00:15 Introduzione
02:28 Frigorifero Intelligente
05:28 Bias di sopravvivenza
07:28 La storia finora
08:46 Sui Tabù (ripasso)
12:06 Euristiche di rifiuto (ripasso)
13:34 Conoscenza positiva di bassa qualità
15:27 Antipatterns del Software, 1/2
20:11 Antipatterns del Software, 2/2
25:34 Antipatterns della Supply Chain
27:00 Previsioni Nude
32:36 Il livello di servizio al 100%
37:06 L’iniziazione Jedi
44:31 L’Orrore Non Euclideo
51:45 Avvocato del diavolo
57:35 Ripasso, conoscenza negativa per la supply chain
01:01:04 Conclusione
01:02:45 Prossima lezione e domande dal pubblico
Descrizione
Antipatterns sono gli stereotipi di soluzioni che sembrano buone ma non funzionano in pratica. Lo studio sistematico degli antipatterns è stato avviato alla fine degli anni ‘90 dal campo dell’ingegneria del software. Quando applicabili, gli antipatterns sono superiori ai risultati negativi grezzi, poiché sono più facili da memorizzare e analizzare. La prospettiva degli antipatterns è di primaria importanza per la supply chain, e dovrebbe essere considerata come uno dei pilastri della sua conoscenza negativa.
Trascrizione completa

Ciao a tutti, benvenuti in questa serie di lezioni sulla supply chain. Sono Joannes Vermorel, e oggi presenterò la conoscenza negativa nella supply chain. Per coloro che stanno guardando la lezione in diretta, potete porre domande in qualsiasi momento tramite la chat di YouTube. Non leggerò la chat durante la lezione; tuttavia, tornerò a consultarla alla fine della lezione per la sessione di Q&A.
Oggi, l’argomento di interesse è ciò che un’azienda guadagna veramente quando assume un direttore della supply chain esperto, con forse due o tre decenni di esperienza. Cosa cerca realmente l’azienda, e potremmo, in misura marginale, replicare l’acquisizione di questa esperienza in un tempo molto più breve? Questo è esattamente il significato della conoscenza negativa.
Quando osserviamo una persona molto esperta, che ha lavorato per due decenni in un determinato campo, stiamo davvero cercando che questa persona replichi soluzioni, processi o tecnologie che ha implementato uno o due decenni fa in altre aziende? Probabilmente no. Anche se potrebbe accadere marginalmente, sospetto che, di solito, questa sia una ragione molto marginale.
Quando cerchi una persona molto esperta, l’obiettivo non è necessariamente replicare ciò che è stato fatto in passato. Il valore chiave che desideri acquisire è avere al tuo fianco qualcuno che sappia come evitare ogni sorta di errore e che abbia l’esperienza necessaria per assicurarsi che non vengano implementate nella tua azienda numerose idee naïve e sbagliate. C’è un detto che in teoria la pratica e la teoria sono la stessa cosa, ma in pratica non lo sono. Questo è esattamente il nodo centrale della conoscenza negativa.
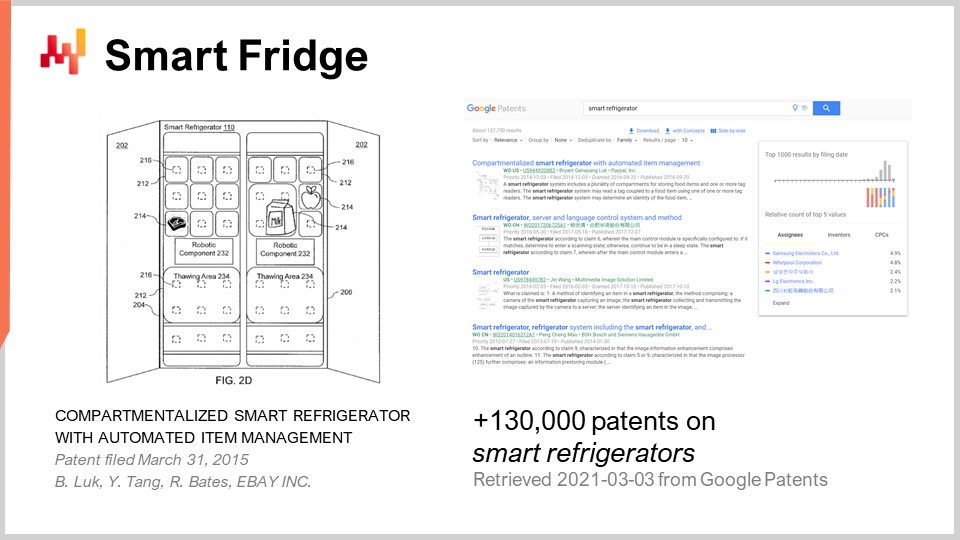
La mia proposta per voi è che le cattive idee imprenditoriali sono ovunque. Quando dico cattive, intendo idee che, se implementate, risulterebbero completamente non redditizie per l’azienda. Per illustrarlo, ho appena inserito la query “frigoriferi intelligenti” nel motore di ricerca di Google Patents. Google Patents è un motore di ricerca specializzato fornito da Google, e permette di ricercare in un database di brevetti. Ed ecco, otteniamo 130.000 risultati di brevetti depositati sui frigoriferi intelligenti.
Considerate questo numero con le dovute cautele, poiché probabilmente ci sono molti duplicati. Tuttavia, un’ispezione sommaria dei risultati indica chiaramente che abbiamo diverse centinaia, se non migliaia, di aziende che, negli ultimi decenni, si sono adoperate per fare ricerca e sviluppo al fine di depositare un brevetto sui frigoriferi intelligenti. Quando osservate le tipologie di idee contenute in quei brevetti, vedrete che si tratta sempre di prendere questo elettrodomestico così diffuso, un frigorifero, e aggiungere qualcosa, come ad esempio elettronica a basso costo. Unendo i due elementi, voilà, abbiamo una soluzione di qualche tipo.
Per quale tipo di problema, però? È molto poco chiaro. Basta dare un’idea generale della maggior parte dei brevetti: si tratta di un’idea in cui, se possedete un frigorifero dotato di qualche tipo di sensori, il frigorifero stesso rileverà se vi state esaurendo il latte e provvederà automaticamente a effettuare un riapprovvigionamento. Siamo nel 2021 e, per quanto ne so, i frigoriferi intelligenti non esistono. Non è che non siano tecnicamente fattibili – lo sono molto. È solo che, letteralmente, non c’è alcun mercato per essi. Quindi, abbiamo una quantità enorme di soluzioni sul mercato alla ricerca di un problema. Negli ultimi due decenni, credo di aver assistito, in media, a due volte l’anno, a una startup che promuoveva un frigorifero intelligente di un certo tipo. Curiosamente, non ho mai ricevuto riscontri da nessuna di quelle startup. Non ho tenuto veramente traccia, ma sospetto fortemente che ogni singola startup che ho visto promuovere un frigorifero intelligente negli ultimi due decenni abbia fallito. Tuttavia, mentre l’idea è molto diffusa e popolare, come dimostrato da quei migliaia di brevetti, le conseguenze di quelle idee, cattive perché probabilmente la maggior parte di quelle startup è andata semplicemente in bancarotta, non si è propagata.
Qui, osserviamo qualcosa di molto interessante: attraverso l’esperienza, si può accedere a una sorta di conoscenza che non è facilmente accessibile agli osservatori del mercato. Si può vedere il lato oscuro, ovvero quelle cose che mancano, quel tipo di elementi che erano stati promessi e divulgati, ma che non si sono rivelati particolarmente di successo.

