00:05 イントロダクション
02:50 二つの妄想
09:09 コンパイラパイプライン
14:23 これまでの経緯
18:49 船荷証券
19:40 言語設計
23:52 未来
30:35 過去
35:57 戦いの選択
39:45 文法 1/3
42:41 文法 2/3
49:02 文法 3/3
53:02 静的解析 1/2
58:50 静的解析 2/2
01:04:55 型システム
01:11:59 コンパイラ内部構造
01:27:48 ランタイム環境
01:33:57 結論
01:36:33 次回の講義と聴衆からの質問
説明
大多数のサプライチェーンは依然としてスプレッドシート(例:Excel)によって運用されています。一方で、企業向けシステムは1、2、時には3十年もの間稼働しており、理論上はそれらに取って代わるためのものでした。実際、スプレッドシートは手軽なプログラム的表現力を提供しますが、これらのシステムは一般的にそうではありません。より一般的には、1960年代以降、ソフトウェア産業全体とそのプログラミング言語は常に共に発展してきました。次の段階のサプライチェーンパフォーマンスは、プログラミング言語、もしくはより正確にはプログラム可能な環境の開発と採用によって大きく推進されるだろうという証拠が存在します。
完全な文字起こし

このサプライチェーン講義シリーズへようこそ。私はジョアンネス・ヴェルモレルです。本日は「サプライチェーンのための言語とコンパイラ」をお届けします。サプライチェーンの教科書でコンパイラが議論されるのを見たことがなかったと記憶していますが、それは極めて重要なトピックです。このシリーズの最初の章、「プロダクト指向の提供」において、ご覧いただいたように、プログラミングがサプライチェーンの専門家が費やす時間を有効活用する鍵となっています。プログラミングがなければ、彼らの時間を有効活用することはできず、サプライチェーンの専門家は使い捨てと見なされてしまいます。
さらに、この第4章において、「サプライチェーンのための数学的最適化」と「サプライチェーンのための機械学習」という前の二つの講義を通して、これら二つの分野―最適化と学習―が過去には単なるアルゴリズムとモデルの集合であったにもかかわらず、過去10年間でプログラミングパラダイムによって推進されるようになったことが明らかになりました。これらすべての要素はプログラミング言語の重要性を示唆しており、したがってサプライチェーンの課題に対応するために設計されたプログラミング言語とコンパイラの存在が問われるのです。
この講義の目的は、サプライチェーン用に意図されたプログラミング言語の設計を解明することにあります。おそらく、あなたの会社が独自のプログラミング言語をエンジニアリングすることは滅多にないでしょう。それにもかかわらず、このトピックに関する洞察を持つことは、現在使用しているツールの適合性を評価し、また将来サプライチェーンの課題に対応するために購入を検討しているツールの適合性を評価する上で基本的な意味を持ちます。さらに、本講義は、この分野に全く洞察を持たない人々が陥りがちな大きな過ちを回避するのにも役立つはずです。

ここで、ここ30年余りエンタープライズソフトウェアの世界で蔓延してきた二つの妄想を払拭することから始めましょう。第一の妄想は「レゴプログラミング」の妄想で、プログラミングが全く省略可能なものと考えられている点です。確かにプログラミングは難しいものであり、常に供給されるベンダーは、彼らの製品と素晴らしい技術によって、プログラミングそのものの難しさを完全に取り除き、まるで誰でもアクセス可能な視覚的体験、つまりレゴの組み立てのような体験に変えることができると約束します。
この試みは過去数十年で何度も行われ、必ず失敗に終わってきました。せいぜい、視覚的体験を提供することを意図していた製品であっても、通常のプログラミング言語に転じ、他のプログラミング言語と比べて特に習得しやすくなるわけではありません。ちなみに、これは例えばMicrosoft製品のシリーズにおいて、「Visual」シリーズ、例えばVisual Basic for ApplicationやVisual Studioが存在する理由の一例として挙げられます。これらの視覚的製品は、1990年代にプログラミングを単なるドラッグアンドドロップで済む純粋な視覚的体験に変えるという希望のもとに導入されたものです。現実には、これらのツールは最終的には非常に大きな成功を収めたものの、現代においてはただの普通のプログラミング言語にすぎなくなっています。これらの製品の冒頭にあった視覚的要素はほとんど残っていません。
レゴアプローチが失敗したのは、本質的にボトルネックがプログラミング構文の障壁ではないからです。確かに構文は一つのハードルですが、洗練された自動化を展開する上で必要となる概念の習得と比べればごく小さいものです。最終的には、あなたの心がボトルネックとなり、そこに関与する概念の理解が構文よりはるかに重要となるのです。
第二の妄想は「スター・ウォーズ・テック」の妄想で、素晴らしい技術部品を簡単にプラグアンドプレイできると考える点にあります。この妄想は、ベンダーや社内プロジェクトの間で非常に魅力的に映ります。本質的には、「この素晴らしいNoSQLデータベースをそのまま投入できる」とか、「この素晴らしいディープラーニングスタックを採用できる」とか、このグラフデータベース、あるいはこの分散型アクティブフレームワークなどといった発言が非常に誘惑的になるのです。
スター・ウォーズは、たとえばメカニカルハンドがあれば、主人公がそのメカニカルハンドを手に入れるだけで機能するという考えを回避します。しかし実際には、統合に関する問題が支配的です。
スター・ウォーズは、一連の問題が発生する現実を無視しています。まず、抗生物質が必要であり、次にそのハンドを使用できるように長期間の再教育が必要となるでしょう。また、そのハンドが機械式であるため、メンテナンスプログラムも必要ですし、電源はどうするのか、といった問題もあります。これらの問題はすべて無視されるのです。あなたはただ、その素晴らしい技術部品を差し込めばよいのです。しかし現実には、統合の問題が支配しており、例えば大手ソフトウェア企業では、ほとんどのソフトウェアエンジニアが決して極めてクールな技術部品に取り組んでいるわけではありません。これら大手ソフトウェアベンダーのエンジニアリング労働力の大部分は、すべての部品の統合と、それらを統合しようとした際に生じる問題に対処することに専念しています。
ちなみに、逸話的な話として、クールな技術部品に関して私が目にしたもう一つの問題は、それがエンジニア間にダニング=クルーガー効果を引き起こすということです。あなたがスタックにクールな技術部品を導入すると、ほとんど理解していない技術部品に触れるだけで、エンジニアたちは突然自分たちがAIの専門家であるかのように振る舞い始めるのです。これは典型的なダニング=クルーガー効果であり、あなたのソリューションに投入するクールな技術部品の数と強く関連しています。結論として、これら二つの妄想により、プログラミングの問題を実際に回避することができないことが示されます。私たちはその難しい部分も含め、機能的に対処しなければなりません。
さて、そう言った上で興味深いのは、企業向けソフトウェアベンダーがプログラミング言語を偶然にも再発明し続けている点です。実際、サプライチェーンにおいては構成の柔軟性が激しく求められます。前の講義で見たように、サプライチェーンの世界は多様であり、問題は数多く、さまざまです。したがって、サプライチェーンのソフトウェア製品を持つ場合、piece of softwareの構成が通常、数か月、時には数年に及ぶプロジェクトとなるのは、その構成に膨大な複雑さが伴うからなのです。
構成設定はしばしば複雑であり、単なるボタンやチェックボックスだけではありません。トリガー、数式、ループ、そしてその他あらゆるブロックが伴うことがあります。それはあっという間に手に負えなくなり、その結果、構成設定を通じて得られるものは、新たに発現したプログラミング言語と言えるものなのです。しかし、これは新たに発現したプログラミング言語であるため、非常に質の低いものになりがちです。
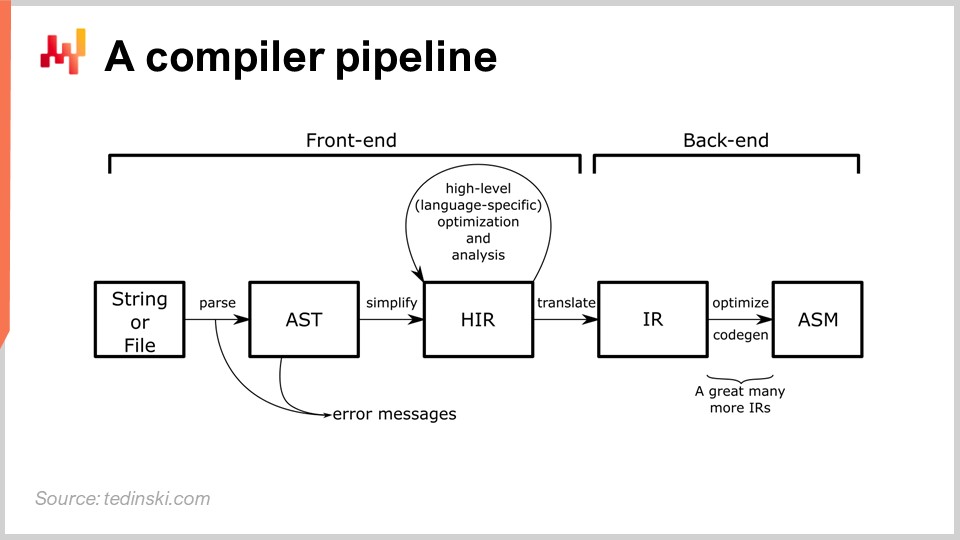
実際のプログラミング言語をエンジニアリングすることは、確立された工学的課題です。生産グレードのコンパイラをエンジニアリングする実践に関する書籍は数十冊存在します。コンパイラとは、通常テキストの命令をマシンコードやそれ以下の低レベルな命令に変換するプログラムです。プログラミング言語が存在する限り、必ずコンパイラが伴います。例えば、Excelのスプレッドシート内には数式があり、Excel自身がそれらの数式をコンパイルし実行するコンパイラを有しています。おそらく、聴衆の多くは知らず知らずのうちにキャリアの全期間にわたってコンパイラを使用していることになるでしょう。
図では一般的なパイプラインが示されており、この原型はおそらく皆さんが聞いたことのあるPython、JavaScript、Java、C#などほとんどのプログラミング言語に当てはまります。すべての言語が、ここに概説されたものと本質的に同様のパイプラインを持っています。コンパイラパイプラインでは、一連の変換が行われ、その各段階でプログラム全体を表す表現が存在します。コンパイラのエンジニアリングは、明確に定義された一連の変換を有し、各段階でプログラム全体を扱うという方法に基づいています。それは、ただ単に異なる形で表現されているだけなのです。
この考え方は、すべての変換が明確に定義された問題群に対して責任を持つというものです。これらの問題に対処し、次の変換に進み、その変換がプロセスの別の側面に対処するという流れです。通常、各段階を経ることで、マシンレベルのコードに近づいていきます。コンパイラはスクリプトから始まり、対象となるプログラミング言語の構文に非常に近い変換からスタートします。これら初期の変換段階では、通常、プログラムとして有効でないスクリプトを実行可能なものに変換することを妨げる構文上の誤りを捉えます。後ほど、この講義でコンパイラパイプラインについてより詳しく見ていきます。
本講義は、このシリーズの第4章の第5講義にあたります。第一章では、私がサプライチェーンを学問分野として、また実践としてどう捉えているかについて述べました。第二章では、サプライチェーンにおける状況に対処するために適切な方法論を概観しました。ご覧のとおり、ほとんどのサプライチェーンの状況は非常に対立的な性質を持つため、企業内外の全ての関係者からの対立的な行動にレジリエンスを持つ戦略や方法論が必要となります。
第三章はサプライチェーンの担当者に捧げられており、サプライチェーンそのものの問題の研究に全く焦点を当てています。私たちは、発見している問題と、それに対して考えうる解決策とを混同しないよう、非常に注意を払う必要があります。これらは明確に分けるべき二つの懸念事項です。
この講義シリーズの第四章、現講義は、サプライチェーンの補助科学に捧げられています。これらの補助科学はサプライチェーンそのものではありませんが、現代のサプライチェーンの実践に非常に役立つものです。現在、私たちは抽象度の階段を上っている最中です。まず計算機の物理から始まり、次にアルゴリズム、そしてソフトウェアの領域へと進みました。数学的最適化を紹介しましたが、これはサプライチェーンにとって非常に重要であり、同時に機械学習の基礎となっています。
本日は、あらゆるプログラミングパラダイムを実装する上で不可欠な、言語とコンパイラを紹介します。言語とコンパイラというトピックは聴衆にとって驚きかもしれませんが、現時点ではそれほど驚くべきものではないと思います。数学的最適化と機械学習は、今日ではプログラミングパラダイムを通じて取り組むべきであると示されており、それはこれらのプログラミングパラダイムをいかに実装するかという疑問を投げかけます。これが、言語とそれを支えるコンパイラの設計、すなわち本日のテーマにつながるのです。

