00:05 Einführung
02:50 Zwei Täuschungen
09:09 Eine Compiler-Pipeline
14:23 Die bisherige Entwicklung
18:49 Frachtbrief
19:40 Sprachdesign
23:52 Die Zukunft
30:35 Die Vergangenheit
35:57 Die Schlachten wählen
39:45 Grammatiken 1/3
42:41 Grammatiken 2/3
49:02 Grammatiken 3/3
53:02 Statische Analyse 1/2
58:50 Statische Analyse 2/2
01:04:55 Typsystem
01:11:59 Compiler-Interna
01:27:48 Laufzeitumgebung
01:33:57 Fazit
01:36:33 Kommende Vorlesung und Fragen des Publikums
Beschreibung
Die Mehrheit der supply chains wird immer noch über Tabellenkalkulationen (d.h. Excel) betrieben, während Enterprise-Systeme seit einer, zwei, manchmal sogar drei Jahrzehnten im Einsatz sind – angeblich um sie zu ersetzen. Tatsächlich bieten Tabellenkalkulationen eine zugängliche programmatische Ausdruckskraft, während diese Systeme dies in der Regel nicht tun. Allgemeiner gesagt, kam es seit den 1960er Jahren zu einer konstanten Ko-Entwicklung der gesamten Softwareindustrie und ihrer Programmiersprachen. Es gibt Hinweise darauf, dass die nächste Stufe der supply chain performance weitgehend durch die Entwicklung und Einführung von Programmiersprachen, oder genauer gesagt von programmierbaren Umgebungen, angetrieben wird.
Vollständiges Transkript

Willkommen zu dieser Reihe von supply chain Vorlesungen. Ich bin Joannes Vermorel, und heute werde ich „Sprachen und Compiler für supply chain“ präsentieren. Ich erinnere mich nicht, jemals gesehen zu haben, dass Compiler in einem supply chain Lehrbuch behandelt wurden, und dennoch ist das Thema von grundlegender Bedeutung. Wir haben bereits im allerersten Kapitel dieser Reihe, in der Vorlesung mit dem Titel “Produktorientierte Lieferung”, gesehen, dass Programmierung der Schlüssel dazu ist, die Zeit, die supply chain Experten investieren, zu nutzen. Ohne Programmierung können wir ihre Zeit nicht gewinnbringend einsetzen, und wir behandeln supply chain Experten als entbehrlich.
Darüber hinaus haben wir in diesem vierten Kapitel, durch die beiden vorangegangenen Vorlesungen “Mathematical Optimization for supply chain” und “Machine Learning for supply chain”, festgestellt, dass diese beiden Bereiche – Optimierung und Lernen – im Laufe des letzten Jahrzehnts von Programmierparadigmen geprägt wurden, anstatt wie früher nur als eine Ansammlung von Algorithmen und Modellen zu existieren. All diese Elemente unterstreichen die grundlegende Bedeutung von Programmiersprachen, und somit stellt sich die Frage nach einer Programmiersprache und einem Compiler, die dazu entwickelt wurden, supply chain Herausforderungen zu bewältigen.
Das Ziel dieser Vorlesung ist es, das Design einer solchen Programmiersprache, die für supply chain Zwecke vorgesehen ist, zu entzaubern. Ihr Unternehmen wird wahrscheinlich niemals eine solche Programmiersprache eigenständig entwickeln. Dennoch ist es grundlegend, einige Einblicke in das Thema zu gewinnen, um die Angemessenheit der vorhandenen Werkzeuge beurteilen zu können und die Eignung der Werkzeuge zu bewerten, die Sie zu erwerben beabsichtigen, um den supply chain Herausforderungen Ihres Unternehmens zu begegnen. Darüber hinaus sollte Ihnen diese Vorlesung auch dabei helfen, einige der großen Fehler zu vermeiden, die Personen, die keinerlei Einblick in dieses Thema haben, in diesem Bereich zu machen pflegen.

Beginnen wir damit, zwei Täuschungen aufzuklären, die in den Kreisen der enterprise software in den letzten drei Jahrzehnten verbreitet waren. Die erste ist die Täuschung des “Lego-Programmings”, bei der man annimmt, dass Programmierung vollständig umgangen werden kann. In der Tat ist Programmierung schwierig, und es gibt immer wieder Anbieter, die versprechen, dass man durch ihr Produkt und fantastische Technologie die Programmierung in ein visuelles Erlebnis verwandeln könne, das für jedermann zugänglich ist und sämtliche Schwierigkeiten der Programmierung vollständig beseitigt, sodass das Erlebnis im Grunde dem Zusammenbauen von Lego ähnelt – etwas, das sogar ein Kind tun kann.
Dies wurde in den letzten Jahrzehnten unzählige Male versucht und ist stets gescheitert. Im besten Fall verwandelten sich Produkte, die ein visuelles Erlebnis bieten sollten, in herkömmliche Programmiersprachen, die nicht wesentlich einfacher zu erlernen sind als andere Programmiersprachen. Dies ist übrigens, wenn auch nur anekdotisch, der Grund, warum es beispielsweise in der Reihe der Microsoft-Produkte die “Visual”-Serie gibt, wie Visual Basic for Application und Visual Studio. All diese visuellen Produkte wurden in den 90er Jahren eingeführt, in der Hoffnung, die Programmierung in ein rein visuelles Erlebnis mit Designern zu verwandeln, bei dem es nur um Drag-and-Drop gehen würde. In Wirklichkeit haben all diese Werkzeuge letztlich einen sehr signifikanten Erfolg erzielt, aber heutzutage sind sie doch nur ziemlich normale Programmiersprachen. Von den visuellen Aspekten, die anfangs dieser Produkte vorhanden waren, ist kaum etwas übrig geblieben.
Der Lego-Ansatz scheiterte, weil im Grunde genommen nicht die Hürde der Programmiersyntax das eigentliche Engpassproblem darstellt. Es ist zwar eine Hürde, aber eine minimale, besonders im Vergleich zur Beherrschung der Konzepte, die vonnöten sind, wenn man irgendeine Art von anspruchsvoller Automatisierung umsetzen möchte. Dabei wird der Geist zum Engpass, und Ihr Verständnis der zugrunde liegenden Konzepte ist weitaus bedeutender als die Syntax.
Die zweite Täuschung ist die “Star Wars tech”-Täuschung, die darin besteht, zu glauben, dass es ganz einfach sei, fantastische Technologiekomponenten einfach anzuschließen und zu nutzen. Diese Täuschung ist sowohl für Anbieter als auch für interne Projekte sehr verlockend. Im Wesentlichen wird es verführerisch zu behaupten, es gäbe diese fantastische NoSQL-Datenbank, die man einfach einfügen könnte, oder es gäbe diesen fantastischen deep learning Stack, den man integrieren könnte, oder diese Graph-Datenbank, oder dieses verteilte aktive Framework usw. Das Problem bei diesem Ansatz ist, dass er Technologie so behandelt, wie sie in Star Wars behandelt wird. Wenn man eine mechanische Hand hat, kann der Held einfach die mechanische Hand nehmen, und sie funktioniert. In Wirklichkeit dominieren jedoch Integrationsprobleme.
Star Wars ignoriert die Tatsache, dass eine Reihe von Problemen auftreten würde: Zunächst bräuchte man Antibiotika, dann eine lange Umschulung der Hand, um sie überhaupt nutzen zu können. Außerdem wäre ein Wartungsprogramm für die Hand erforderlich, weil sie mechanisch ist, und was ist mit der Stromquelle, usw. All diese Probleme werden einfach umgangen. Man schließt einfach das fantastische Technologiebauteil an, und es funktioniert. In Wirklichkeit ist dies jedoch nicht der Fall. Integrationsprobleme dominieren, und beispielsweise in großen Softwareunternehmen arbeiten die meisten Softwareingenieure nicht an fantastisch coolen Technologielösungen. Der Großteil der Ingenieursarbeitskraft der überwiegenden Mehrheit dieser großen Softwareanbieter ist ausschließlich der Integration all der Teile gewidmet.
Wenn Sie Module, Komponenten oder Apps haben, benötigen Sie eine kleine Armee von Ingenieuren, um all diese Dinge zusammenzukleben und alle Probleme zu bewältigen, die entstehen, wenn man versucht, diese zusammenzuführen. Selbst nachdem alle Integrationshürden überwunden sind, benötigt man noch eine umfangreiche Ingenieurskapazität, um damit umzugehen, dass bei jeder Änderung eines Teils des Systems in der Regel Probleme in anderen Teilen des Systems entstehen. Daher muss diese Ingenieurskapazität ständig herumlaufen, um diese Probleme zu beheben.
Übrigens, als Anekdote: Ein weiteres Problem, das ich bei coolen Technologien beobachtet habe, ist der Dunning-Kruger-Effekt, den sie unter Ingenieuren hervorruft. Man führt ein cooles Technologieteil in den eigenen Stack ein, und plötzlich glauben Ingenieure, nur weil sie angefangen haben, mit einem Technologieteil zu spielen, den sie kaum verstehen, dass sie auf einmal AI-Experten oder dergleichen seien. Das ist ein typischer Fall des Dunning-Kruger-Effekts und steht in engem Zusammenhang mit der Anzahl an coolen Technologieteilen, die man in die Lösung einbindet. Zusammenfassend zeigt sich, dass wir das Problem der Programmierung mit diesen beiden Täuschungen nicht wirklich umgehen können. Wir müssen es funktional angehen, einschließlich der schwierigen Teile.
Nun, das Interessante an Programmiersprachen ist, dass Enterprise-Software-Anbieter immer wieder – wenn auch versehentlich – Programmiersprachen neu erfinden und dies ständig tun. Tatsächlich besteht im supply chain ein enormer Bedarf an Konfigurierbarkeit. Wie wir in den vorangegangenen Vorlesungen gesehen haben, ist die Welt des supply chain vielfältig und die Probleme sind zahlreich und unterschiedlich. Daher besteht bei einem supply chain Software-Produkt ein außerordentlich hoher Bedarf an Konfigurierbarkeit. Anekdotisch ist dies der Grund, weshalb die Konfiguration einer Softwarekomponente typischerweise ein mehrmonatiges und manchmal sogar ein mehrjähriges Projekt ist. Dies liegt daran, dass eine enorme Komplexität in diese Konfiguration einfließt.
Konfigurationseinstellungen sind oft komplex, nicht nur Knöpfe oder Checkboxen. Man kann Trigger, Formeln, Schleifen und allerlei andere Blöcke haben. Es gerät schnell außer Kontrolle, und das, was durch diese Konfigurationseinstellungen entsteht, ist eine emergente Programmiersprache. Da es sich jedoch um eine emergente Programmiersprache handelt, ist sie in der Regel eine sehr schlechte.
Die Entwicklung einer tatsächlichen Programmiersprache ist eine gut etablierte ingenieurtechnische Aufgabe. Es gibt dutzende Bücher, die sich mit den praktischen Aspekten der Entwicklung eines Compilers in Produktionsqualität beschäftigen. Ein Compiler ist ein Programm, das Anweisungen – typischerweise in Textform – in Maschinencode oder eine niedrigere Form von Anweisungen umwandelt. Wo es eine Programmiersprache gibt, ist in der Regel auch ein Compiler im Spiel. Zum Beispiel enthalten Excel-Tabellenkalkulationen Formeln, und Excel verfügt über einen eigenen Compiler, um diese Formeln zu kompilieren und auszuführen. Höchstwahrscheinlich hat das gesamte Publikum sein Berufsleben lang Compiler benutzt, ohne es zu wissen.
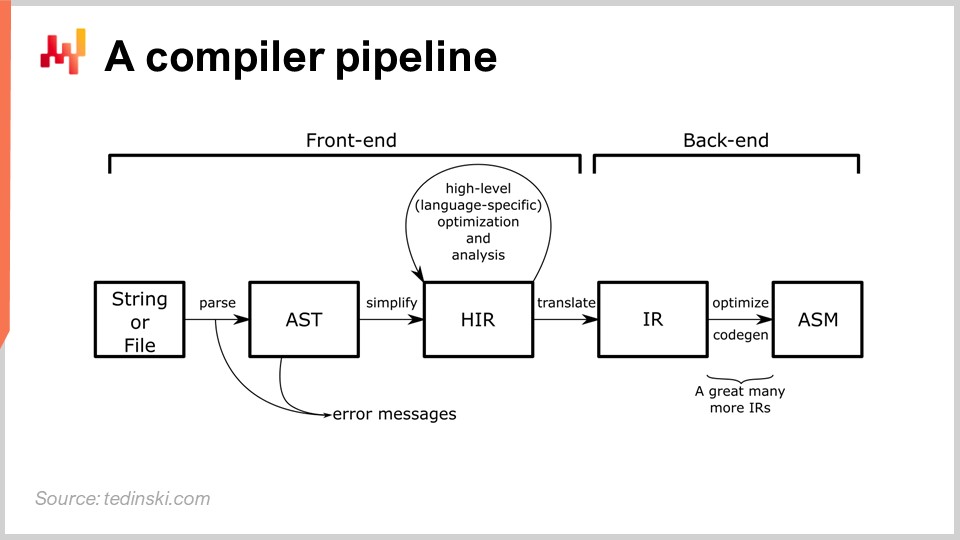
Im Diagramm sieht man eine typische Pipeline, und dieses Archetyp passt zu den meisten Programmiersprachen, von denen Sie wahrscheinlich schon gehört haben, wie Python, JavaScript, Java und C#. All diese Sprachen haben im Wesentlichen eine Pipeline, die der hier beschriebenen ähnelt. In einer Compiler-Pipeline gibt es eine Reihe von Transformationen, und in jeder Phase des Prozesses haben Sie eine Darstellung, die das gesamte Programm repräsentiert. Die Art und Weise, wie ein Compiler entwickelt wird, besteht darin, dass es eine Reihe klar definierter Transformationen gibt, und in jeder Phase des Prozesses arbeitet man mit dem gesamten Programm – nur, dass es unterschiedlich dargestellt wird.
Die Idee dahinter ist, dass jede Transformation für eine genau definierte Reihe von Problemen verantwortlich ist. Sie beheben diese Probleme und gehen dann zur nächsten Transformation über, die einen weiteren Aspekt des Prozesses adressiert. Typischerweise rückt man in jeder Phase näher an den Maschinencode heran. Der Compiler beginnt mit dem Skript und startet mit Transformationen, die der Syntax der betreffenden Programmiersprache sehr nahe kommen. In diesen frühen Transformationen wird ein typischer Compiler syntaktische Fehler erfassen, die ihn daran hindern, ein Skript, das nicht einmal ein gültiges Programm darstellt, in etwas Ausführbares zu verwandeln. Später in dieser Vorlesung werden wir einen genaueren Blick auf eine Compiler-Pipeline werfen.
Diese Vorlesung ist die fünfte Vorlesung des vierten Kapitels dieser Reihe. Im ersten Kapitel habe ich meine Ansichten über supply chain sowohl als Studienbereich als auch in der Praxis vorgestellt. Im zweiten Kapitel habe ich die für den Umgang mit in supply chain auftretenden Situationen geeigneten Methodologien untersucht. Wie wir gesehen haben, sind die meisten supply chain Situationen recht konfrontativ, weshalb wir Strategien und Methodologien benötigen, die gegenüber feindseligen Verhaltensweisen aller Beteiligten innerhalb und außerhalb der Unternehmen resilient sind.
Das dritte Kapitel widmet sich dem Personal im supply chain und ist vollständig der Untersuchung der supply chain Probleme selbst gewidmet. Wir müssen sehr darauf achten, das entdeckte Problem nicht mit der Art von Lösung zu vermischen, die wir uns vorstellen, um dieses Problem zu lösen. Das sind zwei getrennte Anliegen: Wir müssen das Problem von der Lösung trennen.
Das vierte und aktuelle Kapitel dieser Vorlesungsreihe widmet sich den Hilfswissenschaften des supply chain. Diese Hilfswissenschaften sind nicht supply chain per se, aber sie sind sehr hilfreich für die Praxis des modernen supply chain. Wir bewegen uns derzeit auf der Abstraktionsleiter. Wir begannen dieses Kapitel mit der Physik des Rechnens, dann mit Algorithmen, und stiegen in den Bereich der Software ein. Wir führten die mathematische Optimierung ein, die für supply chain von hohem Interesse ist und zudem die Grundlage des machine learning bildet.
Heute führen wir Sprachen und Compiler ein, die wesentlich für die Implementierung jeglicher Art von Programmierparadigmen sind. Auch wenn das Thema Sprachen und Compiler für das Publikum überraschend sein mag, glaube ich, dass es an diesem Punkt nicht allzu sehr überraschen sollte. Wir haben gesehen, dass mathematische Optimierung und machine learning heutzutage über Programmierparadigmen angegangen werden sollten, was die Frage aufwirft, wie diese Programmierparadigmen umgesetzt werden können. Das führt uns zum Design einer Programmiersprache und ihres unterstützenden Compilers, welches genau das Thema des heutigen Vortrags ist.

