00:15 Introduction
02:28 Smart Fridge
05:28 Survivorship bias
07:28 The story so far
08:46 On Taboos (recap)
12:06 Rejection heuristics (recap)
13:34 Low quality positive knowledge
15:27 Software Antipatterns, 1/2
20:11 Software Antipatterns, 2/2
25:34 Supply Chain Antipatterns
27:00 Naked Forecasts
32:36 The 100% service level
37:06 The Jedi initiation
44:31 The Non-Euclidian Horror
51:45 Devil’s advocate
57:35 Recap, negative knowledge for supply chains
01:01:04 Conclusion
01:02:45 Upcoming lecture and audience questions
Description
Antipatterns are the stereotypes of solutions that look good but don’t work in practice. The systematic study of antipatterns was pioneered in the late 1990s by the field of software engineering. When applicable, antipatterns are superior to raw negative results, as they are easier to memorize and reason about. The antipattern perspective is of prime relevance to supply chain, and should be considered as one of the pillars for its negative knowledge.
Full transcript

Hi everyone, welcome to this series of supply chain lectures. I’m Joannes Vermorel, and today I will be presenting negative knowledge in supply chain. For those of you who are watching the lecture live, you can ask questions at any point in time via the YouTube chat. I will not be reading the chat during the lecture; however, I will be coming back to the chat at the very end of the lecture for the Q&A session.
Today, the topic of interest is what a company actually gains when it hires an experienced supply chain director with maybe two or three decades of experience. What is it that the company is looking for, and could we, to a marginal extent, replicate the acquisition of this experience in a much shorter amount of time? That’s exactly what negative knowledge is about.
When we look at a very experienced person, somebody who has been working for two decades in a field, are we really looking for this person to replicate solutions, processes, or technologies that they implemented one or two decades ago in other companies? Probably not. While it might marginally happen, I suspect that usually, that’s a very fringe reason at best.
When you’re looking for a very experienced person, the goal is not necessarily to replicate things as they were done in the past. The key value that you want to acquire is to take someone who knows how to avoid all sorts of mistakes and has the experience to ensure that plenty of very naive and bad ideas will not be implemented in your company. There is this saying that in theory, practice and theory are the same, but in practice, they are not. That’s exactly the crux of negative knowledge.
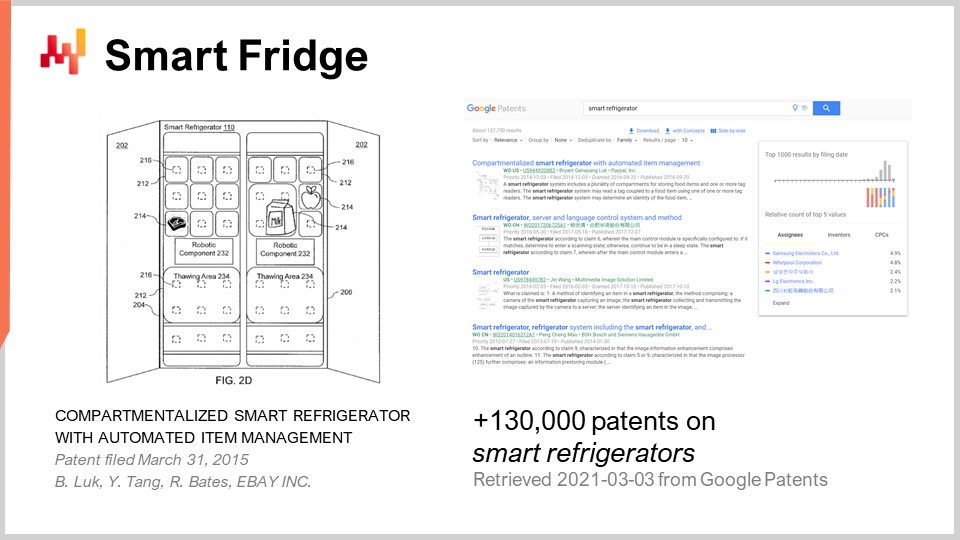
My proposition for you is that bad business ideas are all over the place. When I say bad, I mean ideas that, if implemented, would turn out to be completely unprofitable for the company. To illustrate this, I just put the query “smart refrigerators” in the Google Patents search engine. Google Patents is a specialized search engine provided by Google, and you can search a patent database. Lo and behold, we get 130,000 results of patents filed on smart fridges.
Take this number with a grain of salt, as there are probably many duplicates. However, a cursory inspection of the results indicates that very clearly, we have several hundred, if not several thousand companies that, over the last few decades, went out of their way to do research and development to file a patent on smart refrigerators. When you look at the sort of ideas found in those patents, you will see that it’s always a combination of taking this very ubiquitous appliance, a fridge, and adding something, like cheap electronics. We combine the two, and voilà, we have a solution of some kind.
For what sort of problem, though? It’s very unclear. Just to give you the gist of most of the patents, it’s the sort of idea where, if you have a fridge that has some kind of sensors, the fridge itself is going to detect if you’re running low on milk and will automatically place a reorder for you. We are in 2021, and to the best extent of my knowledge, smart fridges are non-existent. It’s not that they are not technically feasible – they very much are. It’s just that there is literally no market for them. So, we have a massive amount of solutions on the market looking for a problem. Over the last two decades, I believe that I’ve witnessed twice a year, on average, a startup promoting a smart fridge of some kind. Interestingly enough, I never heard back from any of those startups. I didn’t really keep track, but I would strongly suspect that every single startup that I’ve seen promoting a smart fridge during the last two decades has failed. However, while the idea is very widespread and popular, as demonstrated by those thousands of patents, the consequences of those ideas, which are bad because probably most of those startups went simply bankrupt, did not propagate.
Here, we see something very interesting: through experience, you can access a sort of knowledge that is not readily accessible to observers in the market. You can see the dark side, which is the things that are missing, the sort of things that were promised and broadcasted but didn’t turn out to be very successful.

