00:54 Introduction
02:25 Sur la nature du progrès
05:26 L’histoire jusqu’à présent
06:10 Quelques principes quantitatifs : principes d’observation
07:27 Résolution de “l’aiguille dans une botte de foin” via l’entropie
14:58 Les populations de SC sont Zipf-distribuées
22:41 Les petits nombres prédominent dans les décisions en SC
29:44 Les motifs se retrouvent partout dans la SC
36:11 Quelques principes quantitatifs : principes d’optimisation
37:20 Il faut entre 5 et 10 itérations pour régler tout problème en SC
44:44 Les supply chain vieillissantes sont quasi-optimales de manière unidirectionnelle
49:06 Les optimisations locales de SC ne font que déplacer les problèmes
52:56 De meilleurs problèmes l’emportent sur de meilleures solutions
01:00:08 Conclusion
01:02:24 Prochaine conférence et questions du public
Description
Bien que les supply chain ne puissent être caractérisées par des lois quantitatives définitives - contrairement à l’électromagnétisme - des principes quantitatifs généraux peuvent néanmoins être observés. Par “général”, nous entendons qu’ils s’appliquent à (presque) toutes les supply chain. La découverte de tels principes est d’un intérêt majeur car ils peuvent être utilisés pour faciliter l’ingénierie de recettes numériques destinées à l’optimisation prédictive des supply chain, tout en renforçant la puissance globale de ces recettes numériques. Nous passons en revue deux listes succinctes de principes : quelques principes d’observation et quelques principes d’optimisation.
Transcription complète

Bonjour à tous, et bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter quelques “Principes Quantitatifs pour la Supply Chain.” Pour ceux d’entre vous qui regardent la conférence en direct sur YouTube, vous pouvez poser vos questions à tout moment via le chat YouTube. Cependant, je ne lirai pas vos questions pendant les conférences. Je reviendrai vers le chat à la fin de la conférence et ferai de mon mieux pour répondre à la plupart d’entre elles.
Les principes quantitatifs présentent un grand intérêt car, dans les supply chain, comme nous l’avons vu lors des premières conférences, ils impliquent la maîtrise de l’optionnalité. La plupart de ces options sont de nature quantitative. Vous devez décider combien acheter, combien produire, combien de stocks déplacer, et potentiellement le niveau de prix – que vous souhaitiez l’augmenter ou le diminuer. Ainsi, un principe quantitatif susceptible de stimuler les améliorations des recettes numériques pour les supply chain revêt un intérêt majeur.
Cependant, si je demandais à la plupart des autorités ou experts en supply chain de nos jours quels sont leurs principes quantitatifs fondamentaux pour les supply chain, je suppose que, fréquemment, j’obtiendrais une réponse consistant en une série de techniques pour une meilleure prévision des séries temporelles ou quelque chose d’équivalent. Ma réaction personnelle est que, bien que cela soit intéressant et pertinent, cela passe à côté de l’essentiel. Je crois qu’au fond, la méprise réside dans la nature même du progrès – qu’est-ce que le progrès et comment peut-on mettre en œuvre quelque chose qui s’apparente au progrès en ce qui concerne les supply chain ? Permettez-moi de commencer par un exemple illustratif.

Il y a six mille ans, la roue fut inventée, et six mille ans plus tard, la valise à roulettes fut inventée. L’invention est datée de 1949, comme l’illustre ce brevet. Au moment de l’invention de la valise à roulettes, nous avions déjà maîtrisé l’énergie atomique et même fait exploser les premières bombes atomiques.
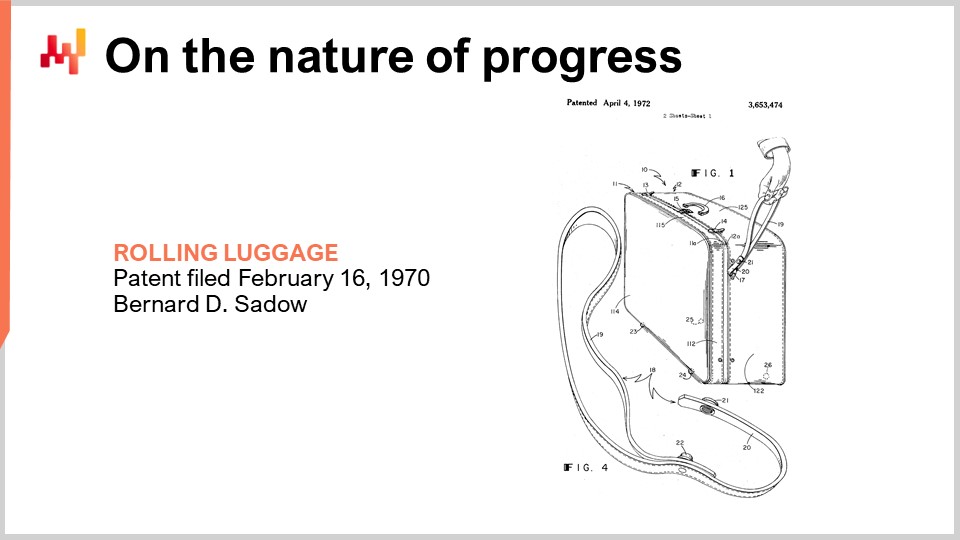
Avance rapide de 20 ans, en 1969, l’humanité a envoyé les premières personnes sur la lune. L’année suivante, la valise à roulettes est améliorée avec une poignée légèrement meilleure, qui ressemble à une laisse, comme l’illustre ce brevet. Elle reste toutefois assez médiocre.

Puis, 20 ans plus tard, à cette époque, nous disposions déjà du système de positionnement global GPS qui servait les civils depuis presque une décennie, et la poignée adéquate pour la valise à roulettes fut enfin inventée.
Il y a au moins deux leçons intéressantes ici. Premièrement, il n’existe pas de flèche du temps évidente en ce qui concerne le progrès. Le progrès se réalise de manière hautement chaotique et non linéaire, et il est très difficile d’évaluer le progrès qui devrait survenir dans un domaine à partir de ce qui se passe dans d’autres domaines. C’est un élément que nous devons garder à l’esprit aujourd’hui.
La deuxième chose est que le progrès ne doit pas être confondu avec la sophistication. On peut avoir quelque chose de bien supérieur tout en étant beaucoup plus simple. Si je prends l’exemple de la valise, une fois que vous en avez vu une, son design vous paraît complètement évident et logique. Mais était-ce un problème facile à résoudre ? Je dirais absolument que non. La preuve évidente que la gestion de la supply chain était un problème difficile à résoudre est qu’il a fallu à une civilisation industrielle avancée un peu plus de quatre décennies pour remédier à cette question. Le progrès est trompeur dans le sens où il ne suit pas la règle de la sophistication. Il est très difficile d’identifier à quoi ressemblait le monde avant que le progrès ne survienne, car il modifie littéralement votre perception du monde au fur et à mesure.

Revenons maintenant à notre discussion sur la supply chain. Il s’agit de la sixième et dernière conférence de ce prologue. Vous pouvez consulter en ligne un plan complet sur le site web de Lokad concernant l’ensemble de la série de conférences sur la supply chain. Il y a deux semaines, j’ai présenté les tendances du 20e siècle pour les supply chain en adoptant une perspective purement qualitative sur le problème. Aujourd’hui, j’adopte l’approche opposée en adoptant une perspective assez quantitative sur cet ensemble de problèmes, en guise de contrepoint.