Dies ist eine Zusammenfassung des weiteren Verlaufs dieser Vorlesung. Wir beginnen mit übergreifenden Beobachtungen zur Geschichte und zum Markt der Programmiersprachen. Wir werden Branchen betrachten, die, wie ich glaube, sowohl die Zukunft als auch die Vergangenheit des supply chain repräsentieren. Anschließend werden wir uns schrittweise mit dem Design von Programmiersprachen und Compilern auseinandersetzen, wobei wir uns zu zunehmend detaillierteren und technischen Aspekten des Compiler-Designs vorarbeiten.

Seit den 1950er Jahren wurden Tausende von Programmiersprachen in den produktiven Einsatz gebracht. Schätzungen gehen auseinander, aber die Anzahl der Programmiersprachen, die für produktive Zwecke genutzt wurden, liegt vermutlich zwischen eintausend und zehntausend. Viele dieser Sprachen sind lediglich Varianten oder verwandte Formen voneinander, manchmal sogar nur der Codebase des Compilers, der in eine leicht abgewandelte Richtung geforkt wurde. Bemerkenswert ist, dass mehrere sehr große Unternehmen aus der Unternehmenssoftwarebranche durch die Einführung eigener Programmiersprachen erheblich wachsen konnten. Zum Beispiel führte SAP 1983 ABAP ein, Salesforce führte 2006 Apex ein, und sogar Microsoft begann vor Windows, indem es 1975 Altair BASIC entwickelte.
Historisch gesehen erinnern sich diejenigen unter Ihnen, die alt genug sind, um sich an die 90er zu erinnern, dass Anbieter damals Dritt- und Viertgenerations-Programmiersprachen vermarkteten. Tatsache ist, dass es eine klar definierte Reihe von Generationen gab – erste, zweite, dritte, vierte usw. – bis hin zur fünften, bei der die Community im Grunde aufgehört hat, in Generationen zu zählen. Während der ersten drei bis vier Jahrzehnte folgten all diese Programmiersprachen einem schönen Fortschreiten hin zu höheren Abstraktionsebenen. Allerdings gab es gegen Ende der 90er bereits viele weitere Ansätze, abgesehen von einer höheren Abstraktionsebene, abhängig vom Anwendungsfall.
Die Entwicklung einer neuen Programmiersprache wurde schon oft durchgeführt. Es ist ein etabliertes ingenieurwissenschaftliches Gebiet, und es gibt ganze Bücher, die sich aus einer sehr praktischen Perspektive mit dem Thema befassen. Die Konstruktion einer neuen Programmiersprache ist ein Verfahren, das viel fundierter und vorhersehbarer ist als beispielsweise die Durchführung eines data science-Experiments. Es besteht nahezu Gewissheit, dass Sie das gewünschte Ergebnis erzielen, wenn Sie die angemessene Ingenieurskunst anwenden, basierend auf dem, was heute bekannt und als Wissen verfügbar ist.
All dies wirft tatsächlich die Frage auf: Was ist mit einer Programmiersprache, die speziell für supply chain Zwecke entwickelt wurde? In der Tat kann dies erhebliche Vorteile in Bezug auf Produktivität, Zuverlässigkeit und sogar supply chain Performance bringen.

