00:05 Introduzione
02:50 Due illusioni
09:09 Un pipeline di compilazione
14:23 La storia finora
18:49 Bollettino di spedizione
19:40 Progettazione del linguaggio
23:52 Il futuro
30:35 Il passato
35:57 Scegliere le battaglie
39:45 Grammatiche 1/3
42:41 Grammatiche 2/3
49:02 Grammatiche 3/3
53:02 Analisi statica 1/2
58:50 Analisi statica 2/2
01:04:55 Sistema di tipi
01:11:59 Internals del compilatore
01:27:48 Ambiente di runtime
01:33:57 Conclusioni
01:36:33 Prossima lezione e domande del pubblico
Descrizione
La maggior parte delle supply chain viene ancora gestita tramite fogli di calcolo (ad esempio Excel), mentre i sistemi aziendali sono stati implementati da uno, due, talvolta tre decenni - presumibilmente per sostituirli. Infatti, i fogli di calcolo offrono un’espressività programmatica accessibile, mentre quei sistemi in genere no. Più in generale, dal 1960, c’è stata una costante co-sviluppo dell’industria del software nel suo complesso e dei suoi linguaggi di programmazione. Ci sono prove che la prossima fase delle performance della supply chain sarà in gran parte guidata dallo sviluppo e dall’adozione di linguaggi di programmazione, o meglio di ambienti programmabili.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Linguaggi e Compilatori per la Supply Chain”. Non ricordo di aver mai visto i compilatori discussi in alcun libro di testo sulla supply chain eppure l’argomento è di primaria importanza. Abbiamo visto nel primo capitolo di questa serie, nella lezione intitolata “Consegna Orientata al Prodotto”, che la programmazione è la chiave per capitalizzare il tempo investito dagli esperti di supply chain. Senza programmazione, non possiamo capitalizzare il loro tempo e trattiamo gli esperti di supply chain come sostituibili.
Inoltre, in questo stesso quarto capitolo, attraverso le due lezioni precedenti “Ottimizzazione Matematica per la Supply Chain” e “Apprendimento Automatico per la Supply Chain”, abbiamo visto che questi due campi - ottimizzazione e apprendimento - sono diventati guidati dai paradigmi di programmazione nel corso dell’ultimo decennio, invece di rimanere un insieme di algoritmi e modelli come era solito essere in passato. Tutti questi elementi indicano l’importanza primaria dei linguaggi di programmazione e quindi sorge la domanda di un linguaggio di programmazione e di un compilatore progettati per affrontare le sfide della supply chain.
Lo scopo di questa lezione è svelare il mistero della progettazione di un linguaggio di programmazione appositamente pensato per scopi legati alla supply chain. La tua azienda probabilmente non svilupperà mai un linguaggio di programmazione proprio. Tuttavia, avere una certa conoscenza dell’argomento è fondamentale per valutare l’adeguatezza degli strumenti che hai a disposizione e quelli che intendi acquisire per affrontare le sfide della supply chain che la tua azienda deve affrontare. Inoltre, questa lezione ti aiuterà anche a evitare alcuni dei grandi errori che le persone che non hanno alcuna conoscenza in questo campo tendono a commettere.

Iniziamo col dissipare due illusioni che sono state prevalenti nei circoli del software aziendale negli ultimi tre decenni circa. La prima è l’illusione della “programmazione Lego”, in cui la programmazione viene considerata come qualcosa che può essere completamente bypassato. In effetti, la programmazione è difficile e ci sono sempre fornitori che promettono che attraverso il loro prodotto e la loro tecnologia fantastica, la programmazione può essere trasformata in un’esperienza visiva accessibile a chiunque, eliminando completamente tutte le difficoltà della programmazione stessa in modo che l’esperienza diventi essenzialmente simile all’assemblaggio di Lego, qualcosa che persino un bambino può fare.
Questo è stato tentato innumerevoli volte negli ultimi due decenni e ha sempre fallito. Al massimo, i prodotti che erano destinati a offrire un’esperienza visiva si sono trasformati in linguaggi di programmazione regolari che non sono particolarmente più facili da padroneggiare rispetto ad altri linguaggi di programmazione. Questa è, tra l’altro, la ragione per cui, ad esempio, nella serie di prodotti Microsoft, ci sono le serie “Visual”, come Visual Basic for Application e Visual Studio. Tutti quei prodotti visivi sono stati introdotti negli anni ‘90 con la speranza di trasformare la programmazione in un’esperienza puramente visiva con designer in cui si potesse semplicemente trascinare e rilasciare. La realtà è che tutti quegli strumenti hanno alla fine raggiunto un grado molto significativo di successo, ma sono solo linguaggi di programmazione abbastanza regolari al giorno d’oggi. È rimasto ben poco delle parti visive che erano all’origine di quei prodotti.
L’approccio Lego è fallito perché fondamentalmente il collo di bottiglia non è l’ostacolo della sintassi di programmazione. Questo è un ostacolo, ma è minimo, soprattutto rispetto alla padronanza dei concetti che sono coinvolti ogni volta che si vuole implementare qualsiasi tipo di automazione sofisticata. La tua mente diventa il collo di bottiglia e la tua comprensione dei concetti in gioco è molto più significativa della sintassi.
La seconda illusione è l’illusione della “tecnologia di Star Wars”, che consiste nel pensare che sia facile collegare e utilizzare fantastiche tecnologie. Questa illusione è molto allettante per i fornitori e per i progetti interni. Fondamentalmente, diventa molto tentante dire che c’è questo fantastico database NoSQL che possiamo semplicemente inserire, o c’è questa fantastica pila di deep learning che possiamo adottare, o questo database a grafo, o questo framework attivo distribuito, ecc. Il problema di questo approccio è che tratta la tecnologia come viene trattata in Star Wars. Quando hai una mano meccanica, l’eroe può semplicemente prendere la mano meccanica e funziona. Ma nella realtà, i problemi di integrazione dominano.
Star Wars bypassa il fatto che ci sarebbero una serie di problemi: prima di tutto, avresti bisogno di antibiotici, poi di una lunga rieducazione della mano per poterla usare. Avresti anche bisogno di un programma di manutenzione per la mano perché è meccanica, e che dire della fonte di alimentazione, ecc. Tutti questi problemi vengono semplicemente bypassati. Basta collegare il fantastico pezzo di tecnologia e funziona. Questo non è il caso nella realtà. I problemi di integrazione dominano e ad esempio, nelle grandi aziende di software, la maggior parte degli ingegneri del software non sta lavorando su pezzi di tecnologia fantastici e cool. La maggior parte della forza lavoro di ingegneria della stragrande maggioranza di quei grandi fornitori di software è dedicata solo all’integrazione di tutte le parti.
Quando hai moduli, componenti o app, hai bisogno di un piccolo esercito di ingegneri solo per incollare tutte queste cose insieme e far fronte a tutti i problemi che sorgono quando si cerca di unire queste cose. Anche una volta superati tutti gli ostacoli dell’integrazione, hai comunque bisogno di molta forza lavoro di ingegneria solo per far fronte al fatto che quando modifichi una parte del sistema, tendi a creare problemi in altre parti del sistema. Quindi hai bisogno di questa forza lavoro di ingegneria per correre in giro e risolvere quei problemi.
A proposito, come aneddoto, un altro problema che ho osservato con pezzi di tecnologia cool è l’effetto Dunning-Kruger che crea tra gli ingegneri. Introduci un pezzo di tecnologia cool nel tuo stack e improvvisamente gli ingegneri, solo perché hanno iniziato a giocare con un pezzo di tecnologia che capiscono appena, pensano di essere improvvisamente esperti di intelligenza artificiale o qualcosa del genere. Questo è un tipico caso dell’effetto Dunning-Kruger ed è molto strettamente legato al numero di pezzi di tecnologia cool che inserisci nella tua soluzione. In conclusione, con queste due illusioni, vediamo che non possiamo davvero bypassare il problema della programmazione. Dobbiamo affrontarlo in modo funzionale, comprese le parti difficili.
Ora, detto questo, la cosa interessante dei linguaggi di programmazione è che i fornitori di software aziendali continuano a reinventare, accidentalmente, linguaggi di programmazione, e lo fanno tutto il tempo. Infatti, nella supply chain, c’è un enorme bisogno di configurabilità. Come abbiamo visto nelle lezioni precedenti, il mondo della supply chain è vario e i problemi sono numerosi e diversi. Pertanto, quando hai un prodotto software per la supply chain, c’è un bisogno estremamente intenso di configurabilità. Aneddoticamente, è per questo che configurare un pezzo di software è tipicamente un progetto di diversi mesi e talvolta di diversi anni. È perché c’è una quantità enorme di complessità che entra in questa configurazione.
Le impostazioni di configurazione sono spesso complesse, non solo pulsanti o caselle di controllo. Puoi avere trigger, formule, cicli e tutti i tipi di blocchi che vanno con essi. Rapidamente sfugge al controllo e ciò che ottieni attraverso queste impostazioni di configurazione è un linguaggio di programmazione emergente. Tuttavia, poiché è un linguaggio di programmazione emergente, tende ad essere molto scadente.
Progettare un vero e proprio linguaggio di programmazione è un compito di ingegneria ben consolidato. Ci sono dozzine di libri sulle pratiche dell’ingegneria di un compilatore di produzione. Un compilatore è un programma che converte istruzioni, tipicamente istruzioni di testo, in codice macchina o in una forma di istruzioni di livello inferiore. Ogni volta che c’è un linguaggio di programmazione, è coinvolto un compilatore. Ad esempio, all’interno di un foglio di calcolo Excel, hai formule e Excel ha un suo compilatore per compilare quelle formule ed eseguirle. Molto probabilmente, l’intero pubblico ha utilizzato compilatori per tutta la sua vita professionale senza saperlo.
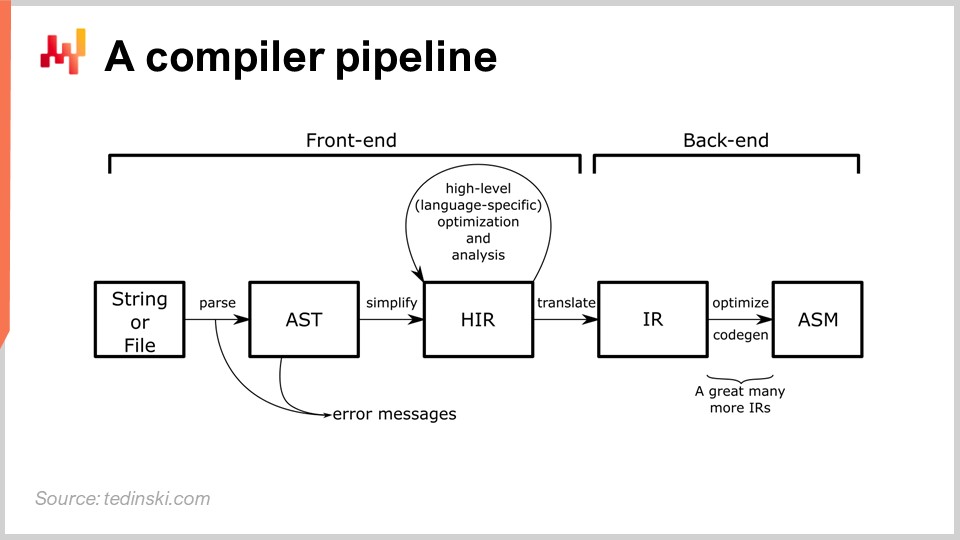
Nel diagramma puoi vedere un tipico pipeline e questo archetipo si adatta alla maggior parte dei linguaggi di programmazione che hai probabilmente sentito parlare, come Python, JavaScript, Java e C#. Tutti questi linguaggi hanno una pipeline essenzialmente simile a quella descritta qui. In una pipeline di compilazione, hai una serie di trasformazioni e in ogni fase del processo hai una rappresentazione che rappresenta l’intero programma. Il modo in cui un compilatore è progettato è avere una serie di trasformazioni ben identificate e in ogni fase del processo stai lavorando con l’intero programma. È solo rappresentato in modo diverso.
L’idea è che ogni trasformazione sia responsabile di un insieme di problemi ben specificato. Affronti quei problemi e poi passi alla prossima trasformazione che affronterà un altro aspetto del processo. Tipicamente, ad ogni stadio, ti avvicini al codice di livello macchina. Il compilatore inizia con lo script e inizia con trasformazioni molto vicine alla sintassi del linguaggio di programmazione di interesse. Durante queste prime trasformazioni, un compilatore tipico catturerà errori sintattici che impediscono al compilatore di trasformare uno script che non rappresenta nemmeno un programma valido in qualcosa di eseguibile. Torneremo a dare un’occhiata più da vicino a una pipeline di compilazione più avanti in questa lezione.
Questa lezione è la quinta lezione del quarto capitolo di questa serie. Nel primo capitolo ho presentato le mie opinioni sulla supply chain sia come campo di studio che come pratica. Nel secondo capitolo ho esaminato le metodologie appropriate per affrontare le situazioni che si trovano nella supply chain. Come abbiamo visto, la maggior parte delle situazioni della supply chain sono piuttosto avverse per natura, quindi abbiamo bisogno di strategie e metodologie che siano resilienti ai comportamenti avversari di tutte le parti all’interno e all’esterno delle aziende.
Il terzo capitolo è dedicato al personale della supply chain ed è interamente dedicato allo studio dei problemi della supply chain stessa. Dobbiamo fare molta attenzione a non confondere il problema che stiamo scoprendo con il tipo di soluzione che possiamo immaginare per affrontare questo problema. Queste sono due preoccupazioni distinte: dobbiamo separare il problema dalla soluzione.
Il quarto e attuale capitolo di questa serie di lezioni è dedicato alle scienze ausiliarie della supply chain. Queste scienze ausiliarie non sono la supply chain di per sé, ma sono molto utili per la pratica della moderna supply chain. Attualmente stiamo avanzando nella scala delle astrazioni. Abbiamo iniziato questo capitolo con la fisica del calcolo, poi con gli algoritmi, siamo passati al campo del software. Abbiamo introdotto l’ottimizzazione matematica, che è di grande interesse per la supply chain ed è anche la base del machine learning.
Oggi stiamo introducendo linguaggi e compilatori, essenziali per implementare qualsiasi tipo di paradigma di programmazione. Sebbene l’argomento dei linguaggi e dei compilatori possa sorprendere il pubblico, credo che a questo punto non dovrebbe essere troppo sorprendente. Abbiamo visto che l’ottimizzazione matematica e il machine learning dovrebbero essere affrontati oggi attraverso paradigmi di programmazione, il che solleva la questione di come implementare quei paradigmi di programmazione. Ciò ci porta alla progettazione di un linguaggio di programmazione e del suo compilatore di supporto, che è esattamente l’argomento di oggi.

