00:00 Einführung
02:53 Entscheidungen vs Artefakte
10:07 Experimentelle Optimierung
13:51 Bisherige Geschichte
17:01 Heutige Entscheidungen
19:36 Das Manifest der Quantitative Supply Chain
21:01 Das Problem der Einzelhandelsbestandszuweisung
24:49 Ökonomische Kräfte auf die Filial-SKU
29:35 Die Zukunft greifbar machen
32:41 Die Optionen greifbar machen - 1/3
38:25 Die Optionen greifbar machen - 2/3
43:02 Die Optionen greifbar machen - 3/3
44:44 Bestands-Belohnungsfunktion - 1/2
51:41 Bestands-Belohnungsfunktion - 2/2
56:19 Priorisierte Bestandszuweisungen - 1/4
59:59 Priorisierte Bestandszuweisungen - 2/4
01:03:39 Priorisierte Bestandszuweisungen - 3/4
01:06:34 Priorisierte Bestandszuweisungen - 4/4
01:12:58 Glätten des Lagerflusses - 1/2
01:16:48 Glätten des Lagerflusses - 2/2
01:22:12 Aktions-Belohnungsfunktion
01:25:02 Die reale Welt ist chaotisch
01:27:38 Fazit
01:30:00 Kommende Vorlesung und Zuschauerfragen
Beschreibung
supply chain Entscheidungen erfordern risikoadjustierte wirtschaftliche Bewertungen. Die Umwandlung probabilistischer Prognosen in wirtschaftliche Bewertungen ist nicht trivial und erfordert spezielle Werkzeuge. Die daraus resultierende wirtschaftliche Priorisierung, veranschaulicht durch Bestandszuweisungen, erweist sich jedoch als wirksamer als traditionelle Techniken. Wir beginnen mit der Herausforderung der Einzelhandelsbestandszuweisung. In einem 2-Ebenen-Netzwerk, das sowohl ein Distributionszentrum (DC) als auch mehrere Filialen umfasst, müssen wir entscheiden, wie der Bestand des DC auf die Filialen verteilt wird, wobei alle Filialen um denselben Bestand konkurrieren.
Vollständiges Transkript

Willkommen zu dieser Reihe von supply chain Vorlesungen. Ich bin Joannes Vermorel, und heute werde ich „Retail Stock Allocation with Probabilistic Forecasts“ präsentieren. Die Einzelhandelsbestandszuweisung ist eine einfache, aber grundlegende Herausforderung: Wann und wie viel Bestand entscheiden Sie zu bewegen, zu jedem Zeitpunkt zwischen den Distributionszentren und den von Ihnen betriebenen Filialen? Die Entscheidung, Bestand zu bewegen, hängt von der zukünftigen Nachfrage ab, weshalb eine Nachfrageprognose notwendig ist.
Jedoch ist die Einzelhandelsnachfrage auf Filialebene unsicher, und die Unsicherheit der zukünftigen Nachfrage ist irreduzibel. Wir benötigen eine Prognose, die diese irreduzible Unsicherheit der Zukunft angemessen widerspiegelt, weshalb eine probabilistische Prognose notwendig ist. Dennoch ist es keine triviale Aufgabe, das Beste aus probabilistischen Prognosen herauszuholen, um supply chain optimieren Entscheidungen zu treffen. Es wäre verlockend, eine bestehende Inventartechnik wiederzuverwenden, die ursprünglich für eine klassische deterministische Prognose entwickelt wurde. Doch dies würde den eigentlichen Grund, warum wir probabilistische Prognosen überhaupt eingeführt haben, zunichtemachen.
Ziel dieser Vorlesung ist es, zu lernen, wie man probabilistische Prognosen in ihrer ursprünglichen Form optimal nutzt, um supply chain Entscheidungen zu optimieren. Als ein erstes Beispiel werden wir das Problem der Einzelhandelsbestandszuweisung betrachten, und durch die Untersuchung dieses Problems werden wir sehen, wie wir tatsächlich den Bestand auf Filialebene optimieren können. Darüber hinaus können wir durch die Untersuchung probabilistischer Prognosen sogar neue Klassen von supply chain Problemen angehen, wie zum Beispiel das Glätten des Materialflusses von den Distributionszentren zu den Filialen, um die Betriebskosten des Netzwerks zu optimieren und zu senken.
Diese Vorlesung eröffnet das sechste Kapitel dieser Reihe, das sich Entscheidungsfindungstechniken und -prozessen im Kontext der supply chain widmet. Wir werden sehen, dass Entscheidungen unter Berücksichtigung des gesamten supply chain Netzwerks als ein integriertes System optimiert werden müssen, im Gegensatz zu einer Reihe isolierter lokaler Optimierungen. Zum Beispiel, wenn man eine zu enge Perspektive auf die SKU (stock-keeping unit) einnimmt.
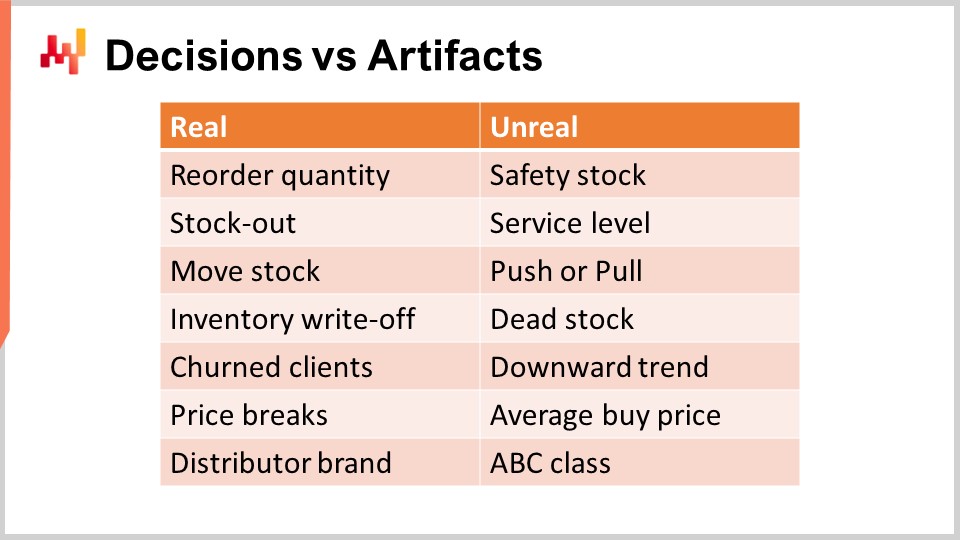
Der erste Schritt zur Bewältigung von supply chain Entscheidungen besteht darin, tatsächliche supply chain Entscheidungen zu identifizieren. Eine supply chain Entscheidung hat eine direkte, physische, greifbare Auswirkung auf die supply chain. Zum Beispiel ist das Verschieben einer Einheit Bestand vom Distributionszentrum zu einer Filiale real; sobald Sie dies tun, befindet sich eine zusätzliche Einheit in den Regalen der Filiale und eine Einheit fehlt nun im Distributionszentrum und kann nirgendwo anders zugewiesen werden.
Im Gegensatz dazu hat ein Artefakt keine direkte physische, greifbare Auswirkung auf die supply chain. Ein Artefakt ist typischerweise entweder ein Zwischenschritt in einer Berechnung, der letztlich zu einer supply chain Entscheidung führt, oder es handelt sich um eine statistische Schätzung, die eine Eigenschaft eines Teils Ihres supply chain Systems charakterisiert. Leider kann ich nicht umhin, in der supply chain Literatur eine große Verwirrung bei der Unterscheidung von Entscheidungen und Artefakten zu beobachten.
Achtung, Renditen werden ausschließlich durch die Verbesserung von Entscheidungen erzielt. Die Verbesserung von Artefakten ist nahezu immer unwesentlich, wenn überhaupt. Im schlimmsten Fall, wenn ein Unternehmen zu viel Zeit in die Verbesserung von Artefakten investiert, wird dies zu einer Ablenkung, die das Unternehmen daran hindert, seine tatsächlichen supply chain Entscheidungen zu verbessern. Auf dem Bildschirm wird eine Liste von Verwirrungen angezeigt, die ich häufig in den Mainstream supply chain Kreisen beobachte.
Zum Beispiel fangen wir an mit Sicherheitsbestand. Dieser Bestand ist nicht real; es gibt nicht zwei Bestände, den Sicherheitsbestand und den Arbeitsbestand. Es gibt nur einen Bestand, und die einzige Entscheidung, die getroffen werden kann, ist, ob mehr benötigt wird oder nicht. Lagerauffüllung einer Menge ist real, aber der Sicherheitsbestand ist es nicht. Ebenso ist das Service Level ebenfalls nicht real. Das Service Level ist stark modellabhängig. Tatsächlich sind bei der Einzelhandelsnachfrage die Verkaufsdaten spärlich. Wenn Sie also eine beliebige SKU betrachten, haben Sie typischerweise zu wenig Daten, um ein sinnvolles Service Level allein durch Inspektion der SKU zu berechnen. Der Ansatz zur Bestimmung des Service Levels erfolgt über Modellierungstechniken und statistische Schätzungen, die in Ordnung sind, aber wiederum handelt es sich dabei um ein Artefakt, nicht um die Realität. Dies ist buchstäblich eine mathematische Perspektive, die Sie auf Ihre supply chain haben.
Ähnlich ist es bei Push oder Pull, was ebenfalls eine Frage der Perspektive ist. Ein ordnungsgemäßes numerisches Verfahren, das das gesamte supply chain Netzwerk berücksichtigt, wird nur die Möglichkeit in Betracht ziehen, eine Einheit Bestand von einem Ursprung zu einem Ziel zu bewegen. Was real ist, ist die Bestandbewegung; was lediglich eine Frage der Perspektive ist, ist, ob Sie diese Bestandbewegung basierend auf Bedingungen, die mit dem Ursprung oder dem Ziel zusammenhängen, auslösen möchten. Dies definiert Push oder Pull, ist jedoch bestenfalls eine geringe technische Feinheit des numerischen Verfahrens und stellt nicht die Kernrealität Ihrer supply chain dar.
Fehlbestand ist im Wesentlichen eine Schätzung des Bestands, der in naher Zukunft Gefahr läuft, abgeschrieben zu werden. Aus Kundensicht gibt es nicht so etwas wie Fehlbestand und lebendigen Bestand. Beide sind Produkte, die nicht gleichermaßen attraktiv sein müssen, aber Fehlbestand ist schlichtweg eine bestimmte Risikobewertung Ihres Bestands. Das ist in Ordnung, sollte aber nicht mit Inventurabschreibungen verwechselt werden, die endgültig sind und anzeigen, dass ein Wert verloren gegangen ist.
Ebenso ist der Abwärtstrend auch ein mathematisches Element, das in der Art und Weise existieren kann, wie Sie die beobachtete Nachfrage modellieren. Es wird typischerweise ein zeitabhängiger Faktor in das Nachfragemodell eingeführt, wie eine lineare Abhängigkeit von der Zeit oder vielleicht eine exponentielle Zeitabhängigkeit. Dies entspricht jedoch nicht der Realität. Die Realität könnte sein, dass Ihr Geschäft infolge von Kundenverlusten schrumpft, weshalb Kundenabwanderung unter anderem die Realität der supply chain darstellt. Der Abwärtstrend ist lediglich ein Artefakt, das Sie zur Aggregation des Musters verwenden können.
Ebenso wird Ihnen kein Lieferant etwas zum durchschnittlichen Einkaufspreis verkaufen. Die einzige Realität ist, dass Sie eine Bestellung erstellen, Mengen auswählen, und je nach den von Ihnen gewählten Mengen erhalten Sie Preisnachlässe, die Ihre Lieferanten anbieten können. Sie erhalten Einkaufspreise basierend auf diesen Preisnachlässen und auf dem, was Sie zusätzlich verhandeln. Der durchschnittliche Einkaufspreis ist nicht real, also seien Sie vorsichtig, diese numerischen Artefakte nicht fälschlicherweise als ein fundamentales Wahrheitselement zu betrachten.
Abschließend ist die ABC-Klassifikation, die von Topsellern bis zu den Langsamdrehern reicht, lediglich eine triviale, volumenbasierte Klassifizierung der SKUs oder Produkte, die Sie haben. Diese Klassen sind keine realen Attribute. Typischerweise ändert sich die ABC-Klasse bei etwa der Hälfte der Produkte von einem Quartal zum nächsten, obwohl aus der Sicht der Kunden oder des Marktes für diese Produkte eigentlich nichts passiert ist. Es handelt sich lediglich um ein numerisches Artefakt, das dem Produkt zugeordnet wurde, und sollte nicht mit zutiefst relevanten Attributen verwechselt werden, wie zum Beispiel, ob ein Produkt Teil einer Händlermarke ist. Dies ist ein wirklich fundamentales Attribut des Produkts, das weitreichende Konsequenzen für Ihre supply chain hat. In diesem Kapitel sollte zunehmend deutlich werden, warum es unerlässlich ist, sich auf supply chain Entscheidungen zu konzentrieren, anstatt Zeit und Aufmerksamkeit mit numerischen Artefakten zu verschwenden.
Wenn das Wort „Optimierung“ ausgesprochen wird, kommt einer gut gebildeten Zuhörerschaft in der Regel die Perspektive der mathematischen Optimierung in den Sinn. Angesichts eines Satzes von Variablen und einer Verlustfunktion besteht das Ziel darin, Variablenwerte zu identifizieren, die die Verlustfunktion minimieren. Leider funktioniert dieser Ansatz in der supply chain schlecht, da er davon ausgeht, dass die relevanten Variablen bekannt sind, was in der Regel nicht der Fall ist. Selbst wenn dies der Fall ist, gibt es viele Variablen, wie Wetterdaten, die bekanntlich einen Einfluss auf Ihre supply chain haben, aber mit erheblichen Kosten verbunden sind, wenn Sie diese Daten erwerben möchten. Daher ist nicht klar, ob es den Aufwand wert ist, diese Daten zu beschaffen, um Ihre supply chain zu optimieren.
