistische Genauigkeit zu erlangen, sondern sicherzustellen, dass die Logik häufig genug ausgeführt wird, um Probleme oder Fehler innerhalb eines angemessenen Zeitrahmens zu beheben.
Diese Beobachtung ist nicht einzigartig für das Supply Chain Management. Smarte Engineering-Teams bei Unternehmen wie Netflix haben die Idee des Chaos Engineering populär gemacht. Sie haben erkannt, dass Randfälle selten sind und der einzige Weg, diese Probleme zu beheben, darin besteht, die Erfahrung häufiger zu wiederholen. Als Ergebnis haben sie eine Software namens Chaos Monkey entwickelt, die Chaos in ihre Softwareinfrastruktur bringt, indem sie Netzwerkstörungen und zufällige Abstürze verursacht. Der Zweck des Chaos Monkey besteht darin, Randfälle schneller sichtbar zu machen, damit das Engineering-Team sie schneller beheben kann.
Obwohl es kontraintuitiv erscheinen mag, eine zusätzliche Ebene des Chaos in Ihre Operationen einzuführen, hat sich dieser Ansatz für Netflix als wirksam erwiesen, das für seine ausgezeichnete Zuverlässigkeit bekannt ist. Sie verstehen, dass es viele Iterationen braucht, um ein softwarebasiertes Problem zu lösen, und der einzige Weg, das Problem auf den Grund zu gehen, besteht darin, schnell zu iterieren. Der Chaos Monkey ist nur eine Möglichkeit, die Geschwindigkeit der Iteration zu erhöhen.
Aus Sicht der Lieferkette ist der Chaos Monkey möglicherweise nicht direkt anwendbar, aber das Konzept, die Häufigkeit der Ausführung Ihrer Logik zur Optimierung der Lieferkette zu erhöhen, ist dennoch sehr relevant. Welche Logik Sie auch immer haben, um Ihre Lieferkette zu optimieren, sie muss mit hoher Geschwindigkeit und hoher Frequenz ausgeführt werden, sonst werden Sie keines der Probleme beheben, mit denen Sie konfrontiert sind.

Nun sind gealterte Lieferketten quasi-optimal, und wenn ich von gealtert spreche, meine ich Lieferketten, die seit zwei Jahrzehnten oder länger in Betrieb sind. Eine andere Möglichkeit, dieses Prinzip auszudrücken, ist, dass Ihre Vorgänger in der Lieferkette nicht alle inkompetent waren. Wenn Sie sich Optimierungsinitiativen für die Lieferkette ansehen, gibt es allzu oft große Ambitionen wie die Halbierung der Lagerbestände, die Erhöhung der Servicelevel von 95% auf 99%, die Beseitigung von Fehlbeständen oder die Halbierung der Durchlaufzeiten. Dies sind große, unidirektionale Schritte, bei denen Sie sich auf einen KPI konzentrieren und versuchen, ihn massiv zu verbessern. Ich habe jedoch beobachtet, dass diese Initiativen fast immer aus einem sehr plumpen Grund scheitern: Wenn Sie eine Lieferkette übernehmen, die seit Jahrzehnten in Betrieb ist, gibt es in der Regel eine gewisse verborgene Weisheit in der Art und Weise, wie die Dinge erledigt wurden.
Zum Beispiel, wenn die Servicelevel bei 95% liegen, besteht die Wahrscheinlichkeit, dass Sie, wenn Sie versuchen, sie auf 99% zu erhöhen, die Lagerbestände erheblich erhöhen und dabei eine massive Menge an totem Lagerbestand schaffen. Ebenso, wenn Sie eine bestimmte Menge an Lagerbestand haben und eine massive Initiative starten, um ihn um die Hälfte zu reduzieren, werden Sie wahrscheinlich erhebliche Probleme bei der Servicequalität schaffen, die nicht nachhaltig sind.
Was ich beobachtet habe, ist, dass viele Lieferkettenpraktiker, die das Prinzip nicht verstehen, dass gealterte Lieferketten unidirektional quasi-optimal sind, um den lokalen Optimum herum oszillieren. Beachten Sie, dass ich nicht sage, dass gealterte Lieferketten optimal sind, aber sie sind unidirektional quasi-optimal. Wenn Sie sich das Beispiel des Grand Canyon ansehen, schnitzt der Fluss den optimalen Weg aufgrund der unidirektionalen Kraft der Schwerkraft. Wenn Sie eine zehnmal stärkere Kraft anwenden würden, würde der Fluss immer noch viele Windungen durchlaufen.
