00:28 Introducción
00:43 Robert A. Heinlein
03:03 La historia hasta ahora
06:52 Una selección de paradigmas
08:20 Análisis estático
18:26 Programación con arrays
28:08 Miscibilidad de hardware
35:38 Programación probabilística
40:53 Programación diferenciable
55:12 Versionado de código+datos
01:00:01 Programación segura
01:05:37 En conclusión, las herramientas también importan en Supply Chain
01:06:40 Próxima conferencia y preguntas de la audiencia
Descripción
Mientras que la teoría de supply chain convencional lucha por prevalecer en las empresas en general, una herramienta; a saber, Microsoft Excel, ha disfrutado de un considerable éxito operacional. Reimplementar las recetas numéricas de la teoría de supply chain convencional mediante hojas de cálculo es trivial, sin embargo, esto no fue lo que ocurrió en la práctica a pesar del conocimiento de la teoría. Demostramos que las hojas de cálculo ganaron al adoptar paradigmas de programación que demostraron ser superiores para entregar resultados en supply chain.
Transcripción completa

Hola a todos, bienvenidos a esta serie de conferencias sobre supply chain. Soy Joannes Vermorel, y hoy presentaré mi cuarta conferencia: Paradigmas de programación para Supply Chain.

Así que cuando me preguntan, “Señor Vermorel, ¿cuáles cree que son las áreas de mayor interés en términos de conocimiento sobre supply chain?” una de mis respuestas principales suele ser los paradigmas de programación. Y luego, no muy frecuentemente, pero lo suficiente, la reacción de la persona con la que hablo es, “¿Paradigmas de programación, Señor Vermorel? ¿De qué carajo está hablando? ¿Cómo es siquiera remotamente relevante para la tarea en cuestión?” Y ese tipo de reacciones, obviamente, no son tan frecuentes, pero cuando ocurren, invariablemente me recuerdan esta cita completamente increíble de Robert A. Heinlein, quien es considerado el decano de los escritores de ciencia ficción.
Heinlein tiene una cita fantástica sobre el hombre competente, que resalta la importancia de la competencia en diversos campos, especialmente en supply chain donde enfrentamos problemas complejos. Estos problemas son casi tan desafiantes como la vida misma, y creo que realmente vale la pena explorar la idea de los paradigmas de programación, ya que podría aportar mucho valor a tu supply chain.
Hasta ahora, en la primera conferencia, hemos visto que los problemas de supply chain son complejos. Cualquiera que hable de soluciones óptimas se equivoca; no existe nada siquiera remotamente cercano a la optimalidad. En la segunda conferencia, delineé la Supply Chain Quantitativa, una visión con cinco requisitos clave para alcanzar la grandeza en la gestión de supply chain. Estos requisitos por sí solos no son suficientes, pero no pueden ser eludidos si deseas lograr la grandeza.
En la tercera conferencia, hablé sobre la entrega de productos de software en el contexto de la optimización de supply chain. Defendí la propuesta de que la optimización de supply chain requiere que un producto de software sea abordado de manera adecuada en un enfoque capitalista, pero no puedes encontrar tal producto en las estanterías. Hay demasiada diversidad, y los desafíos a los que nos enfrentamos están muy por encima de las tecnologías que poseemos en la actualidad. Así que, por necesidad, será algo completamente hecho a la medida. Por lo tanto, si se trata de un producto de software que será hecho a la medida para la empresa o para el supply chain de interés, surge la cuestión de cuáles son las herramientas adecuadas para entregar realmente este producto. Esto me lleva al tema de hoy: la herramienta adecuada comienza con los paradigmas de programación correctos, porque tendremos que programar este producto de una forma u otra.

Hasta ahora, requerimos capacidades programáticas para lidiar con el lado de la optimización del problema, sin confundirse con el lado de la gestión. Lo que hemos visto, que fue el tema de mi conferencia anterior, es que Microsoft Excel ha sido el vencedor hasta ahora. Desde empresas muy pequeñas hasta compañías muy grandes, es ubicuo, se utiliza en todas partes. Incluso en empresas que han invertido millones de dólares en sistemas súper inteligentes, Excel sigue reinando, ¿y por qué? Porque tiene las propiedades de programación adecuadas. Es muy expresivo, ágil, accesible y mantenible. Sin embargo, Excel no es el fin del camino. Estoy firmemente convencido de que podemos hacer mucho más, pero necesitamos tener las herramientas, la mentalidad, las perspectivas y los paradigmas de programación correctos.

Los paradigmas de programación pueden parecer demasiado oscuros para la audiencia, pero en realidad es un campo de estudio que se ha investigado intensivamente durante las últimas cinco décadas. Se ha realizado una cantidad inmensa de trabajo en este campo de estudio. No es ampliamente conocido por el público en general, pero existen bibliotecas completas llenas de trabajos de alta calidad realizados por muchas personas. Así que hoy, voy a presentar una serie de siete paradigmas que Lokad ha adoptado. No inventamos ninguna de estas ideas; las tomamos de personas que las inventaron antes que nosotros. Todos estos paradigmas han sido implementados en el producto de software de Lokad, y después de casi una década de operar Lokad en producción, aprovechando estos paradigmas, creo que han sido absolutamente críticos para nuestro éxito operacional hasta ahora.

Procedamos a través de esta lista comenzando con el análisis estático. El problema aquí es la complejidad. ¿Cómo se maneja la complejidad en supply chain? Te enfrentarás a sistemas empresariales que tienen cientos de tablas, cada una con docenas de campos. Si consideras un problema tan simple como el reabastecimiento de existencias en un almacén, tienes tantas cosas que tener en cuenta. Puedes tener MOQs, price breaks, previsión de la demanda, previsión de tiempos de entrega, y todo tipo de devoluciones. Puedes tener limitaciones de espacio en estanterías, límites en la capacidad de recepción y fechas de caducidad que hacen que algunos de tus lotes queden obsoletos. Así que terminas con toneladas de cosas a considerar. En supply chain, la idea de “moverse rápido y romper cosas” simplemente no es la mentalidad adecuada. Si accidentalmente ordenas mercadería por un valor de un millón de dólares que no necesitas en absoluto, esto es un error muy costoso. No puedes tener una pieza de software dirigiendo tu supply chain, tomando decisiones rutinarias, y cuando hay un error, cuesta millones. Necesitamos tener algo con un grado muy alto de corrección por diseño. No queremos descubrir los errores en producción. Esto es muy diferente de tu software promedio, donde un fallo no es gran cosa.
Cuando se trata de la optimización de supply chain, este no es el típico problema. Si acabas de enviar un pedido masivo e incorrecto a un proveedor, no puedes simplemente llamarlo una semana después para decir: “Oh, fue mi error, no, olvídalo, nunca lo ordenamos.” Esos errores van a costar mucho dinero. Se llama análisis estático porque se trata de analizar un programa sin ejecutarlo. La idea es que tienes un programa escrito con sentencias, palabras clave y todo, y sin siquiera ejecutar este programa, ¿puedes ya decir si el programa presenta problemas que casi seguramente impactarían negativamente tu producción, especialmente la producción de supply chain? La respuesta es sí. Estas técnicas existen, y están implementadas y son sumamente valiosas.
