Specie delle previsioni: classificazione vs. regressione
La parola forecasting copre uno spettro molto ampio di processi, tecnologie e persino mercati. In passato, abbiamo presentato i mondi del software per forecasting, distinguendo tra:
- Software di simulazione deterministica
- Software di aggregazione esperta
- Software di forecasting statistico
Lokad rientra nell’ultima categoria in quanto la nostra tecnologia è puramente statistica. Tuttavia, Lokad è ben lontana dall’aver coperto l’intero spettro statistico da sola. Esistono due ampie categorie di previsioni nel forecasting statistico (*):
- Previsioni di classificazione
- Previsioni di regressione
_ (*) Stiamo semplificando eccessivamente qui per chiarezza, poiché le sottigliezze dell’apprendimento statistico esulano ben oltre lo scopo di questo modesto post sul blog._
La classificazione tenta di separare (o classificare) gli oggetti in base alle loro proprietà. L’illustrazione qui sotto di Tomasz Malisiewicz illustra un compito di classificazione che cerca di separare immagini raffiguranti una sedia da immagini raffiguranti un tavolo.
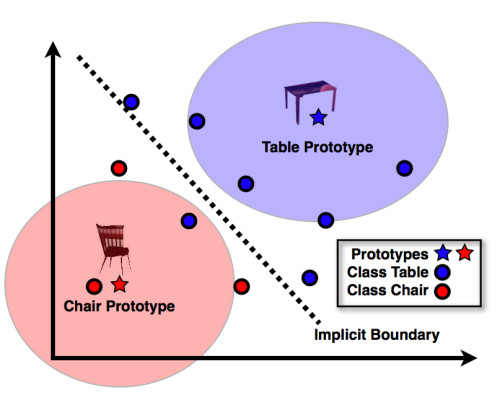
Illustrazione dal blog di tombone
L’output di una classificazione è binario (o meglio, discreto): gli oggetti vengono assegnati a classi con maggiore o minore confidenza, cioè probabilità più alte o più basse.
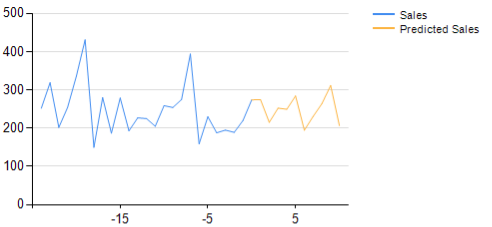
D’altra parte, le regressioni tipicamente producono curve. L’illustrazione qui sotto sta considerando una time-series che rappresenta le vendite storiche, e mostra la corrispondente previsione.
La previsione di regressione è una curva piuttosto che un’impostazione binaria (o una combinazione di impostazioni binarie). Gli input vengono prolungati nel futuro.
In che modo questa distinzione incide sul business?
Beh, si è scoperto che Lokad - allo stato dell’arte all’inizio del 2010 - fornisce solo previsioni di regressione. Pertanto, ci sono molti problemi interessanti che non possono essere affrontati da Lokad perché si tratta di problemi di classificazione:
- Segmentazione dei clienti: per ogni cliente, vorremmo valutare la probabilità di ottenere un up-sale di successo tramite una azione di direct marketing. Seguendo la stessa idea, potremmo cercare di prevedere anche l’abbandono.
- Rilevamento delle frodi: per ogni transazione, vorremmo valutare - in base al modello della transazione - la probabilità che l’operazione sia un tentativo di frode.
- Prioritizzazione degli affari: basandoci sulle proprietà del prospect (disponibilità del budget, settore, grado di contatto in azienda, livello di interesse espresso, …), vorremmo valutare la probabilità di ottenere un affare redditizio da ogni prospect per dare priorità agli sforzi del team di vendita.
Spesso ci viene chiesto se Lokad potrà fornire anche previsioni di classificazione. Sfortunatamente, la risposta, per il momento, sarà negativa. Pur essendo radicate nella stessa teoria matematica, la classificazione e la regressione implicano tecnologie molto diverse; e Lokad sta concentrando tutti i suoi sforzi sui problemi di regressione.
Anche se non sottovalutiamo i problemi di classificazione, essi meritano davvero attenzione e sforzi. Per il 2010, ci atteniamo alla nostra roadmap, ma in futuro, la classificazione potrebbe essere una naturale estensione dei nostri servizi di forecasting.