Aujourd’hui, nous allons passer en revue un ensemble de principes. Par principe, j’entends quelque chose qui peut être utilisé pour améliorer la conception des recettes numériques en général pour toutes les supply chain. Nous avons ici l’ambition de généralisation, et c’est là qu’il est assez difficile de trouver des éléments d’une importance primordiale pour toutes les supply chain et pour l’ensemble des méthodes numériques visant à les optimiser. Nous passerons en revue deux listes succinctes de principes : les principes d’observation et les principes d’optimisation.
Les principes d’observation s’appliquent à la manière dont vous pouvez acquérir des connaissances et des informations quantitatives sur les supply chain. Les principes d’optimisation concernent la façon dont vous intervenez une fois que vous avez acquis des connaissances qualitatives sur votre supply chain, notamment comment utiliser ces principes pour améliorer vos processus d’optimisation.
Commençons par observer une supply chain. Il me semble étrange que l’on parle de supply chain comme si l’on pouvait les observer directement à l’œil nu. Pour moi, c’est une perception très déformée de la réalité des supply chain. Les supply chain ne peuvent pas être observées directement par l’humain, du moins pas d’un point de vue quantitatif. Cela s’explique par le fait que les supply chain, par conception, sont distribuées géographiquement, impliquant potentiellement des milliers de SKU et des dizaines de milliers d’unités. Avec vos yeux humains, vous ne pouvez observer la supply chain que telle qu’elle est aujourd’hui et non telle qu’elle était dans le passé. Vous ne pouvez pas retenir plus que quelques chiffres ou une infime fraction des nombres associés à votre supply chain.
Chaque fois que vous souhaitez observer une supply chain, vous effectuerez ces observations de manière indirecte via un logiciel d’entreprise. C’est une manière très spécifique d’appréhender les supply chain. Toutes les observations quantitatives que l’on peut faire sur les supply chain se réalisent par ce biais spécifique : le logiciel d’entreprise.
Essayons de caractériser un logiciel d’entreprise typique. Il contiendra une base de données, puisque la grande majorité de ces logiciels sont conçus de cette manière. Le logiciel risque de comporter environ 500 tables et 10,000 champs (un champ est essentiellement une colonne dans une table). Comme point d’entrée, nous avons un système qui renferme potentiellement une énorme quantité d’informations. Cependant, dans la plupart des situations, seule une infime fraction de cette complexité logicielle est réellement pertinente pour la supply chain d’intérêt.
Les éditeurs de logiciels conçoivent des logiciels d’entreprise en tenant compte de situations très diverses. Lorsqu’on examine un client spécifique, il y a de fortes chances que seule une infime partie des fonctionnalités du logiciel soit réellement utilisée. Cela signifie que, bien qu’il puisse y avoir 10,000 champs à explorer en théorie, en réalité, les entreprises n’utilisent qu’une petite fraction de ces champs.
Le défi consiste à distinguer les informations pertinentes des données inexistantes ou non pertinentes. Nous ne pouvons observer les supply chain que via des logiciels d’entreprise, et il peut y avoir plus d’un logiciel impliqué. Dans certains cas, un champ n’a jamais été utilisé, et les données sont constantes, ne contenant que des zéros ou des valeurs nulles. Dans cette situation, il est facile d’éliminer le champ car il ne renferme aucune information. Toutefois, en pratique, le nombre de champs pouvant être éliminés par cette méthode peut ne représenter qu’environ 10 %, de nombreuses fonctionnalités du logiciel ayant été utilisées au fil des ans, même si ce n’était que par inadvertance.
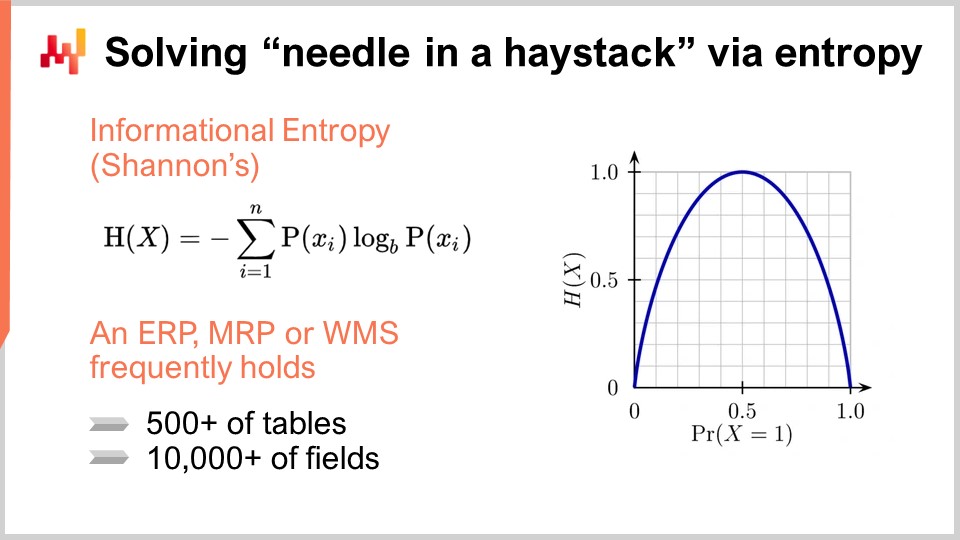
Pour identifier les champs qui n’ont jamais été utilisés de manière significative, nous pouvons recourir à un outil appelé entropie informationnelle. Pour ceux qui ne sont pas familiers avec la théorie de l’information de Shannon, ce terme peut sembler intimidant, mais il est en réalité plus simple qu’il n’y paraît. L’entropie informationnelle consiste à quantifier la quantité d’information présente dans un signal, ce dernier étant défini comme une séquence de symboles. Par exemple, si nous avons un champ qui contient seulement deux types de valeurs, vrai ou faux, et que la colonne oscille de manière aléatoire entre ces valeurs, la colonne contient beaucoup de données. En revanche, s’il n’y a qu’une seule ligne sur un million où la valeur est vraie et que toutes les autres lignes sont fausses, le champ de la base de données contient presque aucune information.
L’entropie informationnelle est très intéressante car elle vous permet de quantifier, en bits, la quantité d’information présente dans chaque champ de votre base de données. En réalisant une analyse, vous pouvez classer ces champs du plus riche au plus pauvre en termes d’information et éliminer ceux qui renferment à peine des informations pertinentes pour l’optimisation de la supply chain. L’entropie informationnelle peut sembler compliquée au premier abord, mais elle n’est pas difficile à comprendre.