Noch problematischer ist, dass die Verlustfunktion selbst weitgehend unbekannt ist. Die Verlustfunktion kann irgendwie geschätzt werden, aber nur der Abgleich der Verlustfunktion mit dem realen Feedback, das Sie aus Ihrer supply chain erhalten können, liefert Ihnen valide Informationen über die Angemessenheit dieser Verlustfunktion. Es geht nicht um mathematische Korrektheit, sondern um Angemessenheit. Reflektiert diese Verlustfunktion, die ein mathematisches Konstrukt ist, adäquat das, was Sie in Ihrer supply chain zu optimieren versuchen? Wir haben dieses Dilemma der Optimierung, während die Variablen und die Verlustfunktion unbekannt sind, in Vorlesung 2.2, betitelt “Experimentelle Optimierung”, behandelt. Die Perspektive der experimentellen Optimierung besagt, dass das Problem nicht gegeben ist; das Problem muss durch wiederholte, iterative Experimente entdeckt werden. Der Nachweis der Korrektheit der Verlustfunktion und ihrer Variablen ergibt sich nicht als mathematische Eigenschaft, sondern durch eine Reihe von Beobachtungen, die durch gut gewählte Experimente, gewonnen aus der supply chain selbst, vorangetrieben werden. Die experimentelle Optimierung stellt die Art und Weise, wie wir Optimierung betrachten, grundlegend in Frage, und dies ist eine Perspektive, die ich in diesem Kapitel übernehmen werde. Die Werkzeuge und Techniken, die ich hier einführen werde, sind auf die Perspektive der experimentellen Optimierung ausgerichtet.
Zu jedem Zeitpunkt kann das numerische Verfahren, das wir haben, als veraltet erklärt werden und durch ein alternatives numerisches Verfahren ersetzt werden, das enger mit der vorhandenen supply chain übereinstimmt. Somit sollten wir jederzeit in der Lage sein, das numerische Verfahren, das wir haben, in die Produktion zu überführen und den Optimierungsprozess im großen Maßstab durchzuführen. Zum Beispiel können wir nicht sagen, dass wir die Verlustfunktion identifizieren und dann ein Team von data scientists für drei Monate mit der Entwicklung einiger Software-Optimierungstechniken beauftragen. Stattdessen sollten wir, sobald wir ein neues Verfahren haben, in der Lage sein, es direkt in Produktion zu nehmen und die supply chain Entscheidungen sofort von dieser neu identifizierten Problemform profitieren zu lassen.
Diese Vorlesung ist Teil einer Reihe von supply chain Vorlesungen. Ich versuche, diese Vorlesungen einigermaßen unabhängig zu halten, aber wir sind an dem Punkt angekommen, an dem es mehr Sinn macht, diese Vorlesungen in Folge anzusehen. Falls Sie die vorherigen Vorlesungen nicht gesehen haben, sollte das in Ordnung sein, aber diese Reihe wird wahrscheinlich mehr Sinn ergeben, wenn Sie sie in der Reihenfolge anschauen, in der sie präsentiert wurde.
Im ersten Kapitel habe ich meine Ansichten zur supply chain sowohl als Studienfeld als auch als Praxis vorgestellt. Im zweiten Kapitel präsentierte ich eine Reihe von Methodologien, die wesentlich sind, um supply chain Herausforderungen anzugehen, einschließlich der experimentellen Optimierung. Diese Methodologien sind notwendig aufgrund der adversarialen Natur der meisten supply chain Probleme. Im dritten Kapitel konzentrierte ich mich auf die Probleme selbst, im Gegensatz zu den Lösungen. Im vierten Kapitel stellte ich eine Reihe von Disziplinen vor, die nicht genau supply chain per se sind – die Hilfswissenschaften der supply chain – die für eine moderne Praxis der supply chain unerlässlich sind. Im fünften Kapitel präsentierte ich eine Reihe von prädiktiven Modellierungstechniken, insbesondere probabilistische Prognosen, die notwendig sind, um mit der irreduziblen Unsicherheit der Zukunft umzugehen.
Heute tauchen wir in dieser ersten Vorlesung des sechsten Kapitels in Entscheidungsfindungstechniken ein. Die wissenschaftliche Literatur hat in den letzten sieben Jahrzehnten eine Fülle von Entscheidungsfindungstechniken und Algorithmen hervorgebracht, von der dynamischen Programmierung in den 1950er Jahren bis hin zu Reinforcement Learning und sogar Deep Reinforcement Learning. Die Herausforderung besteht jedoch darin, produktionstaugliche supply chain Ergebnisse zu erzielen. Tatsächlich leiden die meisten dieser Techniken unter versteckten Schwächen, die sie aus dem einen oder anderen Grund für supply chain Zwecke unpraktisch machen. Heute konzentrieren wir uns auf die Einzelhandelsbestandszuweisung als Archetyp einer supply chain Entscheidung. Diese Vorlesung ebnet den Weg für komplexere Entscheidungen und Situationen.
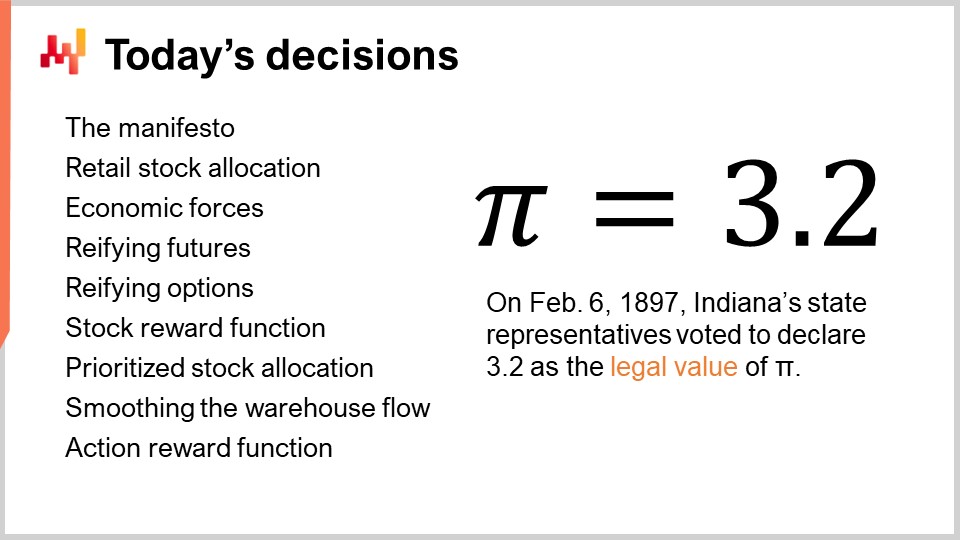
Auf dem Bildschirm wird die Zusammenfassung der heutigen Vorlesung dargestellt. Selbst wenn man das einfachste supply chain Problem, die Einzelhandelsbestandszuweisung, betrachtet, gibt es eine Menge zu erarbeiten. Diese Elemente stellen Bausteine für komplexere Situationen dar. Ich werde damit beginnen, das Manifest der die Quantitative Supply Chain zu wiederholen. Anschließend werde ich klären, was ich unter dem Problem der Einzelhandelsbestandszuweisung verstehe. Wir werden auch die in diesem Problem vorhandenen wirtschaftlichen Kräfte überprüfen. Ich werde den Begriff der probabilistischen Prognosen und unsere Darstellungsmethoden – oder zumindest eine der Möglichkeiten, diese darzustellen – nochmals aufgreifen. Wir werden sehen, wie man die Entscheidung modelliert, indem man die Prognose verfeinert und gleichzeitig die Optionen, also die potenziellen Entscheidungsalternativen, verfeinert.
Anschließend führen wir die Lagerbelohnungsfunktion ein. Diese Funktion kann als ein minimales Rahmenwerk betrachtet werden, um eine probabilistische Prognose in einen wirtschaftlichen Score umzuwandeln, der jeder Option der Bestandszuweisung zugeordnet werden kann, wobei eine Reihe wirtschaftlicher Faktoren berücksichtigt wird. Sobald die Optionen bewertet sind, können wir mit einer Prioritätenliste fortfahren. Eine Prioritätenliste ist trügerisch einfach, erweist sich jedoch als unglaublich mächtig und praktisch in realen supply chain, sowohl in Bezug auf numerische Stabilität als auch auf White-Box-Charakteristika.
Mit der Prioritätenliste können wir den Fluss des Inventars vom Distributionszentrum zu den Filialen fast mühelos glätten, wodurch die Betriebskosten des Distributionszentrums reduziert werden. Schließlich werden wir kurz die Aktionsbelohnungsfunktion überblicken, die heutzutage bei Lokad in nahezu jeder Dimension – außer in der Einfachheit – die Lagerbelohnungsfunktion ablöst.
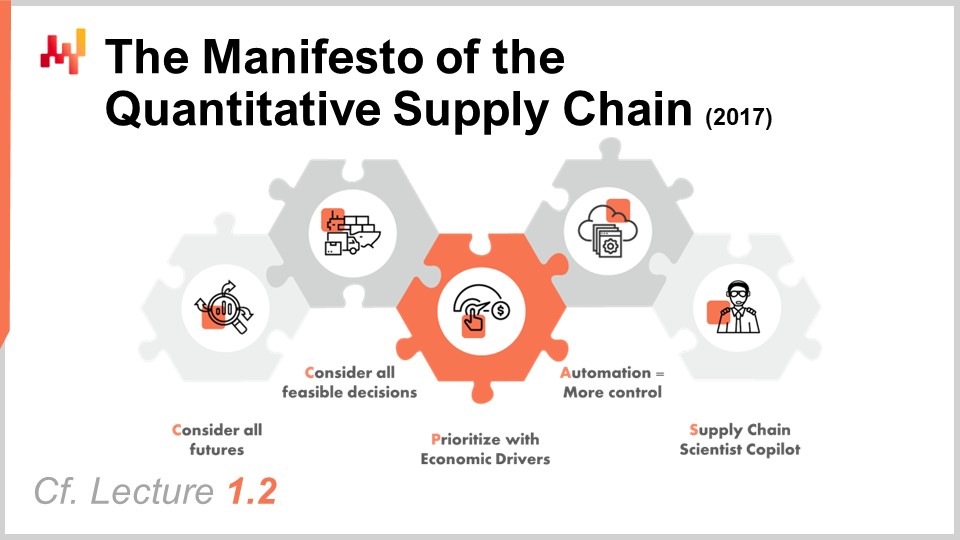
Das Manifest der die Quantitative Supply Chain ist ein Dokument, das ich ursprünglich im Jahr 2017 veröffentlicht habe. Diese Perspektive wurde in Vorlesung 1.2 ausführlich behandelt, aber der Klarheit halber werde ich heute eine kurze Zusammenfassung geben. Es gibt fünf Säulen, aber nur die ersten drei sind für uns heute relevant. Die ersten drei Säulen lauten:
Berücksichtige alle möglichen Zukunftsszenarien, das heißt probabilistische Prognosen sowie die Vorhersage aller anderen Elemente mit einem Unsicherheitsaspekt, wie etwa variierende Durchlaufzeiten oder zukünftige Preise. Berücksichtige alle machbaren Entscheidungen, wobei der Fokus auf den Entscheidungen und nicht auf Artefakten liegt. Priorisiere anhand wirtschaftlicher Treiber, was das Thema der heutigen Vorlesung ist.
Insbesondere werden wir sehen, wie wir probabilistische Prognosen in Schätzungen wirtschaftlicher Erträge umwandeln können.
Beim Problem der Einzelhandelsbestandszuweisung. Dies ist eine Definition, die ich gebe; sie ist etwas willkürlich, aber dies ist die Definition, die ich heute verwenden werde. Wir nehmen ein Netzwerk mit zwei Ebenen an: Wir haben ein Distributionszentrum und mehrere Filialen. Das Distributionszentrum bedient alle Filialen, und falls es mehrere Distributionszentren gibt, nehmen wir an, dass eine Filiale nur von einem einzigen Distributionszentrum beliefert wird. Das Ziel ist es, den Bestand, der im Distributionszentrum vorhanden ist, korrekt auf die Filialen zu verteilen, wobei alle Filialen um denselben Bestand im Distributionszentrum konkurrieren.
Wir nehmen an, dass alle Filialen täglich anhand eines Tagesplans vom Distributionszentrum beliefert werden können. Somit müssen wir jeden einzelnen Tag entscheiden, wie viele Einheiten für jedes einzelne Produkt zu jeder Filiale transportiert werden. Die Gesamtanzahl der transportierten Einheiten darf den im Distributionszentrum verfügbaren Bestand nicht überschreiten, und es ist auch naheliegend, dass es Begrenzungen der Regalfläche in den Filialen gibt. Hätte das Distributionszentrum unbegrenzte Bestände, würde sich das Problem in eine supply chain mit nur einer Ebene verwandeln, da es niemals notwendig wäre, irgendeine Art von Arbitrage oder Abwägung zwischen der Zuteilung des Bestands an die eine oder andere Filiale vorzunehmen. Die Eigenschaft eines Netzwerks mit zwei Ebenen entsteht einzig dadurch, dass die Filialen um denselben Bestand konkurrieren.
Selbstverständlich nehmen wir an, dass Einblick in die Verkaufszahlen der Filialen und in die Bestandsniveaus sowohl auf Ebene des Distributionszentrums als auch der Filialen besteht, das heißt, wir gehen davon aus, dass die Transaktionsdaten verfügbar sind. Wir nehmen außerdem an, dass die eingehenden Lieferungen, die im Distributionszentrum eingehen sollen, mit voraussichtlichen Ankunftszeiten (ETAs) bekannt sind, die mit einem gewissen Grad an Unsicherheit einhergehen können. Wir gehen auch davon aus, dass alle banalen, aber kritischen Informationen vorliegen, wie etwa der Einkaufspreis des Produkts, der Verkaufspreis, die Produktkategorien – falls vorhanden – etc. All diese Informationen finden sich in jedem ERP, selbst in drei Jahrzehnte alten Systemen, sowie in WMS und Kassensystemen.
Heute schließen wir die Auffüllung des Distributionszentrums (DC) nicht als Teil des Problems ein. In der Praxis sind die Auffüllung des Distributionszentrums und die Filialzuteilungen eng miteinander verbunden, sodass es sinnvoll ist, diese Probleme gemeinsam anzugehen. Der Grund, warum ich das heute nicht mache, liegt in der Klarheit und Prägnanz dieser Vorlesung; wir werden zunächst das einfachere Problem behandeln. Bitte beachten Sie jedoch, dass der heute vorgestellte Ansatz sich natürlich auch erweitern lässt, um die DC-Auffüllung einzubeziehen.

