00:00 Introducción
02:53 Decisiones vs Artefactos
10:07 Optimización experimental
13:51 La historia hasta ahora
17:01 Decisiones de hoy
19:36 El manifiesto de Supply Chain Quantitativa
21:01 El problema de asignación de stock retail
24:49 Fuerzas económicas sobre el SKU de la tienda
29:35 Reificar los futuros
32:41 Reificar las opciones - 1/3
38:25 Reificar las opciones - 2/3
43:02 Reificar las opciones - 3/3
44:44 Función de recompensa de stock - 1/2
51:41 Función de recompensa de stock - 2/2
56:19 Asignaciones de stock priorizadas - 1/4
59:59 Asignaciones de stock priorizadas - 2/4
01:03:39 Asignaciones de stock priorizadas - 3/4
01:06:34 Asignaciones de stock priorizadas - 4/4
01:12:58 Suavizando el flujo en el almacén - 1/2
01:16:48 Suavizando el flujo en el almacén - 2/2
01:22:12 Función de recompensa de acción
01:25:02 El mundo real es desordenado
01:27:38 Conclusión
01:30:00 Próxima conferencia y preguntas de la audiencia
Descripción
Supply chain decisions requieren evaluaciones económicas ajustadas al riesgo. Convertir previsiones probabilísticas en evaluaciones económicas no es trivial y requiere herramientas dedicadas. Sin embargo, la priorización económica resultante, ilustrada por stock allocations, se demuestra más poderosa que las técnicas tradicionales. Empezamos con el desafío de la asignación de stock retail. En una red de 2 niveles que incluye tanto un centro de distribución (DC) como múltiples tiendas, necesitamos decidir cómo asignar el stock del DC a las tiendas, sabiendo que todas las tiendas compiten por el mismo stock.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy presentaré “Retail Stock Allocation with Probabilistic Previsiones.” La asignación de stock retail es un desafío simple pero fundamental: ¿cuándo y cuánta cantidad de stock decides mover en cualquier momento entre los centros de distribución y las tiendas que operas? La decisión de mover stock depende de la demanda futura, por lo que se necesita algún tipo de demand previsión.
Sin embargo, la demanda retail a nivel de tienda es incierta, y la incertidumbre de la demanda futura es irreducible. Necesitamos una previsión que refleje adecuadamente esta incertidumbre irreducible del futuro, por lo que se requiere una previsión probabilística. No obstante, aprovechar al máximo las previsiones probabilísticas para optimize supply chain decisiones es una tarea no trivial. Sería tentador reciclar una técnica de inventario existente que fue diseñada originalmente con una previsión determinista clásico en mente. Sin embargo, hacerlo derrotaría la razón misma por la cual introdujimos las previsiones probabilísticas en primer lugar.
El objetivo de esta conferencia es aprender a aprovechar al máximo las previsiones probabilísticas en su forma nativa para optimizar las decisiones de supply chain. Como primer ejemplo, consideraremos el problema de asignación de stock retail, y mediante el examen de este problema, veremos cómo podemos optimizar realmente el stock level a nivel de tienda. Además, a través del análisis de previsiones probabilísticas, incluso podemos abordar nuevas clases de supply chain problems, tales como suavizar el flujo de inventario desde los centros de distribución hacia las tiendas para optimizar y reducir el costo operacional de la red.
Esta conferencia abre el sexto capítulo de esta serie, que está dedicado a las técnicas y procesos de toma de decisiones en un contexto de supply chain. Veremos que las decisiones deben optimizarse teniendo en cuenta toda la red de supply chain, como un sistema integrado, en lugar de realizar una serie de optimizaciones locales aisladas. Por ejemplo, al tomar una perspectiva reducida del SKU (unidad de mantenimiento de inventario).
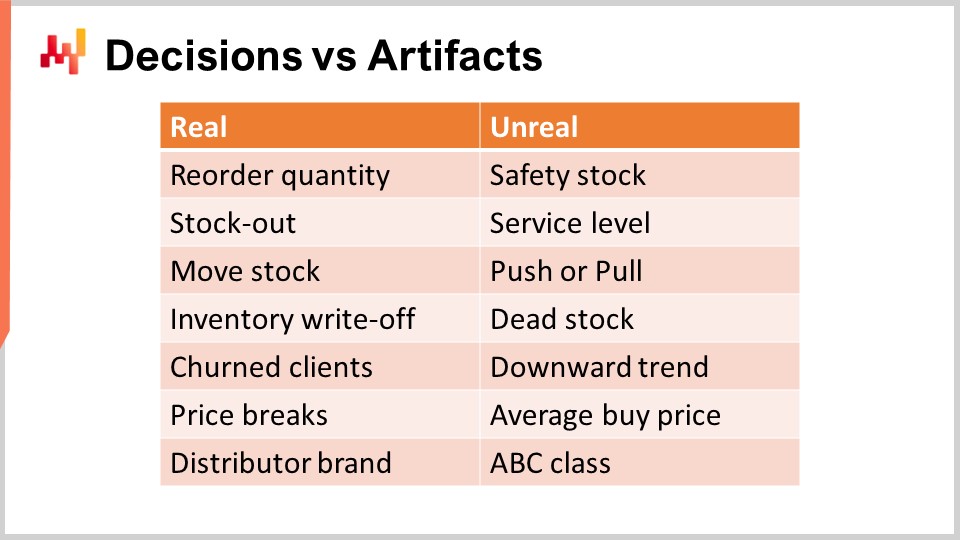
El primer paso para abordar las decisiones de supply chain es identificar las decisiones de supply chain reales. Una decisión de supply chain tiene un impacto directo, físico y tangible en la supply chain. Por ejemplo, mover una unidad de stock del centro de distribución a una tienda es real; tan pronto como haces eso, hay una unidad extra en los estantes de la tienda y hay una unidad que ahora falta en el centro de distribución y que no puede ser reasignada a ningún otro lado.
Por el contrario, un artefacto no tiene un impacto físico tangible directo en la supply chain. Un artefacto es, típicamente, ya sea un paso intermedio de cálculo que finalmente conduce a una decisión de supply chain, o una estimación estadística de algún tipo que caracteriza una propiedad de una parte de tu sistema de supply chain. Desafortunadamente, no puedo evitar observar una gran cantidad de confusión en la literatura de supply chain cuando se trata de distinguir decisiones de artefactos.
Ten en cuenta, los retornos de inversión se obtienen exclusivamente mediante la mejora de las decisiones. Mejorar artefactos casi siempre es intrascendente, y eso es lo mejor. En el peor de los casos, si una empresa gasta demasiado tiempo mejorando artefactos, esto se convierte en una distracción que impide que la empresa mejore sus decisiones reales de supply chain. En la pantalla hay una lista de confusiones que frecuentemente observo en los círculos principales de supply chain.
Por ejemplo, comencemos con safety stock. Este stock no es real; no tienes dos stocks, el safety stock y el working stock. Solo hay un stock, y la única decisión que se puede tomar es si se necesita más o no. Reordering una cantidad es real, pero el safety stock no lo es. De manera similar, el nivel de servicio tampoco es real. El nivel de servicio depende en gran medida del modelo. De hecho, en la demanda retail, los datos de ventas son escasos. Así, si tomas cualquier SKU dado, generalmente tienes muy pocos datos para calcular un nivel de servicio significativo solo inspeccionando el SKU. La forma en que abordas el nivel de servicio es a través de técnicas de modelado y estimaciones estadísticas, lo cual está bien, pero de nuevo, esto es un artefacto, no la realidad. Esta es literalmente una perspectiva matemática que tienes sobre tu supply chain.
De manera similar, push o pull también es una cuestión de perspectiva. Una receta numérica adecuada que opere, teniendo en cuenta toda la red de supply chain, solo considerará la posibilidad de mover una unidad de stock de un origen hacia un destino. Lo que es real es el movimiento de stock; lo que es simplemente una cuestión de perspectiva es si deseas desencadenar este movimiento de stock basado en condiciones relacionadas con el origen o el destino. Esto definirá push o pull, pero es, en el mejor de los casos, una minoritaria tecnicidad de la receta numérica y no representa la realidad fundamental de tu supply chain.
El dead stock es esencialmente una estimación del stock en riesgo de sufrir una baja por inventario en un futuro próximo. Desde la perspectiva de un cliente, no existe algo como dead stock y stock que esté vivo. Ambos son productos que pueden no ser igualmente atractivos, pero el dead stock es simplemente una determinada evaluación del riesgo realizada sobre tu stock. Está bien, pero esto no debe confundirse con las bajas de inventario, que son definitivas e indican que se ha perdido valor.
De manera similar, la tendencia a la baja es también un componente matemático que puede existir en la forma en que modelas la demanda que observas. Normalmente será un factor dependiente del tiempo introducido en el modelo de demanda, como una dependencia lineal al tiempo o tal vez una dependencia exponencial al tiempo. Sin embargo, esto no es la realidad. La realidad podría ser que tu negocio está disminuyendo debido a la pérdida de clientes, por lo que el churn es, entre otras posibilidades, la realidad del supply chain. La tendencia a la baja es meramente un artefacto que puedes usar para agregar el patrón.
De manera similar, ningún proveedor te venderá nada al precio promedio de compra. La única realidad es que compones una orden de compra, eliges cantidades, y dependiendo de las cantidades seleccionadas, podrás aprovechar descuentos que tus proveedores puedan ofrecer. Obtendrás precios de compra basados en esos descuentos y en lo que negocies adicionalmente. El precio promedio de compra no es real, así que ten cuidado de no cometer errores al tomar estos artefactos numéricos como si tuvieran algún elemento de verdad fundamental.
Por último, la clasificación ABC, que abarca desde los más vendidos hasta los de lenta rotación, es solo una clasificación trivial impulsada por el volumen de los SKUs o productos que tienes. Estas clases no son atributos reales. Típicamente, la mitad de los productos cambiará de una clase ABC a la siguiente de un trimestre a otro, aunque en realidad no ocurrió nada en los ojos de los clientes o del mercado para esos productos. Es simplemente un artefacto numérico que se ha aplicado al producto y no debe confundirse con atributos profundamente relevantes, como si un producto forma parte de una marca distribuidora. Este es un atributo fundamental verdadero del producto que tiene consecuencias de gran alcance para tu supply chain. En este capítulo, debería quedar cada vez más claro por qué es imperativo centrarse en las decisiones de supply chain, en lugar de perder tiempo y atención tratando artefactos numéricos.
Cuando se pronuncia la palabra “optimization”, la perspectiva habitual que viene a la mente para una audiencia bien educada es la perspectiva de mathematical optimization. Dado un conjunto de variables y una loss function, el objetivo es identificar los valores de las variables que minimicen la loss function. Desafortunadamente, este enfoque funciona mal en supply chain porque asume que las variables relevantes se conocen, lo cual generalmente no es el caso. Incluso cuando es así, hay muchas variables, como los datos meteorológicos, que se sabe que tienen un impacto en tu supply chain pero que implican muchos costos si deseas adquirir estos datos. Por lo tanto, no está claro si vale la pena el esfuerzo de adquirir estos datos para optimizar tu supply chain.
