00:17 Introduzione
03:35 Ordini di grandezza
06:55 Fasi dell’ottimizzazione della supply chain
12:17 Le curve a S dell’hardware
15:52 La storia finora
17:34 Scienze ausiliarie
20:25 Computer moderni
20:57 Latenza 1/2
27:15 Latenza 2/2
30:37 Calcolo, velocità del clock
36:36 Calcolo, pipelining, 1/3
39:11 Calcolo, pipelining, 2/3
40:27 Calcolo, pipelining, 3/3
46:36 Calcolo, superscalare 1/2
49:55 Calcolo, superscalare 2/2
56:45 Memoria 1/3
01:00:42 Memoria 2/3
01:06:43 Memoria 3/3
01:11:13 Archiviazione dati 1/2
01:14:06 Archiviazione dati 2/2
01:18:36 Larghezza di banda
01:23:20 Conclusioni
01:27:33 Prossima lezione e domande del pubblico
Descrizione
Le supply chain moderne richiedono risorse informatiche per funzionare, proprio come i nastri trasportatori motorizzati richiedono elettricità. Tuttavia, i sistemi di supply chain lenti rimangono diffusi, mentre la potenza di elaborazione dei computer è aumentata di un fattore superiore a 10.000 volte dal 1990. Una mancanza di comprensione delle caratteristiche fondamentali delle risorse informatiche moderne - anche tra i circoli IT o di data science - contribuisce in gran parte a spiegare questa situazione. La progettazione del software alla base delle ricette numeriche non dovrebbe ostacolare il substrato informatico sottostante.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel e oggi presenterò “Computer moderni per la supply chain”. Le supply chain occidentali sono state digitalizzate da molto tempo, talvolta fino a tre decenni fa. Le decisioni basate su computer sono ovunque e le relative ricette numeriche vengono chiamate in vari modi, come punti di riordino, pianificazione delle scorte min-max e scorte di sicurezza, con diversi gradi di supervisione umana.
Tuttavia, se guardiamo alle grandi aziende di oggi che gestiscono supply chain di dimensioni equivalenti, vediamo milioni di decisioni che sono essenzialmente guidate dal computer e che determinano le prestazioni della supply chain. Pertanto, quando si tratta di migliorare le prestazioni della supply chain, si riduce rapidamente al miglioramento delle ricette numeriche che guidano la supply chain. Qui, inevitabilmente, quando iniziamo a considerare ricette numeriche superiori di qualsiasi tipo, dove vogliamo modelli migliori e previsioni più accurate, queste ricette superiori finiscono per costare molto di più in termini di risorse di calcolo.
Le risorse di calcolo sono state una lotta per la supply chain in quanto costano molto denaro e c’è sempre la prossima fase di evoluzione per il prossimo modello o il prossimo sistema di previsione che richiede dieci volte più risorse di calcolo rispetto al precedente. Sì, potrebbe portare a una maggiore performance della supply chain, ma comporta un aumento dei costi di calcolo. Negli ultimi decenni, l’hardware di calcolo ha fatto enormi progressi, ma come vedremo oggi, questo progresso, sebbene ancora in corso, è spesso ostacolato dal software aziendale. Di conseguenza, il software non diventa più veloce con hardware più moderno; al contrario, molto spesso può diventare più lento.
Lo scopo di questa lezione è instillare nel pubblico una certa dose di simpatia meccanica, in modo che possiate valutare se un software aziendale che dovrebbe implementare ricette numeriche destinate a fornire prestazioni superiori della supply chain abbraccia l’hardware di calcolo così com’è già esistente e come esisterà tra dieci anni, o se lo ostacola e quindi non sfrutta appieno l’hardware di calcolo che abbiamo oggi.

Uno degli aspetti più sorprendenti dei computer moderni è la gamma di ordini di grandezza coinvolti. Dal punto di vista della supply chain, di solito abbiamo circa cinque ordini di grandezza, e questo è già un’estensione; di solito non è nemmeno così. Cinque ordini di grandezza significano che possiamo passare da un’unità a 100.000 unità. Ricordate che qualcosa di cui ho parlato nelle lezioni precedenti è la legge dei numeri piccoli in gioco. Se avete un gran numero di unità, non le elaborerete singolarmente; le metterete in scatole e quindi vi troverete con un numero molto più piccolo di scatole. Allo stesso modo, se avete molte scatole, le metterete su pallet, ecc., in modo da avere un numero molto più piccolo di pallet. Le economie di scala inducono previsioni di quantità e dal punto di vista della supply chain, quando si tratta del flusso di beni fisici, un’inefficienza del 10% tende già ad essere significativa.
Nel campo dei computer, è molto diverso; stiamo affrontando 15 ordini di grandezza, che è assolutamente gigantesco. Passiamo da un’unità a un milione di miliardi di unità, il numero è così grande che è effettivamente molto difficile da visualizzare. Passiamo da un byte, che sono solo otto bit e possono essere utilizzati per rappresentare una lettera o una cifra, a un petabyte, che è un milione di gigabyte. Un petabyte è circa l’ordine di grandezza della quantità di dati che Lokad gestisce attualmente e le grandi aziende che operano grandi supply chain gestiscono anche set di dati dell’ordine di grandezza di un petabyte.
Passiamo da un FLOP (operazione in virgola mobile al secondo) a un petaFLOP, che è un milione di gigaFLOPS. Questi ordini di grandezza sono assolutamente giganteschi e molto ingannevoli. Di conseguenza, nel campo della supply chain, dove il 10% è considerato inefficiente, ciò che di solito accade nel campo dei computer è che non si tratta di essere inefficienti del 10%, ma piuttosto di essere inefficienti di un fattore di 10 e talvolta di diversi ordini di grandezza. Quindi, se si commette un errore in termini di prestazioni nel campo dei computer, la penalità non sarà del 10%; invece, il sistema sarà 10 volte più lento di quanto dovrebbe essere, o 100 volte, e talvolta anche mille volte più lento di quanto dovrebbe essere. Questo è ciò che è davvero in gioco: avere un vero allineamento, che richiede una sorta di simpatia meccanica tra il software aziendale e l’hardware di calcolo sottostante.
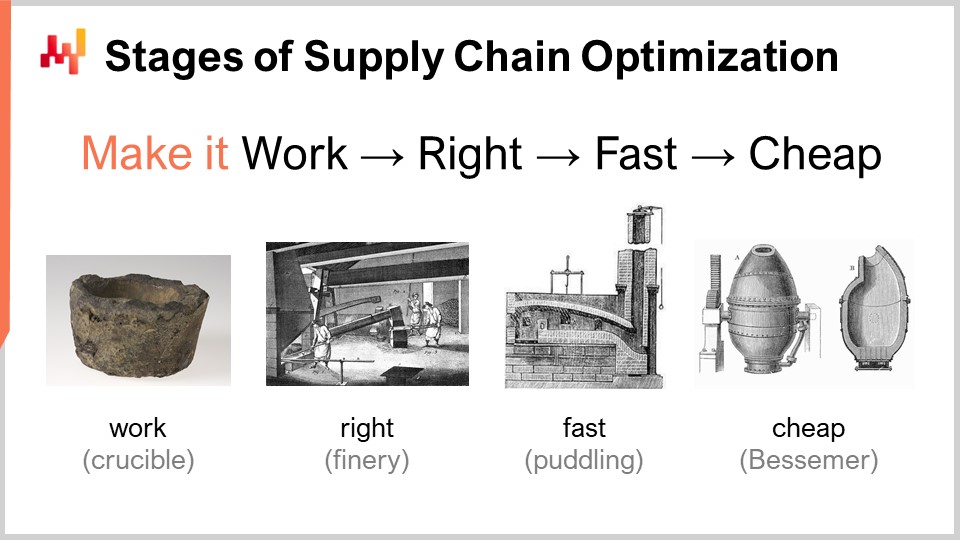
Quando si considera una ricetta numerica che dovrebbe fornire una sorta di prestazione superiore della supply chain, ci sono una serie di fasi di maturità che sono di interesse concettuale. Ovviamente, nella pratica i risultati possono variare, ma questo è tipicamente ciò che abbiamo identificato in Lokad. Queste fasi possono essere riassunte come: farlo funzionare, farlo corretto, farlo veloce e farlo economico.
“Farlo funzionare” significa valutare se una ricetta numerica prototipo sta realmente fornendo i risultati desiderati, come livelli di servizio più elevati, meno stock morto, migliore utilizzo delle risorse o qualsiasi altro obiettivo che sia valido dal punto di vista della supply chain. L’obiettivo è prima di tutto assicurarsi che la nuova ricetta numerica funzioni effettivamente nella prima fase di maturità.
Poi, bisogna “farlo corretto”. Dal punto di vista della supply chain, questo significa trasformare ciò che era essenzialmente un prototipo unico in qualcosa con una qualità di produzione. Questo comporta tipicamente l’aggiunta alla ricetta numerica di un certo grado di correttezza progettuale. Le supply chain sono vaste, complesse e, cosa più importante, molto disordinate. Se si ha una ricetta numerica molto fragile, anche se il metodo numerico è buono, è molto facile sbagliare e si finisce per creare molti più problemi rispetto ai benefici che si intendeva apportare in primo luogo. Questa non è una proposta vincente. Farlo corretto significa assicurarsi di avere qualcosa che può essere implementato su larga scala con attrito minimo. Quindi, si vuole rendere questa ricetta numerica veloce e quando dico veloce, intendo veloce in termini di tempo effettivo. Quando si avvia il calcolo, si dovrebbero ottenere i risultati entro pochi minuti, o forse un’ora o due al massimo, ma non più. Le supply chain sono disordinate e ci sarà un momento nella storia della vostra azienda in cui ci saranno interruzioni, come navi portacontainer bloccate nel mezzo del Canale di Suez, una pandemia o un magazzino allagato. Quando ciò accade, è necessario essere in grado di reagire rapidamente. Non sto dicendo di reagire nei prossimi millisecondi, ma se si hanno ricette numeriche che impiegano giorni per essere completate, si crea un’enorme attrito operativo. È necessario avere cose che possano essere gestite entro un breve periodo di tempo umano, quindi deve essere veloce.
Ricordate, il software aziendale moderno viene eseguito su cloud e è sempre possibile pagare per ulteriori risorse di calcolo su piattaforme di cloud computing. Pertanto, il vostro software può essere effettivamente veloce solo perché state affittando molta potenza di elaborazione. Non è che il software stesso debba essere progettato correttamente per sfruttare tutta la potenza di elaborazione che un cloud può fornire, ma può essere veloce e molto inefficiente solo perché state affittando molta potenza di elaborazione dal vostro fornitore di cloud computing.
La prossima fase è rendere il metodo economico, nel senso che non utilizza troppe risorse di cloud computing. Se non si passa a questa fase finale, significa che non si può mai migliorare il proprio metodo. Se si ha un metodo che funziona, è corretto e veloce ma consuma molte risorse, quando si vuole passare alla fase successiva della ricetta numerica, che inevitabilmente comporterà qualcosa che costa ancora più risorse di calcolo rispetto a quelle attualmente utilizzate, si rimarrà bloccati. È necessario rendere il metodo che si ha estremamente efficiente in modo da poter iniziare a sperimentare con ricette numeriche che sono meno efficienti rispetto a quelle attuali.
