00:00 Einführung
02:31 Ursachen für das Scheitern in der Praxis
07:20 Ergebnis: ein numerisches Rezept 1/2
09:31 Ergebnis: ein numerisches Rezept 2/2
13:01 Der bisherige Verlauf
14:57 Erledigung der Aufgaben heute
15:59 Zeitplan der Initiative
21:48 Umfang: Anwendungsbereich 1/2
24:24 Umfang: Anwendungsbereich 2/2
27:12 Umfang: Systemeffekte 1/2
29:21 Umfang: Systemeffekte 2/2
32:12 Rollen: 1/2
37:31 Rollen: 2/2
41:50 Datenpipeline - Wie
44:13 Ein Wort zu Transaktionssystemen
49:13 Ein Wort zum Data Lake
52:59 Ein Wort zu analytischen Systemen
57:56 Datenqualität: auf niedriger Ebene
01:02:23 Datenqualität: auf hoher Ebene
01:06:24 Dateninspektoren
01:08:53 Fazit
01:10:32 Nächste Vorlesung und Fragen des Publikums
Beschreibung
Die erfolgreiche Durchführung einer vorhersagenden Optimierung einer Supply Chain ist eine Mischung aus weichen und harten Problemen. Leider ist es nicht möglich, diese Aspekte voneinander zu trennen. Die weichen und harten Facetten sind tief miteinander verflochten. In der Regel kollidiert diese Verflechtung frontal mit der Arbeitsteilung, wie sie im Organigramm des Unternehmens definiert ist. Wir stellen fest, dass bei gescheiterten Supply Chain-Initiativen die Ursachen für das Scheitern in der Regel in Fehlern liegen, die in den frühesten Phasen des Projekts gemacht wurden. Frühe Fehler neigen dazu, die gesamte Initiative zu prägen und sind daher kaum nachträglich zu beheben. Wir präsentieren unsere wichtigsten Erkenntnisse, um diese Fehler zu vermeiden.
Vollständiges Transkript

Herzlich willkommen zu dieser Reihe von Vorlesungen zur Supply Chain. Ich bin Joannes Vermorel und heute werde ich “Einführung in eine quantitative Supply Chain Initiative” präsentieren. Die überwiegende Mehrheit der datenbasierten Supply Chain-Initiativen scheitert. Seit 1990 haben die meisten Unternehmen mit großen Supply Chains alle drei bis fünf Jahre große vorhersagende Optimierungsinitiativen gestartet, die jedoch kaum oder gar keine Ergebnisse erzielt haben. Heutzutage realisieren die meisten Teams in Supply Chains oder Data Science, die eine weitere Runde der vorhersagenden Optimierung starten - typischerweise als Prognoseprojekt oder Bestandsoptimierungsprojekt - nicht einmal, dass ihr Unternehmen dies bereits getan hat und möglicherweise bereits ein halbes Dutzend Mal gescheitert ist.
Ein weiterer Versuch wird manchmal mit dem Glauben unternommen, dass es dieses Mal anders sein wird, aber häufig sind die Teams sich nicht einmal der vielen gescheiterten Versuche bewusst, die zuvor stattgefunden haben. Ein Anhaltspunkt für diesen Zustand ist, dass Microsoft Excel nach wie vor das wichtigste Tool zur Steuerung von Supply Chain-Entscheidungen ist, obwohl diese Initiativen eigentlich bessere Tools anstelle von Tabellenkalkulationen ersetzen sollten. Dennoch gibt es heutzutage immer noch sehr wenige Supply Chains, die ohne Tabellenkalkulationen auskommen können.
Das Ziel dieser Vorlesung ist es zu verstehen, wie man einer Supply Chain-Initiative, die irgendeine Art von vorhersagender Optimierung liefern soll, eine Chance auf Erfolg gibt. Wir werden eine Reihe von kritischen Bestandteilen überprüfen - diese Bestandteile sind einfach und dennoch kommen sie für die meisten Organisationen sehr häufig kontraintuitiv daher. Im Gegenzug werden wir eine Reihe von Anti-Patterns überprüfen, die das Scheitern einer solchen Initiative nahezu garantieren.
Heute liegt mein Fokus auf der taktischen Umsetzung des ganz frühen Starts einer Supply Chain-Initiative mit einer “Dinge erledigen”-Mentalität. Ich werde nicht über die großen strategischen Auswirkungen für das Unternehmen diskutieren. Strategie ist sehr wichtig, aber ich werde dieses Thema in einer späteren Vorlesung behandeln.

Die meisten Supply Chain-Initiativen scheitern und das Problem wird kaum jemals öffentlich erwähnt. Die Akademie veröffentlicht jedes Jahr Zehntausende von Papieren, in denen alle Arten von Supply Chain-Innovationen, einschließlich Frameworks, Algorithmen und Modellen, angepriesen werden. Häufig behaupten die Papiere sogar, dass die Innovation irgendwo in der Produktion eingesetzt wurde. Und doch zeigt meine eigene beiläufige Beobachtung der Supply Chain-Welt, dass diese Innovationen nirgendwo zu sehen sind. Ebenso versprechen Softwareanbieter seit drei Jahrzehnten überlegene Ersatzlösungen für Tabellenkalkulationen, und auch hier zeigt meine beiläufige Beobachtung, dass Tabellenkalkulationen allgegenwärtig sind.
Wir kehren zu einem Punkt zurück, der bereits im zweiten Kapitel dieser Reihe von Supply Chain-Vorlesungen angesprochen wurde. Einfach ausgedrückt haben Menschen keinerlei Anreize, Misserfolge zu bewerben, und tun dies daher auch nicht. Darüber hinaus wird das Problem in Unternehmen mit Supply Chains in der Regel durch den natürlichen Verlust des institutionellen Gedächtnisses verstärkt, da Mitarbeiter von einer Position zur nächsten wechseln. Deshalb erkennen weder die Akademie noch die Anbieter diese eher trübe Situation an.
Ich schlage vor, mit einer kurzen Umfrage über die häufigsten Ursachen für Misserfolge aus taktischer Sicht zu beginnen. Diese Ursachen treten typischerweise in der frühesten Phase der Initiative auf.
Die erste Ursache für das Scheitern besteht darin, dass versucht wird, die falschen Probleme zu lösen - Probleme, die nicht existieren, unbedeutend sind oder auf eine Art Missverständnis über die Supply Chain selbst zurückzuführen sind. Die Optimierung von Prozentsätzen der Prognosegenauigkeit ist wahrscheinlich das Archetyp dieser falschen Probleme. Die Reduzierung des Prozentsatzes des Prognosefehlers führt nicht direkt zu zusätzlichen Euros oder Dollar für das Unternehmen. Die gleiche Situation tritt auf, wenn ein Unternehmen bestimmte Service Levels für seinen Bestand verfolgt. Es ist sehr selten, dass dies zu einem finanziellen Gewinn führt.
Die zweite Ursache für das Scheitern ist der Einsatz von ungeeigneter Softwaretechnologie und Softwaredesign. Zum Beispiel versuchen ERP-Anbieter immer, eine Transaktionsdatenbank zur Unterstützung von Datenanalyseinitiativen zu verwenden, da dies auf dem ERP aufbaut. Umgekehrt versuchen Datenwissenschaftsteams immer, das modernste Open-Source-Machine-Learning-Toolkit des Tages zu verwenden, weil es cool ist. Leider erzeugen ungeeignete Technologien in der Regel immense Reibung und eine Menge zufälliger Komplexität.
Die dritte Ursache für das Scheitern ist eine falsche Arbeitsteilung und Organisation. In dem Versuch, Spezialisten in jeder Phase des Prozesses zuzuweisen, neigen Unternehmen dazu, die Initiative auf zu viele Personen zu fragmentieren. Zum Beispiel wird die Datenbereitung sehr häufig von Personen durchgeführt, die nicht für die Prognose verantwortlich sind. Dadurch entstehen überall “Garbage-in-Garbage-out”-Situationen. Eine marginale Verdünnung der Verantwortung für die endgültigen Supply-Chain-Entscheidungen ist ein Rezept für Misserfolg.
Ein Punkt, den ich in dieser kurzen Liste nicht als Ursache aufgeführt habe, ist schlechte Daten. Daten werden häufig für das Scheitern von Supply-Chain-Initiativen verantwortlich gemacht, was sehr bequem ist, da Daten nicht genau auf diese Vorwürfe reagieren können. Daten sind jedoch in der Regel nicht schuld, zumindest nicht im Sinne von Problemen mit schlechten Daten. Die Supply Chain großer Unternehmen wurde vor Jahrzehnten digitalisiert. Jeder Artikel, der gekauft, transportiert, transformiert, produziert oder verkauft wird, hat elektronische Aufzeichnungen. Diese Aufzeichnungen sind möglicherweise nicht perfekt, aber in der Regel sehr genau. Wenn Menschen Schwierigkeiten haben, ordnungsgemäß mit den Daten umzugehen, liegt es nicht wirklich an den Transaktionen selbst.

Um eine quantitative Initiative zum Erfolg zu führen, müssen wir den richtigen Kampf kämpfen. Was versuchen wir überhaupt zu liefern? Eine der wichtigsten Leistungen für eine quantitative Supply Chain ist ein Kernnumerisches Rezept, das die Supply-Chain-Entscheidungen am Ende berechnet. Dieser Aspekt wurde bereits in Vorlesung 1.3 im ersten Kapitel “Produktorientierte Lieferung für die Supply Chain” diskutiert. Lassen Sie uns die beiden wichtigsten Eigenschaften dieser Leistung erneut betrachten.
Erstens muss die Ausgabe eine Entscheidung sein. Zum Beispiel ist die Entscheidung, wie viele Einheiten heute für eine bestimmte SKU nachzubestellen sind, eine Entscheidung. Im Gegensatz dazu ist die Prognose, wie viele Einheiten heute für eine bestimmte SKU angefordert werden, ein numerisches Artefakt. Um eine Entscheidung zu generieren, die das Endergebnis ist, sind viele Zwischenergebnisse erforderlich, das heißt viele numerische Artefakte. Wir dürfen jedoch nicht die Mittel mit dem Zweck verwechseln.
Die zweite Eigenschaft für diese Leistung ist, dass die Ausgabe, die eine Entscheidung ist, als Ergebnis eines rein automatisierten Softwareprozesses vollständig automatisiert sein muss. Das numerische Rezept selbst, das Kernnumerische Rezept, darf keine manuellen Operationen beinhalten. Natürlich hängt das Design des numerischen Rezepts selbst wahrscheinlich stark von einem menschlichen Experten in der Wissenschaft ab. Die Ausführung sollte jedoch nicht von direktem menschlichem Eingriff abhängig sein.
Ein numerisches Rezept als Leistung ist entscheidend, um die Supply-Chain-Initiative zu einem kapitalistischen Unterfangen zu machen. Das numerische Rezept wird zu einem produktiven Vermögenswert, der Renditen generiert. Das Rezept muss gewartet werden, aber dies erfordert ein oder zwei Größenordnungen weniger Personen im Vergleich zu Ansätzen, bei denen Menschen auf Mikroentscheidungsebene eingebunden sind.

