00:21 Introduzione
01:53 Dalla previsione all’apprendimento
05:32 Apprendimento automatico 101
09:51 La storia finora
11:49 Le mie previsioni per oggi
13:54 Preciso sui dati che non abbiamo 1/4
16:30 Preciso sui dati che non abbiamo 2/4
20:03 Preciso sui dati che non abbiamo 3/4
25:11 Preciso sui dati che non abbiamo 4/4
31:49 Gloria al template matcher
35:36 Una profondità nell’apprendimento 1/4
39:11 Una profondità nell’apprendimento 2/4
44:27 Una profondità nell’apprendimento 3/4
47:29 Una profondità nell’apprendimento 4/4
51:59 Vai grosso o torna a casa
56:45 Oltre la perdita 1/2
01:00:17 Oltre la perdita 2/2
01:04:22 Oltre l’etichetta
01:10:24 Oltre l’osservazione
01:14:43 Conclusioni
01:16:36 Prossima lezione e domande del pubblico
Descrizione
Le previsioni sono irriducibili nella supply chain poiché ogni decisione (acquisti, produzione, stoccaggio, ecc.) riflette un’anticipazione degli eventi futuri. L’apprendimento statistico e l’apprendimento automatico hanno in gran parte sostituito il campo classico delle ‘previsioni’, sia dal punto di vista teorico che pratico. Cercheremo di capire cosa significa un’anticipazione basata sui dati dal punto di vista dell’apprendimento moderno.
Trascrizione completa

Benvenuti alla serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Machine Learning per la Supply Chain”. Non possiamo stampare in 3D beni in tempo reale e non possiamo teletrasportarli dove devono essere consegnati. In realtà, quasi tutte le decisioni della supply chain devono essere prese guardando avanti, anticipando la domanda futura o le variazioni di prezzo, riflettendo implicitamente o esplicitamente alcune condizioni di mercato future previste, sia dal lato della domanda che dal lato dell’offerta. Di conseguenza, la previsione è una parte integrante e irriducibile della supply chain. Non conosciamo mai il futuro con certezza; possiamo solo fare congetture sul futuro con diversi gradi di certezza. Lo scopo di questa lezione è capire cosa l’apprendimento automatico sta portando sul tavolo per quanto riguarda la cattura del futuro.

Vedremo in questa lezione che fornire previsioni più accurate è, nel grande schema delle cose, una preoccupazione relativamente secondaria. Infatti, nella supply chain di oggi, la previsione significa previsione delle serie temporali. Storicamente, le previsioni delle serie temporali sono diventate popolari all’inizio del XX secolo negli Stati Uniti. Infatti, gli Stati Uniti sono stati il primo paese ad avere milioni di dipendenti della classe media che possedevano anche azioni. Poiché le persone volevano essere investitori esperti, volevano avere informazioni sulle loro investimenti, e si è scoperto che le serie temporali e le previsioni delle serie temporali erano un modo intuitivo ed efficace per trasmettere queste informazioni. Si potevano avere previsioni delle serie temporali sui futuri prezzi di mercato, futuri dividendi e futuri quote di mercato.
Negli anni ‘80 e ‘90, quando la supply chain è stata essenzialmente digitalizzata, i software aziendali della supply chain hanno iniziato a beneficiare anche delle previsioni delle serie temporali. In effetti, le previsioni delle serie temporali sono diventate onnipresenti in quel tipo di software aziendale. Tuttavia, se guardi questa immagine, puoi renderti conto che le previsioni delle serie temporali sono in realtà un modo molto semplicistico e ingenuo di guardare al futuro.
Vedi, se guardo solo questa immagine, posso già dire cosa succederà dopo: molto probabilmente arriverà una squadra, pulirà questo disordine e molto probabilmente ispezionerà i carrelli elevatori per motivi di sicurezza. Potrebbero persino effettuare alcune riparazioni leggere e con un alto grado di certezza posso dire che molto probabilmente questo carrello elevatore verrà presto rimesso in funzione. Solo guardando questa immagine, possiamo anche prevedere che tipo di condizioni hanno portato a questa situazione. Nessuna di queste cose si adatta alla prospettiva di una previsione delle serie temporali, eppure tutte queste previsioni sono molto rilevanti.
Queste previsioni non riguardano il futuro in sé, poiché questa immagine è stata scattata un po’ di tempo fa e anche gli eventi che sono seguiti allo scatto di questa immagine fanno ora parte del nostro passato. Ma comunque, sono previsioni nel senso che stiamo facendo affermazioni su cose che non conosciamo con certezza. Non abbiamo una misurazione diretta. Quindi la cosa principale di interesse è: come faccio anche solo a produrre queste previsioni e fare queste affermazioni?
Si scopre che come essere umano, ho vissuto, ho assistito a eventi e ho imparato da essi. Ecco come posso effettivamente produrre queste affermazioni. E si scopre che l’apprendimento automatico è proprio questo: è l’ambizione di essere in grado di replicare questa capacità di apprendimento con le macchine, il tipo di macchine preferito di gran lunga sono i computer al giorno d’oggi. A questo punto, potresti chiederti come l’apprendimento automatico sia anche diverso da altri termini come intelligenza artificiale, tecnologie cognitive o apprendimento statistico. Beh, si scopre che questi termini dicono molto di più sulle persone che li usano piuttosto che sul problema stesso. Per quanto riguarda il problema, i confini tra tutti questi campi sono molto sfumati.

Ora approfondiamo con una revisione dell’archetipo dei framework di apprendimento automatico, coprendo una breve serie di concetti centrali dell’apprendimento automatico. La caratteristica rappresenta un pezzo di dati che viene reso disponibile per eseguire il compito di previsione. L’idea è che tu abbia un compito di previsione che desideri eseguire e una caratteristica (o più caratteristiche) rappresenta ciò che è reso disponibile per eseguire tale compito. Nel contesto delle previsioni delle serie temporali, la caratteristica rappresenterebbe la sezione passata della serie temporale e avresti un vettore di caratteristiche che rappresentano tutti i punti dati passati.
L’etichetta rappresenta la risposta al compito di previsione. Nel caso di una previsione delle serie temporali, rappresenta tipicamente la porzione della serie temporale che non conosci, dove si trova il futuro. Se hai un insieme di caratteristiche più un’etichetta, viene definita come osservazione. La tipica configurazione dell’apprendimento automatico assume che tu abbia un set di dati contenente sia caratteristiche che etichette, che rappresenta il tuo set di dati di addestramento.
L’obiettivo è creare un programma chiamato modello che prende le caratteristiche in input e calcola l’etichetta prevista desiderata. Questo modello è tipicamente progettato attraverso un processo di apprendimento che attraversa l’intero set di dati di addestramento e costruisce il modello. L’apprendimento nell’apprendimento automatico è la parte in cui effettivamente costruisci il programma che fa le previsioni.
Infine, c’è la perdita. La perdita è essenzialmente la differenza tra l’etichetta reale e quella prevista. L’obiettivo è che il processo di apprendimento generi un modello che effettui previsioni il più vicine possibile alle etichette reali. Vuoi un modello che mantenga le etichette previste il più vicine possibile alle etichette reali.
L’apprendimento automatico può essere visto come una vasta generalizzazione delle previsioni delle serie temporali. Dal punto di vista dell’apprendimento automatico, le caratteristiche possono essere qualsiasi cosa, non solo un segmento passato di una serie temporale. Le etichette possono essere anche qualsiasi cosa, non solo il segmento futuro di una serie temporale. Il modello può essere qualsiasi cosa e anche la perdita può essere praticamente qualsiasi cosa. Quindi, abbiamo un framework che è molto più espressivo delle previsioni delle serie temporali. Tuttavia, come vedremo, la maggior parte dei principali risultati dell’apprendimento automatico come campo di studio e pratica derivano dalle scoperte di elementi che ci costringono a rivedere e mettere in discussione l’elenco di concetti che ho appena brevemente introdotto.
Questa lezione è la quarta lezione della serie di lezioni sulla supply chain. Le scienze ausiliarie rappresentano elementi che non sono la supply chain di per sé, ma rappresentano qualcosa di fondamentale importanza per la supply chain. Nel primo capitolo, ho presentato le mie opinioni sulla supply chain sia come studio fisico che come pratica. Nel secondo capitolo, abbiamo esaminato una serie di metodologie necessarie per affrontare un dominio come la supply chain che presenta molti comportamenti avversari e non può essere facilmente isolato. Il terzo capitolo è interamente dedicato alle personae della supply chain, che è un modo per concentrarsi sui problemi che stiamo cercando di risolvere.
In questo quarto capitolo, ho gradualmente attraversato la scala di astrazione, iniziando con i computer, poi gli algoritmi e la precedente lezione sull’ottimizzazione matematica, che può essere considerata come il livello base dell’apprendimento automatico moderno. Oggi, ci stiamo avventurando nell’apprendimento automatico, che è essenziale per catturare il futuro che è predominante in tutte le decisioni della supply chain che dobbiamo prendere ogni singolo giorno.

Quindi, qual è il piano per questa lezione? L’apprendimento automatico è un campo di ricerca enorme e questa lezione sarà guidata da una breve serie di domande che riguardano i concetti e le idee che ho introdotto in precedenza. Vedremo come le risposte a queste domande ci costringono a rivedere la stessa nozione di apprendimento e il modo in cui ci avviciniamo ai dati. Uno dei risultati più spettacolari dell’apprendimento automatico è che ci ha costretto a realizzare che ci sono molti più fattori in gioco rispetto alle grandi ambizioni iniziali dei ricercatori che pensavano di poter replicare l’intelligenza umana entro un decennio.
In particolare, daremo un’occhiata all’apprendimento profondo, che è probabilmente il miglior candidato che abbiamo per emulare un grado più elevato di intelligenza in questo momento. Sebbene l’apprendimento profondo sia emerso come una pratica incredibilmente empirica, i progressi e i risultati ottenuti attraverso l’apprendimento profondo gettano una nuova luce sulla prospettiva fondamentale dell’apprendimento dai fenomeni osservati.
