00:18 Introduzione
02:18 Contesto
12:08 Perché ottimizzare? 1/2 Previsione con Holt-Winters
17:32 Perché ottimizzare? 2/2 - Problema del routing dei veicoli
20:49 La storia finora
22:21 Scienze ausiliarie (riassunto)
23:45 Problemi e soluzioni (riassunto)
27:12 Ottimizzazione matematica
28:09 Convessità
34:42 Stocasticità
42:10 Multi-obiettivo
46:01 Progettazione del risolutore
50:46 Lezioni di (apprendimento) profondo
01:10:35 Ottimizzazione matematica
01:10:58 “Vero” programmazione
01:12:40 Ricerca locale
01:19:10 Discesa del gradiente stocastico
01:26:09 Differenziazione automatica
01:31:54 Programmazione differenziale (circa 2018)
01:35:36 Conclusioni
01:37:44 Prossima lezione e domande del pubblico
Descrizione
L’ottimizzazione matematica è il processo di minimizzazione di una funzione matematica. Quasi tutte le moderne tecniche di apprendimento statistico - ad esempio, la previsione se adottiamo una prospettiva di supply chain - si basano sull’ottimizzazione matematica al loro nucleo. Inoltre, una volta che le previsioni sono stabilite, l’individuazione delle decisioni più redditizie si basa, al loro nucleo, sull’ottimizzazione matematica. I problemi della supply chain coinvolgono spesso molte variabili. Sono anche di solito di natura stocastica. L’ottimizzazione matematica è un pilastro di una moderna pratica di supply chain.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Ottimizzazione Matematica per la Supply Chain”. L’ottimizzazione matematica è il modo ben definito, formalizzato e computazionalmente trattabile per identificare la migliore soluzione per un dato problema. Tutti i problemi di previsione possono essere visti come problemi di ottimizzazione matematica. Tutte le situazioni di presa di decisione nella supply chain e al di fuori delle supply chain possono anche essere viste come problemi di ottimizzazione matematica. In realtà, la prospettiva dell’ottimizzazione matematica è così radicata nella nostra visione moderna del mondo che è diventato molto difficile definire il verbo “ottimizzare” al di fuori del piccolo box che ci viene dato dal paradigma dell’ottimizzazione matematica.
Ora, la letteratura scientifica sull’ottimizzazione matematica è vasta, così come l’ecosistema software che fornisce strumenti per l’ottimizzazione matematica. Purtroppo, la maggior parte di essa è di scarso utilizzo e rilevanza per quanto riguarda la supply chain. L’obiettivo di questa lezione sarà duplice: prima di tutto, vogliamo capire come affrontare l’ottimizzazione matematica per ottenere qualcosa di valore e di utilità pratica da una prospettiva di supply chain. Il secondo elemento sarà quello di identificare, in questo vasto panorama, alcuni degli elementi più preziosi che si possono trovare.

La definizione formale dell’ottimizzazione matematica è semplice: si pensa a una funzione che viene tipicamente chiamata funzione di perdita, e questa funzione produce solo numeri reali. Ciò che si desidera è identificare l’input (X0) che rappresenta il miglior valore che minimizza la funzione di perdita. Questo è tipicamente il paradigma dell’ottimizzazione matematica ed è ingannevolmente semplice. Vedremo che ci sono molte cose che possono essere dette su questa prospettiva generale.
Questo campo, credo, quando pensiamo in termini di ottimizzazione matematica applicata, è stato sviluppato principalmente con il nome di ricerca operativa, che definiamo in modo più specifico come la ricerca operativa classica che va dagli anni ‘40 alla fine degli anni ‘70 nel XX secolo. L’idea è che la ricerca operativa classica, rispetto all’ottimizzazione matematica, si preoccupava davvero dei problemi aziendali. L’ottimizzazione matematica si preoccupa della forma generale del problema di ottimizzazione, molto meno del fatto che il problema abbia una qualche rilevanza aziendale. Al contrario, la ricerca operativa classica stava essenzialmente facendo ottimizzazione, ma non su qualsiasi tipo di problema, bensì su problemi che erano stati identificati come importanti per le aziende.
Curiosamente, siamo passati dalla ricerca operativa all’ottimizzazione matematica più o meno allo stesso modo in cui siamo passati dalla previsione, che è emersa all’inizio del XX secolo come un campo interessato alla previsione generale dei futuri livelli di attività economica, tipicamente associata alle previsioni delle serie temporali. Questo dominio è stato essenzialmente superato dall’apprendimento automatico, che si preoccupava più ampiamente di fare previsioni su un campo molto più ampio di problemi. Potremmo dire che abbiamo avuto in modo approssimativo lo stesso tipo di transizione dalla ricerca operativa all’ottimizzazione matematica come è stato dalla previsione all’apprendimento automatico. Ora, quando ho detto che l’era classica della ricerca operativa è durata fino alla fine degli anni ‘70, avevo una data molto specifica in mente. Nel febbraio 1979, Russell Ackoff pubblicò un articolo sorprendente dal titolo “Il futuro della ricerca operativa è passato”. Per capire questo articolo, che ritengo essere davvero una pietra miliare nella storia della scienza dell’ottimizzazione, è necessario capire che Russell Ackoff è essenzialmente uno dei padri fondatori della ricerca operativa.
Quando pubblicò questo articolo, non era più un giovane; aveva 60 anni. Ackoff era nato nel 1919 e aveva trascorso praticamente tutta la sua carriera lavorando sulla ricerca operativa. Quando pubblicò il suo articolo, affermò fondamentalmente che la ricerca operativa aveva fallito. Non solo non aveva prodotto risultati, ma l’interesse nell’industria stava diminuendo, quindi c’era meno interesse alla fine degli anni ‘90 rispetto a quello che c’era nel campo 20 anni prima.
La cosa interessante da capire è che la causa non è assolutamente il fatto che i computer dell’epoca fossero molto più deboli di quelli che abbiamo oggi. Il problema non ha nulla a che fare con la limitazione in termini di potenza di elaborazione. Siamo alla fine degli anni ‘70; i computer sono molto modesti rispetto a quelli che abbiamo oggi, ma possono comunque eseguire milioni di operazioni aritmetiche in un tempo ragionevole. Il problema non è legato alla limitazione della potenza di elaborazione, soprattutto in un momento in cui la potenza di elaborazione sta progredendo incredibilmente velocemente.
A proposito, questo articolo è una lettura fantastica. Suggerisco davvero al pubblico di dargli un’occhiata; è possibile trovarlo facilmente con il proprio motore di ricerca preferito. Questo articolo è molto accessibile e ben scritto. Sebbene il tipo di problemi che Ackoff evidenzia in questo articolo risuoni ancora molto fortemente a distanza di quattro decenni, in molti modi, l’articolo è molto preveggente su molti dei problemi che ancora affliggono le supply chain odierna.
Quindi, qual è il problema allora? Il problema è che questo paradigma, in cui si prende una funzione e la si ottimizza, si può dimostrare che il processo di ottimizzazione identifica una buona o forse una soluzione ottimale. Tuttavia, come si può dimostrare che la funzione di perdita che si sta effettivamente ottimizzando ha qualche interesse per l’azienda? Il problema è che quando dico che possiamo ottimizzare un determinato problema o una determinata funzione, cosa succede se ciò che si sta ottimizzando è in realtà una fantasia? Cosa succede se questa cosa non ha nulla a che fare con la realtà dell’azienda che si sta cercando di ottimizzare?
Qui sta la crux del problema, e qui sta il motivo per cui quei primi tentativi essenzialmente sono tutti falliti. È perché si è scoperto che quando si evoca una sorta di espressione matematica che dovrebbe rappresentare l’interesse dell’azienda, ciò che si ottiene è una fantasia matematica. Questo è letteralmente ciò che Russell Ackoff sta evidenziando in questo articolo, ed è ad un punto della sua carriera in cui ha giocato a questo gioco per molto tempo e riconosce che in sostanza non porta da nessuna parte. Nel suo articolo, condivide la visione che il settore abbia fallito e propone la sua diagnosi, ma non ha molto da offrire in termini di soluzione. È molto interessante perché uno dei padri fondatori, un ricercatore molto rispettato e riconosciuto, afferma che l’intero campo di ricerca è un vicolo cieco. Trascorrerà il resto della sua vita, che è ancora piuttosto lunga, passando completamente da una prospettiva quantitativa sull’ottimizzazione aziendale a una prospettiva qualitativa. Trascorrerà gli ultimi tre decenni della sua vita adottando metodi qualitativi e produrrà comunque lavori molto interessanti nella seconda parte della sua vita dopo questo punto di svolta.
Ora, per quanto riguarda questa serie di lezioni, cosa facciamo perché i punti che Russell Ackoff solleva sull’operational research rimangono molto validi al giorno d’oggi? In realtà, ho già iniziato ad affrontare i maggiori problemi che Ackoff stava evidenziando, e all’epoca lui e i suoi colleghi non avevano soluzioni da offrire. Potevano diagnosticare il problema, ma non avevano una soluzione. In questa serie di lezioni, le soluzioni che sto proponendo sono di natura metodologica, proprio come il fatto che Ackoff evidenzia che c’è un profondo problema metodologico con questa prospettiva dell’operational research.
I metodi che propongo sono essenzialmente di due tipi: da un lato, il personale della supply chain, e dall’altro lato, il metodo intitolato “experimental optimization” che si rivela davvero complementare all’ottimizzazione matematica. Inoltre, a differenza dell’operational research che sostiene di essere di interesse o rilevanza aziendale, il modo in cui affronto il problema oggi non è attraverso l’angolo o le lenti dell’operational research. Sto affrontando il problema attraverso le lenti dell’ottimizzazione matematica, che posiziono come una scienza ausiliaria pura per la supply chain. Dico che non c’è nulla di intrinsecamente fondamentale nell’ottimizzazione matematica per la supply chain; è solo di interesse fondamentale. È solo un mezzo, non una fine. Qui sta la differenza. Il punto può sembrare molto semplice, ma ha grande importanza quando si tratta di ottenere risultati di previsione con tutto ciò.

Ora, perché vogliamo ottimizzare in primo luogo? La maggior parte degli algoritmi di previsione ha un problema di ottimizzazione matematica al loro centro. In questa schermata, quello che si può vedere è il classico algoritmo di previsione delle serie storiche Holt-Winters moltiplicativo. Questo algoritmo è principalmente di interesse storico; non consiglierei a nessuna supply chain odierna di sfruttare effettivamente questo algoritmo specifico. Ma per semplicità, si tratta di un metodo parametrico molto semplice ed è così conciso che si può mettere interamente su una schermata. Non è nemmeno molto verboso.
Tutte le variabili che puoi vedere sullo schermo sono solo numeri semplici; non ci sono vettori coinvolti. Fondamentalmente, Y(t) è la tua stima; questa è la tua previsione delle serie temporali. Qui sullo schermo, si prevede H periodi in avanti, quindi H è come l’orizzonte. E puoi pensare di lavorare effettivamente su Y(t), che è essenzialmente la tua serie temporale. Puoi pensare a dati di vendita aggregati settimanalmente o mensilmente. Questo modello ha essenzialmente tre componenti: ha Lt, che è il livello (hai un livello per ogni periodo), Bt, che è la tendenza, e St, che è una componente stagionale. Quando dici che vuoi imparare il modello Holt-Winters, hai tre parametri: alpha, beta e gamma. Questi tre parametri sono essenzialmente solo numeri tra zero e uno. Quindi, hai tre parametri, tutti numeri tra zero e uno, e quando dici che vuoi applicare l’algoritmo Holt-Winters, significa solo che identificherai i valori appropriati per quei tre parametri, e basta. L’idea è che questi parametri, alpha, beta e gamma, saranno i migliori se minimizzano il tipo di errore che hai specificato per la tua previsione. Su questa schermata, puoi vedere un errore quadratico medio, che è molto classico.