Viele Supply-Chain-Initiativen scheitern jedoch, weil sie Supply-Chain-Entscheidungen nicht korrekt als das Ergebnis der Initiative darstellen. Stattdessen konzentrieren sich diese Initiativen darauf, numerische Artefakte bereitzustellen. Numerische Artefakte sollen dazu dienen, zu einer endgültigen Lösung des Problems zu gelangen und die Entscheidungen selbst zu unterstützen. Die häufigsten Artefakte, die in der Supply Chain anzutreffen sind, sind Prognosen, Sicherheitsbestände, EOQs und KPIs. Obwohl diese Zahlen interessant sein können, sind sie nicht real. Diese Zahlen haben kein unmittelbares greifbares physisches Gegenstück in der Supply Chain und spiegeln willkürliche Modellierungsperspektiven auf die Supply Chain wider.
Die Konzentration auf die numerischen Artefakte führt zum Scheitern der Initiative, weil diesen Zahlen eine entscheidende Zutat fehlt: direktes Feedback aus der realen Welt. Wenn die Entscheidung falsch ist, können die negativen Folgen auf die Entscheidung zurückgeführt werden. Bei numerischen Artefakten ist die Situation jedoch viel mehrdeutiger. Tatsächlich ist die Verantwortung auf viele Artefakte verteilt, die zu jeder einzelnen Entscheidung beitragen. Das Problem wird noch schlimmer, wenn es menschlichen Eingriff gibt.
Dieses Fehlen von Feedback ist für numerische Artefakte tödlich. Moderne Supply Chains sind komplex. Wählen Sie eine beliebige Formel zur Berechnung eines Sicherheitsbestands, einer optimalen Bestellmenge oder eines KPIs aus, und es ist überwältigend wahrscheinlich, dass diese Formel in vielerlei Hinsicht falsch ist. Das Problem der Richtigkeit der Formel ist kein mathematisches Problem, sondern ein geschäftliches Problem. Es geht darum, die Frage zu beantworten: “Spiegelt diese Berechnung wirklich die strategische Absicht wider, die ich für mein Unternehmen habe?” Die Antwort variiert von einem Unternehmen zum anderen und ändert sich sogar von einem Jahr zum nächsten, da sich Unternehmen im Laufe der Zeit weiterentwickeln.
Da numerische Artefakte kein direktes Feedback aus der realen Welt erhalten, fehlt ihnen der Mechanismus, mit dem von einer naiven, vereinfachten und höchstwahrscheinlich weitgehend falschen ersten Implementierung zu einer annähernd korrekten Version der Formel iteriert werden kann, die als produktionsreif angesehen werden kann. Dennoch sind numerische Artefakte sehr verlockend, weil sie die Illusion erwecken, der Lösung näher zu kommen. Sie erwecken den Anschein von Rationalität, Wissenschaftlichkeit und sogar Unternehmertum. Wir haben Zahlen, Formeln, Algorithmen, Modelle. Es ist sogar möglich, Benchmarks durchzuführen und diese Zahlen mit ebenso erfundenen Zahlen zu vergleichen. Eine Verbesserung gegenüber einem erfundenen Benchmark erweckt ebenfalls den Anschein von Fortschritt und ist sehr tröstlich. Aber am Ende des Tages bleibt es eine Illusion, eine Frage der Modellierungsperspektive.
Unternehmen erzielen keine Gewinne, indem sie Menschen dafür bezahlen, KPIs anzusehen oder Benchmarks durchzuführen. Sie erzielen Gewinne, indem sie eine Entscheidung nach der anderen treffen und hoffentlich bei jeder einzelnen Entscheidung besser werden.
Diese Vorlesung ist Teil einer Reihe von Supply-Chain-Vorlesungen. Ich versuche, diese Vorlesungen einigermaßen unabhängig zu halten, aber wir haben einen Punkt erreicht, an dem es sinnvoller ist, diese Vorlesungen in der richtigen Reihenfolge anzusehen. Diese Vorlesung ist die allererste Vorlesung des siebten Kapitels, das der Durchführung von Supply-Chain-Initiativen gewidmet ist. Mit Supply-Chain-Initiativen meine ich quantitative Supply-Chain-Initiativen - Initiativen, die etwas in der Größenordnung von vorhersagender Optimierung für das Unternehmen liefern sollen.
Das allererste Kapitel war meinen Ansichten über Supply Chain sowohl als Forschungsfeld als auch als Praxis gewidmet. Im zweiten Kapitel habe ich eine Reihe von Methoden vorgestellt, die für die Supply Chain unerlässlich sind, da naive Methoden aufgrund der gegnerischen Natur vieler Supply-Chain-Situationen besiegt werden. Im dritten Kapitel habe ich eine Reihe von Supply-Chain-Personae mit einem reinen Fokus auf die Probleme vorgestellt; mit anderen Worten, was versuchen wir zu lösen?
Im vierten Kapitel habe ich eine Reihe von Bereichen vorgestellt, die zwar nicht direkt zur Supply Chain gehören, aber meiner Meinung nach für eine moderne Praxis der Supply Chain unerlässlich sind. In den fünften und sechsten Kapiteln habe ich die intelligenten Bestandteile eines numerischen Rezepts vorgestellt, das dazu bestimmt ist, Supply-Chain-Entscheidungen zu steuern, nämlich vorhersagende Optimierung (die generalisierte Perspektive der Prognose) und Entscheidungsfindung (im Wesentlichen mathematische Optimierung, die auf Supply-Chain-Probleme angewendet wird). In diesem siebten Kapitel besprechen wir, wie man diese Elemente in einer tatsächlichen Supply-Chain-Initiative zusammenführt, die diese Methoden und Technologien in die Produktion bringen soll.

Heute werden wir besprechen, was als korrekte Vorgehensweise für die Durchführung einer Supply-Chain-Initiative gilt. Dies umfasst die Rahmung der Initiative mit dem richtigen Ergebnis, über das wir gerade gesprochen haben, aber auch mit dem richtigen Zeitplan, dem richtigen Umfang und den richtigen Rollen. Diese Elemente stellen den ersten Teil der heutigen Vorlesung dar.
Der zweite Teil der Vorlesung wird dem Daten-Pipeline gewidmet sein, einer entscheidenden Komponente für den Erfolg einer datengetriebenen oder datenabhängigen Initiative. Obwohl die Daten-Pipeline ein recht technisches Thema ist, erfordert sie eine angemessene Arbeitsteilung und Organisation zwischen IT und Supply Chain. Insbesondere werden wir sehen, dass Qualitätskontrollen größtenteils in den Händen der Supply Chain liegen sollten, mit der Gestaltung von Datenqualitätsberichten und Dateninspektoren.
Das Onboarding ist die erste Phase der Initiative, in der das Kernnumerische Rezept, das die Entscheidung zusammen mit nur unterstützenden Elementen generiert, erstellt wird. Das Onboarding endet mit einer schrittweisen Einführung in die Produktion, und während dieser Einführung werden die früheren Prozesse allmählich durch das numerische Rezept selbst automatisiert.
Bei der Festlegung des angemessenen Zeitplans für die erste quantitative Supply-Chain-Initiative in einem Unternehmen könnte man denken, dass dies von der Größe des Unternehmens, der Komplexität, der Art der Supply-Chain-Entscheidungen und dem Gesamtkontext abhängt. Obwohl dies in begrenztem Umfang zutrifft, zeigen die Erfahrungen, die Lokad in einem Jahrzehnt und Dutzenden solcher Initiativen gesammelt hat, dass sechs Monate nahezu immer der angemessene Zeitplan sind. Überraschenderweise hat dieser sechsmonatige Zeitplan wenig mit der Technologie oder sogar den spezifischen Merkmalen der Supply Chain zu tun; er hat viel mehr mit den Menschen und den Organisationen selbst zu tun und der Zeit, die sie benötigen, um sich mit dem, was in der Regel als sehr unterschiedliche Art der Durchführung der Supply Chain wahrgenommen wird, wohlzufühlen.
Die ersten beiden Monate sind der Einrichtung der Daten-Pipeline gewidmet. Wir werden in wenigen Minuten auf diesen Punkt zurückkommen, aber diese Verzögerung von zwei Monaten wird durch zwei Faktoren verursacht. Erstens müssen wir die Daten-Pipeline zuverlässig machen und seltene Probleme beseitigen, die Wochen dauern können, um sich zu manifestieren. Der zweite Faktor ist, dass wir die Semantik der Daten herausfinden müssen, das heißt, verstehen, was die Daten aus einer Supply-Chain-Perspektive bedeuten.
Die Monate drei und vier sind der schnellen Iteration über das numerische Rezept selbst gewidmet, das die Supply-Chain-Entscheidungen steuern wird. Diese Iterationen sind erforderlich, weil die Generierung tatsächlicher Endspielentscheidungen in der Regel der einzige Weg ist, um festzustellen, ob etwas mit dem zugrunde liegenden Rezept oder allen in das Rezept eingebauten Annahmen nicht stimmt. Diese beiden Monate sind auch in der Regel die Zeit, die Supply-Chain-Praktiker benötigen, um sich an die sehr quantitative, finanzielle Perspektive zu gewöhnen, die diese softwaregesteuerten Entscheidungen antreibt.
Schließlich sind die letzten beiden Monate der Stabilisierung des numerischen Rezepts gewidmet, nachdem in der Regel eine relativ intensive Phase schneller Iterationen stattgefunden hat. In dieser Phase bietet sich auch die Möglichkeit, das Rezept in einer produktionsähnlichen Umgebung auszuführen, jedoch noch nicht die Produktion anzutreiben. Diese Phase ist wichtig, um das Vertrauen der Supply-Chain-Teams in diese aufkommende Lösung zu gewinnen.
Obwohl es wünschenswert sein könnte, diesen Zeitplan weiter zu verkürzen, stellt sich heraus, dass dies in der Regel sehr schwierig ist. Die Einrichtung der Daten-Pipeline kann in gewissem Maße beschleunigt werden, wenn die richtige IT-Infrastruktur bereits vorhanden ist, aber das Vertrautwerden mit den Daten erfordert Zeit, um zu verstehen, was die Daten aus einer Supply-Chain-Perspektive bedeuten. In der zweiten Phase, wenn die Iteration über das numerische Rezept sehr schnell konvergiert, werden die Supply-Chain-Teams wahrscheinlich beginnen, die Feinheiten des numerischen Rezepts zu erkunden, was auch die Verzögerung verlängert. Schließlich sind die letzten beiden Monate in der Regel erforderlich, um die Saisonalität zu beobachten und Vertrauen in die Software zu gewinnen, die wichtige Supply-Chain-Entscheidungen in der Produktion steuert.
Insgesamt dauert es etwa sechs Monate, und obwohl es wünschenswert wäre, dies weiter zu verkürzen, ist es eine Herausforderung, dies zu tun. Allerdings ist sechs Monate bereits ein beträchtlicher Zeitrahmen. Wenn von Anfang an, während der Einarbeitungszeit, in der das numerische Rezept noch nicht die Supply-Chain-Entscheidungen steuert, erwartet wird, dass dies länger als sechs Monate dauert, dann ist die Initiative bereits gefährdet. Wenn die zusätzliche Verzögerung mit der Datenextraktion und der Einrichtung der Daten-Pipeline verbunden ist, dann gibt es ein IT-Problem. Wenn die zusätzliche Verzögerung mit dem Design oder der Konfiguration der Lösung zusammenhängt, möglicherweise verursacht durch einen Drittanbieter, dann gibt es ein Problem mit der Technologie selbst. Schließlich, wenn nach zwei Monaten stabilisierter produktionsähnlicher Ausführung die Produktionsbereitstellung nicht erfolgt, dann gibt es in der Regel ein Problem mit dem Management der Initiative.