Aún más problemático, la loss function en sí misma es en gran medida desconocida. La loss function se puede estimar de alguna manera, pero solo la confrontación de la loss con el feedback del mundo real que puedes obtener de tu supply chain te dará información válida sobre la adecuación de esta loss function. No se trata de una cuestión de corrección desde una perspectiva matemática; es una cuestión de adecuación. ¿Refleja adecuadamente esta loss function, que es un constructo matemático, lo que intentas optimizar en tu supply chain? Abordamos este enigma de realizar optimization mientras no conocemos las variables y la loss function en la Conferencia 2.2, titulada “Optimización experimental.” La perspectiva de optimización experimental sostiene que el problema no es dado; el problema debe ser descubierto a través de experimentos repetidos e iterados. La prueba de la corrección de la loss function y sus variables emerge no como una propiedad matemática, sino a través de una serie de observaciones impulsadas por experimentos bien elegidos obtenidos del propio supply chain. La optimización experimental desafía profundamente la forma en que vemos la optimization, y esta es una perspectiva que adoptaré en este capítulo. Las herramientas y técnicas que presentaré aquí están orientadas hacia la perspectiva de optimización experimental.
En cualquier momento, la receta numérica que tenemos puede ser declarada obsoleta, y puede ser reemplazada por una receta numérica alternativa que se considere más alineada con el supply chain que poseemos. Por lo tanto, en cualquier momento, deberíamos ser capaces de poner en producción la receta numérica que tenemos y realizar el proceso de optimization a gran escala. Por ejemplo, no podemos decir que identificamos la loss function y luego poner a un equipo de data scientists a trabajar en el caso durante tres meses para diseñar algunas técnicas de optimization de software. En cambio, cada vez que tengamos una nueva receta, deberíamos ser capaces de ponerla directamente en producción y permitir de inmediato que las decisiones de supply chain se beneficien de esta nueva forma identificada del problema.
Esta conferencia es parte de una serie de conferencias de supply chain. Estoy intentando mantener estas conferencias algo independientes, pero hemos pasado un punto en el que tiene más sentido ver estas conferencias en secuencia. Si no has visto las conferencias anteriores, debería estar bien, pero esta serie probablemente tendrá más sentido si la ves en el orden en que fue presentada.
En el primer capítulo, presenté mis puntos de vista sobre supply chain tanto como campo de estudio como práctica. En el segundo capítulo, presenté una serie de metodologías esenciales para abordar los desafíos de supply chain, incluida la optimización experimental. Estas metodologías son necesarias debido a la naturaleza adversaria de la mayoría de los problemas de supply chain. En el tercer capítulo, me centré en los problemas en sí, en oposición a las soluciones. En el cuarto capítulo, presenté una serie de campos que no son exactamente supply chain per se – las ciencias auxiliares de supply chain – que son esenciales para una práctica moderna de supply chain. En el quinto capítulo, presenté una serie de técnicas de modelado predictivo, sobre todo previsiones probabilísticas, que son esenciales para enfrentar la incertidumbre irreducible del futuro.
Hoy, en esta primera conferencia del sexto capítulo, profundizamos en las técnicas de toma de decisiones. La literatura científica ha ofrecido una abundancia de técnicas y algoritmos de toma de decisiones durante las últimas siete décadas, desde la programación dinámica en los años 50 hasta el reinforcement learning e incluso deep reinforcement learning. El desafío, sin embargo, es lograr resultados de supply chain a nivel de producción. De hecho, la mayoría de estas técnicas sufren defectos ocultos que las hacen poco prácticas para los propósitos de supply chain por una u otra razón. Hoy, nos centramos en la asignación de stock en retail como el arquetipo de una decisión de supply chain. Esta conferencia allana el camino para decisiones y situaciones más complejas.
En la pantalla se muestra el resumen de la conferencia de hoy. Incluso al considerar el problema de supply chain más simple, la asignación de stock en retail, tenemos mucho terreno que cubrir. Estos elementos representan bloques fundamentales para situaciones más complejas. Comenzaré repasando el manifiesto de Supply Chain Quantitativa. Luego, aclararé a qué me refiero con el problema de asignación de stock en retail. También revisaremos las fuerzas económicas presentes en este problema. Repasaré la noción de previsión probabilística y cómo los representamos en la práctica, o al menos una de las opciones para representarlos. Veremos cómo modelar la decisión refinando la previsión y afinando las opciones, que son las decisiones potenciales candidatas.
Luego, introduciremos la función de recompensa de stock. Esta función puede verse como un marco mínimo para convertir una previsión probabilística en una puntuación económica que puede asociarse a cada opción de asignación de stock, teniendo en cuenta una serie de factores económicos. Una vez que las opciones se puntúan, podemos proceder con una lista de prioridades. Una lista de prioridades es aparentemente simple, pero resulta ser increíblemente poderosa y práctica en supply chains del mundo real, tanto en términos de estabilidad numérica como en características de white-boxing.
Con la lista de prioridades, podemos suavizar casi sin esfuerzo el flujo de inventario desde el centro de distribución hacia las tiendas, reduciendo el costo operativo del centro de distribución. Finalmente, realizaremos un breve repaso de la función de recompensa de acción, la cual hoy en día reemplaza a la función de recompensa de stock en Lokad en prácticamente todas las dimensiones, salvo en la simplicidad.
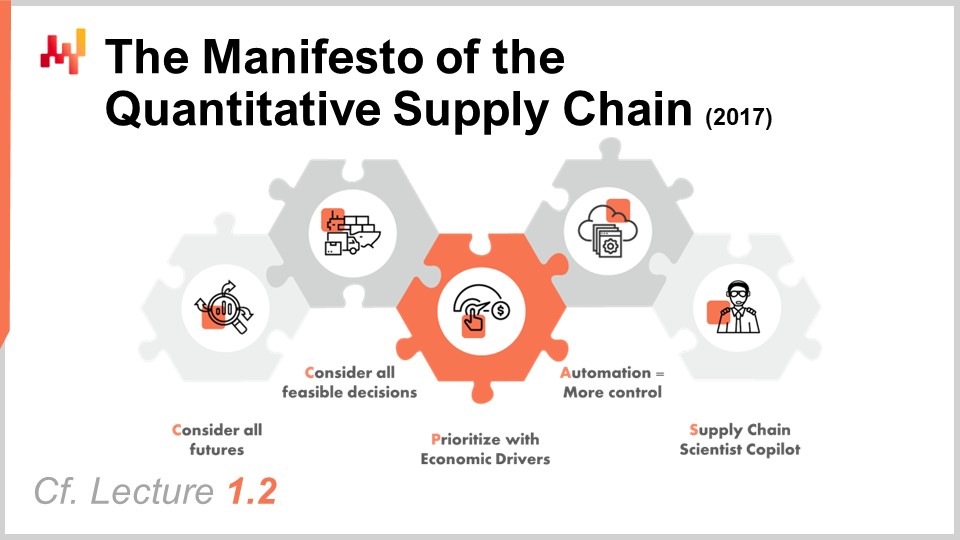
El manifiesto de Supply Chain Quantitativa es un documento que publiqué originalmente en 2017. Esta perspectiva ha sido ampliamente tratada en la Conferencia 1.2, pero para efectos de claridad, proporcionaré un breve resumen hoy. Hay cinco pilares, pero sólo los primeros tres son relevantes para nosotros hoy. Los primeros tres pilares son:
Considerar todos los futuros posibles, lo que significa previsiones probabilísticas así como pronosticar todos los demás elementos con un aspecto de incertidumbre, tales como tiempos de entrega variables o precios futuros. Considerar todas las decisiones factibles, centrándose en las decisiones y no en artefactos. Priorizar con impulsores económicos, que es el tema de la conferencia de hoy.
En particular, veremos cómo podemos convertir previsiones probabilísticas en estimaciones de retornos económicos.
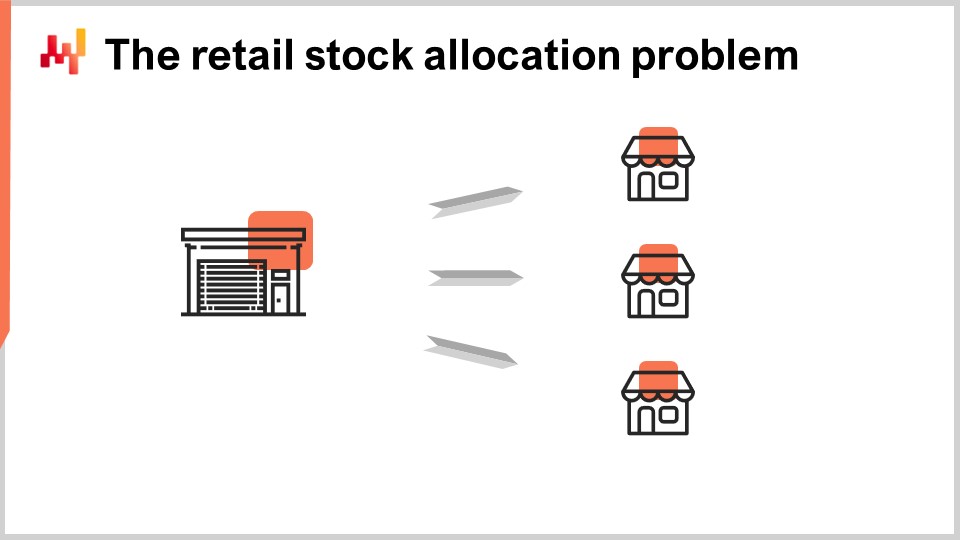
En el problema de asignación de stock en retail. Esta es una definición que estoy dando; es algo arbitraria, pero es la definición que utilizaré hoy. Asumimos una red con dos escalones: tenemos un centro de distribución y múltiples tiendas. El centro de distribución atiende a todas las tiendas, y si hay múltiples centros de distribución, asumimos que una tienda es atendida por un único centro de distribución. El objetivo es asignar adecuadamente el stock existente en el centro de distribución entre las tiendas, y todas las tiendas compiten por el mismo stock que existe en el centro de distribución.
Asumimos que todas las tiendas pueden reabastecerse a diario con un horario diario desde el centro de distribución. Así, cada día, debemos decidir cuántas unidades mover para cada producto hacia cada tienda. La cantidad total de unidades movidas no puede exceder el stock disponible en el centro de distribución, y también es razonable esperar que existan límites de capacidad en las estanterías de las tiendas. Si el centro de distribución tuviera stocks ilimitados, el problema se convertiría en un supply chain de un solo escalón, ya que nunca habría necesidad de realizar ningún tipo de arbitraje o compromiso entre asignar el stock a una tienda u otra. La propiedad de dos escalones de la red sólo surge debido al hecho de que las tiendas compiten por el mismo stock.
Naturalmente, asumiremos visibilidad sobre las ventas en tienda y los niveles de stock tanto a nivel del centro de distribución como de la tienda, lo que significa que presumeos que los datos transaccionales están disponibles. También asumiremos que las entregas entrantes que se realizarán en el centro de distribución se conocen con tiempos estimados de llegada (ETAs), que pueden venir con cierto grado de incertidumbre. Además, asumimos que toda la información mundana pero crítica está disponible, como el precio de compra del producto, el precio de venta, las categorías del producto en caso de existir, etc. Toda esta información se encontraría en cualquier ERP, incluso de hace tres décadas, así como en WMS y en sistemas de punto de venta.
Hoy, no incluimos el reabastecimiento del centro de distribución (DC) como parte del problema. En la práctica, el reabastecimiento del centro de distribución y las asignaciones a tiendas están estrechamente acoplados, por lo que tiene sentido abordar esos problemas conjuntamente. La razón por la que no lo hago hoy es por claridad y concisión en esta conferencia; abordaremos primero el problema más simple. Sin embargo, ten en cuenta que el enfoque que presento hoy puede extenderse naturalmente para incluir también el reabastecimiento del DC.