Questo è un riassunto del resto di questa lezione. Inizieremo con osservazioni di alto livello sulla storia e il mercato dei linguaggi di programmazione. Esamineremo settori che rappresentano, a mio parere, sia il futuro che il passato della supply chain. Poi ci immergeremo gradualmente nella progettazione di linguaggi di programmazione e compilatori, procedendo con preoccupazioni di livello inferiore e le tecniche coinvolte nella progettazione di un compilatore.

Dagli anni ‘50, sono stati sviluppati migliaia di linguaggi di programmazione. Le stime variano, ma il numero di linguaggi di programmazione utilizzati per scopi produttivi probabilmente varia tra mille e diecimila. Molti di questi linguaggi sono solo variazioni o cugini l’uno dell’altro, a volte persino solo il codice del compilatore biforcato in una direzione leggermente diversa. È notevole che diverse grandi aziende di software enterprise si siano espandate molto attraverso l’introduzione di linguaggi di programmazione di loro creazione. Ad esempio, SAP ha introdotto ABAP nel 1983, Salesforce ha introdotto Apex nel 2006 e persino Microsoft ha iniziato prima di Windows progettando l’Altair BASIC nel 1975.
Storicamente, coloro di voi nel pubblico abbastanza vecchi da ricordare gli anni ‘90 potrebbero ricordare che i fornitori dell’epoca stavano promuovendo linguaggi di programmazione di terza e quarta generazione. La realtà è che c’era una serie ben identificata di generazioni - prima, seconda, terza, quarta, ecc. - che portava alla quinta, dove essenzialmente la comunità ha smesso di contare in termini di generazioni. Durante i primi tre o quattro decenni, tutti quei linguaggi di programmazione seguivano una bella progressione verso livelli più elevati di astrazione. Tuttavia, alla fine degli anni ‘90, c’erano già molte altre direzioni oltre ad avere un grado di astrazione più elevato, a seconda del caso d’uso.
Creare un nuovo linguaggio di programmazione è stato fatto molte volte. È un campo di ingegneria ben consolidato, e ci sono interi libri dedicati all’argomento da un punto di vista molto pratico. L’ingegneria di un nuovo linguaggio di programmazione è una pratica molto più concreta e prevedibile rispetto, diciamo, a condurre un esperimento di data science. C’è una quasi certezza che otterrai il risultato desiderato se stai facendo l’ingegneria adeguata, considerando ciò che è noto oggi e ciò che è prontamente disponibile come conoscenza.
Tutto ciò solleva davvero la domanda: che ne dici di un linguaggio di programmazione appositamente progettato per scopi di supply chain? In effetti, ci possono essere significativi vantaggi in termini di produttività, affidabilità e persino prestazioni della supply chain.

