00:02 Introduzione
01:43 Meccanicizzazione
07:34 Oltre il paradosso
12:14 La storia finora
14:32 I submoduli di oggi
16:24 Requisiti (mainstream 1/5)
20:12 Progettazione (mainstream 2/5)
25:37 Costruzione (mainstream 3/5)
30:29 Testing (mainstream 4/5)
34:09 Manutenzione (mainstream 5/5)
41:12 Identità (trenches 1/8)
46:35 Riepilogo (trenches 2/8)
51:43 Pratiche (trenches 3/8)
56:47 Bastioni (trenches 4/8)
01:02:00 Scrittori di codice (trenches 5/8)
01:06:23 Tolleranza al dolore (trenches 6/8)
01:14:55 Produttività (trenches 7/8)
01:21:37 L’Ignoto (trenches 8/8)
01:27:00 Conclusione
01:29:55 4.6 Ingegneria del software per supply chain - Domande?
Descrizione
Domare la complessità e il caos è la pietra angolare dell’ingegneria del software. Considerando che le supply chains sono sia complesse che caotiche, non dovrebbe sorprendere troppo che la maggior parte dei problemi del enterprise software affrontati dalle supply chains si riduca a una cattiva ingegneria del software. Le numerical recipes usate per optimize supply chains sono software e, come tali, soggette allo stesso problema. Questi problemi crescono in intensità insieme alla sofisticazione delle stesse numerical recipes. L’ingegneria del software adeguata per le supply chains è per esse ciò che l’asepsi è per gli ospedali: da sola non fa nulla - come trattare i pazienti - ma senza di essa, tutto crolla.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel, e oggi presenterò “Software Engineering for Supply Chain.” Il software è la base di una moderna supply chain practice, eppure la maggior parte dei libri di testo sulla supply chain sottovaluta ampiamente il ruolo del software nella supply chain. Il software per la supply chain non è un mero requisito come l’accesso ai mezzi di trasporto; è molto più di così. Dal punto di vista dei professionisti della supply chain, la maggior parte del lavoro è guidata dal software, dagli errori del software o dalle limitazioni del software, e da problematiche legate al software.
L’ingegneria del software è la disciplina che ha l’ambizione di aiutare le persone a creare software migliore, ottenere di più dal software, creare questo software più velocemente e spendere meno per ottenere di più. L’obiettivo di questa lezione è comprendere in cosa consiste l’ingegneria del software e capirne la rilevanza fondamentale per la supply chain. L’obiettivo di questa lezione è anche capire cosa, in qualità di professionista della supply chain, si può fare per evitare di compromettere la propria supply chain, sia attraverso azioni che inazioni che, sfortunatamente, hanno antagonizzato le vostre iniziative software.

Il XX secolo è stato il secolo della meccanicizzazione della forza lavoro. Grandi aziende e grandi supply chains, come le conosciamo, sono emerse nel XX secolo, e i progressi apportati dalla meccanicizzazione della forza lavoro sono stati incredibili. Nel corso dell’ultimo secolo, per quasi ogni attività che richiede un’intensa manodopera rilevante per la supply chain, come produzione o distribuzione, la produttività è aumentata di cento volte.
Al contrario, credo che il XXI secolo sia e sarà il secolo della meccanicizzazione del lavoro intellettuale, e questa transizione è molto difficile da comprendere. L’intuizione che si applica quando passiamo dalla meccanicizzazione della forza lavoro fisica non si traduce affatto nell’intuizione che si applica quando si tratta della meccanicizzazione del lavoro intellettuale. Non sto dicendo che la transizione sia meno drammatica, ma la realtà è che, a questo punto, la transizione verso l’eliminazione della forza lavoro che si occupava di compiti intensivi dal punto di vista della manodopera è già alle nostre spalle.
Nel 2020 in Francia, c’erano 27 milioni di persone con lavori impiegatizi – essenzialmente impiegati d’ufficio – mentre ne restavano meno di un milione che lavoravano in fabbrica. Il rapporto è di 27 a 1. Quando iniziamo a esaminare cosa comporta la meccanicizzazione del lavoro intellettuale, è molto sorprendente e strettamente legato a un paradosso noto come il paradosso di Moravec.
Hans Moravec, un informatico, osservò nel 1980 che, per quanto riguarda il calcolo, i compiti che sembravano i più difficili per la mente umana, come diventare un grande maestro di scacchi, erano in realtà i tipi di compiti più facili da affrontare con i computer. Al contrario, se osserviamo compiti che sembrano estremamente facili per gli esseri umani, come stare in piedi su due gambe, quei compiti si rivelano incredibilmente impegnativi per i computer. Questa è l’essenza del paradosso di Moravec: la nostra intuizione su ciò che è difficile da raggiungere in termini di compiti intellettuali con i computer è molto ingannevole.
Una cosa che complica ulteriormente il problema è che, improvvisamente, quando si parla dell’automazione dei lavoratori impiegatizi, essa viene realizzata dagli stessi impiegati. Questo non avveniva con i lavoratori di fabbrica; non erano loro a decidere che la fabbrica sarebbe stata ulteriormente meccanicizzata e che i loro lavori sarebbero stati eliminati. Eppure, questo è ciò che sta accadendo con i lavori impiegatizi. Pertanto, abbiamo una sfida in cui non solo il processo di meccanicizzazione è profondamente controintuitivo a causa del paradosso di Moravec, ma anche la gestione delle persone incaricate di implementare questa meccanicizzazione, ossia gli ingegneri del software, è essa stessa molto controintuitiva. Questa è probabilmente una delle sfide più grandi per la supply chain: la gestione delle persone che, in un modo o nell’altro, si occuperanno di affrontare questa meccanicizzazione.
Qui non posso fare a meno di osservare che molte supply chains e le aziende ad esse associate sono ancora saldamente ancorate a una mentalità del XX secolo, in cui si affronta il mondo aziendale come se aveste persone impiegatizie a svolgere il lavoro intellettuale, e poi queste elaborano la soluzione o il piano, che viene consegnato ai lavoratori di fabbrica per l’esecuzione. Tuttavia, con un rapporto di 27 a 1 tra impiegati d’ufficio e operai in fabbrica in Francia, e probabilmente statistiche simili nella maggior parte dei paesi sviluppati, questo non è più il caso. Si tratta letteralmente di automatizzare il proprio lavoro, e significa che in questo mondo del XXI secolo, i migliori impiegati sono quelli che riescono costantemente ad automatizzare se stessi, rendersi obsoleti, e poi passare ad altro. Questa è una sfida molto ardua per molte aziende ancora profondamente radicate nella mentalità del XX secolo.

Le opinioni divergono ampiamente sulla stessa nozione di ingegneria del software. Una delle critiche più forti provenne da Edsger Dijkstra, uno dei padri fondatori dell’informatica. Secondo il suo punto di vista, l’ingegneria del software non è neanche possibile come disciplina o campo di ricerca, e disse che si riduce, o degenera, in un “how to program if you cannot,” una sorta di ricetta. La critica di Dijkstra, che è molto interessante, è che l’ingegneria del software degenera in una sorta di auto-aiuto fittizio che non può in alcun modo avere successo. Infatti, se proponiamo che l’obiettivo dell’ingegneria del software sia garantire il successo nella creazione di software utile e superiore, allora l’ingegneria del software è per lo più condannata. Il successo nel software è incredibilmente difficile; è tanto difficile quanto il successo nella scienza. Ci vuole una scintilla di genio, un bel po’ di fortuna, e non esiste una ricetta per questo. Inoltre, ogni singolo successo tende a consumare l’opportunità stessa che ha permesso di raggiungere quel successo, e così l’intero processo diventa non replicabile.
Tuttavia, non sono d’accordo con la visione che l’ingegneria del software sia condannata. Credo che il problema principale sia definire l’ambizione dell’ingegneria del software. Se decidiamo che l’ambizione dell’ingegneria del software è il successo nella creazione del software, allora in effetti è condannata. Tuttavia, se decidiamo di affrontare l’ingegneria del software come un sottobranco limitato della psicologia sperimentale, credo che possiamo ottenere, attraverso questo approccio, intuizioni molto preziose e applicabili, ed è questa la prospettiva che adotterò oggi in questa lezione. Così, l’ingegneria del software riguarda gli stessi ingegneri del software e le loro interazioni. Concentrarsi sugli ingegneri del software è un buon punto di partenza perché la natura umana è stabile nel tempo, a differenza della tecnologia del software, che è in costante cambiamento. La natura delle persone che stanno lottando con questa tecnologia non lo è; la natura umana è rimasta molto stabile per un lungo periodo.
Se osserviamo altri campi, come la scienza, possiamo vedere che avvicinarsi a un campo attraverso l’analisi di ciò che fanno i suoi professionisti può essere molto fruttuoso. Ad esempio, nella scienza, è ormai ampiamente accertato che un conflitto di interessi porta a una cattiva scienza e a una corruzione della conoscenza. Questo punto è stato trattato in precedenza nella lezione intitolata “Adversarial Market Research for Enterprise Software.” Da questa prospettiva, vediamo che è possibile raccogliere intuizioni di ampia applicabilità e rilevanza se ci concentriamo sui professionisti stessi. Così, l’ingegneria del software riguarda le persone che si occupano della tecnologia del software, le loro lotte e i loro processi, e non tanto la tecnologia in sé.
Questa è la sesta lezione dei quattro capitoli. Questo capitolo è dedicato alle scienze ausiliarie della supply chain. Queste scienze ausiliarie rappresentano elementi che ritengo di fondamentale importanza per una pratica moderna della supply chain, ma non sono strettamente elementi della supply chain. Sono più elementi di supporto per la vostra pratica della supply chain.
Finora, in questo quarto capitolo, abbiamo iniziato con la fisica del computing, occupandoci dei computer moderni, per poi salire lungo una scala di astrazioni. Siamo passati dai computer agli algoritmi, che rappresentano i minimi, più piccoli elementi di interesse nel software. Successivamente siamo arrivati all’ottimizzazione matematica, che è di interesse per la supply chain ma anche per molti altri progetti software rilevanti, come il machine learning. Abbiamo visto che l’ottimizzazione matematica è direttamente interessante per la supply chain, ma è anche direttamente interessante per il machine learning, che, a sua volta, è di interesse anche per la supply chain.
Per quanto riguarda l’ottimizzazione matematica e il machine learning, la maggior parte dei concetti e paradigmi interessanti al giorno d’oggi è di natura programmatica. Non si tratta solo di semplici algoritmi; è qualcosa di incredibilmente espressivo e che necessita di essere affrontato attraverso la prospettiva dei linguaggi di programmazione. Ecco perché l’ultima lezione è stata sui linguaggi e i compilatori.
Oggi, stiamo ancora salendo questa scala di astrazioni, e ci concentriamo sulle persone invece che su ciò che fanno. Ci concentreremo sugli ingegneri del software stessi, ed è questo il punto centrale di questa analisi sull’ingegneria del software.