Um diese Frage zu beantworten, müssen wir einen Blick in die Zukunft werfen. Glücklicherweise ist der einfachste Weg, in die Zukunft zu blicken, eine Branche zu untersuchen, die in den letzten drei Jahrzehnten konstant ein Jahrzehnt voraus war – und das ist die Videospielbranche. Heutzutage ist dies eine sehr große Branche, und um Ihnen ein Gefühl für das Ausmaß zu geben: Die Videospielbranche entspricht nun zwei Dritteln der Größenordnung der Luft- und Raumfahrtindustrie weltweit und wächst viel schneller als diese. In einem Jahrzehnt könnten Videospiele tatsächlich größer sein als die Luft- und Raumfahrt.
Das Interessante an der Videospielbranche ist, dass sie über eine sehr gut etablierte Struktur verfügt. Zunächst haben wir die Game Engines, wobei die beiden führenden Anbieter Unity und Unreal sind. Diese Game Engines beinhalten die Low-Level-Komponenten, die für extrem anspruchsvolle und feingliedrige 3D-Grafiken von Interesse sind, und sie legen die Basis für die Infrastruktur Ihres Codes. Es gibt einige Unternehmen, die sehr komplexe Produkte namens Game Engines entwickeln, und diese Engines werden in der gesamten Branche verwendet.
Als Nächstes kommen die Game Studios, die den Spielcode für jedes einzelne Spiel entwickeln. Der Spielcode wird in der Regel eine Codebase sein, die spezifisch für das jeweilige Spiel ist. Die Game Engine erfordert sehr anspruchsvolle Softwareingenieure, die technisch hochqualifiziert sind, aber nicht unbedingt viel über Gaming wissen. Die Entwicklung des Spielcodes erfordert nicht dieselbe Intensität reiner technischer Fähigkeiten. Allerdings müssen die Softwareingenieure, die den Spielcode entwickeln, das Spiel, an dem sie arbeiten, verstehen. Der Spielcode bildet die Grundlage für die Spielmechanik, spezifiziert jedoch nicht alle Details.
Diese Aufgabe wird in der Regel von Game Designern übernommen, die keine Softwareingenieure sind, aber Code in den Skriptsprachen schreiben, die ihnen vom Engineering-Team, das den Spielcode betreut, zur Verfügung gestellt werden. Wir haben diese drei Stufen: Game Engines, in denen super-technische, anspruchsvolle Softwareingenieure die grundlegenden Bausteine erstellen; Studios, die über Engineering-Teams verfügen – in der Regel eines pro Spiel – in denen das Spiel als Plattform für die Spielmechanik entwickelt wird; und schließlich Game Designer, die zwar keine Softwareingenieure, sondern Gaming-Spezialisten sind und das Verhalten implementieren, das die Spieler, also die Endkunden der Kette, glücklich macht.
Heutzutage wird der Spielcode häufig der Community zugänglich gemacht, sodass Game Designer Regeln schreiben und das Spiel potenziell modifizieren können; aber auch Fans, die gewöhnliche Konsumenten der Spiele sind, haben diese Möglichkeit. Es gibt einige interessante Anekdoten in der Branche. Zum Beispiel begann das unglaublich erfolgreiche Spiel Dota 2 als Modifikation eines bestehenden Spiels. Die erste Version, einfach Dota genannt, war eine reine Fan-Modifikation des Spiels World of Warcraft 3. Dieses Maß an Konfigurierbarkeit und Programmierbarkeit auf der Ebene der Spielregeln ist sehr umfangreich, denn es war möglich, aus einem bestehenden kommerziellen Spiel – World of Warcraft 3 – ein völlig neues Spiel zu kreieren, das sich durch seine zweite Version zu einem massiven kommerziellen Erfolg entwickelte. Das ist interessant, und wir können beginnen, uns zu fragen, was das für die supply chain Branche bedeuten könnte.
Man könnte darüber nachdenken, welche Parallele man ziehen könnte. Wir könnten eine supply chain engine haben, die sich um die sehr schwierigen algorithmischen Teile, die Low-Level-Infrastruktur und die zentralen technologischen Bausteine wie mathematische Optimierung und maschinelles Lernen kümmert. Die Idee ist, dass für jede einzelne supply chain ein Engineering-Team benötigt wird, um alle relevanten Daten zusammenzuführen und die gesamte anwendungsspezifische Landschaft zu integrieren.
In einer ersten Stufe bräuchten wir das Äquivalent zu den Game Designern, nämlich supply chain Spezialisten. Diese Spezialisten sind keine Softwareingenieure, aber sie sind diejenigen, die mittels vereinfachtem Code alle Regeln und Mechaniken schreiben, die erforderlich sind, um die prädiktive Optimierung, die für die supply chain von Interesse ist, zu implementieren. Die Gaming-Branche liefert ein anschauliches Beispiel dafür, was in den kommenden Jahrzehnten im Bereich der supply chain wahrscheinlich passieren wird.

Bisher bleibt der Ansatz der Gaming-Branche im Bereich supply chain Science-Fiction, abgesehen von einigen wenigen Unternehmen. Ich glaube, dass die meisten dieser Unternehmen zufällig Kunden von Lokad sind. Zurück zum heutigen Thema: Wir haben in vorherigen Vorträgen gesehen, dass Excel nach wie vor die Nummer-eins Programmiersprache in dieser Branche ist. Übrigens, was Programmiersprachen betrifft, so ist Excel eine funktional reaktive Programmiersprache, sodass es sogar eine eigene Kategorie darstellt.
Heutzutage hört man vielleicht von Anbietern, die vorschlagen, supply chains mit einer Art data science Setup aufzurüsten. Meine beiläufige Beobachtung der letzten Dekade ist jedoch, dass die überwiegende Mehrheit dieser Initiativen gescheitert ist. Das gehört bereits der Vergangenheit an, und um zu verstehen, warum, müssen wir uns die Liste der beteiligten Programmiersprachen ansehen. Betrachtet man Excel, sieht man, dass es im Wesentlichen zwei Programmiersprachen umfasst: Excel-Formeln und VBA. VBA ist nicht einmal zwingend erforderlich; man kommt auch sehr gut allein mit VLOOKUPs in Excel zurecht. Typischerweise handelt es sich also um nur eine Programmiersprache, die auch für Nicht-Softwareingenieure zugänglich ist.
Andererseits ist die Liste der Programmiersprachen, die erforderlich sind, um die Fähigkeiten von Excel mit einem data science Setup zu replizieren, recht umfangreich. Wir werden SQL benötigen und möglicherweise mehrere SQL-Dialekte, um auf die Daten zuzugreifen. Wir werden Python brauchen, um die Kernlogik zu implementieren. Allerdings ist Python für sich genommen tendenziell langsam, sodass Sie möglicherweise eine Unter-Sprache wie NumPy benötigen. An diesem Punkt betreiben Sie noch nichts im Bereich maschinelles Lernen oder mathematische Optimierung, sodass Sie für echte, anspruchsvolle numerische Analysen noch etwas anderes brauchen – eine weitere eigene Programmiersprache, wie zum Beispiel PyTorch. Nun, da Sie all diese Elemente zusammenhaben, gibt es bereits eine Vielzahl von beweglichen Teilen, sodass Ihre Konfiguration der Anwendung selbst sehr komplex sein wird. Sie werden eine Konfiguration benötigen, und diese wird mit einer weiteren Programmiersprache geschrieben, wie JSON oder XML. Man könnte argumentieren, dass dies keine besonders komplexen Programmiersprachen sind, aber es ist einfach noch etwas mehr, das hinzugefügt werden muss.
Wenn Sie so viele bewegliche Teile haben, benötigen Sie typischerweise ein Build-System, etwas, das alle Compiler und routinemäßigen Abläufe ausführen kann, die zur Erstellung der Software nötig sind. Build-Systeme haben ihre eigenen Sprachen. Der traditionelle Ansatz ist eine Sprache namens Make, aber es gibt viele andere. Außerdem, da Excel in der Lage ist, Ergebnisse anzuzeigen, brauchen Sie eine Möglichkeit, dem Nutzer Dinge darzustellen und visuell aufzubereiten. Dies wird mit einer Mischung aus JavaScript, HTML und CSS erledigt, was der Liste noch weitere Sprachen hinzufügt.
An diesem Punkt haben wir eine lange Liste von Programmiersprachen, und ein tatsächlicher Produktionsaufbau könnte noch komplexer sein. Das erklärt, warum die meisten Unternehmen, die im letzten Jahrzehnt versucht haben, diese data science Pipeline umzusetzen, überwältigend gescheitert sind und in der Praxis einfach bei Excel geblieben sind. Der Grund daran ist, dass es erfordert, nahezu ein Dutzend Programmiersprachen zu beherrschen, anstatt nur eine, wie es bei Excel der Fall ist. Wir haben noch gar nicht begonnen, echte supply chain Probleme anzupacken; wir haben uns bisher nur mit den technischen Details beschäftigt, die erforderlich sind, um überhaupt etwas in die Wege zu leiten.

Nun wollen wir darüber nachdenken, wie eine Programmiersprache für supply chain aussehen würde. Zunächst müssen wir entscheiden, was in der Sprache integriert ist und was als First-Class-Bürger der Sprache gilt und was zu Bibliotheken gehört. Tatsächlich ist es bei Programmiersprachen immer möglich, Funktionen an Bibliotheken auszulagern. Schauen wir uns zum Beispiel die Programmiersprache C an. Sie gilt als relativ Low-Level-Programmiersprache, und C besitzt keinen Garbage Collector. Es ist jedoch machbar, einen Garbage Collector von Drittanbietern als Bibliothek in einem C-Programm zu verwenden. Aufgrund der Tatsache, dass die Speicherbereinigung in C keinen First-Class-Status hat, tendiert die Syntax dazu, relativ wortreich und mühsam zu sein.
Für supply chain Zwecke gibt es Aspekte wie mathematische Optimierung und maschinelles Lernen, die üblicherweise als Bibliotheken behandelt werden. Wir haben also eine Programmiersprache, und all diese Aspekte werden im Wesentlichen an Drittanbieter-Bibliotheken ausgelagert. Wenn wir jedoch eine Programmiersprache für supply chain entwickeln würden, würde es wirklich Sinn machen, diese Aspekte als First-Class-Bürger in der Programmiersprache selbst zu verankern. Ebenso wäre es sinnvoll, relationale Daten als integralen Bestandteil der Sprache zu haben. In supply chain besteht die anwendungsspezifische Landschaft – die viele Stücke Unternehmenssoftware umfasst – aus relationalen Daten in Form von relationalen Datenbanken, wie SQL-Datenbanken, die überall vorhanden sind. So gut wie alle heutigen Unternehmenssoftwareprodukte haben im Kern eine relationale Datenbank, was bedeutet, dass wir für supply chain Zwecke, sobald wir die Daten berühren wollen, tatsächlich mit Daten interagieren, die von Natur aus relational sind. Die Daten präsentieren sich als eine Liste von Tabellen, die aus all jenen Datenbanken extrahiert wurden, die verschiedene Apps antreiben, und jede Tabelle hat eine Liste von Spalten oder Feldern.
Es erscheint wirklich sinnvoll, relationale Daten innerhalb der Sprache zu haben. Darüber hinaus, was ist mit der Benutzeroberfläche (UI) und der Benutzererfahrung (UX)? Einer der starken Punkte von Excel ist, dass all dies vollständig in die Sprache eingebettet ist, sodass Sie nicht erst eine Programmiersprache haben und dann allerlei Drittanbieter-Bibliotheken, die sich um Präsentation, Rendering und Benutzerinteraktion kümmern. All dies ist Teil der Sprache. Dass all dies als First-Class-Bürger behandelt wird, wäre auch von sehr großem Interesse für supply chain – zumindest, wenn wir so gut sein wollen, wie Excel es für supply chains sein kann.

