00:00 Introduzione
02:53 Decisioni vs Artefatti
10:07 Ottimizzazione sperimentale
13:51 La storia finora
17:01 Le decisioni di oggi
19:36 Il manifesto della supply chain quantitativa
21:01 Il problema dell’assegnazione delle scorte al dettaglio
24:49 Le forze economiche sulle SKU del negozio
29:35 Reificazione dei futuri
32:41 Reificazione delle opzioni - 1/3
38:25 Reificazione delle opzioni - 2/3
43:02 Reificazione delle opzioni - 3/3
44:44 Funzione di ricompensa delle scorte - 1/2
51:41 Funzione di ricompensa delle scorte - 2/2
56:19 Assegnazioni delle scorte prioritarie - 1/4
59:59 Assegnazioni delle scorte prioritarie - 2/4
01:03:39 Assegnazioni delle scorte prioritarie - 3/4
01:06:34 Assegnazioni delle scorte prioritarie - 4/4
01:12:58 Smussamento del flusso del magazzino - 1/2
01:16:48 Smussamento del flusso del magazzino - 2/2
01:22:12 Funzione di ricompensa dell’azione
01:25:02 Il mondo reale è caotico
01:27:38 Conclusioni
01:30:00 Prossima lezione e domande del pubblico
Descrizione
Le decisioni sulla supply chain richiedono valutazioni economiche corrette dal punto di vista del rischio. La conversione delle previsioni probabilistiche in valutazioni economiche non è banale e richiede strumenti dedicati. Tuttavia, la prioritizzazione economica risultante, illustrata dalle assegnazioni delle scorte, si dimostra più potente delle tecniche tradizionali. Iniziamo con la sfida dell’assegnazione delle scorte al dettaglio. In una rete a 2 livelli che include sia un centro di distribuzione (DC) che più negozi, dobbiamo decidere come assegnare le scorte del DC ai negozi, sapendo che tutti i negozi competono per le stesse scorte.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Assegnazione delle Scorte al Dettaglio con Previsioni Probabilistiche”. L’assegnazione delle scorte al dettaglio è una sfida semplice ma fondamentale: quando e quanto stock decidete di spostare in qualsiasi momento tra i centri di distribuzione e i negozi che gestite? La decisione di spostare le scorte dipende dalla domanda futura, quindi è necessaria una previsione di domanda di qualche tipo.
Tuttavia, la domanda al dettaglio a livello di negozio è incerta e l’incertezza della domanda futura è irriducibile. Abbiamo bisogno di una previsione che rifletta correttamente questa irriducibile incertezza del futuro, quindi è necessaria una previsione probabilistica. Tuttavia, sfruttare al meglio le previsioni probabilistiche al fine di ottimizzare le decisioni della supply chain è un compito non banale. Sarebbe tentante riciclare una tecnica di inventario esistente che è stata originariamente progettata con una previsione deterministica classica in mente. Tuttavia, farlo significherebbe sconfessare la stessa ragione per cui abbiamo introdotto le previsioni probabilistiche in primo luogo.
Lo scopo di questa lezione è imparare come sfruttare al meglio le previsioni probabilistiche nella loro forma nativa per ottimizzare le decisioni della supply chain. Come primo esempio, considereremo il problema dell’assegnazione delle scorte al dettaglio e attraverso l’esame di questo problema vedremo come possiamo effettivamente ottimizzare il livello di stock a livello di negozio. Inoltre, attraverso l’esame delle previsioni probabilistiche, possiamo affrontare anche nuove classi di problemi della supply chain, come ad esempio l’ottimizzazione e la riduzione dei costi operativi della rete attraverso la regolarizzazione del flusso di inventario dai centri di distribuzione ai negozi.
Questa lezione apre il sesto capitolo di questa serie, che è dedicato alle tecniche e ai processi decisionali in un contesto di supply chain. Vedremo che le decisioni devono essere ottimizzate tenendo conto di tutta la rete della supply chain, come un sistema integrato, invece di eseguire una serie di ottimizzazioni locali isolate. Ad esempio, assumendo una prospettiva ristretta dell’SKU (stock-keeping unit).
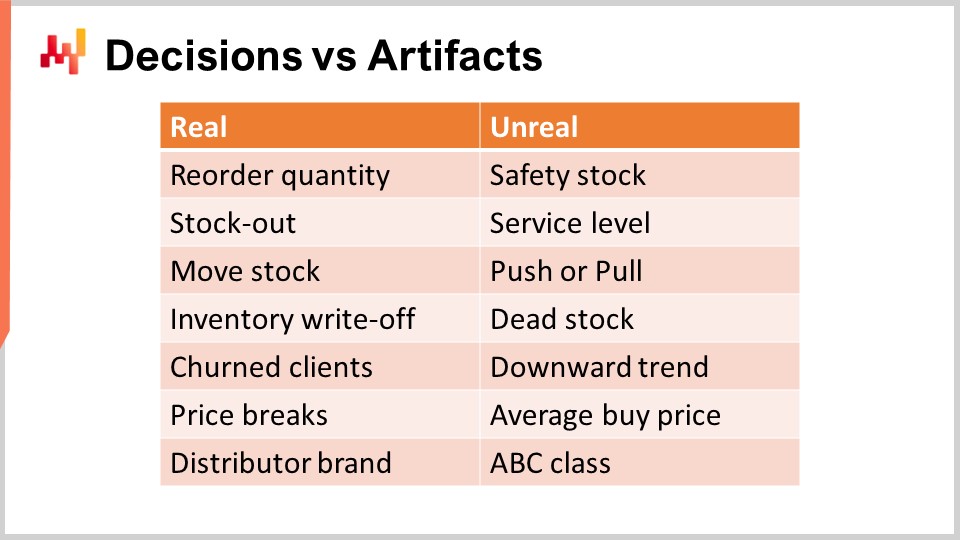
Il primo passo per affrontare le decisioni della supply chain è identificare le effettive decisioni della supply chain. Una decisione della supply chain ha un impatto diretto, fisico e tangibile sulla supply chain. Ad esempio, spostare una unità di stock dal centro di distribuzione a un negozio è reale; non appena lo fai, c’è un’unità in più sugli scaffali del negozio e c’è un’unità che ora manca dal centro di distribuzione e che non può essere riallocata altrove.
Al contrario, un artefatto non ha un impatto fisico tangibile diretto sulla supply chain. Un artefatto è tipicamente o una fase di calcolo intermedia che alla fine porta a una decisione della supply chain, o è una stima statistica di qualche tipo che caratterizza una proprietà di una parte del sistema della tua supply chain. Purtroppo, non posso fare a meno di osservare una grande confusione nella letteratura sulla supply chain quando si tratta di distinguere le decisioni dagli artefatti.
Attenzione, i rendimenti sugli investimenti si ottengono esclusivamente migliorando le decisioni. Migliorare gli artefatti è quasi sempre insignificante, e questo è al meglio. Al peggio, se un’azienda dedica troppo tempo a migliorare gli artefatti, questo diventa una distrazione che impedisce all’azienda di migliorare le sue effettive decisioni della supply chain. Sullo schermo è riportato un elenco di confusioni che osservo frequentemente nei circoli mainstream della supply chain.
Ad esempio, iniziamo con scorte di sicurezza. Questa scorta non è reale; non hai due scorte, la scorta di sicurezza e la scorta di lavoro. C’è solo una scorta, e l’unica decisione che può essere presa è se ne serve di più o meno. Riapprovvigionamento di una quantità è reale, ma la scorta di sicurezza no. Allo stesso modo, il livello di servizio non è reale. Il livello di servizio dipende molto dal modello. Infatti, nella domanda al dettaglio, i dati di vendita sono scarsi. Pertanto, se prendi un determinato SKU, di solito hai troppi pochi dati per calcolare un livello di servizio significativo semplicemente ispezionando l’SKU. Il modo in cui affronti il livello di servizio è attraverso tecniche di modellazione e stime statistiche, che vanno bene, ma ancora una volta, questo è un artefatto, non la realtà. Questa è letteralmente una prospettiva matematica che hai sulla tua supply chain.
Allo stesso modo, push o pull è anche una questione di prospettiva. Una ricetta numerica corretta che opera, tenendo conto di tutta la rete della supply chain, prenderà in considerazione solo l’opportunità di spostare una unità di stock da un’origine verso una destinazione. Quello che è reale è il movimento delle scorte; quello che è solo una questione di prospettiva è se si desidera attivare questo movimento delle scorte in base a condizioni legate all’origine o alla destinazione. Questo definirà push o pull, ma è, al massimo, una piccola questione tecnica della ricetta numerica e non rappresenta la realtà centrale della tua supply chain.
Le scorte morte sono essenzialmente una stima delle scorte a rischio di subire una cancellazione dell’inventario nel prossimo futuro. Dal punto di vista del cliente, non esiste una cosa del genere come scorte morte e scorte vive. Entrambi sono prodotti che potrebbero non essere altrettanto attraenti, ma le scorte morte sono semplicemente una valutazione del rischio fatto sulle tue scorte. Va bene, ma questo non dovrebbe essere confuso con le cancellazioni dell’inventario, che sono definitive e indicano che il valore è stato perso.
Allo stesso modo, il trend al ribasso è anche un elemento matematico che può esistere nel modo in cui modelli la domanda che osservi. Tipicamente sarà un fattore dipendente dal tempo introdotto nel modello di domanda, come una dipendenza lineare dal tempo o forse una dipendenza esponenziale dal tempo. Tuttavia, questa non è la realtà. La realtà potrebbe essere che la tua attività sta diminuendo a causa della perdita di clienti, quindi il churn è, tra le altre possibilità, la realtà della supply chain. Il trend al ribasso è semplicemente un artefatto che puoi usare per aggregare il pattern.
Allo stesso modo, nessun fornitore ti venderà nulla al prezzo medio di acquisto. L’unica realtà è che componi un ordine di acquisto, scegli le quantità e in base alle quantità che hai scelto, sarai in grado di sfruttare gli sconti di prezzo che i tuoi fornitori possono offrire. Otterrai prezzi di acquisto basati su quegli sconti di prezzo e su quanto negozierai in più. Il prezzo medio di acquisto non è reale, quindi fai attenzione a non commettere errori prendendo questi artefatti numerici come se avessero un elemento di verità fondamentale.
Infine, la classificazione ABC, che va dai prodotti più venduti ai prodotti più lenti, è solo una classificazione banale basata sul volume degli SKU o dei prodotti che hai. Queste classi non sono attributi reali. Tipicamente, la metà dei prodotti cambierà da una classe ABC all’altra da un trimestre all’altro, eppure non è successo nulla agli occhi dei clienti o del mercato per quei prodotti. È solo un artefatto numerico che è stato applicato al prodotto e non dovrebbe essere confuso con attributi profondamente rilevanti, come ad esempio se un prodotto fa parte di un marchio di distributore. Questo è un vero attributo fondamentale del prodotto che ha conseguenze di vasta portata per la tua supply chain. In questo capitolo, diventerà sempre più chiaro perché è imperativo concentrarsi sulle decisioni della supply chain, anziché sprecare tempo e concentrazione occupandosi di artefatti numerici.
Quando si pronuncia la parola “ottimizzazione”, la prospettiva abituale che viene in mente per un pubblico ben istruito è la prospettiva dell’ottimizzazione matematica. Dato un insieme di variabili e una funzione di perdita, l’obiettivo è identificare i valori delle variabili che minimizzano la funzione di perdita. Purtroppo, questo approccio funziona male nella supply chain perché assume che le variabili rilevanti siano note, il che di solito non è il caso. Anche quando lo è, ci sono molte variabili, come i dati meteorologici, che si sa che hanno un impatto sulla tua supply chain ma che comportano molti costi se si desidera acquisire questi dati. Pertanto, non è chiaro se vale la pena sforzarsi di acquisire questi dati per ottimizzare la tua supply chain.