Vi è un esempio storico molto notevole dalla Seconda Guerra Mondiale. L’esercito statunitense ha condotto un’indagine sugli aerei che tornavano alla base per raccogliere la distribuzione degli impatti dei proiettili sugli aerei. Quello che vedete sullo schermo è sostanzialmente la raccolta delle posizioni dei proiettili osservate sugli aerei in ritorno dai campi di battaglia verso la base. Inizialmente, gli ufficiali dell’esercito seguivano il ragionamento secondo cui era necessario aggiungere piastre corazzate nelle aree maggiormente colpite, le zone che erano chiaramente sottoposte al maggior fuoco durante la battaglia.
Poi, un altro signore, Abraham Wald, disse di no, perché è esattamente il contrario. Il punto è che ciò che vedete sono gli aerei che sono riusciti a tornare alla base. Quello che non vedete è che, in tutte le aree in cui non si osservano impatti di proiettili, molto probabilmente, ogni volta che c’era un impatto in quella zona, l’effetto risultava letale sia per l’aereo che per l’equipaggio, o per entrambi. Quindi, se dovete aggiungere delle piastre corazzate, dovete farlo esattamente in tutte le aree in cui non vedete aerei tornare alla base con impatti di proiettili. Queste sono le aree che necessitano di protezione.
Ciò che Abraham ha evidenziato è che esisteva un fenomeno noto come bias di sopravvivenza, in cui ciò che osservate sono essenzialmente i sopravvissuti, non tutti gli aerei che non sono riusciti a tornare alla base. L’idea della conoscenza negativa è esattamente questa: prendete questa fotografia e il negativo, e sono le parti rimanenti a dover catturare davvero la vostra attenzione, perché è lì che accadono le cose veramente negative. Questa è, direi, l’essenza della conoscenza negativa.
Questa è la quarta lezione della mia serie di lezioni, e la prima lezione del secondo capitolo. Nel primo capitolo del prologo, ho presentato le mie opinioni sulla supply chain, sia come campo di studio che nella pratica. Ciò che abbiamo visto è che la supply chain è sostanzialmente un insieme di problemi complessi (wicked problems), in contrapposizione a problemi più semplici. I wicked problems sono molto difficili da affrontare perché non si prestano né a studi facili né a una pratica semplice. C’è fondamentalmente qualcosa di avverso, sia in termini di studio che di pratica, nei wicked problems. Ecco perché il secondo capitolo è dedicato alle metodologie.
In questa lezione presente, adottiamo un approccio qualitativo, proprio come abbiamo fatto con la persona della supply chain, che è stata la primissima lezione di questo capitolo. Espanderemo il tipo di approcci qualitativi che possiamo utilizzare per apportare miglioramenti alla supply chain in modi controllati, affidabili e potenzialmente misurabili.

Ripasso: Sebbene questa lezione sia dedicata alla conoscenza negativa, non è la prima volta in questa serie di lezioni in cui tocco elementi che potrebbero essere qualificati come frammenti di conoscenza negativa. Durante la prima lezione di questo secondo capitolo sulle persona della supply chain, ho presentato le mie opinioni sui case study. Ho detto che i case study positivi, cioè quelli che presentano risultati positivi associati a una soluzione di interesse, sono accompagnati da conflitti di interesse massicci che minano completamente la fiducia nella validità dei risultati. D’altra parte, ho affermato che i case study negativi vanno benissimo, perché quei conflitti di interesse, sebbene possano essere presenti, sono molto meno intensi.
In questa lezione sulle persona della supply chain, ho presentato un fantastico case study negativo, “The Last Days of Target Canada” di Joe Castaldo, che descriveva un fallimento epico della supply chain che alla fine ha portato al fallimento di Target Canada. Si tratta di una sorta di conoscenza negativa, in cui l’oggetto di studio è letteralmente ciò che non ha funzionato, contrapposto a ciò che possiamo fare per ottenere qualcosa che funzioni davvero.
Ora, potremmo utilizzare i case study negativi come pratica fondamentale per la nostra conoscenza negativa della supply chain? Direi per lo più no, per due ragioni ben distinte. La prima ragione è semplicemente che i case study negativi sono estremamente rari. Suppongo, solo a titolo indicativo, che in realtà ci siano oltre 100 volte più brevetti sui frigoriferi intelligenti, che sono completamente inutili, rispetto ai case study negativi sulla supply chain. Quindi, abbiamo un problema molto pratico: sebbene quei case study negativi siano di primaria importanza e di altissimo interesse scientifico, capita semplicemente che siano estremamente rari. Ne abbiamo così pochi che è molto difficile avere questo materiale come base della nostra conoscenza negativa della supply chain.
Il secondo problema è l’intelligibilità. Quelli case study negativi, come il fantastico articolo “The Last Days of Target Canada”, dimostrano che ci sono decine di problemi in atto contemporaneamente, e tutti quei problemi sono completamente intrecciati per portare infine a un fallimento epico. Il punto è che quei case study rappresentano letteralmente la vita reale in azione, e quegli eventi sono molto complessi. È difficile comunicare e ragionare su quei case study perché i dettagli contano, e sono molto densi. C’è anche un problema più banale: come si comunica questo a un pubblico più ampio?