Para dar un ejemplo, puedes ver en la pantalla una captura de Envision. Envision es un lenguaje de programación específico del dominio que ha sido desarrollado durante casi una década por Lokad y está dedicado a la optimización predictiva de supply chain. Lo que ves es una captura de pantalla del editor de código de Envision, una aplicación web que puedes usar en línea para editar código. La sintaxis está fuertemente influenciada por Python. En esta pequeña captura, con solo cuatro líneas, estoy ilustrando la idea de que si estás escribiendo una gran pieza de lógica para el reabastecimiento de inventario en un almacén, y introduces algunas variables económicas, como price breaks, mediante un análisis lógico del programa, puedes ver que esos price breaks no tienen ninguna relación con los resultados finales que devuelve el programa, que son las cantidades a reabastecer. Aquí, tienes un problema obvio. Has introducido una variable importante, price breaks, y esos price breaks lógicamente no tienen ninguna influencia en los resultados finales. Así que aquí, tenemos un problema que puede ser detectado mediante análisis estático. Es un problema obvio porque si introducimos variables en el código que no tienen ningún impacto en la salida del programa, entonces no cumplen ningún propósito.
El análisis estático es absolutamente fundamental para lograr cualquier grado de corrección por diseño. Se trata de corregir las cosas en tiempo de compilación cuando escribes el código, incluso antes de tocar los datos. Si surgen problemas al ejecutarlo, lo más probable es que estos ocurran únicamente durante la noche, cuando el proceso nocturno impulsa el reabastecimiento del almacén. Es probable que el programa se ejecute a horas extrañas cuando nadie lo está atendiendo, por lo que no quieres que algo falle mientras no hay nadie frente al programa. Debería fallar en el momento en que las personas estén realmente escribiendo el código.
El análisis estático tiene muchos propósitos. Por ejemplo, en Lokad, usamos el análisis estático para la edición WYSIWYG de dashboards. WYSIWYG significa “lo que ves es lo que obtienes.” Imagina que estás construyendo un dashboard para reportes, con gráficos de líneas, gráficos de barras, tablas, colores y varios efectos de estilo. Quieres poder hacerlo de forma visual, no ajustar el estilo de tu dashboard mediante el código, ya que resulta muy engorroso. Todas las configuraciones que has implementado se van a reinyectar en el propio código, y eso se logra mediante análisis estático.
Otro aspecto en Lokad, que puede no ser de tal importancia para el supply chain en general pero ciertamente crítico para emprender el proyecto, fue lidiar con un lenguaje de programación llamado Envision que estamos desarrollando. Sabíamos desde el primer día, hace casi una década, que se cometerían errores. No teníamos una bola de cristal para tener la visión perfecta desde el primer día. La pregunta fue, ¿cómo podemos asegurarnos de que podemos arreglar esos errores de diseño en el propio lenguaje de programación de la manera más conveniente posible? Aquí, Python fue para mí un cuento de advertencia.
Python, que no es un lenguaje nuevo, fue lanzado por primera vez en 1991, hace casi 30 años. La migración de Python 2 a Python 3 tomó a toda la comunidad casi una década, y fue un proceso de pesadilla, muy doloroso para las empresas involucradas en esta migración. Mi percepción fue que el propio lenguaje no tenía suficientes construcciones. No fue diseñado de tal manera que pudieras migrar programas de una versión del lenguaje de programación a otra. Fue realmente extremadamente difícil hacerlo de forma completamente automatizada, y eso se debe a que Python no ha sido desarrollado pensando en el análisis estático. Cuando tienes un lenguaje de programación para supply chain, realmente deseas uno que tenga una calidad excelente en términos de análisis estático porque tus programas tendrán una larga vida. Las supply chain no tienen el lujo de decir, “Espera tres meses; simplemente estamos reescribiendo el código. Espéranos; la caballería está en camino. Simplemente no va a estar funcionando por un par de meses.” Es literalmente como arreglar un tren mientras el tren circula a toda velocidad por las vías, y quieres arreglar el motor mientras el tren está en funcionamiento. Así es como se ve arreglar cosas de supply chain que están realmente en producción. No tienes el lujo de simplemente pausar el sistema; nunca se pausa.

El segundo paradigma es la programación con arrays. Queremos tener la complejidad bajo control, ya que ese es un gran tema recurrente en supply chain. Queremos tener una lógica donde no existan ciertas clases de errores de programación. Por ejemplo, siempre que tienes bucles o condicionales escritos explícitamente por los programadores, te expones a clases enteras de problemas muy difíciles. Se vuelve sumamente complicado cuando las personas pueden simplemente escribir bucles arbitrarios para tener garantías sobre la duración del cálculo. Aunque podría parecer un problema de nicho, no es del todo el caso en la optimización de supply chain.
En la práctica, digamos que tienes una cadena minorista. A medianoche, habrán consolidado completamente todas las ventas de toda la red, y los datos serán consolidados y pasados a algún tipo de sistema para la optimización. Este sistema tendrá exactamente una ventana de 60 minutos para realizar la previsión, la optimización de inventario y las decisiones de reasignación para cada tienda de la red. Una vez terminado, los resultados serán enviados al sistema de gestión de almacenes para que puedan comenzar a preparar todos los envíos. Los camiones se cargarán, quizás a las 5:00 AM, y para las 9:00 AM, las tiendas abrirán con la mercadería ya recibida y colocada en las estanterías.
Sin embargo, tienes un tiempo muy estricto, y si tu cálculo se extiende fuera de este plazo de 60 minutos, estarás poniendo en riesgo la ejecución de toda la supply chain. No quieres algo en lo que simplemente descubras en producción cuánto tiempo toman las cosas. Si tienes bucles en los que las personas pueden decidir cuántas iteraciones van a tener, es muy difícil tener alguna prueba de la duración de tu cálculo. Ten en cuenta que estamos hablando de optimización de supply chain. No tienes el lujo de hacer revisión por pares y verificar todo dos veces. A veces, debido a la pandemia, algunos países se están cerrando mientras que otros vuelven a abrir de manera bastante errática, usualmente con un aviso de 24 horas. Necesitas reaccionar rápidamente.
Entonces, la programación con arrays es la idea de que puedes operar directamente sobre arrays. Si miramos el fragmento de código que tenemos aquí, este es código de Envision, el DSL de Lokad. Para entender lo que está pasando, tienes que comprender que cuando escribo “orders.amounts”, lo que viene es una variable y “orders” es en realidad una tabla en el sentido de una tabla relacional, como en una tabla de tu base de datos. Por ejemplo, aquí en la primera línea, “amounts” sería una columna en la tabla. En la línea uno, lo que estoy haciendo es literalmente decir que para cada línea de la tabla orders, simplemente voy a tomar la “quantity”, que es una columna, y multiplicarla por “price”, y luego obtengo una tercera columna que se genera dinámicamente, que es “amount”.
