00:00 Introduzione
02:52 Contesto e disclaimer
07:39 Rationalismo ingenuo
13:14 La storia finora
16:37 Scienziati, abbiamo bisogno di voi!
18:25 Human + Machine (the problem 1/4)
23:16 La configurazione (the problem 2/4)
26:44 La manutenzione (the problem 3/4)
30:02 Il backlog IT (the problem 4/4)
32:56 La missione (il lavoro dello scientist 1/6)
35:58 Terminologia (il lavoro dello scientist 2/6)
37:54 Risultati attesi (il lavoro dello scientist 3/6)
41:11 Il campo d’azione (il lavoro dello scientist 4/6)
44:59 La routine quotidiana (il lavoro dello scientist 5/6)
46:58 Responsabilità (il lavoro dello scientist 6/6)
49:25 Una posizione supply chain (HR 1/6)
51:13 Assunzione di uno scientist (HR 2/6)
53:58 Formazione dello scientist (HR 3/6)
55:43 Valutazione dello scientist (HR 4/6)
57:24 Mantenimento dello scientist (HR 5/6)
59:37 Da uno scientist all’altro (HR 6/6)
01:01:17 Sul fronte IT (dinamiche aziendali 1/3)
01:03:50 Su Finanza (dinamiche aziendali 2/3)
01:05:42 Sulla leadership (dinamiche aziendali 3/3)
01:09:18 Pianificazione vecchia scuola (modernization 1/5)
01:11:56 Fine di S&OP (modernization 2/5)
01:13:31 BI old-school (modernization 3/5)
01:15:24 Uscita dalla Data Science (modernization 4/5)
01:17:28 Un nuovo accordo per l’IT (modernization 5/5)
01:19:28 Conclusione
01:22:05 7.3 Il Supply Chain Scientist - Domande?
Descrizione
Nel cuore di un’iniziativa Quantitative Supply Chain, c’è il Supply Chain Scientist (SCS) che esegue la data preparation, la modellizzazione economica e il reporting dei KPI. L’automazione intelligente delle supply chain decisions è il prodotto finale del lavoro svolto dal SCS. Il SCS si assume la responsabilità delle decisioni generate. Il SCS offre un’intelligenza umana amplificata dalla potenza di calcolo delle macchine.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Io sono Joannes Vermorel, e oggi presenterò il supply chain scientist dal punto di vista della quantified supply chain. Il supply chain scientist è la persona o, eventualmente, il piccolo gruppo di persone incaricate di guidare l’iniziativa supply chain. Questa persona sovrintende alla creazione e successiva manutenzione delle ricette numeriche che generano le decisioni di interesse. Inoltre, è responsabile di fornire tutte le evidenze necessarie al resto dell’azienda, dimostrando che le decisioni generate sono fondate.
Il motto della quantified supply chain è sfruttare al massimo ciò che l’hardware moderno e il software moderno hanno da offrire alle supply chain. Tuttavia, l’essenza incarnata di questa prospettiva è ingenua. L’intelligenza umana rimane un pilastro fondamentale dell’intera impresa e, per una varietà di ragioni, non può ancora essere confezionata in maniera ottimale quando si tratta di supply chain. L’obiettivo di questa lezione è capire perché e come il ruolo del supply chain scientist sia diventato, nell’ultimo decennio, una soluzione collaudata per sfruttare al meglio il software moderno a scopi di supply chain.
Raggiungere questo obiettivo inizia con la comprensione dei grandi colli di bottiglia che il software moderno deve ancora affrontare quando tenta di automatizzare le supply chain decisions. Basandoci su questa nuova consapevolezza, introdurremo il ruolo del supply chain scientist, che è, a tutti gli effetti, una risposta a tali colli di bottiglia. Infine, vedremo come questo ruolo plasmi, in modi piccoli e grandi, l’azienda nel suo complesso. In effetti, il supply chain scientist non può operare come un silo all’interno dell’azienda. Proprio come lo scientist deve collaborare con il resto dell’azienda per ottenere risultati, anche il resto dell’azienda deve cooperare con lo scientist perché ciò avvenga.

Prima di procedere oltre, vorrei ribadire un disclaimer che ho fatto nella primissima lezione di questa serie. La presente lezione si basa quasi interamente su un esperimento decennale alquanto unico condotto presso Lokad, un enterprise software specializzato in supply chain optimization. Tutte queste lezioni sono state plasmate dal percorso di Lokad, ma quando si parla del ruolo del supply chain scientist il legame è ancor più forte. In larga misura, il viaggio di Lokad può essere interpretato attraverso le lenti della nostra graduale scoperta del ruolo del supply chain scientist.
Questo processo è ancora in corso. Ad esempio, abbiamo abbandonato, circa cinque anni fa, la prospettiva del data scientist mainstream con l’introduzione dei programming paradigms per scopi di apprendimento e ottimizzazione. Attualmente, Lokad impiega tre dozzine di supply chain scientists. I nostri scientist più capaci, grazie al loro curriculum, hanno guadagnato la fiducia per prendere decisioni su larga scala. Alcuni di loro sono responsabili, individualmente, di parametri che superano il valore di mezzo miliardo di dollari in inventario. Questa fiducia si estende a una vasta gamma di decisioni, come ordini di acquisto, ordini di produzione, ordini di inventory allocation o determinazione dei prezzi.