Der Punkt ist, dass Sie bei gealterten Lieferketten viele Variablen gleichzeitig anpassen müssen, um signifikante Verbesserungen zu erzielen. Sich nur auf eine Variable zu konzentrieren, wird nicht die gewünschten Ergebnisse bringen, insbesondere wenn Ihr Unternehmen seit Jahrzehnten mit dem Status quo arbeitet. Ihre Vorgänger haben wahrscheinlich in ihrer Zeit einiges richtig gemacht, daher ist die Wahrscheinlichkeit gering, dass Sie auf eine stark dysfunktionale Lieferkette stoßen, der niemand jemals Aufmerksamkeit geschenkt hat. Lieferketten sind komplexe Probleme, und obwohl es möglich ist, völlig dysfunktionale Situationen im großen Maßstab zu konstruieren, wird dies höchstens sehr selten vorkommen.

Ein weiterer Aspekt, der berücksichtigt werden muss, ist, dass die lokale Optimierung Probleme nur verdrängt, anstatt sie zu lösen. Um dies zu verstehen, müssen Sie erkennen, dass Lieferketten Systeme sind und dass es bei der Betrachtung der Leistung der Lieferkette nur auf die systemweite Leistung ankommt. Die lokale Leistung ist relevant, aber sie ist nur ein Teil des Bildes.
Eine häufige Denkweise ist, dass Sie die Teile-und-Herrsche-Strategie anwenden können, um Probleme im Allgemeinen zu lösen, nicht nur Lieferkettenprobleme. Zum Beispiel könnten Sie in einem Einzelhandelsnetzwerk mit vielen Filialen die Lagerbestände in jeder Filiale optimieren wollen. Das Problem ist jedoch, dass es, wenn Sie ein Netzwerk von Filialen und Vertriebszentren haben, von denen jedes viele Filialen bedient, völlig trivial ist, eine Filiale mikrozuoptimieren und eine ausgezeichnete Servicequalität für diese Filiale auf Kosten aller anderen Filialen zu erreichen.
Die richtige Perspektive besteht darin, zu denken, dass Sie, wenn Sie eine Einheit im Vertriebszentrum zur Verfügung haben, sich fragen sollten: Wo wird diese Einheit am dringendsten benötigt? Was ist der profitabelste Schritt für mich? Das Problem der Optimierung der Warenverteilung oder des Bestandsallokationsproblems macht nur auf Systemebene Sinn, nicht auf Filialebene. Wenn Sie optimieren, was in einer Filiale passiert, werden Sie wahrscheinlich Probleme in einer anderen Filiale schaffen.
Wenn ich von “lokal” spreche, sollte dieses Prinzip nicht nur aus geografischer Sicht verstanden werden, sondern kann auch eine rein logische Angelegenheit innerhalb der Lieferkette sein. Wenn Sie zum Beispiel ein E-Commerce-Unternehmen mit vielen Produktkategorien sind, möchten Sie möglicherweise unterschiedliche Budgets für die verschiedenen Kategorien zuweisen. Dies ist eine weitere Art der Teile-und-Herrsche-Strategie. Wenn Sie jedoch Ihr Budget aufteilen und zu Beginn des Jahres einen festen Betrag für jede Kategorie zuweisen, was passiert, wenn die Nachfrage nach Produkten in einer Kategorie sich verdoppelt, während die Nachfrage nach Produkten in einer anderen Kategorie halbiert wird? In diesem Fall haben Sie ein Problem der falschen Mittelzuweisung zwischen diesen beiden Kategorien. Die Herausforderung besteht hier darin, dass Sie keine Art von Teile-und-Herrsche-Logik anwenden können. Wenn Sie lokale Optimierungstechniken verwenden, können Sie Probleme schaffen, während Sie Ihre vermeintlich optimierte Lösung erstellen.