Oggi presenterò due punti di vista specifici sull’ingegneria del software. Innanzitutto, presenterò il punto di vista mainstream, che ritengo domini il campo. Purtroppo, questo punto di vista mainstream ha generato critiche, come già menzionato, con persone che propongono approcci di auto-aiuto che alcuni, me compreso, hanno ragioni per opporsi perché non presentano un’ambizione realistica per la disciplina dell’ingegneria del software. Tuttavia, esaminerò questo punto di vista mainstream, se solo perché alcune intuizioni fuorvianti sono ancora incredibilmente popolari. Essere familiari con questi concetti fuorvianti è di fondamentale importanza, se solo per eliminare le persone incompetenti che potrebbero mettere in pericolo la vostra supply chain a causa della loro incompetenza.
Poi, passerò a un punto di vista dal fronte, che è una raccolta di elementi radicati nella mia esperienza personale come CEO di un’azienda di software che opera proprio nel campo del software per la supply chain aziendale. Come vedremo, le intuizioni riguardano molto le persone e non tanto la tecnologia in sé.

Il punto di vista mainstream dell’ingegneria del software afferma che un’iniziativa software inizia con la raccolta dei requisiti per il software di interesse. La maggior parte delle iniziative software nelle grandi aziende adotta questa prospettiva attraverso un processo che tipicamente inizia con una Request for Proposal (RFP), Request for Quote (RFQ) o Request for Information (RFI). Questo approccio deriva dalle pratiche del XX secolo che hanno avuto molto successo nell’ingegneria meccanica e nei lavori di costruzione. Tuttavia, credo che, per quanto riguarda il software, questi approcci alla raccolta dei requisiti siano profondamente fuorvianti.
Nel software, non sai cosa vuoi; semplicemente non lo sai. Capire cosa vuoi è inesorabilmente la parte più difficile del software. Ad esempio, se consideriamo un problema semplice come il riapprovvigionamento dell’inventario, la formulazione del problema è incredibilmente semplice: in qualsiasi momento, voglio sapere la quantità che dovrei riapprovvigionare o riordinare per ogni singolo SKU. Il problema in sé è semplice, eppure definire qual è una buona quantità diventa diabolicamente complesso e difficile. In linea di massima, chiarire i requisiti è di gran lunga più difficile che scrivere il pezzo di software stesso.
È solo confrontando la tua intuizione con il feedback fornito dal mondo reale che puoi far emergere gradualmente i requisiti. I requisiti non cadono dal cielo; possono essere ottenuti solo attraverso un processo abbastanza sperimentale, e devi avere questa interazione con il mondo reale. Tuttavia, l’unico modo per avere questa interazione è possedere il prodotto software, poiché raccogliere i requisiti è fondamentalmente un processo molto empirico ed emergente. Il problema è che, quando hai finito di raccogliere i requisiti, averli diventa irrilevante perché, se li possiedi, significa che hai già il prodotto corrispondente che li implementa. Quindi, quando finalmente hai accesso ai requisiti adeguati, hai già il prodotto in produzione, attivo e funzionante, e il fatto di averli è in qualche modo irrilevante.
Quindi, il punto è che iniziare il processo attraverso la lente dei requisiti è, credo, una follia. I requisiti probabilmente dovrebbero venire per ultimi, come documentazione di fase finale, in cui documenti tutte le ragioni principali che ti hanno portato a implementare il prodotto nel modo in cui lo hai fatto, e non il contrario.
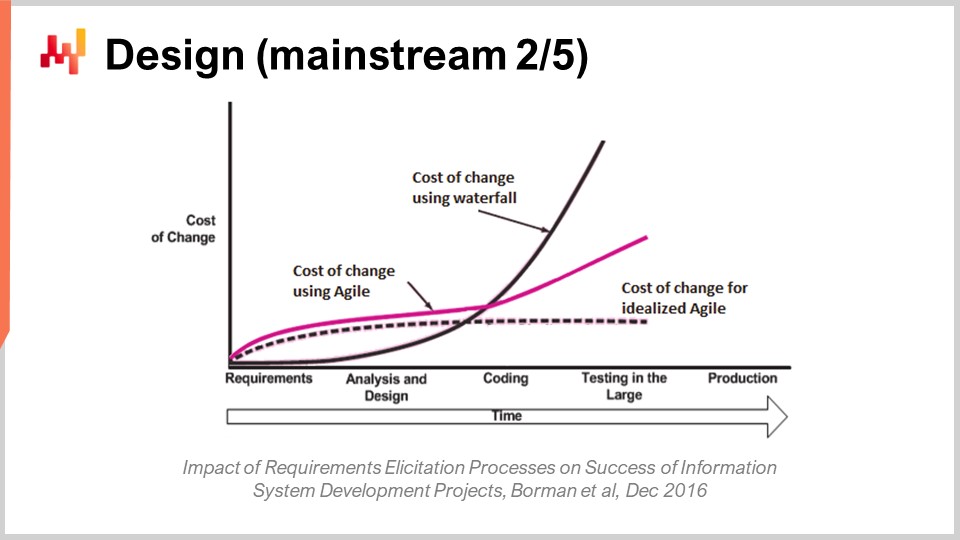
Una volta definiti i requisiti, l’approccio classico sostiene che si debba procedere con la fase di design. Concordo sul fatto che, a un certo punto, possa intervenire un po’ di design. Tuttavia, il tipo di ragionamento che caratterizza questa fase di design è spesso fuorviante. Il problema si riduce al controllo del costo del cambiamento. La visione classica non-software sul costo del cambiamento è che questo aumenti esponenzialmente nel tempo. Ad esempio, se cambi il design di un’auto molto presto, quando stai soltanto lavorando a un progetto, il costo del cambiamento è minimo. Al contrario, se aspetti che milioni di quelle auto siano sulle strade, il costo del cambiamento diventa incredibilmente alto perché implica un richiamo, che può essere estremamente costoso.
Tuttavia, a differenza del mondo fisico, nel mondo del software il costo del cambiamento non aumenta naturalmente in maniera esponenziale. L’aumento del costo non può essere completamente eliminato; tuttavia, in larga misura, può essere gestito. Infatti, il costo del cambiamento aumenta col tempo, principalmente perché le codebase tendono a crescere. Non ho mai visto una codebase di un software enterprise ridursi significativamente da un anno all’altro; tende a continuare a crescere. Eppure, è possibile gestire il costo del cambiamento in una certa misura.
Al giorno d’oggi, questo aspetto viene riconosciuto sempre di più, anche nei circoli del software. A proposito, questa è l’essenza della metodologia Agile. Avrai sentito questi termini quando qualcuno dice: “Oh, abbiamo questa metodologia Agile per il software.” Uno degli obiettivi principali della metodologia Agile è mettere sotto controllo il costo del cambiamento. Non entrerò nei dettagli oggi sulla metodologia Agile, ma basta dire che credo questo approccio sia in parte fuorviante per quanto riguarda il modo in cui esattamente si gestisce il costo del cambiamento.
Ho osservato che il costo del cambiamento origina principalmente dalle decisioni che vengono prese riguardo al software e, più specificamente, dal fatto che è molto difficile resistere all’impulso di prendere decisioni. Immagina di osservare un potenziale prodotto software futuro, e che vi siano innumerevoli decisioni da prendere. Il tentativo iniziale sarebbe quello di prendere queste decisioni solo per chiarire ciò che hai di fronte. Al contrario, una fase di design veramente buona, piuttosto che il solo buon design, consiste nella capacità di posticipare tutte le decisioni non assolutamente necessarie, ovvero quelle per cui il prodotto non richiede che vengano prese subito. Infatti, se non prendi una decisione, fintanto che essa non viene presa e non hai stabilito che è necessario adottare questo specifico approccio di design o tecnologico, essa rimane in sospeso, pronta per essere cambiata perché nulla è ancora stato deciso.
Uno degli aspetti per mantenere sotto controllo il costo del cambiamento è imparare a posticipare tutte le decisioni nella misura massima praticamente possibile. Dal punto di vista della supply chain, questo appare molto strano perché significa che per tutte le persone nel team software e per chi osserva il prodotto e il team, sembra che vengano tenute all’oscuro. È addirittura peggio, perché vengono volutamente tenute all’oscuro, il che è davvero sconcertante. Eppure, è proprio questo che deve accadere, e deve essere fatto di proposito. È per questo che è, per dirla meno, sconcertante.

