00:00 イントロダクション
02:31 失敗の根本原因(実例)
07:20 成果物: 数値レシピ 1/2
09:31 成果物: 数値レシピ 2/2
13:01 これまでの経緯
14:57 本日の作業内容
15:59 施策のタイムライン
21:48 対象範囲: アプリケーション領域 1/2
24:24 対象範囲: アプリケーション領域 2/2
27:12 対象範囲: システム効果 1/2
29:21 対象範囲: システム効果 2/2
32:12 役割: 1/2
37:31 役割: 2/2
41:50 データパイプライン - 方法
44:13 トランザクションシステムについて
49:13 データレイクについて
52:59 分析システムについて
57:56 データの健全性: 低レベル
01:02:23 データの健全性: 高レベル
01:06:24 データ監査者
01:08:53 結論
01:10:32 次回の講義と聴講者からの質問
説明
サプライチェーンの成功する予測最適化の実施は、ソフトな課題とハードな課題が混在するものであり、これらの要素を切り離すことはできません。ソフトな側面とハードな側面は深く絡み合っています。通常、この絡み合いは、企業の組織図によって定義される業務分担と正面衝突します。私たちは、サプライチェーン施策が失敗する場合、その失敗の根本原因はプロジェクトの初期段階で犯されるミスであることが多いと観察しています。さらに、初期のミスは施策全体の方向性を決定し、その後の修正をほぼ不可能にしてしまいます。これらのミスを回避するための重要な発見を提示します。
完全な書き起こし

このサプライチェーン講座シリーズへようこそ。私はジョアンネス・ヴェルモレルです。本日は「量的サプライチェーン施策の始め方」をご紹介します。データ解析を基にしたサプライチェーン施策の大多数は失敗に終わっています。1990年以降、大規模なサプライチェーンを運営するほとんどの企業は、三年から五年ごとに大規模な予測最適化施策を立ち上げていますが、その成果はほとんど見られません。現在、サプライチェーンやデータサイエンスの大多数のチームは、別の予測最適化ラウンドを開始しているものの(通常、これらは予測プロジェクトや在庫最適化プロジェクトとして位置付けられます)、自社が既に同様の試みを行い、半ダースもの失敗を経験していることに気付いていません。
再度試みるのは、今回は結果が違うという信念からである場合もありますが、実際には多くの失敗事例に気付いていないチームがほとんどです。この状況の逸話的な証拠として、Microsoft Excelが依然としてサプライチェーンの意思決定を推進するための第一のツールであることが挙げられます。本来、これらの施策はスプレッドシートに代わる優れたツールを導入するはずでしたが、今日に至るまでスプレッドシートなしで運営できるサプライチェーンは非常に少ないのが現状です。
本講義の目的は、あらゆる予測最適化を実現しようとするサプライチェーン施策に成功の可能性を与える方法を理解することにあります。いくつかの重要な要素(これらの要素はシンプルでありながら、多くの組織にとって直感に反するものとして現れることが多い)を検証します。逆に、そうした施策の失敗をほぼ確実にするアンチパターンについても検証します。
本日は、物事を着実に進めるマインドセットでサプライチェーン施策の開始時点における戦術的な実行に焦点を当てます。企業全体の壮大な戦略的影響については議論しません。戦略は非常に重要ですが、この件については後の講義で取り上げます。

ほとんどのサプライチェーンの取り組みは失敗しており、その問題はほとんど公に語られることがありません。学界は毎年何万もの論文を発表し、フレームワーク、アルゴリズム、モデルなどあらゆる種類のサプライチェーン革新を自慢しています。しばしば、論文の中ではその革新がどこかで実際に運用されていると主張されています。しかし、私自身がサプライチェーンの現場を何気なく観察すると、これらの革新は一切見受けられません。同様に、software vendorsは過去30年間、スプレッドシートに代わる優れたシステムを約束してきましたが、私の何気ない観察ではスプレッドシートが依然として普及しています。
このサプライチェーン講義シリーズの第2章でも触れた点に立ち返ります。簡単に言えば、人々は失敗を宣伝するインセンティブを全く持っていないため、何も宣伝しないのです。さらに、サプライチェーンを運営する企業は大企業であることが多く、社員が次々と異動する自然な組織記憶の喪失により、問題が一層深刻化します。だからこそ、学界もベンダーもこのどんよりとした状況を認めようとはしません。
ここでは、戦術レベルでの実行において失敗する最も頻繁な根本原因について、簡単な調査を行うことを提案します。実際、これらの根本原因は取り組みの初期段階で典型的に見られるものです。
失敗の第一の原因は、存在しない、または重要ではない、あるいはサプライチェーンそのものに対する誤解に基づく誤った問題を解決しようとする試みです。予測精度の最適化は、このような誤った問題の典型例と言えるでしょう。予測誤差の割合を減らすことは、企業にとって直接的にユーロやドルの追加収益に結びつくわけではありません。同様の状況は、企業が自社の在庫に対して特定のサービスレベルを追求するときにも見られ、実際に収益に結びつくことは非常に稀です。
失敗の第二の根本原因は、適合しないソフトウェア技術や設計の使用にあります。たとえば、ERPベンダーは、ERPの基盤となるトランザクショナルデータベースを利用してデータ解析の取り組みを支援しようとします。一方、データサイエンスチームは、その時々の最先端のオープンソース機械学習ツールキットを使用しようとする傾向があります。不幸なことに、適合しない技術は通常、膨大な摩擦と予期せぬ複雑性を生み出します。
失敗の第三の根本原因は、労働分担や組織の不適切な分割にあります。各段階に専門家を配置しようとする誤った試みの結果、企業は取り組みをあまりにも多くの人々に分散させがちです。たとえば、データ抽出パイプラインは、予測を担当していない人々によって行われることが非常に多く、その結果、「ゴミが入ればゴミが出る」状況が至る所に発生します。最終的なサプライチェーンの意思決定の責任が薄まることは、失敗のレシピとなります。
ここで短いリストに挙げなかった根本原因のひとつに、悪いデータがあります。サプライチェーンの取り組みの失敗についてデータが非難されることは非常に多いですが、これは都合がよすぎる話であり、データ自体がその非難に応じるわけではありません。しかし、データが問題なのではなく、少なくとも悪いデータに苦しむという意味での問題ではありません。大企業のサプライチェーンは何十年も前にデジタル化され、購入、輸送、変換、製造、販売されるあらゆるアイテムにelectronic recordsが存在します。これらの記録は完璧ではない場合もありますが、通常は非常に正確です。もしデータの取り扱いに失敗したとしても、非難されるべきは取引そのものではありません。

定量的な取り組みを成功させるためには、正しい課題に取り組む必要があります。そもそも、私たちは何を提供しようとしているのでしょうか?定量的サプライチェーンの主要な成果物のひとつは、最終的なサプライチェーンの意思決定を算出するコアとなる数値レシピです。この点は、「Product-Oriented Delivery for Supply Chain」という最初の章の講義 1.3 ですでに論じられました。では、この成果物の最も重要な二つの特性を再確認してみましょう。
まず、出力は意思決定でなければなりません。例えば、本日何ユニットをreorderするかを決定する際、特定のSKUに対して行う判断は意思決定です。一方、特定のSKUに対して本日要求されるユニット数を予測することは、単なる数値的な成果物に過ぎません。最終的な意思決定を生み出すためには、多くの中間成果物、すなわち数多くの数値的アーティファクトが必要となります。しかし、手段と目的を混同してはなりません。
この成果物の第二の特性は、出力である意思決定が、完全に自動化されたソフトウェアプロセスの結果として実現されなければならないことです。数値レシピそのもの、すなわちコアとなる数値レシピは、いかなる手作業も含んではいけません。当然、数値レシピの設計自体は、科学の非常に優れた人間の専門家に大いに依存する可能性があります。しかし、実行段階では直接的な人間の介入に依存するべきではありません。
成果物として数値レシピを持つことは、サプライチェーンの取り組みを資本主義的な事業とするために不可欠です。その数値レシピはリターンを生み出す生産的資産となります。レシピは維持されなければなりませんが、これは微細な意思決定レベルで人間を関与させるアプローチと比べ、必要な人数が1桁または2桁分少なくて済むのです。