Das bringt mich zum letzten Prinzip, das wahrscheinlich das kniffligste unter allen Prinzipien ist, die ich heute vorgestellt habe: Bessere Probleme übertrumpfen bessere Lösungen. Dies kann äußerst verwirrend sein, insbesondere in bestimmten akademischen Kreisen. Die typische Art und Weise, wie Dinge durch eine klassische Ausbildung präsentiert werden, ist, dass Ihnen ein klar definiertes Problem präsentiert wird und Sie dann nach Lösungen für diese Probleme suchen. Bei einem mathematischen Problem kann zum Beispiel ein Student mit einer präziseren, eleganteren Lösung kommen, und das gilt als die beste Lösung.
In der Realität läuft es jedoch nicht so ab im Supply Chain Management. Um dies zu veranschaulichen, gehen wir 60 Jahre zurück und betrachten das Problem des Kochens, eine sehr zeitaufwändige Tätigkeit. Die Menschen in der Vergangenheit stellten sich vor, dass Roboter in der Zukunft eingesetzt werden könnten, um Kochaufgaben auszuführen und so die Produktivität für die Person, die für das Kochen zuständig ist, erheblich zu steigern. Diese Art des Denkens war in den 1950er und 1960er Jahren weit verbreitet.
Blicken wir heute in die Gegenwart, wird offensichtlich, dass sich die Dinge nicht so entwickelt haben. Um den Kochaufwand zu minimieren, kaufen die Menschen jetzt vorgekochte Mahlzeiten. Dies ist ein weiteres Beispiel für Problemverlagerung. Die Bereitstellung von Supermärkten mit vorgekochten Mahlzeiten ist aus logistischer Sicht anspruchsvoller als die Bereitstellung von Rohprodukten, aufgrund der erhöhten Anzahl von Referenzen und kürzeren Verfallsdaten. Das Problem wurde durch eine überlegene Supply-Chain-Lösung gelöst, nicht durch eine bessere Kochlösung. Das Kochproblem wurde vollständig entfernt und neu definiert als Bereitstellung einer halbwegs anständigen Mahlzeit mit minimalem Aufwand.
In Bezug auf Lieferketten liegt der akademische Blickwinkel oft darauf, bessere Lösungen für bestehende Probleme zu finden. Ein gutes Beispiel dafür sind Kaggle-Wettbewerbe, bei denen Sie einen Datensatz, ein Problem und potenziell Hunderte oder Tausende von Teams haben, die um die beste Vorhersage für diese Datensätze konkurrieren. Sie haben ein klar definiertes Problem und Tausende von Lösungen, die gegeneinander antreten. Das Problem bei dieser Denkweise ist, dass Sie den Eindruck vermittelt bekommen, dass Sie, wenn Sie Verbesserungen für Ihre Lieferkette erzielen möchten, eine bessere Lösung benötigen.
Die Essenz des Prinzips besteht darin, dass eine bessere Lösung möglicherweise marginal hilft, aber nur marginal. In der Regel hilft es wirklich, wenn Sie das Problem neu definieren, und das ist überraschend schwierig. Dies gilt auch für quantitative Probleme. Sie müssen Ihre tatsächliche Supply-Chain-Strategie und das Hauptproblem, das Sie optimieren sollten, neu überdenken.
In vielen Kreisen betrachten Menschen Probleme als statisch und unveränderlich und suchen nach besseren Lösungen. Ich bestreite nicht, dass ein besseres Zeitreihenprognose-Algorithmus hilfreich sein kann, aber die Zeitreihenprognose gehört zum Bereich der statistischen Prognose, nicht zur Beherrschung des Supply Chain Managements. Wenn wir zu meinem anfänglichen Beispiel des Reisekoffers zurückkehren, bestand die wichtigste Verbesserung für einen Koffer mit Rädern nicht in den Rädern, sondern im Griff. Es war etwas, das auf den ersten Blick nichts mit den Rädern zu tun hatte, und deshalb dauerte es 40 Jahre, um eine Lösung zu finden - man muss über den Tellerrand hinausdenken, um das bessere Problem entstehen zu lassen.
Dieses quantitative Prinzip besteht darin, die Probleme, mit denen Sie konfrontiert sind, in Frage zu stellen. Vielleicht denken Sie nicht hart genug über das Problem nach, und es besteht die Tendenz, sich in die Lösung zu verlieben, während Sie sich auf das Problem und die Dinge konzentrieren sollten, die Sie daran nicht verstehen. Sobald Sie ein klar definiertes Problem haben, ist eine gute Lösung in der Regel nur eine banale Frage der Umsetzung, die nicht so schwierig ist.

