00:00 Introduction
02:31 Les causes profondes de l’échec sur le terrain
07:20 Livrable : une recette numérique 1/2
09:31 Livrable : une recette numérique 2/2
13:01 L’histoire jusqu’ici
14:57 Réaliser les choses aujourd’hui
15:59 Chronologie de l’initiative
21:48 Périmètre : paysage applicatif 1/2
24:24 Périmètre : paysage applicatif 2/2
27:12 Périmètre : effets système 1/2
29:21 Périmètre : effets système 2/2
32:12 Rôles : 1/2
37:31 Rôles : 2/2
41:50 Pipeline de données - Comment
44:13 Un mot sur les systèmes transactionnels
49:13 Un mot sur le data lake
52:59 Un mot sur les systèmes analytiques
57:56 Santé des données : niveau bas
01:02:23 Santé des données : niveau haut
01:06:24 Inspecteurs de données
01:08:53 Conclusion
01:10:32 Prochaine conférence et questions du public
Description
Réaliser une optimisation prédictive réussie d’une supply chain est un mélange de problématiques soft et hard. Malheureusement, il n’est pas possible de dissocier ces aspects. Les facettes soft et hard sont profondément imbriquées. Habituellement, cet enchevêtrement entre en collision frontale avec la division du travail telle que définie par l’organigramme de l’entreprise. Nous constatons que, lorsque les initiatives supply chain échouent, les causes profondes de l’échec sont généralement des erreurs commises dès les premières étapes du projet. De plus, les erreurs précoces tendent à façonner l’ensemble de l’initiative, les rendant presque impossibles à corriger a posteriori. Nous présentons nos conclusions clés pour éviter ces erreurs.
Transcription complète

Bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui, je vais présenter “Getting Started with a Quantitative Supply Chain Initiative.” La grande majorité des initiatives supply chain axées sur le traitement de données échouent. Depuis 1990, la plupart des entreprises opérant de grandes supply chains lancent des initiatives majeures d’optimisation prédictive tous les trois à cinq ans, avec peu ou pas de résultats. De nos jours, la plupart des équipes en supply chain ou data science, entamant une nouvelle série d’optimisation prédictive—typiquement présentée comme un projet de prévision ou un projet d’optimisation de stocks—ne réalisent même pas que leur entreprise a déjà tenté, et échoué, possiblement une demi-douzaine de fois.
Se lancer dans une nouvelle tentative est parfois motivé par la conviction que cette fois-ci, ce sera différent, mais fréquemment, les équipes ne sont même pas conscientes des nombreuses tentatives infructueuses qui ont eu lieu auparavant. Une preuve anecdotique de cet état de choses est que Microsoft Excel reste l’outil numéro un pour piloter les décisions supply chain, alors que ces initiatives étaient censées remplacer les tableurs par de meilleurs outils. Pourtant, de nos jours, il existe encore très peu de supply chains qui peuvent fonctionner sans tableurs.
L’objectif de cette conférence est de comprendre comment donner une chance de succès à une initiative supply chain qui a l’intention de fournir tout type d’optimisation prédictive. Nous passerons en revue une série d’ingrédients critiques — ces ingrédients sont simples et pourtant ils apparaissent très souvent comme contre-intuitifs pour la plupart des organisations. Inversement, nous examinerons une série d’anti-patterns qui garantissent presque l’échec d’une telle initiative.
Aujourd’hui, je me concentre sur l’exécution tactique du tout début d’une initiative supply chain avec une mentalité “get things done”. Je ne traiterai pas des implications stratégiques globales pour l’entreprise. La stratégie est très importante, mais j’aborderai ce sujet dans une conférence ultérieure.

La plupart des initiatives supply chain échouent, et le problème est rarement évoqué publiquement. Le monde académique publie des dizaines de milliers d’articles par an vantant toutes sortes d’innovations supply chain, y compris des cadres, des algorithmes et des modèles. Souvent, les articles prétendent même que l’innovation a été mise en production quelque part. Et pourtant, mon observation informelle de l’univers de la supply chain est que ces innovations sont introuvables. De même, les software vendors promettent depuis trois décennies des remplacements supérieurs aux tableurs, et encore une fois, mon observation informelle indique que les tableurs restent omniprésents.
Nous revenons sur un point déjà abordé dans le deuxième chapitre de cette série de conférences sur la supply chain. Tout simplement, les gens n’ont aucun intérêt à mettre en avant leurs échecs, et donc ils ne le font pas. De plus, comme les entreprises qui opèrent des supply chains tendent à être de grande taille, le problème est généralement aggravé par la perte naturelle de mémoire institutionnelle au fur et à mesure que les employés changent de poste. C’est pourquoi ni le monde académique ni les vendors ne reconnaissent cette situation plutôt désolante.
Je propose de commencer par une brève enquête sur les causes profondes d’échec les plus fréquentes du point de vue de l’exécution tactique. En effet, ces causes racines se trouvent généralement dès les premières étapes de l’initiative.
La première cause d’échec est la tentative de résoudre les mauvais problèmes — des problèmes inexistants, sans conséquence, ou reflétant une méprise sur la supply chain elle-même. Optimiser les pourcentages de précision des prévisions est probablement l’archétype d’un tel problème erroné. Réduire le pourcentage d’erreur de prévision ne se traduit pas directement par un retour en euros ou dollars supplémentaire pour l’entreprise. La même situation se produit lorsqu’une entreprise poursuit des taux de service spécifiques pour ses stocks. Il est très rare d’obtenir un retour en euros ou dollars pour cela.
La deuxième cause d’échec est l’utilisation d’une technologie logicielle et d’une conception logicielle inadaptées. Par exemple, les ERP vendors tentent invariablement d’utiliser une base de données transactionnelle pour supporter des initiatives de traitement de données, car c’est sur cette base que l’ERP est construit. À l’inverse, les équipes de data science essaient invariablement d’utiliser la boîte à outils de machine learning open-source ultra moderne du moment, parce que c’est tendance. Malheureusement, des technologies inadaptées génèrent généralement une friction immense et beaucoup de complexité accidentelle.
La troisième cause d’échec est une répartition du travail et une organisation incorrectes. Dans une tentative mal avisée d’allouer des spécialistes à chaque étape du processus, les entreprises ont tendance à fragmenter l’initiative entre trop de personnes. Par exemple, la data preparation est très souvent effectuée par des personnes qui ne sont pas responsables de la prévision. En conséquence, on assiste à des situations de garbage-in-garbage-out généralisées. Diluer marginalement la responsabilité des décisions supply chain est une recette pour l’échec.
Un élément que je n’ai pas inclus dans cette courte liste en tant que cause d’échec est la mauvaise qualité des données. Les données sont très souvent pointées du doigt pour expliquer l’échec des initiatives supply chain, ce qui est fort commode, car les données ne peuvent pas vraiment répondre à ces accusations. Cependant, ce n’est généralement pas la faute des données, du moins pas dans le sens où l’on serait aux prises avec de mauvaises données. La supply chain des grandes entreprises s’est digitalisée il y a des décennies. Chaque article acheté, transporté, transformé, produit ou vendu possède des enregistrements électroniques. Ces enregistrements ne sont peut-être pas parfaits, mais ils sont généralement très précis. Si les gens échouent à bien gérer les données, ce n’est pas vraiment la transaction qui est en cause.

Pour qu’une initiative de la Supply Chain Quantitative réussisse, nous devons mener le bon combat. Qu’est-ce que nous cherchons à livrer en premier lieu ? L’un des livrables clés d’une Supply Chain Quantitative est une recette numérique de base qui calcule les décisions supply chain finales. Cet aspect a déjà été abordé dans la Conférence 1.3 du tout premier chapitre, “Product-Oriented Delivery for Supply Chain.” Revisitons les deux propriétés les plus critiques de ce livrable.
Premièrement, le résultat doit être une décision. Par exemple, décider du nombre d’unités à réapprovisionner aujourd’hui pour un SKU donné est une décision. En revanche, prévoir combien d’unités seront demandées aujourd’hui pour un SKU donné est un artefact numérique. Afin de générer une décision en tant que résultat final, de nombreux résultats intermédiaires sont nécessaires, c’est-à-dire, de nombreux artefacts numériques. Cependant, il ne faut pas confondre les moyens avec la fin.
La deuxième propriété de ce livrable est que le résultat, qui est une décision, doit être entièrement automatisé grâce à un processus logiciel totalement automatisé. La recette numérique elle-même, la recette numérique de base, ne doit impliquer aucune opération manuelle. Naturellement, la conception de la recette numérique est susceptible de dépendre fortement d’un expert humain en science. Cependant, l’exécution ne devrait pas dépendre d’une intervention humaine directe.
Avoir une recette numérique en tant que livrable est essentiel pour faire de l’initiative de la supply chain une entreprise capitalistique. La recette numérique devient un actif productif qui génère des retours. La recette doit être entretenue, mais cela requiert une ou deux ordres de grandeur moins de personnes comparativement aux approches qui maintiennent l’humain dans la boucle au niveau des micro-décisions.