ここでは、本講義の残りの概要を示します。まず、プログラミング言語の歴史と市場についての高レベルな観察から始めます。次に、サプライチェーンの未来と過去の両方を表すと考えられる業界を概観します。その後、徐々にプログラミング言語とコンパイラの設計、すなわちより低レベルの懸念事項や、コンパイラ設計における技術的な詳細について掘り下げていきます。

1950年代以降、何千ものプログラミング言語が実運用に投入されてきた。推定はさまざまであるが、実運用目的で使用されたプログラミング言語の数はおそらく千から一万の間に及ぶ。その多くは、互いに異なる変種や親戚関係にあるにすぎず、時にはコンパイラのコードベースそのものがわずかに異なる方向へと分岐したものである。特筆すべきは、いくつかの大手エンタープライズソフトウェア企業が、自社製のプログラミング言語の導入によって大きく拡大したことである。たとえば、SAPは1983年にABAPを、Salesforceは2006年にApexを、さらにはMicrosoftでさえ、Windows以前の1975年にAltair BASICの開発に着手している。
歴史的に見ると、90年代を覚えている皆さんは、当時ベンダーが第3世代や第4世代のプログラミング言語を売り出していたことを思い出すかもしれない。実際、初代、第二代、第三代、第四代…と明確な世代の系列が存在し、そして第五代に至った時点で、コミュニティは世代という枠組みでの区分をやめた。最初の3、4十年の間、これらのプログラミング言語は、より高い抽象度へと着実に進化していった。しかし、90年代の終わりには、利用ケースに応じて単に抽象度が高くなるだけではなく、さまざまな方向性が現れていた。
新しいプログラミング言語を生み出すことは何度も行われてきた。これは確立された工学分野であり、実践的な視点からこのテーマに特化した書籍も丸ごと一冊分存在する。新たなプログラミング言語の設計は、たとえばdata scienceの実験を行うよりも、はるかに現実的で予測可能な実践である。今日知られていることや利用可能な知識を踏まえて、適切な工学的手法を用いれば、ほぼ確実に望む結果が得られる。
これらすべてを踏まえると、本当に疑問が湧く。つまり、供給連鎖向けに特別に設計されたプログラミング言語はどうなるのだろうか?実際、生産性、信頼性、さらには供給連鎖のパフォーマンスという点で、大きな利点をもたらす可能性がある。