Il punto sull’ottimizzazione matematica è trovare un metodo per identificare i giusti valori dei parametri alpha, beta e gamma. Cosa possiamo fare? Beh, il metodo più semplice e più semplicistico è qualcosa come la ricerca in griglia. La ricerca in griglia direbbe che stiamo solo esplorando tutti i valori. Poiché questi sono numeri frazionari, ci sono un numero infinito di valori, quindi in realtà sceglieremo una risoluzione, diciamo passi di 0,1, e andremo con incrementi di 0,1. Poiché abbiamo tre variabili tra 0 e 1, andiamo con incrementi di 0,1; ciò significa circa 1.000 iterazioni per passare attraverso e identificare il miglior valore, considerando questa risoluzione.
Tuttavia, questa risoluzione è piuttosto debole. 0,1 ti dà una risoluzione del 10% sul tipo di scala che hai per i tuoi parametri. Quindi forse vuoi optare per 0,01, che è molto meglio; è una risoluzione del 1%. Tuttavia, se fai così, il numero di combinazioni esplode davvero. Passi da 1.000 combinazioni a un milione di combinazioni, e vedi che è il problema della ricerca in griglia: molto rapidamente, si arriva a un muro combinatorio e si hanno un’enorme quantità di opzioni.
L’ottimizzazione matematica consiste nel creare algoritmi che ti diano più risultati con le risorse di calcolo che vuoi dedicare al problema. Puoi ottenere una soluzione molto migliore rispetto alla semplice ricerca esaustiva? La risposta è sì, assolutamente.
Quindi, cosa possiamo fare in questo caso per ottenere una soluzione migliore investendo meno risorse di calcolo? Innanzitutto, potremmo usare qualche tipo di gradiente. L’intera espressione per Holt-Winters è completamente differenziabile, tranne per una singola divisione che è un caso limite molto piccolo che è relativamente facile da gestire. Quindi, l’intera espressione, compresa la funzione di perdita, è completamente differenziabile. Potremmo usare un gradiente per guidare la nostra ricerca; sarebbe un approccio.
Un altro approccio potrebbe dire che nella pratica, nella supply chain, forse hai tonnellate di serie temporali. Quindi forse invece di trattare ogni singola serie temporale in modo indipendente, quello che vuoi fare è una ricerca in griglia per le prime 1.000 serie temporali, e investirai, e poi identificherai combinazioni per alpha, beta e gamma che sono buone. Quindi, per tutte le altre serie temporali, sceglierai semplicemente da questa breve lista di candidati per identificare la soluzione migliore.
Vedi, ci sono molte idee semplici su come puoi effettivamente fare molto meglio rispetto a un approccio di ricerca in griglia pura, e l’essenza dell’ottimizzazione matematica, e poi tutti i tipi di problemi decisionali possono anche essere visti tipicamente come problemi di ottimizzazione matematica.
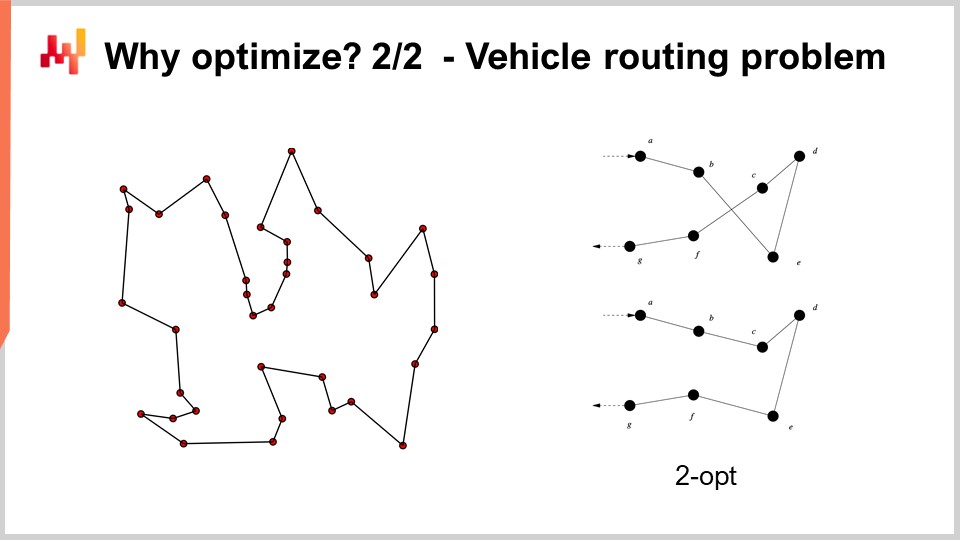
Ad esempio, il problema del routing dei veicoli che puoi vedere sullo schermo può essere visto come un problema di ottimizzazione matematica. Si tratta di scegliere l’elenco dei punti. Non ho scritto la versione formale del problema perché è relativamente variabile e non porta molta chiarezza alla discussione. Ma se vuoi pensarci, puoi pensare semplicemente: “Ho dei punti, posso assegnare una sorta di pseudo-rango che è solo un punteggio a ogni singolo punto, e poi ho un algoritmo che ordina tutti i punti per pseudo-rank in ordine crescente, e quella è la mia rotta”. L’obiettivo dell’algoritmo sarà identificare i valori di quei pseudo-rank che ti danno le migliori rotte.
Ora, con questo problema, vediamo che abbiamo un problema in cui improvvisamente la ricerca in griglia non è nemmeno lontanamente un’opzione. Abbiamo decine di punti, e se dovessimo provare tutte le combinazioni, sarebbe troppo grande. Inoltre, il gradiente non ci aiuterà, almeno non è ovvio come ci possa aiutare, perché il problema è molto discreto per natura, e non c’è nulla che assomigli a una discesa del gradiente ovvia per questo tipo di problema.
Tuttavia, si scopre che se vogliamo affrontare questo tipo di problema, ci sono euristiche molto potenti che sono state identificate nella letteratura. Ad esempio, l’euristica del two-opt, pubblicata da Croes nel 1958, ti fornisce un’euristica molto semplice. Inizi con una rotta casuale, e in questa rotta, ogni volta che la rotta si incrocia, applichi una permutazione per rimuovere l’incrocio. Quindi, inizi con una rotta casuale, e il primo incrocio che osservi, fai la permutazione per rimuovere l’incrocio, e poi ripeti il processo. Ripeti il processo con l’euristica finché non hai più incroci. Quello che otterrai da questa euristica molto semplice è effettivamente una soluzione molto buona. Potrebbe non essere ottimale nel vero senso matematico, quindi non è necessariamente la soluzione perfetta; tuttavia, è una soluzione molto buona, e puoi ottenerla con una quantità relativamente minima di risorse computazionali.
Il problema con l’euristica del two-opt è che è un’euristica molto specifica per questo unico problema. Quello che è davvero interessante per l’ottimizzazione matematica è identificare metodi che funzionano su grandi classi di problemi invece di avere un’euristica che funziona solo per una versione specifica di un problema. Quindi, vogliamo avere metodi molto generali.
Finora nella serie di lezioni: questa lezione fa parte di una serie di lezioni, e questo capitolo attuale è dedicato alle scienze ausiliarie della supply chain. Nel primo capitolo, ho presentato le mie opinioni sulla supply chain sia come campo di studio che come pratica. Il secondo capitolo è stato dedicato alla metodologia e, in particolare, abbiamo introdotto una metodologia che è di estrema rilevanza per la presente lezione, che è l’ottimizzazione sperimentale. Questa è la chiave per affrontare il problema molto valido identificato da Russell Ackoff decenni fa. Il terzo capitolo è interamente dedicato al personale della supply chain. In questa lezione, ci concentriamo sull’identificazione del problema che stiamo per risolvere, invece di mescolare insieme la soluzione e il problema. In questo quarto capitolo, stiamo indagando su tutte le scienze ausiliarie della supply chain. C’è una progressione dal livello più basso in termini di hardware, passando al livello degli algoritmi e poi all’ottimizzazione matematica. Stiamo progredendo in termini di livelli di astrazione in tutta questa serie.

Solo un breve riassunto sulle scienze ausiliarie: offrono una prospettiva sulla supply chain stessa. La presente lezione non riguarda la supply chain in sé, ma piuttosto una delle scienze ausiliarie della supply chain. Questa prospettiva fa una differenza significativa rispetto alla prospettiva classica della ricerca operativa, che doveva essere un fine, rispetto all’ottimizzazione matematica, che è un mezzo per un fine ma non un fine in sé, almeno per quanto riguarda la supply chain. L’ottimizzazione matematica non si preoccupa delle specificità aziendali e la relazione tra l’ottimizzazione matematica e la supply chain è simile alla relazione tra chimica e medicina. Da una prospettiva moderna, non è necessario essere un chimico brillante per essere un medico brillante; tuttavia, un medico che afferma di non sapere nulla di chimica sembrerebbe sospetto.

L’ottimizzazione matematica assume che il problema sia noto. Non si preoccupa della validità del problema, ma si concentra piuttosto nel sfruttare al massimo ciò che si può fare per un dato problema in termini di ottimizzazione. In un certo senso, è come un microscopio - molto potente ma con un focus incredibilmente stretto. Il pericolo, tornando alla discussione sul futuro della ricerca operativa, è che se punti il tuo microscopio nel posto sbagliato, potresti distrarti con sfide intellettuali interessanti ma alla fine irrilevanti.
Ecco perché l’ottimizzazione matematica deve essere utilizzata in combinazione con l’ottimizzazione sperimentale. L’ottimizzazione sperimentale, che abbiamo affrontato nella lezione precedente, è il processo mediante il quale puoi iterare con il feedback dal mondo reale verso versioni migliori del problema stesso. L’ottimizzazione sperimentale è un processo per mutare non la soluzione ma il problema, in modo che iterativamente si possa convergere verso un buon problema. Questo è il nocciolo della questione e dove Russell Ackoff e i suoi colleghi all’epoca non avevano una soluzione. Avevano gli strumenti per ottimizzare un dato problema, ma non gli strumenti per mutare il problema fino a quando il problema non era buono. Se prendi un problema matematico come puoi scriverlo nella tua torre d’avorio, senza feedback dal mondo reale, ciò che ottieni è una fantasia. Il tuo punto di partenza, quando inizi un processo di ottimizzazione sperimentale, è solo una fantasia. Ci vuole il feedback del mondo reale per farlo funzionare. L’idea è di andare avanti e indietro tra l’ottimizzazione matematica e l’ottimizzazione sperimentale. Ad ogni fase del tuo processo di ottimizzazione sperimentale, userai strumenti di ottimizzazione matematica. L’obiettivo è minimizzare sia le risorse computazionali che gli sforzi di ingegneria, consentendo al processo di iterare verso la prossima versione del problema.

In questa lezione, per prima cosa affineremo la nostra comprensione della prospettiva dell’ottimizzazione matematica. La definizione formale è ingannevolmente semplice, ma ci sono complessità di cui dobbiamo essere consapevoli per raggiungere una rilevanza pratica per scopi di supply chain. Esploreremo poi due ampie classi di risolutori che rappresentano lo stato dell’arte nell’ottimizzazione matematica da una prospettiva di supply chain.