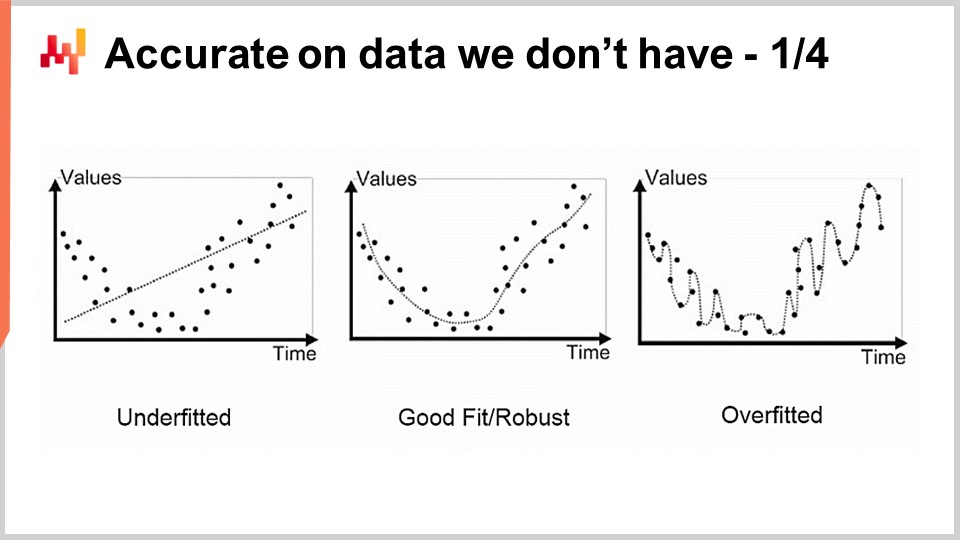
Il primo problema che abbiamo con la modellazione, statistica o meno, è l’accuratezza dei dati che non abbiamo. Da una prospettiva di supply chain, questo è essenziale perché il nostro interesse è quello di essere in grado di catturare il futuro. Per definizione, il futuro rappresenta un insieme di dati che non abbiamo ancora. Ci sono tecniche, come il backtesting o la cross-validation, che possono fornirci alcune misurazioni empiriche su cosa dovremmo aspettarci dall’accuratezza dei dati che non abbiamo. Tuttavia, perché questi metodi funzionano è un problema relativamente intrigante e difficile. Il problema non è avere un modello che si adatta ai dati che abbiamo; è facile costruire un modello che si adatta ai dati utilizzando un polinomio con un grado sufficiente. Tuttavia, questo modello non è molto soddisfacente perché non sta catturando ciò che vorremmo catturare.
L’approccio classico a questo problema è noto come trade-off tra bias e varianza. A destra, abbiamo un modello con pochissimi parametri che sottostima il problema, che diciamo ha molto bias. A sinistra, abbiamo un modello con troppi parametri che sovrastima e ha troppa varianza. Al centro, abbiamo un modello che trova un buon equilibrio tra bias e varianza, che chiamiamo una buona adattabilità. Fino alla fine del XX secolo, non era molto chiaro come affrontare questo problema oltre il trade-off tra bias e varianza.

La prima vera intuizione sull’accuratezza dei dati che non abbiamo è venuta dalle teorie di apprendibilità pubblicate da Valiant nel 1984. Valiant ha introdotto la teoria PAC - Probabilmente Approssimativamente Corretto. In questa teoria PAC, la parte “probabilmente” si riferisce a un modello con una data probabilità di fornire risposte abbastanza buone. La parte “approssimativamente” significa che la risposta non è troppo lontana da ciò che è considerato buono o valido.
Valiant ha dimostrato che in molte situazioni, non è semplicemente possibile imparare qualcosa o, più precisamente, che per imparare avremmo bisogno di un numero di campioni così stravagantemente grande da non essere pratico. Questo era già un risultato molto interessante. La formula visualizzata proviene dalla teoria PAC ed è una disuguaglianza che ti dice che se vuoi produrre un modello che è probabilmente approssimativamente corretto, devi avere un numero di osservazioni, n, maggiore di una certa quantità. Questa quantità dipende da due fattori: epsilon, il tasso di errore (la parte approssimativamente corretta), e eta, la probabilità di fallimento (uno meno eta è la probabilità di non fallire).
Quello che vediamo è che se vogliamo avere una probabilità di fallimento più bassa o un epsilon più piccolo (un intervallo abbastanza buono), abbiamo bisogno di più campioni. Questa formula dipende anche dalla cardinalità dello spazio delle ipotesi. L’idea è che più numerose sono le ipotesi competitive, più osservazioni abbiamo bisogno per ordinarle. Questo è molto interessante perché, fondamentalmente, anche se la teoria PAC ci fornisce principalmente risultati negativi, ci dice cosa non possiamo fare, ovvero costruire un modello probabilmente approssimativamente corretto con meno campioni. La teoria non ci dice davvero come fare qualcosa; non è molto prescrittiva nel modo di diventare effettivamente migliori nel risolvere qualsiasi tipo di compito di previsione. Tuttavia, è stato un punto di riferimento perché ha cristallizzato l’idea che fosse possibile affrontare questo problema di accuratezza e dati che non avevamo in modi molto più robusti rispetto a fare semplicemente alcune misurazioni molto empiriche con, diciamo, la cross-validation o il backtesting.
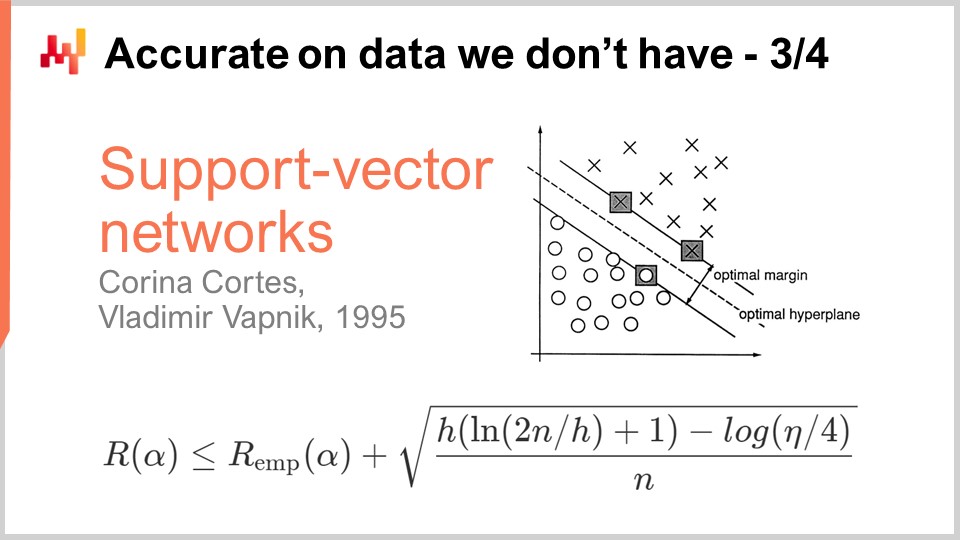
Un decennio dopo, la prima svolta operativa è arrivata quando Vapnik e alcuni altri hanno stabilito ciò che oggi è noto come teoria Vapnik-Chervonenkis (VC). Questa teoria mostra che è possibile catturare la vera perdita, chiamata rischio, che è la perdita che osserverai sui dati che non avevi. Era possibile dimostrare matematicamente che avevi la capacità di sapere qualcosa sull’errore reale, che per definizione non puoi mai misurare. Questo è un risultato molto sorprendente.
Fondamentalmente, questa formula, direttamente dalla teoria VC, ci dice che il rischio reale è limitato superiormente dal rischio empirico, che è il rischio che possiamo misurare sui dati che abbiamo, più un altro termine spesso chiamato rischio strutturale. Abbiamo il numero di osservazioni, n, e eta, che è la probabilità di fallimento, proprio come nella teoria PAC. Abbiamo anche h, che è una misura della dimensione VC del modello. La dimensione VC riflette la capacità del modello di apprendere; maggiore è la capacità del modello di apprendere, maggiore è la dimensione VC.
Con questi risultati, vediamo che per i modelli che hanno la capacità di imparare qualsiasi cosa, non possiamo dire nulla su di loro. Questo è molto sorprendente. Se il tuo modello può imparare qualsiasi cosa, allora non puoi dire nulla, almeno matematicamente, su di esso.
La svolta nel 1995 è arrivata da un’implementazione di Cortes e Vapnik di ciò che sarebbe poi stato conosciuto come Support Vector Machines (SVM). Queste SVM sono letteralmente l’implementazione diretta di questa teoria matematica. L’idea è che, avendo una teoria che ci fornisce questa disuguaglianza, possiamo implementare un modello che bilancia la quantità di errore che commettiamo sui dati (il rischio empirico) e la dimensione VC. Possiamo costruire direttamente un modello matematico che bilancia esattamente questi due fattori per rendere l’uguaglianza il più stretta e bassa possibile. Ecco di cosa si tratta esattamente Support Vector Machines (SVM). Questi risultati sono stati così sorprendenti, operativamente, che hanno ottenuto risultati molto buoni e hanno avuto un impatto significativo sulla comunità di apprendimento automatico. Per la prima volta, l’accuratezza sui dati che non abbiamo non era un’idea secondaria; è stata ottenuta direttamente dal design matematico del metodo stesso. Questo era così sorprendente e potente che ha tenuto l’intera comunità di apprendimento automatico distratta per un decennio perseguendo questa strada. Come vedremo, questa strada si è rivelata per lo più un vicolo cieco, ma c’era una buona ragione per questo: è stato un risultato assolutamente sorprendente.
Operativamente, a causa del fatto che le SVM sono emerse principalmente da una teoria matematica, avevano pochissima simpatia meccanica. Non erano adatte all’hardware di calcolo che abbiamo. Più specificamente, l’implementazione ingenua delle SVM comporta un costo quadratico in termini di occupazione di memoria rispetto al numero di osservazioni. Questo è molto, e di conseguenza, rende le SVM molto lente. Ci sono state successivamente migliorie con alcune varianti online delle SVM che hanno notevolmente ridotto i requisiti di memoria, ma comunque, le SVM non sono mai state considerate un approccio veramente scalabile per eseguire l’apprendimento automatico.