Quest’ultima fase è dove è davvero necessario abbracciare l’hardware sottostante disponibile nei computer moderni. Si può gestire le prime tre fasi senza troppa affinità, ma l’ultima è fondamentale. Ricordate, se non si arriva alla fase “rendilo economico”, non si sarà in grado di iterare e quindi si rimarrà bloccati. Ecco perché, anche se è l’ultima fase, questo è un gioco iterativo ed è essenziale passare attraverso tutte le fasi se si vuole iterare ripetutamente.
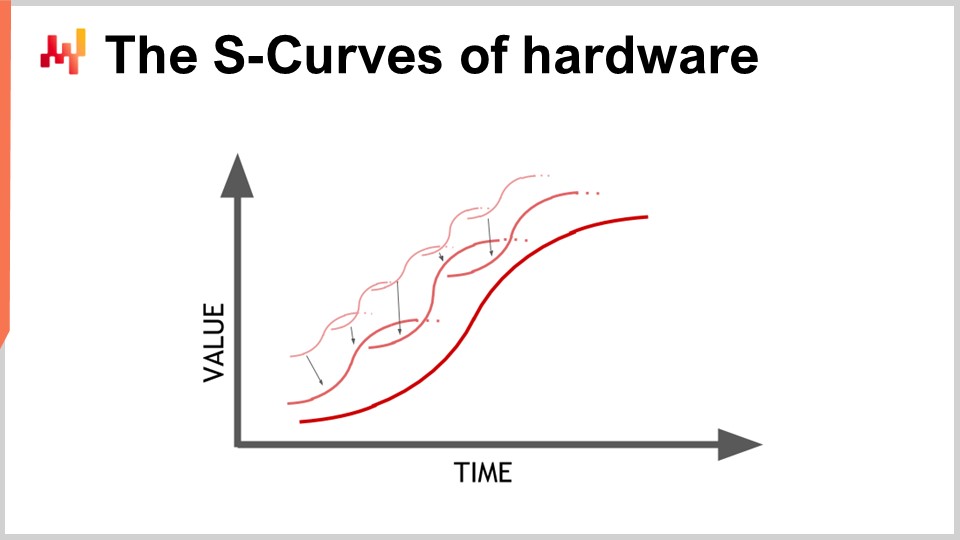
L’hardware sta progredendo e sembra una progressione esponenziale, ma la realtà è che questa progressione esponenziale dell’hardware di calcolo è effettivamente composta da migliaia di curve a S. Una curva a S è una curva in cui si introduce un nuovo design, processo, materiale o architettura e inizialmente non è realmente migliore di quello che si aveva prima. Poi, l’effetto dell’innovazione prevista entra in gioco e si ha una rampa di crescita, seguita da un plateau dopo aver sfruttato tutti i benefici dell’innovazione. Le curve a S in fase di plateau sono caratteristiche del progresso dell’hardware informatico, che è composto da migliaia di queste curve. Da una prospettiva di profano, questo appare come una crescita esponenziale. Tuttavia, gli esperti vedono le singole curve a S che si stabilizzano, il che può portare a una visione pessimistica. Anche gli esperti non vedono sempre l’emergere di nuove curve a S che sorprendono tutti e continuano la crescita esponenziale del progresso.
Sebbene l’hardware di calcolo stia ancora progredendo, il ritmo di progresso è lontano da quello che abbiamo sperimentato negli anni ‘80 o ‘90. Il ritmo è ora molto più lento e abbastanza prevedibile, in gran parte a causa degli enormi investimenti necessari per costruire nuove fabbriche per la produzione di hardware di calcolo. Questi investimenti spesso ammontano a centinaia di milioni di dollari, fornendo una visibilità a cinque o dieci anni. Sebbene il progresso si sia rallentato, abbiamo comunque una visione abbastanza accurata di ciò che accadrà in termini di progresso dell’hardware di calcolo per il prossimo decennio.
La lezione per il software aziendale che implementa ricette numeriche è che non si può passivamente aspettarsi che l’hardware futuro migliori tutto per voi. L’hardware sta ancora progredendo, ma catturare questo progresso richiede uno sforzo da parte del software. Sarà possibile fare di più con l’hardware che esisterà tra dieci anni, ma solo se l’architettura alla base del vostro software aziendale abbraccia l’hardware di calcolo sottostante. Altrimenti, potreste effettivamente fare peggio di quanto state facendo oggi, una proposta che non è così irragionevole come sembra.
Questa lezione è la prima del quarto capitolo di questa serie di lezioni sulla supply chain. Non ho ancora finito il terzo capitolo sulla personae della supply chain. Nelle prossime lezioni, probabilmente alternerò tra il presente capitolo, in cui sto trattando le scienze ausiliarie della supply chain, e il terzo capitolo sulle personae della supply chain.
Nel primo capitolo del prologo, ho presentato il mio punto di vista sulla supply chain come campo di studio e pratica. Abbiamo visto che la supply chain è essenzialmente una collezione di problemi complessi, contrapposti ai problemi semplici, afflitti da comportamenti avversari e giochi competitivi. Pertanto, dobbiamo prestare molta attenzione alla metodologia perché le metodologie dirette naive hanno prestazioni scadenti in questo campo. Ecco perché il secondo capitolo è stato dedicato alla metodologia necessaria per studiare le supply chain e stabilire pratiche per migliorarle nel tempo.
Il terzo capitolo, Personae della Supply Chain, si è concentrato sulla caratterizzazione dei problemi della supply chain stessa, con il motto “innamorati del problema, non della soluzione”. Il quarto capitolo che stiamo aprendo oggi riguarda le scienze ausiliarie delle supply chain.

Le scienze ausiliarie sono discipline che supportano lo studio di un’altra disciplina. Non c’è un giudizio di valore; non si tratta di una disciplina superiore a un’altra. Ad esempio, la medicina non è superiore alla biologia, ma la biologia è una scienza ausiliaria per la medicina. La prospettiva delle scienze ausiliarie è ben consolidata e diffusa in molti campi di ricerca, come le scienze mediche e la storia.
Nelle scienze mediche, le scienze ausiliarie includono la biologia, la chimica, la fisica e la sociologia, tra le altre. Un medico moderno non sarebbe considerato competente se non avesse conoscenze di fisica. Ad esempio, capire le basi della fisica è necessario per interpretare un’immagine a raggi X. Lo stesso vale per la storia, che ha una lunga serie di scienze ausiliarie.
Quando si tratta di supply chain, una delle mie principali critiche ai materiali, ai corsi, ai libri e agli articoli tipici sulla supply chain è che trattano l’argomento senza approfondire le scienze ausiliarie. Trattano la supply chain come se fosse una conoscenza isolata e autonoma. Tuttavia, ritengo che la pratica moderna della supply chain possa essere realizzata solo sfruttando appieno le scienze ausiliarie delle supply chain. Una di queste scienze ausiliarie, e l’oggetto della lezione di oggi, è l’hardware di calcolo.
Questa lezione non è strettamente una lezione sulla supply chain, ma piuttosto sull’hardware di calcolo con applicazioni nella supply chain in mente. Credo che sia fondamentale per praticare la supply chain in modo moderno, a differenza di come veniva fatto un secolo fa.

Diamo un’occhiata ai computer moderni. In questa lezione, esamineremo cosa possono fare per la supply chain, concentrandoci in particolare sugli aspetti che hanno un impatto enorme sulle prestazioni del software aziendale. Esamineremo la latenza, il calcolo, la memoria, l’archiviazione dei dati e la larghezza di banda.

La velocità della luce è di circa 30 centimetri per nanosecondo, che è relativamente lenta. Se si considera la distanza caratteristica di interesse per una CPU moderna che opera a 5 gigahertz (5 miliardi di operazioni al secondo), la distanza di andata e ritorno che la luce può percorrere in 0,2 nanosecondi è solo di 3 centimetri. Ciò significa che, a causa del limite della velocità della luce, le interazioni non possono avvenire oltre i 3 centimetri. Questo è un limite rigido imposto dalle leggi della fisica e non è chiaro se saremo mai in grado di superarlo.
La latenza è un vincolo estremamente difficile. Dal punto di vista della supply chain, sono coinvolti almeno due distribuzioni di hardware di calcolo. Quando parlo di hardware di calcolo distribuito, intendo hardware di calcolo che coinvolge molti dispositivi che non possono occupare lo stesso spazio fisico. Ovviamente, è necessario tenerli separati solo perché hanno dimensioni proprie. Tuttavia, la prima ragione per cui abbiamo bisogno di calcolo distribuito è la natura delle supply chain, che sono distribuite geograficamente. Per definizione, le supply chain sono distribuite su diverse aree geografiche e, quindi, anche l’hardware di calcolo sarà distribuito su tali aree geografiche. Dal punto di vista della velocità della luce, anche se hai dispositivi distanti solo tre metri, è già molto lento perché ci vogliono 100 cicli di clock per il viaggio di andata e ritorno. Tre metri sono una distanza considerevole dal punto di vista della velocità della luce e della frequenza di clock delle CPU moderne.
Un altro tipo di distribuzione è la scalabilità orizzontale. Il modo moderno di avere più potenza di elaborazione a disposizione non è avere un dispositivo di calcolo 10 volte o un milione di volte più potente; non è così che è progettato. Se si desidera avere più risorse di elaborazione, è necessario disporre di dispositivi di calcolo aggiuntivi, più processori, più chip di memoria e più hard disk. È accumulando l’hardware che è possibile avere più risorse di calcolo a disposizione. Tuttavia, tutti questi dispositivi occupano spazio e quindi si finisce per distribuire l’hardware di calcolo solo perché non è possibile centralizzarlo in un computer largo un centimetro.
Per quanto riguarda le latenze, guardando le latenze che abbiamo su Internet professionale (le latenze che si possono ottenere in un data center, non sulla propria rete Wi-Fi domestica), siamo già al 30% della velocità della luce. Ad esempio, la latenza tra un data center vicino a Parigi, Francia, e New York, Stati Uniti, è solo al 30% della velocità della luce. Questo è un incredibile risultato per l’umanità; le informazioni stanno fluendo su Internet quasi alla velocità della luce. Sì, c’è ancora margine di miglioramento, ma siamo già vicini ai limiti imposti dalla fisica.
Di conseguenza, ci sono persino aziende che vogliono posare cavi attraverso il fondo del mare artico per collegare Londra a Tokyo con un cavo che passerebbe sotto il Polo Nord, solo per ridurre di qualche millisecondo la latenza delle transazioni finanziarie. Fondamentalmente, la latenza e la velocità della luce sono preoccupazioni molto reali e l’Internet che abbiamo è essenzialmente il migliore che potrà mai essere a meno che non ci siano progressi nella fisica. Tuttavia, non abbiamo nulla del genere in vista per il prossimo decennio.