There is a very notable historical example from World War II. The US Army conducted a survey on aircraft returning to base to collect the placement of bullet impacts on the aircraft. What you see on the screen was essentially the collection of the placement of the bullets as observed on aircraft returning from the battlefields to the base. Initially, the army officers were following the line of thought that they needed to add armor plating in the areas that were hit the most, the areas that were obviously under the most significant amount of fire during the battle.
Then, another gentleman, Abraham Wald, said no, this is exactly the opposite. The thing is, what you see is aircraft that managed to make it back to the base. What you do not see is that, for all the areas where you do not see bullet impacts, it’s most likely that when there was a bullet impact in this area, it turned out to be lethal either for the aircraft or for the crew, or both. So, if you have to add any armor plating, you have to do it precisely on all the areas where you don’t see aircraft coming back to base with bullet impacts. Those are the areas that need to be protected.
What Abraham pointed out is that there was a phenomenon known as survivorship bias, where what you observe are essentially the survivors, not all the aircraft that didn’t make it back to the base. The idea of negative knowledge is exactly like that: you take this photographic picture and the negative, and it’s the rest that you really need to capture your attention because that’s where the really bad stuff happens. That’s the essence, I would say, of negative knowledge.
This is the fourth lecture in my series of lectures, the first lecture of the second chapter. In the first chapter of the prologue, I presented my views on supply chain, both the field of study and the practice. What we have seen is that supply chain is essentially a collection of wicked problems, as opposed to tame problems. Wicked problems are very difficult to approach because they don’t lend themselves to either easy studies or easy practice. There is fundamentally something adverse in terms of study and practice with wicked problems. That’s why the second chapter is dedicated to methodologies.
In this present lecture, we are taking a qualitative approach, just like what we did with the supply chain persona, which was the very first lecture in this chapter. We will expand on the sort of qualitative approaches that we can have to deliver improvement to supply chains in ways that are controlled, reliable, and potentially ultimately measurable.

Recap: Although this is a lecture dedicated to negative knowledge, this is not the first time in this series of lectures that I touch on elements that would qualify as tidbits of negative knowledge. During the first lecture of this second chapter on supply chain personas, I presented my views on case studies. I said that positive case studies, meaning case studies presenting positive outcomes associated with a solution of interest, come with massive conflicts of interest that essentially completely undermine any trust we could have in the validity of the results. On the other hand, I stated that negative case studies are just fine because those conflicts of interest, although they may be present, are much less intense.
In this lecture on supply chain personas, I presented a fantastic negative case study, “The Last Days of Target Canada” by Joe Castaldo, which detailed an epic-scale supply chain failure that ultimately led to the bankruptcy of Target Canada. This is a sort of negative knowledge, where the object of study is literally stuff that didn’t work, as opposed to what we can do to have something that actually works.
Now, could we use negative case studies as a foundational practice for our negative knowledge for supply chain? I would say mostly no, for two very distinct reasons. The first reason is simply that negative case studies are super rare. I would surmise, just as a guesstimation, that there are actually more than 100 times more patents on smart fridges, which are completely useless, than there are negative case studies about supply chains. So, we have a very practical problem: although those negative case studies are of prime relevance and very high scientific interest, they just happen to be extremely rare. We have so little of it that it’s very difficult to have this material as the foundation of our negative knowledge for supply chain.
The second problem is intelligibility. Those negative case studies, like the fantastic article “The Last Days of Target Canada,” show that there are dozens of problems going on at the same time, and all those problems are completely entangled to ultimately lead to an epic failure. The issue is that those case studies are literally real life at play, and those events are very complex. It is difficult to communicate and reason about those case studies because details matter, and they are very dense. There is a more pedestrian problem: how do you communicate that to a larger audience?