Come potrete intuire, questa fiducia doveva essere guadagnata. Infatti, pochissime aziende si fiderebbero dei propri dipendenti in possesso di tali poteri, per non parlare di un fornitore terzo come Lokad. Ottenere questo grado di fiducia è un processo che solitamente richiede anni, indipendentemente dai mezzi tecnologici. Eppure, un decennio dopo, Lokad sta crescendo più velocemente di quanto non abbia mai fatto nei suoi primi anni, e una parte considerevole di questa crescita proviene dai nostri clienti esistenti, che stanno ampliando l’ambito delle decisioni affidate a Lokad.
Questo mi riporta al mio punto iniziale: questa lezione quasi certamente porta con sé ogni sorta di pregiudizi. Ho cercato di ampliare questa prospettiva attraverso esperienze simili fuori da Lokad; tuttavia, c’è poco da dire in tal senso. Per quanto ne so, ci sono poche compagnie tecnologiche giganti, più precisamente qualche grande azienda di e-commerce, che raggiungono un grado di automazione decisionale paragonabile a quello che Lokad è in grado di conseguire.
Tuttavia, questi giganti solitamente allocano risorse di due ordini di grandezza in più rispetto a quanto possano permettersi le normali grandi aziende, con un organico ingegneristico che raggiunge le centinaia. La fattibilità di questi approcci rimane incerta per me, in quanto potrebbero funzionare solo in aziende estremamente redditizie. Altrimenti, i costi salariali schiaccianti potrebbero facilmente superare i benefici derivanti da una migliore esecuzione della supply chain.
Inoltre, attrarre talenti ingegneristici su tale scala diventa una sfida a sé stante. Assumere un ingegnere del software di talento è già abbastanza difficile; assumerne 100 richiede un marchio del datore di lavoro notevole. Fortunatamente, la prospettiva presentata oggi è molto più snella. Molte iniziative supply chain realizzate da Lokad vengono gestite da un singolo supply chain scientist, con un secondo che agisce da sostituto. Oltre ai risparmi sui costi salariali, la nostra esperienza indica che ci sono sostanziali benefici supply chain legati a un organico più ridotto.

La prospettiva mainstream della supply chain adotta l’approccio della matematica applicata. Metodi e algoritmi sono presentati in modo da escludere completamente l’operatore umano. Ad esempio, la formula dello safety stock e la formula dell’economic order quantity sono presentate come mera materia di matematica applicata. L’identità della persona che utilizza queste formule, le sue competenze o il suo background, ad esempio, non è solo irrilevante, ma non fa neppure parte della presentazione.
Più in generale, questo approccio è ampiamente adottato nei manuali di supply chain e, conseguentemente, nel software supply chain. Sicuramente sembra più oggettivo eliminare la componente umana. Dopotutto, la validità di un teorema non dipende dalla persona che enuncia la dimostrazione, così come le prestazioni di un algoritmo non dipendono da colui che, alla fine, preme l’ultimo tasto della sua implementazione. Questo approccio mira a conseguire una forma superiore di razionalità.
Tuttavia, sostengo che questo approccio sia ingenuo e rappresenti un ulteriore esempio di razionalismo ingenuo. La mia proposta è sottile ma importante: non sto affermando che l’esito di una ricetta numerica dipenda dalla persona che alla fine la esegue, né che il carattere di un matematico abbia a che fare con la validità dei suoi teoremi. Piuttosto, la mia tesi è che l’atteggiamento intellettuale associato a questa prospettiva non sia adeguato per affrontare le supply chain.
Una ricetta supply chain nel mondo reale è un complesso lavoro di artigianato, e l’autore della ricetta non è affatto così neutro o irrilevante come potrebbe sembrare. Illustreremo questo punto considerando due ricette numeriche identiche che differiscono solo nella denominazione delle variabili. A livello numerico, le due ricette producono output identici. Tuttavia, la prima ricetta presenta nomi di variabili ben scelti e significativi, mentre la seconda ricetta ha nomi criptici e incoerenti. In produzione, la seconda ricetta (quella con nomi di variabili criptici e incoerenti) è un disaster in attesa di accadere. Ogni evoluzione o correzione di bug applicata alla seconda ricetta comporterà uno sforzo di ordini di grandezza superiore rispetto allo stesso compito svolto sulla prima ricetta. Infatti, i problemi di denominazione delle variabili sono così frequenti e gravi che molti manuali di ingegneria del software dedicano un intero capitolo a questa singola questione.
Né la matematica, né l’algoritmica, né la statistica dicono nulla riguardo all’adeguatezza dei nomi delle variabili. L’adeguatezza di tali nomi risiede ovviamente nell’occhio di chi guarda. Sebbene abbiamo due ricette numericamente identiche, una è considerata molto superiore all’altra per ragioni apparentemente soggettive. La tesi che difendo qui è che vi sia razionalità anche in queste preoccupazioni soggettive. Anzi, l’esperienza di Lokad indica che, dato lo stesso insieme di strumenti software, strumenti matematici e librerie di algoritmi, alcuni supply chain scientists ottengono risultati superiori. Infatti, l’identità dello scientist responsabile è uno dei migliori indicatori che abbiamo per il successo dell’iniziativa.
Supponendo che il talento innato non possa spiegare pienamente le discrepanze nel successo delle supply chain, dovremmo abbracciare gli elementi che contribuiscono al successo delle iniziative, siano essi obiettivi o soggettivi. Per questo, in Lokad, abbiamo dedicato molti sforzi negli ultimi decenni a perfezionare il nostro approccio al ruolo del supply chain scientist, che è proprio l’argomento di questa lezione. Le sfumature associate alla posizione di un supply chain scientist non devono essere sottovalutate. L’entità dei miglioramenti portati da questi elementi soggettivi è paragonabile alle nostre conquiste tecnologiche più notevoli.