Par exemple, en imaginant un langage de programmation spécifique à un domaine, nous avons implémenté l’entropie informationnelle en tant qu’agrégateur. En prenant une table, par exemple, des données d’un fichier plat nommé data.csv comportant trois colonnes, nous pouvons tracer le résumé de la quantité d’entropie présente dans chaque colonne. Ce processus vous permet de déterminer facilement quels champs contiennent le moins d’information et de les éliminer. En utilisant l’entropie comme guide, vous pouvez lancer rapidement un projet au lieu d’y passer des années.
Passons à l’étape suivante, nous faisons nos premières observations sur les supply chain et envisageons ce à quoi il faut s’attendre. Dans les sciences naturelles, la distribution normale – également appelée courbe en cloche ou distribution gaussienne – est généralement attendue. Par exemple, la taille d’un homme de 20 ans ou son poids suivent une distribution normale. Dans le domaine du vivant, de nombreuses mesures suivent ce schéma. Cependant, en ce qui concerne les supply chain, ce n’est pas le cas. Il n’existe pratiquement rien d’intéressant qui soit normalement distribué dans les supply chain.
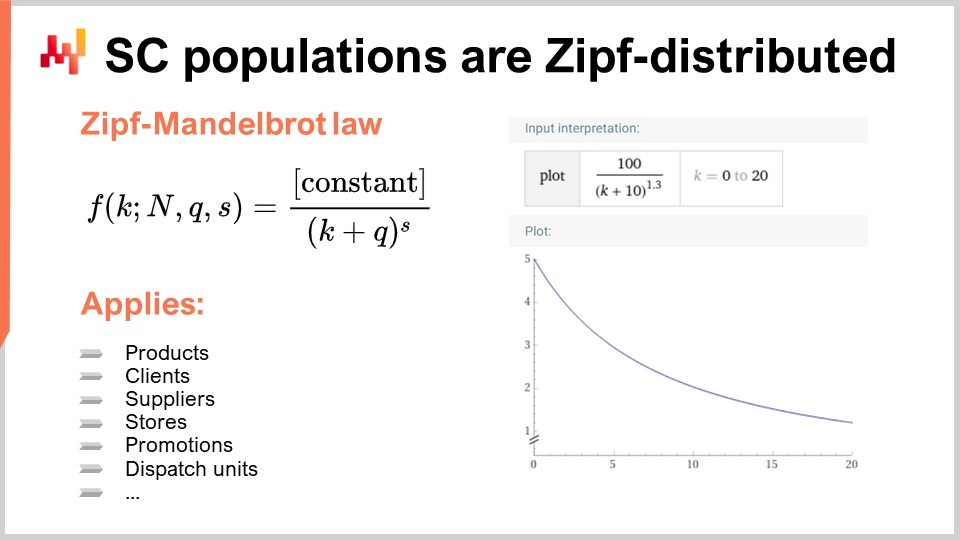
Au lieu de cela, presque toutes les distributions intéressantes dans les supply chain sont distribuées selon Zipf. La distribution de Zipf est illustrée par la formule donnée. Pour comprendre ce concept, considérez une population de produits, avec comme mesure d’intérêt le volume des ventes de chaque produit. Vous classeriez les produits du volume de ventes le plus élevé au plus faible sur une période donnée, par exemple une année. La question devient alors de savoir s’il existe un modèle qui prédit la forme de la courbe et, étant donné le rang, fournit le volume de ventes attendu. C’est précisément de cela qu’il s’agit avec la distribution de Zipf. Ici, f représente la forme d’une loi de Zipf-Mandelbrot, et k fait référence au k-ième plus grand élément. Il y a deux paramètres, q et s, qui sont essentiellement appris, tout comme vous avez mu (la moyenne) et sigma (l’écart-type) pour une distribution normale. Ces paramètres peuvent être utilisés pour ajuster la distribution à une population d’intérêt. La loi de Zipf-Mandelbrot englobe ces paramètres.
Il est important de noter que pratiquement chaque population d’intérêt dans la supply chain suit une distribution de Zipf. Cela est vrai pour les produits, les clients, les fournisseurs, les promotions, et même les unités de dispatch. La distribution de Zipf est essentiellement une descendance du principe de Pareto, mais elle est plus maniable et, à mon avis, plus intéressante, car elle fournit un modèle explicite de ce à quoi s’attendre pour toute population d’intérêt dans la supply chain. Si vous rencontrez une population qui n’est pas distribuée selon Zipf, il est plus probable qu’il y ait un problème avec les données, plutôt qu’une véritable déviation par rapport au principe.

Pour exploiter le concept de distribution de Zipf dans le monde réel, vous pouvez utiliser Envision. Si nous regardons cet extrait de code, vous verrez qu’il ne faut que quelques lignes de code pour appliquer ce modèle à un jeu de données réel. Ici, je suppose qu’il existe une population d’intérêt dans un fichier plat appelé “data.csv” avec une colonne représentant la quantité. Normalement, vous auriez un identifiant de produit et la quantité. À la ligne 4, je calcule les rangs en utilisant l’agrégateur de rangs et en triant par rapport à la quantité. Ensuite, entre les lignes 6 et 11, j’entre dans un bloc differentiable programming rendu explicite par Autodev, où je déclare trois paramètres scalaires : c, q et s, exactement comme dans la formule à gauche de l’écran. Je calcule ensuite les prédictions du modèle de Zipf et j’utilise une erreur quadratique moyenne entre la quantité observée et la prédiction du modèle. Vous pouvez littéralement effectuer une régression de la distribution de Zipf avec seulement quelques lignes de code. Même si cela semble sophistiqué, c’est assez simple avec les outils appropriés.