Nell’ultima lezione sull’ottimizzazione sperimentale, abbiamo visto anche un altro tipo di conoscenza negativa: le euristiche di rifiuto. Questi erano fondamentalmente trucchi semplici che possono essere utilizzati quando viene proposta una soluzione quantitativa come potenziale candidato per il miglioramento della supply chain. È possibile utilizzare una serie di euristiche o regole semplici per scartare soluzioni che, con un altissimo grado di certezza, semplicemente non funzioneranno. Tuttavia, qui abbiamo un problema di scalabilità. Queste euristiche funzionano solo perché sono oscure. Se dovessero diventare ben note tra i circoli della supply chain, sia i articoli scientifici che il software per la supply chain si adatterebbero e cambierebbero il loro discorso, rendendo la situazione più confusa. Quelle euristiche sono molto efficienti, ma se dovessero diventare popolari, conserverebbero comunque la loro validità, ma perderebbero la loro efficienza come filtri, semplicemente perché le persone presterebbero attenzione per aggirarle.
Ecco perché queste euristiche, sebbene molto interessanti, non possono essere utilizzate come fondamenta per la nostra conoscenza negativa che vogliamo costituire per la supply chain.

Inoltre, non dovremmo confondere la conoscenza negativa con la conoscenza positiva di bassa qualità. La differenza è veramente una questione di intento. Ad esempio, l’intento delle scorte di sicurezza è quello di fornire alle aziende un modo controllato per gestire la qualità del servizio che otterranno. L’intento è positivo; è una soluzione per qualcosa che dovrebbe funzionare. Ora, la realtà è che il modello delle scorte di sicurezza si basa su presupposti completamente abusivi: la domanda futura e i lead time si presume siano distribuiti normalmente, anche se questi presupposti sono di fatto errati. Non ho mai osservato nei dataset della supply chain che la domanda o i lead time fossero distribuiti normalmente. Le distribuzioni di interesse sono in realtà distribuite secondo Zipf, come ho spiegato nelle mie lezioni precedenti sui principi quantitativi per la supply chain. Da una prospettiva corretta, la scorta di sicurezza risulta falsificata, ma comunque, essa è sicuramente ancorata nel regno della conoscenza positiva, sebbene si possa sostenere che sia una conoscenza positiva di bassa qualità.
Durante questa lezione, non avremo il tempo di approfondire tutti gli elementi che, secondo me, possono essere qualificati come conoscenza positiva di bassa qualità, ma sarei felice di accontentare se qualcuno volesse farmi domande su uno qualsiasi di questi elementi durante la sessione di Q&A.

Quando si tratta di conoscere in modo negativo elementi di interesse pratico, esiste un libro intitolato “Anti-Patterns: Refactoring Software, Architectures, and Projects in Crisis” che rappresenta una pietra miliare nella storia dell’ingegneria del software. Pubblicato nel 1998, questo libro inizia con l’osservazione casuale che, nell’industria del software, quando ci sono buone idee e progetti che ne traggono vantaggio, i fornitori di software vedono le buone idee essere assorbite dal successo del progetto. Gli autori si chiedono se una buona idea rimanga una buona pratica dopo l’implementazione del prodotto, e la risposta è sostanzialmente no. Esiste un vantaggio da first-mover molto specifico per l’industria del software e, di conseguenza, abbiamo un problema. Praticamente ogni insieme di regole che si potrebbe usare per prevedere il successo di qualsiasi cosa nell’industria del software si auto-sconfigge, poiché i migliori approcci tendono a essere assorbiti dal successo che generano. Gli autori di “Anti-Patterns” hanno notato che, a loro avviso, è quasi impossibile garantire il successo di un’iniziativa software. Tuttavia, hanno anche osservato che la situazione è molto asimmetrica quando si tratta di fallimenti. Hanno sottolineato che è possibile prevedere, con un grado molto elevato di confidenza (a volte quasi con certezza), che un determinato progetto stia per fallire. Questo è molto interessante perché non si può garantire il successo, ma si può avere qualcosa di simile a una scienza che garantisce il fallimento. Ancora meglio, questa conoscenza degli elementi che garantiscono il fallimento sembra essere estremamente stabile nel tempo e largamente indipendente dalle specificità tecniche dell’azienda o del settore considerato.
Se torniamo all’idea iniziale del frigorifero intelligente, possiamo vedere che tutti quei brevetti sul frigorifero intelligente sono incredibilmente diversificati nelle soluzioni che propongono. Ma si scopre che tutti quei brevetti conducono a fallimenti aziendali perché rientrano tutti nello stesso ombrello: una soluzione in cerca di un problema. La combinazione di un elettrodomestico onnipresente con elettronica a basso costo crea una soluzione, ma è davvero qualcosa che abbia senso? In questo caso, quasi mai.
Gli autori di “Anti-Patterns” hanno iniziato il loro percorso studiando le cause profonde dei fallimenti software e hanno identificato i sette peccati capitali dell’ingegneria del software, ovvero: fretta, apatia, mentalità ristretta, avarizia, ignoranza, orgoglio e invidia. Questi problemi sono indipendenti dal contesto e dalle tecnologie coinvolte perché sono invarianti della natura umana stessa. Quando si cerca un supply chain director con due decenni di esperienza, si tratta di qualcuno che ha semplicemente vissuto più a lungo e ha interiorizzato la maggior parte dei problemi che sorgono quando sono coinvolti esseri umani veri, con ogni sorta di difetti.
L’idea degli autori è che sia utile formalizzare questa conoscenza per renderla più digeribile e comprensibile, in modo da facilitare la comunicazione e il ragionamento su questi problemi. Questa è l’essenza degli anti-pattern – un formato per catturare frammenti di conoscenza negativa.