しかし、多くのサプライチェーンの取り組みは、取り組みの成果物としてサプライチェーンの意思決定を正しく位置付けられないために失敗します。代わりに、それらの取り組みは数値的アーティファクトの提供に重点を置いています。数値的アーティファクトは、最終的な問題解決に至るための要素、通常は意思決定自体を支えるための材料として意図されます。サプライチェーンで最も一般的に見られるアーティファクトは、予測、安全在庫、EOQsおよびKPIです。これらの数値は興味深いものの、実体はありません。サプライチェーンにおいて、これらの数値は即座に具体的な物理的対応物を持たず、サプライチェーンに対する恣意的なモデリングの視点を反映しているにすぎません。
数値的アーティファクトに注目すると、取り組みが失敗する原因になります。なぜなら、これらの数値は重要な要素である直接的な実世界からのフィードバックを欠いているからです。意思決定が誤っている場合、その悪影響はその意思決定にまで遡ります。しかし、数値的アーティファクトにおいては、責任が多数のアーティファクトに分散されるため、状況は非常に曖昧になります。特に、途中で人間の介入が入ると、その問題はさらに悪化します。
このフィードバックの欠如は、数値的アーティファクトにとって致命的です。現代のサプライチェーンは非常に複雑です。安全在庫、経済発注量、またはKPIを算出する任意の数式を選んでみても、その数式があらゆる面で誤っている可能性が圧倒的に高いのです。数式の正しさの問題は数学的な問題ではなく、ビジネス上の問題なのです。つまり、「この計算は本当に自分のビジネスに対する戦略的意図を反映しているのか?」という問いに答える問題です。その答えは企業ごとに、さらには企業が時とともに進化する中で年ごとにも変わっていきます。
数値的アーティファクトは直接的な実世界からのフィードバックを欠いているため、初歩的で単純かつ大いに誤った初期実装から、実運用に耐えうる概ね正しい数式への反復改善の仕組みを持っていません。それでも、数値的アーティファクトは、解決策に近づいているという錯覚を与えるため非常に魅力的です。合理的で科学的、さらには実行可能であるかのように錯覚させます。我々は数値、数式、アルゴリズム、モデルを持っています。ベンチマークを行い、それらの数値を同様に捏造された数値と比較することすら可能です。捏造されたベンチマークに対して改善を示すことは、進歩の錯覚を与え、非常に心強いものです。しかし、結局のところ、それはあくまで錯覚に過ぎず、モデリングの視点の問題です。
企業は、KPIを眺めたりベンチマークを行うために人件費を支払うことで利益を上げるのではありません。企業が利益を生み出すのは、一つの意思決定のあとに次の意思決定を下し、そのたびに次の意思決定をより良くしていくからです。
この講義は一連のサプライチェーン講義の一部です。できるだけ独立性を保とうとしていますが、これらの講義を順に視聴した方が意味がある段階に達しました。本講義は、第7章の最初の講義であり、第7章はサプライチェーンの取り組みの実行に捧げられています。ここでいうサプライチェーンの取り組みとは、企業向けの予測最適化のような定量的サプライチェーンの取り組みを意味します。
最初の章では、サプライチェーンを学問としても実践としても捉えた私の見解について述べました。第2章では、サプライチェーンに不可欠な一連の方法論を提示しました。なぜなら、素朴な方法論は多くのサプライチェーンの状況における敵対性によって打ち負かされるからです。第3章では、私たちが何を解決しようとしているのか、すなわち問題に純粋に焦点を当てた一連のサプライチェーンpersonaeを紹介しました。
第4章では、厳密にはサプライチェーンそのものではないものの、現代のサプライチェーン実践に不可欠であると考える一連の分野を提示しました。第5章と第6章では、サプライチェーンの意思決定を推進するために意図された数値レシピの賢い部分、すなわち予測最適化(予測の一般化された視点)と意思決定(本質的にサプライチェーン問題に適用される数学的最適化)を紹介しました。本第7章では、これらの要素をどのように実際のサプライチェーンの取り組みに組み込んで、これらの手法や技術を実運用に移すかについて論じます。

本日は、サプライチェーンの取り組みを実施する際に正しいとされる実践方法を振り返ります。これには、先ほど議論した適切な成果物による取り組みの枠組みづくりだけでなく、適切なタイムライン、適切な範囲、そして適切な役割の設定も含まれます。これらの要素は、本日の講義の第一部を構成しています。
講義の第二部では、データ主導またはデータ依存の取り組みの成功に不可欠な要素であるデータパイプラインについて詳しく解説します。データパイプラインは技術的には非常に専門的なトピックですが、IT部門とサプライチェーン部門との間で適切な労働分担と組織体制が求められます。特に、品質管理は主にサプライチェーン側が担い、データヘルスレポートやデータインスペクターの設計を行うべきであることがわかります。
オンボーディングは取り組みの第一段階であり、主要な数値レシピ、すなわち意思決定を生み出すための中核となるレシピ(補助要素を伴うもの)が作成されるフェーズです。オンボーディングは段階的に本番環境へ展開され、この展開過程で初期のプロセスは数値レシピ自体によって徐々に自動化されていきます。
企業における初の定量的サプライチェーン取り組みに適切なタイムラインを検討する際、企業の規模や複雑性、サプライチェーンの意思決定の種類、そして全体の状況に依存すると考えられるかもしれません。限定的にはその通りですが、Lokadが10年以上にわたって数十件の取り組みから蓄積した経験では、ほぼ常に6か月が適切なタイムラインであることが示されています。驚くべきことに、この6か月というタイムラインは技術やサプライチェーンの細部とはほとんど関係がなく、むしろ人々や組織が従来とは大きく異なるサプライチェーン運営方法に慣れるまでの時間に大きく依存しています。
最初の2か月間は、データパイプラインの構築に充てられます。この点については数分後に再度触れますが、この2か月の遅延は2つの要因によるものです。まず第一に、データパイプラインを信頼性の高いものにし、数週間かかる可能性のあるまれな問題を排除する必要があります。第二に、サプライチェーンの観点からデータの意味を理解する、いわゆるデータのセマンティクスを把握する必要があるのです。
3か月目と4か月目は、サプライチェーンの意思決定を支える数値レシピ自体の迅速な反復作業に充てられます。実際の最終的な意思決定を生成することが、根本的なレシピやその前提条件に問題があるかどうかを評価する唯一の方法であるため、こうした反復作業は必要です。この2か月は、サプライチェーンの実務者が、この非常に定量的かつ財務的視点に慣れるためにも通常必要な期間です。
最後の2か月間は、通常、激しい迅速な反復期間を経た後の数値レシピの安定化に充てられます。この期間は、レシピが本番環境に近いセットアップで動作する機会でもありますが、まだ実際に生産を担う段階ではありません。このフェーズは、サプライチェーンチームがこの新たなソリューションに信頼を寄せるために重要です。
このタイムラインをさらに短縮できれば望ましいものの、実際には非常に困難であることが判明しています。適切なITインフラがすでに整っていれば、データパイプラインの構築はある程度加速可能ですが、データの意味をサプライチェーンの観点から理解するには時間がかかります。第二フェーズでは、数値レシピの反復作業が極めて迅速に収束した場合、サプライチェーンチームは数値レシピの細部に目を向け始め、結果として遅延が拡大する可能性があります。最後の2か月は、通常、季節性が展開し、ソフトウェアが生産における重要なサプライチェーン意思決定を担っていることへの信頼を得るのに必要な期間です。
全体として、約6か月を要し、さらに短縮できれば望ましいものの、それは困難です。しかし、6か月という期間自体はすでに相当な長さです。もし、初日からオンボーディング期間、つまり数値レシピがまだサプライチェーンの意思決定を担っていない期間が6か月以上かかると予想されるなら、その取り組みはすでに危機に瀕していることになります。追加の遅延がデータ抽出やデータパイプラインの構築に起因するなら、IT上の問題があるということです。もし、追加の遅延がソリューションの設計または構成に関係しており、場合によっては第三者ベンダーによってもたらされたものであれば、技術自体に問題があるということです。最後に、2か月間の安定した本番環境に類似した運用後に本番展開がなされない場合は、通常、その取り組みの運営に問題があると言えるでしょう。

