00:01 Einführung
01:56 Die M5 Unsicherheits-Challenge - Daten (1/3)
04:52 Die M5 Unsicherheits-Challenge - Regeln (2/3)
08:30 Die M5 Unsicherheits-Challenge - Ergebnisse (3/3)
11:59 Die bisherige Geschichte
14:56 Was (wahrscheinlich) als Nächstes passieren wird
15:43 Pinball-Verlust – Grundlage 1/3
20:45 Negative Binomial – Grundlage 2/3
24:04 Innovationsraum-Zustandsmodell (ISSM) – Grundlage 3/3
31:36 Verkaufsstruktur – Das REMT-Modell 1/3
37:02 Zusammenführung – Das REMT-Modell 2/3
39:10 Aggregierte Ebenen – Das REMT-Modell 3/3
43:11 Einstufiges Lernen – Diskussion 1/4
45:37 Muster vollständig – Diskussion 2/4
49:05 Fehlende Muster – Diskussion 3/4
53:20 Grenzen des M5 – Diskussion 4/4
56:46 Fazit
59:27 Kommende Vorlesung und Fragen des Publikums
Beschreibung
Im Jahr 2020 erreichte ein Team bei Lokad den 5. Platz unter 909 konkurrierenden Teams beim M5, einem weltweiten Prognosewettbewerb. Allerdings erzielten diese Prognosen auf der SKU-Aggregierungsebene die Nr. 1. Die Nachfrageprognose ist von zentraler Bedeutung für supply chain. Der in diesem Wettbewerb verfolgte Ansatz erwies sich als untypisch und unterschied sich von den anderen Methoden, die von den weiteren Top-50-Konkurrenten angewendet wurden. Aus dieser Leistung sind zahlreiche Lektionen zu ziehen, die als Auftakt dienen, um weitere prädiktive Herausforderungen für supply chain anzugehen.
Vollständiges Transkript

Willkommen zu dieser Reihe von supply chain Vorträgen. Ich bin Joannes Vermorel, und heute präsentiere ich “Nr. 1 auf SKU-Ebene im M5 Prognosewettbewerb.” Eine präzise Nachfrageprognose gilt als einer der Pfeiler der Optimierung der supply chain. Tatsächlich spiegelt jede einzelne supply chain Entscheidung eine gewisse Voraussicht wider. Wenn wir über überlegene Einsichten in die Zukunft verfügen, können wir Entscheidungen ableiten, die quantitativ überlegen für unsere supply chain Zwecke sind. Daher ist die Identifizierung von Modellen, die eine erstklassige prädiktive Genauigkeit liefern, von zentraler Bedeutung und von Interesse für die Optimierung der supply chain.
Heute präsentiere ich ein einfaches Verkaufsprognosemodell, das trotz seiner Schlichtheit auf SKU-Ebene in einem weltweiten Prognosewettbewerb, bekannt als der M5, den ersten Platz belegte, basierend auf einem von Walmart bereitgestellten Datensatz. Diese Vorlesung verfolgt zwei Ziele. Das erste Ziel besteht darin zu verstehen, was erforderlich ist, um eine erstklassige Prognosegenauigkeit im Verkauf zu erreichen. Dieses Verständnis wird eine grundlegende Bedeutung für spätere Bemühungen im Bereich predictive modeling haben. Das zweite Ziel besteht darin, die richtige Perspektive in Bezug auf prädiktives Modellieren für supply chain Zwecke zu etablieren. Diese Perspektive wird auch verwendet, um unseren weiteren Fortschritt in diesem Bereich des prädiktiven Modellierens für supply chain zu leiten.

Der M5 war ein Prognosewettbewerb, der 2020 stattfand. Dieser Wettbewerb ist benannt nach Spyros Makridakis, einem bedeutenden Forscher im Bereich der Prognose. Es war die fünfte Ausgabe dieses Wettbewerbs. Diese Wettbewerbe finden alle paar Jahre statt und variieren in ihrem Schwerpunkt je nach Art des verwendeten Datensatzes. Der M5 war eine supply chain-bezogene Herausforderung, da der verwendete Datensatz Einzelhandelsdaten von Walmart waren. Die M6-Herausforderung, die noch bevorsteht, wird sich auf finanzielle Prognosen konzentrieren.
Der für den M5 verwendete Datensatz war und ist ein öffentlicher Datensatz. Es handelte sich um Einzelhandelsdaten von Walmart, die auf Tagesbasis aggregiert wurden. Dieser Datensatz umfasste etwa 30.000 SKUs, was – bezogen auf den Einzelhandel – ein ziemlich kleiner Datensatz ist. Tatsächlich enthält ein einzelner Supermarkt in der Regel etwa 20.000 SKUs, und Walmart betreibt über 10.000 Filialen. Insgesamt entsprach dieser Datensatz – der M5-Datensatz – somit weniger als 0,1 % des weltweiten Datensatzes im Walmart-Maßstab, der aus supply chain Perspektive relevant wäre.
Außerdem gab es, wie im Folgenden zu sehen sein wird, ganze Klassen von Daten, die im M5-Datensatz fehlten. Daher schätze ich grob, dass dieser Datensatz tatsächlich näher an 0,01 % des Umfangs liegt, den man im Walmart-Maßstab benötigen würde. Dennoch ist dieser Datensatz mehr als ausreichend, um einen sehr soliden Benchmark von Prognosemodellen in einer realen Umgebung durchzuführen. In einem realen Szenario müssten wir großen Wert auf Skalierbarkeitsaspekte legen. Aus der Perspektive eines Prognosewettbewerbs ist es jedoch gerecht, den Datensatz so klein zu halten, dass die meisten Methoden, selbst die weithin ineffizienten, im Prognosewettbewerb eingesetzt werden können. Zudem stellt dies sicher, dass die Teilnehmer nicht durch die Menge an verfügbaren Rechenressourcen eingeschränkt werden, die sie in den Prognosewettbewerb einbringen können.
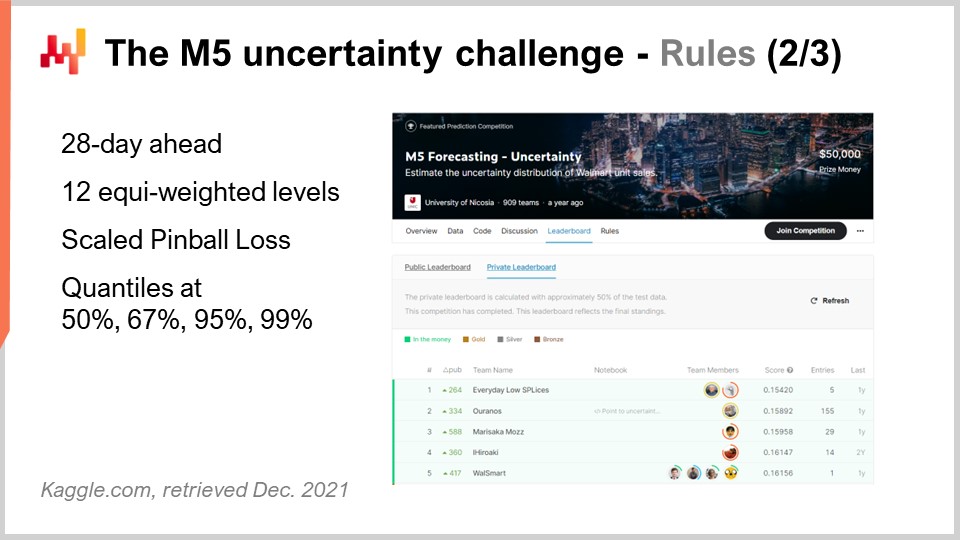
Der M5-Wettbewerb umfasste zwei verschiedene Herausforderungen, bekannt als Accuracy und Uncertainty. Die Regeln waren einfach: Es gab einen öffentlichen Datensatz, auf den jeder Teilnehmer zugreifen konnte, und um an einer oder beiden dieser Herausforderungen teilzunehmen, musste jeder Teilnehmer einen eigenen Datensatz – seinen Prognosedatensatz – erstellen und diesen auf der Kaggle-Plattform einreichen. Die Accuracy-Challenge zielte darauf ab, einen durchschnittlichen time series-Prognosewert zu liefern, was die klassischste Form einer formalen Prognose darstellt. In diesem speziellen Fall ging es darum, eine tägliche Durchschnittsprognose für etwa 40.000 Zeitreihen zu erstellen. Die Uncertainty-Challenge hingegen zielte darauf ab, quantile forecasts zu liefern. Quantile sind Prognosen mit einer systematischen Verzerrung; diese Verzerrung ist jedoch beabsichtigt. Das ist der ganze Sinn von Quantilen. Diese Vorlesung konzentriert sich ausschließlich auf die Uncertainty-Challenge, und der Grund dafür ist, dass es in supply chain der unerwartet hohe Bedarf ist, der zu stockouts führt, und der unerwartet niedrige Bedarf zu Inventarabschreibungen führt. Die Kosten in supply chains konzentrieren sich an den Extremen. Es ist nicht der Durchschnitt, der uns interessiert.