Le SVM hanno aperto la strada a un’altra classe di modelli migliori che probabilmente non facevano overfitting. L’overfitting consiste essenzialmente nell’essere molto imprecisi sui dati che non si hanno. Gli esempi più notevoli sono probabilmente Random Forests e Gradient Boosted Trees, che sono i loro discendenti quasi immediati. Al loro nucleo c’è il boosting, un meta-algoritmo che trasforma modelli deboli in modelli più forti. Il boosting è emerso da domande sollevate alla fine degli anni ‘80 tra Kearns e Valiant, che abbiamo menzionato in precedenza in questa lezione.
Per capire come funziona una Random Forest, è relativamente semplice: prendi il tuo dataset di addestramento e poi prendi un campione del tuo dataset. Su questo campione, costruisci un albero decisionale. Ripeti questo processo, creando un altro campione dal dataset di addestramento iniziale e costruendo un altro albero decisionale. Itera questo processo e alla fine avrai molti alberi decisionali. Gli alberi decisionali sono relativamente deboli in termini di modelli di apprendimento automatico, poiché non possono catturare pattern molto complessi. Tuttavia, se metti insieme tutti questi alberi e fai la media dei risultati, otterrai una foresta, chiamata Random Forest, perché ogni albero è stato costruito su un sottocampione casuale del dataset di addestramento iniziale. Quello che ottieni con una Random Forest è un modello di apprendimento automatico molto più forte e migliore.
Gradient Boosted Trees sono solo una piccola variazione su questa intuizione. La principale variazione è che, invece di campionare il tuo dataset di addestramento e costruire un albero in modo casuale, con tutti gli alberi costruiti indipendentemente, Gradient Boosted Trees prima costruisce la foresta e poi l’albero successivo viene costruito guardando i residui della foresta che hai già. L’idea è che hai iniziato a costruire un modello composto da molti alberi e fai previsioni che si discostano dalla realtà. Hai questi delta, che sono le differenze tra i valori reali e quelli previsti, chiamati residui. L’idea è che addestrerai il prossimo albero non sul dataset originale ma su un campione di residui. I Gradient Boosted Trees funzionano ancora meglio delle Random Forests. In pratica, le Random Forests fanno overfitting, ma solo un po’. Ci sono alcune prove che mostrano, in determinate condizioni, che le Random Forests non dovrebbero fare overfitting.
È interessante notare che i Gradient Boosted Trees hanno dominato i punteggi più alti di quasi tutte le competizioni di machine learning per un decennio e mezzo. Quando si guarda all'80-90% delle competizioni di Kaggle, si può vedere che è essenzialmente un Gradient Boosted Tree che arriva primo. Tuttavia, nonostante questa incredibile dominanza nelle competizioni di machine learning, ci sono stati pochissimi progressi nell’applicazione dei Gradient Boosted Trees ai problemi della supply chain nel mondo reale. Il motivo principale è che i Gradient Boosted Trees hanno una scarsa simpatia meccanica; il loro design non è affatto amichevole per l’hardware di calcolo che abbiamo.
È facile capire perché: si costruisce un modello con una serie di alberi e il modello finisce per essere grande quanto una frazione del tuo dataset. In molte situazioni, ti ritrovi con un modello che è più grande, in termini di dati, del dataset con cui hai iniziato. Quindi, se il tuo dataset è già molto grande, il tuo modello è gigantesco e questo è un problema molto problematico.
Per quanto riguarda la storia dei Gradient Boosted Trees, ci sono state una serie di implementazioni, a partire da GBM (Gradient Boosted Machines) nel 2007, che ha reso molto popolare questo approccio in un pacchetto R. Fin dall’inizio, ci sono stati problemi di scalabilità. Le persone hanno rapidamente iniziato a parallelizzare l’esecuzione con PGBRT (Parallel Gradient Boosted Regression Trees), ma era comunque molto lento. XGBoost è stato un punto di svolta perché ha guadagnato un ordine di grandezza in termini di scalabilità. L’idea chiave in XGBoost è stata quella di adottare un design a colonne nei dati per rendere più veloce la costruzione dell’albero. Successivamente, LightGBM ha riutilizzato tutte le intuizioni di XGBoost ma ha cambiato la strategia su come costruire gli alberi. XGBoost ha fatto crescere l’albero in modo livello per livello, mentre LightGBM ha deciso di far crescere l’albero in modo foglia per foglia. Il risultato netto è che LightGBM è ora di diversi ordini di grandezza più veloce, considerando lo stesso hardware di calcolo, rispetto a quanto GBM sia mai stato. Tuttavia, dal punto di vista pratico della supply chain, l’utilizzo dei Gradient Boosted Trees è di solito troppo lento. Non è impossibile usarli; è solo che è un ostacolo così grande che di solito non ne vale la pena.

La cosa sorprendente è che i Gradient Boosted Trees sono abbastanza potenti da vincere quasi tutte le competizioni di machine learning eppure, secondo la mia modesta opinione, questi modelli sono un vicolo cieco tecnologico. Support Vector Machines, Random Forests e Gradient Boosted Trees hanno tutti in comune il fatto che non sono altro che corrispondenze di modelli. Sono corrispondenze di modelli molto buone, va detto, ma davvero nient’altro. Quello che fanno straordinariamente bene è essenzialmente la selezione delle variabili e sono molto bravi in questo, ma c’è davvero poco altro. In particolare, non c’è espressività nella loro capacità di trasformare l’input in qualcosa di diverso da una selezione o un filtraggio diretto dell’input.
Se torniamo all’immagine del carrello elevatore che ho presentato all’inizio di questa lezione, non c’è alcuna speranza che uno qualsiasi di quei modelli possa fare le stesse affermazioni che ho appena fatto, non importa quanto grande sia il dataset di immagini. Potresti letteralmente alimentare tutti quei modelli con milioni di immagini prese da magazzini in tutto il mondo e ancora non sarebbero in grado di fare affermazioni come “Oh, ho visto un carrello elevatore in questa situazione; una squadra si presenterà e farà delle riparazioni”. Non proprio.
Nella pratica, quello che abbiamo visto è che il fatto che questi modelli vincono le competizioni di machine learning è ingannevole perché ci sono fattori che giocano a loro favore in tali situazioni. Primo, i dataset del mondo reale sono molto complessi, il che è diverso dalle competizioni di machine learning dove, al massimo, si hanno dataset di giocattolo che rappresentano solo una frazione delle complessità affrontate nelle configurazioni del mondo reale. Secondo, per vincere una competizione di machine learning utilizzando modelli come i Gradient Boosted Trees, è necessario fare un’ingegnerizzazione delle caratteristiche estesa. A causa del fatto che questi modelli sono corrispondenze di modelli esaltate, è necessario avere le giuste caratteristiche in modo che solo la selezione delle variabili faccia funzionare il modello alla grande. Devi iniettare una grande dose di intelligenza umana nella preparazione dei dati perché funzioni. Questo è un grosso problema perché, nel mondo reale, quando si cerca di risolvere un problema per le catene di approvvigionamento reali, il numero di ore di ingegnerizzazione che puoi dedicare al problema è limitato. Non puoi passare sei mesi su un piccolo, limitato e temporaneo problema giocattolo della tua catena di approvvigionamento.
Il terzo problema è che, nelle catene di approvvigionamento, i dataset cambiano costantemente. Non è solo che i dati cambiano, ma il problema sta anche cambiando gradualmente. Questo complica i problemi che hai con l’ingegnerizzazione delle caratteristiche. Fondamentalmente, ci troviamo con modelli che vincono competizioni di machine learning e previsione, ma se guardiamo a dieci anni nel futuro, vediamo che questi modelli non sono il futuro del machine learning; sono il passato.

Il deep learning è stata la risposta a queste corrispondenze superficiali di modelli. Il deep learning viene spesso presentato come il discendente delle reti neurali artificiali, ma la realtà è che il deep learning ha preso il volo solo il giorno in cui i ricercatori hanno deciso di abbandonare le metafore biologiche e concentrarsi invece sulla simpatia meccanica. Di nuovo, la simpatia meccanica, che significa andare d’accordo con i computer che abbiamo, è essenziale. Il problema che avevamo con le reti neurali artificiali era che stavamo cercando di imitare la biologia, ma i computer che abbiamo sono completamente diversi dai substrati biologici che supportano i nostri cervelli. Questa situazione ricorda i primi tempi della storia dell’aviazione, in cui numerosi inventori cercavano di costruire macchine volanti imitando gli uccelli. Oggi abbiamo macchine volanti che volano molte volte più veloci dei più veloci uccelli, ma il modo in cui queste macchine volano ha quasi nulla in comune con il volo degli uccelli.
La prima intuizione sul deep learning è stata la necessità di qualcosa di profondo ed espressivo che potesse applicare qualsiasi tipo di trasformazione ai dati di input, consentendo l’emergere di un comportamento predittivo intelligente dal modello. Tuttavia, doveva anche andare d’accordo con l’hardware di calcolo che avevamo. L’idea era che se avessimo modelli complessi che andassero molto d’accordo con l’hardware di calcolo, probabilmente saremmo in grado di imparare funzioni che sono di diversi ordini di grandezza più complesse, tutto considerato uguale, rispetto a qualsiasi metodo che non avrebbe avuto lo stesso grado di simpatia meccanica.
Programmazione differenziabile, che è stata presentata nella precedente lezione, può essere considerata come il livello base del deep learning. Non tornerò sulla programmazione differenziabile in questa lezione, ma invito il pubblico a guardare la lezione precedente se non l’ha ancora vista. Dovreste essere in grado di capire ciò che segue anche se non avete visto la lezione precedente. La lezione precedente dovrebbe chiarire alcuni dei dettagli più tecnici del processo di apprendimento stesso. In sintesi, la programmazione differenziabile è solo un modo per, se scegliamo una forma specifica di modello, identificare i migliori valori per i parametri che esistono all’interno di questo modello.