Per affrontare questa domanda, dobbiamo dare un’occhiata al futuro. Fortunatamente per noi, il modo più semplice per guardare al futuro è esaminare un’industria che è stata costantemente un decennio avanti a tutti gli altri negli ultimi tre decenni circa, ed è l’industria dei videogiochi. Questa è un’industria molto grande al giorno d’oggi, e solo per darvi un’idea della scala, l’industria dei videogiochi rappresenta ora i due terzi dell’industria aerospaziale a livello mondiale in termini di dimensioni comparative, e sta crescendo molto più velocemente dell’aerospaziale. Tra dieci anni, i videogiochi potrebbero essere addirittura più grandi dell’aerospaziale.
La cosa interessante dell’industria dei videogiochi è che ha una struttura molto consolidata. Innanzitutto, abbiamo i motori di gioco, con i due leader che sono Unity e Unreal. Questi motori di gioco presentano i componenti a basso livello che sono di interesse per grafica 3D super intensiva e raffinata, e delineano il panorama per il livello di infrastruttura del tuo codice. Ci sono alcune aziende che progettano prodotti molto complessi chiamati motori di gioco, e questi motori vengono utilizzati da tutta l’industria.
Successivamente, abbiamo gli studi di gioco, che sviluppano il codice di gioco per ogni singolo gioco. Il codice di gioco sarà una base di codice tipicamente specifica per il gioco in fase di sviluppo. Il motore di gioco richiede ingegneri del software molto esperti che hanno competenze tecniche molto elevate ma non necessariamente sanno molto di giochi. Lo sviluppo del codice di gioco non è così intensivo in termini di pura abilità tecnica. Tuttavia, gli ingegneri del software che sviluppano il codice di gioco devono capire il gioco su cui stanno lavorando. Il codice di gioco stabilisce la piattaforma per le meccaniche di gioco, ma non specifica i dettagli.
Questo compito è tipicamente gestito dai game designer, che non sono ingegneri del software, ma scrivono codice nei linguaggi di scripting resi disponibili loro dal team di ingegneria che si occupa del codice di gioco. Abbiamo queste tre fasi: motori di gioco, che coinvolgono ingegneri del software super tecnici che creano blocchi di base; studi, che hanno team di ingegneria, tipicamente uno per gioco, che sviluppano il gioco come piattaforma per le meccaniche di gioco; e infine, game designer, che non sono ingegneri del software ma sono specialisti di giochi, che implementano il comportamento che renderà felici i giocatori, i clienti alla fine del processo.
Oggi, il codice di gioco è spesso reso accessibile alla base di fan, il che significa che i game designer possono scrivere regole e potenzialmente modificare il gioco, ma anche i fan, che sono semplici consumatori dei giochi, possono farlo. Ci sono alcune interessanti anecdote nell’industria. Ad esempio, il gioco Dota 2, che è incredibilmente di successo, è nato come una modifica di un gioco esistente. La prima versione, chiamata semplicemente Dota, era una modifica pura della base di fan del gioco World of Warcraft 3. Si può vedere che questo grado di configurabilità e programmabilità a livello di regole di gioco è molto esteso perché è stato possibile, da un gioco commerciale esistente, World of Warcraft 3, creare un gioco completamente nuovo, che poi è diventato un enorme successo commerciale attraverso la seconda versione. Ora, questo è interessante, e possiamo iniziare a pensare, guardando all’industria dei videogiochi, cosa significa per l’industria della supply chain?
Beh, potremmo pensare a quale tipo di parallelismo potremmo tracciare. Potremmo avere un motore di supply chain che si occupa delle parti algoritmiche molto complesse, dell’infrastruttura a basso livello e dei blocchi tecnologici fondamentali, come l’ottimizzazione matematica e l’apprendimento automatico. L’idea è che, per ogni singola supply chain, avresti bisogno di un team di ingegneri per portare tutti i dati rilevanti e integrare l’intero panorama applicativo.
Come primo passo, avremmo bisogno dell’equivalente dei game designer, che sarebbero gli specialisti della supply chain. Questi specialisti non sono ingegneri del software, ma sono le persone che scriveranno, attraverso un codice semplificato, tutte le regole e le meccaniche necessarie per implementare l’ottimizzazione predittiva di interesse per la supply chain. L’industria dei videogiochi fornisce un esempio vivido di ciò che è probabile che accada nello spazio della supply chain nel prossimo decennio.

Finora, l’approccio dell’industria dei videogiochi nella supply chain rimane fantascienza, ad eccezione di alcune aziende. Credo che la maggior parte di queste aziende sia cliente di Lokad. Tornando all’argomento di oggi, abbiamo visto nelle lezioni precedenti che Excel rimane il linguaggio di programmazione numero uno in questa industria. A proposito, in termini di linguaggio di programmazione, Excel è un linguaggio di programmazione funzionale reattivo, quindi è persino una classe a sé stante.
Potresti sentire parlare in questi giorni di fornitori che propongono di aggiornare le supply chain utilizzando qualche tipo di configurazione di data science. Tuttavia, la mia osservazione occasionale nell’ultimo decennio è che la stragrande maggioranza di queste iniziative è fallita. Questo è già passato, e per capire il motivo, dobbiamo iniziare a guardare l’elenco dei linguaggi di programmazione coinvolti. Se guardiamo Excel, vediamo che coinvolge essenzialmente due linguaggi di programmazione: le formule di Excel e VBA. VBA non è nemmeno un requisito; puoi andare lontano con solo VLOOKUP in Excel. Tipicamente, sarà solo un linguaggio di programmazione, ed è accessibile anche a non ingegneri del software.
D’altra parte, l’elenco dei linguaggi di programmazione necessari per replicare le capacità di Excel con una configurazione di data science è piuttosto esteso. Avremo bisogno di SQL e potenzialmente di diversi dialetti di SQL per accedere ai dati. Avremo bisogno di Python per implementare la logica principale. Tuttavia, Python da solo tende ad essere lento, quindi potresti aver bisogno di un sotto-linguaggio come NumPy. A questo punto, non stai ancora facendo nulla in termini di apprendimento automatico o ottimizzazione matematica, quindi per un’analisi numerica hardcore, avrai bisogno di qualcos’altro, un altro linguaggio di programmazione a sé stante, come ad esempio PyTorch. Ora che hai tutti questi elementi, hai già parecchie parti in movimento, quindi la configurazione dell’applicazione stessa sarà piuttosto complessa. Avrai bisogno di una configurazione, e questa configurazione sarà scritta con un altro linguaggio di programmazione, come JSON o XML. Indiscutibilmente, questi non sono linguaggi di programmazione super complessi, ma è solo un’altra cosa da aggiungere al piatto.
Cosa succede quando hai così tante parti in movimento è che tipicamente hai bisogno di un sistema di compilazione, qualcosa che può eseguire tutti i compilatori e le ricette banali necessarie per produrre il software. I sistemi di compilazione hanno linguaggi propri. L’approccio tradizionale è un linguaggio chiamato Make, ma ce ne sono molti altri. Inoltre, poiché Excel è in grado di visualizzare i risultati, hai bisogno di un modo per mostrare le cose all’utente e visualizzare le cose. Questo verrà fatto con una combinazione di JavaScript, HTML e CSS, aggiungendo altri linguaggi all’elenco.
A questo punto, abbiamo un lungo elenco di linguaggi di programmazione, e una configurazione di produzione effettiva potrebbe essere ancora più complessa. Questo spiega perché la maggior parte delle aziende che hanno cercato di adottare questa pipeline di data science durante l’ultimo decennio hanno fallito in modo schiacciante e sono rimaste solo con Excel nella pratica. Il motivo è che implica padroneggiare quasi una dozzina di linguaggi di programmazione invece di uno solo, come nel caso di Excel. Non abbiamo nemmeno iniziato a toccare nessuno dei veri problemi della supply chain; abbiamo solo discusso delle tecniche che impediscono di iniziare effettivamente a fare qualcosa.

Ora, iniziamo a pensare a come potrebbe essere un linguaggio di programmazione per la supply chain. Prima di tutto, dobbiamo decidere cosa è incluso nel linguaggio e cosa appartiene al linguaggio come cittadino di prima classe e cosa appartiene alle librerie. Infatti, con i linguaggi di programmazione, è sempre possibile spostare le capacità nelle librerie. Ad esempio, prendiamo in considerazione il linguaggio di programmazione C. È considerato un linguaggio di programmazione piuttosto a basso livello e C non ha un garbage collector. Tuttavia, è possibile utilizzare un garbage collector di terze parti come libreria in un programma C. A causa del fatto che la garbage collection non è un cittadino di prima classe nel linguaggio di programmazione C, la sintassi tende ad essere relativamente verbosa e noiosa.
Per scopi di supply chain, ci sono preoccupazioni come l’ottimizzazione matematica e l’apprendimento automatico che di solito vengono trattate come librerie. Quindi, abbiamo un linguaggio di programmazione e tutte queste preoccupazioni vengono essenzialmente spostate su librerie di terze parti. Tuttavia, se dovessimo progettare un linguaggio di programmazione per la supply chain, avrebbe davvero senso avere queste preoccupazioni progettate come cittadini di prima classe nel linguaggio di programmazione stesso. Inoltre, avrebbe senso avere dati relazionali come parte del linguaggio come cittadino di prima classe. Nella supply chain, il panorama applicativo, che include molti pezzi di software aziendale, ha dati relazionali sotto forma di database relazionali, come database SQL, ovunque. Praticamente tutti i prodotti software aziendali che esistono al giorno d’oggi hanno al loro centro un database relazionale, il che significa che per scopi di supply chain, non appena vogliamo toccare i dati, la realtà è che interagiremo con dati di natura relazionale. I dati si presentano come un elenco di tabelle estratte da tutti quei database che alimentano varie app, e ogni tabella ha un elenco di colonne o campi.
Ha davvero senso avere dati relazionali all’interno del linguaggio. Inoltre, cosa dire dell’interfaccia utente (UI) e dell’esperienza utente (UX)? Uno dei punti di forza di Excel è che tutto questo è completamente integrato nel linguaggio, quindi non hai un linguaggio di programmazione e poi tutte le librerie di terze parti per gestire la presentazione, il rendering e l’interazione dell’utente. Tutto questo fa parte del linguaggio. Avere tutto ciò come cittadino di prima classe sarebbe anche di grande interesse per quanto riguarda la supply chain, almeno se vogliamo essere altrettanto buoni quanto Excel può essere per le supply chain.