Questa serie di lezioni è pensata come materiale di formazione per i supply chain scientists di Lokad. Tuttavia, spero anche che queste lezioni possano risultare interessanti per un pubblico più ampio di professionisti della supply chain o addirittura per studenti di supply chain. È consigliabile seguire queste lezioni in sequenza per una comprensione approfondita delle sfide che i supply chain scientists affrontano.
Nel primo capitolo, abbiamo visto perché le supply chain devono diventare programmatiche e perché è fortemente auspicabile poter mettere in produzione una ricetta numerica. La complessità in continuo aumento delle supply chain rende l’automazione più urgente che mai. Inoltre, esiste un imperativo finanziario per rendere capitalistiche le pratiche della supply chain.
Il secondo capitolo è dedicato alle metodologie. Le supply chain sono sistemi competitivi, e questa combinazione sconfigge le metodologie ingenue. Il ruolo degli scientist può essere visto come un antidoto alla metodologia ingenua della matematica applicata.
Il terzo capitolo esamina i problemi affrontati dal personale della supply chain. Questo capitolo tenta di caratterizzare le tipologie di sfide decisionali che devono essere affrontate. Dimostra che prospettive semplicistiche, come scegliere la giusta quantità di stock per ogni SKU, non si adattano alle situazioni reali; c’è invariabilmente una profondità nel processo decisionale.
Il quarto capitolo esamina gli elementi necessari per comprendere una pratica moderna della supply chain, dove gli elementi software sono onnipresenti. Questi elementi sono fondamentali per comprendere il contesto più ampio in cui opera la digital supply chain.
I capitoli 5 e 6 sono dedicati rispettivamente alla modellizzazione predittiva e al processo decisionale. Questi capitoli trattano gli aspetti “smart” della ricetta numerica, includendo machine learning e l’ottimizzazione matematica. In particolare, questi capitoli raccolgono tecniche che si sono dimostrate efficaci nelle mani dei supply chain scientists.
Infine, il settimo e presente capitolo è dedicato all’esecuzione di un’iniziativa Quantitative Supply Chain. Abbiamo visto cosa serve per avviare un’iniziativa gettando le basi appropriate. Abbiamo visto come superare il traguardo e mettere in produzione la ricetta numerica.

Oggi vedremo che tipo di persona è necessaria per far accadere tutto questo.
Il ruolo dello scienziato mira a risolvere i problemi individuati nella letteratura accademica. Esamineremo il lavoro del Supply Chain Scientist, inclusa la sua missione, il suo ambito, la routine quotidiana e gli aspetti di interesse. Questa descrizione del lavoro riflette la pratica attuale di Lokad.
Una nuova posizione all’interno dell’azienda genera una serie di preoccupazioni, per cui è necessario assumere, formare, valutare e fidelizzare gli scienziati. Affronteremo queste problematiche dal punto di vista delle risorse umane. Ci si aspetta che lo scienziato collabori con altri dipartimenti dell’azienda, al di là del dipartimento di supply chain. Vedremo quali interazioni sono previste tra gli scienziati e IT, finanza e perfino la direzione aziendale.
Lo scienziato rappresenta anche un’opportunità per l’azienda di modernizzare il personale e le operazioni. Questa modernizzazione è la parte più difficile del percorso, poiché eliminare una posizione che ha cessato di essere rilevante è molto più impegnativo che introdurne una nuova.
La sfida che ci siamo posti in questa serie di lezioni è il miglioramento sistematico delle supply chains attraverso metodi quantitativi. L’idea alla base di questo approccio è sfruttare al massimo ciò che l’informatica moderna e il software possono offrire alle supply chains. Tuttavia, è necessario chiarire cosa appartenga ancora al regno dell’intelligenza umana e cosa possa essere automatizzato con successo.
La linea di demarcazione tra intelligenza umana e automazione dipende ancora fortemente dalla tecnologia. Ci si aspetta che tecnologie superiori meccanizzino un ambito decisionale più ampio e producano risultati migliori. Dal punto di vista della supply chain, ciò significa prendere decisioni più diversificate, come decisioni di pricing oltre alle decisioni di inventario riapprovvigionamento, e produrne di migliori che incrementino ulteriormente la redditività dell’azienda.
Il ruolo dello scienziato è l’incarnazione di questo confine tra intelligenza umana e automazione. Sebbene le annunce di routine sull’intelligenza artificiale possano dare l’impressione che l’intelligenza umana sia sul punto di essere sostituita dall’automazione, la mia comprensione dello stato dell’arte indica che l’intelligenza artificiale generale è ancora lontana. Infatti, gli approfondimenti umani sono ancora estremamente necessari per progettare metodi quantitativi rilevanti per la supply chain. Stabilire anche una strategia base per la supply chain rimane in gran parte al di là delle capacità del software.
In generale, non disponiamo ancora di tecnologie in grado di affrontare problemi mal formulati o non identificati, così comuni nella supply chain. Tuttavia, una volta isolato un problema ristretto e ben definito, è concepibile che un processo automatizzato possa apprenderne la soluzione e persino automatizzarla con poca o nessuna supervisione umana.