Cela m’amène à un autre aspect observationnel des supply chains : les nombres que vous attendez à n’importe quel niveau de la supply chain sont petits, généralement inférieurs à 20. Non seulement vous aurez peu d’observations, mais les nombres que vous observez seront également petits. Bien sûr, ce principe dépend des unités utilisées, mais quand je dis “nombres”, je veux dire ceux qui ont un sens canonique du point de vue de la supply chain, c’est-à-dire ce que vous cherchez à observer et à optimiser.
La raison pour laquelle nous n’avons que de petits nombres est due aux économies d’échelle. Prenons les t-shirts dans un magasin comme exemple. Le magasin pourrait avoir des milliers de t-shirts en stock, ce qui semble être un grand nombre, mais en réalité, il possède des centaines de types différents de t-shirts avec des variations de taille, de couleur et de design. Lorsque vous commencez à examiner les t-shirts à la granularité pertinente d’un point de vue de la supply chain, c’est-à-dire le SKU, le magasin n’aura pas des milliers d’unités de t-shirts pour un SKU donné ; à la place, il n’en aura qu’une poignée. Si vous avez un plus grand nombre de t-shirts, vous n’allez pas vous retrouver avec des milliers de t-shirts traînant partout, car cela serait un cauchemar en termes de traitement et de déplacement. Au lieu de cela, vous emballerez ces t-shirts dans des boîtes pratiques, ce qui est précisément ce qui se passe en pratique. Si vous disposez d’un centre de distribution qui traite de nombreux t-shirts, parce que vous les expédiez vers des magasins, alors il y a de fortes chances que ces t-shirts se trouvent en réalité dans des boîtes. Vous pourriez même avoir une boîte contenant un assortiment complet de t-shirts avec des tailles et des couleurs variées, facilitant ainsi le traitement tout au long de la chaîne. Si vous avez de nombreuses boîtes traînant partout, vous n’allez pas avoir des milliers de boîtes de ce type. Au lieu de cela, si vous avez des dizaines de boîtes, vous allez les organiser soigneusement sur des palettes. Une palette peut contenir plusieurs dizaines de boîtes. Si vous disposez de nombreuses palettes, vous ne les organiserez pas en palettes individuelles ; très probablement, vous les organiserez sous forme de conteneurs. Et si vous avez de nombreux conteneurs, vous utiliserez un cargo ou quelque chose de similaire. Mon point est que, lorsqu’il s’agit de nombres en supply chain, le nombre réellement pertinent est toujours un petit nombre. Cette situation ne peut être contournée simplement en passant à un niveau d’agrégation supérieur car, à mesure que vous montez en niveau d’agrégation, une sorte d’économies d’échelle intervient, et vous souhaitez introduire un mécanisme de regroupement pour réduire vos coûts d’exploitation. Cela se produit à plusieurs reprises, donc peu importe l’échelle à laquelle vous regardez, qu’il s’agisse du produit final vendu à l’unité dans un magasin ou d’un article produit en série, c’est toujours une affaire de petits nombres.
Même si vous disposez d’une usine qui produit des millions de t-shirts, il est probable que vous ayez d’énormes lots, et les nombres qui vous intéressent ne sont pas le nombre de t-shirts mais le nombre de lots, qui sera bien plus réduit.
Où est-ce que je veux en venir avec ce principe ? Tout d’abord, vous devez examiner l’aspect que prennent la plupart des méthodes en calcul scientifique ou en statistiques. Il s’avère que dans la plupart des autres domaines qui ne sont pas liés à la supply chain, c’est l’inverse qui prévaut : un grand nombre d’observations et de grands nombres quand la précision compte. En supply chain, en revanche, les nombres sont petits et discrets.
Ma proposition est que nous avons besoin d’outils basés sur ce principe qui intègrent pleinement le fait que nous allons avoir de petits nombres plutôt que de grands nombres. Si vous disposez d’outils conçus uniquement en pensant à la loi des grands nombres, que ce soit en raison d’un grand nombre d’observations ou de grands nombres eux-mêmes, vous avez un décalage complet lorsque qu’il s’agit de supply chain.
Au fait, cela a de profondes implications sur le plan logiciel. Si vous avez de petits nombres, il existe de nombreuses façons de faire en sorte que les couches logicielles tirent parti de cette observation. Par exemple, si vous examinez le jeu de données des lignes de transaction pour un hypermarché, vous remarquerez que, d’après mon expérience et mes observations, 80 % des lignes présentent une quantité vendue à un client final dans un hypermarché qui est exactement de un. Alors, avez-vous besoin de 64 bits d’information pour représenter cette donnée ? Non, c’est un gaspillage total d’espace et de temps de traitement. Adopter ce concept peut aboutir à un gain opérationnel d’un ou deux ordres de grandeur. Ce n’est pas seulement de l’utopie ; il existe de véritables gains opérationnels. Vous pourriez penser que les ordinateurs de nos jours sont très puissants, et ils le sont, mais si vous disposez de plus de puissance de calcul, vous pouvez recourir à des algorithmes plus avancés qui réalisent des opérations encore meilleures pour votre supply chain. Il est inutile de gaspiller cette puissance de traitement simplement parce que vous disposez d’un paradigme qui s’attend à de grands nombres alors que ce sont les petits nombres qui priment.
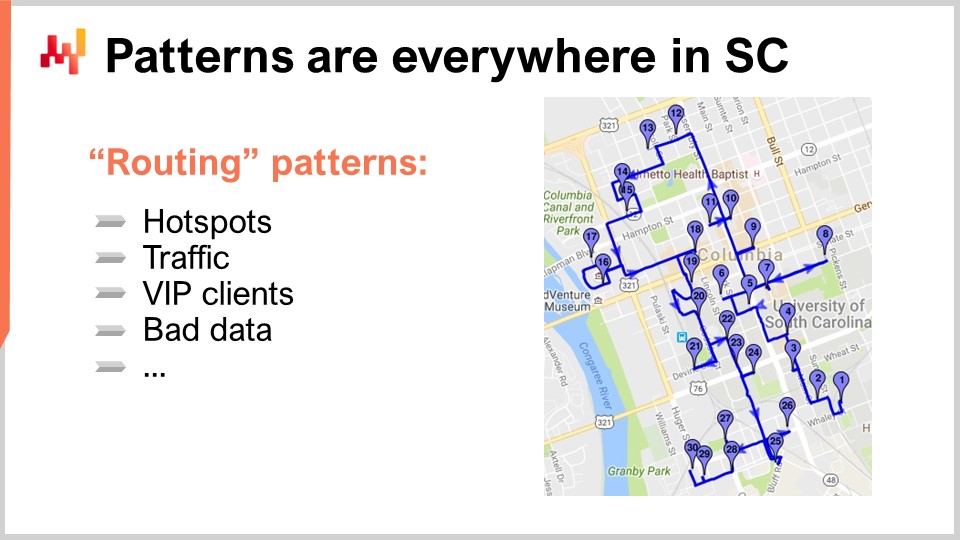
Cela m’amène à mon dernier principe d’observation pour aujourd’hui : les motifs sont partout en supply chain. Pour comprendre cela, examinons un problème classique de supply chain dans lequel on considère généralement que les motifs sont absents : l’optimisation d’itinéraire. Le problème classique d’optimisation d’itinéraire consiste en une liste de livraisons à effectuer. Vous pouvez situer les livraisons sur une carte, et vous souhaitez trouver l’itinéraire qui minimise le temps de transport. Vous voulez établir un itinéraire qui passe par chaque point de livraison tout en réduisant le temps total de transport. À première vue, ce problème semble être un problème purement géométrique sans qu’aucun motif ne soit impliqué dans sa résolution.
Cependant, je propose que cette perspective est complètement erronée. En abordant le problème sous cet angle, vous vous concentrez sur le problème mathématique et non sur le problème de supply chain. Les supply chains sont des jeux itératifs dans lesquels les problèmes se manifestent de manière récurrente. Si vous êtes dans le secteur de l’organisation des livraisons, il est fort probable que vous effectuiez des livraisons chaque jour. Ce n’est pas seulement un itinéraire ; c’est littéralement un itinéraire par jour, du moins.
De plus, si vous êtes dans le secteur des livraisons, vous disposez probablement d’une flotte complète de véhicules et de chauffeurs. Le problème n’est pas seulement d’optimiser un itinéraire ; il s’agit d’optimiser toute une flotte, et ce jeu se répète chaque jour. C’est là que tous les motifs apparaissent.
Tout d’abord, les points ne sont pas répartis de manière aléatoire sur la carte. Vous avez des points chauds, ou des zones géographiques avec une forte densité de livraisons. Vous pouvez avoir des adresses qui reçoivent des livraisons presque tous les jours, comme le siège social d’une grande entreprise dans une grande ville. Si vous êtes une grande entreprise de le e-commerce, vous livrez probablement des colis à cette adresse chaque jour ouvré. Ces points chauds ne sont pas immuables; ils ont leur seasonality. Certains quartiers peuvent être très calmes pendant l’été ou l’hiver. Il existe des schémas, et si vous voulez exceller dans l’optimisation des itinéraires, vous devez prendre en compte non seulement où ces points chauds vont se produire, mais aussi comment ils vont se déplacer au cours de l’année. De plus, il faut tenir compte du trafic. Vous ne devez pas penser uniquement à la distance géométrique, car le trafic dépend du temps. Si un chauffeur démarre à un certain moment de la journée, au fur et à mesure de son trajet, le trafic changera. Pour bien jouer ce jeu, vous devez tenir compte des schémas de trafic, qui changent et peuvent être prédits de manière fiable à l’avance. Par exemple, à Paris, à 9h00 et à 18h00, toute la ville est complètement embouteillée, et il n’est pas nécessaire d’être un expert en prévision pour le savoir.
Il y a également des événements qui se produisent sur place, comme des accidents qui perturbent les schémas habituels du trafic. Si nous examinons les livraisons d’un point de vue mathématique, on suppose que tous les points de livraison sont identiques, mais ce n’est pas le cas. Vous pouvez avoir des clients VIP, ou des adresses spécifiques où vous devez livrer la moitié de votre expédition. Ces étapes clés de votre itinéraire doivent être prises en compte pour une optimisation efficace des itinéraires.
Vous devez également être conscient du contexte, et il est courant d’avoir des données imparfaites sur le monde. Par exemple, si un pont est fermé et que le logiciel n’en a pas connaissance, le problème n’est pas de ne pas savoir que le pont était fermé la première fois, mais plutôt que le logiciel n’apprend jamais de ce problème et propose toujours un trajet censé être optimal mais qui finit par être absurde. Les gens se rebellent alors contre le système, ce qui n’est pas une bonne solution d’optimisation d’itinéraires du point de vue de supply chain.
Le fait est que lorsque nous examinons les situations de supply chain, il existe de nombreux schémas partout. Nous devons veiller à ne pas être distraits par des structures mathématiques élégantes et nous rappeler que ces considérations s’appliquent également à la prévision des séries temporelles. J’ai choisi le problème de l’optimisation des itinéraires comme exemple car il était plus manifeste dans ce cas.
En conclusion, nous devons observer la supply chain sous toutes ses dimensions observables, et pas seulement celles qui sont évidentes ou où la solution se présente de manière élégante.