Ora, se le decisioni di design premature sono radicate nel, a volte fuorviante, bisogno di controllo, i problemi associati a questo bisogno non finiscono qui. Una volta superata la fase di design, la visione tradizionale dell’ingegneria del software afferma che si debba procedere con la costruzione del software, fase spesso chiamata anche di implementazione. Il modo tipico di fare ciò è presentare una sorta di proiezione a cascata, nota anche come diagrammi di Gantt. Questo è ciò che vedi sullo schermo. Credo che questo approccio, i diagrammi di Gantt e le cascata, sia incredibilmente tossico, e la tossicità di questo approccio non dovrebbe essere sottovalutata per quanto riguarda il software. Affrontare il problema in questo modo significa letteralmente condannare la tua supply chain al fallimento, almeno per quanto riguarda le sue iniziative software.
Un modo molto migliore per comprendere il problema e affrontare la costruzione del software è considerarlo come un processo di apprendimento. La costruzione del software riguarda l’apprendere tutto ciò che serve per ottenere un buon prodotto. È un processo di apprendimento, e tutte le parti apprese sono un sottoprodotto del lasciar interagire il mondo con il software che emerge dal processo di costruzione. Il problema chiave di una previsione a cascata è che stai proiettando ciò che stai per scoprire. Questo, per definizione, non è possibile. Quello che stai per scoprire era sconosciuto fino a quando non l’hai scoperto. Non puoi prevedere le tue scoperte. Puoi aspettarti che accadano, ma non puoi pianificare nel dettaglio ciò che stai per scoprire. Puoi avere intuizioni, ma è il meglio che puoi ottenere. L’idea che tu possa trasformare quelle vaghe intuizioni in una previsione a cascata precisa è, ancora una volta, una completa follia.
A proposito, questo piccolo apparente paradosso sulla costruzione del software come processo di apprendimento spiega anche perché a volte replicare un pezzo di software può essere incredibilmente facile o incredibilmente difficile. Se un team tenta di replicare un prodotto software già presente sul mercato, e questo team ha accesso alla comprensione o alle lezioni che hanno portato alla produzione del software che stanno cercando di copiare, allora replicare il prodotto – re-implementarlo o riscriverlo – può solitamente essere fatto con solo una piccolissima frazione del tempo e del budget necessari per creare il software in origine. Al contrario, se il team non ha accesso a queste intuizioni di alto livello, e per esempio l’unica cosa a cui ha accesso è il codice sorgente, finirà molto spesso con un prodotto di bassa qualità perché, sostanzialmente, tutte le parti di apprendimento o i frammenti di conoscenza saranno andati persi. Avrai semplicemente replicato l’aspetto superficiale del prodotto.
Dal punto di vista della supply chain, la sfida più grande qui è rinunciare volontariamente e domare il tuo bisogno di controllo. Il processo a cascata esprime il desiderio di un’azienda di controllare il processo. Per esempio, se dico “mettiamo questo progetto sotto controllo”, ciò verrebbe percepito come molto ragionevole. Perché fare l’opposto? Perché dichiarare, per esempio, “facciamo in modo che questo progetto sia completamente fuori controllo?” Ma la realtà è che questo grado di controllo è una completa illusione per quanto riguarda il software, e danneggia completamente la tua capacità di consegnare un prodotto di alta qualità alla fine. Domare il tuo desiderio di controllo è, dal punto di vista della supply chain, probabilmente la sfida più grande quando si tratta della costruzione del software.

Fin dall’emergere dei programmi per computer, essi sono stati afflitti da bug e difetti. Per affrontare questi evidenti problemi, la visione tradizionale è che debba essere effettuato il testing. Il testing assume molte forme. Per quanto riguarda la necessità del testing, sono d’accordo, anche se a questo punto è molto vago. Alcuni strumenti sottolineano che il testing debba essere fatto dopo la costruzione, altri che debba essere fatto durante la costruzione, e altri ancora che debba essere fatto prima della costruzione. Alcuni approcci affermano che il testing debba avvenire prima, durante e dopo la costruzione del software.
La mia visione generale sul problema è che dovresti fare tutto il possibile per mantenere il ciclo di feedback il più breve possibile. Ne abbiamo discusso nella lezione precedente: mantenere il ciclo di feedback breve è di importanza critica per ottenere qualcosa che funzioni realmente nel mondo reale. Pertanto, consiglierei di prestare attenzione a capire se quello che stai facendo in termini di testing stia effettivamente accorciando questo ciclo di feedback oppure no. Per esempio, in molte situazioni non raccomanderei naturalmente lo sviluppo guidato dai test (una metodologia che sostiene che il testing venga prima), semplicemente perché, solitamente, testare prima ritarda il tempo necessario per ricevere feedback sul tuo software dal mondo esterno.
Tuttavia, la mia più grande preoccupazione riguardo al testing è una limitazione non detta, qualcosa che sembra essere generalmente trascurato. In fin dei conti, il testing può valutare solo la conformità alle stesse regole che hai stabilito tu stesso. Il problema è che, nel software, non esistono vincoli rigidi. Non esiste un modo “chimico” per valutare l’adeguatezza del tuo prodotto rispetto al problema che stai cercando di risolvere. Questo è molto diverso dal mondo fisico. Per esempio, nell’ingegneria meccanica esiste un criterio canonico: la tolleranza dimensionale di un componente. Qualunque cosa tu stia progettando in ambito ingegneria meccanica, la tolleranza dimensionale sarà di primaria importanza. È un candidato ovvio e naturale. Tuttavia, nel software non esiste nulla che possa essere definito candidato naturale e ovvio.
Il problema qui diventa uno di adeguatezza. Se vogliamo prendere un esempio dalla supply chain, come safety stocks, è completamente semplice progettare una suite di test automatizzati per validare i calcoli degli safety stocks. È molto semplice implementare questo tipo di logica di testing. Tuttavia, questo non può dirti che gli safety stocks siano un’idea sbagliata in primo luogo. Stai solo testando ciò che conosci.
Quando si tratta di una macchina fisica, ci si aspetta usura e logoramento e, di conseguenza, una qualche forma di manutenzione per mantenere la macchina in condizioni operative. Tuttavia, perché il software dovrebbe necessitare di manutenzione per continuare a funzionare? Certo, dobbiamo sostituire i computer poiché, di tanto in tanto, si guastano con il passare del tempo. Tuttavia, questo aspetto è molto marginale, e nel software enterprise i guasti fisici delle macchine non rappresentano nemmeno il 10% dei costi effettivi di manutenzione. Esiste, ma l’impatto di questo tipo di manutenzione è incredibilmente esiguo.
Tuttavia, la manutenzione nel software enterprise è di primaria importanza. I costi di manutenzione sono enormi. Per molti fornitori di software enterprise, la manutenzione rappresenta letteralmente l'80% o più del costo di ingegneria. Si scopre che i fattori che generano questa necessità di manutenzione hanno ben poco a che fare con la fisica. Il primo fattore è la willingness to pay degli stessi clienti. Se un fornitore riesce a ottenere una quota annua di manutenzione pari al 20% rispetto a quanto pagato per l’installazione del software nel primo anno, allora il fornitore addebiterà quella somma. Essenzialmente, dal punto di vista dei costi, il costo della manutenzione è guidato dalla willingness to pay dei clienti enterprise.
Il secondo fattore è il tipo di manutenzione che deve essere effettuato solo per mantenere il software operativo. Infatti, per ogni singolo giorno che passa, l’ambiente che circonda il prodotto di interesse si discosta dal prodotto stesso. Il sistema operativo continua a evolversi, il database evolve e lo stesso vale per tutte le librerie di terze parti utilizzate dal software. Nessun prodotto software è un’isola. Ogni prodotto software dipende da una miriade di altri prodotti software, e questi ultimi evolvono autonomamente. Le persone che sviluppano quei prodotti continuano a lavorarci, e mentre lo fanno, continuano a modificarli. Così, arriva il momento in cui il prodotto smette di funzionare a causa di un’incompatibilità. Non hai fatto altro che non tenere il passo con il resto del mercato. Il secondo fattore è tutta la manutenzione necessaria solo per mantenere il software funzionante e compatibile col resto del mercato.
Il terzo fattore è la quantità di lavoro necessaria per mantenere il prodotto utile. Infatti, il software è stato progettato e ingegnerizzato in un determinato momento, e ogni giorno che passa il mondo si discosta da ciò che si era previsto al momento dell’ingegnerizzazione del prodotto. Così, anche se nulla si rompe in termini di compatibilità hardware, risulta che, con il cambiare del mondo, l’utilità del prodotto diminuisce inevitabilmente perché il mondo si sta discostando dalle aspettative inizialmente incorporate nel prodotto. Se vuoi mantenere il software utile, devi costantemente mantenerlo.
Dal punto di vista della supply chain, la manutenzione è una grande sfida, e questo aspetto lo abbiamo toccato nella lezione precedente, che trattava della consegna orientata al prodotto per la supply chain. Il costo della manutenzione incide significativamente sui benefici capitalistici che puoi ottenere dal tuo investimento in software. Idealmente, vuoi che il tuo investimento in software offra un ritorno molto elevato, ma per farlo devi assicurarti di non ritrovarti con costi di manutenzione massicci. Questi costi annulleranno completamente il profitto e il ritorno capitalistico che puoi ottenere dal tuo investimento in software.
La sfida più grande qui, ancora da una prospettiva supply chain, è che il modo più semplice per minimizzare il costo della manutenzione è concentrarsi su ciò che non cambia. Come ho già menzionato, la maggior parte dei costi sono legati alle cose che risultano essere in cambiamento, sia nell’ecosistema del software sia nel mondo in generale. Tuttavia, se ti concentri su ciò che non cambia, ciò che ottieni è essenzialmente la maggior parte del tuo software che decadrà lentamente perché, precisamente, la maggior parte di ciò che il tuo software affronta sono le cose che non cambiano.
Il problema è che concentrarsi su ciò che non cambia è più facile a dirsi che a farsi, perché c’è una forza molto umana che si oppone a questo intento: la paura di perdersi qualcosa. Quando guardi la stampa, i media, i tuoi colleghi, ecc., c’è un flusso costante di novità, buzzword, e ogni singola buzzword ha questo impulso, dovuto alla paura di perdersi qualcosa, di fare semplicemente la cosa e non rimanere indietro. Ad esempio, tutte quelle buzzword sarebbero AI, blockchain, IoT, e tutte quelle cose molto presenti. Credo che nella supply chain, queste buzzword siano davvero una distrazione e contribuiscano in modo significativo ai problemi di manutenzione perché distraggono da ciò che non cambia. Al contrario, quando inizi a guardare quelle buzzword, stai cavalcando un’onda, e stai cavalcando esattamente quel tipo di cose che molto probabilmente cambieranno col tempo, gonfiando così il costo della manutenzione nel tempo.