Die Entscheidung, eine zusätzliche Einheit eines Produkts an einem bestimmten Tag in eine Filiale zu verlagern, hängt von einer Reihe wirtschaftlicher Kräfte ab. Ist der Transport der Einheit profitabel, wollen wir ihn durchführen; andernfalls nicht. Die wichtigsten wirtschaftlichen Kräfte sind auf dem Bildschirm aufgelistet, und im Wesentlichen bringt das Einbringen von mehr Bestand in eine Filiale eine Reihe von Vorteilen mit sich. Dazu gehören eine höhere Bruttomarge durch Vermeidung von entgangenen Verkäufen, eine bessere Servicequalität durch Verringerung von Stockouts sowie eine gesteigerte Attraktivität der Filiale. Tatsächlich muss eine Filiale, um attraktiv zu wirken, reichhaltig erscheinen; andernfalls wirkt sie trostlos und die Kunden sind möglicherweise weniger kaufwillig. Dies ist eine gängige Beobachtung im Einzelhandel, auch wenn sie nicht zwangsläufig auf alle Segmente, wie beispielsweise den Bereich hard luxury, zutrifft. Für Handel mit allgemeinen Waren oder Modefilialen gilt dieser Aspekt jedoch.
Leider bringt das Einlagern von zusätzlichem Bestand auch Nachteile mit sich, da der Ertrag, der aus einem höheren Lagerbestand in der Filiale erwartet werden könnte, abnimmt. Diese Nachteile umfassen erhöhte Lagerhaltungskosten, die in Form von Inventarabschreibungen auftreten können, wenn ein echter Überschuss an Bestand vorliegt. Es besteht außerdem das Risiko einer Überlastung bei der Wareneingangsbearbeitung, die auftritt, wenn das Filialpersonal eine zu große Lieferung nicht verarbeiten kann. Dies führt zu Verwirrung und Unordnung in der Filiale, falls die gelieferte Menge die Kapazität des Personals zum Einräumen übersteigt. Zusätzlich gibt es Opportunitätskosten: Immer wenn eine Einheit in einer Filiale platziert wird, kann sie nicht in einer anderen platziert werden. Zwar könnte sie zurück ins Distributionszentrum gebracht und erneut versendet werden, doch dies ist in der Regel sehr kostspielig und stellt daher meist die letzte Möglichkeit dar. Einzelhändler sollten auf eine effiziente Filialzuteilung abzielen, ohne den Bestand zurückschieben zu müssen.
Das Glätten des Lagerflusses ist ebenfalls sehr wünschenswert. Ein Distributionszentrum (DC) verfügt über eine nominale Kapazität, bei der es mit maximaler wirtschaftlicher Effizienz arbeitet. Diese Spitzenleistung wird durch die physische Einrichtung des DC sowie die Anzahl des festangestellten Personals bestimmt. Idealerweise sollte das DC täglich arbeiten und dabei seiner nominalen Kapazität sehr nahe bleiben, um kosteneffizient zu sein. Die Aufrechterhaltung dieser Spitzenleistung im DC erfordert jedoch ein geglättetes Lagerniveau vom DC zu den Filialen. Die wirtschaftliche Perspektive weicht von den traditionellen, dienstleistungsorientierten Ansätzen ab, wie sie häufig in der Mainstream supply chain Literatur zu finden sind. Wir streben nach wirtschaftlichen Erträgen in Dollar, nicht nach Prozentpunkten. Der einzige Weg, um zu entscheiden, ob es vertretbar ist, das Zuteilungsschema auf Netzwerkebene anzupassen, um Betriebskosten zu senken, gegenüber einer leichten Verschlechterung der Servicequalität in den Filialen, besteht darin, die hier vorgestellte wirtschaftliche Perspektive zu übernehmen. Wenn Sie eine serviceorientierte Perspektive einnehmen, kann diese Art von Antwort nicht geliefert werden. Unser Ziel besteht darin, numerische Rezepturen aufzustellen, die die wirtschaftlichen Ergebnisse jeder gegebenen Bestandszuweisungsentscheidung abschätzen können.
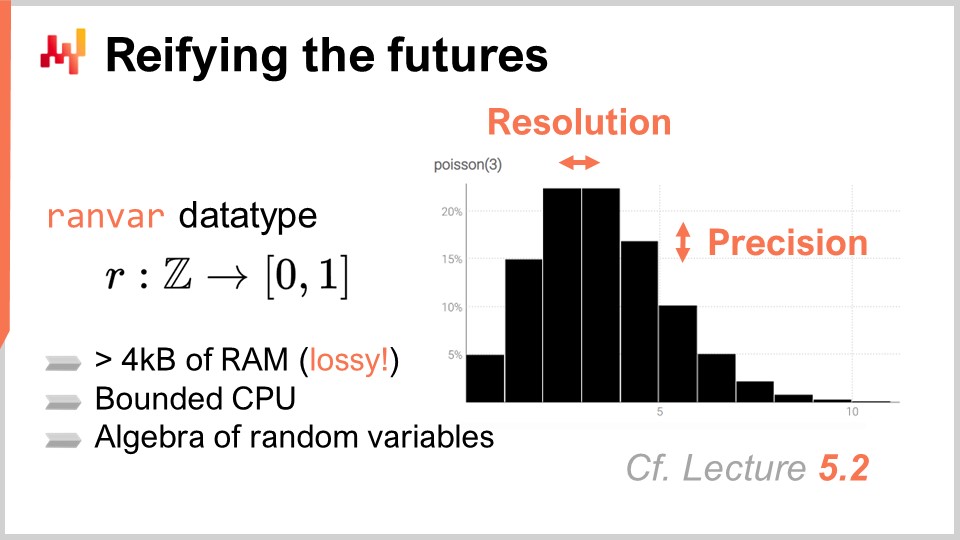
Im vorherigen Kapitel, dem fünften Kapitel, haben wir besprochen, wie probabilistische Prognosen erstellt werden, und einen speziellen Datentyp eingeführt, den “ranvar”, der eindimensionale diskrete Wahrscheinlichkeitsverteilungen darstellt. Kurz gesagt, ist ein ranvar ein spezieller Datentyp, der verwendet wird, um eine einfache, eindimensionale probabilistische Prognose in Envision darzustellen.
Envision ist eine domänenspezifische Programmiersprache, die von Lokad ausschließlich für die prädiktive Optimierung von supply chains entwickelt wurde. Auch wenn an Envision in diesen Vorlesungen grundsätzlich nichts Einzigartiges sein sollte, wird es zur besseren Übersichtlichkeit und Prägnanz verwendet. Die heute beschriebenen numerischen Rezepturen können in jeder beliebigen Sprache implementiert werden, wie etwa Python, Julia oder Visual Basic.
Der entscheidende Aspekt des ranvar besteht darin, dass er eine leistungsstarke Algebra von Zufallsvariablen bietet. Leistung ist ein Gleichgewicht zwischen den Rechenkosten, den Speicherkosten und dem Grad der numerischen Approximation, den man zu tolerieren bereit ist. Die Rechenleistung ist besonders wichtig im Umgang mit Einzelhandelsnetzwerken, da es Millionen oder sogar zig Millionen SKUs geben kann, von denen jede wahrscheinlich mindestens eine probabilistische Prognose oder einen ranvar hat. Folglich kann es passieren, dass Sie mit Millionen oder zig Millionen von Histogrammen enden.
Die wesentliche Eigenschaft des ranvar im Vergleich zu einem Histogramm besteht darin, sowohl die CPU-Kosten als auch die Speicherkosten nach oben begrenzt und so gering wie möglich zu halten. Es ist auch entscheidend sicherzustellen, dass die eingeführte numerische Approximation aus supply chain Sicht unbedeutend bleibt. Es ist wichtig zu beachten, dass es hier nicht um wissenschaftliches Rechnen geht, sondern um supply chain Berechnungen. Zwar sollten numerische Berechnungen präzise sein, aber eine extreme Präzision ist nicht erforderlich. Bedenken Sie, dass wir hier nicht wissenschaftlich rechnen, sondern supply chain Berechnungen durchführen. Wenn Sie eine Approximation von einem Teil pro Milliarde haben, ist sie aus supply chain Sicht unbedeutend. Numerische Berechnungen sollten präzise sein, aber eine extreme Präzision ist nicht notwendig.
Im Folgenden gehen wir davon aus, dass die probabilistische Prognose in Form von ranvars bereitgestellt wird, also einer Reihe von Variablen mit einem spezifischen Datentyp. In der Praxis können Sie ranvars durch Histogramme ersetzen und überwiegend dasselbe Ergebnis erzielen, abgesehen von den Aspekten der Leistung und Bequemlichkeit.
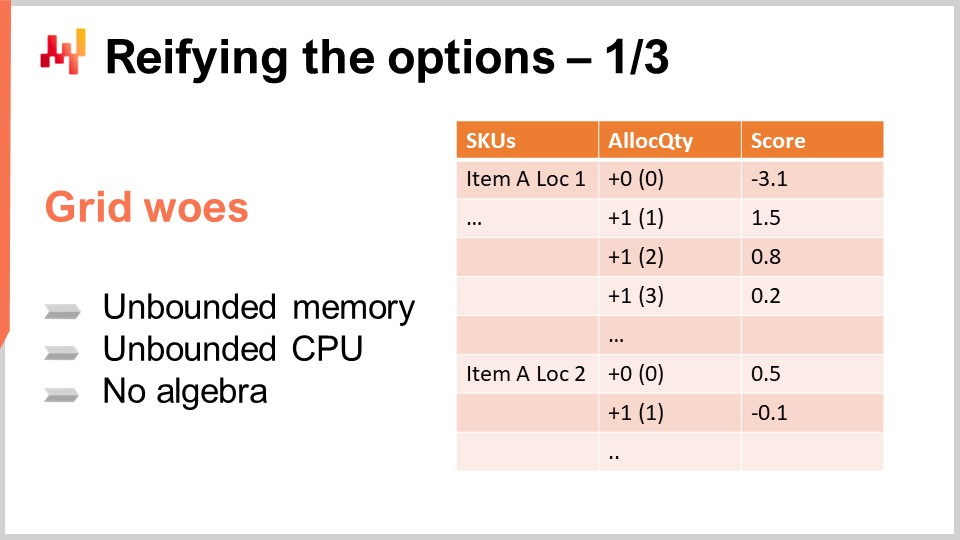
Da wir nun unsere probabilistischen Prognosen haben, wollen wir betrachten, wie wir die Entscheidungen angehen werden. Beginnen wir mit den Optionen. Die Optionen sind die potenziellen Entscheidungen – zum Beispiel, einem bestimmten Produkt an einem bestimmten Tag in einer bestimmten Filiale null Einheiten oder ein, zwei oder drei Einheiten zuzuordnen. Wenn wir uns entscheiden, zwei Einheiten zuzuweisen, dann wird dies unsere Entscheidung. Die Optionen umfassen all das, was auf dem Tisch liegt und darauf wartet, entschieden zu werden.
Eine einfache Möglichkeit, diese Optionen zu organisieren, besteht darin, sie in einer Liste zusammenzufassen, wie auf dem Bildschirm dargestellt. Die Liste umfasst mehrere SKUs, und für jede SKU fügen Sie eine Zeile pro Option hinzu. Jede Option repräsentiert eine zuzuweisende Menge. Sie können null, eine, zwei, drei usw. zuordnen. In Wirklichkeit müssen Sie nicht ins Unendliche gehen; Sie können bei der Menge, die im Distributionszentrum vorrätig ist, stoppen. Realistischerweise haben Sie üblicherweise auch eine Untergrenze, wie zum Beispiel die maximale Regalfläche für das Produkt in der Filiale.
So haben Sie eine Liste, die jede SKU umfasst, und für jede SKU stehen alle Mengen zur Auswahl, die als Kandidaten für die Zuteilung aus dem Distributionszentrum in Betracht gezogen werden können. Die Bewertungsspalte ist mit dem Grenzergebnis verknüpft, das Sie durch diese Zuteilung erwarten würden. Eine gut konzipierte Bewertung stellt sicher, dass die Auswahl der Zeilen in absteigender Punkte-Reihenfolge das wirtschaftliche Ergebnis für das Einzelhandelsnetzwerk optimiert.
Für die beiden auf dem Bildschirm gezeigten SKUs nimmt die Bewertung ab, je mehr zugewiesen wird, was das vorherrschende Phänomen der abnehmenden Grenzerträge bei den meisten SKUs veranschaulicht. Grundsätzlich generiert die erste Einheit in einer Filiale fast immer höhere Erträge als die zweite. Die erste Einheit, die Sie in eine Filiale bringen, ist fast immer profitabler als die zweite. Anfangs hat man nichts, sodass man sich in einer Fehlbestandsituation befindet. Wenn Sie eine Einheit zuweisen, haben Sie bereits den Fehlbestand für den ersten Kunden behoben. Wenn Sie eine zweite Einheit zuweisen, wird der erste Kunde zwar versorgt sein, aber erst wenn zwei Kunden erscheinen, kommt die zweite Einheit zum Einsatz, sodass ihr wirtschaftlicher Ertrag geringer ausfällt. Die Erträge nehmen jedoch im Allgemeinen ab, wenn der Bestand erhöht wird. Es gibt einige Ausnahmen, bei denen die wirtschaftlichen Erträge nicht streng von einer Zeile zur nächsten abnehmen, aber diesen Fall werde ich in einer späteren Vorlesung noch einmal aufgreifen. Für den Moment halten wir uns an die einfache Situation, in der die Erträge mit zunehmendem Bestand strikt abnehmen.
Die Darstellung, bei der wir alle SKUs und Optionen sehen können, wird typischerweise als Gitter bezeichnet. Ziel ist es, dieses Gitter nach absteigendem ROI (Return on Investment) zu sortieren. An sich ist nichts an diesen Gittern falsch, aber sie sind weder rechen- noch speichereffizient und bieten darüber hinaus keine Unterstützung, abgesehen davon, dass sie eine große Tabelle darstellen. Bedenken Sie, dass es sich um ein Einzelhandelsnetzwerk handelt und dieses Gitter möglicherweise eine Milliarde Zeilen oder mehr enthalten könnte. Big Data ist in Ordnung, aber kleinere Datenmengen sind besser, da sie weniger Reibungsverluste verursachen und mehr Agilität ermöglichen. Wir wollen unser Big-Data-Problem in ein Small-Data-Problem umwandeln, da kleinere Datenmengen alles in der Produktion vereinfachen.

Daher ist eine der von Lokad übernommenen Lösungen, um mit einer großen Anzahl von Optionen umzugehen, zedfuncs. Dieser Datentyp ist, genau wie ranvars, das Gegenstück von ranvar, jedoch aus der Entscheidungsperspektive. Ranvars repräsentieren alle möglichen Zukünfte, während zedfuncs alle möglichen Entscheidungen repräsentieren. Anstatt Wahrscheinlichkeiten wie ranvars abzubilden, stellt ein zedfunc alle wirtschaftlichen Ergebnisse dar, die mit einer eindimensionalen, diskreten Optionsreihe verbunden sind.