Cela m’amène à la deuxième série de principes relatifs à la manière dont nous devons examiner notre supply chain. Jusqu’à présent, nous avons vu quatre principes relatifs à la manière dont nous devons examiner notre supply chain : l’observation indirecte, le logiciel d’entreprise, le tri du chaos pour déterminer ce qui est pertinent et ce qui ne l’est pas, et l’entropie. Nous avons observé que les distributions suivent souvent la loi de Zipf, et même avec de petits nombres, nous pouvons encore voir émerger des schémas. La question est maintenant, comment agir ? D’un point de vue mathématique, lorsque nous voulons décider de la meilleure démarche à suivre, nous effectuons une optimisation de quelque sorte, ce qui correspond à la perspective quantitative.

La première chose à noter est que dès que nous avons une logique d’optimisation en production pour les supply chain, des problèmes surgissent, tels que des bugs. Le logiciel d’entreprise est une bête très complexe et est souvent rempli de bugs. En élaborant votre propre logique d’optimisation pour votre supply chain, vous rencontrerez de nombreux problèmes. Cependant, si une logique est suffisamment bonne pour être mise en production, les problèmes que nous rencontrons actuellement sont probablement des cas limites. Si ce n’était pas un cas limite et que le logiciel ou la logique défaillait à chaque fois, elle ne serait jamais passée en production.
L’idée derrière ce principe est qu’il faut entre cinq et dix itérations pour résoudre un problème. Quand je dis cinq à dix itérations, je veux dire que vous allez rencontrer un problème, l’examiner, comprendre la cause racine, puis tenter d’appliquer une correction. Mais la plupart du temps, la correction ne résoudra pas le problème. Vous découvrirez qu’il y avait un problème caché à l’intérieur du problème, ou que le problème que vous pensiez avoir résolu n’était pas la cause réelle, ou que la situation a révélé une catégorie plus large de problèmes. Vous avez peut-être corrigé un petit cas d’une catégorie plus étendue de problèmes, mais d’autres problèmes continueront de se produire, variantes de celui que vous pensiez avoir résolu.
Les supply chain sont des entités complexes et en constante évolution qui opèrent dans le monde réel, ce qui rend difficile l’obtention d’un design parfaitement adapté à toutes les situations. Dans la plupart des cas, vous faites de votre mieux pour résoudre un problème, puis vous devez mettre votre logique révisée à l’épreuve de l’expérience du monde réel pour voir si elle fonctionne ou non. Vous devrez itérer pour résoudre le problème. Avec le principe selon lequel il faut entre cinq et dix itérations pour résoudre un problème, cela a de profondes conséquences sur la vélocité des adaptations et la fréquence à laquelle vous actualisez ou recalculiez votre logique d’optimisation de supply chain. Par exemple, si vous avez une logique qui produit une prévision trimestrielle pour les deux prochaines années et que vous n’exécutez cette logique qu’une fois par trimestre, il faudra entre un et deux ans pour résoudre les problèmes auxquels vous êtes confronté avec cette logique de prévision, ce qui représente un temps incroyablement long.
Même si vous disposez d’une logique qui s’exécute chaque mois, comme dans le cas d’un processus S&OP (Sales and Operations Planning), il pourrait encore falloir jusqu’à un an pour résoudre un problème. C’est pourquoi il est important d’augmenter la fréquence d’exécution de votre logique d’optimisation de supply chain. Chez Lokad, par exemple, chaque morceau de logique s’exécute quotidiennement, même pour des prévisions à cinq ans. Ces prévisions sont actualisées quotidiennement, même si elles ne changent pas beaucoup d’un jour à l’autre. Le but n’est pas d’obtenir une accuracy statistique, mais de veiller à ce que la logique s’exécute suffisamment fréquemment pour corriger tout problème ou bug dans un délai raisonnable.
Cette observation n’est pas unique à la gestion de supply chain. Des équipes d’ingénierie intelligentes dans des entreprises comme Netflix ont popularisé l’idée de chaos engineering. Elles ont réalisé que les cas limites étaient rares et que la seule façon de résoudre ces problèmes était de répéter l’expérience plus fréquemment. En conséquence, elles ont créé un logiciel appelé Chaos Monkey, qui ajoute du chaos à leur infrastructure logicielle en générant des disruptions réseau et des plantages aléatoires. Le but du Chaos Monkey est de faire apparaître les cas limites plus rapidement, permettant ainsi à l’équipe d’ingénierie de les corriger plus rapidement.
Même s’il peut sembler contre-intuitif d’introduire un niveau supplémentaire de chaos dans vos opérations, cette approche s’est révélée efficace pour Netflix, réputée pour son excellente fiabilité. Ils comprennent que lorsqu’ils sont confrontés à un problème lié au logiciel, il faut de nombreuses itérations pour le résoudre, et que la seule façon d’en venir à bout est d’itérer rapidement. Le Chaos Monkey n’est qu’une manière d’augmenter la vitesse d’itération.
Vu d’un point de vue supply chain, le Chaos Monkey peut ne pas être directement applicable, mais le concept d’augmenter la fréquence d’exécution de votre logique d’optimization de la supply chain reste très pertinent. Quelle que soit la logique que vous utilisez pour optimiser votre supply chain, elle doit fonctionner à grande vitesse et à haute fréquence ; sinon, vous ne résoudrez jamais les problèmes auxquels vous êtes confronté.