In my last lecture about experimental optimization, we also saw another kind of negative knowledge: rejection heuristics. These were essentially simple tricks that can be used when there is a proposition in terms of a quantitative solution put forward as a potential candidate for the improvement of your supply chain. You can use a series of heuristics or simple rules to discard solutions that, with a very high degree of certainty, will simply not work out. However, here we have a problem of scalability. These heuristics only work because they are obscure. If they were to become well-known among supply chain circles, both scientific papers and supply chain software would adapt and change their discourse, making the situation more confused. Those heuristics are very efficient, but if they were to become popular, they would still retain their validity, but lose their efficiency as filters, just because people would pay attention to work around those heuristics.
That’s why these heuristics, although very interesting, cannot be used as foundations for our negative knowledge that we want to constitute for supply chain.

Also, we should not confuse negative knowledge with low-quality positive knowledge. The difference is really a matter of intent. For example, the intent of safety stocks is to give companies a controlled way to drive the quality of service they will get. The intent is positive; it is a solution for something that should work. Now, the reality is that the safety stock model is based on completely abusive assumptions: future demand and lead times are assumed to be normally distributed, although these assumptions are factually wrong. I’ve never observed any supply chain datasets where either demand or lead times were normally distributed. The distributions of interest are actually Zipf distributed, as I addressed in my previous lectures about the quantitative principles for supply chain. From a proper perspective, safety stock is falsified, but nonetheless, safety stock is definitely anchored in the realm of positive knowledge, although it may be arguably very low-quality positive knowledge.
During this lecture, we won’t have time to delve into all the elements that, from my perspective, qualify as very low-quality positive knowledge, but I would be happy to oblige if some people want to ask me questions about any of those elements during the Q&A session.

When it comes to actual negative knowledge of practical interest, there is a book called “Anti-Patterns: Refactoring Software, Architectures, and Projects in Crisis” that is a landmark in the history of software engineering. Published in 1998, this book starts with a casual observation that in the software industry, when there are good ideas and projects that take advantage of the good ideas, software vendors see the good ideas being consumed by the success of the project. The authors question whether a good idea remains a good practice after the product is implemented, and the answer is essentially no. There is a first-mover advantage that is very specific to the software industry, and as a result, we have a problem. Pretty much any set of rules that you would use to predict the success of anything in the software industry is self-defeating, due to the fact that the very best approaches tend to be consumed by the success they generate. The authors of “Anti-Patterns” noticed that it’s almost impossible, in their view, to guarantee the success of a software initiative. However, they also noticed that the situation is very asymmetric when it comes to failures. They remarked that it’s possible to predict, with a very high degree of confidence (sometimes bordering on certainty), that a given project is about to fail. This is very interesting because you cannot guarantee success, but you can have something like a science that guarantees failure. Even better, this knowledge of elements that guarantee failure appears to be exceedingly stable over time and very much independent of the technicalities of the company or the vertical being considered.
If we go back to the initial smart fridge idea, we can see that all those smart fridge patents are incredibly diverse in the solutions they present. But it turns out that all those smart fridge patents lead to business failures because they all fall under the same umbrella: a solution looking for a problem. The combination of an ubiquitous appliance with cheap electronics creates a solution, but is it something that actually makes sense? In this case, almost never.
The authors of “Anti-Patterns” started their journey by studying the root causes behind software failures and identified the seven deadly sins of software engineering, which are haste, apathy, narrow-mindedness, avarice, ignorance, pride, and envy. These problems are going to be independent of the context and the technologies involved because they are invariants of human nature itself. When looking for a supply chain director with two decades of experience, it’s going to be someone who has just lived longer and has internalized most of the problems that come when you have actual humans involved, with all sorts of flaws.
The idea of the authors is that it’s good to formalize this knowledge to make it more digestible and intelligible so that it will be easier to communicate and reason about these problems. That’s the essence of anti-patterns – a format to capture tidbits of negative knowledge.