Cependant, de nombreuses initiatives supply chain échouent parce qu’elles ne cadrent pas correctement les décisions supply chain comme étant le livrable de l’initiative. Au lieu de cela, ces initiatives se concentrent sur la fourniture d’artefacts numériques. Les artefacts numériques sont destinés à être des ingrédients pour parvenir à la résolution finale du problème, soutenant typiquement les décisions elles-mêmes. Les artefacts les plus courants rencontrés en supply chain sont les prévisions, les safety stocks, les EOQs, les KPIs. Bien que ces chiffres puissent être intéressants, ils ne sont pas réels. Ces chiffres n’ont pas d’équivalent physique tangible immédiat dans la supply chain, et ils reflètent des points de vue de modélisation arbitraires sur la supply chain.
Se concentrer sur les artefacts numériques conduit à l’échec de l’initiative car ces chiffres manquent d’un ingrédient critique : un retour direct du monde réel. Lorsque la décision est erronée, les mauvaises conséquences peuvent être attribuées à la décision. Cependant, la situation est beaucoup plus ambiguë en ce qui concerne les artefacts numériques. En effet, la responsabilité est diluée partout, car de nombreux artefacts contribuent à chaque décision unique. Le problème est encore pire lorsqu’il y a une intervention humaine au milieu.
Ce manque de retour s’avère fatal pour les artefacts numériques. Les supply chains modernes sont complexes. Choisissez n’importe quelle formule arbitraire pour calculer un safety stock, une quantité économique de commande, ou un KPI ; il y a de fortes chances que cette formule soit erronée de toutes sortes de manières. Le problème de la justesse de la formule n’est pas un problème mathématique ; c’est un problème d’affaires. Il s’agit de répondre à la question : “Ce calcul reflète-t-il véritablement l’intention stratégique que j’ai pour mon entreprise ?” La réponse varie d’une entreprise à l’autre et même d’une année à l’autre, à mesure que les entreprises évoluent.
Comme les artefacts numériques manquent de retour direct du monde réel, ils ne disposent pas du mécanisme permettant d’itérer à partir d’une implémentation initiale naïve, simpliste, et très probablement largement incorrecte, vers une version approximativement correcte de la formule qui pourrait être considérée comme de niveau production. Pourtant, les artefacts numériques sont très tentants car ils donnent l’illusion de se rapprocher de la solution. Ils donnent l’illusion d’être rationnels, scientifiques, voire entreprenants. Nous avons des chiffres, des formules, des algorithmes, des modèles. Il est même possible de réaliser des benchmarks et de comparer ces chiffres avec d’autres tout aussi inventés. Améliorer par rapport à un benchmark fictif donne également l’illusion du progrès, et c’est très réconfortant. Mais à la fin de la journée, cela reste une illusion, une question de perspective de modélisation.
Les entreprises ne réalisent pas des profits en payant des personnes pour regarder des KPIs ou réaliser des benchmarks. Elles réalisent des profits en prenant une décision après l’autre et, espérons-le, en s’améliorant à prendre la décision suivante à chaque fois.
Cette conférence fait partie d’une série de conférences sur la supply chain. J’essaie de garder ces conférences quelque peu indépendantes, mais nous sommes arrivés à un point où il est plus logique de les regarder en séquence. Cette conférence est la toute première du septième chapitre, qui est dédié à l’exécution des initiatives supply chain. Par initiatives supply chain, j’entends des initiatives de la Supply Chain Quantitative – des initiatives qui ont l’intention de fournir quelque chose dans le domaine de l’optimisation prédictive pour l’entreprise.
Le tout premier chapitre était dédié à mes points de vue sur la supply chain à la fois en tant que domaine d’étude et en tant que pratique. Dans le deuxième chapitre, j’ai présenté une série de méthodologies essentielles à la supply chain, car les méthodologies naïves sont vaincues en raison de la nature conflictuelle de nombreuses situations supply chain. Dans le troisième chapitre, j’ai présenté une série de personae supply chain avec un focus pur sur les problèmes; en d’autres termes, qu’est-ce que nous essayons de résoudre ?
Dans le quatrième chapitre, j’ai présenté une série de domaines qui, bien qu’ils ne soient pas supply chain à proprement parler, me semblent essentiels à une pratique moderne de la supply chain. Dans les cinquième et sixième chapitres, j’ai présenté les éléments intelligents d’une recette numérique destinée à piloter les décisions supply chain, à savoir l’optimisation prédictive (la perspective généralisée de la prévision) et la prise de décision (essentiellement l’optimisation mathématique appliquée aux problèmes supply chain). Dans ce septième chapitre, nous discutons de la manière de réunir ces éléments dans une initiative supply chain concrète qui a l’intention de mettre en production ces méthodes et technologies.

Aujourd’hui, nous examinerons ce qui est considéré comme la pratique correcte pour mener une initiative supply chain. Cela inclut le cadrage de l’initiative avec le livrable approprié, dont nous venons de discuter, mais également avec le calendrier adéquat, le périmètre approprié et les bons rôles. Ces éléments représentent la première partie du cours d’aujourd’hui.
La deuxième partie du cours sera consacrée à la data pipeline, un ingrédient essentiel pour le succès d’une initiative pilotée ou dépendante des données. Bien que la data pipeline soit un sujet assez technique, elle nécessite une répartition adéquate des tâches et une organisation entre l’IT et la supply chain. En particulier, nous verrons que les contrôles de qualité devraient être principalement confiés à la supply chain, avec la conception de rapports sur la santé des données et des inspecteurs de données.
L’onboarding est la première phase de l’initiative, où la recette numérique centrale, celle qui génère la décision avec seulement des éléments de soutien, est élaborée. L’onboarding se termine par un déploiement progressif en production, et pendant ce déploiement, les processus antérieurs sont progressivement automatisés par la recette numérique elle-même.
Lorsqu’on envisage le calendrier approprié pour la première initiative de la Supply Chain Quantitative au sein d’une entreprise, on pourrait penser qu’il dépend de la taille, de la complexité de l’entreprise, du type de décisions supply chain et du contexte global. Bien qu’il soit vrai dans une certaine mesure, l’expérience que Lokad a accumulée sur plus d’une décennie et des dizaines d’initiatives de ce type indique que six mois est presque invariablement le délai approprié. Étonnamment, ce délai de six mois a peu à voir avec la technologie ou même les spécificités de la supply chain ; il est bien plus lié aux personnes et aux organisations elles-mêmes et au temps qu’il leur faut pour s’habituer à ce qui est généralement perçu comme une manière très différente de mener la supply chain.
Les deux premiers mois sont consacrés à la mise en place de la data pipeline. Nous reviendrons sur ce point dans quelques minutes, mais ce délai de deux mois est causé par deux facteurs. Premièrement, nous devons rendre la data pipeline fiable et éliminer les problèmes rares qui pourraient prendre des semaines à se manifester. Le deuxième facteur est que nous devons déterminer la sémantique des données, c’est-à-dire comprendre ce que signifient les données d’un point de vue supply chain.
Les troisième et quatrième mois sont consacrés à l’itération rapide sur la recette numérique elle-même, qui pilotera les décisions supply chain. Ces itérations sont nécessaires car générer des décisions concrètes est généralement la seule façon d’évaluer si la recette sous-jacente ou toutes les hypothèses intégrées dans la recette comportent un quelconque problème. Ces deux mois correspondent également typiquement au temps nécessaire aux praticiens de la supply chain pour s’habituer à la perspective très quantitative et financière qui sous-tend ces décisions pilotées par des logiciels.
Enfin, les deux derniers mois sont consacrés à la stabilisation de la recette numérique après ce qui est généralement une période relativement intense d’itérations rapides. Cette période offre également l’opportunité pour la recette de fonctionner dans un environnement proche de la production, sans pour autant piloter la production. Cette phase est importante pour que les équipes supply chain gagnent la confiance dans cette solution émergente.
Bien qu’il puisse être souhaitable de compresser davantage ce calendrier, il s’avère que c’est généralement très difficile. La mise en place de la data pipeline peut être accélérée dans une certaine mesure si l’infrastructure IT adéquate est déjà en place, mais se familiariser avec les données prend du temps pour comprendre ce que signifient les données d’un point de vue supply chain. Dans la deuxième phase, si l’itération sur la recette numérique converge très rapidement, alors les équipes supply chain risquent de commencer à explorer les nuances de la recette numérique, ce qui prolongera également le délai. Enfin, les deux derniers mois correspondent généralement au temps nécessaire pour observer le déploiement de la saisonnalité et gagner la confiance dans le logiciel qui pilote d’importantes décisions supply chain en production.
En somme, il faut environ six mois, et bien qu’il serait souhaitable de réduire encore ce délai, il est difficile de le faire. Cependant, six mois constituent déjà une période assez conséquente. Si dès le premier jour, la période d’onboarding, où la recette numérique ne pilote pas encore les décisions supply chain, devait prendre plus de six mois, alors l’initiative est déjà en danger. Si le retard supplémentaire est lié à l’extraction des données et à la mise en place de la data pipeline, alors il s’agit d’un problème IT. Si le retard supplémentaire est associé à la conception ou à la configuration de la solution, éventuellement apportée par un fournisseur tiers, alors il y a un problème avec la technologie elle-même. Enfin, si après deux mois de fonctionnement stabilisé en environnement de production, le déploiement en production n’a pas lieu, alors il y a généralement un problème dans la gestion de l’initiative.