Mentre la programmazione differenziabile si concentra sull’identificazione dei migliori parametri, l’apprendimento automatico si concentra sull’identificazione delle forme superiori di modelli che hanno la capacità più elevata di apprendere dai dati.

Quindi, come creiamo un modello per una funzione arbitrariamente complessa che può riflettere qualsiasi trasformazione arbitrariamente complessa sui dati di input? Iniziamo con un circuito di valori in virgola mobile. Perché valori in virgola mobile? Beh, è perché è il tipo di cosa su cui possiamo applicare la discesa del gradiente, che, come abbiamo visto nella lezione precedente, è molto scalabile. Quindi, sono i numeri in virgola mobile. Avremo una sequenza di numeri in virgola mobile, il che significa numeri in virgola mobile in ingresso e numeri in virgola mobile in uscita.
Ora, cosa facciamo nel mezzo? Facciamo algebra lineare, e più specificamente, facciamo moltiplicazione di matrici. Perché? La risposta a perché la moltiplicazione di matrici è stata data nella prima lezione di questo quarto capitolo. È legata al modo in cui i computer moderni sono progettati; fondamentalmente, è possibile ottenere un aumento di velocità relativamente drammatico in termini di velocità di elaborazione se ci si attiene all’algebra lineare. Quindi, è algebra lineare. Ora, se prendo i miei input e applico una trasformazione lineare, che è semplicemente una moltiplicazione di matrici con una matrice chiamata W (questa matrice contiene i parametri che vogliamo imparare in seguito), come possiamo renderla più complessa? Possiamo aggiungere una seconda moltiplicazione di matrici. Tuttavia, se ricordate i vostri corsi di algebra lineare, quando si moltiplica una funzione lineare con un’altra funzione lineare, si ottiene una funzione lineare. Quindi, se componiamo semplicemente la moltiplicazione di matrici, abbiamo ancora una moltiplicazione di matrici, ed è ancora completamente lineare.
Quello che faremo è intercalare non linearità tra le operazioni lineari. Questo è esattamente quello che ho fatto su questo schermo. Ho intercalato una funzione tipicamente conosciuta nella letteratura del deep learning come Unità Lineare Rettificata (ReLU). Questo nome, che è fantasticaente complicato rispetto a ciò che fa, è solo una funzione molto semplice che dice se prendo un numero e se questo numero è positivo, allora restituisco lo stesso numero esatto (quindi è una funzione identità), ma se il numero è negativo, restituisco 0. Puoi anche scriverlo come il massimo del tuo valore e zero. Questa è una non linearità molto banale.
Potremmo usare funzioni non lineari molto più sofisticate. Storicamente, quando le persone facevano reti neurali, volevano usare funzioni di sigmoidi sofisticate perché si supponeva che fosse così che funzionavano nei nostri neuroni. Ma la realtà è che perché dovremmo voler sprecare potenza di elaborazione per calcolare cose che sono irrilevanti? L’idea chiave è che dobbiamo introdurre qualcosa di non lineare, e non importa davvero quale funzione non lineare usiamo. L’unica cosa che conta è renderla molto veloce. Vogliamo mantenere il tutto il più veloce possibile.
Quello che sto costruendo qui si chiama strati densi. Uno strato denso è essenzialmente una moltiplicazione di matrici con una non linearità (l’Unità Lineare Rettificata). Possiamo impilarli. Sullo schermo puoi vedere una rete, che viene tipicamente chiamata perceptron multi-strato, e abbiamo tre strati. Possiamo continuare ad impilarli, e potremmo averne 20 o 2.000; non importa davvero. La realtà è che, per quanto semplice possa sembrare, se prendi una tale rete con solo un paio di strati e la inserisci nel tuo framework di programmazione differenziabile, che ti darà i parametri, la programmazione differenziabile come base sarà in grado di addestrare i parametri, che vengono inizialmente scelti casualmente. Se vuoi inizializzarlo, inizializza semplicemente tutti i parametri casualmente. Otterrai risultati abbastanza decenti per una grande varietà di problemi.
Questo è molto interessante perché, a questo punto, hai praticamente tutti gli ingredienti fondamentali del deep learning. Quindi, per il pubblico, congratulazioni! Probabilmente puoi iniziare ad aggiungere “specialista di deep learning” al tuo curriculum perché questo è quasi tutto ciò che c’è. Beh, non proprio, ma diciamo che è un buon punto di partenza.

La realtà è che il deep learning coinvolge molto poco di teoria oltre all’algebra tensoriale, che è essenzialmente l’algebra lineare computerizzata. Tuttavia, il deep learning coinvolge tonnellate di trucchi. Ad esempio, dobbiamo normalizzare gli input e stabilizzare i gradienti. Se iniziamo ad impilare molte operazioni del genere, i gradienti possono crescere in modo esponenziale man mano che andiamo indietro nella rete, e ad un certo punto, ciò farà traboccare la capacità di rappresentare quei numeri. Abbiamo computer del mondo reale e non sono in grado di rappresentare numeri arbitrariamente grandi. Ad un certo punto, superi semplicemente la tua capacità di rappresentare il numero con un valore floating-point a 32-bit o 16-bit. Ci sono tonnellate di trucchi per la stabilizzazione del gradiente. Ad esempio, il trucco è tipicamente la normalizzazione del batch, ma ci sono altri trucchi per quello.
Se hai input che hanno una struttura geometrica, ad esempio, unidimensionale come una serie temporale (vendite storiche, come vediamo nella supply chain), che può essere bidimensionale (pensaci come un’immagine), tridimensionale (potrebbe essere un film), o quadridimensionale, ecc. Se gli input hanno una struttura geometrica, allora ci sono strati speciali che possono catturare questa struttura geometrica. I più famosi sono probabilmente chiamati strati convoluzionali.
Poi, hai anche tecniche e trucchi per gestire input categorici. Nel deep learning, tutti i tuoi input sono valori floating-point, quindi come gestisci le variabili categoriche? La risposta sono gli embedding. Hai perdite surrogate, che sono perdite alternative che mostrano gradienti molto ripidi e facilitano il processo di convergenza, amplificando in definitiva ciò che puoi imparare dai dati. Ci sono tonnellate di trucchi, e tutti quei trucchi possono tipicamente essere inseriti nel programma che stai componendo perché operiamo con la programmazione differenziabile come nostra base.
Il deep learning riguarda davvero come componiamo un programma che, una volta eseguito attraverso il processo di addestramento offerto dalla programmazione differenziabile, ha una capacità molto elevata di apprendimento. La maggior parte degli elementi che ho appena elencato sullo schermo sono anche di natura programmabile, il che è molto conveniente considerando che abbiamo la programmazione differenziabile, un paradigma di programmazione, per supportare tutto ciò.
A questo punto, dovrebbe diventare più chiaro perché il deep learning è diverso dal classico machine learning. Il deep learning non riguarda i modelli. In effetti, la maggior parte delle librerie di deep learning open source non include nemmeno modelli. Nel deep learning, ciò che conta veramente sono le architetture dei modelli, che puoi pensare come template che devono essere pesantemente personalizzati quando vuoi adattarli a una situazione specifica. Tuttavia, se adotti un’architettura adeguata, puoi prevedere che la tua personalizzazione preserverà comunque l’essenza della capacità del tuo modello di apprendere. Con il deep learning, spostiamo l’interesse dal modello finale, che diventa qualcosa di poco interessante, verso l’architettura, che diventa il vero oggetto di ricerca.
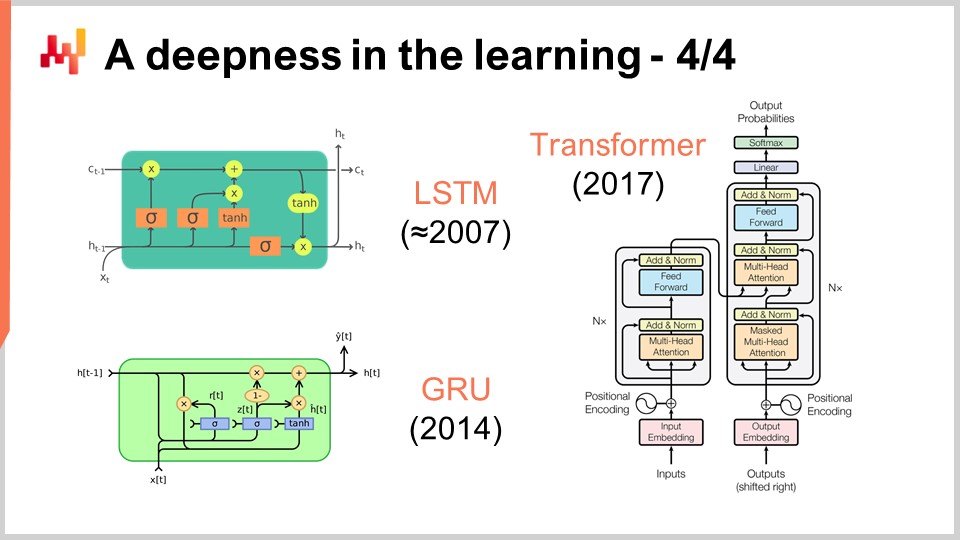
Sullo schermo, puoi vedere una serie di esempi di architetture notevoli. Prima, LSTM, che sta per Long Short-Term Memory, ha iniziato a funzionare intorno al 2007. La storia delle pubblicazioni di LSTM è un po’ più complicata, ma essenzialmente ha iniziato a funzionare in stile deep learning nel 2007. È stata superata dalle Gated Recurrent Units (GRU), che essenzialmente sono la stessa cosa di LSTM ma più semplici e migliori. In sostanza, molta della complessità di LSTM deriva dalle metafore biologiche. Si scopre che puoi abbandonare le metafore biologiche e ottenere qualcosa di più semplice che funziona praticamente allo stesso modo. Queste sono le Gated Recurrent Units (GRU). Successivamente, sono arrivate le trasformazioni, che hanno reso obsolete sia LSTM che GRU. Le trasformazioni sono state una svolta perché erano molto più veloci, più leggere in termini di risorse di calcolo necessarie e avevano una capacità di apprendimento ancora maggiore.