Das zedfunc, oder zedfunction, ist technisch gesehen eine Funktion, die ganze Zahlen – sowohl positive als auch negative – auf reelle Werte abbildet. Dies ist die technische Definition. Allerdings ist es, genau wie bei ranvars, nicht möglich, eine beliebige oder komplexe Funktion wie zedfuncs mit einer endlichen Menge an Speicher darzustellen. Dabei muss auch ein Kompromiss zwischen Präzision und Auflösung eingegangen werden.
Im Supply Chain Management existieren nicht beliebig komplexe ökonomische Funktionen. Es können zwar ziemlich komplexe Kostenfunktionen vorliegen, sie dürfen jedoch nicht beliebig komplex sein. In der Praxis ist es möglich, zedfuncs auf unter vier Kilobyte zu komprimieren. Dadurch erhalten Sie einen Datentyp, der Ihre gesamte Kostenfunktion repräsentiert und so komprimiert, dass sie stets weniger als vier Kilobyte beträgt, während der Grad der numerischen Approximation aus Sicht der supply chain unerheblich bleibt. Wenn Sie die numerische Approximation so klein halten, dass sie die endgültige, diskrete Entscheidung, die Sie treffen, nicht ändert, dann kann man sagen, dass die numerische Approximation völlig unerheblich ist, da Sie am Ende dasselbe Ergebnis erzielen, selbst wenn Sie unendliche Präzision hätten.
Der Grund für die Verwendung von vier Kilobyte hängt mit der Computer-Hardware zusammen. Wie wir in einer früheren Vorlesung über moderne Computer-Hardware im Supply Chain Management gesehen haben, erlaubt der Arbeitsspeicher (RAM) in einem modernen Computer – sei es ein Workstation, Notebook oder ein Computer in der Cloud – nicht, auf den Speicher Byte für Byte zuzugreifen. Sobald Sie den RAM berühren, wird ein Segment von vier Kilobyte abgerufen. Daher ist es am besten, die Datenmenge unter vier Kilobyte zu halten, da dies der Art und Weise entspricht, wie die Hardware gestaltet ist und im Supply Chain operiert.
Der von Lokad für zedfuncs verwendete Kompressionsalgorithmus unterscheidet sich von dem für ranvars, da wir es hier mit anderen numerischen Problemen zu tun haben. Bei ranvars geht es hauptsächlich darum, die Masse der Wahrscheinlichkeiten unserer zusammenhängenden Segmente zu erhalten. Bei einem zedfunc liegt der Fokus anderswo. Wir möchten in der Regel die Variation, die von einer Position zur nächsten beobachtet wird, bewahren, da es gerade diese Variation ist, mit der wir entscheiden können, ob es sich um die letzte profitable Option handelt oder ob wir anhalten sollten. Daher ist auch der Kompressionsalgorithmus unterschiedlich.

Auf dem Bildschirm sehen Sie ein Diagramm, das für einen zedfunc erstellt wurde und einige erwartete Lagerhaltungskosten darstellt, die von der Anzahl der Einheiten im Bestand abhängen. Zedfuncs profitieren davon, ein Vektorraum zu sein, was bedeutet, dass sie wie im klassischen Vektorraum, der Funktionen zugeordnet ist, addiert und subtrahiert werden können. Durch die Wahrung der Speicherlokalität können Operationen um eine Größenordnung schneller ausgeführt werden als bei einer naiven Gitterimplementierung, bei der Sie eine sehr große Tabelle ohne eine spezifische Datenstruktur zur Erfassung der zusammenwirkenden Optionen haben.
Das in der vorherigen Folie gezeigte Diagramm wurde durch ein Skript erzeugt. In den Zeilen eins und zwei deklarieren wir zwei lineare Funktionen, f und g. Die Funktion “linear” ist Teil der Standardbibliothek, und “linear of one” ist lediglich die Identitätsfunktion, ein Polynom ersten Grades. Die Funktion “linear” gibt einen zedfunc zurück, und es ist möglich, zu einem zedfunc eine Konstante hinzuzufügen. Wir haben zwei Polynome ersten Grades, f und g. In Zeile drei konstruieren wir ein Polynom zweiten Grades durch das Produkt von f und g. Die Zeilen 5 bis 10 sind Hilfsprogramme, im Grunde Boilerplate, um den zedfunc zu plotten.
An dieser Stelle haben wir unseren Datencontainer für den zedfunc und die wirtschaftlichen Ergebnisse. Der zedfunc ist ein Datencontainer, so wie es der ranvar für die probabilistische Prognose war. Allerdings benötigen wir noch numerische Rezepte, um diese wirtschaftlichen Ergebnisse zu berechnen. Wir haben den Datencontainer, aber ich habe noch nicht erläutert, wie wir diese wirtschaftlichen Ergebnisse berechnen und die zedfuncs befüllen.

Die Stock Reward Function ist ein kleines Framework, das dazu dient, die wirtschaftlichen Erträge für jeden Lagerbestand eines einzelnen SKU zu berechnen, wobei eine probabilistische Prognose und eine kurze Reihe wirtschaftlicher Faktoren berücksichtigt werden. Die Stock Reward Function wurde historisch bei Lokad eingeführt, um unsere Praktiken zu vereinheitlichen. Bereits 2015 arbeitete Lokad seit einigen Jahren mit probabilistischen Prognosen, und durch Versuch und Irrtum hatten wir eine Reihe von numerischen Rezepten entdeckt, die gut funktionierten. Allerdings waren sie nicht wirklich einheitlich; es war ein ziemliches Durcheinander. Die Stock Reward Function fasste all diese Erkenntnisse damals in einem sauberen, ordentlichen, minimalistischen Framework zusammen. Seit 2015 wurden zwar bessere Methoden entwickelt, aber diese sind auch komplexer. Der Klarheit halber ist es immer noch besser, mit der Stock Reward Function zu beginnen und diese Funktion zuerst vorzustellen.
Bei der Stock Reward Function geht es im Grunde darum, ein numerisches Rezept zu finden, das uns eine Berechnung der wirtschaftlichen Ergebnisse liefert, die diesen probabilistischen Prognosen zugeordnet sind. Die Stock Reward Function folgt der Gleichung, die Sie auf dem Bildschirm sehen, und definiert die wirtschaftlichen Erträge zum Zeitpunkt t, die Sie für den vorhandenen Lagerbestand k erhalten können. Die Variable R steht für den wirtschaftlichen Ertrag, der in Einheiten wie Dollar oder Euro ausgedrückt wird. Die Funktion hat zwei Variablen: Zeit (t) und Lagerbestand (k). Wir möchten diesen Ertrag für alle möglichen Bestandswerte berechnen.
Es gibt vier wirtschaftliche Variablen, die berücksichtigt werden müssen:
M ist die Bruttomarge pro verkaufter Einheit. Es ist die Marge, die Sie verdienen, wenn Sie eine Einheit erfolgreich bedienen. S ist die Stockout-Strafe, eine Art virtuelle Kosten, die anfallen, wenn es Ihnen nicht gelingt, einem Kunden eine Einheit zu bedienen. Selbst wenn Sie Ihrem Kunden keine Strafe zahlen müssen, entstehen Kosten, wenn Sie keinen ordnungsgemäßen Service bieten, und diese Kosten müssen modelliert werden. Eine der einfachsten Methoden, diese Kosten zu modellieren, besteht darin, für jede Einheit, die Sie nicht bedienen, eine Strafe zu veranschlagen. C sind die Lagerhaltungskosten, die Kosten pro Einheit und Zeitraum. Wenn Sie eine Einheit drei Perioden lang auf Lager haben, wären das drei mal C; wenn Sie zwei Einheiten drei Perioden lang auf Lager haben, wären das sechs mal C. Alpha wird verwendet, um zukünftige Erträge abzuzinsen. Die Idee ist, dass das, was in ferner Zukunft geschieht, weniger wichtig ist als das, was in naher Zukunft passieren wird. Die Stock Reward Function ist so einfach, wie sie sein kann, ohne übermäßig simpel zu sein. Die Gleichung zeigt, dass, wenn die Nachfrage den vorhandenen Lagerbestand übersteigt, der Ertrag die Marge für den gesamten Bestand umfasst.
Das besagt die erste Zeile: Wir haben k Margen, also verkaufen wir alle Einheiten, die wir haben, und dann entsteht eine Strafe von Y(t) - k für alle Einheiten, die wir nicht bedienen konnten.
Andernfalls, wenn der vorhandene Lagerbestand die Nachfrage übersteigt, profitieren wir von Y(t) mal M, was die Marge dessen darstellt, was wir heute verkauft haben. Anschließend müssen wir die Lagerhaltungskosten bezahlen. Die Lagerhaltungskosten für heute betragen das, was am Ende des Tages übrig bleibt, nämlich (k - Y(t)) mal C, plus alpha mal der Stock Reward Function R* für den nächsten Tag.
Es gibt einen Haken bei R*. Es ist nahezu identisch zur Stock Reward Function R, außer dass wir die Stockout-Strafe einfach auf null setzen. Der Grund ist einfach: Aus der Sicht des Lagerbestands gehen wir davon aus, dass wir später die Möglichkeit haben werden, den Bestand wieder aufzufüllen. Wenn wir heute einen Stockout beobachten, ist es zu spät, sodass wir die Stockout-Strafe in Kauf nehmen. Eine Stockout-Strafe, die hingegen für morgen angesetzt wird, gilt als vermeidbar.
Wenn eine Stockout-Strafe jedoch für die Zukunft, in einer späteren Periode, angesetzt wird, gehen wir davon aus, dass in jeder Periode eine Nachbestellung erfolgen kann. Somit ist bei einem Stockout, der in einer späteren Periode eintreten würde – wenn wir noch Zeit für eine verspätete Nachbestellung haben – der Stockout noch nicht eingetreten. Wir haben immer noch die Gelegenheit dazu, weshalb wir die Stockout-Strafe auf null setzen, da wir davon ausgehen, dass es hoffentlich eine weitere Nachbestellung geben wird, die den Stockout verhindert.
Das zeitliche Abzinsen mit alpha ist sehr nützlich, da es im Wesentlichen die Notwendigkeit beseitigt, einen spezifischen Zeithorizont anzugeben. Die Stock Reward Function arbeitet nicht mit einem endlichen Zeithorizont; sie läuft ins Unendliche. Dank alpha, einem Wert, der strikt kleiner als eins ist, werden die wirtschaftlichen Ergebnisse, die Ereignissen in ferner Zukunft zugeordnet sind, verschwindend klein und damit unerheblich. Wir haben keinen beliebigen Abschneidepunkt, wie beispielsweise einen Supply Chain-Horizont von 60 Tagen, 90 Tagen, einem Jahr oder zwei Jahren.

In Envision nimmt die Stock Reward Function einen ranvar als Eingabe und gibt einen zedfunc zurück. Die Stock Reward Function ist ein kleiner Baustein, der eine probabilistische Prognose (einen ranvar) in einen zedfunc verwandelt, der ein Container für die geschätzten wirtschaftlichen Erträge einer Reihe von Optionen ist. Wie der Name schon sagt, ist die Stock Reward Function der wirtschaftliche Ertrag, der mit jeder einzelnen Lagerposition verbunden ist: was passiert, wenn ich null, eine, zwei, drei Einheiten auf Lager habe und so weiter. Der zedfunc wird die wirtschaftlichen Ergebnisse für jedes Lagerniveau widerspiegeln, indem er den wirtschaftlichen Ertrag codiert, der mit dem entsprechenden Bestandsniveau verbunden ist.
Der Prozess zur Berechnung dieser zedfuncs wird auf dem Bildschirm veranschaulicht. In Zeile 1 führen wir eine simulierte Nachfrage für einen einzigen Tag ein, die lediglich einer zufälligen Poisson-Verteilung entspricht. In den Zeilen 2 bis 7 führen wir die wirtschaftlichen Variablen ein, und übrigens haben wir zwei alphas. Es gibt einen weiteren Haken: Wir haben einen Ratschlüsseleffekt beim Inventar. Sobald der Lagerbestand in Richtung des Geschäfts verschoben wurde, ist es in der Regel sehr teuer, ihn wieder zurückzubringen. Dies spiegelt wider, dass jede einem Geschäft zugewiesene Menge weitgehend endgültig ist. Hinsichtlich der Lagerhaltungskosten sollte das Alpha nicht zu klein sein, da uns diese Kosten wirklich belasten, wenn wir übervorraten. Wir können diese Entscheidung nicht rückgängig machen. Wenn es jedoch um das Alpha geht, das sich auf die Marge bezieht, ist die Realität, dass wir, genauso wie wir weitere Gelegenheiten haben werden, zukünftige Stockouts zu adressieren, auch weitere Gelegenheiten haben werden, mehr Lagerbestand zu beschaffen und dieselbe Marge mit Lagerbestand zu erzielen, der zu einem späteren Zeitpunkt verschoben wird. Daher müssen wir das, was auf der Margenseite passiert, viel aggressiver abzinsen als das, was auf der Seite der Lagerhaltungskosten geschieht.
In den Zeilen 9 bis 11 führen wir die Stock Reward Function selbst ein. Diese Funktion, die ich in der vorherigen Folie vorgestellt habe, kann linear in ihre drei Komponenten zerlegt werden, die jeweils die Marge, die Lagerhaltungskosten und die Stockout-Strafe separat adressieren. Tatsächlich haben wir eine lineare Trennung, und in Envision werden diese drei Komponenten getrennt berechnet. Wir können den zedfunc mit dem Faktor M multiplizieren, was der Bruttomarge entspricht.
In den Zeilen 13 bis 15 wird der endgültige Ertrag wieder zusammengesetzt, indem die drei wirtschaftlichen Komponenten addiert werden. In diesem Skript nutzen wir die Tatsache, dass wir einen Vektorraum von zedfuncs haben. Diese zedfuncs sind keine Zahlen; sie sind Funktionen. Aber wir können sie addieren, und das Ergebnis der Addition ist eine weitere Funktion, die ebenfalls ein zedfunc ist. Die Variable reward ist das Ergebnis der Addition dieser drei Komponenten. Im Hintergrund erfolgt die Berechnung der Stock Reward Function mittels einer Fixpunktanalyse, die für jede Komponente in konstanter Zeit durchgeführt werden kann. Diese konstante Zeitberechnung mag wie eine kleine technische Kleinigkeit erscheinen, aber wenn Sie mit einem großen Einzelhandelsnetzwerk zu tun haben, macht sie den Unterschied zwischen einem ausgefallenen Prototyp und einer produktionsreifen Lösung aus.

