00:00 Introducción
02:31 Causas raíz del fracaso en la práctica
07:20 Entregable: una receta numérica 1/2
09:31 Entregable: una receta numérica 2/2
13:01 La historia hasta ahora
14:57 Haciendo las cosas hoy
15:59 Cronología de la iniciativa
21:48 Alcance: panorama aplicativo 1/2
24:24 Alcance: panorama aplicativo 2/2
27:12 Alcance: efectos del sistema 1/2
29:21 Alcance: efectos del sistema 2/2
32:12 Roles: 1/2
37:31 Roles: 2/2
41:50 Tubería de datos - Cómo
44:13 Una palabra sobre sistemas transaccionales
49:13 Una palabra sobre data lake
52:59 Una palabra sobre sistemas analíticos
57:56 Salud de los datos: bajo nivel
01:02:23 Salud de los datos: alto nivel
01:06:24 Inspectores de datos
01:08:53 Conclusión
01:10:32 Próxima lección y preguntas de la audiencia
Descripción
Realizar una exitosa optimización predictiva de un supply chain es una combinación de problemas blandos y duros. Desafortunadamente, no es posible separar esos aspectos. Las facetas blandas y duras están profundamente entrelazadas. Usualmente, este entrelazamiento choca frontalmente con la división del trabajo definida por el organigrama de la empresa. Observamos que, cuando las iniciativas de supply chain fracasan, las causas raíz del fracaso son usualmente errores cometidos en las primeras etapas del proyecto. Además, los errores tempranos tienden a moldear toda la iniciativa, haciendo que sea casi imposible corregirlos ex post. Presentamos nuestros hallazgos clave para evitar esos errores.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy presentaré “Empezando con una iniciativa de Supply Chain Quantitativa”. La gran mayoría de las iniciativas de supply chain centradas en el análisis de datos están fracasando. Desde 1990, la mayoría de las empresas que operan grandes supply chains han lanzado importantes iniciativas de optimización predictiva cada tres a cinco años con pocos o ningún resultado. Hoy en día, la mayoría de los equipos en supply chains o de ciencia de datos, al comenzar otra ronda de optimización predictiva—típicamente enmarcada como un proyecto de previsión o un proyecto de optimización de inventario—ni siquiera se dan cuenta de que su empresa ya ha pasado por esto, lo ha hecho y ha fracasado, posiblemente, media docena de veces.
Emprender otra ronda a veces se debe a la creencia de que esta vez será diferente, pero con frecuencia, los equipos ni siquiera son conscientes de los muchos intentos fallidos que ocurrieron anteriormente. La evidencia anecdótica de este estado de cosas es que Microsoft Excel sigue siendo la herramienta número uno para tomar decisiones de supply chain, mientras que se suponía que esas iniciativas iban a reemplazar las hojas de cálculo por herramientas mejores. Sin embargo, hoy en día, aún hay muy pocos supply chains que puedan operar sin hojas de cálculo.
El objetivo de esta lección es entender cómo dar una oportunidad de éxito a una iniciativa de supply chain que pretende ofrecer cualquier tipo de optimización predictiva. Revisaremos una serie de ingredientes críticos—esos ingredientes son simples y, sin embargo, a menudo resultan contraintuitivos para la mayoría de las organizaciones. Por el contrario, revisaremos una serie de anti-patrones que casi garantizan el fracaso de dicha iniciativa.
Hoy, mi enfoque está en la ejecución táctica del inicio mismo de una iniciativa de supply chain con una mentalidad de “hacer las cosas”. No discutiré las grandes implicaciones estratégicas para la empresa. La estrategia es muy importante, pero trataré este asunto en una lección posterior.

La mayoría de las iniciativas de supply chain fracasan, y el problema casi nunca se menciona públicamente. La academia publica decenas de miles de artículos al año presumiendo todo tipo de innovaciones de supply chain, incluidos marcos de trabajo, algoritmos y modelos. Con frecuencia, los artículos incluso afirman que la innovación se ha puesto en producción en algún lugar. Y, sin embargo, mi propia observación casual del mundo de supply chain es que esas innovaciones no se ven por ningún lado. De igual forma, los software vendors han estado prometiendo reemplazos superiores para las hojas de cálculo durante las últimas tres décadas, y nuevamente, mi observación casual indica que las hojas de cálculo siguen siendo ubicuas.
Estamos retomando un punto que ya se tocó en el segundo capítulo de esta serie de conferencias de supply chain. En pocas palabras, la gente no tiene incentivos para publicitar el fracaso, y por ello no lo hacen. Además, como las empresas que operan supply chains suelen ser grandes, el problema se agrava típicamente por la pérdida natural de la memoria institucional a medida que los empleados van rotando de un puesto a otro. Por eso, ni la academia ni los vendors reconocen esta situación tan desalentadora.
Propongo comenzar con una breve encuesta de las causas raíz más frecuentes del fracaso desde una perspectiva de ejecución táctica. De hecho, estas causas raíz se encuentran típicamente en la etapa más temprana de la iniciativa.
La primera causa del fracaso es el intento de resolver los problemas equivocados—problemas que son inexistentes, insignificantes, o que reflejan algún tipo de malentendido acerca del supply chain en sí. Optimizar los porcentajes de precisión de la previsión es probablemente el arquetipo de un problema incorrecto. Reducir el porcentaje de error de la previsión no se traduce directamente en euros o dólares adicionales de retorno para la empresa. La misma situación ocurre cuando una empresa persigue niveles específicos de niveles de servicio para su inventario. Es muy raro obtener euros o dólares de retorno por ello.
La segunda causa raíz del fracaso es el uso de tecnología de software y de un diseño de software inadecuados. Por ejemplo, los ERP vendors intentan invariablemente utilizar una base de datos transaccional para soportar iniciativas de análisis de datos, ya que es en lo que se basa el ERP. Por el contrario, los equipos de ciencia de datos intentan invariablemente utilizar el toolkit de machine learning open-source de vanguardia del momento porque es algo cool de hacer. Desafortunadamente, las piezas de tecnología inadecuadas generan típicamente una inmensa fricción y mucha complejidad accidental.
La tercera causa raíz del fracaso es una división y organización del trabajo incorrectas. En un intento erróneo de asignar especialistas en cada etapa del proceso, las empresas tienden a fragmentar la iniciativa entre demasiadas personas. Por ejemplo, la data preparation es muy frecuentemente realizada por personas que no están a cargo de la previsión. Como resultado, las situaciones de “garbage in, garbage out” se presentan en todas partes. Diluir marginalmente la responsabilidad de las decisiones finales de supply chain es una receta para el fracaso.
Un elemento que no he incluido en esta breve lista como causa raíz es la mala data. A menudo, se culpa a la data por los fracasos de las iniciativas de supply chain, lo cual es demasiado conveniente, ya que la data no puede responder exactamente a esas acusaciones. Sin embargo, la data usualmente no es la culpable, al menos no en el sentido de luchar contra una data mala. El supply chain de las grandes empresas se digitalizó hace décadas. Cada artículo que se compra, transporta, transforma, produce o vende tiene electronic records. Esos registros pueden no ser perfectos, pero usualmente son muy precisos. Si las personas fallan en tratar adecuadamente la data, en realidad no es la transacción a la que se le debe echar la culpa.

Para que una iniciativa cuantitativa tenga éxito, necesitamos luchar la batalla correcta. ¿Qué es lo que estamos intentando entregar en primer lugar? Uno de los entregables clave para un supply chain cuantitativo es una receta numérica central que calcula las decisiones finales de supply chain. Este aspecto ya se discutió en la Lección 1.3 del primer capítulo, “Entrega Orientada al Producto para Supply Chain.” Revisemos las dos propiedades más críticas de este entregable.
Primero, el resultado debe ser una decisión. Por ejemplo, decidir cuántas unidades reabastecer hoy para un SKU es una decisión. Por el contrario, previsión de cuántas unidades serán solicitadas hoy para un determinado SKU es un artefacto numérico. Para generar una decisión que sea el resultado final, se necesitan muchos resultados intermedios, es decir, muchos artefactos numéricos. Sin embargo, no debemos confundir los medios con el fin.
La segunda propiedad de este entregable es que el resultado, que es una decisión, debe estar completamente automatizado como consecuencia de un proceso de software puramente automatizado. La receta numérica en sí misma, la receta numérica central, no debe involucrar ninguna operación manual. Naturalmente, el diseño de la receta numérica en sí es probable que dependa fuertemente de un experto humano en la ciencia. Sin embargo, la ejecución no debería depender de la intervención humana directa.
Tener una receta numérica como entregable es esencial para convertir la iniciativa de supply chain en un emprendimiento capitalista. La receta numérica se convierte en un activo productivo que genera retornos. La receta debe ser mantenida, pero esto requiere una o dos órdenes de magnitud menos personas en comparación con los enfoques que mantienen a los humanos en el proceso en el nivel de micro-decisiones.