La maggior parte di queste architetture è accompagnata da metafore. LSTM ha una metafora cognitiva, la memoria a lungo termine, mentre le trasformazioni sono accompagnate da una metafora di recupero delle informazioni. Tuttavia, queste metafore hanno molto poco potere predittivo e potrebbero effettivamente essere più una fonte di confusione e distrazione da ciò che fa davvero funzionare queste architetture, che non è ancora del tutto compreso in questo momento.
Le trasformazioni sono di grande interesse per la supply chain perché sono una delle architetture più versatili. Vengono utilizzate praticamente per tutto oggi, dalla guida autonoma alla traduzione automatica e molti altri problemi complessi. Questo è una testimonianza del potere di scegliere l’architettura giusta, che può poi essere utilizzata per affrontare una grande varietà di problemi. Per quanto riguarda la supply chain, una delle principali difficoltà nel fare qualsiasi cosa con il machine learning è che abbiamo una tale incredibile diversità di problemi da affrontare. Non possiamo permetterci di avere un team che dedica cinque anni agli sforzi di ricerca per ogni singolo sotto-problema che affrontiamo. Abbiamo bisogno di qualcosa in cui possiamo muoverci velocemente e non dover reinventare metà del machine learning ogni volta che vogliamo risolvere il problema successivo.
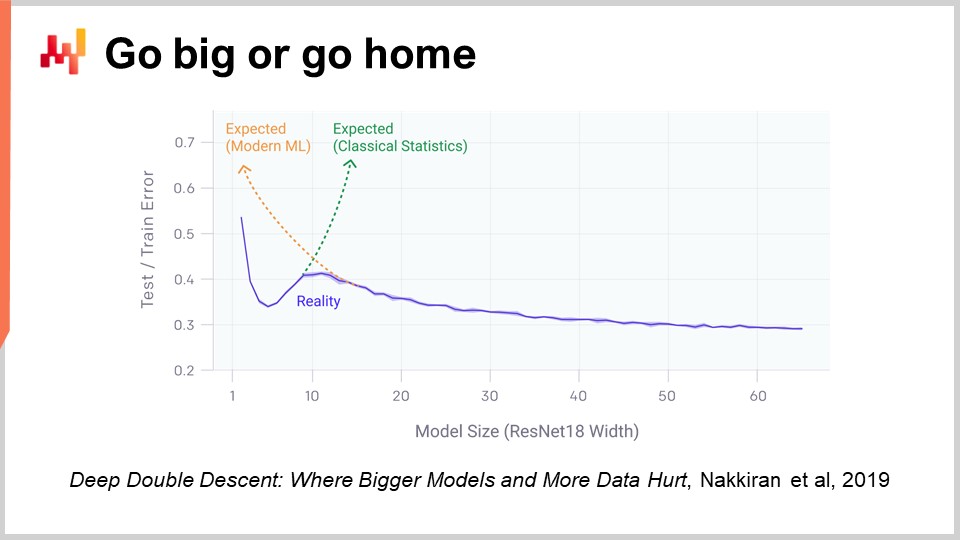
Un aspetto del deep learning che è davvero sorprendente quando si inizia a pensarci è il numero massiccio di parametri. Nella perceptron multistrato che ho presentato qualche minuto fa, con livelli densi che coinvolgono la moltiplicazione di matrici, possiamo avere molti parametri in quelle matrici. Infatti, non è molto difficile avere tanti parametri quanti abbiamo punti dati o osservazioni nei nostri set di dati di addestramento. Come abbiamo visto all’inizio della nostra lezione, se abbiamo un modello con così tanti parametri, dovrebbe soffrire drasticamente di overfitting.
La realtà con il deep learning è ancora più sorprendente. Ci sono molte situazioni in cui abbiamo molti più parametri di quante osservazioni abbiamo, eppure non abbiamo problemi di overfitting drammatici. Ancora più sorprendente, i modelli di deep learning tendono a adattarsi completamente al set di dati di addestramento, quindi finisci per avere un errore quasi zero sul tuo set di dati di addestramento, e conservano comunque il loro potere predittivo per i dati che non abbiamo.
Due anni fa, il paper Deep Double Descent pubblicato da OpenAI ha gettato una luce molto interessante su questa situazione. Il team ha dimostrato che abbiamo essenzialmente una “valle inquietante” nel campo dell’apprendimento automatico. L’idea è che se prendi un modello e hai solo pochi parametri, hai molta distorsione e la qualità dei tuoi risultati su dati non visti non è così buona. Questo si conforma alla visione classica dell’apprendimento automatico e alla visione statistica classica. Se aumenti il numero di parametri, migliorerai la qualità del tuo modello, ma ad un certo punto inizierai ad overfitting. Questo è esattamente ciò che abbiamo visto nella precedente discussione sull’underfitting e l’overfitting. C’è un equilibrio da trovare.
Tuttavia, ciò che hanno dimostrato è che se continui ad aumentare il numero di parametri, accadrà qualcosa di molto strano: overfitting sempre meno, il che è esattamente l’opposto di ciò che la teoria classica dell’apprendimento statistico prevederebbe. Questo comportamento non è casuale. Gli autori hanno dimostrato che questo comportamento è molto robusto e diffuso. Accade praticamente tutto il tempo in una grande varietà di situazioni. Non è ancora molto ben compreso il motivo, ma ciò che è molto ben compreso in questo momento è che il double descent è molto reale e diffuso.
Questo aiuta anche a capire perché il deep learning è stato relativamente tardivo nel campo dell’apprendimento automatico. Perché il deep learning avesse successo, prima dovevamo riuscire a costruire modelli in grado di elaborare decine di migliaia o addirittura centinaia di migliaia di parametri per superare questa “valle inquietante”. Negli anni ‘80 e ‘90, non sarebbe stato possibile ottenere alcuna svolta nel deep learning, semplicemente perché le risorse di calcolo hardware non erano in grado di superare questa “valle inquietante”.
Fortunatamente, con l’hardware di calcolo attuale, è possibile addestrare modelli senza molto sforzo che hanno milioni o addirittura miliardi di parametri. Come abbiamo sottolineato nelle lezioni precedenti, ci sono ora aziende come Facebook che stanno addestrando modelli con oltre un trilione di parametri. Quindi possiamo arrivare molto lontano.

Fino ad ora, abbiamo supposto che la funzione di perdita fosse nota. Ma perché dovrebbe essere così? Infatti, consideriamo la situazione di un negozio di moda da una prospettiva della supply chain. Un negozio di moda ha livelli di stock per ogni singolo SKU, e vogliamo proiettare la domanda futura. Vogliamo proiettare uno scenario possibile che sia credibile per la domanda futura per questo singolo negozio. Quello che succederà è che man mano che certi SKU rimangono senza stock, dovremmo osservare cannibalizzazione e sostituzione. Quando un dato SKU raggiunge una rottura di stock, normalmente la domanda dovrebbe, in parte, tornare a prodotti simili.
Ma se cerchiamo di affrontare questo tipo di approccio con metriche di previsione classiche come l’Errore Percentuale Medio Assoluto (MAPE), l’Errore Medio Assoluto (MAE), l’Errore Quadratico Medio (MSE) o altre metriche che operano SKU per SKU, giorno per giorno o settimana per settimana, non riusciremo a catturare nessuno di questi comportamenti. Quello che vogliamo veramente è una metrica che riesca a catturare se siamo bravi a catturare tutti quegli effetti di cannibalizzazione e sostituzione. Ma com’è che dovrebbe essere questa funzione di perdita? È molto poco chiaro e sembra richiedere un comportamento piuttosto sofisticato. Una delle principali innovazioni del deep learning è stata essenzialmente quella di capire che la funzione di perdita dovrebbe essere appresa. Ed è esattamente così che è stata prodotta l’immagine sullo schermo. Questa è un’immagine completamente generata dalla macchina; nessuna di quelle persone è reale. Sono state generate, e il problema era: come si costruisce una funzione di perdita o una metrica che ti dica se un’immagine è un ritratto umano fotorealistico o no?
La realtà è che se si inizia a pensare in termini di stile di Errore Percentuale Medio Assoluto (MAPE), si finisce con una metrica che opera pixel per pixel. Il problema è che una metrica che opera pixel per pixel non ti dice nulla su come l’immagine nel suo complesso assomigli a un volto umano. Abbiamo lo stesso problema nel negozio di moda per gli SKU e la proiezione della domanda. È molto facile avere una metrica a livello di SKU, ma questo non ci dice nulla dell’immagine complessiva del negozio nel suo insieme. Eppure, da una prospettiva della supply chain, non siamo interessati all’accuratezza a livello di SKU; siamo interessati all’accuratezza a livello di negozio. Vogliamo sapere se i livelli di stock sono buoni nella loro totalità per il negozio, non se sono buoni per un SKU e poi per un altro SKU. Quindi come ha affrontato questo problema la comunità del deep learning?
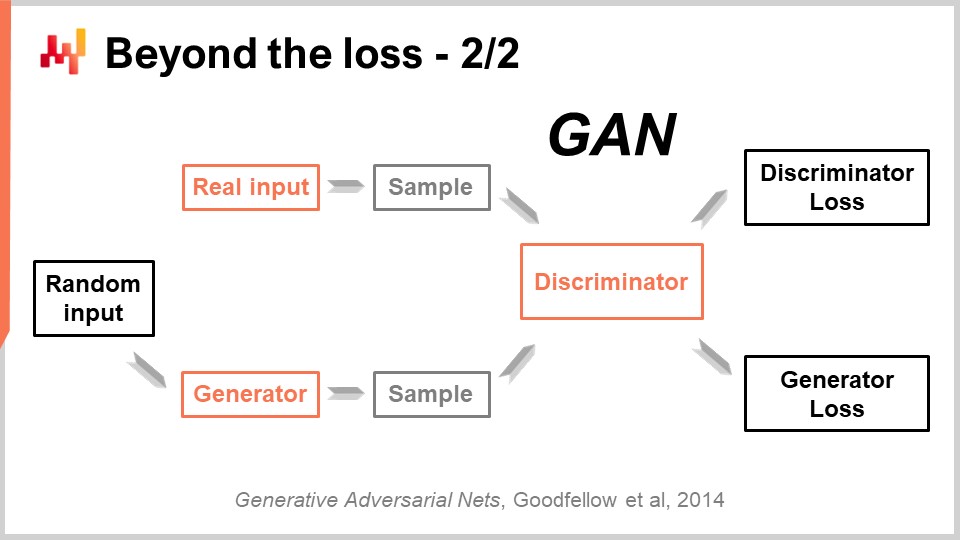
Questo risultato molto impressionante è stato ottenuto con una tecnica bellissimamente semplice chiamata Generative Adversarial Networks (GAN). Nella stampa, potreste aver sentito parlare di queste tecniche come deepfake. I deepfake sono immagini che sono state prodotte con questa tecnica GAN. Come funziona?
