Differenzierbares Programmieren zur Optimierung großskaliger relationaler Daten
In der komplexen Welt des supply chain management sind relationale Daten das A und O. ERPs, WMS, PMS und andere Softwaretools, die in der supply chain allgegenwärtig sind, arbeiten auf der Basis relationaler Datenbanken, die alles von Bestandsniveaus bis zu Lieferantenbeziehungen nachverfolgen. Relationale Daten bestehen aus einer Reihe miteinander verbundener Tabellen, die jeweils reich an Informationsspalten sind. Wenn es jedoch um machine learning und mathematische Optimierung geht, werden relationale Daten oft von einfacheren Formen wie Vektoren, Sequenzen und Graphen überschattet.
Relationale Daten – dank ihrer reichen Komplexität – bieten einen tieferen, nuancierteren Einblick in die Abläufe als ihre einfacheren Gegenstücke (die oben genannten Vektoren, Sequenzen und Graphen). Dennoch hat die meiste enterprise software Schwierigkeiten, Daten in ihrer relationalen Form effektiv zu nutzen. Das Ergebnis? Ein erzwungener Versuch, quadratische Pfosten in runde Löcher zu zwängen, in dem man verzweifelt versucht, relationale Daten in für einfachere Modelle entwickelte Werkzeuge zu pressen. Diese Fehlanpassung benachteiligt Unternehmen, vergleichbar mit der Verwendung eines Hockeyschlägers im Golf – theoretisch machbar, aber weit entfernt von der optimalen Verbindung von Werkzeug und Zweck.
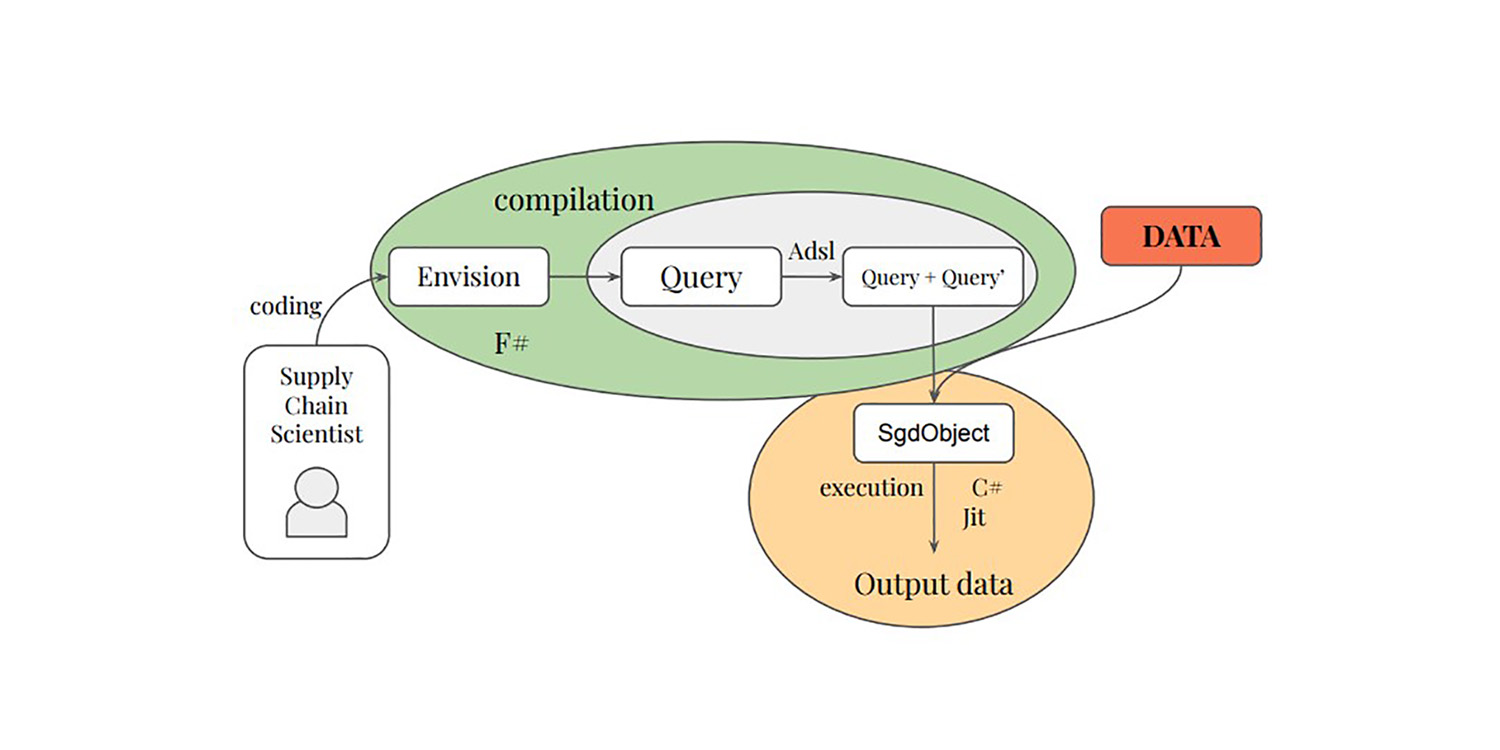
Entschlossen, diese blinde Stelle zu untersuchen, begann Paul Peseux vor einigen Jahren bei Lokad seine Promotion mit dem Ziel, relationale Daten sowohl für Lern- als auch für Optimierungszwecke zu einer erstklassigen Bürgerin zu machen. Seine Forschungsbemühungen führten zu einer Reihe bemerkenswerter Verbesserungen unserer differenzierbaren Programmierung innerhalb von Envision – Lokads DSL (domänenspezifische Programmiersprache) für supply chain-Optimierung. Pauls beeindruckende Erkenntnisse sind nun in der Produktion, typischerweise verborgen in den autodiff Fähigkeiten des DSLs.