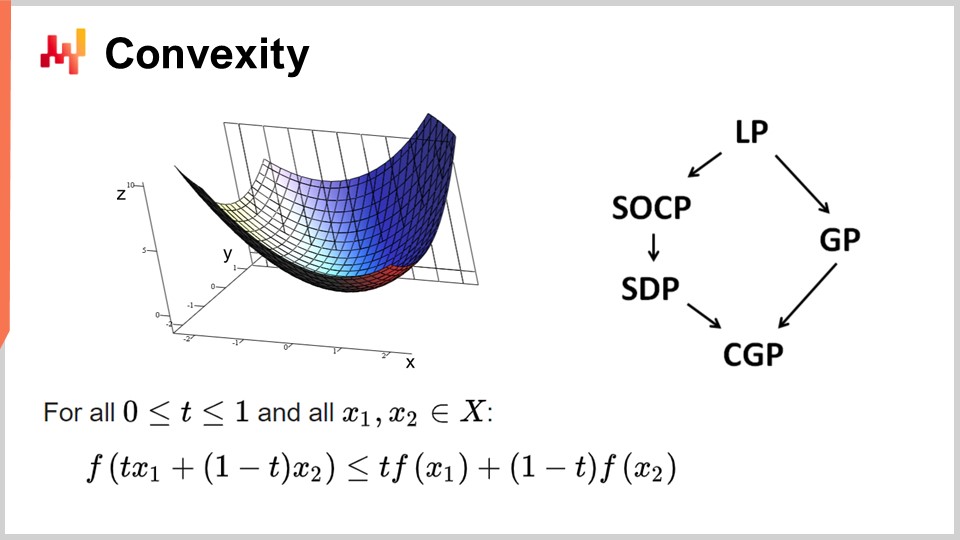
Per prima cosa, discutiamo di convessità e dei primi lavori sull’ottimizzazione matematica. La ricerca operativa si è inizialmente concentrata sulle funzioni di perdita convessi. Una funzione si dice convessa se rispetta determinate proprietà. In modo intuitivo, una funzione è convessa se, per ogni due punti sulla varietà definita dalla funzione, la retta che collega quei punti sarà sempre al di sopra dei valori assunti dalla funzione tra quei punti.
La convessità è fondamentale per consentire una vera ottimizzazione matematica, in cui è possibile dimostrare i risultati. In modo intuitivo, quando si ha una funzione convessa, significa che per ogni punto della funzione (ogni soluzione candidata), è sempre possibile guardarsi intorno e trovare una direzione in cui è possibile scendere. Non importa da dove si parta, si può sempre scendere e scendere è sempre una mossa vantaggiosa. L’unico punto in cui non si può scendere ulteriormente è essenzialmente il punto ottimale. Sto semplificando qui; ci sono casi limite in cui si hanno soluzioni non univoche o nessuna soluzione affatto. Ma mettendo da parte alcuni casi limite, l’unico punto in cui non si può ottimizzare ulteriormente con una funzione convessa è il punto ottimale. Altrimenti, si può sempre scendere e scendere è una mossa vantaggiosa.
È stato condotto un enorme quantità di ricerca sulle funzioni convessi e nel corso degli anni sono emersi vari paradigmi di programmazione. LP sta per programmazione lineare, e altri paradigmi includono la programmazione conica di secondo ordine, la programmazione geometrica (che tratta i polinomi), la programmazione semidefinita (che coinvolge matrici con autovalori positivi) e la programmazione conica geometrica. Questi framework hanno tutti in comune il fatto di occuparsi di problemi convessi strutturati. Sono convessi sia nella funzione di perdita che nei vincoli che limitano le soluzioni ammissibili.
Questi framework hanno suscitato molto interesse, con una intensa produzione di letteratura scientifica. Tuttavia, nonostante i loro nomi impressionanti, questi paradigmi hanno una capacità espressiva molto limitata. Anche problemi semplici superano le capacità di questi framework. Ad esempio, l’ottimizzazione dei parametri di Holt-Winters, un modello di previsione di base degli anni ‘60, supera già ciò che questi framework possono fare. Allo stesso modo, il problema del routing dei veicoli e il problema del commesso viaggiatore, entrambi problemi semplici, superano le capacità di questi framework.
Ecco perché dicevo all’inizio che c’è stata una enorme quantità di letteratura, ma c’è molto poco utilizzo. L’unico punto in cui non si può scendere ulteriormente è essenzialmente il punto ottimale. Sto semplificando qui; ci sono casi limite in cui si hanno soluzioni non univoche o nessuna soluzione affatto. Ma mettendo da parte alcuni casi limite, l’unico punto in cui non si può ottimizzare ulteriormente con una funzione convessa è il punto ottimale. Altrimenti, si può sempre scendere e scendere è una mossa vantaggiosa.
È stato condotto un enorme quantità di ricerca sulle funzioni convessi e nel corso degli anni sono emersi vari paradigmi di programmazione. LP sta per programmazione lineare, e altri paradigmi includono la programmazione conica di secondo ordine, la programmazione geometrica (che tratta i polinomi), la programmazione semidefinita (che coinvolge matrici con autovalori positivi) e la programmazione conica geometrica. Questi framework hanno tutti in comune il fatto di occuparsi di problemi convessi strutturati. Sono convessi sia nella funzione di perdita che nei vincoli che limitano le soluzioni ammissibili.
Questi framework hanno suscitato molto interesse, con una intensa produzione di letteratura scientifica. Tuttavia, nonostante i loro nomi impressionanti, questi paradigmi hanno una capacità espressiva molto limitata. Anche problemi semplici superano le capacità di questi framework. Ad esempio, l’ottimizzazione dei parametri di Holt-Winters, un modello di previsione di base degli anni ‘60, supera già ciò che questi framework possono fare. Allo stesso modo, il problema del routing dei veicoli e il problema del commesso viaggiatore, entrambi problemi semplici, superano le capacità di questi framework.
Ecco perché dicevo fin dall’inizio che c’è stata una grande quantità di letteratura, ma c’è molto poco utilizzo. Una parte del problema era un focus sbagliato sui risolutori di ottimizzazione matematica pura. Questi risolutori sono molto interessanti dal punto di vista matematico perché è possibile produrre dimostrazioni matematiche, ma possono essere utilizzati solo con problemi giocattolo o problemi completamente inventati. Una volta nel mondo reale, falliscono, e negli ultimi decenni c’è stato molto poco progresso in questi campi. Per quanto riguarda la supply chain, quasi nulla, tranne poche nicchie, ha rilevanza per questi risolutori.

Un altro aspetto, che è stato completamente trascurato durante l’era classica della ricerca operativa, è la casualità. La casualità o la stocasticità è di fondamentale importanza in due modi radicalmente diversi. Il primo modo in cui dobbiamo affrontare la casualità è nel risolutore stesso. Oggi tutti i risolutori all’avanguardia sfruttano ampiamente i processi stocastici internamente. Questo è molto interessante rispetto a un processo completamente deterministico. Sto parlando del funzionamento interno del risolutore, del pezzo di software che implementa le tecniche di ottimizzazione matematica.
Il motivo per cui tutti i risolutori all’avanguardia sfruttano ampiamente i processi stocastici ha a che fare con il modo in cui esiste l’hardware di calcolo moderno. L’alternativa alla casualità nell’esplorazione delle soluzioni è ricordare ciò che hai fatto in passato, in modo da non rimanere bloccato nello stesso ciclo. Se devi ricordare, consumerai memoria. Il problema sta nel fatto che abbiamo bisogno di fare molti accessi alla memoria. Un modo per introdurre casualità è di solito un modo per alleviare in gran parte la necessità di accesso casuale alla memoria.
Rendendo il tuo processo stocastico, puoi evitare di sondare il tuo stesso database di ciò che hai testato o non testato tra le possibili soluzioni per il problema che vuoi ottimizzare. Lo fai un po’ casualmente, ma non completamente. Questo ha un’importanza fondamentale in praticamente tutti i risolutori moderni. Uno degli aspetti in qualche modo controintuitivi di avere un processo stocastico è che, anche se puoi avere un risolutore stocastico, l’output può comunque essere abbastanza deterministico. Per capire questo, considera l’analogia di una serie di setacci. Un setaccio è fondamentalmente un processo stocastico fisico, in cui si applicano movimenti casuali e si svolge il processo di setacciatura. Anche se il processo è completamente stocastico, il risultato è completamente deterministico. Alla fine, ottieni un risultato completamente prevedibile dal processo di setacciatura, anche se il tuo processo era fondamentalmente casuale. Questo è esattamente il tipo di cosa che accade con i risolutori stocastici ben progettati. Questo è uno degli ingredienti chiave dei risolutori moderni.
Un altro aspetto, che è ortogonale quando si tratta di casualità, è la natura stocastica dei problemi stessi. Questo era per lo più assente nell’era classica della ricerca operativa: l’idea che la tua funzione di perdita sia rumorosa e che qualsiasi misurazione che otterrai avrà un certo grado di rumore. Questo è quasi sempre il caso nella supply chain. Perché? La realtà è che nella supply chain, ogni volta che prendi una decisione, è perché prevedi qualche tipo di evento futuro. Se decidi di acquistare qualcosa, è perché prevedi che ci sarà bisogno di essa in futuro. Il futuro non è scritto, quindi puoi avere alcune intuizioni sul futuro, ma l’intuizione non è mai perfetta. Se decidi di produrre un prodotto ora, è perché ti aspetti che in futuro ci sarà domanda per questo prodotto. La qualità della tua decisione, che è quella di produrre oggi, dipende da condizioni future incerte, e quindi qualsiasi decisione che prendi nella supply chain avrà una funzione di perdita che varia a seconda di queste condizioni future che non possono essere controllate. Il tipo di casualità dovuto alla gestione degli eventi futuri è irriducibile, ed è di grande interesse perché significa che stiamo affrontando fondamentalmente problemi stocastici.
Tuttavia, se torniamo ai risolutori matematici classici, vediamo che questo aspetto è completamente assente, il che è un grosso problema. Significa che abbiamo classi di risolutori che non possono nemmeno comprendere il tipo di problemi che affronteremo, perché i problemi che saranno di interesse, in cui vogliamo applicare l’ottimizzazione matematica, saranno di natura stocastica. Sto parlando del rumore nella funzione di perdita.
C’è un’obiezione che se hai un problema stocastico, puoi sempre trasformarlo in un problema deterministico attraverso il campionamento. Se valuti la tua funzione di perdita rumorosa 10.000 volte, puoi ottenere una funzione di perdita approssimativamente deterministica. Tuttavia, questo approccio è incredibilmente inefficiente perché introduce un overhead di 10.000 volte sul tuo processo di ottimizzazione. La prospettiva dell’ottimizzazione matematica consiste nel ottenere i migliori risultati per le tue risorse computazionali limitate. Non si tratta di investire una quantità infinitamente grande di risorse computazionali per risolvere il problema. Dobbiamo affrontare una quantità finita di risorse computazionali, anche se questa quantità è abbastanza grande. Pertanto, quando guardiamo ai risolutori in seguito, dobbiamo tenere presente che è di primaria importanza avere risolutori che possano comprendere nativamente problemi stocastici anziché ricorrere all’approccio deterministico.
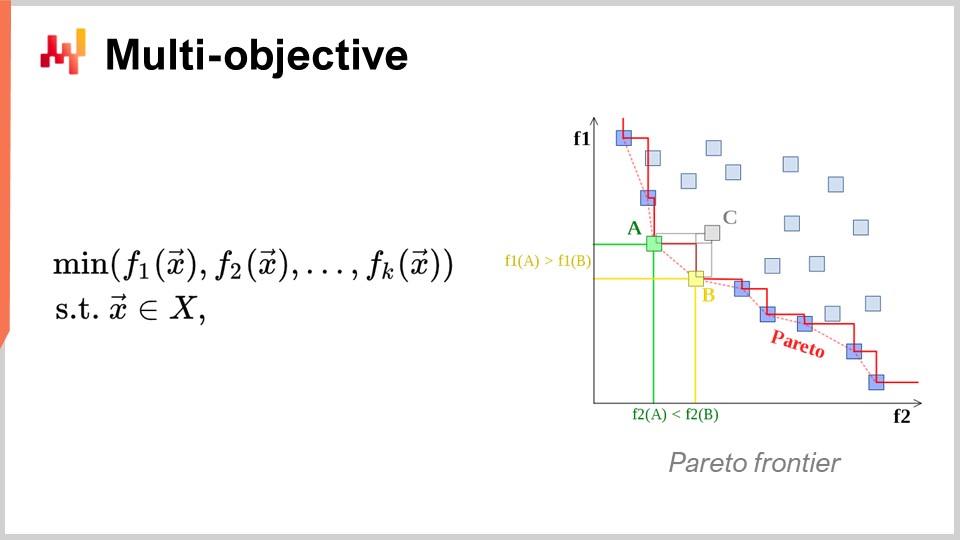
Un altro aspetto, che è anche di primaria importanza, è l’ottimizzazione multi-obiettivo. Nell’espressione ingenua del problema di ottimizzazione matematica, ho detto che la funzione di perdita era essenzialmente univalente, quindi avevamo un valore che volevamo minimizzare. Ma cosa succede se abbiamo un vettore di valori e vogliamo trovare la soluzione che dà il punto più basso secondo l’ordine lessicografico di tutti i vettori, come f1, f2, f3, ecc.?