Beh, il modo in cui funziona è che si inizia con un generatore. Il generatore prende in input del rumore, che sono solo valori casuali, e produrrà un’immagine nel caso presente. Se torniamo al caso della supply chain, produrrebbe traiettorie per tutti i punti di domanda osservati per ogni singolo SKU per, diciamo, i prossimi tre mesi in questo negozio di moda. Questo generatore è a sua volta una rete di deep learning.
Ora, avremo un discriminatore. Un discriminatore è anche una rete di deep learning, e l’obiettivo del discriminatore è imparare se predire se ciò che è appena stato generato è reale o sintetico. Il discriminatore è un classificatore binario che deve solo dire se è reale o non reale. Se il discriminatore è in grado di predire correttamente che un campione è falso, è sintetico, condurremo i gradienti verso il generatore e faremo imparare il generatore da esso.
Ciò che succede da questa configurazione è che il generatore inizia a imparare come generare campioni che ingannano e confondono il discriminatore. Allo stesso tempo, il discriminatore impara come migliorare nel discriminare tra i campioni reali e quelli sintetici. Se prendiamo questo processo, si spera che converga a uno stato in cui si ottiene sia un generatore di alta qualità che genera campioni incredibilmente realistici, sia un discriminatore molto buono che può dirti se è reale o no. Questo è esattamente ciò che viene fatto con le GAN per generare quelle immagini fotorealistiche. Se torniamo alla supply chain, troverai esperti nel settore della supply chain che dicono che per una situazione particolare, la migliore metrica è MAPE, o MAPE ponderata, o qualunque altra cosa. Ti daranno delle ricette che ti dicono che in determinate situazioni devi usare questa metrica o quella. La realtà è che il deep learning dimostra che una metrica di previsione è un concetto superato. Se vuoi ottenere un’accuratezza ad alta dimensione, non solo un’accuratezza puntiforme, devi imparare la metrica. Anche se al momento sospetto che ci siano pochissime supply chain che stanno sfruttando queste tecniche, ad un certo punto in futuro lo faranno. Diventerà la norma imparare la metrica di previsione utilizzando le reti generative avversariali o i discendenti di queste tecniche perché è un modo per catturare il comportamento sottile e ad alta dimensione che è veramente interessante, invece di avere solo un’accuratezza puntiforme.

Ora, finora, ogni singola osservazione è stata accompagnata da una label, e la label era l’output che vogliamo prevedere. Tuttavia, ci sono situazioni che non possono essere formulate come problemi di input-output. Le label semplicemente non sono disponibili. Se prendiamo ad esempio una supply chain, potrebbe essere un ipermercato. Negli ipermercati, i livelli di stock non sono perfettamente accurati. Le merci possono essere danneggiate, rubate o scadute, e ci sono molte ragioni per cui i record elettronici nel tuo sistema non riflettono veramente ciò che è disponibile sullo scaffale come percepito dai clienti. L’inventario è troppo costoso per essere una fonte di dati in tempo reale sull’inventario accurato. Puoi fare l’inventario, ma non puoi girare per tutto l’ipermercato ogni singolo giorno. Quello che ottieni è una grande quantità di stock leggermente inaccurato. Ne hai un sacco, ma non puoi davvero dire quali sono accurati e quali no.
Questa è essenzialmente il tipo di situazione in cui l’apprendimento non supervisionato ha davvero senso. Vogliamo imparare qualcosa; abbiamo i dati, ma non abbiamo le risposte corrette disponibili. Non abbiamo quelle label. Quello che abbiamo sono solo tonnellate di dati. L’apprendimento non supervisionato è stato considerato per decenni dalla comunità di machine learning come un obiettivo ambizioso. Per molto tempo, era il futuro ma un futuro lontano. Tuttavia, di recente ci sono stati alcuni incredibili progressi in questo settore. Uno dei progressi è stato, ad esempio, realizzato da un team di Facebook con un articolo intitolato “Unsupervised Machine Translation Using Monolingual Corpora Only”.
Ciò che il team di Facebook ha fatto in questo articolo è stato costruire un sistema di traduzione che utilizzava solo un corpus di testo in inglese e un corpus di testo in francese. Questi due corpora non hanno nulla in comune; non è nemmeno lo stesso testo. È solo testo in inglese e testo in francese. Quindi, senza fornire alcuna traduzione effettiva al sistema, hanno imparato un sistema che traduce dall’inglese al francese. Questo è un risultato assolutamente sorprendente. A proposito, il modo in cui viene realizzato è utilizzando una tecnica che ricorda incredibilmente le reti generative avversariali che ho appena presentato in precedenza. Allo stesso modo, un team di Google ha pubblicato BERT (Bidirectional Encoder Representations from Transformers) due anni fa. BERT è un modello che viene addestrato in modo largamente non supervisionato. Stiamo parlando di testo di nuovo. Il modo in cui viene fatto con BERT è prendere enormi database di testo e mascherare casualmente le parole. Quindi, si addestra il modello a prevedere quelle parole e si ripete per l’intero corpus. Alcune persone si riferiscono a questa tecnica come auto-supervisionata, ma ciò che è molto interessante con BERT e dove diventa rilevante per la supply chain è che improvvisamente il modo in cui si affrontano i dati è quello di costruire una macchina in cui è possibile nascondere parti dei dati e la macchina è comunque in grado di completare i dati.
Il motivo per cui questo è di primaria importanza per la supply chain è che fondamentalmente ciò che viene fatto con BERT nel contesto dell’elaborazione del linguaggio naturale può essere esteso a molti altri settori. È la macchina definitiva per rispondere alle domande “cosa succederebbe se”. Ad esempio, cosa succederebbe se avessi un altro negozio? Questo “cosa succederebbe se” può essere risposto perché è sufficiente modificare i dati, aggiungere il negozio e interrogare il modello di machine learning che hai appena costruito. Cosa succederebbe se avessi un prodotto in più? Cosa succederebbe se avessi un cliente in più? Cosa succederebbe se avessi un prezzo diverso per questo prodotto? E così via. L’apprendimento non supervisionato è di interesse primario perché si inizia a trattare i dati nel loro insieme, non solo come una lista di coppie. Si ottiene un meccanismo completamente generale e in grado di fare previsioni su qualsiasi aspetto che si trova in qualche modo presente nei dati. Questo è molto potente.
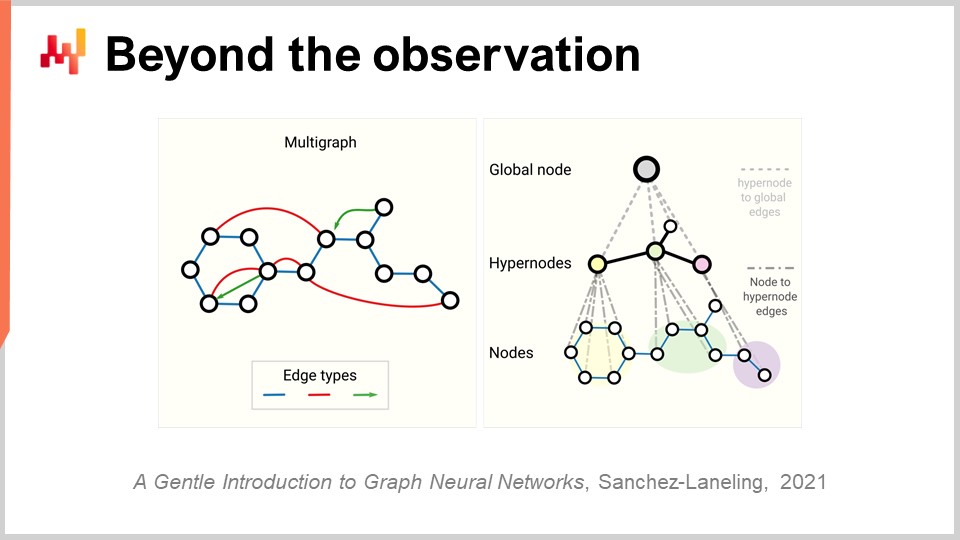
Ora, finalmente, dobbiamo riesaminare l’intero concetto di osservazione. Inizialmente, abbiamo detto che un’osservazione era una coppia di caratteristiche più una label. Abbiamo visto come possiamo rimuovere la label, ma cosa succede alle caratteristiche stesse e all’osservazione? Il problema con la supply chain è che non abbiamo davvero osservazioni. Non è nemmeno chiaro che possiamo scomporre una supply chain in una lista di osservazioni indipendenti o omogenee. Come discusso in una lezione precedente, ciò che dobbiamo osservare in una supply chain non è un’osservazione scientifica diretta della supply chain stessa. Quello che abbiamo sono una serie di pezzi di software aziendale e l’unico modo in cui possiamo osservare una supply chain è indirettamente attraverso i record raccolti in quei pezzi di software aziendale. Questo può essere l’ERP, il WMS, il punto vendita, ecc. Ma la cosa fondamentale è che tutto ciò che abbiamo sono essenzialmente record elettronici che hanno natura transazionale perché tutti quei sistemi sono tipicamente implementati su database transazionali. Pertanto, le osservazioni non sono indipendenti. I record che abbiamo sono relazionali, letteralmente, perché vivono in un database relazionale. Quando dico che hanno relazioni, intendo che se guardi un cliente con una carta fedeltà, ad esempio, sono collegati a tutti i prodotti che hanno acquistato. Ogni singolo prodotto è collegato a tutti i negozi in cui il prodotto fa parte dell’assortimento. Ogni singolo negozio è collegato a tutti i magazzini che hanno la capacità di servire il negozio di interesse. Quindi, non abbiamo osservazioni indipendenti; abbiamo dati con tonnellate di struttura relazionale sovrapposta e nessuno di questi elementi è veramente indipendente dagli altri.