新たな革新、プロセス、または技術を組織に導入する場合、一般的な知恵として、小規模で始め、機能することを確認し、初期の成功を基盤として徐々に拡大していくことが推奨されます。しかし、残念ながらサプライチェーンはこの一般的な知恵にあまり寛容ではなく、スコーピング(範囲設定)に関して特有のひねりがあります。スコーピングの観点では、サプライチェーンの取り組みにおいて何が適切なスコープであり何が適切でないかを大きく定義する2つの主要な推進要因が存在します。
アプリケーション環境は、スコーピングに影響を与える第一の要因です。サプライチェーン全体を直接観察することはできず、エンタープライズソフトウェアのレンズを通してのみ間接的に観察できます。データはこれらのソフトウェアから取得され、その複雑さは、これらのソフトウェアの数と多様性に大きく依存します。各アプリはそれ自体がデータソースであり、特定の業務アプリからのデータ抽出および分析は通常、大規模な作業となります。アプリが多ければ多いほど、複数のデータベース技術、不統一な用語、不一致の概念に対処しなければならず、状況は非常に複雑になります。
したがって、スコープを設定する際には、適切な境界は通常、業務アプリやそのデータベース構造によって定義されることを認識しなければなりません。この文脈では、初期のデータ統合のフットプリントをできるだけ小さく保ちつつも、サプライチェーン取り組み全体の整合性を維持することが「スモールスタート」として理解されるべきです。アプリ統合においては、広く手を広げるよりも、深く掘り下げる方が効果的です。一度、あるアプリのテーブルからいくつかのレコードを取得するためのITシステムが整えば、そのテーブルの全レコードおよび同じアプリ内の別テーブルの全レコードを取得することは通常容易になります。

一般的なスコーピングの誤りのひとつは、サンプリングに陥ることです。サンプリングは通常、限られた製品カテゴリ、サイト、またはサプライヤーのリストを選ぶことで行われます。善意から行われるサンプリングですが、アプリケーション環境で定義された境界に従っていないため、データ抽出時にフィルターを適用する必要があり、そのプロセスが一連の問題を引き起こし、サプライチェーン取り組みを危険にさらす可能性があります。
まず、エンタープライズソフトウェアからフィルターを掛けたデータ抽出は、フィルターを掛けない抽出に比べて、ITチームにより多くの労力を要求します。まずフィルターを設計する必要があり、そのプロセス自体がエラーを起こしやすいのです。不適切なフィルターのデバッグは非常に手間がかかり、ITチームとの多くのやり取りを必要とするため、取り組みが遅延し、結果として危険にさらされます。
第二に、取り組みのオンボーディングをデータサンプル上で実施させると、後に取り組みが全体スコープへ拡大した際、膨大なソフトウェアパフォーマンスの問題を引き起こすことになります。大量のデータを処理しながら計算コストを抑制する能力の不足、すなわちスケーラビリティの問題は、ソフトウェアにおける非常に一般的な欠陥です。取り組みをサンプル上で運用すると、スケーラビリティの問題は隠蔽されますが、後になって大きな問題として表面化します。
データサンプル上での運用は、統計解析を容易にするどころか、むしろ困難なものにします。実際、より多くのデータにアクセスできることは、ほぼすべての機械学習アルゴリズムの精度と安定性を向上させる最も簡単な方法と言えます。データのサンプリングはこの考えに反するものであり、小規模なデータサンプルを使用すると、サンプル上で見られる不規則な数値挙動により取り組みが失敗する可能性があります。全データセットが使用されていれば、これらの挙動は大いに緩和されたでしょう。
システム効果は、スコーピングに影響を与える第二の要因です。サプライチェーンはシステムであり、そのすべての要素はある程度連動しています。システム全体の一部分を改善しようとする試みは、問題を根本的に解決するのではなく、単に別の場所に問題をシフトしてしまう傾向があります。例えば、1つの配送センターと多数の店舗を有する小売ネットワークにおける在庫割り当ての問題を考えてみましょう。初期のスコープとして単一の店舗を選んだ場合、その店舗に対しては、あらかじめ在庫を予約することで配送センターから非常に高いサービス品質を提供することが容易に可能です。そうすることで、この店舗をサービスする間、配送センターが品切れになることは決してありません。しかし、こうした在庫予約は、ネットワーク内の他店舗のサービス品質を犠牲にして行われることになります。
したがって、サプライチェーン取り組みのスコープを検討する際には、システム効果を十分に考慮しなければなりません。スコープは、範囲外の要素を犠牲にして局所的な最適化を行わないように設計されるべきです。このスコーピングの課題は、すべてのスコープがある程度の漏れを伴うため、非常に困難です。例えば、サプライチェーンのすべての部分は最終的には企業全体で利用可能な同じ資金を巡って競合します。どこかに割り当てられた1ドルは、他の用途に使えなくなる1ドルです。それでもなお、あるスコープは他のものよりも操作しやすい傾向にあります。システム効果を増幅させるのではなく、むしろ緩和するスコープを選ぶことが重要です。

サプライチェーン取り組みのスコーピングをシステム効果の観点から考えることは、多くのサプライチェーン実務者にとって奇妙に感じられるかもしれません。スコーピングに関しては、ほとんどの企業が内部組織の構造をそのままスコーピング作業に投影してしまいがちです。結果として、スコープとして選択される境界は、企業内で既に存在する労働分担の境界を模倣する傾向にあります。この現象はコンウェイの法則として知られており、半世紀前にメルヴィン・コンウェイによって通信システムのために提唱され、その後、サプライチェーン管理にも非常に広範囲で適用可能であることが判明しています。
現代のサプライチェーンを支配する境界やサイロは、サプライチェーンの意思決定を推進するために存在する、かなり手作業によるプロセスに起因する労働分担から生じています。例えば、ある企業が需要と供給のプランナー1人では最大1,000 SKUしか管理できないと判断し、全体で50,000 SKUを管理する必要がある場合、その企業は50名のプランナーを必要とするでしょう。しかし、サプライチェーンの最適化を50人に分割して任せると、企業全体で多くの非効率性がもたらされるのは明らかです。
それに対して、これらの意思決定を自動化する取り組みは、時代遅れまたはすぐに時代遅れとなる労働分担の境界に従う必要がありません。数値レシピは、これら50,000 SKUを一度に最適化し、数十のサイロが互いに競合することによって生じる非効率性を排除することができます。したがって、これらの意思決定を大幅に自動化する取り組みが、企業内の既存の多数の境界と重なるのは自然なことです。企業、正確にはその経営陣は、特にスコーピングの段階において、既存の組織的境界を模倣する衝動に抵抗しなければなりません。これは、その後の展開の方向性を大きく左右するためです。