Por cierto, el término moderno para la programación con arrays hoy en día también se conoce como programación con data frames. El campo de estudio es bastante antiguo; se remonta a tres o cuatro décadas, tal vez incluso cuatro o cinco. Se le ha conocido como programación con arrays, aunque hoy en día la gente suele estar más familiarizada con la idea de los data frames. En la línea dos, lo que estamos haciendo es aplicar un filtro, tal como en SQL. Estamos filtrando las fechas, y resulta que la tabla orders tiene una fecha. Va a ser filtrada, y digo “fecha que es mayor que hoy menos 365”, es decir, en días. Conservamos los datos del año pasado, y luego estamos escribiendo “products.soldLastYear = SUM(orders.amount)”.
Ahora, lo interesante es que tenemos lo que llamamos un natural join entre products y orders. ¿Por qué? Porque cada línea de pedido está asociada con un producto y sólo un producto, y un producto está asociado con cero o más líneas de pedido. En esta configuración, puedes decir directamente, “quiero calcular algo a nivel de producto que sea simplemente la suma de lo que ocurre a nivel de orders”, y eso es exactamente lo que se hace en la línea nueve. Puedes notar que la sintaxis es muy sencilla; no tiene muchos incidentales o tecnicismos. Diría que este código está casi completamente desprovisto de incidentales cuando se trata de programación con data frames. Luego, en las líneas 10, 11 y 12, simplemente estamos mostrando una tabla en nuestro dashboard, lo cual se puede hacer de manera muy conveniente: “LIST(PRODUCTS)”, y luego “TO(products)”.
Existen muchas ventajas de la programación con arrays para las supply chains. Primero, elimina clases enteras de problemas. No tendrás bugs de desfasado en tus arrays. Va a ser mucho más fácil paralelizar e incluso distribuir el cálculo. Eso es muy interesante porque significa que puedes escribir un programa y que se ejecute no en una máquina local, sino directamente en una flota de máquinas que viven en la nube, y por cierto, esto es exactamente lo que se está haciendo en Lokad. Esta paralelización automática es de altísimo interés.
Verás, la forma en que funciona es que cuando realizas optimización de supply chain, tus patrones típicos de consumo en términos de hardware de cómputo son muy intermitentes. Si vuelvo al ejemplo que estaba dando sobre la ventana de 60 minutos para las redes de retail durante la reposición de tiendas, significa que hay una hora por día en la que necesitas poder de cómputo para hacer todos tus cálculos, pero el resto del tiempo, las otras 23 horas, no lo necesitas. Así que lo que deseas es un programa que, cuando estés a punto de ejecutarlo, se distribuya en muchas máquinas y luego, una vez que termine, simplemente libere todas esas máquinas para que puedan realizarse otros cálculos. La alternativa sería tener muchas máquinas que estás rentando y pagando durante todo el día, pero usándolas solo el 5% del tiempo, lo cual es muy ineficiente.
Esta idea de que puedes distribuir rápidamente y de manera predecible en muchas máquinas, y luego ceder el poder de procesamiento, requiere de la nube en una configuración multiinquilino y una serie de otras cosas adicionales que está haciendo Lokad. Pero ante todo, requiere la cooperación del propio lenguaje de programación. Es algo que simplemente no es factible con un lenguaje de programación genérico como Python, porque el propio lenguaje no se presta a este tipo de enfoque tan inteligente y relevante. Esto es más que simples trucos; es literalmente dividir tus costos de hardware de TI por 20, acelerar masivamente la ejecución y eliminar clases enteras de posibles errores en tu supply chain. Esto cambia las reglas del juego.
La programación con arrays ya existe en muchos aspectos, como en NumPy y pandas en Python, que son tan populares para el segmento de la audiencia de data scientist. Pero la pregunta que tengo para ti es: si es tan importante y útil, ¿por qué estas cosas no son ciudadanos de primera clase del propio lenguaje? Si todo lo que haces es canalizar a través de NumPy, entonces NumPy debería ser un ciudadano de primera clase. Yo diría que puedes ir incluso mejor que NumPy. NumPy se trata solo de programación con arrays en una máquina, pero ¿por qué no hacer programación con arrays en una flota de máquinas? Es mucho más poderoso y adecuado cuando tienes una nube con capacidad de hardware accesible.
Entonces, ¿cuál será el cuello de botella en la optimización de supply chain? Existe ese dicho de Goldratt que afirma, “Cualquier mejora aportada al lado del cuello de botella en una supply chain es una ilusión”, y estoy muy de acuerdo con esta afirmación. Realistamente, cuando queremos hacer optimización de supply chain, el cuello de botella serán las personas, y más específicamente, los Supply Chain Scientist que, desafortunadamente para Lokad y mis clientes, no crecen en los árboles.
El cuello de botella son los Supply Chain Scientist, las personas que pueden elaborar las recetas numéricas que tienen en cuenta todas las estrategias de la empresa, los comportamientos adversarios de los competidores, y que transforman toda esa inteligencia en algo mecánico que se puede ejecutar a escala. La tragedia de la forma ingenua de hacer data science, cuando comencé mi doctorado —el cual, por cierto, nunca terminé— era que podía ver que todos en el laboratorio literalmente estaban haciendo data science. La mayoría de la gente escribía código para algún tipo de modelo avanzado de machine learning, presionaban enter y luego empezaban a esperar. Si tienes un conjunto de datos grande, digamos de 5 a 10 gigabytes, no será en tiempo real. Así, todo el laboratorio estaba lleno de personas que escribían unas pocas líneas, presionaban enter y luego se iban a tomar una taza de café o a leer algo en línea. De ese modo, la productividad era sumamente baja.
Cuando comencé a crear mi propia empresa, tenía en mente que no quería terminar pagando a un ejército de personas súper inteligentes que pasaran la mayor parte del día tomando café, esperando a que sus programas se completaran para obtener resultados y continuar. En teoría, podrían paralelizar muchas cosas a la vez y ejecutar experimentos, pero en la práctica, nunca lo he visto realmente. Intelectualmente, cuando estás comprometido en encontrar una solución para un problema, quieres probar tu hipótesis y necesitas el resultado para avanzar. Es muy difícil hacer multitarea en temas altamente técnicos y perseguir múltiples líneas intelectuales al mismo tiempo.