Ancora più problematico, la funzione di perdita stessa è in gran parte sconosciuta. La funzione di perdita può essere stimata in qualche modo, ma solo il confronto della perdita con il feedback del mondo reale che si può ottenere dalla tua supply chain ti fornirà informazioni valide sull’adeguatezza di questa funzione di perdita. Non è una questione di correttezza da un punto di vista matematico; è una questione di adeguatezza. Questa funzione di perdita, che è una costruzione matematica, riflette adeguatamente ciò che stai cercando di ottimizzare per la tua supply chain? Abbiamo affrontato questo dilemma di eseguire l’ottimizzazione mentre non conosciamo le variabili e la funzione di perdita nella Lezione 2.2, intitolata “Ottimizzazione sperimentale”. La prospettiva dell’ottimizzazione sperimentale afferma che il problema non è dato; il problema deve essere scoperto attraverso esperimenti ripetuti e iterati. La prova della correttezza della funzione di perdita e delle sue variabili emerge non come una proprietà matematica ma attraverso una serie di osservazioni guidate da esperimenti ben scelti ottenuti dalla stessa supply chain. L’ottimizzazione sperimentale sfida profondamente il modo in cui guardiamo all’ottimizzazione, ed è una prospettiva che adotterò in questo capitolo. Gli strumenti e le tecniche che introdurrò qui sono orientati alla prospettiva dell’ottimizzazione sperimentale.
In qualsiasi momento, la ricetta numerica che abbiamo può essere dichiarata obsoleta e può essere sostituita da una ricetta numerica alternativa che è ritenuta più strettamente allineata alla supply chain che abbiamo. Pertanto, in qualsiasi momento, dovremmo essere in grado di mettere in produzione la ricetta numerica che abbiamo e eseguire il processo di ottimizzazione su larga scala. Ad esempio, non possiamo dire di identificare la funzione di perdita e poi mettere una squadra di scienziati dei dati al lavoro per tre mesi per sviluppare alcune tecniche di ottimizzazione del software. Invece, ogni volta che abbiamo una nuova ricetta, dovremmo essere in grado di metterla direttamente in produzione e far subito beneficiare le decisioni della supply chain da questa nuova forma identificata del problema.
Questa lezione fa parte di una serie di lezioni sulla supply chain. Sto cercando di mantenere queste lezioni in qualche modo indipendenti, ma siamo oltre un punto in cui ha più senso guardare queste lezioni in sequenza. Se non hai guardato le lezioni precedenti, dovrebbe andare bene, ma questa serie avrà probabilmente più senso se la guardi nell’ordine in cui è stata presentata.
Nel primo capitolo, ho presentato le mie opinioni sulla supply chain sia come campo di studio che come pratica. Nel secondo capitolo, ho presentato una serie di metodologie essenziali per affrontare le sfide della supply chain, compresa l’ottimizzazione sperimentale. Queste metodologie sono necessarie a causa della natura avversaria della maggior parte dei problemi della supply chain. Nel terzo capitolo, mi sono concentrato sui problemi stessi, invece che sulle soluzioni. Nel quarto capitolo, ho presentato una serie di campi che non sono esattamente supply chain di per sé - le scienze ausiliarie della supply chain - che sono essenziali per una pratica moderna della supply chain. Nel quinto capitolo, ho presentato una serie di tecniche di modellazione predittiva, in particolare previsioni probabilistiche, che sono essenziali per affrontare l’incertezza irriducibile del futuro.
Oggi, in questa prima lezione del sesto capitolo, approfondiremo le tecniche di decisione. La letteratura scientifica ha fornito un’abbondanza di tecniche e algoritmi di decisione negli ultimi sette decenni, dalla programmazione dinamica negli anni ‘50 all’apprendimento per rinforzo e persino all’apprendimento per rinforzo profondo. La sfida, tuttavia, è ottenere risultati di supply chain di produzione. Infatti, la maggior parte di queste tecniche soffre di difetti nascosti che le rendono impraticabili per scopi di supply chain per una ragione o l’altra. Oggi, ci concentriamo sull’allocazione dei prodotti nei punti vendita come archetipo di una decisione di supply chain. Questa lezione apre la strada a decisioni e situazioni più complesse.
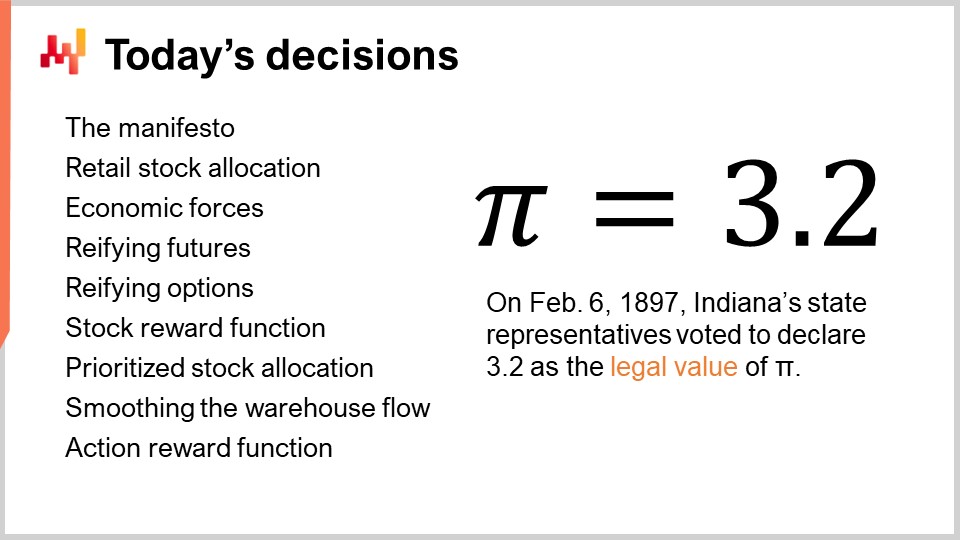
Sullo schermo è riassunto della lezione di oggi. Anche considerando il problema di supply chain più semplice, l’allocazione dei prodotti nei punti vendita, abbiamo molto da coprire. Questi elementi rappresentano i mattoni per situazioni più complesse. Inizierò riprendendo il manifesto della supply chain quantitativa. Poi, chiarirò cosa intendo con il problema di allocazione dei prodotti nei punti vendita. Rivedremo anche le forze economiche presenti in questo problema. Riprenderò la nozione di previsioni probabilistiche e come le rappresentiamo effettivamente, o almeno una delle opzioni per rappresentarle. Vedremo come modellare la decisione affinando la previsione e affinando le opzioni, che sono le potenziali decisioni candidate.
Introdurremo quindi la funzione di ricompensa per gli stock. Questa funzione può essere vista come un quadro minimo per convertire una previsione probabilistica in un punteggio economico che può essere associato a ogni opzione di allocazione degli stock, tenendo conto di una serie di fattori economici. Una volta valutate le opzioni, possiamo procedere con una lista di priorità. Una lista di priorità è ingannevolmente semplice ma si rivela incredibilmente potente e pratica nelle supply chain del mondo reale, sia in termini di stabilità numerica che di caratteristiche di white-boxing.
Con la lista di priorità, possiamo quasi senza sforzo regolare il flusso di inventario dal centro di distribuzione ai negozi, riducendo i costi operativi del centro di distribuzione. Infine, faremo una breve panoramica della funzione di ricompensa per l’azione, che al giorno d’oggi sostituisce la funzione di ricompensa per gli stock in Lokad in praticamente ogni dimensione, tranne la semplicità.
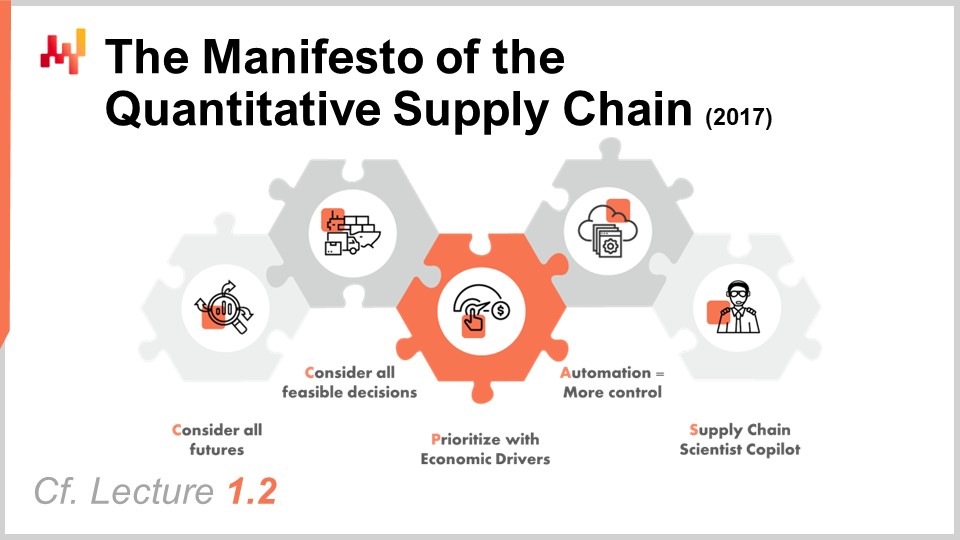
Il manifesto della supply chain quantitativa è un documento che ho pubblicato originariamente nel 2017. Questa prospettiva è stata ampiamente trattata nella Lezione 1.2, ma per chiarezza, fornirò un breve riassunto oggi. Ci sono cinque pilastri, ma solo i primi tre sono rilevanti per noi oggi. I primi tre pilastri sono:
Considerare tutti i futuri possibili, il che significa previsioni probabilistiche così come la previsione di tutti gli altri elementi con un aspetto di incertezza, come i tempi di consegna variabili o i prezzi futuri. Considerare tutte le decisioni fattibili, concentrandosi sulle decisioni e non sugli artefatti. Dare priorità ai driver economici, che è l’argomento della lezione di oggi.
In particolare, vedremo come possiamo convertire le previsioni probabilistiche in stime dei rendimenti economici.
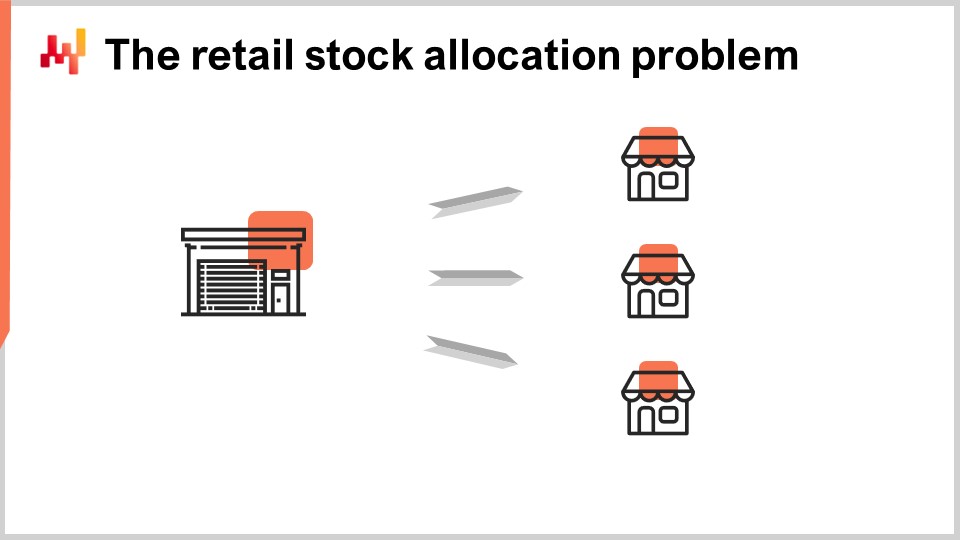
Nel problema di allocazione delle scorte al dettaglio. Questa è una definizione che sto dando; è in qualche modo arbitraria, ma questa è la definizione che userò oggi. Assumiamo una rete con due echeloni: abbiamo un centro di distribuzione e più negozi. Il centro di distribuzione serve tutti i negozi e se ci sono più centri di distribuzione, assumiamo che un negozio sia servito solo da un singolo centro di distribuzione. L’obiettivo è allocare correttamente le scorte esistenti nel centro di distribuzione tra i negozi e tutti i negozi competono per le stesse scorte esistenti nel centro di distribuzione.
Assumiamo che tutti i negozi possano essere riforniti su base giornaliera con un programma giornaliero dal centro di distribuzione. Quindi, ogni singolo giorno, dobbiamo decidere quante unità spostare per ogni singolo prodotto verso ogni negozio. La quantità totale di unità spostate non può superare le scorte disponibili nel centro di distribuzione ed è anche ragionevole aspettarsi che ci siano limiti di capacità sugli scaffali dei negozi. Se il centro di distribuzione avesse scorte illimitate, il problema si ridurrebbe a una supply chain a singolo echelon, poiché non ci sarebbe mai bisogno di fare alcun tipo di arbitraggio o compromesso tra l’allocazione delle scorte a un negozio o a un altro. La proprietà a due echeloni della rete emerge solo dal fatto che i negozi competono per le stesse scorte.