Sin embargo, muchas iniciativas de supply chain fracasan porque no enmarcan correctamente las decisiones de supply chain como el entregable de la iniciativa. En cambio, esas iniciativas se enfocan en entregar artefactos numéricos. Los artefactos numéricos están destinados a ser ingredientes para llegar a la resolución final del problema, típicamente apoyando las propias decisiones. Los artefactos más comunes que se encuentran en supply chain son previsión, safety stocks, EOQs, KPIs. Aunque esos números pueden ser de interés, no son reales. Esos números no tienen un contraparte físico tangible inmediato en el supply chain, y reflejan perspectivas arbitrarias de modelado sobre el supply chain.
Enfocarse en los artefactos numéricos conduce al fracaso de la iniciativa porque a esos números les falta un ingrediente crítico: la retroalimentación directa del mundo real. Cuando la decisión es equivocada, las malas consecuencias se pueden rastrear hasta la decisión. Sin embargo, la situación es mucho más ambigua en lo que respecta a los artefactos numéricos. De hecho, la responsabilidad se diluye por todas partes, ya que hay muchos artefactos que contribuyen a cada decisión. El problema es aún peor cuando hay intervención humana en medio.
Esta falta de retroalimentación resulta letal para los artefactos numéricos. Los supply chains modernos son complejos. Elige cualquier fórmula arbitraria para calcular un safety stock, una economic order quantity o un KPI; las probabilidades son enormes de que esta fórmula sea incorrecta de múltiples maneras. El problema de la corrección de la fórmula no es un problema matemático; es un problema de negocio. Se trata de responder a la pregunta, “¿Refleja realmente este cálculo la intención estratégica que tengo para mi negocio?” La respuesta varía de una empresa a otra e incluso varía de un año a otro a medida que las empresas evolucionan con el tiempo.
Como los artefactos numéricos carecen de retroalimentación directa del mundo real, carecen del mecanismo mediante el cual es posible iterar desde una implementación inicial ingenua, simplista y, muy probablemente, ampliamente incorrecta, hacia una versión aproximadamente correcta de la fórmula que pueda considerarse de calidad de producción. Sin embargo, los artefactos numéricos son muy tentadores porque dan la ilusión de acercarse a la solución. Dan la ilusión de ser racionales, científicos, incluso emprendedores. Tenemos números, fórmulas, algoritmos, modelos. Es incluso posible hacer benchmarks y comparar esos números con números igualmente inventados. Mejorar en base a un benchmark inventado también da la ilusión de progreso, y es muy reconfortante. Pero al final del día, sigue siendo una ilusión, una cuestión de perspectiva de modelado.
Las empresas no obtienen beneficios pagando a las personas para que miren KPIs o realicen benchmarks. Obtienen beneficios tomando una decisión tras otra y, con suerte, mejorando en la toma de la siguiente decisión cada vez.
Esta lección es parte de una serie de conferencias de supply chain. Estoy intentando mantener estas conferencias algo independientes, pero hemos llegado a un punto en el que tiene más sentido verlas en secuencia. Esta lección es la primera lección del séptimo capítulo, que está dedicada a la ejecución de iniciativas de supply chain. Por iniciativas de supply chain, me refiero a iniciativas de supply chain cuantitativas – iniciativas que pretenden ofrecer algo en el orden de la optimización predictiva para la empresa.
El primer capítulo se dedicó a mis puntos de vista sobre el supply chain tanto como campo de estudio como de práctica. En el segundo capítulo, presenté una serie de metodologías esenciales para el supply chain, ya que las metodologías ingenuas son derrotadas debido a la naturaleza adversa de muchas situaciones de supply chain. En el tercer capítulo, presenté una serie de personae de supply chain con un enfoque puro en los problemas; en otras palabras, ¿qué es lo que estamos tratando de resolver?
En el cuarto capítulo, presenté una serie de campos que, aunque no son supply chain per se, creo que son esenciales para una práctica moderna de supply chain. En el quinto y sexto capítulos, presenté los aspectos inteligentes de una receta numérica destinada a impulsar decisiones de supply chain, a saber, la optimización predictiva (la perspectiva generalizada de la previsión) y la toma de decisiones (esencialmente la optimización matemática aplicada a problemas de supply chain). En este séptimo capítulo, discutimos cómo unir esos elementos en una iniciativa real de supply chain que pretende llevar estos métodos y tecnologías a producción.

Hoy, revisaremos lo que se considera como la práctica correcta para llevar a cabo una iniciativa de supply chain. Esto incluye encuadrar la iniciativa con el entregable adecuado, que acabamos de discutir, pero también con el cronograma adecuado, el alcance adecuado y los roles adecuados. Estos elementos representan la primera parte de la conferencia de hoy.
La segunda parte de la conferencia se dedicará a la canalización de datos, un ingrediente crítico para el éxito de una iniciativa tan impulsada o dependiente de datos. Aunque la canalización de datos es un tema bastante técnico, requiere una adecuada división de trabajo y organización entre IT y supply chain. En particular, veremos que los controles de calidad deberían estar mayormente en manos de supply chain, con el diseño de reportes de salud de los datos e inspectores de datos.
El onboarding es la primera fase de la iniciativa, donde se elabora la receta numérica central, la que genera la decisión junto con solo elementos de apoyo. El onboarding finaliza con un despliegue progresivo en producción, y durante este despliegue, los procesos anteriores se automatizan gradualmente por la misma receta numérica.
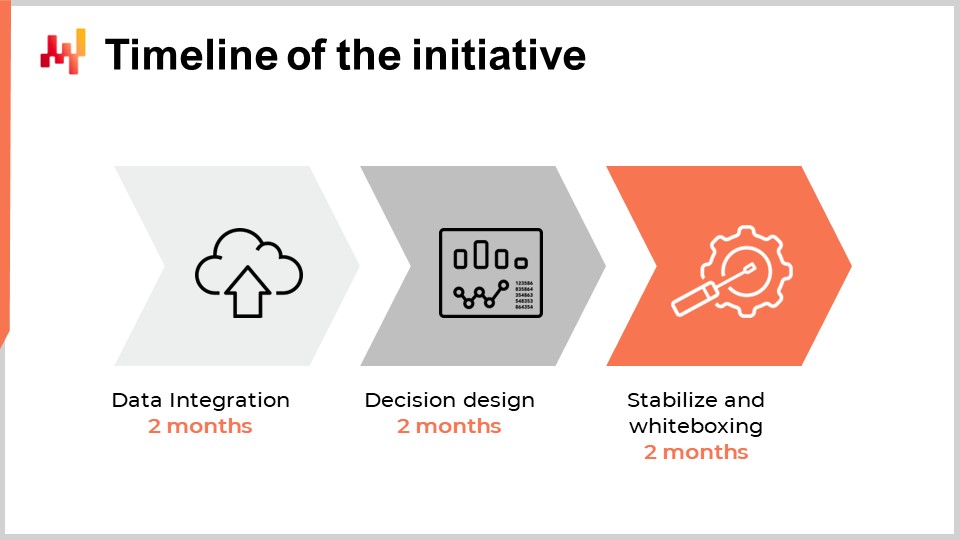
Al considerar el cronograma adecuado para la primera iniciativa de Supply Chain Quantitativa en una empresa, se podría pensar que depende del tamaño, la complejidad, el tipo de decisiones de supply chain y el contexto general de la empresa. Si bien esto es cierto en cierta medida, la experiencia que Lokad ha acumulado durante una década y docenas de iniciativas de este tipo indican que seis meses es casi invariablemente el plazo adecuado. Sorprendentemente, este plazo de seis meses tiene poco que ver con la tecnología o incluso con los detalles específicos del supply chain; tiene mucho más que ver con las personas y las organizaciones en sí, y con el tiempo que les toma familiarizarse con lo que típicamente se percibe como una manera muy diferente de llevar a cabo supply chain.
Los primeros dos meses se dedican a la configuración de la canalización de datos. Retomaremos este punto en unos minutos, pero este retraso de dos meses se debe a dos factores. Primero, necesitamos hacer que la canalización de datos sea confiable y eliminar problemas infrecuentes que pueden tardar semanas en manifestarse. El segundo factor es que debemos descifrar la semántica de los datos, es decir, entender lo que los datos significan desde una perspectiva de supply chain.
Los meses tres y cuatro se dedican a la iteración rápida sobre la receta numérica en sí, la cual impulsará las decisiones de supply chain. Estas iteraciones son necesarias porque generar decisiones finales reales es usualmente la única forma de evaluar si hay algo mal o no con la receta subyacente o con todas las suposiciones incorporadas en la receta. Estos dos meses son también típicamente el tiempo que le toma a los profesionales de supply chain acostumbrarse a la perspectiva tan cuantitativa y financiera que impulsa estas decisiones basadas en software.
Finalmente, los dos últimos meses se dedican a la estabilización de la receta numérica tras lo que suele ser un período relativamente intenso de iteración rápida. Este período es también la oportunidad para que la receta funcione en un entorno similar a producción, pero sin aún impulsar la producción. Esta fase es importante para que los equipos de supply chain ganen confianza en esta solución emergente.