Sin embargo, había un lado positivo. Los data scientists, y ahora los Supply Chain Scientist en Lokad, no terminan escribiendo mil líneas de código y luego diciendo “por favor, ejecuta”. Usualmente añaden dos líneas a un script que ya tiene mil líneas, y luego piden que se ejecute el script. Este script se ejecuta contra exactamente los mismos datos que acaban de procesar hace unos minutos. Es casi exactamente la misma lógica, salvo por esas dos líneas. Entonces, ¿cómo puedes procesar terabytes de datos en segundos en lugar de varios minutos? La respuesta es: si en la ejecución anterior del script has registrado todos los pasos intermedios del cálculo y los has guardado en almacenamiento (típicamente en discos de estado sólido o SSD), los cuales son muy baratos, rápidos y convenientes.
La próxima vez que ejecutes tu programa, el sistema notará que es casi el mismo script. Va a hacer un diff, y ver que en términos del grafo de cómputo es casi idéntico, salvo por unos pocos detalles. En términos de datos, usualmente es 100% idéntico. A veces hay algunos cambios, pero casi nada. El sistema autodiagnosticará que solo tienes unas pocas cosas que necesitas calcular, de modo que puedes obtener los resultados en segundos. Esto puede aumentar dramáticamente la productividad de tu Supply Chain Scientist. Puedes pasar de personas que presionan enter y esperan 20 minutos por el resultado a algo en lo que presionan enter y 5 o 10 segundos después tienen el resultado y pueden continuar.
Estoy hablando de algo que puede parecer muy oscuro, pero en la práctica estamos hablando de algo que tiene un impacto de 10x en la productividad. Esto es masivo. Entonces, lo que estamos haciendo aquí es usar un truco ingenioso que Lokad no inventó. Estamos sustituyendo un recurso bruto de cómputo, que es compute, por otro, que es la memoria y el almacenamiento. Tenemos los recursos fundamentales de cómputo: compute, memoria (ya sea volátil o persistente) y ancho de banda. Estos son los recursos fundamentales por los que pagas cuando compras recursos en una plataforma de computación en la nube. En realidad, puedes sustituir un recurso por otro, y el objetivo es obtener el mayor rendimiento por tu inversión.
Cuando la gente dice que deberías estar usando in-memory computing, yo diría que eso no tiene sentido. Si dices in-memory computing, significa que estás poniendo un énfasis de diseño en un recurso en detrimento de los demás. Pero no, hay compensaciones, y lo interesante es que puedes tener un lenguaje de programación y un entorno que hagan que estas compensaciones y perspectivas sean más fáciles de implementar. En un lenguaje de programación de propósito general, es posible hacer eso, pero tienes que hacerlo manualmente. Esto significa que la persona que lo haga tiene que ser un ingeniero de software profesional. Un Supply Chain Scientist no va a realizar estas operaciones de bajo nivel con los recursos fundamentales de cómputo de tu plataforma. Esto tiene que estar diseñado a nivel del propio lenguaje de programación.
Ahora, hablemos de programación probabilística. En la segunda conferencia donde presenté la visión para el Supply Chain Quantitativa, mi primer requisito fue que necesitábamos considerar todos los posibles futuros. La respuesta técnica a este requisito es previsión probabilística. Quieres tratar con futuros en los que hay probabilidades. Todos los futuros son posibles, pero no todos son igualmente probables. Necesitas tener un álgebra en la que puedas hacer cálculos con incertidumbre. Una de mis grandes críticas a Excel es que es sumamente difícil representar la incertidumbre en una hoja de cálculo, sin importar si es Excel o alguna versión más moderna basada en la nube.
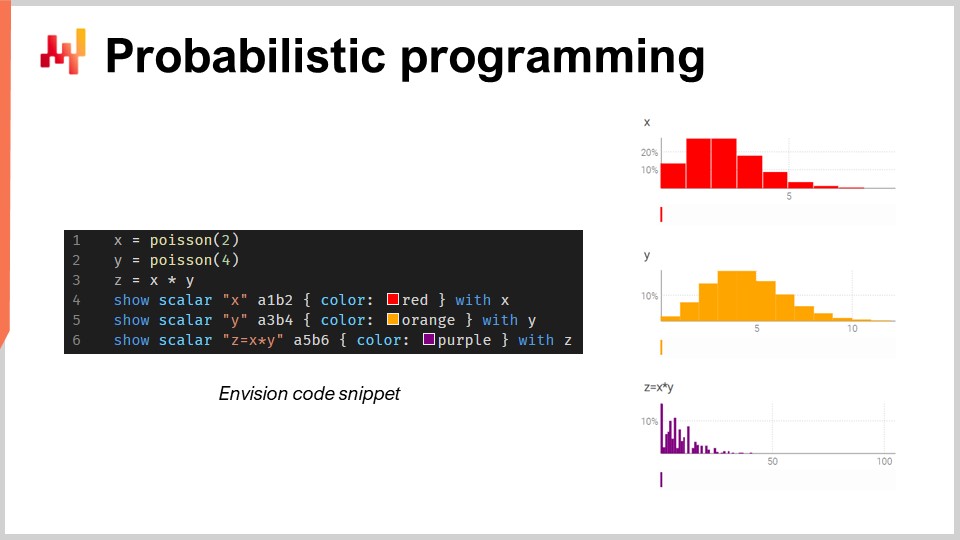
En este pequeño fragmento, estoy ilustrando el álgebra de variables aleatorias, que es una característica nativa de Envision. En la línea uno, estoy generando una distribución de Poisson que es discreta, con una media de 2, y la asigno a la variable X. Luego, hago lo mismo para otra distribución de Poisson, Y. Después, calculo Z como la multiplicación de X por Y. Esta operación, la multiplicación de variables aleatorias, puede parecer muy extraña. ¿Por qué necesitas este tipo de cosas desde una perspectiva de supply chain? Permíteme darte un ejemplo.
Supongamos que estás en el mercado de repuestos automotrices y estás vendiendo pastillas de freno. La gente no compra pastillas de freno por unidad; compran dos o cuatro. Entonces, la cuestión es, si quieres hacer una previsión, puede que desees pronosticar las probabilidades de que los clientes se presenten para comprar un cierto tipo de pastillas de freno. Esa será tu primera variable aleatoria que te dé la probabilidad de observar cero unidades de demanda, una unidad de demanda, dos, tres, cuatro, etc. para las pastillas de freno. Luego tendrás otra distribución de probabilidad que representa si la gente va a comprar dos o cuatro pastillas de freno. Tal vez sea 50-50, o quizá sea 10 por ciento comprando dos y 90 por ciento comprando cuatro. La cuestión es que tienes estos dos ángulos, y si quieres conocer el consumo total real de pastillas de freno, quieres multiplicar la probabilidad de que un cliente se presente para estas pastillas de freno y luego la distribución de probabilidad de comprar ya sea dos o cuatro. Así, necesitas hacer esta multiplicación de estas dos cantidades inciertas.