Naturalmente, assumeremo la visibilità sulle vendite dei negozi e sui livelli di scorte sia a livello di centro di distribuzione che a livello di negozio, il che significa che assumiamo che i dati transazionali siano disponibili. Assumeremo anche che le consegne in arrivo da effettuare presso il centro di distribuzione siano note con tempi di arrivo stimati (ETAs), che possono presentare un certo grado di incertezza. Assumeremo anche che tutte le informazioni banali ma critiche siano disponibili, come il prezzo di acquisto del prodotto, il prezzo di vendita del prodotto, le categorie di prodotti, se presenti, ecc. Tutte queste informazioni si trovano in qualsiasi ERP, anche tre decenni fa, così come nei sistemi WMS e nei sistemi di punto vendita.
Oggi, non includiamo il rifornimento del centro di distribuzione (DC) come parte del problema. In pratica, il rifornimento del centro di distribuzione e l’allocazione dei negozi sono strettamente collegati, quindi ha senso affrontare questi problemi insieme. Il motivo per cui non lo faccio oggi è per chiarezza e concisione in questa lezione; affronteremo prima il problema più semplice. Tuttavia, si noti che l’approccio che sto presentando oggi può essere naturalmente esteso per includere anche il rifornimento del DC.

Decidere di spostare una unità in più di scorte in un negozio per un determinato prodotto in un determinato giorno dipende da una serie di forze economiche. Se spostare l’unità è redditizio, vogliamo farlo; altrimenti, no. Le principali forze economiche sono elencate sullo schermo e fondamentalmente, mettere più scorte in un negozio comporta una serie di vantaggi. Questi includono un maggiore margine lordo grazie all’evitare le vendite perse, una migliore qualità del servizio riducendo la quantità di stockout e un miglior attrattiva del negozio. Infatti, affinché un negozio sia attrattivo, deve apparire abbondante; altrimenti, sembra triste e le persone potrebbero essere meno propense a comprare. Questa è un’osservazione comune nel settore del commercio al dettaglio, anche se potrebbe non applicarsi necessariamente a tutti i segmenti, come il lusso. Tuttavia, questa considerazione si applica ai negozi di articoli generici o di moda.
Sfortunatamente, mettere più scorte comporta anche svantaggi, che diminuiscono il rendimento che ci si potrebbe aspettare da avere più scorte nel negozio. Questi svantaggi includono costi aggiuntivi di trasporto, che possono trasformarsi in svalutazioni di magazzino se c’è un vero e proprio eccesso di scorte. C’è anche il rischio di sovraccarico di ingresso, che si verifica se il personale del negozio non riesce a gestire una spedizione troppo grande. Ciò crea confusione e disordine nel negozio se la quantità consegnata supera ciò che il personale può mettere sugli scaffali. Inoltre, c’è un costo opportunità: ogni volta che un’unità viene posizionata in un negozio, non può essere messa in un altro negozio. Anche se potrebbe essere riportata al centro di distribuzione e rispedita, questo è tipicamente molto costoso, quindi di solito è un’opzione di ultima risorsa. I rivenditori dovrebbero puntare a un’allocazione efficiente dei negozi senza dover spostare le scorte indietro.
Rendere più fluido il flusso delle scorte è anche molto desiderabile. Un centro di distribuzione (CD) ha una capacità nominale a cui opera con efficienza economica massima. Questa efficienza massima è determinata dalla configurazione fisica del CD, così come dal numero di dipendenti permanenti ad esso collegati. Idealmente, il CD dovrebbe operare su base giornaliera, rimanendo molto vicino alla sua capacità nominale per essere più efficiente dal punto di vista dei costi. Tuttavia, mantenere l’efficienza massima al centro di distribuzione (CD) richiede di rendere più fluido il flusso dal CD ai negozi. La prospettiva economica si discosta dalle prospettive tradizionali orientate al livello di servizio spesso presenti nella letteratura mainstream sulla supply chain. Cerchiamo dollari di ritorno, non punti percentuali. L’unico modo per decidere se è ragionevole regolare lo schema di allocazione delle scorte a livello di rete per ridurre i costi operativi, rispetto a una lieve degradazione della qualità del servizio nei negozi, è adottare la prospettiva economica presentata qui. Se si adotta una prospettiva di livello di servizio, non può fornire questo tipo di risposte. Il nostro obiettivo in questo momento è stabilire ricette numeriche che stimino i risultati economici per qualsiasi decisione di allocazione delle scorte.
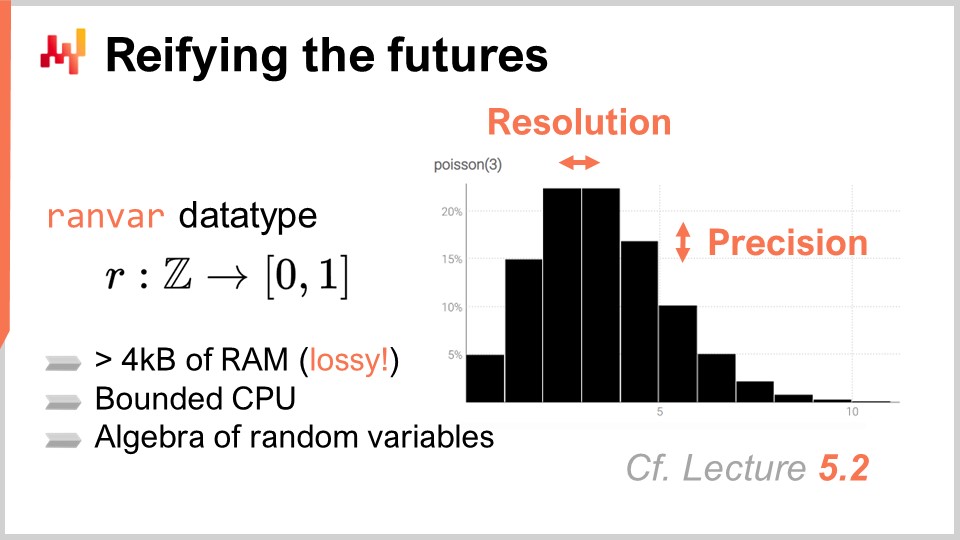
Nel capitolo precedente, il quinto capitolo, abbiamo discusso come produrre previsioni probabilistiche e introdotto un tipo di dati specializzato, il “ranvar”, che rappresenta distribuzioni di probabilità discrete unidimensionali. In breve, un ranvar è un tipo di dati specializzato utilizzato per rappresentare una semplice previsione probabilistica unidimensionale in Envision.
Envision è un linguaggio di programmazione specifico del dominio sviluppato da Lokad con l’unico scopo di ottimizzazione predittiva delle supply chain. Sebbene non ci sia nulla di fondamentalmente unico in Envision in queste lezioni, viene utilizzato per chiarezza e concisione nella presentazione. Le ricette numeriche descritte oggi possono essere implementate in qualsiasi linguaggio, come Python, Julia o Visual Basic.
L’aspetto chiave di ranvar è che fornisce un’algebra ad alte prestazioni di variabili casuali. Le prestazioni sono un equilibrio tra il costo di calcolo, il costo di memoria e il grado di approssimazione numerica che si è disposti a tollerare. Le prestazioni di calcolo sono fondamentali quando si tratta di reti di vendita al dettaglio, poiché possono esserci milioni o addirittura decine di milioni di SKU, ognuno probabilmente con almeno una previsione probabilistica o ranvar. Di conseguenza, potresti finire con milioni o decine di milioni di istogrammi.
La proprietà chiave di ranvar rispetto a un istogramma è quella di mantenere sia il costo della CPU che il costo della memoria limitati superiormente e il più basso possibile. È anche cruciale garantire che l’approssimazione numerica introdotta rimanga insignificante dal punto di vista della supply chain. È importante notare che qui non stiamo trattando di calcolo scientifico, ma di calcolo della supply chain. Sebbene i calcoli numerici debbano essere precisi, non c’è bisogno di una precisione estrema. Tieni presente che qui non stiamo facendo calcoli scientifici; stiamo facendo calcoli della supply chain. Se hai un’approssimazione di una parte su un miliardo, è insignificante dal punto di vista della supply chain. I calcoli numerici devono essere precisi, ma non c’è bisogno di una precisione estrema.
Nel seguito, assumiamo che la previsione probabilistica verrà fornita sotto forma di ranvars, che sono una serie di variabili con un tipo di dati specifico. In pratica, è possibile sostituire i ranvars con gli istogrammi e ottenere per lo più lo stesso risultato, ad eccezione delle prestazioni e della comodità.
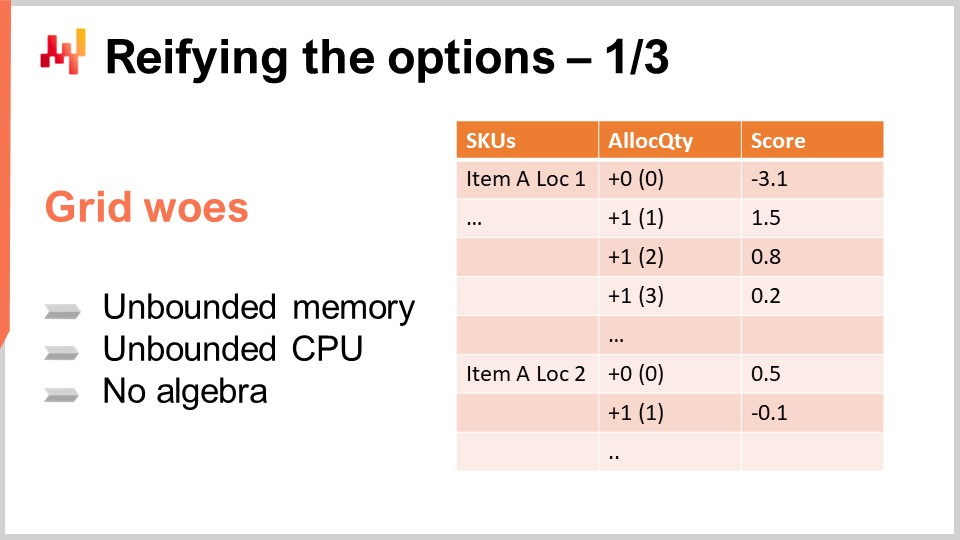
Ora che abbiamo le nostre previsioni probabilistiche, consideriamo come affrontare le decisioni. Iniziamo considerando le opzioni. Le opzioni sono le decisioni potenziali, ad esempio, assegnare zero unità per un determinato prodotto a un determinato negozio in un determinato giorno o assegnare una, due o tre unità. Se decidiamo di assegnare due unità, quella diventa la nostra decisione. Le opzioni sono tutte le cose sul tavolo in attesa di essere decise.
Un modo semplice per organizzare queste opzioni è metterle in una lista, come mostrato sullo schermo. La lista copre più SKU e per ogni SKU si aggiunge una riga per ogni opzione. Ogni opzione rappresenta una quantità da assegnare. Puoi assegnare zero, uno, due, tre e così via. In realtà, non è necessario andare all’infinito; puoi fermarti alla quantità in magazzino nel centro di distribuzione. In modo più realistico, di solito hai un limite inferiore, come la capacità massima dello scaffale per il prodotto nel negozio.
Quindi, hai una lista che include ogni SKU e per ogni SKU hai tutte le quantità che possono essere considerate come candidati per l’assegnazione dal centro di distribuzione. La colonna del punteggio è collegata all’esito marginale che ti aspetteresti ottenere effettuando questa assegnazione. Un punteggio ben progettato garantisce che la selezione delle righe in ordine decrescente di punteggio ottimizzi l’esito economico per la rete di vendita al dettaglio.
Per i due SKU mostrati sullo schermo, il punteggio diminuisce all’aumentare dell’assegnazione, illustrando il fenomeno dominante dei rendimenti decrescenti osservato per la maggior parte degli SKU. Fondamentalmente, mettere la prima unità in un negozio genera quasi sempre più rendimenti della seconda. La prima unità che metti in un negozio è quasi sempre più redditizia della seconda. Inizialmente, non hai nulla, quindi ti trovi in una situazione di esaurimento delle scorte. Se metti una unità, hai già risolto l’esaurimento delle scorte per il primo cliente. Se metti una seconda unità, il primo cliente sarà a posto, ma solo se si presentano due clienti la seconda unità sarà utile, quindi ha un ritorno economico più piccolo. Tuttavia, i rendimenti sono generalmente decrescenti all’aumentare delle scorte. Ci sono alcune eccezioni in cui i rendimenti economici potrebbero non diminuire strettamente da una riga all’altra, ma tornerò su questo caso in una lezione successiva. Per ora, ci atteniamo alla situazione semplice in cui i rendimenti diminuiscono strettamente all’aumentare delle scorte.