Nun, an diesem Punkt haben wir alle Zutaten zusammengetragen, die erforderlich sind, um das Problem der Lagerverteilung anzugehen. Wir haben probabilistische Prognosen in Form von ranvars, eine Technik, diese ranvars in eine Funktion zu transformieren, die wirtschaftliche Erträge für jeden Wert des vorhandenen Bestands liefert, und diese wirtschaftlichen Ergebnisse können bequem als zedfuncs dargestellt werden. Um schließlich das Problem der Lagerverteilung anzugehen, müssen wir die entscheidende Frage beantworten: Wenn wir nur eine einzelne Einheit Lagerbestand bewegen können, welche bewegen wir und warum? Alle Geschäfte im Netzwerk konkurrieren um denselben Lagerbestand im Distributionszentrum, und die Qualität der Entscheidung, eine Einheit Lagerbestand vom Distributionszentrum in ein bestimmtes Geschäft zu bewegen, hängt vom Gesamtzustand des Netzwerks ab. Man kann nicht beurteilen, ob diese Entscheidung gut ist, indem man nur ein Geschäft betrachtet.
Zum Beispiel nehmen wir an, dass wir ein Geschäft haben, das bereits zwei Einheiten auf Lager hat, und wenn wir eine dritte Einheit hinzufügen, erhöhen wir das erwartete Servicelevel von 80 % auf 90 %. Das ist gut, und vielleicht würden mehr im Netzwerk der Idee zustimmen, eine zusätzliche Einheit hinzuzufügen, damit das Servicelevel von 80 auf 90 steigen kann. Das erscheint sehr vernünftig, sodass man sagen würde, dies sei ein guter Schritt. Aber was, wenn diese Einheit, die wir verschieben wollen, diese dritte Einheit, tatsächlich die letzte im Distributionszentrum verfügbare Einheit ist? Wir haben ein anderes Geschäft im Netzwerk, das bereits an einem Stockout leidet, und wenn wir diese Einheit in das Geschäft verschieben, in dem sie zur dritten Einheit wird, verlängern wir den Stockout für das Geschäft, das bereits für dasselbe Produkt keinen Bestand hat. In dieser Situation ist es fast sicher, dass das Verschieben der Einheit in das Geschäft, das bereits ausverkauft ist, die bessere Entscheidung ist und Vorrang haben sollte.
Deshalb macht es keinen Sinn, die Lagerbestände wirtschaftlich auf SKU-Ebene zu bewerten. Das Problem bei lokalen Optimierungen besteht darin, dass sie in größeren Systemen nicht funktionieren. In Supply Chains, wenn man Dinge lokal angeht, verlagert man nur Probleme; man löst nichts. Die Angemessenheit eines Lagerbestands einer SKU hängt vom Zustand des Netzwerks ab. Dieses einfache Beispiel verdeutlicht, warum Sicherheitsbestandsberechnungen oder reorder point-Berechnungen größtenteils Unsinn sind, zumindest für reale Situationen, im Vergleich zu Spielzeugebeispielen, die in Supply Chain-Lehrbüchern zu finden sind.
Hier möchten wir wirklich alle Lagerzuweisungen gegeneinander priorisieren, und die Option, die dabei an oberster Stelle steht, ist die Antwort auf unsere Frage: Dies wird die eine Einheit sein, die bewegt werden sollte, wenn wir nur eine einzige Einheit verschieben können.

Die Bewertung von Lagerallokationsoptionen ist mit den richtigen Werkzeugen relativ einfach. Lassen Sie uns dieses Envision-Skript durchgehen. In Zeile 1 erstellen wir drei SKUs namens A, B und C. In Zeile 2 generieren wir zufällige Einkaufspreise zwischen 1 und 10 als Mock-Daten. In Zeile 3 erzeugen wir Mock-zedfuncs, die den Ertrag darstellen sollen, den wir für jede dieser SKUs erhalten. In der Praxis sollte ein zedfunc mit der Lagerertragsfunktion berechnet werden, aber um den Code prägnant zu halten, verwenden wir hier Mock-Daten. Der Ertrag ist eine abnehmende lineare Funktion, die bei einem Lagerbestand von 6 null erreicht. In Zeile 4 erstellen wir eine Tabelle G, eine Abkürzung für das Raster, das unseren Lagerbestand darstellt. Wir gehen davon aus, dass Lagerbestände über 10 nicht näher betrachtet werden. Diese Annahme ist stichhaltig, wenn man bedenkt, dass wir bei den Mock-Daten eine Ertragsfunktion haben, die jenseits eines Lagerbestands von 6 negativ wird. In Zeile 6 extrahieren wir den Grenzertrag für jede lagervorrätige Einheit, sodass uns diese Rastertabelle vorliegt. Wir verwenden die zedfunc, eine Funktion, die Erträge darstellt, um den Wert für die Lagerposition G.N zu extrahieren. Es ist anzumerken, dass es ab Zeile 6 keine Rolle spielt, wie die Daten ursprünglich generiert wurden. Von Zeile 1 bis 4 handelt es sich lediglich um Mock-Daten, die in einer Produktionsumgebung nicht verwendet würden, aber ab Zeile 6 wäre es im Grunde dasselbe, wenn man in der Produktion wäre.
In Zeile 7 definieren wir den Score als das Verhältnis zwischen den Dollar-Erträgen (die der zedfunc angibt) und dem investierten Dollar, also dem Einkaufspreis. Wir bilden das Verhältnis zwischen der Summe an Dollar, die Sie zurückerhalten, und dem Dollarbetrag, den Sie für eine Einheit zahlen müssen. Im Wesentlichen wird der höchste Score für die Lagerallokation erzielt, die die höchste Rendite pro Dollar bringt, der diesem Store zugewiesen wurde.
Schließlich zeigen wir in den Zeilen 9 bis 15 eine Tabelle an, die nach abnehmenden Scores sortiert ist. Es ist wichtig zu betonen, dass im Skript keine ausgeklügelte Logik steckt. Die ersten vier Zeilen dienen nur der Erzeugung von Mock-Daten, und die letzten sechs Zeilen zeigen lediglich die Anzeige der priorisierten Allokation. Sobald die zedfuncs vorhanden sind und wir eine Funktion haben, die den wirtschaftlichen Ertrag pro Lagerbestand darstellt, ist es völlig unkompliziert, diese zedfuncs in eine prioritized list umzuwandeln.

Auf dem Bildschirm zeigt die Tabelle, die durch Ausführen des vorangegangenen Envision-Skripts erstellt wurde, dass die SKU namens C den ersten Platz belegt. Alle SKUs erzielen bei der ersten Einheit denselben wirtschaftlichen Ertrag, nämlich $5. Allerdings hat C mit $3,99 den niedrigsten Einkaufspreis, und wenn man den Ertrag von $5 durch $3,99 teilt, erhält man einen Score von ungefähr 1,25, was der höchste Score im Raster ist. Die zweite Einheit von C erzielt einen Score von circa 1, dem zweithöchsten Score.
Für die dritte Position im Raster haben wir eine weitere SKU namens B. B hat einen höheren Einkaufspreis, weshalb der Score für die erste Einheit nur 0,96 beträgt. Allerdings erzielt aufgrund der abnehmenden Erträge, die sich durch die Zuweisung der ersten beiden Einheiten an SKU C ergeben, die erste Einheit von B einen höheren Score als die dritte Einheit von C und wird deshalb über dieser eingestuft. Im Wesentlichen geht diese Prioritätenliste sehr in die Tiefe, soll aber mit einem Schwellenwert abgeschnitten werden. Beispielsweise können wir festlegen, dass eine minimale Rendite vorhanden sein muss, und nur die Einheiten oberhalb dieser Rendite zuweisen. Sobald der Schwellenwert definiert ist, können wir alle Zeilen oberhalb des Schnittpunkts heranziehen und die Anzahl der Zeilen pro SKU zählen. Das ergibt die Gesamtzahl der Einheiten, die jeder einzelnen SKU zugewiesen werden sollen. Dieses Cutoff-Problem werden wir in Kürze erneut behandeln, aber die Idee ist, dass, sobald Sie einen Cutoff haben, Sie die Zählungen pro SKU aggregieren und so die Gesamtmenge erhalten, die jeder SKU zugewiesen werden soll. Genau das erwartet Ihr WMS oder ERP im Verteilzentrum, um den Versand am nächsten Tag an die Stores zu organisieren.
Die Prioritätenliste ist lediglich eine konzeptionelle Sichtweise, um tatsächlich zu entscheiden, was Vorrang hat. Allerdings definieren Sie einen Cutoff, aggregieren, und anschließend kehren Sie zu den Allokationsmengen pro SKU für jede einzelne SKU in Ihrem Einzelhandelsnetzwerk zurück.
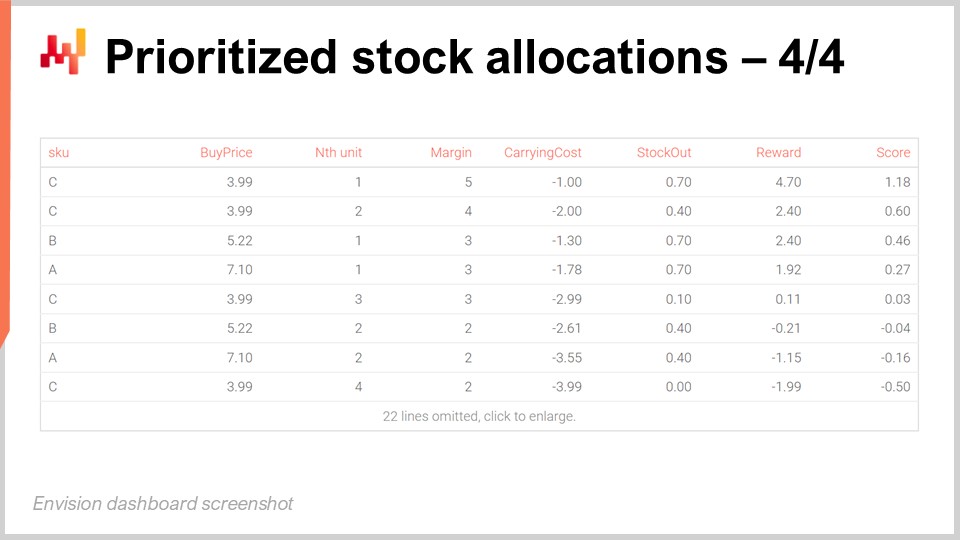
Die Darstellung der priorisierten Lagerallokation ist trügerisch einfach und dennoch wirkungsvoll. Wenn wir von einer Zeile zur nächsten gehen, erkennen wir, wie der Wettbewerb zwischen unseren Allokationsoptionen entsteht. Die besten SKUs werden zuerst zugewiesen, aber sobald wir höhere Lagerbestände erreichen, werden diese SKUs weniger wettbewerbsfähig im Vergleich zu anderen SKUs, die nicht so viel Bestand haben. Die Prioritätenliste wechselt von einer SKU zur nächsten und maximiert so die erwarteten Kapitalerträge, die den Stores zugewiesen werden.
Auf diesem Bildschirm sehen wir eine Variante der vorangegangenen Tabelle, die mit einem weiteren Envision-Skript erstellt wurde – einer minimalen Variante des vor zwei Folien vorgestellten Skripts. Im Wesentlichen zerlege ich die wirtschaftlichen Faktoren, die zum Ertrag beitragen. Hier haben wir drei zusätzliche Spalten: Marge, Lagerhaltungskosten und Stockout. Die Marge ist die erwartete durchschnittliche Bruttomarge für die zugewiesene Einheit. Die Lagerhaltungskosten stellen die erwarteten durchschnittlichen Kosten dar, eine Einheit im Store zu lagern. Der Stockout-Wert ist die erwartete Strafe, die vermieden wird, weshalb der Stockout-Wert hier positiv ist. Der endgültige Ertrag ist einfach die Summe dieser drei Komponenten, und alle diese Werte werden in monetären Einheiten, wie Dollar, ausgedrückt. Die Spalte, die Marge in Dollar, Lagerhaltungskosten in Dollar, Stockout in Dollar und Erträge anzeigt, entspricht dem Gesamtbetrag in Dollar, den Sie erwarten können, wenn Sie diese eine Einheit in den Store bringen.
Dies erleichtert das Verstehen und Debuggen dieser numerischen Rezeptur, ausgedrückt in Dollar, erheblich im Vergleich zu Prozentwerten. Tatsächlich ist jede nicht triviale numerische Rezeptur von Natur aus ziemlich undurchsichtig. Man benötigt kein deep learning, um tiefgreifende Undurchsichtigkeit zu erzielen; schon eine einfache lineare Regression ist ziemlich undurchsichtig, sobald mehrere Einflussfaktoren in die Regression einfließen. Diese Undurchsichtigkeit, die bei jeder nicht trivialen numerischen Rezeptur auftritt, setzt eine real-world supply chain einem Risiko aus, da supply chain Praktiker sich leicht verirren, verwirrt werden und durch technische Modellierungsdetails abgelenkt werden.
Die priorisierte Allokationsliste, die die wirtschaftlichen Treiber aufgliedert, ist ein mächtiges Prüfungsinstrument. Sie ermöglicht es den supply chain Praktikern, die Grundlagen direkt anzufechten, anstatt sich in den technischen Details zu verlieren. Man kann direkt Fragen stellen wie: Haben wir Lagerhaltungskosten, die angesichts unserer Situation sinnvoll sind? Stimmen diese Kosten mit den Risiken überein, die wir eingehen? Man kann die Prognose, die Saisonalität sowie die Art und Weise, wie man die Saisonalität modelliert und den abnehmenden Trend berücksichtigt, getrost außer Acht lassen. Das Endergebnis – der Dollar-Ertrag aus diesen Lagerhaltungskosten – kann direkt hinterfragt werden. Sind diese Werte real? Ergibt das Sinn? Sehr häufig entdeckt man unsinnige Zahlen und kann sie direkt korrigieren.