In der Tat, wenn wir betrachten, was der Durchschnitt in der Situation von Walmart überhaupt bedeutet, stellt sich heraus, dass für die meisten Produkte, in den meisten Filialen, an den meisten Tagen der beobachtete Durchschnittsumsatz null beträgt. Somit haben die meisten Produkte eine fraktionierte Durchschnittsprognose. Solche Durchschnittsprognosen sind für supply chain äußerst unbedeutend. Wenn Ihre Optionen entweder darin bestehen, null zu lagern oder eine Einheit nachzufüllen, sind Durchschnittsprognosen von geringem Nutzen. Der Einzelhandel befindet sich hier nicht in einer einzigartigen Position; es ist nahezu dieselbe Situation, ob wir über FMCG, aviation, die Fertigung oder Luxusgüter sprechen – praktisch jede andere Branche.
Zurück zur M5 Uncertainty-Challenge: Es mussten vier Quantile erstellt werden, und zwar jeweils bei 50%, 67%, 95% und 99%. Diese Quantilziele kann man als Service-Level-Ziele betrachten. Die Genauigkeit dieser Quantilprognosen wurde anhand eines Metriks bewertet, der als pinball loss function bekannt ist. Auf diesen Fehler-Metrik werde ich später in dieser Vorlesung noch einmal eingehen.

Bei dieser Uncertainty-Challenge traten 909 Teams weltweit an. Ein Team von Lokad belegte insgesamt den fünften Platz, jedoch auf SKU-Ebene die Nr. 1. Tatsächlich repräsentierten SKUs etwa drei Viertel der Zeitreihen in dieser Challenge, wobei es verschiedene Aggregierungsebenen gab, die von Landesebene (wie in den USA – Texas, Kalifornien etc.) bis zur SKU reichten, und alle Aggregierungsebenen im Endergebnis des Wettbewerbs gleich gewichtet wurden. Somit machten SKUs, obwohl sie etwa drei Viertel der Zeitreihen ausmachten, nur etwa 8 % des Gesamtgewichts in der Endwertung des Wettbewerbs aus.
Die von diesem Lokad-Team verwendete Methode wurde in einem Paper mit dem Titel “A White Box ISSM Approach to Estimate Uncertainty Distribution of Walmart’s Sales” veröffentlicht. Ich werde in der Videobeschreibung einen Link zu diesem Paper einfügen, sobald diese Vorlesung abgeschlossen ist. Alle Details finden Sie dort ausführlicher. Der Klarheit und Kürze halber werde ich das in diesem Paper vorgestellte Modell als das BRAMPT-Modell bezeichnen, benannt nach den Initialen der vier Co-Autoren.
Auf dem Bildschirm habe ich die Top-Fünf-Ergebnisse für den M5 aufgelistet, die aus einem Paper stammen, das allgemeine Einblicke in den Ausgang dieses Prognosewettbewerbs bietet. Die Feinabstimmung des Rankings ist stark von der gewählten Metrik abhängig. Das ist nicht überraschend. Die Uncertainty-Challenge verwendete eine skalierte Variante der Pinball-Loss-Funktion. Wir werden in Kürze noch einmal auf diese Fehler-Metrik zurückkommen. Obwohl die M5 Uncertainty-Challenge gezeigt hat, dass wir nicht die Mittel haben, um Unsicherheit mit den vorhandenen forecasting methods vollständig zu beseitigen – weit gefehlt –, ist dies keineswegs ein überraschendes Ergebnis. Betrachtet man, dass die Verkaufszahlen von Einzelhandelsgeschäften tendenziell unregelmäßig und intermittierend sind, unterstreicht dies die Bedeutung, Unsicherheit anzunehmen, anstatt sie gänzlich zu ignorieren. Es ist jedoch bemerkenswert, dass supply chain software vendors bei den Top-50-Rängen dieses Prognosewettbewerbs vollständig abwesend waren, was umso faszinierender ist, wenn man bedenkt, dass diese Anbieter angeblich über eine überlegene, moderne Prognosetechnologie verfügen.
Diese Vorlesung ist Teil einer Reihe von supply chain Vorträgen. Diese aktuelle Vorlesung ist der erste Teil dessen, was mein fünftes Kapitel in dieser Reihe sein wird. Dieses fünfte Kapitel wird sich dem prädiktiven Modellieren widmen. Tatsächlich ist es notwendig, quantitative Einblicke zu gewinnen, um eine supply chain zu optimieren. Wann immer eine supply chain Entscheidung getroffen wird – sei es die Entscheidung, Materialien zu kaufen, ein bestimmtes Produkt zu produzieren, Lagerbestände von einem Ort zum anderen zu verlagern oder den Preis eines verkauften Artikels zu erhöhen oder zu senken – geht mit dieser Entscheidung eine gewisse Erwartung bezüglich der zukünftigen Nachfrage einher. Jede einzelne supply chain Entscheidung bringt im Grunde eine in sich eingebaute Erwartung an die Zukunft mit. Diese Erwartung kann implizit und versteckt sein. Wenn wir jedoch die Qualität unserer Erwartung bezüglich der Zukunft verbessern wollen, müssen wir diese Erwartung konkretisieren, was typischerweise durch eine Prognose geschieht, obwohl es nicht zwangsläufig eine Zeitreihenprognose sein muss.
Das fünfte und aktuelle Kapitel trägt den Titel “Predictive Modeling” statt “Forecasting” aus zwei Gründen. Erstens wird Forecasting nahezu immer mit der Zeitreihenprognose assoziiert. Wie wir jedoch in diesem Kapitel sehen werden, gibt es viele supply chain Situationen, die sich nicht wirklich der Perspektive der Zeitreihenprognose unterordnen lassen. Insofern ist prädiktives Modellieren ein neutralerer Begriff. Zweitens ist es das Modellieren, das den wahren Einblick liefert, nicht die Modelle selbst. Wir suchen nach Modellierungstechniken, und es ist durch diese Techniken, dass wir in der Lage sein werden, mit der schieren Vielfalt der in realen supply chains auftretenden Situationen fertig zu werden.
Die vorliegende Vorlesung dient als Prolog für unser Kapitel über prädiktives Modellieren, um zu verdeutlichen, dass prädiktives Modellieren nicht irgendeine Wunschvorstellung von Forecasting ist, sondern als eine erstklassige Prognosetechnik gilt. Dies kommt zusätzlich zu all den weiteren Vorteilen, die nach und nach deutlich werden, während ich dieses Kapitel durchgehe.
Der Rest dieser Vorlesung wird in drei Teile gegliedert. Zuerst werden wir eine Reihe mathematischer Bestandteile durchgehen, die im Wesentlichen die Bausteine des BRAMPT-Modells darstellen. Zweitens werden wir diese Bestandteile zusammenfügen, um das BRAMPT-Modell zu konstruieren, genau so wie es während des M5-Wettbewerbs gemacht wurde. Drittens werden wir erörtern, was getan werden kann, um das BRAMPT-Modell zu verbessern und auch, was unternommen werden könnte, um die Prognose-Herausforderung selbst, wie sie im M5-Wettbewerb dargestellt wurde, zu optimieren.

Die Uncertainty-Challenge des M5 zielt darauf ab, Quantilschätzungen zukünftiger Verkäufe zu berechnen. Ein Quantil ist ein Punkt in einer eindimensionalen Verteilung, und per Definition ist ein 90-Prozent-Quantil der Punkt, an dem eine 90-prozentige Wahrscheinlichkeit besteht, unter diesem Wert zu liegen, und eine 10-prozentige Wahrscheinlichkeit, ihn zu überschreiten. Der Median ist definitionsgemäß das 50-Prozent-Quantil.
Die Pinball-Loss-Funktion ist eine Funktion, die eine tiefe Beziehung zu Quantilen aufweist. Im Wesentlichen kann für jeden gegebenen tau-Wert zwischen Null und Eins tau, aus der Perspektive der supply chain, als ein Service-Level-Ziel interpretiert werden. Für jeden tau-Wert entspricht das mit tau assoziierte Quantil genau dem Wert innerhalb der Wahrscheinlichkeitsverteilung, der die Pinball-Loss-Funktion minimiert. Auf dem Bildschirm sehen wir eine unkomplizierte Implementierung der Pinball-Loss-Funktion, geschrieben in Envision, der fachspezifischen Programmiersprache von Lokad, die der Optimierung von supply chain dient. Die Syntax erinnert stark an Python und sollte für das Publikum relativ transparent sein.
Wenn wir diesen Code genauer betrachten, haben wir y, was der tatsächliche Wert ist, y-hat, was unsere Schätzung darstellt, und tau, welches unser Quantilziel ist. Noch einmal: Das Quantilziel entspricht grundsätzlich dem Service-Level-Ziel in supply chain Begriffen. Wir sehen, dass die Unterprognose mit einem Gewicht von tau einhergeht, während die Überprognose mit einem Gewicht von eins minus tau versehen ist. Die Pinball-Loss-Funktion ist eine Generalisierung des absoluten Fehlers. Wenn wir zu tau gleich 0,5 zurückkehren, erkennen wir, dass die Pinball-Loss-Funktion lediglich dem absoluten Fehler entspricht. Haben wir eine Schätzung, die den absoluten Fehler minimiert, erhalten wir eine Schätzung des Medians.