Ora, nel design del linguaggio, la grammatica rappresenta la rappresentazione formale delle regole che definiscono un programma valido secondo il tuo nuovo linguaggio di programmazione introdotto. Fondamentalmente, si parte da un pezzo di testo e prima si applica un lexer, che è una classe specifica di algoritmi o un piccolo programma. Il lexer scompone il tuo pezzo di testo, il programma che hai appena scritto, in una sequenza di token. Il lexer isola tutte le variabili e i simboli in gioco nel tuo linguaggio di programmazione. La grammatica aiuta a convertire la sequenza di token nella semantica effettiva del programma, definendo cosa significa il programma e l’esatto insieme non ambiguo di operazioni che devono essere eseguite per eseguirlo.
La grammatica stessa è tipicamente affrontata come un trade-off tra le preoccupazioni che si desidera internalizzare all’interno del proprio linguaggio e i concetti che si desidera esternalizzare. Ad esempio, se si affronta il dato relazionale come una preoccupazione esterna, il programmatore avrebbe bisogno di introdurre molte strutture dati specializzate come dizionari, ricerche e tabelle hash per eseguire manualmente all’interno del linguaggio di programmazione tutte quelle operazioni. Se la grammatica vuole internalizzare l’algebra relazionale, significa che il programmatore può tipicamente scrivere tutta la logica relazionale direttamente nella sua forma relazionale. Tuttavia, ciò significa che improvvisamente tutti questi vincoli relazionali e tutta questa algebra relazionale diventano parte del carico che la grammatica deve sopportare.
Da una prospettiva della catena di fornitura, dato che i dati relazionali sono estremamente diffusi nel software aziendale, ha molto senso avere una grammatica che si occupi direttamente di tutte le preoccupazioni relazionali a livello grammaticale nel linguaggio.

Le grammatiche nell’informatica sono un argomento enormemente studiato. Esistono da decenni eppure è probabilmente l’unico settore in cui i fornitori di software aziendale falliscono maggiormente. Infatti, finiscono invariabilmente per creare linguaggi di programmazione accidentali che emergono naturalmente ogni volta che ci sono impostazioni di configurazione complesse in gioco. Quando si hanno condizioni, trigger, cicli e risposte, di solito è necessario occuparsi di questo linguaggio anziché lasciarlo emergere da solo.

Quello che succede è che quando non si ha una grammatica, ogni volta che si apportano modifiche all’applicazione, si finisce con conseguenze casuali sul comportamento effettivo del sistema. A proposito, questo spiega anche perché l’aggiornamento da una versione di un software aziendale a un’altra è di solito molto complesso. La configurazione dovrebbe essere la stessa, ma quando si prova effettivamente a eseguire la stessa configurazione nella versione successiva del software, si ottengono risultati completamente diversi. La causa principale di questi problemi è la mancanza di una grammatica e di una semantica formalizzata stabilita per ciò che la configurazione andrà a significare.
Il modo tipico per rappresentare una grammatica è formalmente utilizzando la Forma di Backus-Naur (BNF), che è una notazione speciale. Sullo schermo, quello che si può vedere è un mini linguaggio di programmazione che rappresenta gli indirizzi postali degli Stati Uniti. Ogni riga con un segno di uguale rappresenta una regola di produzione. Quello che si ha a sinistra è un simbolo non terminale e a destra del segno di uguale c’è una sequenza di simboli terminali e non terminali. I simboli terminali sono in rosso e rappresentano simboli che non possono essere derivati ulteriormente. I simboli non terminali sono tra parentesi quadre e possono essere derivati ulteriormente. Questa grammatica qui non è completa; ci sarebbero molte altre regole di produzione da aggiungere per una grammatica completa. Volevo solo mantenere questa diapositiva ragionevolmente concisa.
Una grammatica è qualcosa di molto semplice da definire in termini di sintassi per il tuo linguaggio di programmazione e garantisce anche che sarà non ambigua. Tuttavia, non è perché è scritta con la Forma di Backus-Naur che sarà una grammatica valida o anche una buona grammatica. Per avere una buona grammatica, dobbiamo fare un po’ di più. Il modo matematico per caratterizzare una buona grammatica è avere una grammatica senza contesto. Una grammatica si dice senza contesto se le regole di produzione possono essere applicate per qualsiasi non terminale, indipendentemente dai simboli che si trovano a destra e a sinistra. L’idea è che una grammatica senza contesto è qualcosa in cui è possibile applicare le regole di produzione in qualsiasi ordine e non appena si vede una corrispondenza o una derivazione, la si applica.
Ciò che si ottiene da una grammatica senza contesto è una grammatica che, se si apporta una modifica e questa modifica crea un’ambiguità, il compilatore non sarà in grado di compilare il programma in cui si verifica l’ambiguità. Questo è di interesse primario quando si intende mantenere una configurazione per un lungo periodo di tempo. Nelle catene di approvvigionamento, la maggior parte del software aziendale ha una durata molto lunga. Non è raro vedere pezzi di software aziendale che operano da due a tre decenni. Da Lokad, stiamo servendo oltre 100+ aziende ed è abbastanza comune che estraiamo dati da sistemi che sono stati in uso per oltre tre decenni, soprattutto con grandi aziende.
Con una grammatica senza contesto, si ottiene la garanzia che se c’è una modifica da apportare a questo linguaggio (e ricorda, quando dico “linguaggio”, posso intendere qualcosa di semplice come le impostazioni di configurazione), sarai in grado di identificare le ambiguità che emergono quando si applica questa modifica. Questo invece di avere queste ambiguità che si verificano senza che tu ti renda conto di avere un problema, il che può portare a difficoltà durante l’aggiornamento da un sistema all’altro.
Cosa succede quando le persone non sanno nulla sulle grammatiche è che scrivono manualmente un parser. Se non hai mai sentito parlare di una grammatica, un ingegnere del software scriverà un parser, che è un programma che crea in modo casuale una sorta di albero che rappresenta la versione analizzata del tuo programma. Il problema è che si finisce con una semantica per il proprio programma che è incredibilmente specifica per la versione del programma che si ha. Quindi, se si cambia questo programma, si cambia la semantica e si otterranno risultati diversi, il che significa che si può avere la stessa configurazione ma un comportamento diverso per la catena di approvvigionamento.
Fortunatamente, nel 2004, è stato introdotto un piccolo progresso da Brian Ford con un articolo intitolato “Parsing Expression Grammars: A Recognition-Based Syntactic Foundation”. Con questo lavoro, Ford ha fornito alla comunità un modo per formalizzare il tipo di parser ad hoc accidentale che esiste nel campo. Ad esempio, queste grammatiche sono chiamate Parsing Expression Grammars (PEG) e con le PEG è possibile convertire quei parser empirici semi-accidentali in grammatiche formali effettive di qualche tipo.
Python, ad esempio, non ha esattamente una grammatica senza contesto ma ha una PEG. Le PEG sono abbastanza buone se si dispone di un ampio set di test automatizzati perché, in questo caso, si può gestire la conservazione della semantica nel tempo. Infatti, con le PEG si ha una formalizzazione della propria grammatica, quindi si è in una situazione migliore rispetto a non avere alcuna grammatica e avere solo un parser. Tuttavia, in termini di evoluzione della semantica, con una PEG non si rileverà automaticamente che si ha un cambiamento di semantica se si cambia la grammatica stessa. Pertanto, è necessario disporre di un ampio set di test automatizzati oltre alla propria PEG, che, tra l’altro, è esattamente ciò che ha la comunità di Python. Hanno un set di test automatizzati molto robusto ed esteso. Ora, dal punto di vista della catena di approvvigionamento, credo che le grammatiche non solo abbiano un interesse nel farti rendere conto della loro importanza, ma costituiscano anche un test diagnostico. È possibile testare effettivamente i fornitori di software aziendale quando si discute di un pezzo di software con una complessità significativa. Si dovrebbe chiedere al fornitore quale grammatica utilizzano per la configurazione complessa. Se il fornitore risponde con “cosa è una grammatica?”, allora si sa di essere in difficoltà e la manutenzione sarà probabilmente lenta ed costosa.