サプライチェーンは、ハードウェア、ソフトウェア、そして人に関して非常に複雑です。不運なことに、定量的サプライチェーン取り組みを開始することで、少なくとも初期段階ではサプライチェーン自体の複雑さがさらに増大してしまいます。長期的には、実際にサプライチェーンの複雑さを大幅に軽減できる可能性もありますが、その点についてはおそらく後の講義で触れるでしょう。さらに、取り組みに関わる人が増えれば増えるほど、取り組み自体の複雑性も高まります。この追加の複雑さがすぐに管理されなければ、その取り組みは自身の複雑さに押し潰される危険性が非常に高まります。
したがって、取り組みにおける役割、つまり誰が何を担うのかを考える際には、その取り組みを成立させるために可能な限り最小限の役割のセットを検討する必要があります。役割の数を最小限に抑えることで取り組みの複雑さを軽減し、その結果、成功の可能性を大いに高めることができます。この視点は、極めて細分化された労働分担で運営することを好む大企業にとっては、直感に反するかもしれません。大企業は、特定の一つのことだけを専門とする極端なスペシャリストを好む傾向があります。しかし、サプライチェーンはシステムであり、いかなるシステムにおいても重要なのは、エンドツーエンドの視点です。
Lokadがこれらの取り組みを実施する中で得た経験に基づき、通常、取り組みを実現するために必要な最小限の労働分担は、サプライチェーン・エグゼクティブ、データオフィサー、サプライチェーンサイエンティスト、そしてサプライチェーン・プラクティショナーの4つの役割で構成されることが確認されました。
サプライチェーン・エグゼクティブの役割は、取り組みが実行されるための基盤を支援することにあります。適切に設計された数値レシピが本番環境でサプライチェーンの意思決定を担うことは、収益性と生産性の両面で大幅な向上をもたらします。しかし、それはまた非常に大きな変革を伴うため、大企業においては、上層部からの多大なエネルギーと支援が必要となります。
データオフィサーの役割は、データパイプラインの構築および維持管理にあります。彼らの主要な貢献は、取り組み開始から最初の2か月間に集中すると期待されます。データパイプラインが正しく設計されていれば、その後、データオフィサーによる継続的な作業はほとんど必要なくなります。通常、データオフィサーは取り組みの後半段階にはあまり関与しません。
サプライチェーンサイエンティストの役割は、中核となる数値レシピを作り上げることにあります。この役割は、データオフィサーが利用可能にした生の取引データから始まります。データオフィサーに期待されるのはデータ抽出のみであり、データ準備ではありません。サプライチェーンサイエンティストの役割は、生成されたサプライチェーンの意思決定の責任を引き受けるところで終わります。意思決定に責任を負うのはソフトウェアではなく、サプライチェーンサイエンティストです。生成された各意思決定について、その妥当性を本人が説明できなければなりません。
最後に、サプライチェーン実務者の役割は、数値レシピによって生成された意思決定に異議を唱え、サプライチェーンサイエンティストにフィードバックを提供することにあります。実務者は自ら意思決定を行うことを目指すべきではありません。この人物は、少なくとも限定された範囲において、これまでそれらの意思決定を担当してきたことが一般的であり、通常は既存のスプレッドシートやシステムの助けを借りています。小規模な企業では、サプライチェーンエグゼクティブとサプライチェーン実務者の両方の役割を1人が担うことも可能です。データが容易に利用できるなら、データオフィサーの必要性を省ける場合もあります。これは、データインフラが非常に成熟している企業で起こり得ます。逆に、企業が非常に大規模である場合、各役割を担う人数は複数であっても、ごく少数にとどめるべきです。
中核となる数値レシピの本番展開が成功すると、サプライチェーン実務者の世界には大きな影響が及びます。実際、この取り組みの要点のかなりの部分は、従来のサプライチェーン実務者の仕事を自動化することにあります。しかし、それは数値レシピが本番稼働した後に、その実務者たちを解雇するのが最善策だという意味ではありません。この点については、次回の講義で改めて取り上げます。

整理されていることは、効率的であることや有効であることを意味しません。善意であっても、サプライチェーンの取り組みに摩擦を持ち込み、しばしばその取り組み全体を失敗に追い込む役割があります。今日では、そのような取り組みを失敗させる最大の要因になりがちな役割はデータサイエンティストであり、とりわけデータサイエンスチーム全体が関与する場合はなおさらです。ちなみに、Lokadも約10年前にこのことを痛い形で学びました。
データサイエンティストとサプライチェーンサイエンティストは名称こそ似ていますが、実際には全く異なる役割です。サプライチェーンサイエンティストが第一に重視するのは、現実世界で通用する本番品質の意思決定を提供することです。それが比較的単純な数値レシピで実現できるなら、なおさら好都合です。保守も容易になります。サプライチェーンサイエンティストは、サプライチェーンのごく細かな詳細に対処することに全面的な責任を負います。洗練度よりも、信頼性と周囲の混沌に対するレジリエンスの方が重要なのです。
これに対して、データサイエンティストは数値レシピの賢い部分、すなわちモデルやアルゴリズムに焦点を当てます。一般論として、データサイエンティストは自らを機械学習と数理最適化の専門家と見なしています。技術面では、最新の先端的なオープンソース数値ツールキットを学ぶ意欲はある一方で、会社を動かしている30年前のERPについて学ぶ意欲は通常あまりありません。また、データサイエンティストはサプライチェーンの専門家ではなく、そうなろうとする意欲も一般には高くありません。データサイエンティストは、合意された指標に従って最良の結果を出そうとしますが、サプライチェーンの非常に地味な細部に対処する志向は持っていません。それらは他の人々が扱うべきものだと考えられています。
このような取り組みにデータサイエンティストを関与させることは、失敗の呼び水になりがちです。なぜなら、データサイエンティストが入った瞬間に、もはや焦点はサプライチェーンではなく、アルゴリズムやモデルそのものへ移ってしまうからです。技術志向の強い優秀な人にとって、最新のモデルやアルゴリズムがどれほど強い注意散漫の要因になり得るかを、決して過小評価してはいけません。
サプライチェーンの取り組みに摩擦を加えがちな2つ目の役割は、ビジネスインテリジェンス(BI)チームです。BIチームが取り組みに加わると、データサイエンスチームほどではないにせよ、助けになるというより障害になりがちです。BIの問題の大半は文化的なものです。BIが提供するのは意思決定ではなくレポートです。BIチームは通常、社内のあらゆる部門から要求されるままに、終わりのない指標の壁を作ることをいといません。しかし、これは定量的サプライチェーンの取り組みにふさわしい姿勢ではありません。
また、ソフトウェアとしてのビジネスインテリジェンスは、キューブやOLAPキューブを中心に構成された非常に特定の種類のデータ分析基盤であり、エンタープライズソフトウェア内の主なインメモリシステムを多面的に切り分けて分析できるようにするものです。しかし、この設計は通常、サプライチェーンの意思決定を駆動する用途にはあまり適していません。

Now that we have framed the initiative, let’s have a look at the high-level IT architecture that the initiative requires.
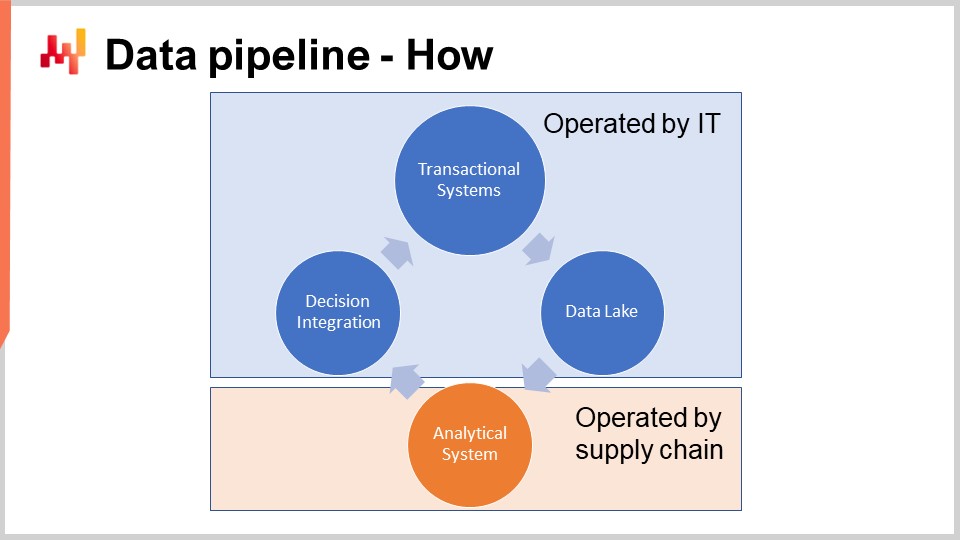
画面上の図は、定量的サプライチェーンの取り組みにおける典型的なデータパイプライン構成を示しています。この講義で扱っているのは、低レイテンシ要件を満たすためのパイプラインではありません。私たちが目指すのは、1秒で1サイクルを終えることではなく、約1時間で完全な1サイクルを完了できることです。発注のような大半のサプライチェーン意思決定には、低レイテンシ構成は必要ありません。エンドツーエンドで低レイテンシを実現するには別種のアーキテクチャが必要であり、それは今日の講義の範囲外です。