Auf dem Bildschirm sehen Sie ein Diagramm der Pinball-Verlustfunktion. Diese Verlustfunktion ist asymmetrisch, und mithilfe einer asymmetrischen Verlustfunktion erhalten wir nicht den Durchschnitts- oder Medianprognosewert, sondern eine Prognose mit einer kontrollierten Verzerrung, was genau dem entspricht, was wir für eine Quantilschätzung benötigen. Das Schöne an der Pinball-Verlustfunktion ist ihre Einfachheit. Wenn Sie eine Schätzung haben, die die Pinball-Verlustfunktion minimiert, dann besitzen Sie per Definition eine Quantilprognose. Somit, wenn Sie ein Modell mit Parametern haben und die Optimierung dieser Parameter durch die Linse der Pinball-Verlustfunktion steuern, erhalten Sie im Wesentlichen ein Quantilprognosemodell.
Die M5 Uncertainty Challenge präsentierte eine Reihe von vier Quantilzielen bei 50, 67, 95 und 99. Solche Reihen von Quantilzielen bezeichne ich typischerweise als Quantilgitter. Ein Quantilgitter, oder quantisierte Gitterprognosen, sind noch keine vollständig probabilistischen Prognosen; es kommt nahe, ist aber noch nicht so weit. Mit einem Quantilgitter wählen wir unsere Ziele immer noch aus. Wenn wir beispielsweise sagen, dass wir eine Quantilprognose für 95 Prozent erstellen möchten, stellt sich die Frage: Warum 95 und nicht 94 oder 96? Diese Frage bleibt unbeantwortet. Später in diesem Kapitel werden wir dies näher betrachten, jedoch nicht in dieser Vorlesung. Es genügt zu sagen, dass der Hauptvorteil probabilistischer Prognosen darin besteht, diesen selektiven Aspekt der Quantilgitter vollständig zu eliminieren.
Der Großteil des Publikums kennt wahrscheinlich die Normalverteilung, die gaußsche, glockenförmige Kurve, die sehr häufig in natürlichen Phänomenen auftritt. Eine Zählverteilung ist eine Wahrscheinlichkeitsverteilung über alle Ganzzahlen. Im Gegensatz zu kontinuierlichen reellen Verteilungen wie der Normalverteilung, die Ihnen für jede einzelne reelle Zahl eine Wahrscheinlichkeit liefert, interessieren sich Zählverteilungen nur für nicht-negative Ganzzahlen. Es gibt viele Klassen von Zählverteilungen; heute liegt unser Interesse jedoch auf der negativen Binomialverteilung, die vom REM-Modell verwendet wird.
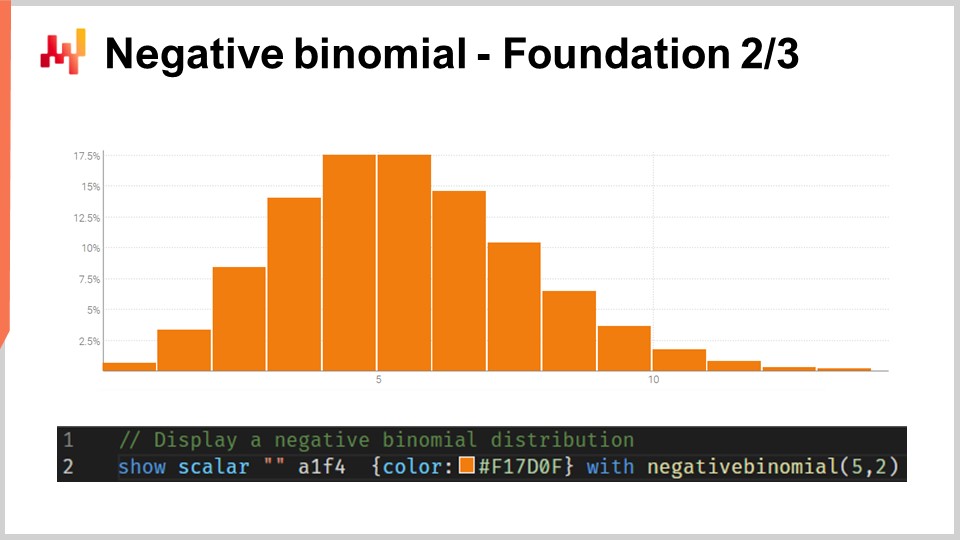
Die negative Binomialverteilung verfügt – genau wie die Normalverteilung – über zwei Parameter, die effektiv den Mittelwert und die Varianz der Verteilung steuern. Wenn wir den Mittelwert und die Varianz für eine negative Binomialverteilung so wählen, dass der Großteil der Wahrscheinlichkeitsmasse weit von Null entfernt liegt, nähert sich das Verhalten der negativen Binomialverteilung asymptotisch dem der Normalverteilung an, wenn wir alle Wahrscheinlichkeitswerte zu den nächstgelegenen Ganzzahlen zusammenfassen würden. Wenn wir jedoch Verteilungen betrachten, bei denen der Mittelwert klein ist – insbesondere im Vergleich zur Varianz – werden wir sehen, dass die negative Binomialverteilung in ihrem Verhalten deutlich von der Normalverteilung abweicht. Insbesondere bei negativen Binomialverteilungen mit kleinem Mittelwert werden diese Verteilungen stark asymmetrisch, im Gegensatz zur Normalverteilung, die vollkommen symmetrisch bleibt, egal welchen Mittelwert und welche Varianz man wählt.
Auf dem Bildschirm wird eine negative Binomialverteilung mittels Envision dargestellt. Die Codezeile, mit der dieses Diagramm erzeugt wurde, wird unten angezeigt. Die Funktion nimmt zwei Argumente entgegen, was zu erwarten ist, da diese Verteilung zwei Parameter besitzt, und das Ergebnis ist lediglich eine Zufallsvariable, die als Histogramm dargestellt wird. In dieser Vorlesung werde ich nicht auf die feinen Details der negativen Binomialverteilung eingehen. Es handelt sich um reine Wahrscheinlichkeitstheorie. Wir haben explizite, geschlossene analytische Formeln für den Modus, den Median, die kumulative Verteilungsfunktion, die Schiefe, die Kurtosis usw. Die Wikipedia-Seite bietet eine recht ordentliche Zusammenfassung all dieser Formeln, daher lade ich das Publikum ein, einen Blick darauf zu werfen, wenn es mehr über diese spezielle Art von Zählverteilung erfahren möchte.
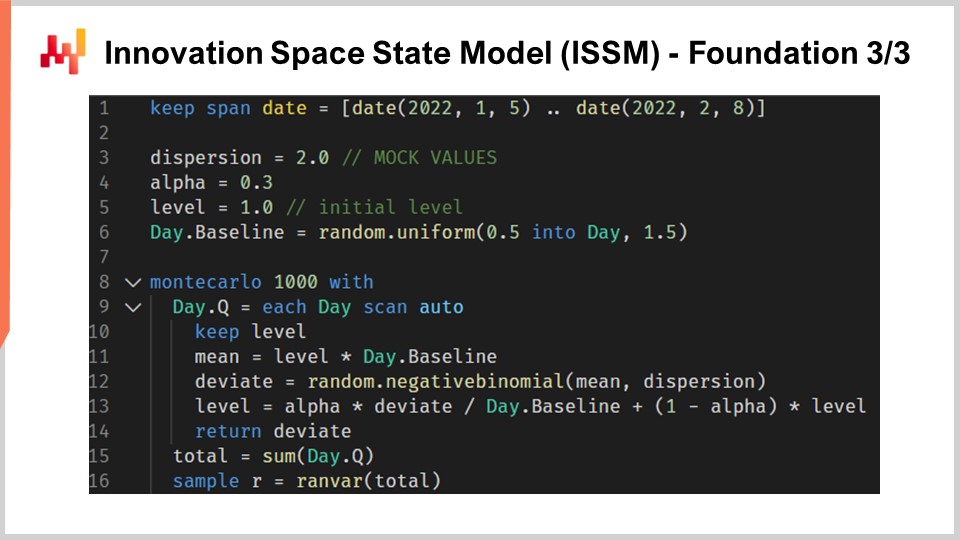
Lassen Sie uns zum Innovation Space State Model, oder ISSM, übergehen. Das Innovation Space State Model ist ein langer und beeindruckend klingender Name für etwas, das jedoch sehr einfach ist. Tatsächlich ist das ISSM ein Modell, das eine Zeitreihe in einen Random Walk umwandelt. Mit ISSM können Sie eine einfache, durchschnittliche Zeitreihenprognose – und wenn ich durchschnittlich sage, meine ich eine Prognose, bei der für jede Periode ein Wert als Durchschnitt festgelegt wird – in eine probabilistische Prognose verwandeln, und zwar nicht nur in eine Quantilprognose, sondern direkt in eine probabilistische Prognose. Auf dem Bildschirm sehen Sie eine vollständige ISSM-Implementierung, die erneut in Envision geschrieben wurde. Man sieht, dass es nur ungefähr ein Dutzend Zeilen Code sind, und tatsächlich bewirken die meisten dieser Zeilen auch nicht viel. ISSM ist buchstäblich sehr unkompliziert, und es wäre sehr einfach, diesen Code in eine andere Sprache wie Python zu portieren.