Aunque podría ser deseable comprimir este cronograma aún más, resulta que típicamente es muy difícil. La configuración de la canalización de datos puede acelerarse hasta cierto punto si ya se cuenta con la infraestructura IT adecuada, pero familiarizarse con los datos lleva tiempo para entender lo que significan desde una perspectiva de supply chain. En la segunda fase, si la iteración sobre la receta numérica converge muy rápidamente, es probable que los equipos de supply chain comiencen a explorar las sutilezas de la receta numérica, lo que también extenderá el retraso. Finalmente, los dos últimos meses son típicamente lo que se necesita para ver cómo se despliega la estacionalidad y ganar confianza en el software que impulsa decisiones importantes de supply chain en producción.
En resumen, se necesitan aproximadamente seis meses, y aunque sería deseable comprimirlo aún más, es un desafío hacerlo. Sin embargo, seis meses ya es un plazo considerable. Si desde el primer día, el período de onboarding, en el que la receta numérica aún no impulsa las decisiones de supply chain, se espera que tome más de seis meses, entonces la iniciativa ya está en riesgo. Si el retraso extra se asocia con la extracción de datos y la configuración de la canalización de datos, entonces hay un problema de IT. Si el retraso extra se asocia con el diseño o la configuración de la solución, posiblemente llevada por un proveedor externo, entonces hay un problema con la tecnología misma. Finalmente, si después de dos meses de funcionamiento estabilizado en un entorno similar a producción, el despliegue en producción no ocurre, entonces típicamente existe un problema con la gestión de la iniciativa.

Al intentar introducir una novedad, un nuevo proceso o una nueva tecnología en una organización, la sabiduría común sugiere empezar en pequeño, asegurarse de que funcione y aprovechar el éxito temprano para expandirse gradualmente. Desafortunadamente, supply chain no es amable con la sabiduría común, y esta perspectiva viene con un giro específico en lo que respecta al alcance de supply chain. En términos de alcance, existen dos fuerzas motrices principales que definen en gran medida lo que es y lo que no es un alcance elegible en lo que se refiere a una iniciativa de supply chain.
El panorama aplicativo es la primera fuerza que impacta el alcance. Un supply chain en su totalidad no puede observarse directamente; solo puede observarse indirectamente a través de las lentes del software empresarial. Los datos se obtendrán a través de estas piezas de software. La complejidad de la iniciativa depende en gran medida del número y la diversidad de estas piezas de software. Cada aplicación es su propia fuente de datos, y extraer y analizar los datos de cualquier aplicación empresarial dada tiende a ser una tarea significativa. Manejar más aplicaciones generalmente significa lidiar con múltiples tecnologías de bases de datos, terminologías inconsistentes, conceptos inconsistentes y complicar enormemente la situación.
Por lo tanto, al establecer el alcance, debemos reconocer que las fronteras o límites elegibles suelen estar definidos por las propias aplicaciones empresariales y su estructura de base de datos. En este contexto, empezar en pequeño debe entenderse como mantener la huella inicial de integración de datos lo más reducida posible, sin perder la integridad de la iniciativa de supply chain en su conjunto. Es mejor profundizar que ampliarse en términos de integración de aplicaciones. Una vez que se tiene el sistema IT en funcionamiento para obtener algunos registros de una tabla en una aplicación determinada, generalmente es sencillo obtener todos los registros de esta tabla y todos los registros de otra tabla en la misma aplicación.

Un error común en el establecimiento del alcance consiste en el muestreo. El muestreo se logra generalmente seleccionando una lista corta de categorías de productos, sitios o proveedores. El muestreo es bien intencionado, pero no sigue las fronteras definidas por el panorama aplicativo. Para implementar el muestreo, se deben aplicar filtros durante la extracción de datos, y este proceso crea una serie de problemas que probablemente pondrán en riesgo la iniciativa de supply chain.
Primero, una extracción de datos filtrada de una pieza de software empresarial requiere más esfuerzo por parte del equipo IT en comparación con una extracción sin filtros. Los filtros deben ser diseñados en primer lugar, y el propio proceso de filtrado es propenso a errores. Depurar filtros incorrectos es invariablemente tedioso porque requiere numerosos intercambios con los equipos IT, lo que ralentizará la iniciativa y, a su vez, la pondrá en riesgo.
Segundo, permitir que la iniciativa realice su onboarding sobre una muestra de datos es la receta para problemas masivos de rendimiento del software a medida que la iniciativa se expande más adelante hacia el alcance completo. La pobre escalabilidad, o la incapacidad de procesar una gran cantidad de datos mientras se mantienen bajo control los costos de computación, es un defecto muy frecuente en el software. Al permitir que la iniciativa opere sobre una muestra, los problemas de escalabilidad se enmascaran, pero regresarán con fuerza en una etapa posterior.
Operar sobre una muestra de datos hace que la estadística sea más difícil, no más fácil. De hecho, tener acceso a más datos es probablemente la manera más sencilla de mejorar la precisión y estabilidad de casi todos los algoritmos de machine learning. El muestreo de los datos va en contra de este principio. Por lo tanto, al usar una muestra pequeña de datos, la iniciativa puede fallar debido a comportamientos numéricos erráticos observados en la muestra. Estos comportamientos se habrían mitigado en gran medida si se hubiera utilizado el conjunto de datos completo.
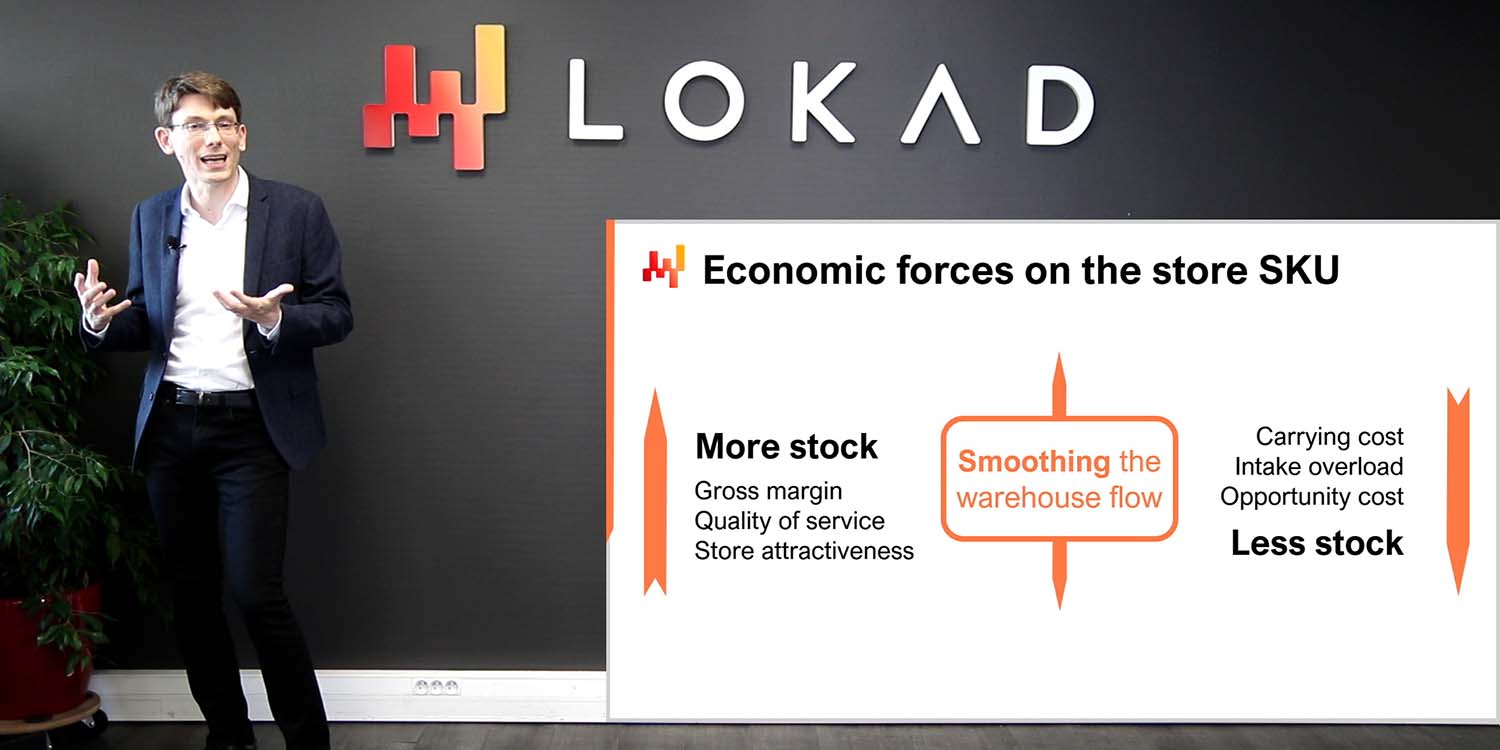
Los efectos de sistema son la segunda fuerza que impacta en el alcance. Un supply chain es un sistema, y todas sus partes están acopladas hasta cierto punto. El desafío con los sistemas, cualquier sistema, es que los intentos de mejorar una parte del sistema tienden a desplazar los problemas en lugar de solucionarlos. Por ejemplo, consideremos un problema de asignación de inventario para una red minorista con un centro de distribución y muchas tiendas. Si elegimos una sola tienda como el alcance inicial para nuestro problema de asignación de inventario, es trivial asegurar que esta tienda obtenga un servicio de muy alta calidad del centro de distribución al reservar inventario para ella con antelación. Al hacer esto, podemos asegurar que el centro de distribución nunca sufra un faltante de stock mientras atiende a esta tienda. Sin embargo, esta reserva de stock se realizaría a expensas de la calidad del servicio para las otras tiendas de la red.