Decidir mover una unidad adicional de stock a una tienda para un producto determinado en un día dado depende de una serie de fuerzas económicas. Si mover la unidad es rentable, queremos hacerlo; de lo contrario, no lo hacemos. Las principales fuerzas económicas se enumeran en la pantalla y, esencialmente, colocar más stock en una tienda resulta en una serie de beneficios. Estos incluyen un mayor gross margin debido a evitar ventas perdidas, una mejor calidad de servicio al reducir la cantidad de faltantes de stock, y una mayor atractividad de la tienda. De hecho, para que una tienda sea atractiva, necesita parecer abundante; de lo contrario, se ve triste y la gente puede estar menos dispuesta a comprar. Esta es una observación común en el retail, aunque puede no aplicarse necesariamente a todos los segmentos, como hard luxury. Para tiendas de mercancía general o de moda, sin embargo, esta consideración aplica.
Desafortunadamente, colocar más stock también conlleva inconvenientes, disminuyendo el retorno que se podría esperar de tener más stock en la tienda. Estos inconvenientes incluyen costos adicionales de mantenimiento de inventario, los cuales pueden derivar en bajas de inventario si existe un verdadero exceso de stock. También existe el riesgo de sobrecarga en la recepción, que ocurre si el personal de la tienda no puede procesar un envío que es demasiado grande. Esto crea confusión y desorden en la tienda si la cantidad entregada excede lo que el personal puede colocar en las estanterías. Además, existe un costo de oportunidad: cada vez que se coloca una unidad en una tienda, no puede colocarse en otra. Aunque podría devolverse al centro de distribución y reenviarse, esto suele ser bastante costoso, por lo que generalmente es una opción de último recurso. Los minoristas deben aspirar a una asignación de stock en tiendas eficiente sin tener que devolver el stock.
Suavizar el flujo de inventario también es altamente deseable. Un centro de distribución (DC) tiene una capacidad nominal a la que opera con la máxima eficiencia económica. Esta eficiencia máxima se debe tanto a la configuración física del DC como al número de personal permanente asignado. Idealmente, el DC debería operar a diario, manteniéndose muy cerca de su capacidad nominal para ser lo más rentable posible. Sin embargo, mantener la eficiencia máxima en el centro de distribución requiere suavizar el flujo desde el DC hacia las tiendas. La perspectiva económica difiere de las perspectivas tradicionales orientadas al nivel de servicio que se observan a menudo en la literatura general de supply chain. Buscamos dólares de retorno, no puntos porcentuales. La única forma de decidir si es razonable ajustar el esquema de asignación de stock a nivel de red para reducir los costos operativos, frente a una leve degradación de la calidad de servicio en las tiendas, es adoptar la perspectiva económica presentada aquí. Si adoptas una perspectiva orientada al nivel de servicio, no puede proporcionar este tipo de respuestas. Nuestro objetivo en este punto es establecer recetas numéricas que estimen los resultados económicos para cualquier decisión de asignación de stock.
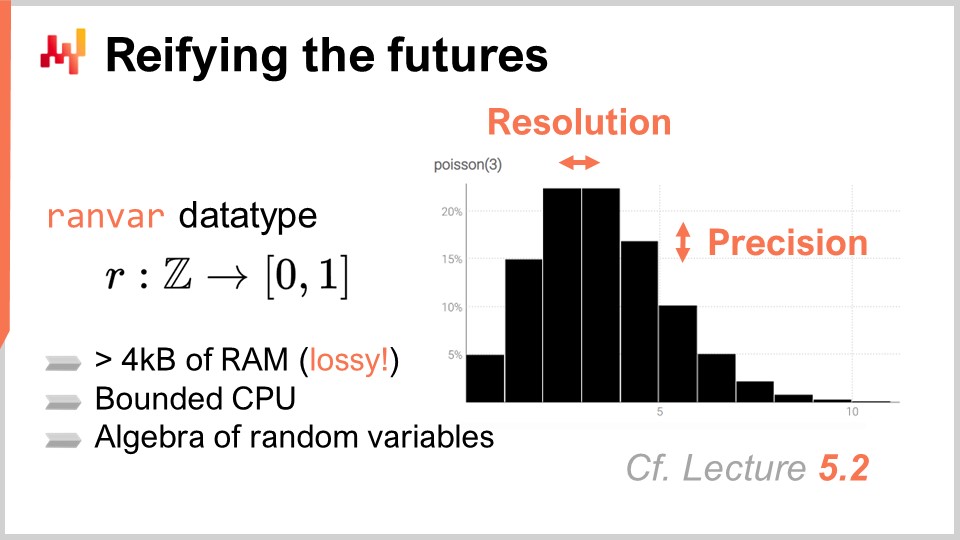
En el capítulo anterior, el quinto capítulo, discutimos cómo producir previsiones probabilísticas e introdujimos un tipo de dato especializado, el “ranvar”, que representa distribuciones de probabilidad discretas unidimensionales. En resumen, un ranvar es un tipo de dato especializado utilizado para representar un simple previsión probabilística unidimensional en Envision.
Envision es un lenguaje de programación específico de dominio diseñado por Lokad con el único propósito de la optimización predictiva de supply chains. Aunque no hay nada fundamentalmente único en Envision en estas conferencias, se utiliza por la claridad y concisión en la presentación. Las recetas numéricas descritas hoy se pueden implementar en cualquier lenguaje, como Python, Julia o Visual Basic.
El aspecto clave de ranvar es que proporciona un álgebra de variables aleatorias de alto rendimiento. El rendimiento es un equilibrio entre el costo computacional, el costo de memoria y el grado de aproximación numérica que estás dispuesto a tolerar. El rendimiento computacional es crítico al tratar con redes de retail, ya que puede haber millones o incluso decenas de millones de SKUs, cada uno de los cuales probablemente tenga al menos una previsión probabilística o ranvar. En consecuencia, podrías terminar con millones o decenas de millones de histogramas.
La propiedad clave del ranvar en comparación con un histograma es mantener tanto el costo de CPU como el de memoria acotados y lo más bajos posible. También es crucial asegurar que la aproximación numérica introducida sea intrascendente desde la perspectiva del supply chain. Es importante notar que no estamos lidiando con computación científica aquí, sino con computación de supply chain. Aunque los cálculos numéricos deben ser precisos, no es necesario alcanzar una precisión extrema. Recuerda que no estamos haciendo computación científica aquí; estamos haciendo computación de supply chain. Si tienes una aproximación de una parte por billón, es insignificante desde la perspectiva del supply chain. Los cálculos numéricos deben ser precisos, pero no se requiere una precisión extrema.
A continuación, asumimos que la previsión probabilística se proporcionará bajo la forma de ranvars, que son una serie de variables con un tipo de dato específico. En la práctica, puedes reemplazar los ranvars por histogramas y lograr en su mayoría el mismo resultado, salvo en los aspectos de rendimiento y conveniencia.
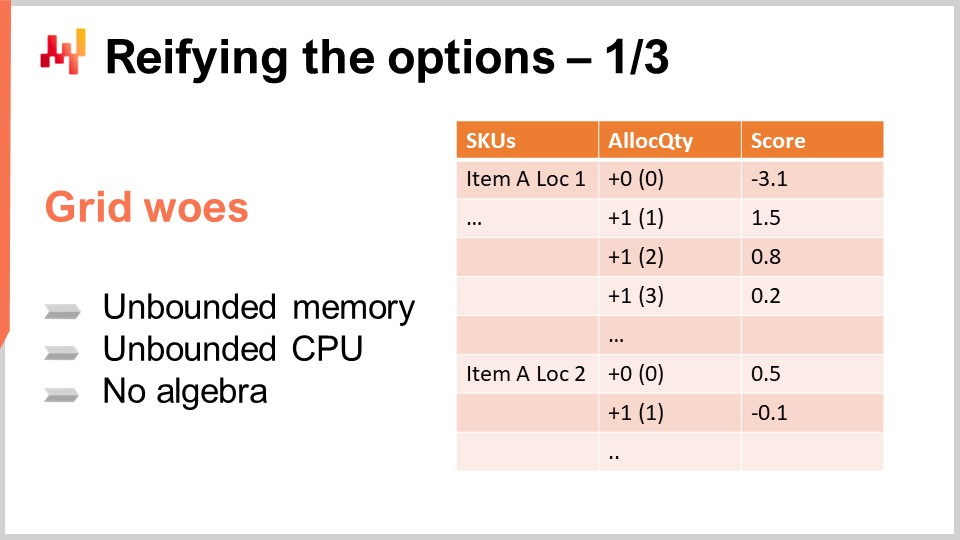
Ahora que tenemos nuestros previsiones probabilísticas, consideremos cómo abordaremos las decisiones. Empecemos por considerar las opciones. Las opciones son las decisiones potenciales – por ejemplo, asignar cero unidades para un producto determinado a una tienda en un día dado o asignar una, dos o tres unidades. Si decidimos asignar dos unidades, entonces esa se convierte en nuestra decisión. Las opciones son todas las posibilidades sobre la mesa a la espera de ser decididas.
Una manera simple de organizar estas opciones es ponerlas en una lista, tal como se muestra en la pantalla. La lista abarca múltiples SKUs, y para cada SKU se añade una línea por opción. Cada opción representa una cantidad a asignar. Puedes asignar cero, una, dos, tres, etc. En realidad, no es necesario llegar hasta el infinito; puedes detenerte en la cantidad en stock en el centro de distribución. Más realísticamente, usualmente tienes un límite inferior, como la capacidad máxima de estantería para el producto en la tienda.
Entonces, tienes una lista que incluye cada SKU, y para cada uno, dispones de todas las cantidades que pueden considerarse como candidatas para la asignación desde el centro de distribución. La columna de puntuación está asociada al resultado marginal que se esperaría al realizar esta asignación. Una puntuación bien diseñada asegura que seleccionar las líneas en orden decreciente de puntuación optimice el resultado económico para la red retail.
Para los dos SKUs mostrados en la pantalla, la puntuación disminuye a medida que aumenta la asignación, ilustrando el fenómeno dominante de retornos decrecientes observado en la mayoría de los SKUs. Esencialmente, colocar la primera unidad en una tienda casi siempre genera mayores retornos que la segunda. La primera unidad que colocas en una tienda casi siempre es más rentable que la segunda. Inicialmente, no tienes nada, por lo que te encuentras en una situación de faltante de stock. Si colocas una unidad, ya has solucionado el faltante de stock para el primer cliente. Si colocas una segunda unidad, el primer cliente estará bien, pero solo si se presentan dos clientes la segunda unidad tendrá alguna utilidad, por lo que su retorno económico es menor. Sin embargo, los retornos generalmente disminuyen a medida que aumenta el stock. Hay algunas excepciones en las que los retornos económicos podrían no disminuir estrictamente de una línea a la siguiente, pero revisaré este caso en una conferencia posterior. Por ahora, nos limitaremos a la situación simple en la que los retornos disminuyen estrictamente conforme aumenta el stock.
La representación que tenemos, donde se pueden ver todos los SKUs y opciones, se conoce típicamente como una cuadrícula. La intención es ordenar esta cuadrícula en orden decreciente de ROI (retorno sobre la inversión). No hay nada malo con estas cuadrículas per se, pero no son muy eficientes, especialmente en términos de computación o memoria, y no ofrecen soporte adicional más allá de ser una gran tabla. Ten en cuenta que estamos hablando de una red retail, y esta cuadrícula podría terminar teniendo alrededor de mil millones de líneas. El big data está bien, pero los datos más pequeños son mejores, ya que crean menos fricción y permiten mayor agilidad. Queremos intentar transformar nuestro problema de big data en uno de datos pequeños, ya que esto hace que todo sea más sencillo en producción.

