00:54 Introducción
02:25 Sobre la naturaleza del progreso
05:26 La historia hasta ahora
06:10 Algunos principios cuantitativos: principios observacionales
07:27 Resolviendo “la aguja en un pajar” mediante la entropía
14:58 Las poblaciones de SC están distribuidas según Zipf
22:41 Los números pequeños prevalecen en las decisiones de SC
29:44 Los patrones están en todas partes en SC
36:11 Algunos principios cuantitativos: principios de optimización
37:20 Se necesitan de 5 a 10 rondas para solucionar cualquier problema de SC
44:44 Los SC envejecidos son cuasi-óptimos de manera unidireccional
49:06 Las optimizaciones locales de SC solo desplazan los problemas
52:56 Los mejores problemas superan a las mejores soluciones
01:00:08 Conclusión
01:02:24 Próxima lección y preguntas de la audiencia
Descripción
Aunque las supply chains no pueden ser caracterizadas por leyes cuantitativas definitivas - a diferencia del electromagnetismo - aún se pueden observar principios cuantitativos generales. Por “general” entendemos que son aplicables a (casi) todas las supply chains. Descubrir tales principios es de gran interés porque pueden utilizarse para facilitar la ingeniería de recetas numéricas destinadas a la optimización predictiva de supply chains, pero también para hacer que esas recetas numéricas sean más potentes en general. Revisamos dos breves listas de principios: algunos principios observacionales y algunos principios de optimización.
Transcripción completa

Hola a todos, bienvenidos a esta serie de conferencias sobre supply chain. Soy Joannes Vermorel, y hoy presentaré algunos “Quantitative Principles for Supply Chains.” Para aquellos que estén viendo la conferencia en vivo en YouTube, pueden hacer sus preguntas en cualquier momento a través del chat de YouTube. Sin embargo, no leeré sus preguntas durante las conferencias. Volveré al chat al final de la conferencia e intentaré responder al menos a la mayoría de las preguntas.
Los principios cuantitativos son de gran interés porque, en las supply chains, como hemos visto durante las primeras conferencias, implican el dominio de la opcionalidad. La mayoría de estas opciones son de naturaleza cuantitativa. Debes decidir cuánto comprar, cuánto producir, cuánta inventario mover y, potencialmente, el punto de precio – ya sea que desees aumentar o disminuir el punto de precio. Por lo tanto, un principio cuantitativo que pueda impulsar mejoras en las recetas numéricas para las supply chains es de gran interés.
Sin embargo, si preguntara a la mayoría de las autoridades o Supply Chain Scientists en la actualidad cuáles son sus principios cuantitativos fundamentales para las supply chains, sospecho que frecuentemente obtendría una respuesta en la línea de una serie de técnicas para mejores previsión de series temporales o algo equivalente. Mi reacción personal es que, aunque esto es interesante y relevante, también se pierde el punto. Creo que, en el fondo, la mala interpretación radica en la misma naturaleza del progreso: ¿qué es el progreso y cómo se puede implementar algo tan concreto como el progreso en lo que respecta a las supply chains? Permítanme comenzar con un ejemplo ilustrativo.

Hace seis mil años se inventó la rueda, y seis mil años después se inventó la maleta con ruedas. La invención está fechada en 1949, como ilustra esta patente. Para cuando se inventó la maleta con ruedas, ya habíamos aprovechado la energía atómica e incluso detonado las primeras bombas atómicas.
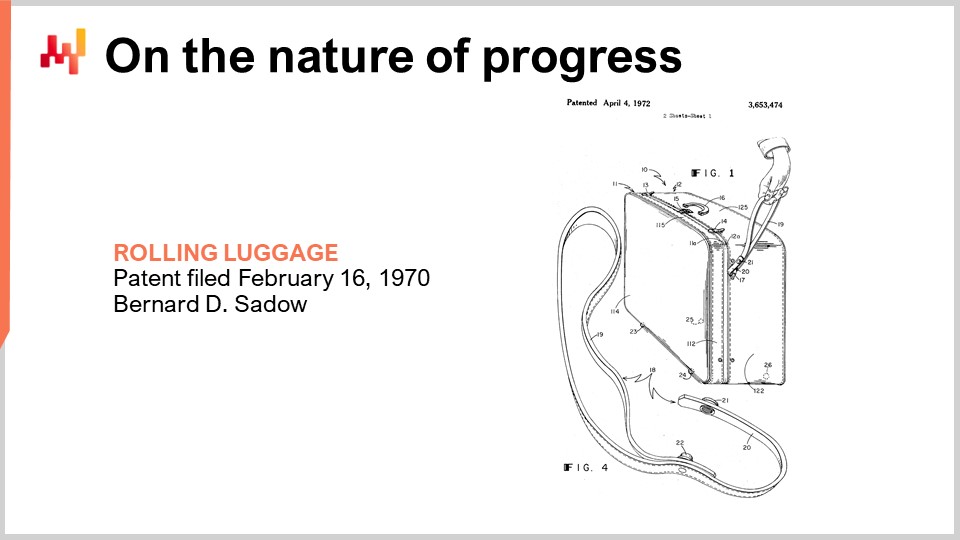
Avanzando 20 años más, en 1969, la humanidad envió a las primeras personas a la luna. Al año siguiente, la maleta con ruedas se mejora con un asa un poco mejor, que se parece a una correa, como ilustra esta patente. Aún así, no es muy buena.

Luego, 20 años después, para entonces ya contábamos con el sistema de posicionamiento global (GPS) que había estado sirviendo a los civiles durante casi una década, y finalmente se inventó el asa adecuada para la maleta con ruedas.
Hay al menos dos lecciones de interés aquí. Primero, no existe una flecha del tiempo obvia en lo que respecta al progreso. El progreso ocurre de manera altamente caótica y no lineal, y es muy difícil evaluar el progreso que debería ocurrir en un campo basándose en lo que sucede en otros. Este es un elemento que debemos tener en cuenta hoy.
Lo segundo es que no se debe confundir el progreso con la sofisticación. Puedes tener algo que es enormemente superior pero también enormemente más simple. Si tomo el ejemplo de la maleta, una vez que has visto una, el diseño resulta completamente obvio y evidente por sí mismo. ¿Pero fue un problema fácil de resolver? Diría que absolutamente no. La simple prueba de que la gestión de supply chain fue un problema difícil de resolver es que a una civilización industrial avanzada le tomó un poco más de cuatro décadas abordar este tema. El progreso es engañoso en el sentido de que no se rige por la regla de la sofisticación. Es muy difícil identificar cómo era el mundo antes de que ocurriera el progreso, porque literalmente cambia tu visión del mundo a medida que se produce.