Por lo tanto, al considerar el alcance de una iniciativa de supply chain, debemos tener en cuenta los efectos de sistema. El alcance debe diseñarse de forma que se evite en gran medida realizar una optimización local a expensas de los elementos que están fuera del alcance. Esta parte del ejercicio de definición del alcance es difícil porque todos los alcances tienen fugas en cierto grado. Por ejemplo, todas las partes del supply chain finalmente compiten por la misma cantidad de efectivo disponible a nivel de la empresa. Cada dólar asignado en algún lugar es un dólar que no estará disponible para otros propósitos. Sin embargo, ciertos alcances son mucho más vulnerables a manipulaciones que otros. Es importante elegir un alcance que tienda a mitigar los efectos de sistema en lugar de magnificarlos.

Pensar en el alcance de una iniciativa de supply chain en términos de efectos de sistema puede parecer extraño para muchos profesionales de supply chain. En lo que respecta al alcance, la mayoría de las empresas tienden a proyectar su organización interna sobre el ejercicio del alcance. Así, las fronteras elegidas para el alcance invariablemente tienden a imitar las fronteras de la división del trabajo que existen dentro de la empresa. Este patrón se conoce como Ley de Conway. Propuesta por Melvin Conway hace medio siglo para sistemas de comunicación, la ley ha demostrado tener una aplicabilidad mucho más amplia, incluyendo una relevancia primordial para la gestión de supply chain.
Las fronteras y silos que dominan los supply chains actuales están impulsados por divisiones del trabajo que son consecuencia de procesos bastante manuales puestos en marcha para impulsar las decisiones de supply chain. Por ejemplo, si una empresa evalúa que un planificador de supply and demand no puede gestionar más de 1,000 SKUs, y la empresa tiene 50,000 SKUs para gestionar en total, la empresa requerirá 50 planificadores de supply and demand para ello. Sin embargo, dividir la optimización del supply chain entre 50 manos está garantizado a introducir muchas ineficiencias a nivel empresarial.
Por el contrario, una iniciativa que automatiza estas decisiones no necesita atender a aquellas fronteras que solo reflejan una división del trabajo obsoleta o próxima a quedar obsoleta. Una receta numérica puede optimizar esos 50,000 SKUs de una vez y eliminar las ineficiencias que resultan de tener docenas de silos enfrentados entre sí. Por lo tanto, es natural que una iniciativa que pretende automatizar ampliamente estas decisiones se superponga con muchas fronteras preexistentes en la empresa. La empresa, o más bien la dirección de la empresa, debe resistir la tentación de imitar las fronteras organizacionales existentes, especialmente a nivel del alcance, ya que tiende a marcar el tono de lo que sigue.

Los supply chains son complejos en términos de hardware, software y personas. Aunque es lamentable, iniciar una iniciativa de Supply Chain Quantitativa incrementa aún más la complejidad del supply chain, al menos inicialmente. A largo plazo, en realidad puede disminuir sustancialmente la complejidad del supply chain, pero probablemente lo abordaremos en una conferencia futura. Además, cuantas más personas estén involucradas en la iniciativa, mayor será la complejidad de la iniciativa misma. Si esta complejidad extra no se controla de inmediato, es muy probable que la iniciativa colapse bajo su propia complejidad.
Por lo tanto, al pensar en los roles de la iniciativa, es decir, quién hará qué, debemos considerar el conjunto mínimo posible de roles que haga viable la iniciativa. Al minimizar el número de roles, minimizamos la complejidad de la iniciativa, lo que a su vez mejora en gran medida las posibilidades de éxito. Esta perspectiva tiende a ser contraintuitiva para las grandes empresas a las que les encanta operar con una división del trabajo extremadamente detallada. Las grandes empresas suelen favorecer a especialistas extremos que hacen una cosa y solo una cosa. Sin embargo, un supply chain es un sistema, y como todos los sistemas, es la perspectiva de extremo a extremo la que importa.
Basándonos en la experiencia adquirida en Lokad al llevar a cabo este tipo de iniciativas, hemos identificado cuatro roles que usualmente representan la división mínima viable del trabajo para llevar a cabo la iniciativa: un ejecutivo de supply chain, un data officer, un Supply Chain Scientist y un practicante de supply chain.
La función del ejecutivo de supply chain es apoyar la iniciativa para que pueda suceder en primer lugar. Conseguir una receta numérica bien diseñada para impulsar las decisiones de supply chain en producción representa un gran impulso tanto en términos de rentabilidad como de productividad. Sin embargo, también es mucho cambio para asimilar. Se requiere mucha energía y apoyo de la alta dirección para que un cambio así ocurra en una gran organización.
La función del data officer es configurar y mantener el pipeline de datos. Se espera que la mayor parte de sus contribuciones ocurra durante los primeros dos meses de la iniciativa. Si el pipeline de datos está correctamente diseñado, habrá muy poco esfuerzo continuo para el data officer posteriormente. Típicamente, el data officer no se involucra mucho en las etapas posteriores de la iniciativa.
La función del Supply Chain Scientist es elaborar la receta numérica central. Este rol comienza a partir de los datos transaccionales sin procesar que pone a disposición el data officer. No se espera preparación de datos por parte del data officer, solo extracción de datos. La función del Supply Chain Scientist termina al asumir la propiedad de la decisión de supply chain generada. No es un software el que es responsable de la decisión; es el Supply Chain Scientist. Por cada decisión generada, el científico debe ser capaz de justificar por qué esa decisión es adecuada.
Finalmente, la función del practicante de supply chain es desafiar las decisiones generadas por la receta numérica y proporcionar retroalimentación al Supply Chain Scientist. Al practicante no le cabe la posibilidad de tomar la decisión. Típicamente, esta persona ha estado a cargo de esas decisiones hasta ahora, al menos en un subconjunto, y usualmente con la ayuda de hojas de cálculo y sistemas existentes. En una pequeña empresa, es posible que una sola persona cumpla con ambas funciones, la del ejecutivo de supply chain y la del practicante de supply chain. También es posible eludir la necesidad de un data officer si los datos son fácilmente accesibles. Esto podría suceder en empresas que tienen una infraestructura de datos muy madura. Por el contrario, si la empresa es muy grande, es posible que unas pocas, pero solo unas pocas, personas cumplan cada función.
El exitoso despliegue en producción de la receta numérica central tiene un gran impacto en el mundo del practicante de supply chain. De hecho, en gran medida, el propósito de la iniciativa es automatizar el trabajo previo del practicante de supply chain. Sin embargo, esto no implica que la mejor opción sea despedir a esos practicantes una vez que la receta numérica esté en producción. Revisaremos este aspecto específico en la próxima conferencia.

Estar organizado no significa ser eficiente o ser efectivo. Existen roles que, a pesar de tener buenas intenciones, añaden fricción a las iniciativas de supply chain, frecuentemente hasta el punto de hacerlas fracasar por completo. Hoy en día, el primer rol que más contribuye a que tales iniciativas fracasen tiende a ser el rol del data scientist, y aún más cuando se involucra a un equipo completo de data science. Por cierto, Lokad aprendió esto de la manera difícil hace aproximadamente una década.
A pesar de la similitud en el nombre entre data scientists y Supply Chain Scientists, los dos roles son en realidad muy diferentes. El Supply Chain Scientist se preocupa, ante todo, por ofrecer decisiones de producción de calidad en el mundo real. Si esto puede lograrse con una receta numérica semi-trivial, mucho mejor; el mantenimiento será pan comido. El Supply Chain Scientist asume la completa responsabilidad de manejar hasta los detalles más minuciosos del supply chain. La fiabilidad y la resiliencia frente al caos ambiental importan más que la sofisticación.
Por el contrario, el data scientist se enfoca en las partes inteligentes de la receta numérica, los modelos y los algoritmos. El data scientist, en términos generales, se percibe a sí mismo como un experto en machine learning y optimización matemática. En cuanto a tecnologías, un data scientist está dispuesto a aprender el último toolkit numérico de código abierto y de vanguardia, pero típicamente esta persona no está dispuesta a aprender sobre el ERP de tres décadas de antigüedad que dirige la empresa. Además, el data scientist no es un experto en supply chain, ni generalmente está dispuesto a convertirse en uno. El data scientist intenta ofrecer los mejores resultados según las métricas acordadas. El científico no tiene ambición de ocuparse de los detalles tan mundanos del supply chain; se espera que esos elementos sean manejados por otras personas.
Involucrar a data scientists condena estas iniciativas porque, en cuanto se involucran data scientists, el supply chain deja de ser el foco – los algoritmos y modelos lo son. Nunca subestimes el poder de distracción que el último modelo o algoritmo representa para una persona inteligente y con mentalidad tecnológica.