Maintenant, les supply chains matures sont quasi-optimales, et quand je dis matures, je veux dire des supply chains qui sont en activité depuis deux décennies ou plus. Une autre manière d’exprimer ce principe est que vos prédécesseurs en supply chain n’étaient pas tous incompétents. Lorsque vous examinez les initiatives d’optimization de la supply chain, il y a trop souvent de grandes ambitions comme réduire de moitié les niveaux de stocks, augmenter les taux de service de 95 % à 99 %, éliminer les ruptures de stock, ou diviser les délais d’approvisionnement par deux. Ce sont des démarches importantes et unidirectionnelles dans lesquelles vous vous concentrez sur un seul KPI pour tenter de l’améliorer massivement. Cependant, j’ai observé que ces initiatives échouent presque toujours pour une raison fort simple : lorsqu’on prend une supply chain en activité depuis des décennies, il y a généralement une certaine sagesse latente dans la façon dont les choses ont été faites.
Par exemple, si les taux de service sont à 95 %, il y a de fortes chances que, si vous essayez de les porter à 99 %, vous augmentiez considérablement les niveaux de stocks et créiez une quantité massive de stocks dormants dans le processus. De même, si vous disposez d’une certaine quantité de stocks et lancez une initiative massive pour la réduire de moitié, vous risquez fort d’engendrer des problèmes significatifs de qualité de service qui ne seront pas soutenables.
Ce que j’ai observé, c’est que de nombreux praticiens de la supply chain qui ne comprennent pas le principe selon lequel les supply chains matures sont unidirectionnellement quasi-optimales ont tendance à osciller autour de l’optimum local. Gardez à l’esprit que je ne dis pas que les supply chains matures soient optimales, mais qu’elles sont unidirectionnellement quasi-optimales. Si vous prenez l’analogie du Grand Canyon, la rivière trace le chemin optimal en raison de la force unidirectionnelle de la gravité. Si vous appliquiez une force dix fois plus forte, la rivière subirait tout de même de nombreuses convolutions.
Le point est que, avec des supply chains matures, si vous voulez apporter des améliorations considérables, vous devez ajuster de nombreuses variables en même temps. Se concentrer uniquement sur une variable ne donnera pas les résultats escomptés, surtout si votre entreprise fonctionne depuis des décennies avec le statu quo. Vos prédécesseurs ont probablement fait quelques choses correctement à leur époque, si bien que les chances de tomber sur une supply chain complètement dysfonctionnelle à laquelle personne ne s’est jamais intéressé sont minimes. Les supply chains sont des problèmes complexes, et bien qu’il soit possible d’ingénier des situations entièrement dysfonctionnelles à grande échelle, cela restera, au mieux, très rare.

Un autre aspect à considérer est que l’optimisation locale ne fait que déplacer les problèmes au lieu de les résoudre. Pour comprendre ceci, vous devez reconnaître que les supply chains sont des systèmes et que, lorsqu’on pense en termes de performance de la supply chain, c’est la performance globale du système qui importe. La performance locale est pertinente, mais ce n’est qu’une partie de l’ensemble.
Une façon de penser courante est que l’on peut appliquer la stratégie du divisage et de la conquête pour résoudre des problèmes en général, et pas seulement des problèmes de supply chain. Par exemple, dans un réseau de distribution comportant de nombreux magasins, vous pourriez vouloir optimiser les niveaux de stocks dans chaque magasin. Cependant, le problème est que, si vous disposez d’un réseau de magasins et de centres de distribution, chacun desservant de nombreux magasins, il est tout à fait trivial de micro-optimaliser un magasin et d’obtenir une qualité de service excellente pour celui-ci au détriment de tous les autres.
La perspective correcte est de penser que, lorsqu’une unité est disponible dans le centre de distribution, la question à se poser est : où cette unité est-elle la plus nécessaire ? Quelle est l’action la plus rentable pour moi ? Le problème d’optimiser l’expédition des stocks, ou le problème de l’allocation des stocks, n’a de sens qu’au niveau du système, et non au niveau du magasin. Si vous optimisez ce qui se passe dans un magasin, vous risquez fort de créer des problèmes dans un autre magasin.
Quand je dis « local », ce principe ne doit pas être compris uniquement d’un point de vue géographique ; il peut également s’agir d’une question purement logique au sein de la supply chain. Par exemple, si vous êtes une entreprise de le e-commerce avec de nombreuses catégories de produits, vous pourriez vouloir allouer des budgets variables pour chacune des catégories. C’est une autre forme de stratégie de divisage et de conquête. Cependant, si vous répartissez votre budget et affectez une somme fixe en début d’année pour chaque catégorie, que se passe-t-il si la demande de produits dans une catégorie double alors que celle dans une autre est réduite de moitié ? Dans ce cas, vous vous retrouvez avec un problème d’allocation incorrecte des fonds entre ces deux catégories. Le défi ici est que vous ne pouvez appliquer aucune forme de logique de divisage et de conquête. Si vous utilisez des techniques d’optimisation locale, vous risquez de créer des problèmes en construisant votre solution prétendument optimisée.

Cela m’amène au dernier principe, qui est probablement le plus complexe parmi tous ceux que j’ai présentés aujourd’hui : de meilleurs problèmes priment sur de meilleures solutions. Cela peut être extrêmement déroutant, notamment dans certains cercles universitaires. La manière typique dont les choses sont présentées dans une éducation classique est qu’un problème bien défini vous est exposé, puis vous commencez à chercher des solutions à ce problème. Dans un problème mathématique, par exemple, un étudiant peut proposer une solution plus concise, plus élégante, et celle-ci est alors considérée comme la meilleure solution.
Cependant, en réalité, les choses ne se déroulent pas ainsi dans la gestion de la supply chain. Pour illustrer cela, revenons 60 ans en arrière et observons le problème de la cuisine, une activité très chronophage. Autrefois, les gens imaginaient que des robots pourraient, dans le futur, accomplir les tâches de cuisine, augmentant ainsi considérablement la productivité de la personne chargée de cuisiner. Ce genre de pensée était répandu dans les années 1950 et 1960.
Avançons jusqu’à aujourd’hui, et il est évident que ce n’est pas ainsi que les choses ont évolué. Pour minimiser les efforts en cuisine, les gens achètent désormais des repas pré-cuits. C’est un autre exemple de déplacement du problème. Fournir aux supermarchés des repas pré-cuits est plus difficile d’un point de vue supply chain que de leur fournir des produits bruts, en raison du nombre accru de références et de dates de péremption plus courtes. Le problème a été résolu par une solution supply chain supérieure, et non en proposant une meilleure solution de cuisine. Le problème de la cuisine a été totalement éliminé et redéfini comme celui de fournir un repas passable avec un minimum d’effort.
En ce qui concerne les supply chains, la perspective académique se concentre souvent sur la recherche de meilleures solutions aux problèmes existants. Un bon exemple est celui des compétitions Kaggle, où vous disposez d’un jeu de données, d’un problème et potentiellement des centaines, voire des milliers d’équipes, en concurrence pour obtenir la meilleure prédiction sur ces jeux de données. Vous avez un problème bien défini et des milliers de solutions qui se font concurrence. Le souci avec cet état d’esprit, c’est qu’il vous donne l’impression que, pour améliorer votre supply chain, il vous faut une meilleure solution.
L’essence du principe est qu’une meilleure solution peut aider marginalement, mais seulement marginalement. Habituellement, ce qui aide réellement, c’est de redéfinir le problème, et cela s’avère étonnamment difficile. Cela s’applique également aux problèmes quantitatifs. Vous devez repenser votre véritable stratégie de supply chain et le problème clé que vous devriez optimiser.
Dans de nombreux cercles, les gens considèrent les problèmes comme s’ils étaient statiques et immuables, cherchant de meilleures solutions. Je ne nie pas qu’avoir un meilleur algorithme de prévision des séries temporelles puisse être utile, mais cette prévision relève du domaine de statistical forecasting, et non de la maîtrise de la gestion de la supply chain. Si nous revenons à mon exemple initial de la valise de voyage, l’amélioration clé pour une valise à roulettes ne concernait pas les roues, mais la poignée. C’était quelque chose qui, a priori, n’avait rien à voir avec les roues, et c’est pourquoi il a fallu 40 ans pour trouver une solution – il faut penser en dehors des sentiers battus pour laisser émerger un meilleur problème.
Ce principe quantitatif consiste à remettre en question les problèmes auxquels vous êtes confronté. Peut-être ne réfléchissez-vous pas assez intensément au problème, et il y a une tendance à tomber amoureux de la solution alors que vous devriez vous concentrer sur le problème et sur ce que vous n’en comprenez pas. Dès que vous avez un problème bien défini, disposer d’une bonne solution n’est généralement qu’une question banale d’exécution, qui n’est pas si difficile.