Bei der Sprachgestaltung stellt die Grammatik die formale Darstellung der Regeln dar, die ein gültiges Programm gemäß Ihrer neu eingeführten Programmiersprache definieren. Im Wesentlichen beginnen Sie mit einem Textfragment, auf das zunächst ein Lexer angewendet wird – eine spezielle Algorithmusklasse oder ein kleines Programm. Der Lexer zerlegt Ihren Text, das Programm, das Sie gerade geschrieben haben, in eine Folge von Tokens. Dabei isoliert der Lexer alle Variablen und Symbole, die in Ihrer Programmiersprache eine Rolle spielen. Die Grammatik hilft dabei, diese Token-Folge in die eigentliche Semantik des Programms zu überführen, indem sie definiert, was das Programm bedeutet und welche exakte, eindeutige Menge an Operationen zur Ausführung erforderlich ist.
Die Grammatik selbst wird typischerweise als ein Trade-off betrachtet zwischen den Aspekten, die Sie in Ihrer Sprache internalisieren möchten, und den Konzepten, die Sie externalisieren möchten. Wenn wir beispielsweise relationale Daten als einen externen Aspekt betrachten, müsste der Programmierer viele spezialisierte Datenstrukturen wie Wörterbücher, Lookups und Hashtabellen einführen, um all diese Operationen manuell innerhalb der Programmiersprache durchzuführen. Möchte die Grammatik hingegen die relationale Algebra internalisieren, bedeutet dies, dass der Programmierer in der Regel die gesamte relationale Logik direkt in ihrer relationalen Form schreiben kann. Allerdings bedeutet das zugleich, dass all diese relationalen Einschränkungen und die relationale Algebra Teil der zu tragenden Last der Grammatik werden.
Aus der Sicht der supply chain, da relationale Daten in Unternehmenssoftware allgegenwärtig sind, macht es sehr viel Sinn, eine Grammatik zu haben, die sich direkt auf der Ebene der Sprache um alle relationalen Aspekte kümmert.

Grammatiken in der Informatik sind ein enorm erforschtes Thema. Sie gibt es seit Jahrzehnten, und dennoch ist es wahrscheinlich der einzige Bereich, in dem Unternehmenssoftwareanbieter am allermeisten scheitern. Tatsächlich landen sie unweigerlich damit, accidentelle Programmiersprachen zu beschwören, die ganz natürlich entstehen, sobald komplexe Konfigurationseinstellungen ins Spiel kommen. Wenn Sie Bedingungen, Trigger, Schleifen und Reaktionen haben, müssen Sie sich in der Regel um diese Sprache kümmern, anstatt sie einfach von selbst entstehen zu lassen.

Was passiert, ist, dass wenn man keine Grammatik hat, immer wenn man Änderungen an der Anwendung vornimmt, man letztlich unkoordinierte Konsequenzen auf das tatsächliche Verhalten des Systems erfährt. Übrigens erklärt dies auch, warum das Upgrade von einer Version einer Unternehmenssoftware auf eine andere in der Regel sehr komplex ist. Die Konfiguration soll zwar gleich bleiben, aber wenn man versucht, dieselbe Konfiguration in der nächsten Version der Software auszuführen, erhält man völlig andere Ergebnisse. Die Hauptursache dieser Probleme ist das Fehlen einer Grammatik und etablierter, formalisierter Semantiken dafür, was die Konfiguration bedeuten soll.
Der typische Weg, eine Grammatik darzustellen, erfolgt formal unter Verwendung der Backus-Naur-Form (BNF), einer speziellen Notation. Auf dem Bildschirm sieht man eine Mini-Programmiersprache, die US-Postadressen repräsentiert. Jede Zeile mit einem Gleichheitszeichen entspricht einer Produktionsregel. Was sich links befindet, ist ein Nichtterminalsymbol, und rechts vom Gleichheitszeichen folgt eine Sequenz aus Terminal- und Nichtterminalsymbolen. Terminalsymbole sind rot dargestellt und stehen für Zeichen, die nicht weiter abgeleitet werden können. Nichtterminalsymbole stehen in Klammern und können weiter abgeleitet werden. Diese Grammatik hier ist nicht vollständig; es müssten noch viele weitere Produktionsregeln hinzugefügt werden, um eine vollständige Grammatik zu erhalten. Ich wollte diese Folie nur übersichtlich halten.
Eine Grammatik ist etwas, das sehr einfach in Bezug auf die Syntax Ihrer Programmiersprache zu definieren ist, und sie stellt auch sicher, dass sie eindeutig ist. Allerdings bedeutet es nicht, dass sie automatisch eine gültige oder sogar gute Grammatik ist, nur weil sie in der Backus-Naur-Form geschrieben ist. Um eine gute Grammatik zu erhalten, müssen wir noch ein wenig mehr tun. Der mathematische Ansatz, eine gute Grammatik zu charakterisieren, besteht darin, eine kontextfreie Grammatik zu haben. Eine Grammatik gilt als kontextfrei, wenn die Produktionsregeln für jedes Nichtterminal anwendbar sind, unabhängig von den Symbolen, die man links oder rechts vorfindet. Die Idee ist, dass eine kontextfreie Grammatik etwas ist, bei der man die Produktionsregeln in beliebiger Reihenfolge anwenden kann und sie sofort anwendet, sobald man eine passende Ableitung sieht.
Was man aus einer kontextfreien Grammatik erhält, ist eine Grammatik, bei der, wenn man etwas ändert und diese Änderung eine Mehrdeutigkeit erzeugt, der Compiler das Programm, in dem die Mehrdeutigkeit auftritt, nicht kompilieren kann. Dies ist von zentralem Interesse, wenn man beabsichtigt, eine Konfiguration über einen langen Zeitraum zu pflegen. In supply chain ist die meiste Unternehmenssoftware sehr langlebig. Es ist nicht ungewöhnlich, dass Teile von Unternehmenssoftware zwei oder drei Jahrzehnte in Betrieb sind. Bei Lokad betreuen wir über 100+ Unternehmen, und es ist durchaus üblich, dass wir Daten aus Systemen extrahieren, die seit über drei Jahrzehnten eingesetzt werden, insbesondere bei großen Unternehmen.
Mit einer kontextfreien Grammatik erhält man die Garantie, dass, wenn an dieser Sprache – und denken Sie daran, wenn ich „Sprache“ sage, meine ich damit etwas so Grundlegendes wie Konfigurationseinstellungen – eine Änderung vorgenommen wird, die daraus entstehenden Mehrdeutigkeiten erkannt werden können. So wird vermieden, dass diese Mehrdeutigkeiten unbemerkt auftreten und zu Schwierigkeiten beim Upgrade von einem System zum anderen führen.
Was passiert, wenn Menschen nichts über Grammatiken wissen, ist, dass sie einen Parser manuell schreiben. Wer noch nie von einer Grammatik gehört hat, würde einen Parser schreiben – ein Programm, das planlos eine Art Baum erzeugt, der die geparste Version des Programms darstellt. Das Problem daran ist, dass man eine Semantik für das Programm erhält, die unglaublich spezifisch für die jeweilige Programmversion ist. Ändert man dieses Programm, ändert sich auch die Semantik, was zu unterschiedlichen Ergebnissen führt, sodass man dieselbe Konfiguration, jedoch ein unterschiedliches Verhalten für die supply chain erhalten kann.
Glücklicherweise gab es 2004 einen kleinen Durchbruch, als Brian Ford in einem Artikel mit dem Titel “Parsing Expression Grammars: A Recognition-Based Syntactic Foundation” einen Ansatz vorstellte. Mit dieser Arbeit gab Ford der Community eine Möglichkeit, die Art von zufälligen, ad-hoc geschriebenen Parsern, die in der Praxis existieren, zu formalisieren. Diese Grammatiken werden beispielsweise Parsing Expression Grammars (PEGs) genannt, und mit PEGs können Sie diese halb-zufälligen empirischen Parser in tatsächlich formale Grammatiken umwandeln.
Python hat zum Beispiel nicht exakt eine kontextfreie Grammatik, sondern eine PEG. PEGs sind in Ordnung, wenn Sie über einen umfangreichen Satz automatisierter Tests verfügen, da sie so den Erhalt der Semantik über die Zeit sicherstellen können. Tatsächlich besitzen Sie mit PEGs eine Formalisierung Ihrer Grammatik, sodass Sie in einer besseren Situation sind, als wenn überhaupt keine Grammatik vorhanden wäre und lediglich ein Parser existiert. Allerdings wird bei der Entwicklung der Semantik mittels einer PEG nicht automatisch erkannt, dass sich die Semantik ändert, wenn Sie die Grammatik selbst abändern. Daher benötigen Sie eine umfangreiche Suite von automatisierten Tests zusätzlich zu Ihrer PEG – was übrigens genau das ist, was die Python-Community hat. Sie verfügen über einen sehr robusten und umfangreichen Satz automatisierter Tests. Aus der Perspektive der supply chain glaube ich, dass Grammatiken nicht nur ihre Wichtigkeit verdeutlichen, sondern auch als Lackmustest fungieren. Sie können Unternehmenssoftwareanbieter tatsächlich testen, wenn Sie eine Software mit erheblicher Komplexität besprechen. Sie sollten den Anbieter nach der Grammatik fragen, die er für die komplexe Konfiguration verwendet. Wenn der Anbieter antwortet: “Was ist eine Grammatik?”, wissen Sie, dass Sie in Schwierigkeiten sind und die Wartung vermutlich langsam und teuer wird.

Programmierung ist sehr schwierig, und die Menschen machen viele Fehler. Wäre sie einfach, bräuchte man gar keine Programmierung. Eine gute Programmiersprache minimiert die Zeit, die benötigt wird, um einen Fehler zu erkennen und zu beheben. Dies ist einer der kritischsten Aspekte einer Programmiersprache und sorgt für eine angemessene Produktivität für alle, die Code schreiben.
Betrachten wir folgendes Szenario: Wenn während des Schreibens des Codes ein Fehler, wie z. B. ein Tippfehler mit rotem Unterstrich in Microsoft Word, in Echtzeit erkannt wird, kann die Rückkopplungsschleife zur Behebung des Fehlers so kurz wie 10 Sekunden sein – ideal. Wird der Fehler jedoch erst erkannt, wenn das Programm gestartet wird, dauert die Rückkopplungsschleife mindestens 10 Minuten. In supply chain haben wir oft große Datensätze zu verarbeiten, und man kann nicht erwarten, dass das Programm in wenigen Sekunden alle Daten durchläuft. Folglich beträgt die Rückkopplung bei Problemen, die erst zur Laufzeit auftreten, 10 Minuten oder mehr.
Wenn ein Fehler erst nach Abschluss des Skripts erkannt wird, das heißt, das Programm enthält einen Fehler, schlägt aber nicht fehl, dauert die Rückkopplungsschleife etwa 10 Stunden oder mehr. Wir sind von 10 Sekunden Echtzeit-Rückmeldung zu 10 Minuten gegangen, wenn wir das Programm ausführen müssen, und dann zu 10 Stunden, wenn wir die numerischen Ergebnisse und KPIs, die das Programm liefert, überprüfen müssen.
Es gibt ein noch schlimmeres Szenario: Wenn die Plattform, auf der Sie arbeiten, nicht strikt deterministisch ist, das heißt, dass sie bei gleichem Input und gleichen Daten unterschiedliche Ergebnisse liefern kann. Das ist nicht so seltsam, wie es klingen mag, denn in supply chain können beispielsweise Monte-Carlo-Simulationen im Einsatz sein. Wenn in den Ergebnissen irgendeine Zufälligkeit auftritt, kann es passieren, dass etwas nur gelegentlich fehlschlägt, und dann ist die Rückkopplungsschleife typischerweise länger als 10 Tage. Wir sind also von 10 Sekunden auf 10 Tage gekommen, und es gibt enorme Vorteile, diese Rückkopplungsschleife zu verkürzen. Statische Analyse umfasst eine Reihe von Techniken, die Probleme, Fehler oder Ausfälle erkennen, ohne das Programm überhaupt auszuführen. Bei statischer Analyse besteht die Idee darin, dass Sie das Programm nicht einmal ausführen, was bedeutet, dass Sie den Fehler in Echtzeit melden können, während die Leute tippen – ähnlich wie ein roter Unterstrich bei Tippfehlern in Microsoft Word. Allgemein besteht ein starkes Interesse daran, jedes Problem so zu transformieren, dass es in eine frühere Rückkopplungskategorie rückt, sodass Probleme, die Tage zur Identifizierung bräuchten, in Minuten oder Sekunden erkannt werden.
Aus der Perspektive der supply chain haben wir in einer der vorherigen Vorlesungen gesehen, dass in supply chain viel Chaos zu erwarten ist. Wir können nicht klassische Release-Zyklen haben, bei denen man auf die nächste Version der Software warten muss. Manchmal gibt es außergewöhnliche Ereignisse wie eine Zolländerung, ein Containerschiff, das in einem Kanal stecken bleibt, oder eine Pandemie. Diese Notfallsituationen erfordern sofortige Korrekturen, und das Ausmaß der statischen Analyse, die Sie an Ihrer Programmiersprache durchführen können, bestimmt im Wesentlichen, wie viel Chaos in der Produktion durch Fehler entsteht, die nicht in Echtzeit beim Tippen erkannt werden. Außergewöhnliche Ereignisse mögen selten erscheinen, aber in der Praxis sind Überraschungen in supply chain durchaus üblich.