Autor: Paul Peseux
Datum: September 2023
Zusammenfassung:
Diese Doktorarbeit präsentiert drei Beiträge im Bereich der differenzierbaren Programmierung mit Fokus auf relationale Daten. Relationale Daten sind in Branchen wie Gesundheitswesen und supply chain weit verbreitet, wo Daten oft in strukturierten Tabellen oder Datenbanken organisiert sind. Traditionelle Ansätze im maschinellen Lernen kämpfen mit dem Umgang relationaler Daten, während White-Box-Modelle im maschinellen Lernen zwar besser geeignet, aber schwierig zu entwickeln sind.
Differenzierbare Programmierung bietet eine potenzielle Lösung, indem Abfragen an relationalen Datenbanken als differenzierbare Programme behandelt werden, was die Entwicklung von White-Box-Modellen im maschinellen Lernen ermöglicht, die direkt über relationale Daten nachdenken können. Das Hauptziel dieser Forschung ist es, den Einsatz von maschinellem Lernen bei relationalen Daten unter Verwendung differenzierbarer Programmiertechniken zu untersuchen.
Der erste Beitrag der Dissertation führt eine differenzierbare Schicht in relationale Programmiersprachen sowohl theoretisch als auch praktisch ein. Die Programmiersprache Adsl wurde entwickelt, um Differenzierung durchzuführen und relationale Operationen einer Abfrage zu transkribieren. Die domänenspezifische Sprache Envision wurde um differenzierbare Programmierfunktionen erweitert, sodass Modelle entwickelt werden können, die relationale Daten in einer nativen, relationalen Programmierumgebung nutzen.
Der zweite Beitrag entwickelt einen neuartigen Gradientenabschätzer namens GCE, der für kategoriale Merkmale, die in relationalen Daten repräsentiert sind, konzipiert wurde. Es wird gezeigt, dass GCE auf verschiedenen kategorialen Datensätzen und Modellen nützlich ist und für deep learning Modelle implementiert wurde. GCE ist ebenfalls als nativer Gradientenabschätzer in die differenzierbare Programmierungsschicht von Envision integriert, ermöglicht durch den ersten Beitrag dieser Dissertation.
Der dritte Beitrag entwickelt einen generalisierten Gradientenabschätzer namens Stochastic Path Automatic Differentiation (SPAD), der seine Stochastizität aus der Codezerlegung ableitet. SPAD führt die Idee ein, einen Teil des Gradienten rückwärts zu propagieren, um den Speicherverbrauch während der Parameteraktualisierungen zu reduzieren. Die Implementierung dieses Gradientenabschätzungsverfahrens wurde durch die Designentscheidungen bei der Differenzierung von Adsl ermöglicht.
Diese Forschung hat bedeutende Auswirkungen auf Branchen, die auf relationale Daten angewiesen sind, da sie neue Erkenntnisse erschließt und die Entscheidungsfindung verbessert, indem White-Box-Modelle des maschinellen Lernens auf relationale Daten mittels differenzierbarer Programmiertechniken angewandt werden.
Jury:
Die Verteidigung fand vor einer Jury statt, die sich zusammensetzte aus:
- Thierry Paquet, Universitätsprofessor (University of Rouen Normandy), Promotionsleiter.
- Maxime Berar, Dozent (University of Rouen Normandy), Co-Betreuer der Dissertation.
- Romain Raveaux, Dozent (University of Tours), Berichterstatter.
- Thierry Artières, Universitätsprofessor (ECM / LIS – AMU – CNRS), Berichterstatter.
- Cécilia Zanni-Merk, Universitätsprofessorin (INSA Rouen Normandie), Prüferin.
- Laurent Wendling, Universitätsprofessor (Paris Cité University), Prüfer.
- Victor Nicolet, CTO von Lokad, Berater.


