00:05 Введение
02:50 Два заблуждения
09:09 Конвейер компилятора
14:23 История до настоящего момента
18:49 Накладная
19:40 Проектирование языка
23:52 Будущее
30:35 Прошлое
35:57 Выбор сражений
39:45 Грамматики 1/3
42:41 Грамматики 2/3
49:02 Грамматики 3/3
53:02 Статический анализ 1/2
58:50 Статический анализ 2/2
01:04:55 Система типов
01:11:59 Внутреннее устройство компилятора
01:27:48 Среда выполнения
01:33:57 Заключение
01:36:33 Предстоящая лекция и вопросы аудитории
Описание
Большинство цепочек поставок по-прежнему управляются с помощью электронных таблиц (то есть Excel), в то время как корпоративные системы используются уже одну, две, а иногда и три декады — предположительно для их замены. Действительно, электронные таблицы обеспечивают доступную программную выразительность, в то время как эти системы, как правило, этого не делают. Более того, с 1960-х годов наблюдается постоянное совместное развитие всей IT-индустрии и её языков программирования. Имеются данные, что следующий этап эффективности цепочек поставок во многом будет определяться развитием и принятием языков программирования, а точнее программируемых сред.
Полная транскрипция

Добро пожаловать на эту серию лекций о цепочках поставок. Меня зовут Иоаннес Верморель, и сегодня я представлю лекцию «Языки и компиляторы для цепочки поставок». Я не припоминаю, чтобы когда-либо видел упоминание компиляторов в учебниках по цепочкам поставок, однако эта тема имеет первостепенное значение. Мы увидели в самой первой главе этой серии, в лекции под названием “Ориентированная на продукт доставка”, что программирование — это ключ к рациональному использованию времени экспертов по цепочкам поставок. Без программирования мы не можем эффективно использовать их время, и обращаемся с экспертами по цепочкам поставок как с расходным материалом.
Кроме того, в этой четвёртой главе, через две предыдущие лекции “Математическая оптимизация для цепочки поставок” и “Машинное обучение для цепочки поставок”, мы увидели, что эти две области — оптимизация и обучение — за последнее десятилетие стали управляться парадигмами программирования вместо того, чтобы оставаться просто набором алгоритмов и моделей, как было раньше. Все эти факторы указывают на первостепенное значение языков программирования, что поднимает вопрос о создании языка программирования и компилятора, разработанных для решения проблем цепочки поставок.
Цель этой лекции — развенчать миф о проектировании такого языка программирования, предназначенного для нужд цепочек поставок. Скорее всего, ваша компания никогда не будет разрабатывать собственный язык программирования подобного рода. Тем не менее, знание темы является фундаментальным для оценки адекватности имеющихся у вас инструментов и для оценки пригодности тех инструментов, которые вы намерены приобрести для решения проблем цепочки поставок, с которыми сталкивается ваша компания. Кроме того, эта лекция поможет вам избежать крупных ошибок, которые зачастую совершают люди, не имеющие никакого представления об этой теме.

Давайте начнём с развенчания двух заблуждений, которые на протяжении около трёх десятилетий были распространены в кругах корпоративного ПО. Первое — заблуждение «Лего-программирование», когда программирование считают чем-то, что можно полностью обойти стороной. Действительно, программирование сложно, и всегда находят поставщиков, обещающих, что благодаря их продукту и фантастическим технологиям программирование можно превратить в визуальный опыт, доступный каждому, устранив все сложности, присущие самому процессу, так что он превращается практически в сборку конструктора Лего, которую может выполнить даже ребёнок.
Такие попытки предпринимались бесчисленное количество раз за последние пару десятилетий и неизменно заканчивались неудачей. В лучшем случае продукты, предназначенные для создания визуального опыта, превращались в обычные языки программирования, освоение которых не было заметно проще по сравнению с другими языками. Кстати, это объясняет, почему, например, в линейке продуктов Microsoft имеется серия “Visual”, такая как Visual Basic for Application и Visual Studio. Все эти визуальные продукты были представлены в 90-х годах с надеждой превратить программирование в исключительно визуальный процесс с использованием дизайнеров, где всё сводилось к перетаскиванию элементов. Но на деле, несмотря на значительный успех этих инструментов, сегодня они являются довольно обычными языками программирования. Из визуальных компонентов, присутствовавших в самом начале, осталось очень мало.
Подход «Лего» провалился, потому что, по сути, узким местом является не синтаксис программирования. Да, это препятствие, но оно минимально по сравнению с освоением концепций, необходимых для реализации любого сложного автоматизированного процесса. Ограничивающим фактором становится ваш ум, а понимание задействованных концепций гораздо важнее синтаксиса.
Второе заблуждение — “технологии Star Wars”, состоящее в мысли, что можно просто подключить и использовать фантастические технологические новинки. Это заблуждение очень привлекательно как для поставщиков, так и для внутренних проектов. По сути, становится заманчиво утверждать, что существует эта фантастическая NoSQL база данных, которую можно просто подключить, или этот великолепный глубокого обучения стек, или эта графовая база данных, или этот распределённый активный фреймворк и т.д. Проблема такого подхода в том, что технологии рассматриваются так, как это делается в “Звёздных войнах”. Когда у героя есть механическая рука, он просто получает её, и всё работает. Но на деле интеграционные проблемы выходят на первый план.
“Звёздные войны” обходят тот факт, что возникла бы целая серия проблем: во-первых, потребовались бы антибиотики, затем длительное переобучение руки, чтобы научиться её использовать. Кроме того, необходима программа обслуживания, ведь рука механическая, а что насчёт источника питания и т.д.? Все эти проблемы просто игнорируются. Вы просто подключаете фантастическую технологическую новинку, и она работает. Но в реальности всё не так: интеграционные проблемы преобладают, и, например, в крупных IT-компаниях большинство инженеров-разработчиков не работают над фантастическими технологиями. Основная масса инженерного персонала большинства крупных поставщиков ПО занимается исключительно интеграцией всех компонентов.
Когда у вас есть модули, компоненты или приложения, требуется целая армия инженеров, чтобы соединить все эти части вместе и справиться со всеми проблемами, возникающими при их объединении. И даже после преодоления сложностей интеграции вам всё равно понадобится большой штат инженеров, чтобы устранять проблемы, возникающие при изменении одной части системы и влияющих на другие. Таким образом, необходим этот инженерный ресурс для устранения возникающих проблем.
Кстати, в качестве анекдота, ещё одна проблема, которую я наблюдал при использовании крутых технологий — это эффект Даннинга-Крюгера, возникающий среди инженеров. Вы вводите крутую технологическую новинку в свой стек, и внезапно инженеры, начавшие экспериментировать с тем, что они едва понимают, начинают считать себя экспертами по ИИ или чем-то подобным. Это типичный пример эффекта Даннинга-Крюгера, который тесно связан с количеством крутых технологических элементов, добавляемых в ваше решение. В заключение, с учётом этих двух заблуждений, становится ясно, что проблему программирования невозможно просто обойти. Её необходимо решать функционально, включая и самые сложные аспекты.
Теперь, после всего сказанного, интересный момент в том, что поставщики корпоративного ПО постоянно, практически случайно, изобретают заново языки программирования, и делают это постоянно. Действительно, в цепочках поставок существует острая потребность в настраиваемости. Как мы видели в предыдущих лекциях, мир цепочек поставок разнообразен, а проблем — многочисленные и разнообразные. Таким образом, когда речь идёт о продукте для цепочки поставок, возникает чрезвычайно острая потребность в возможности тонкой настройки. По опыту, именно поэтому настройка бизнес-приложений обычно занимает несколько месяцев, а иногда и несколько лет. Это связано с колоссальной сложностью, входящей в процесс настройки.
Параметры настройки зачастую сложны и включают не только кнопки или флажки. Могут присутствовать триггеры, формулы, циклы и всевозможные блоки, связанные с этим. Всё быстро выходит из-под контроля, и в результате таких настроек возникает самопроизвольно сформированный язык программирования. Однако, поскольку это порожденный язык, он, как правило, оказывается весьма посредственным.
Разработка настоящего языка программирования является хорошо налаженной инженерной задачей. Существует десятки книг, посвящённых практическим аспектам создания компилятора промышленного уровня. Компилятор — это программа, которая преобразует инструкции, обычно текстовые, в машинный код или в инструкции более низкого уровня. Где бы ни использовался язык программирования, там обязательно есть компилятор. Например, в Excel-таблице присутствуют формулы, и у Excel имеется собственный компилятор для их преобразования и выполнения. Возможно, вся аудитория на протяжении всей своей профессиональной жизни использовала компиляторы, даже не подозревая об этом.
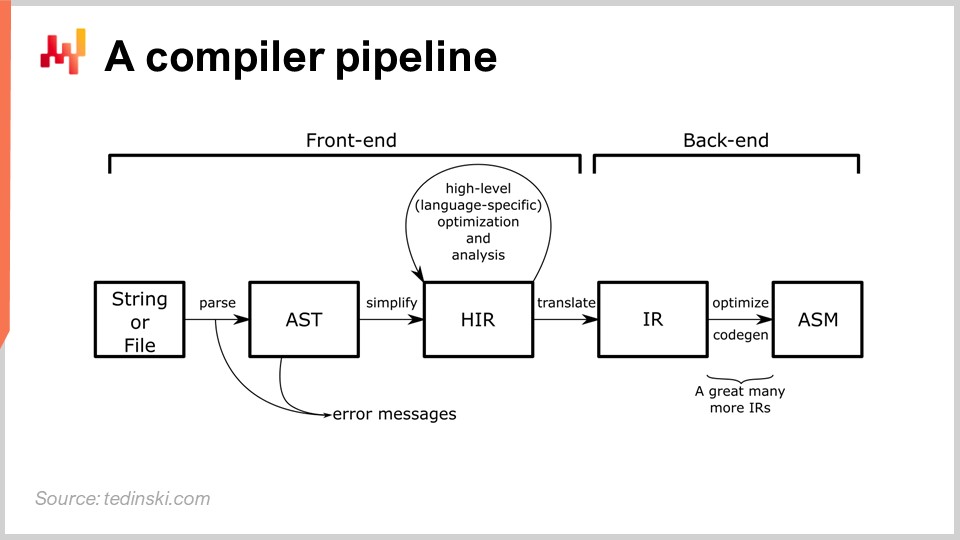
На диаграмме вы видите типичный конвейер, и этот архетип подходит для большинства языков программирования, о которых вы, вероятно, слышали, таких как Python, JavaScript, Java и C#. Все эти языки по сути имеют схожий конвейер, как показано здесь. В конвейере компилятора имеется ряд преобразований, и на каждом этапе процесса представлена некоторая модель, охватывающая всю программу целиком. Проектирование компилятора основывается на наборе чётко определённых преобразований, при этом на каждом этапе работы используется полное представление программы, просто в различном виде.
Идея заключается в том, что каждое преобразование отвечает за чётко определённый набор задач. Вы решаете эти задачи и затем переходите к следующему преобразованию, которое будет заниматься другим аспектом процесса. Обычно на каждом этапе вы приближаетесь к машинному коду. Компилятор начинает с исходного скрипта, и первые преобразования тесно связаны с синтаксисом рассматриваемого языка программирования. На этих ранних этапах типичный компилятор выявляет синтаксические ошибки, которые мешают преобразовать код, даже если он не представляет собой корректную программу, в исполняемый файл. Позже в этой лекции мы подробнее рассмотрим конвейер компилятора.
Эта лекция является пятой лекцией четвёртой главы данной серии. В первой главе я изложил свои взгляды на цепочки поставок как на область исследований, так и на практику. Во второй главе я рассмотрел методологии, подходящие для решения ситуаций, встречающихся в цепочках поставок. Как мы видели, большинство ситуаций в цепочках поставок по своей природе достаточно конфликтны, поэтому нам необходимы стратегии и методологии, которые были бы устойчивыми к враждебному поведению всех участников, как внутри, так и за пределами компаний.
Третья глава посвящена персоналу цепочки поставок и полностью сосредоточена на изучении самих проблем цепочки поставок. Мы должны быть очень осторожны, чтобы не перепутать выявляемую проблему с решением, которое мы можем предложить для её устранения. Это два совершенно разных вопроса: необходимо отделять проблему от решения.
Четвёртая, нынешняя глава этой серии лекций посвящена вспомогательным наукам в цепочке поставок. Эти вспомогательные науки не являются самими цепочками поставок, но очень полезны для практики современной цепочки поставок. В данный момент мы поднимаемся по лестнице абстракций. Мы начали эту главу с физики вычислений, затем перешли к алгоритмам, а потом в сферу программного обеспечения. Мы ввели математическую оптимизацию, которая представляет большой интерес для цепочек поставок и, к тому же, является основой для машинного обучения.
Сегодня мы представляем языки и компиляторы, необходимые для реализации любой программной парадигмы. Хотя тема языков и компиляторов может удивлять аудиторию, я считаю, что к этому моменту это не должно быть настолько неожиданно. Мы увидели, что математическую оптимизацию и машинное обучение следует в наше время рассматривать через призму программных парадигм, что поднимает вопрос о том, как реализовать эти парадигмы. Это подводит нас к проектированию языка программирования и его поддерживающего компилятора, что и является темой сегодняшней лекции.