Así, una de las soluciones adoptadas por Lokad para lidiar con un gran número de opciones es zedfuncs. Este tipo de dato, al igual que ranvars, es la contraparte de ranvar pero desde la perspectiva de la decisión. Los ranvars representan todos los posibles futuros, mientras que los zedfuncs representan todas las posibles decisiones. En lugar de representar probabilidades como los ranvars, un zedfunc representa todos los resultados económicos asociados con una serie discreta unidimensional de opciones.
El zedfunc, o zedfunction, es técnicamente una función que mapea enteros, tanto positivos como negativos, a valores reales. Esta es la definición técnica. Sin embargo, al igual que con los ranvars, no es posible representar cualquier función arbitraria o compleja como zedfuncs con una cantidad finita de memoria. En este caso, también hay un compromiso entre precisión y resolución.
En la gestión de supply chain, no existen funciones económicas arbitrariamente complejas. Puedes tener funciones de costo bastante complejas, pero no pueden ser arbitrariamente complejas. En la práctica, es posible comprimir los zedfuncs a menos de cuatro kilobytes. Al hacer esto, tienes un tipo de dato que representa toda tu función de costo y se comprime de modo que siempre se mantiene por debajo de cuatro kilobytes, manteniendo el grado de aproximación numérica inconsecuente desde una perspectiva de supply chain. Si mantienes la aproximación numérica tan pequeña que no cambia la decisión final que estás a punto de tomar, la cual es discreta, entonces se puede decir que la aproximación numérica es completamente inconsecuente porque terminas haciendo lo mismo al final, incluso si tuvieras precisión infinita.
La razón de usar cuatro kilobytes está relacionada con el hardware de computación. Como hemos visto en una conferencia anterior sobre hardware de computación moderno para la gestión de supply chain, la memoria de acceso aleatorio (RAM) en una computadora moderna, ya sea una estación de trabajo, un notebook o una computadora en la nube, no te permite acceder a la memoria byte por byte. Tan pronto como tocas la RAM, se recupera un segmento de cuatro kilobytes. Por lo tanto, es mejor mantener la cantidad de datos por debajo de cuatro kilobytes porque coincidirá con la forma en que el hardware está diseñado y opera para tu supply chain.
El algoritmo de compresión utilizado por Lokad para los zedfuncs difiere del utilizado para los ranvars porque no nos enfrentamos a los mismos problemas numéricos. Para los ranvars, nos importa principalmente preservar la masa de probabilidades de nuestros segmentos contiguos. Para un zedfunc, el enfoque es diferente. Normalmente, queremos preservar la cantidad de variación observada de una posición a la siguiente, ya que es con esta variación que podemos decidir si es la última opción rentable o si debemos detenernos. Por lo tanto, el algoritmo de compresión también es diferente.

En la pantalla, puedes ver un gráfico obtenido para un zedfunc que refleja algunos costos de mantenimiento esperados que dependen del número de unidades en stock. Los zedfuncs se benefician de ser un espacio vectorial, lo que significa que se pueden sumar y restar, al igual que el espacio vectorial clásico asociado con las funciones. Al preservar la localidad en memoria, las operaciones se pueden realizar una orden de magnitud más rápido en comparación con una implementación ingenua de cuadrícula en la que tienes una tabla muy grande sin una estructura de datos específica para capturar la localidad de las opciones que interactúan.
El gráfico que viste en la diapositiva anterior fue generado por un script. En las líneas uno y dos, declaramos dos funciones lineales, f y g. La función “linear” es parte de la biblioteca estándar, y “linear of one” es simplemente la función identidad, un polinomio de grado uno. La función “linear” devuelve un zedfunc, y es posible sumar una constante a un zedfunc. Tenemos dos polinomios de grado uno, f y g. En la línea tres, construimos un polinomio de segundo grado mediante el producto de f y g. Las líneas 5 a 10 son utilidades, esencialmente código boilerplate, para graficar el zedfunc.
En este punto, tenemos nuestro contenedor de datos para el zedfunc y los resultados económicos. El zedfunc es un contenedor de datos, al igual que lo fue el ranvar para la previsión probabilística. Sin embargo, aún necesitamos recetas numéricas para calcular esos resultados económicos. Tenemos el contenedor de datos, pero aún no he descrito cómo computamos esos resultados económicos y llenamos los zedfuncs.

La función de recompensa de stock es un pequeño marco destinado a calcular los retornos económicos para cada nivel de stock de un único SKU, considerando una previsión probabilística y una corta serie de factores económicos. La función de recompensa de stock fue introducida históricamente en Lokad para unificar nuestras prácticas. En 2015, Lokad ya llevaba trabajando durante un par de años con previsiones probabilísticas, y mediante ensayo y error, ya habíamos descubierto una serie de recetas numéricas que funcionaban bien. Sin embargo, no estaban realmente unificadas; era un poco un caos. La función de recompensa de stock consolidó todas esas ideas en ese momento en un marco limpio, ordenado y minimalista. Desde 2015 se han desarrollado mejores métodos, pero también son más complejos. Por claridad, sigue siendo mejor comenzar con la función de recompensa de stock y presentar esta función primero.
La función de recompensa de stock se trata realmente de encontrar una receta numérica que nos proporcione un cálculo para los resultados económicos asociados con esos previsiones probabilísticas. La función de recompensa de stock obedece la ecuación que puedes ver en la pantalla, y define los retornos económicos en el tiempo t que puedes obtener para el stock en mano, k. La variable R representa el retorno económico, que se expresa en unidades como dólares o euros. La función tiene dos variables: tiempo (t) y stock en mano (k). Queremos calcular esta recompensa para todos los niveles de stock posibles.
Hay cuatro variables económicas a considerar:
M es el margen bruto por unidad vendida. Es el margen que obtendrás al servir exitosamente una unidad. S es la penalización por faltante de stock, una especie de costo virtual que incurres cada vez que fallas en servir una unidad a un cliente. Incluso si no tienes que pagar una penalización a tu cliente, existe un costo asociado con no proporcionar un servicio adecuado, y este costo debe modelarse. Una de las formas más simples de modelar este costo es asignar una penalización por cada unidad que no logres servir. C es el costo de mantenimiento, el costo por unidad por periodo de tiempo. Si tienes una unidad en stock durante tres periodos, eso sería tres veces C; si tienes dos unidades en stock durante tres periodos, serían seis veces C. Alpha se utiliza para descontar los retornos futuros. La idea es que lo que sucede en un futuro lejano importa menos que lo que está a punto de suceder en el corto plazo. La función de recompensa de stock es tan simple como se puede ser sin resultar excesivamente simplista. La ecuación indica que si la demanda excede el stock en mano, el retorno incluye el margen de todas las unidades que tenemos.
Esto es lo que dice la primera línea: tenemos k márgenes, así que vendemos todas las unidades que tenemos, y luego incurremos en una penalización que será Y(t) - k por todas las unidades que fallamos en servir.
De lo contrario, si el stock en mano excede la demanda, podemos beneficiarnos de Y(t) multiplicado por M, que representa el margen de lo que se ha vendido hoy. Luego, tenemos que pagar por los costos de mantenimiento. Los costos de mantenimiento de hoy serán lo que quede al final del día, que es (k - Y(t)) por C, más alpha por la función de recompensa de stock R* para el día siguiente.
Hay una complicación con R*. Es casi idéntica a la función de recompensa de stock R, excepto que simplemente establecemos la penalización por faltante de stock a cero. La razón es sencilla: asumimos desde la perspectiva del stock que tendremos oportunidades posteriores para reabastecer. Si observamos un faltante de stock hoy, es demasiado tarde, por lo que incurres en la penalización por faltante de stock. Sin embargo, una penalización por faltante de stock que se considere que ocurrirá mañana se considera evitable.
Sin embargo, una penalización por faltante de stock que se considere que ocurrirá en el futuro, en un periodo posterior, se asume que el reabastecimiento puede ocurrir en cada periodo. Así, para el faltante de stock que ocurriría en un periodo posterior, cuando aún tenemos tiempo para hacer un reorden tardío, el faltante de stock aún no ha ocurrido. Todavía tenemos la oportunidad de hacerlo, y por eso establecemos la penalización por faltante de stock a cero, anticipando que, con suerte, habrá otro reorden que evite que ocurra el faltante de stock.
El descuento temporal alpha es muy útil porque esencialmente elimina la necesidad de especificar un horizonte temporal específico. La función de recompensa de stock no funciona con un horizonte temporal finito; se extiende hasta el infinito. Gracias a alpha, que es un valor estrictamente menor que uno, los resultados económicos asociados con eventos en un futuro muy lejano se vuelven insignificantes, por lo que resultan inconsecuentes. No tenemos ningún tipo de corte, el cual siempre es arbitrario, como recortar el horizonte de supply chain a 60 días, 90 días, un año o dos años.

En Envision, la función de recompensa de stock toma un ranvar como entrada y devuelve un zedfunc. La función de recompensa de stock es un pequeño bloque de construcción que transforma una previsión probabilística (un ranvar) en un zedfunc, que es un contenedor para los retornos económicos estimados sobre una serie de opciones. Como su nombre lo indica, la función de recompensa de stock es el retorno económico asociado con cada posición de stock individual: lo que sucede si tengo cero unidades en stock, una unidad en stock, dos unidades, tres unidades, y así sucesivamente. El zedfunc reflejará los resultados económicos para cada nivel de stock, codificando el retorno económico asociado con el correspondiente nivel de stock.
El proceso para calcular estos zedfuncs se ilustra en la pantalla. En la línea 1, introducimos una demanda simulada para un solo día, que es simplemente una distribución de Poisson aleatoria. En las líneas 2 a 7, introducimos las variables económicas, y por cierto, tenemos dos alphas. Hay otra complicación: tenemos un efecto ratchet en el inventario. Una vez que el stock ha sido empujado hacia la tienda, normalmente es muy costoso devolverlo. Esto refleja que cualquier asignación hecha a una tienda es prácticamente definitiva. En términos de costos de mantenimiento, el alpha no debería ser demasiado pequeño, ya que incurriríamos en esos costos si sobrecargamos de stock. No podemos deshacer esta decisión. Sin embargo, en lo que respecta al alpha relacionado con el margen, la realidad es que, así como tendremos otras oportunidades para abordar futuros faltantes de stock, tendremos otras oportunidades para traer más stock y obtener el mismo margen con stock que se empuja en una fecha posterior. Por lo tanto, necesitamos descontar de manera mucho más agresiva lo que sucede en el lado del margen en comparación con lo que sucede en el lado de los costos de mantenimiento.
En las líneas 9 a 11, introducimos la propia función de recompensa de stock. Esta función, la función de recompensa de stock que presenté en la diapositiva anterior, se puede descomponer linealmente en sus tres componentes, abordando respectivamente el margen, el costo de mantenimiento y la penalización por faltante de stock por separado. De hecho, tenemos una separación lineal, y en Envision, estos tres componentes se calculan por separado. Podemos multiplicar el zedfunc por el factor M, que sería el margen bruto.
En las líneas 13 a 15, la recompensa final se recompone sumando los tres componentes económicos. En este script, estamos aprovechando el hecho de que tenemos un espacio vectorial de zedfuncs. Estos zedfuncs no son números; son funciones. Pero podemos sumarlos, y el resultado de la suma es otra función, que también es un zedfunc. La variable reward es el resultado de sumar esos tres componentes. Bajo el capó, el cálculo de la función de recompensa de stock se realiza mediante un análisis de punto fijo, que se puede hacer en tiempo constante para cada componente. Este cálculo en tiempo constante podría parecer una pequeñez técnica, pero cuando se trata de una red de retail grande, marca la diferencia entre un prototipo elegante y una solución de producción de grado real.