Ora che abbiamo terminato con la visione mainstream dell’ingegneria del software, addentriamoci in una serie di intuizioni personali che, si spera, si riveleranno utili per condurre iniziative software tenendo a mente la supply chain. Uno dei problemi più frequenti quando si ha a che fare con il personale software è un’errata concezione della propria identità, e sto riprendendo questa idea da un imprenditore di nome Paul Graham. Un ingegnere, per esempio, dirà: “Sono un ingegnere Python.” Pur non essendo così estremo, è molto comune che gli ingegneri del software percepiscano la propria identità attraverso una breve serie di tecnologie che hanno padroneggiato, le quali costituiscono il loro set di competenze. Questa confusione tra la loro identità e il loro attuale set di competenze tende ad essere rafforzata dalle pratiche di assunzione che sono prevalenti nel mondo IT e del software in generale. Dal punto di vista delle assunzioni, molte aziende affermano nei loro annunci di lavoro, “Ho bisogno di un programmatore Python.” Quindi, da un lato c’è chi pensa, “Sono un programmatore Python,” e dall’altro c’è un’azienda che pubblicherà una posizione lavorativa in cui è fondamentalmente scritto, “Ho bisogno di un programmatore Python.” Così, avere all’improvviso la giusta identità non è solo una questione di percezione; ci sono ricompense finanziarie legate all’avere la giusta identità, l’etichetta giusta, il tag giusto che puoi associare a te stesso, rendendoti più attraente sul mercato.
Tuttavia, questa percezione guidata dall’identità, in cui le tecnologie si legano all’individuo come ingegnere del software, porta a numerosi problemi che influenzano praticamente ogni singolo progetto software, e in particolare i progetti software della supply chain. Quando si interagisce con una persona, tipicamente un ingegnere del software, che ha la propria identità fortemente legata alla tecnologia in uso nella tua azienda, il problema diventa che ogni critica alla tecnologia tende a essere considerata in chiave personale. Se dici “Sono un programmatore Python” e critichi il mio software, lo prendo sul personale. Il problema è che non appena le persone interpretano la critica alla tecnologia come una critica personale, diventa molto difficile ragionare su quei problemi. Questi ingegneri del software, purtroppo, tenderanno a deflettere tutti i feedback, solo perché in parte li vedono come critiche personali.
Al contrario, se l’azienda usa una tecnologia che non è quella percepita come identità centrale dall’ingegnere del software, per esempio, se la tua azienda ha alcuni sistemi implementati in Java e hai un ingegnere del software che dice, “Sono un programmatore Python,” allora tutti i problemi saranno percepiti con l’idea che quel pezzo di tecnologia sia inferiore. Ancora, questo è un altro problema per il quale la critica e il feedback saranno deflessi con l’atteggiamento di “non è un mio problema; questo succede solo a causa di questa tecnologia molto scadente che è stata usata qui e ora in questa azienda.” In entrambe le situazioni, sia che l’ingegnere del software abbia un’identità legata alla tecnologia che stai usando sia che abbia un’identità legata a una tecnologia che non stai usando, si creano una serie di problemi, e il feedback viene deflesso invece di essere sfruttato per migliorare la tecnologia.
Ora, da una prospettiva supply chain, dobbiamo tenere a mente che l’ambiente della supply chain è incredibilmente caotico, e quindi i problemi accadranno continuamente. Proprio a causa di questo caos ambientale, è molto importante avere team di ingegneri del software che siano in grado di guardare dritto negli occhi questi problemi e fare qualcosa al riguardo, e non solo deflettere il feedback quando si presenta. È cruciale assemblare team che non alimentino il dramma sopra il caos della supply chain a causa della loro percezione della propria identità.

Questa idea si estende agli ingegneri del software, che spesso scelgono tecnologie che si adattano alla loro identità o a quella che desiderano acquisire. Scelgono una tecnologia per acquisire competenze, in modo da poter aggiungere un’altra keyword al loro curriculum. Tuttavia, questo approccio porta a scegliere tecnologie per motivi non correlati alla risoluzione dei problemi che l’azienda deve affrontare. Questa è la prospettiva sbagliata per decidere se una tecnologia sia rilevante o adeguata ad affrontare le problematiche specifiche dell’organizzazione.
Costruire un curriculum può essere un forte incentivo per gli ingegneri del software, poiché esistono benefici finanziari concreti associati al possesso di una lista di keyword. Le migliori aziende di software spesso guardano con disprezzo ai curriculum con una lunga lista di keyword. In qualità di CEO di Lokad, se vedo un curriculum con mezza pagina di keyword, lo scarto immediatamente. Tuttavia, molte aziende, soprattutto quelle mediocri, cercano attivamente persone con molte keyword, pensando che questi individui saranno incredibilmente versatili e agili all’interno dell’organizzazione. Dalla mia esperienza, spesso è il contrario.
Proseguendo con il tema dell’identità e della costruzione del curriculum, è fondamentale prestare attenzione al fatto che gli architetti del software non dovrebbero essere troppo legati a una tecnologia in particolare. Già di per sé è difficile assumere ingegneri del software, quindi a volte si devono fare compromessi. Tuttavia, quando si tratta di architetti del software, compromettere selezionando individui con un attaccamento emotivo a una certa tecnologia può essere disastroso. Questi individui avranno un impatto su larga scala sulla tua azienda.
Questo problema del bias nella costruzione del curriculum non è limitato agli ingegneri del software o ai professionisti IT. Si verifica anche tra il personale IT. Ad esempio, ho incontrato diversi direttori IT in grandi aziende che desideravano passare a SAP mentre il loro legacy ERP esistente andava benissimo. I costi enormi associati al passaggio a SAP non sarebbero mai compensati dai benefici attesi di un ERP più moderno. In questi casi, si manifestava un comportamento irrazionale, dove l’interesse personale del direttore IT nel far comparire SAP nel proprio curriculum prevaleva sull’interesse dell’azienda stessa.
Da una prospettiva supply chain, è essenziale prestare attenzione a questi conflitti di interesse. Non servono molte competenze software per rilevare i conflitti di interesse. In altri campi, come la scienza medica, anche i medici possono prescrivere farmaci sbagliati a causa dei conflitti di interesse, anche quando in gioco vi sono vite umane. Questo dimostra che i conflitti di interesse sono incredibilmente tossici. Basta immaginare come questi problemi si manifestino nella gestione della supply chain, dove non ci sono vite in gioco e l’unica preoccupazione è il denaro. C’è ancora meno riluttanza a lasciare che i conflitti di interesse si sviluppino in questo contesto.

