(短期)販売予測におけるデータクレンジングの誤謬
データ分析に関しては data analysis を始める前にクリーンなデータセットを用意する重要性が専門家によって(正当にも)頻繁に強調されます。さもなければ、Garbage In, Garbage Out となってしまいます。
その結果、ほとんどの予測ツールキットはデータクレンジング / データ準備をサポートするための豊富な機能を提供しています; それにもかかわらず、Lokad はデータクレンジングを明示的にサポートする機能を提供していません.
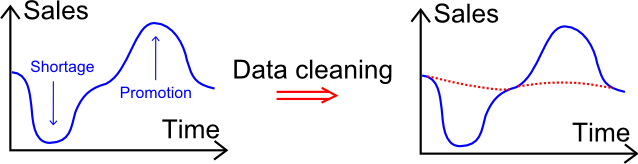
ここで何か大きなことを見落としていませんか?
私たちはそうは思いません。短期販売予測のためのデータクレンジングに関して、いくつかの誤解が存在します。実際、今日ではほとんどの小売業者、卸売業者、製造業者の販売は、ERP もしくは何らかの会計システムに保存されています。私たちの経験では、2010年時点で販売に関連する取引データは非常にクリーンです。もし2010年11月1日に製品Xが数量Yで販売されたという取引が記録されていれば、その情報が正確である確率は非常に高く、ほとんどの販売プロセスで99.9%以上の信頼性があります。
実際、企業は 何を販売しているかを知らない 余裕がありません。その結果、販売データが信頼できるものであることを確実にするため、過去20年間にわたり膨大な努力が払われてきました。システムに誤った販売エントリが一度も入力されないと言っているわけではなく、その割合は通常は重要ではないというだけです。
もし販売データがクリーンであるなら、なぜまだデータクレンジングに注力しているのでしょうか?
業界における多くのデータクレンジングの慣行を観察してきた結果、_cleaning_と呼ばれる操作は実際のところ0.1%の誤った取引を探す以上のものであることが判明しました。上記の図は、一般的なデータクレンジング段階で関与する_実際の_操作についての洞察を与えており、それはすべて極端な値の平滑化に関するものです。例えば、品薄時の部分的な販売は手動で増加され、プロモーションや例外的な販売は制限されます。
言うまでもなく、私たちはこのアプローチを信奉しているわけではありません。 実際の 販売データは 架空の 販売データに置き換えられるべきではありません。実際、品薄がなかった場合にどれだけの製品が_販売されたであろうか_を100%の確信をもって示すものはありません。部分的な販売こそが、統計的外挿に依存していない唯一の具体的なデータなのです。
しかしながら、smooth-_the-extreme_の手法には興味深い副作用があります:平滑化は、移動平均のように振る舞う_naive_な予測手法の精度を向上させるのです。
ハンマーしか持っていないなら、すべてを釘のように扱いたくなるというのは誘惑に抗えないものです。, Abraham Maslow, 1966
手元にある唯一の予測モデルに合わせるために販売データを調整しようとするのは、単に道具の法則の悪い例にすぎません。私たちのアプローチは、それらを回避しようとするのではなく、複雑なパターンに直接取り組むことにあります。