Zusammenfassend lässt sich sagen, dass die Supply Chain als Forschungsfeld viele beeindruckende und autoritative Perspektiven bietet. Diese können anspruchsvoll sein, aber die Frage, die ich diesem Publikum stellen möchte, lautet: Könnte es sein, dass all das stark fehlgeleitet sein könnte? Sind wir wirklich zuversichtlich, dass Elemente wie Zeitreihenprognose und Operationsforschung die richtigen Perspektiven auf das Problem sind? Unabhängig von der Raffinesse und den Jahrzehnten an Ingenieurwesen und Aufwand, die in diese Richtungen investiert wurden, sind wir wirklich auf dem richtigen Weg?
Heute präsentiere ich eine Reihe von Prinzipien, die ich für äußerst relevant für das Supply Chain Management halte. Sie mögen den meisten von Ihnen seltsam erscheinen. Hier haben wir zwei Welten - die bewährte und die seltsame - und die Frage ist, was in einigen Jahrzehnten passieren wird.

Fortschritt entfaltet sich tendenziell chaotisch und nichtlinear. Die Idee hinter diesen Prinzipien ist es, Ihnen eine Welt zu ermöglichen, die äußerst chaotisch ist, in der Raum für das Unerwartete ist. Diese Prinzipien können Ihnen helfen, schnellere, zuverlässigere und effizientere Lösungen zu entwickeln, die aus quantitativer Sicht Verbesserungen für Ihre Lieferketten bringen werden.

Nun gehen wir zu einigen Fragen über.
Frage: Wie verhalten sich Zipf-Verteilungen im Vergleich zum Pareto-Gesetz?
Das Pareto-Gesetz ist die Faustregel von 80-20, aber aus quantitativer Sicht ist die Zipf-Verteilung ein explizites Vorhersagemodell. Sie hat Vorhersagefähigkeiten, die auf sehr einfache Weise mit Datensätzen herausgefordert werden können.
Frage: Wäre es nicht besser, die Zipf-Mandelbrot-Verteilung als logarithmische Kurve zu betrachten, um Schwankungen in der Lieferkette zu sehen, wie es Epidemiologen mit der Berichterstattung über Fälle und Todesfälle tun?
Absolut. Auf philosophischer Ebene stellt sich die Frage, ob Sie in Mediokristan oder Extremistan leben. Lieferketten und die meisten menschlichen Angelegenheiten existieren in der Welt der Extreme. Logarithmische Kurven sind tatsächlich nützlich, wenn Sie die Amplitude von Werbeaktionen visualisieren möchten. Wenn Sie beispielsweise die Amplituden aller vergangenen Werbeaktionen für große Einzelhandelsnetzwerke der letzten 10 Jahre sehen möchten, könnte mit einer regulären Skala alles andere unsichtbar werden, einfach weil die größte Werbeaktion aller Zeiten so viel größer war als die anderen. Daher kann Ihnen eine logarithmische Skala helfen, die Variationen klarer zu erkennen. Mit der Zipf-Mandelbrot-Verteilung gebe ich Ihnen ein Modell, das Sie buchstäblich mit wenigen Zeilen Code implementieren können, was mehr ist als nur eine logarithmische Ansicht der Daten. Ich stimme jedoch zu, dass die Kernintuition die gleiche ist. Für eine philosophische Perspektive auf höchster Ebene empfehle ich Ihnen, Nassim Talebs Arbeit über Mediokristan versus Extremistan in seinem Buch “Antifragile” zu lesen.
Frage: Im Zusammenhang mit der Optimierung lokaler Lieferketten beziehen Sie sich auf zugrunde liegende Daten, die die Zusammenarbeit im Lieferketzennetzwerk und SNLP unterstützen?
Mein Problem mit der lokalen Optimierung besteht darin, dass große Unternehmen, die große Lieferketten betreiben, in der Regel Matrixorganisationen haben. Diese Organisationsstruktur mit ihrer Teile-und-Herrsche-Mentalität führt zu einer lokalen Optimierung von vornherein. Betrachten Sie zum Beispiel zwei verschiedene Teams - eines für die Nachfrageprognose und das andere für Einkaufsentscheidungen. Diese beiden Probleme - Nachfrageprognose und Einkaufsoptimierung - sind vollständig miteinander verflochten. Sie können keine lokale Optimierung durchführen, indem Sie sich nur auf den Prozentsatz des Fehlers in der Nachfrageprognose konzentrieren und dann separat den Einkauf basierend auf der Verarbeitungseffizienz optimieren. Es gibt systemische Effekte, und Sie müssen alle zusammen berücksichtigen.