Ahora, volvamos a nuestra discusión sobre supply chain. Esta es la sexta y última conferencia en este prólogo. Existe un plan completo que pueden consultar en línea en el sitio web de Lokad acerca de toda la serie de conferencias sobre supply chain. Hace dos semanas, presenté las tendencias del siglo XX para las supply chains, adoptando una perspectiva puramente cualitativa sobre el problema. Hoy, estoy tomando el enfoque opuesto al adoptar una perspectiva bastante cuantitativa sobre este conjunto de problemas como contrapunto.

Hoy, revisaremos un conjunto de principios. Por principio, me refiero a algo que puede usarse para mejorar el diseño de recetas numéricas en general para todas las supply chains. Tenemos la ambición de generalización aquí, y es ahí donde resulta bastante difícil encontrar elementos de prime relevancia para todas las supply chains y todos los métodos numéricos para mejorarlas. Revisaremos dos listas cortas de principios: principios observacionales y principios de optimización.
Los principios observacionales se aplican en la forma en que puedes obtener conocimiento e información cuantitativa sobre supply chains. Los principios de optimización se relacionan con cómo actúas una vez que has adquirido conocimiento cualitativo sobre tu supply chain, específicamente, cómo usar estos principios para mejorar tus procesos de optimización.
Comencemos por observar una supply chain. Me resulta desconcertante cuando la gente habla de las supply chains como si pudieran ser observadas directamente con sus propios ojos. Para mí, esta es una percepción muy distorsionada de la realidad de las supply chains. Las supply chains no pueden ser observadas directamente por los humanos, al menos no desde una perspectiva cuantitativa. Esto se debe a que las supply chains, por diseño, están distribuidas geográficamente, involucrando potencialmente miles de SKUs y decenas de miles de unidades. Con tus ojos humanos, solo podrías observar la supply chain tal como es hoy y no cómo era en el pasado. No puedes recordar más que unos pocos números o una pequeña fracción de los números asociados con tu supply chain.
Siempre que quieras observar una supply chain, realizarás dichas observaciones de forma indirecta a través de enterprise software. Esta es una forma muy específica de mirar las supply chains. Todas las observaciones que se pueden hacer de manera cuantitativa sobre las supply chains ocurren mediante este medio específico: enterprise software.
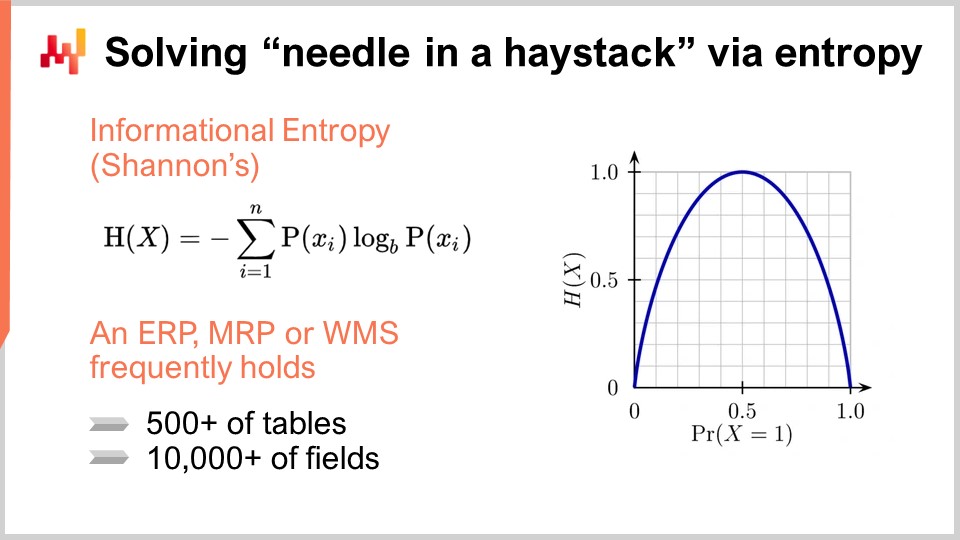
Caractericemos una pieza típica de enterprise software. Contendrá una base de datos, ya que la gran mayoría de este tipo de software está diseñada de esa manera. Es probable que el software tenga alrededor de 500 tablas y 10,000 campos (un campo es esencialmente una columna en una tabla). Como punto de entrada, tenemos un sistema que potencialmente contiene una cantidad masiva de información. Sin embargo, en la mayoría de las situaciones, solo una pequeña fracción de esta complejidad del software es realmente relevante para la supply chain de interés.
Los proveedores de software diseñan el enterprise software teniendo en cuenta situaciones muy diversas. Al mirar a un cliente específico, lo más probable es que solo se utilice una pequeña fracción de las capacidades del software. Esto significa que, aunque en teoría pueda haber 10,000 campos para explorar, en realidad las empresas solo utilizan una pequeña fracción de esos campos.
El desafío es cómo diferenciar la información relevante de los datos inexistentes o irrelevantes. Solo podemos observar las supply chains a través del enterprise software, y puede haber más de una pieza de software involucrada. En algunos casos, un campo nunca ha sido utilizado, y los datos son constantes, conteniendo solo ceros o nulos. En esta situación, es fácil eliminar el campo porque no contiene información alguna. Sin embargo, en la práctica, el número de campos que pueden eliminarse con este método puede ser de solo alrededor del 10%, ya que muchas características del software se han usado a lo largo de los años, aunque sea accidentalmente.
Para identificar los campos que nunca se han utilizado de manera significativa, podemos recurrir a una herramienta llamada entropía informacional. Para quienes no estén familiarizados con la teoría de la información de Shannon, el término puede parecer intimidante, pero en realidad es más sencillo de lo que parece. La entropía informacional se trata de cuantificar la cantidad de información en una señal, definiéndose una señal como una secuencia de símbolos. Por ejemplo, si tenemos un campo que contiene solo dos tipos de valores, verdadero o falso, y la columna oscila aleatoriamente entre estos valores, la columna contiene muchos datos. En contraste, si solo hay una línea de cada millón en la que el valor es verdadero y todas las demás líneas son falsas, el campo en la base de datos contiene casi nada de información.
La entropía informacional es muy interesante porque te permite cuantificar, en bits, la cantidad de información presente en cada campo de tu base de datos. Al realizar un análisis, puedes clasificar estos campos desde el más rico hasta el más pobre en términos de información y eliminar aquellos que apenas contienen información relevante para los propósitos de optimización de supply chain. La entropía informacional puede parecer complicada al principio, pero no es difícil de entender.