La programmazione è molto difficile e le persone commetteranno molti errori. Se fosse facile, non avremmo nemmeno bisogno di programmazione in primo luogo. Un buon linguaggio di programmazione riduce al minimo il tempo necessario per identificare un errore e correggerlo. Questo è uno degli aspetti più critici di un linguaggio di programmazione, garantendo una produttività decente per chiunque si trovi a scrivere codice.
Consideriamo la seguente situazione: mentre scrivi il codice, se l’errore può essere rilevato durante la digitazione, come un errore di battitura sottolineato in rosso in Microsoft Word, allora il ciclo di feedback per correggere l’errore può essere breve come 10 secondi, il che è ideale. Se l’errore può essere rilevato solo quando si avvia il programma, il ciclo di feedback sarà di almeno 10 minuti. Nella supply chain, spesso abbiamo grandi set di dati da elaborare e non possiamo aspettarci che il programma inizi a elaborare tutti i dati in pochi secondi. Di conseguenza, se il problema si verifica solo durante l’esecuzione, il ciclo di feedback sarà di 10 minuti o più.
Se l’errore può essere rilevato solo dopo il completamento dello script, il che significa che il programma ha un errore ma non fallisce, il ciclo di feedback richiederà circa 10 ore o più. Siamo passati da 10 secondi di feedback in tempo reale a 10 minuti se dobbiamo eseguire il programma e poi 10 ore se dobbiamo ispezionare i risultati numerici e gli indicatori di performance prodotti dal programma.
C’è addirittura uno scenario peggiore: se la piattaforma su cui operi non è strettamente deterministica, il che significa che con lo stesso input e dati può darti risultati diversi. Questo non è così strano come potrebbe sembrare, poiché nella supply chain potremmo avere simulazioni Monte Carlo in corso. Se ci sono casualità nei risultati, possiamo avere qualcosa che fallisce solo di tanto in tanto, e in questa situazione, il ciclo di feedback di solito è più lungo di 10 giorni. Quindi, siamo passati da 10 secondi a 10 giorni, e ci sono enormi interessi nel ridurre questo ciclo di feedback. L’analisi statica rappresenta un insieme di tecniche che possono essere applicate per rilevare problemi, errori o fallimenti senza nemmeno eseguire il programma in primo luogo. Con l’analisi statica, l’idea è che non eseguirai nemmeno il programma, il che significa che puoi segnalare l’errore in tempo reale mentre le persone stanno digitando, proprio come un sottolineatura rossa per gli errori di battitura in Microsoft Word. Più in generale, c’è un forte interesse nel trasformare ogni problema in modo che si sposti verso una classe di feedback precedente, trasformando problemi che richiederebbero giorni per essere identificati in minuti o minuti in secondi, e così via.
Dal punto di vista della supply chain, abbiamo visto in una delle lezioni precedenti che le supply chain possono aspettarsi molto caos. Non possiamo avere cicli di rilascio classici in cui si attende la prossima versione del software da consegnare. A volte ci sono eventi straordinari, come un cambio di tariffa, una nave portacontainer bloccata in un canale o una pandemia. Queste situazioni di emergenza richiedono correzioni di emergenza, e la quantità di analisi statica che puoi fare sul tuo linguaggio di programmazione definisce praticamente quanto caos avrai in produzione a causa di errori non rilevati in tempo reale durante la digitazione del codice. Gli eventi straordinari possono sembrare rari, ma nella pratica le sorprese nella supply chain sono piuttosto comuni.

Ci sono prove matematiche che non è possibile rilevare tutti gli errori con un linguaggio di programmazione generale in una situazione generale. Ad esempio, non è nemmeno possibile dimostrare che il programma si completerà, il che significa che non è possibile garantire che ciò che hai scritto non continuerà semplicemente ad eseguirsi all’infinito.
Con l’analisi statica, di solito si ottengono tre categorie: alcune parti del codice sono probabilmente buone, alcune parti sono probabilmente cattive e per molte cose in mezzo, semplicemente non lo sai. L’idea è che più sposti da “non lo sai” a “codice sbagliato”, più sforzo avrai bisogno in termini di progettazione del linguaggio per convincere il compilatore che il tuo programma è valido. Quindi, dobbiamo trovare un equilibrio tra quanto sforzo vuoi investire per convincere il linguaggio di programmazione che il tuo codice è corretto rispetto a quante garanzie vuoi avere sul programma al momento della compilazione, anche prima che il programma venga effettivamente eseguito. Questo è una questione di produttività.
Ora, un elenco rapido degli errori tipici rilevati con l’analisi statica include errori di sintassi, come virgole o parentesi dimenticate. Alcuni linguaggi di programmazione non possono nemmeno evidenziare gli errori di sintassi prima dell’esecuzione, come Bash, il linguaggio della shell su Linux. L’analisi statica può anche rilevare errori di tipo, che si verificano quando hai il tipo o il numero di argomenti errato per una funzione che stai chiamando.
Il codice irraggiungibile può essere rilevato anche, il che significa che il codice è corretto, ma non verrà mai eseguito perché l’intero programma può essere eseguito senza mai raggiungere quella parte di codice. È come un codice morto o una connessione logica dimenticata. Un altro problema che può essere identificato è il codice insignificante, in cui il codice viene eseguito ma non ha alcun impatto sull’output finale. È una variante del codice irraggiungibile.
Può essere rilevato anche il codice che consuma troppa risorsa, che si riferisce al codice che verrebbe eseguito, tranne che la quantità di risorse di calcolo necessarie supera di gran lunga ciò che puoi permetterti per il tuo programma. Un programma consuma risorse di calcolo come memoria, archiviazione e CPU. Attraverso l’analisi statica, puoi dimostrare che un blocco di codice consuma molto più risorse di quanto puoi permetterti, considerando i tuoi vincoli come completare il calcolo entro un determinato intervallo di tempo. Vorresti che questo fallisca al momento della compilazione anziché eseguire il programma per un’ora e poi farlo fallire a causa di un timeout, il che porterebbe a una produttività molto bassa.
Tuttavia, c’è un’eccezione quando si tratta di analisi statica. Mentre digiti, stai lavorando con un programma che è sempre non valido. Man mano che digiti colpo dopo colpo, stai trasformando un programma valido in uno non valido. Una soluzione di livello industriale per questa situazione si chiama Language Server Protocol. Questo strumento viene fornito con un linguaggio di programmazione ed è lo stato dell’arte quando si tratta di feedback sugli errori in tempo reale per i programmi che stai digitando.
Attraverso un Language Server Protocol, puoi accedere a funzionalità come “vai alla definizione” quando fai clic su una variabile. Il Language Server Protocol è fondamentalmente stato, ricordando l’ultima versione del tuo programma che era corretta, insieme alle annotazioni e alla semantica disponibili. Conserva queste annotazioni e dettagli extra quando si tratta del tuo programma non funzionante solo perché hai premuto un tasto in più e non è più un programma valido. È un cambiamento di gioco in termini di produttività e ogni volta che c’è un certo grado di urgenza, fa una grande differenza per scopi di supply chain.