Aquí, estoy asumiendo que las dos variables aleatorias son independientes. Por cierto, esta multiplicación de variables aleatorias se conoce en matemáticas como una convolución discreta. Puedes ver en la captura de pantalla el dashboard generado por Envision. En las primeras tres líneas, estoy realizando este cálculo de álgebra aleatoria, y luego en las líneas cuatro, cinco y seis, estoy mostrando esos elementos en la página web, en el dashboard generado por el script. Estoy graficando A1, B2, por ejemplo, tal como en una cuadrícula de Excel. Los dashboards de Lokad están organizados de manera similar a las cuadrículas de Excel, con posiciones que tienen las columnas B, C, etc., y las filas 1, 2, 3, 4, 5.
Puedes ver que la convolución discreta, Z, tiene este patrón muy extraño y picudo que es comúnmente encontrado en supply chains cuando las personas pueden comprar packs, lotes o múltiples unidades. En este tipo de situación, generalmente es mejor descomponer las fuentes de los eventos multiplicativos asociados con el lote o el pack. Necesitas tener un lenguaje de programación que tenga estas capacidades disponibles al alcance de tu mano, como ciudadanos de primera clase. De eso se trata exactamente la programación probabilística, y así es como la implementamos en Envision.

Ahora, vamos a discutir programación diferenciable. Debo poner una advertencia aquí: no espero que la audiencia entienda realmente lo que está pasando, y me disculpo por ello. No es que a tu inteligencia le falte; es solo que este tema merece una serie completa de conferencias. De hecho, si miras el plan para las próximas conferencias, hay una serie entera dedicada a la programación diferenciable. Voy a ir super rápido, y va a ser bastante críptico, así que me disculpo de antemano.
Continuemos con el problema de supply chain que nos interesa aquí, que es la canibalización y la sustitución. Estos problemas son muy interesantes, y probablemente sean donde la previsión de series temporales, que es ubicuo, falla de la manera más brutal. ¿Por qué? Porque frecuentemente, tenemos clientes o prospectos que se me acercan y preguntan si podemos hacer, por ejemplo, previsiones a 13 semanas de anticipación para ciertos artículos como mochilas. Yo diría que sí, podemos, pero obviamente, si tomamos una mochila y queremos previsión la demanda de este producto, depende masivamente de lo que estés haciendo con tus otras mochilas. Si tienes solo una mochila, tal vez vayas a concentrar toda la demanda de mochilas en este único producto. Si introduces 10 variantes diferentes, obviamente habrá toneladas de canibalización. No vas a multiplicar el total de ventas por un factor de 10 solo porque has multiplicado el número de referencias por 10. Así que, obviamente, se produce canibalización y sustitución. Estos fenómenos son prevalentes en supply chains.
¿Cómo analizas la canibalización o sustitución? La forma en que lo hacemos en Lokad, y no pretendo que sea la única manera, pero sin duda es una forma que funciona, es típicamente observando el gráfico que conecta a clientes y productos. ¿Por qué es así? Porque la canibalización ocurre cuando los productos compiten entre sí por los mismos clientes. La canibalización es literalmente la manifestación de que tienes un cliente con una necesidad, pero tiene preferencias y va a elegir un producto entre el conjunto de productos que se ajusten a su afinidad, y escoger solo uno. Esa es la esencia de la canibalización.
Si quieres analizar eso, necesitas analizar no las series de tiempo de las ventas, porque no capturas esa información en primer lugar. Quieres analizar el gráfico que conecta las transacciones históricas entre clientes y productos. Resulta que en la mayoría de los negocios, estos datos están disponibles de inmediato. Para e-commerce, eso es un hecho. Cada unidad que vendes, sabes el cliente. En B2B, es lo mismo. Incluso en B2C en el retail, la mayoría de las veces, las cadenas de retail hoy en día tienen programas de loyalty donde conocen un porcentaje de dos dígitos de los clientes que se presentan con sus tarjetas, así sabes quién compra qué. No para el 100% del tráfico, pero no lo necesitas. Si tienes el 10% o más de tus transacciones históricas en las que conoces la pareja cliente-producto, es suficientemente bueno para este tipo de análisis.
En este fragmento relativamente pequeño, voy a detallar un análisis de afinidad entre clientes y productos. Ese es literalmente el paso fundamental que necesitas dar para hacer cualquier tipo de análisis de canibalización. Echemos un vistazo a lo que está pasando en este código.
Desde las líneas uno hasta cinco, esto es muy mundano; simplemente estoy leyendo un archivo plano que contiene un historial de transacciones. Estoy leyendo un archivo CSV que tiene cuatro columnas: date, product, client, y quantity. Algo muy básico. Ni siquiera estoy utilizando todas esas columnas, pero es solo para hacer el ejemplo un poco más concreto. En el historial de transacciones, asumo que los clientes son conocidos en todas esas transacciones. Así que, es muy mundano; solo estoy leyendo datos de una tabla.
Luego, en las líneas siete y ocho, simplemente estoy creando la tabla para productos y la tabla para clientes. En un entorno de producción real, normalmente no crearía esas tablas; las leería desde otros archivos planos en otro lugar. Quería mantener el ejemplo super simple, así que solo estoy extrayendo una tabla de productos a partir de los productos que observé en el historial de transacciones, y hago lo mismo para los clientes. Verás, es solo un truco para mantenerlo super simple.
Ahora, las líneas 10, 11 y 12 involucran espacios latentes, y esto se va a volver un poco más oscuro. Primero, en la línea 10, estoy creando una tabla con 64 líneas. La tabla no contiene nada; está definida únicamente por el hecho de que tiene 64 líneas, y eso es todo. Así que esto es como un marcador de posición, una tabla trivial con muchas líneas y sin columnas. No es tan útil solo así. Luego, “P” es básicamente un producto cartesiano, una operación matemática que genera todos los pares. Es una tabla donde tienes una línea por cada línea en los productos y por cada línea en la tabla “L”. Entonces, esta tabla “P” tiene 64 líneas más que la tabla de productos, y hago lo mismo para los clientes. Simplemente estoy inflando esas tablas a través de esta dimensión extra, que es esta tabla “L”.
Esto será mi soporte para mis espacios latentes, que es exactamente lo que voy a aprender. Lo que quiero aprender es, para cada producto, un espacio latente que va a ser un vector de 64 valores, y para cada cliente, un espacio latente de 64 valores también. Si quiero conocer la afinidad entre un cliente y un producto, solo quiero poder hacer el producto punto entre ambos. El producto punto es simplemente la multiplicación elemento por elemento de todos los términos de esos dos vectores, y luego se realiza la suma. Puede sonar muy técnico, pero es solo multiplicación elemento por elemento más suma – ese es el producto punto.
Estos espacios latentes son solo una jerga elegante para crear un espacio con parámetros que son un poco inventados, donde solo quiero aprender. Toda la magia de la programación diferenciable ocurre en solo cinco líneas, de la línea 14 a la 18. Tengo una palabra clave, “autodiff”, y “transactions”, que indica que esta es una tabla de interés, una tabla de observaciones. Voy a procesar esta tabla línea por línea para realizar mi proceso de aprendizaje. En este bloque, estoy declarando un conjunto de parámetros. Los parámetros son las cosas que quieres aprender, como números, pero simplemente aún no conoces los valores. Esas cosas se van a inicializar de manera aleatoria, con números aleatorios.