トランザクションシステムは、主要なデータソースであり、データパイプラインの出発点でもあります。これらのシステムには ERP、WMS、EDI などが含まれます。調達、輸送、生産、販売といったモノの流れを扱っており、中核となる数値レシピが必要とするデータのほぼすべてを保持しています。ある程度の規模を持つ企業であれば、こうしたシステム、もしくはその前身が少なくとも20年にわたって使われてきたのが普通です。
これらのシステムには必要なデータのほぼすべてが含まれているため、数値レシピを直接そこへ実装したくなるのは自然な発想です。実際、なぜそうしないのかと思うかもしれません。数値レシピを ERP に直接組み込めば、このデータパイプライン全体を構築する手間を省けるからです。しかし残念ながら、トランザクションシステムの設計そのものが、そのやり方を成立させません。
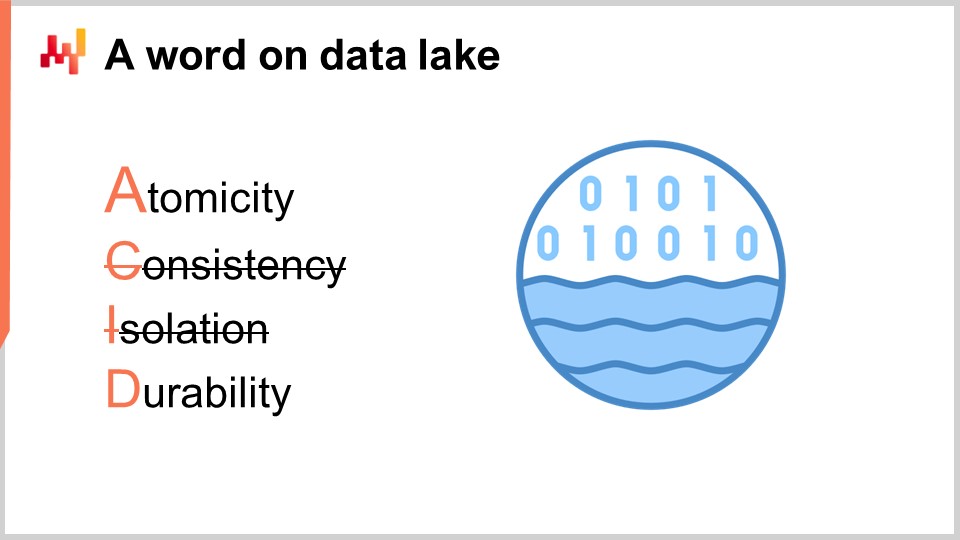
こうしたトランザクションシステムは、例外なく中核にトランザクショナルデータベースを抱えています。このようなエンタープライズソフトウェアの設計様式は、過去40年間きわめて安定してきました。適当な会社を1社選べば、本番稼働している業務アプリのほぼすべてがトランザクショナルデータベースの上に実装されている可能性が高いでしょう。トランザクショナルデータベースには ACID と総称される4つの重要な性質があります。Atomicity、Consistency、Isolation、Durability です。細部には立ち入りませんが、要するにこれらの性質によって、多数の小さな読み取りと多数の小さな書き込みを、安全かつ並行して処理する用途に非常に適したデータベースになります。しかも、読み取りと書き込みの量はおおむね均衡していることが前提です。
However, the price to pay for those very useful ACID properties at the most granular level is that the transactional database is also very inefficient when it comes to servicing big read operations. A read operation that covers a sizable portion of the entire database, as a rule of thumb, if the data is serviced through a database that focuses on a very granular delivery of those ACID properties, then you can expect the cost of the computing resources to be inflated by a factor of 100 compared to architectures that don’t focus as much on those ACID properties at such a granular level. ACID is nice, but it comes at a massive premium.
Moreover, when someone attempts to read a sizable portion of the entire database, the database is likely to become unresponsive for a while as it dedicates the bulk of its resources to servicing this one big request. Many companies complain that their entire business systems are sluggish and that those systems frequently freeze for one second or more. Usually, this poor quality of service can be traced back to heavy SQL queries that attempt to read too many lines at once.
したがって、中核となる数値レシピを本番を支えるトランザクションシステムと同じ環境で動かしてはいけません。数値レシピは実行のたびにデータの大部分へアクセスする必要があるからです。ゆえに、数値レシピは専用のサブシステムとして厳密に分離しておかなければなりません。少なくとも、トランザクションシステムの性能をこれ以上悪化させないためです。
By the way, while it has been known for decades that it is a terrible idea to have a data-intensive process operating within a transactional system, this does not prevent most vendors of transaction systems (ERP, MRP, WMS) from selling integrated analytical modules, for example, inventory optimization modules. Having those modules integrated inevitably leads to quality of service problems while delivering underwhelming capabilities. All of those problems can be traced back to this single design problem: the transaction system and the analytical system must be kept in strict isolation.
The data lake is simple. It is a mirror of the transactional data geared towards very large read operations. Indeed, we have seen that transaction systems are optimized for many small read operations, not very large ones. Thus, in order to preserve the quality of service of the transactional system, the correct design consists of carefully replicating the transactional data into another system, namely the data lake. This replication must be implemented with care, precisely to preserve the quality of service of the transactional system, which typically means reading the data in very incremental ways and avoiding putting pressure spikes on the transactional system.
Once the relevant transactional data is mirrored into the data lake, the data lake itself serves all the data requests. An additional benefit of the data lake is its ability to serve multiple analytical systems. While we are discussing supply chain here, if marketing wants their own analytics, they will need this very same transactional data, and the same could be said for finance, sales, etc. Thus, instead of having every single department in the company implementing their own data extraction mechanism, it makes sense to consolidate all those extractions into the same data lake, the same system.
At the technical level, a data lake can be implemented with a relational database, typically tuned for big data extraction, adopting a columnar data storage. Data lakes can also be implemented as a repository of flat files served over a distributed file system. Compared to a transactional system, a data lake gives up on the fine-grained transactional properties. The goal is to serve a large amount of data as cheaply and as reliably as possible—nothing more, nothing less.
The data lake must mirror the original transactional data, which means copying without modifying anything. It is important not to prepare the data in the data lake. Unfortunately, the IT team in charge of setting up the data lake can be tempted to make things easier and simpler for other teams and thus prepare the data a little bit. However, modifying the data invariably introduces complications that undermine analytics at a later stage. In addition, sticking to a strict mirroring policy vastly diminishes the amount of effort needed for the IT team to set up and later maintain the data lake.
In companies where there is already a BI team in place, it can be tempting to use the BI systems as a data lake. However, I strongly advise against doing so and never use a BI setup as a data lake. Indeed, the data in BI systems (business intelligence systems) is invariably heavily transformed already. Leveraging the BI data to drive automated supply chain decisions is a recipe for garbage in, garbage out problems. The data lake must only be fed from primary data sources like ERP, not from secondary data sources like the BI system.
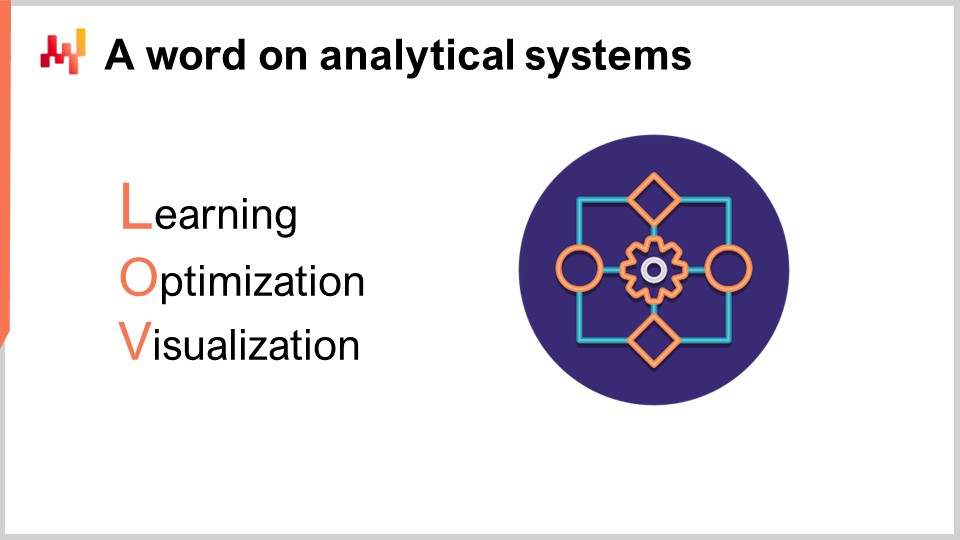
解析システムには、中核となる数値レシピが含まれます。また、意思決定そのものを計器化するために必要な各種レポートを提供するのもこのシステムです。技術的には、解析システムには機械学習アルゴリズムや数理最適化アルゴリズムといった「賢い部分」が含まれます。ただし実務では、その賢い部分が解析システムのコードベースの大半を占めるわけではありません。通常、データ準備やデータ計器化のコード量は、学習や最適化を扱う部分の少なくとも10倍に達します。
The analytical system must be decoupled from the data lake because those two systems are completely at odds in terms of technological perspectives. As a piece of software, the data lake is expected to be very simple, very stable, and extremely reliable. On the contrary, the analytical system is expected to be sophisticated, under constant evolution, and extremely performant in terms of サプライチェーン-パフォーマンス-テスト. Unlike the data lake, which must deliver near-perfect uptime, the analytical system does not even have to be up most of the time. For example, if we are considering daily inventory replenishment decisions, then the analytical system only has to run and be up once per day.
As a rule of thumb, it’s better to have the analytical system fail at producing decisions rather than generating incorrect decisions and letting them flow into production. Delaying supply chain decisions by a few hours, like purchase orders, is typically much less dire than taking incorrect decisions. As the design of the analytical system tends to be heavily influenced by the smart bits it contains, there is not necessarily much to be said in general about the design of the analytical system. However, there is at least one key design property that must be enforced for the ecosystem: this system must be stateless.
解析システムは、可能な限り内部状態を持たないようにすべきです。言い換えれば、このエコシステム全体はデータレイクが提示するデータから始まり、生成されたサプライチェーン意思決定とそれを支えるレポートで終わるべきです。実際には、解析システム内に機械学習アルゴリズムのような遅いコンポーネントがあると、状態を導入したくなります。つまり、前回実行時の情報を保持して次回実行を高速化したくなるのです。しかし、そのように毎回ゼロから再計算する代わりに過去の計算結果へ依存するのは危険です。
実際、解析システム内に状態を持つことは、意思決定を危険にさらします。データの問題は避けられずデータレイクの段階で修正されるとしても、解析システムはすでに修正済みの問題を反映している意思決定を返す可能性があります。たとえば、需要予測モデルが破損した販売データセットで学習された場合、その予測モデルは修正済みの新たなデータセットで再学習されるまで破損したままです。解析システムがデータレイクで既に修正されたデータ問題の反響を受けない唯一の方法は、その都度すべてをリフレッシュすることです。これがステートレスであるという本質です。
一般的な経験則として、解析システムの一部が日々置き換え可能なほど高速でなければ、その部分はパフォーマンス問題に苦しんでいると見なさなければなりません。サプライチェーンは混沌としており、火災、封鎖、サイバー攻撃といった何かが起こり、即時の介入が必要となる日が必ず来ます。企業は1時間以内にすべてのサプライチェーンの意思決定をリフレッシュできなければなりません。遅い機械学習のトレーニング段階が進行する間に10時間も待たされてはなりません。