Questa prospettiva non è nuova. Ad esempio, i filtri antispam sono stati ampiamente adottati. Tali filtri svolgono il difficile compito di distinguere il rilevante dall’irrilevante. Tuttavia, la progettazione della prossima generazione di filtri è in gran parte affidata agli esseri umani, anche se dati più recenti possono essere usati per aggiornarli. Infatti, gli spammer che cercano di eludere i filtri antispam continuano a inventare nuovi metodi che sconfiggono i semplici aggiornamenti basati sui dati.
Pertanto, sebbene siano ancora necessari approfondimenti umani per progettare l’automazione, non è chiaro perché un fornitore di software come Lokad, ad esempio, non possa sviluppare un grandioso supply chain engine in grado di affrontare tutte queste sfide. Sicuramente, l’economia del software è fortemente a favore della realizzazione di un tale grandioso supply chain engine. Anche se l’investimento iniziale è elevato, dato che il software può essere replicato a costi trascurabili, il fornitore si arricchirà con le tariffe di licenza rivendendo questo grandioso engine a un gran numero di aziende.
Nel 2008, Lokad intraprese il percorso per creare un grandioso engine che avrebbe potuto essere distribuito come prodotto software confezionato. Più precisamente, all’epoca Lokad si concentrava su un grandioso forecasting engine piuttosto che su un grandioso supply chain engine. Eppure, nonostante queste ambizioni relativamente più modeste – considerando che il forecasting rappresenta solo una piccola parte della sfida globale della supply chain – Lokad non riuscì a realizzare un tale grandioso forecasting engine. La prospettiva quantitativa della supply chain presentata in questa serie di lezioni nacque dalle ceneri di quell’ambizione.
Per quanto riguarda la supply chain, si è scoperto che esistono tre grandi colli di bottiglia da affrontare. Vedremo perché questo grandioso engine era destinato al fallimento sin dal primo giorno e perché probabilmente siamo ancora a decenni di distanza da una simile impresa ingegneristica.
Il paesaggio applicativo della tipica supply chain è una giungla cresciuta in modo disordinato negli ultimi due o tre decenni. Questo paesaggio non è un giardino formale francese con linee geometriche ordinate e cespugli ben potati; è una giungla, vivace ma anche piena di spine e di fauna ostile. Più seriamente, le supply chain sono il prodotto della loro storia digitale. Potrebbero esistere molteplici ERPs, personalizzazioni homemade parzialmente finalizzate, integrazioni batch – specialmente con sistemi provenienti da aziende acquisite – e piattaforme software sovrapposte che competono per le stesse aree funzionali.
L’idea che un grandioso engine possa essere semplicemente integrato è illusoria, considerando lo stato attuale delle tecnologie software. Unire tutti i sistemi che operano la supply chain è un’impresa notevole, totalmente dipendente dagli sforzi ingegneristici umani.
L’analisi delle spese collettive indica che la gestione dei dati rappresenta almeno i tre quarti dell’impegno tecnico complessivo associato a un’iniziativa di supply chain. Al contrario, la realizzazione degli aspetti intelligenti della ricetta numerica, come forecasting e ottimizzazione, incide per non più di qualche percento sugli sforzi totali. Pertanto, la disponibilità di un grandioso engine confezionato è in gran parte irrilevante in termini di costi o ritardi. Richiederebbe un’intelligenza di livello umano integrata affinché questo engine potesse integrarsi automaticamente nel paesaggio IT spesso disordinato che si riscontra nelle supply chain.
Inoltre, l’esistenza di un grandioso engine rende quest’impresa ancora più ardua. Invece di dover gestire un unico sistema complesso, il paesaggio applicativo, ora abbiamo due sistemi complessi: il paesaggio applicativo e il grandioso engine. La complessità dell’integrazione di questi due sistemi non è data dalla somma delle rispettive complessità, ma dal loro prodotto.
L’impatto di questa complessità sul costo ingegneristico è altamente non lineare, come già evidenziato nel primo capitolo di questa serie di lezioni. Il primo grande collo di bottiglia per l’ottimizzazione della supply chain è l’implementazione della ricetta numerica, che richiede un impegno ingegneristico dedicato. Questo collo di bottiglia elimina in gran parte i benefici che potrebbero derivare da un qualsiasi tipo di grandioso engine confezionato per la supply chain.

Se da un lato l’implementazione richiede un notevole sforzo ingegneristico, potrebbe trattarsi di un investimento una tantum, simile al pagamento di un biglietto d’ingresso. Sfortunatamente, le supply chain sono entità viventi in costante evoluzione. Il giorno in cui una supply chain smette di cambiare è il giorno in cui l’azienda va in bancarotta. I cambiamenti sono sia interni che esterni.
Internamente, il paesaggio applicativo è in continuo mutamento. Le aziende non possono congelare il proprio paesaggio applicativo, anche se lo volessero, poiché molti aggiornamenti sono imposti dai fornitori di software aziendale. Ignorare tali obblighi solleverebbe i fornitori dai loro impegni contrattuali, un esito inaccettabile. Oltre agli aggiornamenti puramente tecnici, una supply chain rilevante è destinata a far entrare e uscire pezzi di software man mano che l’azienda stessa cambia.
Esternamente, i mercati sono in continuo mutamento. Nuovi concorrenti, canali di vendita e potenziali fornitori emergono costantemente, mentre altri scompaiono. Le normative continuano a cambiare. Sebbene gli algoritmi possano captare automaticamente alcuni dei cambiamenti più evidenti, come la crescita della domanda per una determinata categoria di prodotti, non abbiamo ancora algoritmi in grado di gestire variazioni qualitative del mercato, piuttosto che semplici variazioni quantitative. I problemi che l’ottimizzazione della supply chain cerca di risolvere sono essi stessi in evoluzione.
