ビジネスインテリジェンス(BI)
BI(ビジネスインテリジェンス)とは、企業が業務運営に用いる様々なビジネスシステムから収集されたトランザクションデータに基づく分析レポートの作成に特化したエンタープライズソフトウェアの一群を指します。BIは、IT専門家でないユーザーにもセルフサービスによるレポート作成機能を提供することを目的としており、既存レポートのパラメータ調整から新規レポートの作成まで、幅広いセルフサービス機能を備えています。多くの大企業は、トランザクションシステムの上に少なくとも1つのBIシステムを稼働させており、しばしばERPを含んでいます。
起源と動機
現代の分析レポートは、20世紀初頭に主にアメリカで最初の経済予測者12とともに登場しました。この初期の試みは非常に人気を博し、主流メディアで注目され、広く流通しました。この人気は、高情報密度の定量的レポートに対する強い関心があったことを示しています。1980年代、多くの大企業はビジネス取引を電子記録として保存し、初期のERPソリューションを活用してトランザクションデータベースに格納し始めました。これらのERPソリューションは、既存プロセスを合理化して生産性と信頼性を向上させることを目的としていました。しかし、多くの人々はこれらの記録に秘められた巨大な未開発の可能性を理解し、1983年にSAPはERP内で収集されたデータに基づくレポート生成に特化したABAP3プログラミング言語を導入しました。
しかし、1980年代に一般的に販売されていたリレーショナルデータベースシステムには、分析レポート作成に関して2つの主要な制約がありました。まず、レポートの設計は高度な訓練を受けたIT専門家によって行われる必要があり、これによりプロセスは遅く高額になり、導入できるレポートの多様性が大幅に制限されました。次に、レポート生成はコンピューティングハードウェアに非常に負荷をかけ、通常、業務が停止している夜間(バッチ処理)にのみ生成可能でした。これは、当時のハードウェアの制限だけでなく、ソフトウェアの制限も反映していました。
1990年代初頭、コンピュータハードウェアの進歩により、4異なる種類のソフトウェアソリューション、すなわちビジネスインテリジェンスソリューションが登場しました。RAM(ランダムアクセスメモリ)の価格は着実に低下し、その記憶容量は着実に増加していました。その結果、専用のよりコンパクトな形でビジネスデータをメモリ(RAM)内に保存し、即時にアクセス可能とする手法が技術的・経済的に実現可能となりました。これにより、10年前に実装された報告システムの2点の制約、すなわち非専門家向けのアクセス性の低さと、OLAP技術を備えた新しいバックエンドによる一部IT制約の解消が実現され、10年の終わりまでにBIソリューションは大企業の間で主流となりました。
コンピュータハードウェアの進化が続く中、2000年代後半には新世代のBIツールが登場しました5。1980年代のリレーショナルデータベースシステムは、レポート生成に不向きでしたが、2000年代には企業の全トランザクション履歴をRAMに保持できるようになりました。その結果、専用のOLAPバックエンドを持たなくても、複雑な分析クエリを数秒以内で完了できるようになり、BIソリューションの焦点はフロントエンドに移り、主にSaaS(サービスとしてのソフトウェア)によるよりアクセスしやすいウェブユーザーインターフェイスと、リレーショナルバックエンドの柔軟性を活かしたインタラクティブなダッシュボードが実現されました。
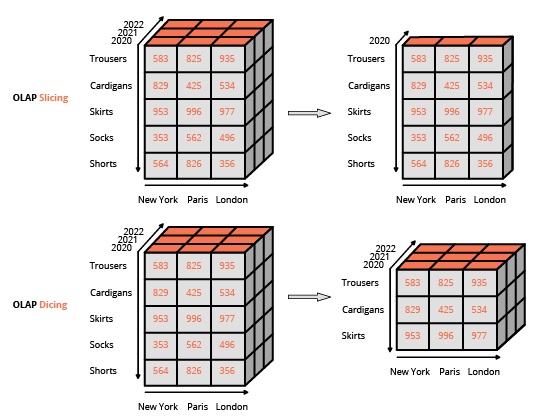
OLAPと多次元キューブ
OLAPはオンライン分析処理の略です。OLAPはBIソリューションのバックエンド設計に関連しており、この用語は1993年にエドガー・コッドによって造られ、6多くは1990年代以前に遡るソフトウェア設計の概念と、1960年代にまでさかのぼるアイデアを統合しています。これらの概念は、1990年代にBIを独自のソフトウェア製品群として確立する上で重要な役割を果たしました。OLAPは、レポート作成に必要なデータ量が多すぎて迅速な処理が困難な場合でも、タイムリーに新しい分析レポートを生成するという課題に対応しました。
新しい分析レポートを作成する最も単純な方法は、少なくとも一度データを読み込むことです。しかし、7データセットが非常に大きく、全体を読み込むのに数時間(場合によっては数日)かかる場合、新しいレポートの生成にも同様に長い時間が必要になります。したがって、数秒で更新されたレポートを生成するためには、レポート更新のたびに完全なデータセットを再読み込みする方法は採用できません。