Perché questo è interessante anche dal punto di vista della supply chain? La realtà è che se adotti questa prospettiva multi-obiettivo, puoi esprimere tutti i tuoi vincoli come una sola funzione di perdita dedicata. Puoi prima avere una funzione che conta le violazioni dei tuoi vincoli. Perché hai vincoli nella supply chain? Beh, hai vincoli ovunque. Ad esempio, se effettui un ordine di acquisto, devi assicurarti di avere abbastanza spazio nel tuo magazzino per conservare la merce quando arriva. Quindi, hai vincoli sullo spazio di archiviazione, sulla capacità di produzione e altro ancora. L’idea è che, invece di avere un risolutore in cui devi gestire i vincoli in modo specifico, è più interessante avere un risolutore che possa gestire l’ottimizzazione multi-obiettivo e in cui puoi esprimere i vincoli come uno degli obiettivi. Basta contare il numero di violazioni dei vincoli e si vuole minimizzare tale numero, portando questo numero di violazioni a zero.
Il motivo per cui questa mentalità è molto rilevante per la supply chain è perché i problemi di ottimizzazione che le supply chain affrontano non sono enigmi crittografici. Questi non sono problemi combinatori super stretti in cui o hai una soluzione ed è buona, o sei solo un bit fuori dalla soluzione e non hai nulla. Nella supply chain, ottenere ciò che viene tipicamente chiamata una soluzione fattibile - una soluzione che soddisfa tutti i vincoli - è tipicamente completamente banale. Identificare una soluzione che soddisfi i vincoli non è un’impresa difficile. Quello che è molto difficile è, tra tutte le soluzioni che soddisfano i vincoli, identificare quella che è più redditizia per l’azienda. Qui diventa molto difficile. Trovare una soluzione che non violi i vincoli è molto semplice. Questo non è il caso in altri campi, ad esempio, nell’ottimizzazione matematica per il design industriale, dove si desidera posizionare i componenti all’interno di un cellulare. Questo è un problema incredibilmente vincolato e non puoi barare rinunciando a un vincolo e avendo una piccola protuberanza sul tuo cellulare. È un problema incredibilmente stretto e combinatorio, e in cui devi davvero trattare i vincoli come cittadini di prima classe. Questo non è necessario, credo, per la grande maggioranza dei problemi di supply chain. Pertanto, è di grande interesse avere tecniche che possano gestire l’ottimizzazione multi-obiettivo in modo nativo.
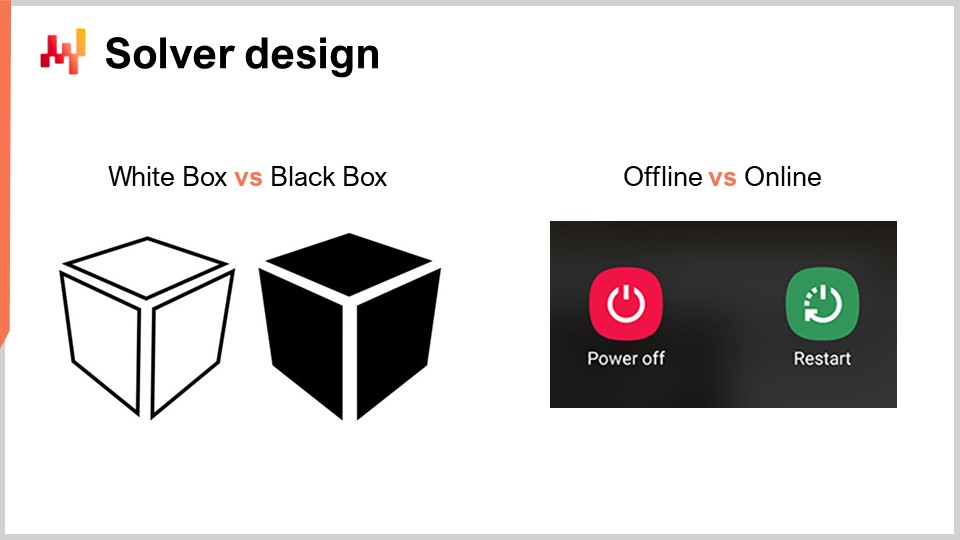
Ora, parliamo un po’ di più del design del risolutore. Da una prospettiva molto generale su come vogliamo progettare un pezzo di software che produrrà soluzioni per una classe molto ampia di problemi, ci sono due aspetti di design molto notevoli che vorrei mettere in evidenza. Il primo aspetto da considerare è se opereremo da una prospettiva di white box o black box. L’idea di una prospettiva di black box è che possiamo elaborare qualsiasi programma arbitrario, quindi la funzione di perdita può essere qualsiasi programma arbitrario. Non ci interessa; trattiamo tutto come una scatola nera completa. L’unica cosa che vogliamo è un programma in cui possiamo valutare il programma e ottenere il valore di una soluzione tentativa. Al contrario, un approccio di white box enfatizza il fatto che la funzione di perdita stessa ha una struttura che possiamo ispezionare e sfruttare. Possiamo vedere all’interno della funzione di perdita. A proposito, quando stavo discutendo di convessità qualche slide prima, tutti quei modelli e risolutori matematici puri erano veramente approcci di white box. Sono il caso estremo degli approcci di white box, in cui non solo puoi vedere all’interno del problema, ma il problema ha una struttura molto rigida, come la programmazione semidefinita, in cui la forma è molto stretta. Tuttavia, senza optare per qualcosa di rigido come un framework matematico, puoi, ad esempio, dire che come parte della white box, hai qualcosa come il gradiente che ti aiuterà. Un gradiente della funzione di perdita è di grande interesse perché improvvisamente puoi sapere in quale direzione vuoi andare per scendere, anche se non hai un problema convesso in cui la semplice discesa del gradiente garantisce un buon risultato. Come regola generale, se puoi rendere white box il tuo risolutore, avrai un risolutore che è di ordini di grandezza più performante rispetto a un risolutore black box.
Ora, come secondo aspetto, abbiamo solutori offline versus online. Il solutore offline opera tipicamente in batch, quindi un solutore offline prenderà semplicemente il problema, lo eseguirà e dovrai aspettare fino a quando non sarà completato. A questo punto, quando il solutore completa, ti fornisce la soluzione migliore o qualcosa che è la soluzione migliore identificata. Al contrario, un solutore online lavora molto di più con un approccio di miglior tentativo. Identificherà una soluzione che è accettabile e quindi investirà risorse computazionali per iterare verso soluzioni sempre migliori man mano che passa il tempo e man mano che investi più risorse computazionali. Quello che è davvero di interesse chiave è che quando affronti un problema con un solutore online, significa che puoi praticamente mettere in pausa il processo in qualsiasi momento e ottenere una soluzione candidata anticipata. Puoi persino riprendere il processo. Se torniamo ai solutori matematici, sono tipicamente solutori batch in cui devi aspettare fino alla fine del processo.
Sfortunatamente, operare nel mondo della supply chain può essere un viaggio molto accidentato, come trattato in una delle precedenti lezioni di questa serie. Ci saranno situazioni in cui di solito puoi permetterti di spendere, diciamo, tre ore per eseguire questo processo di ottimizzazione matematica. Ma a volte, puoi avere problemi informatici, problemi del mondo reale o un’emergenza nella tua supply chain. In tali casi, sarà un salvavita se ciò che di solito richiedeva tre ore può essere interrotto dopo cinque minuti e fornire una risposta, anche se cattiva, invece di nessuna risposta affatto. C’è un detto nell’esercito che il peggior piano è l’assenza di un piano, quindi è meglio avere un piano molto approssimativo piuttosto che niente affatto. Questo è esattamente ciò che ti offre un solutore online. Questi sono gli elementi di progettazione chiave che terremo presenti nella discussione seguente.
Ora, per concludere questa prima sezione della lezione sull’approccio all’ottimizzazione matematica, diamo un’occhiata alle lezioni di deep learning. Il deep learning è stata una rivoluzione completa per il campo dell’apprendimento automatico. Tuttavia, nel suo nucleo, il deep learning ha anche un problema di ottimizzazione matematica. Credo che il deep learning abbia generato una rivoluzione all’interno dell’ottimizzazione matematica stessa e abbia completamente cambiato il modo in cui guardiamo i problemi di ottimizzazione. Il deep learning ha ridefinito ciò che consideriamo lo stato dell’arte dell’ottimizzazione matematica.
Oggi, i modelli di deep learning più grandi si occupano di più di un trilione di parametri, che corrisponde a mille miliardi. Solo per mettere le cose in prospettiva, la maggior parte dei solutori matematici fatica persino a gestire 1.000 variabili e di solito collassa con solo alcune decine di migliaia di variabili, non importa quanto hardware di calcolo ci si dedichi. Al contrario, il deep learning ha successo, utilizzando argomenti computazionali di grandi dimensioni, ma comunque fattibili. Ci sono modelli di deep learning in produzione che hanno oltre un trilione di parametri, e tutti questi parametri vengono ottimizzati, il che significa che abbiamo processi di ottimizzazione matematica che possono scalare fino a un trilione di parametri. Questo è assolutamente sorprendente e radicalmente diverso dalle prestazioni che abbiamo visto con prospettive di ottimizzazione classiche.
La cosa interessante è che anche i problemi che sono completamente deterministici, come giocare a Go o a scacchi, che sono non statistici, discreti e combinatori, sono stati risolti con maggior successo con metodi che sono completamente stocastici e statistici. Questo è sorprendente perché giocare a Go o a scacchi può essere visto come problemi di ottimizzazione discreta, eppure vengono risolti in modo più efficiente oggi con metodi che sono completamente stocastici e statistici. Questo va contro l’intuizione che la comunità scientifica aveva su questi problemi due decenni fa.
Riprendiamo la comprensione che è stata sbloccata dal deep learning riguardo all’ottimizzazione matematica. La prima cosa è rivedere completamente la maledizione della dimensionalità. Credo che questo concetto sia per lo più fallace, e il deep learning sta dimostrando che questo concetto non è il modo in cui dovresti nemmeno pensare alla difficoltà di un problema di ottimizzazione. Si scopre che quando si guardano classi di problemi matematici, si può dimostrare matematicamente che certi problemi sono estremamente difficili da risolvere perfettamente. Ad esempio, se hai mai sentito parlare di problemi NP-hard, sai che aggiungendo dimensioni al problema, diventa esponenzialmente più difficile da risolvere. Ogni dimensione aggiuntiva rende il problema più difficile e c’è una barriera cumulativa. Puoi dimostrare che nessun algoritmo potrà mai sperare di risolvere il problema perfettamente con una quantità limitata di risorse computazionali. Tuttavia, il deep learning ha dimostrato che questa prospettiva era per lo più fallace.
Prima di tutto, dobbiamo differenziare tra la complessità rappresentativa del problema e la complessità intrinseca del problema. Voglio chiarire questi due termini con un esempio. Diamo un’occhiata all’esempio di previsione delle serie temporali dato inizialmente. Diciamo che abbiamo un’analisi delle vendite, aggregata giornalmente per tre anni, quindi abbiamo un vettore temporale aggregato giornalmente di circa 1.000 giorni. Questa è la rappresentazione del problema.