Ora, approfondiamo il sistema di tipi. Come prima approssimazione approssimativa, un sistema di tipi è un insieme di regole che sfrutta la categorizzazione degli oggetti nel tuo programma, o la categorizzazione degli elementi che manipoli, per chiarire se determinate interazioni sono consentite o vietate. Ad esempio, i tipi tipici includono stringhe, interi e numeri in virgola mobile, tutti tipi molto basilari. Definirà che l’aggiunta di due interi insieme è valida, ma l’aggiunta di una stringa e un intero non è valida, tranne in JavaScript perché la semantica è diversa lì.
I sistemi di tipi, in generale, sono un problema di ricerca aperto e possono diventare incredibilmente astratti. Per fare un po’ di chiarezza, dobbiamo chiarire che ci sono due tipi di tipi, che vengono spesso confusi. In primo luogo, ci sono i tipi di valori, che esistono solo durante l’esecuzione quando il programma viene effettivamente eseguito. Ad esempio, in Python, se stiamo considerando una funzione che restituisce il primo elemento di un array di interi, allora il tipo del valore restituito da questa funzione sarà un intero. Da questa prospettiva, tutti i linguaggi di programmazione hanno tipi - sono tutti tipizzati.
In secondo luogo, ci sono i tipi di variabili, che esistono solo durante la compilazione mentre il programma viene compilato e non ancora eseguito. La sfida con i tipi di variabili è estrarre il maggior numero possibile di informazioni su quelle variabili durante la compilazione. Se torniamo all’esempio precedente, in Python potrebbe essere possibile o meno identificare il tipo del valore restituito dalla funzione, perché Python non è completamente fortemente tipizzato durante la compilazione.
Da una prospettiva della supply chain, stiamo cercando un sistema di tipi che supporti ciò che intendiamo fare a beneficio della supply chain. Vogliamo essere il più restrittivi possibile per individuare problemi e bug in anticipo, ma anche il più flessibili possibile per consentire tutte le operazioni che potrebbero essere di interesse. Ad esempio, consideriamo l’aggiunta di una data e un numero intero. In un linguaggio di programmazione normale, probabilmente diremmo che non è legittimo, ma da una prospettiva della supply chain, se abbiamo una data e vogliamo aggiungere sette giorni, avrebbe senso scrivere “data + 7”. Ci sono molte operazioni nella pianificazione della supply chain che coinvolgono lo spostamento delle date di un certo numero di giorni, quindi sarebbe utile avere un’algebra in cui è consentito eseguire un’addizione tra una data e un numero.
In termini di tipi, vogliamo consentire l’aggiunta di una data a un’altra? Probabilmente no. Tuttavia, vogliamo consentire la sottrazione tra due date? Perché no? Se sottraiamo una data da un’altra che si verifica prima di essa, otteniamo il delta, che potrebbe essere espresso in giorni. Questo ha molto senso per i calcoli coinvolti nella pianificazione.
Continuando con l’argomento delle date, ci sono anche caratteristiche che potrebbero essere di interesse quando si pensa a cosa un sistema di tipi dovrebbe fare per noi in termini di preoccupazioni della supply chain. Ad esempio, che ne dici di limitare l’intervallo di tempo accettabile? Potremmo dire che le date al di fuori del periodo di 20 anni nel passato e 20 anni nel futuro non sono valide. È probabile che se stiamo effettuando un’operazione di pianificazione e in qualche punto del programma manipoliamo una data che è più di 20 anni nel futuro, le probabilità siano schiaccianti che non si tratti di una pianificazione valida per la maggior parte delle industrie. Nella maggior parte dei casi, non pianificheresti operazioni su base giornaliera più di 20 anni in anticipo. Quindi, non possiamo solo prendere i tipi usuali, ma ridefinirli in modi più restrittivi e più appropriati per scopi della supply chain.
Inoltre, c’è tutto l’aspetto dell’incertezza. Nella gestione della supply chain, stiamo sempre guardando avanti, ma sfortunatamente, il futuro è sempre incerto. Il modo matematico per abbracciare l’incertezza è attraverso le variabili casuali. Avrebbe senso incorporare variabili casuali nel linguaggio per rappresentare la domanda futura incerta, i tempi di consegna e i resi dei clienti, tra le altre cose.
Da Lokad, abbiamo sviluppato Envision, un linguaggio di programmazione dedicato all’ottimizzazione predittiva delle supply chain. Envision è un mix di SQL, Python, ottimizzazione matematica, machine learning e capacità di big data, il tutto racchiuso come cittadini di prima classe all’interno del linguaggio stesso. Questo linguaggio è dotato di un ambiente di sviluppo integrato (IDE) basato sul web, il che significa che è possibile scrivere uno script dal web e disporre di tutte le moderne funzionalità di modifica del codice. Questi script operano su un sistema di file distribuito integrato che fa parte dell’ambiente Lokad, quindi il livello dei dati è completamente integrato nel linguaggio di programmazione.
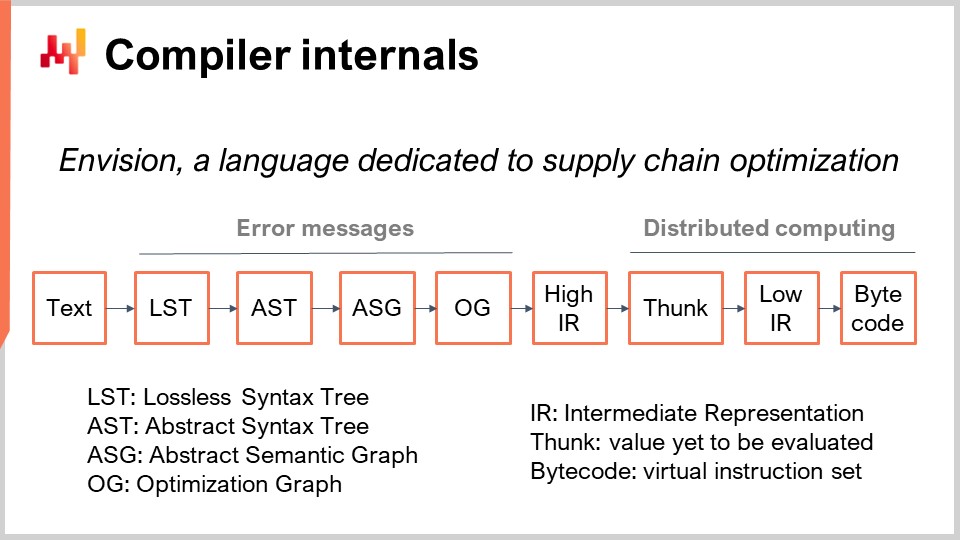
Gli script di Envision vengono eseguiti su un insieme di macchine, progettate per sfruttare un’intera infrastruttura cloud. Quando lo script viene eseguito, si distribuirà su molte macchine per eseguirsi più velocemente. Sullo schermo, puoi vedere la pipeline del compilatore utilizzata da Envision. Oggi, non parleremo di questo linguaggio di programmazione; parleremo solo della sua pipeline del compilatore perché è l’argomento di interesse per la lezione di oggi.
Iniziamo con un pezzo di testo che contiene lo script di Envision. Rappresenta un programma scritto da un esperto di supply chain, non da un ingegnere del software, per affrontare una specifica sfida della supply chain. Questa sfida potrebbe riguardare la decisione su cosa produrre, cosa rifornire, cosa spostare o se modificare un prezzo al rialzo o al ribasso. Questi casi d’uso coinvolgono decisioni su cosa produrre, rifornire, spostare o se modificare i prezzi al rialzo o al ribasso. Il testo dello script contiene le istruzioni e l’idea è elaborare questo script e ottenere l’Albero di Sintassi Senza Perdite (LST). L’LST è di interesse perché è una rappresentazione molto specifica che non scarta nessun singolo carattere. Anche gli spazi bianchi non significativi vengono preservati. Il motivo di ciò è garantire che eventuali riscritture automatizzate del programma non alterino il codice esistente. Questo approccio evita situazioni in cui gli strumenti mescolano il codice, spostano le indentazioni o causano altre interruzioni che rendono il codice difficile da riconoscere.
Un’operazione di refactoring di base, ad esempio, potrebbe comportare la rinomina di una variabile e di tutte le sue occorrenze nel programma senza toccare altro. Dall’LST, passiamo all’Albero di Sintassi Astratta (AST), dove semplifichiamo l’albero. Le parentesi non sono necessarie in questa fase perché la struttura dell’albero definisce le priorità di tutte le operazioni. Inoltre, eseguiamo una serie di operazioni di desugaring per rimuovere qualsiasi sintassi fornita a beneficio del programmatore finale.
Passando dall’AST al Grafo di Sintassi Astratta (ASG), appiattiamo l’albero. Questo processo comporta la decomposizione di istruzioni complesse con espressioni altamente nidificate in una sequenza di istruzioni elementari. Ad esempio, un’istruzione come “a = b + c + d” verrebbe divisa in due istruzioni, ognuna con una sola addizione. Questo è esattamente ciò che accade durante la transizione dall’AST all’ASG.
Dall’ASG, passiamo al Grafo di Ottimizzazione (OG), dove eseguiamo la modellazione dei tipi e la trasmissione, in particolare in relazione all’algebra relazionale. Come accennato in precedenza, Envision incorpora un’algebra relazionale all’interno del linguaggio. Come accennato molte volte prima, Envision incorpora un’algebra relazionale, come nei database relazionali o nei database SQL, come cittadino di prima classe. Ci sono numerose operazioni relazionali e verifichiamo che queste operazioni relazionali siano valide in base allo schema delle tabelle con cui stiamo operando durante la transizione da ASG a OG. Il Grafo di Ottimizzazione (OG) rappresenta l’ultimo passo del nostro front-end del compilatore e consiste in operazioni relazionali pure ed elementari che si applicano al programma, rappresentando piccoli frammenti di logica. Come in SQL, questi elementi sono di natura relazionale.
Il grafo di ottimizzazione viene chiamato “ottimizzazione” perché ci sono numerose trasformazioni che avvengono da OG a OG. Queste trasformazioni avvengono perché, quando si tratta di algebra relazionale, organizzare le operazioni in determinati modi può far eseguire il programma molto più velocemente. Ad esempio, in SQL, se si ha un filtro e poi un’operazione, o un’operazione prima e poi un filtro, è molto meglio filtrare prima i dati e poi applicare l’operazione. In questo modo, le operazioni vengono applicate solo ai dati necessari, migliorando l’efficienza.
Da Lokad, l’ultimo passo del compilatore front-end è la Rappresentazione Intermedia Alta (HIR). L’HIR è un confine pulito, stabile e documentato tra il front-end e il back-end della pipeline del compilatore. A differenza del Grafo di Ottimizzazione (OG), che cambia costantemente a causa di euristiche, l’HIR è stabile e fornisce un input coerente per il back-end del compilatore. Inoltre, l’HIR è serializzabile, il che significa che può essere facilmente trasformato in un pacchetto di byte da spostare da una macchina all’altra. Questa proprietà è essenziale per distribuire i calcoli su più macchine.
Dalla Rappresentazione Intermedia Alta, passiamo a “funcs”. Le funcs sono valori che devono ancora essere valutati e rappresentano i blocchi atomici di calcolo all’interno di un’esecuzione distribuita. Ad esempio, quando si aggiungono due vettori giganteschi da una tabella con miliardi di righe, ci saranno una serie di funcs che rappresentano varie porzioni di questi vettori. Ogni func è responsabile dell’aggiunta di una porzione dei due vettori ed è eseguita su una macchina. I calcoli complessi vengono suddivisi in molte funcs per distribuire il carico di lavoro su più CPU e su più macchine se il calcolo è sufficientemente grande da giustificare questo grado di distribuzione. Le funcs vengono chiamate “lazy” perché non vengono valutate all’inizio; vengono valutate quando necessario. Molti calcoli possono avvenire prima che alcune funcs vengano effettivamente calcolate e una volta che una func viene calcolata, la func stessa viene sostituita dal suo risultato.
All’interno della func, troverai la rappresentazione intermedia bassa, che rappresenta la logica imperativa a basso livello che viene eseguita all’interno della func. Può, ad esempio, includere cicli e accessi a dizionari. Infine, questa rappresentazione intermedia a basso livello viene compilata in bytecode, che rappresenta l’obiettivo finale della nostra pipeline del compilatore. Da Lokad, puntiamo al bytecode .NET, tecnicamente noto come MSIL.
Da una prospettiva della supply chain, ciò che è davvero interessante è che attraverso questa pipeline del compilatore argomentabilmente complessa, stiamo riproducendo il grado di integrazione trovato in Microsoft Excel. Il linguaggio è integrato con il livello dei dati e il livello UI/UX, consentendo agli utenti di visualizzare e interagire con gli output del programma, proprio come farebbero con un foglio di calcolo Excel. Tuttavia, a differenza di Excel, ci addentriamo in territori molto più interessanti per la gestione della supply chain abbracciando concetti relazionali come cittadini di prima classe, nonché l’ottimizzazione matematica e l’apprendimento automatico.
Sia l’ottimizzazione matematica che l’apprendimento automatico in questa pipeline passano attraverso l’intera pipeline, anziché chiamare semplicemente una libreria che si trova da qualche parte. Avere l’apprendimento automatico come cittadino di prima classe nella pipeline consente di ottenere messaggi di errore più comprensibili, il che fa una grande differenza in termini di produttività per gli esperti di supply chain.