OLAPは、興味のあるレポートを反映する、より小型でコンパクトなデータ構造の活用を提案しています。これらの特定のデータ構造は、新たなデータが利用可能になるたびに段階的に更新されることを意図しており、その結果、新しいレポート要求時には、BIシステムは全履歴データを再読み込みするのではなく、レポート生成に必要な情報を含むコンパクトなデータ構造のみを読み込めばよいのです。さらに、そのデータ構造が十分小さい場合、メモリ(RAM)に保持でき、トランザクションデータに用いる永続ストレージよりも高速にアクセスできます。
次の例を考えてみましょう。ある小売ネットワークが100のハイパーマーケットを運営しているとします。最高財務責任者(CFO)は、過去3年間の各店舗ごとの1日あたりのユーロ建て総売上を示すレポートを求めています。過去3年間の生の売上データは、各店舗でスキャンされたすべてのバーコードの1億行以上に達し、生の表形式では50GB以上の容量となります。しかし、100列(各ハイパーマーケット1列)と1095行(3年×365日)からなるテーブルは、1数値あたり4バイトの計算で、合計0.5MB未満に収まります。さらに、取引発生時には対応するセルが適宜更新されます。このようなテーブルの作成と維持は、OLAPシステムが内部でどのように動作しているかを示す好例です。
上記で説明したコンパクトなデータ構造は、通常OLAPキューブの形を取り、多次元キューブとも呼ばれます。キューブ内のセルは、その全体構造を定義する離散的な次元の交点に存在し、各セルには元のトランザクションデータから抽出された指標(または値)が格納され、しばしばファクトテーブルと呼ばれます。このデータ構造は、ほとんどの主流プログラミング言語で見られる多次元配列に似ており、キューブがコンピュータのメモリに収まる限り、次元に沿った効率的な射影や集約(合計、平均など)の操作が可能となります。
インタラクティブなレポート作成とデータ可視化
IT専門家でないエンドユーザーにレポート作成機能を提供することは、BIツール採用の主要な要因でした。そのため、これらの技術はWYSIWYG(見たままが得られる)設計を採用し、豊富なユーザーインターフェイスに依存しました。このアプローチは、SQLのような専門言語を使ってクエリを構築するという、従来のリレーショナルデータベースとのインターフェイスとは異なります。OLAPキューブを操作する通常のインターフェイスは、スプレッドシートのピボットテーブルのようなマトリックス形式で、ユーザーがフィルター(BI用語でslice and diceと呼ばれる)を適用し、平均、最小、最大、合計などの集約を行えるようにしています。
特に大規模なデータセットの処理を除けば、OLAPキューブの必要性は2000年代後半に、コンピュータハードウェアの飛躍的進歩とともに低下しました。新型の「薄型」BIツールはフロントエンドに専念して登場し、OLAPキューブを組み込んだ「厚型」ツールとは異なり、主にリレーショナルデータベースと連携するよう設計されました。この進化は、当時のリレーショナルデータベースが、データセットが一定サイズ以下であれば、全体にわたる複雑なクエリを数秒で実行可能であったために実現しました。薄型BIツールは、サポートする各種SQL方言の統一されたWYSIWYGエディターと見なすことができ(実際、内部ではSQLクエリを生成しています)、生成されたクエリの最適化により基盤データベースの応答時間を最小化することが主要な技術的課題となりました。
The data visualization capabilities of BI tools were largely a matter of data presentation on the client-side, either through a desktop or web app. Presentation capabilities progressed steadily until the 2000s when the end-user’s hardware (e.g., workstations and notebooks) started to vastly exceed (computationally speaking) what was needed for data visualization purposes. Nowadays, even the most elaborate data visualizations are untaxing processes, dwarfed in scale by the consumption of computing resources associated with the extraction and transformation of the underlying data being visualized.