信頼性ある運用を行うためには、解析システムは適切に計器化(インストゥルメンテーション)されなければなりません。それがデータ健康レポートやデータインスペクターの役割です。ちなみに、これらの要素はすべてサプライチェーンの責任であり、ITの責任ではありません。データ健康監視は、実際のデータ準備よりも前に行われる最初のデータ処理段階を表しており、解析システム内で行われます。データ健康は数値レシピの計器化の一部です。データ健康レポートは、数値レシピをそもそも実行して良いかどうかを示し、このレポートは、もしあれば問題の原因を特定して問題解決を迅速化します。
データ健康監視はLokadで実践されている手法です。過去10年間、この手法はエンタープライズソフトウェアの世界に遍在する「ゴミ入力、ゴミ出力」を避けるために非常に有用であることが証明されました。実際、データ処理の取り組みが失敗すると、不良なデータが原因とされることがよくあります。しかし、初めからデータ品質を強制するためのエンジニアリング努力はほとんど行われていないことに注意する必要があります。データ品質は空から降ってくるものではなく、エンジニアリングの努力が必要なのです。
これまでに提示されたデータパイプラインは非常にミニマリスティックです。データミラーリングは可能な限りシンプルであり、これはソフトウェア品質の観点からは良いことです。しかし、このミニマリズムにもかかわらず、多くのテーブル、多くのシステム、多くの人々といった多くの可動部分が存在します。そのため、あちこちにバグが潜んでいます。これがエンタープライズソフトウェアであり、そうでないとしたら非常に驚くべきことです。データ健康監視は、このような環境の混沌の中で解析システムが生き残るために設置されています。
データ健康はデータクリーニングと混同すべきではありません。データ健康は、解析システムに提供されるデータが、トランザクションシステムに存在する取引データを忠実に再現しているかを確認することに関するものであり、データを修正しようとはしません。そのままのデータが分析されるのです。
Lokadでは、通常、低レベルのデータ健康と高レベルのデータ健康を区別します。低レベルのデータ健康は、すべての構造的および体積的な異常を統合するダッシュボードであり、たとえば、妥当な日付や数字さえ成立しないエントリや、期待される対応関係が欠如している孤立した識別子などといった明らかな問題を集約します。これらの問題はすべて見えるもので、実際には容易な問題です。困難な問題は、そもそもデータが存在しないために見えない問題から始まります。例えば、データ抽出に問題があり、昨日抽出された販売データが予定行数の半分しか含んでいなければ、生産に深刻な危険を及ぼすでしょう。不完全なデータは特に厄介で、通常、数値レシピが意思決定を生成するのを妨げることはありませんが、入力データが不完全なため、その意思決定はゴミとなります。
技術的には、Lokadではデータ健康監視を1つのダッシュボードにまとめるようにしており、このダッシュボードは低レベルのデータ健康で検出される問題のほとんどがデータパイプライン自体に関連するため、主にITチーム向けに設計されています。理想的には、ITチームは一目で全てが正常であり、追加の介入が不要であるかどうかを判断できるはずです。