La rappresentazione che abbiamo, in cui possiamo vedere tutti gli SKU e le opzioni, è tipicamente definita come una griglia. L’intento è ordinare questa griglia in base al ROI (ritorno sull’investimento) decrescente. Non c’è nulla di sbagliato in queste griglie di per sé, ma non sono molto efficienti, soprattutto dal punto di vista del calcolo o della memoria, e non offrono alcun supporto oltre ad essere una grande tabella. Tieni presente che stiamo parlando di una rete di vendita al dettaglio e questa griglia potrebbe finire per avere miliardi di righe circa. I big data vanno bene, ma i dati più piccoli sono migliori, poiché creano meno attrito e consentono maggiore agilità. Vogliamo cercare di trasformare il nostro problema di big data in un problema di dati più piccoli, poiché i dati più piccoli semplificano tutto in produzione.

Quindi, una delle soluzioni adottate da Lokad per gestire un gran numero di opzioni è zedfuncs. Questo tipo di dati, proprio come ranvars, è il controparte di ranvar ma dal punto di vista decisionale. ranvars rappresentano tutti i futuri possibili, mentre zedfuncs rappresentano tutte le decisioni possibili. Invece di rappresentare probabilità come ranvars, un zedfunc rappresenta tutti i risultati economici associati a una serie discreta unidimensionale di opzioni.
Lo zedfunc, o zedfunction, è tecnicamente una funzione che mappa numeri interi, sia positivi che negativi, a valori reali. Questa è la definizione tecnica. Tuttavia, proprio come con ranvars, non è possibile rappresentare una qualsiasi funzione arbitraria o complessa come zedfuncs con una quantità finita di memoria. In questo caso, c’è anche un compromesso da fare tra precisione e risoluzione.
Nella gestione della supply chain, non esistono funzioni economiche arbitrariamente complesse. È possibile avere funzioni di costo abbastanza complesse, ma non possono essere arbitrariamente complesse. In pratica, è possibile comprimere zedfuncs in meno di quattro kilobyte. In questo modo, si ha un tipo di dati che rappresenta l’intera funzione di costo e la comprime in modo che rimanga sempre inferiore a quattro kilobyte, mantenendo il grado di approssimazione numerica trascurabile dal punto di vista della supply chain. Se si mantiene l’approssimazione numerica così piccola da non modificare la decisione finale che si sta per prendere, che è discreta, allora l’approssimazione numerica può essere considerata completamente trascurabile perché alla fine si fa la stessa cosa, anche se si avesse una precisione infinita.
Il motivo per cui si utilizzano quattro kilobyte è legato all’hardware di calcolo. Come abbiamo visto in una precedente lezione sull’hardware di calcolo moderno per la gestione della supply chain, la memoria ad accesso casuale (RAM) di un computer moderno, che sia una workstation, un notebook o un computer in cloud, non consente di accedere alla memoria byte per byte. Appena si tocca la RAM, viene recuperato un segmento di quattro kilobyte. Pertanto, è meglio mantenere la quantità di dati inferiore a quattro kilobyte perché corrisponderà al modo in cui l’hardware è progettato e funziona per la tua supply chain.
L’algoritmo di compressione utilizzato da Lokad per zedfuncs differisce da quello utilizzato per ranvars perché non stiamo affrontando gli stessi problemi numerici. Per ranvars, ci interessa principalmente preservare la massa di probabilità dei nostri segmenti contigui. Per uno zedfunc, l’attenzione è diversa. Vogliamo tipicamente preservare la quantità di variazione osservata da una posizione all’altra perché è con questa variazione che possiamo decidere se è l’ultima opzione redditizia o se dovremmo fermarci. Pertanto, anche l’algoritmo di compressione è diverso.

Sullo schermo puoi vedere un grafico ottenuto per uno zedfunc che riflette alcuni costi di gestione previsti che dipendono dal numero di unità in stock. zedfuncs beneficiano di essere uno spazio vettoriale, il che significa che possono essere sommati e sottratti, proprio come lo spazio vettoriale classico associato alle funzioni. Preservando la località della memoria, le operazioni possono essere eseguite con un ordine di grandezza più veloce rispetto a un’implementazione di griglia ingenua in cui si ha una tabella molto grande senza una struttura dati specifica per catturare la località delle opzioni che giocano insieme.
Il grafico che hai visto nella diapositiva precedente è stato generato da uno script. Alle righe uno e due, dichiariamo due funzioni lineari, f e g. La funzione “linear” fa parte della libreria standard e “linear of one” è semplicemente la funzione identità, un polinomio di grado uno. La funzione “linear” restituisce uno zedfunc ed è possibile aggiungere una costante con uno zedfunc. Abbiamo due polinomi di grado uno, f e g. Alla riga tre, costruiamo un polinomio di secondo grado attraverso il prodotto di f e g. Le righe 5-10 sono utility, essenzialmente boilerplate, per tracciare lo zedfunc.
A questo punto, abbiamo il nostro contenitore di dati per lo zedfunc e gli esiti economici. Lo zedfunc è un contenitore di dati, proprio come il ranvar era per la previsione probabilistica. Tuttavia, abbiamo ancora bisogno di ricette numeriche per calcolare quegli esiti economici. Abbiamo il contenitore di dati, ma non ho ancora descritto come calcoliamo quegli esiti economici e riempiamo gli zedfuncs.

La funzione di ricompensa per lo stock è un piccolo framework destinato a calcolare i rendimenti economici per ogni livello di stock di un singolo SKU, considerando una previsione probabilistica e una breve serie di fattori economici. La funzione di ricompensa per lo stock è stata introdotta storicamente presso Lokad per unificare le nostre pratiche. Nel 2015, Lokad aveva già lavorato per un paio di anni con previsioni probabilistiche e, attraverso tentativi ed errori, avevamo già scoperto una serie di ricette numeriche che funzionavano bene. Tuttavia, non erano davvero unificate; era un po’ un disastro. La funzione di ricompensa per lo stock ha consolidato tutti quei suggerimenti in quel momento in un framework pulito, ordinato e minimalista. Dal 2015 sono stati sviluppati metodi migliori, ma sono anche più complessi. Per una questione di chiarezza, è ancora meglio iniziare con la funzione di ricompensa per lo stock e presentare questa funzione per prima.
La funzione di ricompensa per lo stock riguarda davvero la ricerca di una ricetta numerica che ci darà un calcolo per gli esiti economici legati a quelle previsioni probabilistiche. La funzione di ricompensa per lo stock obbedisce all’equazione che puoi vedere sullo schermo e definisce i rendimenti economici al tempo t che puoi ottenere per lo stock disponibile, k. La variabile R rappresenta il rendimento economico, che è espresso in unità come dollari o euro. La funzione ha due variabili: tempo (t) e stock disponibile (k). Vogliamo calcolare questa ricompensa per tutti i possibili livelli di stock.
Ci sono quattro variabili economiche da considerare:
M è il margine lordo per unità venduta. È il margine che guadagnerai fornendo con successo un’unità. S è la penalità per mancanza di stock, una sorta di costo virtuale che incorri ogni volta che non riesci a fornire un’unità a un cliente. Anche se non devi pagare una penalità al tuo cliente, c’è un costo associato al fallimento nel fornire un servizio adeguato e questo costo deve essere modellato. Uno dei modi più semplici per modellare questo costo è assegnare una penalità per ogni unità che non riesci a servire. C è il costo di mantenimento, il costo per unità per periodo di tempo. Se hai una unità in stock per tre periodi, sarebbero tre volte C; se hai due unità in stock per tre periodi, sarebbero sei volte C. Alpha viene utilizzato per scontare i rendimenti futuri. L’idea è che ciò che accade nel futuro remoto conta meno di ciò che sta per accadere nel futuro prossimo. La funzione di ricompensa per lo stock è semplice quanto può essere senza essere eccessivamente semplicistica. L’equazione indica che se la domanda supera lo stock disponibile, il rendimento include il margine per tutto lo stock che abbiamo.
Questo è ciò che sta dicendo la prima riga: abbiamo k margini, quindi vendiamo tutte le unità che abbiamo e poi incorriamo in una penalità che sarà Y(t) - k per tutte le unità che non siamo riusciti a servire.
Altrimenti, se lo stock disponibile supera la domanda, possiamo beneficiare di Y(t) volte M, che rappresenta il margine di ciò che abbiamo venduto oggi. Poi, dobbiamo pagare i costi di mantenimento. I costi di mantenimento per oggi saranno ciò che rimane alla fine della giornata, ovvero k - Y(t) volte C, più alpha volte la funzione di ricompensa per lo stock R* per il giorno successivo.
C’è un trucco con R*. È quasi identica alla funzione di ricompensa per lo stock R, tranne che mettiamo la penalità per la mancanza di stock a zero. Il motivo è semplice: assumiamo dal punto di vista dello stock che avremo altre opportunità in seguito per riempire lo stock. Se osserviamo una mancanza di stock oggi, è troppo tardi, quindi subiamo la penalità per la mancanza di stock. Tuttavia, una penalità per la mancanza di stock che si presume accadrà domani è considerata evitabile.
Tuttavia, una penalità per la mancanza di stock che si presume accadrà in futuro, in un periodo successivo, assumiamo che il rifornimento possa avvenire in ogni periodo. Pertanto, per la mancanza di stock che si verificherebbe in un periodo successivo, quando abbiamo ancora tempo per effettuare un riordino tardivo, la mancanza di stock non è ancora avvenuta. Abbiamo ancora l’opportunità di farlo, ed è per questo che mettiamo la penalità per la mancanza di stock a zero, perché prevediamo che ci sarà, sperabilmente, un altro riordino che impedirà che si verifichi la mancanza di stock.
Lo sconto temporale alpha è molto utile perché essenzialmente elimina la necessità di specificare un orizzonte temporale specifico. La funzione di ricompensa per lo stock non funziona con un orizzonte temporale finito; si va all’infinito. Grazie ad alpha, che è un valore strettamente inferiore a uno, gli esiti economici legati agli eventi nel futuro molto lontano diventano infinitamente piccoli, quindi diventano trascurabili. Non abbiamo alcun tipo di limite, che è sempre arbitrario, come tagliare l’orizzonte della catena di approvvigionamento a 60 giorni, 90 giorni, un anno o due anni.

In Envision, la funzione di ricompensa per lo stock prende in input una ranvar e restituisce una zedfunc. La funzione di ricompensa per lo stock è un piccolo mattoncino che trasforma una previsione probabilistica (una ranvar) in una zedfunc, che è un contenitore per i rendimenti economici stimati su una serie di opzioni. Come suggerisce il nome, la funzione di ricompensa per lo stock è il rendimento economico associato a ogni singola posizione di stock: cosa succede se ho zero unità in stock, una unità in stock, due unità, tre unità e così via. La zedfunc rifletterà gli esiti economici per ogni livello di stock, codificando il rendimento economico associato al corrispondente livello di stock.
Il processo per calcolare queste zedfuncs è illustrato sullo schermo. Alla riga 1, introduciamo una domanda simulata per un singolo giorno, che è solo una distribuzione di Poisson casuale. Alle righe 2-7, introduciamo le variabili economiche, e tra l’altro, abbiamo due alfa. C’è un altro trucco: abbiamo un effetto di bloccaggio sull’inventario. Una volta che lo stock è stato spinto verso il negozio, è tipicamente molto costoso riportare lo stock indietro. Questo riflette il fatto che qualsiasi allocazione fatta a un negozio è praticamente definitiva. Per quanto riguarda i costi di mantenimento, l’alfa non dovrebbe essere troppo piccolo, perché subiremo davvero quei costi di mantenimento se sovraffolliamo. Non possiamo annullare questa decisione. Tuttavia, per quanto riguarda l’alfa che è legato al margine, la realtà è che proprio come avremo altre opportunità per affrontare future mancanze di stock, avremo altre opportunità per portare più stock e ottenere lo stesso margine con stock che viene spinto in una data successiva. Pertanto, dobbiamo scontare in modo molto più aggressivo ciò che accade sul lato del margine rispetto a ciò che accade sul lato dei costi di mantenimento.
Alle righe 9-11, introduciamo la funzione di ricompensa per lo stock stesso. Questa funzione, la funzione di ricompensa per lo stock che ho introdotto nella diapositiva precedente, può essere decomposta linearmente nei suoi tre componenti, che affrontano rispettivamente il margine, il costo di mantenimento e la penalità per la mancanza di stock. Infatti, abbiamo una separazione lineare e in Envision, questi tre componenti vengono calcolati separatamente. Possiamo moltiplicare la zedfunc per il fattore M, che sarebbe il margine lordo.