Lorsqu’on tente d’introduire une nouveauté, un nouveau processus ou une nouvelle technologie dans une organisation, le bon sens recommande de commencer petit, de s’assurer que cela fonctionne, et de s’appuyer sur les premiers succès pour s’étendre progressivement. Malheureusement, la supply chain n’accorde pas sa clémence au bon sens, et cette perspective comporte une particularité spécifique concernant le cadrage supply chain. En termes de cadrage, il existe deux principales forces motrices qui définissent en grande partie ce qui constitue un périmètre éligible ou non pour une initiative supply chain.
Le paysage applicatif est la première force qui impacte le cadrage. Une supply chain dans son ensemble ne peut pas être observée directement ; elle ne peut être observée qu’indirectement à travers le prisme des logiciels d’entreprise. Les données seront obtenues via ces logiciels. La complexité de l’initiative dépend en grande partie du nombre et de la diversité de ces logiciels. Chaque application constitue sa propre source de données, et extraire et analyser les données d’une application métier donnée tend à être une tâche considérable. Gérer un plus grand nombre d’applications implique habituellement de devoir traiter avec plusieurs technologies de bases de données, des terminologies inconsistantes, des concepts incohérents et de complexifier considérablement la situation.
Ainsi, lors de l’établissement du périmètre, nous devons reconnaître que les frontières ou limites éligibles sont généralement définies par les applications métiers elles-mêmes et leur structure de base de données. Dans ce contexte, commencer petit doit être compris comme le fait de maintenir l’empreinte initiale d’intégration des données aussi réduite que possible tout en préservant l’intégrité de l’initiative supply chain dans son ensemble. Il vaut mieux approfondir plutôt qu’élargir l’intégration des applications. Une fois que vous disposez du système IT nécessaire pour obtenir quelques enregistrements d’une table dans une application donnée, il est généralement simple d’obtenir tous les enregistrements de cette table et tous les enregistrements d’une autre table dans la même application.

Une erreur courante dans le cadrage consiste à procéder par échantillonnage. L’échantillonnage est généralement réalisé en sélectionnant une courte liste de catégories de produits, de sites ou de fournisseurs. L’échantillonnage est bien intentionné, mais il ne suit pas les limites telles que définies par le paysage applicatif. Pour mettre en œuvre l’échantillonnage, des filtres doivent être appliqués pendant l’extraction des données, et ce processus engendre une série de problèmes susceptibles de compromettre l’initiative supply chain.
Premièrement, une extraction de données filtrée à partir d’un logiciel d’entreprise demande plus d’efforts de la part de l’équipe IT qu’une extraction non filtrée. Les filtres doivent d’abord être conçus, et le processus de filtrage lui-même est sujet aux erreurs. Le débogage de filtres incorrects est invariablement fastidieux car il nécessite de nombreux échanges avec les équipes IT, ce qui ralentira l’initiative et, par conséquent, la mettra en danger.
Deuxièmement, laisser l’initiative effectuer son onboarding sur un échantillon de données est une recette pour d’énormes problèmes de performance logicielle à mesure que l’initiative s’étend par la suite vers l’ensemble du périmètre. Une mauvaise scalabilité, ou l’incapacité de traiter une grande quantité de données tout en gardant les coûts informatiques sous contrôle, est un défaut très fréquent dans les logiciels. En laissant l’initiative fonctionner sur un échantillon, les problèmes de scalabilité sont masqués mais reviendront avec vengeance à un stade ultérieur.
Opérer sur un échantillon de données complique les statistiques, au lieu de les faciliter. En effet, avoir accès à plus de données est probablement la façon la plus simple d’améliorer l’exactitude et la stabilité de presque tous les algorithmes de machine learning. L’échantillonnage des données va à l’encontre de cette constatation. Ainsi, lorsqu’un petit échantillon de données est utilisé, l’initiative peut échouer en raison de comportements numériques erratiques observés sur l’échantillon. Ces comportements auraient été largement atténués si l’ensemble du jeu de données avait été utilisé à la place.
Les effets systémiques sont la deuxième force qui impacte le cadrage. Une supply chain est un système, et toutes ses parties sont couplées dans une certaine mesure. Le défi avec les systèmes, tout système, est que les tentatives d’améliorer une partie du système tendent à déplacer les problèmes plutôt qu’à les résoudre. Par exemple, considérons un problème d’allocation des stocks pour un réseau de distribution avec un centre de distribution et de nombreux magasins. Si nous choisissons un seul magasin comme périmètre initial pour notre problème d’allocation des stocks, il est trivial de s’assurer que ce magasin bénéficiera d’un taux de service très élevé de la part du centre de distribution en lui réservant des stocks à l’avance. Ce faisant, nous pouvons nous assurer que le centre de distribution ne sera jamais en rupture de stock lors de la desserte de ce magasin. Cependant, cette réservation de stocks se ferait au détriment de la qualité de service pour les autres magasins du réseau.
Ainsi, lorsqu’on envisage un périmètre pour une initiative supply chain, nous devons prendre en compte les effets systémiques. Le périmètre doit être conçu de manière à prévenir en grande partie l’optimisation locale au détriment des éléments situés en dehors du périmètre. Cette partie de l’exercice de cadrage est difficile car tous les périmètres sont fuyants dans une certaine mesure. Par exemple, toutes les parties de la supply chain sont finalement en concurrence pour la même somme d’argent disponible au niveau de l’entreprise. Chaque dollar alloué à un endroit est un dollar qui ne sera pas disponible pour d’autres usages. Néanmoins, certains périmètres sont beaucoup plus facilement manipulables que d’autres. Il est important de choisir un périmètre qui tend à atténuer les effets systémiques plutôt que de les amplifier.

Penser au cadrage d’une initiative supply chain en termes d’effets systémiques peut sembler étrange pour de nombreux praticiens de la supply chain. En matière de cadrage, la plupart des entreprises ont tendance à projeter leur organisation interne sur l’exercice de cadrage. Ainsi, les limites choisies pour le périmètre ont invariablement tendance à imiter les frontières de la division du travail en place au sein de l’entreprise. Ce schéma est connu sous le nom de loi de Conway. Proposée par Melvin Conway il y a un demi-siècle pour les systèmes de communication, cette loi s’est depuis avérée avoir une applicabilité beaucoup plus large, y compris une pertinence primordiale pour la gestion de la supply chain.
Les frontières et silos qui dominent les supply chain actuelles sont entraînés par des divisions du travail qui résultent de processus assez manuels en place pour piloter les décisions supply chain. Par exemple, si une entreprise estime qu’un planificateur de l’offre et de la demande ne peut pas gérer plus de 1 000 SKU, et que l’entreprise doit gérer 50 000 SKU au total, il faudra 50 planificateurs de l’offre et de la demande pour le faire. Cependant, diviser l’optimisation de la supply chain entre 50 paires de mains entraîne inévitablement de nombreuses inefficacités au niveau de l’entreprise.
Au contraire, une initiative qui automatise ces décisions n’a pas besoin de se cantonner à ces frontières qui ne reflètent qu’une division du travail obsolète ou sur le point de le devenir. Une recette numérique peut optimiser ces 50 000 SKU simultanément et éliminer les inefficacités résultant de la confrontation de dizaines de silos. Il est donc tout à fait naturel qu’une initiative visant à automatiser largement ces décisions chevauche de nombreuses limites préexistantes au sein de l’entreprise. L’entreprise, ou plus précisément sa direction, doit résister à l’envie d’imiter les frontières organisationnelles existantes, en particulier au niveau du cadrage, car cela tend à définir la tonalité de ce qui suit.