El segundo rol que tiende a añadir fricción a una iniciativa de supply chain es el equipo de business intelligence (BI). Cuando el equipo BI forma parte de la iniciativa, tiende a ser un obstáculo más que otra cosa, aunque en menor medida que el equipo de data science. El problema con BI es mayormente cultural. BI entrega reportes, no decisiones. Típicamente, el equipo BI está dispuesto a producir interminables paredes de métricas según lo requerido por cada división de la empresa. Esta no es la actitud correcta para una iniciativa de Supply Chain Quantitativa.
Además, el business intelligence como software es una clase muy específica de analítica de datos orientada a cubos o cubos OLAP que te permiten segmentar la mayoría de los sistemas en memoria en sistemas empresariales. Este diseño usualmente no es adecuado para impulsar decisiones de supply chain.

Ahora que hemos enmarcado la iniciativa, echemos un vistazo a la arquitectura IT de alto nivel que la iniciativa requiere.
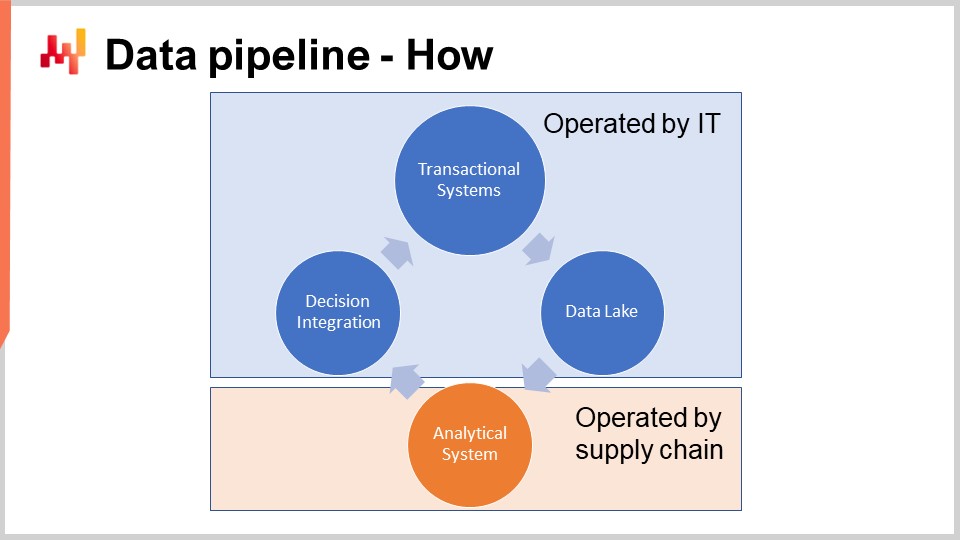
El esquema en la pantalla ilustra una configuración típica de pipeline de datos para una iniciativa de Supply Chain Quantitativa. En esta conferencia, estoy discutiendo un pipeline de datos que no soporta requisitos de baja latencia. Queremos poder completar un ciclo completo en aproximadamente una hora, no en un segundo. La mayoría de las decisiones de supply chain, como las órdenes de compra, no requieren una configuración de baja latencia. Lograr una latencia baja de extremo a extremo requiere un tipo diferente de arquitectura, que está más allá del alcance de la conferencia de hoy.

Los sistemas de transacción representan la fuente principal de datos y el punto de partida del pipeline de datos. Estos sistemas incluyen el ERP, WMS y EDI. Gestionan el flujo de bienes, tales como la compra, el transporte, la producción y la venta. Estos sistemas contienen casi todos los datos que la receta numérica central requiere. Para prácticamente cualquier empresa de tamaño considerable, estos sistemas o sus predecesores han estado en funcionamiento durante al menos dos décadas.
Como estos sistemas contienen casi todos los datos que necesitamos, resultaría tentador implementar la receta numérica directamente en estos sistemas. De hecho, ¿por qué no? Al integrar la receta numérica directamente en el ERP, eliminaríamos la necesidad de emprender el esfuerzo de configurar todo este pipeline de datos. Desafortunadamente, esto no funciona debido al diseño mismo de esos sistemas transaccionales.
Estos sistemas de transacción se construyen invariablemente con una base de datos transaccional en su núcleo. Este enfoque para el diseño de software empresarial ha sido extraordinariamente estable durante las últimas cuatro décadas. Elige cualquier empresa al azar, y lo más probable es que cada aplicación empresarial en producción haya sido implementada sobre una base de datos transaccional. Las bases de datos transaccionales ofrecen cuatro propiedades clave que se conocen bajo el acrónimo ACID, que significa Atomicidad, Consistencia, Aislamiento y Durabilidad. No voy a profundizar en los pormenores de esas propiedades, pero basta con decir que estas propiedades hacen que la base de datos sea muy adecuada para realizar de forma segura y concurrente muchas operaciones de lectura pequeñas y muchas operaciones de escritura pequeñas. Se espera que la cantidad respectiva de operaciones de lectura y escritura también esté bastante equilibrada.
Sin embargo, el precio a pagar por esas propiedades ACID tan útiles a nivel muy granular es que la base de datos transaccional también es muy ineficiente cuando se trata de atender grandes operaciones de lectura. Una operación de lectura que abarca una porción considerable de toda la base de datos, como regla general, si los datos se gestionan a través de una base de datos que se centra en una entrega muy granular de esas propiedades ACID, entonces puedes esperar que el costo de los recursos informáticos se infle en un factor de 100 en comparación con arquitecturas que no se centran tanto en esas propiedades ACID a un nivel tan granular. ACID es bueno, pero tiene un costo muy elevado.
Además, cuando alguien intenta leer una porción considerable de toda la base de datos, es probable que la base de datos se vuelva no responsiva por un tiempo mientras dedica la mayor parte de sus recursos a atender esta gran petición. Muchas empresas se quejan de que todos sus sistemas empresariales son lentos y de que esos sistemas frecuentemente se congelan durante un segundo o más. Normalmente, esta baja calidad de servicio puede atribuirse a consultas SQL intensas que intentan leer demasiadas líneas a la vez.
Por lo tanto, no se puede permitir que la receta numérica central opere en el mismo entorno que los sistemas transaccionales que respaldan la producción. De hecho, las recetas numéricas necesitarán acceder a la mayoría de los datos cada vez que se ejecuten. Así, la receta numérica debe mantenerse estrictamente aislada en su propio subsistema, aunque sea solo para evitar degradar aún más el rendimiento de esos sistemas transaccionales.
Por cierto, aunque se sabe desde hace décadas que es una idea terrible tener un proceso intensivo en datos operando dentro de un sistema transaccional, esto no impide que la mayoría de los proveedores de sistemas transaccionales (ERP, MRP, WMS) vendan módulos analíticos integrados, por ejemplo, módulos de optimización de inventario. Tener esos módulos integrados conduce inevitablemente a problemas de calidad de servicio mientras se entregan capacidades poco impresionantes. Todos esos problemas se pueden atribuir a este único problema de diseño: el sistema transaccional y el sistema analítico deben mantenerse en estricto aislamiento.
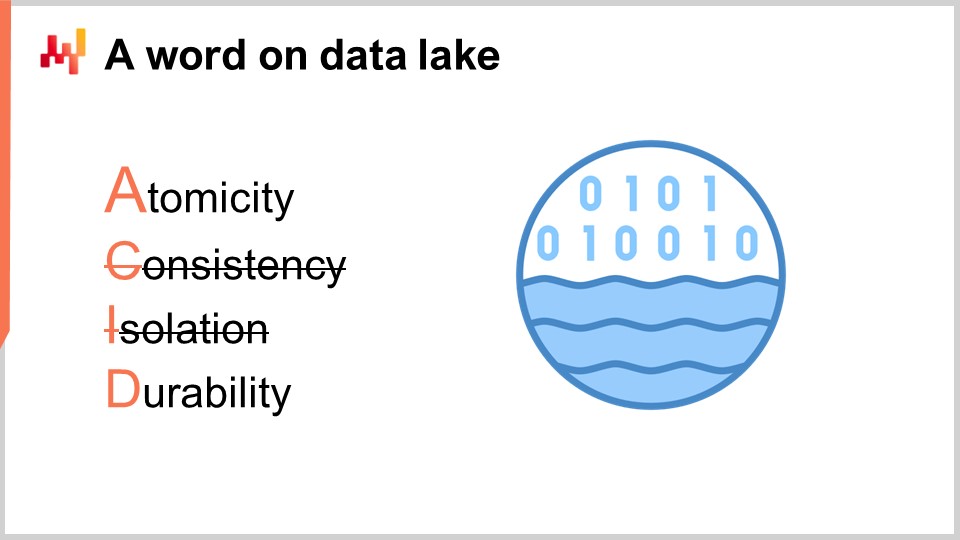
El data lake es simple. Es un espejo de los datos transaccionales orientado a operaciones de lectura muy grandes. De hecho, hemos visto que los sistemas de transacción están optimizados para muchas operaciones de lectura pequeñas, no para operaciones muy grandes. Así, con el fin de preservar la calidad de servicio del sistema transaccional, el diseño correcto consiste en replicar cuidadosamente los datos transaccionales en otro sistema, a saber, el data lake. Esta replicación debe implementarse con cuidado, precisamente para preservar la calidad de servicio del sistema transaccional, lo que típicamente significa leer los datos de manera muy incremental y evitar picos de presión en el sistema transaccional.