En conclusion, la supply chain en tant que domaine d’étude possède de nombreuses perspectives impressionnantes et autorisées. Elles peuvent être sophistiquées, mais la question que je souhaiterais poser à cet auditoire est la suivante : se pourrait-il que tout cela soit gravement mal orienté ? Avons-nous vraiment la certitude que des éléments comme la prévision des séries temporelles et la recherche opérationnelle soient les bonnes perspectives pour aborder le problème ? Peu importe le degré de sophistication et les décennies d’ingénierie et d’efforts investis dans la poursuite de ces directions, sommes-nous réellement sur la bonne voie ?
Aujourd’hui, je présente une série de principes que je considère d’une importance primordiale pour la gestion de la supply chain. Cependant, ils pourraient vous sembler étranges. Nous avons ici deux mondes – le prouvé et l’étrange – et la question se pose de savoir ce qui se passera dans quelques décennies.

Le progrès tend à se déployer de manière chaotique et non linéaire. L’idée avec ces principes est de vous permettre d’embrasser un monde hautement chaotique, où il y a de la place pour l’imprévu. Ces principes peuvent vous aider à développer des solutions plus rapides, plus fiables et plus efficaces qui amélioreront vos supply chains d’un point de vue quantitatif.

Passons maintenant à quelques questions.
Question : Comment les distributions de Zipf se comparent-elles à la loi de Pareto ?
La loi de Pareto est la règle empirique du 80-20, mais d’un point de vue quantitatif, la distribution de Zipf est un modèle prédictif explicite. Elle dispose de capacités prédictives qui peuvent être confrontées aux jeux de données de manière très directe.
Question : La distribution de Zipf-Mandelbrot ne serait-elle pas mieux envisagée comme une courbe logarithmique pour visualiser les fluctuations de la supply chain, comme le font les épidémiologistes pour les cas et les décès rapportés ?
Absolument. À un niveau philosophique, la question est de savoir si vous vivez dans le pays de la Médiocrité ou dans celui de l’Extrême. Les supply chains et la plupart des affaires humaines existent dans un monde d’extrêmes. Les courbes logarithmiques sont en effet utiles si vous souhaitez visualiser l’amplitude des promotions. Par exemple, si vous voulez voir l’amplitude de toutes les promotions passées pour de grands réseaux de distribution sur les dix dernières années, utiliser une échelle régulière pourrait rendre tout le reste invisible, simplement parce que la plus grande promotion jamais réalisée était bien plus importante que les autres. Ainsi, utiliser une échelle logarithmique peut vous aider à mieux percevoir les variations. Avec la distribution de Zipf-Mandelbrot, je vous propose un modèle que vous pouvez littéralement déployer avec quelques lignes de code, ce qui va au-delà d’une simple vision logarithmique des données. Cependant, je reconnais que l’intuition de base est la même. Pour une perspective philosophique de haut niveau, je recommande la lecture des travaux de Nassim Taleb sur Mediocristan versus Extremistan dans son livre “Antifragile.”
Question : Sur le sujet de l’optimisation locale de la supply chain, faites-vous référence aux données sous-jacentes qui soutiennent la collaboration en réseau de supply chain et le SNLP ?
Mon problème avec l’optimisation locale est que les grandes entreprises qui gèrent d’importantes supply chains disposent généralement d’organisations matricielles. Cette structure organisationnelle, avec sa mentalité de divisage et de conquête, conduit à une optimisation locale par conception. Par exemple, considérez deux équipes distinctes – l’une chargée de la prévision de la demande et l’autre des décisions d’achat. Ces deux problèmes – la prévision de la demande et l’optimisation des achats – sont entièrement imbriqués. Vous ne pouvez pas procéder à une optimisation locale en vous concentrant uniquement sur le pourcentage d’erreur dans la prévision de la demande, puis en optimisant séparément les achats en fonction de l’efficacité du traitement. Il existe des effets systémiques, et vous devez les prendre tous en considération ensemble.
Le plus grand défi pour la plupart des grandes entreprises établies qui gèrent des supply chains importantes aujourd’hui est que, lorsqu’il s’agit d’optimisation quantitative, vous devez penser à l’échelle du système et de l’entreprise. Cela va à l’encontre de décennies de sédimentation des organisations matricielles au sein de l’entreprise, où chacun s’est focalisé uniquement sur ses limites bien définies, oubliant la vue d’ensemble.
Un autre exemple de ce problème serait les stocks en magasin. Les stocks remplissent deux fonctions : d’une part, ils répondent à la demande des clients, et d’autre part, ils constituent la marchandise. Pour disposer de la quantité adéquate de stocks, vous devez prendre en compte le problème de la qualité de service ainsi que celui de l’attrait du magasin. L’attrait du magasin consiste à rendre le magasin attrayant et intéressant pour la clientèle, ce qui relève davantage du marketing. Dans une entreprise, vous avez une division marketing et une division supply chain, et elles ne travaillent pas naturellement ensemble en matière d’optimisation de la supply chain. Mon propos est que, si vous n’agréguez pas tous ces aspects, l’optimisation ne fonctionnera pas.
Concernant votre inquiétude au sujet du SNLP, le problème est que les gens se réunissent uniquement pour tenir des réunions, ce qui n’est pas très efficace. Nous avons publié un épisode de Lokad TV sur le SNLP il y a quelques mois, donc vous pouvez vous y référer si vous souhaitez avoir une discussion spécifique à ce sujet.
Question : Comment devons-nous répartir le temps et l’énergie entre la stratégie de supply chain et l’exécution quantitative ?
C’est une excellente question. La réponse, comme je l’ai indiqué dans ma deuxième conférence, est que vous devez procéder à une robotisation complète des tâches banales. Cela vous permet de consacrer tout votre temps et votre énergie à l’amélioration stratégique continue de vos recettes numériques. Si vous passez plus de 10 % de votre temps à traiter des aspects banals de l’exécution de la supply chain, c’est que votre méthodologie présente un problème. Les experts de la supply chain sont trop précieux pour gaspiller leur temps et leur énergie sur des problèmes d’exécution banals qui devraient être automatisés dès le départ.
Vous devez suivre une méthodologie qui vous permet de consacrer presque toute votre énergie à la réflexion stratégique, laquelle est immédiatement mise en œuvre sous forme de recettes numériques supérieures qui pilotent l’exécution quotidienne de la supply chain. Cela fait référence à ma troisième conférence sur la livraison orientée produit, c’est-à-dire la livraison orientée produit logiciel.
Question: Est-il possible d’hypothétiser une sorte d’analyse de plafond, la meilleure amélioration possible pour les problèmes de supply chain compte tenu de leur formulation systémique ?
Je dirais non, absolument pas. Penser qu’il existe une sorte d’optimum ou de plafond revient à dire qu’il y a une limite à l’ingéniosité humaine. Bien que je n’aie aucune preuve qu’il n’existe pas de limite à l’ingéniosité humaine, c’est l’une de mes convictions fondamentales. Les supply chains sont des problèmes épineux. Vous pouvez transformer le problème, et même transformer ce qui semble être un grand problème en une grande solution et en un potentiel de croissance pour l’entreprise. Par exemple, regardez Amazon. Jeff Bezos, au début des années 2000, a compris que pour être un détaillant prospère, il aurait besoin d’une infrastructure logicielle massive et solide. Mais cette infrastructure de cloud computing industrielle de niveau production, dont il avait besoin pour faire fonctionner le le e-commerce d’Amazon, était incroyablement coûteuse, coûtant à l’entreprise des milliards. Ainsi, les équipes d’Amazon ont décidé de transformer cette infrastructure de cloud computing, qui représentait un énorme investissement, en un produit commercial. De nos jours, cette infrastructure informatique à grande échelle est en réalité l’une des principales sources de profit pour Amazon.