A causa del fatto che la latenza è un problema estremamente difficile, le implicazioni per il software aziendale sono significative. I viaggi di andata e ritorno in termini di flusso di informazioni sono letali e le prestazioni del software aziendale dipenderanno in gran parte dal numero di viaggi di andata e ritorno tra i vari sottosistemi presenti nel software. Il numero di viaggi di andata e ritorno caratterizzerà la latenza incompressibile che si subisce. Ridurre al minimo i viaggi di andata e ritorno e migliorare le latenze è, per la maggior parte dei software aziendali, compresi quelli dedicati all’ottimizzazione predittiva delle supply chain, il problema numero uno. Mitigare le latenze spesso equivale a fornire migliori prestazioni.

Un trucco interessante, anche se non qualcosa che tutti in questa platea utilizzeranno in produzione, è affrontare le complicazioni introdotte dalla latenza. Il tempo stesso diventa sfuggente e sfocato quando si entra nel campo dei calcoli al nanosecondo. È difficile trovare orologi precisi nel calcolo distribuito e la loro assenza introduce complicazioni all’interno del software aziendale distribuito. Sono necessari numerosi viaggi di andata e ritorno per sincronizzare le varie parti del sistema. A causa della mancanza di un orologio preciso, si finisce con alternative algoritmiche come orologi vettoriali o timestamp multipli, che sono strutture dati che riflettono un ordinamento parziale degli orologi dei dispositivi nel sistema. Questi viaggi di andata e ritorno extra possono danneggiare le prestazioni.
Un design intelligente adottato da Google oltre un decennio fa è stato quello di utilizzare orologi atomici a livello di chip. La risoluzione di questi orologi atomici è significativamente migliore rispetto a quella degli orologi a base di quarzo presenti negli orologi elettronici o nei computer. NIST ha dimostrato una nuova configurazione di orologio atomico a livello di chip con una deriva giornaliera ancora più precisa. Google ha utilizzato orologi atomici interni per sincronizzare le varie parti del loro database SQL distribuito globalmente, Google Spanner, al fine di risparmiare viaggi di andata e ritorno e migliorare le prestazioni su scala globale. Questo è un modo per aggirare la latenza attraverso misurazioni temporali molto precise.
Guardando a dieci anni nel futuro, è probabile che Google non sia l’ultima azienda a utilizzare questo tipo di trucco intelligente e sono relativamente accessibili, con orologi atomici a livello di chip che costano circa $1.500 ciascuno.

Ora, diamo un’occhiata al calcolo, che riguarda l’esecuzione di calcoli con un computer. La velocità dell’orologio è stata l’ingrediente magico del miglioramento negli anni ‘80 e ‘90. Infatti, se potessi raddoppiare la velocità dell’orologio del tuo computer in generale, potresti effettivamente raddoppiare le prestazioni del tuo computer, indipendentemente dal tipo di software coinvolto. Tutto il software sarebbe più veloce in modo lineare in base alla velocità dell’orologio. È estremamente interessante aumentare la velocità dell’orologio ed è ancora in miglioramento, anche se il miglioramento si è appiattito nel tempo. Quasi 20 anni fa, la velocità dell’orologio era di circa 2 GHz e oggi è di 5 GHz.
La ragione principale di questo miglioramento appiattito è il muro di potenza. Il problema è che quando aumenti la velocità dell’orologio su un chip, tendi a raddoppiare approssimativamente il consumo di energia e poi devi dissipare questa energia. Il problema è la dissipazione termica perché, se non puoi dissipare l’energia, il tuo dispositivo accumula calore fino al punto in cui danneggia il dispositivo stesso. Oggi, l’industria dei semiconduttori è passata da avere più operazioni al secondo a avere più operazioni per watt.
Questa regola di un aumento del 30% che raddoppia il consumo di energia è una spada a doppio taglio. Se ti va bene rinunciare a un quarto della potenza di elaborazione per unità di tempo sulla CPU, puoi effettivamente dividere il consumo di energia per due. Questo è particolarmente interessante per gli smartphone, dove il risparmio energetico è cruciale, e anche per il cloud computing, dove uno dei principali fattori di costo è l’energia stessa. Per avere una potenza di elaborazione del cloud computing conveniente, non si tratta di avere CPU super veloci, ma piuttosto di avere CPU sottovalutate che possono essere lente come 1 GHz, in quanto forniscono più operazioni al secondo per il tuo investimento energetico.
Il muro di potenza è un problema così grande che le moderne architetture delle CPU stanno utilizzando tutti i tipi di trucchi intelligenti per mitigarlo. Ad esempio, le moderne CPU possono regolare la loro velocità dell’orologio, aumentandola temporaneamente per un secondo o più prima di ridurla per dissipare il calore. Possono anche sfruttare ciò che viene chiamato silicio scuro. L’idea è che se la CPU può alternare le aree calde sul chip, è più facile dissipare l’energia rispetto ad avere sempre la stessa area attiva ciclo di clock dopo ciclo di clock. Questo è un ingrediente molto importante del design moderno. Dal punto di vista del software aziendale, significa che si desidera davvero essere in grado di scalare. Si desidera essere in grado di fare di più con molte volte più CPU, ma individualmente, quei processori saranno più deboli rispetto ai precedenti che avevi. Non si tratta di ottenere processori migliori nel senso che tutto è migliore in generale; si tratta di avere processori che ti offrono più operazioni per watt e questa tendenza continuerà.
Forse tra dieci anni, raggiungeremo, con difficoltà, sette o forse otto gigahertz, ma non sono nemmeno sicuro che ci arriveremo. Quando guardo la velocità dell’orologio nel 2021 nella maggior parte dei fornitori di cloud computing, è più allineata con tipicamente 2 GHz, quindi siamo tornati alla velocità dell’orologio che avevamo 20 anni fa ed è la soluzione più conveniente.
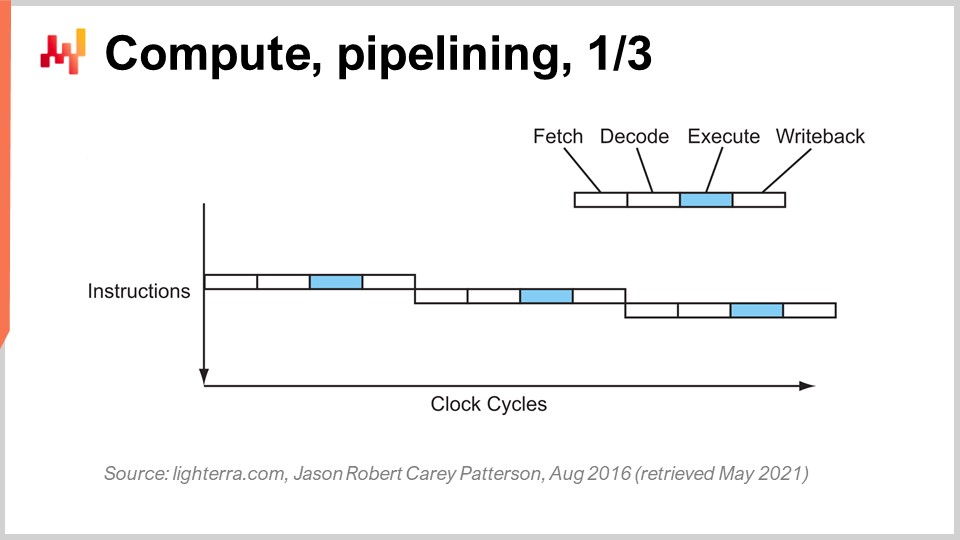
Raggiungere le prestazioni attuali della CPU ha richiesto una serie di innovazioni chiave. Presenterò alcune di esse, in particolare quelle che hanno avuto il maggior impatto sul design del software aziendale. In questa schermata, quello che stai vedendo è il flusso di istruzioni di un processore sequenziale, come i processori erano fatti essenzialmente fino agli anni ‘80. Hai una serie di istruzioni che vengono eseguite dall’alto del grafico verso il basso, rappresentando il tempo. Ogni istruzione passa attraverso una serie di fasi: fetch, decode, execute e write back.
Durante la fase di fetch, si recupera l’istruzione, si registra, si prende la prossima istruzione, si incrementa il contatore delle istruzioni e si prepara la CPU. Durante la fase di decode, si decodifica l’istruzione ed emette il microcodice interno, che è ciò che la CPU sta eseguendo internamente. La fase di esecuzione comporta il recupero degli input pertinenti dai registri e l’esecuzione del calcolo effettivo, mentre la fase di write back comporta l’ottenimento del risultato appena calcolato e la sua posizionamento in uno dei registri. In questo processore sequenziale, ogni singola fase richiede un ciclo di clock, quindi sono necessari quattro cicli di clock per eseguire un’istruzione. Come abbiamo visto, è molto difficile aumentare la frequenza dei cicli di clock stessi a causa di molte complicazioni.
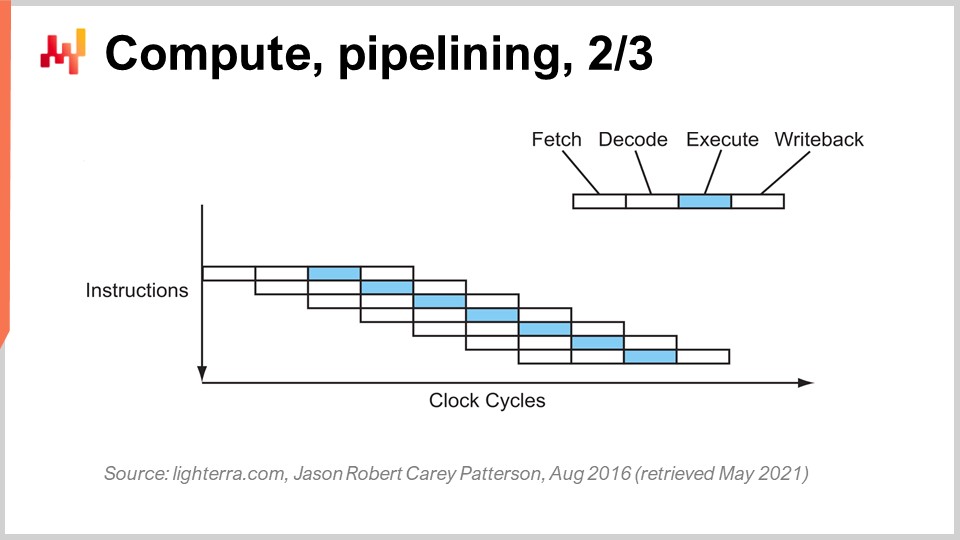
Il trucco chiave che è stato in uso fin dagli anni ‘80 in poi è noto come pipelining. Il pipelining può enormemente velocizzare il calcolo del tuo processore. L’idea è che, dato il fatto che ogni singola istruzione passa attraverso una serie di fasi, sovrapporremo le fasi e quindi la CPU stessa avrà un’intera pipeline di istruzioni. In questo diagramma, puoi vedere una CPU con una pipeline di profondità quattro, in cui vengono eseguite sempre quattro istruzioni contemporaneamente. Tuttavia, non sono nella stessa fase: un’istruzione è nella fase di fetch, una nella fase di decode, una nella fase di esecuzione e una nella fase di write-back. Con questo semplice trucco, rappresentato qui come un processore a pipeline, abbiamo moltiplicato le prestazioni effettive del processore per quattro semplicemente pipelining delle operazioni. Tutte le CPU moderne utilizzano il pipelining.