Una vez que se replica en el data lake la data transaccional relevante, el data lake mismo atiende todas las solicitudes de datos. Un beneficio adicional del data lake es su capacidad para servir a múltiples sistemas analíticos. Si bien estamos hablando de supply chain aquí, si el departamento de marketing desea sus propias analíticas, necesitarán estos mismos datos transaccionales, y lo mismo se podría decir para finanzas, ventas, etc. Así, en lugar de que cada departamento de la empresa implemente su propio mecanismo de extracción de datos, tiene sentido consolidar todas esas extracciones en el mismo data lake, en el mismo sistema.
A nivel técnico, un data lake puede implementarse con una base de datos relacional, típicamente ajustada para la extracción de big data, adoptando un almacenamiento de datos columnar. Los data lakes también pueden implementarse como un repositorio de archivos planos servidos a través de un sistema de archivos distribuido. En comparación con un sistema transaccional, un data lake renuncia a las propiedades transaccionales de granularidad fina. El objetivo es servir una gran cantidad de datos de la manera más económica y confiable posible—nada más, nada menos.
El data lake debe replicar los datos transaccionales originales, lo que significa copiarlos sin modificar nada. Es importante no preparar los datos en el data lake. Desafortunadamente, el equipo de IT encargado de configurar el data lake puede verse tentado a facilitar las cosas para otros equipos y, por lo tanto, preparar un poco los datos. Sin embargo, modificar los datos invariablemente introduce complicaciones que socavan las analíticas en una etapa posterior. Además, adherirse a una política estricta de replicación disminuye en gran medida el esfuerzo necesario para que el equipo de IT configure y posteriormente mantenga el data lake.
En empresas donde ya existe un equipo de BI, puede resultar tentador utilizar los sistemas de BI como data lake. Sin embargo, recomiendo encarecidamente no hacerlo y nunca usar una configuración de BI como data lake. De hecho, los datos en los sistemas de BI (business intelligence) ya están invariablemente fuertemente transformados. Aprovechar los datos de BI para impulsar decisiones automatizadas de supply chain es una receta para problemas de garbage in, garbage out. El data lake solo debe alimentarse de fuentes de datos primarias como el ERP, y no de fuentes de datos secundarias como el sistema de BI.
El sistema analítico es el que contiene la receta numérica central. También es el sistema que proporciona todos los reportes necesarios para instrumentar las propias decisiones. A nivel técnico, el sistema analítico contiene las partes “inteligentes”, como los algoritmos de machine learning y los algoritmos de optimización matemática. Aunque en la práctica, esas partes inteligentes no dominan la base de código de los sistemas analíticos. Usualmente, la preparación de datos y la instrumentación de datos ocupan al menos diez veces más líneas de código que las partes que se ocupan del aprendizaje y la optimización.
El sistema analítico debe estar desacoplado del data lake porque esos dos sistemas están completamente en desacuerdo en términos de perspectivas tecnológicas. Como software, se espera que el data lake sea muy simple, muy estable y extremadamente confiable. Por el contrario, se espera que el sistema analítico sea sofisticado, esté en constante evolución y sea extremadamente eficiente en términos de rendimiento de supply chain. A diferencia del data lake, que debe ofrecer un tiempo de actividad casi perfecto, el sistema analítico ni siquiera tiene que estar operativo la mayor parte del tiempo. Por ejemplo, si estamos considerando decisiones diarias de reposición de inventario, entonces el sistema analítico solo tiene que ejecutarse y estar operativo una vez al día.
Como regla general, es preferible que el sistema analítico falle al producir decisiones en lugar de generar decisiones incorrectas y permitir que estas fluyan hacia la producción. Retrasar las decisiones de supply chain por unas pocas horas, como las órdenes de compra, es típicamente mucho menos grave que tomar decisiones incorrectas. Dado que el diseño del sistema analítico tiende a estar fuertemente influenciado por las partes inteligentes que contiene, no hay necesariamente mucho que decir en general sobre el diseño del sistema analítico. Sin embargo, existe al menos una propiedad clave de diseño que debe implementarse en el ecosistema: este sistema debe ser sin estado.
El sistema analítico debe evitar tener un estado interno en la mayor medida posible. Es decir, todo el ecosistema debe comenzar con los datos tal como son presentados por el data lake y terminar con las decisiones de supply chain previstas generadas, junto con los informes de apoyo. Lo que suele suceder es que, siempre que haya un componente dentro del sistema analítico que sea demasiado lento, como un algoritmo de machine learning, resulta tentador introducir un estado, es decir, persistir alguna información de la ejecución anterior para acelerar la siguiente ejecución. Sin embargo, hacerlo, basándose en resultados previamente calculados en lugar de volver a calcular todo desde cero cada vez, es peligroso.
De hecho, tener un estado dentro del sistema analítico pone en riesgo la decisión. Aunque los problemas de datos inevitablemente surgirán y se solucionarán a nivel del data lake, el sistema analítico aún podría devolver decisiones que reflejen un problema que ya ha sido solucionado. Por ejemplo, si un modelo de previsión de la demanda se entrena con un conjunto de datos de ventas corrupto, entonces el modelo de previsión permanece corrupto hasta que se reentrene sobre una versión nueva y corregida del conjunto de datos. La única manera de evitar que el sistema analítico sufra de ecos de problemas de datos que ya han sido solucionados en el data lake es refrescar todo cada vez. Esa es la esencia de ser sin estado.
Como regla general, si una parte del sistema analítico resulta ser demasiado lenta para ser reemplazada diariamente, entonces esa parte debe considerarse como que sufre de un problema de rendimiento. Las supply chains son caóticas, y llegará un día en que algo suceda – un incendio, un confinamiento, un ciberataque – que requerirá una intervención inmediata. La empresa debe ser capaz de refrescar todas sus decisiones de supply chain en el plazo de una hora. La empresa no debe esperar y quedar bloqueada durante 10 horas mientras se lleva a cabo la lenta fase de entrenamiento de machine learning.

Para operar de manera confiable, el sistema analítico debe estar debidamente instrumentado. De eso se tratan el informe de salud de los datos y los inspectores de datos. Por cierto, todos esos elementos son responsabilidad de la supply chain; no son responsabilidad de TI. El monitoreo de la salud de los datos representa la primera fase del procesamiento de datos, incluso antes de la preparación de los datos en sí, y ocurre dentro del sistema analítico. La salud de los datos es parte de la instrumentación de la receta numérica. El informe de salud de los datos indica si es aceptable o no ejecutar la receta numérica en absoluto. Este informe también precisa el origen del problema de los datos, en caso de haber alguno, para acelerar la resolución del problema.
El monitoreo de la salud de los datos es una práctica en Lokad. Durante la última década, esta práctica ha demostrado ser invaluable para evitar situaciones de “garbage in, garbage out” que parecen ser ubicuas en el mundo del software empresarial. De hecho, cuando falla una iniciativa de procesamiento de datos, frecuentemente se culpa a los datos malos. Sin embargo, es importante notar que, usualmente, casi no hay esfuerzo de ingeniería alguno para garantizar la calidad de los datos en primer lugar. La calidad de los datos no cae del cielo; requiere esfuerzos de ingeniería.
El pipeline de datos que se ha presentado hasta ahora es bastante minimalista. La replicación de datos es tan simple como puede ser, lo cual es algo bueno en términos de calidad del software. Sin embargo, a pesar de este minimalismo, aún hay muchas partes móviles: muchas tablas, muchos sistemas, muchas personas. Por lo tanto, hay errores por todas partes. Esto es software empresarial, y lo contrario sería bastante sorprendente. El monitoreo de la salud de los datos está en marcha para ayudar al sistema analítico a sobrevivir al caos ambiental.
La salud de los datos no debe confundirse con la limpieza de datos. La salud de los datos se trata únicamente de asegurarse de que los datos puestos a disposición del sistema analítico sean una representación fiel de los datos transaccionales que existen en los sistemas transaccionales. No se intenta arreglar los datos; los datos se analizan tal como están.
En Lokad, típicamente distinguimos la salud de los datos a nivel bajo de la salud de los datos a nivel alto. La salud de los datos a nivel bajo es un dashboard que consolida todas las rarezas estructurales y volumétricas de los datos, tales como problemas evidentes como entradas que ni siquiera son fechas o números razonables, por ejemplo, o identificadores huérfanos que carecen de sus contrapartes esperadas. Todos estos problemas pueden ser vistos y, de hecho, son los fáciles. El problema difícil comienza con asuntos que no se pueden ver porque los datos faltan en primer lugar. Por ejemplo, si algo salió mal con una extracción de datos y los datos de ventas extraídos de ayer solo contienen la mitad de las líneas esperadas, realmente puede poner en peligro la producción. Los datos incompletos son particularmente insidiosos porque usualmente no evitarán que la receta numérica genere decisiones, excepto que esas decisiones van a ser basura, ya que los datos de entrada están incompletos.