Ahora, en este punto, hemos consolidado todos los ingredientes necesarios para abordar el problema de asignación de stock. Tenemos previsiones probabilísticas expresados como ranvars, una técnica para transformar estos ranvars en una función que da los retornos económicos para cualquier valor de stock en mano, y esos resultados económicos se pueden representar convenientemente como zedfuncs. Para finalmente abordar el problema de asignación de stock, necesitamos responder a la pregunta clave: si solo podemos mover una única unidad de stock, ¿cuál movemos y por qué? Todas las tiendas en la red están compitiendo por el mismo stock en el centro de distribución, y la calidad de la decisión de mover una unidad de stock del centro de distribución a una tienda específica depende del estado general de la red. No puedes evaluar si esta decisión es buena solo observando una tienda.
Por ejemplo, supongamos que tenemos una tienda que ya posee dos unidades en stock, y si añadimos una tercera unidad, aumentamos la previsión esperado de servicio del 80% al 90%. Esto es bueno, y quizás más dentro de la red estarían de acuerdo con la idea de traer una unidad extra para que el nivel de servicio pase del 80 al 90. Eso parece muy razonable, por lo que dirían que es un buen movimiento. Sin embargo, ¿qué pasa si esta unidad que estamos a punto de mover, esta tercera unidad, es en realidad la última disponible en el centro de distribución? Tenemos otra tienda en la red que ya sufre un faltante de stock, y si movemos esta unidad a la tienda donde se convierte en la tercera unidad, prolongamos el faltante de stock para la tienda que ya no tiene stock del mismo producto. En esta situación, es casi seguro que mover la unidad a la tienda que ya está sin stock es una mejor decisión y debería tener mayor prioridad.
Por eso no tiene sentido evaluar económicamente los niveles de stock a nivel de SKU. El problema con las optimizaciones locales es que no funcionan si operas en sistemas de mayor tamaño. En las supply chains, si abordas las cosas de manera local, simplemente desplazas los problemas; no se resuelve nada. La adecuación de un nivel de stock de un SKU depende del estado de la red. Este simple ejemplo aclara por qué los cálculos de stock de seguridad o los cálculos de punto de reorden son en su mayoría un sinsentido, al menos para situaciones del mundo real, en comparación con los ejemplos teóricos encontrados en los libros de texto de supply chain.
Aquí, realmente queremos priorizar todas las asignaciones de stock entre sí, y la opción que salga en primer lugar es la respuesta a nuestra pregunta: esta será la única unidad que debería moverse si solo podemos mover una unidad.

El ranking de las opciones de asignación de stock es relativamente sencillo con las herramientas adecuadas. Revisemos este script de Envision. En la línea 1, creamos tres SKUs llamados A, B y C. En la línea 2, generamos precios de compra aleatorios entre 1 y 10 como datos simulados. En la línea 3, generamos zedfuncs simulados que se supone representan la recompensa que tenemos para cada uno de esos SKUs. En la práctica, un zedfunc debería calcularse con la función de recompensa de stock, pero solo para mantener el código conciso, estamos usando datos simulados aquí. La recompensa es una función lineal decreciente que llegará a cero al nivel de stock 6. En la línea 4, creamos una tabla G, una abreviatura para la cuadrícula que representa nuestros niveles de stock disponibles. Suponemos que los niveles de stock superiores a 10 no valen la pena evaluar. Esta suposición es razonable, considerando que en términos de datos simulados, tenemos una función de recompensa que se vuelve negativa más allá de un nivel de stock disponible de 6. En la línea 6, extraemos la recompensa marginal para cualquier unidad en stock para tener esta tabla de cuadrícula. Usamos el zedfunc, una función que representa recompensas, para extraer el valor de la posición de stock G.N. Cabe destacar que a partir de la línea 6, no importaría cómo se generaron originalmente los datos. De la línea 1 a la 4, son solo datos simulados que no se usarían en una configuración de producción, pero a partir de la línea 6, sería esencialmente lo mismo si estuvieras en producción.
En la línea 7, definimos el score como una razón entre los dólares de retorno (que el zedfunc te indica) y el dólar invertido, que es el precio de compra. Calculamos una razón entre la cantidad de dólares que recuperarás dividida por la cantidad de dólares que tienes que pagar por una unidad. Esencialmente, el score más alto se obtiene para la asignación de stock que genera la mayor tasa de retorno por cada dólar asignado a esta tienda.
Finalmente, en las líneas 9 a 15, mostramos una tabla ordenada por scores decrecientes. Es importante señalar que no hay ninguna lógica sofisticada en el script. Las primeras cuatro líneas son solo generación de datos simulados, y las últimas seis líneas son simplemente la visualización de la asignación priorizada. Una vez que los zedfuncs están presentes y tenemos una función que representa los retornos económicos por nivel de stock, convertir esos zedfuncs en una lista priorizada es completamente sencillo.

En la pantalla, la tabla obtenida al ejecutar el script de Envision anterior muestra que el SKU llamado C está clasificado en primer lugar. Todos los SKUs tienen los mismos retornos económicos para su primera unidad, es decir, $5 de retorno. Sin embargo, C tiene el precio de compra más bajo a $3.99, y por lo tanto, al dividir la recompensa de $5 entre $3.99, obtenemos un score de aproximadamente 1.25, que resulta ser el score más alto en la cuadrícula. La segunda unidad de C tiene un score de aproximadamente 1, que es el segundo score más alto.
Para la tercera posición en la cuadrícula, tenemos otro SKU llamado B. B tiene un precio de compra más alto, y por lo tanto, su score para la primera unidad es solo de 0.96. Sin embargo, debido a los retornos decrecientes que obtenemos al asignar las dos primeras unidades al SKU C, la primera unidad de B obtiene un score mayor que la tercera unidad de C, y así se clasifica por encima de la tercera unidad de C. Esencialmente, esta lista priorizada es muy profunda, pero está pensada para truncarse con un umbral. Por ejemplo, podemos decidir que existe un retorno mínimo de inversión, y solo se asignan las unidades que superan este retorno de inversión. Una vez que se define el umbral, podemos tomar todas las líneas que están por encima del corte y contar el número de líneas por SKU. Esto nos da el número total de unidades a asignar para cada SKU. Revisaremos este problema del umbral en un momento, pero la idea es que una vez que tienes un umbral, agregas los conteos por SKU, y eso te da la cantidad total a asignar para cada SKU. Esto es exactamente lo que tu WMS o ERP que existe en el centro de distribución esperaría para organizar el envío del día siguiente hacia las tiendas.
La lista priorizada es solo una visión conceptual para decidir qué tiene prioridad. Sin embargo, tomas un umbral, agregas, y luego vuelves a las cantidades de asignación por SKU para cada SKU que existe en tu red de tiendas minoristas.
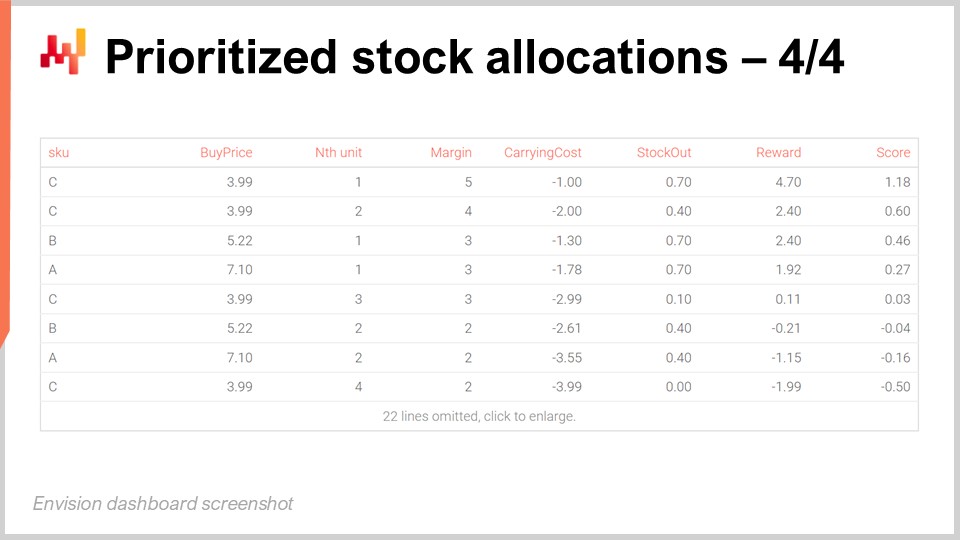
La visualización de la asignación priorizada de stock es engañosamente simple y, sin embargo, poderosa. A medida que avanzamos de una línea a la siguiente, vemos cómo se desarrolla la competencia entre nuestras opciones de asignación. Los mejores SKUs se asignan primero, pero tan pronto como alcanzamos niveles de stock más altos, esos SKUs se vuelven menos competitivos en comparación con otros SKUs que no tienen tanto stock. La lista priorizada cambia de un SKU a otro, maximizando los retornos esperados del capital asignado a las tiendas.
En esta pantalla, tenemos una variante de la tabla anterior, obtenida con otro script de Envision que es una variante mínima del que se presentó hace dos diapositivas. Esencialmente, estoy descomponiendo los factores económicos que contribuyen a la recompensa. Aquí tenemos tres columnas extra: margen, costo de mantenimiento y faltante de stock. El margen es el margen bruto promedio esperado para esta unidad que se asigna. El costo de mantenimiento es el costo promedio esperado de poner esta unidad en stock en la tienda. El faltante de stock es la penalización esperada que se va a evitar, por lo que la penalización por faltante de stock es un valor positivo aquí. La recompensa final es solo la suma de esos tres componentes, y todos esos valores se expresan en cantidades monetarias, como dólares. La columna que representa dólares de margen, dólares de costo de mantenimiento, dólares de faltante de stock y recompensas, es solo la cantidad total de dólares que puedes esperar al poner esta unidad en la tienda.
Esto hace que comprender y depurar esta receta numérica, expresada en dólares, sea muchísimo más fácil en comparación con porcentajes. De hecho, cualquier receta numérica no trivial va a ser bastante opaca por diseño. No necesitas deep learning para obtener una opacidad profunda; incluso una modesta regresión lineal será bastante opaca en cuanto tienes un par de factores involucrados en esta regresión. Esta opacidad, que se obtiene nuevamente con cualquier receta numérica no trivial, pone en riesgo una supply chain del mundo real porque los profesionales de supply chain pueden perderse, confundirse y distraerse con las tecnicidades del modelado.
La lista priorizada de asignación, que descompone los impulsores económicos, es una herramienta de auditoría poderosa. Permite a los profesionales de supply chain cuestionar directamente los fundamentos en lugar de enredarse en las tecnicidades. Puedes preguntar directamente: ¿Tenemos costos de mantenimiento que tengan sentido considerando la situación en la que nos encontramos? ¿Están esos costos alineados con el tipo de riesgos que estamos asumiendo? Puedes olvidar la previsión, la estacionalidad, y la forma en que modelas la estacionalidad, la forma en que consideras la tendencia decreciente, y demás. Puedes desafiar directamente el resultado final, que es la cantidad de dólares de retorno por esos costos de mantenimiento. ¿Son reales? ¿Tienen sentido? Muy frecuentemente, puedes detectar números que no tienen sentido y corregirlos directamente.
Obviamente, quieres evitar esas situaciones, pero no operes bajo la suposición de que en supply chain todos los problemas son problemas de previsión increíblemente sutiles. La mayoría de las veces, los problemas son brutales. Puede haber algún tipo de error, como datos que no se procesan correctamente, y entonces obtienes números completamente sin sentido, como márgenes negativos o costos de mantenimiento negativos que causan estragos en tu supply chain.