Werfen wir einen genaueren Blick auf die Details dieser Codezeilen. In Zeile eins gebe ich den Bereich der Perioden an, in denen der Random Walk stattfinden wird. Aus der Perspektive des M5 wünschen wir einen Random Walk für einen Zeitraum von 28 Tagen, also haben wir 28 Punkte, einen Punkt pro Tag. In den Zeilen drei, vier und fünf führen wir eine Reihe von Parametern ein, die den Random Walk selbst steuern. Der erste Parameter ist die Dispersion, die als Argument verwendet wird, um die Form der negativen Binomialverteilungen zu steuern, die im ISSM-Prozess auftreten. Dann haben wir Alpha, das im Wesentlichen der Faktor ist, der den exponentiellen Glättungsprozess steuert, der ebenfalls im ISSM stattfindet. In Zeile fünf befindet sich der Level, der einfach den Anfangszustand des Random Walks darstellt. Schließlich haben wir in Zeile sechs eine Reihe von Faktoren, die typischerweise dazu gedacht sind, alle Kalendermuster zu erfassen, die wir in unser Prognosemodell einbetten möchten.
Nun, die Werte aus den Zeilen drei bis sechs kommen lediglich mit einer simulierten Initialisierung. Der Kürze halber werde ich in einer Minute darauf eingehen, wie diese Werte tatsächlich optimiert werden, aber hier sind alle Initialisierungen, die Sie sehen, nur simulierte Werte. Ich ziehe einfach zufällige Werte für die Basislinie. Wir werden später in dieser Vorlesung darauf eingehen, wie Sie diese Werte in der Realität korrekt initialisieren müssen, falls Sie dieses Modell verwenden möchten.
Werfen wir nun einen Blick auf den Kern des ISSM-Prozesses. Der Kern beginnt in Zeile acht und startet mit einer Schleife von 1000 Iterationen. Ich habe bereits erwähnt, dass der ISSM-Prozess ein Verfahren zur Erzeugung von Random Walks ist, sodass wir hier 1000 Iterationen durchführen, beziehungsweise 1000 Random Walks generieren. Wir könnten mehr oder weniger Iterationen haben; es handelt sich um einen einfachen Monte-Carlo-Prozess. Dann, in Zeile neun, erfolgt eine zweite Schleife. Diese Schleife iteriert einen Tag nach dem anderen über den interessierenden Zeitraum. Somit haben wir die äußere Schleife, die im Wesentlichen eine Iteration pro Random Walk darstellt, und dazu die innere Schleife, die jeden einzelnen Tag innerhalb des Random Walks abbildet.
In Zeile 10 haben wir einen “keep level”. Das Beibehalten des Levels bedeutet einfach, dass dieser Parameter innerhalb der inneren Schleife verändert wird, nicht aber in der äußeren Schleife. Das heißt, der Level variiert von einem Tag zum nächsten, wird aber beim Übergang von einem Random Walk zum nächsten im Monte-Carlo-Prozess auf seinen oben deklarierten Anfangswert zurückgesetzt. In Zeile 11 berechnen wir den Mittelwert. Der Mittelwert ist der zweite Parameter, den wir zur Steuerung der negativen Binomialverteilung verwenden. Also haben wir den Mittelwert, die Dispersion und eine negative Binomialverteilung. In Zeile 12 ziehen wir einen Abweichungswert entsprechend der normalen Binomialverteilung. Einen Abweichungswert zu ziehen bedeutet schlicht, dass wir eine zufällige Stichprobe aus dieser Zählverteilung entnehmen. Dann, in Zeile 13, aktualisieren wir diesen Level basierend auf dem gezogenen Abweichungswert, und der Aktualisierungsprozess ist ein sehr einfacher exponentieller Glättungsprozess, gesteuert durch den Alpha-Parameter. Wenn wir Alpha sehr groß wählen, also gleich eins, bedeutet das, dass wir das gesamte Gewicht auf die letzte Beobachtung legen. Im Gegensatz dazu, wenn wir Alpha gleich Null setzen würden, hätte das zur Folge, dass es keinen Drift gibt; wir blieben der ursprünglichen Zeitreihe, wie sie in der Basislinie definiert ist, treu.
Übrigens: In Envision, wenn “.baseline” geschrieben steht, erkennen wir, dass es sich um eine Tabelle handelt, sagen wir, NDM5, die 28 Werte enthält, und baseline ist einfach ein Vektor, der zu dieser Tabelle gehört. In Zeile 15 sammeln wir alle Abweichungswerte und summieren sie über “someday.q”. Wir übergeben sie einer Variablen namens “total”, sodass wir innerhalb eines Random Walks die Summe der für jeden einzelnen Tag erfassten Abweichungswerte erhalten. Somit erhalten wir die Gesamtsumme der Verkäufe über 28 Tage. Schließlich fassen wir in Zeile 16 diese Stichproben in einem “render” zusammen. Ein render ist ein spezifisches Objekt in Envision, welches im Wesentlichen eine Wahrscheinlichkeitsverteilung relativer Ganzzahlen – positiver wie negativer – darstellt.
Zusammenfassend haben wir das ISSM als einen Zufallsgenerator eindimensionaler Random Walks. Im Kontext der Absatzprognose können Sie diese Random Walks als mögliche zukünftige Beobachtungen der Verkäufe ansehen. Es ist interessant, da wir die Prognose nicht als Durchschnitt oder Median betrachten; wir sehen unsere Prognose buchstäblich als eine mögliche Ausprägung einer Zukunft.

An diesem Punkt haben wir alles zusammengetragen, was wir benötigen, um das REMT-Modell zusammenzustellen, was wir nun tun werden.
Das REMT-Modell verwendet eine multiplikative Struktur, die an das Holt-Winters-Prognosemodell erinnert. Jeder Tag erhält eine Basislinie, einen Einzelwert, der das Produkt von fünf Kalendereffekten darstellt. Diese Effekte umfassen nämlich den Monat des Jahres, den Wochentag, den Tag des Monats sowie die Effekte von Weihnachten und Halloween. Diese Logik wird als ein prägnantes Envision-Skript implementiert.
Envision verfügt über eine relationale Algebra, die Broadcast-Beziehungen zwischen Tabellen bietet, was in dieser Situation sehr praktisch ist. Die fünf erstellten Tabellen – eine Tabelle pro Kalendermuster – werden als Gruppierungstabellen aufgebaut. Wir haben also die Datumstabelle, und diese besitzt einen Primärschlüssel namens “date”. Wenn wir angeben, dass wir eine neue Tabelle mit einer “by”-Aggregation deklarieren und dann das Datum einbeziehen, bauen wir eine Tabelle, die eine direkte Broadcast-Beziehung zur Datumstabelle hat.
Wenn wir uns speziell die Wochentagetabelle in Zeile vier ansehen, bauen wir eine Tabelle auf, die genau sieben Zeilen haben wird. Jede Zeile der Tabelle wird mit einer und nur einer Zeile des Wochentags verknüpft sein. Daher können wir, wenn wir Werte in diese Wochentagetabelle einfügen, diese Werte ganz natürlich übertragen, da jede Zeile auf der Empfängerseite, in der Datumstabelle, eine entsprechende Zeile in der Wochentagetabelle zugeordnet bekommt.
In Zeile neun wird der Vektor “de.dot.baseline” als einfache Multiplikation der fünf Faktoren auf der rechten Seite der Zuweisung berechnet. Alle diese Faktoren werden zunächst an die Datumstabelle übertragen, und anschließend führen wir für jede Zeile in der Datumstabelle eine einfache zeilenweise Multiplikation durch.
Nun haben wir ein Modell, das einige Dutzend Parameter beinhaltet. Wir können diese Parameter abzählen: Es gibt 12 Parameter für den Monat des Jahres, von 1 bis 12; 7 Parameter für den Wochentag; und 31 Parameter für den Tag des Monats. Im Falle von NDM5 werden wir jedoch nicht für jede einzelne SKU einen eigenen Parameterwert lernen, da wir sonst mit einer massiv hohen Anzahl von Parametern enden würden, die den Walmart-Datensatz höchstwahrscheinlich stark überanpassen würden. Stattdessen wurde bei NDM5 ein Trick namens Parameter Sharing angewendet.