A differenza del mondo fisico, il mondo del software offre pochissimi vincoli su come procedere con le iniziative software e affrontare il lavoro. La natura umana non ama il vuoto, e le persone possono sentirsi a disagio per la mancanza di struttura. Di conseguenza, nel corso degli anni sono apparse numerose pratiche e continuano a emergere. Con ogni pratica si accompagna una nozione di ortodossia. Alcuni esempi di queste pratiche includono extreme programming, domain-driven design, test-driven design, microservices, Scrum e agile programming. Ci sono molte pratiche, e ogni anno ne emergono di nuove.
Con ogni pratica si accompagna una nozione di ortodossia. Non appena le persone iniziano a seguire una pratica, possono interrogarsi sul fatto se stiano aderendo ai principi fondamentali. Gli ingegneri del software sono solo persone, e le persone amano i rituali e le tribù. Una pratica offre un senso di appartenenza a una tribù con credenze condivise. Questo è il motivo per cui troverai anche meetup associati a queste pratiche, soddisfacendo un bisogno molto umano.
Può essere difficile e persino deprimente fissare un problema, incerti su tutto, e avere quasi nessuno con cui confrontarsi nell’affrontare la questione. La cosa interessante è che, sebbene una pratica possa essere discutibile o leggermente irrazionale, i benefici possono essere concreti. Promuovere una pratica all’interno e all’esterno della tua azienda può aumentare il morale e aiutare a reclutare potenziali candidati.
In un colloquio di lavoro, quando le persone chiedono come lavori, non è esattamente convincente dire che improvvisi e che non hai regole. È più efficace ispirare fiducia presentando una pratica come se risolvesse i problemi all’interno dell’azienda. Il punto chiave è che, a breve termine, queste pratiche non sono tutte cattive, anche se sono per lo più irrazionali. Generare un senso di appartenenza può essere benefico. Tuttavia, diventa velenoso se le pratiche vengono prese troppo sul serio o per troppo tempo. Una pratica può essere interessante semplicemente perché ti costringe a guardare il problema da un’angolazione diversa. Ma una volta che hai guardato il problema da un’angolazione diversa, dovresti cercare un’altra angolazione. Non dovresti attardarti troppo a lungo su una sola angolazione. Da una prospettiva supply chain, questo illustra l’assurdità radicale del mondo del software.
Sul pavimento della fabbrica, l’eccellenza significa fare sempre esattamente la stessa cosa. Nel mondo del software, è esattamente il contrario. Se fai sempre la stessa cosa, allora è una ricetta per la stagnazione e il fallimento col tempo.

Il software è complesso, e il software aziendale ancora di più. Spesso, più ingegneri finiscono per lavorare su una data iniziativa, il che porta a una naturale tendenza alla specializzazione. Quando un ingegnere lavora su una certa parte del codice, c’è un’inclinazione naturale a assegnare la stessa persona quando nuovi compiti richiedono di intervenire su quella stessa porzione di codice. I benefici sono reali, poiché questa persona conosce già il codice e può essere più produttiva.
Il problema principale della specializzazione è che può portare a un senso di proprietà su porzioni del codice, creando vari problemi. Ci sono due categorie di problemi associati a questa proprietà: il “truck factor” e i giochi di potere. Il truck factor si riferisce al rischio di perdere un dipendente che possiede conoscenze o competenze uniche. Ciò potrebbe essere dovuto al fatto che il dipendente lasci per un’altra azienda o non possa lavorare per qualsiasi altro motivo. I giochi di potere possono verificarsi se un dipendente si rende conto che il suo contributo è vitale per l’azienda e usa questo vantaggio per esigere uno stipendio più alto o altri benefit.
Dalla mia esperienza, gli ingegneri del software di solito non hanno una forte propensione a giocare a giochi di potere, ma questi problemi possono diventare sempre più frequenti nelle aziende più grandi. Esistono molte pratiche di ingegneria del software che cercano di affrontare questo problema in modo diretto, come il pair programming. Tuttavia, l’intuizione chiave è che troppo del bene può diventare velenoso per l’azienda. La cosa migliore è essere consapevoli di questa categoria di problemi, invece di attenersi a una pratica particolare che dovrebbe risolvere il problema. Questo perché tali pratiche possono creare altri problemi, distrarti o limitare la tua capacità di prestare attenzione ad altre cose che non hai ancora osservato. Dal punto di vista software, la lezione chiave qui è che la cultura è l’antidoto a questa categoria di problemi, non il processo.
Ci troviamo di fronte a una situazione in cui esiste un compromesso molto sottile tra i guadagni di produttività ottenuti facendo specializzare le persone su parti del codice e i rischi associati al fatto che quelle persone possiedano quelle parti del codice. Quello che desideri è coltivare una situazione in cui vi sia sempre un certo grado di ridondanza in termini di conoscenza del codice da parte dell’intero team, in modo che ogni singolo ingegnere abbia una certa sovrapposizione di competenze. Questo è un compromesso molto sottile che bisogna raggiungere se si vuole mantenere un certo grado di produttività. L’unico modo per fare effettivamente questo nel mondo reale è attraverso una cultura ben compresa dell’ingegneria del software. Non esiste un processo che possa garantire che le persone siano curiose del lavoro dei loro colleghi. Non puoi avere un processo per la curiosità; deve far parte della cultura.

Valutare le competenze e le abilità degli ingegneri del software è difficile, e questa questione è fondamentale perché, sebbene il software sia chiaramente un lavoro di squadra e il team sia più della somma dei suoi membri, il livello base dei membri del team ha un grande impatto sulle prestazioni complessive del gruppo.
Un aspetto che ho osservato essere largamente sottovalutato dalle persone al di fuori dell’industria del software, e talvolta anche da quelle al suo interno, è l’importanza delle capacità di scrittura. Se stai creando software, ti rivolgi a due pubblici distinti. Da un lato, c’è il pubblico della macchina—il tuo compilatore. Scrivi il codice, e il tuo compilatore lo accetterà o lo rifiuterà. Questa è la parte facile. Il tuo compilatore è il tuo compagno instancabile che ti dirà se il tuo codice è corretto o sbagliato. Il compilatore è completamente prevedibile e ha un’infinita pazienza.
Dall’altro lato, hai il pubblico dei tuoi colleghi, che probabilmente includerà te stesso tra sei mesi. Scrivi codice e alla fine lo dimenticherai. Sei mesi dopo, guarderai il codice che hai scritto, pensando che sia stato scritto da qualcun altro perché appare così sconosciuto. Quando scrivi codice per i tuoi colleghi, il vantaggio è che, a differenza dei compilatori, i tuoi colleghi cercheranno di capire cosa stai cercando di ottenere. Il compilatore non tenta di comprendere le tue intenzioni; applica meccanicamente una serie di regole.
I tuoi colleghi cercheranno di comprendere, ma sfortunatamente non sono come i compilatori. Non hanno una pazienza infinita e possono facilmente essere confusi e fuorviati dal tuo codice. Per questo, ad esempio, scegliere nomi memorabili, significativi e appropriati è di primaria importanza. Un buon programma non riguarda solo l’essere corretto; anche la scelta dei nomi di variabili, funzioni e moduli è di importanza critica se desideri avere un codice che collabori bene con i tuoi colleghi, e ancora, i tuoi colleghi includono te stesso tra sei mesi. Da una prospettiva di supply chain, il punto fondamentale è che le capacità di scrittura sono di primaria importanza, e oserei dire che le capacità di scrittura sono frequentemente più importanti delle sole competenze tecniche. Le buone capacità di scrittura sono la competenza numero uno di cui avrai bisogno per domare la complessità presente nella tua supply chain. Domare la complessità del tuo panorama applicativo non è una grande sfida tecnica; è una sfida nell’organizzare idee ed elementi e nell’avere una narrazione coerente. Queste sono in gran parte capacità di scrittura, e abbiamo toccato questo aspetto in una precedente lezione intitolata “Writing for Supply Chain.”