Introduzco “X”, “X*” y “Y”. No voy a profundizar en lo que hace exactamente “X*”; tal vez en las preguntas. Estoy retornando una expresión que es mi función de pérdida, y esa es la suma. La idea del filtrado colaborativo o la descomposición matricial es simplemente que quieres aprender espacios latentes que se ajusten a todos los bordes en tu grafo bipartito. Sé que es un poco técnico, pero lo que estamos haciendo es literalmente muy simple, en términos de supply chain. Estamos aprendiendo la afinidad entre productos y clientes.
Sé que probablemente parece super opaco, pero quédate conmigo, y habrá más conferencias en las que te brindaré una introducción más profunda sobre esto. Todo se hace en cinco líneas, y eso es completamente notable. Cuando digo cinco líneas, no estoy haciendo trampa al decir, “Mira, son solo cinco líneas, pero en realidad estoy haciendo una llamada a una biblioteca de terceros de complejidad gigantesca donde estoy enterrando toda la inteligencia.” No, no, no. Aquí, en este ejemplo, literalmente no hay magia de machine learning además de las dos palabras clave “autodiff” y “params”. “Autodiff” se utiliza para definir un bloque donde ocurrirá la programación diferenciable, y por cierto, este es un bloque donde puedo programar cualquier cosa, así que literalmente, puedo inyectar nuestro programa. Luego, tengo “params” para declarar mis problemas, y eso es todo. Así que, ves, no hay ninguna magia opaca ocurriendo; no hay una biblioteca de un millón de líneas en segundo plano haciendo todo el trabajo por ti. Todo lo que necesitas saber está literalmente en esta pantalla, y esa es la diferencia entre un paradigma de programación y una biblioteca. El paradigma de programación te da acceso a capacidades aparentemente increíblemente sofisticadas, como hacer análisis de canibalización con solo unas pocas líneas de código, sin recurrir a masivas bibliotecas de terceros que encierran la complejidad. Transciende el problema, haciéndolo mucho más simple, para que puedas tener algo que parece súper complicado resuelto en solo unas pocas líneas.
Ahora, unas palabras sobre cómo funciona la programación diferenciable. Hay dos conceptos clave. Uno es la diferenciación automática. Para aquellos de ustedes que han tenido el lujo de recibir formación en ingeniería, han visto dos maneras de calcular derivadas. Existe la derivada simbólica, por ejemplo, si tienes x al cuadrado, haces la derivada con respecto a x y te da 2x. Esa es la derivada simbólica. Luego tienes la derivada numérica, de modo que si tienes una función f(x) que deseas derivar, será f’(x) ≈ (f(x + ε) - f(x))/ε. Esa es la derivación numérica. Ninguna de las dos es adecuada para lo que intentamos hacer aquí. La derivación simbólica tiene problemas de complejidad, ya que tu derivada podría ser un programa mucho más complejo que el programa original. La derivación numérica es numéricamente inestable, por lo que tendrás muchos problemas de estabilidad numérica.
La diferenciación automática es una idea fantástica que data de los años 70 y que fue redescubierta por el gran público en la última década. Es la idea de que puedes calcular la derivada de un programa de computadora arbitrario, lo cual es alucinante. Aún más asombroso, el programa que es la derivada tiene la misma complejidad computacional que el programa original, lo que es impresionante. La programación diferenciable es simplemente una combinación de la diferenciación automática y de parámetros que deseas aprender.
Entonces, ¿cómo aprendes? Cuando tienes la derivación, significa que puedes propagar gradientes, y con el descenso de gradiente estocástico, puedes hacer pequeños ajustes a los valores de los parámetros. Al modificar esos parámetros, te irás acercando de manera incremental, a través de muchas iteraciones del descenso de gradiente estocástico, a parámetros que tengan sentido y logren lo que deseas aprender u optimizar.
La programación diferenciable puede usarse para problemas de aprendizaje, como el que estoy ilustrando, en el que quiero aprender la afinidad entre mis clientes y mis productos. También puede utilizarse para problemas de optimización numérica, tales como optimizar cosas bajo ciertas restricciones, y es muy escalable como paradigma. Como puedes ver, este aspecto ha sido considerado de primera clase en Envision. Por cierto, aún hay algunas cosas en progreso en cuanto a la sintaxis de Envision, así que no esperes exactamente esas cosas todavía; todavía estamos afinando algunos aspectos. Pero la esencia está presente. No voy a discutir los detalles de las pocas cosas que aún están en evolución.

Ahora pasemos a otro problema relevante para la preparación de la producción de tu configuración. Típicamente, en la optimización de la supply chain, te enfrentas a los Heisenbugs. ¿Qué es un Heisenbug? Es un tipo de error frustrante en el que se realiza una optimización y se producen resultados basura. Por ejemplo, tuviste un cálculo por lotes para la reposición de inventario durante la noche, y por la mañana descubres que algunos de esos resultados no tenían sentido, causando errores costosos. No quieres que el problema vuelva a suceder, así que vuelves a ejecutar tu proceso. Sin embargo, cuando lo vuelves a ejecutar, el problema ha desaparecido. No puedes reproducir el fallo, y el Heisenbug no se manifiesta.
Puede sonar como un caso atípico, pero en los primeros años de Lokad, enfrentamos estos problemas de manera recurrente. He visto muchas iniciativas de supply chain, especialmente del tipo de data science, fracasar debido a Heisenbugs sin resolver. Tenían errores ocurriendo en producción, intentaron reproducir los problemas localmente pero no pudieron, por lo que los problemas nunca se solucionaron. Después de un par de meses en modo pánico, el proyecto completo usualmente se cerraba silenciosamente, y la gente volvía a usar hojas de cálculo de Excel.
Si deseas lograr una replicabilidad completa de tu lógica, necesitas versionar el código y los datos. La mayoría de las personas en la audiencia que son ingenieros de software o data scientists pueden estar familiarizados con la idea de versionar el código. Sin embargo, también quieres versionar todos los datos para que, cuando se ejecute tu programa, sepas exactamente qué versión del código y de los datos se está utilizando. Puede que no puedas replicar el problema al día siguiente porque los datos han cambiado debido a nuevas transacciones u otros factores, por lo que las condiciones que desencadenaron el error en primer lugar ya no están presentes.