Вот краткое содержание оставшейся части этой лекции. Мы начнем с общих наблюдений о истории и рынке языков программирования. Мы рассмотрим отрасли, которые, по моему мнению, представляют как будущее, так и прошлое цепочек поставок. Затем мы постепенно углубимся в проектирование языков программирования и компиляторов, переходя к вопросам более низкого уровня и техническим деталям, связанным с созданием компилятора.

Начиная с 1950-х годов, в производство было внедрено тысячи языков программирования. Оценки различны, но, вероятно, количество языков, использованных в производственных целях, варьируется от одной до десятки тысяч. Многие из этих языков представляют собой лишь вариации или родственные друг другу версии, иногда даже просто форк исходного кода компилятора, пошедший в несколько ином направлении. Примечательно, что несколько очень крупных предприятий-разработчиков программного обеспечения значительно расширились благодаря внедрению собственных языков программирования. Например, SAP представила ABAP в 1983 году, Salesforce — Apex в 2006, а даже Microsoft начала до эпохи Windows, разработав Altair BASIC в 1975 году.
Исторически, те из вас в аудитории, кто достаточно взрослый, чтобы помнить 90-е, возможно, вспомнят, что в то время поставщики продвигали языки программирования третьего и четвертого поколения. На самом деле, существовала чётко определённая последовательность поколений — первое, второе, третье, четвёртое и т.д., вплоть до пятого, после которого сообщество практически перестало делить их на поколения. В течение первых трёх-четырёх десятилетий все эти языки программирования следовали приятной прогрессии к более высоким уровням абстракции. Однако к концу 90-х уже появилось множество направлений, отличных от просто повышения степени абстракции, в зависимости от конкретного применения.
Создание нового языка программирования выполнялось множество раз. Это устоявшаяся инженерная область, и существуют целые книги, посвящённые этому вопросу с очень практической точки зрения. Разработка нового языка программирования является практикой, которая гораздо более опирается на инженерные принципы и предсказуема, чем, скажем, проведение научно-исследовательского эксперимента по данным. Практически наверняка вы получите желаемый результат, если проведёте соответствующую инженерную работу, учитывая сегодняшние знания и доступные ресурсы.
Все это действительно поднимает вопрос: а как насчёт языка программирования, специально разработанного для целей цепей поставок? Действительно, такой язык может дать значительные преимущества с точки зрения производительности, надёжности и даже эффективности цепочки поставок.