Es gibt mathematische Beweise dafür, dass es unmöglich ist, in einer allgemeinen Situation alle Fehler mit einer allgemeinen Programmiersprache zu erkennen. Zum Beispiel ist es nicht einmal möglich zu beweisen, dass das Programm beendet wird, das heißt, es ist nicht möglich zu garantieren, dass das Geschriebene nicht endlos weiterläuft.
Bei der statischen Analyse erhalten Sie typischerweise drei Kategorien: Einige Codeabschnitte sind vermutlich gut, einige vermutlich schlecht, und bei vielen Dingen dazwischen weiß man einfach nicht. Die Idee ist, dass je mehr Sie von “weiß nicht” zu “schlechtem Code” übergehen, desto mehr Aufwand im Sprachdesign erforderlich ist, um den Compiler davon zu überzeugen, dass Ihr Programm gültig ist. Wir müssen also ein Gleichgewicht finden zwischen dem Aufwand, den Sie investieren möchten, um die Programmiersprache davon zu überzeugen, dass Ihr Code korrekt ist, und den Garantien, die Sie bereits zur Kompilierzeit – noch bevor das Programm tatsächlich läuft – erhalten. Das ist eine Frage der Produktivität.
Nun, eine kurze Liste typischer Fehler, die durch statische Analyse erkannt werden, umfasst Syntaxfehler, wie vergessene Kommas oder Klammern. Einige Programmiersprachen können Syntaxfehler noch vor der Laufzeit nicht einmal aufzeigen, wie Bash, die Shell-Sprache unter Linux. Statische Analyse kann auch Typfehler erkennen, die auftreten, wenn Sie den falschen Typ oder eine falsche Anzahl von Argumenten für eine Funktion verwenden.
Auch nicht erreichbarer Code kann erkannt werden, was bedeutet, dass der Code an sich in Ordnung ist, aber niemals ausgeführt wird, weil das gesamte Programm auch ohne diesen Abschnitt funktionieren kann. Es ist wie toter Code oder eine vergessene logische Verbindung. Unbedeutender Code ist ein weiteres Problem, bei dem der Code zwar ausgeführt wird, jedoch keinen Einfluss auf das Endergebnis hat. Es handelt sich dabei um eine Variante von nicht erreichbarem Code.
Übermäßig ressourcenintensiver Code kann ebenfalls erkannt werden, was sich auf Code bezieht, der zwar ausgeführt wird, dessen benötigte Rechenressourcen jedoch bei weitem den Rahmen sprengen, den Sie sich für Ihr Programm leisten können. Ein Programm verbraucht Rechenressourcen wie Speicher, Datenspeicher und CPU. Durch statische Analyse können Sie nachweisen, dass ein Codeblock weit mehr Ressourcen verbraucht, als Sie sich leisten können, wenn man Ihre Vorgaben wie die Berechnung innerhalb eines bestimmten Zeitrahmens berücksichtigt. Sie würden es vorziehen, dass dies bereits zur Kompilierzeit fehlschlägt, anstatt das Programm eine Stunde lang laufen zu lassen und es dann aufgrund eines Timeouts scheitern zu sehen, was zu sehr niedriger Produktivität führen würde.
Bei der statischen Analyse gibt es jedoch einen Haken. Während Sie tippen, arbeiten Sie mit einem Programm, das ständig ungültig ist. Mit jedem Tastendruck verwandeln Sie ein gültiges Programm in ein ungültiges. Eine industriefähige Lösung für diese Situation heißt Language Server Protocol. Dieses Tooling wird mit einer Programmiersprache geliefert und ist der aktuelle Stand der Technik, wenn es um Echtzeit-Fehlerrückmeldungen für die von Ihnen geschriebenen Programme geht.
Mit einem Language Server Protocol haben Sie Zugriff auf Funktionen wie “Gehe zur Definition”, wenn Sie auf eine Variable klicken. Das Language Server Protocol ist grundsätzlich zustandsbehaftet und merkt sich die letzte korrekte Version Ihres Programms sowie die verfügbaren Annotationen und Semantiken. Es bewahrt diese Annotationen und zusätzlichen Informationen auch dann, wenn Ihr Programm fehlerhaft ist, nur weil Sie einen zusätzlichen Tastendruck ausgeführt haben und es nicht mehr gültig ist. Es ist ein Wendepunkt in Bezug auf die Produktivität, und wann immer es einen gewissen Grad an Dringlichkeit gibt, macht es einen großen Unterschied für supply chain Zwecke.