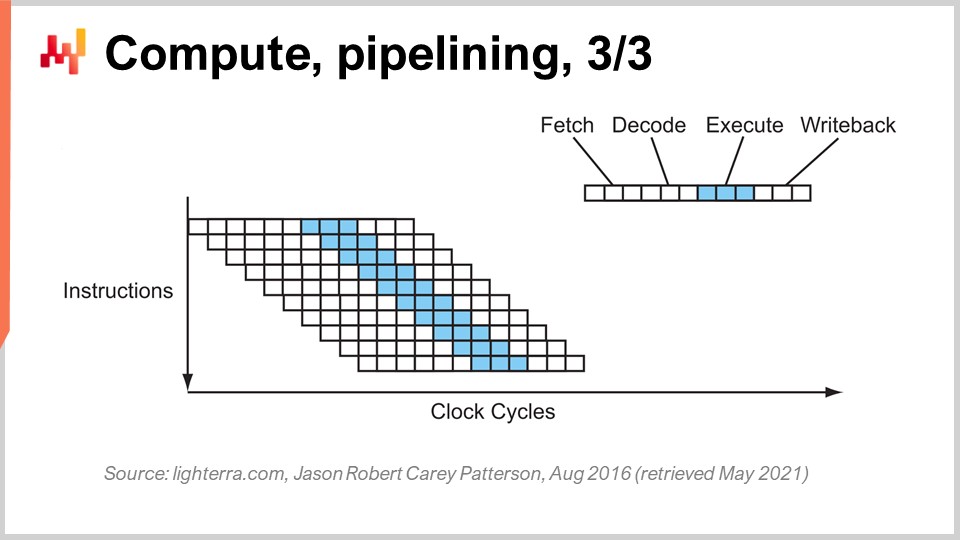
La fase successiva di questo miglioramento è chiamata super pipelining. Le CPU moderne vanno ben oltre il semplice pipelining. In realtà, il numero di fasi coinvolte in una CPU moderna reale è più simile a 30 fasi. Nel grafico, puoi vedere una CPU con 12 fasi come esempio, ma in realtà sarebbero più simili a 30 fasi. Con questa pipeline più profonda, possono essere eseguite contemporaneamente 12 operazioni, il che è molto buono per le prestazioni pur utilizzando lo stesso ciclo di clock.
Tuttavia, c’è un nuovo problema: la prossima istruzione inizia prima che la precedente sia finita. Ciò significa che se hai operazioni che dipendono l’una dall’altra, hai un problema perché il calcolo degli input per la prossima istruzione non è ancora pronto e devi aspettare. Vogliamo utilizzare l’intera pipeline a nostra disposizione per massimizzare la potenza di elaborazione. Pertanto, le CPU moderne non recuperano solo un’istruzione alla volta, ma circa 500 istruzioni alla volta. Guardano molto avanti nella lista delle prossime istruzioni e le riorganizzano per mitigare le dipendenze, intrecciando i flussi di esecuzione per sfruttare la piena profondità della pipeline.
Ci sono molte cose che complicano questa operazione, soprattutto i branch. Un branch è semplicemente una condizione nella programmazione, come quando scrivi un’istruzione “if”. Il risultato della condizione può essere vero o falso e a seconda del risultato, il tuo programma eseguirà una parte di logica o un’altra. Questo complica la gestione delle dipendenze perché la CPU deve indovinare la direzione in cui andranno i branch futuri. Le CPU moderne utilizzano la previsione dei branch, che coinvolge euristiche semplici e ha una precisione di previsione molto elevata. Possono prevedere la direzione dei branch con una precisione superiore al 99%, che è migliore di quello che la maggior parte di noi può fare in un contesto di supply chain reale. Questa precisione è necessaria per sfruttare le pipeline super profonde.
Solo per darti un’idea delle euristiche utilizzate per la previsione dei branch, una euristica molto semplice è dire che il branch andrà nella stessa direzione, nello stesso senso, in cui è andato l’ultima volta. Questa semplice euristica ti dà una precisione di circa il 90%, che è abbastanza buona. Se aggiungi un’aggiunta a questa euristica, che è che il branch andrà nella stessa direzione dell’ultima volta, ma devi considerare l’origine, quindi è lo stesso branch proveniente dalla stessa origine, allora otterrai una precisione di circa il 95%. Le CPU moderne stanno effettivamente utilizzando perceptron abbastanza complessi, che è una tecnica di apprendimento automatico, per prevedere la direzione dei branch.
Nelle giuste condizioni, puoi prevedere i branch in modo abbastanza accurato e quindi sfruttare l’intera pipeline per ottenere il massimo da un processore moderno. Tuttavia, dal punto di vista dell’ingegneria del software, è necessario comportarsi correttamente con il processore, soprattutto con la previsione dei branch. Se non ti comporti correttamente, significa che il predittore dei branch sbaglierà e quando ciò accade, la CPU prevederà la direzione del branch, organizzerà la pipeline e inizierà a fare calcoli in anticipo. Quando il branch viene effettivamente incontrato e il calcolo viene effettivamente eseguito, la CPU si renderà conto che la previsione del branch era sbagliata. Una previsione del branch errata non comporta un risultato errato; comporta una perdita di prestazioni. La CPU non avrà altra scelta che svuotare l’intera pipeline, o una grande parte di essa, attendere che vengano effettuati altri calcoli e quindi riavviare il calcolo. Il calo delle prestazioni può essere molto significativo e si possono perdere facilmente uno o due ordini di grandezza in termini di prestazioni a causa della logica del software aziendale che non si comporta bene con la logica di previsione dei branch della CPU.
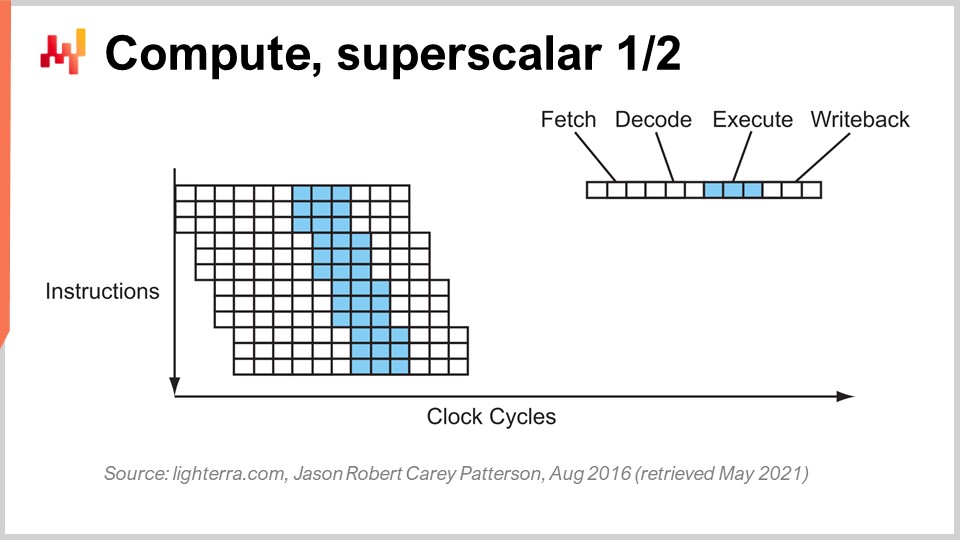
Un altro trucco degno di nota oltre al pipelining è l’istruzione superscalare. Le CPU elaborano tipicamente scalari, o coppie di scalari, contemporaneamente, ad esempio due numeri con una precisione in virgola mobile a 32 bit. Eseguono operazioni scalari, essenzialmente elaborando un numero alla volta. Tuttavia, le CPU moderne degli ultimi dieci anni hanno praticamente tutte caratteristiche di istruzioni superscalari, che possono effettivamente elaborare diversi vettori di numeri e eseguire operazioni vettoriali direttamente. Ciò significa che una CPU può prendere un vettore di, diciamo, otto numeri in virgola mobile e un secondo vettore di otto numeri in virgola mobile, eseguire un’addizione e ottenere un vettore di numeri in virgola mobile che rappresentano i risultati di questa addizione. Tutto ciò viene fatto in un solo ciclo.
Ad esempio, i set di istruzioni specializzate come AVX2 ti consentono di eseguire operazioni considerando 32 bit di precisione con pacchetti di otto numeri, mentre AVX512 ti consente di farlo con pacchetti di 16 numeri. Se sei in grado di sfruttare queste istruzioni, significa che puoi letteralmente guadagnare un ordine di grandezza in termini di velocità di elaborazione perché un’istruzione, un ciclo di clock, fa molti più calcoli rispetto all’elaborazione dei numeri uno per uno. Questo processo è noto come SIMD (Single Instruction, Multiple Data) ed è molto potente. Ha guidato la maggior parte dei progressi degli ultimi dieci anni in termini di potenza di elaborazione e i processori moderni sono sempre più basati su vettori e superscalari. Tuttavia, dal punto di vista del software aziendale, è relativamente complicato. Con il pipelining, il tuo software deve comportarsi correttamente e forse si comporta correttamente con la previsione dei branch accidentalmente. Tuttavia, quando si tratta di istruzioni superscalari, non c’è nulla di accidentale. Il tuo software deve davvero fare alcune cose in modo esplicito, nella maggior parte dei casi, per sfruttare questa potenza di elaborazione aggiuntiva. Non lo ottieni gratuitamente; devi abbracciare questo approccio e, di solito, devi organizzare i dati stessi in modo da avere il parallelismo dei dati e i dati sono organizzati in modo adatto alle istruzioni SIMD. Non è una scienza esatta, ma non accade per caso e ti offre un enorme aumento in termini di potenza di elaborazione.

Oggi, le moderne CPU possono avere molti core e un singolo core di CPU può fornire un flusso distinto di istruzioni. Con le CPU molto moderne che hanno molti core, tipicamente le CPU attuali possono arrivare fino a 64 core, quindi 64 flussi di esecuzione concorrenti indipendenti. È possibile raggiungere circa un teraflop, che è il limite superiore della capacità di elaborazione che si può ottenere da un processore molto moderno. Tuttavia, se si desidera andare oltre, è possibile guardare alle GPU (Unità di elaborazione grafica). Contrariamente a quanto si potrebbe pensare, questi dispositivi possono essere utilizzati per compiti che non hanno nulla a che fare con la grafica.
Una GPU, come quella di NVIDIA, è un processore superscalare. Invece di avere fino a 64 core come le CPU di fascia alta, le GPU possono avere più di 10.000 core. Questi core sono molto più semplici e non sono potenti o veloci come i core delle CPU regolari, ma ce ne sono molti di più. Portano SIMD a un nuovo livello, dove è possibile elaborare non solo pacchetti di 8 o 16 numeri alla volta, ma letteralmente migliaia di numeri alla volta per eseguire istruzioni vettoriali. Con le GPU, è possibile raggiungere una gamma di oltre 30 teraflop su un solo dispositivo, il che è enorme. Le migliori CPU sul mercato possono fornire un teraflop, mentre le migliori GPU forniranno oltre 30 teraflop. Questa è una differenza di oltre un ordine di grandezza, che è molto significativa.