Wenn man versucht, eine Neuheit, einen neuen Prozess oder eine neue Technologie in eine Organisation einzuführen, legt die allgemeine Weisheit nahe, klein anzufangen, sicherzustellen, dass es funktioniert, und auf frühen Erfolgen aufzubauen, um sich allmählich zu erweitern. Leider ist die Supply Chain nicht freundlich zur allgemeinen Weisheit, und diese Perspektive hat einen spezifischen Dreh in Bezug auf die Abgrenzung der Supply Chain. In Bezug auf die Abgrenzung gibt es zwei Hauptkräfte, die weitgehend definieren, was als geeigneter Umfang für eine Supply-Chain-Initiative gilt und was nicht.
Die Anwendungsumgebung ist die erste Kraft, die die Abgrenzung beeinflusst. Eine Supply Chain als Ganzes kann nicht direkt beobachtet werden; sie kann nur indirekt durch die Linse von Unternehmenssoftware beobachtet werden. Die Daten werden durch diese Softwarestücke erhalten. Die Komplexität der Initiative hängt stark von der Anzahl und Vielfalt dieser Softwarestücke ab. Jede App ist ihre eigene Datenquelle, und das Extrahieren und Analysieren der Daten aus einer beliebigen Geschäfts-App ist in der Regel eine bedeutende Aufgabe. Der Umgang mit mehr Apps bedeutet in der Regel den Umgang mit mehreren Datenbanktechnologien, inkonsistenten Terminologien, inkonsistenten Konzepten und kompliziert die Situation erheblich.
Daher müssen wir bei der Festlegung des Umfangs anerkennen, dass die geeigneten Grenzen in der Regel durch die Geschäfts-Apps selbst und ihre Datenbankstruktur definiert sind. In diesem Zusammenhang muss “klein anfangen” als das Halten des anfänglichen Datenintegrations-Fußabdrucks so klein wie möglich verstanden werden, während die Integrität der Supply-Chain-Initiative als Ganzes erhalten bleibt. Es ist besser, tief als breit in Bezug auf die App-Integration zu gehen. Sobald Sie das IT-System haben, um einige Datensätze aus einer Tabelle in einer bestimmten App zu erhalten, ist es in der Regel einfach, alle Datensätze aus dieser Tabelle und alle Datensätze aus einer anderen Tabelle in derselben App zu erhalten.

Ein häufiger Fehler bei der Festlegung des Umfangs besteht darin, eine Stichprobe zu verwenden. Eine Stichprobe wird in der Regel durch die Auswahl einer kurzen Liste von Produktkategorien, Standorten oder Lieferanten erreicht. Eine Stichprobe ist gut gemeint, folgt jedoch nicht den Grenzen, wie sie durch die Anwendungslandschaft definiert sind. Um eine Stichprobe zu implementieren, müssen Filter während der Datenextraktion angewendet werden, und dieser Prozess führt zu einer Reihe von Problemen, die die Supply-Chain-Initiative gefährden können.
Erstens erfordert eine gefilterte Datenextraktion aus einer Unternehmenssoftware mehr Aufwand von dem IT-Team im Vergleich zu einer ungefilterten Extraktion. Filter müssen zunächst entwickelt werden, und der Filterungsprozess selbst ist fehleranfällig. Das Debuggen falscher Filter ist in der Regel mühsam, da es zahlreiche Austausche mit dem IT-Team erfordert, was die Initiative verlangsamt und somit gefährdet.
Zweitens führt es zu massiven Leistungsproblemen der Software, wenn die Initiative später auf den vollen Umfang ausgeweitet wird. Eine schlechte Skalierbarkeit oder die Unfähigkeit, eine große Datenmenge zu verarbeiten und dabei die Rechenkosten unter Kontrolle zu halten, ist ein sehr häufiger Fehler in der Software. Indem die Initiative über eine Stichprobe arbeitet, werden Skalierbarkeitsprobleme maskiert, die jedoch in einer späteren Phase mit aller Macht zurückkehren werden.
Die Arbeit mit einer Datenstichprobe macht Statistiken nicht einfacher, sondern schwieriger. Tatsächlich ist der Zugriff auf mehr Daten wahrscheinlich der einfachste Weg, um die Genauigkeit und Stabilität nahezu aller maschinellen Lernalgorithmen zu verbessern. Das Samplen der Daten widerspricht dieser Erkenntnis. Wenn also eine kleine Datenstichprobe verwendet wird, kann die Initiative aufgrund von unregelmäßigem numerischem Verhalten, das über die Stichprobe beobachtet wird, scheitern. Diese Verhaltensweisen wären weitgehend abgemildert worden, wenn der gesamte Datensatz verwendet worden wäre.
Systemeffekte sind die zweite Kraft, die den Umfang beeinflusst. Eine Supply Chain ist ein System, und alle ihre Teile sind in gewissem Maße miteinander verbunden. Die Herausforderung bei Systemen, jedem System, besteht darin, dass Versuche, einen Teil des Systems zu verbessern, dazu neigen, Probleme zu verlagern, anstatt sie zu beheben. Betrachten wir zum Beispiel ein Problem der Bestandsallokation für ein Einzelhandelsnetzwerk mit einem Distributionszentrum und vielen Filialen. Wenn wir eine einzelne Filiale als den anfänglichen Umfang für unser Bestandsallokationsproblem wählen, ist es trivial, sicherzustellen, dass diese Filiale einen sehr hohen Servicequalität vom Distributionszentrum erhält, indem wir im Voraus Bestände dafür reservieren. Dadurch können wir sicherstellen, dass das Distributionszentrum niemals einen Lagerbestand hat, während es diese eine Filiale bedient. Diese Reservierung von Beständen würde jedoch auf Kosten der Servicequalität für die anderen Filialen im Netzwerk erfolgen.
Daher müssen wir bei der Festlegung des Umfangs einer Supply-Chain-Initiative die Systemeffekte berücksichtigen. Der Umfang sollte so gestaltet sein, dass eine lokale Optimierung zu Lasten der Elemente außerhalb des Umfangs weitgehend vermieden wird. Dieser Teil der Umfangsbestimmung ist schwierig, da alle Umfänge in gewissem Maße undicht sind. Zum Beispiel konkurrieren alle Teile der Supply Chain letztendlich um die gleiche Menge an verfügbarem Bargeld auf Unternehmensebene. Jeder Dollar, der irgendwo zugeordnet wird, ist ein Dollar, der für andere Zwecke nicht verfügbar sein wird. Dennoch lassen sich bestimmte Umfänge viel leichter manipulieren als andere. Es ist wichtig, einen Umfang zu wählen, der dazu neigt, Systemeffekte zu mildern, anstatt sie zu verstärken.

Beim Nachdenken über die Festlegung des Umfangs einer Supply-Chain-Initiative in Bezug auf Systemeffekte mag es für viele Supply-Chain-Praktiker seltsam erscheinen. Wenn es um die Umfangsbestimmung geht, neigen die meisten Unternehmen dazu, ihre interne Organisation auf die Umfangsbestimmung zu projizieren. Die gewählten Grenzen für den Umfang tendieren daher unweigerlich dazu, die Grenzen der Arbeitsteilung innerhalb des Unternehmens nachzuahmen. Dieses Muster wird als Conway’s Law bezeichnet. Vor einem halben Jahrhundert von Melvin Conway für Kommunikationssysteme vorgeschlagen, hat sich das Gesetz seitdem als viel breiter anwendbar erwiesen und ist auch für das Supply-Chain-Management von großer Relevanz.
Die Grenzen und Silos, die in heutigen Supply Chains dominieren, werden durch Arbeitsteilungen bestimmt, die das Ergebnis recht manueller Prozesse sind, um Supply-Chain-Entscheidungen zu treffen. Wenn zum Beispiel ein Unternehmen feststellt, dass ein Supply- und Demand-Planer nicht mehr als 1.000 SKUs verwalten kann und das Unternehmen insgesamt 50.000 SKUs verwalten muss, benötigt das Unternehmen 50 Supply- und Demand-Planer dafür. Die Optimierung der Supply Chain auf 50 Paar Hände aufzuteilen, führt jedoch zwangsläufig zu vielen Ineffizienzen auf Unternehmensebene.
Im Gegensatz dazu muss eine Initiative, die diese Entscheidungen automatisiert, sich nicht an Grenzen orientieren, die nur eine veraltete oder bald veraltete Arbeitsteilung widerspiegeln. Ein numerisches Rezept kann diese 50.000 SKUs auf einmal optimieren und die Ineffizienzen beseitigen, die entstehen, wenn Dutzende von Silos gegeneinander antreten. Daher ist es nur natürlich, dass eine Initiative, die beabsichtigt, diese Entscheidungen weitgehend zu automatisieren, mit vielen bereits vorhandenen Grenzen im Unternehmen überschneidet. Das Unternehmen oder genauer gesagt das Management des Unternehmens, muss dem Drang widerstehen, die bestehenden organisatorischen Grenzen zu imitieren, insbesondere auf der Ebene der Umfangsbestimmung, da dies den Ton für das Folgende setzt.