Parameter Sharing bedeutet, dass wir anstatt für jede einzelne SKU unterschiedliche Parameter zu lernen, Untergruppen bilden und diese Parameter auf der Ebene der Untergruppen trainieren. Anschließend verwenden wir innerhalb dieser Gruppen dieselben Parameterwerte. Parameter Sharing ist eine sehr klassische Technik, die umfangreich im deep learning eingesetzt wird, obwohl sie dem Deep Learning selbst vorausgeht. Während des M5 wurden der Monat des Jahres und der Wochentag auf der Aggregationsebene der Filialabteilungen erlernt. Auf die verschiedenen Aggregationsebenen des M5 werde ich in Kürze zurückkommen. Der Tag-des-Monats-Wert wurde tatsächlich als fest codierte Faktoren auf Landesebene festgelegt – und wenn ich vom Land spreche, meine ich die Vereinigten Staaten, wie Kalifornien, Texas usw. Während des M5 wurden all diese Kalenderparameter einfach als direkte Durchschnittswerte über ihre zugehörigen Bereiche erlernt. Es ist eine sehr direkte Methode, diese Parameter zu setzen: Man nimmt einfach alle SKUs, die demselben Bereich angehören, bildet den Durchschnitt, normalisiert, und schon hat man den Parameter.

An diesem Punkt haben wir alles zusammengetragen, um das REMT-Modell zu erstellen. Wir haben gesehen, wie man die tägliche Basislinie aufbaut, die alle Kalendermuster einbettet. Die Kalendermuster wurden durch direkte Durchschnittswerte eines bestimmten Bereichs erlernt, was ein rudimentärer aber effektiver Lernmechanismus ist. Zudem haben wir gesehen, dass das ISSM eine Zeitreihe in einen Random Walk umwandelt. Es bleibt nur noch, die korrekten Werte für die ISSM-Parameter festzulegen, nämlich Alpha – den Parameter für den exponentiellen Glättungsprozess im SSM –, die Dispersion, einen Parameter zur Steuerung der negativen Binomialverteilung, und den Anfangswert für den Level, der zur Initialisierung unseres Random Walks dient.
Während des M5-Wettbewerbs nutzte das Team von Lokad eine einfache Grid-Search-Optimierung, um diese verbleibenden drei Parameter zu erlernen. Grid Search bedeutet im Wesentlichen, dass man über alle möglichen Kombinationen dieser Werte iteriert, wobei man kleine Inkremente verwendet. Die Grid Search wurde mithilfe der Pinball-Verlustfunktion gesteuert, die ich zuvor beschrieben habe, um die Optimierung dieser drei Parameter zu leiten. Für jede SKU ist Grid Search wahrscheinlich eine der ineffizientesten Formen mathematischer Optimierung. Angesichts der Tatsache, dass wir nur drei Parameter haben, pro Zeitreihe nur eine Optimierung durchführen müssen und der M5-Datensatz selbst relativ klein ist, war dies jedoch für den M5-Wettbewerb angemessen.
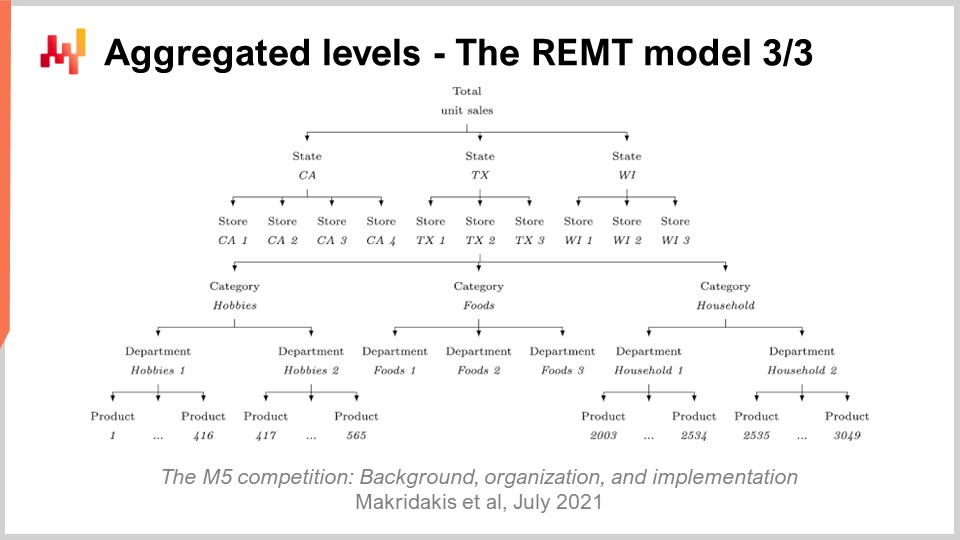
Bis jetzt haben wir dargestellt, wie das REMT-Modell auf SKU-Ebene funktioniert. Allerdings gab es im M5 zwölf verschiedene Aggregationsstufen. Die SKU-Ebene, als die am stärksten desaggregierte Stufe, war die wichtigste. Eine SKU, oder Lagerhaltungseinheit, ist buchstäblich ein Produkt an einem bestimmten Ort. Wenn Sie dasselbe Produkt an 10 Standorten haben, besitzen Sie 10 SKUs. Obwohl die SKU-Ebene womöglich die relevanteste Aggregationsebene für a supply chain ist, finden nahezu alle lagerbezogenen Entscheidungen, wie replenishment und Sortimentsgestaltung, auf SKU-Ebene statt.
Auf dem Bildschirm fassen diese Ebenen die Aggregationsstufen zusammen, die im M5-Datensatz vorhanden waren. Man sieht, dass wir die Bundesstaaten haben, wie Kalifornien und Texas. Um mit den höheren Aggregationsstufen umzugehen, verwendete das Team von Lokad zwei Techniken: Entweder wurden die Random Walks aufsummiert, das heißt, man führt die Random Walks auf einer niedrigeren Aggregationsebene durch, summiert sie und erzielt so Random Walks auf einer höheren Aggregationsebene; oder man startet den Lernprozess komplett neu, indem man direkt auf die höhere Aggregationsebene springt. In der M5-Uncertainty-Challenge war das REMT-Modell auf SKU-Ebene das beste, doch auf den anderen Aggregationsstufen war es nicht das beste, obwohl es insgesamt gute Leistungen zeigte.
Meine eigene Arbeitshypothese, warum das REMT-Modell nicht auf allen Ebenen am besten abschnitt, lautet wie folgt (bitte beachten Sie, dass es sich hierbei nur um eine Hypothese handelt, die wir nicht tatsächlich getestet haben): Die negative Binomialverteilung bietet durch ihre zwei Parameter zwei Freiheitsgrade. Bei relativ spärlichen Daten, wie sie auf SKU-Ebene zu finden sind, stellt diese Anzahl an Freiheitsgraden das richtige Gleichgewicht zwischen Underfitting und Overfitting her. Wenn wir uns jedoch zu den höheren Aggregationsebenen vorwagen, werden die Daten dichter und umfangreicher, sodass sich der trade-off vermutlich in Richtung einer Methode verschiebt, die besser geeignet ist, die Form der Verteilung präziser abzubilden. Hierfür bräuchten wir ein paar zusätzliche Freiheitsgrade – wahrscheinlich nur ein oder zwei zusätzliche Parameter – um dies zu erreichen.
Ich vermute, dass eine Erhöhung des Grades der Parametrisierung der Zählverteilung, die im Kern des REMT-Modells verwendet wird, einen langen Weg gegangen wäre, um etwas zu erreichen, das bei den höheren Aggregationsstufen sehr nahe am Stand der Technik liegt, wenn nicht gar direkt diesem entspricht. Dennoch hatten wir keine Zeit dafür, und wir könnten diesen Fall zu einem späteren Zeitpunkt erneut aufgreifen. Damit endet die Darstellung dessen, was das Team von Lokad während des M5-Wettbewerbs geleistet hat.

Diskutieren wir, was anders oder besser hätte gemacht werden können. Obwohl das REMT-Modell ein niedrigdimensionales, parametrisches Modell mit einer einfachen multiplikativen Struktur ist, war der Prozess, der zur Ermittlung der Parameterwerte während des M5 verwendet wurde, etwas zufällig kompliziert. Es war ein mehrstufiger Prozess, bei dem jedes Kalendermuster eine eigene ad hoc Sonderbehandlung erhielt, der in einer maßgeschneiderten Gitter-Suche zur Vervollständigung des REMT-Modells gipfelte. Der gesamte Prozess war für Datenwissenschaftler ziemlich zeitaufwändig, und ich vermute, dass er in Produktionsumgebungen aufgrund der schieren Menge an ad hoc Code ziemlich unzuverlässig wäre.
Insbesondere meine Ansicht ist, dass wir den Lernprozess aller Parameter vereinheitlichen können und sollten – entweder als einen einstufigen Prozess oder zumindest so, dass derselbe Ansatz wiederholt angewendet wird. Heutzutage verwendet Lokad differenzierbares Programmieren, um genau das zu erreichen. Differenzierbares Programmieren beseitigt die Notwendigkeit ad hoc Aggregationen, was die Kalendermuster betrifft. Es behebt zudem das Problem, die Extraktion der Kalendermuster präzise zu ordnen, indem alle Muster auf einmal extrahiert werden. Schließlich ersetzt differenzierbares Programmieren als ein Optimierungsprozess an sich die Gitter-Suche durch eine wesentlich effizientere Optimierungslogik. In späteren Vorlesungen dieses Kapitels werden wir ausführlicher darauf eingehen, wie differenzierbares Programmieren im Kontext von supply chain-Zwecken für prädiktives Modellieren genutzt werden kann.