Lorsque l’on commence à penser aux problèmes épineux, on peut toujours redéfinir le problème de manière supérieure. C’est pourquoi je pense qu’il est erroné de croire qu’il existe une sorte de solution optimale. Lorsque vous pensez en termes d’analyse de plafond, vous considérez un problème fixe, et de ce point de vue, vous pouvez avoir une solution qui est probablement quasi-optimale. Par exemple, si vous regardez les roues des valises modernes, elles sont probablement quasi-optimales. Mais y a-t-il quelque chose d’absolument évident que nous manquerions ? Peut-être existe-t-il un moyen de rendre les roues bien meilleures, une invention qui n’a pas encore été réalisée. Dès que nous la verrons, cela paraîtra tout à fait évident.
C’est pourquoi nous devons penser qu’il n’existe pas de plafond pour ces problèmes, car les problèmes sont arbitraires. Vous pouvez redéfinir le problème et décider que le jeu se joue selon des règles complètement différentes. C’est déroutant parce que les gens aiment penser qu’ils ont un problème soigneusement conçu et qu’ils peuvent trouver des solutions. Le système éducatif occidental moderne met l’accent sur une mentalité de recherche de solution, où l’on vous donne un problème et l’on évalue la qualité de votre solution. Cependant, une question bien plus intéressante est la qualité même du problème.
Question: Les meilleures solutions résoudront les problèmes, mais parfois trouver la meilleure solution peut coûter à la fois du temps et de l’argent. Existe-t-il des solutions de contournement ?
Absolument. Encore une fois, si vous avez une solution qui est théoriquement correcte mais qui prend une éternité à mettre en œuvre, ce n’est pas une bonne solution. Ce type de pensée tend à être prévalent dans certains cercles académiques, où l’on se concentre sur la recherche de la solution parfaite selon des critères mathématiques étroits qui n’ont rien à voir avec le monde réel. C’est exactement de cela dont je parlais quand j’évoquais le bon problème d’optimisation.
Chaque trimestre environ, un professeur vient me voir et me demande si je peux examiner leur algorithme en ligne pour résoudre le problème d’optimisation d’itinéraire. La plupart des articles que je revois de nos jours se concentrent sur des variantes en ligne. Ma réponse est toujours la même : vous ne résolvez pas le bon problème. Je me fiche de votre solution car vous ne pensez même pas correctement au problème lui-même.
Le progrès ne doit pas être confondu avec la sophistication. C’est une perception erronée que le progrès passe de quelque chose de simple à quelque chose de sophistiqué. En réalité, le progrès est souvent réalisé en partant de quelque chose d’extrêmement complexe et, grâce à une réflexion supérieure et à la technologie, en atteignant la simplicité. Par exemple, si vous regardez ma dernière conférence sur les tendances de la supply chain pour le XXIe siècle, vous verrez la Machine de Marly, qui amenait l’eau au Palais de Versailles. C’était un système d’une complexité folle, tandis que les pompes électriques modernes sont bien plus simples et plus efficaces.
Le progrès ne se trouve pas nécessairement dans une sophistication supplémentaire. Parfois, elle est requise, mais ce n’est pas un ingrédient essentiel du progrès.
Question: Les grands réseaux de distribution gèrent leurs niveaux de stocks, mais doivent satisfaire les commandes presque immédiatement. Parfois, ils décident de lancer une promo par eux-mêmes, qui n’a pas été initiée par le fournisseur. Quelle serait l’approche pour prévoir et se préparer en conséquence au niveau du fournisseur ?
Tout d’abord, nous devons examiner le problème sous un angle différent. Vous adoptez une perspective de prévision, où votre client, un grand détaillant, lance une grande promotion qui surgit de nulle part. D’abord, est-ce vraiment une mauvaise chose ? S’ils promeuvent vos produits sans vous en informer, ce n’est qu’une donnée de la vie. Si vous regardez votre historique, ils font cela régulièrement, et il existe même des schémas.
Si je retourne à mes principes, les schémas sont partout. D’abord, vous devez adopter la perspective que vous ne pouvez pas prévoir l’avenir ; à la place, vous avez besoin de prévisions probabilistes. Même si vous ne pouvez pas anticiper parfaitement les fluctuations, elles ne sont pas totalement inattendues non plus. Peut-être devez-vous changer les règles du jeu au lieu de laisser le fournisseur vous surprendre complètement. Peut-être devez-vous négocier des engagements qui lient le détaillant, le réseau de distribution et le fournisseur. Si le réseau de distribution commence à faire un grand effort sans prévenir le fournisseur, ce dernier ne peut pas être tenu pour responsable de ne pas maintenir la qualité de service.
Peut-être que la solution est quelque chose de plus collaboratif. Peut-être le fournisseur devrait-il avoir une meilleure évaluation des risques. Si les matériaux vendus par le fournisseur ne sont pas périssables, il pourrait être plus rentable d’avoir quelques mois de stock. Les gens pensent souvent à avoir zéro délai, zéro stock, et zéro tout, mais est-ce vraiment ce que vos clients attendent de vous ? Peut-être que ce que vos clients attendent, c’est une valeur ajoutée sous la forme de stocks abondants. Encore une fois, la réponse dépend de divers facteurs.
Vous devez examiner le problème sous de nombreux angles, et il n’existe pas de solution évidente. Vous devez réfléchir sérieusement au problème et considérer toutes les options qui s’offrent à vous. Peut-être que le problème n’est pas d’avoir plus de stocks, mais d’avoir plus de capacité de production. S’il y a un fort pic de demande et que ce n’est pas trop coûteux d’avoir une forte hausse, et que les fournisseurs des fournisseurs peuvent fournir les matériaux assez rapidement, peut-être tout ce dont vous avez besoin, c’est d’une capacité de production plus polyvalente. Cela vous permettrait de rediriger votre capacité de production vers ce qui connaît un pic actuellement.
Au fait, cela existe dans certaines industries. Par exemple, l’industrie de l’emballage dispose de capacités massives. La plupart des machines dans l’industrie de l’emballage sont des imprimantes industrielles, qui sont relativement peu coûteuses. Les acteurs du secteur de l’emballage possèdent généralement de nombreuses imprimantes qui ne sont pas utilisées la plupart du temps. Cependant, lorsqu’il y a un grand événement ou qu’une grande marque souhaite faire une poussée massive, ils ont la capacité d’imprimer des tonnes de nouveaux emballages correspondant à la nouvelle stratégie marketing de la marque.
Donc, cela dépend vraiment de divers facteurs, et je m’excuse de ne pas avoir de réponse définitive. Mais ce que je peux dire avec certitude, c’est que vous devez réfléchir sérieusement au problème auquel vous êtes confronté.
Cela conclut la conférence d’aujourd’hui, la sixième et dernière du prologue. Dans deux semaines, le même jour et à la même heure, je présenterai sur les personnalités de la supply chain. À la prochaine.