Die größte Herausforderung für die meisten großen etablierten Unternehmen, die heute bedeutende Lieferketten betreiben, besteht darin, dass Sie bei der quantitativen Optimierung systemweit und unternehmensweit denken müssen. Dies steht im Widerspruch zu Jahrzehnten der Sedimentation der Matrixorganisation innerhalb des Unternehmens, in dem sich die Menschen ausschließlich auf ihre klar definierten Grenzen konzentriert haben und das größere Bild vergessen haben.
Ein weiteres Beispiel für dieses Problem wäre der Warenbestand im Geschäft. Der Bestand erfüllt zwei Zwecke: Einerseits deckt er die Kundennachfrage ab, andererseits dient er als Ware. Um die richtige Menge an Bestand zu haben, müssen Sie sich mit dem Problem der Servicequalität und dem Problem der Attraktivität des Geschäfts auseinandersetzen. Die Attraktivität des Geschäfts besteht darin, das Geschäft für Kunden attraktiv und interessant zu gestalten, was eher ein Marketingproblem ist. In einem Unternehmen haben Sie eine Marketingabteilung und eine Supply-Chain-Abteilung, und sie arbeiten nicht natürlicherweise zusammen, wenn es um die Optimierung der Lieferkette geht. Mein Punkt ist, dass die Optimierung nicht funktioniert, wenn Sie nicht all diese Aspekte zusammenbringen.
In Bezug auf Ihre Bedenken bezüglich SNLP ist das Problem, dass sich die Leute nur treffen, um Meetings abzuhalten, was nicht sehr effizient ist. Wir haben vor einigen Monaten eine Folge von Lokad TV über SNLP veröffentlicht, auf die Sie sich beziehen können, wenn Sie eine spezifische Diskussion über SNLP führen möchten.
Frage: Wie sollten wir die Zeit und Energie zwischen Lieferkettenstrategie und quantitativer Ausführung verteilen?
Das ist eine großartige Frage. Die Antwort, wie ich es in meinem zweiten Vortrag erwähnt habe, besteht darin, dass Sie eine vollständige Robotisierung der banalen Aufgaben benötigen. Dadurch können Sie Ihre gesamte Zeit und Energie der kontinuierlichen strategischen Verbesserung Ihrer numerischen Rezepte widmen. Wenn Sie mehr als 10% Ihrer Zeit mit banalen Aspekten der Lieferkettenausführung verbringen, haben Sie ein Problem mit Ihrer Methodik. Lieferkettenexperten sind zu wertvoll, um ihre Zeit und Energie mit banalen Ausführungsproblemen zu verschwenden, die von Anfang an automatisiert werden sollten.
Sie müssen einer Methodik folgen, die es Ihnen ermöglicht, fast all Ihre Energie dem strategischen Denken zu widmen, das dann sofort als überlegene numerische Rezepte umgesetzt wird, die die tägliche Lieferkettenausführung antreiben. Dies bezieht sich auf meinen dritten Vortrag über produktorientierte Lieferung, bei dem ich softwarebasierte produktorientierte Lieferung meine.
Frage: Ist es möglich, eine Art Deckenanalyse zu hypothetisieren, die die beste mögliche Verbesserung für Lieferkettenprobleme anhand ihrer systemischen Formulierung liefert?
Ich würde sagen, nein, absolut nicht. Die Annahme, dass es eine Art Optimum oder Decke gibt, ist gleichbedeutend mit der Annahme, dass es eine Grenze für menschliche Genialität gibt. Obwohl ich keinen Beweis dafür habe, dass es keine Grenze für menschliche Genialität gibt, ist es eine meiner Grundüberzeugungen. Lieferketten sind komplexe Probleme. Sie können das Problem transformieren und sogar das, was ein großes Problem zu sein scheint, in eine große Lösung und ein Wachstumspotenzial für das Unternehmen verwandeln. Schauen Sie sich zum Beispiel Amazon an. Jeff Bezos hat Anfang der 2000er Jahre erkannt, dass er als erfolgreicher Einzelhändler eine massive, robuste Softwareinfrastruktur benötigen würde. Aber diese massive, industrielle Produktionsinfrastruktur, die er für den Betrieb des E-Commerce von Amazon benötigte, war unglaublich teuer und kostete das Unternehmen Milliarden. Also beschlossen die Teams bei Amazon, diese Cloud-Computing-Infrastruktur, die eine riesige Investition war, in ein kommerzielles Produkt umzuwandeln. Heutzutage ist diese groß angelegte Recheninfrastruktur tatsächlich eine der Hauptquellen für Gewinn für Amazon.
