スライスを用いたリアルタイムデータ探索
2か月前、我々はLokad向けに_画期的な_新機能、初のリアルタイムデータ探索機能をリリースしました。この機能はダッシュボード・スライシングと呼ばれ、Envisionを支える低レベルデータ処理バックエンドの全面的な刷新を余儀なくされました。ダッシュボードのスライスを用いることで、各ダッシュボードはまるでダッシュボードビューの辞書のようになり、検索バーを使ってリアルタイムに探索することが可能になります。
例えば、製品に関する全ての情報(確率論的需要やリードタイムの予測などを含む)が一箇所に集約された_製品検査_用ダッシュボードを_スライス_することで、リアルタイムに一つの製品から次の製品へ切り替えることが可能になりました。
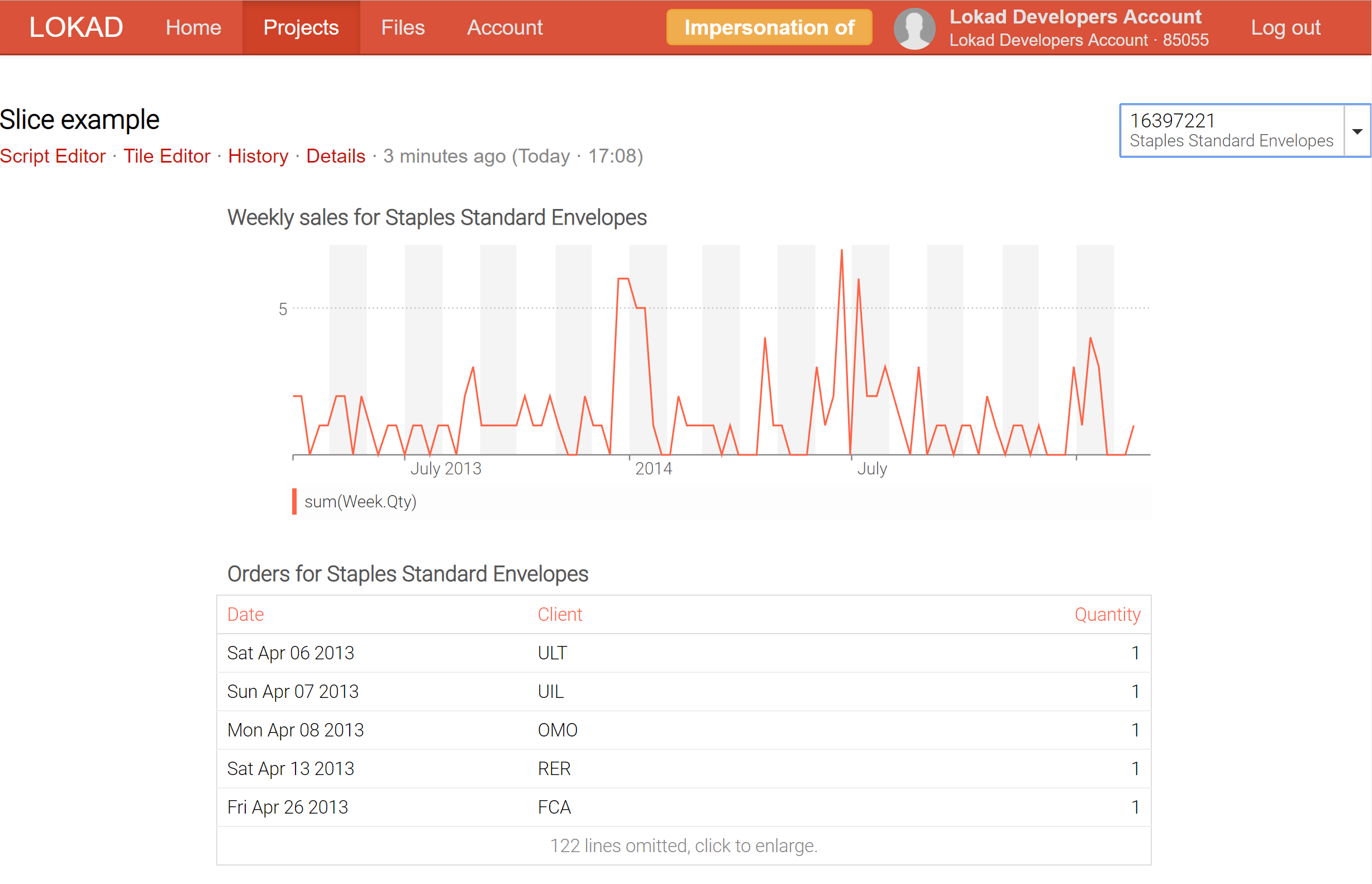
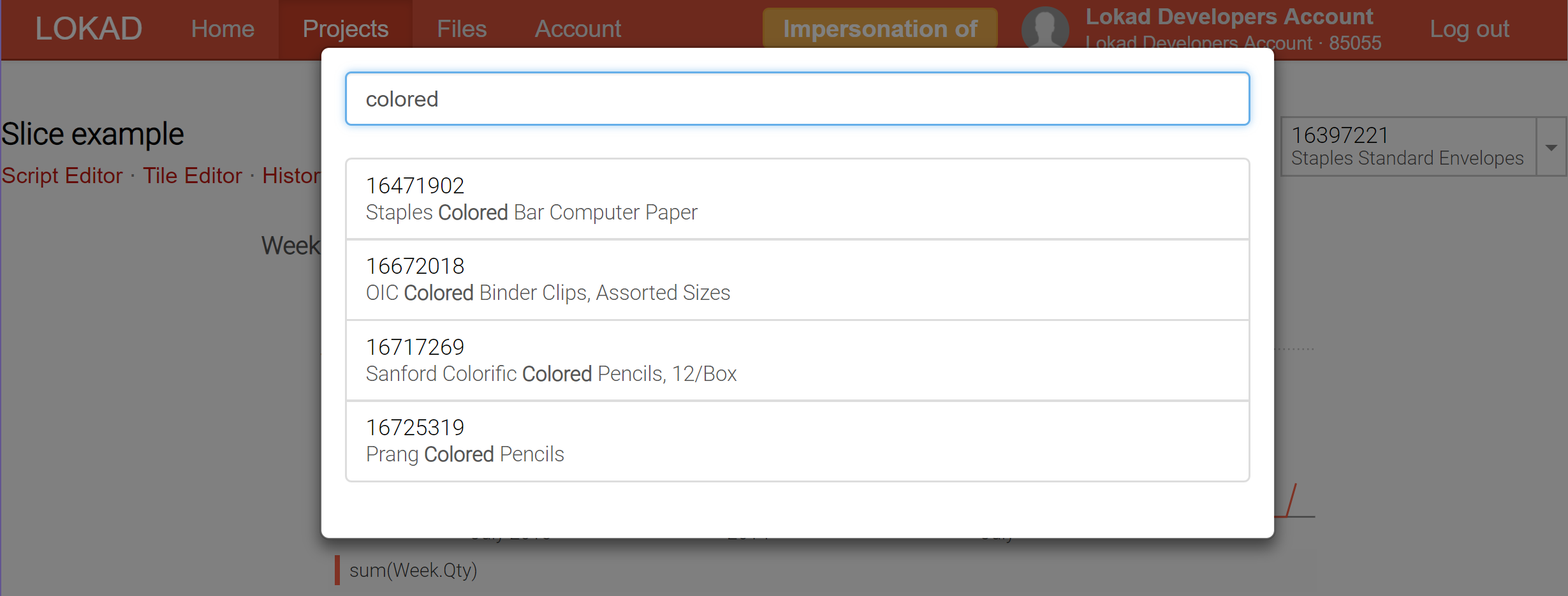
現時点で、Lokadは単一ダッシュボードに対して最大200,000スライス(すなわちダッシュボードビュー)の作成をサポートしており、これらのスライスはリアルタイム検索機能付きのセレクターを通じて即時に表示されます。ビジネス-インテリジェンス(BI)ツールとは異なり、これらのスライスは単なるOLAPキューブ上のslice-and-diceに留まらず、非常に複雑な計算を内包することができます.