Les supply chain sont complexes en termes de matériel, de logiciels et de personnes. Bien qu’il soit regrettable, lancer une initiative de la Supply Chain Quantitative augmente encore la complexité de la supply chain, du moins au début. À long terme, cela peut en réalité diminuer substantiellement la complexité de la supply chain, mais nous y reviendrons probablement dans un cours ultérieur. De plus, plus il y a de personnes impliquées dans l’initiative, plus celle-ci est complexe. Si cette complexité supplémentaire n’est pas immédiatement maîtrisée, il y a de fortes chances que l’initiative s’effondre sous son propre poids.
Ainsi, lorsqu’on réfléchit aux rôles au sein de l’initiative, c’est-à-dire qui fera quoi, nous devons envisager l’ensemble de rôles le plus réduit possible qui rende l’initiative viable. En minimisant le nombre de rôles, nous réduisons la complexité de l’initiative, ce qui améliore considérablement ses chances de succès. Cette perspective a tendance à être contre-intuitive pour les grandes entreprises qui aiment fonctionner avec une division du travail extrêmement fine. Les grandes entreprises ont tendance à favoriser des spécialistes extrêmes qui ne font qu’une seule chose. Cependant, une supply chain est un système, et comme tous les systèmes, c’est la perspective de bout en bout qui compte.
D’après l’expérience acquise chez Lokad en menant ce type d’initiatives, nous avons identifié quatre rôles qui représentent habituellement la division du travail minimale viable pour mener l’initiative : un cadre supply chain, un data officer, un Supply Chain Scientist, et un praticien de la supply chain.
Le rôle du dirigeant de la supply chain est de soutenir l’initiative afin qu’elle puisse se réaliser dès le départ. Obtenir une recette numérique bien conçue pour piloter les décisions de la supply chain en production représente un coup de pouce considérable tant en termes de rentabilité que de productivité. Cependant, il s’agit aussi d’un changement important à assimiler. Il faut énormément d’énergie et de soutien de la part de la direction générale pour qu’un tel changement ait lieu dans une grande organisation.
Le rôle du data officer est de mettre en place et de maintenir le pipeline de données. La majeure partie de ses contributions est censée intervenir durant les deux premiers mois de l’initiative. Si le pipeline de données est correctement conçu, l’effort requis ultérieurement pour le data officer sera minime. Le data officer n’est généralement pas très impliqué lors des étapes ultérieures de l’initiative.
Le rôle du Supply Chain Scientist est de concevoir la recette numérique de base. Ce rôle part des données transactionnelles brutes mises à disposition par le data officer. Aucune préparation des données n’est attendue de la part du data officer, seulement leur extraction. Le rôle du Supply Chain Scientist s’achève en assumant la responsabilité de la décision supply chain générée. Ce n’est pas un logiciel qui est responsable de la décision, c’est le Supply Chain Scientist lui-même. Pour chaque décision générée, le scientifique doit être capable de justifier pourquoi celle-ci est adéquate.
Enfin, le rôle du supply chain practitioner est de remettre en question les décisions générées par la recette numérique et de fournir un retour d’information au Supply Chain Scientist. Le praticien n’a aucune chance de se voir confier la décision. Cette personne a généralement été responsable de ces décisions jusque-là, du moins pour un sous-ensemble, et ce, généralement à l’aide de tableurs et de systèmes existants. Dans une petite entreprise, il est possible qu’une seule personne cumule les rôles de dirigeant de la supply chain et de supply chain practitioner. Il est également envisageable de se passer d’un data officer si les données sont facilement accessibles. Cela peut se produire dans des entreprises dont l’infrastructure de données est très mature. En revanche, dans une très grande entreprise, il est possible d’avoir quelques personnes, mais seulement un nombre très restreint, pour remplir chaque rôle.
Le déploiement réussi en production de la recette numérique de base a un impact considérable sur le quotidien du supply chain practitioner. En effet, dans une large mesure, l’objectif de l’initiative est d’automatiser l’emploi précédent du supply chain practitioner. Toutefois, cela n’implique pas que la meilleure solution soit de licencier ces praticiens une fois que la recette numérique est en production. Nous reviendrons sur cet aspect précis lors de la prochaine conférence.

Être organisé ne signifie pas être efficace ou efficient. Il existe des rôles qui, malgré de bonnes intentions, créent des frictions dans les initiatives supply chain, souvent jusqu’au point de provoquer leur échec complet. De nos jours, le rôle qui contribue le plus à l’échec de ces initiatives tend à être celui du data scientist, et ce d’autant plus lorsqu’une équipe entière de data scientists est impliquée. D’ailleurs, Lokad l’a appris à la dure il y a une dizaine d’années.
Bien que la dénomination « data scientist » soit similaire à celle de « Supply Chain Scientist », les deux rôles sont en réalité très différents. Le Supply Chain Scientist se préoccupe avant tout de fournir des décisions concrètes et prêtes pour la production. Si cela peut être réalisé avec une recette numérique semi-triviale, tant mieux ; la maintenance sera un jeu d’enfant. Le Supply Chain Scientist assume l’entière responsabilité des moindres détails de la supply chain. La fiabilité et la résilience face au chaos ambiant comptent bien plus que la sophistication.
Au contraire, le data scientist se concentre sur les parties intelligentes de la recette numérique, c’est-à-dire sur les modèles et les algorithmes. De manière générale, le data scientist se considère comme un expert en machine learning et en optimisation mathématique. En matière de technologies, un data scientist est prêt à apprendre le tout dernier toolkit numérique open source à la pointe, mais il est généralement réticent à se former sur l’ERP vieux de trois décennies qui fait fonctionner l’entreprise. De plus, le data scientist n’est pas un expert de la supply chain, ni n’est habituellement désireux de le devenir. Le data scientist s’efforce de fournir les meilleurs résultats selon des métriques établies. Le scientifique n’a aucune ambition de s’occuper des détails vraiment banals de la supply chain, ces aspects étant censés être pris en charge par d’autres personnes.
Impliquer des data scientists condamne ces initiatives, car dès que ceux-ci interviennent, la supply chain n’est plus au centre de l’attention – ce sont les algorithmes et les modèles qui priment. Ne sous-estimez jamais le pouvoir de distraction que représente le dernier modèle ou algorithme pour une personne intelligente et tournée vers la technologie.
Le deuxième rôle qui a tendance à créer des frictions dans une initiative supply chain est celui de l’équipe de business intelligence (BI). Lorsque l’équipe BI fait partie de l’initiative, elle tend à constituer un obstacle plutôt qu’autre chose, quoique dans une moindre mesure que l’équipe de data science. Le problème avec la BI est principalement culturel. La BI fournit des rapports, pas des décisions. L’équipe BI est généralement prête à produire une quantité infinie de métriques, comme le demande chaque division de l’entreprise. Ce n’est pas la bonne attitude pour une initiative de la Supply Chain Quantitative.
De plus, la business intelligence en tant que logiciel constitue une catégorie très spécifique d’analytique de données axée sur des cubes ou cubes OLAP qui permettent de segmenter et d’analyser la plupart des systèmes en mémoire dans les environnements d’entreprise. Cette conception est généralement inadaptée pour piloter les décisions de la supply chain.