Come argomento finale, i compilatori oggigiorno quasi sempre puntano a una macchina virtuale, ma queste macchine virtuali, a loro volta, vengono compilati verso un’altra macchina virtuale. Sullo schermo, i tipici livelli di VM trovati in un ambiente basato su server sono molto simili a quelli che abbiamo con uno script Envision. Ho appena presentato la pipeline del compilatore, ma fondamentalmente, sarebbe praticamente la stessa pila se stessimo pensando a uno script Python o a un foglio di calcolo Excel operato da un server. Quando si progetta un compilatore, si sceglie essenzialmente il livello in cui si intende iniettare il codice. Più profondo è il livello, più tecnicità devi affrontare. Per scegliere il livello, ci sono una serie di questioni che devono essere affrontate.
Innanzitutto, c’è la sicurezza. Come proteggi la tua memoria e cosa il programma dovrebbe o non dovrebbe accedere? Se hai un linguaggio di programmazione generico, le tue opzioni sono limitate. Potresti aver bisogno di operare a livello del sistema operativo guest, anche se anche quello potrebbe non essere molto sicuro. Ci sono modi per creare un ambiente controllato, ma è molto complicato, quindi potresti dover scendere ancora più in basso.
In secondo luogo, c’è la preoccupazione per le funzionalità a basso livello di cui sei interessato. Ad esempio, questo potrebbe essere importante se si desidera ottenere un’esecuzione più performante, riducendo la quantità di risorse di calcolo necessarie per completare il programma. Puoi decidere di scendere abbastanza in basso da gestire la memoria e i thread. Tuttavia, con questo potere viene la responsabilità di gestire effettivamente la memoria e i thread.
In terzo luogo, ci sono funzionalità di comodità come la garbage collection, la stack trace, il debugger e il profiler. Tipicamente, tutta l’strumentazione attorno al compilatore è più complessa del compilatore stesso. La quantità di funzionalità di comodità di cui beneficierai non deve essere sottovalutata.
In quarto luogo, ci sono le preoccupazioni per l’allocazione delle risorse. Se stai operando con un foglio di calcolo Excel sul tuo desktop, Excel può consumare tutte le risorse di calcolo nella tua postazione di lavoro. Tuttavia, con Envision o SQL, hai più utenti da servire e devi decidere come allocare le risorse. Inoltre, con Envision, non si tratta solo di più utenti, ma di più aziende da servire, poiché Lokad è multi-tenant. Questo ha senso nella supply chain perché il bisogno di risorse di calcolo è molto intermittente per la maggior parte delle supply chain.
Tipicamente, hai solo bisogno di un’intensa esplosione di calcolo per circa mezz’ora o forse un’ora, e poi nulla per le successive 23 ore. Quindi, risciacqua e ripeti quotidianamente. Se dovessi allocare risorse di calcolo hardware per un’azienda, quelle risorse rimarrebbero inutilizzate per il 90% del tempo o anche di più. Quindi, vuoi essere in grado di distribuire il carico di lavoro su molte macchine e su molte aziende, potenzialmente aziende che operano su diversi fusi orari.
Infine, c’è la preoccupazione per l’ecosistema. L’idea è che quando decidi su uno specifico livello e una specifica VM da mirare per il tuo compilatore, sarà abbastanza conveniente integrare e interfacciare il tuo compilatore con ciò che sta mirando anche alle stesse macchine virtuali esatte. Questo solleva la questione dell’ecosistema: cosa puoi trovare allo stesso livello di ciò che stai mirando, per non reinventare la ruota per ogni singolo dettaglio coinvolto in tutta la tua stack? Questa è l’ultima e importante preoccupazione.

In conclusione, congratulazioni ai pochi fortunati che sono arrivati fin qui in questa serie di lezioni sulla supply chain. Questa è probabilmente una delle lezioni più tecniche finora. I compilatori sono un pezzo argomentabile molto tecnico; tuttavia, la realtà delle moderne supply chain è che tutto viene mediato attraverso un linguaggio di programmazione. Non esiste più una supply chain grezza e direttamente osservabile. L’unico modo per osservare una supply chain è attraverso la mediazione di registri elettronici prodotti da tutti i pezzi di software aziendale che costituiscono il panorama applicativo. Pertanto, è necessario un linguaggio di programmazione e per impostazione predefinita, questo linguaggio di programmazione si rivela essere Excel.
Tuttavia, se vogliamo fare meglio di Excel, dobbiamo riflettere attentamente su cosa significhi “meglio” dal punto di vista della supply chain e cosa significhi in termini di linguaggi di programmazione. Se un’azienda non ha la giusta strategia o cultura, nessuna tecnologia la salverà. Tuttavia, se la strategia e la cultura sono solide, allora gli strumenti contano davvero. Gli strumenti, compresi i linguaggi di programmazione, definiranno la tua capacità di esecuzione, la produttività che puoi aspettarti dai tuoi esperti di supply chain e le prestazioni che otterrai dalla tua supply chain quando trasformerai la macro strategia nelle migliaia di decisioni quotidiane banali che la tua supply chain deve prendere. Essere in grado di valutare l’adeguatezza degli strumenti, compresi i linguaggi di programmazione che intendi utilizzare per affrontare le sfide della supply chain, è di primaria importanza. Se non sei in grado di valutare, allora è solo un culto del carico completo.