Por ejemplo, imaginando un lenguaje de programación específico para el dominio, hemos implementado la entropía informacional como un agregador. Tomando una tabla, como datos de un archivo plano llamado data.csv con tres columnas, podemos graficar un resumen de cuánta entropía hay en cada columna. Este proceso te permite determinar fácilmente qué campos contienen la menor cantidad de información y eliminarlos. Usando la entropía como guía, puedes iniciar rápidamente un proyecto en lugar de tardar años en hacerlo.
Pasando a la siguiente etapa, hacemos nuestras primeras observaciones sobre las supply chains y consideramos qué esperar. En las ciencias naturales, la expectativa por defecto son las distribuciones normales, también conocidas como curvas en forma de campana o gaussianas. Por ejemplo, la altura de un hombre de 20 años o su peso tendrá una distribución normal. En el ámbito de los seres vivos, muchas mediciones siguen este patrón. Sin embargo, cuando se trata de supply chain, este no es el caso. Prácticamente no hay nada de interés que esté distribuido normalmente en las supply chains.
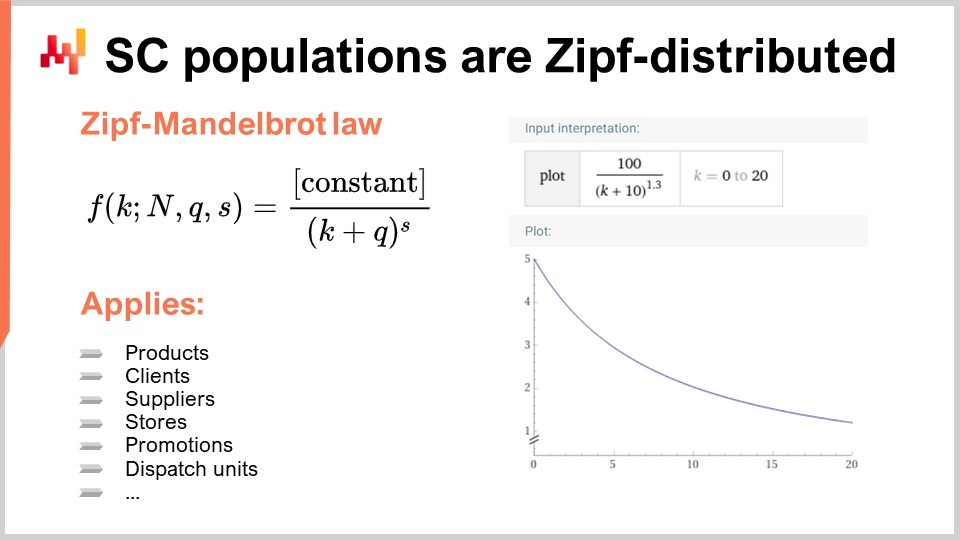
En cambio, casi todas las distribuciones de interés en las supply chains están distribuidas según Zipf. La distribución Zipf se ilustra en la fórmula dada. Para entender este concepto, considera una población de productos, siendo la medida de interés el volumen de ventas de cada producto. Ordenarías los productos desde el mayor hasta el menor volumen de ventas durante un período determinado, como un año. La pregunta entonces es si existe un modelo que prediga la forma de la curva y, dado el rango, proporcione el volumen de ventas esperado. Esto es precisamente de lo que se trata la distribución Zipf. Aquí, f representa la forma de una ley de Zipf-Mandelbrot, y k se refiere al k-ésimo elemento más grande. Existen dos parámetros, q y s, que se aprenden esencialmente, tal como tienes mu (la media) y sigma (la desviación estándar) para una distribución normal. Estos parámetros pueden usarse para ajustar la distribución a una población de interés. La ley de Zipf-Mandelbrot abarca estos parámetros.
Es importante señalar que prácticamente todas las poblaciones de interés en supply chain siguen una distribución Zipf. Esto es cierto para productos, clientes, proveedores, promotions e incluso unidades de despacho. La distribución Zipf es esencialmente un descendiente del principio de Pareto, pero es más manejable y, en mi opinión, más interesante, ya que proporciona un modelo explícito de lo que se puede esperar para cualquier población de interés en la supply chain. Si encuentras una población que no esté distribuida según Zipf, es más probable que haya un problema con los datos, en lugar de una verdadera desviación del principio.

Para explotar el concepto de distribución Zipf en el mundo real, puedes utilizar Envision. Si observamos este fragmento de código, verás que solo se requieren unas pocas líneas de código para aplicar este modelo a un conjunto de datos real. Aquí, asumo que existe una población de interés en un archivo plano llamado “data.csv” con una columna que representa la cantidad. Normalmente, tendrías un identificador de producto y la cantidad. En la línea 4, estoy calculando los rangos utilizando el agregador de ranking y ordenando según la cantidad. Luego, entre las líneas 6 y 11, entro en un bloque de programación diferenciable hecho explícito por Autodev, donde declaro tres parámetros escalares: c, q y s, al igual que en la fórmula a la izquierda de la pantalla. Luego, calculo las predicciones del modelo Zipf y utilizo un error cuadrático medio entre la cantidad observada y la predicción del modelo. Literalmente, puedes realizar una regresión de la distribución Zipf con solo unas pocas líneas de código. Aunque suene sofisticado, es bastante simple con las herramientas adecuadas.