Maintenant que nous avons cadré l’initiative, examinons l’architecture informatique de haut niveau qu’elle requiert.
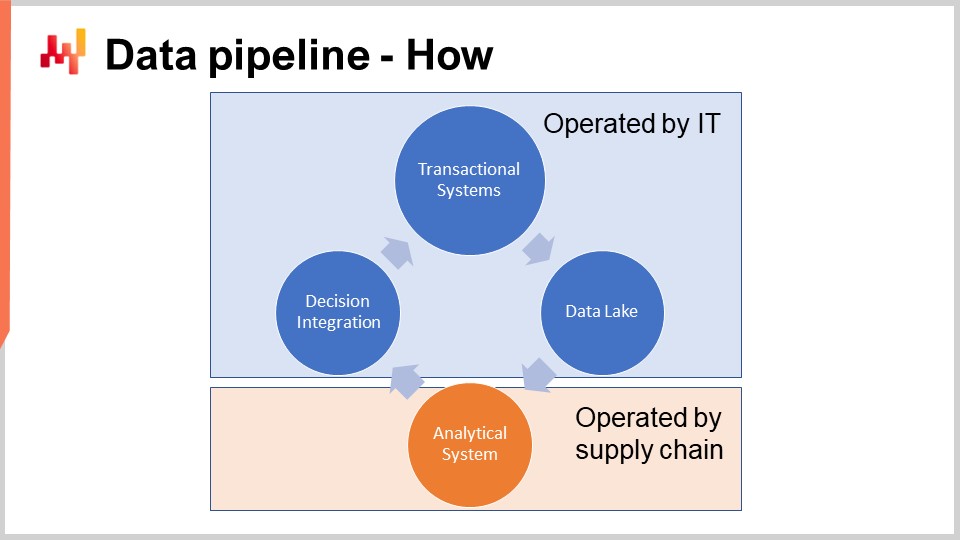
Le schéma à l’écran illustre une configuration typique de pipeline de données pour une initiative de la Supply Chain Quantitative. Dans cette conférence, je traite d’un pipeline de données qui ne supporte pas des exigences de faible latence. Nous souhaitons pouvoir compléter un cycle complet en environ une heure, et non en une seconde. La plupart des décisions de la supply chain, comme les bons de commande, ne nécessitent pas une configuration à faible latence. Obtenir une latence faible de bout en bout requiert une architecture différente, ce qui sort du cadre de la conférence d’aujourd’hui.

Les systèmes transactionnels représentent la source de données principale et le point de départ du pipeline de données. Ces systèmes incluent l’ERP, le WMS et l’EDI. Ils gèrent le flux de marchandises, que ce soit pour l’achat, le transport, la production ou la vente. Ces systèmes contiennent presque toutes les données requises par la recette numérique de base. Pour pratiquement toute entreprise de taille conséquente, ces systèmes ou leurs prédécesseurs sont en place depuis au moins deux décennies.
Comme ces systèmes contiennent presque toutes les données dont nous avons besoin, il serait tentant d’implémenter la recette numérique directement au sein de ces systèmes. En effet, pourquoi pas ? En intégrant la recette numérique directement dans l’ERP, nous éliminerions la nécessité de mettre en place l’ensemble de ce pipeline de données. Malheureusement, cela ne fonctionne pas en raison de la conception même de ces systèmes transactionnels.
Ces systèmes transactionnels sont invariablement construits autour d’une base de données transactionnelle. Cette approche de conception des logiciels d’entreprise s’est révélée extrêmement stable au cours des quatre dernières décennies. Prenez n’importe quelle entreprise, et il y a de fortes chances que chaque application métier en production ait été implémentée sur une base de données transactionnelle. Les bases de données transactionnelles offrent quatre propriétés clés connues sous l’acronyme ACID, signifiant Atomicité, Cohérence, Isolation et Durabilité. Je ne vais pas m’attarder sur les détails de ces propriétés, il suffit de dire qu’elles rendent la base de données très adaptée à l’exécution en toute sécurité et de manière concurrente de nombreuses petites opérations de lecture et d’écriture. Les volumes d’opérations de lecture et d’écriture sont également supposés être assez équilibrés.
Cependant, le prix à payer pour ces propriétés ACID si utiles au niveau le plus granulaire est que la base de données transactionnelle se révèle également très inefficace lorsqu’il s’agit de traiter de grosses opérations de lecture. Une opération de lecture couvrant une part importante de l’ensemble de la base, en règle générale, lorsqu’elle est effectuée via une base axée sur une fourniture très granulaire de ces propriétés ACID, peut voir son coût en ressources informatiques multiplié par 100 par rapport à des architectures qui ne mettent pas autant l’accent sur ces propriétés ACID à un niveau aussi granulaire. ACID, c’est bien, mais cela a un coût considérable.
De plus, lorsque quelqu’un tente de lire une portion importante de l’ensemble de la base de données, celle-ci risque de devenir non réactive pendant un certain temps, car elle consacre la majeure partie de ses ressources au traitement de cette unique et lourde requête. De nombreuses entreprises se plaignent que l’ensemble de leurs systèmes métiers est lent et que ces systèmes se figent fréquemment pendant une seconde, voire plus. Habituellement, cette mauvaise qualité de service peut être attribuée à des requêtes SQL trop lourdes qui tentent de lire trop de lignes à la fois.
Par conséquent, la recette numérique de base ne peut pas être autorisée à fonctionner dans le même environnement que les systèmes transactionnels qui supportent la production. En effet, les recettes numériques auront besoin d’accéder à la majorité des données à chaque exécution. Ainsi, la recette numérique doit être strictement isolée dans son propre sous-système, ne serait-ce que pour éviter de dégrader davantage les performances de ces systèmes transactionnels.
Au fait, bien qu’il soit connu depuis des décennies qu’il est une très mauvaise idée de faire fonctionner un processus intensif en données au sein d’un système transactionnel, cela n’empêche pas la plupart des fournisseurs de systèmes transactionnels (ERP, MRP, WMS) de vendre des modules analytiques intégrés, par exemple des modules d’optimisation de stocks. L’intégration de ces modules conduit inévitablement à des problèmes de qualité de service tout en offrant des capacités décevantes. Tous ces problèmes trouvent leur origine dans ce problème de conception unique : le système transactionnel et le système analytique doivent être maintenus en stricte isolation.
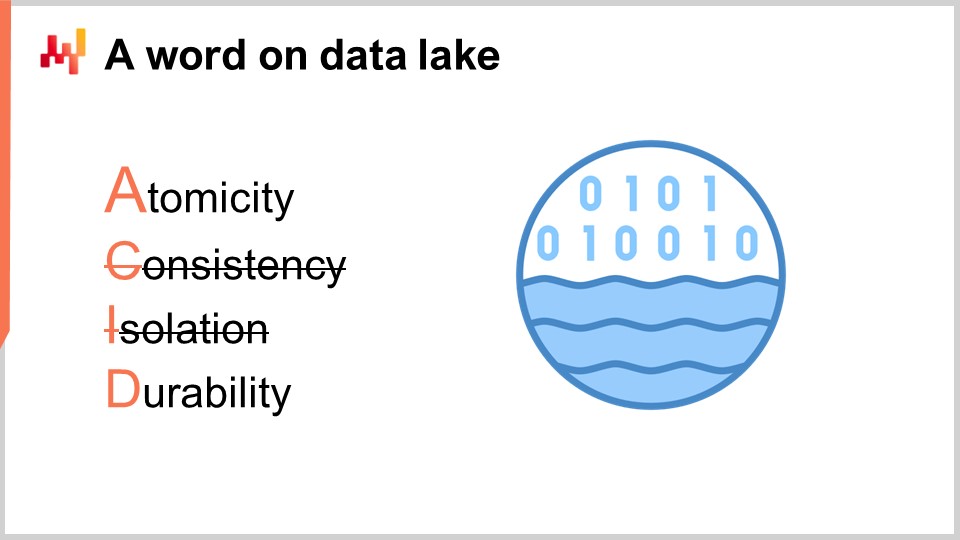
Le data lake est simple. Il est le miroir des données transactionnelles conçu pour de très grandes opérations de lecture. En effet, nous avons vu que les systèmes transactionnels sont optimisés pour de nombreuses petites lectures, et non pour de très grandes. Ainsi, afin de préserver la qualité de service du système transactionnel, la conception adéquate consiste à répliquer soigneusement les données transactionnelles dans un autre système, à savoir le data lake. Cette réplication doit être mise en œuvre avec soin, précisément pour préserver la qualité de service du système transactionnel, ce qui signifie généralement lire les données de manière très incrémentale et éviter de générer des pics de charge sur le système transactionnel.
Une fois que les données transactionnelles pertinentes sont répliquées dans le data lake, ce dernier répond à toutes les demandes de données. Un avantage supplémentaire du data lake est sa capacité à servir plusieurs systèmes analytiques. Bien que nous parlions ici de supply chain, si le marketing souhaite disposer de ses propres analyses, il aura besoin de ces mêmes données transactionnelles, et il en va de même pour la finance, les ventes, etc. Ainsi, plutôt que chaque département de l’entreprise implémente son propre mécanisme d’extraction de données, il est judicieux de consolider toutes ces extractions dans le même data lake, le même système.
Au niveau technique, un data lake peut être implémenté avec une base de données relationnelle, généralement optimisée pour l’extraction de big data, en adoptant un stockage de données en colonnes. Les data lakes peuvent également être réalisés en tant que répertoire de fichiers plats servis sur un système de fichiers distribué. Comparé à un système transactionnel, un data lake renonce aux propriétés transactionnelles fines. L’objectif est de fournir une grande quantité de données de la manière la plus économique et fiable possible — rien de plus, rien de moins.
Le data lake doit être le miroir des données transactionnelles d’origine, c’est-à-dire recopier sans rien modifier. Il est important de ne pas préparer les données dans le data lake. Malheureusement, l’équipe IT chargée de mettre en place le data lake peut être tentée de faciliter la tâche aux autres équipes en préparant légèrement les données. Cependant, modifier ces données introduit invariablement des complications qui compromettront l’analytique à un stade ultérieur. De plus, s’en tenir à une politique stricte de duplication réduit considérablement l’effort nécessaire pour l’équipe IT lors de la mise en place et de la maintenance ultérieure du data lake.
Dans les entreprises où une équipe BI est déjà en place, il peut être tentant d’utiliser les systèmes BI comme data lake. Cependant, je déconseille formellement de le faire et de n’employer jamais une configuration BI comme data lake. En effet, les données dans les systèmes BI (business intelligence systems) sont invariablement déjà fortement transformées. Exploiter les données BI pour piloter des décisions automatisées de supply chain est une recette pour des problèmes de garbage in, garbage out. Le data lake ne doit être alimenté qu’à partir de sources de données primaires telles que l’ERP, et non à partir de sources de données secondaires comme le système BI.
Le système analytique est celui qui contient la recette numérique de base. C’est également le système qui fournit tous les rapports nécessaires pour instrumenter les décisions elles-mêmes. Au niveau technique, le système analytique contient les “smart bits”, tels que les algorithmes de machine learning et les algorithmes d’optimisation mathématique. Bien qu’en pratique, ces smart bits ne dominent pas la base de code du système analytique. Habituellement, la préparation des données et leur instrumentation nécessitent au moins dix fois plus de lignes de code que les parties dédiées à l’apprentissage et à l’optimisation.
Le système analytique doit être découplé du data lake car ces deux systèmes sont complètement opposés en termes de perspectives technologiques. En tant que logiciel, le data lake est censé être très simple, très stable et extrêmement fiable. En revanche, le système analytique est supposé être sophistiqué, en constante évolution et extrêmement performant en termes de performances de la supply chain. Contrairement au data lake, qui doit offrir une disponibilité quasi-parfaite, le système analytique n’a même pas besoin d’être opérationnel la majeure partie du temps. Par exemple, si nous envisageons des décisions quotidiennes de réapprovisionnement de stocks, alors le système analytique n’a qu’à fonctionner et être opérationnel une fois par jour.
En règle générale, il est préférable que le système analytique échoue à produire des décisions plutôt que de générer des décisions incorrectes et de les laisser se diffuser en production. Retarder les décisions supply chain de quelques heures, comme les bons de commande, est généralement bien moins grave que de prendre de mauvaises décisions. Comme la conception du système analytique tend à être fortement influencée par les éléments intelligents qu’il contient, il n’y a pas forcément grand-chose à dire en général sur cette conception. Cependant, il y a au moins une propriété de conception clé qui doit être imposée pour l’écosystème : ce système doit être sans état.
Le système analytique doit éviter, autant que possible, d’avoir un état interne. Autrement dit, l’ensemble de l’écosystème doit débuter avec les données telles que présentées par le data lake et se terminer par les décisions supply chain générées, accompagnées des rapports de support. Ce qui se passe souvent, c’est que, lorsqu’il y a un composant à l’intérieur du système analytique qui est trop lent, comme un algorithme de machine learning, il devient tentant d’introduire un état, c’est-à-dire de conserver certaines informations de l’exécution précédente pour accélérer la suivante. Cependant, faire cela, en se fiant à des résultats antérieurement calculés plutôt qu’en tout recalculant à partir de zéro à chaque fois, est dangereux.
En effet, avoir un état au sein du système analytique met la décision en péril. Alors que des problèmes de données surgiront inévitablement et seront corrigés au niveau du data lake, le système analytique peut tout de même retourner des décisions qui reflètent un problème déjà résolu. Par exemple, si un modèle de prévision de la demande est entraîné sur un jeu de données de ventes corrompu, alors ce modèle restera corrompu jusqu’à ce qu’il soit réentraîné sur une version fraîche et corrigée du jeu de données. La seule manière d’éviter que le système analytique ne subisse les échos de problèmes de données déjà corrigés dans le data lake est de tout rafraîchir à chaque fois. Voilà l’essence même d’être sans état.
En règle générale, si une partie du système analytique se révèle trop lente pour être remplacée quotidiennement, alors cette partie doit être considérée comme souffrant d’un problème de performance. Les supply chains sont chaotiques, et il viendra un jour où quelque chose se passera – un incendie, un confinement, une cyberattaque – qui exigera une intervention immédiate. L’entreprise doit être capable de rafraîchir l’ensemble de ses décisions supply chain en une heure. Elle ne doit pas attendre et rester bloquée pendant 10 heures pendant la phase d’entraînement lent du machine learning.