Kommen wir nun zum Typensystem. Als erste grobe Annäherung ist ein Typensystem eine Menge von Regeln, die die Kategorisierung der Objekte in Ihrem Programm oder der Elemente, die Sie manipulieren, nutzt, um zu klären, ob bestimmte Interaktionen erlaubt oder unzulässig sind. Beispielsweise gehören typische Typen zu Zeichenketten, ganzen Zahlen und Gleitkommazahlen, die alle sehr grundlegende Typen sind. Es legt fest, dass das Addieren zweier ganzer Zahlen gültig ist, das Addieren einer Zeichenkette und einer ganzen Zahl jedoch nicht – außer in JavaScript, da dort die Semantik anders ist.
Typensysteme sind im Allgemeinen ein offenes Forschungsproblem und können unglaublich abstrakt werden. Um etwas Licht ins Dunkel zu bringen, müssen wir klarstellen, dass es zwei Arten von Typen gibt, die häufig verwechselt werden. Zum einen gibt es die Typen von Werten, die nur zur Laufzeit existieren, wenn das Programm tatsächlich läuft. Beispielsweise, wenn in Python eine Funktion das erste Element eines Arrays von ganzen Zahlen zurückgibt, dann wird der Typ des zurückgegebenen Wertes eine ganze Zahl sein. Aus dieser Perspektive besitzen alle Programmiersprachen Typen – sie sind alle typisiert.
Zum anderen gibt es die Typen von Variablen, die nur zur Kompilierzeit existieren, während das Programm kompiliert wird und noch nicht läuft. Die Herausforderung bei Variablentypen besteht darin, bereits zur Kompilierzeit so viele Informationen wie möglich über diese Variablen zu extrahieren. Wenn wir auf das vorherige Beispiel zurückkommen, ist es in Python möglicherweise nicht immer möglich, den Typ des von der Funktion zurückgegebenen Wertes eindeutig zu bestimmen, da Python zur Kompilierzeit nicht vollständig stark typisiert ist.
Aus der Sicht der supply chain betrachten wir ein Typsystem, das unterstützt, was wir für den Nutzen der supply chain beabsichtigen. Wir wollen so restriktiv wie möglich sein, um Probleme und Bugs früh zu erfassen, aber auch so flexibel wie möglich, um alle Operationen zuzulassen, die von Interesse sein könnten. Zum Beispiel, betrachten Sie die Addition eines Datums und eines Ganzzahlwerts. In einer regulären Programmiersprache würden Sie wahrscheinlich sagen, dass es nicht legitim ist, aber aus der Sicht der supply chain, wenn wir ein Datum haben und sieben Tage hinzufügen wollen, würde es Sinn machen, “date + 7” zu schreiben. Es gibt viele Operationen in der supply chain-Planung, die das Verschieben von Daten um eine bestimmte Anzahl von Tagen beinhalten, daher wäre es nützlich, eine Algebra zu haben, bei der es in Ordnung ist, eine Addition zwischen einem Datum und einer Zahl durchzuführen.
In Bezug auf Typen, wollen wir erlauben, dass man ein Datum zu einem anderen hinzufügt? Wahrscheinlich nicht. Möchten wir jedoch die Subtraktion zwischen zwei Daten erlauben? Warum nicht? Wenn wir ein Datum von einem anderen subtrahieren, das davor liegt, erhalten wir die Differenz, die in Tagen ausgedrückt werden könnte. Dies ist sehr sinnvoll für die in der Planung involvierten Berechnungen.
Setzt man das Thema Datum fort, gibt es auch Eigenschaften, die von Interesse sein könnten, wenn man darüber nachdenkt, was ein Typsystem für uns in Bezug auf supply chain-Angelegenheiten tun sollte. Zum Beispiel, was ist mit der Einschränkung des zulässigen Zeitbereichs? Wir könnten sagen, dass Daten außerhalb des Rahmens von 20 Jahren in der Vergangenheit und 20 Jahren in der Zukunft einfach nicht gültig sind. Wahrscheinlich, wenn wir eine Planungsoperation durchführen und zu einem bestimmten Zeitpunkt im Programm ein Datum manipulieren, das mehr als 20 Jahre in der Zukunft liegt, ist es überwältigend wahrscheinlich, dass es sich für die meisten Branchen nicht um ein gültiges Planungsscenario handelt. In den meisten Fällen würde man Operationen nicht auf täglicher Basis mehr als 20 Jahre im Voraus planen. So können wir nicht nur die üblichen Typen verwenden, sondern sie auf Weise neu definieren, die restriktiver und besser für supply chain-Zwecke geeignet ist.
Zudem gibt es den ganzen Aspekt der Unsicherheit. Im supply chain-Management blicken wir immer in die Zukunft, aber leider ist die Zukunft immer unsicher. Der mathematische Weg, Unsicherheit zu umarmen, führt über Zufallsvariablen. Es wäre sinnvoll, Zufallsvariablen in die Sprache zu integrieren, um unsichere zukünftige Nachfrage, lead times und Kundenrücksendungen, unter anderem, darzustellen.
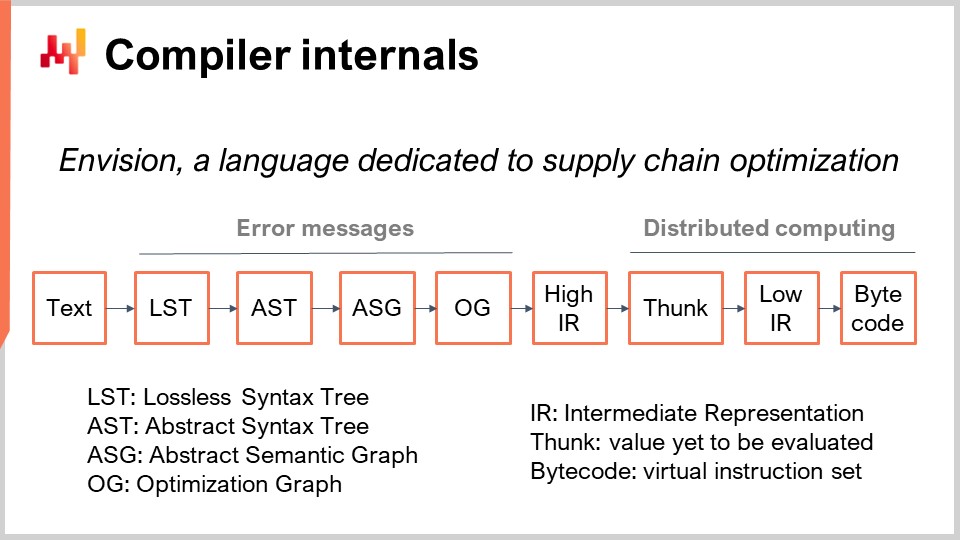
Bei Lokad haben wir Envision entwickelt, eine Programmiersprache, die der prädiktiven Optimierung von supply chains gewidmet ist. Envision ist eine Mischung aus SQL, Python, mathematischer Optimierung, Machine Learning und Big-Data-Fähigkeiten, alles eingeschlossen als erstklassige Bürger innerhalb der Sprache selbst. Diese Sprache wird mit einer webbasierten Integrierten Entwicklungsumgebung (IDE) bereitgestellt, was bedeutet, dass man ein Skript über das Web schreiben kann und alle modernen Funktionen der Code-Bearbeitung zur Verfügung stehen. Diese Skripte operieren über ein integriertes, verteiltes Dateisystem, das mit der Lokad-Umgebung mitgeliefert wird, sodass die Datenschicht vollständig in die Programmiersprache integriert ist.
Envision-Skripte werden auf einer Flotte von Maschinen ausgeführt, die dafür ausgelegt sind, die gesamte Cloud zu nutzen. Wenn das Skript ausgeführt wird, verteilt es sich auf viele Maschinen, um schneller zu laufen. Auf dem Bildschirm sehen Sie die Compiler-Pipeline, die von Envision verwendet wird. Heute werden wir diese Programmiersprache nicht diskutieren; wir werden nur ihre Compiler-Pipeline besprechen, da dies das zentrale Thema der heutigen Vorlesung ist.
Zuerst beginnen wir mit einem Textstück, das das Envision-Skript enthält. Es repräsentiert ein Programm, das von einem supply chain-Experten, nicht von einem Software-Ingenieur, geschrieben wurde, um eine spezifische supply chain-Herausforderung zu adressieren. Diese Herausforderung könnte darin bestehen zu entscheiden, was produziert werden soll, was aufgefüllt, was bewegt werden soll, oder ob ein Preis erhöht oder gesenkt werden soll. Diese Anwendungsfälle beinhalten Entscheidungen darüber, was produziert, aufgefüllt, bewegt werden soll oder ob Preise erhöht oder gesenkt werden sollen. Der Text des Skripts enthält die Anweisungen, und die Idee ist, dieses Skript zu verarbeiten und den Lossless Syntax Tree (LST) zu erhalten. Der LST ist interessant, weil er eine sehr spezifische Darstellung darstellt, die keinen einzigen Charakter verwirft. Selbst unwichtige Leerzeichen werden beibehalten. Der Grund hierfür ist sicherzustellen, dass automatisierte Neuschreibungen des Programms den bestehenden Code nicht verändern. Dieser Ansatz vermeidet Situationen, in denen Werkzeuge Code umsortieren, Einrückungen verschieben oder andere Störungen verursachen, die den Code schwer erkennbar machen.
Ein grundlegender Refaktorisierungsvorgang könnte beispielsweise darin bestehen, eine Variable und alle ihre Vorkommen im Programm umzubenennen, ohne etwas anderes zu verändern. Aus dem LST gelangen wir zum Abstract Syntax Tree (AST), in welchem wir den Baum vereinfachen. Klammern sind in dieser Phase nicht notwendig, da die Baumstruktur die Prioritäten aller Operationen definiert. Zusätzlich führen wir eine Reihe von Desugaring-Operationen durch, um jegliche Syntax zu entfernen, die zum Nutzen des Endprogrammierers bereitgestellt wird.
Von dem AST bewegen wir uns zum Abstract Syntax Graph (ASG), wobei wir den Baum abflachen. Dieser Prozess beinhaltet das Zerlegen komplexer Anweisungen mit stark verschachtelten Ausdrücken in eine Sequenz von elementaren Anweisungen. Zum Beispiel würde eine Anweisung wie “a = b + c + d” in zwei Anweisungen aufgeteilt, die jeweils nur eine Addition enthalten. Genau das geschieht während des Übergangs vom AST zum ASG.
Vom ASG gehen wir zum Optimization Graph (OG) über, wo wir Typanpassungen und Broadcasting, insbesondere in Bezug auf relationale Algebra, vornehmen. Wie bereits erwähnt, bettet Envision eine relationale Algebra in die Sprache ein. Wie schon oft angedeutet, bettet Envision eine relationale Algebra, wie sie in relationalen Datenbanken oder SQL-Datenbanken verwendet wird, als erstklassigen Bürger ein. Es gibt zahlreiche relationale Operationen, und wir überprüfen, dass diese relationalen Operationen gemäß dem Schema der Tabellen, mit denen wir arbeiten, gültig sind, wenn wir vom ASG zum OG übergehen. Der Optimization Graph (OG) stellt den letzten Schritt unseres Compiler-Frontends dar und besteht aus reinen, elementaren relationalen Operationen, die auf das Programm angewendet werden und winzige Logikbausteine repräsentieren. Wie in SQL sind diese Elemente relationaler Natur.
Der Optimierungsgraph wird “Optimization” genannt, weil zahlreiche Transformationen von OG zu OG stattfinden. Diese Transformationen erfolgen, weil bei der Arbeit mit relationaler Algebra das Organisieren von Operationen auf bestimmte Weise dazu führen kann, dass das Programm viel schneller läuft. Zum Beispiel ist es in SQL, wenn man zuerst einen Filter und dann eine Operation hat, oder umgekehrt, viel besser, zuerst die Daten zu filtern und dann die Operation anzuwenden. Dies gewährleistet, dass Operationen nur auf die notwendigen Daten angewendet werden, was die Effizienz verbessert.
Bei Lokad ist der letzte Schritt des Frontend-Compilers der High Intermediate Representation (HIR). Der HIR ist eine saubere, stabile und dokumentierte Grenze zwischen dem Frontend und dem Backend der Compiler-Pipeline. Im Gegensatz zum Optimization Graph (OG), der sich ständig durch Heuristiken ändert, ist der HIR stabil und liefert einen konsistenten Input für das Backend des Compilers. Zudem ist der HIR serialisierbar, das heißt, er kann problemlos in ein Byte-Paket umgewandelt werden, um von einer Maschine zur anderen verschoben zu werden. Diese Eigenschaft ist essentiell für die Verteilung von Berechnungen über mehrere Maschinen.
Aus der High Intermediate Representation gehen wir zu den “funcs” über. Funcs sind Werte, die noch nicht ausgewertet wurden und die atomaren Rechenblöcke innerhalb einer verteilten Ausführung repräsentieren. Zum Beispiel, wenn zwei gigantische Vektoren aus einer Tabelle mit Milliarden von Zeilen addiert werden, wird es eine Reihe von funcs geben, die verschiedene Teile dieser Vektoren repräsentieren. Jede func ist dafür verantwortlich, einen Teil der beiden Vektoren zu addieren und wird auf einer Maschine ausgeführt. Große Berechnungen werden in viele funcs aufgeteilt, um die Arbeitslast über mehrere CPUs und, falls die Berechnung ausreichend groß ist, über mehrere Maschinen zu verteilen. Funcs werden “lazy” genannt, weil sie zunächst nicht ausgewertet werden; sie werden erst bei Bedarf ausgewertet. Viele Berechnungen können stattfinden, bevor einige funcs tatsächlich berechnet werden, und sobald eine func berechnet wurde, wird sie durch ihr Ergebnis ersetzt.
Innerhalb der func finden Sie die Low Intermediate Representation, welche die imperative low-level Logik repräsentiert, die innerhalb der func läuft. Sie kann beispielsweise Schleifen und Dictionary-Zugriffe beinhalten. Schließlich wird diese low-level Intermediate Representation in Bytecode kompiliert, welcher das Endziel unserer Compiler-Pipeline darstellt. Bei Lokad zielen wir auf den .NET-Bytecode, technisch bekannt als MSIL.
Aus der Sicht der supply chain ist es wirklich interessant, dass wir durch diese durchaus komplexe Compiler-Pipeline den Integrationsgrad reproduzieren, der in Microsoft Excel zu finden ist. Die Sprache ist mit der Datenschicht und der UI/UX-Schicht integriert, sodass Benutzer die Ausgaben des Programms sehen und damit interagieren können, genau wie bei einer Excel-Tabelle. Im Gegensatz zu Excel begeben wir uns jedoch in viel interessantere Bereiche des supply chain-Managements, indem wir relationale Konzepte als erstklassige Bürger sowie mathematische Optimierung und Machine Learning einbeziehen.
Sowohl mathematische Optimierung als auch Machine Learning durchlaufen in dieser Pipeline den gesamten Prozess, anstatt lediglich eine Bibliothek aufzurufen, die irgendwo liegt. Machine Learning als erstklassigen Bürger in der Pipeline zu haben, ermöglicht verständlichere Fehlermeldungen, was in Bezug auf die Produktivität für supply chain-Experten einen großen Unterschied macht.