In their book, the authors present a template for an anti-pattern, which starts with a catchy name that is easy to memorize. You need to characterize the scale, whether it’s at the source code level, the software architecture level, the company level, or the industry level. You want to identify the actual root causes and the consequences that are typically associated with them. You want to characterize the forces at play, the symptoms, and the unintended consequences that people do not expect, which will completely undermine the expected benefits of the initial solution.
The authors argue that you need to present anecdotal evidence, and that’s why they use fictitious companies in their anti-patterns. This is done to avoid the taboos involved in discussing real companies and real people, which could prevent honest communication from being established. The anti-pattern template must conclude with a refactored solution, which is a path to transform what is essentially a misguided solution into a variant of that solution that actually works in the real world, where the unintended consequences are mitigated and ideally eliminated.
This lecture is not about supply chain anti-patterns, but just to give two examples of software anti-patterns that you may have heard about, the first is the Golden Hammer. The Golden Hammer is the idea that when you have a golden hammer in your hand, everything else is a nail. This anti-pattern essentially states that if you ask a Java programmer how they would address a new problem, they will likely suggest writing a program in Java to solve that problem. If you present another problem to the very same person, the very same person would say that this other problem could also be solved with a Java program. If you present 20 different problems, every single time the answer will be, “I believe that a Java program would do just fine.” This is a massive bias where people with experience in a given technology have a tendency to recycle their technical knowledge to solve new problems, instead of taking the time to assess whether their knowledge is really relevant technically speaking to address the new problem. It’s much easier intellectually to just default to what you actually know.
Another one is Analysis Paralysis. In the world of software, there are many situations where possibilities are endless, and it’s tempting to say, “Instead of testing out 20 different approaches that are going to fail, let’s think very hard about the design, and once we are absolutely confident that we have the right solution in mind, then we will roll out the implementation.” Unfortunately, this is very difficult to execute, and usually leads to analysis paralysis, where more time and effort are spent considering tons of potential options instead of just trying a solution and seeing if it works or not.

Now, obviously, we have discussed that this book was about software anti-patterns, and I believe that software engineering has many similarities with the problems we face in supply chain, especially supply chain optimization. Both fields are essentially collections of wicked problems, and modern supply chain is very much about delivering a software product. So, there is a certain degree of overlap between supply chain problems and software engineering problems, but these two fields are not completely light years apart.
Here, I will be presenting five supply chain anti-patterns, which can be found in written form on the Lokad website, with a more extensive presentation available for those interested.

The first is Naked Forecast. Inspired by the short story “The Emperor’s New Clothes” by Hans Christian Andersen, the context is a company with an ongoing initiative to improve forecasting accuracy. Some symptoms include long-standing forecasts that everyone complains about—production, marketing, sales, purchasing, and even supply chain, with the forecasting division typically being part of the supply chain. There have been attempts to improve the accuracy of the forecast over the last one or two decades, but it seems that no matter how much effort is put into the case, there is an endless series of excuses from the people in charge of the forecast to justify its poor accuracy.
The thing is, there is this next initiative where the intent is to get the forecast accuracy straight, to fix this inaccurate forecast issue once and for all. That’s the Naked Forecast anti-pattern at play. The unintended consequences of that are, first, it’s not going to deliver meaningfully more accurate forecasts. Second, going through yet another initiative is just going to create an even more Byzantine organization where what started as a tiny practice to deliver the forecast grows more and more complex, with more people involved in the production of those forecasts. Down the road, you end up with something that is still as inaccurate as ever but has turned from something modest and inaccurate to a big bureaucracy that is still as inaccurate as ever.
I believe that the root cause here is what I refer to as naive rationalism or the illusion of science. When this initiative starts, the problem presents itself as if it were perfectly objective: “We are going to produce more accurate forecasts according to a metric, let’s say mean absolute error.” The whole thing seems very straightforward, with a well-defined problem. However, the problem is that all of that is very naive because there is no direct correlation between forecasting accuracy and the profitability of the company. What you should be looking for is ways to improve the profitability of the company, so you should think in terms of dollars or euros of error, not percentages of error.
Fundamentally, the root cause is that these forecasts are standalone and don’t get any feedback from the actual business. Forecasting accuracy is just a numerical artifact; it’s not a real, tangible return on investment for the business. As a tidbit of anecdotal evidence, if I had gotten an extra paycheck of a thousand dollars every single time I had a discussion over the phone with a supply chain director who told me they were starting a new initiative to improve the forecasting accuracy, I would be an even richer man.
The bottom line is that, in terms of refactored solution, as long as the forecasts are naked, it’s not going to work. You need to put clothes on them, and those clothes are decisions. As we explored in the previous lecture with experimental optimization, if the forecasts are not directly connected to real-life, tangible decisions, such as how much to buy, how much to produce, or whether to move prices up or down, you never get the real feedback that matters. The real feedback that matters is not the back-test KPI on the measurement; what matters are those decisions. Thus, in terms of refactored solution to address the Naked Forecast anti-pattern, it’s basically to decide that the same people who generate the forecast have to live with the consequences of those forecasts when it comes to the actual supply chain decisions that get implemented on top of it.