Nel loro libro, gli autori presentano un modello per un anti-pattern, che inizia con un nome accattivante facile da memorizzare. È necessario caratterizzare la scala, che si tratti del livello del codice sorgente, del livello dell’architettura del software, del livello aziendale o di quello dell’industria. Bisogna identificare le vere cause radice e le conseguenze che tipicamente vi sono associate. Occorre caratterizzare le forze in gioco, i sintomi e le conseguenze non intenzionali che le persone non si aspettano, e che minano completamente i benefici attesi della soluzione iniziale.
Gli autori sostengono che bisogna presentare prove aneddotiche, ed è per questo che utilizzano aziende fittizie nei loro anti-pattern. Ciò è fatto per evitare i tabù legati al discutere di aziende e persone reali, che potrebbero impedire l’instaurarsi di una comunicazione onesta. Il modello dell’anti-pattern deve concludersi con una soluzione rifattorizzata, un percorso per trasformare quella che è essenzialmente una soluzione mal indirizzata in una variante che funzioni davvero nel mondo reale, dove le conseguenze non intenzionali vengono mitigate e, idealmente, eliminate.
Questa lezione non riguarda gli anti-pattern della supply chain, ma è solo per fornire due esempi di anti-pattern software di cui probabilmente avete sentito parlare; il primo è il Golden Hammer. Il Golden Hammer è l’idea che, quando hai un martello d’oro in mano, tutto il resto è un chiodo. Questo anti-pattern sostanzialmente afferma che se si chiede a un programmatore Java come affronterebbe un nuovo problema, è probabile che suggerisca di scrivere un programma in Java per risolverlo. Se si presenta un altro problema alla stessa persona, anche lei dirà che quell’altro problema potrebbe essere risolto con un programma Java. Se si presentano venti problemi differenti, ogni volta la risposta sarà: “Ritengo che un programma Java andrebbe benissimo.” Si tratta di un enorme bias in cui le persone con esperienza in una determinata tecnologia tendono a riciclare le loro conoscenze tecniche per risolvere nuovi problemi, invece di prendersi il tempo per valutare se le proprie conoscenze siano effettivamente rilevanti dal punto di vista tecnico per affrontare il nuovo problema. È molto più facile, dal punto di vista intellettuale, affidarsi semplicemente a ciò che si conosce.
Un altro esempio è l’Analysis Paralysis. Nel mondo del software, ci sono molte situazioni in cui le possibilità sono infinite, ed è allettante dire: “Invece di sperimentare 20 approcci diversi destinati a fallire, riflettiamo intensamente sul design, e una volta assolutamente certi di avere la soluzione giusta in mente, procederemo con l’implementazione.” Purtroppo, questo è estremamente difficile da realizzare e solitamente porta a una paralisi da analisi, in cui si sprecano tempo e sforzi nel considerare innumerevoli opzioni potenziali anziché provare una soluzione e vedere se funziona o meno.

Ora, ovviamente, abbiamo discusso che questo libro trattava di anti-pattern software, e credo che l’ingegneria del software presenti molte similitudini con i problemi che affrontiamo nella supply chain, in particolare nell’ottimizzazione della supply chain. Entrambi i campi sono essenzialmente insiemi di problemi complessi, e la supply chain moderna riguarda in gran parte la consegna di un prodotto software. Quindi, esiste un certo grado di sovrapposizione tra i problemi della supply chain e quelli dell’ingegneria del software, ma questi due campi non sono affatto a anni luce di distanza.
Qui presenterò cinque anti-pattern della supply chain, che si possono trovare in forma scritta sul sito di Lokad, con una presentazione più estesa disponibile per chi è interessato.

Il primo è Naked Forecast. Ispirato alla fiaba “Il vestito nuovo dell’imperatore” di Hans Christian Andersen, il contesto è quello di un’azienda con un’iniziativa in corso per migliorare la accuratezza delle previsioni. Alcuni sintomi includono previsioni consolidate di lungo periodo su cui tutti si lamentano — produzione, marketing, vendite, acquisti e persino la supply chain, dove la divisione previsioni tipicamente rientra nella supply chain. Sono stati fatti tentativi per migliorare l’accuratezza delle previsioni negli ultimi uno o due decenni, ma sembra che, per quanto sforzati, non manchi mai una serie infinita di scuse da parte dei responsabili delle previsioni per giustificarne la scarsa accuratezza.
Il fatto è che c’è questa nuova iniziativa in cui l’intento è quello di sistemare l’accuratezza delle previsioni, per risolvere una volta per tutte il problema delle previsioni imprecise. Questo è l’anti-pattern Naked Forecast in azione. Le conseguenze non intenzionali di ciò sono, innanzitutto, che non si otterranno previsioni significativamente più accurate. In secondo luogo, intraprendere un’altra iniziativa creerà un’organizzazione ancora più bizantina, in cui ciò che era iniziato come una piccola pratica per fornire le previsioni diventa via via più complesso, con sempre più persone coinvolte nella loro produzione. Col tempo, si finisce con qualcosa che resta impreciso come sempre, ma che è passato dall’essere modesto e impreciso a una grande burocrazia che continua ad esserlo.
Credo che la causa principale qui sia ciò che definisco razionalismo ingenuo o l’illusione della scienza. Quando questa iniziativa inizia, il problema si presenta come se fosse perfettamente oggettivo: “Produrremo previsioni più accurate secondo una metrica, diciamo l’errore assoluto medio.” L’intera faccenda sembra molto semplice, con un problema ben definito. Tuttavia, il problema è che tutto ciò è molto ingenuo perché non esiste una correlazione diretta tra l’accuratezza delle previsioni e la redditività dell’azienda. Quello che si dovrebbe cercare sono modi per migliorare la redditività dell’azienda, quindi si dovrebbe pensare in termini di dollari o euro di errore, non in percentuali.
Fondamentalmente, la causa principale è che queste previsioni sono autonome e non ricevono alcun feedback dall’attività aziendale reale. L’accuratezza delle previsioni è solo un artefatto numerico; non rappresenta un ritorno reale e tangibile sull’investimento per l’azienda. A titolo aneddotico, se avessi ricevuto un assegno extra di mille dollari ogni volta che ho avuto una conversazione telefonica con un supply chain director che mi diceva che stavano avviando una nuova iniziativa per migliorare l’accuratezza delle previsioni, sarei diventato ancora più ricco.
La conclusione è che, per quanto riguarda la soluzione rifattorizzata, fintanto che le previsioni rimangono naked, non funzioneranno. Bisogna vestirle, e quel vestiario sono le decisioni. Come abbiamo esaminato nella lezione precedente sull’ottimizzazione sperimentale, se le previsioni non sono direttamente collegate a decisioni reali e tangibili, come quanto acquistare, quanto produrre o se alzare o abbassare i prezzi, non si ottiene mai il vero feedback che conta. Il vero feedback che conta non è il KPI del back-test sulla misurazione; ciò che conta sono quelle decisioni. Pertanto, per quanto riguarda la soluzione rifattorizzata per affrontare l’anti-pattern Naked Forecast, si tratta fondamentalmente di decidere che le stesse persone che generano la previsione debbano convivere con le conseguenze di quelle previsioni per quanto riguarda le supply chain decisions effettivamente implementate.