データ集計とレポート作成においては、通常、オンライン処理とバッチ処理の2つの手法があります。オンライン処理はデータフィードを取り込み、システム上のすべての表示内容が常に最新であることが期待されます。つまり、システムは現実に比べ数分、時には数秒以上の遅れを取らないよう設計されています。OLAPキューブや_ビジネスインテリジェンス_と呼ばれる多くのツールはこのカテゴリに属します。リアルタイム1分析は、ビジネス(新鮮なデータは停滞データより優れる)だけでなく、エンドユーザーの観点からも(パフォーマンスは機能である)非常に望ましいものですが、多くの厳しい制約も伴います。要するに、リアルタイムでスマートな分析2を提供するのは極めて困難なのです。その結果、オンライン分析システムは実施可能な分析の種類において、重大な制限を受けることになります。
一方、バッチ処理は通常、すべての履歴データ(またはその大部分)が入力された状態で、スケジュールに従って実行されます(例:毎日の実行)。その結果の新鮮さはスケジュール頻度によって制限され、日次バッチでは常に昨日の状況を反映する結果となり、本日の状況を示すものではありません。初めから全データが揃っているため、バッチ処理はプロセス全体の計算性能を大幅に向上させる各種計算最適化を実行するのに理想的です。その結果、バッチ処理を通じて、オンライン処理では手の届かない複雑な計算群を実行することが可能になります。また、ITの観点からは、バッチ処理の実装や運用は3においても遥かに容易です。バッチ処理の主な欠点は、処理がバッチ単位で行われるために生じる遅延です。
ソフトウェアプラットフォームとして、Lokadは確実に_バッチ処理_陣営に属します。確かに、量的-供給-チェーン-マニフェストの最適化には高い反応性が求められますが、例えば追加のパレットを生産するか、在庫を一掃するために価格を下げるかといった即時の反応を必要としない多くの判断が存在します。こうした判断においては、最善の決定を下すことが最重要であり、たった1時間の計算投資でその決定が明確に改善されるのであれば、その1時間は十分に有効な投資と言えるでしょう4。
このように、Envisionはバッチ処理の視点を基に設計されています。テラバイト級のデータを扱う際にもEnvisionを非常に高速に動作させるために、多くの工夫を施していますが、この規模では結果を得るまでに数秒ではなく数分を要します。実際、Envisionの計算モデルが高度に分散化されているため、数メガバイトのデータであっても、Lokadが_いかなる_ Envisionスクリプトの実行を5秒未満で完了するのは困難です。システムがより_分散化_されるほど、全パーツの同期に内部慣性が働き、拡張性の向上は待機時間の増加を招くのです。
数年前、Envisionにエントリーフォームの概念を導入しました。これは、ダッシュボード上に設定可能なフォームを追加し、その入力値をEnvisionスクリプトから利用可能にする機能です。例えば、この機能を利用すれば、指定された製品に関する全ての関連情報を表示する_製品検査システム_としてのダッシュボードの設計が容易になりました。しかし、新たなフォーム値に合わせてダッシュボードを更新するためにはEnvisionスクリプトの再実行が必要となり、その結果、更新結果を得るまでに数秒の遅延が生じ、データ探索としてはあまりにも長い時間となってしまいました。
ダッシュボードスライス(詳しくは当社の技術ドキュメントをご覧ください)は、オンライン処理とバッチ処理の双方の利点を享受するための試みを示しています。つまり、Lokadは各スライス(各スライスは製品、地域、シナリオ、またはそれらの組み合わせを表す)をバッチで計算し、すべてが事前に計算されていることで、リアルタイムにスライス間を切り替えることが可能になったのです。もちろん、大量のスライスを事前計算するのは計算コストがかかりますが、それほど高額ではありません。通常、Lokadでは1スライスずつ100回独立して実行するよりも、一度に10,000スライスを計算する方が効率的です。
スライスを通じて、Lokadは飛躍的なビジネスインテリジェンス機能を獲得しています。これにより、リアルタイムで製品、地域、期間など多様な視点からデータを探索できるだけでなく、従来のオンライン処理アーキテクチャの制約からも解放されます。
-
分散システムにおいては「リアルタイム」という概念は存在しません。光の速度そのものが複数大陸にまたがるシステムの同期に厳しい制約を課しているため、この用語はやや誤解を招くものです。しかし、全体のレイテンシが1秒未満程度であれば、データ集計アプリを「リアルタイム」と呼ぶことは一般的に許容されます。 ↩︎
-
自動運転などに用いられる先進的なリアルタイムデータ処理システムでさえ、リアルタイム動作時には_学習_操作を極力避けています。全ての機械学習モデルは事前に計算され、静的なものとなっています。 ↩︎
-
バッチ処理の典型的な実装はフラットファイルの移動から成り、これは現代のほぼ全てのシステムでサポートされる基本機能です。さらに、運用面では、バッチ処理の一部コンポーネントが一時的に停止しても、単純な再試行ポリシーで通常は問題が解決します。対照的に、オンラインシステムでは、1つのコンポーネントが停止すると全体に悪影響を及ぼす傾向があります。 ↩︎
-
現在、主要なクラウドコンピューティングプラットフォームにおける従量課金制を用いた場合、現代CPUでの1時間の計算コストは通常$0.02未満です。したがって、たった1つのより良いサプライチェーンの意思決定によって生み出される利益が$0.02以上の価値がある限り、その1時間の計算投資は十分に合理的と言えます。 ↩︎