Als letztes Thema zielen Compiler heutzutage fast immer auf eine virtuelle Maschine ab, aber diese virtuellen Maschinen werden wiederum für eine andere virtuelle Maschine kompiliert. Auf dem Bildschirm sind die typischen VM-Schichten, wie man sie in einer serverbasierten Umgebung findet, sehr ähnlich zu dem, was wir bei einem Envision-Skript haben. Ich habe gerade die Compiler-Pipeline vorgestellt, aber grundsätzlich wäre es im Grunde der gleiche Stack, wenn wir an ein Python-Skript oder eine Excel-Tabelle denken würden, die von einem Server aus betrieben wird. Bei der Gestaltung eines Compilers wählt man im Wesentlichen die Ebene, in die man den Code einspeisen möchte. Je tiefer die Ebene, desto mehr technische Details müssen berücksichtigt werden. Um die Ebene zu wählen, gibt es eine Reihe von Anliegen, die berücksichtigt werden müssen.
Erstens gibt es die Sicherheit. Wie schützt man seinen Speicher und was sollte oder sollte das Programm nicht zugreifen? Wenn man eine generische Programmiersprache hat, sind die Optionen begrenzt. Man könnte auf Betriebssystemebene des Gasts arbeiten müssen, obwohl auch dies möglicherweise nicht sehr sicher ist. Es gibt Möglichkeiten zum Sandboxing, aber das ist sehr knifflig, sodass man vielleicht noch tiefer gehen muss als das.
Zweitens gibt es die Frage der low-level Features, an denen Sie interessiert sind. Zum Beispiel könnte das wichtig sein, wenn Sie eine leistungsfähigere Ausführung erreichen wollen, um die Menge der benötigten Rechenressourcen zur Ausführung Ihres Programms zu reduzieren. Sie können sich entscheiden, so tief zu gehen, dass Sie den Speicher und die Threads selbst verwalten. Mit dieser Macht kommt jedoch auch die Verantwortung, den Speicher und die Threads tatsächlich zu verwalten.
Drittens gibt es Komfortfunktionen wie Garbage Collection, Stack Trace, Debugger und Profiler. Typischerweise ist die gesamte Instrumentierung rund um den Compiler komplexer als der Compiler selbst. Die Menge an Komfortfunktionen, von denen Sie profitieren, sollte nicht unterschätzt werden.
Viertens gibt es Bedenken hinsichtlich der Ressourcenallokation. Wenn Sie mit einer Excel-Tabelle auf Ihrem Desktop arbeiten, kann Excel alle Rechenressourcen Ihres Workstations verbrauchen. Bei Envision oder SQL hingegen haben Sie mehrere Benutzer zu bedienen, und Sie müssen entscheiden, wie Sie die Ressourcen allokieren. Darüber hinaus geht es bei Envision nicht nur um mehrere Benutzer, sondern um mehrere Unternehmen, da Lokad Multi-Tenant ist. Dies macht im supply chain Sinn, da der Bedarf an Rechenressourcen für die meisten supply chains sehr intermittierend ist.
Typischerweise benötigt man nur einen sehr intensiven Burst an Rechenleistung für etwa eine halbe Stunde oder vielleicht eine Stunde, und dann nichts für die nächsten 23 Stunden. Dann wiederholt sich das täglich. Wenn Sie Hardware-Rechenressourcen für ein Unternehmen zuweisen würden, blieben diese Ressourcen 90% der Zeit oder sogar länger ungenutzt. Daher möchten Sie in der Lage sein, die Arbeitslast über viele Maschinen und über viele Unternehmen zu verteilen, möglicherweise Unternehmen, die in verschiedenen Zeitzonen operieren.
Schließlich gibt es das Anliegen des Ökosystems. Die Idee ist, dass wenn man sich für eine spezifische Ebene und eine spezifische virtuelle Maschine entscheidet, auf die man seinen Compiler ausrichtet, es ziemlich bequem sein wird, den Compiler in das zu integrieren und mit ihm zu interagieren, was ebenfalls exakt auf dieselben virtuellen Maschinen zielt. Dies wirft die Frage des Ökosystems auf: Was kann man auf derselben Ebene finden wie das, worauf man zielt, um nicht für jeden kleinen Teil Ihres gesamten Stacks das Rad neu zu erfinden? Dies ist das letzte und wichtige Anliegen.

Abschließend gratuliere ich den glücklichen wenigen, die es so weit in dieser Reihe von supply chain-Vorlesungen geschafft haben. Dies ist wahrscheinlich eine der technischsten Vorlesungen bislang. Compiler sind ein durchaus technisches Stück; jedoch besteht die Realität moderner supply chains darin, dass alles durch eine Programmiersprache vermittelt wird. Es gibt so etwas wie eine rohe, direkt beobachtbare supply chain nicht mehr. Der einzige Weg, eine supply chain zu beobachten, besteht darin, dass sie durch die Vermittlung elektronischer Aufzeichnungen erfolgt, die von all den Bestandteilen der Unternehmenssoftware erzeugt werden, die die anwendungsbezogene Landschaft bilden. Daher wird eine Programmiersprache benötigt, und per Definition ist diese Programmiersprache Excel.
Sollten wir jedoch etwas Besseres als Excel anstreben, müssen wir genau darüber nachdenken, was “besser” überhaupt aus der Perspektive der supply chain bedeutet und was es in Bezug auf Programmiersprachen bedeutet. Wenn ein Unternehmen nicht die richtige Strategie oder Kultur hat, wird keine Technologie es retten. Wenn jedoch die Strategie und Kultur solide sind, spielt das Werkzeug eine wesentliche Rolle. Werkzeuge, einschließlich Programmiersprachen, definieren Ihre Fähigkeit zur Ausführung, die Produktivität, die Sie von Ihren supply chain-Experten erwarten können, und die Performance, die Sie aus Ihrer supply chain herausholen, wenn Sie die Makrostrategie in die tausenden von alltäglichen, banalen Entscheidungen umsetzen, die Ihre supply chain treffen muss. Die Fähigkeit, die Angemessenheit der Werkzeuge, einschließlich der Programmiersprachen, die Sie zur Bewältigung supply chain-Herausforderungen einsetzen wollen, zu beurteilen, ist von höchster Bedeutung. Wenn Sie dies nicht beurteilen können, ist es einfach kompletter Cargo Cult.