Offensichtlich möchte man solche Situationen vermeiden, aber man sollte nicht davon ausgehen, dass in der supply chain alle Probleme unglaublich subtile Prognoseprobleme sind. Die meisten Probleme sind brutal. Es kann zu Problemen kommen, beispielsweise dass Daten nicht korrekt verarbeitet werden, wodurch Zahlen entstehen, die völlig unsinnig sind – wie negative Margen oder negative Lagerhaltungskosten, die in Ihrer supply chain Chaos verursachen.
Wenn sich Ihre Supply Chain-Instrumentierung ausschließlich auf die Prognosegenauigkeit der Nachfrage konzentriert, blenden Sie 90 % (oder mehr) der tatsächlichen Probleme aus. In einer groß angelegten supply chain würde dieser Anteil wahrscheinlich etwa 99 % betragen. Supply Chain-Instrumentierung ist absolut entscheidend, um die Schlüsselgrößen, die zu den Entscheidungen beitragen, hervorzuheben – und diese Größen müssen wirtschaftlicher Natur sein, wenn Sie hoffen, sich auf das zu konzentrieren, was Ihr Unternehmen profitabel macht. Andernfalls, wenn Sie mit Prozentwerten arbeiten, können Sie Ihre eigenen Maßnahmen nicht priorisieren und werden Fehler wahllos beheben. Bei einer groß angelegten supply chain gibt es immer eine Vielzahl numerischer Unstimmigkeiten. Behandeln Sie all diese Unstimmigkeiten gleichgültig, bedeutet das, dass Sie ständig an Dingen arbeiten, die im Wesentlichen unbedeutend sind. Deshalb benötigen Sie Dollar an Erträgen und Dollar an Kosten. So können Sie tatsächlich Ihre Arbeit und Entwicklungsanstrengungen für Ihre numerischen Rezepte priorisieren. Manchmal müssen Sie nicht einmal entscheiden, ob ein Fehler behoben werden sollte; wenn es sich um ein paar Dollar pro Jahr an Reibungsverlusten handelt, ist es in der Praxis nicht einmal ein Fehler, der behoben werden müsste.
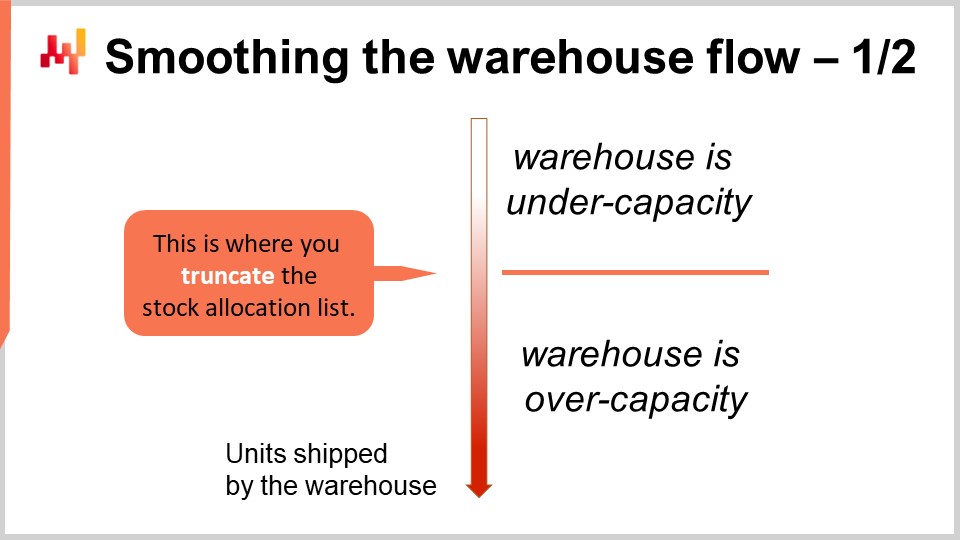
Nun, kommen wir zurück zur Frage, den richtigen Cutoff für die Allokationsliste zu wählen. Wir haben gesehen, dass die Erträge ungefähr abnehmen, wenn mehr Lagerbestand den Store-SKUs zugewiesen wird. Allerdings müssen wir die gesamte supply chain betrachten und nicht nur das warehouse oder das Verteilzentrum. Hierbei werden die beiden Begriffe synonym verwendet. Das Warehouse oder Verteilzentrum wird von Fixkosten dominiert. Zwar ist es möglich, das Personal mit Zeitarbeitskräften zu erweitern, aber dies kostet in der Regel mehr und bringt weitere Probleme mit sich, etwa dass Zeitarbeitskräfte typischerweise weniger qualifiziert sind als Festangestellte.
Daher hat jedes Warehouse oder jedes Verteilzentrum eine Zielkapazität, bei der es mit maximaler wirtschaftlicher Effizienz arbeitet. Die Zielkapazität kann erhöht oder verringert werden, doch meist erfordert dies eine Anpassung der Größe des Festpersonals, weshalb es ein relativ langsamer Prozess ist. Man kann erwarten, dass ein Warehouse seine Zielkapazität von einem Quartal zum nächsten anpasst, aber nicht, dass es seine nominale Kapazität – also die Kapazität, bei der es Höchstleistung erbringt – von einem Tag auf den anderen ändert. Es ist eben nicht so dynamisch.
Wir möchten, dass das Warehouse durchgängig mit maximaler Effizienz arbeitet – oder zumindest so nah wie möglich an dieser Effizienz bleibt –, sofern kein wirtschaftlicher Anreiz vorliegt, etwas anderes zu tun. Die Perspektive der priorisierten Lagerallokation ebnet den Weg, genau dies zu erreichen. Wir können die Liste kürzen, indem wir sie etwas verkürzen oder verlängern und den Cutoff anpassen, um sie mit der Zielkapazität des Warehouses in Einklang zu bringen. In der Praxis bringt dies drei wesentliche Vorteile mit sich.
Erstens: das Glätten des Materialflusses im Warehouse. Dadurch bleibt das Warehouse die meiste Zeit bei maximaler Kapazität in Betrieb, was zahlreiche Betriebskosten einspart. Zweitens wird Ihr Lagerallokationsprozess deutlich resilienter gegenüber all den kleinen Zwischenfällen, die in einer real-world supply chain ständig auftreten. Ein Lkw kann in einen kleineren Verkehrsunfall verwickelt werden, einige Mitarbeiter erscheinen nicht, weil sie krank sind – es gibt zahllose kleine Gründe, die Ihre Pläne stören. Dies verhindert nicht, dass Ihr Warehouse arbeitet, aber es könnte nicht exakt mit der von Ihnen erwarteten Kapazität laufen. Mit dieser Prioritätenliste können Sie das Beste aus der Kapazität herausholen, die Ihr Warehouse gerade nutzt, selbst wenn dies nicht exakt der von Ihnen geplanten Kapazität entspricht.
Der dritte Vorteil besteht darin, dass Ihr supply chain Team mit diesem Ansatz einer Prioritätenliste für die Lagerallokation das Mikromanagement der Personalstärke im Warehouse überflüssig macht. Sie müssen nur noch die Zielkapazität Ihres Warehouses anpassen, sodass sie annähernd der Verkaufsgeschwindigkeit Ihres Einzelhandelsnetzwerks entspricht. Das tägliche Mikromanagement der Kapazität wird somit weitgehend unbedeutend.
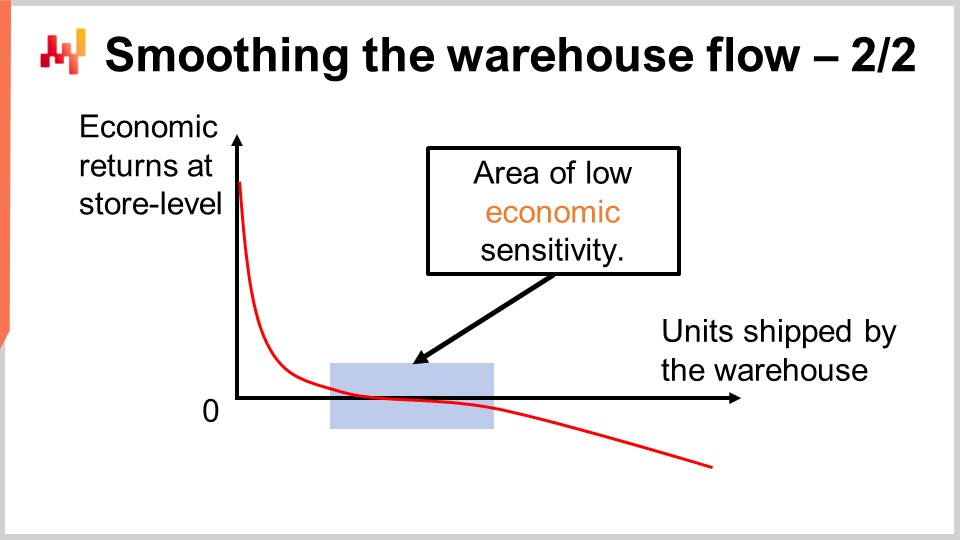
Die Erfahrung von Lokad zeigt, dass das Glätten des Materialflusses im Warehouse durch einen einheitlichen Kapazitäts-Cutoff in den meisten Einzelhandelssituationen sehr gut funktioniert. Auf dem Bildschirm sehen Sie die typische wirtschaftliche Ertragskurve, die man beobachten würde, wenn man alle möglichen Cutoffs betrachtet. Auf der X-Achse ist die Anzahl der Einheiten abgebildet, die vom Warehouse versandt werden. Wir gehen konzeptionell davon aus, dass die Einheiten einzeln verschickt werden, sodass wir den Grenzbeitrag jeder einzelnen Einheit beobachten können. Natürlich werden in der Produktion die Einheiten in Chargen versandt und nicht einzeln, aber das dient lediglich dazu, die Kurve darzustellen. Auf der Y-Achse sind die marginalen wirtschaftlichen Ergebnisse auf Store-Ebene abgebildet, also für die n-te Einheit, die an einen Store geschickt wird – unabhängig davon, um welchen Store es sich handelt. Die allerersten zugewiesenen Einheiten erwirtschaften den Großteil der Erträge. In der Praxis besteht der obere Bereich der Liste unweigerlich aus Stockout-Situationen, die sofortige Maßnahmen erfordern. Deshalb adressieren die ersten Einheiten Stockouts, und deshalb sind die wirtschaftlichen Erträge sehr hoch. Danach nehmen die Erträge ab, und wir gelangen in einen flachen Abschnitt der Kurve.
Diesen Bereich bezeichne ich als den Bereich geringer wirtschaftlicher Sensitivität. Im Wesentlichen nähern wir uns schrittweise einem Service-Level von 100 %, ohne dabei jedoch einen nennenswerten Überschuss an unverkauftem Lagerbestand zu erzeugen. Wenn Sie eine solche priorisierte Allokation durchführen und den Lagerbestand über das Beheben von Stockout-Problemen hinaus erhöhen, häufen sich die Bestände bei den schnell verkaufenden Artikeln an. Es entsteht Lagerbestand an Orten, an denen er gerade nicht wirklich benötigt wird. Zwar bieten sich in der Zukunft Gelegenheiten, den Lagerbestand aufzufüllen, ohne dabei ein Stockout-Problem zu riskieren, jedoch ist der Effekt minimal, da der Bestand relativ zügig verkauft wird. Im Grunde geht es hierbei nur um die Opportunitätskosten, den Lagerbestand vom Verteilzentrum in einen Store zu verlagern. Mit zunehmender Allokation verlieren wir schrittweise zukünftige Optionen.
Dieser Bereich ist relativ flach und beginnt erst dann, deutlich negativ zu werden, wenn wir so viel Lagerbestand zuweisen, dass Situationen entstehen, die mit nicht unerheblicher Wahrscheinlichkeit zu Inventurabschreibungen führen. Wenn Sie weiterhin drängen, schaffen Sie noch gravierendere Überbestands-Situationen, wodurch die Kurve sehr negativ wird. Drücken Sie es zu sehr, werden Sie in Zukunft zahlreiche Inventurabschreibungen erzeugen. Solange der Cutoff in diesem Bereich geringer Sensitivität liegt, ist alles in Ordnung, und der genaue Schnittpunkt ist nicht von entscheidender Bedeutung. Deshalb muss die Kapazität des Warehouses nicht exakt das tägliche Verkaufsvolumen widerspiegeln.
Tatsächlich beobachten Sie in den meisten Einzelhandelsnetzwerken ein sehr starkes wochentägliches zyklisches Muster in Ihren Verkäufen, bei dem bestimmte Tage, beispielsweise Samstag, der Tag sind, an dem Sie am meisten verkaufen. Aber das Lager muss dieses wochentägliche zyklische Muster nicht exakt nachahmen. Sie können einen sehr ebenen Durchschnitt beibehalten, und die Idee ist, dass Ihre Zielkapazität im Großen und Ganzen Ihrem gesamten Verkaufsvolumen für Ihr Ladenetz entsprechen sollte. Wenn Ihre Zielkapazität im Netzwerk immer etwas unter Ihrem gesamten Verkaufsvolumen liegt, wird zunächst allmählich der Bestand aller Ihrer Geschäfte aufgebraucht und dann entsteht ein großes Problem. Umgekehrt, wenn Sie jeden einzelnen Tag ein wenig mehr bereitstellen, als Sie tatsächlich verkaufen, dann werden Sie sehr schnell Ihre Geschäfte vollständig sättigen.
Solange Sie es relativ ausgeglichen halten, müssen Sie sich nicht mit dem wochentäglichen Muster im Detail befassen; es wird einwandfrei funktionieren. Der Grund, warum es nicht nötig ist, das wochentägliche Muster detailliert zu steuern, liegt darin, dass die allerersten Einheiten den Großteil der Renditen liefern, und das System ist aus wirtschaftlicher Sicht nicht so empfindlich, solange der Schwellenwert ungefähr in diesem flachen Segment bleibt.

Nun habe ich die Bestands-Belohnungsfunktion der Klarheit und Prägnanz halber vorgestellt, da wir in dieser Vorlesung bereits viel zu behandeln hatten. Allerdings ist die Bestands-Belohnungsfunktion nicht der Höhepunkt der supply chain science.
Im Jahr 2021 veröffentlichte einer von uns bei Lokad die Aktions-Belohnungsfunktion. Die Aktions-Belohnungsfunktion ist der geistige Nachfahre, wenn man will, der Bestands-Belohnungsfunktion, bietet jedoch eine wesentlich differenziertere Perspektive auf die probabilistischen Forecasts selbst. Tatsächlich sind nicht alle probabilistischen Forecasts gleich. Saisonalität, schwankende Vorlaufzeiten und Intake-ETAs für die Distributionszentren werden in der Aktions-Belohnungsfunktion berücksichtigt, während sie in der Bestands-Belohnungsfunktion unberücksichtigt blieben.