Ora, cosa succede se passo a una rappresentazione delle serie temporali al secondo? Questa è la stessa analisi delle vendite, ma invece di rappresentare i dati delle vendite in aggregati giornalieri, rappresenterò questa serie temporale, la stessa identica serie temporale, in aggregati al secondo. Ci sono 86.400 secondi in ogni singolo giorno, quindi aumenterò la dimensione e la dimensione della mia rappresentazione del problema di 86.000.
Ma se iniziamo a pensare alla dimensione intrinseca, non è perché ho un’analisi delle vendite e non è perché passo da un’aggregazione al giorno a un’aggregazione al secondo che sto aumentando la complessità o la complessità dimensionale del problema di 1.000. Molto probabilmente, se passo a vendite aggregate al secondo, la serie temporale sarà incredibilmente sparsa, quindi sarà per lo più composta da zeri per praticamente tutti i bucket. Non sto aumentando la dimensionalità interessante del problema di un fattore di 100.000. L’apprendimento profondo chiarisce che non è perché hai una rappresentazione del problema con molte dimensioni che il problema è fondamentalmente difficile.
Un altro aspetto associato alla dimensionalità è che, anche se è possibile dimostrare che certi problemi sono NP-completi, ad esempio il problema del commesso viaggiatore (una versione semplificata del problema del routing dei veicoli presentato all’inizio di questa lezione), il commesso viaggiatore è tecnicamente ciò che è noto come un problema NP-hard. Quindi, è un problema in cui se vuoi trovare la migliore soluzione nel caso generale, sarà esponenzialmente costoso man mano che aggiungi punti alla tua mappa. Ma la realtà è che questi problemi sono molto facili da risolvere, come illustrato con l’euristica del two-opt; puoi ottenere soluzioni eccellenti con una quantità minima di risorse computazionali. Quindi, attenzione alle dimostrazioni matematiche che dimostrano che alcuni problemi sono molto difficili, possono essere ingannevoli. Non ti dicono che se sei d’accordo ad avere una soluzione approssimata, l’approssimazione può essere eccellente e a volte non è nemmeno un’approssimazione; otterrai la soluzione ottimale. È solo che non puoi dimostrare che sia ottimale. Questo non dice nulla sulla possibilità di approssimare il problema e molto spesso, quei problemi suppostamente afflitti dalla maledizione della dimensionalità sono facili da risolvere perché le loro dimensioni interessanti non sono così alte. L’apprendimento profondo ha dimostrato con successo che molti problemi ritenuti incredibilmente difficili non erano così difficili in primo luogo.
Il secondo punto chiave sono i minimi locali. La maggior parte dei ricercatori che lavorano sull’ottimizzazione matematica e sulla ricerca operativa si sono concentrati sulle funzioni convessi perché non ci sono minimi locali. Per molto tempo, le persone che non lavoravano su funzioni convessi stavano pensando a come evitare di rimanere bloccati in un minimo locale. La maggior parte degli sforzi era dedicata a lavorare su cose come le meta-euristiche. L’apprendimento profondo ha fornito una comprensione rinnovata: non ci importa dei minimi locali. Questa comprensione deriva da lavori recenti provenienti dalla comunità dell’apprendimento profondo.
Se hai una dimensione molto alta, puoi dimostrare che i minimi locali svaniscono all’aumentare della dimensione del problema. I minimi locali sono molto frequenti nei problemi a bassa dimensione, ma se aumenti la dimensione dei problemi a centinaia o migliaia, statisticamente parlando, i minimi locali diventano incredibilmente improbabili. Al punto che, guardando dimensioni molto grandi come milioni, svaniscono completamente.
Invece di pensare che una dimensione più alta sia il tuo nemico, come era associato alla maledizione della dimensionalità, cosa succederebbe se potessi fare esattamente l’opposto e aumentare la dimensione del problema fino a renderla così grande che diventa banale avere una discesa pulita senza minimi locali? Si scopre che è esattamente ciò che viene fatto nella comunità dell’apprendimento profondo e con modelli che hanno un trilione di parametri. Questo approccio ti offre un modo molto pulito per procedere con la discesa del gradiente.
Fondamentalmente, la comunità dell’apprendimento profondo ha dimostrato che non è rilevante avere una prova sulla qualità della discesa o sulla convergenza finale. Quello che conta è la velocità della discesa. Vuoi iterare e scendere molto rapidamente verso una soluzione molto buona. Se puoi avere un processo che scende più velocemente, alla fine andrai più lontano in termini di ottimizzazione. Queste intuizioni vanno contro la comprensione generale dell’ottimizzazione matematica, o di quella che era la comprensione dominante due decenni fa.
Ci sono altre lezioni da trarre dall’apprendimento profondo, poiché è un campo molto ricco. Una di queste è la simpatia per l’hardware. Il problema con i risolutori matematici, come la programmazione conica o la programmazione geometrica, è che si concentrano prima sull’intuizione matematica e non sull’hardware di calcolo. Se progettate un risolutore che antagonizza fondamentalmente l’hardware di calcolo, non importa quanto sia intelligente la vostra matematica, è probabile che siate estremamente inefficienti a causa di un uso inefficiente dell’hardware di calcolo.
Una delle intuizioni chiave della comunità dell’apprendimento profondo è che è necessario collaborare con l’hardware di calcolo e progettare un risolutore che lo abbracci. Questo è il motivo per cui ho iniziato questa serie di lezioni sulle scienze ausiliarie per la supply chain con i computer moderni per la supply chain. È importante capire l’hardware che si ha a disposizione e come sfruttarlo al meglio. Questa simpatia per l’hardware è ciò che consente di ottenere modelli con un trilione di parametri, anche se richiede un grande cluster di computer o un supercomputer.
Un’altra lezione dell’apprendimento profondo è l’uso di funzioni surrogate. Tradizionalmente, i risolutori matematici miravano ad ottimizzare il problema così com’era, senza deviare da esso. Tuttavia, l’apprendimento profondo ha dimostrato che a volte è meglio utilizzare funzioni surrogate. Ad esempio, molto spesso per le previsioni, i modelli di apprendimento profondo utilizzano entropia incrociata come metrica di errore invece del quadrato medio. Praticamente nessuno nel mondo reale è interessato all’entropia incrociata come metrica, poiché è abbastanza bizzarra.
Quindi perché le persone utilizzano l’entropia incrociata? Fornisce gradienti incredibilmente ripidi e, come ha dimostrato l’apprendimento profondo, è tutto una questione di velocità di discesa. Se hai gradienti molto ripidi, puoi scendere molto rapidamente. Le persone potrebbero obiettare e dire: “Se voglio ottimizzare il quadrato medio, perché dovrei usare l’entropia incrociata? Non è nemmeno lo stesso obiettivo.” La realtà è che se ottimizzi l’entropia incrociata, avrai gradienti molto ripidi e alla fine, se valuti la tua soluzione rispetto al quadrato medio, otterrai una soluzione migliore anche secondo il criterio del quadrato medio, molto spesso, se non sempre. Sto semplificando solo per il bene di questa spiegazione. L’idea delle funzioni surrogate è che il vero problema non è assoluto; è solo qualcosa che userai per il controllo per valutare la validità finale della tua soluzione. Non è necessariamente qualcosa che userai mentre il risolutore è in corso. Questo va completamente contro le idee coinvolte nei risolutori matematici che erano popolari negli ultimi due decenni.
Infine, c’è l’importanza di lavorare in paradigmi. Con l’ottimizzazione matematica, c’è implicitamente una divisione del lavoro coinvolta nell’organizzazione della tua forza lavoro ingegneristica. La divisione del lavoro implicita associata ai risolutori matematici è che avrai ingegneri matematici da una parte, responsabili dell’ingegnerizzazione del risolutore, e ingegneri del problema dall’altra parte, il cui compito è esprimere il problema in una forma adatta per il trattamento da parte dei risolutori matematici. Questa divisione del lavoro era diffusa e l’idea era renderla il più semplice possibile per l’ingegnere del problema, in modo che dovesse solo esprimere il problema nel modo più minimalista e puro possibile, lasciando che il risolutore facesse il lavoro.
L’apprendimento profondo ha dimostrato che questa prospettiva era profondamente inefficiente. Questa divisione del lavoro arbitraria non era affatto il modo migliore per affrontare il problema. Se fai così, ti ritrovi con situazioni estremamente difficili, che superano di gran lunga lo stato dell’arte per gli ingegneri matematici che lavorano sul problema di ottimizzazione. Un modo molto migliore è far sì che gli ingegneri del problema facciano uno sforzo extra per riformulare i problemi in modi che li rendano molto più adatti all’ottimizzazione da parte dell’ottimizzatore matematico.
L’apprendimento profondo riguarda un insieme di ricette che ti permettono di formulare il problema sopra il tuo risolutore, in modo da ottenere il massimo dal tuo ottimizzatore. La maggior parte degli sviluppi nella comunità dell’apprendimento profondo si sono concentrati sulla creazione di queste ricette che sono molto efficaci nell’apprendimento, pur giocando bene nel paradigma dei risolutori che hanno a disposizione (ad esempio, TensorFlow, PyTorch, MXNet). La conclusione è che è davvero importante collaborare con l’ingegnere del problema, o, in termini di supply chain, con lo scienziato della supply chain.

Ora passiamo alla seconda e ultima sezione di questa lezione sugli elementi più preziosi della letteratura. Daremo uno sguardo a due ampie classi di risolutori: la ricerca locale e la programmazione differenziabile.

Prima di tutto, fermiamoci ancora sul termine “programmazione”. Questa parola è di importanza critica perché, da una prospettiva di supply chain, vogliamo davvero essere in grado di esprimere il problema che affrontiamo, o il problema che pensiamo di affrontare. Non vogliamo una sorta di versione a bassa risoluzione del problema che si adatta solo ad un’ipotesi matematica semi-assurda, come ad esempio la necessità di esprimere il problema in un cono o qualcosa del genere. Quello che ci interessa davvero è avere accesso a un vero paradigma di programmazione.
Ricordiamo che quei risolutori matematici come la programmazione lineare, la programmazione conica di secondo ordine e la programmazione geometrica sono tutti forniti con una parola chiave di programmazione. Tuttavia, negli ultimi decenni, ciò che ci aspettiamo da un paradigma di programmazione è cambiato radicalmente. Oggi vogliamo qualcosa che ci permetta di gestire programmi quasi arbitrari, programmi in cui abbiamo cicli, rami e possibili allocazioni di memoria, ecc. Vogliamo davvero qualcosa il più possibile simile a un programma arbitrario, non una sorta di versione giocattolo super limitata che ha alcune interessanti proprietà matematiche. Nella supply chain, è meglio essere approssimativamente corretti piuttosto che esattamente sbagliati.

Per affrontare l’ottimizzazione generica, iniziamo con la ricerca locale. La ricerca locale è una tecnica di ottimizzazione matematica ingannevolmente semplice. Il pseudocodice prevede di partire da una soluzione casuale, che rappresenti come un pacchetto di bit. Inizializzi quindi la tua soluzione in modo casuale e inizi a invertire casualmente i bit per esplorare il vicinato della soluzione. Se, attraverso questa esplorazione casuale, trovi una soluzione che risulta essere migliore, questa diventa la tua nuova soluzione di riferimento.
Questo approccio sorprendentemente potente può funzionare con qualsiasi programma, trattandolo come una scatola nera, e può anche ripartire da qualsiasi soluzione conosciuta. Ci sono molti modi per migliorare questo approccio. Un modo è la computazione differenziale, da non confondere con la computazione differenziabile. La computazione differenziale è l’idea che se esegui il tuo programma su una soluzione data e poi inverti un bit, puoi rieseguire lo stesso programma con una esecuzione differenziale, senza dover rieseguire l’intero programma. Ovviamente, i risultati possono variare e dipendono molto dalla struttura del problema. Un modo per velocizzare il processo non è sfruttare qualche tipo di informazione extra sul programma scatola nera con cui operiamo, ma semplicemente essere in grado di velocizzare il programma stesso, trattandolo ancora principalmente come una scatola nera, perché non si riesegue l’intero programma ogni volta.