Se si va oltre, per tipi specializzati di calcoli come l’algebra lineare (a proposito, cose come l’apprendimento automatico e il deep learning sono essenzialmente algebra lineare coinvolta in tutto il posto), è possibile avere processori come le TPU (Unità di elaborazione tensoriale). Google ha deciso di chiamarle Tensori a causa di TensorFlow, ma la realtà è che le TPU sarebbero meglio chiamate Unità di elaborazione della moltiplicazione di matrici. La cosa interessante della moltiplicazione di matrici è che non solo è coinvolto un sacco di parallelismo dei dati, ma è anche coinvolta un’enorme quantità di ripetizione perché le operazioni sono altamente ripetitive. Organizzando una TPU come un array sistolico, che è essenzialmente una griglia bidimensionale con unità di calcolo sulla griglia, è possibile superare la barriera del petaflop - raggiungendo oltre 1000 teraflop su un singolo dispositivo. Tuttavia, c’è un avvertimento: Google lo fa con numeri in virgola mobile a 16 bit invece dei soliti 32 bit. Dal punto di vista della supply chain, una precisione di 16 bit non è male; significa che si ha circa l’accuratezza dello 0,1% nelle operazioni e per molte operazioni di apprendimento automatico o statistiche, un’accuratezza dello 0,1% è abbastanza buona se fatta correttamente e senza accumulare un bias.
Quello che vediamo è che il percorso del progresso in termini di hardware di calcolo, guardando solo il calcolo, è stato quello di optare per dispositivi più specializzati e rigidi. Grazie a questa specializzazione, è possibile ottenere enormi guadagni in potenza di elaborazione. Se si passa da un’istruzione superscalare, si guadagna un ordine di grandezza; se si opta per una scheda grafica, si guadagna uno o due ordini di grandezza; e se si opta per l’algebra lineare pura, si guadagnano essenzialmente due ordini di grandezza. Questo è molto significativo.
A proposito, tutti questi design hardware sono bidimensionali. I chip moderni e le strutture di elaborazione sono molto piatti. Una CPU moderna non coinvolge più di 20 strati e poiché questi strati hanno solo pochi micron di spessore, le CPU, le GPU o le TPU sono essenzialmente strutture piatte. Potresti pensare, “E la terza dimensione?” Beh, si scopre che a causa del muro di potenza, che è il problema della dissipazione dell’energia, non possiamo davvero andare nella terza dimensione perché non sappiamo come evacuare tutta l’energia che viene versata nel dispositivo.
Quello che possiamo prevedere per il prossimo decennio è che questi dispositivi rimarranno essenzialmente bidimensionali. Dal punto di vista del software aziendale, la lezione più importante è che è necessario progettare il parallelismo dei dati direttamente al centro del software. Se non lo si fa, non si sarà in grado di cogliere tutto il progresso che sta avvenendo per quanto riguarda la potenza di calcolo grezza. Tuttavia, non può essere un’idea dopo. Deve accadere al centro stesso dell’architettura, al livello in cui si organizzano tutti i dati che devono essere elaborati nei sistemi. Se non lo si fa, si rimarrà bloccati con il tipo di processori che avevamo due decenni fa.
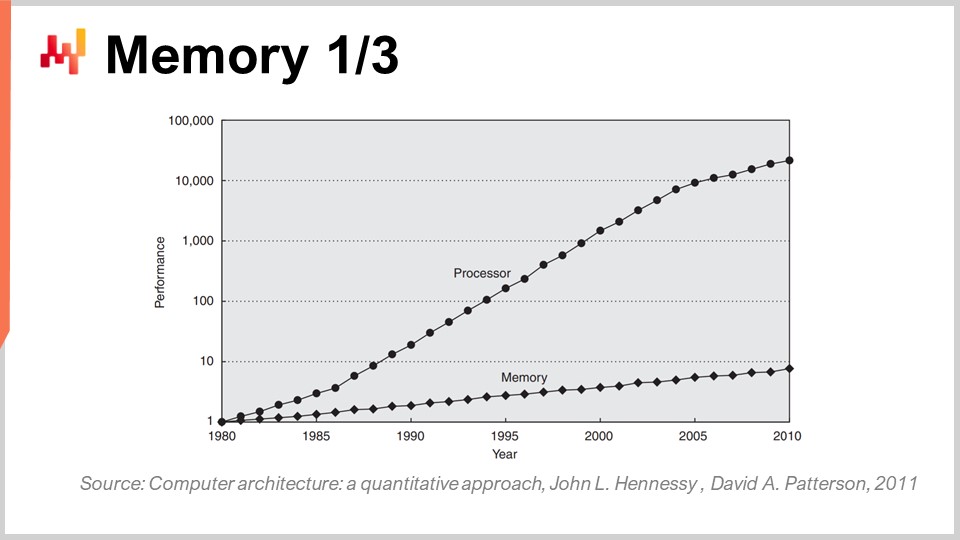
Ora, la memoria all’inizio degli anni ‘80 era veloce quanto i processori, il che significa che un ciclo di clock era un ciclo di clock per la memoria e uno per la CPU. Tuttavia, questo non è più il caso. Nel corso del tempo, dagli anni ‘80, il rapporto tra la velocità della memoria e le latenze per accedere ai dati già presenti nei registri del processore è solo aumentato. Abbiamo iniziato con un rapporto di uno, e ora abbiamo un rapporto tipicamente superiore a mille. Questo problema è noto come “memory wall” e si è solo aggravato negli ultimi quattro decenni. Sta ancora aumentando oggi, sebbene molto lentamente, principalmente perché la velocità di clock dei processori sta aumentando molto lentamente. A causa del fatto che i processori non stanno progredendo molto in termini di velocità di clock, questo problema del “memory wall” non sta aumentando ulteriormente. Tuttavia, il punto in cui ci troviamo al momento è incredibilmente sbilanciato, dove l’accesso alla memoria è essenzialmente tre ordini di grandezza più lento dell’accesso ai dati che si trovano già comodamente all’interno del processore.
Questa prospettiva sconfigge completamente tutta l’algoritmica classica come viene ancora insegnata oggi nella maggior parte delle università. Il punto di vista algoritmico classico assume che si abbia un tempo uniforme per accedere alla memoria, il che significa che l’accesso a qualsiasi bit di memoria richiede lo stesso tempo. Ma nei sistemi moderni, questo non è assolutamente il caso. Il tempo necessario per accedere a una determinata porzione di memoria dipende molto da dove si trovano fisicamente i dati effettivi nel sistema informatico.
Dal punto di vista del software aziendale, si scopre che sfortunatamente la maggior parte dei design software che sono stati stabiliti negli anni ‘80 e ‘90 hanno ignorato completamente il problema perché era molto minore durante il primo decennio. Si è solo inflazionato davvero negli ultimi due decenni, ma come risultato, la maggior parte dei modelli visti nei software aziendali attuali contrastano completamente con questo design, perché si assume che si abbia un accesso a tempo costante per tutta la memoria.
A proposito, se si inizia a pensare ai linguaggi di programmazione come Python (rilasciato per la prima volta nel 1989) o Java (nel 1995) che presentano la programmazione orientata agli oggetti, va molto contro il modo in cui funziona la memoria nei computer moderni. Ogni volta che si hanno oggetti, ed è ancora peggio se si hanno collegamenti tardivi come in Python, significa che per fare qualsiasi cosa, si dovranno seguire i puntatori e fare salti casuali nella memoria. Se uno di quei salti capita di essere sfortunato perché è una porzione che non si trova già nel processore, può essere mille volte più lento. Questo è un problema molto grande.

Per comprendere meglio l’entità del “memory wall”, è interessante guardare le latenze tipiche in un computer moderno. Se ridimensioniamo queste latenze in termini umani, supponiamo che un processore funzioni a un ciclo di clock al secondo. In base a questa ipotesi, la latenza tipica della CPU sarebbe di un secondo. Tuttavia, se vogliamo accedere ai dati in memoria, potrebbe richiedere fino a sei minuti. Quindi, mentre si può eseguire un’operazione al secondo, se si vuole accedere a qualcosa in memoria, bisogna aspettare sei minuti. E se si vuole accedere a qualcosa sul disco, può richiedere fino a un mese o addirittura un intero anno. Questo è incredibilmente lungo, ed è di questo che si tratta quegli ordini di grandezza di prestazioni di cui ho parlato all’inizio di questa lezione. Quando si ha a che fare con 15 ordini di grandezza, è molto ingannevole; non ci si rende necessariamente conto del grande impatto sulle prestazioni che si può avere, dove letteralmente si può finire per dover aspettare l’equivalente umano di mesi se non si mettono le informazioni nel posto giusto. Questo è assolutamente gigantesco.
A proposito, gli ingegneri del software aziendale non sono gli unici a lottare con questa evoluzione dell’hardware informatico moderno. Se guardiamo alle latenze che otteniamo con le schede SSD super veloci, come la serie Intel Optane, possiamo vedere che la metà della latenza per accedere alla memoria su questo dispositivo è causata dall’overhead del kernel stesso, in questo caso, il kernel Linux. È il sistema operativo stesso che genera la metà della latenza. Cosa significa? Beh, significa che anche le persone che sviluppano Linux hanno ancora del lavoro da fare per stare al passo con l’hardware moderno. Tuttavia, è una grande sfida per tutti.
Tuttavia, fa davvero male al software aziendale, soprattutto quando si pensa all’ottimizzazione della supply chain, a causa del fatto che abbiamo tonnellate di dati da elaborare. È già un’impresa piuttosto complessa fin dall’inizio. Dal punto di vista del software aziendale, è davvero necessario adottare un design che si integri bene con la cache perché la cache contiene copie locali che sono più veloci da accedere e più vicine alla CPU.
Il modo in cui funziona è che quando si accede a un byte nella memoria principale, non si può accedere solo a un byte nel software moderno. Quando si vuole accedere anche a un solo byte nella RAM, l’hardware copierà effettivamente 4 kilobyte, essenzialmente l’intera pagina che è grande 4 kilobyte. L’assunzione sottostante è che quando si inizia a leggere un byte, il byte successivo che si richiederà sarà quello successivo. Questo è il principio della località, il che significa che se si rispetta la regola e si applica un accesso che preserva la località, allora si può avere una memoria che sembra funzionare quasi velocemente come il processore.
Tuttavia, ciò richiede un allineamento tra gli accessi alla memoria e la località dei dati. In particolare, ci sono molti linguaggi di programmazione, come Python, che non offrono queste cose in modo nativo. Al contrario, presentano una sfida enorme per apportare qualsiasi grado di località. Questa è una lotta immensa e, in definitiva, è una battaglia in cui si ha un linguaggio di programmazione che è stato progettato attorno a modelli che sono completamente antagonisti all’hardware a nostra disposizione. Questo problema non cambierà nel prossimo decennio; solo peggiorerà.
Pertanto, dal punto di vista del software aziendale, si desidera imporre la località dei dati ma anche la minimizzazione. Se si può rendere piccoli i grandi dati, saranno più veloci. Questo è qualcosa che non è molto intuitivo, ma se si può ridurre la dimensione dei dati, tipicamente eliminando alcune ridondanze, si può rendere il programma più veloce perché si sarà molto più gentili con la cache. Si potranno inserire più dati rilevanti nei livelli di cache inferiori che hanno latenze molto più basse, come mostrato in questa immagine.