Esto me lleva a otro aspecto observacional de supply chain: los números que esperarías en cualquier nivel de supply chain son pequeños, generalmente menos de 20. No solo tendrás pocas observaciones, sino que los números que observes también serán pequeños. Por supuesto, este principio depende de las unidades utilizadas, pero cuando digo “números”, me refiero a aquellos que tienen sentido canónico desde el punto de vista de supply chain, que son los que intentas observar y optimizar.
La razón por la que solo tenemos números pequeños se debe a economías de escala. Tomemos como ejemplo las camisetas en una tienda. La tienda podría tener miles de camisetas en stock, lo que parece un número grande, pero en realidad, tiene cientos de tipos diferentes de camisetas con variaciones en talla, color y diseño. Cuando comienzas a observar las camisetas con la granularidad relevante para supply chain, que es el SKU, la tienda no tendrá miles de unidades de camisetas para un SKU dado; en cambio, tendrá solo un puñado.
Si tienes un mayor número de camisetas, no vas a tener miles de camisetas sueltas, ya que sería una pesadilla en términos de procesamiento y traslado. En cambio, empacarás esas camisetas en cajas convenientes, que es precisamente lo que ocurre en la práctica. Si tienes un centro de distribución que se ocupa de muchas camisetas, porque las envías a tiendas, lo más probable es que esas camisetas estén en cajas. Incluso podrías tener una caja que contenga una gama completa de camisetas con tallas y colores variados, facilitando su procesamiento a lo largo de la cadena. Si tienes muchas cajas sueltas, no tendrás miles de cajas así. En cambio, si tienes docenas de cajas, las organizarás ordenadamente en pallets. Un pallet puede contener varias docenas de cajas. Si tienes muchos pallets, no los tendrás organizados como pallets individuales; lo más probable es que los organices como contenedores. Y si tienes muchos contenedores, vas a utilizar un buque de carga o algo similar.
Mi punto es que, cuando se trata de números en supply chain, el número verdaderamente relevante es siempre pequeño. Esta situación no se puede evadir simplemente pasando a un nivel de agregación superior, porque, a medida que te mueves a un nivel mayor de agregación, entra en juego algún tipo de economías de escala, y deseas introducir un mecanismo de agrupación para reducir tus costos operativos. Esto sucede múltiples veces, así que sin importar la escala que estés observando, ya sea el producto final vendido por unidad en una tienda o un artículo de producción masiva, siempre es un juego de números pequeños.
Incluso si tienes una fábrica que produce millones de camisetas, lo más probable es que tengas lotes gigantes, y los números que te interesan no son el número de camisetas, sino el número de lotes, que será un número mucho menor.
¿A qué quiero llegar con este principio? Primero, hay que observar cómo son la mayoría de los métodos en computación científica o estadística. Resulta que, en la mayoría de los otros campos que no están relacionados con supply chain, prevalece lo contrario: grandes cantidades de observaciones y números grandes donde la precisión importa. En supply chain, sin embargo, los números son pequeños y discretos.
Mi propuesta es que necesitamos herramientas basadas en este principio que acomoden y abracen profundamente el hecho de que vamos a tener números pequeños en lugar de números grandes. Si tienes herramientas que han sido diseñadas únicamente con la ley de los grandes números en mente, ya sea por muchas observaciones o por los números grandes en sí, tienes un desajuste completo cuando se trata de supply chain.
Por cierto, esto tiene profundas implicaciones en el software. Si tienes números pequeños, hay muchas maneras de aprovechar que las capas de software se beneficien de esta observación. Por ejemplo, si observas el conjunto de datos de líneas de transacción para un hipermercado, notarás que, según mi experiencia y observación, el 80% de las líneas tienen una cantidad que se vende a un cliente final en un hipermercado que es exactamente uno. Entonces, ¿necesitas 64 bits de información para representar esta información? No, eso es un completo desperdicio de espacio y tiempo de procesamiento. Abrazar este concepto puede resultar en una ganancia operativa de una o dos órdenes de magnitud. Esto no es solo un pensamiento ilusorio; hay ganancias operativas reales. Podrías pensar que las computadoras hoy en día son muy poderosas, y lo son, pero si dispones de más poder de procesamiento, puedes tener algoritmos más avanzados que hagan cosas incluso mejores para tu supply chain. Es inútil desperdiciar este poder de procesamiento solo porque tienes un paradigma que espera números grandes cuando prevalecen los números pequeños.
Esto me lleva a mi último principio observacional de hoy: los patrones están en todas partes en supply chain. Para entender esto, echemos un vistazo a un problema clásico de supply chain donde usualmente se consideran ausentes los patrones: la optimización de rutas. El problema clásico de la optimización de rutas implica una lista de entregas por realizar. Puedes ubicar las entregas en un mapa, y deseas encontrar la ruta que minimice el tiempo de transporte. Quieres establecer una ruta que pase por cada punto de entrega mientras minimizas el tiempo total de transporte. A primera vista, este problema parece ser un problema completamente geométrico sin patrones involucrados en su resolución.
Sin embargo, propongo que esta perspectiva es completamente errónea. Al abordar el problema desde este ángulo, estás mirando el problema matemático, no el problema de supply chain. Las supply chains son juegos iterativos donde los problemas se manifiestan repetidamente. Si te dedicas a organizar entregas, lo más probable es que realices entregas cada día. No es solo una ruta; es literalmente una ruta por día, al menos.
Además, si te dedicas a realizar entregas, es probable que cuentes con una flota completa de vehículos y conductores. El problema no es solo optimizar una ruta; es optimizar toda una flota, y este juego se repite cada día. Ahí es donde aparecen todos los patrones.
Primero, los puntos no se distribuyen aleatoriamente en el mapa. Tienes puntos críticos, o áreas geográficas con una alta densidad de entregas. Puede que tengas direcciones que reciben entregas casi todos los días, como la sede de una gran empresa en una ciudad importante. Si eres una gran empresa de ecommerce, probablemente estés entregando paquetes a esta dirección en cada día hábil. Estos puntos críticos no son inmutables; tienen su estacionalidad. Algunos barrios pueden estar muy tranquilos durante el verano o el invierno. Existen patrones, y si quieres ser muy bueno en el juego de la optimización de rutas, debes tener en cuenta no solo dónde van a ocurrir estos puntos críticos, sino también cómo se desplazarán a lo largo del año. Además, debes considerar el tráfico. No debes pensar únicamente en la distancia geométrica, ya que el tráfico depende del tiempo. Si un conductor comienza en cierto momento del día, a medida que avanza por su ruta, el tráfico cambiará. Para jugar bien este juego, necesitas tener en cuenta los patrones de tráfico, que cambian y pueden preverse de forma confiable con antelación. Por ejemplo, en París, a las 9:00 AM y a las 6:00 PM, toda la ciudad está completamente congestionada, y no es necesario ser un experto en previsión para saberlo.
También ocurren cosas en el momento, como accidentes que alteran los patrones habituales del tráfico. Si observamos las entregas desde una perspectiva matemática, se asume que todos los puntos de entrega son iguales, pero no lo son. Podrías tener clientes VIP, o direcciones específicas donde debes entregar la mitad de tu envío. Estos hitos clave en tu ruta deben ser considerados para una optimización efectiva de la ruta.
También debes estar al tanto del contexto, y es común tener datos imperfectos sobre el mundo. Por ejemplo, si un puente está cerrado y el software no lo sabe, el problema no es que no se supiera que el puente estaba cerrado la primera vez, sino que el software nunca aprende del problema y siempre propone una ruta que se supone que es óptima pero termina siendo absurda. La gente entonces se enfrenta al sistema, lo cual no es una buena solución práctica de optimización de rutas desde la perspectiva de supply chain.
La cuestión es que cuando observamos situaciones de supply chain, hay abundantes patrones por todas partes. Tenemos que tener cuidado de no distraernos con estructuras matemáticas elegantes y recordar que estas consideraciones también se aplican a la previsión de series temporales. Tomé el problema de la optimización de rutas como ejemplo porque en este caso era más evidente.
En conclusión, necesitamos observar supply chain desde todas las dimensiones que sean observables, no solo aquellas que sean obvias o donde la solución se presente de manera elegante.