Quieres asegurarte de que tu entorno de programación pueda replicar exactamente la lógica y los datos tal como estaban en producción en un momento específico. Esto requiere una versionación completa de todo. Nuevamente, el lenguaje de programación y la pila de programación deben cooperar para hacer esto posible. Es alcanzable sin que el paradigma de programación sea un ciudadano de primera clase en tu pila, pero entonces el Supply Chain Scientist debe ser sumamente cuidadoso con todas las cosas que hace y con la forma en que programa. De lo contrario, no podrá replicar sus resultados. Esto pone una presión inmensa sobre los hombros de los Supply Chain Scientists, quienes ya están bajo una presión significativa por parte de la supply chain misma. No quieres que estos profesionales tengan que lidiar con una complejidad accidental, como el no poder replicar sus propios resultados. En Lokad, llamamos a esto una “máquina del tiempo” donde puedes replicar todo en cualquier punto del pasado.
Cuidado, no se trata solo de replicar lo que ocurrió anoche. A veces, descubres un error mucho tiempo después de que sucedió. Por ejemplo, si realizas una orden de compra a un proveedor que tiene un plazo de entrega de tres meses, puede que descubras tres meses después que la orden era absurda. Necesitas retroceder tres meses en el tiempo hasta el punto en que generaste esta orden de compra falsa para averiguar cuál fue el problema. No se trata de versionar solo las últimas horas de trabajo; se trata literalmente de tener un historial completo del último año de ejecución.

Otra preocupación es el aumento del ransomware y de los ciberataques a las supply chains. Estos ataques son extremadamente disruptivos y pueden ser muy costosos. Al implementar soluciones basadas en software, necesitas considerar si estás haciendo que tu empresa y la supply chain sean más vulnerables a ciberataques y riesgos. Desde esta perspectiva, Excel y Python no son ideales. Estos componentes son programables, lo que significa que pueden tener numerosas vulnerabilidades de seguridad.
Si tienes un equipo de científicos de datos o Supply Chain Scientist lidiando con problemas de supply chain, no pueden permitirse el cuidadoso e iterativo proceso de revisión por pares del código que es común en la industria del software. Si un arancel cambia de la noche a la mañana o un almacén se inunda, necesitas una respuesta rápida. No puedes pasar semanas produciendo especificaciones de código, revisiones, y así sucesivamente. El problema es que le estás dando capacidades de programación a personas que, por defecto, tienen el potencial de causar daño a la empresa de forma accidental. Puede ser incluso peor si hay un empleado rebelde intencional, pero dejando eso a un lado, aún tienes el problema de que alguien exponga accidentalmente una parte interna de los sistemas de TI. Recuerda, los sistemas de optimización de supply chain, por definición, tienen acceso a una gran cantidad de datos en toda la empresa. Estos datos no son solo un activo, sino también un pasivo.
Lo que quieres es un paradigma de programación que promueva la programación segura. Quieres un lenguaje de programación en el que existan clases enteras de cosas que no puedes hacer. Por ejemplo, ¿por qué deberías tener un lenguaje de programación que pueda hacer llamadas al sistema para propósitos de optimización de supply chain? Python puede hacer llamadas al sistema, y Excel también. Pero, ¿por qué querrías un sistema programable con tales capacidades en primer lugar? Es como comprar una pistola para dispararte en el pie.
Quieres algo en lo que clases enteras o características estén ausentes porque no las necesitas para la optimización de supply chain. Si estas características están presentes, se convierten en una responsabilidad masiva. Si introduces capacidades programables sin las herramientas que aseguran la programación segura por diseño, aumentas el riesgo de ciberataques y ransomware, empeorando las cosas.
Por supuesto, siempre es posible compensar duplicando el tamaño del equipo de ciberseguridad, pero eso es muy costoso y no es ideal cuando se enfrentan situaciones urgentes de supply chain. Necesitas actuar rápida y seguramente, sin el tiempo para los procesos, revisiones y aprobaciones habituales. También deseas una programación segura que elimine problemas triviales como excepciones por referencias nulas, errores de falta de memoria, bucles off-by-one y efectos secundarios.

En conclusión, las herramientas son importantes. Hay un adagio: “No lleves una espada a un tiroteo.” Necesitas las herramientas y paradigmas de programación adecuados, no solo los que aprendiste en la universidad. Necesitas algo profesional y de grado de producción para satisfacer las necesidades de tu supply chain. Si bien podrías lograr algunos resultados con herramientas inferiores, no será excelente. Un músico fantástico puede hacer música con solo una cuchara, pero con un instrumento adecuado puede hacerlo mucho mejor.

Ahora, procedamos con las preguntas. Por favor, ten en cuenta que hay un retraso de alrededor de 20 segundos, por lo que existe cierta latencia en la transmisión entre el video que ves y yo leyendo tus preguntas.
Pregunta: ¿Qué pasa con la programación dinámica en términos de investigación operativa?
La programación dinámica, a pesar del nombre, no es un paradigma de programación. Es más bien una técnica algorítmica. La idea es que, si deseas realizar una tarea algorítmica o resolver un determinado problema, repetirás la misma suboperación muy frecuentemente. La programación dinámica es un caso específico del compromiso entre espacio y tiempo que mencioné anteriormente, donde inviertes un poco más en memoria para ahorrar tiempo en el cálculo. Fue una de las primeras técnicas algorítmicas, remontándose a los años 60 y 70. Es buena, pero el nombre es algo desafortunado porque en realidad no hay nada verdaderamente dinámico en ella, y no se trata realmente de programación. Es más acerca de la concepción de algoritmos. Así que, para mí, a pesar del nombre, no califica como un paradigma de programación; es más bien una técnica algorítmica específica.
Pregunta: Johannes, ¿podrías proporcionar algunos libros de referencia que todo buen ingeniero de supply chain debería tener? Desafortunadamente, soy nuevo en el campo, y mi enfoque actual es la ciencia de datos y la ingeniería de sistemas.
Tengo una opinión muy dividida sobre la literatura existente. En mi primera conferencia, presenté dos libros que considero el pináculo de los estudios académicos sobre supply chain. Si quieres leer dos libros, puedes leer esos libros. Sin embargo, tengo un problema constante con los libros que he leído hasta ahora. Básicamente, hay personas que presentan colecciones de recetas numéricas de juguete para supply chains idealizadas, y creo que estos libros no abordan el supply chain desde el ángulo correcto, y pierden completamente el punto de que es un problema malvado. Existe un extenso cuerpo de literatura que es muy técnica, con ecuaciones, algoritmos, teoremas y demostraciones, pero creo que pierde completamente el sentido.
Luego, tienes otro estilo de libros de gestión de supply chain, que son más de estilo consultor. Puedes reconocer fácilmente estos libros porque usan analogías deportivas cada dos páginas. Estos libros tienen todo tipo de diagramas simplistas, como variantes 2x2 de diagramas SWOT (Fortalezas, Debilidades, Oportunidades, Amenazas), que considero formas de razonamiento de baja calidad. El problema con estos libros es que tienden a comprender mejor que el supply chain es una tarea malvada. Entienden mucho mejor que es un juego jugado por personas, donde pueden suceder todo tipo de cosas extrañas, y se puede ser inteligente en cuanto a los métodos. Les doy crédito por eso. El problema con esos libros, típicamente escritos por consultores o profesores de escuelas de gestión, es que no son muy aplicables. El mensaje se reduce a “sé un mejor líder,” “sé más inteligente,” “ten más energía,” y para mí, esto no es accionable. No te proporciona elementos que puedas convertir en algo altamente valioso, como puede hacerlo el software.