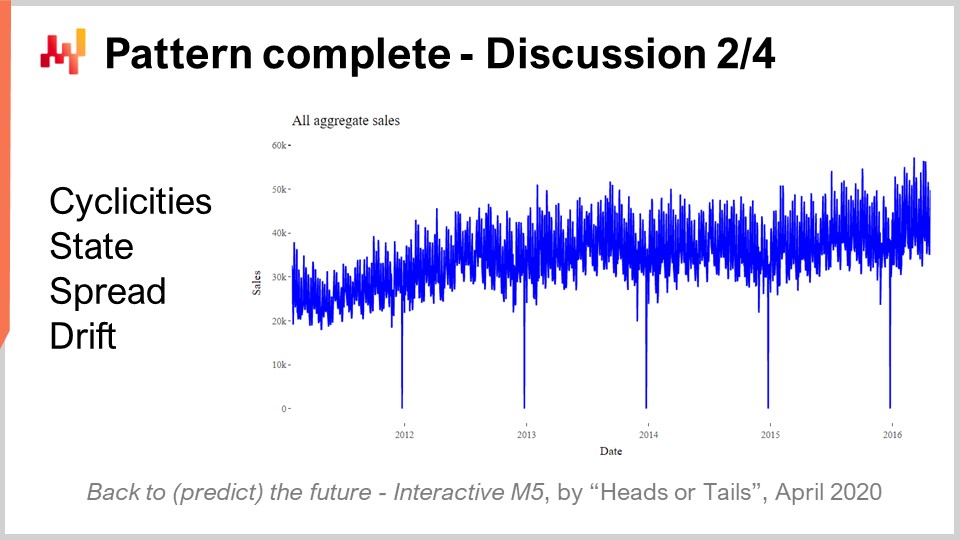
Eines der überraschendsten Ergebnisse des M5-Wettbewerbs war, dass kein statistisches Muster unbenannt blieb. Wir hatten buchstäblich vier Muster: simplicities, state, spread und drift, und diese reichten aus, um im M5-Wettbewerb prognostische Genauigkeiten auf dem neuesten Stand der Technik zu erzielen.
Simplicities basieren alle auf Kalenderdaten und keines davon ist auch nur annähernd überraschend. Der state kann als eine einzelne Zahl dargestellt werden, die das Niveau repräsentiert, welches die SKU zu einem bestimmten Zeitpunkt erreicht hat. Der spread kann mit einer einzelnen Zahl dargestellt werden, die die Streuung ist, die zur Parametrisierung der negativen Binomialverteilung verwendet wird, und der drift kann mit einer einzelnen Zahl veranschaulicht werden, die mit dem exponentiellen Glättungsprozess innerhalb des SSM verknüpft ist. Wir mussten nicht einmal den Trend einbeziehen, der für einen 28-Tage-Horizont zu schwach war.
Wenn wir uns die aggregierten Verkäufe der gesamten fünf Jahre des M5, wie auf dem Bildschirm gezeigt, ansehen, zeigt die Aggregation eindeutig einen moderaten Aufwärtstrend. Dennoch arbeitet das REMT-Modell ohne diesen Trend und es hatte keinerlei Auswirkungen auf die Genauigkeit. Die Leistung des REMT-Modells wirft die Frage auf: Gibt es ein weiteres Muster, das erfasst werden könnte, und haben wir möglicherweise Muster übersehen?
Mindestens zeigt die Leistung des REMT-Modells, dass keines der anspruchsvolleren Modelle, die an diesem Wettbewerb beteiligt waren – wie gradient boosting trees oder Deep-Learning-Methoden – etwas erfasst hat, das über diese vier Muster hinausgeht. Tatsächlich, wenn eines dieser Modelle etwas Wesentliches erfassen könnte, hätten sie das REMT-Modell auf SKU-Ebene bei weitem übertroffen, was nicht der Fall war. Dasselbe gilt für alle anspruchsvolleren statistischen Methoden wie ARIMA. Auch diese Modelle konnten nichts erfassen, was über das hinausgeht, was dieses sehr einfache multiplikative parametrische Modell erfasst hat.
Das Occam’s-Razor-Prinzip besagt, dass, sofern wir keinen sehr guten Grund finden, anzunehmen, dass uns ein Muster entgeht oder dass eine sehr interessante Eigenschaft die Einfachheit dieses Modells übertrumpft, wir keinen Grund haben, etwas anderes als ein Modell zu verwenden, das mindestens so einfach ist wie das REMT-Modell.

Allerdings fehlte im M5-Wettbewerb aufgrund des Designs des M5-Datensatzes eine Reihe von Mustern. Diese Muster sind wichtig, und in der Praxis wird jedes Modell, das sie ignoriert, in einer realen Einzelhandelsumgebung schlecht funktionieren. Diese Aussage stütze ich auf meine eigene Erfahrung.
Zunächst haben wir die Produkteinführungen. Der M5-Wettbewerb umfasste nur Produkte, die über mindestens fünf Jahre Verkaufsverlauf verfügten. Dies ist eine unvernünftige Annahme, was die supply chain betrifft. Tatsächlich haben FMCG-Produkte typischerweise eine Lebensdauer von nur ein paar Jahren, weshalb in einem tatsächlichen Laden stets ein beträchtlicher Anteil des Sortiments weniger als ein Jahr Verkaufsverlauf aufweist. Darüber hinaus müssen bei Produkten mit langen lead times zahlreiche supply chain-Entscheidungen getroffen werden, noch bevor das Produkt auch nur einmal verkauft wurde. Folglich benötigen wir Prognosemodelle, die auch mit einer null Verkaufsbilanz für ein bestimmtes Produkt arbeiten können.
Das zweite, von entscheidender Bedeutung, Muster sind Ausverkäufe. Ausverkäufe treten im Einzelhandel auf, und der M5-Datensatz ignorierte sie vollständig. Allerdings begrenzen Ausverkäufe den Umsatz. Wenn ein Produkt im Laden nicht vorrätig ist, wird es an diesem Tag nicht verkauft, und somit führen Ausverkäufe zu einer erheblichen Verzerrung der beobachteten Verkaufszahlen. Das Problem bei Walmart und in allgemeinen Kaufhäusern ist noch komplexer, da den elektronischen Aufzeichnungen, die den Lagerbestand erfassen, nicht voll vertraut werden kann. Es gibt zahlreiche Inventurungenauigkeiten, die ebenfalls berücksichtigt werden müssen.
Drittens haben wir promotions. Der M5-Wettbewerb beinhaltete zwar historische Preisdaten; jedoch wurden die Preisdaten für den Prognosezeitraum nicht bereitgestellt. Folglich scheint es, dass es keinem Teilnehmer in diesem Wettbewerb gelungen ist, die Preisinformationen zur Verbesserung der Prognosegenauigkeit zu nutzen. Das REMT-Modell verwendet Preisinformationen überhaupt nicht. Abgesehen davon, dass uns die Preisdaten für den Prognosezeitraum fehlten, geht es bei Promotions nicht nur um Preise. Ein Produkt kann beworben werden, indem es in einem Geschäft prominent ausgestellt wird, was die Nachfrage erheblich steigern kann, unabhängig davon, ob der Preis gesenkt wurde. Zudem müssen bei Promotions Kannibalisierungs- und Substitutionseffekte berücksichtigt werden.
Insgesamt kann der M5-Datensatz aus supply chain-Sicht als ein Spielzeug-Datensatz betrachtet werden. Obwohl er vermutlich der beste öffentliche Datensatz ist, der zur Durchführung von supply chain-Benchmarks existiert, ist er doch weit davon entfernt, einem tatsächlichen Produktionsszenario in einer auch nur mäßig großen Einzelhandelskette wirklich zu entsprechen.

Die Einschränkungen des M5-Wettbewerbs ergeben sich jedoch nicht nur aus dem Datensatz. Aus supply chain-Sicht gibt es grundlegende Probleme mit den Regeln, die zur Durchführung des M5-Wettbewerbs verwendet wurden.
Das erste grundlegende Problem besteht darin, Verkäufe nicht mit der Nachfrage zu verwechseln. Wir haben dieses Thema bereits bei Ausverkäufen angesprochen. Aus supply chain-Sicht liegt das wahre Interesse darin, die Nachfrage vorherzusagen und nicht die Verkäufe. Das Problem geht jedoch noch tiefer. Die korrekte Schätzung der Nachfrage ist grundsätzlich ein Problem des unüberwachten Lernens. Nur weil willkürliche Entscheidungen über das anzuwendende Sortiment in einem Geschäft getroffen wurden, sollte die Nachfrage für ein Produkt nicht geschätzt werden. Wir müssen die Nachfrage für Produkte schätzen, unabhängig davon, ob sie Teil des Sortiments in einem bestimmten Geschäft sind.