Supply Chains sind in Bezug auf Hardware, Software und Menschen komplex. Es ist bedauerlich, dass der Start einer quantitativen Supply-Chain-Initiative die Komplexität der Supply Chain zunächst weiter erhöht. Langfristig kann es die Komplexität der Supply Chain tatsächlich erheblich verringern, aber das werden wir wahrscheinlich in einer späteren Vorlesung behandeln. Darüber hinaus erhöht sich die Komplexität der Initiative selbst umso mehr, je mehr Personen daran beteiligt sind. Wenn diese zusätzliche Komplexität nicht sofort unter Kontrolle gebracht wird, besteht eine hohe Wahrscheinlichkeit, dass die Initiative unter ihrer eigenen Komplexität zusammenbricht.
Daher müssen wir, wenn wir über die Rollen der Initiative nachdenken, also darüber, wer was tun wird, über die kleinste mögliche Anzahl von Rollen nachdenken, die die Initiative lebensfähig machen. Durch Minimierung der Anzahl von Rollen minimieren wir die Komplexität der Initiative, was wiederum die Erfolgschancen erheblich verbessert. Diese Perspektive tendiert dazu, für große Unternehmen gegenintuitiv zu sein, die es lieben, mit einer äußerst feingranulierten Arbeitsteilung zu arbeiten. Große Unternehmen neigen dazu, extreme Spezialisten zu bevorzugen, die nur eine Sache tun. Eine Supply Chain ist jedoch ein System, und wie alle Systeme zählt die End-to-End-Perspektive.
Basierend auf den bei Lokad gesammelten Erfahrungen bei der Durchführung solcher Initiativen haben wir vier Rollen identifiziert, die in der Regel die minimale lebensfähige Arbeitsteilung für die Durchführung der Initiative darstellen: einen Supply-Chain-Manager, einen Datenbeauftragten, einen Supply-Chain-Wissenschaftler und einen Supply-Chain-Praktiker.
Die Rolle des Supply-Chain-Managers besteht darin, die Initiative zu unterstützen, damit sie überhaupt stattfinden kann. Die Einführung eines gut konzipierten numerischen Rezepts zur Steuerung der Supply-Chain-Entscheidungen in der Produktion stellt einen massiven Schub sowohl in Bezug auf Rentabilität als auch Produktivität dar. Es ist jedoch auch eine große Veränderung, die verdaut werden muss. Es erfordert viel Energie und Unterstützung von der obersten Führungsebene, damit eine solche Veränderung in einer großen Organisation stattfinden kann.
Die Rolle des Datenbeauftragten besteht darin, die Datenpipeline einzurichten und aufrechtzuerhalten. Der Großteil ihrer Beiträge wird in den ersten beiden Monaten der Initiative erwartet. Wenn die Datenpipeline richtig konzipiert ist, erfordert sie danach nur sehr wenig fortlaufenden Aufwand für den Datenbeauftragten. Der Datenbeauftragte ist in der Regel nicht stark in den späteren Phasen der Initiative involviert.
Die Rolle des Supply-Chain-Wissenschaftlers besteht darin, das Kernnumerikum zu erstellen. Diese Rolle beginnt mit den rohen Transaktionsdaten, wie sie vom Datenbeauftragten zur Verfügung gestellt werden. Vom Datenbeauftragten wird keine Datenaufbereitung erwartet, nur die Datenextraktion. Die Rolle des Supply-Chain-Wissenschaftlers endet mit der Übernahme der generierten Supply-Chain-Entscheidung. Nicht eine Software ist für die Entscheidung verantwortlich, sondern der Supply-Chain-Wissenschaftler. Für jede generierte Entscheidung muss der Wissenschaftler selbst in der Lage sein, zu rechtfertigen, warum diese Entscheidung angemessen ist.
Schließlich besteht die Rolle des Supply-Chain-Praktikers darin, die von der numerischen Rezeptur generierten Entscheidungen herauszufordern und Feedback an den Supply-Chain-Wissenschaftler zu geben. Der Praktiker hat keine Hoffnung, die Entscheidung zu treffen. Diese Person war bisher in der Regel für diese Entscheidungen zuständig, zumindest für einen Teilbereich, und zwar in der Regel mit Hilfe von Tabellenkalkulationen und vorhandenen Systemen. In einem kleinen Unternehmen ist es möglich, dass eine Person sowohl die Rolle des Supply-Chain-Executives als auch die des Supply-Chain-Praktikers übernimmt. Es ist auch möglich, die Notwendigkeit eines Datenbeauftragten zu umgehen, wenn die Daten leicht zugänglich sind. Dies kann in Unternehmen geschehen, die hinsichtlich ihrer Dateninfrastruktur sehr ausgereift sind. Im Gegensatz dazu ist es bei sehr großen Unternehmen möglich, dass nur wenige Personen jede Rolle ausfüllen, aber nur sehr wenige.
Der erfolgreiche Rollout des Kernnumerikums in der Produktion hat einen erheblichen Einfluss auf die Welt des Supply-Chain-Praktikers. Tatsächlich besteht der Zweck der Initiative weitgehend darin, den bisherigen Job des Supply-Chain-Praktikers zu automatisieren. Dies bedeutet jedoch nicht, dass die beste Vorgehensweise darin besteht, diese Praktiker zu entlassen, sobald das numerische Rezept in Produktion ist. Wir werden dieses spezifische Aspekt in der nächsten Vorlesung erneut behandeln.

Organisiert zu sein bedeutet nicht, effizient oder effektiv zu sein. Es gibt Rollen, die trotz guter Absichten Reibung in Supply-Chain-Initiativen verursachen, oft bis hin zum Scheitern. Heutzutage ist die erste Rolle, die am meisten dazu beiträgt, solche Initiativen scheitern zu lassen, in der Regel die Rolle des Datenwissenschaftlers, insbesondere wenn ein ganzes Datenwissenschaftsteam involviert ist. Übrigens hat Lokad dies vor etwa einem Jahrzehnt auf die harte Tour gelernt.
Trotz der Namensähnlichkeit zwischen Datenwissenschaftlern und Supply-Chain-Wissenschaftlern sind die beiden Rollen tatsächlich sehr unterschiedlich. Der Supply-Chain-Wissenschaftler kümmert sich in erster Linie darum, realitätsnahe, produktionsreife Entscheidungen zu treffen. Wenn dies mit einem halbtrivialen numerischen Rezept erreicht werden kann, umso besser; die Wartung wird ein Kinderspiel sein. Der Supply-Chain-Wissenschaftler übernimmt die volle Verantwortung für die kleinsten Details der Supply Chain. Zuverlässigkeit und Resilienz gegenüber Umgebungschaos sind wichtiger als Raffinesse.
Im Gegensatz dazu konzentriert sich der Datenwissenschaftler auf die intelligenten Teile des numerischen Rezepts, die Modelle und Algorithmen. Der Datenwissenschaftler sieht sich im Allgemeinen als Experten für maschinelles Lernen und mathematische Optimierung. In Bezug auf Technologien ist ein Datenwissenschaftler bereit, das neueste Open-Source-Numerik-Toolkit zu erlernen, aber diese Person ist in der Regel nicht bereit, sich mit dem dreißig Jahre alten ERP-System zu beschäftigen, das zufällig im Unternehmen läuft. Der Datenwissenschaftler ist auch kein Supply-Chain-Experte und ist in der Regel nicht bereit, einer zu werden. Der Datenwissenschaftler versucht, die besten Ergebnisse gemäß vereinbarter Metriken zu liefern. Der Wissenschaftler hat nicht den Ehrgeiz, sich mit den sehr banalen Details der Supply Chain zu befassen; diese Elemente sollen von anderen Personen behandelt werden.
Die Einbeziehung von Datenwissenschaftlern bedeutet das Scheitern dieser Initiativen, denn sobald Datenwissenschaftler involviert sind, steht die Supply Chain nicht mehr im Fokus - Algorithmen und Modelle sind es. Unterschätzen Sie niemals die Ablenkungskraft, die das neueste Modell oder der neueste Algorithmus für eine intelligente, technologieorientierte Person darstellt.
Die zweite Rolle, die Reibung in eine Supply-Chain-Initiative bringt, ist das Business Intelligence (BI)-Team. Wenn das BI-Team Teil der Initiative ist, neigt es dazu, eher eine Behinderung als etwas anderes zu sein, wenn auch in viel geringerem Maße als das Data Science-Team. Das Problem mit BI ist hauptsächlich kultureller Natur. BI liefert Berichte, keine Entscheidungen. Das BI-Team ist in der Regel bereit, endlose Wände von Metriken zu produzieren, wie von jeder einzelnen Abteilung des Unternehmens angefordert. Dies ist nicht die richtige Einstellung für eine quantitative Supply-Chain-Initiative.
Außerdem ist Business Intelligence als Software eine sehr spezifische Klasse von Datenanalyse, die sich um Würfel oder OLAP-Würfel dreht, mit denen Sie die meisten In-Memory-Systeme in Unternehmenssystemen analysieren können. Diese Gestaltung ist in der Regel ungeeignet, um Supply-Chain-Entscheidungen zu treffen.