Чтобы ответить на этот вопрос, нам необходимо взглянуть в будущее. К счастью, самый простой способ увидеть будущее — изучить одну отрасль, которая последние три десятилетия постоянно опережала всех на одно десятилетие, а именно индустрию видеоигр. Сегодня это очень крупная отрасль, и, чтобы представить масштабы, индустрия видеоигр сейчас составляет две трети размера мировой аэрокосмической промышленности и растёт намного быстрее, чем аэрокосмическая отрасль. Через десятилетие видеоигры могут даже обойти аэрокосмическую промышленность по величине.
Интересно, что в индустрии видеоигр существует чётко налаженная структура. Во-первых, есть игровые движки, лидерами которых являются Unity и Unreal. Эти движки содержат низкоуровневые компоненты, необходимые для супер-интенсивной, высококачественной 3D-графики, и задают основу инфраструктуры вашего кода. Несколько компаний разрабатывают очень сложные продукты, называемые игровыми движками, и всё отрасль ими пользуется.
Затем идут игровые студии, которые разрабатывают код для каждой конкретной игры. Код игры, как правило, представляет собой уникальную кодовую базу, специфичную для разрабатываемой игры. Игровой движок требует от программистов экстремально высоких технических навыков, хотя они не обязательно должны глубоко разбираться в самих играх. Разработка игрового кода не требует такой интенсивности чистых технических навыков. Однако программистам, разрабатывающим игровой код, необходимо понимать игру, над которой они работают. Игровой код задаёт платформу для игровых механик, но не прописывает все мелкие детали.
Эту задачу обычно выполняют игровые дизайнеры, которые не являются программистами, но пишут код на скриптовых языках, предоставляемых им инженерной командой, работающей над игровым кодом. У нас есть три уровня: игровые движки, где задействованы сверхтехнические программисты, создающие основные строительные блоки; студии, в которых команды инженеров, обычно по одной на игру, разрабатывают игру как платформу для игровых механик; и, наконец, игровые дизайнеры, не являющиеся программистами, но специалисты по играм, реализующие поведение, которое сделает довольными игроков, конечных клиентов.
На сегодняшний день игровой код часто доступен фанатам, что означает, что игровые дизайнеры могут писать правила и потенциально модифицировать игру, как и обычные потребители. В отрасли существует несколько интересных анекдотов. Например, игра Dota 2, невероятно успешная, началась как модификация существующей игры. Первая версия, просто названная Dota, была чисто фанатской модификацией игры World of Warcraft 3. Такой уровень настраиваемости и программируемости на уровне игровых правил очень обширен, поскольку из коммерческой игры, такой как World of Warcraft 3, можно было создать совершенно новую игру, которая затем благодаря второй версии стала огромным коммерческим успехом. Это интересно и заставляет задуматься: что это может означать для индустрии цепей поставок?
Мы могли бы провести аналогию. Можно создать «движок» для цепей поставок, который займётся сложнейшими алгоритмическими задачами, низкоуровневой инфраструктурой и основными технологическими строительными блоками, такими как математическая оптимизация и машинное обучение. Идея заключается в том, что для каждой конкретной цепи поставок потребуется инженерная команда, способная собрать все необходимые данные и интегрировать весь прикладной ландшафт.
На первом этапе нам понадобятся аналоги игровых дизайнеров, но в роли специалистов по цепям поставок. Эти специалисты не являются программистами, однако именно они будут писать, с помощью упрощённого кода, все правила и механики, необходимые для реализации предиктивной оптимизации в цепях поставок. Индустрия видеоигр наглядно демонстрирует, что может произойти в области цепей поставок в ближайшее десятилетие.

Пока что подход игровой индустрии к цепям поставок остаётся фантастикой, за исключением нескольких компаний. Я считаю, что большинство из этих компаний являются клиентами Lokad. Вернёмся к сегодняшней теме: как мы уже видели на предыдущих лекциях, Excel остаётся языком программирования номер один в этой сфере. Кстати, с точки зрения языков программирования, Excel является функционально-реактивным языком, так что это даже отдельная категория.
В наши дни вы можете слышать от поставщиков, предлагающих модернизировать цепи поставок с использованием какого-либо решения по науке о данных. Однако, по моим наблюдениям за последнее десятилетие, подавляющее большинство этих инициатив потерпели неудачу. Это уже осталось в прошлом, и чтобы понять почему, нам нужно взглянуть на перечень используемых языков программирования. Если обратить внимание на Excel, то можно увидеть, что там по сути используются два языка программирования: формулы Excel и VBA. VBA даже не является обязательным; можно обойтись и лишь VLOOKUP в Excel. Как правило, это всего лишь один язык программирования, доступный даже для тех, кто не является программистом.
С другой стороны, перечень языков программирования, необходимых для воспроизведения возможностей Excel с использованием решения по науке о данных, довольно обширен. Нам понадобится SQL, а возможно, и несколько его диалектов для доступа к данным. Нам понадобится Python для реализации основной логики. Однако сам по себе Python оказывается медленным, поэтому может понадобиться субъязык, такой как NumPy. На данном этапе вы всё ещё не занимаетесь машинным обучением или математической оптимизацией, поэтому для настоящего углублённого численного анализа потребуется нечто иное, отдельный язык программирования, например, PyTorch. Теперь, когда в вашем распоряжении все эти элементы, у вас уже достаточно движущихся частей, так что конфигурация самого приложения окажется довольно сложной. Вам понадобится конфигурация, и она будет написана на ещё одном языке программирования, таком как JSON или XML. Возможно, эти языки не являются сверхсложными, но их добавление лишь увеличивает общую сложность.
Когда в системе так много движущихся частей, обычно требуется система сборки — что-то, что может запустить все компиляторы и выполнить рутинные задачи, необходимые для создания программного обеспечения. У систем сборки есть свой собственный язык. Традиционный подход использует язык под названием Make, но существует множество других вариантов. Кроме того, поскольку Excel способен отображать результаты, вам нужен способ визуализировать информацию для пользователя. Это будет сделано с использованием комбинации JavaScript, HTML и CSS, что добавляет ещё языков в список.
На данный момент у нас имеется длинный список языков программирования, и реальная производственная среда могла бы быть ещё более сложной. Это объясняет, почему большинство компаний, пытавшихся внедрить такой конвейер науки о данных за последнее десятилетие, подавляюще терпели неудачу и на практике оставались с Excel. Причина в том, что для этого требуется освоить почти дюжину языков программирования, а не один, как в случае с Excel. И мы даже ещё не приступили к решению конкретных задач цепей поставок; мы только обсуждали технические детали, предшествующие началу реальной работы.

Теперь давайте подумаем, каким может быть язык программирования для цепей поставок. В первую очередь, нам нужно решить, что должно быть частью языка в качестве первоклассного элемента, а что может быть предоставлено библиотеками. Действительно, с языками программирования всегда можно перенести некоторые возможности в библиотеки. Например, рассмотрим язык C. Он считается довольно низкоуровневым, и в нём отсутствует сборка мусора. Однако вполне возможно использовать сторонний сборщик мусора в виде библиотеки в программе на C. Из-за того, что сборка мусора не является первостепенной функцией языка C, синтаксис, как правило, оказывается довольно многословным и утомительным.
Для целей цепей поставок существуют вопросы, такие как математическая оптимизация и машинное обучение, которые обычно рассматриваются как библиотеки. Таким образом, в существующем языке программирования все эти вопросы по сути передаются сторонним библиотекам. Однако если бы мы создавали язык программирования для цепей поставок, имело бы смысл интегрировать эти возможности как первоклассные элементы самого языка. Также логично включить реляционные данные в язык в качестве первоклассного компонента. В цепях поставок прикладной ландшафт, включающий множество компонентов корпоративного программного обеспечения, всегда сопровождается реляционными данными в виде реляционных баз данных, например, SQL-баз данных. Практически все существующие сегодня программные продукты для предприятий имеют в своей основе реляционную базу данных, что означает, что для работы с данными нам придётся взаимодействовать с реляционными данными по своей природе. Данные представлены в виде списка таблиц, извлечённых из многочисленных баз данных, поддерживающих различные приложения, причем каждая таблица имеет перечень столбцов или полей.
Действительно, имеет смысл включить реляционные данные прямо в язык. Кроме того, как быть с пользовательским интерфейсом (UI) и пользовательским опытом (UX)? Одним из главных достоинств Excel является то, что всё это полностью интегрировано в язык, поэтому вам не нужен язык программирования плюс куча сторонних библиотек для работы с презентацией, рендерингом и взаимодействием с пользователем. Всё это является частью самого языка. Интеграция этих возможностей как первоклассного компонента также будет чрезвычайно важной для цепей поставок, по крайней мере, если мы хотим быть столь же эффективными, как Excel в этой сфере.