Alle righe 13-15, la ricompensa finale viene ricomposta aggiungendo i tre componenti economici. In questo script, stiamo sfruttando il fatto che abbiamo uno spazio vettoriale di zedfuncs. Queste zedfuncs non sono numeri; sono funzioni. Ma possiamo aggiungerle e il risultato dell’addizione è un’altra funzione, che è anche una zedfunc. La variabile reward è il risultato dell’aggiunta di questi tre componenti insieme. Sotto il cofano, il calcolo della funzione di ricompensa per lo stock viene effettuato attraverso un’analisi a punto fisso, che può essere fatta in tempo costante per ogni componente. Questo calcolo in tempo costante potrebbe sembrare una piccola questione tecnica, ma quando si tratta di una grande rete di vendita al dettaglio, fa la differenza tra un prototipo di lusso e una soluzione di produzione effettiva.

Ora, a questo punto, abbiamo consolidato tutti gli ingredienti necessari per affrontare il problema di allocazione dello stock. Abbiamo previsioni probabilistiche espresse come ranvars, una tecnica per trasformare questi ranvars in una funzione che fornisce rendimenti economici per qualsiasi valore di stock disponibile e questi risultati economici possono essere comodamente rappresentati come zedfuncs. Per affrontare definitivamente il problema di allocazione dello stock, dobbiamo rispondere alla domanda chiave: se possiamo spostare solo un’unità di stock, quale spostiamo e perché? Tutti i negozi nella rete competono per lo stesso stock nel centro di distribuzione e la qualità della decisione di spostare un’unità di stock dal centro di distribuzione a un negozio specifico dipende dallo stato complessivo della rete. Non puoi valutare se questa decisione è buona guardando solo un negozio.
Ad esempio, supponiamo di avere un negozio con già due unità in stock e se aggiungiamo una terza unità, aumentiamo il livello di servizio atteso dall'80% al 90%. Questo è buono e forse più persone nella rete sarebbero d’accordo con l’idea di portare un’unità in più in modo che il livello di servizio possa passare dall'80 al 90. Questo sembra molto ragionevole, quindi direbbero che questo è un buon movimento. Tuttavia, cosa succede se questa unità che stiamo per spostare, questa terza unità, è effettivamente l’ultima disponibile nel centro di distribuzione? Abbiamo un altro negozio nella rete che sta già subendo una mancanza di stock e se spostiamo questa unità nel negozio in cui diventa la terza unità, prolunghiamo la mancanza di stock per il negozio che è già senza stock per lo stesso prodotto. In questa situazione, è quasi certo che spostare l’unità nel negozio già senza stock sia una decisione migliore e dovrebbe avere una priorità più alta.
Ecco perché non ha senso valutare economicamente i livelli di stock a livello di SKU. Il problema delle ottimizzazioni locali è che non funzionano se operi in sistemi più grandi. Nelle supply chain, se affronti le cose a livello locale, sposti solo i problemi; non risolvi nulla. L’adeguatezza di un livello di stock di un SKU dipende dallo stato della rete. Questo semplice esempio chiarisce perché i calcoli dello stock di sicurezza o i calcoli del punto di riordino sono per lo più senza senso, almeno per situazioni reali, rispetto agli esempi giocattolo che si trovano nei manuali di supply chain.
Qui, vogliamo davvero dare priorità a tutte le allocazioni di stock l’una rispetto all’altra, e l’opzione che emerge in cima è la risposta alla nostra domanda: questa sarà l’unità che dovrebbe essere spostata se possiamo spostare solo un’unità.

La classificazione delle opzioni di allocazione dello stock è relativamente semplice con gli strumenti appropriati. Analizziamo questo script di Envision. Alla riga 1, creiamo tre SKU chiamati A, B e C. Alla riga 2, generiamo prezzi di acquisto casuali tra 1 e 10 come dati di esempio. Alla riga 3, generiamo zedfuncs di esempio che dovrebbero rappresentare la ricompensa che abbiamo per ciascuno di quegli SKU. In pratica, un zedfunc dovrebbe essere calcolato con la funzione di ricompensa dello stock, ma solo per mantenere il codice conciso, qui stiamo usando dati di esempio. La ricompensa è una funzione lineare decrescente che raggiungerà lo zero al livello di stock 6. Alla riga 4, creiamo una tabella G, un abbreviazione per la griglia che rappresenta i nostri livelli di stock disponibili. Assumiamo che i livelli di stock superiori a 10 non siano degni di valutazione. Questa assunzione è ragionevole, considerando che in termini di dati di esempio, abbiamo una funzione di ricompensa che diventa negativa oltre un livello di stock disponibile di 6. Alla riga 6, estraiamo la ricompensa marginale per ogni unità in stock in modo da ottenere questa tabella a griglia. Utilizziamo il zedfunc, una funzione che rappresenta le ricompense, per estrarre il valore per la posizione di stock G.N. È importante notare che a partire dalla riga 6, non importa come i dati sono stati originariamente generati. Dalla riga 1 alla 4, sono solo dati di esempio che non verrebbero utilizzati in un ambiente di produzione, ma a partire dalla riga 6, sarebbe essenzialmente lo stesso se fossi in produzione.
Alla riga 7, definiamo il punteggio come un rapporto tra i dollari di ritorno (che il zedfunc ti dice) e il dollaro investito, che è il prezzo di acquisto. Facciamo un rapporto tra la quantità di dollari che otterrai indietro diviso per la quantità di dollari che devi pagare per un’unità. Fondamentalmente, il punteggio più alto viene ottenuto per l’allocazione dello stock che genera il tasso di rendimento più alto per dollaro allocato a questo negozio.
Infine, alle righe 9-15, mostriamo una tabella ordinata per punteggio decrescente. È importante sottolineare che non c’è una logica complicata nello script. Le prime quattro righe sono solo la generazione di dati di esempio e le ultime sei righe sono solo la visualizzazione dell’allocazione prioritaria. Una volta che i zedfuncs sono presenti e abbiamo una funzione che rappresenta i rendimenti economici per livello di stock, trasformare quei zedfuncs in una lista prioritizzata è completamente semplice.

Sullo schermo, la tabella ottenuta eseguendo lo script di Envision precedente mostra che l’SKU chiamato C è classificato al primo posto. Tutti gli SKU hanno gli stessi rendimenti economici per la loro prima unità, ovvero un ritorno di $5. Tuttavia, C ha il prezzo di acquisto più basso, $3.99, e quindi, quando dividiamo la ricompensa di $5 per $3.99, otteniamo un punteggio di circa 1.25, che risulta essere il punteggio più alto nella griglia. La seconda unità di C ha un punteggio di circa 1, che è il secondo punteggio più alto.
Per la terza posizione nella griglia, abbiamo un altro SKU chiamato B. B ha un prezzo di acquisto più alto e quindi il suo punteggio per la prima unità è solo dello 0.96. Tuttavia, a causa dei rendimenti decrescenti che otteniamo dall’assegnazione delle prime due unità all’SKU C, la prima unità di B ottiene un punteggio più alto rispetto alla terza unità di C e quindi viene classificata sopra la terza unità di C. Fondamentalmente, questa lista di priorità va molto in profondità, ma è destinata ad essere troncata con una soglia. Ad esempio, possiamo decidere che c’è un ritorno minimo sull’investimento e solo le unità al di sopra di questo ritorno sull’investimento vengono allocate. Una volta definita la soglia, possiamo prendere tutte le righe che sono al di sopra del limite e contare il numero di righe per SKU. Questo ci dà il numero totale di unità da allocare per ogni singolo SKU. Rivedremo questo problema di soglia tra un minuto, ma l’idea è che una volta che hai una soglia, aggreghi i conteggi per SKU e questo ti dà la quantità totale da allocare per ogni singolo SKU. Questo è esattamente ciò che il tuo WMS o ERP che esiste nel centro di distribuzione si aspetterebbe per organizzare la spedizione del giorno successivo verso i negozi.
La lista di priorità è solo una visione concettuale per decidere effettivamente cosa ha la priorità. Tuttavia, si prende una soglia, si aggrega e si torna alle quantità di allocazione per SKU per ogni singolo SKU che esiste nella rete di negozi al dettaglio.
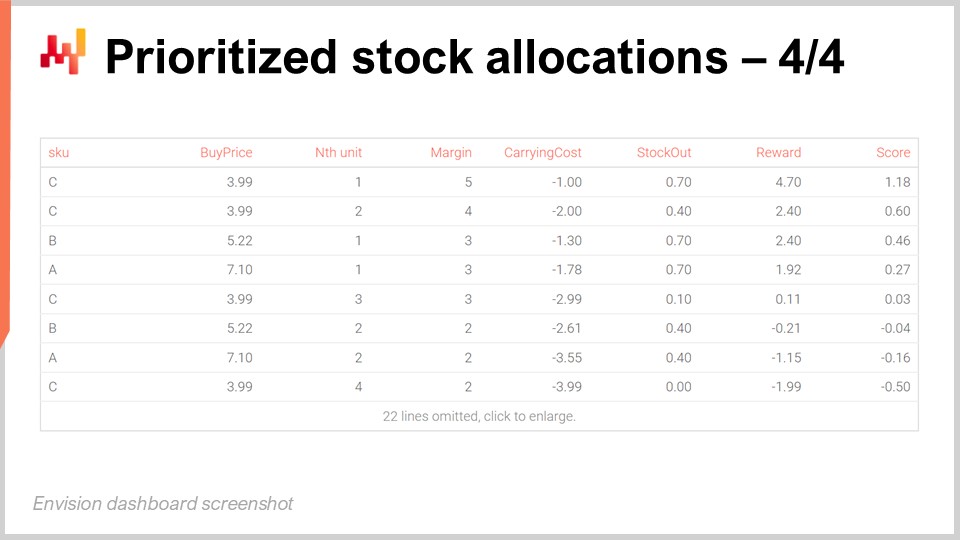
La visualizzazione sul display dell’allocazione di magazzino prioritizzata è ingannevolmente semplice eppure potente. Man mano che scendiamo da una riga all’altra, vediamo svolgersi la competizione tra le nostre opzioni di allocazione. I migliori SKU vengono allocati per primi, ma non appena raggiungiamo livelli di magazzino più alti, quegli SKU diventano meno competitivi rispetto ad altri SKU che non hanno così tanto stock. La lista di priorità passa da un SKU all’altro, massimizzando i rendimenti attesi sul capitale allocato ai negozi.
In questa schermata, abbiamo una variante della tabella precedente, ottenuta con un altro script di Envision che è una variante minima di quello introdotto due slide fa. Fondamentalmente, sto scomponendo i fattori economici che contribuiscono alla ricompensa. Qui abbiamo tre colonne extra: margine, costo di mantenimento e mancanza di stock. Il margine è il margine lordo medio atteso per questa singola unità allocata. Il costo di mantenimento è il costo medio atteso di mettere questa singola unità in magazzino nel negozio. La mancanza di stock è la penalità attesa che verrà evitata, motivo per cui la penalità per la mancanza di stock è un valore positivo qui. La ricompensa finale è semplicemente la somma di questi tre componenti e tutti questi valori sono espressi in importi monetari, come dollari. La colonna che rappresenta i dollari di margine, i dollari di costo di mantenimento, i dollari di mancanza di stock e le ricompense, è semplicemente l’importo totale di dollari che ci si può aspettare mettendo questa singola unità nel negozio.
Ciò rende la comprensione e il debug di questa ricetta numerica, espressa in dollari, molto più facile rispetto ai percentuali. Infatti, qualsiasi ricetta numerica non banale sarà abbastanza opaca per design. Non hai bisogno di deep learning per ottenere un’opacità profonda; anche una modesta regressione lineare sarà abbastanza opaca non appena hai un paio di fattori coinvolti in questa regressione. Questa opacità, che si ottiene nuovamente con qualsiasi ricetta numerica non banale, mette a rischio una supply chain del mondo reale perché i professionisti della supply chain possono perdersi, confondersi e distrarsi con le tecniche di modellazione.