Pour fonctionner de manière fiable, le système analytique doit être correctement instrumenté. C’est ce dont parlent le rapport de santé des données et les inspecteurs de données. D’ailleurs, tous ces éléments relèvent de la responsabilité de la supply chain ; ils ne relèvent pas de celle de l’IT. Le monitoring de la santé des données représente la toute première phase de traitement des données, même avant la préparation des données à proprement parler, et se déroule au sein du système analytique. La santé des données fait partie de l’instrumentation de la recette numérique. Le rapport de santé des données indique s’il est acceptable ou non de lancer la recette numérique. Ce rapport identifie également, le cas échéant, l’origine du problème de données afin d’en accélérer la résolution.
La surveillance de la santé des données est une pratique chez Lokad. Au cours de la dernière décennie, cette pratique s’est avérée inestimable pour éviter les situations « garbage in, garbage out » qui semblent omniprésentes dans le monde des logiciels d’entreprise. En effet, lorsqu’une initiative de traitement des données échoue, ce sont souvent les mauvaises données qui sont pointées du doigt. Cependant, il est important de remarquer que, généralement, il n’y a presque aucun effort d’ingénierie pour garantir la qualité des données dès le départ. La qualité des données ne tombe pas du ciel ; elle demande des efforts d’ingénierie.
Le pipeline de données présenté jusqu’ici est assez minimaliste. Le mirroring des données est aussi simple que possible, ce qui est une bonne chose du point de vue de la qualité logicielle. Pourtant, malgré ce minimalisme, il y a encore de nombreuses parties mobiles : de nombreuses tables, de nombreux systèmes, de nombreuses personnes. Ainsi, les bogues pullulent partout. Ceci est un logiciel d’entreprise, et le contraire serait pour le moins surprenant. La surveillance de la santé des données est en place pour aider le système analytique à survivre au chaos ambiant.
La santé des données ne doit pas être confondue avec le nettoyage des données. Il s’agit uniquement de s’assurer que les données mises à la disposition du système analytique représentent fidèlement les données transactionnelles existant dans les systèmes transactionnels. Aucune tentative n’est faite pour corriger les données ; elles sont analysées telles quelles.
Chez Lokad, nous distinguons généralement la santé des données à faible niveau de celle à haut niveau. La santé des données à faible niveau est un tableau de bord qui consolide toutes les anomalies structurelles et volumétriques des données, telles que des problèmes évidents comme des entrées qui ne représentent même pas des dates ou des nombres raisonnables, par exemple, ou des identifiants orphelins dépourvus de leurs contreparties attendues. Tous ces problèmes sont visibles et représentent en réalité les cas faciles. Le problème difficile débute avec les questions qui ne peuvent être détectées parce que les données font défaut dès le départ. Par exemple, si une extraction de données se passe mal et que les données de ventes extraites d’hier ne contiennent que la moitié des lignes attendues, cela peut réellement compromettre la production. Des données incomplètes sont particulièrement insidieuses car elles n’empêcheront généralement pas la recette numérique de générer des décisions, sauf que ces décisions seront erronées, puisque les données d’entrée sont incomplètes.
Techniquement, chez Lokad, nous essayons de centraliser la surveillance de la santé des données sur un seul tableau de bord, et ce tableau de bord est généralement destiné à l’équipe IT, car la plupart des problèmes relevés par la santé des données à faible niveau tendent à être liés au pipeline de données lui-même. Idéalement, l’équipe IT devrait être capable de déterminer d’un coup d’œil si tout va bien ou non et si aucune intervention supplémentaire n’est requise.