Nachdem wir die Initiative umrissen haben, werfen wir einen Blick auf die IT-Architektur auf hoher Ebene, die die Initiative erfordert.
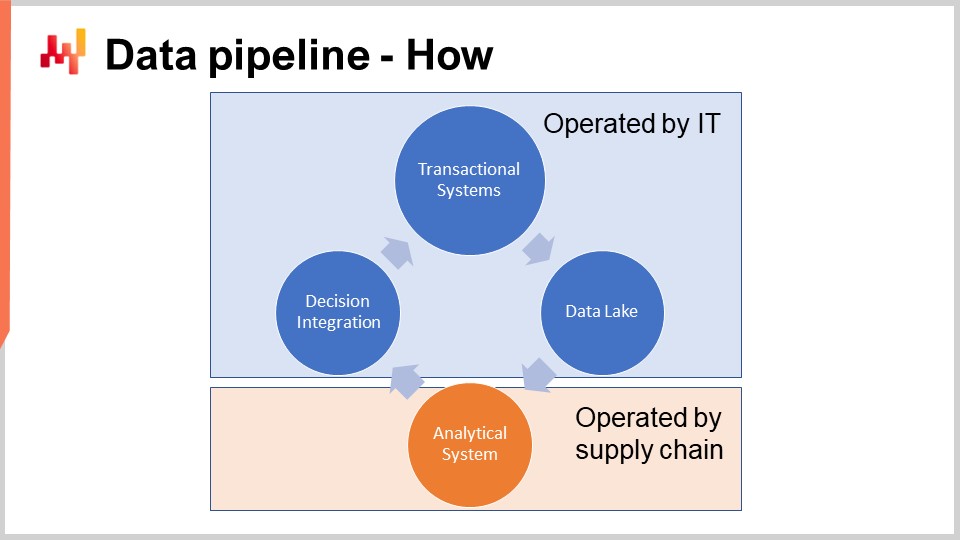
Das Schema auf dem Bildschirm veranschaulicht den typischen Aufbau einer Datenpipeline für eine quantitative Supply-Chain-Initiative. In diesem Vortrag diskutiere ich eine Datenpipeline, die keine Anforderungen an geringe Latenz unterstützt. Wir möchten einen vollständigen Zyklus in etwa einer Stunde abschließen, nicht in einer Sekunde. Die meisten Supply-Chain-Entscheidungen, wie Bestellungen, erfordern keine geringe Latenz. Um eine End-to-End-Geringlatenz zu erreichen, ist eine andere Art von Architektur erforderlich, die über den Rahmen des heutigen Vortrags hinausgeht.

Die Transaktionssysteme stellen die primäre Datenquelle und den Ausgangspunkt der Datenpipeline dar. Diese Systeme umfassen ERP, WMS und EDI. Sie befassen sich mit dem Fluss von Waren wie Einkauf, Transport, Produktion und Verkauf. Diese Systeme enthalten fast alle Daten, die das Kernnumerikrezept erfordert. Für praktisch jedes größere Unternehmen sind diese Systeme oder ihre Vorgänger seit mindestens zwei Jahrzehnten im Einsatz.
Da diese Systeme fast alle Daten enthalten, die wir benötigen, wäre es verlockend, das numerische Rezept direkt in diese Systeme zu implementieren. Warum nicht? Indem wir das numerische Rezept direkt in das ERP integrieren, würden wir den Aufwand für den Aufbau dieser gesamten Datenpipeline einsparen. Leider funktioniert dies aufgrund des Designs dieser Transaktionssysteme nicht.
Diese Transaktionssysteme sind in der Regel auf der Grundlage einer Transaktionsdatenbank aufgebaut. Dieser Ansatz für das Design von Unternehmenssoftware ist in den letzten vier Jahrzehnten äußerst stabil gewesen. Wählen Sie ein beliebiges Unternehmen aus, und die Chancen stehen gut, dass jede einzelne Geschäftsanwendung in Produktion auf einer Transaktionsdatenbank implementiert wurde. Transaktionsdatenbanken bieten vier Schlüsseleigenschaften, die unter dem Akronym ACID bekannt sind, was für Atomicity, Consistency, Isolation und Durability steht. Ich werde nicht auf die Details dieser Eigenschaften eingehen, aber es sei gesagt, dass diese Eigenschaften die Datenbank sehr gut für das sichere und gleichzeitige Ausführen vieler kleiner Lese- und Schreiboperationen geeignet machen. Die jeweiligen Mengen an Lese- und Schreiboperationen sollten auch ziemlich ausgeglichen sein.
Der Preis für diese sehr nützlichen ACID-Eigenschaften auf der granularen Ebene ist jedoch, dass die Transaktionsdatenbank auch sehr ineffizient ist, wenn es darum geht, große Leseoperationen zu bedienen. Eine Leseoperation, die einen beträchtlichen Teil der gesamten Datenbank abdeckt, kostet in der Regel etwa das Hundertfache der Rechenressourcen im Vergleich zu Architekturen, die sich nicht so stark auf diese ACID-Eigenschaften auf einer so granularen Ebene konzentrieren. ACID ist schön, aber es hat seinen Preis.
Darüber hinaus wird die Datenbank wahrscheinlich für eine Weile nicht reagieren, wenn jemand versucht, einen beträchtlichen Teil der gesamten Datenbank zu lesen, da sie den Großteil ihrer Ressourcen der Bedienung dieser einen großen Anfrage widmet. Viele Unternehmen beklagen, dass ihre gesamten Geschäftssysteme träge sind und dass diese Systeme häufig für eine Sekunde oder länger einfrieren. In der Regel lässt sich diese schlechte Servicequalität auf schwere SQL-Abfragen zurückführen, die versuchen, zu viele Zeilen auf einmal zu lesen.
Daher darf das Kernnumerikrezept nicht in der gleichen Umgebung wie die Transaktionssysteme, die die Produktion unterstützen, ausgeführt werden. Tatsächlich müssen numerische Rezepte auf die meisten Daten zugreifen, wann immer sie ausgeführt werden. Das numerische Rezept muss daher streng isoliert in seinem eigenen Subsystem gehalten werden, wenn nur um die Leistung dieser Transaktionssysteme nicht weiter zu beeinträchtigen.
Übrigens verhindert dies nicht, dass die meisten Anbieter von Transaktionssystemen (ERP, MRP, WMS) integrierte analytische Module verkaufen, z. B. Bestandsoptimierungs-Module. Die Integration dieser Module führt zwangsläufig zu Problemen bei der Servicequalität und zu enttäuschenden Leistungsfähigkeiten. Alle diese Probleme lassen sich auf dieses eine Designproblem zurückführen: Das Transaktionssystem und das analytische System müssen streng isoliert gehalten werden.
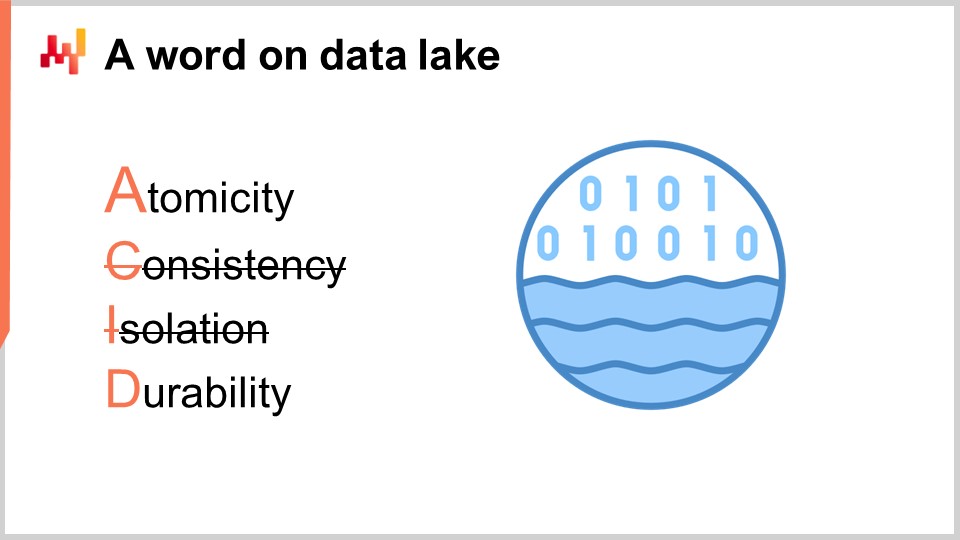
Der Data Lake ist einfach. Es ist ein Spiegelbild der Transaktionsdaten, das auf sehr große Leseoperationen ausgerichtet ist. Tatsächlich haben wir gesehen, dass Transaktionssysteme für viele kleine Leseoperationen optimiert sind, nicht für sehr große. Daher besteht die richtige Gestaltung darin, die Transaktionsdaten sorgfältig in ein anderes System, nämlich den Data Lake, zu replizieren, um die Servicequalität des Transaktionssystems zu erhalten. Diese Replikation muss sorgfältig implementiert werden, um den Druck auf das Transaktionssystem zu minimieren und die Servicequalität zu erhalten.
Sobald die relevanten Transaktionsdaten in den Data Lake gespiegelt sind, bedient der Data Lake selbst alle Datenanfragen. Ein weiterer Vorteil des Data Lake besteht darin, dass er mehrere analytische Systeme bedienen kann. Wenn beispielsweise das Marketing eigene Analysen wünscht, benötigt es dieselben Transaktionsdaten, und dasselbe gilt für Finanzen, Vertrieb usw. Anstatt dass jede Abteilung im Unternehmen ihren eigenen Mechanismus zur Datenextraktion implementiert, ist es sinnvoll, all diese Extraktionen in den gleichen Data Lake, das gleiche System, zu konsolidieren.
Auf technischer Ebene kann ein Data Lake mit einer relationalen Datenbank implementiert werden, die typischerweise für die Extraktion großer Datenmengen optimiert ist und eine spaltenorientierte Datenspeicherung verwendet. Data Lakes können auch als Repository von Flatfiles implementiert werden, die über ein verteiltes Dateisystem bereitgestellt werden. Im Vergleich zu einem Transaktionssystem verzichtet ein Data Lake auf die feinkörnigen transaktionalen Eigenschaften. Das Ziel besteht darin, eine große Menge an Daten so kostengünstig und zuverlässig wie möglich bereitzustellen - nicht mehr und nicht weniger.
Der Data Lake muss die ursprünglichen Transaktionsdaten spiegeln, was bedeutet, dass nichts geändert werden darf. Es ist wichtig, die Daten im Data Lake nicht vorzubereiten. Leider kann das IT-Team, das für die Einrichtung des Data Lake verantwortlich ist, versucht sein, es anderen Teams einfacher und einfacher zu machen und die Daten ein wenig vorzubereiten. Das Ändern der Daten führt jedoch zwangsläufig zu Komplikationen, die die Analyse in einem späteren Stadium beeinträchtigen. Darüber hinaus verringert die strikte Spiegelungsrichtlinie den Aufwand, den das IT-Team für die Einrichtung und spätere Wartung des Data Lake benötigt, erheblich.
In Unternehmen, in denen bereits ein BI-Team vorhanden ist, kann es verlockend sein, die BI-Systeme als Data Lake zu verwenden. Ich rate jedoch dringend davon ab, dies zu tun und niemals ein BI-Setup als Data Lake zu verwenden. Die Daten in BI-Systemen (Business Intelligence-Systemen) sind in der Regel bereits stark transformiert. Die Nutzung der BI-Daten zur Steuerung automatisierter Supply-Chain-Entscheidungen führt zu Problemen mit schlechter Datenqualität. Der Data Lake darf nur aus primären Datenquellen wie ERP gespeist werden, nicht aus sekundären Datenquellen wie dem BI-System.
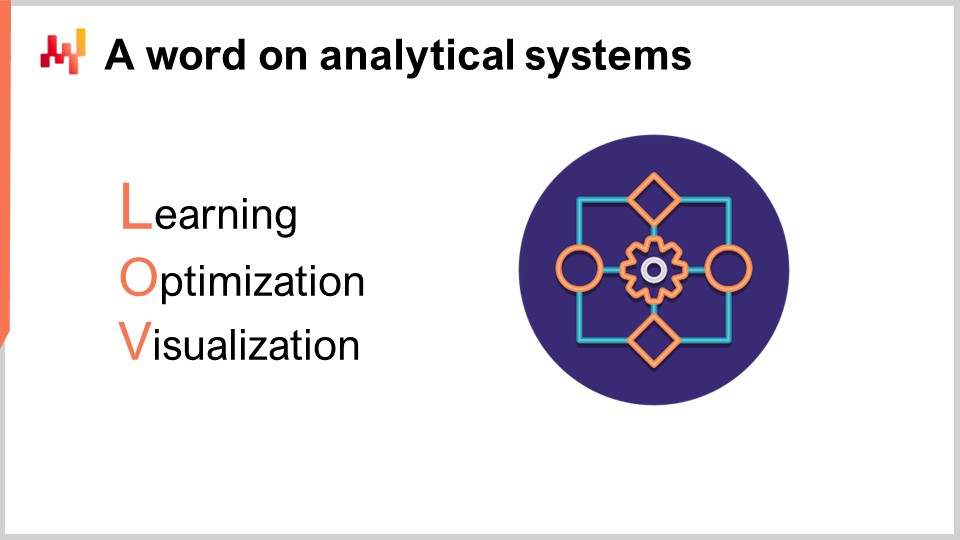
Das analytische System enthält das Kernrezept für die numerische Analyse. Es ist auch das System, das alle für die Entscheidungen erforderlichen Berichte bereitstellt. Auf technischer Ebene enthält das analytische System die “intelligenten Bestandteile” wie maschinelles Lernen und mathematische Optimierungsalgorithmen. In der Praxis dominieren diese intelligenten Bestandteile jedoch nicht den Code des analytischen Systems. In der Regel erfordern die Datenaufbereitung und die Dateninstrumentierung mindestens zehnmal so viele Codezeilen wie die Teile, die sich mit dem Lernen und der Optimierung befassen.
Das analytische System muss vom Data Lake entkoppelt sein, da diese beiden Systeme in technologischer Hinsicht völlig unterschiedlich sind. Als Software wird erwartet, dass der Data Lake sehr einfach, stabil und äußerst zuverlässig ist. Im Gegensatz dazu wird vom analytischen System erwartet, dass es anspruchsvoll, ständig weiterentwickelt und in Bezug auf die Leistung der Lieferkette äußerst leistungsfähig ist. Anders als der Data Lake, der eine nahezu perfekte Betriebszeit gewährleisten muss, muss das analytische System nicht einmal die meiste Zeit aktiv sein. Wenn beispielsweise tägliche Bestandsauffüllungsentscheidungen betrachtet werden, muss das analytische System nur einmal täglich ausgeführt und aktiv sein.
Als Faustregel gilt, dass es besser ist, wenn das analytische System keine Entscheidungen trifft, als falsche Entscheidungen zu generieren und diese in die Produktion fließen zu lassen. Die Verzögerung von Lieferkettenentscheidungen um einige Stunden, wie beispielsweise Bestellungen, ist in der Regel weniger problematisch als falsche Entscheidungen zu treffen. Da das Design des analytischen Systems tendenziell stark von den intelligenten Bestandteilen beeinflusst wird, gibt es im Allgemeinen nicht viel über das Design des analytischen Systems zu sagen. Es gibt jedoch mindestens eine wichtige Designeigenschaft, die für das Ökosystem durchgesetzt werden muss: Dieses System muss zustandslos sein.
Das analytische System sollte nach Möglichkeit keinen internen Zustand haben. Mit anderen Worten, das gesamte Ökosystem muss mit den Daten beginnen, wie sie vom Data Lake präsentiert werden, und mit den generierten beabsichtigten Lieferkettenentscheidungen zusammen mit den unterstützenden Berichten enden. Oftmals wird, wenn es eine Komponente im analytischen System gibt, die zu langsam ist, wie beispielsweise ein maschinelles Lernalgorithmus, versucht, einen Zustand einzuführen, d.h. einige Informationen von der vorherigen Ausführung zu speichern, um die nächste Ausführung zu beschleunigen. Dies ist jedoch gefährlich, da man sich auf zuvor berechnete Ergebnisse verlässt, anstatt alles jedes Mal von Grund auf neu zu berechnen.
Tatsächlich gefährdet ein Zustand im analytischen System die Entscheidung. Während Datenprobleme unweigerlich auftreten und auf Ebene des Data Lakes behoben werden, kann das analytische System immer noch Entscheidungen zurückgeben, die ein Problem widerspiegeln, das bereits behoben wurde. Wenn beispielsweise ein Nachfrageprognosemodell auf einem korrupten Verkaufsdatensatz trainiert wird, bleibt das Prognosemodell korrupt, bis es über eine frische, korrigierte Version des Datensatzes neu trainiert wird. Die einzige Möglichkeit, zu verhindern, dass das analytische System unter den Auswirkungen von Datenproblemen leidet, die bereits im Data Lake behoben wurden, besteht darin, alles jedes Mal zu aktualisieren. Das ist das Wesen des Zustandslosen.
Als Faustregel gilt, wenn ein Teil des analytischen Systems zu langsam ist, um täglich ersetzt zu werden, dann muss dieser Teil als Leistungsproblem betrachtet werden. Lieferketten sind chaotisch und es wird einen Tag geben, an dem etwas passiert - ein Brand, eine Sperrung, ein Cyberangriff -, der sofortiges Eingreifen erfordert. Das Unternehmen muss in der Lage sein, alle seine Lieferkettenentscheidungen innerhalb einer Stunde zu aktualisieren. Das Unternehmen darf nicht warten und 10 Stunden lang feststecken, während die langsame Phase des maschinellen Lernens stattfindet.