Ci sono altri approcci per migliorare la ricerca locale. Puoi migliorare il tipo di mosse che fai. La strategia più basilare si chiama k-flips, in cui inverti un numero k di bit con k che è un numero molto piccolo, qualcosa come un paio o una dozzina. Invece di invertire solo i bit, puoi far sì che l’ingegnere del problema indichi il tipo di mutazioni da applicare alla soluzione. Ad esempio, puoi esprimere che vuoi applicare una sorta di permutazione nel tuo problema. L’idea è che queste mosse intelligenti spesso preservano la soddisfazione di alcuni vincoli nel tuo problema, il che può aiutare il processo di ricerca locale a convergere più velocemente.
Un altro modo per migliorare la ricerca locale è quello di non esplorare completamente lo spazio in modo casuale. Invece di invertire casualmente i bit, puoi cercare di imparare le direzioni giuste, identificando le aree più promettenti per le inversioni. Alcuni recenti articoli hanno dimostrato che puoi inserire un piccolo modulo di deep learning in cima alla ricerca locale, agendo come un generatore. Tuttavia, questo approccio può essere complicato in termini di ingegneria, poiché devi assicurarti che il sovraccarico introdotto dal processo di apprendimento automatico produca un ritorno positivo in termini di risorse computazionali.
Ci sono altre euristiche ben note, e se vuoi una visione sintetica molto buona di ciò che serve per implementare un moderno motore di ricerca locale, puoi leggere l’articolo “LocalSolver: A Black-Box Local-Search Solver for 0-1 Programs”. L’azienda che gestisce LocalSolver ha anche un prodotto con lo stesso nome. In questo articolo, forniscono una prospettiva ingegneristica su ciò che sta accadendo sotto il cofano nel loro solver di produzione. Utilizzano il multi-start e il simulated annealing per ottenere risultati migliori.
Un avvertimento che vorrei aggiungere sulla ricerca locale è che non gestisce molto bene o nativamente i problemi stocastici. Con i problemi stocastici, non è così semplice come dire semplicemente “ho una soluzione migliore” e decidere immediatamente che diventa la migliore soluzione. È più complicato di così, e devi mettere un po’ di sforzo extra prima di passare alla soluzione valutata come la nuova migliore.

Ora, passiamo alla seconda classe di solutori di cui parleremo oggi, che è la programmazione differenziabile. Ma prima, per capire la programmazione differenziabile, dobbiamo comprendere la discesa del gradiente stocastico. La discesa del gradiente stocastico è una tecnica di ottimizzazione iterativa basata sul gradiente. È emersa come una serie di tecniche sviluppate nei primi anni ‘50, rendendola quasi vecchia di 70 anni. È rimasta piuttosto di nicchia per quasi sei decenni, e abbiamo dovuto aspettare l’avanzamento del deep learning per capire il vero potenziale e la potenza della discesa del gradiente stocastico.
La discesa del gradiente stocastico assume che la funzione di perdita possa essere decomposta in modo additivo in una serie di componenti. Nell’equazione, Q(W) rappresenta la funzione di perdita, che viene decomposta in una serie di funzioni parziali, Qi. Questo è rilevante perché la maggior parte dei problemi di apprendimento può essere vista come la necessità di apprendere una previsione basata su una serie di esempi. L’idea è che puoi decomporre la tua funzione di perdita come l’errore medio commesso sull’intero set di dati, con un errore locale per ogni punto dati. Molti problemi di supply chain possono anche essere decomposti in modo additivo in questo modo. Ad esempio, puoi decomporre la tua rete di supply chain in una serie di prestazioni per ogni singolo SKU, con una funzione di perdita associata a ciascun SKU. La vera funzione di perdita che vuoi ottimizzare è la totale.
Quando hai questa decomposizione in atto, che è molto naturale per i problemi di apprendimento, puoi iterare con il processo di discesa del gradiente stocastico (SGD). Il vettore dei parametri W può essere una serie molto grande, poiché i modelli di deep learning più grandi hanno un trilione di parametri. L’idea è che ad ogni passo del processo, aggiorni i tuoi parametri applicando una piccola quantità di gradiente. Eta è il tasso di apprendimento, un numero piccolo di solito compreso tra 0 e 1, spesso intorno a 0,01. Nabla di Q è il gradiente per una funzione di perdita parziale Qi. Sorprendentemente, questo processo funziona bene.
SGD è detto stocastico perché scegli casualmente il tuo prossimo elemento i, saltando attraverso il tuo set di dati e applicando un piccolo bit di gradiente ai tuoi parametri ad ogni singolo passo. Questa è l’essenza della discesa del gradiente stocastico.
È rimasto relativamente di nicchia e in gran parte ignorato dalla comunità per quasi sei decenni, perché è piuttosto sorprendente che la discesa del gradiente stocastico funzioni del tutto. Funziona perché offre un ottimo compromesso tra il rumore nella funzione di perdita e il costo computazionale di accedere alla stessa funzione di perdita. Invece di avere una funzione di perdita che deve essere valutata sull’intero set di dati, con la discesa del gradiente stocastico, possiamo prendere un punto dati alla volta e comunque applicare un po’ di gradiente. Questa misurazione sarà molto frammentaria e rumorosa, eppure questo rumore è effettivamente accettabile perché è molto veloce. Puoi eseguire ordini di grandezza di ottimizzazioni piccole e rumorose in più rispetto all’elaborazione dell’intero set di dati.
Sorprendentemente, il rumore introdotto aiuta la discesa del gradiente. Uno dei problemi negli spazi ad alta dimensione è che i minimi locali diventano relativamente inesistenti. Tuttavia, puoi comunque affrontare grandi aree di plateau in cui il gradiente è molto piccolo e la discesa del gradiente non ha una direzione da scegliere per la discesa. Il rumore ti fornisce gradienti più ripidi e rumorosi che aiutano nella discesa.
Ciò che è interessante anche con la discesa del gradiente è che è un processo stocastico, ma può gestire problemi stocastici gratuitamente. Se Qi è una funzione stocastica con rumore e restituisce un risultato casuale che varia ogni volta che lo valuti, non è nemmeno necessario modificare una singola riga dell’algoritmo. La discesa del gradiente stocastico è di grande interesse perché ti offre qualcosa che è completamente allineato con il paradigma rilevante per gli scopi della catena di approvvigionamento.

La seconda domanda è: da dove viene il gradiente? Abbiamo un programma e prendiamo semplicemente il gradiente della funzione di perdita parziale, ma da dove viene questo gradiente? Come si ottiene un gradiente per un programma arbitrario? Si scopre che c’è una tecnica molto elegante e minimalista scoperta molto tempo fa chiamata differenziazione automatica.
La differenziazione automatica è emersa negli anni ‘60 ed è stata perfezionata nel tempo. Ci sono due tipi: la modalità in avanti, scoperta nel 1964, e la modalità inversa, scoperta nel 1980. La differenziazione automatica può essere vista come un trucco di compilazione. L’idea è che hai un programma da compilare e con la differenziazione automatica hai il tuo programma che rappresenta la funzione di perdita. Puoi ricompilare questo programma per ottenere un secondo programma e l’output del secondo programma non è la funzione di perdita ma i gradienti di tutti i parametri coinvolti nel calcolo della funzione di perdita.
Inoltre, la differenziazione automatica ti fornisce un secondo programma con una complessità computazionale essenzialmente identica a quella del tuo programma iniziale. Ciò significa che non solo hai un modo per creare un secondo programma che calcola i gradienti, ma anche che il secondo programma ha le stesse caratteristiche di calcolo in termini di prestazioni del primo programma. È un fattore costante di inflazione in termini di costo computazionale. La realtà, tuttavia, è che il secondo programma ottenuto non ha esattamente le stesse caratteristiche di memoria del programma iniziale. Sebbene i dettagli tecnici vadano oltre lo scopo di questa lezione, possiamo discuterne durante le domande. Fondamentalmente, il secondo programma, chiamato inverso, richiederà più memoria e in alcune situazioni patologiche potrà richiedere molta più memoria rispetto al programma iniziale. Ricorda che più memoria crea problemi con le prestazioni di calcolo, poiché non puoi assumere un accesso uniforme alla memoria.
Per illustrare un po’ come appare la differenziazione automatica, come ho detto, ci sono due modalità: avanti e indietro. Da una prospettiva di apprendimento o di ottimizzazione della catena di approvvigionamento, l’unica modalità di interesse per noi è la modalità inversa. Quello che puoi vedere sullo schermo è una funzione di perdita F, completamente inventata. Puoi vedere la traccia in avanti, una sequenza di operazioni aritmetiche o elementari che si svolgono per calcolare la tua funzione per due valori di input dati, X1 e X2. Questo ti fornisce tutti i passaggi elementari effettuati per calcolare il valore finale.
L’idea è che per ogni passaggio elementare, e la maggior parte di essi sono solo operazioni aritmetiche di base come moltiplicazione o addizione, la modalità inversa è un programma che esegue gli stessi passaggi ma in ordine inverso. Invece di avere i valori in avanti, avrai gli adiacenti. Per ogni operazione aritmetica, avrai il loro corrispettivo inverso. La transizione dall’operazione in avanti al corrispettivo è molto semplice.
Anche se sembra complicato, hai un’esecuzione in avanti e un’esecuzione inversa, dove la tua esecuzione inversa non è altro che una trasformazione elementare applicata ad ogni singola operazione. Alla fine dell’inversa, ottieni i gradienti. La differenziazione automatica può sembrare complicata, ma non lo è. Il primo prototipo che abbiamo implementato era di meno di 100 righe di codice, quindi è molto semplice ed essenzialmente un trucco di trasposizione economico.
Ora, questo è interessante perché abbiamo la discesa del gradiente stocastico, che è un meccanismo di ottimizzazione incredibilmente potente. È estremamente scalabile, online, su lavagna e funziona nativamente con problemi stocastici. L’unico problema che rimaneva era come ottenere il gradiente, e con la differenziazione automatica, abbiamo il gradiente per un sovraccarico fisso o un fattore costante, per praticamente qualsiasi programma arbitrario. Quello che otteniamo alla fine è la programmazione differenziabile.
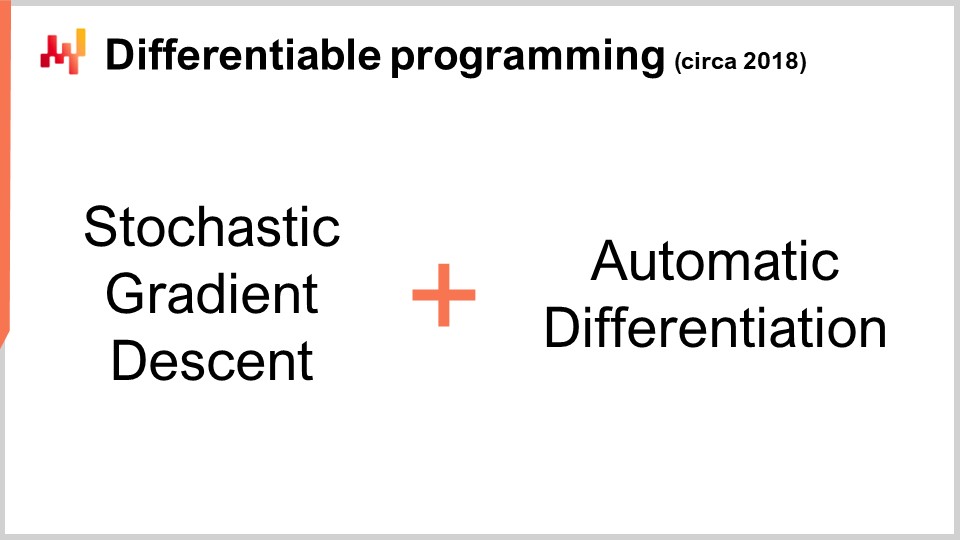
Curiosamente, la programmazione differenziabile è una combinazione di discesa del gradiente stocastico e differenziazione automatica. Anche se queste due tecniche, la discesa del gradiente stocastico e la differenziazione automatica, sono vecchie di decenni, la programmazione differenziabile è emersa solo nel 2018 quando Yann LeCun, il responsabile dell’IA di Facebook, ha iniziato a parlare di questo concetto. LeCun non ha inventato questo concetto, ma è stato determinante nel renderlo popolare.