Wenn Sie an komplexe Probleme denken, können Sie das Problem immer auf überlegene Weise neu definieren. Deshalb halte ich es für fehlgeleitet zu glauben, dass es eine Art optimale Lösung gibt. Wenn Sie an Deckenanalyse denken, betrachten Sie ein festes Problem, und aus der Perspektive eines festen Problems haben Sie wahrscheinlich eine quasi-optimale Lösung. Wenn Sie sich zum Beispiel die Räder an modernen Koffern ansehen, sind sie wahrscheinlich quasi-optimal. Aber gibt es etwas Offensichtliches, das uns entgeht? Vielleicht gibt es eine Möglichkeit, die Räder viel besser zu machen, eine Erfindung, die noch nicht gemacht wurde. Sobald wir sie sehen, wird sie völlig selbstverständlich erscheinen.
Deshalb müssen wir denken, dass es für diese Probleme keine Decke gibt, weil die Probleme willkürlich sind. Sie können das Problem neu definieren und entscheiden, dass das Spiel nach völlig anderen Regeln gespielt werden soll. Das ist verwirrend, weil die Leute gerne denken, dass sie ein sorgfältig gestaltetes Problem haben und Lösungen finden können. Das moderne westliche Bildungssystem betont eine lösungsorientierte Denkweise, bei der wir Ihnen ein Problem geben und die Qualität Ihrer Lösung bewerten. Eine viel interessantere Frage ist jedoch die Qualität des Problems selbst.
Frage: Die besten Lösungen werden die Probleme lösen, aber manchmal kann die Suche nach der besten Lösung sowohl Zeit als auch Geld kosten. Gibt es dafür Lösungen?
Absolut. Wenn Sie eine theoretisch korrekte Lösung haben, die jedoch ewig dauert, um implementiert zu werden, ist es keine gute Lösung. Diese Art des Denkens ist in bestimmten akademischen Kreisen weit verbreitet, wo der Fokus darauf liegt, die perfekte Lösung gemäß engstirnigen mathematischen Kriterien zu finden, die nichts mit der realen Welt zu tun haben. Genau das habe ich gemeint, als ich von dem richtigen Optimierungsproblem gesprochen habe.
Etwa alle drei Monate kommt ein Professor zu mir und fragt, ob ich ihren Online-Algorithmus zur Lösung des Routenoptimierungsproblems überprüfen könnte. Die meisten Artikel, die ich heutzutage überprüfe, konzentrieren sich auf Online-Varianten. Meine Antwort ist immer die gleiche: Sie lösen nicht das richtige Problem. Es interessiert mich nicht, welche Lösung Sie haben, weil Sie nicht einmal richtig über das Problem selbst nachdenken.
Fortschritt sollte nicht mit Raffinesse verwechselt werden. Es ist eine fehlgeleitete Wahrnehmung, dass Fortschritt von etwas Einfachem zu etwas Raffiniertem führt. In Wirklichkeit wird Fortschritt oft erreicht, indem man mit etwas unendlich kompliziertem beginnt und durch überlegtes Denken und Technologie Einfachheit erreicht. Zum Beispiel, wenn Sie sich meine letzte Vorlesung über Trends in der Lieferkette für das 21. Jahrhundert ansehen, werden Sie die Maschine von Marly sehen, die Wasser zum Schloss Versailles brachte. Es war ein wahnsinnig kompliziertes System, während moderne elektrische Pumpen viel einfacher und effizienter sind.
Fortschritt findet sich nicht unbedingt in zusätzlicher Raffinesse. Manchmal ist es erforderlich, aber es ist keine wesentliche Zutat für Fortschritt.