L’elenco prioritario di allocazione, che scompone i driver economici, è uno strumento di audit potente. Consente ai professionisti della supply chain di sfidare direttamente i fondamenti anziché confondersi con le tecniche. Puoi fare domande dirette come: Abbiamo costi di mantenimento che hanno senso considerando la situazione in cui ci troviamo? Quei costi sono allineati con il tipo di rischi che stiamo assumendo? Puoi dimenticare la previsione, la stagionalità, il modo in cui modelli la stagionalità, il modo in cui consideri il trend decrescente e così via. Puoi sfidare direttamente il risultato finale, che sono i dollari di output per quei costi di mantenimento. Sono reali? Hanno senso? Molto spesso, puoi individuare numeri che non hanno senso e correggerli direttamente.
Ovviamente, vuoi evitare quelle situazioni, ma non operare con l’assunzione che nella supply chain tutti i problemi siano problemi di previsione incredibilmente sottili. La maggior parte delle volte, i problemi sono brutali. Potrebbe esserci qualche tipo di problema, come dati non elaborati correttamente, e poi ottieni numeri completamente insensati, come margini negativi o costi di mantenimento negativi che creano caos nella tua supply chain.
Se la tua strumentazione della supply chain si concentra esclusivamente sull’accuratezza della previsione della domanda, sei cieco al 90% (o più) dei problemi effettivi. In una supply chain su larga scala, questa stima sarebbe probabilmente qualcosa come il 99%. La strumentazione della supply chain è assolutamente fondamentale per evidenziare i fattori chiave che contribuiscono alle decisioni, e quei fattori devono essere di natura economica se vuoi avere qualche speranza di concentrarti su ciò che rende la tua azienda redditizia. Altrimenti, se operi in percentuali, non puoi dare priorità alle tue azioni e affronti le anomalie indiscriminatamente. Stiamo parlando di una supply chain su larga scala, quindi c’è sempre una legione di anomalie numeriche. Se affronti tutte quelle anomalie in modo indifferente, significa che stai sempre lavorando su cose che sono in gran parte irrilevanti. Ecco perché hai bisogno di avere ritorni in dollari e costi in dollari. In questo modo puoi effettivamente dare priorità al tuo lavoro e ai tuoi sforzi di sviluppo per le tue ricette numeriche. A volte, non è nemmeno necessario decidere se un bug vale la pena di essere corretto; se stai parlando di una manciata di dollari all’anno di attrito, non è nemmeno un bug che vale la pena correggere in pratica.
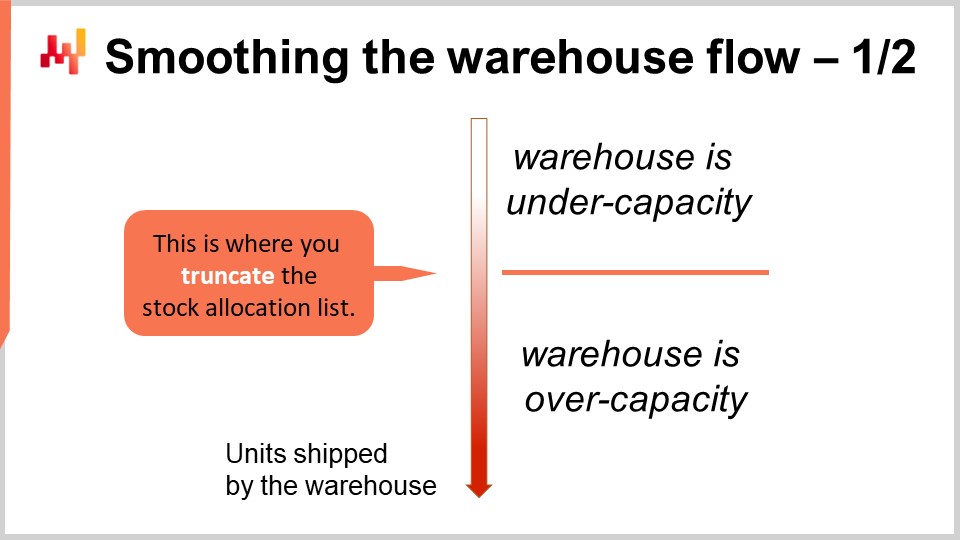
Ora, torniamo alla questione di scegliere il giusto punto di taglio per l’elenco di allocazione. Abbiamo visto che abbiamo un rendimento approssimativamente decrescente mentre allocando più stock agli SKU del negozio. Tuttavia, dobbiamo guardare a tutta la supply chain, non solo al magazzino o al centro di distribuzione. Sto usando i due termini in modo interscambiabile qui. Il magazzino o il centro di distribuzione è dominato dai costi fissi. Infatti, è possibile estendere il personale con lavoratori temporanei, ma tende a costare di più e crea altri problemi, come il fatto che la forza lavoro temporanea sia tipicamente meno qualificata di quella permanente.
Pertanto, ogni magazzino o centro di distribuzione ha una capacità target in cui opera con massima efficienza economica. La capacità target può essere aumentata o diminuita, ma di solito comporta l’adeguamento delle dimensioni del personale permanente, quindi è un processo relativamente lento. Puoi aspettarti che un magazzino adatti la sua capacità target da un trimestre all’altro, ma non puoi aspettarti che il magazzino adatti la sua capacità nominale, dove ha efficienza massima, da un giorno all’altro. Non è così dinamico.
Vogliamo mantenere il magazzino che opera con massima efficienza, o il più vicino possibile all’efficienza massima, tutto il tempo, a meno che non abbiamo un incentivo economico abbastanza forte per fare diversamente. La prospettiva dell’allocazione prioritaria delle scorte apre la strada per fare esattamente questo. Possiamo troncare l’elenco rendendolo un po’ più corto o più lungo e spostando il punto di taglio per mantenerlo allineato con la capacità target del magazzino. In pratica, ciò comporta tre benefici principali.
Innanzitutto, si ottiene una maggiore fluidità del flusso del magazzino. In questo modo, si mantiene il magazzino che opera con massima capacità la maggior parte del tempo, risparmiando così molti costi operativi. In secondo luogo, il processo di allocazione delle scorte diventa molto più resiliente a tutti i piccoli incidenti che si verificano in una supply chain reale. Un camion potrebbe essere coinvolto in un incidente stradale minore, alcuni dipendenti potrebbero non presentarsi perché sono malati: ci sono tonnellate di piccole ragioni che possono interrompere i tuoi piani. Ciò non impedirà al tuo magazzino di operare, ma potrebbe non operare esattamente alla capacità che avevi previsto. Con questa lista di prioritizzazione, puoi sfruttare al massimo la capacità che il tuo magazzino sta utilizzando, anche se non è esattamente la capacità che avevi pianificato inizialmente.
Il terzo beneficio è che con questo approccio di una lista prioritaria per l’allocazione delle scorte, il tuo team di supply chain non deve più gestire in modo dettagliato i livelli di personale del magazzino. Devi solo regolare la capacità target del tuo magazzino in modo che corrisponda approssimativamente alla velocità di vendita della tua rete di vendita al dettaglio. La gestione dettagliata della capacità a livello giornaliero diventa in gran parte irrilevante.
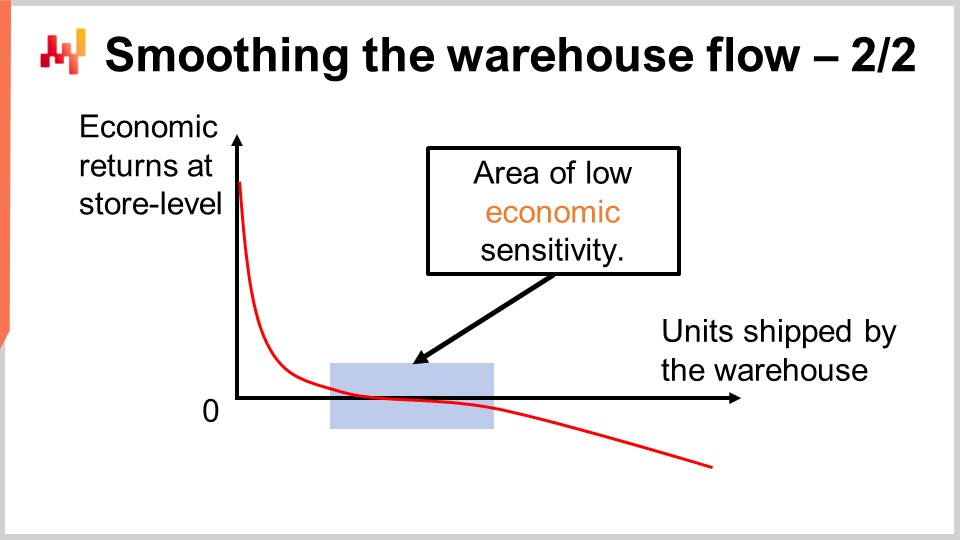
L’esperienza di Lokad indica che la fluidità del flusso del magazzino attraverso un punto di taglio di capacità piatta funziona bene nella maggior parte delle situazioni di vendita al dettaglio. Sullo schermo, puoi vedere la tipica curva di rendimento economico che osserveresti considerando tutti i possibili punti di taglio. Sull’asse X, abbiamo il numero di unità spedite dal magazzino. Assumiamo concettualmente che le unità vengano spedite una per una in modo da poter osservare il contributo marginale di ogni singola unità. Naturalmente, in produzione, le unità vengono spedite a lotti, non una per una, ma questo è solo per poter effettivamente tracciare la curva. Sull’asse Y, abbiamo i risultati economici marginali a livello di negozio, quindi per l’n-esima unità spedita in un negozio, qualsiasi negozio nella rete. Le prime unità allocate generano la maggior parte dei rendimenti. In pratica, la parte superiore dell’elenco consiste invariabilmente di situazioni di stockout che richiedono una risoluzione immediata. Ecco perché le prime unità affrontano gli stockout e ecco perché i rendimenti economici sono molto alti. Successivamente, i rendimenti diminuiscono e entriamo in una porzione piatta della curva.
Questa area è ciò a cui mi riferisco come l’area di bassa sensibilità economica. Fondamentalmente, stiamo spingendo gradualmente il livello di servizio verso il 100% ma non stiamo ancora creando molto stock morto. Quando si fa questo tipo di allocazione prioritaria, se spingiamo le scorte oltre il problema degli stockout, finiamo per accumulare scorte sui prodotti che si muovono velocemente. Creiamo scorte in luoghi che non sono esattamente necessari in questo momento. Avremo opportunità in futuro per rifornire le scorte senza affrontare un problema di stockout nel frattempo, ma l’impatto è minimo perché le scorte verranno vendute relativamente rapidamente. Fondamentalmente, si tratta solo del costo opportunità di spostare le scorte dal centro di distribuzione a un negozio. Perdiamo gradualmente future opzioni man mano che allocamo più scorte.
Questa area è relativamente piatta e inizierà a diventare abbastanza negativa quando spingiamo così tante scorte che iniziamo a generare situazioni che causeranno svalutazioni delle scorte con una probabilità non trascurabile. Se continui a spingere, generi situazioni di sovrastock molto gravi e quindi vedi che la curva diventa molto negativa. Se spingi troppo, genererai tonnellate di svalutazioni delle scorte in futuro. Finché il punto di taglio si trova in questo segmento di bassa sensibilità, siamo a posto e il punto di taglio non è super sensibile a dove lo tagli. Questo è il motivo per cui la capacità del magazzino non deve riprodurre direttamente il volume di vendite giornaliere.
Infatti, nella maggior parte delle reti di vendita al dettaglio, si osserva un forte modello ciclico giorno della settimana nelle vendite, in cui certi giorni, ad esempio il sabato, sono quelli in cui si vende di più. Ma il magazzino non deve riprodurre esattamente questo modello ciclico giorno della settimana. Puoi mantenere una media molto piatta e l’idea è che la capacità target dovrebbe semplicemente corrispondere approssimativamente al volume complessivo delle vendite per la tua rete di negozi. Se la capacità target è sempre leggermente inferiore al volume complessivo delle vendite nella rete, ciò che accadrà è che esaurirai gradualmente tutti i tuoi negozi e poi affronterai un grosso problema. Al contrario, se spingi ogni giorno un po’ più di quanto effettivamente vendi, allora molto rapidamente saturerai completamente i tuoi negozi.
Finché lo mantieni relativamente equilibrato, non è necessario gestire in modo dettagliato il modello ciclico giorno della settimana; funzionerà bene. Il motivo per cui non è necessario gestire in modo dettagliato il modello ciclico giorno della settimana è che le prime unità consegnano la maggior parte dei rendimenti e il sistema, da un punto di vista economico, non è così sensibile fintanto che il punto di taglio rimane approssimativamente in questo segmento piatto.