В дизайне языка грамматика представляет собой формальное описание правил, определяющих корректную программу согласно вашему новому языку программирования. По сути, вы начинаете с фрагмента текста, к которому сначала применяется лексер — специальный класс алгоритмов или небольшая программа. Лексер разбивает ваш текст, написанную программу, на последовательность токенов, выделяя все переменные и символы, используемые в языке. Грамматика затем помогает преобразовать эту последовательность токенов в фактическую семантику программы, определяя, что означает программа и какой именно, недвусмысленный набор операций необходимо выполнить для её исполнения.
Сама грамматика обычно рассматривается как компромисс между аспектами, которые вы хотите интернализовать внутри языка, и концепциями, которые хотите вынести наружу. Например, если рассматривать реляционные данные как внешний аспект, программисту придётся вводить множество специализированных структур данных, таких как словари, таблицы поиска и хэш-таблицы для выполнения всех этих операций вручную в рамках языка. Если же грамматика стремится интегрировать реляционную алгебру, это означает, что программист сможет написать всю реляционную логику напрямую в реляционной форме. Однако это значит, что внезапно все эти реляционные ограничения и реляционная алгебра становятся частью нагрузки, которую должна нести грамматика.
С точки зрения цепей поставок, поскольку реляционные данные чрезвычайно распространены в корпоративном программном обеспечении, имеет огромный смысл, чтобы грамматика языка непосредственно учитывала все реляционные аспекты.

Грамматики в информатике являются чрезвычайно изучаемой темой. Они существуют уже десятилетиями, и всё же, пожалуй, это единственная область, в которой поставщики корпоративного программного обеспечения терпят наибольшие неудачи. Действительно, они неизбежно создают случайные языки программирования, которые возникают естественным образом, когда используются сложные настройки конфигурации. Когда у вас есть условия, триггеры, циклы и отклики, обычно необходимо контролировать этот язык, а не позволять ему возникать самостоятельно.

Когда отсутствует грамматика, при внесении изменений в приложение возникают случайные последствия для реального поведения системы. Кстати, это также объясняет, почему обновление с одной версии корпоративного программного обеспечения на другую обычно является очень сложным. Конфигурация предположительно должна оставаться той же, но когда вы фактически пытаетесь запустить ту же конфигурацию в следующей версии программного обеспечения, вы получаете совершенно иные результаты. Основная причина этих проблем — отсутствие грамматики и установленных формализованных семантик того, что означает конфигурация.
Обычный способ представления грамматики — это формально с использованием Бэкус-Науровой формы (BNF), которая является специальным обозначением. На экране вы видите мини-язык программирования, представляющий почтовые адреса США. Каждая строка с знаком равенства представляет правило продукции. То, что слева, является нетерминальным символом, а справа от знака равенства находится последовательность терминальных и нетерминальных символов. Терминальные символы выделены красным и представляют собой символы, которые нельзя дальше развернуть. Нетерминальные символы заключены в скобки и могут быть развернуты дальше. Эта грамматика не является полной; для полной грамматики потребовалось бы добавить намного больше правил продукции. Я просто хотел сохранить этот слайд достаточно кратким.
Грамматику можно определить очень просто с точки зрения синтаксиса вашего языка программирования, и она также гарантирует отсутствие неоднозначностей. Однако то, что она написана в форме Бэкуса-Наура, не означает, что она будет корректной или даже хорошей. Для того чтобы грамматика была хорошей, нам нужно сделать немного больше. Математический способ охарактеризовать хорошую грамматику заключается в том, чтобы она была контекстно-свободной. Грамматика считается контекстно-свободной, если правила продукции могут применяться к любому нетерминалу, независимо от символов, которые находятся справа или слева. Идея заключается в том, что в контекстно-свободной грамматике правила продукции можно применять в любом порядке, и как только вы обнаружите совпадение или развертывание, вы просто применяете его.
Что вы получаете от контекстно-свободной грамматики, так это то, что если вы что-то в ней измените и это изменение создаст неоднозначность, компилятор не сможет скомпилировать программу, в которой возникает неоднозначность. Это имеет первостепенное значение, когда вы планируете поддерживать конфигурацию в течение длительного периода времени. В цепочках поставок большинство корпоративного программного обеспечения имеет очень долгий срок службы. Нередко можно встретить элементы корпоративного программного обеспечения, работающие два или три десятилетия. В компании Lokad мы обслуживаем более 100 компаний, и вполне часто мы извлекаем данные из систем, которые существуют более трёх десятилетий, особенно в крупных компаниях.
С контекстно-свободной грамматикой вы получаете гарантию, что если в этот язык будет внесено изменение (и помните, когда я говорю «язык», я могу иметь в виду что-то настолько простое, как настройки конфигурации), вы сможете выявить неоднозначности, возникающие при применении этого изменения. Это вместо того, чтобы эти неоднозначности происходили незамеченными, что может привести к проблемам при обновлении системы на другую.
Когда люди ничего не знают о грамматиках, они пишут парсер вручную. Если вы никогда не слышали о грамматике, программист напишет парсер, то есть программу, которая наугад создаёт своего рода дерево, представляющее разобранную версию вашей программы. Проблема в том, что в итоге вы получаете семантику вашей программы, которая невероятно специфична для той версии программы, которая у вас есть. Таким образом, если вы изменяете программу, вы меняете семантику, и получаете разные результаты, что означает, что у вас может быть одна и та же конфигурация, но разное поведение в вашей цепочке поставок.
К счастью, в 2004 году произошёл небольшой прорыв, представленный Брайаном Фордом в статье под названием “Parsing Expression Grammars: A Recognition-Based Syntactic Foundation.” Благодаря этой работе Форд предоставил сообществу способ формализовать тот случайный, ад-хок парсер, который существует в этой области. Например, эти грамматики называются Parsing Expression Grammars (PEG), и с их помощью вы можете преобразовать полуслучайные эмпирические парсеры в настоящие формальные грамматики того или иного вида.
Например, в Python отсутствует строго контекстно-свободная грамматика, но используется PEG. Грамматики PEG вполне подходят, если у вас есть обширный набор автоматических тестов, потому что в этом случае можно сохранить семантику с течением времени. Действительно, с PEG у вас есть формализация вашей грамматики, так что вы находитесь в лучшем положении по сравнению с отсутствием грамматики и наличием лишь парсера. Однако с точки зрения эволюции семантики, с PEG вы не сможете автоматически обнаружить изменение семантики, если измените саму грамматику. Таким образом, вам потребуется обширный набор автоматических тестов поверх вашего PEG, что, кстати, именно и имеет сообщество Python. У них очень надёжный и обширный набор автоматических тестов. Теперь, с точки зрения цепочки поставок, я считаю, что грамматики не только помогают осознать их важность, но и служат своего рода лакмусовой бумажкой. Вы можете реально проверить поставщиков корпоративного программного обеспечения, обсуждая программное обеспечение со значительной сложностью. Вам следует спросить у поставщика, какую грамматику они используют для сложной конфигурации. Если поставщик ответит: “Что такое грамматика?”, значит, вы в беде, и поддержка, вероятно, будет медленной и дорогостоящей.

Программирование — это очень сложно, и люди совершают множество ошибок. Если бы это было просто, программирование вообще не понадобилось бы. Хороший язык программирования минимизирует время, необходимое для обнаружения и исправления ошибки. Это один из самых критичных аспектов языка программирования, обеспечивающих приличную производительность для того, кто пишет код.
Рассмотрим следующую ситуацию: когда вы пишете код, если ошибка может быть обнаружена в процессе набора, например, орфографическая ошибка с красным подчёркиванием в Microsoft Word, то цикл обратной связи для исправления ошибки может составлять всего 10 секунд, что является идеальным. Если ошибка может быть обнаружена только при запуске программы, цикл обратной связи будет как минимум 10 минут. В цепочках поставок у нас часто бывают большие наборы данных для обработки, и мы не можем ожидать, что программа начнёт обрабатывать все данные в считанные секунды. В результате, если проблема проявляется только во время выполнения, цикл обратной связи займет 10 минут или более.
Если ошибка может быть обнаружена только после завершения скрипта, то есть программа содержит ошибку, но не завершается с её обнаружением, цикл обратной связи займет около 10 часов или более. Мы перешли от 10 секунд обратной связи в реальном времени к 10 минутам — если нам приходится запускать программу, — и затем к 10 часам, если нам нужно анализировать числовые результаты и ключевые показатели эффективности, производимые программой.
Существует ещё более худший сценарий: если платформа, на которой вы работаете, не является строго детерминированной, что означает, что при одинаковом вводе и данных она может выдавать разные результаты. Это не так странно, как может показаться, поскольку в цепочках поставок могут использоваться, например, метод Монте-Карло. Если в результатах присутствует какая-либо случайность, может случиться так, что сбой произойдет лишь время от времени, и в такой ситуации цикл обратной связи, как правило, длится более 10 дней. Таким образом, мы перешли от 10 секунд до 10 дней, и имеются огромные ставки в сокращении этого цикла обратной связи. Статический анализ представляет собой набор техник, которые можно применять для обнаружения проблем, ошибок или сбоев, даже не запуская программу. При статическом анализе идея заключается в том, что вы даже не запускаете программу, что означает, что вы можете сообщить об ошибке в режиме реального времени, пока люди набирают текст, так же, как красное подчеркивание для опечаток в Microsoft Word. Более того, существует большой интерес к тому, чтобы преобразовывать каждую проблему так, чтобы она переходила на более ранний этап обратной связи, превращая вопросы, на выявление которых уходят дни, в минуты или минуты — в секунды, и так далее.
С точки зрения цепочки поставок, мы видели на одном из предыдущих лекций, что в цепочках поставок можно ожидать много хаоса. Мы не можем иметь классических циклов выпуска, когда вы ждете, пока следующая версия вашего программного обеспечения будет доставлена. Иногда происходят чрезвычайные события, такие как изменение тарифов, задержка контейнеровозов в канале или пандемия. Эти чрезвычайные ситуации требуют экстренных исправлений, и объем статического анализа, который вы можете провести для своего языка программирования, фактически определяет, сколько хаоса вы получите в производстве из-за ошибок, не обнаруженных в режиме реального времени во время набора кода. Чрезвычайные ситуации могут казаться редкостью, но на практике сюрпризы в цепочке поставок довольно распространены.