Il secondo è il Mitico Service Level. La situazione inizia generalmente così: il consiglio di amministrazione si riunisce e, da qualche parte sulla stampa o sui social network, alcune persone si lamentano ad alta voce della qualità del servizio. La situazione non appare favorevole per l’azienda, poiché sembra che essa non stia mantenendo le promesse fatte. Il consiglio esercita un’enorme pressione sul CEO affinché faccia qualcosa per risolvere questo problema di qualità del servizio, che sta impattando negativamente il marchio, l’immagine e potenzialmente la crescita dell’azienda. Il CEO dice: “Dobbiamo davvero porre fine a questa serie infinita di problemi di qualità del servizio.” Così, il CEO si rivolge al VP of Supply Chain e gli chiede di risolvere questi problemi. Il VP of Supply Chain, a sua volta, chiede al supply chain director di fare lo stesso, e quest’ultimo chiede al supply chain manager di affrontare il problema. Il supply chain manager poi innalza il livello di servizio a un valore molto alto, vicino al 100%.
Ebbene, anche se a breve termine si ottengono livelli di servizio marginalmente più elevati, molto presto i problemi di qualità del servizio ritornano. Questi livelli superiori non sono sostenibili, e si finisce per avere fluttuazioni dell’inventario, inventario sprecato e, nonostante l’intento fosse quello di aumentare il livello di servizio, frequentemente, dopo sei o dodici mesi, il livello di servizio viene abbassato.
La causa principale qui non è solo l’ignoranza, ma anche il pensiero desideroso. Matematicamente parlando, se si desidera un service level al 100%, ciò implica una quantità infinita di inventario, cosa tecnicamente impossibile. Si instaura questo potente pensiero desideroso che si possa risolvere completamente il problema, sebbene non sia possibile. Al massimo, si possono mitigare i problemi di qualità del servizio; non è possibile eliminarli del tutto.
A titolo aneddotico, ho notato che molte aziende incontrano maggiori difficoltà perché adottano questa mentalità dell’obiettivo mitico del service level al 100%. Se la tua azienda non è disposta ad accettare che, per alcuni prodotti (non per tutti o per i più importanti), i livelli di servizio vengano deliberatamente abbassati, allora ti stai dirigendo verso seri problemi. L’unico modo per migliorare veramente la qualità del servizio è, innanzitutto, accettare che se l’attenzione è su tutto, è come se l’attenzione fosse su nulla. Finché non sarai pronto ad accettare che, per alcuni SKUs, un livello di servizio inferiore venga considerato un risultato accettabile, non sarai in grado di migliorare la qualità complessiva del servizio.
Per quanto riguarda le soluzioni rifattorizzate, la soluzione è rappresentata dai driver economici. È un punto che ho presentato nella seconda lezione del primissimo capitolo, la visione per la quantitative supply chain. I driver economici mostrano che esistono il costo degli stockouts e il costo di gestione del magazzino, e bisogna trovare un equilibrio. Non si può semplicemente puntare a un service level del 100% perché è completamente sbilanciato da un punto di vista economico; non è sostenibile. Tentare di spingere in quella direzione risulta molto mal indirizzato, in quanto finirà solo per danneggiare l’azienda. La soluzione è iniettare una sana dose di driver economici nella pratica della supply chain.

Ora, il terzo anti-pattern, Jedi Initiation, si osserva quando il top management di molte grandi aziende è sotto costante pressione da parte dei media a causa del flusso continuo di parole d’ordine. Queste parole d’ordine includono intelligenza artificiale, blockchain, cloud computing, big data, IoT, ecc. Gli influencer affermano che se la loro azienda non si adatta a queste tendenze, diventerà obsoleta. Esiste una costante paura di restare indietro, che agisce come una forza potente, esercitando una pressione costante sul top management della maggior parte delle grandi aziende che gestiscono grandi supply chain.
I sintomi dell’Iniziazione Jedi possono essere osservati se la tua azienda ha una divisione con ingegneri giovani ed entusiasti che sfoggiano parole d’ordine nei loro titoli, come ricercatori di intelligenza artificiale, ingegneri blockchain, o data scientists. Il motto è “dominare la forza”, dove la forza rappresenta la parola d’ordine di interesse in quel preciso momento. La direzione prende persone, probabilmente giovani o inesperte, e dice loro di fare qualcosa di grandioso per l’azienda, pur non essendo direttamente coinvolta o a conoscenza degli aspetti tecnici di questi concetti.
Ciò che accade è che questi team creano prototipi interessanti che, alla fine, non riescono a fornire un valore reale per l’azienda. Di conseguenza, anche se tutto è iniziato con l’idea che l’azienda sarebbe stata rivoluzionata in base alla parola d’ordine del momento, le pratiche e la tecnologia legacy rimangono predominanti, inalterate dalla parola d’ordine o dal team supplementare creato attorno ad essa.
In termini di prove aneddotiche, al giorno d’oggi, nel 2021, la stragrande maggioranza delle aziende con un team di data science ottiene esattamente zero ritorni sul proprio investimento. Il team di data science crea sofisticati prototipi in Python utilizzando librerie open-source davvero interessanti, ma in termini di ritorno pratico sull’investimento per la maggior parte del mercato, il risultato è esattamente zero. Ed è proprio questo il tipo di Iniziazione Jedi in cui la direzione superiore inciampa: leggono sulla stampa che la data science è la nuova tendenza, così assumono un team di data science. Come ulteriore prova aneddotica, noto che questi team non sono solo piuttosto giovani ed inesperti, ma rimangono tali nel tempo. Ciò è dovuto al turnover estremamente elevato. Puoi avere un’azienda solida e robusta, con un turnover medio tipico di cinque o dieci anni, tranne che per il team di data science, dove le persone rimangono in media per 18 mesi. Uno dei motivi per cui non esce nulla di valore da questi team è che le persone entrano, realizzano qualche prototipo e poi se ne vanno. Per l’azienda non c’è alcuna capitalizzazione, e non si riesce mai veramente a trasformare l’azienda.
Per quanto riguarda la ristrutturazione di questa soluzione, innanzitutto, non c’è altra via se non fare da esempio. Se vuoi davvero praticare la data science, la direzione superiore deve essere estremamente competente in materia. Ad esempio, Jeff Bezos ha dimostrato di conoscere le tecniche di machine learning all’avanguardia del suo tempo. Amazon può ottenere un enorme successo grazie al machine learning, ma ciò accade perché la direzione superiore conosce nei minimi dettagli ogni particolare. Dare l’esempio è essenziale.
In secondo luogo, devi assicurarti che, quando assumi questi giovani ingegneri entusiasti e potenzialmente talentuosi, li metti di fronte a problemi reali, non a problemi meta. Devono essere connessi alla realtà. Questo richiama la mia lezione precedente sull’ottimizzazione empirica e sperimentale. Se assumi un data scientist per effettuare la segmentazione dei clienti o per una migliore ABC analysis per la tua azienda, questi non sono problemi reali. Sono solo numeri inventati. Se assumi queste persone e le incarichi dell’approvvigionamento reale, affidando loro la responsabilità delle quantità esatte da reintegrare da una serie di fornitori, allora il problema diventa concreto. Questo è il motivo per cui, un decennio fa, Lokad ha effettuato il passaggio interno dai data scientist ai Supply Chain Scientist.