Esto me lleva a la segunda serie de principios relacionados con cómo debemos observar nuestra supply chain. Hasta ahora, hemos visto cuatro principios relacionados con cómo debemos observar nuestra supply chain: la observación indirecta, el software empresarial, ordenar el caos para determinar qué es relevante y qué no, y la entropía. Hemos observado que las distribuciones a menudo siguen la ley de Zipf, y aún con números pequeños, podemos ver cómo emergen patrones. La pregunta ahora es, ¿cómo actuamos? Matemáticamente hablando, cuando queremos decidir el mejor curso de acción, realizamos algún tipo de optimización, que es la perspectiva cuantitativa.

Lo primero a notar es que tan pronto como tenemos una pieza de lógica de optimización en producción para supply chain, surgirán problemas, como errores. El software empresarial es una bestia muy compleja y a menudo está lleno de bugs. Mientras elaboras tu propia lógica de optimización para tu supply chain, habrá muchos problemas. Sin embargo, si una pieza de lógica es lo suficientemente buena como para ponerse en producción, cualquier problema que enfrentemos ahora probablemente sean casos extremos. Si no fuera un caso extremo y el software o la lógica fallara cada vez, nunca habría llegado a producción.
La idea de este principio es que se necesitan entre cinco y diez rondas para solucionar cualquier problema. Cuando digo cinco a diez rondas, me refiero a que te enfrentarás a un problema, lo examinarás, comprenderás la causa raíz y luego intentarás aplicar una solución. Pero la mayoría de las veces, la solución no resolverá el problema. Descubrirás que había un problema oculto dentro del problema, o que el problema que pensaste haber solucionado no era la causa real, o que la situación ha revelado una clase más amplia de problemas. Puede que hayas solucionado una pequeña instancia de una clase más amplia de problemas, pero otros problemas seguirán ocurriendo que son variantes del que creíste haber resuelto.
Las supply chains son bestias complejas y en constante cambio que operan en el mundo real, lo que dificulta tener un diseño que sea correctamente adecuado para todas las situaciones. En la mayoría de los casos, haces un esfuerzo máximo para solucionar un problema, y luego tienes que poner a prueba tu lógica revisada con la experiencia del mundo real para ver si funciona o no. Tendrás que iterar para solucionar el problema. Con el principio de que se necesitan entre cinco y diez iteraciones para solucionar un problema, hay consecuencias profundas en la velocidad de las adaptaciones y en la frecuencia con la que actualizas o recalculas tu lógica de optimización de supply chain. Por ejemplo, si tienes una pieza de lógica que está produciendo una previsión trimestral para los próximos dos años y solo ejecutas esta lógica una vez por trimestre, tomará entre uno y dos años solucionar cualquier problema que enfrentes con esta lógica de previsión, lo cual es un tiempo increíblemente largo.
Incluso si tienes una pieza de lógica que se ejecuta cada mes, como en el caso de un S&OP (Sales and Operations Planning), aún podría tomar hasta un año solucionar un problema. Por ello, es importante aumentar la frecuencia con la que se ejecuta tu lógica de optimización de supply chain. En Lokad, por ejemplo, cada porción de lógica se ejecuta a diario, incluso para previsiones a cinco años vista. Estos previsiones se actualizan diariamente, incluso si no cambian mucho de un día para el siguiente. El objetivo no es ganar precisión estadística, sino asegurar que la lógica se ejecute con la frecuencia suficiente para solucionar cualquier problema o bug en un plazo razonable.
Esta observación no es exclusiva de la gestión de supply chain. Equipos de ingeniería inteligentes en compañías como Netflix han popularizado la idea de la chaos engineering. Se dieron cuenta de que los casos extremos eran raros y que la única manera de solucionar estos problemas era repetir la experiencia con mayor frecuencia. Como resultado, crearon un software llamado Chaos Monkey, que añade caos a su infraestructura de software creando disrupciones en la red y caídas aleatorias. El propósito de Chaos Monkey es hacer que los casos extremos se manifiesten más rápidamente, permitiendo al equipo de ingeniería solucionarlos más rápidamente.
Aunque pueda parecer contraintuitivo introducir un nivel extra de caos en tus operaciones, este enfoque ha demostrado ser efectivo para Netflix, que es conocida por su excelente fiabilidad. Ellos entienden que cuando se enfrentan a un problema impulsado por software, se requieren muchas iteraciones para resolverlo, y la única manera de llegar al fondo del problema es iterar rápidamente. Chaos Monkey es solo una forma de aumentar la velocidad de iteración.
Desde una perspectiva de supply chain, el Chaos Monkey puede no ser directamente aplicable, pero el concepto de aumentar la frecuencia de ejecutar la lógica de optimización de supply chain sigue siendo muy relevante. Sea cual sea la lógica que tengas para optimizar tu supply chain, necesita ejecutarse a alta velocidad y alta frecuencia; de lo contrario, nunca solucionarás ninguno de los problemas a los que te enfrentas.

Ahora, los supply chains envejecidos son cuasi-óptimos, y cuando digo envejecidos, me refiero a aquellos supply chains que han estado en operación por dos décadas o más. Otra forma de enunciar este principio es que tus predecesores en supply chain no eran todos incompetentes. Cuando observas las iniciativas de optimización de supply chain, con demasiada frecuencia, existen grandes ambiciones como reducir los niveles de stock a la mitad, aumentar los niveles de servicio del 95% al 99%, eliminar faltante de stock, o dividir los tiempos de entrega a la mitad. Estos son movimientos grandes y unidireccionales en los que te concentras en un solo KPI e intentas mejorarlo masivamente. Sin embargo, he observado que estas iniciativas casi siempre fallan por una razón muy directa: cuando tomas un supply chain que ha estado en operación durante décadas, generalmente hay una sabiduría latente en la forma en que se han hecho las cosas.
Por ejemplo, si los niveles de servicio están al 95%, es probable que si intentas aumentarlos al 99%, incrementarás enormemente los niveles de stock y crearás una cantidad masiva de stock muerto en el proceso. De igual forma, si tienes cierta cantidad de stock y lanzas una iniciativa masiva para reducirlo a la mitad, probablemente crearás problemas significativos de calidad de servicio que serán insostenibles.
Lo que he observado es que muchos practitioners de supply chain que no entienden el principio de que los supply chains envejecidos son cuasi-óptimos de forma unidireccional tienden a oscilar alrededor del óptimo local. Ten en cuenta que no estoy diciendo que los supply chains envejecidos sean óptimos, sino que son cuasi-óptimos de forma unidireccional. Si miras la analogía del Gran Cañón, el río talla el camino óptimo debido a la fuerza unidireccional de la gravedad. Si aplicases una fuerza diez veces mayor, el río aún sufriría muchas convoluciones.
El punto es que con los supply chains envejecidos, si deseas lograr mejoras considerables, necesitas ajustar muchas variables a la vez. Centrarse en una sola variable no dará los resultados deseados, especialmente si tu empresa ha estado operando durante décadas con el status quo. Tus predecesores probablemente hicieron algunas cosas bien en su momento, por lo que las probabilidades de que te encuentres con un supply chain tremendamente disfuncional al que nadie le haya prestado atención son mínimas. Los supply chains son problemas perversos, y aunque es posible diseñar situaciones completamente disfuncionales a gran escala, será extremadamente poco frecuente, en el mejor de los casos.