Der zweite Aspekt ist, dass Quantilsprognosen weniger nützlich sind als probabilistische Prognosen. Das Heraussuchen von Servicelevels lässt Lücken im Gesamtbild zurück, und Quantilsprognosen sind im supply chain-Einsatz relativ schwach. Eine probabilistische Prognose liefert ein deutlich vollständigeres Bild, da sie die gesamte Wahrscheinlichkeitsverteilung bereitstellt und somit diese Problematik beseitigt. Der einzige wesentliche Nachteil probabilistischer Prognosen besteht darin, dass sie mehr Werkzeuge erfordern, insbesondere wenn es darum geht, nach der Erstellung der Prognose tatsächlich mit ihr zu arbeiten. Übrigens liefert das REMT-Modell tatsächlich etwas, das als probabilistische Prognose qualifiziert werden kann, da man durch den Monte-Carlo-Prozess eine vollständige Wahrscheinlichkeitsverteilung generieren kann. Man muss lediglich die Anzahl der Monte-Carlo-Durchläufe abstimmen.
Im Einzelhandel interessieren sich die Kunden nicht wirklich für die SKU-Perspektive oder das Servicelevel, das bei einer bestimmten SKU erreicht werden kann. Die Wahrnehmung der Kunden in einem Kaufhaus wie Walmart wird durch den gesamten Warenkorb geprägt. Typischerweise betreten Kunden einen Walmart-Laden mit einer ganzen Einkaufsliste im Kopf, und nicht nur mit einem einzelnen Produkt. Außerdem gibt es im Laden zahlreiche Ersatzprodukte. Das Problem bei der Verwendung einer einzigen SKU-Metrik zur Beurteilung der Servicequalität besteht darin, dass sie völlig außer Acht lässt, was Kunden als Servicequalität im Geschäft wahrnehmen.
Zusammenfassend lässt sich sagen, dass der M5-Wettbewerb als Benchmark für Zeitreihenprognosen in Bezug auf Datensätze und Methodik solide ist. Allerdings mangelt es der Zeitreihenperspektive selber, was die supply chain betrifft. Zeitreihen spiegeln nicht die Daten wider, wie sie in supply chains vorzufinden sind, noch stellen sie die Probleme so dar, wie sie in supply chains auftreten. Während des M5-Wettbewerbs gab es viele wesentlich anspruchsvollere Methoden unter den Spitzenreitern. Meiner Ansicht nach sind diese Modelle jedoch de facto Sackgassen. Sie sind bereits zu kompliziert für den praktischen Einsatz, und sie verhaften sich so sehr in der Zeitreihenperspektive, dass sie keinen Spielraum haben, um sich in die frische Perspektive zu entwickeln, die nötig ist, um diese Modelle an unsere eigenen supply chain-Bedürfnisse anzupassen.
Im Gegenteil, als Ausgangspunkt ist das REMT-Modell so gut wie es nur geht. Es ist eine sehr einfache Kombination von Komponenten, die für sich genommen sehr simpel sind. Außerdem bedarf es keiner großen Vorstellungskraft, um zu erkennen, dass es zahlreiche Möglichkeiten gibt, diese Elemente zu nutzen und zu kombinieren – jenseits der spezifischen Zusammenstellung, die für den M5-Wettbewerb entwickelt wurde. Die Platzierung, die das REMT-Modell im M5-Wettbewerb erreichte, zeigt, dass wir – solange nichts anderes bewiesen wird – bei einem sehr einfachen Modell bleiben sollten, da wir keinen zwingenden Grund haben, zu allzu komplizierten Modellen zu greifen, die nahezu garantiert schwerer zu debuggen, schwieriger in der Produktion zu betreiben und weitaus mehr Rechenressourcen verbrauchen.
In den kommenden Vorlesungen dieses fünften Kapitels werden wir sehen, wie wir die Bestandteile des REMT-Modells sowie noch einige andere Komponenten nutzen können, um die große Vielfalt an prädiktiven Herausforderungen anzugehen, wie sie in supply chains vorkommen. Das Entscheidende, woran man sich erinnern sollte, ist, dass das Modell unwichtig ist – es ist das Modellieren, das zählt.

Frage: Warum negative Binomialverteilungen? Was war der Grund, als Sie sich dafür entschieden haben?
Das ist eine sehr gute Frage. Nun, es stellt sich heraus, dass es, wenn es ein weltweites Bestiarium von Zählverteilungen gäbe, wahrscheinlich zwanzig- oder mehr weithin bekannte Zählverteilungen gibt. Bei Lokad haben wir für unsere internen Bedürfnisse ein Dutzend davon getestet. Es hat sich gezeigt, dass Poisson, eine sehr simple Zählverteilung mit nur einem Parameter, recht gut funktioniert, wenn die Daten sehr spärlich sind. Also ist Poisson durchaus gut, aber tatsächlich war der M5-Datensatz etwas umfangreicher. Im Fall des Walmart-Datensatzes haben wir Zählverteilungen ausprobiert, die ein paar zusätzliche Parameter aufwiesen, und es schien zu funktionieren. Wir haben keinen Beweis dafür, dass es tatsächlich die beste Option ist; es gibt vermutlich bessere Alternativen. Die negative Binomialverteilung weist einige entscheidende Vorteile auf: Die Implementierung ist sehr unkompliziert, und sie ist eine ausgiebig untersuchte Zählverteilung. So verfügt man über einen sehr bekannten Algorithmus, nicht nur zur Berechnung der Wahrscheinlichkeiten, sondern auch um Stichproben zu ziehen, den Mittelwert zu ermitteln oder die kumulative Verteilung zu berechnen. All die Werkzeuge, die man im Zusammenhang mit Zählverteilungen erwartet, sind vorhanden – was nicht für alle Zählverteilungen gilt.
Es steckt ein gewisser Pragmatismus hinter dieser Wahl, aber auch ein wenig Logik. Bei Poisson hat man einen Freiheitsgrad; die negative Binomialverteilung hat zwei. Dann kann man Tricks wie zero-inflated negative binomial verwenden, was so etwas wie zweieinhalb Freiheitsgrade ergibt, usw. Ich würde nicht sagen, dass es einen bestimmten definitiven Wert für diese Zählverteilung gibt.
Frage: Es gab andere supply chain Optimierungssoftware-Anbieter im M5, aber niemand nutzte Live-Modelle, die in der Produktion gut skalierten. Benutzt die Mehrheit schwere Machine-Learning-Modelle?
Zunächst würde ich sagen, dass wir unterscheiden und klarstellen müssen, dass der M5 auf Kaggle durchgeführt wurde, einer Plattform für Data Science. Auf Kaggle hat man einen enormen Anreiz, die komplizierteste verfügbare Maschinerie zu nutzen. Der Datensatz ist klein, man hat viel Zeit, und um den Spitzenrang zu erreichen, muss man nur 0,1% genauer sein als der Andere. Das ist alles, was zählt. In nahezu jedem einzelnen Kaggle-Wettbewerb sieht man also, dass die Top-Plätze von Leuten besetzt sind, die äußerst komplizierte Dinge gemacht haben, nur um 0,1% zusätzliche Genauigkeit zu erzielen. So gibt einem die Natur eines Forecasting-Wettbewerbs einen starken Anreiz, alles auszuprobieren, einschließlich der schwergewichtigsten Modelle, die man finden kann.
Wenn wir fragen, ob die Leute diese schweren Machine-Learning-Modelle tatsächlich in der Produktion einsetzen, ist meine eigene beiläufige Beobachtung, dass dies absolut nicht der Fall ist. Es ist tatsächlich äußerst selten. Als CEO von Lokad, einem supply chain Software-Anbieter, habe ich mit Hunderten von supply chain Direktoren gesprochen. Buchstäblich werden über 90% der großen supply chains über Excel betrieben. Ich habe noch nie eine groß angelegte supply chain gesehen, die mit gradient-boosted trees oder Deep-Learning-Netzwerken betrieben wurde. Wenn man Amazon außen vor lässt – Amazon ist wahrscheinlich einzigartig –, gibt es vielleicht ein halbes Dutzend Unternehmen, wie Amazon, Alibaba, JD.com und einige andere – die wirklich diese Art von Technologie nutzen. Aber sie sind in dieser Hinsicht eine Ausnahme. Die gängigen großen FMCG-Unternehmen oder großen stationären Einzelhandelsunternehmen setzen diese Art von Dingen in der Produktion nicht ein.
Frage: Es ist seltsam, dass du eine Menge mathematischer und statistischer Begriffe erwähnst, aber die Natur des Einzelhandels und die wichtigsten Einflussfaktoren ignorierst.
Ich würde sagen, ja, das ist eher ein Kommentar, aber meine Frage an dich wäre: Was bringst du zu bieten? Genau das meinte ich, als supply chain Anbieter, die mit überlegener Forecasting-Technologie prahlten, alle fehlten. Warum ist es so, dass, wenn man absolut überlegene Forecasting-Technologie besitzt, man zufällig abwesend ist, wann immer es etwas wie einen öffentlichen Benchmark gibt? Die andere Erklärung ist, dass die Leute bluffen.