Frage: Große Einzelhandelsnetzwerke erhöhen ihren Lagerbestand, müssen aber Bestellungen fast sofort erfüllen. Manchmal entscheiden sie sich, eine Werbeaktion auf eigene Faust durchzuführen, die nicht vom Lieferanten initiiert wurde. Wie könnte man auf Lieferantenebene voraussagen und entsprechend vorbereiten?
Zunächst müssen wir das Problem aus einer anderen Perspektive betrachten. Sie gehen von einer prognostischen Perspektive aus, bei der Ihr Kunde, ein großer Einzelhändler, eine große Werbeaktion durchführt, die aus dem Nichts kommt. Ist das wirklich so schlimm? Wenn sie Ihre Produkte bewerben, ohne Sie zu informieren, ist das einfach eine Tatsache des Lebens. Wenn Sie sich Ihre Geschichte anschauen, machen sie das in der Regel regelmäßig und es gibt sogar Muster.
Wenn ich zu meinen Prinzipien zurückkehre, sind Muster überall. Zunächst müssen Sie eine Perspektive annehmen, dass Sie die Zukunft nicht vorhersagen können; stattdessen benötigen Sie probabilistische Vorhersagen. Auch wenn Sie Schwankungen nicht perfekt vorhersehen können, müssen sie nicht völlig unerwartet sein. Vielleicht müssen Sie die Spielregeln ändern, anstatt sich vom Lieferanten völlig überraschen zu lassen. Vielleicht müssen Sie Verpflichtungen aushandeln, die den Einzelhändler, das Einzelhandelsnetzwerk und den Lieferanten binden. Wenn das Einzelhandelsnetzwerk eine große Werbeaktion startet, ohne den Lieferanten vorher zu informieren, kann der Lieferant nicht realistisch für die Aufrechterhaltung der Servicequalität verantwortlich gemacht werden.
Vielleicht ist die Lösung etwas kooperativer. Vielleicht sollte der Lieferant eine bessere Risikobewertung haben. Wenn die vom Lieferanten verkauften Materialien nicht verderblich sind, könnte es profitabler sein, ein paar Monate Lagerbestand zu haben. Die Leute denken oft daran, keinen Verzug, keinen Lagerbestand und nichts zu haben, aber ist das wirklich das, was Ihre Kunden von Ihnen erwarten? Vielleicht erwarten Ihre Kunden Mehrwert in Form von reichlich Lagerbestand. Auch hier hängt die Antwort von verschiedenen Faktoren ab.
Sie müssen das Problem aus vielen Blickwinkeln betrachten, und es gibt keine einfache Lösung. Sie müssen wirklich intensiv über das Problem nachdenken und alle Ihnen zur Verfügung stehenden Optionen in Betracht ziehen. Vielleicht geht es nicht um mehr Lagerbestand, sondern um mehr Produktionskapazität. Wenn es eine große Nachfragesteigerung gibt und es nicht zu teuer ist, einen massiven Anstieg zu haben, und die Lieferanten der Lieferanten die Materialien schnell genug liefern können, brauchen Sie vielleicht nur eine vielseitigere Produktionskapazität. Dadurch können Sie Ihre Produktionskapazität auf das umleiten, was gerade steigt.
Übrigens gibt es das in bestimmten Branchen. Zum Beispiel hat die Verpackungsindustrie massive Kapazitäten. Die meisten Maschinen in der Verpackungsindustrie sind Industriedrucker, die relativ günstig sind. Die Leute in der Verpackungsbranche haben in der Regel viele Drucker, die die meiste Zeit nicht genutzt werden. Wenn es jedoch eine große Veranstaltung oder eine große Marke gibt, die einen massiven Schub machen möchte, haben sie die Kapazität, Tonnen von neuen Verpackungen zu drucken, die zum neuen Marketing-Schub der Marke passen.
Es hängt also wirklich von verschiedenen Faktoren ab, und ich entschuldige mich dafür, dass ich keine endgültige Antwort habe. Aber was ich definitiv sagen kann, ist, dass Sie wirklich intensiv über das Problem nachdenken müssen, dem Sie gegenüberstehen.
Dies schließt die heutige Vorlesung ab, die sechste und letzte des Prologs. In zwei Wochen, am gleichen Tag und zur gleichen Uhrzeit, werde ich über Persönlichkeiten in der Supply Chain sprechen. Bis zum nächsten Mal.


