Programmazione differenziabile per ottimizzare dati relazionali su larga scala
Nel complicato mondo della supply chain management, i dati relazionali sono sovrani. ERPs, WMS, PMS e altri strumenti software onnipresenti nella supply chain operano su database relazionali che tracciano tutto, dai livelli di inventario alle relazioni con i fornitori. I dati relazionali consistono in una serie di tabelle interconnesse, ciascuna ricca di colonne di informazioni. Tuttavia, quando si tratta di machine learning e ottimizzazione matematica, i dati relazionali spesso vengono oscurati da forme più semplici come vettori, sequenze e grafi.
I dati relazionali - grazie alla loro ricca complessità - offrono una visione più profonda e sfumata delle operazioni rispetto alle loro controparti più semplici (i suddetti vettori, sequenze e grafi). Tuttavia, la maggior parte dei software aziendali fatica a utilizzare in modo efficace i dati nella loro forma relazionale. Il risultato? Un tentativo forzato di adattare pezzi quadrati in buchi rotondi, cercando disperatamente di comprimere i dati relazionali in strumenti progettati per modelli più semplici. Questo divario penalizza le aziende, come usare un bastone da hockey nel golf - teoricamente possibile, ma ben lontano dal matrimonio ottimale tra strumento e scopo.
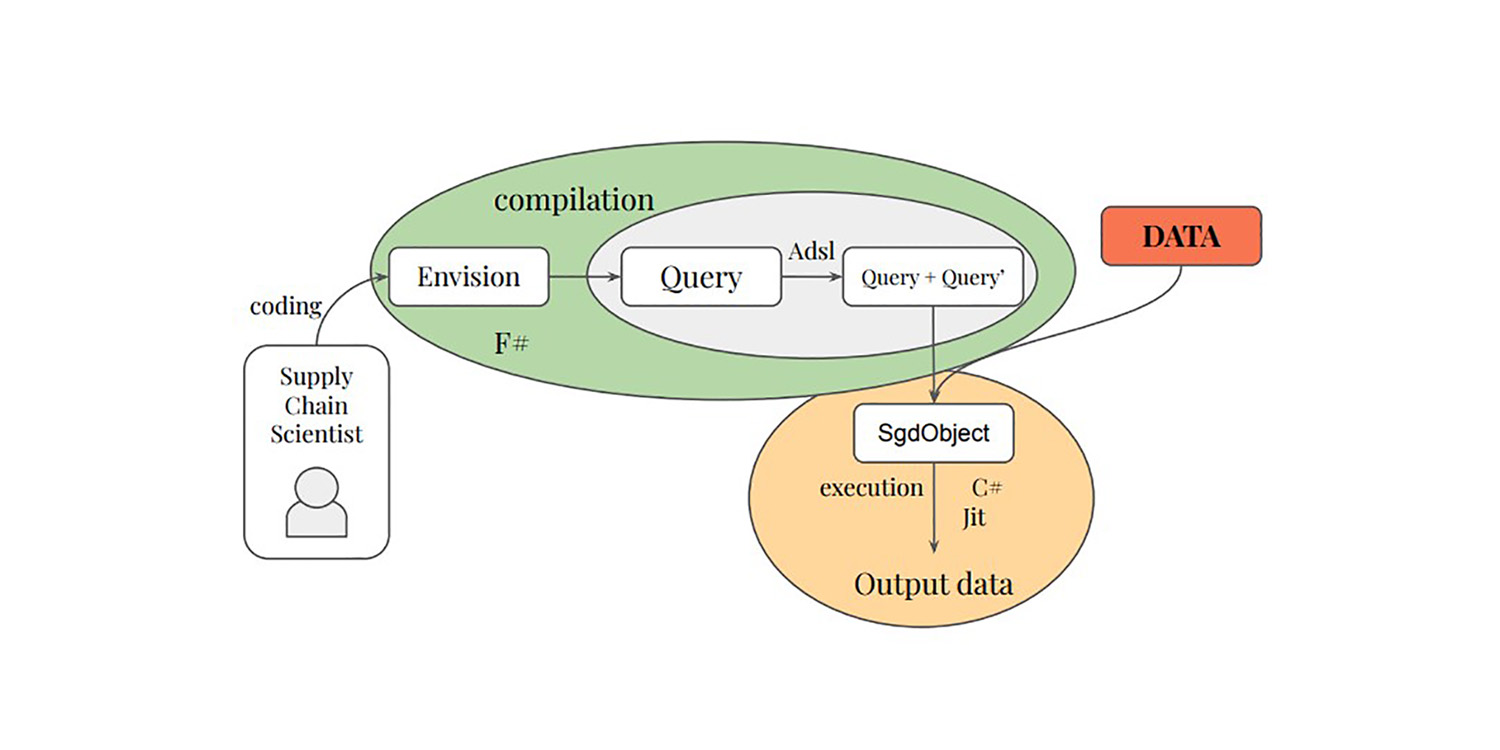
Determinato a indagare su questo punto cieco, alcuni anni fa Paul Peseux ha iniziato un dottorato presso Lokad con l’intento di rendere i dati relazionali cittadini di prima classe sia per l’apprendimento che per l’ottimizzazione. I suoi sforzi di ricerca hanno portato a una serie di notevoli miglioramenti nel nostro supporto alla programmazione differenziabile all’interno di Envision – il DSL di Lokad (linguaggio di programmazione specifico per il dominio) dedicato all’ottimizzazione della supply chain. I notevoli risultati di Paul sono ora in produzione, tipicamente nascosti nelle capacità di autodiff del DSL.