Übrigens erfordern diese Fähigkeiten auch einen granulareren Forecast, sodass Sie über überlegene Forecasting-Technologie verfügen müssen, die all diese probabilistischen Forecasts generieren kann, um die Bestands-Belohnungsfunktion zu nutzen. In dieser Hinsicht ist die Bestands-Belohnungsfunktion weniger anspruchsvoll. Auf konzeptioneller Ebene bietet die Aktions-Belohnungsfunktion zudem eine saubere Entkopplung der Bestellfrequenz (wie häufig Sie bestellen) von der Beschaffungs-Lieferzeit (wie viel Zeit es benötigt, um den Bestand aufzufüllen, nachdem die Entscheidung getroffen wurde). Diese beiden Elemente waren in der Bestands-Belohnungsfunktion zusammengefasst; bei der Aktions-Belohnungsfunktion werden sie klar getrennt.
Abschließend verfügt die Aktions-Belohnungsfunktion auch über eine Perspektive des Entscheidungsbesitzes, ein simpler, aber durchaus cleverer Trick, um den Großteil der Vorteile einer echten Policy zu erlangen, ohne tatsächlich eine Policy einführen zu müssen. Wir werden in späteren Vorlesungen technisch darauf eingehen, was Policies wirklich bedeuten, aber im Endeffekt heißt das: Sobald man Policies einführt, wird es komplizierter. Es ist interessant, aber definitiv komplexer. Hierbei hat die Aktions-Belohnungsfunktion einen cleveren Trick, mit dem man buchstäblich die Notwendigkeit, auf eine Policy auszuweichen, umgehen kann und dennoch den Großteil der wirtschaftlichen Vorteile daraus zieht.

Sowohl die Bestands-Belohnungsfunktion als auch ihre überlegene Alternative, die Aktions-Belohnungsfunktion, werden seit Jahren in der Produktion bei Lokad eingesetzt. Diese Funktionen vereinfachen im Wesentlichen ganze Klassen von Problemen, die sonst Einzelhandelsnetzwerke plagen würden. Beispielsweise wird toter Bestand trivial beurteilbar, indem man einfach die wirtschaftlichen Erträge betrachtet, die jeder Bestands-Einheit zugeordnet sind, die bereits in einem Geschäft vorhanden ist. Dennoch gibt es etliche Aspekte, die ich heute nicht behandelt habe. Diese werde ich in späteren Vorlesungen ansprechen.
Einige dieser Aspekte können tatsächlich mit verhältnismäßig geringfügigen Varianten dessen angegangen werden, was ich heute vorgestellt habe. Dies ist beispielsweise der Fall bei Losmultiplikatoren und der Bestands-Neuausrichtung. Man muss nur sehr wenig an den Skripten ändern, die ich heute gezeigt habe, um diese Probleme in Angriff zu nehmen. Wenn ich von Bestands-Neuausrichtung spreche, meine ich die Umverteilung des Bestands zwischen den Geschäften des Netzwerks – entweder durch Rückführung des Bestands ins Distributionszentrum oder durch direkten Transfer zwischen den Geschäften, wobei spezifische Transportkosten berücksichtigt werden.
Daneben gibt es einige Aspekte, die mehr Arbeit erfordern, aber dennoch relativ unkompliziert sind. Zum Beispiel die Berücksichtigung von Opportunitätskosten, flachen Transportkosten und Überlastungen beim Wareneingang im Geschäft, die dann entstehen, wenn das Personal eines Geschäfts nicht in der Lage ist, alle eingegangenen Einheiten zu verarbeiten. Sie haben an einem bestimmten Tag schlichtweg nicht die Zeit, diese in die Regale zu stellen, und so entsteht ein großes Chaos im Geschäft. Diese Aspekte sind umsetzbar, erfordern jedoch definitiv erheblichen Mehraufwand zu dem, was ich heute präsentiert habe.
Es gibt weitere Aspekte, wie Merchandising oder die Verbesserung der allgemeinen Attraktivität des Geschäfts, die in die Priorisierung einbezogen werden sollten. Diese erfordern einen überlegenen technologischen Ansatz, da geringfügige Variationen dessen, was ich heute vorgestellt habe, schlicht nicht ausreichen. Wie üblich rate ich zu einer gesunden Portion Skepsis, wann immer ein Experte behauptet, eine optimale Methode zu besitzen. In der supply chain existieren keine optimalen Methoden; wir haben Werkzeuge, von denen einige besser sind, aber keines kommt auch nur annähernd in den Genuss des Begriffs „optimal“.
Zusammenfassend sind prozentuale Fehler irrelevant; es zählen nur die Dollar-Fehler. Diese Dollar werden von dem angetrieben, was Ihre supply chain auf physischer Ebene leistet. Die meisten KPIs sind bestenfalls unerheblich; sie sind Teil des supply chain-Prozesses, um die numerischen Rezepte, die supply chain Entscheidungen steuern, kontinuierlich zu verbessern. Selbst wenn man KPIs betrachtet, die dazu beitragen, die numerischen Rezepte zu optimieren, sprechen wir von ziemlich indirekten Ergebnissen im Vergleich zur direkten Verbesserung des numerischen Rezepts, das die Entscheidung steuert und sofort bessere Ergebnisse für Ihre supply chain erzielt.
Excel-Tabellen sind in der supply chain allgegenwärtig, und ich glaube, das liegt daran, dass die Mainstream-supply chain Theorie es versäumt hat, Entscheidungen als erstklassige Bürger zu fördern. Infolgedessen verschwenden Unternehmen Zeit, Geld und Aufmerksamkeit an zweitklassige Bürger, nämlich Artefakte. Doch letztlich müssen Entscheidungen getroffen werden: Der Bestand muss zugewiesen werden, und Sie müssen den Preis, Ihren Verkaufsansatz und den Angriffspreis festlegen. Mangels angemessener Unterstützung greifen supply chain Praktiker daher auf das eine Werkzeug zurück, das es ihnen ermöglicht, Entscheidungen als erstklassige Bürger zu behandeln – und dieses Werkzeug ist Excel.
Allerdings können supply chain Entscheidungen auch als erstklassige Bürger behandelt werden, genau dazu haben wir heute angestoßen. Die Werkzeuge sind nicht einmal so komplex, zumindest wenn man die allgegenwärtige Komplexität der typischen anwendungstechnischen Landschaft einer modernen supply chain bedenkt. Darüber hinaus erschließen angemessene Werkzeuge Fähigkeiten, wie den Fluss von Inventar von den Distributionszentren zum Geschäft mit minimalem Aufwand zu glätten. Diese Fähigkeiten sind mit den richtigen Werkzeugen zwar unkompliziert zu erreichen, verdeutlichen aber auch die Art von Leistungen, die niemals von Excel-Tabellen erwartet werden können – zumindest nicht in einem produktionsreifen Setup.

Ich denke, das war’s für heute. Die nächste Vorlesung findet am Mittwoch, dem 6. Juli, zur gleichen Tageszeit, 15 Uhr Pariser Zeit, statt. Ich werde zum siebten Kapitel übergehen, um die taktische Ausführung einer die Quantitative Supply Chain Initiative zu diskutieren. Übrigens werde ich in späteren Vorlesungen wieder auf Kapitel 5 zurückkommen, in dem es um probabilistische Forecasts geht, und Kapitel 6, in dem es um Entscheidungstechniken geht. Mein Ziel ist es, einen vollständigen Einstieg in alle Elemente zu bieten, bevor ich mich in ein spezifisches Thema vertiefe.
Also, an diesem Punkt werde ich mir tatsächlich die Fragen anschauen.
Frage: Die zedfunc könnte unendliche Möglichkeiten haben. Wären in diesem Fall nicht alle Lösungen kurzfristig?
Die zedfunktion ist buchstäblich ein Datenspeicher für eine Sequenz von Optionen, sodass der anwendbare Horizont in den Alpha-Werten, den Zeitdiskontierungswerten, die ich in meinen Skripten verwendet habe, eingebettet ist. Grundsätzlich ist der Zielhorizont, den Sie in das wirtschaftliche Ergebnis einer zedfunktion einbetten, nicht wirklich in den zedfunktionen selbst zu finden; er liegt vielmehr in den wirtschaftlichen Berechnungen, die sie füllen. Vergessen Sie nicht, dass die zedfunktionen nur Datenspeicher sind. Das macht sie kurzfristig oder langfristig, und selbstverständlich möchten Sie Ihre numerischen Rezepte so anpassen, dass sie Ihre Prioritäten widerspiegeln. Beispielsweise, wenn Ihr Unternehmen aufgrund von Liquiditätsproblemen unter massivem Druck steht, werden Sie wahrscheinlich eine viel kurzfristigere Perspektive auf den Geldeingang haben – also im Grunde genommen Ihren Bestand liquidieren. Wenn Sie hingegen sehr zahlungsfähig sind, bevorzugen Sie es vielleicht, den Verkauf auf einen späteren Zeitraum zu verschieben, um zu einem besseren Preis zu verkaufen und eine höhere Bruttomarge zu erzielen. All diese Dinge sind mit zedfunktionen möglich. zedfunktionen sind lediglich Behälter; sie setzen nicht zwangsläufig ein bestimmtes numerisches Rezept für die wirtschaftlichen Ergebnisse voraus, die Sie in die zedfunktionen einbringen möchten.
Frage: Ich denke, dass die meisten Annahmen auf bestehenden realen Werten der Zielfunktionen beruhen müssen, oder was meinst du?
Was ist real? Das ist das Wesen des Problems, das ich in der Vorlesung über experimentelle Optimierung behandelt habe. Das Problem ist, dass, wann immer Sie sagen, dass Sie Werte oder Messungen haben, es sich lediglich um mathematische, numerische Konstrukte handelt. Nur weil etwas numerisch ist, heißt das nicht, dass es korrekt ist. Meine Herangehensweise bezüglich einer supply chain ist die einer experimentellen Wissenschaft; Sie müssen den Bezug zur realen Welt herstellen. Nur so können Sie feststellen, ob etwas real ist oder nicht. Die Frage ist – und dem stimme ich voll und ganz zu – dass Annahmen nicht auf vorbestehenden realen Werten beruhen können, denn es gibt so etwas wie vorbestehende reale Werte nicht. Sie müssen immer überprüft werden; diese Annahmen müssen validiert und mit den realen Beobachtungen, die Sie in Ihrer supply chain machen können, abgeglichen werden. Die Korrektheit Ihrer Annahmen kann nur im Kontakt mit der Realität Ihrer supply chain beurteilt werden.
Das ist der Punkt, an dem diese experimentelle Optimierungsperspektive heikel wird, denn die mathematische Optimierungsperspektive nimmt einfach an, dass alle Variablen bekannt, alle Variablen real, alle Variablen beobachtbar sind und dass die Verlustfunktion korrekt sein kann. Aber mein Punkt ist, dass eine supply chain ein super komplexes System ist. Das stimmt einfach nicht. Meistens verfügen Sie nur über ziemlich indirekte Messungen. Wenn ich vom Lagerbestand spreche, gehe ich nicht tatsächlich in das Geschäft, um zu überprüfen, ob dieser korrekt ist. Vielmehr habe ich eine sehr indirekte Messung – einen elektronischen Datensatz, den ich aus einem enterprise software System erhalten habe, das typischerweise vor zwei Jahrzehnten aus Gründen implementiert wurde, die überhaupt nichts mit Data Science zu tun hatten. Das meine ich: Das Problem mit der Realität ist, dass eine supply chain immer geografisch verteilt ist, sodass alles, was Sie messen, und alles, was Sie an Werten sehen, lediglich indirekte Messungen sind. In gewisser Weise steht die Realität dieser Messungen immer zur Debatte. Es gibt so etwas wie eine direkte Beobachtung nicht. Man kann zwar eine direkte Beobachtung zu Kontrollzwecken durchführen, aber sie kann nur einen winzigen Prozentsatz aller Werte ausmachen, die Sie in Ihrer supply chain manipulieren müssen.
Frage: In den Bestands-Belohnungsfunktionen, neben einfachen Parametern wie der Marge, befassen wir uns auch mit Lagerfehlmengstrafen. Wie lernen wir am besten, diese komplexen Parameter zu optimieren?
Das ist eine sehr gute Frage. Tatsächlich sind Lagerfehlmengstrafen real; andernfalls würde sich niemand die Mühe machen, hohe Servicelevels zu gewährleisten. Der Grund, warum Sie Servicelevels anstreben, liegt wirtschaftlich betrachtet darin, dass jeder Einzelhändler, den ich kenne, überzeugt ist, dass Lagerfehlmengstrafen real sind. Kunden sind es nicht lieb, wenn der Service nicht von hoher Qualität ist. Ich würde jedoch nicht sagen, dass sie komplex sind; vielmehr sind sie kompliziert. Sie sind von Natur aus schwierig, und ein Teil dieser Schwierigkeit liegt darin, dass buchstäblich die langfristige Strategie des Einzelhandelsnetzwerks auf dem Spiel steht. Bei den meisten meiner Kunden wird die Lagerfehlmengstrafe beispielsweise direkt mit dem CEO besprochen. Es geht bis in die oberste Führungsebene; es ist die super langfristige Strategie des Einzelhandelsnetzwerks, die hier verhandelt wird.
Also, es ist nicht so komplex, aber definitiv kompliziert, da es sich um eine Diskussion mit sehr hohen Einsätzen handelt. Was genau wollen wir tun? Wie wollen wir unsere Kunden behandeln? Möchten wir sagen, dass wir die allerbesten Preise haben und uns entschuldigen, falls die Servicequalität nicht optimal ist, aber dass Sie etwas Einzigartiges zu sehr günstigen Preisen erhalten? Oder setzen Sie auf Neuheit? Wenn Sie Neuheit anstreben, bedeutet das, dass es new products gibt, die ständig eintreffen – und wenn ständig neue Produkte eintreffen, bedeutet das, dass die alten Produkte auslaufen, sodass Sie Lagerfehlmengen in Kauf nehmen sollten, weil so kontinuierlich Neuheit eingeführt wird.