BIの組織への影響
アクセスの容易さはほとんどのBIツール採用において決定的な要因でしたが、大企業の多様なデータ環境を把握するのは非常に困難です。さらに、BIツール自体が比較的使いやすくても、企業がBIツールを通して実装するレポートロジックは、ビジネスの複雑さを反映しているため、そのロジック自体はツールの操作性以上に使いにくい場合があります。
その結果、BIツールの導入は多くの大企業で専用のアナリティクスチームの創設につながりました。これらのチームは通常、IT部門と並んでサポート機能として運営され、パーキンソンの法則が示すように、仕事はその完了に利用可能な時間を埋めるように膨張するため、生成されるレポートの数に伴い、企業が得る(認識上または実際の)利益に関わらず、次第に規模が拡大していきます。
BIの技術的限界
多くの場合、BIツールは各種利点間のトレードオフを伴い、つまり、使いやすさが向上する一方で、表現力が制限されるということです。具体的には、データに適用される変換は、狭い範囲のフィルターと集約に限定されるため、多くの(あるいはほとんどの)ビジネス上の疑問、例えば*顧客の解約リスクは?*といった問題は、これらの演算子だけでは解決できません。もちろん、BIユーザーインターフェイスに高度な演算子を導入することは可能ですが、そのような「高度な」機能は8ツールを非技術者向けに使いやすくするという初期の目的と矛盾します。結果として、高度なデータクエリの設計は、ソフトウェアの構築と同様に本質的に困難な作業となり、ほとんどのBIツールは「生」のクエリ(通常はSQLまたはSQLに類似した方言)の記述機能を提供し、本来排除すべき技術的手法に頼らざるを得なくなっています。
第二の大きな制約は、パフォーマンスです。この制約は、薄型BIツールと厚型BIツールでそれぞれ異なる形で現れます。薄型BIツールは、生成したデータベースクエリの最適化のための高度なロジックを備えていますが、最終的にはバックエンドとして機能するデータベースが提供できるパフォーマンスに依存します。一見シンプルなクエリであっても、非効率な実行となり長い応答時間を招くことがあり、データベースエンジニアが対策としてデータベースを修正・改善することは可能ですが、これもまたBIツールを非技術者向けに使いやすくするという初期目的を損なう結果となります。
厚型BIツールの場合、そのパフォーマンスはOLAPキューブ自体の設計に起因します。キューブの次元が増加すると、多次元キューブをメモリに保持するために必要なRAMの量は急速に増大し、たとえ中程度の次元数(例:10)でも、キューブのメモリフットプリントに関して深刻な問題を引き起こす可能性があります。一般的に、メモリ内設計(特にOLAPキューブ)は、メモリ関連の問題に悩まされがちです。
さらに、キューブは元のトランザクションデータのロッシー(情報損失のある)表現であり、キューブを用いて行われる分析では、最初に失われた情報を回復することはできません。ハイパーマーケットの例を思い出してください。そのようなシナリオでは、バスケット(同時購入情報)はキューブ内で表現できず、結果として「同時購入」の情報は失われてしまいます。OLAPの「キューブ」設計は、表現可能なデータを厳しく制限しますが、正にこの制約こそが「オンライン」機能を可能にしているのです。
BIのビジネス上の限界
企業におけるBIツールの導入は、一見劇的な変革をもたらすように見えますが、実際には、数値そのものが何の行動にも結びつかなければ、企業にとって価値がないのです。BIツールの設計は「無制限な」レポート生成を強調していますが、実際の行動をサポートするものではなく、ほとんどの場合、BIツールの僅かな表現力では、BIレポートに基づいた自動化を実現するには不十分です。
また、BIツールは大企業の官僚的傾向を助長する傾向があります。逸話的な証拠、概算の数字、そして確かな判断だけで企業の優先順位を決定できる場合もありますが、一方で、BIのような自己目的的な分析ツールの存在は、先延ばしや、実行不可能な疑問指標の絶え間ない流れにより、状況を混乱させる十分な機会を提供してしまいます。