Si la instrumentación de tu supply chain se centra exclusivamente en la precisión de pronostico, estás ciego al 90% (o más) de los problemas reales. En una supply chain a gran escala, esta estimación probablemente sería algo como 99%. La instrumentación de supply chain es absolutamente fundamental para resaltar los factores clave que contribuyen a las decisiones, y esos factores deben ser de naturaleza económica si quieres tener alguna esperanza de enfocarte en lo que hace rentable a tu empresa. De lo contrario, si operas con porcentajes, no puedes priorizar tus propias acciones y abordarás los fallos indiscriminadamente. Estamos hablando de una supply chain a gran escala, por lo que siempre hay una legión de fallos numéricos. Si abordas todos esos fallos de manera indiferente, significa que siempre estarás trabajando en cosas que son en gran medida inconsecuentes. Por eso necesitas tener dólares de retorno y dólares de costo. Así es como realmente puedes priorizar tu trabajo y tus esfuerzos de desarrollo para tus recetas numéricas. A veces, ni siquiera necesitas decidir si un error vale la pena corregirlo; si estás hablando de una cantidad de dólares mínima por año en fricción, ni siquiera es un error que valga la pena corregir en la práctica.
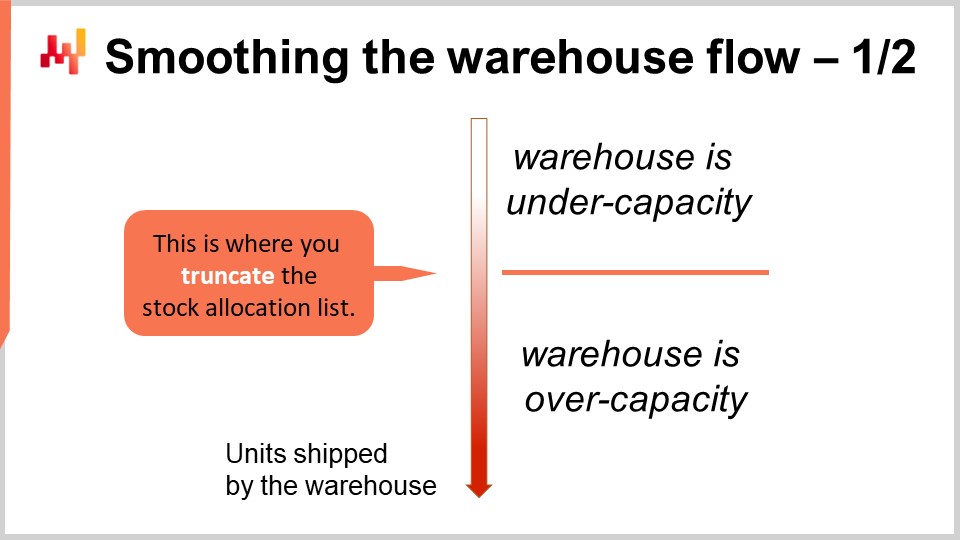
Ahora, volvamos al asunto de elegir el umbral adecuado para la lista de asignación. Hemos visto que tenemos retornos decrecientes al asignar más stock a los SKUs de la tienda. Sin embargo, debemos observar toda la supply chain, no solo el almacén o centro de distribución. Estoy usando ambos términos de manera intercambiable aquí. El almacén o centro de distribución está dominado por costos fijos. De hecho, es posible ampliar el personal con trabajadores temporales, pero tiende a costar más, y crea otros problemas, como que la mano de obra temporal suele estar menos calificada que la permanente.
Así, cualquier almacén o centro de distribución tiene una capacidad objetivo en la que opera con la máxima eficiencia económica. La capacidad objetivo puede aumentarse o disminuirse, pero generalmente involucra ajustar el tamaño del personal permanente, por lo que es un proceso relativamente lento. Puedes esperar que un almacén ajuste su capacidad objetivo de un trimestre a otro, pero no puedes esperar que el almacén ajuste su capacidad nominal, donde tiene la eficiencia máxima, de un día para otro. No es tan dinámico.
Queremos mantener el almacén operando a máxima eficiencia, o lo más cerca posible de ella, todo el tiempo, a menos que tengamos un incentivo económico lo suficientemente fuerte como para actuar de otra manera. La perspectiva de la asignación priorizada de stock allana el camino para hacer precisamente eso. Podemos truncar la lista haciéndola un poco más corta o más larga y ajustando el umbral para mantenerla alineada con la capacidad objetivo del almacén. En la práctica, esto trae consigo tres beneficios principales.
Primero, suavizar el flujo del almacén. Al hacer esto, mantienes el almacén operando a capacidad máxima la mayor parte del tiempo, ahorrando así muchos costos operativos. Segundo, tu proceso de asignación de inventario se vuelve mucho más resiliente frente a todos los pequeños accidentes que ocurren en una supply chain real. Un camión puede verse involucrado en un accidente de tráfico menor, algún personal puede no presentarse porque está enfermo – hay toneladas de pequeñas razones que interrumpirán tus planes. Esto no impedirá que tu almacén opere, pero podría no operar exactamente a la capacidad que anticipaste. Con esta lista de priorización, puedes aprovechar al máximo la capacidad que tu almacén esté utilizando, incluso si no es exactamente la capacidad para la que planeabas inicialmente.
El tercer beneficio es que con este enfoque de una lista priorizada para la asignación de stock, tu equipo de supply chain ya no tiene que microgestionar los niveles de personal del almacén. Solo necesitas ajustar la capacidad objetivo de tu almacén para que se aproxime a la velocidad de ventas de tu red minorista. Microgestionar la capacidad a nivel diario se vuelve en gran medida inconsecuente.
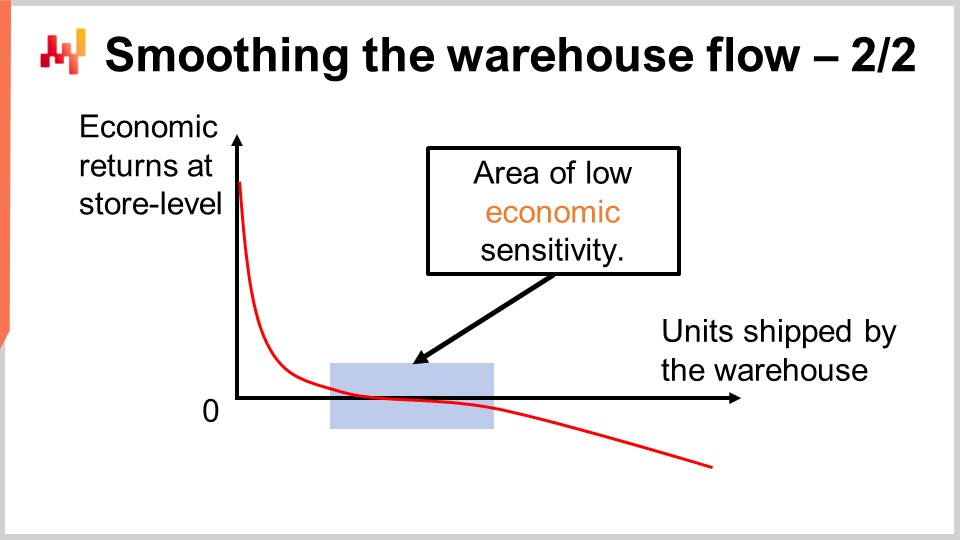
La experiencia de Lokad indica que suavizar el flujo del almacén mediante un umbral de capacidad fijo funciona bien en la mayoría de las situaciones minoristas. En la pantalla, puedes ver la curva típica de retorno económico que se observaría al considerar todos los umbrales posibles. En el eje X, tenemos el número de unidades que se envían desde el almacén. Conceptualmente, estamos asumiendo que las unidades se envían una por una para poder observar la contribución marginal de cada unidad. Naturalmente, en producción, las unidades se envían en lotes, no una por una, pero esto es solo para que podamos trazar la curva. En el eje Y, tenemos los resultados económicos marginales a nivel de la tienda, es decir, para la n-ésima unidad que se envía a una tienda, cualquier tienda de la red. Las primeras unidades que se asignan generan la mayor parte de los retornos. En la práctica, la parte superior de la lista invariablemente consiste en situaciones de faltante de stock que requieren una resolución inmediata. Por eso, las primeras unidades abordan los faltantes de stock, y por eso los retornos económicos son muy altos. Después, los retornos disminuyen, y entramos en una porción plana de la curva.
Esta área es a lo que me refiero como el área de baja sensibilidad económica. Esencialmente, vamos empujando gradualmente el nivel de servicio más cerca del 100%, pero aún no estamos creando mucho stock muerto. Cuando realizas este tipo de asignación priorizada, si empujamos el stock más allá de solucionar problemas de faltante de stock, terminamos acumulando stock en los productos de mayor rotación. Creamos stock en lugares que no es exactamente necesario en este momento. Tendremos oportunidades en el futuro para reponer el stock sin enfrentar un problema de faltante de stock mientras tanto, pero el impacto es mínimo porque el stock se venderá de manera relativamente rápida. Esencialmente, se trata solo del costo de oportunidad de trasladar el stock del centro de distribución a una tienda. Gradualmente perdemos opciones futuras a medida que asignamos más stock.
Esta área es relativamente plana y comenzará a volverse bastante negativa cuando empujamos tanto stock que empezamos a generar situaciones que causarán bajas de inventario con una probabilidad no trivial. Si sigues empujando, generas situaciones de sobrestock más graves, y así, ves que la curva se vuelve muy negativa. Si empujas demasiado, generarás toneladas de bajas de inventario en el futuro. Mientras el umbral se encuentre en este segmento de baja sensibilidad, estamos bien, y el umbral no es súper sensible a dónde se corta. Esa es la razón por la que la capacidad del almacén no tiene que imitar directamente el volumen de ventas diario.
De hecho, en la mayoría de las redes minoristas, se observa un patrón cíclico muy marcado según el día de la semana en las ventas, donde ciertos días, por ejemplo, el sábado, es el día en el que se vende más. Pero el almacén no tiene por qué imitar exactamente este patrón cíclico semanal. Se puede mantener un promedio muy constante, y la idea es que tu capacidad objetivo debe coincidir aproximadamente con el volumen total de ventas de tu red de tiendas. Si tu capacidad objetivo es siempre un poco inferior al volumen total de ventas en la red, lo que ocurrirá es que primero se agotarán todas tus tiendas gradualmente y luego enfrentarás un gran problema. Por el contrario, si impulsas un poco más cada día de lo que realmente vendes, muy rápidamente saturarás completamente tus tiendas.
Siempre que lo mantengas relativamente equilibrado, no es necesario microgestionar el patrón de los días de la semana; funcionará bien. La razón por la que no es necesario microgestionar dicho patrón es que las primeras unidades generan la mayor parte de los retornos, y el sistema, desde una perspectiva económica, no es tan sensible siempre que el corte se mantenga aproximadamente en este segmento plano.

Ahora, presenté la función de recompensa de stock por motivos de claridad y concisión, ya que ya teníamos mucho que cubrir en esta conferencia. Sin embargo, la función de recompensa de stock no es la cúspide de supply chain science. Es un poco ingenua cuando se trata de los detalles de las previsiones probabilísticas.
En 2021, uno de nosotros en Lokad publicó la función de recompensa por acción. La función de recompensa por acción es el descendiente espiritual, si se quiere, de la función de recompensa de stock, pero esta función viene con una perspectiva mucho más detallada sobre las previsiones probabilísticas en sí mismos. De hecho, no todos las previsiones probabilísticas son iguales. La estacionalidad, los tiempos de entrega variables y los ETAs de entrada para los centros de distribución se tienen en cuenta en la función de recompensa por acción, mientras que no se consideraban en la función de recompensa de stock.
