Prognosearten: Klassifizierung vs. Regression
Das Wort Prognose deckt ein sehr breites Spektrum an Prozessen, Technologien und sogar Märkten ab. In der Vergangenheit haben wir die Welten der Forecasting-Software vorgestellt, wobei wir unterscheiden zwischen:
- Deterministische Simulationssoftware
- Software zur Expertenaggregation
- Statistische Prognose Software
Lokad fällt in die letzte Kategorie, da unsere Technologie rein statistisch ist. Dennoch deckt Lokad bei weitem nicht das gesamte statistische Spektrum ab. Zwei grobe Kategorien von Prognosen existieren in der statistischen Prognose (*):
- Klassifizierungsprognosen
- Regressionsprognosen
(*) Wir vereinfachen hier der Klarheit halber, da die Feinheiten des statistischen Lernens den Rahmen dieses bescheidenen Blogbeitrags weit überschreiten.
Die Klassifikation versucht, Objekte anhand ihrer Eigenschaften zu trennen (oder zu klassifizieren). Die Abbildung unten von Tomasz Malisiewicz veranschaulicht eine Klassifikationsaufgabe, bei der versucht wird, Bilder, die einen Stuhl zeigen, von Bildern, die einen Tisch zeigen, zu trennen.
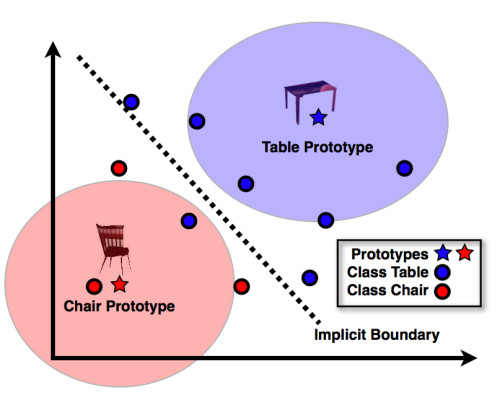
Illustration aus tombones Blog
Die Ausgabe einer Klassifikation ist binär (oder vielmehr diskret): Objekte werden Klassen mit mehr oder weniger Vertrauen, d.h. mit höheren oder niedrigeren Wahrscheinlichkeiten, zugeordnet.
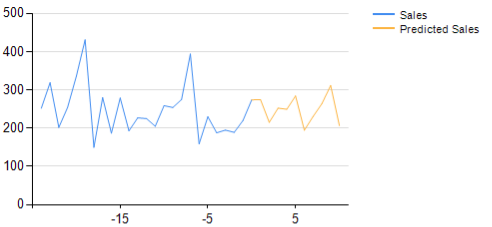
Andererseits liefern Regressionen typischerweise Kurven als Ausgabe. Die Abbildung unten zeigt eine Zeitreihe von historischen Verkaufszahlen und stellt die entsprechende Prognose dar.
Die Regressionsprognose ist eine Kurve und keine binäre (oder Kombination binärer) Einstellung. Die Eingabedaten werden in die Zukunft fortgeschrieben.
Wie wirkt sich dieser Unterschied auf das Geschäft aus?
Nun, es stellt sich heraus, dass Lokad – wie es Anfang 2010 der Fall war \– nur Regressionsprognosen liefert. Daher gibt es viele interessante Probleme, die von Lokad nicht angegangen werden können, da es sich um Klassifikationsprobleme handelt:
- Kundensegmentierung: Für jeden Kunden möchten wir die Wahrscheinlichkeit bewerten, durch eine Direktmarketingmaßnahme einen erfolgreichen Upsell zu erzielen. Dem gleichen Prinzip folgend könnten wir auch versuchen, die Abwanderung vorherzusagen.
- Betrugserkennung: Für jede Transaktion möchten wir basierend auf dem Transaktionsmuster die Wahrscheinlichkeit bewerten, dass es sich bei der Operation um einen Betrugsversuch handelt.
- Deal-Priorisierung: Basierend auf den Eigenschaften des Interessenten (Budgetverfügbarkeit, Branche, Position des Ansprechpartners im Unternehmen, gezeigtes Interesse, …) möchten wir die Wahrscheinlichkeit ermitteln, aus jedem Interessenten einen profitablen Deal zu erzielen, um die Vertriebsaktivitäten zu priorisieren.
Häufig wird uns gefragt, ob Lokad auch Klassifikationsprognosen liefern könnte. Leider wird die Antwort vorerst negativ ausfallen. Obwohl beide auf derselben mathematischen Theorie beruhen, erfordern Klassifikation und Regression sehr unterschiedliche Technologien – und Lokad konzentriert all seine Bemühungen auf Regressionsprobleme.
Obwohl wir Klassifikationsprobleme nicht vernachlässigen, verdienen sie doch tatsächlich Aufmerksamkeit und Einsatz. Für 2010 halten wir an unserer Roadmap fest, aber künftig könnte die Klassifikation eine natürliche Erweiterung unserer Prognosedienstleistungen darstellen.