The second one would be the Mythical 100% Service Level. The situation typically starts as follows: the board of directors meets and, somewhere in the press or on social networks, some people are loudly complaining about the quality of service. It doesn’t look good for the company, as it seems that the company is not delivering on the promises it made. The board puts an enormous amount of pressure on the CEO to do something about this quality of service issue, which is negatively impacting the brand, image, and potentially the growth of the company. The CEO says, “We really need to put an end to these endless series of quality of service problems.” So, the CEO turns to the VP of Supply Chain and asks them to put an end to these quality of service problems. The VP of Supply Chain, in turn, asks the Supply Chain Director to do the same, and the Supply Chain Director asks the Supply Chain Manager to address the issue. The Supply Chain Manager then dials the service level up to something very high, close to 100%.
Lo and behold, even if in the short term you end up with marginally higher service levels, very soon the quality of service problems return. These higher service levels are not sustainable, and you end up with inventory fluctuations, wasted inventory, and, although the intent was to increase service level, you frequently get lowered service levels six or twelve months down the road.
The root cause here is not only ignorance but also wishful thinking. Mathematically speaking, if you want a 100% service level, it means an infinite amount of inventory, which is technically not possible. You have this powerful wishful thinking that you can fully address this problem, although it’s not possible. At best, you can mitigate the quality of service problems; you can’t ever completely eliminate them.
In terms of anecdotal evidence, I’ve seen that many companies struggle the most because they have this mindset of the mythical 100% service level target. If your company is not willing to accept that, for some products (not all or the most important ones), the service levels will actually be lowered on purpose, then you’re heading for deep trouble. The only way to actually improve the quality of service is first to accept that if the focus is on everything, it’s equivalent to saying the focus is on nothing. As long as you’re not ready to accept that, for some SKUs, you will have a lower service level on purpose as an acceptable outcome, you will not be able to improve your overall quality of service.
In terms of refactored solutions, the refactor solution is economic drivers. It’s a point that I presented in the second lecture of the very first chapter, the vision for the quantitative supply chain. The economic drivers show that you have the cost of stockouts and the carrying cost, and there is a balance to be found. You cannot just push for a 100% service level because it’s completely imbalanced from an economic perspective; it’s not sustainable. Trying to push in this direction is very misguided because it’s only going to harm the company. The solution is to inject a healthy dose of economic drivers into your supply chain practice.

Now, the third anti-pattern, Jedi Initiation, can be seen when top management in many large companies are under constant pressure from the media due to the constant stream of buzzwords heading their way. These buzzwords include artificial intelligence, blockchain, cloud computing, big data, IoT, etc. Influencers tell them that if their company doesn’t adapt to these trends, it will become obsolete. There is a constant fear of missing out, which acts as a powerful force, applying constant pressure on the top management of most large companies that operate large supply chains.
The symptoms of Jedi Initiation can be observed if your company has a division with young, enthusiastic engineers that have buzzwords in their job titles, such as artificial intelligence researchers, blockchain engineers, or data scientists. The motto is to “master the force,” the force being the buzzword of interest at that point in time. Management takes arguably young or inexperienced people and tells them to do something great for the company, but without being involved or familiar with the technical aspects of these concepts.
What happens is that these teams create interesting prototypes that ultimately fail to deliver real-world value for the company. As a consequence, although it started with the idea that the company would be revolutionized according to the buzzword of the day, the legacy practices and technology remain prevalent, unmodified by the buzzword or the extra team built around it.
In terms of anecdotal evidence, nowadays, in 2021, the vast majority of companies with a data science team are getting exactly zero returns on their investment. The data science team creates fancy Python prototypes using open-source libraries that are very cool, but in terms of practical return on investment for the vast majority of the market, it’s exactly zero. That’s exactly the sort of Jedi Initiation top management falls for: they read in the press that data science is the new trend, so they hire a data science team. As a tidbit of anecdotal evidence, I see that these teams are not only fairly young and inexperienced, but they also remain that way over time. That’s because the turnover is very large. You can have a company that is very solid and robust, where the average turnover is typically five to ten years, except for the data science team, where people stay on average for 18 months. One of the reasons why there is nothing of value coming out of these teams is that people walk in, do a few prototypes, and then walk away. For the company, there is no capitalization, and it never really manages to transform the company.
In terms of refactoring this solution, first, there is no workaround but to lead by example. If you want to actually do data science, then the top management needs to be very knowledgeable about data science. For example, Jeff Bezos has shown familiarity with state-of-the-art machine learning techniques of his time. Amazon can be very successful with machine learning, but it happens because top management is very familiar with the fine print. Leading by example is essential.
Secondly, you must make sure that when you hire these young, enthusiastic, and potentially talented engineers, you confront them with real problems, not meta problems. It needs to connect to reality. This goes back to my previous lecture about empirical, experimental optimization. If you hire a data scientist to do client segmentation or a better ABC analysis for your company, these are not real problems. They are just made-up numbers. If you hire these people and put them in charge of the actual replenishment, and make them responsible for the exact quantities to be replenished from a series of suppliers, that is very real. This is the reason why, a decade ago, Lokad transitioned internally from data scientists to supply chain scientists. The point was to have a completely different commitment and to get away from this Jedi Initiation anti-pattern.