Otro aspecto a considerar es que la optimización local solo desplaza los problemas en lugar de resolverlos. Para entender esto, tienes que reconocer que los supply chains son sistemas, y cuando se piensa en términos de rendimiento de supply chain, solo el rendimiento a nivel de sistema es de interés. El rendimiento local es relevante, pero es solo una parte del panorama.
Una forma común de pensar es que puedes aplicar la estrategia de divide y vencerás para abordar problemas en general, no solo problemas de supply chain. Por ejemplo, en una red de retail con muchas tiendas, podrías querer optimizar los niveles de stock en cada tienda. Sin embargo, el problema es que si tienes una red de tiendas y centros de distribución, cada uno sirviendo a muchas tiendas, es completamente trivial micro-optimizar una tienda y lograr una excelente calidad de servicio para esa tienda a expensas de todas las demás.
La perspectiva correcta es pensar que cuando tienes una unidad disponible en el centro de distribución, la pregunta que debes hacerte es: ¿dónde se necesita más esta unidad? ¿Cuál es el movimiento más rentable para mí? El problema de optimizar el despacho del inventario, o el problema de asignación de inventario, es uno que solo tiene sentido a nivel sistémico, no a nivel de tienda. Si optimizas lo que sucede en una tienda, es probable que crees problemas en otra.
Cuando digo “local”, este principio no debe entenderse únicamente desde una perspectiva geográfica; también puede ser un asunto puramente lógico dentro del supply chain. Por ejemplo, si eres una empresa de ecommerce con muchas categorías de productos, puede que desees asignar presupuestos variables para las diferentes categorías. Esta es otra estrategia de divide y vencerás. Sin embargo, si particionas tu presupuesto y asignas una cantidad fija al inicio del año para cada categoría, ¿qué sucede si la demanda de productos en una categoría se duplica mientras que en otra se reduce a la mitad? En ese caso, terminas con un problema de asignación incorrecta de fondos entre esas dos categorías. El reto aquí es que no puedes aplicar ningún tipo de lógica de divide y vencerás. Si utilizas técnicas de optimización local, podrías acabar creando problemas mientras elaboras tu supuestamente optimizada solución.

Esto me lleva al último principio, que probablemente es el más complicado de todos los principios que he presentado hoy: los mejores problemas superan a las mejores soluciones. Esto puede ser extremadamente confuso, especialmente entre ciertos círculos académicos. La forma típica en que se presentan las cosas a través de una educación clásica es que se te presenta un problema bien definido, y luego comienzas a buscar soluciones para ese problema. En un problema matemático, por ejemplo, un estudiante puede presentar una solución más concisa y elegante, y esa se considera la mejor solución.
Sin embargo, en la realidad, las cosas no suceden de esa manera en la gestión de supply chain. Para ilustrar esto, volvamos 60 años atrás y observemos el problema de la cocina, una actividad que consume mucho tiempo. Las personas en el pasado imaginaban que en el futuro se podrían utilizar robots para realizar tareas de cocina, aumentando así significativamente la productividad de la persona encargada de cocinar. Este tipo de pensamiento era predominante en los años 50 y 60.
Avanzando rápidamente hasta hoy, es obvio que así no han evolucionado las cosas. Para minimizar el esfuerzo en la cocina, ahora las personas compran comidas pre-cocinadas. Este es otro ejemplo de desplazamiento de problemas. Proveer a los supermercados con comidas pre-cocinadas es más desafiante desde una perspectiva de supply chain que proporcionarles productos crudos, debido al mayor número de referencias y a las fechas de caducidad más cortas. El problema se resolvió mediante una superior solución de supply chain, no ofreciendo una mejor solución de cocina. El problema de la cocina fue eliminado por completo y redefinido como la provisión de una comida medianamente decente con el mínimo esfuerzo.
En términos de supply chain, la perspectiva académica a menudo se centra en encontrar mejores soluciones para problemas existentes. Un buen ejemplo serían las competiciones de Kaggle, donde tienes un conjunto de datos, un problema y potencialmente cientos o miles de equipos compitiendo para obtener la mejor predicción en esos conjuntos de datos. Tienes un problema bien definido y miles de soluciones compitiendo entre sí. El problema con esta mentalidad es que te da la impresión de que, si deseas aportar mejoras a tu supply chain, lo único que necesitas es una mejor solución.
La esencia del principio es que una mejor solución podría ayudar de forma marginal, pero solo de forma marginal. Normalmente, lo que realmente ayuda es cuando redefinís el problema, y eso es sorprendentemente difícil. Esto se aplica también a problemas cuantitativos. Necesitas replantear tu estrategia real de supply chain y el problema clave que deberías estar optimizando.
En muchos círculos, las personas consideran los problemas como si fueran estáticos e inmutables, buscando mejores soluciones. No niego que contar con un mejor algoritmo de previsión de series temporales pueda ser de ayuda, pero la previsión de series temporales pertenece al ámbito de la previsión estadístico, no a la maestría en la gestión de supply chain. Si volvemos a mi ejemplo inicial de la maleta de viaje, la mejora clave para una maleta con ruedas no fue sobre las ruedas, sino sobre el asa. Fue algo que, a primera vista, no tenía nada que ver con las ruedas, y por eso tomó 40 años llegar a una solución – tienes que pensar de manera innovadora para dejar que emerja el mejor problema.
Este principio cuantitativo trata de desafiar los problemas que enfrentas. Tal vez no estés pensando lo suficiente en el problema, y existe la tendencia de enamorarte de la solución cuando deberías estar concentrado en el problema y en los aspectos que no lo entiendes. En cuanto tienes un problema bien definido, contar con una buena solución es usualmente solo un asunto mundano de ejecución, lo cual no es tan difícil.