Ora, ho presentato la funzione di ricompensa delle scorte per chiarezza e concisione, poiché avevamo molto da coprire in questa lezione. Tuttavia, la funzione di ricompensa delle scorte non è l’apice della scienza della supply chain. È un po’ ingenua quando si tratta dei dettagli delle previsioni probabilistiche.
Nel 2021, uno di noi presso Lokad ha pubblicato la funzione di ricompensa delle azioni. La funzione di ricompensa delle azioni è il discendente spirituale, se lo si desidera, della funzione di ricompensa delle scorte, ma questa funzione offre una prospettiva molto più dettagliata sulle previsioni probabilistiche stesse. Infatti, tutte le previsioni probabilistiche non sono uguali. La stagionalità, i tempi di consegna variabili e gli ETA di approvvigionamento per i centri di distribuzione sono tutti presi in considerazione nella funzione di ricompensa delle azioni, mentre non erano presi in considerazione nella funzione di ricompensa delle scorte.
A proposito, queste capacità richiedono anche una previsione più granulare, quindi è necessaria una tecnologia di previsione superiore che possa generare tutte quelle previsioni probabilistiche per utilizzare la funzione di ricompensa delle scorte. A questo riguardo, la funzione di ricompensa delle scorte è meno esigente. A livello concettuale, la funzione di ricompensa delle azioni fornisce anche una decoupling pulita della frequenza di ordinazione (quanto frequentemente si ordina) dal tempo di approvvigionamento (quanto tempo ci vuole per rifornire le scorte una volta presa la decisione). Questi due elementi erano raggruppati insieme nella funzione di ricompensa delle scorte. Con la ricompensa delle azioni, sono chiaramente separati.
Infine, la funzione di ricompensa delle azioni offre anche una prospettiva di proprietà decisionale, che è un trucco semplice ma piuttosto intelligente per ottenere la maggior parte dei benefici che si otterrebbero da una vera politica senza dover introdurre una politica. Discuteremo cosa significano realmente le politiche da un punto di vista tecnico nelle lezioni successive, ma il punto principale è che non appena si inizia a introdurre politiche, diventa più complicato. È interessante, ma sicuramente più complicato. Qui, la ricompensa delle azioni ha un trucco intelligente in cui è possibile bypassare letteralmente la necessità di adottare una politica e comunque ottenere la maggior parte dei benefici economici ad essa associati.

Sia la funzione di ricompensa delle scorte che la sua alternativa superiore, la funzione di ricompensa delle azioni, sono state utilizzate in produzione per anni presso Lokad. Queste funzioni semplificano essenzialmente intere classi di problemi che altrimenti affliggono le reti di vendita al dettaglio. Ad esempio, le scorte morte diventano facili da valutare semplicemente guardando i rendimenti economici associati a qualsiasi unità di stock già presente in qualsiasi negozio. Tuttavia, ci sono tonnellate di aspetti che non ho affrontato oggi. Affronterò quegli aspetti nelle lezioni successive.
Alcuni di questi aspetti possono effettivamente essere affrontati con variazioni piuttosto minori rispetto a quanto ho presentato oggi. Questo è il caso, ad esempio, dei moltiplicatori di lotto e del riequilibrio delle scorte. Devi apportare pochissime modifiche agli script che ho appena mostrato oggi per affrontare questi problemi. Quando parlo di riequilibrio delle scorte, intendo riequilibrare le scorte tra i negozi della rete, sia spostando le scorte al centro di distribuzione che spostando direttamente le scorte tra i negozi, assumendo costi di trasporto specifici.
Poi, ci sono alcuni aspetti che richiedono più lavoro ma sono comunque relativamente semplici. Ad esempio, tenere conto dei costi opportunità, dei costi di trasporto fissi e dell’overload di ingresso del negozio, che si verifica quando il personale di un negozio non è in grado di elaborare tutte le unità che ha ricevuto. Non hanno il tempo in un dato giorno per metterle sugli scaffali e quindi creano un grande disordine nel negozio. Questi aspetti sono possibili ma richiederanno sicuramente molto lavoro oltre a quanto ho presentato oggi.
Ci sono altri aspetti, come il merchandising o il miglioramento dell’attrattiva complessiva del negozio, che dovrebbero far parte della prioritizzazione. Questi richiedono un approccio tecnologico superiore, poiché le variazioni minori di quanto ho presentato oggi non sono sufficienti. Come al solito, consiglio una sana dose di scetticismo quando un esperto sostiene di avere un metodo ottimale. Nella supply chain, non esistono metodi ottimali; abbiamo strumenti, alcuni dei quali si rivelano migliori, ma nessuno di essi si avvicina minimamente a ciò che potrebbe essere considerato ottimale.
In conclusione, le percentuali di errore sono irrilevanti; contano solo i dollari di errore. Quei dollari sono determinati da ciò che la tua supply chain fa a livello fisico. La maggior parte dei KPI è insignificante al massimo; fanno parte del processo di supply chain per migliorare continuamente le ricette numeriche che guidano le decisioni di supply chain. Tuttavia, anche considerando tali KPI che sono strumentali per migliorare le ricette numeriche, stiamo parlando di risultati piuttosto indiretti rispetto al miglioramento diretto della ricetta numerica che guida la decisione e genera immediatamente risultati migliori per la tua supply chain.
I fogli di calcolo di Excel sono onnipresenti nella supply chain e credo che ciò sia dovuto al fatto che la teoria mainstream della supply chain non è riuscita a promuovere le decisioni come cittadini di prima classe. Di conseguenza, le aziende sprecano tempo, denaro e concentrazione su cittadini di seconda classe, ovvero artefatti. Ma alla fine della giornata, le decisioni devono essere prese: le scorte devono essere allocate e devi scegliere il prezzo, il tuo punto di vendita e il prezzo di attacco. In assenza di un adeguato supporto, i professionisti della supply chain ricorrono all’unico strumento che consente loro di trattare le decisioni come cittadini di prima classe, e questo strumento si chiama Excel.
Tuttavia, le decisioni di supply chain possono essere trattate come cittadini di prima classe, ed è esattamente ciò che abbiamo fatto oggi. Lo strumento non è nemmeno così complesso, almeno se si considera la complessità ambientale del tipico panorama applicativo di una supply chain moderna. Inoltre, uno strumento adeguato sblocca capacità come la regolarizzazione del flusso di inventario dai centri di distribuzione al negozio con uno sforzo minimo. Queste capacità sono facili da raggiungere con lo strumento adeguato, ma illustrano anche il tipo di risultati che non possono mai essere attesi dai fogli di calcolo di Excel, almeno non con una configurazione di produzione.

Credo che sia tutto per oggi. La prossima lezione sarà mercoledì 6 luglio, alla stessa ora, alle 15:00 ora di Parigi. Passerò al settimo capitolo per discutere dell’esecuzione tattica di un’iniziativa di supply quantitativa. A proposito, tornerò al Capitolo 5, discutendo le previsioni probabilistiche, e al Capitolo 6, discutendo le tecniche di decisione, nelle lezioni successive. Il mio obiettivo è avere una prospettiva completa a livello base su tutti gli elementi prima di approfondire un argomento specifico.
Quindi a questo punto, darò un’occhiata alle domande.
Domanda: La zedfunc potrebbe avere infinite possibilità. In tal caso, tutte le soluzioni sarebbero a breve termine?
La zedfunction è letteralmente un contenitore di dati per una sequenza di opzioni, quindi il tipo di orizzonte applicabile è incorporato nel valore alfa, i valori di sconto temporale che ho utilizzato nei miei script. Fondamentalmente, l’orizzonte temporale di destinazione che hai incorporato nel risultato economico di una zedfunction non è realmente nelle zedfunction stesse; sono più nelle sorta di calcoli economici che le riempiono. Non dimenticare che le zedfunction sono solo contenitori di dati. Questo è ciò che le rende a breve o a lungo termine e ovviamente, vuoi regolare le tue ricette numeriche in modo che rappresentino le tue priorità. Ad esempio, se la tua azienda è sotto una grande quantità di stress a causa di problemi di flusso di cassa, probabilmente avrai una prospettiva molto più a breve termine sull’ottenere un’entrata di denaro, quindi fondamentalmente liquidando il tuo inventario. Se sei molto ricco di denaro, forse preferisci ritardare le vendite a un periodo successivo, vendendo a un prezzo migliore e garantendo un margine lordo migliore. Quindi ancora una volta, tutte queste cose sono possibili con le zedfunction. Le zedfunction sono solo contenitori; non presuppongono necessariamente alcun tipo di ricetta numerica per i risultati economici che desideri inserire nelle zedfunction.
Domanda: Penso che la maggior parte delle ipotesi debba essere basata su valori reali esistenti delle funzioni obiettivo, non pensi?
Cosa è reale? Questa è l’essenza del problema che ho discusso nella lezione sull’ottimizzazione sperimentale. Il problema è che ogni volta che dici di avere valori o misurazioni o cose del genere, ciò che hai sono costrutti matematici, costrutti numerici. Non è perché è numerico che è corretto. Il modo in cui affronto una supply chain è come una scienza sperimentale; devi connetterti al mondo reale. Ecco come decidi se è reale o no. La domanda è, e sono completamente d’accordo, che le ipotesi devono essere basate non su valori reali preesistenti perché non esiste una cosa del genere come valori reali preesistenti. Devono essere verificate; quelle ipotesi devono essere verificate e sfidate rispetto alle osservazioni del mondo reale che puoi fare sulla tua supply chain. La correttezza delle tue ipotesi può essere valutata solo attraverso il contatto con la realtà della tua supply chain.
È qui che questa prospettiva di ottimizzazione sperimentale è complicata perché la prospettiva di ottimizzazione matematica assume semplicemente che tutte le variabili siano note, tutte le variabili siano reali, tutte le variabili possano essere osservate e che la funzione di perdita possa essere corretta. Ma il punto che sto facendo è che una supply chain è un sistema super complesso. Non è vero. La maggior parte delle volte, ciò che hai sono misurazioni piuttosto indirette. Quando dico livello di stock, non vado effettivamente nel negozio per verificare se il livello di stock è corretto. Quello che ho è una misurazione molto indiretta, un record elettronico che ho ottenuto da un sistema software aziendale che è stato tipicamente messo in atto due decenni fa per motivi che non avevano nulla a che fare con la scienza dei dati in primo luogo. Questo è ciò che sto dicendo; il problema con la realtà è che una supply chain è sempre geograficamente distribuita, quindi tutto ciò che misuri, tutto ciò che vedi in termini di valori, sono misurazioni indirette. In un certo senso, la realtà di queste misurazioni è sempre in discussione. Non esiste una cosa del genere come un’osservazione diretta. Puoi fare un’osservazione diretta solo per fare un controllo o una verifica, ma non può essere altro che una piccola percentuale di tutti i valori che devi manipolare per la tua supply chain.
Domanda: Nelle funzioni di ricompensa per lo stock, oltre a parametri diretti come il margine, stiamo anche affrontando le penalità per la mancanza di stock. Come possiamo imparare al meglio ad ottimizzare questi parametri complessi?
Questa è una domanda molto interessante. Infatti, le penalità per la mancanza di stock sono reali; altrimenti, nessuno si preoccuperebbe di avere livelli di servizio elevati. Il motivo per cui si desidera avere livelli di servizio è che, dal punto di vista economico, ogni rivenditore che conosco è convinto che le penalità per la mancanza di stock siano reali. I clienti non gradiscono non avere un servizio di alta qualità. Ma non direi che sono complesse; sono complicate. Sono intrinsecamente difficili e parte della loro difficoltà è che è letteralmente in gioco la strategia a lungo termine della rete di vendita al dettaglio. Con la maggior parte dei miei clienti, ad esempio, la penalità per la mancanza di stock è qualcosa di cui discuto direttamente con il CEO dell’azienda. Arriva fino in cima; questa è la strategia a super lungo termine della rete di vendita al dettaglio che è in gioco.
Quindi, non è così complesso, ma è sicuramente complicato perché si tratta di una discussione molto importante. Cosa vogliamo fare? Come vogliamo trattare i clienti? Vogliamo dire di avere i prezzi migliori e scusate se la qualità del servizio non è così buona come potete ottenere, ma quello che avete è qualcosa di unico a prezzi molto bassi? O volete avere novità? Se avete novità, significa che ci sono nuovi prodotti che arrivano tutto il tempo e se ci sono nuovi prodotti che arrivano tutto il tempo, significa che i vecchi prodotti stanno uscendo di scena e quindi significa che dovreste tollerare la mancanza di stock perché è così che si introducono le novità.