The non-euclidian horro. In this context, you have a company that operates a large supply chain, and the IT landscape is very complex. There are several pieces of enterprise software, such as ERP, WMS, and EDI, which are complex on their own. Then you have all the glue that connects these things together, and the whole picture is staggeringly complex. So, how do you know that you’re actually in a company that is facing a non-acclimatized solution? What are the symptoms? The symptoms are that everybody in the company feels that there is a rampant incompetence in the IT division. People from IT look overwhelmed and seem like they don’t understand what is going on in the system they’re supposed to manage and run. Another symptom is that you see IT problems that impact production on a daily basis. These are the key symptoms of the non-acclimatized solution.
The consequence of having a non-acclimatized IT landscape is that changes that need to be brought to the company, and usually, when there is a change to be brought to the company, there is a change to be brought to the IT systems as well. Modern supply chains are very much driven by their software components. All these changes happen very slowly, and it’s always a tedious process where even small changes take forever. Whenever there is any degree of change, there are usually tons of regressions. As people say, you take two steps forward and three steps backward, then two steps forward again and one step backward. The change is not only slow but also comes with a constant stream of regression. The situation doesn’t really improve over time; at best, it stagnates.
In terms of root causes, management doesn’t really care about the fine print, and the non-IT management doesn’t really care about all those IT systems. This results in an approach that I call incrementalism, where whatever change they want to happen in the IT system of the company, those changes will be requested by supply chains, for example. Whenever there is a change that needs to happen, management will always say, “Please take the easiest path, the path that requires the least amount of effort and time so that we can see this implemented as quickly as possible.” That’s what incrementalism is about.
I believe that incrementalism is a very dangerous root cause. The problem with incrementalism is that it’s literally a death by a thousand cuts. Every single change that is brought to the system makes it a bit more complex, a bit more unmanageable, and a bit more difficult to test. Although every single change individually is inconsequential, when you pile up a decade of dozens of changes brought to the IT systems on a daily basis, you end up with an ocean of complexity. Every change has made the system more complex, and the big picture is completely lost. Fast forward a decade, and you end up with a massive, convoluted system that looks insane.
As a tidbit of anecdotal evidence, you can see that there are still very large e-commerce companies where, as a consumer, you can routinely see that they have downtimes. These sorts of things should never happen. As an e-commerce company in 2021, your uptime should be something like allowing 10 minutes of downtime per year. Every single second of downtime is a wasted opportunity. Designing shopping cart software in 2021 is not rocket science anymore; it’s actually very vanilla software as far as enterprise software is concerned. There is no reason not to have something that is always on. However, the reality is that when you see e-commerce going down, it’s usually not the shopping cart that fails; it’s a non-acclimatized solution sitting just behind the e-commerce. The e-commerce being down is just a reflection of a problem that happened somewhere in the IT landscape.
If we want to refactor the non-acclimatized solution, we should stop looking for the easiest solution to bring about change. We need to think not of an easy solution, but a simple solution. A simple solution differs from the easy solution in a crucial way: it makes the entire landscape a tiny bit tidier and more sane, making it easier to bring in further changes later on. You might say, “But it’s just a purely technical matter, so this is the job of IT.” I would say, no, absolutely not. It is very much a supply chain problem. Adopting a simple solution is not a matter of having a simple solution from an IT perspective; it’s having a simple solution from a supply chain perspective.
The simplicity of the solution, and its intended consequence of making later changes easier to implement, depends on your roadmap. What sort of future changes do you want to bring into your IT landscape? IT, as a division, doesn’t have the time to be supply chain experts and to know exactly where you want to steer the company a decade from now in terms of supply chain execution. It has to be the supply chain management that has this vision and has to steer the development, potentially with the support of IT, in a direction where changes become easier and easier to implement over time.