この疑問に答えるためには、未来を見据える必要がある。幸いなことに、未来を最も簡単に考察する方法は、過去30年ほど常に他業界より10年先を行っている一つの産業、つまりビデオゲーム産業に注目することである。現在、ビデオゲーム産業は非常に大きな市場となっており、規模感を掴むために言えば、世界の航空宇宙産業の規模の2/3を占め、航空宇宙産業よりもはるかに速い成長を遂げている。今から10年後、ビデオゲームが実際に航空宇宙産業を上回るかもしれない。
ビデオゲーム産業の興味深い点は、その非常に確立された構造にある。まず、ゲームエンジンがあり、そのリーダー格としてUnityとUnrealが挙げられる。これらのゲームエンジンは、超高精度な3Dグラフィックスに必要な低レベルのコンポーネントを持ち、コードのインフラストラクチャーの全体像を形作っている。非常に複雑な製品であるゲームエンジンを設計・開発する企業はごくわずかであり、これらのエンジンは業界全体で利用されている。
次に、ゲームスタジオがあり、各ゲームごとに専用のゲームコードを開発する。ゲームコードは、通常、開発中の特定のゲーム専用のコードベースとなる。ゲームエンジンは、高度な技術力を持つハードコアなソフトウェアエンジニアを必要とするが、必ずしもゲームに精通しているわけではない。ゲームコードの開発は、純粋な技術的スキルの面ではそれほど高度なものではない。しかし、ゲームコードを開発するソフトウェアエンジニアは、自分たちが取り組むゲームの内容を十分に理解していなければならない。ゲームコードはゲームメカニクスの基盤を築くが、細かい仕様までは定めない。 この作業は通常、ソフトウェアエンジニアではないゲームデザイナーが担当し、彼らはゲームコードを扱うエンジニアリングチームから提供されるスクリプト言語を用いてコードを書く。 ここで、3つの段階がある。まず、ゲームエンジンは、超技術的でハードコアなソフトウェアエンジニアが主要な構成要素を作成する。次に、スタジオでは、通常ゲームごとに1つのエンジニアリングチームが組まれ、ゲームメカニクスの基盤としてゲームを開発する。最後に、ゲームデザイナーは、ソフトウェアエンジニアではなくゲームの専門家として、最終顧客であるゲーマーを喜ばせる動作を実装する。
今日では、ゲームコードがファン層に公開されることが多く、ゲームデザイナーがルールを書いたり、場合によってはゲームそのものを改変したりできるが、普通のゲーマーであるファンも同様のことが可能である。業界には興味深い逸話がいくつか存在する。たとえば、非常に成功したゲーム「Dota 2」は、既存のゲームの改造から始まった。最初のバージョンである単に「Dota」と名付けられたものは、World of Warcraft 3のファンによる純粋な改造版であった。この程度の構成可能性とプログラマビリティが、既存の商用ゲームであるWorld of Warcraft 3から全く新しいゲームを生み出し、その後第2版を経て大規模な商業的成功を収めたことからも明らかである。これは非常に興味深く、ゲーム業界を見渡すことで、供給連鎖産業にとっては何を意味するのかを考え始めることができる。
さて、どのような類似性が考えられるだろうか。非常に複雑なアルゴリズム部分、低レベルのインフラ、そして数理最適化や機械学習といった核心的な技術要素を担う供給連鎖エンジンを用意するという考え方である。つまり、各供給連鎖に対して、関連するすべてのデータを収集し、アプリケーション全体の風景を統合するためのエンジニアリングチームが必要になるということだ。
第一段階として、ゲームデザイナーに相当する、供給連鎖のスペシャリストが必要である。これらの専門家はソフトウェアエンジニアではないが、簡略化されたコードを通じて、供給連鎖における予測的最適化を実現するために必要なすべてのルールとメカニクスを記述する役割を担う。ゲーム業界は、今後10年で供給連鎖分野に起こり得る変革の生きた実例を提供している。

これまでのところ、供給連鎖におけるゲーム業界のアプローチは、数社を除いてはフィクションの域を出ていない。おそらく、そのほとんどの企業がLokadの顧客にあたると私は考えている。本日の話題に戻ると、以前の講義で見たように、この業界ではExcelが依然としてナンバーワンプログラミング言語である。ちなみに、プログラミング言語としての観点では、Excelは関数型リアクティブプログラミング言語に属し、実際、独自のカテゴリにまで分けられる。
最近、供給連鎖を何らかのデータサイエンス体制で刷新しようとするベンダーの話を耳にするかもしれない。しかし、私の過去10年にわたるさりげない観察では、これらの取り組みの大半が失敗に終わっている。これは既に過去の話であり、その理由を理解するためには、関与するプログラミング言語の一覧を見始める必要がある。Excelを見ると、本質的にはExcelの数式とVBAという2種類のプログラミング言語しか使われていないことが分かる。VBAは必須ではなく、ExcelのVLOOKUPだけでも十分に機能する。通常、扱うのはたった1種類のプログラミング言語であり、非ソフトウェアエンジニアでも十分に扱える。
一方、データサイエンス体制でExcelの機能を再現するために必要なプログラミング言語のリストは非常に広範である。データにアクセスするためにはSQLが必要であり、場合によっては複数のSQL方言も必要となる。コアロジックの実装にはPythonが欠かせない。しかし、Python単体では動作が遅い傾向があり、NumPyのようなサブ言語が要求される場合がある。この時点では、機械学習や数理最適化に関しては何も手を付けていない。したがって、本格的な数値解析を行うためには、たとえばPyTorchのような、さらに別の専用のプログラミング言語が必要となる。これらの要素がすべて揃えば、すでに多数の可動部品が存在することになり、アプリケーション自体の構成は非常に複雑になる。構成ファイルも必要となり、これもまたJSONやXMLなど、さらに別のプログラミング言語で記述されなければならない。いずれにしても、これらは非常に複雑なプログラミング言語ではないが、負担が増える要因となる。
このように多くの可動部品が存在すると、通常はソフトウェア生成に必要なすべてのコンパイラや定型レシピを実行するビルドシステムが求められる。ビルドシステムにも独自の言語が存在する。従来のアプローチではMakeという言語が用いられるが、ほかにも多くのものがある。さらに、Excelが結果を表示するのと同様に、ユーザーに情報を提示し視覚化する方法も必要となる。これらはJavaScript、HTML、CSSの組み合わせによって実現され、リストにはさらに多くの言語が追加されることになる。
この時点で、膨大な数のプログラミング言語が登場し、実際の運用環境はさらに複雑になり得る。これが、過去10年間にこのデータサイエンスパイプラインを試みたほとんどの企業が圧倒的に失敗し、結局現場ではExcelに頼らざるを得なかった理由である。その理由は、Excelの場合はたった1種類の言語で済むのに対し、ここでは十数種類ものプログラミング言語を習得する必要があるからである。私たちは、供給連鎖の実際の問題に触れ始めたというよりも、何かを始めるための技術的側面について議論しているに過ぎない。

さて、供給連鎖向けのプログラミング言語がどのようなものになるか、考え始めよう。まず、言語内部に組み込むべきものと、ライブラリに委ねるべきもの、つまり第一級市民として扱うべきものを決定する必要がある。実際、プログラミング言語では、機能をライブラリに委譲することが常に可能である。たとえば、Cプログラミング言語を見てみよう。Cは比較的低レベルのプログラミング言語と見なされ、ガーベジコレクションの仕組みを持たない。しかし、Cプログラムにおいてサードパーティのガーベジコレクタをライブラリとして使用することは可能である。C言語では、ガーベジコレクションが第一級市民として扱われていないため、構文が比較的冗長で面倒になりがちである。
供給連鎖の目的では、数理最適化や機械学習といった、通常はライブラリとして扱われる問題が存在する。つまり、現在のプログラミング言語では、それらの問題は基本的にサードパーティのライブラリに委譲されている。しかし、もし供給連鎖向けのプログラミング言語を設計するならば、これらの問題を言語自体の第一級市民として組み込むのは非常に理にかなっている。同様に、リレーショナルデータも第一級市民として言語に組み込む価値がある。供給連鎖における適用領域、つまり多くのエンタープライズソフトウェアが動作する環境では、SQLデータベースのようなリレーショナルデータベースの形でリレーショナルデータが至る所に存在する。今日存在するほぼ全てのエンタープライズソフトウェア製品は、その根幹にリレーショナルデータベースを持っており、これは供給連鎖の目的上、データに触れ始めるとすぐに、本質的にリレーショナルなデータとやり取りすることを意味する。データは、各アプリケーションを支えるデータベースから抽出されたテーブルのリストとして提示され、各テーブルはカラムまたはフィールドの一覧を持つ。
言語内にリレーショナルデータを組み込むことは非常に理にかなっている。さらに、ユーザーインターフェイス(UI)やユーザーエクスペリエンス(UX)はどうか?Excelの大きな強みの一つは、これらすべてが言語に完全に組み込まれている点にある。つまり、プログラミング言語と、それとは別に存在するプレゼンテーション、レンダリング、ユーザーインタラクションを扱うためのサードパーティライブラリが必要になるのではない。これら全体が言語の一部となっている。これらを第一級市民として組み込むことは、少なくとも供給連鎖においてExcel並みの性能を求めるのであれば、非常に重要な意味を持つだろう。