Técnicamente, en Lokad, intentamos mantener el monitoreo de la salud de los datos en un solo dashboard, y este dashboard está típicamente destinado para el equipo de TI, ya que la mayoría de los problemas capturados por la salud de los datos a nivel bajo tienden a estar relacionados con el pipeline de datos en sí mismo. Idealmente, el equipo de TI debería poder determinar de un vistazo si todo está en orden o no y si no se requiere ninguna intervención adicional.

El monitoreo de la salud de los datos a nivel alto considera todas las rarezas a nivel de negocio – elementos que se ven incorrectos cuando se observan desde una perspectiva empresarial. La salud de los datos a nivel alto abarca elementos como niveles de stock negativos o cantidades mínimas de pedido anormalmente grandes. También cubre aspectos como precios que no tienen sentido porque la empresa operaría con pérdidas o con márgenes ridículamente altos. La salud de los datos a nivel alto intenta cubrir todos los elementos en los que un practicante de supply chain observaría los datos y diría, “No puede estar bien; tenemos un problema.”
A diferencia del informe de salud de los datos a nivel bajo, el informe de salud de los datos a nivel alto está destinado principalmente al equipo de supply chain. De hecho, problemas como las cantidades mínimas de pedido anómalas solo serán percibidos como problemas por un practicante que esté algo familiarizado con el entorno empresarial. El propósito de este informe es poder determinar de un vistazo que todo está en orden y que no se requiere ninguna intervención adicional.
Anteriormente, dije que se suponía que el sistema analítico debía ser sin estado. Bueno, resulta que la salud de los datos es la excepción que confirma la regla. De hecho, muchos problemas pueden identificarse comparando los indicadores actuales con los mismos indicadores recogidos en días previos. Así, el monitoreo de la salud de los datos típicamente persistirá algún tipo de estado, que son básicamente indicadores clave observados en días previos, de modo que pueda identificar valores atípicos en el estado actual de los datos. Sin embargo, dado que la salud de los datos es puramente una cuestión de monitoreo, lo peor que puede suceder si se soluciona un problema a nivel del data lake y luego tenemos ecos de problemas pasados en el estado de la salud de los datos, es una serie de falsas alarmas en esos informes. La lógica que genera las decisiones de supply chain permanece completamente sin estado; el estado solo concierne a una pequeña parte de la instrumentación.
El monitoreo de la salud de los datos, tanto a nivel bajo como a nivel alto, es una cuestión de equilibrio entre el riesgo de entregar decisiones incorrectas y el riesgo de no entregar decisiones a tiempo. Al observar grandes supply chains, no es razonable esperar que el 100 por ciento de los datos sea correcto – ocurren entradas transaccionales incorrectas, incluso si son raras. Por lo tanto, debe haber un volumen de problemas que se considere suficientemente bajo para que la receta numérica pueda operar. El equilibrio entre esos dos riesgos – ser excesivamente sensible a fallos de datos o ser demasiado tolerante a los problemas de datos – depende en gran medida de la composición económica de la supply chain.
En Lokad, diseñamos y ajustamos estos informes para cada cliente. En lugar de perseguir cada caso concebible de corrupción de datos, el Supply Chain Scientist, que está a cargo de implementar la salud de los datos a nivel bajo y alto y los inspectores de datos que discutiré en un minuto, intenta ajustar el monitoreo de la salud de los datos para que sea sensible al tipo de problemas que realmente son dañinos y que realmente están ocurriendo para la supply chain de interés.
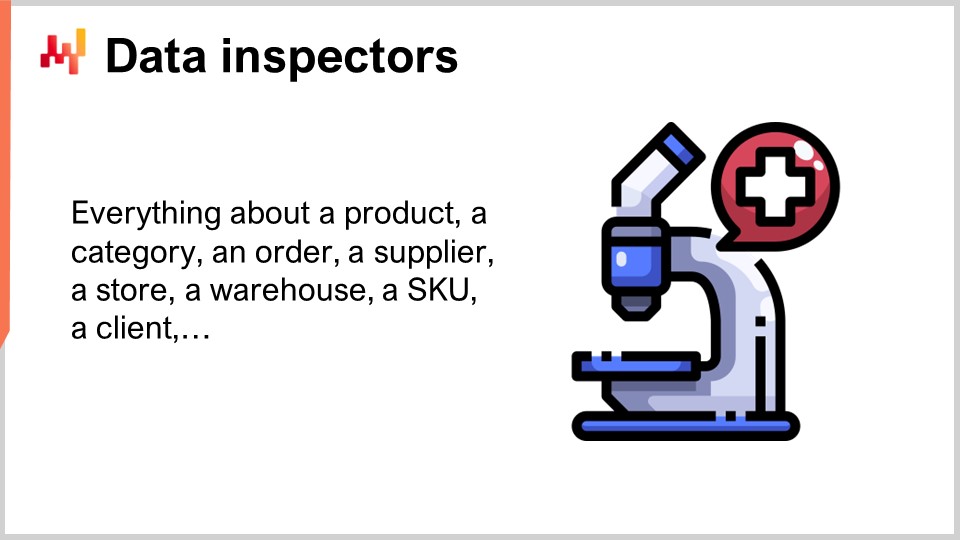
En la jerga de Lokad, un inspector de datos, o simplemente un inspector, es un informe que consolida todos los datos relevantes concernientes a un objeto de interés. Se espera que el objeto de interés sea uno de los ciudadanos de primera clase desde la perspectiva de la supply chain – un producto, un proveedor, un cliente, o un almacén. Por ejemplo, si consideramos un inspector de datos para productos, entonces, para cualquier producto vendido por la empresa, deberíamos poder ver a través del inspector en una sola pantalla todos los datos que están asociados a ese producto. En el inspector de datos para productos, efectivamente hay tantas vistas como productos, porque cuando digo que vemos todos los datos, me refiero a todos los datos que están asociados a un código de barras o número de parte, y no a todos los productos en general.
A diferencia de los informes de salud de los datos a nivel bajo y alto, que se espera sean dos dashboards que puedan ser inspeccionados de un vistazo, los inspectores se implementan para abordar preguntas y preocupaciones que invariablemente surgen al diseñar y luego operar la receta numérica central. De hecho, para tomar una decisión de supply chain, no es infrecuente consolidar datos de una docena de tablas, posiblemente originadas en múltiples sistemas transaccionales. Dado que los datos están dispersos, cuando una decisión parece sospechosa, por lo general es difícil identificar el origen del problema. Puede haber una desconexión entre los datos tal como los ve el sistema analítico y los datos que existen en el sistema transaccional. Puede haber un algoritmo defectuoso que no logra capturar un patrón estadístico en los datos. Puede haber una percepción incorrecta, y la decisión que se considera sospechosa podría, de hecho, ser correcta. En cualquier caso, el inspector está destinado a ofrecer la posibilidad de hacer zoom en el objeto de interés.
Para ser útiles, los inspectores deben reflejar las especificidades tanto de la supply chain como del entorno aplicativo. Como resultado, crear inspectores es casi invariablemente un ejercicio hecho a la medida. No obstante, una vez realizado el trabajo, el inspector representa uno de los pilares de la instrumentación del propio sistema analítico.
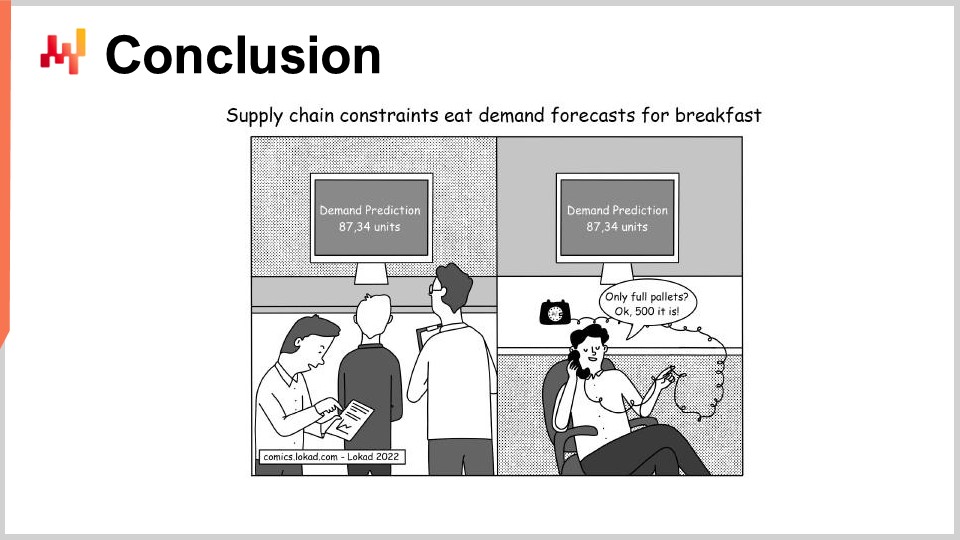
En conclusión, aunque la mayoría de las iniciativas de Supply Chain Quantitativa están destinadas a fracasar incluso antes de su inicio, no tiene por qué ser así. Una elección cuidadosa de entregables, plazos, alcance y reglas es necesaria para evitar problemas que invariablemente condenan a esas iniciativas al fracaso. Desafortunadamente, esas elecciones con frecuencia resultan algo contraintuitivas, como Lokad aprendió a lo difícil durante 14 años de operación hasta ahora.