Die Lagerfehlmengstrafe ist schwer zu beurteilen, weil sie direkt hohe Einsätze in der langfristigen Strategie des Unternehmens hat. In der Praxis besteht der beste Weg, sie zu bewerten, darin, Experimente durchzuführen. Sie wählen einen Wert, schätzen grob den Wert der Lagerfehlmengstrafe, den Strafkoeffizienten, und betrachten dann, welche Art von Beständen in Ihren Geschäften vorhanden sind. Anschließend lassen Sie Menschen anhand ihres Gefühls beurteilen, ob der Bestand dem Ideal entspricht, das sie für ihr Geschäft anstreben. Ist es wirklich das, was sie für ihre Kunden wünschen? Ist es wirklich das, was sie mit ihrem Einzelhandelsnetzwerk erreichen möchten?
Weißt du, es gibt diese Diskussion mit Hin und Her. Typischerweise wird der Supply Chain Scientist eine Reihe von Werten testen, die entsprechenden ökonomischen Ergebnisse präsentieren und auch die Makrokosten erklären, die mit einem Treiber verbunden sind. Sie könnten sagen: “Okay, wir können eine sehr hohe Stockout-Strafgebühr ansetzen, aber Vorsicht, wenn wir das tun, heißt das, dass unsere Lagerzuweisungslogik ständig Unmengen an Bestand in die Geschäfte schiebt.” Denn wenn die Botschaft lautet, dass Stockouts tödlich sind, dann bedeutet das, dass wir alles tun müssen, um diese zu verhindern. Im Grunde müssen wir diese Diskussion in vielen Iterationen führen, damit das Management einen Realitätscheck durchführen kann: “Ist meine langfristige Strategie in ökonomischer Hinsicht tragfähig angesichts dessen, was mein Einzelhandelsnetzwerk tatsächlich leisten kann?” So konvergiert man schrittweise. Übrigens, es ist nichts in Stein gemeißeltes. Unternehmen verändern und passen ihre Strategien mit der Zeit an, sodass es nicht heißt, dass ein Stockout-Strafgebühr-Faktor von 2010 im Jahr 2022 denselben Wert haben muss.
Insbesondere mit dem Aufstieg des E-Commerce. Es gibt viele Einzelhandelsnetzwerke, die einfach sagen: “Nun, ich habe in meinen Geschäften – besonders in Fachgeschäften – eine viel höhere Toleranz für Stockouts entwickelt.” Denn im Grunde, wenn ein Produkt fehlt, speziell eine Variante in Bezug auf die Größe, bestellen die Leute es einfach online über den E-Commerce. Das Geschäft wird zu einer Art Showroom. So wird die Servicequalität eines Showrooms ganz anders, als es erwartet wurde, als das Geschäft buchstäblich der einzige Weg war, die Produkte zu verkaufen.
Frage: Können wir eine zusammengesetzte Lagerbelohnungsfunktion haben, um den Trend innerhalb eines gegebenen Zeitraums korrekt zu verstehen?
Welchen Trend genau verstehen? Wenn es um einen Trend in der Nachfrage geht, ist die Lagerbelohnungsfunktion eine Funktion, die eine probabilistische Prognose verarbeitet. Unabhängig davon, welchen Trend die Nachfrage zeigt, ist dieser typischerweise ein Resultat der Art und Weise, wie Sie Ihre Nachfrage modellieren. Was die Lagerbelohnungsfunktion betrifft, so beinhaltet die probabilistische Prognose bereits all dies, egal ob ein Trend vorliegt oder nicht.
Nun, wenn Sie eine weitere Frage zur stationären Perspektive der Lagerbelohnungsfunktion haben, liegen Sie vollkommen richtig. Die Lagerbelohnungsfunktion hat eine völlig stationäre Perspektive. Sie geht davon aus, dass sich die Nachfrage in jedem Zeitraum probabilistisch exakt gleich wiederholt, sodass es weder einen Trend noch Saisonalität gibt. Es ist eine rein stationäre Sichtweise. In diesem Fall lautet die Antwort nein, die Lagerbelohnungsfunktion ist nicht in der Lage, mit einer nicht-stationären Nachfrage umzugehen. Die Aktionsbelohnungsfunktion hingegen schafft das. Das war auch einer der Gründe, auf die Aktionsbelohnungsfunktion umzusteigen, da sie mit nicht-stationärer probabilistischer Nachfrage umgehen kann.
Frage: Wir gehen davon aus, dass die Lagerkapazität fest ist, aber sie hängt vom Kommissionieren, Verpacken und Versenden ab. Sollten die Cutoff-Punkte in der Liste nicht durch die Optimierung der Lagerabläufe definiert werden?
Ja, absolut. Genau das meinte ich, wenn man diese Zone geringerer ökonomischer Sensitivität hat. Ihre Prioritätenliste, welche die priorisierte Lagerzuweisung darstellt, ist nicht hochsensitiv in Bezug darauf, wo der Schnitt erfolgt, solange dieser innerhalb des entsprechenden Segments liegt. Im Durchschnitt sollten Sie wirklich ausgewogen zwischen dem Drücken und dem Verkaufen agieren – das ist schlicht logisch. Wenn Sie den Cutoff etwas anders anpassen möchten, nachdem Sie die Lageroptimierungslogik durchlaufen haben und dabei alle Kommissionierungs-, Verpackungs- und Versandbemühungen sowie deren Schwankungen berücksichtigen, ist das in Ordnung. Last-Minute-Variationen sind möglich. Das Schöne an dieser priorisierten Lagerzuweisungsliste ist, dass Sie buchstäblich den exakten Umfang der versandten Einheiten in letzter Minute finalisieren können. Die einzige Operation, die Sie benötigen, ist eine Aggregation, die sehr zügig durchgeführt werden kann und Ihnen mehr Optionen bietet. Genau das meinte ich, als ich erwähnte, dass dieser Ansatz neue Klassen der supply chain Optimierung eröffnet. Er ermöglicht es Ihnen, genau rechtzeitig zu entscheiden, um Ihre Kommissionierungs-, Verpackungs- und Versandbemühungen neu zu ordnen, anstatt starr an einem vorgefertigten Versandumschlag festzuhalten, der nicht exakt zu den vorhandenen Ressourcen und dem erforderlichen Aufwand passt.
Frage: Ein Gleiten der Lagerflüsse erfordert einen geglätteten Produktionsfluss. Berücksichtigt dieses Entscheidungsmodell das?
Ich würde sagen, dass es nicht zwangsläufig einen geglätteten Produktionsfluss benötigt. Für viele Einzelhandelsnetzwerke – wie beispielsweise allgemeine Warenhäuser – bestellen sie bei großen FMCG-Unternehmen, die auf ihrer Seite sehr große Chargen produzieren. Es ist nicht erforderlich, den Produktionsfluss zu glätten, um Vorteile in Bezug auf die Betriebskosten des Distributionszentrums zu erzielen. Selbst wenn die Produktion nicht geglättet wurde, ergeben sich bereits Vorteile allein durch den Transport der Sendungen vom Distributionszentrum zu den Geschäften.
Allerdings haben Sie vollkommen recht. Wenn Sie zufällig eine vertikal integrierte Marke sind, die ihre Produktionsstätten, Distributionszentren und Geschäfte intern organisiert hat, besteht ein starkes Interesse an einer supply chain-weiten Optimierung und am Glätten des gesamten Flusses. Dieser Ansatz der netzwerkweiten Optimierung entspricht genau dem Geist dessen, was ich heute präsentiert habe. Wenn Sie jedoch ein echtes, multi-echelon supply chain Netzwerk optimieren möchten, benötigen Sie eine Technik, die sich von dem unterscheidet, was ich heute vorgestellt habe. Es gibt viele Bausteine, die dies ermöglichen, aber man kann nicht einfach die heute präsentierten Skripte anpassen, um dies zu erreichen. Dies wird die Art von Technologie sein, in der wir den Multi-Echelon-Aufbau behandeln – dieser wird in späteren Vorträgen vorgestellt. Das Ganze ist komplexer.
Frage: Der Ansatz der Lagerbelohnung und der erwartete Fehler erinnern mich an das erwartete Wertkonzept aus der Finanzwelt. Aus Ihrer Sicht, warum ist dieser Ansatz in den supply chain Kreisen noch nicht etabliert?
Sie haben vollkommen recht. Solche Dinge, wie eine echte ökonomische Analyse der Ergebnisse, werden in der Finanzwelt seit Ewigkeiten durchgeführt. Ich glaube, dass die meisten Banken diese Berechnungen seit den 80er-Jahren vornehmen – und wahrscheinlich wurden sie sogar schon davor mit Stift und Papier erledigt. Also ja, das ist etwas, das seit Ewigkeiten in anderen Branchen praktiziert wird.
Ich glaube, das Problem bei supply chains war, dass sie bis zum Aufkommen des Internets naturgemäß geografisch verteilt waren, mit Geschäften, Distributionszentren und weiteren Einrichtungen, die weit verstreut waren. Vor 1995 war es möglich, aber sehr kompliziert, Daten über das Internet zu übertragen. Es war machbar, aber es war selten, dies zuverlässig, kostengünstig und mit Unternehmenssystemen zu bewerkstelligen, die eine Konsolidierung all dieser Daten ermöglichen. Im Grunde wurden supply chains also schon sehr früh – so um die 80er-Jahre – digitalisiert, waren aber nicht stark vernetzt. Die Netzwerkkomponente und die gesamte Infrastruktur kamen relativ spät, würde ich sagen nach dem Jahr 2000 für die meisten Unternehmen.
Das Problem war, stellen Sie sich vor, Sie arbeiten in einem Distributionszentrum, das aber ziemlich isoliert vom Rest des Netzwerks operiert, sodass der Lagerverwalter nicht über die Ressourcen verfügte, derartige ausgeklügelte numerische Berechnungen durchzuführen. Der Lagerverwalter hatte ein Lager zu führen und war typischerweise kein Analyst. Daher haben sich die Praktiken, die vor dem Internetzeitalter existierten – als alle Informationen über das Netzwerk zugänglich waren – fortgepflanzt. Das wäre der Grund, und übrigens, supply chains sind typischerweise sehr große, komplexe und verzweigte Gebilde, weshalb Veränderungen langsam vor sich gehen.
Wenn die Daten im Netzwerk geteilt werden, etwa über sehr schöne Data Lakes – sagen wir, es war 2010, also vor 10 Jahren –, beobachte ich, dass einige Unternehmen sich jetzt bewegen, andere haben sich bereits bewegt, aber ein Jahrzehnt ist nicht allzu lang, wenn man die Größe und Komplexität von supply chains bedenkt. Genau deshalb sind diese Arten von Analysen in der Finanzwelt seit etwa vier Jahrzehnten Standard, während sie in supply chains noch erst im Entstehen begriffen sind – zumindest ist das meine bescheidene Meinung.
Frage: Was ist mit den Stockout-Kosten, die hauptsächlich auf Fehlplatzierungskosten basieren?
Das können Sie tun. Nochmals – die Stockout-Kosten sind buchstäblich eine Entscheidung, die Sie treffen. Sie spiegeln Ihre strategische Ausrichtung in Bezug auf den Service wider, den Ihr Einzelhandelsnetzwerk Ihren Kunden bieten soll. Es gibt keine objektive Realität; es ist buchstäblich alles, was Sie wollen. Das Problem bei den Fehlplatzierungskosten ist, dass die Realität so aussieht, dass die meisten Einzelhandelsnetzwerke nur existieren, weil sie eine loyale Kundentreue loyalty besitzen und ein positives Erlebnis in Ihrem Geschäft gewährleisten. Typischerweise übersteigen die Kosten verlorener Loyalität für die meisten Geschäfte bei weitem die Fehlplatzierungskosten. Eine Ausnahme, die mir in den Sinn kommt, sind Einzelhandelsgeschäfte mit einer Markenstrategie, die darauf abzielt, die Günstigsten zu sein. In diesem Fall könnten sie das Sortiment und die Servicequalität opfern und niedrige Preise über alles stellen.
Frage: Was ist das Ziel, Ihr Lager zu bevorraten? Geht es darum, Produkte zu niedrigen Preisen zu halten oder die Geschäfte mit Produkten zu höheren Preisen zu versorgen?
Das ist eine ausgezeichnete Frage. Warum sollte man überhaupt Bestand im Distributionszentrum halten? Warum nicht alles direkt per cross-dock versenden und direkt an die Geschäfte liefern?
Es gibt Einzelhandelsnetzwerke, die alles per Cross-Docking abwickeln, aber selbst bei diesem Ansatz gibt es eine Verzögerung zwischen der Bestellung bei Ihren Lieferanten und dem tatsächlichen Versand des Bestands zu den Geschäften. Sie können bestimmte Mengen mit einem bestimmten Zuweisungssystem bestellen, haben aber die Flexibilität, Ihre Meinung zu ändern, wenn der Bestand im Distributionszentrum eintrifft. Sie müssen nicht starr an dem Zuweisungssystem festhalten, das Sie vor zwei Tagen im Kopf hatten.
Sie können sich entscheiden, keinen Bestand im Distributionszentrum zu halten und nur per Cross-Docking abzuwickeln, aber aufgrund der Verzögerung können Sie Ihre Entscheidung ändern und einen etwas anderen Versand vornehmen. Dies kann beispielsweise nützlich sein, wenn Sie aufgrund eines unerwarteten Nachfrageanstiegs einen Stockout erleben. Auch wenn es vorzuziehen ist, keinen Stockout zu haben, weist dieser darauf hin, dass die Nachfrage die Erwartungen übersteigt – was nicht völlig negativ ist.
In anderen Situationen ist es notwendig, Bestand im Lager zu halten, bedingt durch Bestellbeschränkungen bei den Lieferanten. Beispielsweise erlauben FMCG-Unternehmen Ihnen möglicherweise, nur einmal pro Woche zu bestellen, und sie möchten in der Regel einen kompletten LKW-Ladung zu Ihrem Distributionszentrum liefern. Ihre Bestellungen werden voluminös und in Chargen erfolgen, und Ihr Distributionszentrum dient als Puffer für diese Lieferungen. Zudem bietet das Zentrum Ihnen die Möglichkeit, Ihre Entscheidung bezüglich der Bestandszuweisung zu ändern.
Solange der Bestand im Distributionszentrum ist, können Sie Ihre Meinung ändern. Sobald er jedoch einem bestimmten Geschäft zugewiesen wurde, sind die Transportkosten, ihn zurück ins Lager zu bringen, oft prohibitiv hoch – etwas, das Sie vermeiden möchten.
Vielen Dank und bis zum nächsten Mal. Wir werden besprechen, wie man taktische Strategien umsetzt und eine tatsächliche Initiative für die Quantitative Supply Chain in einem realen Unternehmen startet. Bis zum nächsten Mal!