Ad esempio, la comunità del deep learning inizialmente utilizzava la retropropagazione anziché la differenziazione automatica. Per coloro che sono familiari con le reti neurali, la retropropagazione è un processo complesso che è di ordini di grandezza più complicato da implementare rispetto alla differenziazione automatica. La differenziazione automatica è superiore in tutti gli aspetti. Con questa intuizione, la comunità del deep learning ha affinato la sua visione di ciò che costituisce l’apprendimento nel deep learning. Il deep learning ha combinato l’ottimizzazione matematica con varie tecniche di apprendimento, e la programmazione differenziabile è emersa come un concetto pulito che ha isolato le parti non di apprendimento del deep learning.
Le moderne tecniche di deep learning, come il modello transformer, assumono un ambiente di programmazione differenziabile che opera al di sotto. Ciò consente ai ricercatori di concentrarsi sugli aspetti di apprendimento che sono costruiti sopra. La programmazione differenziabile, sebbene fondamentale per il deep learning, è anche molto rilevante per l’ottimizzazione della catena di approvvigionamento e per supportare i processi di apprendimento della catena di approvvigionamento, come la previsione statistica.
Proprio come nel deep learning, ci sono due parti del problema: la programmazione differenziabile come livello di base e le tecniche di ottimizzazione o apprendimento al di sopra di esso. La comunità del deep learning si propone di identificare architetture che funzionano bene con la programmazione differenziabile, come i transformer. Allo stesso modo, è necessario identificare le architetture che funzionano bene per scopi di ottimizzazione. Questo è ciò che è stato fatto per imparare a giocare a Go o a scacchi in contesti altamente combinatori. Discuteremo delle tecniche che funzionano bene per l’ottimizzazione specifica della catena di approvvigionamento in lezioni successive.

Ma ora è tempo di concludere. Una buona parte della letteratura sulla catena di approvvigionamento e persino la maggior parte delle sue implementazioni software sono piuttosto confuse quando si tratta di ottimizzazione matematica. Questo aspetto di solito non viene nemmeno correttamente identificato come tale e, di conseguenza, i professionisti, i ricercatori e persino gli ingegneri software che lavorano per le aziende di software aziendale spesso mescolano le loro ricette numeriche in modo piuttosto casuale quando si tratta di ottimizzazione matematica. Hanno un grosso problema, poiché un componente non è stato identificato come di natura di ottimizzazione matematica e perché le persone non sono nemmeno consapevoli di ciò che è disponibile nella letteratura, spesso ricorrono a ricerche su griglia approssimative o euristiche affrettate che producono prestazioni erratiche e inconsistenti. Come conclusione di questa lezione, d’ora in poi, ogni volta che ti trovi di fronte a un metodo numerico della catena di approvvigionamento o a un software della catena di approvvigionamento che afferma di offrire qualsiasi tipo di funzionalità analitica, devi chiederti cosa sta succedendo in termini di ottimizzazione matematica e cosa viene fatto. Se ti rendi conto che i fornitori non offrono una visione cristallina da questo punto di vista, le probabilità sono che tu ti trovi sul lato sinistro dell’illustrazione e questo non è il posto in cui vuoi essere.
Ora, diamo un’occhiata alle domande.

Domanda: La transizione verso i metodi computazionali è una competenza prerequisita nelle operazioni e i ruoli operativi diventeranno obsoleti, o viceversa?
Prima di tutto, lasciatemi chiarire alcune cose. Credo che sia un errore spingere questo tipo di preoccupazioni verso il CIO. Le persone si aspettano troppo dai loro CIO. Come Chief Information Officer, devi già occuparti del livello di base dell’infrastruttura software, come le risorse computazionali, i sistemi transazionali a basso livello, l’integrità della rete e la sicurezza informatica. Non si dovrebbe aspettare che il CIO abbia una comprensione di ciò che serve effettivamente per fare qualcosa di valore per la catena di approvvigionamento.
Il problema è che in molte aziende le persone sono così disperatamente ignoranti di tutto ciò che riguarda i computer che il CIO diventa la persona di riferimento per tutto. La realtà è che il CIO dovrebbe occuparsi del livello di base dell’infrastruttura e poi spetta a ogni specialista affrontare le proprie esigenze specifiche con le risorse computazionali e gli strumenti software a disposizione.
Per quanto riguarda l’obsolescenza dei ruoli operativi, se il tuo ruolo consiste nel passare manualmente tutto il giorno attraverso i fogli di calcolo di Excel, allora sì, è molto probabile che il tuo ruolo diventi obsoleto. Questo è un problema noto fin dal 1979, quando Russell Ackoff ha pubblicato il suo articolo. Il problema è che le persone sapevano che questo metodo di gestire le decisioni non era il futuro, ma è rimasto lo status quo per molto tempo. Il nocciolo del problema è che le aziende devono capire il processo sperimentale. Credo che ci sarà una transizione in cui le aziende inizieranno a riacquisire queste competenze. Molte grandi aziende nordamericane dopo la Seconda Guerra Mondiale avevano una certa conoscenza della ricerca operativa tra i loro dirigenti. Era un argomento nuovo e interessante e i consigli di amministrazione delle grandi aziende sapevano cose sulla ricerca operativa. Come sottolinea Russell Ackoff, a causa della mancanza di risultati, queste idee sono state spinte verso il basso nella scala dell’azienda fino a essere addirittura completamente esternalizzate, poiché erano per lo più irrilevanti e non producevano risultati tangibili. Credo che la ricerca operativa tornerà solo se le persone imparano le lezioni su perché l’era classica della ricerca operativa non ha prodotto risultati. Il CIO avrà solo un modesto contributo in questa impresa; è principalmente una questione di ripensare al valore aggiunto delle persone all’interno dell’azienda.
Vuoi avere un contributo capitalista, e questo si ricollega a una delle mie precedenti lezioni sulla consegna orientata al prodotto nel senso di prodotti software per la supply chain. La questione è: quale tipo di valore aggiunto capitalista fornisci alla tua azienda? Se la risposta è nessuno, potresti non far parte di ciò che la tua azienda dovrebbe diventare e diventerà in futuro.
Domanda: Cosa ne pensi dell’utilizzo del risolutore di Excel per minimizzare il valore MRMSC e trovare il valore ottimale per alpha, beta e gamma?
Credo che questa domanda sia rilevante nel caso di Holt-Winters, dove è possibile trovare una soluzione con la ricerca a griglia. Tuttavia, cosa succede in questo risolutore di Excel? È una discesa del gradiente o qualcos’altro? Se ti riferisci al risolutore lineare di Excel, non è un problema lineare, quindi Excel non può fare nulla per te in quel caso. Se hai altri risolutori in Excel o componenti aggiuntivi, sì, possono funzionare, ma questa è una prospettiva molto datata. Non abbraccia una visione più stocastica; il tipo di previsione che ottieni è una previsione non probabilistica, che è un approccio superato.
Non sto dicendo che Excel non possa essere utilizzato, ma la domanda è: quali capacità di programmazione vengono sbloccate in Excel? Puoi fare una discesa del gradiente stocastica in Excel? Probabilmente, se aggiungi un componente aggiuntivo dedicato. Excel ti consente di collegare qualsiasi programma arbitrario al suo interno. Potresti potenzialmente fare programmazione differenziabile in Excel? Sì. È una buona idea farlo in Excel? No. Per capire il motivo, devi tornare al concetto di consegna del software orientata al prodotto, che illustra cosa non va in Excel. Tutto si riduce al modello di programmazione e alla possibilità di mantenere effettivamente il tuo lavoro nel tempo con uno sforzo di squadra.
Domanda: I problemi di ottimizzazione sono tipicamente orientati verso il routing dei veicoli o la previsione. Perché non considerare anche l’ottimizzazione dell’intera supply chain? Non ridurrebbe i costi rispetto all’analisi di aree isolate?
Sono completamente d’accordo. La maledizione dell’ottimizzazione della supply chain è che quando si esegue un’ottimizzazione locale su un sottoproblema, è molto probabile che si sposti il problema, non lo si risolva per l’intera supply chain. Sono completamente d’accordo, e non appena si inizia a considerare un problema più complesso, si sta affrontando un problema ibrido - ad esempio, un problema di routing dei veicoli combinato con una strategia di riapprovvigionamento. Il problema è che hai bisogno di un risolutore molto generico per affrontare questo perché non vuoi essere limitato. Se hai un risolutore molto generico, devi avere meccanismi molto generici invece di fare affidamento su euristiche intelligenti come il two-opt, che funziona bene solo per il routing dei veicoli e non per qualcosa che è un ibrido sia di riapprovvigionamento che di routing dei veicoli contemporaneamente.
Per passare a questa prospettiva olistica, devi non avere paura della maledizione della dimensionalità. Vent’anni fa, le persone dicevano che questi problemi erano già estremamente difficili e NP-completi, come il problema del commesso viaggiatore, e tu vuoi risolvere un problema ancora più difficile intrecciandolo con un altro problema. La risposta è sì; vuoi essere in grado di farlo, ed è per questo che è essenziale avere un risolutore che ti permetta di gestire programmi arbitrari perché la tua soluzione potrebbe essere la consolidazione di molti problemi intrecciati e intercalati.
Infatti, l’idea di risolvere questi problemi in modo isolato è molto più debole rispetto a risolvere tutto. È meglio essere approssimativamente corretti che esattamente sbagliati. È molto meglio avere un risolutore molto debole che affronta l’intera supply chain come un sistema, come un blocco, piuttosto che avere ottimizzazioni locali avanzate che creano solo problemi in altri luoghi mentre si micro-ottimizza localmente. L’ottimizzazione vera del sistema non è necessariamente l’ottimizzazione migliore per ogni parte, quindi è naturale che se ottimizzi per l’interesse dell’intera azienda e della sua intera supply chain, non sarà ottimale a livello locale perché si tiene conto degli altri aspetti dell’azienda e della sua supply chain.
Domanda: Dopo aver svolto un esercizio di ottimizzazione, quando dovremmo riesaminare lo scenario considerando che nuovi vincoli possono apparire in qualsiasi momento? La risposta è che dovresti riesaminare l’ottimizzazione frequentemente. Questo è il ruolo dello scienziato della supply chain che ho presentato nella seconda lezione di questa serie. Lo scienziato della supply chain riesaminerà l’ottimizzazione tutte le volte che sarà necessario. Se emerge un nuovo vincolo, come una nave gigantesca che blocca il Canale di Suez, è stato imprevisto, ma devi affrontare questa disruzione nella tua supply chain. Non hai altra opzione se non affrontare questi problemi; altrimenti, il sistema che hai messo in atto genererà risultati insensati perché opererà in condizioni false. Anche se non hai un’emergenza con cui occuparti, vuoi comunque investire il tuo tempo per pensare all’angolo più probabile di generare il maggior ritorno per l’azienda. Questo è fondamentalmente ricerca e sviluppo. Hai il sistema in atto, funziona, e stai solo cercando di individuare aree in cui puoi migliorare il sistema. Diventa un processo di ricerca applicata che è altamente capitalista e erratico. Come scienziato della supply chain, ci sono giorni in cui passi l’intera giornata testando metodi numerici, nessuno dei quali fornisce risultati migliori di quelli che hai già. In alcuni giorni, fai una piccola modifica e hai molta fortuna, risparmiando milioni all’azienda. È un processo erratico, ma in media, l’esito può essere enorme.
Domanda: Quali sarebbero i casi d’uso per problemi di ottimizzazione diversi dalla programmazione lineare, programmazione intera, programmazione mista e nel caso di Weber e costo delle merci?