Finally, as the last anti-pattern for today, the devil’s advocate. The context is typically a big company that has had significant supply chain problems and has decided to go for a big vendor, putting a lot of money on the table. The initiative gets started, and a few months later, typically six months or so, the vendor has very little to show for it. A lot of money has been pushed towards the vendor, and there is very little to show for it. By the way, in 2021, six months is a lot of time. If you have a software initiative that does not deliver tangible, production-grade results in six months, you should be very worried because, in my experience, if you can’t deliver tangible results in six months, chances are the initiative is doomed, and you will never have a positive ROI for the company.
What happens is that the management sees the project get delayed, and there is very little to show for it. The top management, instead of becoming increasingly aggressive with regard to the tech vendor and being at the forefront of the tech vendor, suddenly changes sides and becomes very defensive of the vendor. This is very puzzling. You start a big initiative, give a lot of money to another company, and the initiative is going forward but badly and has little to show for it. Instead of clarifying that the initiative is actually failing, the management doubles down and starts to defend the vendor, which is very weird. It’s as if there were some kind of Stockholm Syndrome at play, where someone does you harm, but if they do a sufficient amount of harm, at some point you start to like those people.
Management and the initiative itself become too big to fail, and as a consequence, there is tons of wasted money and a massive amount of lost opportunity, especially time-wise. As the initiative goes forward, money is lost, but more importantly, time is lost – six months, one year, two years. The real cost is time. As a sort of anecdotal evidence for this sort of thing, you can read very routinely in the press that there are epic-scale failures in ERP implementation for projects that last almost a decade or sometimes five to ten years. You think, how can you have a five-year project? The answer is, people keep doubling down on this project, and it takes literally years and years to finally admit that it was a complete failure and that it would never work.
Another tidbit of anecdotal evidence is that, having been on the inside witnessing those multi-year, epic-scale, failed ERP implementations, it frequently happens that the project ceases not because people agree that the vendor has actually failed. The way it is being played is that at some point, the upper management involved in the decision of bringing the vendor in the first place just moves on to other companies. When basically all those people who were initially part of the decision to bring the big vendor in have left the company, the other people who don’t feel as committed toward this particular vendor just collectively agree to shut it down and call it a day.
In terms of a refactored solution, I believe that companies have to be more tolerant of failure. You have to be tough on problems but soft on people. If you cultivate a culture where you say things like, “We have to get it right the first time,” this is very harmful because it means that you will not get fewer failures. It is a misunderstanding of the human mind and human nature to think that if you have a culture that tolerates failure, you actually get more failures. Yes, you get marginally more small failures, but what you get is people inclined to recognize mistakes and move on. If, on the contrary, you have a culture of “get it right the first time,” then basically nobody can lose face. So even when there is something completely dysfunctional, the survival instinct of the people involved consists of doubling down on this thing that is not working just to preserve their face and potentially move to another company so they will not have to confront the consequences of their mistakes.

To recap, we have positive knowledge versus negative knowledge. Positive knowledge is essentially about solving problems; it’s a sort of PhD intelligence, problem-solving kind of intelligence, where we have puzzles and can progress from one solution to a better solution. It’s possible to assess that one solution is better than the other, and the pinnacle of this sort of thinking is to achieve an optimal solution. However, what people think they are looking for – optimal solutions that are perfectly valid and immortal – what they get are very ephemeral solutions.
As an example, throughout the lifetime of Lokad, my company, we went through six generations of forecasting engines. The positive knowledge is ephemeral in the sense that this knowledge, this solution, is at risk when something better comes along, and you will just discard this piece of knowledge. At Lokad, we went through the tedious exercise of rewriting our own forecasting technology from scratch six times since the very beginning in 2008. This is why I say that positive knowledge is very ephemeral because it gets obsolete fast as new, better solutions come along.
On the contrary, if you look at negative knowledge, it’s a completely different perspective. You think in terms of wicked blunders, and the sort of intelligence you want to capture is the street-smart intelligence, the kind that helps you survive in a bad street at night. The focus is not so much on puzzles or things that are very complicated to understand and involve transfer; it’s more about what you don’t know or the taboos. It’s not what you don’t know; it’s what people won’t tell you, or the sort of things where people will even lie to you just because they want to save face. Negative knowledge is about fighting against all those taboos that prevent you from seeing the reality for what it is.
With negative knowledge, the mindset is not one of progress; it’s a mindset of survival. You just want to survive so that you can fight another day. That’s a very different perspective, and that’s exactly the sort of thing companies instinctively seek when they go for a very experienced supply chain director. They want to make sure that through this person, the company will live another day. What may be surprising is that negative knowledge tends to be much more durable. These are pretty much the flaws of human nature that are involved, and they don’t change over time just because there is a new technology, approach, or method. These things are here to stay.