L’orrore non euclideo. In questo contesto, hai un’azienda che opera una grande supply chain, e il panorama IT è estremamente complesso. Esistono diversi componenti di software enterprise, come ERP, WMS e EDI, che sono di per sé complessi. Poi c’è tutta la “colla” che li unisce, e l’insieme risulta sbalorditivamente complesso. Allora, come fai a sapere se ti trovi veramente in un’azienda che deve affrontare una soluzione non acclimatata? Quali sono i sintomi? I sintomi sono che tutti in azienda percepiscono una dilagante incompetenza nella divisione IT. Le persone dell’IT appaiono sopraffatte e sembrano non capire cosa stia succedendo nel sistema che dovrebbero gestire e far funzionare. Un altro sintomo è la presenza quotidiana di problemi IT che impattano la produzione. Questi sono i sintomi chiave della soluzione non acclimatata.
La conseguenza di avere un panorama IT non acclimatato è che i cambiamenti da apportare all’azienda – e solitamente, quando c’è un cambiamento in azienda, ciò comporta anche un cambiamento dei sistemi IT – avvengono molto lentamente. Le moderne supply chain sono fortemente guidate dai loro componenti software. Tutti questi cambiamenti avvengono a rilento, ed è sempre un processo faticoso in cui anche piccole modifiche sembrano durare un’eternità. Ogni volta che si introduce un cambiamento, di solito ne seguono innumerevoli regressioni. Come si dice, fai due passi avanti e tre indietro, poi due passi avanti e uno indietro. Il cambiamento non è solo lento, ma è accompagnato da un costante flusso di regressioni. La situazione non migliora realmente nel tempo; al massimo, stagna.
Per quanto riguarda le cause alla radice, la direzione non si preoccupa davvero dei dettagli, e il management non tecnico non dà molta importanza a tutti quei sistemi IT. Ciò genera un approccio che io chiamo incrementalismo, in cui qualunque cambiamento si voglia apportare al sistema IT dell’azienda viene richiesto, ad esempio, dalle supply chain. Ogni volta che è necessario un cambiamento, la direzione dirà sempre: “Si prega di scegliere il percorso più semplice, quello che richiede il minimo sforzo e tempo, in modo da implementarlo il più rapidamente possibile.” Questo è l’essenza dell’incrementalismo.
Credo che l’incrementalismo sia una causa alla radice estremamente pericolosa. Il problema dell’incrementalismo è che equivale letteralmente a una morte a mille tagli. Ogni singola modifica apportata al sistema lo rende un po’ più complesso, un po’ più difficile da gestire e un po’ più arduo da testare. Sebbene ogni singola modifica, presa singolarmente, sia insignificante, l’accumularsi, nel corso di un decennio, di decine di modifiche apportate quotidianamente ai sistemi IT, porta a un oceano di complessità. Ogni cambiamento ha reso il sistema più complesso, e il quadro generale risulta completamente perduto. Avanzando di un decennio, ci si ritrova con un sistema enorme e contorto che sembra fuori di testa.
Come ulteriore prova aneddotica, si può osservare che esistono ancora grandi aziende di e-commerce dove, in quanto consumatore, noti abitualmente periodi di inattività. Queste situazioni non dovrebbero mai verificarsi. Come azienda di e-commerce nel 2021, il tuo uptime dovrebbe garantire al massimo 10 minuti di inattività all’anno. Ogni singolo secondo di inattività rappresenta un’opportunità sprecata. Progettare un software per i carrelli della spesa nel 2021 non è più una scienza missilistica; è, anzi, un software molto basico per quanto riguarda il software enterprise. Non c’è motivo di non avere un sistema sempre attivo. Tuttavia, la realtà è che quando vedi un e-commerce andare in down, di solito non è il carrello a fallire, ma una soluzione non acclimatata che si trova proprio dietro l’e-commerce. Il fatto che l’e-commerce vada in down è solo il riflesso di un problema avvenuto da qualche parte nel panorama IT.
Se vogliamo ristrutturare la soluzione non acclimatata, dobbiamo smettere di cercare la soluzione più facile per apportare cambiamenti. Dobbiamo pensare non a una soluzione facile, ma a una soluzione semplice. Una soluzione semplice si differenzia da quella facile in un aspetto cruciale: rende l’intero panorama un pochino più ordinato e sensato, facilitando l’implementazione di ulteriori cambiamenti in seguito. Potresti dire, “Ma è solo una questione puramente tecnica, quindi questo è compito dell’IT.” Io risponderei: no, assolutamente no. È decisamente un problema di supply chain. Adottare una soluzione semplice non significa avere una soluzione semplice dal punto di vista IT; significa avere una soluzione semplice da una prospettiva di supply chain.
La semplicità della soluzione, e la sua conseguenza voluta di rendere più facili da implementare i cambiamenti successivi, dipende dalla tua roadmap. Che tipo di cambiamenti futuri vuoi apportare al tuo panorama IT? L’IT, in quanto divisione, non ha il tempo di diventare esperto di supply chain e di sapere esattamente dove intendi dirigere l’azienda, a distanza di un decennio, in termini di esecuzione della supply chain. Spetta al management della supply chain avere questa visione e guidare lo sviluppo, eventualmente con il supporto dell’IT, in una direzione in cui i cambiamenti diventino via via più semplici da implementare.