Um zuverlässig zu arbeiten, muss das analytische System ordnungsgemäß instrumentiert sein. Das ist es, worum es bei dem Daten-Gesundheitsbericht und den Dateninspektoren geht. Übrigens liegen all diese Elemente in der Verantwortung der Lieferkette; sie liegen nicht in der Verantwortung der IT. Die Überwachung der Daten-Gesundheit stellt die allererste Phase der Datenverarbeitung dar, noch vor der eigentlichen Datenbereitung, und sie findet innerhalb des analytischen Systems statt. Die Daten-Gesundheit ist ein Teil der Instrumentierung des numerischen Rezepts. Der Daten-Gesundheitsbericht gibt an, ob es überhaupt akzeptabel ist, das numerische Rezept auszuführen. Dieser Bericht zeigt auch den Ursprung des Datenproblems an, falls vorhanden, um die Lösung des Problems zu beschleunigen.
Die Überwachung der Daten-Gesundheit ist eine Praxis bei Lokad. In den letzten zehn Jahren hat sich diese Praxis als unschätzbar erwiesen, um Situationen zu vermeiden, in denen Müll erzeugt wird, die in der Welt der Unternehmenssoftware allgegenwärtig zu sein scheinen. Tatsächlich wird bei einem Datenverarbeitungsprojekt, das scheitert, häufig schlechte Daten als Schuldiger genannt. Es ist jedoch wichtig zu beachten, dass in der Regel kaum Anstrengungen unternommen werden, um die Datenqualität von Anfang an sicherzustellen. Datenqualität fällt nicht vom Himmel; sie erfordert ingenieurtechnische Anstrengungen.
Die bisher vorgestellte Datenpipeline ist ziemlich minimalistisch. Das Daten-Spiegeln ist so einfach wie möglich gehalten, was im Hinblick auf die Softwarequalität eine gute Sache ist. Trotz dieser Minimalismus gibt es jedoch immer noch viele bewegliche Teile: viele Tabellen, viele Systeme, viele Personen. Daher gibt es überall Fehler. Dies ist Unternehmenssoftware, und das Gegenteil wäre ziemlich überraschend. Die Überwachung der Daten-Gesundheit ist dazu da, dem analytischen System zu helfen, im umgebenden Chaos zu überleben.
Die Daten-Gesundheit sollte nicht mit der Datenbereinigung verwechselt werden. Die Daten-Gesundheit geht nur darum sicherzustellen, dass die dem analytischen System zur Verfügung gestellten Daten eine treue Darstellung der Transaktionsdaten sind, die in den Transaktionssystemen vorhanden sind. Es wird kein Versuch unternommen, die Daten zu reparieren; die Daten werden so analysiert, wie sie sind.
Bei Lokad unterscheiden wir in der Regel zwischen der Daten-Gesundheit auf niedriger Ebene und der Daten-Gesundheit auf hoher Ebene. Die Daten-Gesundheit auf niedriger Ebene ist ein Dashboard, das alle strukturellen und volumetrischen Eigenheiten der Daten zusammenfasst, wie offensichtliche Probleme wie Einträge, die nicht einmal vernünftige Daten oder Zahlen sind, oder Waisen-Bezeichner, die ihre erwarteten Gegenstücke vermissen. All diese Probleme können gesehen werden und sind tatsächlich die einfachen. Das schwierige Problem beginnt mit Problemen, die nicht gesehen werden können, weil die Daten erst gar nicht vorhanden sind. Wenn zum Beispiel bei einer Datenextraktion etwas schief gelaufen ist und die gestern extrahierten Verkaufsdaten nur die Hälfte der erwarteten Zeilen enthalten, kann dies die Produktion wirklich gefährden. Unvollständige Daten sind besonders heimtückisch, weil sie in der Regel nicht verhindern, dass das numerische Rezept Entscheidungen generiert, außer dass diese Entscheidungen Müll sein werden, da die Eingangsdaten unvollständig sind.
Technisch gesehen versuchen wir bei Lokad, die Überwachung der Daten-Gesundheit auf einem einzigen Dashboard zu halten, und dieses Dashboard ist in der Regel für das IT-Team bestimmt, da die meisten Probleme, die durch die Daten-Gesundheit auf niedriger Ebene erfasst werden, tendenziell mit der Datenpipeline selbst zusammenhängen. Idealerweise sollte das IT-Team auf einen Blick erkennen können, ob alles in Ordnung ist oder ob keine weiteren Eingriffe erforderlich sind.