言語設計において、文法は、新たに導入したプログラミング言語において有効なプログラムを定義するルールの形式的表現を示す。基本的に、テキストの一部から始まり、最初に字句解析器(lexer)という特定のアルゴリズムまたは小さなプログラムを適用する。字句解析器は、記述されたプログラムのテキストをトークンの列に分解する。これにより、プログラミング言語におけるすべての変数や記号が明確に識別される。文法は、そのトークンの列をプログラムの実際の意味論に変換する手助けをし、プログラムが何を意味するのか、また実行するために必要な正確で曖昧さのない操作のセットを定義する。
文法自体は、言語内に内包させるべき懸念事項と、外部に委譲するべき概念との間のトレードオフとして捉えられる。たとえば、リレーショナルデータを外部の懸念事項として扱う場合、プログラマーは辞書、ルックアップ、ハッシュテーブルなどの特殊なデータ構造を数多く導入し、言語内でこれらの操作を手動で行わなければならなくなる。対して、文法がリレーショナル代数を内包するのであれば、プログラマーは通常、リレーショナルな形式で直接全てのリレーショナルロジックを記述できる。しかし、それは同時に、すべてのリレーショナルな制約やリレーショナル代数が、文法が担うべき負担の一部となることを意味する。
供給連鎖の観点から見ると、エンタープライズソフトウェアにおいてリレーショナルデータが非常に普及しているため、文法レベルでリレーショナルな懸念事項を直接取り扱う文法を持つことは非常に理にかなっている。

コンピュータサイエンスにおける文法は、非常に広範に研究されている主題である。何十年もの歴史があるにもかかわらず、エンタープライズソフトウェアベンダーが最も苦戦する分野であると言っても過言ではない。実際、複雑な設定が絡む際、必然的に偶発的なプログラミング言語が自然発生的に現れてしまう。条件、トリガー、ループ、レスポンスが存在する場合、それらを放置して自然発生させるのではなく、しっかりと制御するための言語として取り扱う必要がある。

文法が存在しない場合、アプリケーションに変更を加えるたびに、システムの実際の挙動に予測不可能な影響が及ぶことになります。ちなみに、これが企業向けソフトウェアのバージョンアップが通常非常に複雑である理由でもあります。本来、設定は同じはずですが、実際に次のバージョンで同じ設定を実行しようとすると、まったく異なる結果が得られてしまうのです。こうした問題の根本原因は、設定が何を意味するのかについての文法や、確立された形式的な意味論が欠如していることにあります。
文法を表現する典型的な方法は、特殊な記法であるBackus-Naur Form (BNF) を用いることです。画面に表示されているのは、米国の郵便住所を表現するミニプログラミング言語です。等号がある各行は生成規則を示しており、左側には非終端記号が、等号の右側には終端記号と非終端記号の並びが記されています。終端記号は赤色で表示され、これ以上の派生が不可能な記号を表します。一方、非終端記号は角括弧で囲まれ、さらに展開可能です。ここで示されている文法は完全なものではなく、完全な文法にするにはさらに多くの生成規則が必要です。私はこのスライドをできるだけ簡潔にまとめたかったのです。
文法は、プログラミング言語の構文という観点から定義する非常に単純なものですが、同時にあいまいさがないことを保証します。しかし、文法がBackus-Naur Formで記述されているからといって、それが有効な文法、あるいは良い文法であるとは限りません。良い文法を持つためには、それ以上の工夫が必要です。良い文法を数学的に特徴づけるには、文脈自由文法である必要があります。文法が文脈自由であるというのは、左右にある記号に関係なく、任意の非終端記号に対して生成規則を適用できることを意味します。つまり、文脈自由文法では、生成規則をどの順番で適用してもよく、該当する導出が見つかったらすぐに適用できるという考え方に基づいています。
文脈自由文法を用いると、もしその文法に何らかの変更を加えてあいまいさが生じた場合、そのあいまいさが存在するプログラムはコンパイラによってコンパイルされなくなります。これは、長期間にわたって設定を維持しなければならない場合に非常に重要な点です。サプライチェーンにおいては、ほとんどの企業向けソフトウェアが非常に長寿命で、企業向けソフトウェアが二、三十年にわたって稼働しているのは珍しいことではありません。Lokadでは100社以上の企業にサービスを提供しており、特に大企業の場合、30年以上稼働しているシステムからデータを抽出することがかなり一般的です。
文脈自由文法を用いることで、この言語(ここでいう「言語」とは、設定のような基本的なものをも含む)に変更を加えた際、どのあいまいさが生じるかを特定できる保証が得られます。これにより、問題に気づかずにあいまいさが発生するのを防ぎ、システム間のアップグレード時の困難を回避できます。
文法について何も知らない人々は、手作りでパーサーを書くものです。文法の存在を知らないソフトウェアエンジニアは、プログラムをパースして木構造のようなものを適当に生成するパーサーを書きます。しかし、この方法では、プログラムの意味論がその特定のバージョンに極めて固有のものになってしまいます。つまり、プログラムを変更すると意味論も変わり、同じ設定でもサプライチェーンの動作が異なる結果となります。
幸運なことに、2004年にBrian Fordが「Parsing Expression Grammars: A Recognition-Based Syntactic Foundation」という論文を発表し、小さなブレイクスルーがもたらされました。この研究により、Fordは現場に存在する偶発的なアドホックパーサーを形式化する方法をコミュニティに提供しました。例えば、これらの文法はParsing Expression Grammars (PEGs) と呼ばれ、PEGsを用いることで、半ば偶発的な経験的パーサーを実際の形式文法へと変換することが可能になります。
例えばPythonは、厳密な文脈自由文法を持ってはいませんが、PEGを採用しています。広範な自動テストが整っていれば、PEGでも意味論の維持に対処できるため、文法が全くない状態でただパーサーだけを持つ場合よりも有利です。しかし、意味論の進化という観点では、PEGでは文法そのものを変更しても意味論の変更を自動で検出することはできません。したがって、PEGの上には広範な自動テストスイートを構築する必要がありますが、これはまさにPythonコミュニティが実施していることです。彼らは非常に堅牢で広範な自動テストを備えています。サプライチェーンの視点から言えば、文法はその重要性を認識させるだけでなく、一種の試金石ともなります。複雑なソフトウェアについて議論する際に、企業向けソフトウェアベンダーに対し、複雑な設定で使用される文法について質問すべきです。もしベンダーが「文法?それは何ですか?」と答えたなら、問題があることが明らかで、その後の保守が遅く高額になる可能性が高いのです。