La penalità per la mancanza di stock è difficile da valutare perché ha direttamente un impatto significativo sulla strategia a lungo termine dell’azienda. In pratica, il modo migliore per valutarla è fare degli esperimenti. Si sceglie un valore, si fa una stima approssimativa del valore della penalità per la mancanza di stock, del fattore di penalità per lo stock, e poi si guarda che tipo di stock si ottiene nei negozi. Poi si lascia alle persone con le loro sensazioni giudicare se sembra il livello di stock che rifletterebbe il loro negozio ideale. È quello che vogliono davvero per i loro clienti? È quello che vogliono davvero ottenere con la loro rete di vendita al dettaglio?
Vedete, c’è questa discussione avanti e indietro. Tipicamente, lo scienziato della supply chain testerà una serie di valori, presenterà il tipo di risultati economici e spiegherà anche i costi macro che sono collegati a un driver. Potrebbero dire: “Ok, possiamo impostare una penalità per la mancanza di stock molto alta, ma attenzione, se facciamo così, significa che la nostra logica di allocazione dello stock spingerà sempre tonnellate di stock verso i negozi”. Perché se il messaggio è che le mancanze di stock sono mortali, significa che dovremmo davvero fare tutto il possibile per evitarle. Fondamentalmente, abbiamo bisogno di avere questa discussione con molte iterazioni in modo che la direzione possa fare un controllo della realtà: “La mia strategia a lungo termine è economicamente sostenibile rispetto a ciò che la mia rete di vendita al dettaglio può effettivamente fare?” È così che si converge gradualmente. A proposito, non è qualcosa di definitivo. Le aziende cambiano e adattano la loro strategia nel tempo, quindi non è perché si prende un fattore di penalità per la mancanza di stock nel 2010 che nel 2022 deve essere lo stesso valore.
Soprattutto, ad esempio, con la crescita del commercio elettronico. Ci sono molte reti di vendita al dettaglio che dicono semplicemente: “Beh, sono diventato molto più tollerante alle mancanze di stock nei miei negozi, soprattutto per i negozi specializzati”. Perché fondamentalmente, quando manca un prodotto, soprattutto una variante in termini di taglia, le persone lo ordinano semplicemente online dal commercio elettronico. Il negozio diventa come una sala mostra. Quindi la qualità del servizio di una sala mostra diventa molto diversa da quella che ci si aspettava quando il negozio era letteralmente l’unico modo per vendere i prodotti.
Domanda: Possiamo avere una funzione di ricompensa per lo stock composta per capire correttamente la tendenza in un determinato periodo?
Capire la tendenza di cosa esattamente? Se si tratta di una tendenza della domanda, la ricompensa per lo stock è una funzione che consuma una previsione probabilistica. Quindi, qualsiasi tendenza ci sia nella domanda, è tipicamente un fattore del modo in cui si modella la domanda. Per quanto riguarda la funzione di ricompensa per lo stock, la previsione probabilistica già incorpora tutto questo, che ci sia una tendenza o meno.
Ora, se hai un’altra domanda con una prospettiva stazionaria sulla ricompensa per lo stock, hai completamente ragione. La funzione di ricompensa per lo stock ha una prospettiva completamente stazionaria. Assume che la domanda si ripeta probabilisticamente ad ogni periodo esattamente allo stesso modo, quindi non c’è tendenza o stagionalità. È una prospettiva puramente stazionaria. In questa situazione, la risposta è no, la funzione di ricompensa per lo stock non è in grado di gestire una domanda non stazionaria. Tuttavia, la funzione di ricompensa per l’azione è in grado di farlo. Questa è stata anche una delle motivazioni per passare alla funzione di ricompensa per l’azione, in quanto può gestire una domanda probabilistica non stazionaria.
Domanda: Stiamo assumendo che la capacità del magazzino sia fissa, ma dipende dall’effort di picking, packing e shipping. Non dovrebbero i punti di taglio della lista essere definiti dall’ottimizzazione delle operazioni del magazzino?
Sì, assolutamente. È quello che ho detto quando hai questa zona di bassa sensibilità economica. La tua lista di priorità, che rappresenta l’allocazione prioritaria dello stock, non è super sensibile rispetto a dove tagli, purché sia all’interno di questo segmento. In media, dovresti essere davvero equilibrato in termini di quanto spingi e quanto vendi, il che ha senso. Se vuoi regolare leggermente il taglio dopo aver eseguito la logica di ottimizzazione del magazzino, tenendo conto di tutti gli sforzi e le variazioni di picking, packing e shipping, va bene. Puoi avere variazioni dell’ultimo minuto. La bellezza di questa lista di allocazione prioritaria dello stock è che puoi letteralmente finalizzare l’esatto scopo delle unità che vengono spedite all’ultimo minuto. L’unica operazione di cui hai bisogno è un’aggregazione, che può essere fatta molto rapidamente, dando più opzioni. È esattamente quello che ho detto quando ho menzionato che questo approccio apre nuove classi di ottimizzazione della supply chain. Ti permette di decidere all’ultimo momento di riorganizzare i tuoi sforzi di picking, packing e shipping anziché essere rigidamente vincolato a una busta di spedizione preordinata che non corrisponde realmente alle risorse esatte che hai e allo sforzo necessario per eseguire questa busta.
Domanda: Lisciare le fluttuazioni del magazzino richiede un flusso di produzione liscio. Questo modello decisionale lo considera?
Direi che non richiede naturalmente un flusso di produzione liscio. Per molte reti di vendita al dettaglio, come i negozi di articoli vari, ordinano da grandi aziende FMCG che producono lotti molto grandi dal loro lato. Non è necessario lisciare il flusso di produzione per ottenere vantaggi in termini di costi operativi dal centro di distribuzione. Anche se la produzione non è stata lisciata, hai già dei vantaggi nel semplice spostamento delle spedizioni dal centro di distribuzione ai negozi.
Tuttavia, hai assolutamente ragione. Se sei un marchio verticalmente integrato che ha internalizzato le sue strutture di produzione, i centri di distribuzione e i negozi, allora c’è un vivo interesse nel fare un’ottimizzazione dell’intera supply chain e lisciare l’intero flusso. Questo approccio di ottimizzazione a livello di rete è molto in linea con lo spirito di ciò che ho presentato oggi. Tuttavia, se vuoi davvero ottimizzare una vera supply chain multi-anello, avrai bisogno di una tecnica diversa da quella che ho presentato oggi. Ci sono molti blocchi di costruzione che ti permetteranno di farlo, ma non puoi semplicemente modificare gli script che ho presentato oggi per ottenerlo. Questa sarà la sorta di tecnologia in cui copriamo l’ambiente multi-anello, che verrà presentata in lezioni successive. Questo è più complicato.
Domanda: L’approccio della ricompensa per lo stock e l’errore atteso mi ricordano il concetto di valore atteso dalla finanza. Dal tuo punto di vista, perché questo approccio non è ancora diffuso nei circoli della supply chain?
Hai completamente ragione. Queste cose, come un’analisi economica vera e propria dei risultati, sono state fatte da tempo nei circoli finanziari. Credo che la maggior parte delle banche faccia questi calcoli dagli anni ‘80 e probabilmente le persone li facevano anche prima con carta e penna. Quindi sì, è qualcosa che è stato fatto da tempo in altri settori.
Credo che il problema con le supply chain fosse che fino all’avvento di Internet, le supply chain erano geograficamente distribuite per natura, con negozi, centri di distribuzione e altro che erano sparsi. Prima del 1995, era possibile ma molto complicato trasferire dati su Internet per le aziende. Era fattibile, ma farlo in modo affidabile, a buon mercato e avere sistemi aziendali che ti permettessero di consolidare tutti quei dati era raro. Quindi, in sostanza, le supply chain sono state digitalizzate molto presto, negli anni ‘80, ma non erano fortemente interconnesse. L’elemento di interconnessione e tutta l’infrastruttura sono arrivate relativamente tardi, direi dopo il 2000 per la maggior parte delle aziende.
Il problema era che, immagina di operare in un centro di distribuzione ma abbastanza isolato dal resto della rete, quindi il responsabile del magazzino non aveva le risorse per fare queste sofisticate calcolazioni numeriche. Il responsabile del magazzino aveva un magazzino da gestire e di solito non era un analista. Quindi quelle pratiche che precedevano l’era di Internet, in cui tutte le informazioni sono disponibili in tutta la rete, sono persistite. Questo sarebbe il motivo e, a proposito, le supply chain sono tipicamente molto grandi, complesse e complesse, quindi si muovono lentamente.
Avere i dati condivisi in tutta la rete con dei bei data lake, diciamo che fosse il 2010, anche se sono passati 10 anni, quello che osservo è che alcune aziende si stanno muovendo ora, alcune si sono già mosse, ma un decennio non è così lungo considerando la dimensione e la complessità delle supply chain. Ecco perché questi tipi di analisi sono stati la norma nella finanza per circa quattro decenni e stanno emergendo solo ora nella supply chain, o almeno questa è la mia modesta opinione sul caso.
Domanda: E per quanto riguarda il costo di mancata disponibilità, calcolato principalmente sul costo di smarrimento?
Puoi farlo. Di nuovo, il costo di mancata disponibilità è letteralmente una decisione che prendi. È la tua prospettiva strategica sul tipo di servizio che vuoi che la tua rete di vendita al dettaglio offra ai tuoi clienti. Non c’è una realtà di base; è letteralmente ciò che vuoi. La questione del costo di smarrimento è che la realtà è che la maggior parte delle reti di vendita al dettaglio sopravvive solo perché ha una base di clienti fedeli. Le persone tornano nei negozi, che si tratti di un negozio di articoli vari che visitano ogni settimana, un negozio di moda che visitano ogni trimestre o un negozio di mobili in cui tornano ogni due anni. La qualità del servizio è essenziale per mantenere la fedeltà a lungo termine dei clienti e garantire un’esperienza positiva nel tuo negozio. Tipicamente, il costo della perdita di fedeltà per la maggior parte dei negozi supera di gran lunga i costi di smarrimento. Un’eccezione che mi viene in mente sono i negozi al dettaglio con una strategia di marca incentrata sul fatto di essere i più economici. In questo caso, potrebbero sacrificare l’assortimento e la qualità del servizio, dando priorità ai prezzi bassi sopra ogni altra cosa.
Domanda: Qual è l’obiettivo di tenere in magazzino i tuoi prodotti? È quello di mantenere i prodotti a prezzi bassi o di fornire ai negozi prodotti a prezzi più alti?
Questa è una domanda eccellente. Perché tenere in magazzino qualsiasi merce nel centro di distribuzione? Perché non cross-dock tutto direttamente, inviandolo tutto ai negozi?
Ci sono reti di vendita al dettaglio che fanno cross-dock di tutto, ma anche con questo approccio c’è un ritardo tra quando si effettua un ordine ai fornitori e quando si invia effettivamente la merce ai negozi. È possibile ordinare quantità specifiche con uno schema di allocazione particolare in mente, ma si ha la flessibilità di cambiare idea quando la merce viene consegnata al centro di distribuzione. Non è necessario essere rigidamente legati allo schema di allocazione che si aveva in mente due giorni fa.
È possibile decidere di non tenere merce nel centro di distribuzione e fare solo cross-docking, ma a causa del ritardo, è possibile cambiare idea e fare una spedizione leggermente diversa. Questo può essere utile, ad esempio, quando si verifica una carenza di magazzino a causa di un’improvvisa impennata della domanda. Sebbene sia preferibile non avere una carenza di magazzino, indica un eccesso di domanda rispetto a quanto previsto, il che non è del tutto negativo.
In altre situazioni, è necessario tenere merce in magazzino a causa di vincoli di ordinazione con i fornitori. Ad esempio, le aziende FMCG potrebbero consentirti di effettuare un ordine solo una volta alla settimana e di solito vogliono consegnare un carico completo al tuo centro di distribuzione. I tuoi ordini saranno ingombranti e raggruppati e il tuo centro di distribuzione funge da buffer per quelle consegne. Il centro ti offre anche la possibilità di cambiare idea sulla destinazione della merce.
Finché la merce è nel centro di distribuzione, puoi cambiare idea. Tuttavia, una volta allocata a un negozio specifico, il costo del trasporto per riportarla indietro al magazzino è spesso proibitivamente elevato e qualcosa che si vorrebbe evitare.
Grazie mille e spero di vederti la prossima volta. Discuteremo come eseguire strategie tattiche e avviare un’iniziativa di supply chain quantitativa effettiva in un’azienda reale. A presto!