Die Überwachung der Daten-Gesundheit auf hoher Ebene betrachtet alle geschäftsbezogenen Eigenheiten - Elemente, die aus geschäftlicher Sicht falsch aussehen. Die Daten-Gesundheit auf hoher Ebene umfasst Elemente wie negative Lagerbestände oder abnormal große Mindestbestellmengen. Sie umfasst auch Dinge wie Preise, die keinen Sinn ergeben, weil das Unternehmen Verluste machen würde oder mit lächerlich hohen Margen arbeiten würde. Die Daten-Gesundheit auf hoher Ebene versucht, alle Elemente abzudecken, bei denen ein Lieferkettenpraktiker auf die Daten schaut und sagt: “Das kann unmöglich richtig sein; wir haben ein Problem.”
Im Gegensatz zum Daten-Gesundheitsbericht auf niedriger Ebene ist der Daten-Gesundheitsbericht auf hoher Ebene in erster Linie für das Lieferkettenteam bestimmt. Tatsächlich werden Probleme wie anomale Mindestbestellmengen nur von einem Praktiker als Problem wahrgenommen, der mit der Geschäftsumgebung einigermaßen vertraut ist. Das Ziel dieses Berichts ist es, auf einen Blick erkennen zu können, dass alles in Ordnung ist und dass keine weiteren Eingriffe erforderlich sind.
Zuvor habe ich gesagt, dass das analytische System zustandslos sein sollte. Nun stellt sich heraus, dass die Daten-Gesundheit eine Ausnahme von dieser Regel darstellt. Tatsächlich können viele Probleme identifiziert werden, indem die aktuellen Indikatoren mit den gleichen Indikatoren verglichen werden, die in den vorherigen Tagen gesammelt wurden. Daher wird die Überwachung der Daten-Gesundheit in der Regel einen gewissen Zustand beibehalten, der im Wesentlichen aus Schlüsselindikatoren besteht, wie sie in den vorherigen Tagen beobachtet wurden, um Ausreißer im aktuellen Zustand der Daten identifizieren zu können. Da es sich bei der Daten-Gesundheit jedoch um eine reine Überwachungsangelegenheit handelt, ist das Schlimmste, was passieren kann, wenn es ein Problem auf der Ebene des Daten-Sees gibt, das behoben wird und dann Echoeffekte vergangener Probleme im Zustand der Daten-Gesundheit auftreten, eine Reihe von Fehlalarmen aus diesen Berichten. Die Logik, die die Lieferkettenentscheidungen generiert, bleibt vollständig zustandslos; der Zustand betrifft nur einen kleinen Teil der Instrumentierung.
Die Überwachung der Daten-Gesundheit, sowohl auf niedriger als auch auf hoher Ebene, ist eine Frage des Kompromisses zwischen dem Risiko, falsche Entscheidungen zu treffen, und dem Risiko, Entscheidungen nicht rechtzeitig zu treffen. Bei großen Lieferketten ist es nicht vernünftig zu erwarten, dass 100 Prozent der Daten korrekt sind - falsche Transaktionseinträge kommen vor, auch wenn sie selten sind. Daher muss es eine Anzahl von Problemen geben, die als ausreichend niedrig angesehen werden sollten, damit das numerische Rezept funktionieren kann. Der Kompromiss zwischen diesen beiden Risiken - zu empfindlich auf Datenfehler zu reagieren oder zu tolerant gegenüber Datenproblemen zu sein - hängt stark von der wirtschaftlichen Zusammensetzung der Lieferkette ab.
Bei Lokad erstellen und optimieren wir diese Berichte kundenindividuell. Anstatt jedem denkbaren Fall von Datenkorruption nachzugehen, versucht der Supply Chain Scientist, der für die Implementierung der Daten-Gesundheit auf niedriger und hoher Ebene und der Dateninspektoren zuständig ist, die Daten-Gesundheitsüberwachung so anzupassen, dass sie empfindlich für die Art von Problemen ist, die tatsächlich schädlich sind und tatsächlich in der Lieferkette auftreten.
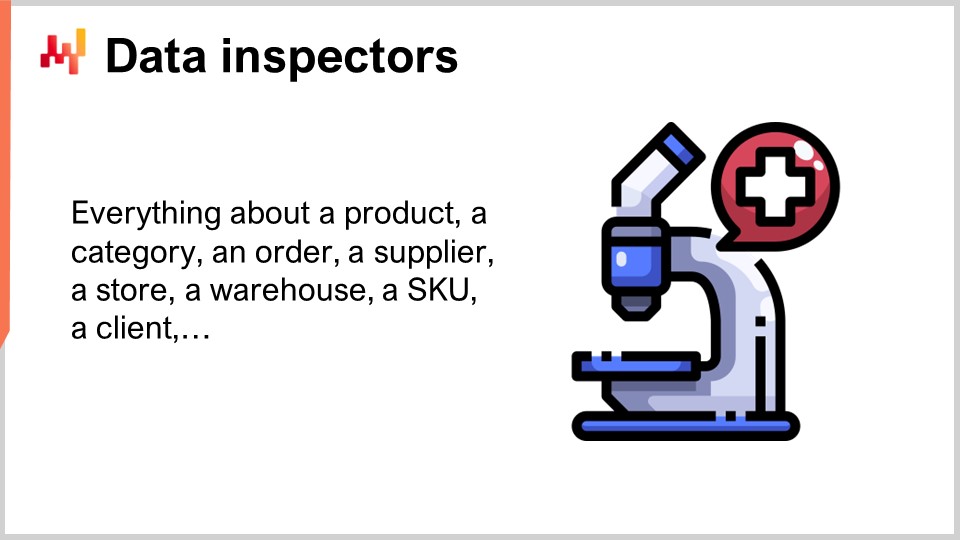
In der Lokad-Sprache ist ein Dateninspektor oder einfach ein Inspektor ein Bericht, der alle relevanten Daten zu einem interessierenden Objekt zusammenfasst. Das interessierende Objekt wird aus Sicht der Lieferkette als Erstklassiger Bürger erwartet - ein Produkt, ein Lieferant, ein Kunde oder ein Lager. Wenn wir zum Beispiel einen Dateninspektor für Produkte betrachten, sollten wir für jedes vom Unternehmen verkaufte Produkt über den Inspektor auf einem Bildschirm alle Daten sehen können, die mit diesem Produkt verknüpft sind. Im Dateninspektor für Produkte gibt es effektiv so viele Ansichten wie Produkte, denn wenn ich sage, dass wir alle Daten sehen, meine ich alle Daten, die mit einem Barcode oder einer Teilenummer verknüpft sind, nicht alle Produkte im Allgemeinen.
Anders als die Daten-Gesundheitsberichte auf niedriger und hoher Ebene, die als zwei Dashboards betrachtet werden können, die auf einen Blick inspiziert werden können, sind Inspektoren dazu gedacht, Fragen und Bedenken anzusprechen, die sich zwangsläufig beim Entwerfen und Betreiben des Kernnumerischen Rezepts ergeben. Tatsächlich ist es nicht ungewöhnlich, dass zur Fällung einer Lieferkettenentscheidung Daten aus einem Dutzend Tabellen konsolidiert werden müssen, die möglicherweise aus mehreren Transaktionssystemen stammen. Da die Daten überall verstreut sind, ist es in der Regel schwierig, die Ursache des Problems zu ermitteln, wenn eine Entscheidung verdächtig aussieht. Es kann eine Diskrepanz zwischen den Daten geben, wie sie vom analytischen System gesehen werden, und den Daten, die im Transaktionssystem vorhanden sind. Es kann einen fehlerhaften Algorithmus geben, der ein statistisches Muster in den Daten nicht erfasst. Es kann eine falsche Wahrnehmung geben, und die als verdächtig angesehene Entscheidung könnte tatsächlich korrekt sein. In jedem Fall soll der Inspektor die Möglichkeit bieten, in das interessierende Objekt hineinzuzoomen.
Um nützlich zu sein, müssen Inspektoren sowohl die Besonderheiten der Lieferkette als auch der Anwendungsumgebung widerspiegeln. Daher ist die Erstellung von Inspektoren fast immer eine maßgeschneiderte Übung. Sobald die Arbeit jedoch erledigt ist, stellt der Inspektor eine der Säulen der Instrumentierung des analytischen Systems selbst dar.
Zusammenfassend lässt sich sagen, dass die meisten quantitativen Lieferketteninitiativen bereits vor ihrem Start zum Scheitern verurteilt sind, aber es muss nicht so sein. Eine sorgfältige Auswahl der Liefergegenstände, Zeitpläne, des Umfangs und der Regeln ist erforderlich, um Probleme zu vermeiden, die diese Initiativen zwangsläufig zum Scheitern bringen. Leider sind diese Entscheidungen häufig etwas kontraintuitiv, wie Lokad in den bisherigen 14 Betriebsjahren schmerzhaft erfahren hat.
Der Beginn der Initiative muss der Einrichtung einer Datenpipeline gewidmet sein. Eine unzuverlässige Datenpipeline ist einer der sichersten Wege, um sicherzustellen, dass jede datengetriebene Initiative scheitert. Die meisten Unternehmen, selbst die meisten IT-Abteilungen, unterschätzen die Bedeutung einer hochzuverlässigen Datenpipeline, die kein fortlaufendes Feuerlöschen erfordert. Während der Großteil der Einrichtung der Datenpipeline in den Händen der IT-Abteilung liegt, muss die Lieferkette selbst für die Instrumentierung des von ihr betriebenen analytischen Systems verantwortlich sein. Erwarten Sie nicht, dass die IT dies für Sie erledigt; das liegt in der Verantwortung des Lieferkettenteams. Wir haben zwei verschiedene Arten von Instrumentierung gesehen, nämlich die Daten-Gesundheitsberichte, die eine unternehmensweite Perspektive einnehmen, und die Dateninspektoren, die eine detaillierte Diagnose unterstützen.