高レベルのデータ健康監視は、ビジネスの視点から見ておかしいと感じるすべてのビジネスレベルの異常を考慮します。高レベルのデータ健康は、負の在庫レベルや異常に大きな最小発注数量などの要素を含み、会社が損失を被るか途方もない高いマージンで運営されるために意味を成さない価格なども対象とします。高レベルのデータ健康は、サプライチェーン担当者がデータを見たときに「これはあり得ない、問題がある」と感じるすべての要素を網羅しようと試みます。
低レベルのデータ健康レポートと異なり、高レベルのデータ健康レポートは主にサプライチェーンチーム向けに考案されています。実際、異常な最小発注数量といった問題は、ビジネス環境にある程度精通している担当者にしか問題として認識されません。このレポートの目的は、一目で全体が正常であり、追加の介入が不要であることを示すことにあります。
以前、解析システムはステートレスであるべきだと言いました。しかし、実際にはデータ健康がその例外であることが判明しました。現状の指標と前日までに収集された同じ指標を比較することで多くの問題が識別できるのです。したがって、データ健康監視は通常、前日までに観測された主要な指標という形で何らかの状態を保持し、現状のデータにおける外れ値を識別できるようにします。しかし、データ健康は純粋に監視の問題であるため、もしデータレイクの段階で問題が修正され、その結果データ健康の状態に過去の問題の反響が見られたとしても、最悪の場合はそのレポートから一連の誤警報が発せられるだけです。サプライチェーンの意思決定を生成するロジックは完全にステートレスであり、状態は計器化の一部にのみ関係します。
低レベルおよび高レベルのデータ健康監視は、誤った意思決定を下すリスクと、意思決定をタイムリーに下せないリスクとの間のトレードオフの問題です。大規模なサプライチェーンを考えると、データの100%が正確であるとは期待できません―誤った取引エントリーは稀ではあるものの発生します。したがって、数値レシピが機能するためには、問題の発生量が十分に低いと見なされなければなりません。データの不具合に過敏になるか、またはデータ問題に対して寛容になりすぎるかというこれら2つのリスクのトレードオフは、サプライチェーンの経済構造に大きく依存します。
Lokadでは、これらのレポートをクライアントごとに作成し、微調整しています。あり得るすべてのデータ破損事例を追いかけるのではなく、これから説明する低レベルおよび高レベルのデータ健康やデータインスペクターの実装を担当するサプライチェーンサイエンティストは、関心のあるサプライチェーンに実際に損害を与えている、または実際に発生している問題に敏感になるようにデータ健康監視の調整を試みます。
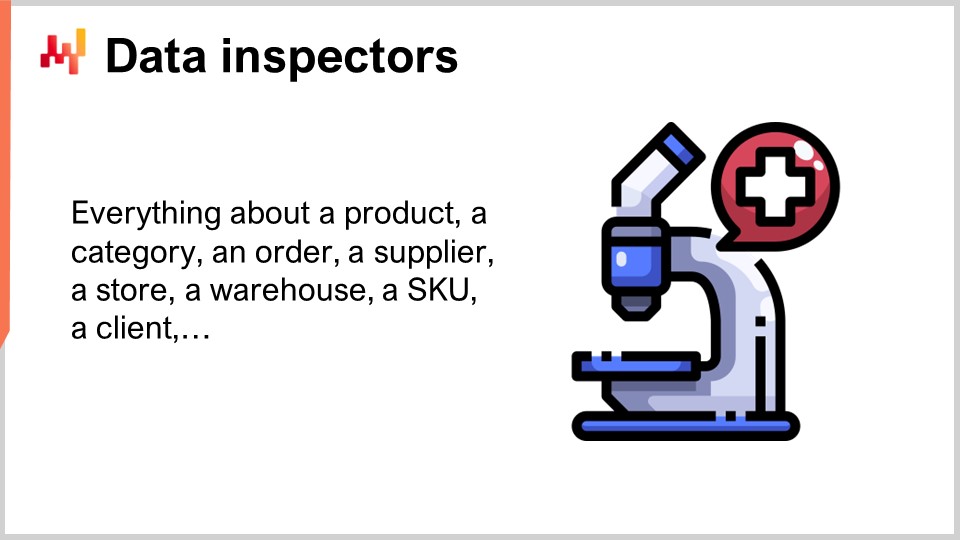
Lokadの業界用語でいうデータインスペクター(または単にインスペクター)とは、対象物に関連するすべてのデータを統合したレポートのことです。対象物は、製品、サプライヤー、クライアント、または倉庫など、サプライチェーンの観点から見て主要な存在であることが期待されます。たとえば、製品のデータインスペクターを検討する場合、企業が販売する任意の製品について、その製品に付随するすべてのデータを1つの画面で確認できなければなりません。製品のデータインスペクターでは、実質的に製品の数だけビューが存在します。なぜなら「すべてのデータを見る」というとき、すべての製品全体ではなく、1つのバーコードまたは部品番号に付随するすべてのデータを見ることを意味するからです。
一目で確認できる2つのダッシュボードとして想定される低レベルおよび高レベルのデータ健康レポートとは異なり、インスペクターはコアとなる数値レシピの設計および運用中に必然的に生じる疑問や懸念に対処するために実装されています。実際、サプライチェーンの意思決定を下すためには、複数の取引システムにまたがる十数のテーブルからデータを統合することは珍しくありません。データがあちこちに散らばっているため、意思決定が疑わしく見える場合、その問題の原因を特定するのは通常困難です。解析システムで見られるデータと取引システムに存在するデータとの間に乖離がある場合もあります。不具合のあるアルゴリズムが、データ中の統計的パターンを正しく捉えられていない可能性もあります。誤った認識があり、疑わしいと判断された意思決定が実際には正しい場合もあります。いずれの場合も、インスペクターは対象物を拡大して詳細を見る機能を提供することが目的です。
有用であるためには、インスペクターはサプライチェーンとアプリケーション環境の双方の特性を反映していなければなりません。その結果、インスペクターの作成はほぼ必ずオーダーメイドの作業となります。しかし、作業が完了すれば、インスペクターは解析システム自体の計器化の柱の1つとなります。
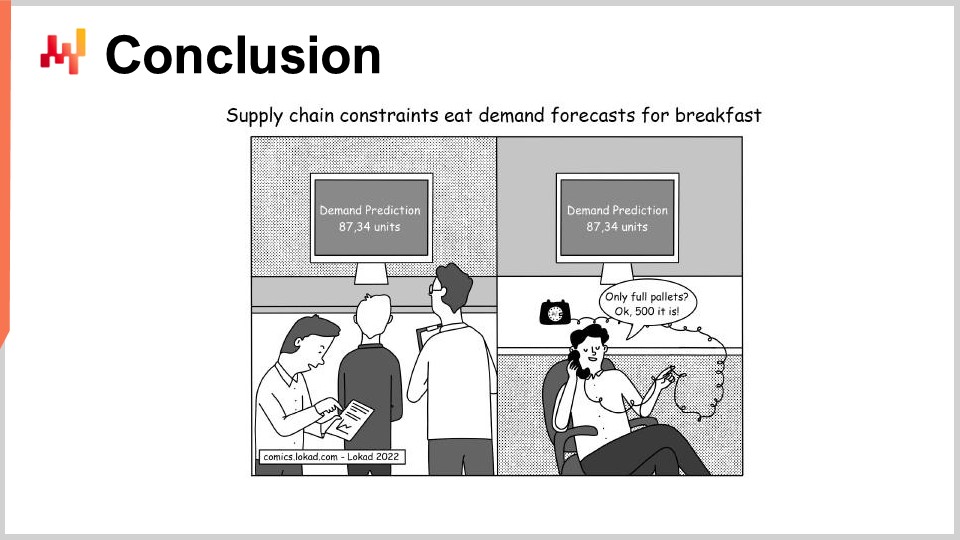
結論として、ほとんどの定量的サプライチェーンの取り組みは、開始前から失敗する運命にあるように見えますが、必ずしもそうである必要はありません。そのような取り組みを失敗に導く問題を避けるためには、成果物、タイムライン、範囲、ルールの慎重な選択が必要です。残念ながら、Lokadがこれまでの14年間の運用で痛感したように、これらの選択はしばしば直感に反するものとなります。
取り組みの最初の段階は、データパイプラインの構築に専念する必要があります。信頼性の低いデータパイプラインは、データ駆動型の取り組みが失敗することを確実にする最も確実な方法の一つです。ほとんどの企業、さらにはほとんどのIT部門でさえ、継続的な火消し作業を必要としない高信頼性のデータパイプラインの重要性を過小評価しています。データパイプラインの構築の大部分はIT部門に委ねられますが、運用する解析システムの計器化はサプライチェーン自身の責任です。これをITに任せてはいけません。これはサプライチェーンチームが担うべき事項です。私たちは、企業全体の視点を採用するデータ健康レポートと、詳細な診断をサポートするデータインスペクターという、2種類の異なる計器化を見てきました。