Существуют математические доказательства того, что невозможно обнаружить все ошибки с помощью общего языка программирования в общей ситуации. Например, невозможно даже доказать, что программа завершится, то есть гарантировать, что написанное вами не будет выполняться бесконечно.
При статическом анализе вы обычно получаете три категории: некоторые части кода, вероятно, хороши, некоторые части, вероятно, плохи, а для многих вещей посередине вы просто не знаете. Идея заключается в том, что чем больше вы перемещаете из категории “не знаю” в категорию “плохой код”, тем больше усилий вам потребуется с точки зрения проектирования языка, чтобы убедить компилятор в том, что ваша программа корректна. Таким образом, нам нужно найти баланс между тем, сколько усилий вы готовы вложить в убеждение языка программирования в том, что ваш код правильный, и тем, сколько гарантий вы хотите иметь по программе на этапе компиляции, даже до того, как программа запустится. Это вопрос производительности.
А теперь краткий список типичных ошибок, выявляемых статическим анализом, включает синтаксические ошибки, такие как забытые запятые или скобки. Некоторые языки программирования даже не могут выявить синтаксические ошибки до времени выполнения, как Bash, командная оболочка в Linux. Статический анализ также может обнаруживать ошибки типов, которые возникают, когда вы используете некорректный тип или неверное количество аргументов для вызываемой функции.
Также может быть обнаружен недостижимый код, что означает, что код корректен, но никогда не выполнится, потому что вся программа может работать, так и не достигнув этого участка кода. Это похоже на “мёртвый код” или забытое логическое соединение. Незначительный код — еще одна проблема, которую можно выявить, когда код выполняется, но не оказывает никакого влияния на конечный результат. Это вариант недостижимого кода.
Также может быть обнаружен избыточно затратный код, что означает код, который мог бы выполниться, но при этом расходует вычислительные ресурсы значительно больше, чем вы можете себе позволить для вашей программы. Программа потребляет вычислительные ресурсы, такие как память, хранение и процессорное время. С помощью статического анализа вы можете доказать, что блок кода потребляет гораздо больше ресурсов, чем позволяет ваш лимит, учитывая ваши ограничения, например, необходимость завершить вычисления в определённые сроки. Вы бы предпочли, чтобы это выявлялось на этапе компиляции, а не чтобы программа работала час, а потом завершалась из-за таймаута, что привело бы к очень низкой производительности.
Однако с статическим анализом есть одна особенность. При наборе кода вы работаете с программой, которая постоянно оказывается некорректной. При каждом нажатии клавиши вы преобразуете корректную программу в некорректную. Решением промышленного уровня для этой ситуации является Language Server Protocol. Этот инструмент поставляется вместе с языком программирования и является передовой технологией, когда речь идет о предоставлении обратной связи об ошибках в режиме реального времени для программ, которые вы набираете.
С помощью Language Server Protocol вы можете получить доступ к таким функциям, как “go to definition”, когда вы щелкаете по переменной. Протокол Language Server Protocol принципиально хранит состояние, запоминая последнюю версию вашей программы, которая была корректной, вместе с доступными аннотациями и семантикой. Он сохраняет эти аннотации и дополнительные детали даже при работе с вашей сломанной программой, просто потому что вы нажали лишнюю клавишу, и программа больше не является корректной. Это настоящее открытие в плане производительности, и когда степень срочности велика, оно существенно влияет на цепочку поставок.