Die nächste Vorlesung wird sich mit Software Engineering befassen. Heute haben wir das Tooling besprochen; jedoch werden wir das nächste Mal die Menschen, die die Tools benutzen, und welche Art von Teamarbeit erforderlich ist, um die Arbeit gut zu machen, thematisieren. Die Vorlesung findet am selben Wochentag, Mittwoch, um 15 Uhr Pariser Zeit statt.
Nun werde ich mir die Fragen ansehen.
Frage: Wenn man Software für supply chains auswählt, wie können Unternehmen, die nicht technikaffin sind, bewerten, ob der Compiler und die Programmierung ihren Anforderungen entsprechen?
Nun, ich bin mir ziemlich sicher, dass ein typisches Unternehmen, das eine typische supply chain betreibt, nicht die Qualifikationen besitzt, ein Fahrzeug zu konstruieren, und dennoch schaffen sie es, Trucks zu erwerben, die für ihre supply chain und Transportanforderungen angemessen sind. Nur weil man kein Experte ist und nicht in der Lage ist, einen Truck wiederaufzubauen und neu zu konstruieren, heißt das nicht, dass man sich keine fundierte Meinung darüber bilden kann, ob es ein guter Truck für die eigenen Transportbedürfnisse ist. Ich behaupte also nicht, dass Unternehmen, die nicht technikaffin sind, einen unglaublichen Sprung nach vorne machen und plötzlich zu Experten im Design von Compilern werden sollten. Allerdings glaube ich, dass wir in nur anderthalb Stunden ziemlich viel Stoff behandelt haben. Mit weiteren 10 Stunden einer detaillierteren und langsamer vorgetragenen Einführung würdet ihr alles lernen, was ihr jemals im Hinblick auf Sprachdesign für supply chain-Zwecke wissen müsstet.
Es gibt einen Unterschied zwischen ein Experte zu sein und so unglaublich unwissend zu sein, dass einem Leute einen Scooter verkaufen können, der als Truck deklariert wird. Würden wir diese Art von Unwissenheit, die ich in Bezug auf das Design von Enterprise-Software beobachtet habe, auf die Automobilindustrie übertragen, würden die Leute behaupten, dass ein Scooter ein Sattzug ist und umgekehrt, und damit durchkommen.
Diese Vorlesungsreihe handelt von Hilfswissenschaften, daher besteht nicht der Anspruch, dass Menschen, die supply chain-Praktiker werden wollen, Experten in diesen Bereichen werden. Dennoch kann man mit ein wenig Einstiegswissen sehr weit kommen, wenn es darum geht, Bewertungen vorzunehmen. In den meisten Fällen benötigt man nur gerade genug Wissen, um schwierige Fragen stellen zu können. Wenn der Anbieter eine unsinnige Antwort gibt, sieht das nicht gut aus. Wenn man nicht einmal weiß, welche technischen Fragen gestellt werden müssen, kann man getäuscht werden.
Mein Vorschlag ist, dass ihr nicht unglaublich technikaffin werden müsst; ihr müsst einfach klug genug sein, um als Einsteiger-Amateur Löcher aufzuzeigen und zu beurteilen, ob das Ganze auseinanderfällt oder ob wirkliche Substanz dahintersteckt. Dasselbe gilt für mathematische Optimierung, Machine Learning, CPUs und so weiter. Es geht darum, genug zu wissen, um zwischen etwas Betrügerischem und etwas Legitimem unterscheiden zu können.
Frage: Hast du das Problem direkt angesprochen, dass bestehende Programmiersprachen nicht für supply chain entworfen wurden?
Das ist eine sehr gute Frage. Eine brandneue Programmiersprache zu entwickeln mag völlig verrückt erscheinen. Warum nicht einfach etwas bereits Etabliertes, wie Python, wählen und die kleinen Änderungen einfügen, die wir benötigen? Das wäre eine Option gewesen. Das Problem ist jedoch, dass es nicht wirklich darum geht, was wir zu diesen Sprachen hinzufügen müssen, sondern was wir entfernen müssen.
Meine Hauptkritik an Python ist nicht, dass es keine probabilistische Algebra oder eine eingebaute relationale Algebra besitzt. Meine Nummer-eins-Kritik ist, dass es eine voll funktionsfähige, generische Programmiersprache ist, und somit denjenigen, der Code schreiben soll, einer Vielzahl von Konzepten aussetzt – wie der objektorientierten Programmierung für Python –, die in Bezug auf supply chain völlig irrelevant sind. Das Problem bestand weniger darin, einer Sprache etwas hinzuzufügen, als darin, zu versuchen, einer Sprache eine Menge an Komponenten zu entziehen. Allerdings ist das Problem, dass sobald man Dinge aus einer bestehenden Programmiersprache entfernt, alles kaputt geht.
Zum Beispiel wurde die erste Version von Python im Jahr 1990 veröffentlicht, sodass es sich um eine 30 Jahre alte Programmiersprache handelt. Die Menge an Code in einem populären Stack wie Python ist absolut enorm, und das hat einen guten Grund. Ich kritisiere es nicht; es ist ein sehr solider Stack, aber auch ein riesiger. Letztlich haben wir verschiedene Optionen abgewogen: entweder man nimmt eine Programmiersprache und subtrahiert eine Menge an Komponenten, bis man mit dem Ergebnis zufrieden ist, oder man stellt fest, dass all diese Programmiersprachen ihre eigenen massiven Altlasten haben.
Wir haben bewertet, wie viel Aufwand es erfordert, eine brandneue Sprache zu erstellen, und letztlich sprach vieles dafür, eine neue Sprache zu schaffen. Das Engineering einer neuen Programmiersprache ist ein fest etabliertes Feld, sodass es, so unglaublich es klingen mag, keineswegs so ist. Es gibt Hunderte von Büchern, die Rezepte anbieten, und es ist mittlerweile sogar für Informatikstudenten zugänglich. Es gibt sogar Professoren an Informatikfakultäten, die ihren Studenten in einem Semester die Aufgabe geben, einen Compiler für eine neue Programmiersprache zu erstellen.
Letztendlich haben wir entschieden, dass supply chains so gewaltig sind, dass sie einen dedizierten Aufwand rechtfertigen. Ja, man kann immer Dinge recyceln, die nicht für supply chains entworfen wurden, aber supply chains sind eine weltweite, enorme Industrie und Problematik. Daher dachten wir, dass es angesichts des Umfangs sinnvoll ist, das Richtige zu tun und etwas direkt für supply chain zu schaffen, statt zufällig zu recyceln.
Frage: Für supply chain-Optimierung ist Envision geeignet, da es SQL, Python usw. umfasst. Aber was ist mit WMS, ERP, wo der Prozessablauf wichtiger ist als mathematische Optimierung – wie kann man dessen Compiler und Programmiersprache bewerten?
Das ist eine sehr gute Frage. Ich habe persönlich mit dem Gedanken gespielt, dass es in dieser Branche Akteure gibt, die tatsächlich eigene Programmiersprachen entwickelt haben, allein um den Vorteil zu nutzen, etwas von Natur aus rein Transaktionales, Workflow-orientiertes umzusetzen. supply chain ist, wie ich es sehe, im Wesentlichen auf prädiktive Optimierung ausgerichtet. Allerdings hat Mr. Nannani vollkommen recht; was ist mit dem gesamten Management-Teil, wie ERP, WMS usw.?
Es stellt sich heraus, dass es in diesem Bereich viele Unternehmen gibt, die ihre eigene Programmiersprache entwickelt haben. Ich erwähnte SAP, das ABAP besitzt, welches genau dafür entworfen wurde. Meiner Meinung nach hat sich ABAP leider nicht gut entwickelt. Es gibt zahlreiche Dinge in ABAP, die im 21. Jahrhundert keinen wirklichen Sinn mehr ergeben. Man sieht eindeutig, dass dieses System bereits 1983 entworfen wurde, und das zeigt sich. Zum Beispiel besitzt das ERP in Microsoft Dynamics eine eigene Programmiersprache. Dynamics AX hat seine eigene Programmiersprache, und es gibt viele ERP-Projekte, die weitgehend ihre eigene Programmiersprache mitbringen. Also, sie existiert.
Nun, sind diese Sprachen wirklich der Gipfel dessen, was wir 2021 in Bezug auf moderne, hochmoderne Programmiersprachen erreichen können? Ich glaube nicht, und das ist auch das Problem, von dem ich sprach: Anbieter von Unternehmenssoftware erfinden Programmiersprachen ständig neu, leisten dabei aber meist einen sehr schlechten Job. Es ist einfach eine planlose ingenieurwissenschaftliche Gestaltung. Sie nehmen sich nicht einmal die Zeit, die zahlreichen auf dem Markt verfügbaren Bücher zu lesen, und dann gibt es arme Ingenieure, die mit einem heissen Haufen Chaos zurechtkommen müssen.
Zurück zu deiner Frage: Ich habe mit dem Gedanken gespielt, dass Lokad in dieses Gebiet vorstößt und eine Sprache entwickelt, die nicht für die Optimierung, sondern zur Unterstützung des Workflows entworfen wurde. Allerdings ist das Wachstum von Lokad inzwischen so stark, dass wir uns nicht abspalten und ausschließlich mit den Workflows beschäftigen können. Ich bin mir absolut sicher, dass dies genau richtig ist, und dass neue Akteure auftauchen werden, die einen sehr guten Job im Management-Teil des Problems machen. Lokad bearbeitet nur den Optimierungsteil von supply chains; es gibt auch den Management-Teil.
Frage: Python gilt derzeit als Standard-Programmiersprache. Gibt es derzeit Weiterentwicklungen auf dem Markt?
Das ist eine sehr gute Frage. Sehen Sie, wenn Leute mir von “den Standards” erzählen, dann habe ich lang genug miterlebt, wie Standards kommen und gehen. Ich bin nicht sehr alt, aber als ich in der High School war, war der Standard C++. In den 90er Jahren war C++ der Standard. Warum sollte man es anders machen? Dann kam Java, um das Jahr 2000, und die Kombination aus Java und XML war der Standard.
Die Leute sagten sogar, dass Universitäten damals zu “Java-Schulen” geworden seien. Das war wörtlich der Begriff des Tages um das Jahr 2000; man sagte: “Das ist keine Informatik-Universität mehr; das ist nur noch eine Java-Schule.” Einige Jahre später, als ich Lokad gründete, war die Programmiersprache für alles, was mit Statistik zu tun hatte, noch immer R. Python war noch sehr marginal, und R dominierte das Feld der statistischen Analyse absolut.
Mit fortschreitender Entwicklung der Programmiersprachen verschwand C++ allmählich. Microsoft führte 2002 C# und die .NET-Plattform ein, die einen erheblichen Teil des C++-Ökosystems kannibalisierten. Ein großer Teil der C++-Entwickler weltweit arbeitete bei Microsoft, einem sehr großen Unternehmen. Der Punkt, den ich machen möchte, ist, dass es einen vollständigen, kontinuierlichen Wandel gibt, und jedes Jahr betrachten die Leute dies, als gäbe es einen Standard, aber dieser Standard verändert sich ständig.
JavaScript gab es schon seit 20 Jahren, aber es war nichts Bedeutendes. Dann veröffentlichte ein Buch, circa 2009 oder 2012, mit dem Titel “JavaScript: The Good Parts”, das zeigte, dass JavaScript nicht völlig verrückt war. Man konnte JavaScript für ein echtes Projekt verwenden, ohne den Verstand zu verlieren; man musste sich einfach an die guten Teile halten. Plötzlich war JavaScript in aller Munde, und die Leute begannen, es serverseitig mit einem System namens Node.js zu nutzen.
Python geriet erst vor einigen Jahren ins Rampenlicht, nachdem die Python-Community ein mühsames Upgrade von Version 2.7 auf Version 3.x durchlaufen hatte. Am Ende dieses Upgrades wurde das Interesse an Python neu entfacht. Allerdings lauern viele Gefahren auf Python. Es ist nach den Maßstäben des 21. Jahrhunderts keine besonders gute Sprache. Es ist eine 30 Jahre alte Sprache, und man merkt ihr Alter. Wenn man in jeder Hinsicht etwas Besseres möchte, abgesehen von der Reife, könnte man Julia in Betracht ziehen. Julia ist in fast jeder Hinsicht überlegen gegenüber Python für Data Science, außer in der Reife, wo Julia noch Jahre hinterherhinkt.
Es gibt zahlreiche fortlaufende Entwicklungen, und es ist leicht, den Zustand der Branche fälschlicherweise als einen Standard zu betrachten, der Bestand haben soll. Zum Beispiel gab es im Apple-Ökosystem Objective-C, und dann entschied sich Apple, Swift als Ersatz zu entwickeln, das nun Objective-C ablöst. Die Landschaft der Programmiersprachen entwickelt sich nach wie vor stark, und obwohl es seine Zeit braucht, wird es in einem zehnjährigen Blick in das Ökosystem wahrscheinlich einen erheblichen Wandel geben. Python könnte sich möglicherweise nicht als die dominierende Programmiersprache durchsetzen, da es viele Konkurrenzoptionen gibt, die bessere Antworten liefern.
Frage: Lebensmittelunternehmen und e-Commerce-Startups glauben oft, sie könnten den Wettkampf mit Data-Science-Teams und universellen Programmiersprachen gewinnen. Was wäre dein wichtigster Argumentationspunkt, um sie dazu zu bringen, diesen Ansatz zu verfeinern und zu erkennen, dass sie etwas spezifischeres für das jeweilige Problem benötigen?
Wie bereits gesagt, ist dies das Problem des Dunning-Kruger-Effekts. Man gibt einem Softwareingenieur ein gemischt-ganzzahliges lineares Programmierungssystem, und eine Woche später denkt diese Person, sie sei plötzlich ein Experte in diskreter Optimierung. Also, wie gewinne ich den Kampf? Wahrheit ist, in der Regel gewinnen wir sie nicht. Was ich mache, ist, den Weg zu beschreiben, wie sich die Katastrophen entfalten werden.
Es ist einfach, wenn man mit generischen Bausteinen von Technologie fantastische Prototypen erstellt. Diese Prototypen funktionieren brillant dank der Star Wars-Illusion – man hat sein Technologieelement isoliert. Sobald diese Unternehmen versuchen, diese Dinge in die Produktion zu überführen, werden sie kämpfen, meist aufgrund sehr alltäglicher Probleme. Sie werden mit fortwährenden Integrationsproblemen konfrontiert sein, ganz im Gegensatz zu Google, Microsoft oder Amazon, die es sich leisten können, tausend Ingenieure für all die Kleinarbeiten einzusetzen.
TensorFlow zum Beispiel ist schwierig zu integrieren. Google verfügt über die tausend Ingenieure, die nötig sind, um TensorFlow in alle ihre data pipelines und Anwendungen für ihre Zwecke einzubinden. Aber die Frage ist: Können sich Startups oder e-Commerce-Unternehmen leisten, so viele Leute zu beschäftigen, die sich um all die Kleinarbeiten kümmern? In der Regel ist die Antwort nein. Die Leute stellen sich vor, dass man einfach diese Tools auswählt, dann Dinge herauspickt und zusammenfügt, und es funktioniert magisch. Aber das funktioniert nicht. Es erfordert einen enormen Ingenieursaufwand.
Übrigens haben einige Anbieter von Unternehmenssoftware genau dasselbe Problem. Sie haben viel zu viele Komponenten in ihrer Lösung, und das erklärt, warum die Implementierung einer Lösung, ganz ohne jegliche Anpassung, bereits Monate dauert, da es so viele wackelige Teile im System gibt, die nur lose integriert sind. Es wird dadurch sehr schwierig.
Ich schätze, das war die letzte Frage. Bis zum nächsten Mal.