Autore: Paul Peseux
Data: settembre 2023
Sommario:
Questa tesi di dottorato presenta tre contributi al campo della programmazione differenziabile con un focus sui dati relazionali. I dati relazionali sono prevalenti in industrie come l’assistenza sanitaria e la supply chain, dove sono spesso organizzati in tabelle o database strutturati. Gli approcci tradizionali di machine learning fanno fatica a gestire i dati relazionali, mentre i modelli di machine learning white box, pur essendo più adatti, risultano difficili da sviluppare.
La programmazione differenziabile offre una soluzione potenziale trattando le query sui database relazionali come programmi differenziabili, permettendo lo sviluppo di modelli di machine learning white box che possono ragionare direttamente sui dati relazionali. L’obiettivo principale di questa ricerca è esplorare l’applicazione del machine learning ai dati relazionali utilizzando tecniche di programmazione differenziabile.
Il primo contributo della tesi introduce uno strato differenziabile nei linguaggi di programmazione relazionale, sia a livello teorico che pratico. Il linguaggio di programmazione Adsl è stato creato per eseguire la differenziazione e trascrivere le operazioni relazionali di una query. Il linguaggio specifico per il dominio Envision è stato potenziato con capacità di programmazione differenziabile, permettendo lo sviluppo di modelli che sfruttano i dati relazionali in un ambiente nativo di linguaggio di programmazione relazionale.
Il secondo contributo sviluppa un nuovo stimatore del gradiente chiamato GCE, progettato per le caratteristiche categoriche rappresentate nei dati relazionali. È stato dimostrato che GCE è utile su vari set di dati e modelli categorici ed è stato implementato per modelli di deep learning. GCE è inoltre integrato come lo stimatore del gradiente nativo nello strato di programmazione differenziabile di Envision, facilitato dal primo contributo di questa tesi.
Il terzo contributo sviluppa un stimatore del gradiente generalizzato chiamato Stochastic Path Automatic Differentiation (SPAD), che deriva la sua stocasticità dalla decomposizione del codice. SPAD introduce l’idea di retropropagare una frazione del gradiente per ridurre il consumo di memoria durante gli aggiornamenti dei parametri. L’implementazione di questo approccio alla stima del gradiente è resa possibile dalle decisioni progettuali adottate durante la differenziazione di Adsl.
Questa ricerca ha implicazioni significative per le industrie che si basano sui dati relazionali, sbloccando nuove intuizioni e migliorando il decision-making applicando modelli di machine learning white box ai dati relazionali mediante tecniche di programmazione differenziabile.
Giuria:
La discussione si è svolta davanti a una giuria composta da:
- Thierry Paquet, Professore universitario (University of Rouen Normandy), relatore della tesi.
- Maxime Berar, Docente (University of Rouen Normandy), co-relatore della tesi.
- Romain Raveaux, Docente (University of Tours), relatore.
- Thierry Artières, Professore universitario (ECM / LIS – AMU – CNRS), relatore.
- Cécilia Zanni-Merk, Professore universitario (INSA Rouen Normandie), esaminatrice.
- Laurent Wendling, Professore universitario (Paris Cité University), esaminatore.
- Victor Nicolet, CTO di Lokad, consulente.