Por cierto, estas capacidades también requieren una previsión más granular, por lo que necesitas una tecnología de previsión superior que pueda generar todos esas previsiones probabilísticas para hacer uso de la función de recompensa de stock. En este sentido, la función de recompensa de stock es menos exigente. A nivel conceptual, la función de recompensa por acción también proporciona una separación clara entre la frecuencia de pedidos (con qué frecuencia se ordena) y el tiempo de reabastecimiento (cuánto tiempo se tarda en reponer el stock una vez tomada la decisión). Estos dos elementos estaban agrupados en la función de recompensa de stock. Con la recompensa por acción, están claramente separados.
Finalmente, la función de recompensa por acción también viene con una perspectiva de propiedad de decisiones, que es un truco simple pero bastante ingenioso para cosechar la mayor parte de los beneficios que se obtendrían de una política verdadera sin tener que introducir una política. Discutiremos lo que realmente significan las políticas desde una perspectiva técnica en futuras conferencias, pero en resumen, en cuanto comienzas a introducir políticas, se vuelve más complicado. Es interesante, pero definitivamente más complicado. Aquí, la recompensa por acción tiene un truco ingenioso que te permite literalmente evitar la necesidad de optar por una política y aún así cosechar la mayor parte de los beneficios económicos que se le atribuirían.

Tanto la función de recompensa de stock como su alternativa superior, la función de recompensa por acción, se han utilizado en producción durante años en Lokad. Estas funciones, esencialmente, agilizan clases enteras de problemas que, de otro modo, aquejarían a las redes minoristas. Por ejemplo, el stock muerto se vuelve trivial de evaluar simplemente observando los retornos económicos asociados a cualquier unidad de stock ya presente en alguna tienda. Sin embargo, hay muchos ángulos que no he abordado hoy. Abordaré esos aspectos en futuras conferencias.
Algunos de esos ángulos pueden ser abordados con variaciones bastante menores de lo que he presentado hoy. Ese es el caso, por ejemplo, de los multiplicadores de lotes y el reequilibrio de stock. Se necesita hacer muy pocos cambios en los scripts que he mostrado hoy para poder abordar esos problemas. Cuando hablo de reequilibrio de stock, me refiero a reestructurar el stock entre las tiendas de la red, ya sea moviendo el stock de vuelta al DC o trasladándolo directamente entre las tiendas, asumiendo costos de transporte específicos.
Luego, hay algunos ángulos que requieren más trabajo, pero aún son relativamente sencillos. Por ejemplo, tener en cuenta los costos de oportunidad, los costos de transporte fijos y la sobrecarga en la recepción de la tienda, que ocurre cuando el personal de una tienda no es capaz de procesar todas las unidades que ha recibido. No disponen del tiempo en un día determinado para colocarlas en los estantes, y así se crea un gran desorden en la tienda. Estos ángulos son posibles, pero definitivamente requerirán bastante trabajo adicional respecto a lo que he presentado hoy.
Existen otros ángulos, como el merchandising o mejorar la atractividad general de la tienda, que deberían formar parte de la priorización. Estos requieren un enfoque tecnológico superior, ya que las variaciones menores de lo que he presentado hoy simplemente no son suficientes. Como es habitual, aconsejo una dosis saludable de escepticismo cada vez que un experto afirma tener un método óptimo. En supply chain, no existe nada como métodos óptimos; contamos con herramientas, algunas de las cuales resultan ser mejores, pero ninguna está ni remotamente cerca de algo que se pueda calificar como óptimo.
En conclusión, los porcentajes de error son irrelevantes; lo único que importa son los dólares de error. Esos dólares están determinados por lo que tu supply chain hace a nivel físico. La mayoría de los KPIs son, en el mejor de los casos, insignificantes; forman parte del proceso de supply chain para mejorar continuamente las recetas numéricas que impulsan las decisiones de supply chain. Sin embargo, incluso cuando se consideran esos KPIs que son instrumentales para mejorar las recetas numéricas, estamos hablando de resultados bastante indirectos en comparación con mejorar directamente la receta numérica que impulsa la decisión y genera de inmediato mejores resultados para tu supply chain.
Las hojas de Excel son ubicuas en supply chain, y creo que esto se debe a que la teoría dominante de supply chain no logró promover las decisiones como ciudadanos de primera categoría. Como resultado, las empresas pierden tiempo, dinero y se centran en ciudadanos de segunda categoría, es decir, en artefactos. Pero al final del día, se deben tomar decisiones: el stock debe asignarse, y necesitas elegir el precio, tu punto de venta y el precio de ataque. Al carecer del soporte adecuado, los profesionales de supply chain recurren a la única herramienta que les permite tratar las decisiones como ciudadanos de primera clase, y esa herramienta resulta ser Excel.
Sin embargo, las decisiones de supply chain pueden ser tratadas como ciudadanos de primera clase, y esto es exactamente lo que hicimos hoy. Las herramientas ni siquiera son tan complejas, al menos cuando se considera la complejidad ambiental del típico panorama aplicativo de un supply chain moderno. Además, contar con herramientas adecuadas desbloquea capacidades como suavizar el flujo de inventario desde los centros de distribución hasta la tienda con un esfuerzo mínimo. Estas capacidades son sencillas de lograr con las herramientas adecuadas, pero también ilustran el tipo de logros que nunca se pueden esperar de las hojas de cálculo de Excel, al menos no con una configuración a nivel de producción.

Creo que eso es todo por hoy. La próxima conferencia será el miércoles 6 de julio, a la misma hora del día, 3 p.m. hora de París. Pasaré al séptimo capítulo para discutir la ejecución táctica de una iniciativa de supply chain cuantitativa. Por cierto, volveré al Capítulo 5, donde se discutirán las previsiones probabilísticas, y al Capítulo 6, donde se abordarán las técnicas de toma de decisiones, en futuras conferencias. Mi objetivo es tener una perspectiva completa y de nivel básico sobre todos los elementos antes de profundizar en algún tema específico.
Así que, en este punto, revisaré las preguntas.
Question: La zedfunc podría tener infinitas posibilidades. ¿No serían todas las soluciones a corto plazo en ese caso?
La zedfunction es literalmente un contenedor de datos para una secuencia de opciones, por lo que el horizonte aplicable está integrado en el valor alpha, los valores de descuento temporal que he usado en mis scripts. Fundamentalmente, el horizonte de tiempo objetivo que has integrado en el resultado económico de una zedfunction no se encuentra realmente en las zedfunctions en sí mismas; está más en el tipo de cálculos económicos que las completan. No olvides que las zedfunctions son solo contenedores de datos. Eso es lo que las hace a corto o largo plazo, y, obviamente, quieres ajustar tus recetas numéricas para que representen tus prioridades. Por ejemplo, si tu empresa está bajo una enorme presión debido a problemas de flujo de caja, probablemente tendrás una perspectiva mucho más a corto plazo en cuanto a la entrada de dinero, básicamente liquidando tu inventario. Si dispones de mucho efectivo, quizá prefieras retrasar las ventas a un período posterior, vendiendo a un mejor precio y asegurando un mejor margen bruto. Así que, nuevamente, todas esas cosas son posibles con las zedfunctions. Las zedfunctions son solo contenedores; no presuponen necesariamente ningún tipo de receta numérica para los resultados económicos que deseas incluir en ellas.
Question: Creo que la mayoría de las suposiciones deben basarse en valores reales existentes de las funciones objetivo, ¿no crees?
¿Qué es real? Esa es la esencia del problema que abordé en la conferencia sobre optimización experimental. El problema es que, cada vez que dices que tienes valores o mediciones o cosas por el estilo, lo que tienes son construcciones matemáticas, construcciones numéricas. No es porque sean numéricas que son correctas. La forma en que trato una supply chain es como una ciencia experimental; tienes que conectarte con el mundo real. Así es como se decide si algo es real o no. La cuestión es, y estoy totalmente de acuerdo, que las suposiciones no deben basarse en valores reales preexistentes, ya que no existe tal cosa como valores reales preexistentes. Deben ser verificadas; esas suposiciones deben ser comprobadas y cuestionadas frente a las observaciones del mundo real que puedas realizar en tu supply chain. La corrección de tus suposiciones solo se puede evaluar mediante el contacto con la realidad de tu supply chain.
Ahí es donde esta perspectiva de optimización experimental se complica, porque la perspectiva de optimización matemática simplemente asume que todas las variables son conocidas, todas las variables son reales, todas las variables pueden ser observadas y que la función de pérdida puede ser correcta. Pero lo que quiero decir es que una supply chain es un sistema súper complejo. No es así. La mayoría de las veces, lo que tienes son mediciones bastante indirectas. Cuando digo nivel de stock, en realidad no entro a la tienda para comprobar si el nivel de stock es correcto. Lo que tengo es una medición muy indirecta, un registro electrónico obtenido de un enterprise software que típicamente se implementó hace dos décadas por razones que no tenían nada que ver con hacer data science en primer lugar. Eso es lo que quiero decir; el problema con la realidad es que una supply chain siempre está distribuida geográficamente, por lo que todo lo que mides, todo lo que ves en términos de valores, son mediciones indirectas. De alguna manera, la realidad de estas mediciones siempre está en entredicho. No existe tal cosa como una observación directa. Puedes hacer una observación directa solo para efectuar un control o verificación, pero no puede representar más que un pequeño porcentaje de todos los valores que necesitas manipular para tu supply chain.
Question: En las funciones de recompensa de stock, además de parámetros sencillos como el margen, también tratamos con penalizaciones por faltante de stock. ¿Cómo aprendemos a optimizar estos parámetros complejos de la mejor manera?
Esta es una muy buena pregunta. De hecho, las penalizaciones por faltante de stock son reales; de lo contrario, a nadie le importaría siquiera tener altos niveles de servicio. La razón por la que se buscan altos niveles de servicio es que, hablando económicamente, cada minorista que conozco está convencido de que las penalizaciones por faltante de stock son reales. A los clientes no les gusta no recibir un servicio de alta calidad. Pero no diría que son complejas; son complicadas. Son intrínsecamente difíciles, y parte de su dificultad radica en que literalmente está en juego la estrategia a muy largo plazo de la red minorista. Con la mayoría de mis clientes, por ejemplo, la penalización por faltante de stock es algo que discuto directamente con el CEO de la compañía. Llega hasta lo más alto; esta es la estrategia super a largo plazo de la red minorista la que está en juego.
Entonces, no es que sea complejo, pero definitivamente es complicado debido a que se trata de una discusión de altísimo riesgo. ¿Qué es lo que queremos hacer? ¿Cómo queremos tratar a los clientes? ¿Queremos decir que tenemos los mejores precios y disculparnos si la calidad del servicio no es tan buena como se podría obtener, pero lo que ofrecemos es algo único con precios muy bajos? ¿O queremos apostar por la novedad? Si optas por la novedad, significa que continuamente llegan nuevos productos, y si entran nuevos productos de manera constante, significa que los productos antiguos se irán retirando, y por lo tanto, se debe tolerar que ocurran faltantes de stock, ya que así se sigue introduciendo novedad.