Así que, vuelvo a la primera conferencia: lee esos dos libros si quieres, pero no estoy seguro de que sea tiempo bien invertido. Es bueno saber lo que la gente ha escrito. En el lado consultor de la literatura, mi favorito es probablemente el trabajo de Katana, que no mencioné en la primera conferencia. No todo es malo; algunas personas tienen más talento, incluso si son más consultores. Puedes revisar el trabajo de Katana; él tiene un libro sobre supply chains dinámicas. Incluiré el libro en las referencias.
Pregunta: ¿Cómo utilizas la paralelización al lidiar con la canibalización o las decisiones de surtido, donde el problema no se puede paralelizar fácilmente?
¿Por qué no se puede paralelizar fácilmente? El descenso por gradiente estocástico es bastante trivial de paralelizar. Tienes pasos de descenso por gradiente estocástico que se pueden tomar en órdenes aleatorios, y puedes tener múltiples pasos al mismo tiempo. Así que, creo que cualquier cosa impulsada por el descenso por gradiente estocástico es bastante trivial de paralelizar.
Al lidiar con la canibalización, lo que es más difícil es tratar con otro tipo de paralelización, que es lo que viene primero. Si pongo este producto primero, luego hago una previsión, pero después tomo otro producto, esto modifica el panorama. La respuesta es que quieres tener una forma de abordar todo el panorama de forma global. No dices, “Primero, introduzco este producto e hago la previsión; luego introduzco otro producto y vuelvo a hacer la previsión, modificando el primero.” Simplemente lo haces de manera frontal, todas esas cosas a la vez, al mismo tiempo. Necesitas más paradigmas de programación. Los paradigmas de programación que he introducido hoy pueden ser de gran ayuda para eso.
Cuando se trata de decisiones de surtido, este tipo de problemas no presenta grandes dificultades para la paralelización. Lo mismo se aplica si tienes una red de venta al por menor a nivel mundial y deseas optimizar el surtido para todas tus tiendas. Puedes tener cálculos que se realizan para todas las tiendas en paralelo. No quieres hacerlo en secuencia, donde optimizas el surtido para una tienda y luego pasas a la siguiente. Esa es la manera equivocada de hacerlo, pero puedes optimizar la red en paralelo, propagar toda la información y luego repetir. Existen todo tipo de técnicas, y las herramientas pueden ayudarte enormemente a hacerlo de maneras mucho más sencillas.
Pregunta: ¿Estás utilizando un enfoque de base de datos gráfica?
No, no en el sentido técnico y canónico. Hay muchas bases de datos gráficas en el mercado que son de gran interés. Lo que utilizamos internamente en Lokad es una integración vertical completa a través de una pila de compiladores unificada y monolítica para eliminar por completo todos los elementos tradicionales que encontrarías en una pila clásica. Así es como logramos un rendimiento muy bueno, en términos de capacidad de cómputo, muy cerca del metal. No es porque seamos codificadores increíblemente inteligentes, sino simplemente porque hemos eliminado prácticamente todas las capas que tradicionalmente existen. Lokad literalmente no utiliza ninguna base de datos. Tenemos un compilador que se encarga de todo, hasta de la organización de las estructuras de datos para la persistencia. Es algo raro, pero es mucho más eficiente hacerlo de esa manera, y de este modo, compilas un script hacia una flota de máquinas en la nube. Tu plataforma objetivo, en términos de hardware, no es una sola máquina; es una flota de máquinas.
Pregunta: ¿Cuál es tu opinión sobre Power BI, que también ejecuta códigos en Python y algoritmos relacionados como descenso de gradiente, greedy, etc.?
El problema que tengo con cualquier cosa relacionada con inteligencia de negocios, siendo Power BI uno de ellos, es que tiene un paradigma que considero inadecuado para supply chain. Ves todos los problemas como un hipercubo, donde tienes dimensiones que solo se segmentan. En el fondo, existe un problema de expresividad, que es muy limitante. Cuando terminas usando Power BI con Python en el medio, necesitas Python porque la expresividad relacionada con el hipercubo es muy pobre. Para recuperar la expresividad, añades Python en el medio. Sin embargo, recuerda lo que mencioné en la pregunta anterior sobre esas capas: la maldición del software empresarial moderno es que tienes demasiadas capas. Cada capa que añades va a introducir ineficiencias y errores. Si usas Power BI más Python, vas a tener demasiadas capas. Así, tienes Power BI que se asienta sobre otros sistemas, lo que significa que ya tienes múltiples sistemas antes de Power BI. Luego, tienes Power BI encima, y sobre Power BI, tienes Python. ¿Pero está Python actuando por sí solo? No, lo más probable es que uses bibliotecas de Python, como Pandas o NumPy. Así, tienes capas en Python que se acumularán, y terminas con docenas de capas. Puedes tener errores en cualquiera de esas capas, por lo que la situación será bastante dantesca.
No soy partidario de aquellas soluciones en las que terminas teniendo una cantidad masiva de pilas. Existe ese chiste de que en C++ siempre puedes resolver cualquier problema añadiendo una capa más de indirección, incluso el problema de tener demasiadas capas de indirección. Obviamente, esto es un tanto ilógico como afirmación, pero estoy profundamente en desacuerdo con el enfoque en el que las personas tienen un producto con un diseño central inadecuado, y en lugar de abordar el problema de frente, terminan apilando cosas sobre cimientos inestables. Esta no es la manera de hacerlo, y tendrás una productividad baja, batallas constantes contra errores que nunca vas a resolver, y luego, en términos de mantenibilidad, es simplemente una receta para una pesadilla.
Pregunta: ¿Cómo se pueden integrar los resultados de un análisis de filtrado colaborativo en el algoritmo de previsión de la demanda para cada producto, como mochilas, por ejemplo?
Lo siento, pero abordaré este tema en la próxima conferencia. La respuesta corta es que no quieres incorporar eso en un algoritmo de previsión existente. Quieres tener algo que esté mucho más integrado de forma nativa. No haces eso y luego vuelves a tus viejas formas de hacer previsión; en cambio, simplemente descartas la antigua forma de hacer la previsión y haces algo radicalmente diferente que lo aproveche. Pero lo discutiré en una conferencia posterior. Sería demasiado para hoy.
Creo que esto es todo por esta conferencia. Muchas gracias a todos por asistir. La próxima conferencia será el miércoles 6 de enero, a la misma hora, el mismo día de la semana. Me tomaré unas vacaciones navideñas, así que les deseo a todos una feliz Navidad y un feliz Año Nuevo. Continuaremos nuestra serie de conferencias el próximo año. Muchas gracias.