La prossima lezione sarà sull’ingegneria del software. Oggi abbiamo discusso degli strumenti; tuttavia, la prossima volta parleremo delle persone che utilizzano gli strumenti e di quale tipo di lavoro di squadra è richiesto per fare bene il lavoro. La lezione si terrà lo stesso giorno della settimana, mercoledì, alle 15:00, ora di Parigi.
Ora, darò un’occhiata alle domande.
Domanda: Quando si selezionano software per le supply chain, come possono le aziende che non sono esperte in tecnologia valutare se il compilatore e il linguaggio di programmazione sono adatti alle loro esigenze?
Beh, sono abbastanza sicuro che un’azienda tipica che gestisce una supply chain tipica non abbia le competenze per progettare un veicolo, eppure riescono ad acquistare camion adeguati alle loro esigenze di supply chain e di trasporto. Non è perché non sei un esperto e non sei in grado di ricostruire e riprogettare un camion che non puoi avere un’opinione molto solida su se è un buon camion per le tue esigenze di trasporto. Quindi, non sto dicendo che le aziende che non sono esperte in tecnologia dovrebbero fare un incredibile salto in avanti e diventare improvvisamente esperti nella progettazione dei compilatori. Tuttavia, credo che in solo un’ora e mezza abbiamo coperto parecchio terreno. Con altre 10 ore di un’introduzione più dettagliata e a ritmo più lento, impareresti tutto ciò che ti serve sapere in termini di progettazione del linguaggio per scopi di supply chain.
C’è una differenza tra essere un esperto e essere così incredibilmente ignorante che le persone possono venderti uno scooter facendolo passare per un camion. Se dovessimo tradurre questo tipo di ignoranza che ho osservato in termini di progettazione di software aziendale nell’industria automobilistica, le persone affermerebbero che uno scooter è un autocarro e viceversa, e se la caverebbero.
Questa serie di lezioni riguarda le scienze ausiliarie, quindi non c’è l’intenzione che le persone che vogliono diventare professionisti della supply chain diventino esperti in questi ambiti. Tuttavia, avendo una conoscenza di base, puoi andare molto lontano nella valutazione. La maggior parte delle volte, devi solo avere conoscenze sufficienti per fare domande difficili. Se il fornitore ti dà una risposta senza senso, non sembra buono. Se non sai nemmeno quali domande tecniche fare, puoi essere ingannato.
Il mio suggerimento è che non è necessario diventare incredibilmente esperti in tecnologia; è sufficiente essere abbastanza esperti da essere un principiante di livello base che può individuare le falle e valutare se l’intero sistema si sgretola o se c’è effettivamente una sostanza dietro di esso. Lo stesso vale per l’ottimizzazione matematica, l’apprendimento automatico, le CPU e così via. L’idea è conoscere abbastanza per differenziare tra qualcosa di fraudolento e qualcosa di legittimo.
Domanda: Hai affrontato direttamente il problema dei linguaggi di programmazione esistenti non progettati per la supply chain?
Questa è una domanda molto interessante. Progettare un nuovo linguaggio di programmazione potrebbe sembrare completamente folle. Perché non optare semplicemente per qualcosa di già ben consolidato, come Python, e apportare le piccole modifiche di cui abbiamo bisogno? Sarebbe stata un’opzione. Il problema è che il problema principale non è davvero ciò che dobbiamo aggiungere a quei linguaggi, ma ciò che dobbiamo rimuovere.
La mia principale preoccupazione con Python non è che non abbia un’algebra probabilistica o che non abbia un’algebra relazionale incorporata. La mia critica principale è che è un linguaggio di programmazione completamente capace e generico, e quindi espone la persona che scriverà il codice a tutti i tipi di concetti, come la programmazione orientata agli oggetti per Python, che sono completamente insignificanti per quanto riguarda la supply chain. Il problema non era tanto prendere un linguaggio e aggiungere qualcosa, ma prendere un linguaggio e cercare di rimuovere tonnellate di cose. Tuttavia, il problema è che non appena si rimuovono cose da un linguaggio di programmazione esistente, tutto si rompe.
Ad esempio, la prima versione di Python è stata rilasciata nel 1990, quindi è un linguaggio di programmazione di 30 anni. La quantità di codice in uno stack popolare come Python è assolutamente gigantesca, e per buoni motivi. Non lo sto criticando; è uno stack molto solido, ma è anche enorme. Quindi alla fine abbiamo valutato varie opzioni: prendere un linguaggio di programmazione, sottrarre tonnellate di cose fino a quando siamo soddisfatti di ciò che abbiamo, o considerare che tutti quei linguaggi di programmazione hanno tonnellate di eredità propria.
Abbiamo valutato quanto sforzo fosse necessario per creare un nuovo linguaggio e alla fine è stato molto a favore di creare un nuovo linguaggio. L’ingegneria di un nuovo linguaggio di programmazione è un campo super consolidato, quindi anche se può sembrare incredibile, non lo è. Ci sono centinaia di libri che ti danno ricette e ora è persino accessibile agli studenti di informatica. Ci sono persino professori nei dipartimenti di informatica che assegnano ai loro studenti, in un semestre, di creare un compilatore per un nuovo linguaggio di programmazione.
Alla fine abbiamo deciso che le supply chain erano abbastanza grandi da giustificare uno sforzo dedicato. Sì, si può sempre riciclare cose che non sono state progettate per le supply chain, ma le supply chain sono un’industria e un insieme di problemi enormi a livello mondiale. Quindi abbiamo pensato che, considerando la scala a cui stiamo guardando, ha senso fare la cosa giusta e creare qualcosa direttamente per la supply chain anziché riciclare accidentalmente.
Domanda: Per l’ottimizzazione della supply chain, Envision è appropriato in quanto comprende SQL, Python, ecc. Tuttavia, per WMS, ERP, dove il flusso di processo è fondamentale più che l’ottimizzazione matematica, come puoi valutare il suo compilatore e il linguaggio di programmazione?
È una domanda molto valida. Personalmente ho giocato con l’idea che ci sono attori in questo settore che hanno effettivamente progettato linguaggi di programmazione propri, solo per i benefici di implementare qualcosa di completamente transazionale per natura, orientato al flusso di lavoro. La supply chain, come la vedo io, riguarda essenzialmente l’ottimizzazione predittiva. Tuttavia, il signor Nannani ha completamente ragione; cosa succede con tutta la parte di gestione, come ERP, WMS, ecc.?
Si scopre che ci sono molte aziende in questo settore che hanno creato il proprio linguaggio di programmazione. Ho menzionato SAP, che ha ABAP, progettato appositamente per questo. Purtroppo, secondo me, ABAP non è invecchiato molto bene. Ci sono molte cose in ABAP che non hanno molto senso nel XXI secolo. Si può davvero vedere che questa cosa è stata progettata nel ‘83, e si vede. Ad esempio, in Microsoft Dynamics, l’ERP ha un proprio linguaggio di programmazione. Dynamics AX ha il suo linguaggio di programmazione e ci sono molti progetti ERP che, in larga misura, portano il proprio linguaggio di programmazione. Quindi, esiste.
Ora, questi linguaggi sono davvero il culmine di ciò che possiamo fare in termini di linguaggi di programmazione moderni e all’avanguardia nel 2021? Non penso proprio, ed è anche il problema di cui parlavo: i fornitori di software aziendale continuano a reinventare linguaggi di programmazione, ma di solito fanno un lavoro molto scadente. È solo un progetto di ingegneria improvvisato. Non si prendono nemmeno il tempo di leggere i molti libri disponibili sul mercato e poi ci sono poveri ingegneri che sono bloccati con un mucchio di confusione.
Tornando alla tua domanda, ho giocato con l’idea che Lokad si avventuri in questa area e crei un linguaggio progettato non per l’ottimizzazione ma per supportare il flusso di lavoro. Tuttavia, in questo momento, la crescita di Lokad è così grande che non possiamo deviare e occuparci dei flussi di lavoro. Sono assolutamente certo che sia esatto e che ci saranno nuovi attori che emergeranno e faranno un ottimo lavoro per la parte di gestione del problema. Lokad si occupa solo della parte di ottimizzazione delle supply chain; c’è anche la parte di gestione.
Domanda: Python è attualmente considerato un linguaggio di programmazione standard. Ci sono evoluzioni in corso nel mercato?
Questa è una domanda molto interessante. Vedi, quando le persone mi parlano di “standard”, sono stato abbastanza a lungo nel settore da vedere gli standard venire e andare. Non sono molto vecchio, ma quando ero al liceo, lo standard era C++. Negli anni ‘90, C++ era lo standard. Perché lo faresti in un altro modo? Poi è arrivato Java, intorno all’anno 2000, e la combinazione di Java e XML era lo standard.
Le persone dicevano persino che le università dell’epoca si erano trasformate in “scuole di Java”. Questo era letteralmente il termine del giorno intorno all’anno 2000; le persone dicevano: “Questa non è più una facoltà di informatica; è solo una scuola di Java”. Alcuni anni dopo, quando ho fondato Lokad, il linguaggio di programmazione per tutto ciò che riguardava le statistiche era ancora R. Python era ancora molto marginale e R dominava assolutamente il campo in termini di analisi statistica.
Man mano che progrediamo in termini di linguaggi di programmazione, C++ è svanito. Microsoft ha introdotto C# nel 2002 e la piattaforma .NET, che ha cannibalizzato una parte significativa dell’ecosistema di C++. Una grande parte degli sviluppatori di C++ in tutto il mondo era in Microsoft, un’azienda molto grande. Il punto a cui sto arrivando è che c’è stata un’evoluzione continua e ogni anno le persone guardano a questo come se ci fosse uno standard, ma questo standard cambia sempre.
JavaScript era presente da 20 anni, ma non era nulla di significativo. Poi, un libro pubblicato intorno al 2009 o al 2012 chiamato “JavaScript: The Good Parts” ha rivelato che JavaScript non era completamente folle. Potevi usare JavaScript per un progetto reale senza perdere la sanità mentale; dovevi solo attenerti alle parti buone. Improvvisamente, JavaScript era molto popolare e le persone hanno iniziato a usarlo lato server con un sistema chiamato Node.js.
Python è emerso solo pochi anni fa, dopo che la comunità di Python ha affrontato un’aggiornamento estenuante dalla versione 2.7 alla versione 3.x. Alla fine di questo aggiornamento, l’interesse per Python è stato rinnovato. Tuttavia, ci sono molti pericoli che si profilano per Python. Non è un linguaggio molto buono secondo gli standard del XXI secolo. È un linguaggio di 30 anni e mostra la sua età. Se vuoi qualcosa di migliore in ogni dimensione tranne che per la maturità, potresti guardare Julia. Julia è superiore a Python in quasi tutti i modi per la scienza dei dati, tranne che per la maturità, dove Julia è ancora indietro di anni.
Ci sono tonnellate di evoluzioni in corso ed è facile confondere lo stato del settore con qualcosa che è uno standard destinato a durare. Ad esempio, nell’ecosistema Apple, c’era Objective-C e poi Apple ha deciso di produrre Swift come sostituto, che ora sta sostituendo Objective-C. Il panorama dei linguaggi di programmazione è ancora in continua evoluzione e, anche se ci vuole tempo, se guardiamo all’ecosistema tra dieci anni, probabilmente ci sarà una quantità significativa di evoluzione. Python potrebbe non emergere come il linguaggio di programmazione dominante, poiché ci sono molte opzioni rivali che offrono risposte migliori.
Domanda: Le aziende alimentari e le startup di e-commerce pensano spesso di poter vincere la battaglia con team di scienziati dei dati e linguaggi generici. Qual sarebbe il tuo punto di vendita principale per far loro raffinare questo approccio e far loro capire che hanno bisogno di qualcosa di più specifico al problema?
Come ho detto, questo è il problema dell’effetto Dunning-Kruger. Dai a un ingegnere del software un sistema di programmazione lineare intera mista per fare la programmazione intera e, una settimana dopo, questa persona penserà di essere improvvisamente diventata un esperto di ottimizzazione discreta. Quindi, come vinco la battaglia? A dire il vero, di solito non le vinciamo. Quello che faccio è descrivere il modo in cui si svolgeranno le catastrofi.
È semplice quando si utilizzano blocchi generici di tecnologia per creare prototipi fantastici. Questi prototipi funzionano brillantemente grazie all’illusione di Star Wars: hai solo il tuo pezzo di tecnologia in isolamento. Quando queste aziende iniziano a cercare di portare queste cose in produzione, avranno difficoltà, nella maggior parte dei casi a causa di problemi molto banali. Affronteranno problemi di integrazione in corso, non come Google o Microsoft o Amazon, che possono permettersi di avere mille ingegneri per occuparsi di tutte le tubature.
TensorFlow, ad esempio, è difficile da integrare. Google ha i 1000 ingegneri necessari per incollare TensorFlow in tutti i loro data pipelines e applicazioni per i loro scopi. Ma la domanda è: le startup o le aziende di e-commerce possono permettersi di avere così tante persone che si occupano di tutte le tubature? Di solito, la risposta è no. Le persone immaginano che semplicemente scegliendo questi strumenti, saranno in grado di scegliere le cose e metterle insieme, e magicamente funzionerà. Ma non è così. Richiede una quantità enorme di ingegneria.
A proposito, alcuni fornitori di software aziendali stanno soffrendo dello stesso identico problema. Hanno troppi componenti nella loro soluzione e questo spiega perché implementare una soluzione, senza alcuna personalizzazione, richiede già mesi perché ci sono così tante parti instabili nel sistema che sono solo vagamente integrate. Diventa molto difficile.
Immagino che questa fosse l’ultima domanda. Ci vediamo la prossima volta.