El inicio mismo de la iniciativa debe estar dedicado a la configuración de un pipeline de datos. Un pipeline de datos poco confiable es una de las maneras más seguras de garantizar que cualquier iniciativa impulsada por datos fracase. La mayoría de las empresas, incluso la mayoría de los departamentos de TI, subestiman la importancia de un pipeline de datos altamente confiable que no requiera intervenciones constantes. Si bien la mayor parte de la configuración del pipeline de datos recae en manos del departamento de TI, la propia supply chain debe ser responsable de la instrumentación del sistema analítico que opera. No esperes que TI lo haga por ti; este corresponde al equipo de supply chain. Hemos visto dos tipos diferentes de instrumentación, a saber, los informes de salud de los datos que adoptan una perspectiva a nivel de toda la empresa y los inspectores de datos, que apoyan el diagnóstico en profundidad.

Hoy, discutimos cómo iniciar una iniciativa, pero la próxima vez veremos cómo terminarla o, mejor dicho, cómo llevarla a buen término. En la siguiente conferencia, que se llevará a cabo el miércoles 14 de septiembre, avanzaremos en nuestro recorrido y veremos qué tipo de ejecución se requiere para elaborar una receta numérica central y luego llevar gradualmente las decisiones que esta genere a producción. También examinaremos más de cerca lo que esta nueva forma de hacer supply chain implica para la operación diaria de los practicantes de supply chain.
Ahora, echemos un vistazo a las preguntas.
Pregunta: ¿Por qué son exactamente seis meses como límite de tiempo después de los cuales una implementación no se hace correctamente?
Yo diría que el problema no es realmente tener seis meses como límite de tiempo. Es que, usualmente, las iniciativas están diseñadas para fracasar desde el principio. Ese es el problema. Si tu iniciativa de optimización predictiva comienza con la perspectiva de que los resultados se entregarán en dos años, es casi una garantía de que la iniciativa se disolverá en algún momento y no logrará entregar nada en producción. Si pudiera, preferiría que la iniciativa alcanzara el éxito en tres meses. Sin embargo, seis meses representa el plazo mínimo, según mi experiencia, para llevar dicha iniciativa a producción. Cualquier retraso adicional incrementa el riesgo de que la iniciativa fracase. Es muy difícil comprimir este plazo aún más, porque una vez que has resuelto todos los problemas técnicos, los retrasos restantes reflejan el tiempo que se necesita para que las personas se pongan en marcha con la iniciativa.
Pregunta: Los practicantes de supply chain pueden frustrarse con una iniciativa que reemplaza la mayor parte de su carga de trabajo, como el departamento de compras, en conflicto con la automatización de decisiones. ¿Cómo aconsejarías manejar esto?
Esta es una pregunta muy importante, que se abordará con suerte en la próxima clase. Por hoy, lo que puedo decir es que creo que la mayor parte de lo que los practicantes de supply chain están haciendo en los supply chains actuales no resulta muy gratificante. En la mayoría de las empresas, las personas reciben un conjunto de SKUs o números de parte y luego los recorren sin cesar, tomando todas las decisiones necesarias. Esto significa que su trabajo consiste esencialmente en mirar una hoja de cálculo y recorrerla una vez a la semana o, posiblemente, una vez al día. Este no es un trabajo satisfactorio.
La respuesta corta es que el enfoque Lokad aborda el problema automatizando todos los aspectos mundanos del trabajo, de modo que las personas con verdadera experiencia en el supply chain puedan empezar a desafiar los fundamentos del supply chain. Esto les permite discutir más con clientes y proveedores para hacer todo más eficiente. Se trata de recopilar insights para que podamos mejorar la receta numérica. Ejecutar la receta numérica es tedioso, y serán muy pocas las personas que lamenten los viejos tiempos en los que tenían que recorrer hojas de cálculo todos los días.
Pregunta: ¿Se espera que los practicantes de supply chain trabajen con informes de salud de los datos para desafiar las decisiones generadas por los Supply Chain Scientist?
Se espera que los practicantes de supply chain trabajen con inspectores de datos, no con informes de salud de los datos. Los informes de salud de los datos son como una evaluación a nivel de toda la empresa que responde a la pregunta de si los datos en la entrada del sistema analítico son lo suficientemente buenos para que una receta numérica opere sobre el conjunto de datos. El resultado del informe de salud de los datos es una decisión binaria: dar luz verde a la ejecución de la receta numérica o oponerse y decir que hay un problema que necesita ser solucionado. Los inspectores de datos, de los cuales se hablará más en la próxima clase, son el punto de entrada para que los practicantes de supply chain obtengan insights sobre una decisión de supply chain propuesta.
Pregunta: ¿Es factible actualizar un modelo analítico, por ejemplo, estableciendo una política de inventario a diario? El sistema de supply chain no puede responder a cambios diarios de política, ¿no solo alimentará ruido al sistema?
Para abordar la primera parte de la pregunta, actualizar un modelo analítico a diario es ciertamente factible. Por ejemplo, cuando Lokad operaba en 2020 con confinamientos en Europa, tuvimos países cerrándose y reabriéndose con tan solo 24 horas de aviso. Esto creó una situación extremadamente caótica que requería revisiones inmediatas constantes cada día. Lokad operó bajo esta extrema presión, gestionando confinamientos que comenzaban o terminaban diariamente en toda Europa durante casi 14 meses.
Así, actualizar un modelo analítico a diario es factible, pero no necesariamente deseable. Es cierto que los sistemas de supply chain tienen mucha inercia, y lo primero que debe reconocer una receta numérica adecuada es el efecto trinquete de la mayoría de las decisiones. Una vez que has ordenado que se realice la producción y se consumen las materias primas, no se puede deshacer la producción. Debes tener en cuenta que muchas decisiones ya se han tomado al hacer nuevas. Sin embargo, cuando te das cuenta de que tu supply chain necesita un cambio drástico en su curso de acción, no tiene sentido retrasar esta corrección solo por el hecho de demorar la decisión. El mejor momento para implementar el cambio es ahora mismo.
En lo que respecta al aspecto del ruido en la pregunta, se reduce al correcto diseño de las recetas numéricas. Existen muchos diseños incorrectos que son inestables, donde pequeños cambios en los datos generan grandes cambios en las decisiones que representan el resultado de la receta numérica. Una receta numérica no debería ser inestable cada vez que hay una pequeña fluctuación en el supply chain. Por eso, Lokad adoptó una perspectiva probabilística en la previsión. Al utilizar una perspectiva probabilística, los modelos pueden diseñarse para ser mucho más estables en comparación con aquellos que intentan capturar la media y se vuelven inestables cada vez que ocurre un outlier en el supply chain.
Pregunta: Uno de los problemas que enfrentamos en supply chain con empresas muy grandes es su dependencia de diferentes sistemas fuente. ¿No es extremadamente difícil reunir todos los datos de estos sistemas fuente en un sistema unificado?
Estoy completamente de acuerdo en que obtener todos los datos es un desafío significativo para muchas empresas. Sin embargo, debemos preguntarnos por qué es un desafío en primer lugar. Como mencioné anteriormente, el 99% de las aplicaciones empresariales operadas por grandes compañías en la actualidad dependen de bases de datos transaccionales comunes y bien diseñadas. Puede que aún existan algunas implementaciones super legacy en COBOL que funcionen en almacenamientos binarios arcanos, pero esto es raro. La gran mayoría de las aplicaciones empresariales, incluso aquellas desplegadas en la década de 1990, operan con una base de datos transaccional limpia de grado producción en el backend.
Una vez que tienes un backend transaccional, ¿por qué debería ser difícil copiar estos datos a un data lake? La mayoría de las veces, el problema es que las empresas no solo intentan copiar los datos, sino que tratan de hacer mucho más. Intentan preparar y transformar los datos, a menudo sobrecomplicando el proceso. La mayoría de las configuraciones modernas de bases de datos tienen capacidades integradas de replicación de datos, lo que te permite replicar todos los cambios de una base de datos transaccional a una base de datos secundaria. Esta es una propiedad incorporada en probablemente los 20 sistemas transaccionales más utilizados en el mercado.
Las empresas tienden a tener problemas para consolidar los datos porque intentan hacerlo demasiado, y sus iniciativas colapsan bajo su propia complejidad. Una vez que los datos están consolidados, las empresas a menudo cometen el error de pensar que la conexión de los datos debe ser realizada por los equipos de IT, BI o data science. El punto que quiero destacar aquí es que el supply chain debe estar a cargo de sus propias recetas numéricas, así como deberían estarlo marketing, ventas y finanzas. No debería ser una división de soporte transversal que intente hacer esto por la empresa. Conectar datos de diferentes sistemas típicamente requiere toneladas de insights empresariales. Las grandes empresas a menudo fracasan porque intentan que un experto de los equipos de IT, BI o data science haga este trabajo cuando debería hacerse dentro de la división de interés.
Muchas gracias por su tiempo hoy, su interés y sus preguntas. Nos vemos la próxima vez después del verano, en septiembre.