今日は取り組みの開始方法について議論しましたが、次回はその終了方法、いや実現に向けた方法について見ていきます。次回の講義は9月14日水曜日に行われ、そこで私たちは旅を進め、コアとなる数値レシピの作成と、それが生成する意思決定を徐々に本番環境に移行するために必要な実行段階を確認します。また、この新たなサプライチェーンのアプローチが、サプライチェーン担当者の日々の業務に何を意味するのかについても詳しく見ていきます。
さて、質問を見ていきましょう。
質問: Why is it exactly six months as a time limit after which an implementation is not done correctly?
私が言いたいのは、タイムリミットが6ヶ月であること自体が問題ではなく、通常、取り組みは最初から失敗するように設定されているという点です。もし予測最適化の取り組みが、結果が2年後に提供されるという視点で開始されれば、その取り組みはいつか解散し、本番環境で何も提供できなくなることがほぼ保証されます。可能であれば、私はその取り組みが3ヶ月で成功することを望みます。しかし、私の経験では、6ヶ月がそのような取り組みを本番環境に導くための最小のタイムラインを示しています。さらに遅れると、取り組みが失敗するリスクが高まります。一度すべての技術的問題が解決されると、残る遅延は、関係者が取り組みに慣れるまでの時間を反映するため、これ以上短縮するのは非常に難しいのです。
質問: Supply chain practitioners may get frustrated with an initiative that replaces the majority of their workload, such as the purchasing department, in conflict with decision automation. How would you advise handling this?
これは非常に重要な質問であり、次回の講義で取り上げる予定です。本日は、現代のサプライチェーンにおけるサプライチェーン担当者の多くの業務が、それほどやりがいのあるものではないと考えているということをお伝えしたいと思います。ほとんどの企業では、担当者はSKUや部品番号のセットを受け取り、それらを終始循環させながら必要な意思決定を行います。つまり、彼らの仕事は本質的にスプレッドシートを見て、週に一度、あるいは日一回、その内容を確認するという作業に過ぎません。これは決して充実感のある仕事ではありません。
簡潔に言えば、Lokad のアプローチは業務の煩雑な部分を自動化することで問題に対処し、サプライチェーンの真の専門知識を持つ人々がその根本を問い直すことを可能にします。これにより、クライアントやサプライヤーとより多く議論し、全体の効率を高めることが可能となります。必要な洞察を収集して数値レシピを改善することに他なりません。数値レシピの実行は面倒で、毎日スプレッドシートをあちこち確認していた過去を懐かしむ人はほとんどいないでしょう。
質問: サプライチェーンの実務担当者は、サプライチェーンサイエンティストが生成する決定に異議を唱えるために、データヘルスレポートではなく、データインスペクターと連携して作業することが期待されるのでしょうか?
サプライチェーンの実務担当者は、データヘルスレポートではなくデータインスペクターと連携して作業することが期待されます。データヘルスレポートは、解析システムに取り込まれるデータが数値レシピを実行するのに十分な質であるかどうかを判断する、全社的な評価のようなものです。その結果は、数値レシピの実行を承認するか、あるいは問題があるとして反対するという二者択一の判断となります。次回の講義で詳しく説明するデータインスペクターは、提案されたサプライチェーンの決定について実務担当者が洞察を得るための入り口となります。
質問: 例えば、解析モデルを毎日更新して在庫方針を設定することは可能でしょうか?サプライチェーンシステムは毎日の方針変更に対応できず、システムにノイズを与えるだけではないでしょうか?
質問の前半に回答すると、解析モデルを毎日更新することは確かに可能です。例えば、2020年にLokadがヨーロッパでロックダウンが実施されていた際、各国がわずか24時間前の通知で閉鎖や再開を余儀なくされました。このため、常に即時の改訂が求められる極めて混沌とした状況が生じました。Lokadはこの極限状態の下、ヨーロッパ全域で日々開始または終了するロックダウンの管理を、ほぼ14ヶ月にわたって行いました。
したがって、解析モデルを毎日更新することは可能ですが、必ずしも望ましいとは限りません。確かにサプライチェーンシステムには大きな慣性があり、適切な数値レシピはまずほとんどの決定におけるラチェット効果を考慮する必要があります。一旦生産を指示し、原材料が消費されれば、その生産を元に戻すことはできません。新たな決定を行う際には、すでに多くの決断がなされていることを考慮に入れなければなりません。しかし、サプライチェーンが劇的な変化を必要としていると判断したならば、単に決断を先延ばしにするためだけに修正を遅らせる意味はありません。変革を実施する最良の時期は、まさに今なのです。
質問のノイズに関する側面については、適切な数値レシピの設計にかかっています。不安定で間違った設計が多く存在し、データのわずかな変動が数値レシピの結果に大きな変化をもたらすことがあります。数値レシピは、サプライチェーンの小さな変動によってむやみに跳ね上がるべきではありません。これが、Lokadが予測において確率的な視点を採用した理由です。確率的視点を用いることで、平均を捉えようとして外れ値が発生するたびに不安定になりがちなモデルと比べ、はるかに安定したモデルの構築が可能となります。
質問: 非常に大きな企業におけるサプライチェーンの問題の一つは、異なるソースシステムへの依存関係です。これらのソースシステムからすべてのデータを統一されたシステムに集約するのは極めて困難ではないでしょうか?
すべてのデータを収集することが多くの企業にとって大きな課題であることには全く同意します。しかし、そもそもなぜそれが課題となるのかを問い直す必要があります。先に述べたように、現在大企業が運用する業務アプリケーションの99%は、主流でしっかりと設計されたトランザクションデータベースに依存しています。依然として、わずかに古いCOBOL実装が難解なバイナリストレージ上で動作している場合もありますが、それは稀なケースです。1990年代に導入されたシステムであっても、業務アプリケーションの大部分はバックエンドでクリーンな生産グレードのトランザクションデータベースを利用しています。
一度トランザクショナルなバックエンドが整えば、このデータをデータレイクへコピーするのがなぜ難しいのでしょうか?多くの場合、企業が直面する問題は、単にデータをコピーするだけでなく、その上で多くの処理をしようとする点にあります。データの準備や変換を試みるあまり、プロセスが過度に複雑化されてしまうのです。現代のほとんどのデータベースシステムには、トランザクションデータベースからセカンダリーデータベースへすべての変更を複製するための組み込みのデータミラーリング機能が備わっており、これは市場で最も頻繁に使用されるトップ20程度のトランザクションシステムの標準機能です。
企業がデータ統合に苦労するのは、やりすぎてしまい、その取り組みが複雑さゆえに崩壊してしまうからです。一度データが統合されると、IT、BI、またはデータサイエンスのチームがデータ接続を行うべきだと誤解しがちです。ここで伝えたいのは、マーケティング、営業、財務が各自の部門で数値レシピを管理するのと同様に、サプライチェーンも自らの数値レシピを掌握すべきだということです。それは、会社全体を横断する支援部門が行うべきものではありません。異なるシステム間のデータ接続には、通常、膨大なビジネス上の知見が必要となります。大企業が失敗するのは、本来その部門内で行うべき作業を、IT、BI、またはデータサイエンスの専門家に委ねようとするからです。
本日はお時間をいただき、またご興味とご質問を誠にありがとうございました。夏休み明けの9月に、またお会いしましょう。