Infine, discutiamo specificamente il caso della DRAM. La DRAM è letteralmente il componente fisico che costituisce la RAM che si utilizza per la postazione di lavoro desktop o il server nel cloud. La DRAM è anche chiamata memoria principale, che è costruita da chip DRAM. Negli ultimi dieci anni, in termini di prezzi, la DRAM è diminuita di poco. Siamo passati da $5 per gigabyte a $3 per gigabyte un decennio dopo. Il prezzo della RAM sta ancora diminuendo, anche se non molto velocemente. Si è stagnato nei prossimi due anni e, dato che ci sono solo tre grandi attori in questo mercato che hanno la capacità di produrre DRAM su larga scala, c’è ben poco da sperare che ci sia qualcosa di inaspettato in questo mercato nel prossimo decennio.
Ma questo non è nemmeno il peggio del problema. C’è anche il consumo di energia per gigabyte. Se guardiamo al consumo di energia, si scopre che la RAM moderna consuma un po’ più di energia per gigabyte rispetto a un decennio fa. La ragione è essenzialmente che la RAM che abbiamo attualmente è più veloce, e si applica la stessa regola del muro di potenza: se aumenti la frequenza del clock, aumenti significativamente il consumo di energia. A proposito, la RAM consuma parecchia energia perché la DRAM è fondamentalmente un componente attivo. È necessario aggiornare costantemente la RAM a causa delle perdite elettriche, quindi se spegni la RAM, perdi tutti i dati. È necessario aggiornare costantemente le celle.
Pertanto, la conclusione per il software aziendale è che la DRAM è l’unico componente che non sta più progredendo. Ci sono tonnellate di cose che stanno ancora progredendo molto rapidamente, come la potenza di elaborazione; tuttavia, questo non è il caso della DRAM - è molto stagnante. Se consideriamo il consumo di energia, che rappresenta anche una parte consistente dei costi di cloud computing, la RAM sta facendo appena progressi. Pertanto, se adotti un design che enfatizza troppo la memoria principale, e questo è tipicamente ciò che otterrai quando hai un fornitore che dice: “Oh, abbiamo un design in memoria per il software”, ricorda queste parole chiave.
Ogni volta che senti un fornitore che ti dice di avere un design in memoria, ciò che il fornitore ti sta dicendo - e questa non è una proposta molto convincente - è che il loro design si basa interamente sull’evoluzione futura della DRAM, dove sappiamo già che i costi non diminuiranno. Quindi, se teniamo conto del fatto che tra 10 anni la tua supply chain avrà probabilmente circa 10 volte più dati da elaborare solo perché le aziende stanno diventando sempre migliori nel raccogliere più dati all’interno delle loro supply chain e collaborare per raccogliere più dati dai loro clienti e fornitori, non è irragionevole aspettarsi che tra un decennio qualsiasi grande azienda che gestisce una grande supply chain raccoglierà 10 volte più dati di quelli attuali. Tuttavia, il prezzo per gigabyte di RAM sarà ancora lo stesso. Quindi, se fai i calcoli, potresti finire con costi di cloud computing o costi IT che sono essenzialmente quasi un ordine di grandezza più costosi, solo per fare praticamente la stessa cosa, solo perché devi far fronte a una massa di dati in continua crescita che non si adatta facilmente alla memoria. La chiave è che si desidera evitare tutti i tipi di design in memoria. Questi design sono molto datati, e vedremo in seguito quale tipo di alternativa abbiamo.

Ora, diamo un’occhiata alla memorizzazione dei dati, che riguarda la memorizzazione persistente dei dati. Fondamentalmente, ci sono due classi di memorizzazione diffusa dei dati. La prima è costituita dai dischi rigidi (HDD) o dischi rotanti. La seconda sono le unità a stato solido (SSD). La cosa interessante è che la latenza sui dischi rotanti è terribile, e quando guardi questa immagine, puoi capire facilmente il perché. Questi dischi ruotano letteralmente, e quando vuoi accedere a un punto qualsiasi dei dati sul disco, in media, devi aspettare mezza rotazione del disco. Considerando che i dischi di fascia alta ruotano a circa 10.000 rotazioni al minuto, significa che hai una latenza intrinseca di tre millisecondi che non può essere compressa. È letteralmente il tempo che ci vuole per far ruotare il disco e poter leggere il punto preciso di interesse sul disco. È meccanico e non migliorerà ulteriormente.
Gli HDD sono terribili in termini di latenza, ma hanno anche un altro problema, che è il consumo di energia. Come regola generale, sia un HDD che un SSD consumano circa tre watt all’ora per dispositivo. Questo è tipicamente lo status quo attuale. Tuttavia, quando l’hard disk è in funzione, anche se non stai leggendo nulla dall’hard disk, consumerai tre watt solo perché devi mantenere il disco in rotazione. Raggiungere 10.000 rotazioni al minuto richiede molto tempo, quindi è necessario mantenere il disco in rotazione tutto il tempo, anche se si utilizza il disco molto raramente.
D’altra parte, per quanto riguarda le unità a stato solido, consumano tre watt quando vi si accede, ma quando non si accede ai dati, consumano quasi nulla energia. Hanno un consumo di energia residua, ma è estremamente basso, nell’ordine dei milliwatt. Questo è molto interessante perché puoi avere tonnellate di SSD; se non li stai usando, non paghi per l’energia che consumano. L’intera industria si è gradualmente trasferita dagli HDD agli SSD nell’ultimo decennio.
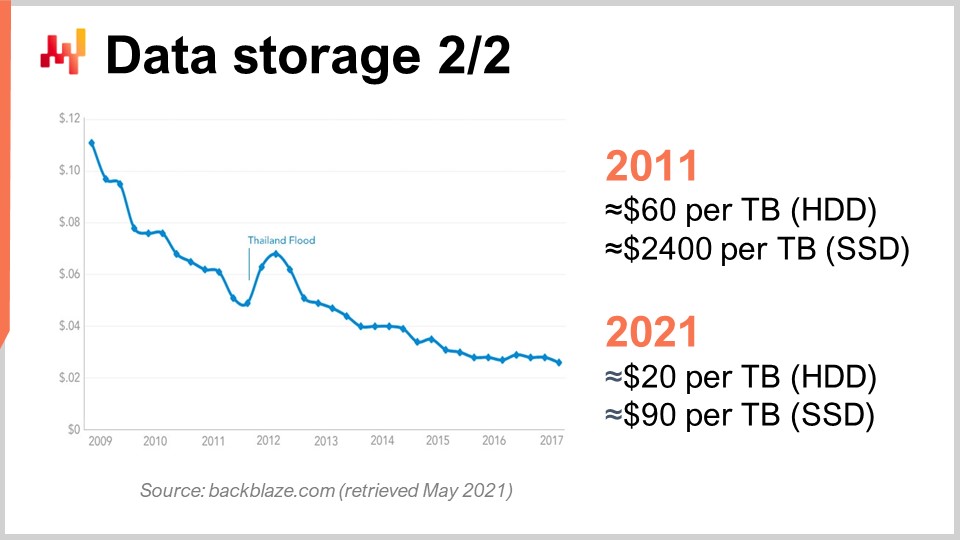
Per capire questo, possiamo guardare questa curva. Quello che vediamo è che il prezzo per gigabyte sia degli HDD che degli SSD è diminuito negli ultimi anni. Tuttavia, il prezzo ora si sta stabilizzando. I dati sono un po’ vecchi, ma non sono variati molto negli ultimi anni. Durante gli ultimi 10 anni, vediamo che un decennio fa, gli SSD erano estremamente costosi a $2.400 per terabyte, mentre gli hard disk erano solo $60 per terabyte. Tuttavia, al giorno d’oggi, il prezzo degli hard disk è stato diviso per tre, essenzialmente a $20 per terabyte. Il prezzo degli SSD è stato diviso per più di 25, e la tendenza al ribasso dei prezzi degli SSD non si ferma. Gli SSD sono al momento, e probabilmente per il decennio a venire, il componente che sta progredendo di più, ed è molto interessante.
A proposito, ti ho detto che il design dei dispositivi di calcolo moderni (CPU, GPU, TPU) era essenzialmente bidimensionale con al massimo 20 strati. Tuttavia, per quanto riguarda gli SSD, il design è sempre più tridimensionale. Gli SSD più recenti hanno circa 176 strati. Stiamo raggiungendo, in termini di ordine, 200 strati. A causa del fatto che questi strati sono incredibilmente sottili, non è irragionevole aspettarsi che in futuro ci siano dispositivi con migliaia di strati e potenzialmente capacità di archiviazione di ordini di grandezza superiori. Ovviamente, il trucco sarà che non sarai in grado di accedere a tutti questi dati tutto il tempo, ancora una volta, a causa del dark silicon e della dissipazione di potenza.
Si scopre che se giochi bene, molti dati vengono accessi molto raramente. Gli SSD comportano un design hardware molto specifico che comporta un sacco di particolarità, come il fatto che puoi solo accendere i bit ma non spegnerli. Fondamentalmente, immagina di avere inizialmente tutti zeri; puoi trasformare uno zero in un uno, tuttavia, non puoi trasformare questo uno in uno zero localmente. Se vuoi farlo, devi ripristinare l’intero blocco che può essere grande fino a otto megabyte, il che significa che quando scrivi, puoi trasformare i bit da zero a uno, ma non da uno a zero. Per trasformare i bit da uno a zero, devi svuotare l’intero blocco e riscriverlo, il che porta a tutti i tipi di problemi noti come amplificazione di scrittura.
Durante l’ultimo decennio, gli SSD hanno internamente uno strato chiamato flash translation layer che può mitigare tutti questi problemi. Questi strati di traduzione flash stanno migliorando sempre di più nel tempo. Tuttavia, ci sono grandi opportunità per migliorare ulteriormente e, in termini di software aziendale, significa che devi davvero ottimizzare il tuo design per sfruttare al massimo gli SSD. Gli SSD sono già un affare molto migliore rispetto alla DRAM quando si tratta di archiviare dati e, se giochi in modo intelligente, puoi aspettarti, tra un decennio, guadagni di ordini di grandezza che verranno ottenuti attraverso il progresso dell’industria hardware, il che non è il caso per quanto riguarda la DRAM.