Se il software responsabile dell’ottimizzazione della supply chain non riesce a gestire questi cambiamenti, i dipendenti ricorrono ai fogli di calcolo. I fogli di calcolo possono essere rudimentali, ma almeno i dipendenti riescono a mantenerli pertinenti al compito da svolgere. Un’osservazione aneddotica: la stragrande maggioranza delle supply chain opera ancora con i fogli di calcolo a livello decisionale, e non transazionale. Questa è la prova vivente del fallimento nella manutenzione del software.
Dagli anni ‘80, i fornitori di software aziendale offrono prodotti per automatizzare le decisioni della supply chain. La maggior parte delle aziende che operano grandi supply chain ha già implementato diverse di queste soluzioni negli ultimi decenni. Tuttavia, i dipendenti ritornano inesorabilmente ai loro fogli di calcolo, dimostrando che, anche se l’implementazione era stata inizialmente considerata un successo, qualcosa è andato storto nella manutenzione.
La manutenzione è il secondo grande collo di bottiglia nell’ottimizzazione della supply chain. La ricetta richiede una manutenzione attiva, anche se l’esecuzione può per lo più restare senza sorveglianza.

A questo punto, abbiamo dimostrato che l’ottimizzazione della supply chain richiede non solo risorse ingegneristiche software iniziali, ma anche risorse ingegneristiche continue. Come già evidenziato in questa serie di lezioni, solo capacità programmatiche possono realisticamente affrontare la varietà di problemi che si presentano nelle supply chain reali. I fogli di calcolo contano come strumenti programmabili, e la loro espressività, in contrapposizione a pulsanti e menu, è ciò che li rende così attraenti per i professionisti della supply chain.
Poiché nelle aziende è necessario assicurare risorse ingegneristiche software, sembra naturale fare appello al dipartimento IT. Sfortunatamente, la supply chain non è l’unico dipartimento a pensare in questo modo. Ogni dipartimento, comprese vendite, marketing e finanza, finisce per rendersi conto che automatizzare i rispettivi processi decisionali richiede risorse ingegneristiche software. Inoltre, devono occuparsi anche dello strato transazionale e di tutta l’infrastruttura sottostante.
Di conseguenza, la maggior parte delle aziende che operano grandi supply chain oggi ha i propri dipartimenti IT sommersi da anni di arretrato. Pertanto, aspettarsi che il dipartimento IT destini ulteriori risorse continue alla supply chain peggiora ulteriormente l’arretrato. L’opzione di allocare più risorse al dipartimento IT è già stata esplorata e, solitamente, non è più praticabile. Queste aziende stanno già affrontando gravi diseconomie di scala per quanto riguarda il dipartimento IT. L’arretrato IT rappresenta il terzo grande collo di bottiglia nell’ottimizzazione della supply chain.
Sono necessarie risorse ingegneristiche continue, ma la maggior parte di esse non può provenire dall’IT. Si può prevedere un certo supporto da parte dell’IT, ma deve essere un intervento di modesta entità.
Questi tre grandi colli di bottiglia definiscono perché è necessario un ruolo specifico: il Supply Chain Scientist è il nome che diamo a quelle risorse ingegneristiche software continue necessarie per automatizzare le decisioni banali e i processi decisionali impegnativi della supply chain.

Procediamo con una definizione più precisa basata sulla pratica di Lokad. La missione del Supply Chain Scientist è creare ricette numeriche che generino le decisioni banali necessarie quotidianamente per far funzionare la supply chain. Il lavoro dello scienziato inizia con gli estratti dal database raccolti da tutto il paesaggio applicativo. Si prevede che lo scienziato codifichi la ricetta che elabora tali estratti e porti queste ricette in produzione. Lo scienziato si assume la piena responsabilità per la qualità delle decisioni generate dalla ricetta. Le decisioni non sono prodotte da un qualche sistema ambientale, ma rappresentano l’espressione diretta degli approfondimenti dello scienziato trasmessi tramite una ricetta.
Questo singolo aspetto segna una svolta critica rispetto a ciò che comunemente si intende per ruolo di data scientist. Tuttavia, la missione non si ferma qui. Ci si aspetta che il Supply Chain Scientist sia in grado di presentare prove a supporto di ogni singola decisione generata dalla ricetta. Non si tratta di un sistema opaco a cui si affida la responsabilità delle decisioni; è la persona, lo scienziato. Lo scienziato dovrebbe essere in grado di incontrare il responsabile della supply chain o addirittura il CEO e fornire una motivazione convincente per ciascuna decisione presa dalla ricetta.
Se lo scienziato non è in una posizione tale da poter potenzialmente arrecare molti danni all’azienda, allora qualcosa non va. Non sto suggerendo di concedere a chiunque, e certamente non al Supply Chain Scientist, ampi poteri senza supervisione o responsabilità. Sto semplicemente sottolineando l’ovvio: se non hai il potere di influire negativamente sulla tua azienda, per quanto male tu possa operare, non hai il potere di influire positivamente sulla tua azienda, per quanto bene tu possa operare.