Le monitoring de la santé des données à haut niveau prend en compte toutes les anomalies métier – des éléments qui semblent erronés lorsqu’on les observe d’un point de vue commercial. La santé des données à haut niveau couvre des éléments tels que des niveaux de stocks négatifs ou des quantités minimales de commande anormalement élevées. Elle englobe également des cas comme des prix qui n’ont aucun sens parce que l’entreprise fonctionnerait alors à perte ou avec des marges ridiculement élevées. Le monitoring de la santé des données à haut niveau tente de couvrir tous les éléments pour lesquels un praticien supply chain regarderait les données et dirait : “Cela ne peut absolument pas être correct ; nous avons un problème.”
Contrairement au rapport de santé des données à faible niveau, le rapport de santé des données à haut niveau est principalement destiné à l’équipe supply chain. En effet, des problèmes comme des quantités minimales de commande anormales ne seront perçus comme tels que par un praticien qui connaît assez bien l’environnement commercial. L’objectif de ce rapport est de pouvoir constater d’un coup d’œil que tout va bien et qu’aucune intervention supplémentaire n’est requise.
Précédemment, j’ai dit que le système analytique était censé être sans état. Eh bien, il s’avère que la santé des données est l’exception qui confirme la règle. En effet, de nombreux problèmes peuvent être identifiés en comparant les indicateurs actuels avec ceux collectés lors des jours précédents. Ainsi, la surveillance de la santé des données va typiquement conserver une sorte d’état, qui se compose essentiellement d’indicateurs clés observés les jours précédents, afin de pouvoir identifier des valeurs aberrantes dans l’état actuel des données. Cependant, comme la santé des données relève uniquement du monitoring, le pire qui puisse se produire, si un problème au niveau du data lake est corrigé, et que nous avons alors des rémanences d’anciens problèmes dans l’état de la santé des données, c’est une série de fausses alertes provenant de ces rapports. La logique qui génère les décisions supply chain reste entièrement sans état ; l’état ne concerne qu’une petite partie de l’instrumentation.
Le monitoring de la santé des données, tant à faible qu’à haut niveau, relève d’un compromis entre le risque de délivrer des décisions incorrectes et le risque de ne pas livrer de décisions à temps. Lorsqu’on observe de grandes supply chains, il n’est pas raisonnable de s’attendre à ce que 100 % des données soient correctes – des entrées transactionnelles erronées surviennent, même si elles sont rares. Ainsi, il doit y avoir un volume de problèmes jugé suffisamment faible pour que la recette numérique puisse fonctionner. Le compromis entre ces deux risques – être trop sensible aux anomalies de données ou être trop tolérant aux problèmes de données – dépend fortement de la composition économique de la supply chain.
Chez Lokad, nous élaborons et ajustons ces rapports pour chaque client. Plutôt que de courir après chaque cas concevable de corruption des données, le Supply Chain Scientist, qui est en charge de la mise en œuvre de la santé des données à faible et à haut niveau ainsi que des inspecteurs de données dont je vais parler dans une minute, essaie d’ajuster le monitoring de la santé des données pour qu’il soit sensible aux problèmes réellement dommageables et effectivement survenant pour la supply chain concernée.
Dans le jargon de Lokad, un inspecteur de données, ou tout simplement un inspecteur, est un rapport qui consolide toutes les données pertinentes concernant un objet d’intérêt. Cet objet d’intérêt est censé être l’un des citoyens de première classe du point de vue de la supply chain – un produit, un fournisseur, un client, ou un warehouse. Par exemple, si l’on considère un inspecteur de données pour les produits, alors pour chaque produit vendu par l’entreprise, nous devrions être capables de visualiser, via l’inspecteur sur un seul écran, toutes les données qui y sont attachées. Dans l’inspecteur de données pour produits, il y a effectivement autant de vues qu’il y a de produits, car lorsque je dis que nous voyons toutes les données, je veux dire toutes celles attachées à un code-barres ou à un numéro de pièce, et non à l’ensemble des produits en général.
Contrairement aux rapports de santé des données à faible et à haut niveau, conçus comme deux tableaux de bord à examiner d’un coup d’œil, les inspecteurs sont mis en place pour répondre aux questions et préoccupations qui surgissent inévitablement lors de la conception puis de l’exploitation de la recette numérique centrale. En effet, pour prendre une décision supply chain, il n’est pas rare de consolider des données provenant d’une douzaine de tables, potentiellement issues de plusieurs systèmes transactionnels. Comme les données sont disséminées, lorsqu’une décision paraît suspecte, il est généralement difficile d’en identifier l’origine. Il peut y avoir un décalage entre les données telles que perçues par le système analytique et celles existant dans le système transactionnel. Un algorithme défectueux peut ne pas réussir à capter un motif statistique dans les données. Il peut également y avoir une mauvaise perception, et la décision jugée suspecte pourrait, en réalité, être correcte. Dans tous les cas, l’inspecteur a pour objectif d’offrir la possibilité de zoomer sur l’objet d’intérêt.
Pour être utiles, les inspecteurs doivent refléter les spécificités à la fois de la supply chain et du paysage applicatif. Par conséquent, créer des inspecteurs est presque invariablement un exercice sur mesure. Néanmoins, une fois le travail accompli, l’inspecteur représente l’un des piliers de l’instrumentation du système analytique lui-même.
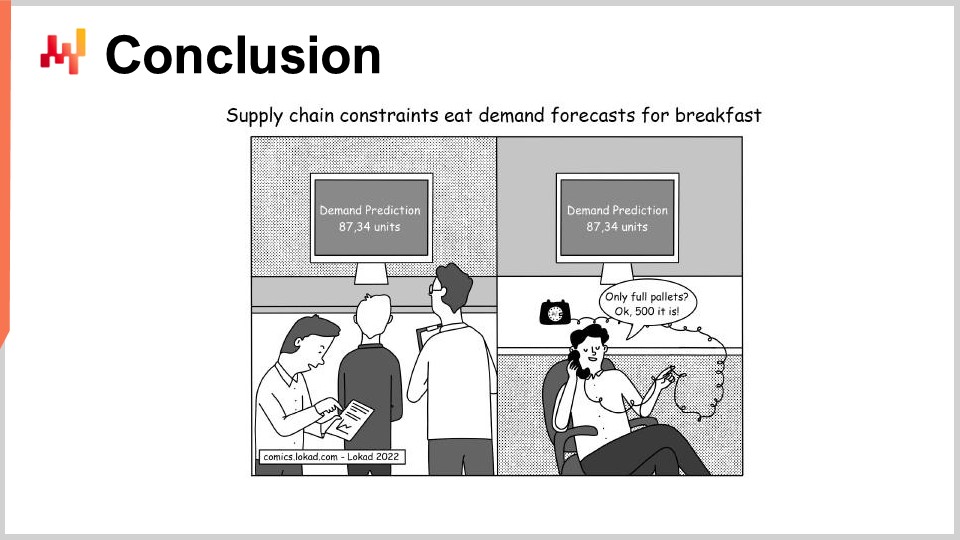
En conclusion, bien que la plupart des initiatives de la Supply Chain Quantitative soient vouées à l’échec avant même leur lancement, cela ne doit pas forcément être le cas. Un choix minutieux des livrables, des délais, du périmètre et des règles est nécessaire pour éviter les problèmes qui condamnent inévitablement ces initiatives à l’échec. Malheureusement, ces choix sont souvent quelque peu contre-intuitifs, comme Lokad l’a appris à la dure en 14 ans d’exploitation jusqu’à présent.
Le tout début de l’initiative doit être consacré à la mise en place d’un pipeline de données. Un pipeline de données peu fiable est l’une des manières les plus sûres de garantir l’échec de toute initiative pilotée par les données. La plupart des entreprises, voire la plupart des départements IT, sous-estiment l’importance d’un pipeline de données extrêmement fiable qui ne nécessite pas d’interventions constantes. Si la majeure partie de la mise en place du pipeline de données incombe au département IT, la supply chain elle-même doit être responsable de l’instrumentation du système analytique qu’elle exploite. N’attendez pas que l’IT le fasse pour vous ; cela relève de l’équipe supply chain. Nous avons observé deux types d’instrumentation, à savoir les rapports de santé des données adoptant une perspective globale et les inspecteurs de données, qui permettent un diagnostic approfondi.