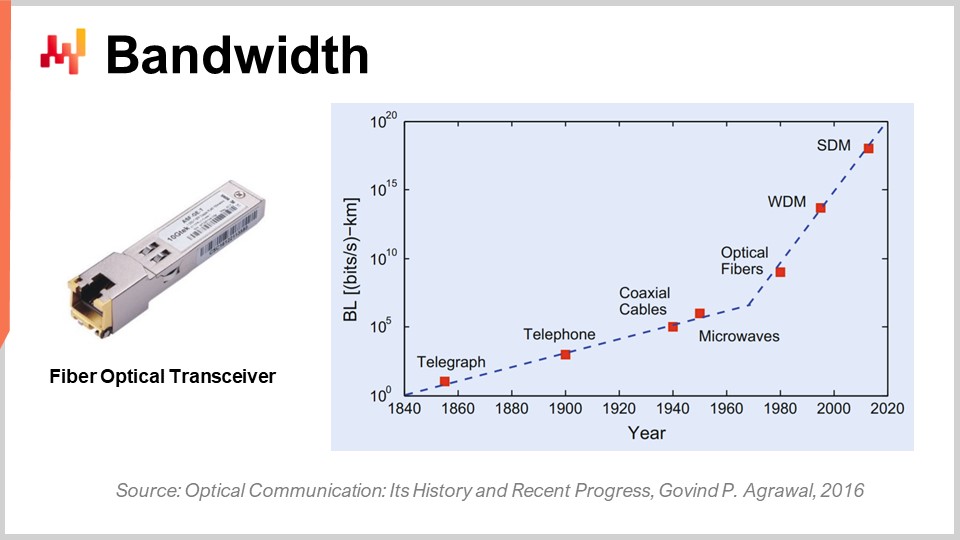
Infine, parliamo di larghezza di banda. La larghezza di banda è probabilmente il problema più risolto in termini di tecnologia. Tuttavia, anche se la larghezza di banda può essere raggiunta, possiamo raggiungere larghezze di banda assolutamente folli alla data odierna. Commercialmente, l’industria delle telecomunicazioni è molto complessa e ci sono un sacco di problemi, quindi i consumatori finali non vedono effettivamente tutti i benefici del progresso che è stato fatto in termini di comunicazioni ottiche.
In termini di comunicazione ottica con trasmettitori a fibra ottica, il progresso è assolutamente folle. È probabilmente una di quelle cose che stanno progredendo come le CPU stavano progredendo negli anni ‘80 o ‘90. Solo per darti un’idea, con la multiplexing a divisione di lunghezza d’onda (WDM) o la multiplexing a divisione di spazio (SDM), ora possiamo raggiungere letteralmente un decimo di terabyte di dati trasferiti al secondo su un singolo cavo di fibra ottica. Questo è assolutamente enorme. Stiamo raggiungendo il punto in cui un singolo cavo può trasportare dati sufficienti per alimentare essenzialmente un intero data center. Ciò che è ancora più impressionante è che l’industria delle telecomunicazioni è stata in grado di sviluppare nuovi trasmettitori che possono offrire queste prestazioni assolutamente folli basate su vecchi cavi. Non è nemmeno necessario installare nuove fibre nelle strade o fisicamente; puoi letteralmente prendere la fibra che è stata installata un decennio fa, installare il nuovo trasmettitore e avere un ordine di grandezza più elevato di larghezza di banda sullo stesso cavo.
La cosa interessante è che c’è una legge generale delle comunicazioni ottiche: ogni decennio, la distanza si riduce a cui diventa interessante sostituire la comunicazione elettrica con le comunicazioni ottiche. Se torniamo indietro di qualche decennio, due decenni fa, ci volevano circa 100 metri affinché la comunicazione ottica superasse la comunicazione elettrica. Quindi, se avevi distanze inferiori a 100 metri, avresti optato per il rame; se avevi più di 100 metri, avresti optato per la fibra. Tuttavia, al giorno d’oggi, con l’ultima generazione, possiamo avere una distanza in cui l’ottica sta vincendo anche a distanze brevi come tre metri. Se guardiamo un decennio avanti, non mi sorprenderebbe se vedessimo situazioni in cui le comunicazioni ottiche stanno vincendo anche se stiamo guardando distanze brevi come mezzo metro. Ciò significa che ad un certo punto, non mi sorprenderebbe se i computer stessi avessero percorsi ottici interni, semplicemente perché sono più performanti dei percorsi elettrici.
Dal punto di vista del software aziendale, questo è anche molto interessante perché significa che se guardi avanti, la larghezza di banda diminuirà massicciamente in termini di costo. Questo è sostanzialmente sussidiato da aziende come Netflix, che hanno un consumo di larghezza di banda drammatico. Ciò significa che, al fine di aggirare la latenza, potresti fare cose come acquisire tonnellate di dati in modo preventivo verso l’utente e quindi consentire all’utente di interagire con dati che sono stati avvicinati a lui con una latenza molto più breve. Anche se porti dati non necessari, ciò che ti uccide è la latenza, non la larghezza di banda. È meglio dire: “Ho dubbi su quale tipo di dati sarà necessario; posso prendere mille volte più dati di quelli che mi servono davvero, portarli più vicini all’utente finale, consentire all’utente o al programma di interagire con questi dati e ridurre al minimo il round trip, e guadagnerò in termini di prestazioni.” Anche questo ha un impatto profondo sul tipo di decisioni architettoniche che vengono prese oggi perché condizioneranno se è possibile ottenere prestazioni con il progresso di questa classe di hardware tra un decennio.

In conclusione, la latenza è la grande battaglia del nostro tempo in termini di ingegneria del software. Questo sta condizionando davvero tutti i tipi di prestazioni che abbiamo e che avremo. Le prestazioni sono assolutamente fondamentali perché non solo guideranno il costo IT, ma guideranno anche la produttività delle persone che operano nella tua supply chain. Alla fine, ciò guiderà anche le prestazioni della stessa supply chain perché se non hai queste prestazioni, non puoi nemmeno implementare una sorta di ricetta numerica che sarebbe davvero intelligente e fornirebbe eventi di ottimizzazione avanzata e predittiva che stiamo cercando. Tuttavia, in generale, questa battaglia per prestazioni migliori non viene vinta, almeno non nel campo del software aziendale. I nuovi sistemi possono essere, e spesso sono, più lenti dei vecchi. Questo è un problema acuto. Le prestazioni software più lente generano costi sconcertanti per le aziende che ne sono vittime.
Solo per darti un esempio, non dovrebbe essere considerato scontato che hardware informatico migliore ti dia prestazioni migliori. Alcune persone su Internet hanno deciso di misurare la latenza di input, o ritardo di input, che è il tempo che intercorre dopo una pressione del tasto affinché la lettera corrispondente venga visualizzata sullo schermo. Con un Apple II nel 1983, che aveva un processore da 1 MHz, il tempo impiegato era di 30 millisecondi. Nel 2016, con un Lenovo X1, dotato di un processore da 2,6 GHz, un notebook molto bello, la latenza si è rivelata essere di 110 millisecondi. Quindi abbiamo hardware informatico che è diverse migliaia di volte migliore, eppure finiamo con una latenza che è quasi quattro volte più lenta. Questo è caratteristico di ciò che accade quando non hai simpatia meccanica e non presti attenzione all’hardware informatico che hai. Se ti metti contro l’hardware informatico, ti ripaga con prestazioni scadenti.
Il problema è molto reale. Il mio suggerimento è, quando inizi a guardare qualsiasi software aziendale per la tua azienda, che sia open-source o meno, ricorda gli elementi di simpatia meccanica che hai imparato oggi. Guarda il software e rifletti attentamente su se abbraccia le tendenze profonde dell’hardware informatico o se le ignora del tutto. Se le ignora, significa che non solo le prestazioni non miglioreranno nel tempo, ma molto probabilmente peggioreranno. La maggior parte dei miglioramenti al giorno d’oggi viene ottenuta attraverso la specializzazione piuttosto che la velocità dell’orologio. Se perdi questa strada, stai prendendo un percorso che diventerà sempre più lento nel tempo. Evita queste soluzioni perché di solito derivano da decisioni di progettazione chiave iniziali che non possono essere annullate. Rimarrai bloccato con loro per sempre, e peggiorerà anno dopo anno. Pensa a un decennio in avanti quando inizi a guardare questi aspetti.

Ora diamo un’occhiata alle domande. È stata una conferenza piuttosto lunga, ma è un argomento impegnativo.
Domanda: Qual è la tua opinione sui computer quantistici e sulla loro utilità nel affrontare problemi complessi di ottimizzazione della supply chain?
Una domanda molto interessante. Mi sono registrato per la versione beta del computer quantistico di IBM 18 mesi fa, quando hanno aperto l’accesso al loro computer quantistico nel cloud. La mia sensazione è che sia entusiasmante, poiché gli esperti possono vedere tutte le curve a S appiattirsi ma non vedono le nuove curve che appaiono dal nulla. I computer quantistici sono uno di questi. Tuttavia, ritengo che i computer quantistici presentino sfide molto difficili per quanto riguarda le supply chain. Prima di tutto, come ho detto, la battaglia del nostro tempo in termini di software aziendale è la latenza, e i computer quantistici non fanno nulla in merito. I computer quantistici ti offrono potenzialmente fino a 10 ordini di grandezza di accelerazione per problemi di calcolo estremamente complessi. Quindi, i computer quantistici sarebbero la prossima fase oltre le unità di elaborazione tensoriale (TPU), dove è possibile eseguire operazioni estremamente complesse in modo incredibilmente veloce.
Questo è molto interessante, ma ad essere onesti, al momento ci sono pochissime aziende, a mia conoscenza, che riescono anche solo a sfruttare le istruzioni superscalari all’interno del loro software aziendale. Ciò significa che l’intero mercato sta lasciando sul tavolo un’accelerazione di 10-28 volte grazie alle GPU superscalari. Ci sono poche persone nel mondo della supply chain che lo fanno; forse Lokad, forse no. Per quanto riguarda le TPU, penso che letteralmente non ci sia nessuno. Google lo fa ampiamente, ma non sono a conoscenza di nessuno che abbia mai utilizzato le TPU per qualcosa legato alla supply chain. I processori quantistici sarebbero la fase successiva alle TPU.
Sono sicuramente molto attento a ciò che sta accadendo con i computer quantistici, ma credo che questo non sia il collo di bottiglia che affrontiamo. È entusiasmante perché stiamo rivedendo il design di von Neumann stabilito circa 70 anni fa, ma questo non è il collo di bottiglia che noi o la supply chain affronteremo per i prossimi dieci anni. Oltre questo periodo, le tue supposizioni sono valide quanto le mie. Sì, potrebbe potenzialmente cambiare tutto o non cambiare nulla.
Domanda: Le offerte di cloud e SaaS stanno consentendo alle organizzazioni di sfruttare e convertire i costi fissi. Le aziende che offrono tali servizi stanno anche lavorando per ridurre i loro costi fissi e il rischio associato?
Beh, dipende. Se sono una piattaforma di cloud computing e ti vendo potenza di calcolo, è davvero nel mio interesse rendere il tuo software aziendale il più efficiente possibile? Non proprio. Ti sto vendendo macchine virtuali, gigabyte di larghezza di banda e spazio di archiviazione, quindi in realtà è esattamente il contrario. Il mio interesse è assicurarmi che tu abbia un software il più inefficiente possibile, in modo da consumare e pagare una quantità folle di risorse.