Heute haben wir besprochen, wie man eine Initiative startet, aber das nächste Mal werden wir sehen, wie man sie beendet oder besser gesagt, hoffentlich, wie man sie zum Erfolg führt. In der nächsten Vorlesung, die am Mittwoch, den 14. September stattfinden wird, werden wir mit unserer Reise voranschreiten und sehen, welche Art von Ausführung erforderlich ist, um ein Kernnumerisches Rezept zu erstellen und dann allmählich die daraus resultierenden Entscheidungen in die Produktion zu bringen. Wir werden auch einen genaueren Blick darauf werfen, was diese neue Art der Lieferkettenarbeit für den täglichen Betrieb der Lieferkettenpraktiker bedeutet.
Werfen wir nun einen Blick auf die Fragen.
Frage: Warum genau ist es sechs Monate als Zeitlimit, nach dem eine Implementierung nicht korrekt abgeschlossen ist?
Ich würde sagen, das Problem besteht nicht darin, dass sechs Monate als Zeitlimit festgelegt sind. Das Problem ist, dass Initiativen in der Regel von Anfang an zum Scheitern verurteilt sind. Das ist das Problem. Wenn Ihre predictive Optimierung-Initiative mit der Perspektive startet, dass Ergebnisse in zwei Jahren geliefert werden, ist es nahezu garantiert, dass die Initiative irgendwann scheitert und nichts in die Produktion liefert. Wenn ich könnte, würde ich es bevorzugen, dass die Initiative in drei Monaten erfolgreich ist. Sechs Monate stellen jedoch das minimale Zeitfenster dar, um eine solche Initiative in die Produktion zu bringen, basierend auf meiner Erfahrung. Jede zusätzliche Verzögerung erhöht das Risiko eines Scheiterns der Initiative. Es ist sehr schwierig, diesen Zeitplan weiter zu verkürzen, denn sobald alle technischen Probleme gelöst sind, spiegeln die verbleibenden Verzögerungen die Zeit wider, die benötigt wird, um die Initiative in Gang zu bringen.
Frage: Lieferkettenpraktiker können frustriert sein von einer Initiative, die den Großteil ihrer Arbeitsbelastung, wie beispielsweise die Einkaufsabteilung, ersetzt und im Widerspruch zur Entscheidungsautomatisierung steht. Wie würden Sie empfehlen, damit umzugehen?
Dies ist eine sehr wichtige Frage, die hoffentlich in der nächsten Vorlesung behandelt wird. Was ich heute sagen kann, ist, dass ich glaube, dass das meiste, was Lieferkettenpraktiker in heutigen Lieferketten tun, nicht sehr belohnend ist. In den meisten Unternehmen erhalten die Mitarbeiter eine Reihe von SKUs oder Teilenummern und gehen dann endlos durch sie hindurch und treffen alle notwendigen Entscheidungen. Das bedeutet, dass ihre Aufgabe im Wesentlichen darin besteht, sich einmal pro Woche oder möglicherweise einmal pro Tag eine Tabelle anzusehen und durchzugehen. Das ist keine erfüllende Arbeit.
Die kurze Antwort ist, dass der Lokad-Ansatz das Problem löst, indem er alle mühsamen Aspekte der Arbeit automatisiert, sodass die Fachleute in der Lieferkette die Grundlagen der Lieferkette in Frage stellen können. Dadurch können sie mehr mit Kunden und Lieferanten diskutieren, um alles effizienter zu gestalten. Es geht darum, Erkenntnisse zu sammeln, damit wir das numerische Rezept verbessern können. Die Ausführung des numerischen Rezepts ist mühsam, und es wird nur sehr wenige Menschen geben, die sich an die alten Zeiten erinnern, als sie jeden Tag Tabellen durchgehen mussten.
Frage: Sollen Lieferkettenpraktiker mit Datenqualitätsberichten arbeiten, um die von Lieferkettenwissenschaftlern generierten Entscheidungen in Frage zu stellen?
Lieferkettenpraktiker sollen mit Dateninspektoren arbeiten, nicht mit Datenqualitätsberichten. Datenqualitätsberichte sind wie eine unternehmensweite Bewertung, die die Frage beantwortet, ob die Daten am Eingang des Analyse-Systems gut genug sind, damit ein numerisches Rezept auf dem Datensatz arbeiten kann. Das Ergebnis des Datenqualitätsberichts ist eine binäre Entscheidung: Das numerische Rezept wird genehmigt oder es wird dagegen Einspruch erhoben und gesagt, dass ein Problem behoben werden muss. Dateninspektoren, die in der nächsten Vorlesung genauer erläutert werden, sind der Einstiegspunkt für Lieferkettenpraktiker, um Einblicke in eine vorgeschlagene Lieferkettenentscheidung zu gewinnen.
Frage: Ist es möglich, ein analytisches Modell zu aktualisieren, indem beispielsweise eine Bestandspolitik täglich festgelegt wird? Kann das Lieferkettensystem nicht auf tägliche Änderungen der Richtlinien reagieren und nur Störungen im System verursachen?
Um den ersten Teil der Frage zu beantworten, ist es durchaus möglich, ein analytisches Modell täglich zu aktualisieren. Zum Beispiel, als Lokad im Jahr 2020 während der Lockdowns in Europa tätig war, wurden Länder mit nur 24 Stunden Vorankündigung geschlossen und wieder geöffnet. Dies führte zu einer äußerst chaotischen Situation, die täglich ständige Überarbeitungen erforderte. Lokad arbeitete unter diesem enormen Druck und verwaltete Lockdowns, die fast 14 Monate lang täglich in ganz Europa begannen oder endeten.
Das Aktualisieren eines analytischen Modells täglich ist also möglich, aber nicht unbedingt wünschenswert. Es stimmt, dass Lieferketten-Systeme eine hohe Trägheit haben und das erste, was ein geeignetes numerisches Rezept berücksichtigen muss, der Ratschlagseffekt der meisten Entscheidungen ist. Sobald Sie die Produktion in Auftrag gegeben haben und Rohstoffe verbraucht werden, können Sie die Produktion nicht rückgängig machen. Sie müssen berücksichtigen, dass bereits viele Entscheidungen getroffen wurden, wenn Sie neue treffen. Wenn Sie jedoch feststellen, dass Ihre Lieferkette eine drastische Änderung in ihrem Handlungsverlauf benötigt, macht es keinen Sinn, diese Korrektur nur um der Entscheidungsverzögerung willen aufzuschieben. Der beste Zeitpunkt, um die Änderung umzusetzen, ist jetzt.
In Bezug auf den Aspekt des Rauschens in der Frage kommt es auf das richtige Design der numerischen Rezepte an. Es gibt viele falsche Designs, die instabil sind, bei denen kleine Änderungen in den Daten große Änderungen in den Entscheidungen bewirken, die das Ergebnis des numerischen Rezepts darstellen. Ein numerisches Rezept sollte nicht sprunghaft sein, wenn es kleine Schwankungen in der Lieferkette gibt. Aus diesem Grund hat Lokad eine probabilistische Perspektive auf die Prognose übernommen. Bei Verwendung einer probabilistischen Perspektive können Modelle so konstruiert werden, dass sie im Vergleich zu Modellen, die versuchen, den Durchschnitt zu erfassen und bei Auftreten eines Ausreißers in der Lieferkette sprunghaft sind, viel stabiler sind.
Frage: Eines der Probleme, mit denen wir in der Lieferkette bei sehr großen Unternehmen konfrontiert sind, ist ihre Abhängigkeit von verschiedenen Quellsystemen. Ist es nicht äußerst schwierig, alle Daten aus diesen Quellsystemen unter einem einheitlichen System zusammenzuführen?
Ich stimme vollkommen zu, dass es für viele Unternehmen eine große Herausforderung ist, alle Daten zu erhalten. Wir müssen uns jedoch fragen, warum dies überhaupt eine Herausforderung ist. Wie ich bereits erwähnt habe, basieren 99% der von großen Unternehmen betriebenen Geschäftsanwendungen heutzutage auf gängigen, gut konstruierten Transaktionsdatenbanken. Es mag immer noch einige super-legacy COBOL-Implementierungen geben, die auf obskurem binärem Speicher laufen, aber das ist selten. Die große Mehrheit der Geschäftsanwendungen, auch solche, die in den 1990er Jahren implementiert wurden, arbeitet mit einer sauberen, produktionsreifen Transaktionsdatenbank im Hintergrund.
Wenn Sie einmal eine transaktionale Backend-Datenbank haben, warum sollte es dann schwierig sein, diese Daten in einen Data Lake zu kopieren? Meistens liegt das Problem darin, dass Unternehmen nicht nur versuchen, die Daten zu kopieren - sie versuchen viel mehr zu tun. Sie versuchen, die Daten vorzubereiten und zu transformieren, wodurch der Prozess oft überkompliziert wird. Die meisten modernen Datenbank-Setups verfügen über integrierte Daten-Spiegelungsfunktionen, mit denen Sie alle Änderungen von einer transaktionalen Datenbank auf eine sekundäre Datenbank replizieren können. Dies ist eine integrierte Eigenschaft für wahrscheinlich die 20 am häufigsten verwendeten transaktionalen Systeme auf dem Markt.
Unternehmen haben oft Schwierigkeiten, Daten zu konsolidieren, weil sie zu viel versuchen und ihre Initiativen unter ihrer eigenen Komplexität zusammenbrechen. Sobald die Daten konsolidiert sind, machen Unternehmen oft den Fehler zu denken, dass die Verbindung der Daten von IT-, BI- oder Data-Science-Teams durchgeführt werden sollte. Der Punkt, den ich hier machen möchte, ist, dass die Supply Chain für ihre eigenen numerischen Rezepte verantwortlich sein sollte, genauso wie Marketing, Vertrieb und Finanzen. Es sollte keine unterstützende Querschnittsabteilung sein, die dies für das Unternehmen versucht. Die Verbindung von Daten aus verschiedenen Systemen erfordert in der Regel eine Vielzahl von Geschäftseinblicken. Große Unternehmen scheitern oft, weil sie versuchen, einen Experten aus IT-, BI- oder Data-Science-Teams mit dieser Aufgabe zu betrauen, obwohl dies innerhalb der interessierten Abteilung erfolgen sollte.
Vielen Dank für Ihre Zeit heute, Ihr Interesse und Ihre Fragen. Wir sehen uns nach dem Sommer im September wieder.