Le grandi aziende sono, sfortunatamente, per natura avverse al rischio. Pertanto, è molto allettante sostituire lo scienziato con un analista. Contrariamente allo scienziato, che è responsabile delle decisioni stesse, l’analista ha il compito di fare luce qua e là. L’analista è per lo più innocuo e non può fare molto oltre a sprecare il proprio tempo e alcune risorse informatiche. Tuttavia, essere innocui non è ciò che concerne il ruolo del Supply Chain Scientist.

Discutiamo per un attimo il termine “Supply Chain Scientist”. Questa terminologia è purtroppo imperfetta. In origine ho coniato questa espressione come una variazione di “data scientist” circa un decennio fa, con l’idea di marchiare questo ruolo come una variante del data scientist, ma con una forte specializzazione in supply chain. L’intuizione sulla specializzazione era corretta, ma quella relativa alla data science non lo era. Riprenderò questo punto alla fine della lezione.
L’uso di “supply chain engineer” potrebbe essere stato un’espressione migliore, poiché enfatizza il desiderio di padroneggiare e controllare il dominio, in contrasto con una mera comprensione. Tuttavia, gli ingegneri, per come sono comunemente intesi, non ci si aspetta che siano in prima linea nell’azione. Il termine appropriato sarebbe probabilmente stato supply chain quant, come nel caso dei praticanti quantitativi della supply chain.
In finanza, un quant o quantitative trader è uno specialista che sfrutta algoritmi e metodi quantitativi per prendere decisioni di trading. I quant possono rendere una banca estremamente redditizia o, al contrario, estremamente in redditizia. L’intelligenza umana viene amplificata attraverso le macchine, sia in senso positivo che negativo.
In ogni caso, spetterà alla comunità in generale decidere sulla terminologia appropriata: analyst, scientist, engineer, operative o quant. Per coerenza, continuerò a usare il termine scientist nel resto di questa lezione.

La consegna principale per lo scientist è un pezzo di software, più precisamente, la ricetta numerica responsabile della generazione quotidiana delle decisioni di interesse per la supply chain. Questa ricetta è una raccolta di tutti gli script coinvolti, dalle fasi iniziali di preparazione dei dati fino alle fasi finali di validazione aziendale delle decisioni stesse. La ricetta deve essere di livello production-grade, ossia in grado di funzionare in modalità autonoma e con decisioni di default considerate affidabili. Naturalmente, tale fiducia doveva essere guadagnata in primo luogo, e una supervisione continua deve garantire che questo livello di fiducia rimanga giustificato nel tempo.
La consegna di una ricetta production-grade è fondamentale per trasformare la pratica della supply chain in un asset produttivo. Questo aspetto è già stato discusso nella lezione precedente sulla consegna orientata al prodotto.
Oltre a questa ricetta, ci sono numerose consegne secondarie. Alcune di esse sono anch’esse software, anche se non contribuiscono direttamente alla generazione delle decisioni. Ciò include, ad esempio, tutta l’instrumentation che lo scientist deve introdurre per creare e successivamente mantenere la ricetta stessa. Altri elementi sono destinati ai colleghi all’interno dell’azienda, inclusa tutta la documentazione dell’iniziativa stessa e della ricetta.
Il codice sorgente della ricetta risponde al “come” – come viene fatto? Tuttavia, il codice sorgente non risponde al “perché” – perché viene fatto? Il “perché” deve essere documentato. Spesso, la correttezza della ricetta dipende da una sottile comprensione dell’intento. La documentazione fornita deve facilitare il più possibile il passaggio fluido da uno scientist all’altro, anche se il precedente scientist non è disponibile per supportare il processo.
Da Lokad, la nostra procedura standard consiste nel produrre e mantenere un grande manuale dell’iniziativa, denominato Joint Procedure Manual (JPM). Questo manuale non è solo un manuale operativo completo della ricetta, ma anche una raccolta di tutte le intuizioni strategiche che stanno alla base delle scelte di modellazione effettuate dagli scientist.
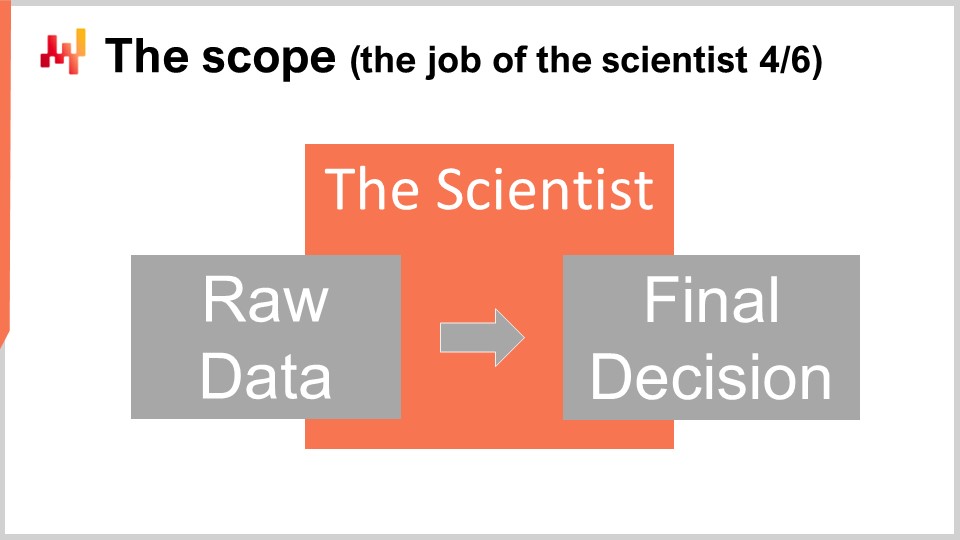
A livello tecnico, il lavoro dello scientist inizia dal momento dell’estrazione dei dati grezzi e termina con la generazione delle decisioni definitive per la supply chain. Lo scientist deve operare partendo dai dati grezzi, così come estratti dai sistemi aziendali esistenti. Poiché ogni sistema aziendale ha il proprio stack tecnologico, l’estrazione stessa è solitamente meglio affidata a specialisti IT. Non è ragionevole aspettarsi che lo scientist diventi esperto in mezza dozzina di dialetti SQL o mezza dozzina di tecnologie API solo per accedere ai dati aziendali. D’altro canto, non ci si deve aspettare dagli specialisti IT altro che estratti di dati grezzi, né trasformazione dei dati né loro preparazione. I dati estratti e resi accessibili allo scientist devono essere il più possibile vicini ai dati così come si presentano all’interno dei sistemi aziendali.