Se la capacità di scrittura è di primaria importanza per essere un buon ingegnere del software, c’è un’altra competenza che lo è altrettanto per essere un ingegnere del software: la tolleranza al dolore. Credo che questa sia la competenza numero uno in termini di ciò che serve realmente per essere un ingegnere del software, non un grande ingegnere, ma semplicemente per esserlo. Più precisamente, quando dico dolore, intendo la resistenza alla noia e alla frustrazione che accompagna il processo di ingegneria del software quando si affrontano sistemi estremamente fragili, mal progettati e trappolati in ogni sorta di modo, a volte da persone che non ci sono nemmeno più. Quando hai a che fare con il software, hai sotto i piedi quattro decenni di problemi accumulati e ci lotti continuamente. Questo può diventare un esercizio incredibilmente frustrante.
Solo per farti un esempio, come ingegnere del software, dovrai avere la pazienza di trascorrere quattro ore a setacciare conversazioni casuali e semi-spazzatura su un forum web che menzionano un codice di errore simile a quello che stai affrontando. Dovrai affrontare questo tipo di sciocchezze per ore per arrivare al nocciolo del problema, e a volte ci vogliono settimane per risolvere un bug apparentemente banale. Di conseguenza, ciò porta a un processo di selezione avversa molto intenso nell’intera industria del software, che seleziona persone con un’elevata tolleranza al dolore. Questo processo di selezione ha due conseguenze principali.
In primo luogo, le persone che rimangono ingegneri del software tendono a essere incredibilmente tolleranti al dolore. Quando dico tolleranti al dolore, intendo la resistenza alla frustrazione derivante dai costanti problemi del software. Dal momento che si selezionano persone con una tolleranza eccezionale al dolore, potrebbero non rendersi nemmeno conto quando le loro azioni aggravano la situazione. Possono aggiungere stranezze extra ai prodotti software, aumentando il disagio nell’interazione con il software per tutti, compresi loro stessi. Tuttavia, se sono estremamente tolleranti al dolore, non ci fanno caso. Questo processo di selezione avversa esclude le persone normali che porrebbero attenzione, ma che non sono diventate ingegneri del software perché non potevano sopportare il dolore. Questo problema è particolarmente intenso per il software di supply chain, perché ci sono molte parti che non sono particolarmente entusiasmanti. Alcuni aspetti possono essere necessari ma banali, il che significa che le persone con un’elevata tolleranza al dolore che operano in questo campo possono peggiorare la situazione a causa dell’abbondanza di compiti potenzialmente noiosi.
Il secondo aspetto di questo processo di selezione avversa è che, quando le persone possono permettersi il lusso di accettare un salario inferiore per evitare problemi che generano un dolore intenso, lo fanno. Se qualcuno è già ben pagato, potrebbe decidere di optare per un lavoro meno remunerativo ma che offre il vantaggio di meno dolore intenso. La maggior parte delle persone probabilmente agirebbe così, e in pratica, molti lo fanno. Ciò significa che le persone che rimangono in questo settore, dove l’intensità del dolore ambientale è molto alta, sono spesso quelle che non possono permettersi di rinunciare all’opportunità di ottenere un salario più elevato. Questo spiega in larga misura perché c’è un numero significativo di ingegneri del software provenienti dall’India e dal Nord Africa. Questi paesi hanno sistemi educativi abbastanza buoni che producono individui ben istruiti, ma rimangono comunque relativamente poveri. Le persone in queste posizioni non hanno il lusso di rinunciare a lavori di ingegneria del software più remunerativi a causa dell’elevata domanda e dei salari più alti rispetto ai loro salari base. Non hanno il lusso di optare per qualcos’altro, e perciò finiscono per essere molto diffusi nel settore.
Non c’è niente di sbagliato in questi paesi; si tratta semplicemente di un’applicazione meccanica delle forze di mercato. Questa non è una valutazione, solo un’osservazione. La questione è che la tolleranza al dolore non è tutto ciò che serve per essere un grande ingegnere del software. È solo una condizione, ma se non ce l’hai, allora non sei affatto un ingegnere del software. Tuttavia, se la tolleranza al dolore è l’unica cosa che possiedi, diventerai un ingegnere del software alquanto scarso. Da una prospettiva di supply chain, la lezione qui è di prestare molta attenzione al tipo di team che la tua azienda sta assemblando, sia internamente che tramite fornitori di software. Assicurati che gli ingegneri coinvolti non abbiano la tolleranza al dolore come unica competenza, perché ciò significa che otterrai un risultato molto scarso in termini di qualità del software e di valore aggiunto. Ancora una volta, la tolleranza al dolore è richiesta, ma non basta.

Nel 1975, Frederick Brooks aveva già sottolineato che i man-month non rappresentavano il valore creato dal software e il valore generato dagli ingegneri del software nel complesso. Quasi cinque decenni dopo, le aziende IT sono tra i maggiori datori di lavoro al mondo. Nel 2020, negli USA, c’erano 3 milioni di dipendenti nel settore IT, ma meno di 1 milione per l’intera industria automobilistica. Oggi, il settore IT conta almeno tre volte più persone rispetto all’industria automobilistica. La maggior parte di queste aziende IT, alcune delle quali sono assolutamente gigantesche con diverse centinaia o migliaia di dipendenti, non addebitano più a man-month. Questi erano gli anni ‘70. Ora addebitiamo per kilo-days, che fondamentalmente equivalgono a mille giorni di lavoro. La situazione è probabilmente peggiorata rispetto al problema delineato da Frederick Brooks quasi cinque decenni fa, principalmente a causa dell’incredibile aumento in termini di scala e magnitudo del problema. Tuttavia, la maggior parte delle prime lezioni rimane valida. “The Mythical Man-Month” resta un libro molto interessante sull’ingegneria del software.
Nel software, la produttività varia enormemente. Da un lato dello spettro, non hai persone a bassa produttività; hai persone con produttività negativa. Ciò significa che, quando iniziano a lavorare su un prodotto software, lo peggiorano. Non si può nemmeno più calcolare un rapporto tra la produttività delle persone. È molto peggio; ci sono persone che degraderanno attivamente il tuo prodotto. Questo è un problema enorme. Dall’altro lato dello spettro, ci sono i cosiddetti 10x engineers, persone che hanno una produttività dieci volte superiore a quella del tuo ingegnere medio, che si spera abbia una produttività positiva. Questi 10x engineers esistono, ma questa produttività massiccia è incredibilmente dipendente dal contesto. Non puoi semplicemente trasferire un ingegnere del software 10x da un’azienda a un’altra o persino da una posizione all’altra e aspettarti che quella persona mantenga la sua incredibile produttività. Di solito, è una combinazione di competenze uniche e di una situazione specifica a generare quella produttività. Tuttavia, è importante tenere a mente che pochissime persone possono generare la maggior parte del valore di un prodotto software. A volte, tutto si riduce a una sola persona che crea la maggior parte degli elementi intelligenti del software e il vero valore aggiunto, mentre il resto si occupa di cose che, nella fattispecie, hanno un valore aggiunto dubbio. La lezione chiave qui, identificata cinque decenni fa, è che quando sei contro una scadenza nella supply chain, l’unica opzione ragionevole a tua disposizione è ridurre l’ambito dell’iniziativa software. Tutte le altre opzioni sono peggiori.
Aggiungere forza lavoro peggiora le cose, poiché si dice spesso che aumentare il personale in un progetto software in ritardo lo farà ritardare ulteriormente. Questa affermazione di Brooks era valida cinque decenni fa ed è ancora valida oggi. Le altre opzioni non funzionano nemmeno. Se fai lavorare le persone in straordinario, questo ritorcerà contro di te perché saranno stanche e produrranno più bug, ritardando ulteriormente il prodotto. Se provi a ridurre la qualità, finirai con qualcosa che non funziona più. Queste situazioni sfuggeranno al controllo e ti esploderanno tra le mani, quindi non puoi scendere a compromessi con la qualità.
Da una prospettiva di supply chain, la lezione chiave qui è che se affronti un’iniziativa che sembra richiedere più di dieci ingegneri del software a tempo pieno, procedi con la massima cautela. Di solito, è un segno che il problema è formulato in modo molto errato. Ci vuole un lavoro di squadra incredibile affinché dieci persone possano lavorare contemporaneamente sullo stesso prodotto mantenendo la produttività. Nella supply chain, osservo che le persone sono spesso troppo ambiziose in termini di scala e del numero di persone coinvolte. Ho visto progetti di migrazione ERP con 50, 100 o 200 persone che vi lavoravano contemporaneamente. Questo è assolutamente insensato. Raggiungere anche un minimo di cooperazione richiede team player incredibilmente capaci per evitare che tutto venga rovinato dall’attrito. Se hai difficoltà, mantieni la tua iniziativa software focalizzata, breve e ristretta.

La mia osservazione finale riguarda un frequente malinteso sulle grandi aziende. La maggior parte delle persone direbbe che le grandi aziende sono avverse al rischio, ma questa non è la mia esperienza. La mia esperienza è che le grandi aziende sono avverse all’uncertainty, non al rischio, anche se da lontano i due concetti possono confondersi. Da lontano, la spiegazione razionale è che le grandi aziende sono avverse al rischio, ma in realtà ho osservato ripetutamente che le grandi aziende, quando si trovano di fronte all’opportunità di scegliere tra un fallimento certo e un successo incerto, favoriscono invariabilmente la certezza del fallimento rispetto all’incertezza del successo.
Le grandi aziende favoriranno invariabilmente la certezza del fallimento rispetto al successo incerto, ancora e ancora. Questo potrebbe sembrare sconcertante e irrazionale in superficie, ma non lo è. Le grandi aziende non sono un’entità singola; sono bestie politiche composte da molte persone. La politica e le apparenze sono fondamentali, soprattutto in strutture molto grandi.
Considera la prospettiva di chiunque sia responsabile di un’iniziativa software. Da un lato, hai un’iniziativa il cui esito è certo – fallirà. Tuttavia, stai seguendo le regole, e tutti sanno che fallirà. Nessuno ti biasimerà per aver agito in sicurezza e aver fallito, perché è ciò che si aspettano. Al contrario, il successo incerto appare strano. Percorrere quella strada significa fare cose insolite e potenzialmente dannose per la carriera, molto più che semplicemente seguire le regole.
Da una prospettiva di supply chain, la lezione qui è che nel mondo del software è estremamente importante non preordinarsi al fallimento solo per il gusto di seguire le regole, soprattutto quando quelle regole sono completamente errate. Ad esempio, ho visto aziende fallire per decenni utilizzando metodi come l’ABC analysis e gli stock di sicurezza, metodi che possono essere dimostrati come errati e garantiscono il fallimento delle relative iniziative. Questi metodi sono sbagliati per ragioni matematiche e statistiche di base, quindi non dovrebbe sorprendere se non riescono a fornire valore aggiunto nella supply chain. Tuttavia, sono stati ritenuti preferibili perché non apparivano folli, essendo materiale da manuale.
Attento al conforto che può derivare dal predisporre il fallimento solo per eliminare l’incertezza. Eliminare l’incertezza non è l’obiettivo; l’obiettivo è massimizzare la possibilità di successo, non ridurre l’incertezza.