En conclusión, el supply chain como campo de estudio tiene muchas perspectivas impresionantes y autoritativas. Estas pueden ser sofisticadas, pero la pregunta que me gustaría hacer a esta audiencia es: ¿podría ser que todo eso esté gravemente mal encaminado? ¿Estamos realmente seguros de que elementos como la previsión de series temporales y la investigación operativa son las perspectivas adecuadas sobre el problema? No importa la cantidad de sofisticación y décadas de ingeniería y esfuerzo invertidas en perseguir esas direcciones, ¿estamos realmente en el camino correcto?
Hoy, presento una serie de principios que creo son de suma relevancia para la gestión de supply chain. Sin embargo, pueden parecer extraños para la mayoría de ustedes. Tenemos dos mundos aquí – el probado y el extraño – y la pregunta es qué pasará dentro de unas décadas.

El progreso tiende a desarrollarse de manera caótica y no lineal. La idea con estos principios es permitirte abrazar un mundo altamente caótico, donde hay espacio para lo inesperado. Estos principios pueden ayudarte a desarrollar soluciones más rápidas, confiables y eficientes que aportarán mejoras a tus supply chains desde una perspectiva cuantitativa.

Ahora, pasemos a algunas preguntas.
Pregunta: ¿Cómo se comparan las distribuciones de Zipf con la ley de Pareto?
La ley de Pareto es la regla del 80-20, pero desde una perspectiva cuantitativa, la distribución de Zipf es un modelo predictivo explícito. Tiene capacidades predictivas que pueden ser contrastadas contra conjuntos de datos de una manera muy directa.
Pregunta: ¿No se vería mejor la distribución Zipf-Mandelbrot como una curva logarítmica para ver las fluctuaciones del supply chain, como lo hacen los epidemiólogos con el reporte de casos y muertes?
Absolutamente. A nivel filosófico, la cuestión es si vives en Mediocrity-land o en Extreme-land. Los supply chains y la mayoría de los asuntos humanos existen en el mundo de los extremos. Las curvas logarítmicas son, de hecho, útiles si quieres visualizar la amplitud de las promociones. Por ejemplo, si quieres ver las amplitudes de todas las promociones pasadas para grandes redes de retail durante los últimos 10 años, usar una escala regular podría hacer que todo lo demás sea invisible, simplemente porque la mayor promoción fue mucho más grande que las demás. Entonces, usar una escala logarítmica puede ayudarte a ver las variaciones con mayor claridad. Con la distribución Zipf-Mandelbrot, te estoy ofreciendo un modelo que literalmente puedes implementar con unas pocas líneas de código, lo cual es más que solo una vista logarítmica de los datos. Sin embargo, concuerdo en que la intuición central es la misma. Para una perspectiva filosófica de alto nivel, recomiendo leer el trabajo de Nassim Taleb sobre Mediocristán versus Extremistán en su libro “Antifragile.”
Pregunta: En el tema de la optimización local de supply chain, ¿te estás refiriendo a los datos subyacentes que respaldan la colaboración en la red de supply chain y el SNLP?
Mi problema con la optimización local es que las grandes empresas que operan supply chains importantes generalmente tienen organizaciones matriciales. Esta estructura organizacional, con su mentalidad de divide y vencerás, resulta en una optimización local por diseño. Por ejemplo, considera dos equipos diferentes: uno responsable de la previsión de la demanda y el otro de las decisiones de compras. Estos dos problemas – la previsión de la demanda y la optimización de compras – están completamente entrelazados. No se puede realizar una optimización local centrándose únicamente en el porcentaje de error en la previsión de la demanda y luego optimizando por separado las compras en función de la eficiencia del procesamiento. Hay efectos sistémicos, y necesitas considerarlos todos en conjunto.
El mayor reto para la mayoría de las grandes empresas establecidas que manejan supply chains significativos hoy en día es que, al apuntar a la optimización cuantitativa, tienes que pensar a nivel de sistema y a nivel de toda la empresa. Esto va en contra de décadas de sedimentación de la organización matricial dentro de la empresa, donde las personas se han enfocado únicamente en sus límites bien definidos, olvidándose del panorama global.
Otro ejemplo de este problema sería el inventario en las tiendas. El stock cumple dos propósitos: por un lado, satisface la demanda del cliente, y por otro, actúa como mercancía. Para tener la cantidad correcta de stock, necesitas abordar el problema de la calidad de servicio y el problema del atractivo de la tienda. El atractivo de la tienda se trata de hacer que la tienda luzca atractiva e interesante para los clientes, lo cual es más un problema de marketing. En una empresa, tienes una división de marketing y una división de supply chain, y no suelen trabajar de manera conjunta cuando se trata de optimización de supply chain. Mi punto es que, si no juntas todos estos aspectos, la optimización no funcionará.
En cuanto a tu preocupación sobre el SNLP, el problema es que la gente se reúne solo para tener reuniones, lo cual no es muy eficiente. Publicamos un episodio de Lokad TV sobre el SNLP hace unos meses, así que puedes referirte a ese si deseas tener una discusión específica sobre el SNLP.
Pregunta: ¿Cómo deberíamos distribuir el tiempo y la energía entre la estrategia de supply chain y la ejecución cuantitativa?
Esa es una excelente pregunta. La respuesta, como mencioné en mi segunda conferencia, es que necesitas una robotización completa de las tareas mundanas. Esto te permite dedicar todo tu tiempo y energía a la mejora estratégica continua de tus recetas numéricas. Si dedicas más del 10% de tu tiempo a lidiar con aspectos mundanos de la ejecución de supply chain, tienes un problema con tu metodología. Los Supply Chain Scientist son demasiado valiosos para desperdiciar su tiempo y energía en problemas de ejecución mundanos que deberían automatizarse en primer lugar.
Necesitas seguir una metodología que te permita dedicar casi toda tu energía al pensamiento estratégico, el cual se implementa de inmediato como recetas numéricas superiores que impulsan la ejecución diaria de supply chain. Esto se relaciona con mi tercera conferencia sobre entrega orientada al producto, donde me refiero a la entrega orientada al producto de software.
Question: ¿Es posible hipotetizar una especie de análisis de techo, la mejor mejora posible para los problemas de supply chain, dada su formulación sistémica?
Yo diría que no, absolutamente no. Pensar que existe algún tipo de óptimo o techo es equivalente a decir que hay un límite al ingenio humano. Aunque no tengo ninguna prueba de que no exista un límite al ingenio humano, es una de mis creencias fundamentales. Las supply chain son problemas complejos. Puedes transformar el problema, e incluso convertir lo que aparentemente es un gran problema en una gran solución y en un potencial de crecimiento para la empresa. Por ejemplo, mira Amazon. Jeff Bezos, a principios de la década de 2000, entendió que, para tener éxito como minorista, necesitaría una infraestructura de software masiva y sólida como una roca. Pero esta infraestructura masiva, de grado industrial y de producción, que necesitaba para operar el ecommerce de Amazon, era increíblemente costosa, costándole a la empresa miles de millones. Así que, los equipos de Amazon decidieron convertir esta infraestructura de computación en la nube, que era una inversión enorme, en un producto comercial. Hoy en día, esta infraestructura de computación a gran escala es, de hecho, una de las fuentes principales de beneficio para Amazon.