Bezüglich der Natur des Einzelhandels und vieler Einflussfaktoren habe ich die Muster aufgelistet, die verwendet wurden, und durch die Verwendung dieser vier Muster landete das REMT-Modell in Bezug auf Genauigkeit auf SKU-Ebene an erster Stelle. Wenn du die Behauptung vertrittst, dass es weitaus wichtigere Muster gibt, liegt die Beweislast bei dir. Mein eigener Verdacht ist, dass, wenn unter über 900 Teams diese Muster nicht beobachtet wurden, sie wahrscheinlich nicht vorhanden waren oder dass das Erfassen dieser Muster so weit außerhalb des Rahmens dessen liegt, was wir mit der Art von Technologie, die wir haben, leisten können, dass es vorerst so ist, als würden diese Muster aus praktischer Sicht nicht existieren.
Frage: Haben Wettbewerber im M5 Ideen angewendet, die, obwohl sie Lokad nicht schlugen, wertvoll wären, insbesondere für generische Anwendungen? Ehrenhafte Erwähnung?
Ich habe meinen Konkurrenten große Aufmerksamkeit geschenkt, und ich bin mir ziemlich sicher, dass sie Lokad auch Beachtung schenken. Ich habe das nicht gesehen. Das REMT-Modell war wirklich einzigartig, völlig anders als das, was im Wesentlichen fast alle der anderen Top-50-Anwärter für beide Aufgaben gemacht haben. Die anderen Teilnehmer verwendeten Dinge, die in den Kreisen des Machine Learnings viel klassischer waren.
Es wurden einige sehr clevere Data-Science-Tricks während des Wettbewerbs demonstriert. Zum Beispiel benutzten einige Leute sehr ausgeklügelte, elegante Tricks zur Datenaugmentation des Walmart-Datensatzes, um ihn viel größer erscheinen zu lassen, als er war, um ein paar zusätzliche Prozent an Genauigkeit zu gewinnen. Dies wurde von dem Teilnehmer gemacht, der im Unsicherheitswettbewerb den ersten Platz belegte. Datenaugmentation, nicht Datenaufblähung, ist der richtige Begriff. Datenaugmentation wird üblicherweise in Deep-Learning-Techniken verwendet, aber hier wurde sie mit gradient-boosted trees auf recht ungewöhnliche Weise genutzt. Es wurden ausgeklügelte und sehr clevere Data-Science-Tricks während dieses Wettbewerbs demonstriert. Ich bin mir nicht ganz sicher, ob diese Tricks sich gut auf die supply chain übertragen lassen, aber ich werde wahrscheinlich im weiteren Verlauf dieses Kapitels ein paar von ihnen erwähnen, falls sich die Gelegenheit bietet.
Frage: Hast du höhere Ebenen durch Aggregation deiner SKU-Ebenen geschätzt oder durch eine neu durchgeführte Middle-out-Berechnung für höhere Ebenen? Falls beides, wie verglichen sie sich?
Das Problem mit Quantil-Gittern ist, dass man dazu neigt, Modelle separat für jedes Ziellevel zu optimieren. Was passieren kann, ist, dass es zu Quantil-Kreuzungen kommt, was bedeutet, dass allein aufgrund numerischer Instabilitäten dein 99. Quantil niedriger ausfällt als dein 97. Quantil. Das ist unbedeutend; typischerweise ordnet man die Werte einfach neu. Grundsätzlich ist das die Art von Problem, auf die ich mich bezog, wenn ich sagte, dass Quantil-Gitter nicht ganz probabilistische Vorhersagen liefern. Man hat Tonnen von kleinlichen Details zu lösen, aber in der Gesamtsicht sind sie unbedeutend. Wenn man zu probabilistischen Vorhersagen übergeht, existieren diese Probleme gar nicht mehr.
Frage: Wenn du einen weiteren Wettbewerb für Software-Anbieter entwerfen würdest, wie würde er aussehen?
Ehrlich gesagt, weiß ich es nicht, und das ist eine sehr schwierige Frage. Ich glaube, dass, trotz all meiner heftigen Kritik, M5 der beste Forecasting-Benchmark ist, den wir haben. Was supply chain Benchmarks angeht, liegt das Problem darin, dass ich nicht einmal vollständig davon überzeugt bin, dass es überhaupt möglich ist. Als ich andeutete, dass einige der Probleme tatsächlich unüberwachtes Lernen erfordern, wird es knifflig. Wenn man in den Bereich des unüberwachten Lernens eintritt, muss man auf Metriken verzichten, und die gesamte fortschrittliche Machine-Learning-Gemeinschaft kämpft immer noch damit, zu verstehen, was es überhaupt bedeutet, überlegene, automatisierte Lernwerkzeuge in einem unüberwachten Umfeld zu betreiben. Wie legt man so etwas überhaupt fest?
Für das Publikum, das nicht bei meinem Vortrag über Machine Learning anwesend war: Im überwachtem Setting versucht man im Wesentlichen, eine Aufgabe zu bewältigen, bei der man Eingaben und Ausgaben sowie eine Metrik zur Bewertung der Qualität der Ergebnisse hat. Wenn man unüberwacht vorgeht, bedeutet das, dass man keine Labels hat, nichts zum Vergleich, und die Dinge werden viel schwieriger. Zudem möchte ich darauf hinweisen, dass es in der supply chain viele Dinge gibt, bei denen man nicht einmal rückwirkend testen kann. Abgesehen vom unüberwachten Aspekt ist die Perspektive des Back-Testings überhaupt nicht befriedigend. Zum Beispiel wird das Forecasting der Nachfrage bestimmte Arten von Entscheidungen hervorrufen, wie Preisentscheidungen. Wenn du dich entscheidest, den Preis nach oben oder unten anzupassen, ist das eine Entscheidung, die du getroffen hast, und sie wird die Zukunft dauerhaft beeinflussen. Man kann also nicht in die Vergangenheit zurückgehen, um zu sagen: “Okay, ich werde eine andere Nachfrageprognose erstellen und dann eine andere Preisentscheidung treffen, und die Geschichte wird sich wiederholen, nur dass ich diesmal einen anderen Preis habe.” Es gibt viele Aspekte, bei denen schon die Idee des Back-Testings nicht funktioniert. Deshalb glaube ich, dass ein Wettbewerb aus der Forecasting-Perspektive sehr interessant ist. Er ist nützlich als Ausgangspunkt für supply chain Zwecke, aber wir müssen besser und anders vorgehen, wenn wir etwas wirklich Befriedigendes für supply chain Zwecke erreichen wollen. In diesem Kapitel über Predictive Modeling werde ich zeigen, warum Modellierung solch einen Fokus verdient.
Frage: Kann diese Methodik in Situationen verwendet werden, in denen man nur wenige Datenpunkte hat?
Ich würde sagen, absolut. Diese Art der strukturierten Modellierung, wie sie hier mit dem REMT-Modell demonstriert wurde, erstrahlt in Situationen, in denen du sehr spärliche Daten hast. Der Grund ist einfach: Du kannst viel menschliches Wissen in die Struktur des Modells einbetten. Die Struktur des Modells wurde nicht aus dem Nichts heraus entwickelt; sie ist buchstäblich die Folge des Verständnisses des Problems durch das Lokad-Team. Zum Beispiel, wenn wir uns Kalendermuster wie Wochentag, Monat des Jahres usw. anschauen, haben wir nicht versucht, diese Muster zu entdecken; das Lokad-Team wusste von Anfang an, dass diese Muster bereits vorhanden waren. Die einzige Unsicherheit betraf die jeweilige Ausprägung des Tages-im-Monat-Musters, welches in vielen Situationen tendenziell schwach ist. Im Fall des Walmart-Setups lag dies einfach daran, dass es in den USA ein Stemp Programm gibt, sodass dieses Muster so stark ist, wie es ist.
Wenn du wenig Daten hast, funktioniert dieser Ansatz außerordentlich gut, weil jeglicher Lernmechanismus, den du zu nutzen versuchst, umfassend die von dir auferlegte Struktur nutzt. Also ja, es drängt sich die Frage auf: Was, wenn die Struktur falsch ist? Aber genau deshalb ist supply chain Denken und Verständnis wirklich wichtig, damit du die richtigen Entscheidungen treffen kannst. Am Ende hast du Möglichkeiten zu beurteilen, ob deine willkürlichen Entscheidungen gut oder schlecht waren, aber grundsätzlich passiert das sehr spät im Prozess. Später in diesem Kapitel über Predictive Modeling werden wir veranschaulichen, wie strukturierte Modellierung effektiv auf Datensätze angewendet werden kann, die unglaublich spärlich sind, wie zum Beispiel in der Luftfahrt, im Hard Luxury und bei Emeralds aller Art. In diesen Situationen glänzen strukturierte Modelle wirklich.
Die nächste Vorlesung wird am 2. Februar stattfinden, was ein Mittwoch ist, zur selben Tageszeit, 15 Uhr Pariser Zeit. Bis dann!
Referenzen
- Ein White-Boxed ISSM-Ansatz zur Schätzung von Unsicherheitsverteilungen der Walmart-Verkäufe, Rafael de Rezende, Katharina Egert, Ignacio Marin, Guilherme Thompson, Dezember 2021 (link)
- Der M5 Uncertainty Wettbewerb: Ergebnisse, Erkenntnisse und Schlussfolgerungen, Spyros Makridakis, Evangelos Spiliotis, Vassilis Assimakopoulos, Zhi Chen, November 2020 (link)