In conclusione, l’ingegneria del software è troppo importante per essere lasciata esclusivamente nelle mani degli ingegneri del software. Il software è ovunque nella supply chain e sta guidando la meccanizzazione del lavoro intellettuale. Siamo ancora in una fase iniziale del processo, ma si può già affermare, senza dubbio, che le aziende che non resteranno estremamente competitive su questo fronte saranno eliminate dal mercato dalle normali forze di mercato. Per la supply chain, la sfida più grande è di natura culturale. Questo non è un problema tecnico, bensì un problema culturale. L’ingegneria del software mette in discussione il modo stesso in cui guardiamo e affrontiamo i problemi. La maggior parte delle soluzioni intuitive tende a essere sbagliata, in modo spettacolare.
In un certo senso, l’ingegneria del software nella supply chain riguarda il domare il caos, domare tutta la complessità e l’incertezza che pervadono la supply chain. Per domare questo caos – che sarà il compito degli ingegneri del software – se il processo stesso è troppo raffinato o ordinato, se non ha un elemento di caos al suo interno, allora non rimane spazio per il cambiamento, il caso o la creatività. Ciò che viene percepito come eccellenza degenera rapidamente in stagnazione e poi in fallimento. Per le aziende più tradizionali, la sfida più grande di questo approccio culturale, oltre allo shock culturale, è lasciar andare l’illusione del controllo. Il tuo piano quinquennale di migrazione ERP è un’illusione; non hai alcun controllo su un progetto così immenso. Allo stesso modo, il tuo business case che delinea i profitti attesi della tua iniziativa attuale è anch’esso un’illusione.
Quando si affronta la meccanizzazione del lavoro intellettuale, il pericolo più grande non è fare cose che non puoi razionalizzare completamente. Il pericolo più grande è fare cose completamente irrazionali sotto l’apparenza di razionalità.