La svolta rilevante nell’apprendimento approfondito per affrontare questo tipo di dati interconnessi è nota come apprendimento dei grafi. L’apprendimento dei grafi è esattamente ciò di cui hai bisogno per affrontare comportamenti come la sostituzione e la cannibalizzazione nella moda. Il modo migliore per vedere la cannibalizzazione è pensare che tutti i prodotti stiano competendo per gli stessi clienti e, analizzando i dati che collegano clienti e prodotti, è possibile analizzare la cannibalizzazione. Attenzione, l’apprendimento dei grafi non ha nulla a che fare con i database dei grafi, che sono qualcosa di completamente diverso. I database dei grafi sono essenzialmente solo database utilizzati per interrogare i grafi, senza alcun apprendimento coinvolto. L’apprendimento dei grafi riguarda l’apprendimento di alcune proprietà aggiuntive sui grafi stessi. Si tratta di apprendere relazioni che possono o non possono essere osservate o che non possono essere osservate completamente, o di decorare il tipo di relazione che abbiamo con un sovrapposizione di conoscenza operativa.
La mia opinione è che, a causa del fatto che per sua stessa natura la supply chain è un sistema in cui tutte le parti sono interconnesse - questa è la maledizione della supply chain, in cui non è possibile ottimizzare localmente nulla senza spostare i problemi - l’apprendimento dei grafi diventerà sempre più diffuso come approccio per affrontare questi problemi nella supply chain e nell’apprendimento automatico. Fondamentalmente, le reti neurali a grafo sono tecniche di apprendimento approfondito progettate per gestire i grafi.
In conclusione, pensare che l’apprendimento automatico consista nel fornire previsioni più accurate è, a dir poco, piuttosto ingenuo. È come dire che il punto principale di un’automobile è avere accesso a un cavallo più veloce. Sì, è vero che molto probabilmente attraverso l’apprendimento automatico possiamo ottenere previsioni più accurate. Tuttavia, questo è solo una piccola parte di un quadro molto più ampio, e un quadro che continua a crescere man mano che vengono fatti progressi nella comunità dell’apprendimento automatico. Abbiamo iniziato con i framework di apprendimento automatico che includevano una serie di concetti: feature, label, observation, model e loss. Questo piccolo framework elementare era già molto più generale rispetto alla prospettiva delle previsioni delle serie temporali. Con lo sviluppo recente dell’apprendimento automatico, vediamo che anche quei concetti stanno gradualmente scomparendo in quanto stiamo scoprendo modi per superarli. Per la supply chain, questo cambiamento di paradigma è di fondamentale importanza perché significa che dobbiamo applicare lo stesso tipo di cambiamento di paradigma quando si tratta di previsioni. L’apprendimento automatico ci costringe a ripensare completamente come affrontare i dati e cosa possiamo fare con i dati. L’apprendimento automatico apre porte che fino a poco tempo fa erano saldamente chiuse.

Ora diamo un’occhiata a alcune domande.
Domanda: Gli alberi decisionali casuali utilizzano il bagging?
Il mio punto è che sì, sono un’estensione di quello, e c’è di più in loro rispetto al solo bagging. Il bagging è una tecnica interessante, ma ogni volta che si vede una tecnica di apprendimento automatico, bisogna chiedersi: questa tecnica mi farà progredire verso la mia capacità di affrontare problemi davvero difficili come la cannibalizzazione o la sostituzione? E, questa sorta di tecnica si adatterà bene all’hardware di calcolo che si ha? Questo è uno dei punti chiave che dovreste trarre da questa lezione.
Domanda: Con la spinta delle aziende ad automatizzare tutto con la robotica, qual è il futuro dei lavoratori dei magazzini logistici? Saranno sostituiti da robot nel prossimo futuro?
Questa domanda non è esattamente correlata all’apprendimento automatico, ma è una domanda molto interessante. Le fabbriche hanno subito una trasformazione massiccia verso un’ampia robotizzazione, che può o meno utilizzare robot. La produttività delle fabbriche è aumentata e anche ora in Cina, le fabbriche sono in gran parte automatizzate. I magazzini sono arrivati tardi alla festa. Tuttavia, ciò che vedo oggi è lo sviluppo di magazzini sempre più meccanici e automatizzati. Non direi che si tratta necessariamente di robot; ci sono molte tecnologie concorrenti per costruire un magazzino che raggiunge un grado più elevato di automazione. La conclusione è che la tendenza è chiara. I magazzini e i centri logistici, in generale, subiranno lo stesso tipo di miglioramento massiccio della produttività che abbiamo già osservato nella produzione.
Per rispondere alla tua domanda, non sto dicendo che le persone saranno sostituite da robot; saranno sostituite dall’automazione. L’automazione assumerà a volte la forma di qualcosa come un robot, ma può anche assumere molte altre forme. Alcune di queste forme sono semplicemente configurazioni intelligenti che migliorano notevolmente la produttività senza coinvolgere il tipo di tecnologia che intuitivamente associamo ai robot. Tuttavia, credo che la parte logistica della catena di approvvigionamento nel complesso si ridurrà. L’unica cosa che mantiene questa crescita al momento è il fatto che con la crescita del commercio elettronico, dobbiamo occuparci dell’ultimo miglio. L’ultimo miglio occupa sempre più la maggior parte della forza lavoro che deve occuparsi della logistica. Anche l’ultimo miglio sarà automatizzato nel futuro non troppo lontano. I veicoli autonomi sono dietro l’angolo; erano promessi per questo decennio e, anche se potrebbero arrivare un po’ in ritardo, stanno arrivando.
Domanda: Pensi che valga la pena investire tempo nell’apprendimento dell’apprendimento automatico per lavorare nella catena di approvvigionamento?
Assolutamente. Secondo me, l’apprendimento automatico è una scienza ausiliaria della catena di approvvigionamento. Considera la relazione che un medico ha con la chimica. Se sei un medico moderno, nessuno si aspetta che tu sia un chimico. Tuttavia, se dici al tuo paziente che non sai assolutamente nulla di chimica, la gente penserà che tu non abbia quello che serve per essere un medico moderno. L’apprendimento automatico dovrebbe essere affrontato allo stesso modo in cui le persone che studiano medicina affrontano la chimica. Non è un fine, ma un mezzo. Se vuoi fare un lavoro serio nella catena di approvvigionamento, devi avere solide basi nell’apprendimento automatico.
Domanda: Potresti dare degli esempi in cui hai applicato l’apprendimento automatico? Lo strumento è diventato operativo?
Parlando di me stesso come Joannes Vermorel, imprenditore e CEO di Lokad, abbiamo oltre 100 aziende in produzione al momento, tutte che utilizzano l’apprendimento automatico per compiti diversi. Questi compiti includono la previsione dei tempi di consegna, la produzione di previsioni probabilistiche della domanda, la previsione dei resi, la previsione dei problemi di qualità, la revisione delle stime del tempo medio tra le riparazioni non programmate e il rilevamento se i prezzi competitivi sono corretti o meno. Ci sono molte applicazioni, come la rivalutazione delle matrici di compatibilità tra auto e parti nel mercato dei ricambi automobilistici. Con l’apprendimento automatico, è possibile correggere automaticamente una grande parte degli errori del database. Da Lokad, non solo abbiamo queste 100 aziende in produzione, ma è così da quasi un decennio ormai. Il futuro è già qui, semplicemente non è distribuito in modo uniforme.
Domanda: Qual è il modo migliore per imparare l’apprendimento automatico nel tuo tempo libero? Consiglieresti siti come Udemy, Coursera o altro?
La mia suggerimento sarebbe una combinazione di Wikipedia e la lettura di articoli scientifici. Come hai visto in questa lezione, è importante comprendere i fondamenti e rimanere aggiornati sugli ultimi sviluppi nel campo. Come hai visto in queste lezioni, sto citando articoli di ricerca effettivi. Non fidarti delle informazioni di seconda mano; vai direttamente a ciò che è stato pubblicato. Tutte queste cose sono direttamente disponibili online. Ci sono articoli sull’apprendimento automatico che sono scritti male e indecifrabili, ma ci sono anche articoli che sono brillantemente scritti e forniscono chiare intuizioni su ciò che sta accadendo. Il mio suggerimento è di consultare Wikipedia per una panoramica generale di un campo, in modo da poter avere una visione d’insieme, e poi iniziare a leggere gli articoli. All’inizio, potrebbe sembrare opaco, ma dopo un po’ ti ci abituerai. Puoi optare per Udemy o Coursera, ma personalmente non l’ho mai fatto. Il mio obiettivo quando faccio queste lezioni è darti qualche intuizione in modo che tu possa avere una visione d’insieme. Se vuoi approfondire i dettagli, immergiti nell’articolo effettivo che è stato pubblicato anni o decenni fa. Vai per informazioni di prima mano e fida della tua intelligenza.
L’apprendimento profondo è un campo di ricerca molto empirico. La maggior parte delle cose che vengono fatte non è estremamente complessa, dal punto di vista matematico. Di solito non va oltre ciò che si impara alla fine delle scuole superiori, quindi è abbastanza accessibile.
Domanda: Con la diffusione di strumenti senza codice come CodeX e Co-Pilot di OpenAI, pensi che i professionisti della supply chain scriveranno modelli in lingua semplice in futuro?
La risposta breve è: no, per niente. L’idea di poter bypassare la scrittura del codice è stata in giro per molto tempo. Ad esempio, Visual Basic di Microsoft era pensato per essere uno strumento visivo in modo che le persone non dovessero più programmare; potevano semplicemente comporre visivamente cose come i Lego. Ma oggi, questo approccio si è rivelato inefficace e la prossima tendenza è esprimere le cose verbalmente.