プログラミングは非常に難しく、多くの人が数々のミスを犯します。もし簡単であれば、そもそもプログラミングなんて必要なかったでしょう。優れたプログラミング言語は、エラーの特定と修正にかかる時間を最小限に抑えます。これは、コードを書く人々の生産性を確保する上で、最も重要な側面の一つです。
次の状況を考えてみましょう。コードを書いている最中に、Microsoft Wordの赤い下線のようにタイプミスが即座に検出されれば、エラー修正のフィードバックループは理想的には10秒程度に収まります。しかし、エラーがプログラム実行時にのみ検出される場合、フィードバックループは最低でも10分以上になります。サプライチェーンでは、大量のデータセットを処理するため、プログラムが数秒で全データに対して動作を開始するとは期待できません。そのため、問題が実行時にのみ発生すると、フィードバックループは10分以上に延びることになります。
もしエラーがスクリプトの実行完了後、つまりプログラムにエラーがあっても致命的な失敗を起こさない場合にのみ検出されると、フィードバックループは約10時間以上かかるでしょう。リアルタイムのフィードバックが10秒で済む場合から、プログラム実行で10分、さらに数値結果やKPIの解析で10時間と、フィードバックループは劇的に長くなります。
さらに悪いシナリオとして、使用しているプラットフォームが厳密な決定論的動作をしない場合があります。つまり、同じ入力とデータであっても異なる結果を返す可能性があるのです。これは一見奇妙に思えるかもしれませんが、サプライチェーンではモンテカルロシミュレーションのようなものが動作している場合があり、結果にランダム性が混じれば、まれに失敗するケースも生まれます。このような場合、フィードバックループは通常10日以上に及びます。つまり、10秒から10日に至るまでフィードバックループが延びる可能性があり、このループを短縮することは極めて重要です。静的解析は、プログラムを実行することなく問題やエラー、障害を検出するための一連の技法を提供します。静的解析を用いれば、実行せずとも、Microsoft Wordでタイポが赤い下線で示されるように、入力中にエラーをリアルタイムで報告できます。より一般的には、検出に数日かかる問題を数分、または数分かかる問題を数秒に短縮するため、すべての問題をより早いフィードバックへとシフトさせることに大きな関心が寄せられています。
サプライチェーンの観点から見ると、以前の講義でも示されたように、サプライチェーンには多くの混沌が予想されます。次のソフトウェアのバージョンがリリースされるのを待つという古典的なリリースサイクルは通用しません。時には、関税の変更、コンテナ船が運河に立ち往生する、あるいはパンデミックといった非常事態が発生します。これらの緊急事態には、緊急の是正措置が必要であり、入力中にリアルタイムで検出されなかったミスによって生産現場で発生する混乱の大きさは、利用しているプログラミング言語でどれだけ静的解析が行えるかにほぼ依存します。非常事態は稀に見えるかもしれませんが、実際にはサプライチェーンにおける予期せぬ事態は非常に一般的です。

一般的なプログラミング言語において、すべてのエラーを検出することは不可能であるという数学的証明があります。例えば、プログラムが必ず終了する、つまり書かれたものが無限に実行され続けないことを保証することさえできないのです。
静的解析では、通常、コードは「おそらく正しい部分」、「おそらく間違っている部分」、そして「判断がつかない部分」の三つに分類されます。要するに、「判断がつかない」状態から「悪いコード」へとシフトすればするほど、プログラムが正しいことをコンパイラに納得させるための言語設計上の労力が増大します。従って、実際にプログラムが実行される前の段階でどれだけの保証を持たせるかと、コードの正しさを証明するためにどれだけの労力を投入するかの間でバランスを取る必要があるのです。これは生産性に直結する問題です。
ここで、静的解析で検出される典型的なエラーの例を挙げます。例えば、カンマや丸括弧の付け忘れなどの構文エラーがあります。Linuxのシェル言語であるBashのように、実行前に構文エラーを検出できないプログラミング言語も存在します。静的解析は、関数呼び出し時に誤った型や引数の数が指定された場合に発生する型エラーも検出可能です。
また、到達不能なコードも検出できます。これは、コード自体は問題ないものの、プログラム全体がその部分に到達しないため、実行されないコードを意味します。いわゆるデッドコードや、忘れ去られた論理的な接続のようなものです。さらに、無意味なコード、つまり実行はされるものの最終的な出力に全く影響を与えないコードも識別可能で、これは到達不能コードの一種と言えます。
計算リソースを過剰に消費するコードも検出できます。これは、実行はされるものの、必要とされる計算資源がプログラムで許容できる量を大幅に超えている場合を指します。プログラムは、メモリ、ストレージ、CPUといった計算リソースを消費しますが、静的解析を通じて、例えば特定の時間内に計算を完了しなければならないという制約を踏まえると、あるコードブロックが許容範囲をはるかに超えるリソースを消費していることを証明できます。こうしたエラーは、プログラムを1時間実行してからタイムアウトで失敗させるよりも、コンパイル時に検出されることが望ましいのです。
しかし、静的解析には一つの落とし穴があります。タイピング中のプログラムは常に無効な状態であり、一打鍵ごとに、有効なプログラムが無効なものへと変化してしまいます。この状況に対する業界水準の解決策が、Language Server Protocolと呼ばれるものです。このツールはプログラミング言語に付属し、入力中のプログラムに対してリアルタイムでエラーをフィードバックする最先端の技術です。
Language Server Protocolを利用すれば、変数をクリックしたときに「定義へ移動」といった機能にアクセスできます。Language Server Protocolは基本的に状態を保持しており、直近で正しかったプログラムのバージョンや、利用可能な注釈、意味論を記憶しています。たとえ余分なキー入力でプログラムが一時的に無効になったとしても、これらの情報は保持されるのです。これは生産性において革新的な変化をもたらし、緊急性が多少でも求められる状況下では、サプライチェーンにおいて大きな差を生み出します。

