Differentiable programming to optimize over large scale relational data
In the intricate world of supply chain management relational data is king. ERPs, WMS, PMS and other software tools omnipresent in supply chain operate on top of relational databases tracking everything from inventory levels to supplier relationships. Relational data consist of a series of interconnected tables, each rich with columns of information. However, when it comes to machine learning and mathematical optimization, relational data often gets overshadowed by simpler forms like vectors, sequences, and graphs.
Relational data - thank to its rich complexity - offers a deeper, more nuanced view of operations than its simpler counterparts (the aforementioned vectors, sequences and graphs). Yet, most enterprise software struggles to effectively utilize data in its relational form. The result? A forced fit of square pegs into round holes, desperately trying to compress relational data into tools designed for simpler models. This mismatch handicaps companies, akin to using a hockey stick in golf - theoretically feasible, but far from the optimal marriage of tool and purpose.
Determined to investigate this blind spot, a few years back, Paul Peseux started a PhD at Lokad with the intent to turn relational data into a first-class citizen both for learning and optimization purposes. His research efforts led to a series of remarkable improvements to our differentiable programming backing within Envision – Lokad’s DSL (domain specific programming language) dedicated to supply chain optimization. Paul’s impressive findings are now in production, typically buried in the DSL’s autodiff capabilities.
Author: Paul Peseux
Date: September 2023
Abstract:
This PhD thesis, titled presents three contributions to the field of differentiable programming with a focus on relational data. Relational data is prevalent in industries such as healthcare and supply chain, where data is often organized in structured tables or databases. Traditional machine learning approaches struggle with handling relational data, while white box machine learning models are better suited but challenging to develop.
Differentiable programming offers a potential solution by treating queries on relational databases as differentiable programs, enabling the development of white box machine learning models that can directly reason about relational data. The primary objective of this research is to explore the application of machine learning to relational data using differentiable programming techniques.
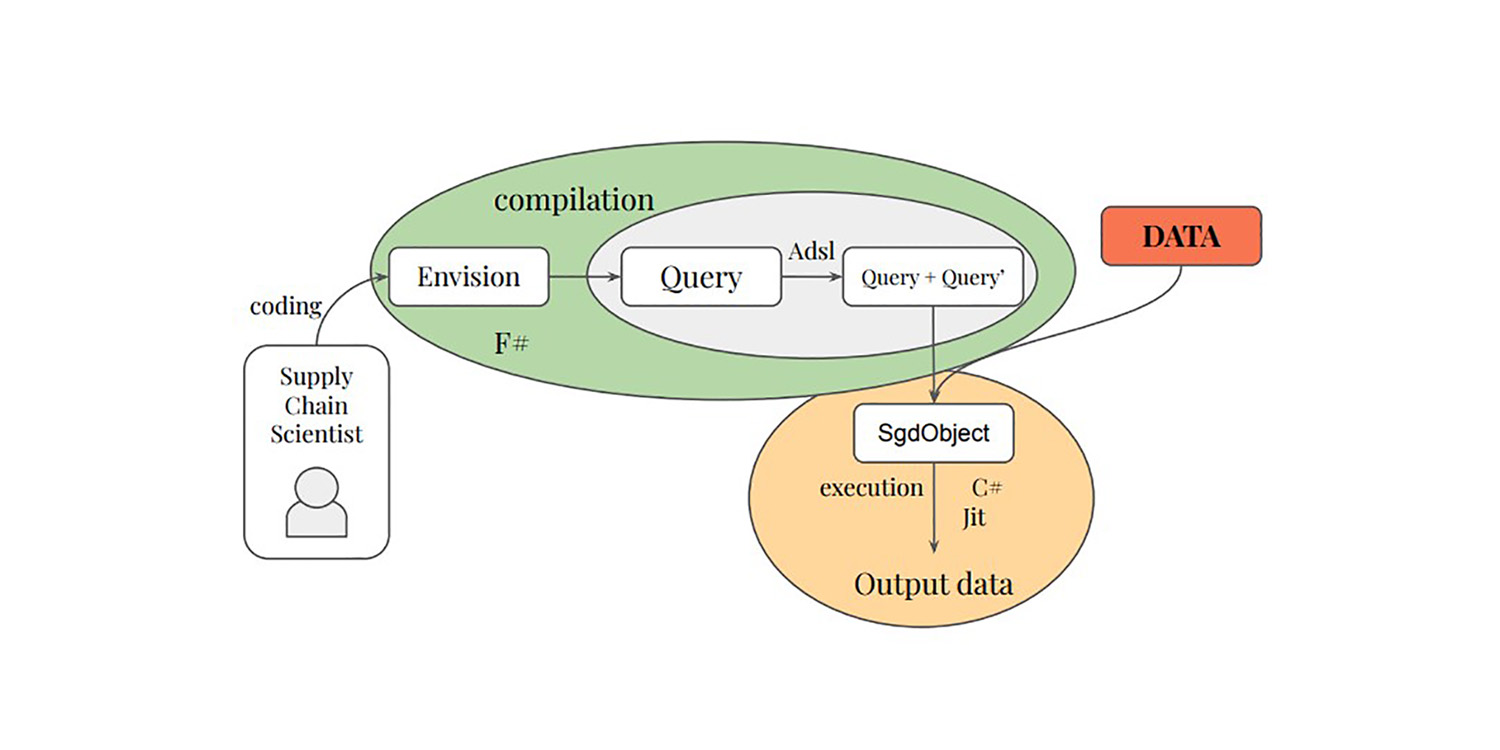
The first contribution of the thesis introduces a differentiable layer into relational programming languages, both theoretically and practically. The Adsl programming language was created to perform differentiation and transcribe relational operations of a query. The domain-specific language Envision has been augmented with differentiable programming capabilities, allowing the development of models that leverage relational data in a native relational programming language environment.
The second contribution develops a novel gradient estimator called GCE, designed for categorical features over represented in relational data. GCE is demonstrated to be useful on various categorical datasets and models and has been implemented for deep learning models. GCE is also integrated as the native gradient estimator in the differentiable programming layer of Envision, facilitated by the first contribution of this thesis.
The third contribution develops a generalized gradient estimator called Stochastic Path Automatic Differentiation (SPAD), which derives its stochasticity from code decomposition. SPAD introduces the idea of backpropagating a fraction of the gradient to reduce memory consumption during parameter updates. The implementation of this gradient estimation approach is made possible by the design decisions during the differentiation of Adsl.
This research has significant implications for industries relying on relational data, unlocking new insights and improving decision-making by applying white box machine learning models to relational data using differentiable programming techniques.
Jury:
The defense took place in front of a jury composed of:
- Thierry Paquet, University Professor (University of Rouen Normandy), thesis director.
- Maxime Berar, Lecturer (University of Rouen Normandy), co-supervisor of the thesis.
- Romain Raveaux, Lecturer (University of Tours), rapporteur.
- Thierry Artières, University Professor (ECM / LIS – AMU – CNRS), rapporteur.
- Cécilia Zanni-Merk, University Professor (INSA Rouen Normandie), examiner.
- Laurent Wendling, University Professor (Paris Cité University), examiner.
- Victor Nicolet, CTO of Lokad, advisor.