Internamente, le grandi aziende tecnologiche come Microsoft, Amazon e Google sono estremamente aggressive quando si tratta di ottimizzare le loro risorse di calcolo. Ma sono anche aggressive quando si trovano in prima linea per pagare il conto quando addebitano a un cliente il noleggio di una macchina virtuale. Se il cliente sta noleggiando una macchina virtuale che è 10 volte più grande di quanto dovrebbe essere solo perché il software aziendale che sta utilizzando è estremamente inefficiente, non è nel loro interesse interrompere l’errore del cliente. Va bene così per loro; è un buon affare. Quando si pensa che gli integratori di sistema e le piattaforme di cloud computing tendono a lavorare a stretto contatto come partner, si può capire che queste categorie di persone non hanno necessariamente il tuo miglior interesse a cuore. Ora, per quanto riguarda il SaaS, è un po’ diverso. Infatti, se finisci per pagare un fornitore di SaaS per utente, allora è nell’interesse dell’azienda, ed è il caso di Lokad, ad esempio. Non addebitiamo le risorse di calcolo che consumiamo; di solito addebitiamo ai nostri clienti tariffe mensili fisse. Pertanto, i fornitori di SaaS tendono ad essere molto aggressivi quando si tratta del proprio consumo di risorse di calcolo.
Tuttavia, attenzione, c’è un pregiudizio: se sei un’azienda SaaS, potresti essere piuttosto riluttante a fare qualcosa che sarebbe molto più bello per i tuoi clienti ma molto più costoso in termini di hardware per te stesso. Non è tutto rose e fiori. C’è una sorta di conflitto di interessi che coinvolge tutti i fornitori di SaaS che operano nel settore della supply chain. Ad esempio, potrebbero investire nella ristrutturazione di tutti i loro sistemi per offrire una migliore latenza e pagine web più veloci, ma la cosa è che costa risorse e i loro clienti non sono naturalmente disposti a pagarli di più se lo fanno.
Il problema tende ad essere amplificato quando si tratta di software aziendale. Perché? Perché la persona che acquista il software di solito non è la persona che lo utilizza. Ecco perché gran parte del sistema aziendale è incredibilmente lento. La persona che acquista il software non soffre tanto quanto un povero pianificatore della domanda o un responsabile dell’inventario che deve fare i conti con un sistema super lento ogni singolo giorno dell’anno. Quindi c’è un altro aspetto specifico del mondo del software aziendale. È davvero necessario analizzare la situazione, guardando a tutti gli incentivi in gioco e, quando si tratta di software aziendale, di solito ci sono molti incentivi contrastanti.
Domanda: Quante volte Lokad ha dovuto rivedere il suo approccio, date le evoluzioni dell’hardware osservate? Puoi menzionare un esempio, se possibile, per mettere questo contenuto nel contesto di problemi reali risolti?
Lokad, credo, ha ristrutturato ampiamente la nostra tecnologia circa mezza dozzina di volte. Tuttavia, Lokad è stata fondata nel 2008 e abbiamo avuto mezza dozzina di riscritture importanti dell’intera architettura. Non è perché il software è progredito così tanto; il software è progredito, sì, ma ciò che ha guidato la maggior parte delle nostre riscritture non è stato il fatto che l’hardware sia progredito così tanto. Era più come se avessimo acquisito una comprensione dell’hardware. Tutto ciò che ho presentato oggi era essenzialmente noto alle persone che prestavano già attenzione un decennio fa. Quindi, vedi, c’è, sì, un’evoluzione dell’hardware, ma è molto lenta e la maggior parte delle tendenze è molto prevedibile, anche un decennio in anticipo. Si sta giocando una partita lunga.
Lokad ha dovuto subire riscritture massive, ma era più una riflessione sul fatto che stavamo gradualmente diventando meno incompetenti. Stavamo acquisendo competenze e quindi avevamo una migliore comprensione di come abbracciare l’hardware, piuttosto che il fatto che l’hardware stesse cambiando il compito. Non era sempre vero; c’erano elementi specifici che erano davvero rivoluzionari per noi. Il più notevole è stato l’SSD. Siamo passati da HDD a SSD ed è stato un cambiamento di gioco completo nelle nostre prestazioni, con impatti massicci sulla nostra architettura. In termini di esempi molto concreti, l’intero design di Envision, il linguaggio di programmazione specifico del dominio fornito da Lokad, si basa sulle intuizioni che abbiamo raccolto a livello hardware. Non è solo un risultato; si tratta di fare tutto ciò che puoi pensare solo più velocemente.
Vuoi elaborare una tabella con un miliardo di righe e 100 colonne e vuoi farlo 100 volte più velocemente con le stesse risorse di calcolo? Sì, puoi farlo. Vuoi essere in grado di fare join tra tabelle molto grandi con risorse di calcolo minime? Sì, di nuovo. Puoi avere dashboard super complesse con letteralmente cento tabelle visualizzate all’utente finale in meno di 500 millisecondi? Sì, ci siamo riusciti. Questi sono risultati banali, ma è perché abbiamo raggiunto tutti questi risultati che possiamo mettere in produzione ricette di ottimizzazione predittiva piuttosto sofisticate. Dobbiamo assicurarci che tutti i passaggi che ci hanno portato fin lì siano fatti con una produttività molto elevata.
La sfida più grande quando si vuole fare qualcosa di molto sofisticato per la supply chain in termini di ricette numeriche non è la fase del “farlo funzionare”. Puoi prendere studenti universitari e ottenere una serie di prototipi che porteranno a un miglioramento delle prestazioni della supply chain in poche settimane. Basta prendere Python e qualsiasi libreria di machine learning open source casuale del giorno, e quegli studenti, se sono intelligenti e volenterosi, produrranno un prototipo funzionante in poche settimane. Tuttavia, non riuscirai mai a metterlo in produzione su larga scala. Questo è il problema. Si tratta di come superare tutte quelle fasi di maturità di “farlo corretto”, “farlo veloce” e “farlo economico”. Ecco dove l’affinità con l’hardware brilla davvero e la tua capacità di iterare.
Non c’è un singolo risultato. Tuttavia, tutto ciò che facciamo, ad esempio quando diciamo che Lokad sta facendo previsione probabilistica, non richiede così tanta potenza di elaborazione. Ciò che richiede davvero potenza di elaborazione è sfruttare distribuzioni molto estese di probabilità e guardare a tutti quei futuri possibili e combinare tutti quei futuri possibili con tutte le decisioni possibili che puoi prendere. In questo modo, puoi scegliere i migliori con l’ottimizzazione finanziaria, che diventa molto costosa. Se non hai qualcosa di molto ottimizzato, sei bloccato. Il fatto stesso che Lokad possa utilizzare la previsione probabilistica in produzione è una testimonianza che abbiamo avuto un’ottimizzazione a livello hardware lungo tutto il percorso per tutti i nostri clienti. Al momento stiamo servendo circa 100 aziende.
Domanda: È meglio avere un server interno per il software aziendale (ERP, WMS) piuttosto che utilizzare servizi cloud per evitare la latenza?
Direi che al giorno d’oggi non importa perché la maggior parte delle latenze che si riscontrano sono all’interno del sistema. Questo non è il problema della latenza tra l’utente e l’ERP. Sì, se hai una latenza molto scarsa, potresti aggiungere circa 50 millisecondi di latenza. Ovviamente, se hai un ERP, non vuoi che sia situato a Melbourne mentre stai operando a Parigi, ad esempio. Vuoi mantenere il data center vicino a dove stai operando. Tuttavia, le moderne piattaforme di cloud computing hanno decine di data center, quindi non c’è molta differenza in termini di latenza tra l’hosting interno e i servizi cloud.
Tipicamente, l’hosting interno non significa mettere l’ERP per terra nel mezzo della fabbrica o del magazzino. Invece, significa mettere il tuo ERP in un data center dove stai noleggiando hardware di calcolo. Credo che non ci sia una differenza pratica tra l’hosting interno e le piattaforme di cloud computing dal punto di vista delle moderne piattaforme di cloud computing con data center in tutto il mondo.
Ciò che fa davvero la differenza è se hai un ERP che minimizza internamente tutti i round trip. Ad esempio, ciò che di solito uccide le prestazioni di un ERP è l’interazione tra la logica aziendale e il database relazionale. Se hai centinaia di interazioni avanti e indietro per visualizzare una pagina web, il tuo ERP sarà terribilmente lento. Quindi, devi considerare progettazioni di software aziendale che non comportano un numero massiccio di round trip. Questa è una proprietà interna del software aziendale che stai guardando e non dipende molto da dove posizioni il software.
Domanda: Pensi che abbiamo bisogno di nuovi linguaggi di programmazione che abbraccino il nuovo design dell’hardware a livello di core, utilizzando le caratteristiche dell’architettura hardware al massimo?
Sì, e sì. Ma per completezza, devo dichiarare un conflitto di interessi qui. Questo è esattamente ciò che Lokad ha fatto con Envision. Envision è nato dall’osservazione che è complicato sfruttare tutta la potenza di elaborazione disponibile nei computer moderni, ma non dovrebbe esserlo se si progetta il linguaggio di programmazione stesso tenendo conto delle prestazioni. Puoi renderlo sovrumano, ed è per questo che nella lezione 1.4 sui paradigmi di programmazione per la supply chain ho detto che se scegli i giusti paradigmi di programmazione, come la programmazione ad array o la programmazione a frame di dati, e costruisci un linguaggio di programmazione che abbracci quei concetti, ottieni prestazioni quasi gratuite.
Il prezzo che paghi è che non sei altrettanto espressivo come un linguaggio di programmazione come Python o C++, ma se sei disposto ad accettare una ridotta espressività e coprire tutti i casi d’uso rilevanti per la supply chain, allora sì, puoi ottenere miglioramenti delle prestazioni massicci. Questa è la mia convinzione, ed è anche per questo che ho affermato che, ad esempio, la programmazione orientata agli oggetti dal punto di vista dell’ottimizzazione della supply chain non porta nulla sul tavolo.
Al contrario, si tratta di un tipo di paradigma che si contrappone solo all’hardware di elaborazione sottostante. Non sto dicendo che la programmazione orientata agli oggetti sia tutta negativa; non è quello che sto dicendo. Sto dicendo che ci sono aree dell’ingegneria del software in cui ha senso completo, ma non ha senso per quanto riguarda l’ottimizzazione predittiva della supply chain. Quindi sì, abbiamo davvero bisogno di linguaggi di programmazione che abbraccino davvero questo concetto.
So che tendo a ripetermi, ma Python è stato essenzialmente progettato alla fine degli anni ‘80 e hanno un po’ perso tutto ciò che c’era da vedere sui computer moderni. Hanno qualcosa in cui, per progettazione, non possono sfruttare il multi-threading. Hanno questa lock globale, quindi non possono sfruttare più core. Non possono sfruttare la località. Hanno il binding tardivo che complica davvero gli accessi alla memoria. Sono molto variabili, quindi consumano molta memoria, il che significa che giocherà contro la cache, ecc.
Questi sono i tipi di problemi in cui, se usi Python, significa che affronterai battaglie in salita per i prossimi decenni, e la battaglia peggiorerà solo col tempo. Non miglioreranno.
La prossima lezione sarà tra tre settimane, lo stesso giorno della settimana, alla stessa ora. Sarà alle 15:00 ora di Parigi, il 9 giugno. Discuteremo degli algoritmi moderni per la supply chain, che sono un po’ il controparte dei computer moderni per la supply chain. Ci vediamo la prossima volta.