Invertirei la domanda: dove vedi che la programmazione lineare ha una qualche rilevanza per qualsiasi problema di supply chain? Non c’è praticamente nessun problema di supply chain che sia lineare. La mia obiezione è che questi framework sono molto semplicistici e non possono nemmeno avvicinarsi a problemi di giocattolo. Come ho detto, questi framework matematici, come la programmazione lineare, non possono nemmeno affrontare un problema di giocattolo come l’ottimizzazione invernale difficile per un modello di previsione parametrico antico e a bassa dimensionalità. Non riescono nemmeno a gestire il problema del commesso viaggiatore o praticamente qualsiasi altra cosa.
La programmazione intera o la programmazione mista intera è solo un termine generico per indicare che alcune delle variabili saranno intere, ma non cambia il fatto che questi framework di programmazione sono solo framework matematici di giocattolo che sono lontani dall’espressività necessaria per affrontare i problemi di supply chain.
Quando chiedi dei casi d’uso dei problemi di ottimizzazione, ti invito a dare un’occhiata a tutte le mie lezioni sulle personae della supply chain. Abbiamo già una serie di personae della supply chain e sto elencando letteralmente tonnellate di problemi che possono essere affrontati attraverso l’ottimizzazione matematica. Nelle lezioni sulle personae della supply chain, abbiamo Parigi, Miami, Amsterdam e una serie mondiale, con altre in arrivo. Abbiamo molti problemi che devono essere affrontati e che meriterebbero di essere affrontati con una prospettiva di ottimizzazione matematica adeguata. Tuttavia, vedrai che per ognuno di quei problemi, non sarai in grado di inquadrarli all’interno dei vincoli super stretti e per lo più bizzarri che emergono da questi framework matematici. Di nuovo, quei framework matematici riguardano principalmente la convessità, e questa non è la prospettiva giusta per la supply chain. La maggior parte dei punti con cui trattiamo sono non convessi. Ma va bene; non è perché sono non convessi che sono impossibilmente difficili. Vedi, è solo che non sarai in grado di avere una prova matematica alla fine della giornata. Ma il tuo capo o la tua azienda si preoccupano del profitto, non se hai una prova matematica a supporto della decisione. Si preoccupano del fatto che tu possa prendere la decisione giusta in termini di produzione, rifornimento, prezzi, assortimenti e così via, non che tu abbia una prova matematica allegata a quelle decisioni.
Domanda: Per quanto tempo dovrebbero essere conservati i dati dell’algoritmo di apprendimento per aiutare nell’apprendimento?
Beh, direi che, considerando che lo storage dei dati oggi è incredibilmente economico, perché non tenerli per sempre? Lo storage dei dati è così economico; ad esempio, basta andare al supermercato e si può vedere che il prezzo di un hard disk da un terabyte è intorno ai 60 o qualcosa del genere. Quindi, è incredibilmente economico.
Ora, ovviamente, c’è una preoccupazione separata che se hai dati personali nei tuoi dati, allora i dati che conservi diventano un rischio. Ma dal punto di vista della supply chain, se assumiamo che tu abbia eliminato tutti i dati personali prima, perché in genere non hai bisogno di avere dati personali in primo luogo. Non hai bisogno di conservare numeri di carte di credito o nomi dei tuoi clienti. Hai solo bisogno di avere identificatori dei clienti e simili. Se elimini tutti i dati personali dai tuoi dati, direi, per quanto tempo? Beh, tienili per sempre.
Uno dei punti della supply chain è che hai dati limitati. Non è come i problemi di deep learning come il riconoscimento delle immagini, dove puoi elaborare tutte le immagini sul web e avere accesso a database quasi infiniti da elaborare. Nella supply chain, i tuoi dati sono sempre limitati. Infatti, se vuoi prevedere la domanda futura, ci sono pochissime industrie in cui guardare oltre un decennio nel passato sia veramente rilevante, statisticamente parlando, per prevedere la domanda per il prossimo trimestre. Ma comunque, direi che è sempre più facile troncare i dati se ne hai bisogno anziché renderti conto che hai scartato dei dati e ora mancano. Quindi il mio suggerimento è di conservare tutto, eliminare i dati personali e alla fine del tuo data pipeline, vedrai se è meglio filtrare i dati molto vecchi. Potrebbe essere, o potrebbe non essere; dipende dall’industria in cui operi. Ad esempio, nell’aerospaziale, quando hai parti e aeromobili con un ciclo di vita operativo di quattro decenni, avere dati nel tuo sistema degli ultimi quattro decenni è rilevante.
Domanda: La programmazione multi-obiettivo è una funzione di due o più obiettivi, come la somma o la minimizzazione di più funzioni in un unico obiettivo?
Ci sono molteplici varianti di come affrontare gli obiettivi multipli. Non si tratta di avere una funzione che è una somma perché, se hai la somma, allora è solo una questione di decomposizione e struttura della funzione di perdita. No, si tratta davvero di avere un vettore. E infatti, ci sono essenzialmente molteplici varianti di programmazione multi-obiettivo. La variante più interessante è quella in cui si vuole ottenere un ordinamento lessicografico. Per quanto riguarda la supply chain, la minimizzazione, quando si vuole dire che si prende la media o il massimo delle molte funzioni, potrebbe essere interessante, ma non ne sono troppo sicuro. Credo che l’approccio multi-obiettivo, in cui è possibile inserire vincoli e trattare i vincoli come parte della tua ottimizzazione regolare, sia molto interessante per scopi di supply chain. Anche le altre varianti potrebbero essere interessanti, ma non ne sono così sicuro. Non sto dicendo che non lo siano; sto solo dicendo che non ne sono sicuro.
Domanda: Come decideresti quando utilizzare una soluzione approssimata rispetto a una soluzione ottimizzata?
Voglio dire, non sono troppo sicuro di capire la domanda. L’idea è che, se c’è una lezione da imparare dal deep learning, è che non esiste una soluzione ottimale. Tutto è un’approssimazione in un certo grado. Anche quando dici di avere dei numeri, nei computer i numeri non hanno una precisione infinita; hanno una precisione finita. E questa precisione finita può effettivamente, in alcune circostanze, tornare indietro e morderti. Quindi la risposta è che è sempre approssimato. Direi che la lezione più grande è che è un’illusione pensare che ci sia anche una soluzione perfetta là fuori. Non esiste una soluzione perfetta e ottimale. Tutte le soluzioni che hai sono approssimazioni, e alcune di esse sono, direi, leggermente più o meno approssimative. Quindi, non sono troppo sicuro del senso della tua domanda, ma dal punto di vista dell’ottimizzazione matematica, significa che hai una funzione di perdita per valutare la qualità, e alla fine della giornata, se hai due soluzioni in competizione, hai la tua funzione di perdita per valutare quale sia la migliore. È così che funziona.
Domanda: Perché la serie temporale, in termini di dati storici, è stata divisa per 86.400 in primo luogo?
Non è stato così. Era solo un esempio. Volevo solo evidenziare e portare la situazione a uno stato assurdo in cui si vede, quando si affronta una serie temporale, un algoritmo classico di previsione delle serie temporali, si adotta ciò che è noto come una serie temporale equispaziata. Ci sono molti modi per rappresentare una serie temporale, e il modo più tipico per rappresentarla è il tipo equispaziato, in cui si aggrega in intervalli di lunghezza uguale. Questo è tipicamente ciò che si ottiene con l’aggregazione giornaliera o settimanale. Si hanno intervalli della stessa lunghezza e la serie ha una struttura simile a un vettore.
Ma ciò che sto sottolineando è che è arbitrario in larga misura. Si può decidere di rappresentare i dati come dati giornalieri, ma si potrebbe decidere di rappresentare i dati al secondo. Avrebbe mai senso rappresentare i dati al secondo? La risposta è sì; dipende dal tipo di problemi. Ad esempio, se si è un fornitore di energia elettrica e si vuole gestire una rete, allora si deve gestire la potenza ogni secondo in modo da avere esattamente il bilanciamento dell’offerta di elettricità nella propria rete con il consumo di energia. E questo bilanciamento è effettivamente regolato al secondo. Quindi, potrebbero esserci situazioni in cui ha senso rappresentare i dati al secondo. Per la vendita nel proprio negozio locale, potrebbe non avere senso. Quello che volevo sottolineare con quel 86.400, tra l’altro, è semplicemente 24 ore per 60 minuti per 60 secondi, e volevo chiarire il fatto che si ha sempre una rappresentazione dei propri dati, e non si dovrebbe confondere la rappresentazione dei propri dati che ha una certa dimensionalità con la dimensione intrinseca dei propri dati, che potrebbe avere una dimensione completamente diversa. La rappresentazione è, in larga misura, completamente inventata e arbitraria. Ti dà un indicatore numerico, come avere tre anni di dati, in modo da avere un vettore di dimensione mille. Ma questo mille è qualcosa che è in gran parte inventato perché si basa sulla decisione di aggregare i dati su base giornaliera. Se si sceglie qualsiasi altro periodo alternativo, si otterrebbe una dimensione diversa. Questo è il punto che volevo fare, ed è ciò che l’apprendimento profondo ha davvero capito: avere altre cose in cui non ti lasci ingannare dalla confusione delle scelte arbitrarie di rappresentazione dei dati. Si vuole essere un po’ indifferenti alla rappresentazione.
Domanda: Introducendo la previsione probabilistica, passiamo a una funzione di costo e a vincoli che sono probabilistici nella loro natura. Quali implicazioni ha sul processo di trovare una soluzione?
Beh, ha un vincolo molto fondamentale e di base. Se si ha un risolutore che non può elaborare problemi, e ancora una volta, ricordate che è sempre possibile tornare da un problema stocastico a un problema deterministico semplicemente facendo la media del risultato su un numero molto grande di campioni, allora si è un po’ in difficoltà in termini di costi computazionali. Significa che si dovrà spendere circa 10.000 volte più potenza di calcolo per arrivare a una soluzione soddisfacente rispetto a una soluzione alternativa. L’implicazione è che si vuole veramente assicurarsi che il proprio strumento di ottimizzazione matematica, l’infrastruttura che si ha, sia nativamente in grado di gestire problemi stocastici. Ecco esattamente ciò che si ottiene con la programmazione differenziabile, non tanto con la ricerca locale, ma si può migliorare o rivedere la ricerca locale in modo che funzioni più agevolmente anche in quelle situazioni.
Fondamentalmente, quando si passa alla previsione probabilistica, non si mette in discussione solo il modo in cui si guarda al futuro; si mette anche profondamente in discussione il tipo di strumenti e strumentazione con cui si deve lavorare su quelle previsioni. Questo è esattamente il tipo di strumentazione che Lokad ha sviluppato negli ultimi dieci anni. Il motivo è che abbiamo bisogno di avere strumenti che possano funzionare bene con il tipo di problemi stocastici che inevitabilmente emergono nella supply chain perché praticamente tutti i problemi nella supply chain hanno un elemento di incertezza, e quindi tutti affrontano in qualche misura un problema stocastico.
Eccellente. Quindi, la prossima lezione sarà nello stesso giorno della settimana, un mercoledì. Ci sarà qualche vacanza tra adesso e allora. La prossima lezione sarà il 22 settembre e spero di vedervi tutti. Questa volta parleremo di machine learning per la supply chain. A presto.
Riferimenti
- Il futuro della ricerca operativa è passato, Russell L. Ackoff, febbraio 1979
- LocalSolver 1.x: un risolutore di ricerca locale a scatola nera per la programmazione 0-1, Thierry Benoist, Bertrand Estellon, Frédéric Gardi, Romain Megel, Karim Nouioua, settembre 2011
- Differentiazione automatica nell’apprendimento automatico: un’indagine, Atilim Gunes Baydin, Barak A. Pearlmutter, Alexey Andreyevich Radul, Jeffrey Mark Siskind, ultima revisione febbraio 2018