All’estremità opposta della pipeline, la ricetta elaborata dallo scientist deve generare le decisioni definitive. Gli elementi associati al rollout delle decisioni non rientrano nella responsabilità dello scientist. Sono importanti, ma in gran parte indipendenti dalla decisione stessa. Ad esempio, nel considerare gli ordini di acquisto, stabilire le quantità finali rientra nell’ambito dello scientist, mentre generare il file PDF – il documento d’ordine atteso dal fornitore – non lo fa. Nonostante questi limiti, l’ambito è relativamente ampio. Di conseguenza, è allettante ma fuorviante frammentare l’ambito in una serie di sotto-ambiti. Nelle aziende più grandi, questa tentazione diventa molto forte e va contrastata. Frammentare l’ambito è la via certa per creare numerosi problemi.
Upstream, se qualcuno tenta di aiutare gli scientist modificando l’input, questo tentativo si traduce invariabilmente in problemi di “garbage in, garbage out”. I sistemi aziendali sono già sufficientemente complessi; trasformare i dati in anticipo non fa altro che aggiungere un ulteriore strato accidentale di complessità. A metà percorso, se qualcuno cerca di aiutare gli scientist occupandosi di una parte complessa della ricetta, come la previsione, allora gli scientist si trovano di fronte a una black box nel mezzo della propria ricetta. Tale black box mina gli sforzi di white-boxing degli scientist. E downstream, se qualcuno tenta di aiutare lo scientist re-ottimizzando ulteriormente le decisioni, questo tentativo crea inevitabilmente confusione, e le logiche di ottimizzazione a due livelli potrebbero addirittura contrastarsi a vicenda.
Questo non implica che lo scientist debba lavorare da solo. Si può formare un team di scientist, ma l’ambito rimane. Se viene formato un team, ci deve essere una proprietà collettiva della ricetta. Ciò implica, ad esempio, che se viene identificato un difetto nella ricetta, qualsiasi membro del team dovrebbe essere in grado di intervenire e risolverlo.

L’esperienza di Lokad indica che un mix sano per un supply chain scientist comporta il trascorrere del 40% del tempo codificando, il 30% dialogando con il resto dell’azienda, e il 30% scrivendo documenti, materiali formativi e scambiando opinioni con colleghi supply chain practitioners o con altri supply chain scientists.
È ovvio che sia necessario codificare per implementare la ricetta stessa. Tuttavia, una volta che la ricetta è in produzione, la maggior parte degli sforzi di coding è diretta non tanto alla ricetta quanto alla sua instrumentation. Per migliorare la ricetta, lo scientist necessita di ulteriori approfondimenti, e a sua volta, tali approfondimenti richiedono l’implementazione di strumentazioni dedicate.
Dialogare con il resto dell’azienda è fondamentale. A differenza di S&OP, lo scopo di queste discussioni non è orientare la previsione verso l’alto o verso il basso. Si tratta di assicurarsi che le scelte di modellazione incorporate nella ricetta riflettano ancora fedelmente sia la strategia aziendale che tutte le sue restrizioni operative.
Infine, coltivare la conoscenza istituzionale che l’azienda possiede sull’ottimizzazione della supply chain, sia attraverso la formazione diretta degli scientist stessi, sia mediante la produzione di documenti destinati ai colleghi, è fondamentale. La performance della ricetta è, in gran parte, una riflessione della competenza dello scientist. Avere accesso ai colleghi e cercare feedback è, a dir poco, uno dei mezzi più efficienti per migliorare la competenza degli scientist.

La più grande differenza tra un supply chain scientist, come immaginato da Lokad, e un data scientist tradizionale è l’impegno personale verso risultati concreti nel mondo reale. Può sembrare una cosa piccola e di poco conto, ma l’esperienza dimostra il contrario. Un decennio fa, Lokad ha imparato a proprie spese che l’impegno nella consegna di una ricetta production-grade non era scontato. Al contrario, l’atteggiamento predefinito delle persone formate come data scientist sembra essere quello di trattare la produzione come una preoccupazione secondaria. Il data scientist tradizionale si aspetta di gestire gli elementi intelligenti, come il machine learning e l’ottimizzazione matematica, mentre occuparsi di tutte le trivia casuali che accompagnano la supply chain reale viene troppo frequentemente percepito come al di sotto delle loro capacità.