Теперь давайте разберемся с типовой системой. Если говорить приблизительно, типовая система — это набор правил, который использует категоризацию объектов в вашей программе или категоризацию элементов, с которыми вы работаете, чтобы прояснить, какие взаимодействия разрешены, а какие нет. Например, типичными типами являются строки, целые числа и числа с плавающей запятой, все из которых являются базовыми типами. Она определяет, что сложение двух целых чисел является допустимым, но сложение строки и целого числа — недопустимо, за исключением JavaScript, где семантика отличается.
Типовые системы, в общем, являются открытой исследовательской проблемой и могут становиться невероятно абстрактными. Чтобы прояснить ситуацию, нужно уточнить, что существует два вида типов, которые часто путают. Во-первых, есть типы значений, которые существуют только во время выполнения, когда программа действительно работает. Например, в Python, если мы рассматриваем функцию, которая возвращает первый элемент массива целых чисел, тогда тип значения, возвращаемого этой функцией, будет целым числом. С этой точки зрения, все языки программирования имеют типы — все они типизированы.
Во-вторых, существуют типы переменных, которые существуют только на этапе компиляции, когда программа компилируется и еще не запущена. Задача с типами переменных заключается в том, чтобы извлечь как можно больше информации об этих переменных во время компиляции. Если мы вернемся к предыдущему примеру, в Python может быть возможно или невозможно определить тип возвращаемого функцией значения, поскольку Python не является полностью строго типизированным на этапе компиляции.
С точки зрения цепочки поставок, мы ищем типовую систему, которая поддерживает то, что мы намерены делать в интересах цепочки поставок. Мы хотим быть как можно более строгими, чтобы выявлять проблемы и ошибки на ранней стадии, но также как можно более гибкими, чтобы позволить все операции, которые могут представлять интерес. Например, рассмотрим сложение даты и целого числа. В обычном языке программирования вы, вероятно, скажете, что это недопустимо, но с точки зрения цепочки поставок, если у нас есть дата и мы хотим прибавить к ней семь дней, было бы логично написать “date + 7”. Есть множество операций в планировании цепочки поставок, которые включают смещение дат на определенное количество дней, поэтому было бы полезно иметь алгебру, где допустимо выполнять сложение между датой и числом.
Что касается типов, хотим ли мы разрешить сложение одной даты с другой? Вероятно, нет. Однако, разрешим ли мы вычитание между двумя датами? Почему бы и нет? Если мы вычтем одну дату из другой, которая предшествует ей, мы получим разницу, которую можно выразить в днях. Это имеет большой смысл для вычислений, связанных с планированием.
Продолжая тему дат, существуют также характеристики, которые могут представлять интерес при рассмотрении того, что типовая система должна для нас делать с точки зрения вопросов цепочки поставок. Например, как насчет ограничения допустимого временного интервала? Мы можем сказать, что даты, выходящие за рамки 20 лет в прошлом и 20 лет в будущем, являются недопустимыми. Скорее всего, если мы выполняем операцию планирования и в какой-то момент программы обрабатываем дату, которая более чем на 20 лет вперед, все шансы говорят о том, что это не является допустимым плановым сценарием для большинства отраслей. Обычно вы не планируете операции на ежедневном уровне более чем на 20 лет вперед. Таким образом, мы можем не только использовать обычные типы, но и переопределять их таким образом, чтобы они были более строгими и подходящими для целей цепочки поставок.
Также существует аспект неопределенности. В управлении цепочками поставок мы всегда смотрим в будущее, но, к сожалению, будущее всегда неопределенно. Математический способ принять неопределенность — это использование случайных переменных. Было бы логично встроить случайные переменные в язык для представления неопределенного будущего спроса, сроков поставки и возвратов клиентов, среди прочего.
В компании Lokad мы разработали Envision — язык программирования, предназначенный для прогностической оптимизации цепочек поставок. Envision представляет собой смесь SQL, Python, математической оптимизации, машинного обучения и возможностей работы с большими данными, все это представлено как объекты первого класса внутри самого языка. Этот язык поставляется с веб-ориентированной интегрированной средой разработки (IDE), что означает, что вы можете писать скрипт через веб-интерфейс и пользоваться всеми современными возможностями редактирования кода. Эти скрипты работают с интегрированной распределенной файловой системой, входящей в состав среды Lokad, таким образом слой данных полностью интегрирован в язык программирования.
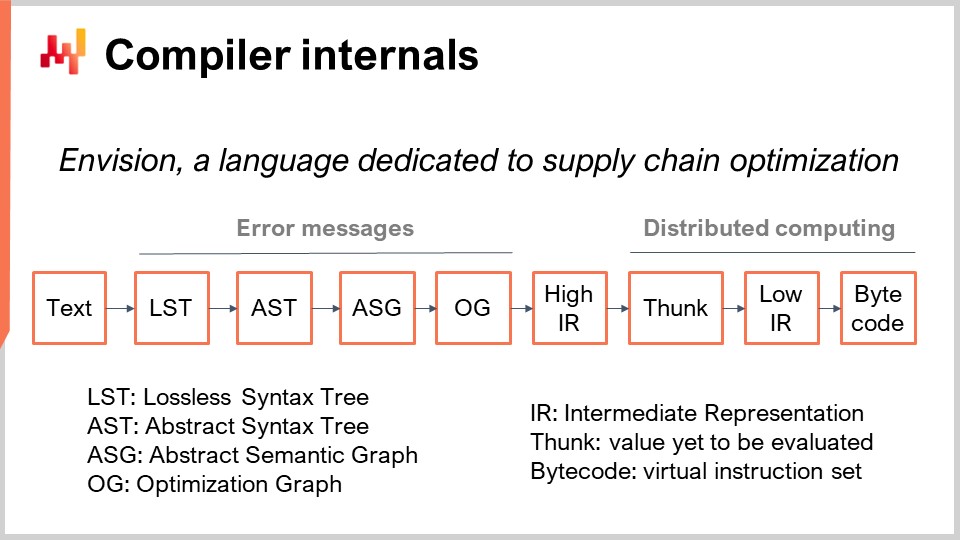
Скрипты Envision выполняются на множестве машин, предназначенных для использования преимуществ облачных вычислений в полном объеме. Когда скрипт запускается, он распределяется между множеством машин для ускорения выполнения. На экране вы можете увидеть конвейер компиляции, используемый в Envision. Сегодня мы не будем подробно обсуждать этот язык программирования; мы просто обсудим его конвейер компиляции, поскольку это тема, представляющая интерес для сегодняшней лекции.
Во-первых, мы начинаем с текстового фрагмента, содержащего скрипт Envision. Он представляет собой программу, написанную экспертом по цепочкам поставок, а не программистом, для решения конкретной задачи в цепочке поставок. Эта задача может заключаться в определении того, что производить, что пополнять, что перемещать или следует ли корректировать цену вверх или вниз. Эти сценарии использования затрагивают решения о том, что производить, пополнять, перемещать или корректировать цены. Текст скрипта содержит инструкции, и идея состоит в том, чтобы обработать этот скрипт и получить Lossless Syntax Tree (LST). LST представляет интерес, поскольку это очень точное представление, которое не отбрасывает ни одного символа. Даже незначимые пробелы сохраняются. Это делается для того, чтобы любое автоматическое переписывание программы не изменяло существующий код. Такой подход предотвращает ситуации, когда инструменты перемешивают код, изменяют отступы или вызывают другие нарушения, затрудняющие распознавание кода.
Базовая операция рефакторинга, например, может заключаться в переименовании переменной и всех её вхождений в программе, не затрагивая ничего другого. Из LST мы переходим к Abstract Syntax Tree (AST), где упрощается дерево. Скобки не требуются на этом этапе, поскольку структура дерева определяет приоритеты всех операций. Кроме того, мы выполняем серию операций по удалению синтаксического сахара, чтобы убрать любой синтаксис, предназначенный для удобства конечного программиста.
Переходя от AST к Abstract Syntax Graph (ASG), мы уплощаем дерево. Этот процесс включает разложение сложных операторов с глубоко вложенными выражениями на последовательность элементарных операторов. Например, оператор вида “a = b + c + d” будет разбит на два оператора, каждый из которых содержит только одно сложение. Именно это и происходит при переходе от AST к ASG.
Из ASG мы переходим к Optimization Graph (OG), где выполняется формирование типов и широковещание, особенно в отношении реляционной алгебры. Как упоминалось ранее, Envision встраивает реляционную алгебру в язык. Как не раз уже намекали, Envision встроил реляционную алгебру, аналогичную той, что используется в реляционных базах данных или SQL, как объект первого класса. Существует множество реляционных операций, и мы проверяем, что эти реляционные операции допустимы согласно схеме таблиц, с которыми мы работаем при переходе от ASG к OG. Optimization Graph (OG) представляет собой последний этап фронтенда компилятора и состоит из чистых, элементарных реляционных операций, применяемых к программе, представляющих собой мельчайшие логические блоки. Как и в SQL, эти элементы по своей природе реляционные.
Оптимизационное графовое представление называется “оптимизацией”, потому что в процессе перехода от OG к OG происходит множество преобразований. Эти преобразования обусловлены тем, что при работе с реляционной алгеброй организация операций определенным образом может значительно ускорить выполнение программы. Например, в SQL, если сначала применяется фильтр, а затем операция, или наоборот, гораздо лучше сначала отфильтровать данные, а затем выполнить операцию. Это гарантирует, что операции применяются только к необходимым данным, повышая эффективность.
В Lokad последний этап фронтенда компилятора — это High Intermediate Representation (HIR). HIR представляет собой чистую, стабильную и документированную границу между фронтендом и бэкендом компиляторного конвейера. В отличие от Optimization Graph (OG), который постоянно меняется из-за эвристик, HIR стабилен и предоставляет единообразный вход для бэкенда компилятора. Кроме того, HIR сериализуем, то есть может быть легко преобразован в последовательность байт для передачи с одной машины на другую. Это свойство имеет решающее значение для распределения вычислений между множеством машин.
Из High Intermediate Representation мы переходим к «funcs». Funcs — это значения, которые еще не были вычислены и представляют собой атомарные блоки вычислений в распределенной системе выполнения. Например, при сложении двух гигантских векторов из таблицы с миллиардами строк будет серия funcs, представляющих различные части этих векторов. Каждый func отвечает за сложение части двух векторов и выполняется на одной машине. Большие вычисления разбиваются на множество funcs, чтобы распределить нагрузку между несколькими ЦП и машинами, если объем вычислений достаточно велик, чтобы требовать такого распределения. Funcs называются “ленивыми”, потому что они не вычисляются сразу; их вычисляют по мере необходимости. Может выполняться множество операций до того, как некоторые funcs будут фактически рассчитаны, и как только func вычислен, он заменяется своим результатом.
Внутри func вы найдете low intermediate representation, который представляет императивную низкоуровневую логику, выполняющуюся внутри func. Он может, например, включать циклы и обращения к словарям. Наконец, этот низкоуровневый промежуточный код компилируется в байт-код, который является конечной целью нашего компиляторного конвейера. В Lokad мы нацелены на .NET байт-код, технически известный как MSIL.
С точки зрения цепочки поставок действительно интересно то, что через этот, можно сказать, сложный компиляторный конвейер мы воспроизводим уровень интеграции, характерный для Microsoft Excel. Язык интегрирован со слоем данных и пользовательским интерфейсом (UI/UX), что позволяет пользователям видеть и взаимодействовать с результатами работы программы так же, как они это делают с таблицей Excel. Однако, в отличие от Excel, мы углубляемся в гораздо более интересные области управления цепочками поставок, принимая реляционные концепции в качестве объектов первого класса, а также математическую оптимизацию и машинное обучение.
И математическая оптимизация, и машинное обучение в этом конвейере проходят через весь процесс, вместо того чтобы просто вызывать библиотеку, находящуюся где-то. Наличие машинного обучения в качестве объекта первого класса в конвейере позволяет получать более понятные сообщения об ошибках, что существенно влияет на продуктивность экспертов по цепочкам поставок.