では、型システムについて詳しく見ていきましょう。大まかに言えば、型システムとは、プログラム内のオブジェクトや操作する要素の分類を活用して、特定の相互作用が許容されるかどうかを明確にするための一連の規則です。例えば、一般的な型としては文字列、整数、浮動小数点数などがあり、これらは非常に基本的な型です。二つの整数を加算することは有効と定義されますが、文字列と整数を加算することは、セマンティクスが異なるJavaScriptを除いては無効です。
型システムは全般的に未解決の研究課題であり、非常に抽象的な側面を持ちます。ここで重要なのは、しばしば混同される二種類の型があるという点です。まず、値の型ですが、これはプログラムが実行されているとき、つまりランタイムにのみ存在します。例えば、Pythonにおいて整数の配列の最初の要素を返す関数の場合、その返り値の型は整数となります。この観点から、すべてのプログラミング言語は型を持っており、全て型付きと言えます。
次に、変数の型があります。これはプログラムが実行される前、すなわちコンパイル時にのみ存在します。変数の型に関する課題は、コンパイル時にそれらの変数について可能な限り多くの情報を抽出することにあります。先の例に戻ると、Pythonでは、関数から返される値の型を特定できる場合もあれば、特定できない場合もあります。なぜなら、Pythonはコンパイル時に完全に強い型付けをしているわけではないからです。
サプライチェーンの観点からすると、我々はサプライチェーンの利益のために実行しようとしていることをサポートする型システムを求めています。問題やバグを早期に捉えるためにできるだけ厳格でありながら、同時に興味を持ちうるすべての操作を許容するためにできるだけ柔軟でありたいのです。例えば、日付と整数の加算を考えてみてください。通常のプログラミング言語では正当ではないとされるかもしれませんが、サプライチェーンの視点からは、ある日付に7日を加える場合、「date + 7」と書くのは理にかなっています。サプライチェーン計画には、日付を一定の日数だけシフトする操作が多く存在するため、日付と数値の加算が許容される代数があれば有用です。
型の観点では、日付同士の加算を許すべきでしょうか?おそらくそうではありません。しかし、2つの日付の差し引きを許すべきでしょうか?それはどうでしょうか?もしもある日付からそれより前の日付を引けば、その差分が得られ、これは日数で表現できます。これは計画に関わる計算において非常に理にかなっています。
日付の話を続けると、サプライチェーンに関する懸念点で型システムが何をしてくれるかを考える際に、興味深い特性も存在します。例えば、許容される時間範囲を制限するというのはどうでしょうか?過去20年および未来20年の範囲外の日付は無効とみなすことができます。計画操作を行っている場合、プログラムのどこかで20年以上未来の日付を操作する状況が発生すれば、大多数の業界にとってそれは有効な計画シナリオではない可能性が非常に高いのです。ほとんどの場合、日々の計画を20年以上先まで立てることはありません。したがって、通常の型をそのまま使用するのではなく、サプライチェーンの目的により適した、より厳格な方法で再定義することができるのです。
また、不確実性という側面も存在します。サプライチェーン管理では常に将来を見据えていますが、残念ながら未来は常に不確実です。不確実性を受け入れる数学的な方法は確率変数を用いることです。不確実な将来需要、リードタイム、顧客からの返品などを表すために、確率変数を言語に組み込むことは理にかなっています。
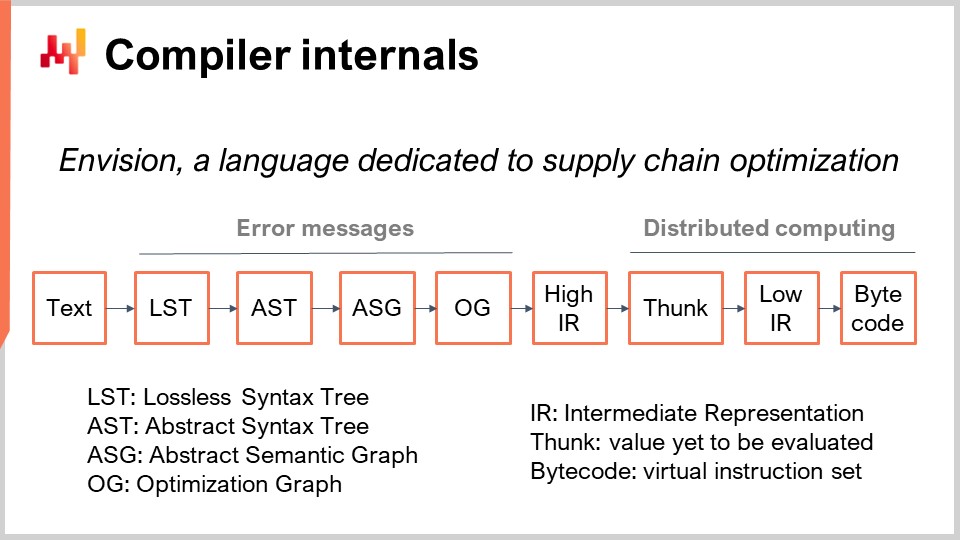
Lokadでは、サプライチェーンの予測最適化に特化したプログラミング言語「Envision」を開発しました。Envisionは、SQL、Python、数理最適化、機械学習、ビッグデータの機能が混在しており、すべてが言語自体の第一級市民として統合されています。この言語にはウェブベースの統合開発環境(IDE)が付属しており、ウェブ上でスクリプトを書き、最新のコード編集機能を利用することができます。これらのスクリプトは、Lokad環境に組み込まれた分散ファイルシステム上で動作するため、データ層がプログラミング言語に完全に統合されています。
Envisionのスクリプトは、クラウド全体の利点を活用するために設計された多数のマシン上で実行されます。スクリプトが実行されると、より高速に動作するために複数のマシンに分散されます。画面上には、Envisionで使用されるコンパイラパイプラインが示されています。本日の講義ではこのプログラミング言語自体について議論するのではなく、そのコンパイラパイプラインについて議論します。これが本日の講義の主題だからです。
まず、Envisionスクリプトを含むテキストから始めます。これは、ソフトウェアエンジニアではなくサプライチェーンの専門家によって書かれた、特定のサプライチェーン課題に対処するためのプログラムを表しています。この課題は、何を生産するか、何を補充するか、何を移動させるか、または価格を上げるか下げるかを決定するというものです。これらのユースケースは、何を生産し、補充し、移動させるか、または価格を調整するかに関する意思決定を伴います。スクリプトのテキストには指示が含まれており、このスクリプトを処理してLossless Syntax Tree(LST)を得るという考えです。LSTは、どんな一文字も破棄せずに保持する非常に特定の表現形式であるため、非常に興味深いものです。非重要な空白文字さえも保存されます。これは、プログラムの自動書き換えが既存のコードを変更しないようにするためです。このアプローチにより、ツールがコードをシャッフルしたり、インデントを移動させたり、コードを認識しにくくするその他の混乱を引き起こす状況を避けることができます。
例えば、基本的なリファクタリング操作では、プログラム内の変数とその全ての出現箇所を他に手を加えることなく名前変更することが含まれるかもしれません。LSTからは、ツリーを単純化するためにAbstract Syntax Tree(AST)に移ります。この段階では、ツリー構造がすべての演算の優先順位を定義するため、括弧は不要です。さらに、エンドプログラマーの便宜のために存在する構文を除去する、一連のデシューガリング操作を行います。
ASTからAbstract Syntax Graph(ASG)に進むと、ツリーがフラット化されます。このプロセスでは、非常に入れ子になった複雑な式を含む文を、一連の基本的な文に分解します。例えば、「a = b + c + d」のような文は、加算が一回ずつの2つの文に分割されます。これがまさにASTからASGへの移行時に行われることです。
ASGからはOptimization Graph(OG)に移り、ここで型の整形やブロードキャスティングを、特にリレーショナル代数に関連して行います。前述したように、Envisionは言語内にリレーショナル代数を組み込んでいます。以前何度も示唆されたように、EnvisionはリレーショナルデータベースやSQLデータベースのように、リレーショナル代数を第一級市民として組み込んでいます。多数のリレーショナル操作が存在し、ASGからOGへの移行時に、これらの操作が対象テーブルのスキーマに沿って有効であるかどうかを確認します。Optimization Graph(OG)は、コンパイラフロントエンドの最終段階を表しており、プログラムに適用される純粋で基本的なリレーショナル操作、すなわち小さな論理の断片で構成されています。SQLと同様に、これらの要素はリレーショナルな性質を持っています。
最適化グラフが「最適化」と呼ばれるのは、OGからOGへの変換が多数行われるためです。これらの変換は、リレーショナル代数を扱う際に操作を特定の方法で整理することが、プログラムの実行速度を大幅に向上させる可能性があるために発生します。例えば、SQLでは、フィルタを適用した後に操作を行う場合、または操作を先に行ってからフィルタを適用する場合、まずデータをフィルタしてから操作を実施する方がはるかに効率的です。これにより、必要なデータにのみ操作が適用され、効率が向上します。
Lokadでは、フロントエンドコンパイラの最後のステップがHigh Intermediate Representation(HIR)です。HIRは、コンパイラパイプラインのフロントエンドとバックエンドとの間の、クリーンで安定した文書化された境界を提供します。ヒューリスティックスにより常に変化するOptimization Graph(OG)とは異なり、HIRは安定しており、バックエンドへの一貫した入力を提供します。さらに、HIRはシリアライズ可能であり、容易にバイトのパックに変換して、あるマシンから別のマシンへ移動することができます。この性質は、複数のマシンにまたがる計算を分散する際に不可欠です。
High Intermediate Representationからは「funcs」に進みます。Funcsは、まだ評価されていない値であり、分散実行における計算の原子ブロックを表します。例えば、数十億行あるテーブルから2つの巨大なベクトルを加算する場合、その各部分を表す一連のfuncsが存在します。各funcは2つのベクトルの一部を加算する責任を持ち、1台のマシン上で実行されます。大規模な計算は、計算量が十分に大きい場合、作業負荷を複数のCPUや複数のマシンに分散するために、多くのfuncsに分割されます。Funcsは最初に評価されず、必要に応じて評価されるため「レイジー」と呼ばれます。多くの計算は、実際にいくつかのfuncが計算される前に発生し、一度funcが計算されると、そのfunc自体は結果に置き換えられます。
Funcの内部には、命令的な低レベルロジックを表すLow Intermediate Representationが存在し、これはfunc内で実行されます。例えば、ループや辞書へのアクセスなどを含むことができます。最後に、この低レベル中間表現はバイトコードにコンパイルされ、これがコンパイラパイプラインの最終ターゲットとなります。Lokadでは、技術的にはMSILとして知られる.NETバイトコードをターゲットとしています。
サプライチェーンの観点から非常に興味深いのは、この一見複雑なコンパイラパイプラインを通じて、Microsoft Excelで見られる統合度合いを再現している点です。この言語はデータ層およびUI/UX層と統合されており、ユーザーはExcelスプレッドシートと同様に、プログラムの出力を確認し、操作することができます。しかし、Excelとは異なり、Envisionではリレーショナル概念を第一級市民として採用することにより、また数理最適化や機械学習を取り入れることで、サプライチェーン管理においてさらに興味深い領域へと踏み込んでいます。
このパイプラインでは、数理最適化と機械学習の両方が、単にどこかのライブラリを呼び出すだけでなく、パイプライン全体を通じて実行されます。パイプライン内で機械学習を第一級市民として扱うことで、より理解しやすいエラーメッセージが提供され、サプライチェーン専門家の生産性向上に大きな違いをもたらします。