BIツールは、委員会方式の設計の欠点にさらされ、誰もがアイデアをプロジェクトに盛り込むことで問題が生じがちです。ツールのセルフサービス性は、新しいレポート導入に際し、非常に包括的なアプローチを強調します。その結果、レポート環境の複雑さは、元々反映すべきビジネスの複雑性とは無関係に、時間とともに増大する傾向があります。虚栄指標という用語は、通常BIツールを通じて実装される、会社の最終利益に寄与しないこのようなメトリクスを表現するために広く用いられるようになりました。
Lokadの見解
現代の計算機ハードウェアの性能を考えれば、1日あたり100万の数字を出力する報告システムの構築は容易ですが、読む価値のある10個の数字を生み出すのは困難です。少量で使用されるBIツールはほとんどの企業にとって有益ですが、使用量が増えると害となります。
実際、BIから得られる洞察には限界があります。レポートを次々に増やすと、追加される各レポートから得られる新た(または改善された)洞察の効果は急速に低下します。UIを通じて非専門家が容易に利用できるよう、BIツールでのデータ解析の深さは意図的に制限されています。
さらに、データから新たな洞察が得られたとしても、それが企業にとって実行可能なものになるとは限りません。BIは本質的に報告技術であり、企業にアクションを促すものではありません。BIのパラダイムは、日常的なものさえも自動化されたビジネス判断を目指していません。
Lokadプラットフォームの機能は、BIと同様に幅広い特注レポーティング機能を備えています。しかし、BIとは異なり、Lokadはビジネス判断、特にサプライチェーンに関するものの最適化を目的としています。実際には、サプライチェーン・サイエンティストに、Lokadを通じて関心のあるサプライチェーンの意思決定を生み出す数値レシピの設計およびその後の維持管理を担当してもらうことを推奨します.
注記
-
『Fortune Tellers: アメリカ初の経済予測者の物語』, ウォルター・フリードマン著 (2013). ↩︎
-
ABAPは1983年にSAPからリリースされたプログラミング言語で、Allgemeiner Berichts-Aufbereitungs-Prozessor(「一般報告処理プロセッサ」の意)の略です。この言語は、ERP(SAPとしても知られる)に報告機能を補完するため、BIシステムの先駆けとして導入されました。ABAPの目的は、カスタムレポート実装に伴うエンジニアリング負担を軽減することでした。1990年代には、ABAPはERP自体の設定および拡張言語として再利用され、この方針転換を反映するため、英語名はAdvanced Business Application Programmingに改名されました. ↩︎
-
1990年に設立され、2008年にSAPに買収されたBusinessObjectsは、1990年代に登場したBIソリューションの原型です. ↩︎
-
2003年に設立され、2019年にSalesforceに買収されたTableauは、2000年代に登場したBIソリューションの原型です. ↩︎
-
今日のOLAP製品の起源, Nigel Pendse, 最終更新: 2007年8月, ↩︎
-
計算機ハードウェアは1950年代から着実に進化してきました。しかし、より多くのデータを処理するコストが低下するたびに、より多くのデータを保存するコストも低下しました。その結果、1970年代以降、ビジネスデータの量は計算機ハードウェアの性能向上にほぼ追随する形で増加しています。したがって、「データが多すぎる」という概念は大きく変動するものとなっています. ↩︎
-
1990年代後半から2000年代初頭にかけ、多くのソフトウェア企業がプログラミング言語を視覚的ツールで置き換えようと試みましたが、失敗に終わりました。詳細は、Joel Spolskyによるレゴプログラミング(2006年12月)も参照してください. ↩︎