Diamo un’occhiata alla domanda. La prossima lezione si terrà mercoledì 15 dicembre, alla stessa ora, alle 15:00, ora di Parigi, e tratterà di cybersecurity. Ora, darò un’occhiata alla domanda.
Domanda: Come si misura il ritorno capitalistico sui tuoi investimenti in software?
Per lo più, non lo fai. La misurazione è il sottoprodotto dell’impresa stessa. È qualcosa che risulta sconcertante se vuoi misurare il ritorno sull’investimento. Presuppone che tu possa concepire una misurazione in anticipo, come implicitamente suggerito da questo tipo di domanda. Presuppone che tu possa elaborare questa misurazione prima di costruire il tuo business case con scenari, e poi prendere una decisione e procedere o meno con il tuo investimento in software. Quello che sto dicendo è che non funziona così con il software. È letteralmente: prima fai la cosa, poi impari ciò che deve essere appreso, e lungo il percorso imparerai persino quali tipi di benefici ci sono. Per guidare la tua azione, hai bisogno di una comprensione a livello alto. La lezione non è fare le cose a caso, ma non fare cose profondamente irrazionali sotto la parvenza di razionalità. L’intuizione a livello alto, se sei assolutamente convinto di qualcosa e il tuo istinto ti dice che è la strada giusta, può essere un argomento molto più razionale rispetto a calcoli sofisticati che hanno solo la pretesa della razionalità ma si basano su numeri fittizi. La realtà è che man mano che procedi con la tua impresa software, le misurazioni diventeranno più chiare perché inizierai a capire cosa stai cercando di raggiungere, e poi imparerai a misurare l’adeguatezza di ciò che stai facendo rispetto a ciò che dovresti fare. La misurazione è qualcosa che verrà in seguito, se lo fai bene. Tuttavia, di conseguenza, significa che per quanto riguarda il software, è molto meglio provare le cose e fallire rapidamente. Non vuoi impegnarti in un impegno massiccio; è meglio farlo in modo incredibilmente incrementale, con meno persone e alta produttività. Impari lungo il percorso come procedere.
Ma poi arriva un altro problema: non appena cominci a fare questo, il management nelle aziende deve essere in grado di gestire molte iniziative contemporaneamente. Questo è molto sconcertante, specialmente per le aziende più tradizionali, perché il management non si aspetta di avere così tante iniziative che procedono in direzioni differenti. Eppure, questo è esattamente ciò che sta già accadendo nelle grandi aziende di software da decenni, ed è una delle essenze degli insegnamenti dell’ingegneria del software da una prospettiva umana.
Domanda: Non è una contraddizione dire che chi ha molte parole chiave non si associa a una particolare tecnologia?
Beh, non dico che avere molte parole chiave ti protegga dall’associarti a una particolare tecnologia. Esistono due problemi differenti. Uno è il problema di avere una persona che ha una forte associazione tra la propria identità personale, la propria identità percepita e le proprie competenze. Questo è il problema numero uno. Il problema numero due è che costruire il tuo curriculum comporta un conflitto latente di interessi molto forte. Il mio messaggio è: da un lato, attenti a quelle politiche identitarie; sono incredibilmente tossiche. Il mio secondo messaggio è: state attenti ai conflitti di interesse in tutte le loro forme; sono anch’essi incredibilmente tossici.
Ora, se enfatizzi davvero una tecnologia in particolare, potresti rimuovere alcune parole chiave relative alla tecnologia che disapprovi dal tuo curriculum. Tuttavia, di solito, i due problemi sono separati, e puoi anche avere qualcuno che dice: “La mia identità è quella di essere un programmatore Python”, come ho mostrato in una slide, e poi nel tuo curriculum inserire più di 20 parole chiave. Le due cose non sono esclusive; possono addirittura verificarsi contemporaneamente. Inoltre, non sottovalutare il fatto che a volte l’identità può essere associata a qualcosa di aspirazionale, qualcosa che vuoi acquisire. Potresti dire: “Finora ho programmato in Python, ma voglio diventare un programmatore Rust, quindi mi considererò un programmatore Rust, anche se finora ho fatto per lo più Python.” Sono possibili ogni sorta di comportamenti.
Domanda: L’ingegneria del software è considerata una scienza ausiliaria per la supply chain. Quali sarebbero le scienze ausiliarie per l’ingegneria del software?
Probabilmente psicologia, sociologia ed etnologia sono tutti campi rilevanti quando si tratta di ingegneria del software. Se inizi ad approcciarla, essenzialmente, come l’interazione tra le persone, queste scienze ausiliarie sono cruciali. Per fare un lavoro serio nell’ingegneria del software, non si tratta esclusivamente della tecnologia software, anche se devi comprendere il contesto del software affinché le interazioni tra le persone abbiano senso. Non è necessario comprendere necessariamente cosa c’entri il codice, ma devi capire concetti come una codebase o gli strumenti che esistono e i problemi che cercano di risolvere. Tuttavia, per lo scopo di questa serie di lezioni sulla supply chain, devo tracciare una linea di confine, decidendo cosa includere e cosa non includere, poiché ovviamente non posso coprire ogni singolo campo di ricerca.
Domanda: Chiedi a dieci persone intelligenti una soluzione, e ne proporranno più di dieci modi. È meglio concordare su una delle prime cinque opzioni e usarla in modo coerente. Come bilanci questi due approcci e benefici contrastanti?
È una domanda molto ampia, ma se provo a inquadrarla nel caso specifico dell’ingegneria del software, puoi avere molte proposte, ma non tutte dovrebbero essere considerate allo stesso peso. Esiste un’abilità nel vedere il software in una prospettiva a lungo termine. Quando dico che dovresti concentrarti su ciò che non cambia, si scopre che alcune persone sono molto brave in questo lavoro, mentre altre no. L’esperienza entra in gioco quando vuoi valutare chi ha le competenze per questa visione a lungo termine e cosa non cambia. Nella mia umile esperienza, di solito ci vuole almeno qualcuno di 35 anni per cominciare a diventare veramente bravo in questo, e le persone migliori hanno più di 60 anni. Ci vogliono anni di esperienza per cogliere il movimento e i modelli.
Quando dici che hai così tante persone, un’illusione è che tutte quelle soluzioni sembrino buone, ma è solo un’apparenza. Non sai quanta fatica ci vorrà per testare le acque. Puoi semplicemente creare un prototipo o provarlo? Tra quelle dieci persone, ce ne sono alcune con competenze uniche nell’individuare soluzioni che a lungo termine saranno velenose? Ricorda che i tuoi costi di manutenzione sono essenzialmente determinati dalle decisioni prese. C’è una decisione importante che potrebbe danneggiarti nel lungo termine?
Questo è un aspetto complicato e, a proposito, qualcuno che ha una visione a lungo termine può spiegare perché una certa opzione, nel lungo periodo, genererà ogni sorta di problemi. Non si tratta solo di un presentimento o di un’intuizione. Ti diranno: “Questo genere di cose, ci sono passato, fatto e visto in altri prodotti.” C’è un detto: l’uomo intelligente impara dai propri errori, ma l’uomo saggio impara dagli errori degli altri. Questo è molto applicabile in questo caso.
Domanda: Come misurano le imprese l’aumento dell’efficienza operativa per ogni dollaro investito nell’implementazione di software per la supply chain?
È una domanda incredibilmente difficile. Il problema è letteralmente l’incommensurabilità dei paradigmi. Proviene dall’epistemologia; l’idea è che quando passi da un modo di operare a un altro, e quei paradigmi sono radicalmente differenti, la maggior parte delle misurazioni diventano semplicemente inutili. Prendiamo ad esempio le televendite rispetto all’e-commerce. Le aziende di vendita per corrispondenza esistevano fin dalla metà del XIX secolo. Se inizi a considerare l’e-commerce come un miglioramento rispetto alle aziende di vendita per corrispondenza, potresti cercare di misurare il miglioramento, ma la realtà è che virtualmente ogni singola azienda di vendita per corrispondenza è fallita. Le aziende di e-commerce che dominano oggi sono di diverse ordini di grandezza più grandi della più grande azienda di vendita per corrispondenza che sia mai esistita. Amazon è probabilmente 100 volte più grande della più grande azienda storica di vendita per corrispondenza, e il confronto è molto sfocato.
La meccanizzazione del lavoro intellettuale è incredibilmente preoccupante e sconcertante perché non è come il regno fisico. Con la produzione fisica, puoi misurare l’efficienza con metodi canonici. Tuttavia, quando inizi a meccanizzare il tuo lavoro intellettuale, cosa significa addirittura efficienza? Per un’azienda come Amazon, l’intera supply chain è completamente gestita dal software. Se le persone stessero semplicemente a casa senza fare nulla, sospetto che l’intera supply chain funzionerebbe perfettamente, anche se tutti quegli ingegneri non facessero nulla per uno o due giorni. Allora, perché Amazon tiene comunque quegli ingegneri? Beh, perché investono nei loro miglioramenti.
A proposito, una cosa interessante su Jeff Bezos è il suo processo di gestione chiamato “disagree but commit.” Egli afferma che ci sono progetti in cui il suo istinto di CEO gli dice che sono sbagliati, e lui non è d’accordo con il progetto. Tuttavia, si impegna a sostenere il progetto dal punto di vista del budget perché ha assunto e si fida delle persone che vi lavorano. È un approccio un po’ schizofrenico – in quanto CEO, si suppone che sia l’autorità suprema nell’azienda, ma rinuncia a questa autorità e dice: “Non sono d’accordo, ma potete avere il budget e procedere.”
La ragione di questo approccio è che le iniziative software sono di solito abbastanza economiche. Se qualcuno propone un’idea apparentemente folle che non è molto costosa e non farà fallire l’azienda, perché non provarla? Se funziona, potrebbe essere un’idea brillante. Questo rappresenta uno shock culturale quando si passa dalle aziende tradizionali della supply chain, dove il management dovrebbe avere la visione e guidare le squadre. Nel campo del software, la leadership consiste principalmente nel risolvere i problemi che emergono tra gli ingegneri del software.
Da Lokad, quando si investe in software, la preoccupazione principale non sono i ritorni in dollari. Invece, l’attenzione è su se l’investimento affronta un aspetto fondamentale della gestione della supply chain. Se è centrale per una vasta gamma di situazioni della supply chain, allora vale la pena perseguirlo.
Ad esempio, nel mercato dell’automotive aftermarket, affrontare il problema della compatibilità meccanica è di primaria importanza. Non stai vendendo pezzi di ricambio per servire le persone; stai vendendo pezzi per servire le auto. Un singolo pezzo può essere compatibile con più veicoli, e alcuni pezzi potrebbero avere sovrapposizione meccanica. Questo problema deve essere affrontato; è centrale per l’attività. Se non lo affronti, qualcun altro lo farà, e alla fine sarai escluso dal mercato.
Per quanto riguarda gli investimenti in software, è importante assumersi dei rischi e abbracciare l’innovazione, purché non minaccino la stabilità finanziaria dell’azienda.
Domanda: È fuorviante dire che i grandi team di progetto sono ridicoli. Nei sistemi ERP, un team di 10 persone potrebbe essere adatto per lo sviluppo, ma progetti più grandi richiedono più persone. Una torre richiede più persone per essere costruita rispetto a una casa. Potresti chiarire i tuoi commenti?
Prenderò una posizione che potrebbe antagonizzare molte persone. Il sostentamento di milioni di persone dipende da aziende IT incredibilmente grandi. Negli USA, nel 2020, le aziende IT rappresentavano tre milioni di dipendenti americani. Quindi, quando dico che non c’è assolutamente nessuna ragione per avere un ERP che richieda così tante persone, ovviamente, tutte le persone che guadagnano da vivere vendendo grandi team o facendone parte saranno in forte disaccordo con me.
Il mio controargomento è: il tuo disaccordo deriva da ragioni scientifiche fondamentali che spiegano perché il lavoro non può essere svolto con meno persone, oppure è nel tuo interesse finanziario mantenere lo status quo e avere un esercito di persone che svolgono il lavoro? Se osserviamo tutte le innovazioni che hanno avuto luogo – la distruzione creativa delineata dall’economista Schumpeter – ogni volta che c’era un’importante innovazione economica, in genere c’era un massiccio miglioramento della produttività. Ma coloro che erano indietro nella curva hanno combattuto strenuamente per impedire che queste innovazioni avvenissero.
Gli ERP non sono una novità; esistono da essenzialmente quattro decenni. La maggior parte degli ERP che vedo oggi non aggiungono molto valore rispetto a quelli che le aziende avevano una o due decadi fa. Ho visto molti ERP più vecchi che vanno benissimo, e i nuovi ERP spesso non sono sostanzialmente migliori, specialmente considerando i milioni investiti nei progetti di migrazione degli ERP. In questi progetti massicci, assisto a una produttività abissale delle aziende IT.
Il mio controargomento è guardare aziende come JD.com, Amazon o Rakuten. Quante persone hanno bisogno queste aziende per svolgere compiti simili? Di solito, si ottengono rapporti folli. Ad esempio, Zalando, una grande azienda europea di e-commerce con sede a Berlino, in Germania, ha costruito il proprio ERP con un team più piccolo rispetto alla maggior parte dei team che ho visto per aziende di dimensioni simili che devono migrare il loro ERP. Quindi vedi, da un lato, c’è un’azienda come Zalando, capace di ingegnerizzare il proprio ERP, completamente su misura per le proprie esigenze. Fa un ottimo lavoro nel fornire un ERP adatto a loro, e il costo e il numero di persone coinvolte sono solo una frazione di quello che altre aziende di dimensioni simili devono sostenere solo per eseguire un aggiornamento di versione. Il costo è di nuovo solo una frazione. Metto in discussione se sia necessario avere così tante persone coinvolte, ed è questo il problema del lavoro intellettuale nel 21° secolo. Per essere un dipendente molto bravo, significa che devi avere il coraggio di automatizzarti, di renderti obsoleto.
Questo è qualcosa di molto peculiare. Quando i lavoratori manuali venivano progressivamente resi obsoleti, lo facevano altri. Ma al giorno d’oggi, quasi non rimangono lavoratori manuali. Ci vuole una mentalità diversa, ed è per questo che c’è una lotta per adattarsi a questo nuovo paradigma, prevalentemente proveniente dall’industria del software. Va bene rendersi obsoleti perché in realtà non ti rendi obsoleto; non c’è limite all’ingegnosità umana. Stai semplicemente automatizzando alcuni compiti, liberandoti per affrontare la prossima sfida, che è persino più interessante della precedente. Aziende come Amazon non licenziano i loro ingegneri del software non appena risolvono un problema. Li ricompensano e li promuovono per affrontare il prossimo problema, più difficile.
In risposta a una domanda riguardante i supply chain practitioners rimasti bloccati in un pensiero analitico post-Seconda Guerra Mondiale, sono d’accordo che per molte aziende – non per tutte – l’ingegneria del software si sia evoluta. Essa si definisce come un processo incentrato sulle persone, o un processo interpretativo. Sono d’accordo. L’industria del software non riguarda solo le tecnologie dure e di base. Sebbene alcune posizioni richiedano competenze tecniche quantitative straordinarie, la maggior parte dell’industria del software si percepisce come avente un approccio orientato alle persone, una cultura condivisa.
In larga misura, credo che il predominio che gli Stati Uniti e la Silicon Valley esercitino sul software in tutto il mondo sia dovuto alla difficoltà di replicare la loro cultura. La cultura tende ad essere molto intangibile e difficile da documentare. Quando la documenti, domi l’ingrediente caotico necessario per l’innovazione. Se documenti la cultura, la organizzi e la processi, improvvisamente perdi quell’aspetto dell’emergere grezzo e caotico di idee e innovazioni.
Esistono luoghi come la Silicon Valley in cui questa cultura è prevalente, e in questo senso sono avanti rispetto ai tempi. Per concludere su questo argomento, vorrei citare William Gibson, che disse, “Il futuro è già qui; non è soltanto distribuito in maniera uniforme.” Osservo che questa cultura ora viene replicata su scale molto più piccole in molti altri luoghi, e il processo continuerà e crescerà nel tempo.
Questo è tutto per oggi. A presto. Nella nostra prossima sessione, discuteremo un argomento che può essere abbastanza deprimente ma è molto importante: la cybersecurity. A presto!