Aujourd’hui, nous avons discuté de la manière de démarrer une initiative, mais la prochaine fois, nous verrons comment la terminer ou plutôt, espérons-le, comment la mener à bien. Lors de la prochaine conférence, qui aura lieu le mercredi 14 septembre, nous poursuivrons notre parcours et verrons quel type d’exécution est nécessaire pour élaborer une recette numérique centrale, puis pour amener progressivement les décisions qu’elle génère en production. Nous examinerons également de plus près ce que cette nouvelle manière de faire la supply chain implique pour le fonctionnement quotidien des praticiens supply chain.
Maintenant, examinons les questions.
Question: Pourquoi la limite de six mois est-elle exactement le délai au-delà duquel une mise en œuvre n’est pas effectuée correctement ?
Je dirais que le problème n’est pas vraiment d’avoir six mois comme limite temporelle. C’est que, généralement, les initiatives sont conçues pour échouer dès le départ. Voilà le problème. Si votre initiative d’optimisation prédictive démarre avec la perspective que les résultats seront délivrés dans deux ans, c’est presque une garantie que l’initiative se désintégrera à un moment donné et ne livrera rien en production. Si je pouvais, je préférerais que l’initiative réussisse en trois mois. Cependant, six mois représentent, d’après mon expérience, le délai minimal nécessaire pour amener une telle initiative en production. Tout retard supplémentaire augmente le risque d’échec de l’initiative. Il est très difficile de compresser davantage ce délai, car une fois tous les problèmes techniques résolus, les délais restants reflètent le temps nécessaire aux personnes pour s’engager dans l’initiative.
Question: Les praticiens supply chain peuvent se montrer frustrés par une initiative qui remplace la majorité de leur charge de travail, comme le service achat, en conflit avec l’automatisation des décisions. Comment conseilleriez-vous de gérer cela ?
Ceci est une question très importante, qui sera abordée, espérons-le, dans le prochain cours. Pour aujourd’hui, ce que je peux dire, c’est que je crois que la plupart de ce que les praticiens de la supply chain font dans les supply chains actuelles n’est pas très gratifiant. Dans la plupart des entreprises, les gens reçoivent un ensemble de SKUs ou de numéros de pièces et les parcourent sans cesse, en prenant toutes les décisions nécessaires. Cela signifie que leur travail consiste essentiellement à consulter un tableur et à le parcourir une fois par semaine ou éventuellement une fois par jour. Ce n’est pas un travail épanouissant.
Réponse courte : l’approche Lokad résout le problème en automatisant tous les aspects routiniers du travail, afin que les personnes en place disposant d’une véritable expertise en supply chain puissent commencer à remettre en question les fondements de la supply chain. Cela leur permet de discuter davantage avec les clients et les fournisseurs pour rendre le tout plus efficace. Il s’agit de recueillir des insights afin que nous puissions améliorer la recette numérique. Exécuter la recette numérique est fastidieux, et très peu de personnes regretteront l’époque où elles devaient parcourir les tableurs chaque jour.
Question: Les praticiens de la supply chain sont-ils censés travailler avec des rapports de santé des données afin de contester les décisions générées par les Supply Chain Scientists ?
Les praticiens de la supply chain sont censés travailler avec des data inspectors, et non avec des rapports de santé des données. Les rapports de santé des données ressemblent à une évaluation à l’échelle de l’entreprise qui répond à la question de savoir si les données à l’entrée du système analytique sont suffisamment bonnes pour que la recette numérique puisse s’exécuter sur le jeu de données. Le résultat du rapport de santé des données est une décision binaire : donner le feu vert à l’exécution de la recette numérique ou s’y opposer en affirmant qu’il y a un problème à résoudre. Les data inspectors, qui seront abordés plus en détail dans le prochain cours, constituent le point d’entrée pour que les praticiens de la supply chain puissent obtenir des insights sur une décision supply chain proposée.
Question: Est-il faisable de mettre à jour un modèle analytique, par exemple, en définissant une politique de stocks sur une base quotidienne ? Le système de supply chain ne peut-il pas répondre aux changements quotidiens de politique, n’introduira-t-il pas simplement du bruit dans le système ?
Pour répondre à la première partie de la question, il est certainement possible de mettre à jour un modèle analytique quotidiennement. Par exemple, lorsque Lokad fonctionnait en 2020 avec les confinements en Europe, nous avions des pays qui fermaient et rouvriaient avec seulement 24 heures de préavis. Cela a créé une situation extrêmement chaotique qui nécessitait des révisions immédiates constantes au quotidien. Lokad a opéré sous cette pression extrême, gérant des confinements qui commençaient ou se terminaient quotidiennement à travers l’Europe pendant près de 14 mois.
Ainsi, mettre à jour un modèle analytique quotidiennement est possible, mais pas nécessairement souhaitable. Il est vrai que les systèmes de supply chain possèdent beaucoup d’inertie, et la première chose qu’une recette numérique appropriée doit reconnaître est l’effet cliquet de la plupart des décisions. Une fois que vous avez ordonné la production et que les matières premières sont consommées, vous ne pouvez pas annuler la production. Vous devez tenir compte du fait que de nombreuses décisions ont déjà été prises lors de la prise de nouvelles décisions. Cependant, lorsque vous réalisez que votre supply chain a besoin d’un changement drastique dans sa trajectoire, il n’y a aucun intérêt à retarder cette correction uniquement pour retarder la décision. Le meilleur moment pour mettre en œuvre le changement, c’est maintenant.
En ce qui concerne l’aspect du bruit évoqué dans la question, tout se résume à la bonne conception des recettes numériques. Il existe de nombreuses conceptions erronées qui sont instables, où de petits changements dans les données génèrent de grands écarts dans les décisions issues de la recette numérique. Une recette numérique ne devrait pas être instable dès qu’il y a une petite fluctuation dans la supply chain. C’est pourquoi Lokad a adopté une perspective probabiliste sur la prévision. En adoptant une perspective probabiliste, les modèles peuvent être conçus pour être bien plus stables par rapport à ceux qui tentent de capturer la moyenne et deviennent instables dès qu’un cas aberrant se produit dans la supply chain.
Question: L’un des problèmes que nous rencontrons en supply chain avec des très grandes entreprises est leur dépendance à différents systèmes sources. N’est-il pas extrêmement difficile de rassembler toutes les données de ces systèmes sources sous un système unifié ?
Je suis tout à fait d’accord pour dire que rassembler toutes les données constitue un défi important pour de nombreuses entreprises. Toutefois, nous devons nous demander pourquoi c’est un défi en premier lieu. Comme je l’ai mentionné précédemment, 99 % des applications métier exploitées par les grandes entreprises de nos jours reposent sur des bases de données transactionnelles grand public et bien conçues. Il pourrait encore y avoir quelques implémentations COBOL super legacy fonctionnant sur des stockages binaires obscurs, mais c’est rare. La grande majorité des applications métier, même celles déployées dans les années 1990, fonctionnent avec une base de données transactionnelle de qualité production en backend.
Une fois que vous disposez d’un backend transactionnel, pourquoi serait-il difficile de copier ces données dans un data lake ? La plupart du temps, le problème est que les entreprises n’essaient pas simplement de copier les données – elles tentent d’en faire beaucoup plus. Elles essaient de préparer et de transformer les données, compliquant souvent excessivement le processus. La plupart des configurations modernes de bases de données disposent de fonctionnalités intégrées de mirroring des données, vous permettant de répliquer tous les changements d’une base de données transactionnelle vers une base de données secondaire. C’est une propriété intégrée à probablement une vingtaine des systèmes transactionnels les plus utilisés sur le marché.
Les entreprises ont tendance à rencontrer des difficultés pour consolider les données parce qu’elles essaient d’en faire trop, et leurs initiatives s’effondrent sous leur propre complexité. Une fois les données consolidées, les entreprises commettent souvent l’erreur de penser que la connexion des données devrait être effectuée par les équipes IT, BI ou data science. Le point que je souhaite faire valoir ici est que la supply chain doit être responsable de ses propres recettes numériques, tout comme le marketing, les ventes et la finance devraient l’être. Ce ne devrait pas être une division de support transverse qui tente de faire cela pour l’entreprise. Connecter les données provenant de différents systèmes nécessite généralement une multitude d’insights métier. Les grandes entreprises échouent souvent parce qu’elles essaient de confier cette tâche à un expert des équipes IT, BI ou data science alors qu’elle devrait être réalisée au sein de la division concernée.
Merci beaucoup pour votre temps aujourd’hui, votre intérêt et vos questions. À la prochaine, après l’été, en septembre.