Cuando comienzas a pensar en problemas complejos, siempre puedes redefinir el problema de una manera superior. Por eso creo que es un error pensar que existe algún tipo de solución óptima. Cuando piensas en términos de análisis de techo, estás viendo un problema fijo, y desde esa perspectiva podrías tener una solución que es probablemente cuasi-óptima. Por ejemplo, si miras las ruedas de las maletas modernas, probablemente sean cuasi-óptimas. Pero, ¿hay algo que sea completamente obvio que nos estemos perdiendo? Tal vez exista una forma de mejorar considerablemente las ruedas, una invención que aún no se ha realizado. En cuanto la veamos, parecerá completamente evidente.
Por eso debemos pensar que no existe tal cosa como un techo para estos problemas, porque los problemas son arbitrarios. Puedes redefinir el problema y decidir que el juego se juegue según reglas completamente diferentes. Esto resulta desconcertante porque a la gente le gusta pensar que tiene un problema cuidadosamente diseñado y puede encontrar soluciones. El sistema educativo occidental moderno enfatiza una mentalidad de búsqueda de soluciones, donde te presentamos un problema y evaluamos la calidad de tu solución. Sin embargo, una pregunta mucho más interesante es la calidad del propio problema.
Question: Las mejores soluciones resolverán los problemas, pero a veces encontrar la mejor solución puede costar tanto tiempo como dinero. ¿Existen soluciones alternativas para esto?
Absolutamente. Además, si tienes una solución que es teóricamente correcta pero que tarda una eternidad en implementarse, no es una buena solución. Este tipo de pensamiento tiende a ser prevalente en ciertos círculos académicos, donde se centran en encontrar la solución perfecta según criterios matemáticos de mente estrecha que no tienen nada que ver con el mundo real. Eso es exactamente de lo que estaba hablando cuando mencioné el problema de optimización correcto.
Cada trimestre o algo así, llega un profesor que me pide si podría revisar su algoritmo online para resolver el problema de optimización de rutas. La mayoría de los artículos que reviso hoy en día se centran en variantes online. Mi respuesta es siempre la misma: no estás resolviendo el problema correcto. No me importa tu solución porque ni siquiera estás pensando correctamente sobre el problema en sí mismo.
El progreso no debe confundirse con la sofisticación. Es una percepción equivocada pensar que el progreso pasa de algo simple a algo sofisticado. En realidad, el progreso a menudo se logra empezando con algo increíblemente enrevesado y, mediante un pensamiento superior y tecnología, alcanzando la simplicidad. Por ejemplo, si miras mi última conferencia sobre tendencias de supply chain para el siglo XXI, verás la Máquina de Marly, que llevó agua al Palacio de Versalles. Era un sistema increíblemente complicado, mientras que las bombas eléctricas modernas son mucho más simples y eficientes.
El progreso no se encuentra necesariamente en una sofisticación adicional. A veces es necesaria, pero no es un ingrediente esencial del progreso.
Question: Las grandes redes minoristas están impulsando su nivel de stock, pero necesitan cumplir los pedidos casi de inmediato. A veces deciden hacer una promoción por su cuenta que no ha sido iniciada por el proveedor. ¿Cuál sería el enfoque para predecir y prepararse en consecuencia a nivel del proveedor?
Primero, tenemos que ver el problema desde una perspectiva diferente. Estás asumiendo una perspectiva de previsión, donde tu cliente, un gran minorista, está realizando una gran promoción que surge de la nada. Primero, ¿es algo tan malo? Si promocionan tus productos sin informarte, eso es simplemente parte de la vida. Si miras tu historial, usualmente lo hacen de forma regular, e incluso existen patrones.
Si vuelvo a mis principios, los patrones están en todas partes. Primero, necesitas adoptar la perspectiva de que no puedes previsión el futuro; en cambio, necesitas previsiones probabilísticas. Aunque no puedas anticipar perfectamente las fluctuaciones, quizás tampoco sean del todo inesperadas. Tal vez necesites cambiar las reglas del juego en lugar de permitir que el proveedor te sorprenda por completo. Quizás necesites negociar compromisos que obliguen al minorista, a la red minorista y al proveedor. Si la red minorista comienza a hacer un gran impulso sin avisar al proveedor, este no puede ser considerado responsable de no mantener la calidad del servicio.
Quizás la solución sea algo más colaborativa. Quizás el proveedor debería tener una mejor evaluación de riesgos. Si los materiales vendidos por el proveedor no son perishable, podría ser más rentable tener un par de meses de stock. La gente a menudo piensa en tener cero retraso, cero stock y cero de todo, pero ¿es eso realmente lo que tus clientes esperan de ti? Quizás lo que tus clientes esperan es valor añadido en forma de un abundante stock. De nuevo, la respuesta depende de varios factores.
Necesitas ver el problema desde muchos ángulos, y no hay una solución trivial. Debes pensar muy detenidamente en el problema y considerar todas las opciones disponibles para ti. Quizás el problema no sea tener más stock, sino más capacidad de producción. Si hay un gran aumento de la demanda y no es demasiado costoso tener un pico masivo, y los proveedores de los proveedores pueden suministrar los materiales lo suficientemente rápido, tal vez lo único que necesites sea una capacidad de producción más versátil. Esto te permitiría redirigir tu capacidad de producción hacia aquello que esté experimentando un pico en este momento.
Por cierto, esto existe en ciertas industrias. Por ejemplo, la industria del empaque tiene capacidades masivas. La mayoría de las máquinas en la industria del empaque son impresoras industriales, las cuales son relativamente económicas. La gente en el negocio del empaque normalmente tiene muchas impresoras que no se utilizan la mayor parte del tiempo. Sin embargo, cuando hay un gran evento o una gran marca quiere hacer un empuje masivo, tienen la capacidad de imprimir toneladas de nuevos empaques que se ajusten al nuevo impulso de marketing de la marca.
Así que, realmente depende de varios factores, y me disculpo por no tener una respuesta definitiva. Pero lo que sí puedo decir con certeza es que debes pensar muy detenidamente en el problema al que te enfrentas.
Esto concluye la conferencia de hoy, la sexta y última del prólogo. Dentro de dos semanas, a la misma hora y día, estaré presentando sobre supply chain personalities. Hasta la próxima.