最後のトピックとして、現代のコンパイラはほとんど常に仮想マシンをターゲットにしていますが、これらの仮想マシン自体もまた別の仮想マシンに向けてコンパイルされます。画面上に示されるサーバーベースのセットアップで見られる典型的なVM層は、Envisionスクリプトで見られるものと非常に似ています。先ほどコンパイラパイプラインを紹介しましたが、基本的にはサーバー上で動作するPythonスクリプトやExcelスプレッドシートを考えた場合とほとんど同じスタックになるでしょう。コンパイラを設計する際には、コードを注入する層を選択する必要があります。層が低いほど、対処すべき技術的な問題が多くなります。層を選ぶ際には、一連の懸念事項に対処しなければなりません。
まず第一にセキュリティです。メモリをどのように保護し、プログラムが何にアクセスすべきか、またはアクセスすべきでないかという点です。汎用のプログラミング言語を使用している場合、選択肢は限られ、ゲストオペレーティングシステムレベルで動作する必要があるかもしれませんが、それさえも十分に安全とは言えません。サンドボックス化する方法もありますが、それは非常に難しいため、さらに低いレベルに行かなければならないかもしれません。
第二に、関心のある低レベルの機能に関する懸念があります。例えば、より高性能な実行を達成し、プログラムの完了に必要な計算リソースを削減したい場合、これは重要です。メモリやスレッドを管理するために十分低いレベルで動作することを選択することもできます。しかし、この力には実際にメモリとスレッドを管理する責任が伴います。
第三に、ガーベジコレクション、スタックトレース、デバッガ、プロファイラといった便利な機能があります。通常、コンパイラ周辺の計測機能は、コンパイラ自体よりも複雑です。利用できる便利な機能の数は決して過小評価されるべきではありません。
第四に、リソース割り当てに関する懸念があります。デスクトップ上でExcelスプレッドシートを操作する場合、Excelはワークステーション上の全計算リソースを消費してしまう可能性があります。しかし、EnvisionやSQLの場合、複数のユーザーにサービスを提供する必要があり、リソースの割り当て方法を決定しなければなりません。さらに、EnvisionではLokadがマルチテナントであるため、単に複数のユーザーだけでなく、複数の企業にサービスを提供する必要があります。これは、ほとんどのサプライチェーンにおいて計算リソースの需要が非常に断続的であるという点で理にかなっています。
通常、計算リソースが非常に激しく必要となるのは30分または1時間程度で、その後の23時間はほとんど使われません。そして、このサイクルが毎日繰り返されます。もし1社に対してハードウェアの計算リソースを割り当てた場合、そのリソースは90%以上の時間、またはそれ以上使われないままとなってしまいます。したがって、負荷を多数のマシンや複数の企業、さらには異なるタイムゾーンで活動する可能性のある企業に分散させる必要があります。
最後に、エコシステムに関する懸念があります。つまり、コンパイラのターゲットとなる特定の層と仮想マシンを選定すると、同じ仮想マシンをターゲットにする他のものと統合・インターフェイスするのがかなり容易になります。これにより、スタック全体に関わるあらゆる細部について、毎回ホイールを再発明しなくても済むというエコシステムが形成されるのです。これが最後であり、非常に重要な懸念事項です。

結論として、このサプライチェーン講義シリーズにここまでたどり着いた幸運な皆さん、おめでとうございます。おそらく、これまでで最も技術的な講義の一つでしょう。コンパイラは非常に技術的な部分ではありますが、現代のサプライチェーンの現実は、すべてがプログラミング言語を介して仲介されるということです。もはや、生の直接観察可能なサプライチェーンというものは存在しません。サプライチェーンを観察する唯一の方法は、企業ソフトウェア全体によって生成される電子記録を介することなのです。従って、プログラミング言語が必要となり、結果としてそのプログラミング言語はExcelとなっているのです。
しかし、Excelよりも優れたものを求めるのであれば、サプライチェーンの観点から「より優れている」とは何を意味するのか、またプログラミング言語においてそれが何を意味するのかを真剣に考えなければなりません。企業が適切な戦略や文化を持たなければ、どんな技術も救いにはなりません。しかし、戦略と文化が確立されていれば、ツーリングは非常に重要な役割を果たします。プログラミング言語を含むツーリングは、実行能力、サプライチェーン専門家に期待できる生産性、そしてマクロ戦略を日々の数千の些細な意思決定に変換する際のサプライチェーンのパフォーマンスを定義するからです。サプライチェーンの課題に対処するために使用するツール、特にプログラミング言語の適合性を評価できることは極めて重要です。評価できなければ、それは単なるカルト的模倣に過ぎません。