Infine, come ultimo anti-pattern per oggi, l’avvocato del diavolo. Il contesto è tipicamente quello di una grande azienda che ha affrontato significativi problemi di supply chain e ha deciso di affidarsi a un grande fornitore, mettendo in gioco una notevole quantità di denaro. L’iniziativa viene avviata e, pochi mesi dopo – tipicamente circa sei mesi – il fornitore ha pochissimo da mostrare. È stata spesa una grossa somma a favore del fornitore, con risultati scarsi. A proposito, nel 2021 sei mesi rappresentano molto tempo. Se hai un’iniziativa software che non produce risultati tangibili e di livello produttivo entro sei mesi, dovresti essere molto preoccupato perché, secondo la mia esperienza, se non riesci a ottenere risultati concreti in sei mesi, è probabile che l’iniziativa sia condannata e non genererà mai un ROI positivo per l’azienda.
Quello che accade è che la direzione osserva il progetto subire ritardi, e c’è pochissimo da mostrare. La direzione superiore, invece di diventare sempre più aggressiva nei confronti del fornitore tecnologico e di mettersi in prima linea contro di lui, improvvisamente cambia schieramento e si mostra molto difensiva nei suoi confronti. Questo è davvero sconcertante. Inizi un’iniziativa importante, destini una grossa somma di denaro a un’altra azienda, e l’iniziativa procede, seppur male, con disponibili risultati scarsi. Invece di ammettere chiaramente che l’iniziativa sta fallendo, la direzione raddoppia gli sforzi e inizia a difendere il fornitore, cosa estremamente strana. È come se operasse una sorta di Sindrome di Stoccolma, in cui, nonostante qualcuno ti faccia del male, se il danno arrecato è sufficiente, a un certo punto inizi ad apprezzare quella persona.
La direzione e l’iniziativa stessa diventano troppo grandi per fallire, e di conseguenza si spreca una quantità enorme di denaro e si perdono innumerevoli opportunità, soprattutto in termini di tempo. Mentre l’iniziativa procede, si perdono soldi, ma, cosa ancor più importante, si perde tempo – sei mesi, un anno, due anni. Il vero costo è il tempo. A titolo di prova aneddotica, è possibile leggere molto spesso sulla stampa di fallimenti epici nell’implementazione di ERP per progetti che durano quasi un decennio o talvolta cinque-dieci anni. Ti chiedi: come può esistere un progetto di cinque anni? La risposta è che le persone continuano a investire in quel progetto, e ci vogliono letteralmente anni e anni per ammettere finalmente che è stato un completo fallimento e che non avrebbe mai funzionato.
Un’altra prova aneddotica è che, avendo vissuto all’interno e assistito a quelle implementazioni ERP multi-annuali, di portata epica e fallite, capita spesso che il progetto si interrompa non perché le persone riconoscano che il fornitore ha effettivamente fallito. Il meccanismo è che, a un certo punto, la direzione superiore coinvolta nella decisione di affidarsi al fornitore passa semplicemente ad altre aziende. Quando praticamente tutte le persone che inizialmente facevano parte della decisione di coinvolgere il grande fornitore hanno lasciato l’azienda, coloro che non si sentono altrettanto legati a quel fornitore decidono collettivamente di chiudere il progetto e considerarlo concluso.
Per quanto riguarda una soluzione ristrutturata, credo che le aziende debbano essere più tolleranti nei confronti del fallimento. Devi essere severo con i problemi, ma mite con le persone. Se coltivi una cultura in cui si dice: “Dobbiamo farlo bene al primo colpo”, questo è molto dannoso perché significa che non otterrai meno fallimenti. È un fraintendimento della mente umana e della natura umana pensare che, se hai una cultura che tollera il fallimento, otterrai in realtà più fallimenti. Sì, potresti avere margine per qualche piccolo fallimento in più, ma quello che si ottiene è che le persone sono più inclini a riconoscere i propri errori e ad andare avanti. Se, al contrario, adotti una cultura del “fallo bene al primo colpo”, praticamente nessuno può perdere la faccia. Così, anche quando c’è qualcosa di completamente disfunzionale, l’istinto di sopravvivenza delle persone coinvolte consiste nel raddoppiare gli sforzi su ciò che non funziona, solo per preservare la propria faccia e, possibilmente, passare a un’altra azienda in modo da non dover affrontare le conseguenze dei propri errori.

Per ricapitolare, abbiamo la conoscenza positiva contro la conoscenza negativa. La conoscenza positiva riguarda essenzialmente la risoluzione dei problemi; è una sorta di intelligenza da dottorato, un’intelligenza orientata al problem solving, in cui ci sono enigmi e si può passare da una soluzione a una migliore. È possibile valutare che una soluzione sia migliore di un’altra, e il culmine di questo tipo di pensiero è raggiungere una soluzione ottimale. Tuttavia, ciò che le persone credono di cercare – soluzioni ottimali, perfettamente valide e immortali – sono in realtà soluzioni molto effimere.
Ad esempio, nel corso della storia di Lokad, la mia azienda, abbiamo attraversato sei generazioni di motori di previsione. La conoscenza positiva è effimera nel senso che essa, questa soluzione, è a rischio non appena ne emerge una migliore, e viene semplicemente scartata. In Lokad, abbiamo affrontato il tedioso compito di riscrivere da zero la nostra tecnologia di forecasting ben sei volte sin dal 2008. Per questo dico che la conoscenza positiva è molto effimera, perché diventa obsoleta rapidamente all’arrivo di soluzioni nuove e migliori.
Al contrario, se guardi alla conoscenza negativa, essa rappresenta una prospettiva completamente diversa. Si pensa in termini di errori clamorosi, e il tipo di intelligenza che si vuole catturare è quella street-smart, quella che ti aiuta a sopravvivere in una zona difficile di notte. L’attenzione non è tanto sugli enigmi o su concetti estremamente complicati da comprendere e che richiedono trasferimenti; è più incentrata su ciò che non sai o sui tabù. Non si tratta di ciò che non conosci, ma di ciò che le persone non ti diranno, o delle cose su cui addirittura potrebbero mentirti solo per salvare la faccia. La conoscenza negativa riguarda il combattere tutti quei tabù che ti impediscono di vedere la realtà per quello che è.
Con la conoscenza negativa, la mentalità non è quella del progresso; è una mentalità di sopravvivenza. Vuoi solo sopravvivere per poter combattere un altro giorno. È una prospettiva molto diversa, e proprio questo è il genere di cosa che le aziende cercano istintivamente quando scelgono un direttore del supply chain molto esperto. Vogliono assicurarsi che, attraverso questa persona, l’azienda viva un altro giorno. Ciò che può sorprendere è che la conoscenza negativa tende ad essere molto più durevole. Questi sono sostanzialmente i difetti della natura umana in gioco, e non cambiano nel tempo solo perché esista una nuova tecnologia, un nuovo approccio o un nuovo metodo. Queste cose sono destinate a rimanere.