La penalización por faltante de stock es difícil de evaluar porque tiene implicaciones directas en la estrategia a largo plazo de la compañía. En la práctica, la mejor forma de evaluarla es realizando experimentos. Escoges un valor, haces una estimación aproximada del valor de la penalización por faltante de stock, el factor de penalización de stock, y luego observas qué tipo de stock resulta en tus tiendas. Posteriormente, dejas que la gente, basándose en sus impresiones, juzgue si parece ser el nivel de stock que reflejaría su tienda ideal. ¿Es eso lo que realmente quieren para sus clientes? ¿Es eso lo que realmente buscan lograr con su red minorista?
Verá, existe esta discusión de ida y vuelta. Típicamente, el Supply Chain Scientist va a probar una serie de valores, presentar el tipo de resultados económicos y también explicar los costos macro que están asociados a un impulsor. Podrían decir, “Está bien, podemos poner una penalización por faltante de stock muy alta, pero cuidado, si hacemos eso, significa que nuestra lógica de asignación de stock siempre va a estar empujando toneladas de stock hacia las tiendas.” Porque si el mensaje es que los faltantes de stock son mortales, entonces significa que realmente debemos hacer todo lo posible para evitar que sucedan. Esencialmente, necesitamos tener esta discusión con mucha iteración para que la gerencia pueda hacer un chequeo de la realidad: “¿Es mi estrategia a largo plazo económicamente viable en relación con lo que mi red de retail realmente puede hacer?” Así es como se converge gradualmente. Por cierto, no es algo definitivo. Las empresas cambian y ajustan su estrategia con el tiempo, así que no es porque tomes un factor de penalización por faltante de stock en 2010 que en 2022 tenga que ser el mismo valor.
Especialmente, por ejemplo, con el auge del ecommerce. Hay muchas redes de retail que simplemente dicen, “Bueno, me he vuelto mucho más tolerante a los faltantes de stock en mis tiendas, especialmente en las tiendas especializadas.” Porque esencialmente, cuando falta un producto, especialmente una variante en términos de tamaño, la gente simplemente lo ordenará en línea desde el ecommerce. La tienda se convierte en una especie de showroom. Así que la calidad del servicio de un showroom se vuelve muy diferente de lo que se esperaba cuando la tienda era literalmente la única forma de vender los productos.
Pregunta: ¿Podemos tener una función compuesta de recompensa de stock para entender correctamente la tendencia dentro de un periodo dado?
¿Entender la tendencia de qué exactamente? Si es una tendencia de la demanda, la función de recompensa de stock es una función que consume una previsión probabilística. Así que, sea cual sea la tendencia que tengas en la demanda, típicamente es un factor de la manera en que modelas tu demanda. En lo que respecta a la función de recompensa de stock, la previsión probabilística ya incorpora todo eso, haya o no tendencia.
Ahora, si tienes otra pregunta respecto a la perspectiva estacionaria de la recompensa de stock, estás completamente en lo correcto. La función de recompensa de stock tiene una perspectiva totalmente estacionaria. Asume que la demanda se repite probabilísticamente en cada periodo de la misma manera, por lo que no hay tendencia ni estacionalidad. Es una perspectiva puramente estacionaria. En esta situación, la respuesta es no, la función de recompensa de stock no es capaz de lidiar con una demanda no estacionaria. Sin embargo, la función de recompensa de acción es capaz de hacerlo. Esa fue también una de las motivaciones para pasar a la función de recompensa de acción, ya que puede manejar una demanda probabilística no estacionaria.
Pregunta: Estamos asumiendo que la capacidad del almacén es fija, pero depende del esfuerzo de picking, packing y shipping. ¿No deberían los puntos de corte de la lista definirse por la optimización de las operaciones del almacén?
Sí, absolutamente. Eso es lo que dije cuando tienes esta zona de baja sensibilidad económica. Tu lista de prioridades, que representa la asignación priorizada de stock, no es súper sensible en cuanto a dónde hacer el corte, siempre y cuando esté dentro de este segmento. En promedio, deberías estar realmente equilibrado en términos de cuánto empujas y cuánto vendes, lo cual tiene sentido. Si deseas ajustar el punto de corte de manera ligeramente diferente después de ejecutar la lógica de optimización del almacén, teniendo en cuenta todos los esfuerzos y variaciones de picking, packing y shipping, está bien. Puedes tener variaciones de último minuto. La belleza de esta lista de asignación priorizada de stock es que literalmente puedes finalizar el alcance exacto de las unidades que se envían en el último minuto. La única operación que necesitas es una agregación, que se puede hacer de manera muy rápida, brindándote más opciones. Eso es exactamente lo que dije cuando mencioné que este enfoque abre nuevas clases de optimización de supply chain. Te permite decidir justo a tiempo para reorganizar tus esfuerzos de picking, packing y shipping en lugar de quedarte rígidamente atado a un sobre de envío preestablecido que realmente no coincide con los recursos exactos que tienes ni con el esfuerzo que se requiere para ejecutar ese sobre.
Pregunta: Suavizar los flujos del almacén exige suavizar el flujo de producción. ¿Considera este modelo de decisión eso?
Yo diría que no requiere de forma natural un flujo de producción suavizado. Para muchas redes de retail, como tiendas de mercancía general, están ordenando a grandes empresas de FMCG que producen lotes muy grandes de su lado. No necesitas suavizar el flujo de producción para generar beneficios en términos de costos operativos del centro de distribución. Incluso si la producción no se ha suavizado, ya tienes beneficios simplemente al mover los envíos desde el centro de distribución hacia las tiendas.
Sin embargo, tienes toda la razón. Si resulta que eres una marca verticalmente integrada que ha internalizado sus instalaciones de producción, centros de distribución y tiendas, entonces hay un interés vivo en realizar una optimización de supply chain a nivel de toda la cadena y suavizar todo el flujo. Este enfoque de optimización a nivel de red está muy alineado con el espíritu de lo que he presentado hoy. Sin embargo, si realmente deseas optimizar una verdadera red de supply chain multi-echelon, necesitarás una técnica diferente a lo que he presentado hoy. Hay muchos componentes que te permitirán hacer eso, pero no puedes simplemente ajustar los scripts que he presentado hoy para lograrlo. Este será el tipo de tecnología en la que cubriremos la configuración multi-echelon, que se presentará en conferencias posteriores. Esto es más complicado.
Pregunta: El enfoque de recompensa de stock y el error esperado me recuerdan el concepto de valor esperado de las finanzas. Desde tu punto de vista, ¿por qué este enfoque aún no es mainstream en los círculos de supply chain?
Estás completamente en lo correcto. Este tipo de cosas, como un verdadero análisis económico de los resultados, se ha hecho durante años en los círculos financieros. Creo que la mayoría de los bancos han estado haciendo estos cálculos desde los años 80, y probablemente la gente los hacía incluso antes con papel y lápiz. Así que sí, es algo que se ha hecho durante mucho tiempo en otros sectores.
Creo que el problema con las supply chain era que, hasta la llegada de internet, las supply chain estaban distribuidas geográficamente por naturaleza, con tiendas, centros de distribución y más esparcidos. Antes de 1995, era posible, pero muy complicado, mover datos a través de internet para las empresas. Era factible, pero hacerlo de manera confiable, económica y contar con sistemas empresariales que te permitieran consolidar todos esos datos era raro. Así que, esencialmente, las supply chain se digitalizaron muy temprano, como en los años 80, pero no estaban fuertemente enredadas en red. El ingrediente de networking y toda la infraestructura llegó relativamente tarde, diría yo, después del año 2000 para la mayoría de las empresas.
El problema era que, imagina que operabas en un centro de distribución pero bastante aislado del resto de la red, por lo que el gerente del almacén no tenía los recursos para realizar este tipo de sofisticados cálculos numéricos. El gerente del almacén tenía un almacén que gestionar y, típicamente, no era un analista. Así que esas prácticas que precedieron a la era de internet, donde toda la información está disponible a través de la red, han persistido. Esa sería la razón, y por cierto, las supply chain son típicamente seres muy grandes, complicados y complejos, por lo que se mueven despacio.
Tener los datos compartidos a través de la red con data lakes muy buenos, digamos que era 2010, aunque eso fue hace 10 años, lo que observo es que algunas empresas se están moviendo ahora, otras ya se han movido, pero una década no es tanto considerando el tamaño y la complejidad de las supply chain. Por eso, este tipo de análisis ha sido el estándar en finanzas por alrededor de cuatro décadas, y todavía apenas están emergiendo en la supply chain, o al menos esa es mi humilde opinión al respecto.
Pregunta: ¿Qué hay del costo por faltante de stock, calculado principalmente sobre el costo de mal emplazamiento?
Puedes hacer eso. Nuevamente, el costo por faltante de stock es literalmente una decisión que tomas. Es tu perspectiva estratégica sobre el tipo de servicio que deseas que tu red de retail brinde a tus clientes. No hay una realidad base; es literalmente lo que tú quieras. La cuestión sobre el costo de mal emplazamiento es que la realidad es que la mayoría de las redes de retail solo sobreviven porque tienen una base de clientes leales. La gente regresa a las tiendas, ya sea una tienda de mercancía general a la que visitan cada semana, una tienda de moda a la que visitan cada trimestre o una tienda de muebles a la que regresan cada dos años. La calidad del servicio es esencial para mantener la lealtad del cliente a largo plazo y garantizar una experiencia positiva en tu tienda. Típicamente, el costo de la lealtad perdida para la mayoría de las tiendas eclipsa los costos de mal emplazamiento. Una excepción que me viene a la mente son las tiendas de retail con una estrategia de marca enfocada en ser las más baratas. En este caso, podrían sacrificar el surtido y la calidad del servicio, priorizando los precios bajos sobre todo lo demás.
Pregunta: ¿Cuál es el objetivo de mantener stock en tu almacén? ¿Es para mantener los productos a precios bajos o para suministrar a las tiendas productos a precios más altos?
Esta es una excelente pregunta. ¿Por qué mantener stock en el centro de distribución? ¿Por qué no cross-dock todo directamente, enviándolo todo a las tiendas?
Hay redes de retail que hacen cross-dock de todo, pero incluso con este enfoque, existe un retraso entre cuando haces un pedido a tus proveedores y cuando realmente despachas el stock a las tiendas. Puedes pedir cantidades específicas con un esquema de asignación particular en mente, pero tienes la flexibilidad de cambiar de opinión cuando el stock llega al centro de distribución. No tienes que estar rígidamente apegado al esquema de asignación que tenías en mente hace dos días.
Puedes decidir no mantener stock en el centro de distribución y simplemente hacer cross-dock, pero debido al retraso, puedes cambiar de opinión y hacer un despacho ligeramente diferente. Esto puede ser útil, por ejemplo, cuando experimentas un faltante de stock debido a un aumento inesperado en la demanda. Aunque es preferible no tener un faltante de stock, indica un exceso de demanda en comparación con lo esperado, lo cual no es completamente negativo.
En otras situaciones, mantener stock en el almacén es necesario debido a las restricciones de pedido con los proveedores. Por ejemplo, las empresas de FMCG podrían permitirte hacer un pedido solo una vez a la semana, y típicamente quieren entregar un camión completo a tu centro de distribución. Tus pedidos serán voluminosos y por lotes, y tu centro de distribución sirve como un amortiguador para esas entregas. El centro también te da la opción de cambiar de opinión con respecto a dónde debe asignarse el stock.
Mientras el stock esté en el centro de distribución, puedes cambiar de opinión. Sin embargo, una vez que está asignado a una tienda específica, el costo de transporte para devolverlo al almacén suele ser prohibiblemente caro y algo que desearías evitar.
Muchas gracias, y espero verlos la próxima vez. Discutiremos cómo ejecutar estrategias tácticas e iniciar una verdadera iniciativa de Supply Chain Quantitativa en una empresa real. ¡Hasta la próxima!