В качестве последней темы, современные компиляторы почти всегда ориентированы на виртуальную машину, но эти виртуальные машины, в свою очередь, компилируются в другую виртуальную машину. На экране типичные слои виртуальной машины, встречающиеся в серверных установках, очень схожи с тем, что мы наблюдаем в скрипте Envision. Я только что представил конвейер компиляции, но в основе своей это практически тот же стек, если речь идет о Python-скрипте или электронных таблицах Excel, работающих на сервере. При проектировании компилятора вы, по существу, выбираете тот уровень, на который будете внедрять код. Чем ниже уровень, тем больше технических деталей придется учитывать. При выборе уровня возникает ряд вопросов, которые необходимо решить.
Во-первых, существует вопрос безопасности. Как защитить память и что программа может или не может использовать? Если у вас универсальный язык программирования, возможности ограничены. Возможно, вам придется работать на уровне гостевой операционной системы, хотя даже это может быть не слишком безопасно. Существуют способы создания песочницы, но это очень непросто, поэтому, возможно, придется идти еще ниже.
Во-вторых, существует вопрос низкоуровневых возможностей, которые вам интересны. Например, это может быть важно, если вы хотите добиться более производительного выполнения, сокращая количество вычислительных ресурсов, необходимых для завершения вашей программы. Вы можете решить работать на достаточно низком уровне, чтобы управлять памятью и потоками. Однако с этой властью приходит ответственность за фактическое управление памятью и потоками.
В-третьих, имеются удобные функции, такие как сборка мусора, трассировка стека, отладчик и профайлер. Обычно вся инструментальная среда вокруг компилятора сложнее самого компилятора. Количество удобных функций, которыми вы можете воспользоваться, не следует недооценивать.
В-четвертых, существуют вопросы распределения ресурсов. Если вы работаете с таблицей Excel на вашем десктопе, Excel может потреблять все вычислительные ресурсы вашей рабочей станции. Однако с Envision или SQL вы обслуживаете множество пользователей, и вам приходится решать, как распределять ресурсы. Более того, с Envision речь идет не только о множестве пользователей, но и о множестве компаний, так как Lokad поддерживает мультиарендность. Это имеет смысл для цепочек поставок, поскольку потребность в вычислительных ресурсах у большинства из них носит прерывистый характер.
Обычно вам требуется очень интенсивный вычислительный всплеск в течение примерно получаса или часа, а затем ничто в последующие 23 часа. Затем этот процесс повторяется ежедневно. Если выделить вычислительные ресурсы для одной компании, они будут простаивать 90% времени или даже больше. Таким образом, вы хотите иметь возможность распределить нагрузку между множеством машин и компаний, возможно, компаний, работающих в разных часовых поясах.
Наконец, имеется вопрос экосистемы. Суть в том, что когда вы выбираете конкретный уровень и конкретную виртуальную машину для вашего компилятора, будет довольно удобно интегрировать и связывать ваш компилятор с тем, что также нацелено на те же виртуальные машины. Это поднимает вопрос об экосистеме: что можно найти на том же уровне, что и ваша цель, чтобы не изобретать велосипед для каждой мелочи, задействованной в вашем стеке? Это последний, но важный вопрос.

В заключение, поздравляем тех немногих счастливчиков, которые дошли до этого момента в серии лекций по цепочкам поставок. Это, вероятно, одна из самых технических лекций на данный момент. Компиляторы, безусловно, представляют собой очень техническую область; однако реальность современных цепочек поставок такова, что все опосредовано через язык программирования. Больше нет понятия необработанной, напрямую наблюдаемой цепочки поставок. Единственный способ наблюдать цепочку поставок — это через посредство электронных записей, создаваемых всеми компонентами корпоративного программного обеспечения, составляющими прикладной ландшафт. Таким образом, необходим язык программирования, и по умолчанию этим языком оказывается Excel.
Однако, если мы хотим создать нечто лучшее, чем Excel, нам нужно тщательно обдумать, что вообще означает «лучше» с точки зрения цепочек поставок и что это значит в терминах языков программирования. Если у компании нет правильной стратегии или культуры, никакая технология её не спасёт. Но если стратегия и культура выстроены правильно, тогда инструменты действительно имеют значение. Инструменты, включая языки программирования, определят вашу способность выполнять задачи, продуктивность, которую можно ожидать от экспертов по цепочкам поставок, и производительность вашей цепочки поставок при преобразовании макро стратегии в тысячи рутинных ежедневных решений, которые необходимо принимать. Способность оценить адекватность используемых инструментов, включая языки программирования, предназначенные для решения задач цепочек поставок, имеет первостепенное значение. Если вы не в состоянии это оценить, то это просто карго-культ.