In conclusione, direi che la conoscenza negativa è di massima rilevanza per tutti i problemi wicked, il supply chain essendo solo il focus di interesse di questa lezione, ma non è l’unico ambito in cui la conoscenza negativa può essere applicata.
Gli anti-patterns del supply chain sono solo alcuni esempi, ma sono abbastanza sicuro che se ne possano identificare altre decine per catturare i problemi che continuano a ripetersi nelle supply chain reali. Non possiamo sperare di catturare tutto mediante gli anti-patterns, ma credo che possiamo cogliere una consistente parte. Dopo aver letto un libro sugli anti-patterns del software, la mia opinione soggettiva è stata che avevo acquisito l’equivalente di cinque anni di esperienza in ingegneria del software in sole 200 pagine. La mia speranza è che, per una raccolta di anti-patterns del supply chain, si possa replicare questo effetto, dove qualcuno potrebbe acquisire un’esperienza equivalente a cinque anni in un arco di tempo molto più breve, forse solo poche settimane.

Questo è tutto per questa lezione. La prossima lezione tratterà la valutazione dei fornitori, un problema molto interessante. I modern supply chains vivono o muoiono in base ai prodotti software che li supportano, e la questione è come ragioniamo su questi prodotti software e come scegliamo quelli giusti e i fornitori giusti. Nonostante abbia avuto la mia giusta quota di conflitti di interesse, è un problema interessante, e la domanda è come possiamo avere una metodologia in cui, anche se tutte le persone hanno dei pregiudizi, possiamo ottenere un risultato in qualche modo imparziale.
Ora risponderò alle domande.
Question: Cosa costituisce una buona previsione in un contesto di ottimizzazione probabilistica, e come si misura la qualità? Esiste un ruolo per gli arricchimenti manuali?
Una buona previsione probabilistica si avvale di metriche per le accuratezze probabilistiche, ma probabilmente non è questo che ti interessa. Nell’ambito di un’iniziativa di ottimizzazione sperimentale, vorrai ottimizzare. Metriche come cross-entropy o likelihood si applicano alle previsioni probabilistiche. Ancora più importante, ci saranno aspetti che scoprirai gradualmente man mano che identifichi decisioni insensate. La previsione è solo un mezzo per un fine, che è la decisione. Devi prestare attenzione alle decisioni. Ne abbiamo parlato brevemente nella lezione precedente sull’ottimizzazione sperimentale. Il processo è lo stesso sia per le previsioni classiche che per quelle probabilistiche. Se desideri esempi concreti di previsioni probabilistiche, questo argomento sarà trattato in modo approfondito nelle lezioni successive. Mi dispiace di divagare un po’ nella risposta a questa domanda.
Question: Cosa ne pensi dell’utilizzo dell’AI (Appreciative Inquiry) per supportare la tua AI (Artificial Intelligence)? Quali tecniche utilizzerai per analizzare in modo logico grandi insiemi di dati, e perché i tassi di conversione stanno diminuendo nonostante le buone performance complessive? Cosa affrontare per risolvere il problema alla base dell’attività?
L’AI, intesa come insieme di algoritmi, si basa attualmente principalmente sul deep learning. Il deep learning è un insieme di tecniche molto capaci di gestire dati altamente non strutturati. La domanda che dovresti veramente porti è come collegare tutto questo alla realtà. Nel supply chain, i dati tendono ad essere molto scarsi. La maggior parte dei prodotti in un qualsiasi negozio viene venduta a meno di un’unità al giorno. I grandi insiemi di dati risultano tali solo in aggregato, quando si considera un’azienda molto grande con tonnellate di transazioni. Se si esaminano le granularità che contano davvero, non si dispone di tanti dati.
Appreciative inquiry, in termini di metodologie, riguarda fondamentalmente l’ottimizzazione sperimentale discussa nella lezione precedente.
Question: Molti manager non comprendono il potere della data science, e presentare loro problemi fittizi è una strada sicura. Se non vogliono approfondire l’apprendimento della data science, qual è un modo alternativo per far loro credere nella data science e negli approcci decision-first? Come iniziare in piccolo e espandersi in grande?
Innanzitutto, se hai persone che non credono in una certa tecnologia, va benissimo. Prendi ad esempio Warren Buffett. È un investitore molto ricco che ha trascorso la sua vita investendo in aziende che comprende. Investe in aziende con modelli di business semplici, come le compagnie di trasporto ferroviario o le società di leasing di mobili. Warren Buffett disse: “Non sono interessato a comprendere tutte quelle tecnologie.” Per esempio, quando gli fu chiesto perché non investisse in Google, Buffett rispose: “Non capisco nulla di ciò che fa Google, quindi, pur essendo un buon investimento, non sono sufficientemente in gamba per farlo. Investirò solo in aziende che comprendo.”
Il mio punto è che, per il management, penso sia un’illusione completa avventurarsi in settori che non si comprendono. A un certo punto, se non sei disposto a fare lo sforzo, semplicemente non funzionerà. Questo è il Jedi anti-pattern in azione – il management non è disposto a impegnarsi, e pensa che basti assumere ingegneri intelligenti, giovani e dotati per risolvere tutto. Se fosse così, Amazon non avrebbe avuto il successo che ha avuto. Se fosse stato possibile per una tradizionale retail chain azienda assumere solo pochi ingegneri per avviare un sito di e-commerce e competere con Amazon, lo avrebbero fatto tutti. Fino al 2005, quelle aziende disponevano di risorse e capacità ingegneristiche significativamente superiori a quelle di Amazon stessa.
Il problema è che si tratta di un’illusione, ed è proprio questo il punto della conoscenza negativa – fare luce sui problemi che sono ovunque. Ecco perché serve un titolo accattivante per comunicare il problema ai manager. Non bisogna poi aver paura di imparare cose nuove. Quando si coglie veramente il lato positivo delle nuove tecnologie, di solito non è così complicato. Non tutto è super tecnico; molte parti possono essere spiegate. Per esempio, anche qualcosa come le blockchain – metà di quelle tecnologie blockchain presumibilmente super avanzate potrebbero essere spiegate a dei bambini di 10 anni. Molte delle idee alla base di queste tecnologie sono in realtà abbastanza semplici. Ci sono un sacco di coincidenze matematiche accidentali che sono molto difficili, ma quella non è l’essenza del problema.
Quindi, la mia risposta per voi sarebbe: se il management vuole credere alle fiabe, non c’è molto che si possa fare in quella situazione. Se il management è disposto a investire nella data science, dovrebbe anche essere disposto a dedicare un minimo di tempo per comprendere di cosa tratta la data science. Altrimenti, è semplicemente un’illusione.
Questo è tutto per oggi. Grazie mille, e la prossima lezione si terrà lo stesso giorno, mercoledì, fra due settimane, alla stessa ora. A presto.
References
- ‘‘AntiPatterns: Refactoring Software, Architectures, and Projects in Crisis’’. y William J. Brown, Raphael C. Malveau, Hays W. “Skip” McCormick, Thomas J. Mowbray, 1998