次の講義はソフトウェアエンジニアリングについてです。本日はツールについて議論しましたが、次回はツールを使用する人々と、仕事をうまく成し遂げるために必要なチームワークについてお話しします。講義は同じ曜日の水曜日、パリ時間の午後3時に行われます。
さて、質問を見てみましょう。
質問: サプライチェーン向けのソフトウェアを選定する際、技術に詳しくない企業は、コンパイラやプログラミングが自社のニーズに合っているかどのように評価できるのでしょうか?
ええ、典型的なサプライチェーンを運営する一般企業は、自動車を設計する資格を持っているわけではありませんが、サプライチェーンと輸送の要件に適したトラックを購入することができます。あなたが専門家でなく、トラックを再構築・再設計できないからといって、輸送ニーズに合った良いトラックかどうかについて確固たる意見を持てないわけではありません。ですから、技術に詳しくない企業が急に飛躍して、コンパイラの設計の専門家になるべきだとは言っていません。しかし、私たちはたった1時間半でかなり多くの知識をカバーしたと考えています。さらに詳細でゆっくりとした10時間の導入があれば、サプライチェーン向けの言語設計に関して必要なすべてを学ぶことができるでしょう。
専門家であることと、あまりにも無知で、他人がスクーターをトラックと偽って売ることができる状態とは大きく異なります。このような企業向けソフトウェア設計における無知を自動車業界に当てはめてみれば、スクーターをセミトレーラーだと主張し、その逆もまた然りとして問題なく通用してしまうのです。
この講義シリーズは補助科学に関するものであり、サプライチェーンの実務者がこれらの分野の専門家になることを意図しているわけではありません。それでも、入門レベルの知識を持つことで、十分に評価することが可能です。大抵の場合、厳しい質問をするために必要な最低限の知識があれば十分です。もしベンダーが意味不明な回答をすれば、それはよくない兆候です。どの技術的な質問をすべきかすら分からなければ、騙される可能性があります。
私の提案は、非常に技術に精通する必要はなく、入門レベルのアマチュアとして、問題点を見抜き、全体が崩壊するのか、あるいは実際にしっかりとした中身があるのかを評価できる程度の知識で十分だということです。数学的最適化、機械学習、CPUなどにおいても同様です。詐欺的なものと正当なものを区別できるだけの知識を持つことが肝心です。
質問: サプライチェーン向けに設計されていない既存のプログラミング言語の問題について、直接取り組みましたか?
これは非常に良い質問です。全く新しいプログラミング言語を設計するのは一見馬鹿げているように思えるかもしれません。なぜ、既に確立されたPythonのようなものを使い、必要な小さな変更を加えないのでしょうか?それも一つの選択肢でした。しかし、問題は、これらの言語に追加すべきものではなく、むしろ取り除くべきものが何かという点にあります。
Pythonに対する私の主な懸念は、確率代数やリレーショナル代数が組み込まれていないということではありません。最大の批判は、Pythonが非常に汎用性の高いプログラミング言語であるため、コードを書く人に対してサプライチェーンにとって全く関係のないオブジェクト指向プログラミングなどのさまざまな概念を晒してしまう点にあります。問題は、言語に何かを追加するというよりも、既存の言語から大量のものを取り除こうとすることにあるのです。しかし、既存のプログラミング言語から何かを取り除くと、すぐにすべてが壊れてしまうのです。
例えば、Pythonの最初のリリースは1990年であり、つまり30年の歴史を持つプログラミング言語です。Pythonのような人気スタックに含まれるコード量は非常に膨大であり、その理由も十分にあります。決して批判しているわけではなく、非常に堅実なスタックですが、その規模もまた巨大です。最終的に、私たちは、プログラミング言語を取り、それから大量のものを取り除いて満足のいく状態にするか、あるいはすべてのプログラミング言語にはそれぞれ大きなレガシーがあると考えるかという選択肢を検討しました。
私たちは全く新しい言語を作るための努力がどれほど必要かを検討し、最終的には新しい言語を作成する方が非常に有利だという結論に至りました。新しいプログラミング言語の設計は確立された分野であり、信じられないかもしれませんが、そうではありません。レシピを提供する本が何百冊もあり、現在ではコンピュータサイエンスの学生にも手が届くものとなっています。実際、コンピュータサイエンス学科の教授が、1学期で新しいプログラミング言語のコンパイラを作成する課題を出すことさえあります。
結局、サプライチェーンは専用の取り組みを行うに足るほど巨大であるとの結論に至りました。確かに、サプライチェーン向けに設計されていないものを再利用することは可能ですが、サプライチェーンは世界的に巨大な産業であり、数多の問題を抱えています。したがって、我々が検討している規模を考慮すれば、偶発的な再利用ではなく、サプライチェーン専用のものを直接作り出すことが理にかなっていると判断しました。
質問: サプライチェーン最適化においてEnvisionはSQL、Python等を含むため適している一方、プロセスフローが重要で数学的最適化ではないWMSやERPにおいては、そのコンパイラやプログラミング言語をどのように評価できるのでしょうか?
これは非常に良い質問です。私自身、この業界には、完全にトランザクション型でワークフロー指向のものを実装するために、独自のプログラミング言語を設計した企業が存在するのではないかと考えてきました。私の見解では、サプライチェーンは本質的に予測的最適化に関するものです。しかし、ナンナニ氏の指摘は完全に正しく、ERPやWMSなどの管理部分はどうなるのでしょうか?
この分野には、独自のプログラミング言語を開発した多くの企業が存在します。たとえば、SAPはそのために設計されたABAPを持っています。残念ながら、私の見解ではABAPは時代にそぐわなくなっています。ABAPには、21世紀にはあまり意味をなさない部分が多く、1983年に設計されたことが明らかに表れています。たとえば、Microsoft DynamicsではERPが独自のプログラミング言語を持っており、Dynamics AXも独自の言語を使用しています。多くのERPプロジェクトでは、独自のプログラミング言語が大部分で採用されているのです。つまり、こうした言語は実際に存在するのです。
では、これらの言語は本当に2021年の最新技術を駆使したプログラミング言語の頂点と言えるのでしょうか?私はそうは思いません。それが企業向けソフトウェアベンダーがプログラミング言語を絶えず再発明しているものの、通常は非常に雑な設計に終始してしまうという問題でもあります。市場に出回っている多数の書籍を読む時間すら取らず、その結果、質の低いエンジニアが混乱した状態に陥っているのです。
さて、質問に戻りますが、私はLokadがこの分野に進出し、最適化ではなくワークフローをサポートするための言語を作るという考えを持っていました。しかし現時点でLokadの成長は著しく、ワークフロー対応のために分岐する余裕はない状況です。これが核心を突いた問題であり、管理部分の問題に対して非常にうまく対処する新たな企業が現れると私は確信しています。Lokadはサプライチェーンの最適化部分のみを扱っており、管理部分もまた存在するのです。
質問: Pythonは現在、標準的なプログラミング言語と見なされていますが、市場には進行中の進化があるのでしょうか?
これは非常に良い質問です。人々が「標準」と言うとき、私はその標準が興亡していくのを十分に見てきました。私自身はそれほど年を取っていませんが、高校時代は標準はC++でした。90年代にはC++が標準で、他にどうやるというのでしょうか?その後、2000年頃にJavaが登場し、JavaとXMLの組み合わせが標準となりました。
当時、大学が「Javaスクール」と化したとまで言われました。2000年代初頭には「もはやコンピュータサイエンスの大学ではなく、単なるJavaスクールだ」とまで言われたものです。数年後、私がLokadを設立した際、統計関連のプログラミング言語としては依然としてRが主流であり、Pythonは非常に周辺的な存在で、Rが統計解析分野を圧倒していました。
プログラミング言語が進化するにつれて、C++は姿を消しました。Microsoftは2002年にC#および.NETプラットフォームを導入し、これがC++エコシステムの大部分を吸収しました。世界中のC++開発者の大部分がMicrosoftに所属していたのです。つまり、毎年、まるで固定された標準が存在するかのように見なされがちですが、その標準は常に変化しているのです。
JavaScriptは既に20年以上存在していましたが、当初は特に重要視されていませんでした。しかし、2009年か2012年頃に出版された「JavaScript: The Good Parts」という書籍が、JavaScriptが全く馬鹿げたものではないことを明らかにしました。良い部分を守れば、現実のプロジェクトでもJavaScriptを用いて正常に動作させることができるのです。すると、突然JavaScriptが大ブームとなり、Node.jsというシステムを利用してサーバーサイドで採用され始めました。
Pythonが注目を浴びるようになったのは、Pythonコミュニティがバージョン2.7から3.xへの厳しいアップグレードを経た数年前のことです。このアップグレードが終わった時、Pythonへの関心は一新されました。しかし、これからPythonには多くの危険が迫っています。21世紀の基準から見ると、Pythonはあまり優れた言語とは言えません。30年の歴史が、その年季の入った様相として表れています。もし成熟度以外のすべての面でより優れたものを求めるなら、Juliaを検討するのも良いでしょう。Juliaはデータサイエンスにおいて、成熟度を除けばほぼ全ての点でPythonより優れているのです。ただし、成熟度においてはJuliaはまだ数年遅れを取っています。
多くの進化が続いており、業界の現状を永続する標準と誤解しやすい状況です。例えば、AppleのエコシステムではObjective-Cが使われていましたが、その後Appleはその代替としてSwiftを開発し、現在Objective-Cに取って代わっています。プログラミング言語の状況は依然として進化しており、時間はかかるものの、10年後のエコシステムを見ると、相当な進化が見込まれるでしょう。Pythonが支配的なプログラミング言語として浮上しない可能性も十分にあります。なぜなら、より良い解答を示す競合する選択肢が多数存在するからです。
質問: 食品会社やeコマースのスタートアップは、データサイエンスチームや汎用言語で勝負できると考えがちです。このアプローチを洗練させ、より問題特化型のものが必要であると認識させるための最大のセールスポイントは何でしょうか?
前述したように、これはダニング=クルーガー効果による問題です。ソフトウェアエンジニアに混合整数線形計画法システムを与えた場合、一週間後にはその人が突然離散最適化の専門家になったと錯覚してしまいます。では、どのようにして勝負に勝つのでしょうか?正直なところ、通常、私たちは勝つことはありません。私がするのは、災害がどのように展開していくかを説明することです。
一般的な技術ブロックを使って素晴らしいプロトタイプを作るのは簡単です。これらのプロトタイプは、あたかもスター・ウォーズの幻想のように、独立した技術の一部だけで動作するため見事に機能します。しかし、これらの企業がそれらを生産に持ち込もうとすると、多くの場合、些細な問題に直面し苦労することになります。GoogleやMicrosoft、Amazonのように、数千人のエンジニアを抱えて全ての配管作業に対処できる企業とは異なり、継続的な統合問題に苦しむのです。
例えば、TensorFlowの統合は非常に困難です。Googleは、TensorFlowをすべてのデータパイプラインやアプリケーションに組み込むために必要な1000人のエンジニアを抱えています。しかし、スタートアップやeコマース企業がそんなに多くの人員を確保して配管作業に対応できるでしょうか?ほとんどの場合、その答えはノーです。多くの人は、ただツールを選べばうまく組み合わせられると考えがちですが、実際はそうではなく、膨大なエンジニアリングが必要なのです。
ちなみに、いくつかの企業向けソフトウェアベンダーも全く同じ問題に直面しています。彼らのソリューションにはあまりにも多くのコンポーネントが含まれており、そのため、カスタマイズなしでソリューションを展開するだけで数ヶ月もかかってしまいます。システム内の多くの不安定な部分が緩く統合されているからです。非常に困難な状況になってしまいます。
これで最後の質問だと思います。では、また次回お会いしましょう。