Следующая лекция будет посвящена инженерии программного обеспечения. Сегодня мы обсудили инструменты; однако в следующий раз мы рассмотрим людей, которые используют эти инструменты, и какой командной работы требуется для качественного выполнения работы. Лекция состоится в тот же день недели, в среду, в 15:00 по парижскому времени.
Теперь я ознакомлюсь с вопросами.
Вопрос: Как, выбирая программное обеспечение для цепочек поставок, предприятия, не обладающие высокой технической подкованностью, могут оценить, подходят ли компилятор и язык программирования для их нужд?
Я уверен, что типичная компания, управляющая стандартной цепочкой поставок, не обладает квалификацией для разработки транспортного средства, но при этом умеет закупать грузовики, которые соответствуют их требованиям к цепочке поставок и транспортировке. Не потому что вы не эксперт и не способны переделать грузовик, что вы не можете иметь обоснованное мнение о том, подходит ли он для ваших транспортных нужд. Я не утверждаю, что компании, не разбирающиеся в технике, должны совершить невероятный скачок и внезапно стать экспертами в проектировании компиляторов. Однако я считаю, что за полтора часа мы охватили довольно много материала. Если бы было дополнительно 10 часов более детального и неспешного введения, вы узнали бы всё, что когда-либо понадобится для понимания дизайна языков программирования для нужд цепочки поставок.
Существует разница между тем, чтобы быть экспертом, и быть настолько невежественным, что вам могут продать скутер, выдавая его за грузовик. Если перевести это невежество, которое я наблюдал в корпоративном программном обеспечении, на автомобильную промышленность, люди утверждали бы, что скутер — это полуторка, и наоборот, и с этим бы справлялись.
Эта серия лекций посвящена вспомогательным наукам, поэтому нет цели, чтобы люди, стремящиеся стать специалистами в области цепочек поставок, превращались в экспертов в этих областях. Тем не менее, обладая начальными знаниями, вы можете намного лучше ориентироваться в оценке. Чаще всего достаточно знать столько, чтобы задавать трудные вопросы. Если поставщик дает нелепый ответ, это выглядит плохо. Если вы даже не знаете, какие технические вопросы задавать, вас могут обмануть.
Мой совет таков: вам не нужно становиться невероятно технически подкованным; достаточно быть достаточно осведомлённым на базовом уровне, чтобы уметь выявлять недостатки и оценивать, развалится ли всё или за этим кроется реальная суть. То же самое относится к математической оптимизации, машинному обучению, ЦПУ и так далее. Главное — знать достаточно, чтобы отличать мошенничество от легитимного решения.
Вопрос: Обсуждали ли вы напрямую проблему существующих языков программирования, не предназначенных для цепочек поставок?
Это очень хороший вопрос. Создание совершенно нового языка программирования может показаться абсолютно безумным. Почему бы не выбрать что-то уже проверенное, например Python, и внести в него небольшие модификации, которые нам нужны? Это был бы вариант. Проблема в том, что главное не в том, что нам нужно добавить в эти языки, а в том, что необходимо убрать.
Моя основная критика в адрес Python не в отсутствии вероятностной алгебры или встроенной реляционной алгебры. Моя главная претензия в том, что это полноценный универсальный язык программирования, и поэтому он подвергает человека, который пишет код, влиянию самых разных концепций, таких как объектно-ориентированное программирование для Python, которые абсолютно не имеют отношения к цепочкам поставок. Проблема заключалась не столько в том, чтобы взять язык и добавить что-то, сколько в том, чтобы взять язык и попытаться убрать кучу вещей. Однако как только вы начинаете удалять элементы из существующего языка программирования, вы всё ломаете.
Например, первый релиз Python состоялся в 1990 году, так что это 30-летний язык программирования. Объём кода в таком популярном стеке, как Python, просто гигантский, и не без оснований. Я не критикую его; это очень надёжный стек, но он также и огромен. В итоге мы оценили различные варианты: взять язык программирования и удалить из него массу ненужного, пока не останется только то, что нам необходимо, или признать, что все эти языки имеют массу собственного наследия.
Мы оценили, сколько усилий потребовалось бы для создания совершенно нового языка, и в конечном итоге всё оказалось в пользу создания нового языка. Создание нового языка программирования — это хорошо отлаженная область, так что, хотя это может звучать невероятно, на самом деле так и есть. Существует сотни книг с инструкциями, и теперь это даже доступно студентам компьютерных наук. Есть даже профессора в университетах, которые дают студентам задание в течение одного семестра создать компилятор для нового языка программирования.
В конечном итоге мы решили, что цепочки поставок настолько масштабны, что требуют специального подхода. Да, вы всегда можете переработать что-то, что не было изначально создано для цепочек поставок, но сама по себе цепочка поставок — это глобальная, огромная индустрия с множеством проблем. Поэтому мы решили, что с учётом масштабов имеет смысл сделать всё правильно и создать что-то специально для цепочек поставок, а не случайно перерабатывать существующее.
Вопрос: Для оптимизации цепочки поставок Envision подходит, так как включает в себя SQL, Python и т.д. Однако для WMS, ERP, где ключевым является процессный поток, а не математическая оптимизация, как можно оценить его компилятор и язык программирования?
Это очень хороший вопрос. Лично я размышлял над тем, что в этой отрасли есть участники, которые собственными силами разработали собственные языки программирования исключительно для того, чтобы реализовать что-то по своей сути транзакционное, ориентированное на рабочий процесс. Цепочка поставок, как я её понимаю, по существу связана с предиктивной оптимизацией. Однако господин Наннани совершенно прав: как быть с управленческой частью, такой как ERP, WMS и т.д.?
Оказывается, что в этой сфере есть множество компаний, которые разработали свои собственные языки программирования. Я упоминал SAP, который имеет ABAP, созданный именно для этого. К сожалению, на мой взгляд, ABAP устарел. В ABAP много элементов, которые в XXI веке уже не имеют смысла. Можно ясно заметить, что этот язык был создан в 83-м году, и это заметно. Например, в Microsoft Dynamics ERP имеет собственный язык программирования. Dynamics AX использует свой язык, и существует множество ERP-проектов, которые в значительной степени используют свой собственный язык программирования. Так что такие языки действительно существуют.
Теперь, являются ли эти языки действительно вершиной современных, передовых языков программирования в 2021 году? Я так не думаю, и это также та проблема, о которой я говорил: поставщики корпоративного программного обеспечения продолжают заново изобретать языки программирования, но чаще всего справляются с этим очень плохо. Это просто хаотичный инженерный подход. Они даже не находят времени, чтобы изучить множество книг, доступных на рынке, и в результате оказываются с неуклюжим набором беспорядков.
Возвращаясь к вашему вопросу, я размышлял о том, чтобы Lokad осваивал эту область и создал язык, предназначенный не для оптимизации, а для поддержки рабочего процесса. Однако на данный момент рост Lokad настолько велик, что мы не можем отделиться и заняться вопросами рабочего процесса. Я абсолютно уверен, что это правильное направление, и появятся новые участники, которые отлично справятся с управленческой частью проблемы. Lokad занимается исключительно оптимизацией цепочек поставок; существует же и управленческая часть.
Вопрос: Python в настоящее время считается стандартным языком программирования. Происходят ли какие-либо эволюционные изменения на рынке?
Это очень хороший вопрос. Видите ли, когда люди говорят мне о «стандартах», я прожил достаточно, чтобы видеть, как стандарты приходят и уходят. Я не очень стар, но когда я учился в старшей школе, стандартом был C++. В 90-х годах стандартом был C++. Зачем поступать иначе? Затем появился Java, примерно в 2000 году, и сочетание Java с XML стало стандартом.
Люди даже говорили, что университеты в то время стали «школами Java». Это буквально был лозунг тех времён около 2000 года; люди говорили: «Это уже не университет компьютерных наук, это просто школа Java». Несколько лет спустя, когда я основал Lokad, язык программирования для всего, что связано со статистикой, всё ещё был R. Python оставался довольно маргинальным, а R абсолютно доминировал в области статистического анализа.
По мере развития языков программирования C++ утратил свою актуальность. В 2002 году Microsoft представила C# и платформу .NET, что привело к существенному сокращению экосистемы C++. Большая часть разработчиков на C++ по всему миру оказалась в Microsoft — очень крупной компании. Суть в том, что происходила настоящая эволюция, и каждый год люди думали, что существует единый стандарт, хотя он постоянно меняется.
JavaScript существует уже 20 лет, но долгое время не имел особого значения. Затем книга, опубликованная около 2009 или 2012 года под названием «JavaScript: The Good Parts», показала, что JavaScript не настолько безумен, как казался. Вы могли использовать JavaScript для реального проекта, не теряя рассудка, если придерживались только его лучших аспектов. Внезапно JavaScript стал нарасхождение, и люди начали использовать его на стороне сервера с помощью системы под названием Node.js.
Python стал набирать популярность лишь несколько лет назад, после того как сообщество Python пережило изнурительное обновление с версии 2.7 до версии 3.x. По завершении этого обновления интерес к Python возрос. Однако впереди для Python таится множество опасностей. Это не самый хороший язык по меркам XXI века. Ему уже 30 лет, и это заметно. Если вам нужно что-то лучшее во всех аспектах, кроме зрелости, можно обратить внимание на Julia. Julia превосходит Python почти во всех отношениях для науки о данных, за исключением зрелости, где Julia всё ещё значительно моложе.
Происходит масса эволюционных изменений, и легко принять нынешнее состояние отрасли за стандарт, который должен сохраняться вечно. Например, в экосистеме Apple раньше использовался Objective-C, а затем Apple решил создать Swift в качестве замены, который теперь вытесняет Objective-C. Ландшафт языков программирования всё ещё активно развивается, и хотя это требует времени, если заглянуть в будущее на десять лет, можно ожидать значительных перемен. Python может не стать доминирующим языком, поскольку существует множество конкурирующих вариантов, которые предоставляют лучшие решения.
Вопрос: Компании из пищевой промышленности и стартапы в сфере электронной коммерции часто думают, что могут выиграть битву с командами по анализу данных и универсальными языками. Какой был бы ваш главный аргумент, чтобы побудить их пересмотреть этот подход и понять, что им необходимо нечто более специфичное для решения проблемы?
Как я уже говорил, это проблема эффекта Даннинга–Крюгера. Вы даёте инженеру программного обеспечения систему для линейного программирования с целыми переменными, чтобы он решил задачу целочисленного программирования, и через неделю этот человек решает, что он внезапно стал экспертом в дискретной оптимизации. Так как же мне выиграть эту битву? По правде говоря, обычно мы их не побеждаем. Я просто описываю, как будут разворачиваться катастрофические события.
Всё предельно просто, когда создаёшь фантастические прототипы, используя универсальные технологические блоки. Эти прототипы работают блестяще благодаря иллюзии «Звёздных войн» — у вас есть отдельный фрагмент технологии в изоляции. Но как только эти компании пытаются внедрить эти решения в производство, они сталкиваются с проблемами, зачастую достаточно банальными. Они будут сталкиваться с постоянными проблемами интеграции, в отличие от Google, Microsoft или Amazon, которые могут позволить себе иметь тысячу инженеров для решения всех мелких задач.
Например, TensorFlow сложно интегрировать. У Google есть 1000 инженеров, способных внедрить TensorFlow во все их конвейеры извлечения данных и приложения для своих нужд. Но вопрос в том, смогут ли стартапы или компании электронной коммерции позволить себе иметь столько специалистов, чтобы заниматься всей этой «водопроводной» работой? Как правило, ответ — нет. Люди думают, что, просто выбрав эти инструменты, можно потом как по щучьему велению собрать их вместе, и всё заработает. Но это не так. Это требует колоссальных инженерных усилий.
Кстати, некоторые поставщики корпоративного программного обеспечения сталкиваются с точно такой же проблемой. У них слишком много компонентов в их решениях, и именно это объясняет, почему развёртывание решения, без какой-либо кастомизации, уже занимает месяцы, поскольку так много нестабильных компонентов системы лишь слабо интегрированы. Это становится очень сложно.
Полагаю, это был последний вопрос. До встречи в следующий раз.