In conclusion, I would say negative knowledge is of prime relevance for all wicked problems, supply chain being just the focus of interest of this lecture, but it’s not the only area where negative knowledge can be applied.
Supply chain anti-patterns are just a few examples, but I’m pretty sure dozens more could be identified to capture the problems that keep happening in real-world supply chains. We can’t hope to capture everything through anti-patterns, but I believe we can capture a decent portion. After reading a book about software anti-patterns, my subjective opinion was that I had gained the equivalent of five years of experience in software engineering in just 200 pages. My hope is that for a collection of supply chain anti-patterns, we could also replicate this effect, where someone could acquire something like five years’ worth of experience in a much shorter amount of time, perhaps just a few weeks.

That’s it for this lecture. The next lecture will be on vendor assessment, which is a very interesting problem. Modern supply chains live or die by the software products that support them, and the question is how we reason about those software products and how we pick the right ones and the right vendors. Despite having my fair share of conflicts of interest, it’s an interesting problem, and the question is how we can have a methodology where even if all the people have biases, we can get some kind of unbiased results out of the method.
Now, I will be addressing the questions.
Question: What constitutes a good forecast in a probabilistic optimization setting, and how to measure the quality? Is there a role for manual enrichments?
A good probabilistic forecast has metrics for probabilistic accuracies, but that’s probably not what you’re looking at. As part of an experimental optimization initiative, you will want to optimize. Metrics such as cross-entropy or likelihood apply to probabilistic forecasts. More importantly, there will be things that you will gradually discover as you identify insane decisions. The forecast is just a means to an end, which is the decision. You need to pay attention to the decisions. We briefly touched on this in the previous lecture about experimental optimization. The process is the same for classic or probabilistic forecasts. If you want to have real-world examples of probabilistic forecasts, this will be treated extensively in subsequent lectures. I’m sorry I’m digressing a bit in answering this question.
Question: What do you think of using AI (Appreciative Inquiry) to support your AI (Artificial Intelligence)? What techniques will you use to logically find out large data sets, and why are conversion rates decreasing despite good overall performance? What to tackle causing the activity?
AI, as a set of algorithms, is primarily deep learning right now. Deep learning is a set of techniques that are very capable of dealing with highly unstructured data. The question you should really ask yourself is how to connect that to reality. In supply chain, data tend to be very sparse. Most products in any given store are sold at less than one unit a day. Large data sets are only large in aggregate when you look at a very large company with tons of transactions. If you look at the granularities that really matter, you don’t have that much data.
Appreciative inquiry, in terms of methodologies, is really about the experimental optimization discussed in the previous lecture.
Question: Many managers don’t understand the power of data science, and giving fictitious problems for them is a safe path. If they don’t want to dig into learning about data science, what is an alternative way to make them believe in data science and decision-first approaches? How to start small and roll out big?
First, if you have people that don’t believe in a piece of technology, it’s perfectly fine. Take Warren Buffett, for example. He’s a very rich investor who spent his life investing in companies that he understands. He invests in companies with simplistic business models, like railroad transportation companies or furniture leasing companies. Warren Buffett said, “I’m not interested in understanding all those technologies.” For example, when people asked him why he didn’t invest in Google, Buffett responded, “I don’t understand anything about what Google is doing, so while it may be a good investment, I’m not smart enough for that. I’m just going to invest in companies that I understand.”
My point is, for management, I think it’s a complete delusion to venture into areas you don’t understand. At some point, if you’re not willing to make the effort, it’s just not going to work. That’s the Jedi anti-pattern at play – management is not willing to make any effort, and they think that just hiring smart, young, intelligent engineers will do the trick. If that were the case, Amazon wouldn’t have had the success it had. If it were possible for a traditional retail chain company to just hire a few engineers to start an e-commerce website and compete with Amazon, they all would have done that. Until around 2005, those companies had significantly more engineering resources and capabilities than Amazon itself.
The problem is that it is delusional, and that’s what negative knowledge is about – shedding light on the sort of problems that are ubiquitous. That’s why you need a catchy title to communicate the problem to managers. You also shouldn’t be afraid to learn about new things. When you really take the good part of new technology, it’s usually not that complicated. Not everything is super technical; many parts could be explained. For example, even something like blockchains – half of those supposedly super advanced blockchain technologies could be explained to 10-year-olds. Many of the ideas behind these technologies are actually fairly simple. There are tons of accidental mathematical technicalities that are very difficult, but that’s not the essence of the problem.
So, my answer to you would be, if management wants to believe in fairy tales, there’s not much that can be done in that situation. If management is willing to invest in data science, they should also be willing to invest a tiny bit of time in understanding what data science is about. Otherwise, it’s just delusional.
That’s it for today. Thank you very much, and the next lecture will be on the same day, Wednesday, two weeks from now, at the same time. See you then.
References
- ‘‘AntiPatterns: Refactoring Software, Architectures, and Projects in Crisis’’. y William J. Brown, Raphael C. Malveau, Hays W. “Skip” McCormick, Thomas J. Mowbray, 1998