Tuttavia, il motivo per cui uso formule matematiche in queste lezioni è che ci sono molte situazioni in cui utilizzare una formula matematica è l’unico modo per trasmettere chiaramente ciò che si sta cercando di dire. Il problema della lingua inglese, o di qualsiasi lingua naturale, è che spesso è imprecisa e soggetta a fraintendimenti. Al contrario, le formule matematiche sono precise e chiare. Il problema del linguaggio semplice è che è incredibilmente sfumato e, sebbene abbia le sue applicazioni, il motivo per cui utilizziamo le formule è fornire un significato inequivocabile a ciò che viene detto. Cerco di fare un uso limitato delle formule, ma quando ne includo una, è perché sento che è l’unico modo per trasmettere chiaramente l’idea, con un livello di chiarezza superiore a quello che posso esprimere verbalmente.
Per quanto riguarda le piattaforme a basso codice, sono molto scettico, poiché questo approccio è stato tentato molte volte in passato senza molto successo. La mia opinione personale è che dovremmo rendere la scrittura del codice più adatta alla gestione della supply chain identificando perché la scrittura del codice è difficile e rimuovendo la complessità accidentale. Quello che rimane è la scrittura del codice fatta correttamente per la supply chain, che è ciò a cui Lokad mira.
Domanda: L’apprendimento automatico rende le previsioni della domanda più accurate per dati storici di vendite stagionali o regolari?
Come ho menzionato in questa presentazione, l’apprendimento automatico rende il concetto di accuratezza obsoleto. Se guardi all’ultima competizione di previsione delle serie temporali su larga scala, la competizione M5, i primi 10 modelli erano tutti modelli di apprendimento automatico in qualche misura. Quindi, l’apprendimento automatico rende le previsioni più accurate? Fattualmente, basandosi sulla competizione di previsione, sì. Ma è solo marginalmente più accurato rispetto ad altre tecniche e non è un’accuratezza straordinaria.
Inoltre, non dovresti pensare alla previsione in una prospettiva unidimensionale. Quando parli di accuratezza per la stagionalità, stai considerando un prodotto alla volta, ma questo non è l’approccio corretto. La vera accuratezza consiste nel valutare come il lancio di un nuovo prodotto influisce su tutti gli altri prodotti, poiché ci sarà un certo grado di cannibalizzazione. La chiave è valutare se il modo in cui rifletti questa cannibalizzazione nel tuo modello è accurato o meno. Improvvisamente, questo diventa un problema multidimensionale. Come ho presentato nella lezione con le reti generative, la metrica di ciò che effettivamente significa l’accuratezza deve essere appresa; non può essere data. Le formule matematiche, come l’errore assoluto medio, l’errore percentuale assoluto medio e l’errore quadratico medio, sono solo criteri matematici. Non sono il tipo di metriche di cui abbiamo effettivamente bisogno; sono solo metriche molto naive.
Domanda: Il lavoro noioso dei previsionisti verrà sostituito dalla previsione in modalità automatica?
Direi che il futuro è già qui, ma non è distribuito in modo uniforme. Da Lokad, già facciamo previsioni per decine di milioni di SKU al giorno e non ho nessuno che regoli le previsioni. Quindi sì, già viene fatto, ma è solo una piccola parte del quadro. Se hai bisogno che le persone regolino le previsioni o regolino i modelli di previsione, indica un approccio disfunzionale. Dovresti considerare la necessità di regolare le previsioni come un difetto e affrontarlo automatizzando quella parte del processo.
Ancora una volta, dall’esperienza di Lokad, queste cose saranno completamente eliminate perché lo abbiamo già fatto. Non siamo gli unici a farlo in questo modo, quindi per noi è quasi storia antica, essendo il caso da quasi un decennio.
Domanda: In che misura l’apprendimento automatico viene attivamente utilizzato per prendere decisioni sulla supply chain?
Dipende dall’azienda. Da Lokad, viene utilizzato ovunque e ovviamente, quando dico “da Lokad”, intendo quando si tratta di aziende servite da Lokad. Tuttavia, la stragrande maggioranza del mercato utilizza ancora essenzialmente Excel, senza alcun apprendimento automatico. Lokad gestisce attivamente miliardi di euro o dollari di inventario, quindi è già una realtà ed è così da molto tempo. Ma Lokad non rappresenta nemmeno lo 0,1% del mercato, quindi siamo ancora un’eccezione. Stiamo crescendo rapidamente, così come molti concorrenti. Sospetto che sia ancora una configurazione di nicchia nell’intero mercato della supply chain, ma ha una crescita a due cifre. Non sottovalutare mai il potere della crescita esponenziale nel corso di un lungo periodo di tempo. Alla fine, diventerà molto grande, sperabilmente con Lokad, ma questa è un’altra storia.
Domanda: Con molte incognite nella supply chain, qual è una strategia che può assumerla come input per un modello?
L’idea è che sì, ci sono tonnellate di incognite, ma gli input del tuo modello non sono davvero una scelta. Si riduce a ciò che hai nei tuoi sistemi aziendali, come ad esempio quali dati esistono nel tuo ERP. Se il tuo ERP ha livelli di stock storici, allora puoi usarli come parte del tuo modello di apprendimento automatico. Se il tuo ERP mantiene solo i livelli di stock attuali, allora questi dati non sono disponibili. Puoi iniziare a fare uno snapshot dei tuoi livelli di stock se vuoi usarli come input aggiuntivi, ma il messaggio principale è che c’è molto poco margine di scelta su ciò che puoi usare come input; è letteralmente ciò che esiste nei tuoi sistemi.
Il mio approccio tipico è che se devi creare nuove fonti di dati, sarà lento e doloroso, e probabilmente non sarà il tuo punto di partenza per l’utilizzo del machine learning nelle supply chain. Le grandi aziende sono state digitalizzate da decenni, quindi ciò che hai nei tuoi sistemi transazionali, come il tuo ERP e il tuo WMS, è già un ottimo punto di partenza. Se in seguito ti rendi conto che vuoi avere di più, come ad esempio informazioni competitive, livelli di stock autorizzati o ETA fornite dai tuoi fornitori, queste saranno aggiunte preziose da utilizzare come input per i tuoi modelli. Di solito, ciò che usi come input è qualcosa che hai una buona intuizione che correla con ciò che stai cercando di prevedere in primo luogo, e l’intuizione di alto livello è di solito sufficiente. Il buon senso, che è difficile da definire, è ampiamente sufficiente. Questo non è il collo di bottiglia in termini di ingegneria.
Domanda: Qual è l’impatto delle decisioni di pricing sulla stima della domanda futura, anche da una prospettiva probabilistica, e come affrontarlo da un punto di vista di machine learning?
Questa è una domanda molto interessante. C’è stato un episodio su LokadTV che ha affrontato questo stesso problema. L’idea è che ciò che impari diventa ciò che è tipicamente noto come una policy, un oggetto che controlla il modo in cui reagisci a vari eventi. Il modo in cui fai previsioni è quello di produrre una sorta di paesaggio, in stile Monte Carlo. Produrrai una traiettoria, ma la tua previsione non sarà costituita da punti dati statici. Sarà un processo molto più generativo, in cui ad ogni fase del processo di previsione dovrai generare il tipo di domanda che puoi osservare, generare le decisioni che prendi e rigenerare il tipo di risposta di mercato a ciò che hai appena fatto.
Diventa molto complicato valutare l’accuratezza del tuo processo generativo di risposta alla domanda, ed è per questo che devi effettivamente imparare le tue metriche di previsione. Questo è molto complicato, ma è per questo che non puoi pensare alle tue metriche di previsione, alle tue metriche di accuratezza, come a un problema unidimensionale. Per riassumere, la previsione della domanda diventa un generatore, quindi è fondamentalmente dinamica, non statica. È qualcosa di generativo. Questo generatore reagisce a un agente, un agente che verrà implementato come una policy. Sia il generatore che il sistema di creazione delle politiche devono essere appresi. Devi anche imparare la funzione di perdita. C’è molto da imparare, ma fortunatamente, il deep learning è un approccio molto modulare e programmabile che si presta bene alla composizione di tutte queste tecniche.
Domanda: È difficile raccogliere dati, soprattutto dalle PMI?
Sì, è molto difficile. Il motivo è che, se stai lavorando con un’azienda che ha un fatturato inferiore a 10 milioni, non esiste un reparto IT. Potrebbe esserci un piccolo ERP in uso, ma anche se gli strumenti sono buoni, decenti e moderni, non hai un team IT in azienda. Quando chiedi i dati, non c’è nessuno nell’azienda cliente che abbia la competenza per eseguire una query SQL per estrarre i dati.
Non sono sicuro di aver capito correttamente la tua domanda, ma il problema non è esattamente raccogliere i dati. La raccolta dei dati avviene naturalmente attraverso il software di contabilità o l’ERP in uso, e oggigiorno ci sono ERP accessibili anche per aziende abbastanza piccole. Il problema è l’estrazione dei dati da quei software aziendali. Se stai lavorando con un’azienda che ha un fatturato inferiore a 20 milioni di dollari e non è un’azienda di e-commerce, è probabile che il reparto IT non esista. Anche quando c’è un piccolo reparto IT, di solito c’è solo una persona responsabile di configurare le macchine e i desktop Windows per tutti. Non è qualcuno che conosce i database e compiti amministrativi più avanzati in termini di configurazioni IT.
Va bene, penso che sia tutto. La prossima sessione sarà tra un paio di settimane. Sarà mercoledì 13 ottobre. Ci vediamo la prossima volta!
Riferimenti
- A theory of the learnable, L. G. Valiant, novembre 1984
- Support-vector networks, Corinna Cortes, Vladimir Vapnik, settembre 1995
- Random Forests, Leo Breiman, ottobre 2001
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree, Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu, 2017
- Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, ultima revisione dicembre 2017
- Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, dicembre 2019
- Analyzing and Improving the Image Quality of StyleGAN, Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila, ultima revisione marzo 2020
- Generative Adversarial Networks, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, giugno 2014
- Unsupervised Machine Translation Using Monolingual Corpora Only, Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, ultima revisione aprile 2018
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, ultima revisione maggio 2019
- A Gentle Introduction to Graph Neural Networks, Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko, settembre 2021