Tuttavia, l’impegno per una ricetta production-grade implica affrontare anche le questioni più casuali. Ad esempio, nel luglio 2021, molti paesi europei hanno subito alluvioni catastrofiche. Un cliente di Lokad con sede in Germania ha visto inondati la metà dei suoi warehouses. Lo supply chain scientist responsabile di questo account ha dovuto riprogettare la ricetta quasi da un giorno all’altro per trarre il massimo da questa situazione fortemente degradata. La soluzione non è stata una sorta di grandioso algoritmo di machine learning, bensì un insieme di euristiche decodificate. Al contrario, se lo supply chain scientist non è il proprietario della decisione, questa persona non sarà in grado di creare una ricetta production-grade. È una questione di psicologia. Fornire una ricetta production-grade richiede un immenso sforzo intellettuale, e le poste in gioco devono essere reali per raggiungere il necessario livello di concentrazione da parte di un dipendente.
Avendo chiarito il ruolo di uno supply chain scientist, discutiamo ora di come funziona da una prospettiva delle risorse umane. Innanzitutto, tra le questioni aziendali, lo scientist deve riferire al responsabile della supply chain o, almeno, a qualcuno che possa essere qualificato come senior supply chain leadership. Non importa se lo scientist è interno o esterno, come spesso accade in Lokad. Il punto rimane che lo scientist deve essere sotto la supervisione diretta di qualcuno che detiene il potere esecutivo nella supply chain.
Un errore comune è quello di far riferire lo scientist al responsabile IT o al responsabile dell’analisi dei dati. Poiché creare una ricetta è un esercizio di coding, la leadership della supply chain potrebbe non sentirsi completamente a suo agio nel supervisionare tale impresa. Tuttavia, ciò è errato. Lo scientist necessita di una supervisione da parte di qualcuno che possa approvare se le decisioni generate sono accettabili o meno, o che almeno possa far avvenire tale approvazione. Collocare lo scientist in qualsiasi posizione eccetto quella di sotto la supervisione diretta della leadership della supply chain è una ricetta per operare all’infinito tramite prototipi che non raggiungono mai la produzione. In questa situazione, il ruolo inevitabilmente ritorna a quello di analyst, e le ambizioni iniziali dell’iniziativa quantitativa della supply chain vengono abbandonate.

I migliori supply chain scientists generano ritorni sproporzionati rispetto alla media. Questa è stata l’esperienza di Lokad e rispecchia il modello identificato decenni fa nell’industria del software. Le aziende software hanno da tempo osservato che i migliori software engineers hanno almeno 10 volte la produttività degli medi, e ingegneri medi possono persino avere una produttività negativa, peggiorando il software per ogni ora spesa sul codice.
Nel caso dei supply chain scientists, una competenza superiore non solo migliora la produttività ma, soprattutto, migliora la supply chain performance finale. Dati gli stessi strumenti software e gli stessi strumenti matematici, due scientist non ottengono lo stesso risultato. Pertanto, assumere qualcuno con il potenziale per diventare uno dei migliori scientist è di primaria importanza.
L’esperienza di Lokad, basata sull’assunzione di oltre 50 scientist, indica che i profili ingegneristici non specializzati sono solitamente abbastanza validi. Per quanto controintuitivo, le persone con una formazione formale in data science, statistica o informatica non sono tipicamente la scelta migliore per le posizioni di supply chain scientist. Questi individui tendono troppo spesso a complicare eccessivamente la ricetta e non dedicano abbastanza attenzione agli aspetti banali ma critici della supply chain. La capacità di prestare attenzione a una moltitudine di dettagli e la capacità di perseverare senza sosta nella ricerca di artefatti numerici marginali sembrano essere le qualità principali dei migliori scientist.
In maniera aneddotica, da Lokad c’è stata una buona esperienza con giovani ingegneri che hanno passato alcuni anni come auditor. Oltre alla familiarità con la finanza aziendale, sembra che auditor talentuosi sviluppino la capacità di farsi strada attraverso un oceano di documenti aziendali, il che si allinea con la realtà quotidiana di un supply chain scientist.

Sebbene l’assunzione garantisca che i nuovi assunti abbiano il giusto potenziale, il passo successivo è assicurarsi che siano adeguatamente formati. La posizione di default di Lokad è che non ci si aspetta che le persone sappiano già nulla della supply chain. Avere conoscenze sulla supply chain è un vantaggio, ma il mondo accademico rimane in qualche modo carente in questo ambito. La maggior parte dei corsi di laurea sulla supply chain si concentra su management e leadership, ma per i giovani laureati è essenziale avere una solida conoscenza di base su argomenti come quelli trattati nel secondo, terzo o quarto capitolo di questa serie di lezioni. Purtroppo, spesso non è così, e le parti quantitative di questi corsi possono risultare deludenti. Di conseguenza, i supply chain scientists devono essere formati dai loro datori di lavoro. Questa serie di lezioni riflette il tipo di materiali formativi usati da Lokad.

Le revisioni delle performance per i supply chain scientists sono importanti per varie ragioni, come garantire che i soldi dell’azienda siano ben spesi e determinare le promotions. I criteri usuali si applicano: atteggiamento, diligenza, competenza, ecc. Tuttavia, esiste un aspetto controintuitivo: i migliori scientist ottengono risultati che fanno apparire le sfide della supply chain quasi invisibili, con un dramma minimo.

Formare uno scientist a mantenere le ricette esistenti, mantenendo al contempo il precedente livello di supply chain performance, richiede circa sei mesi, mentre formare uno scientist a implementare una ricetta di livello prediction-grade da zero richiede circa due anni. La retention dei talenti è critica, specialmente poiché l’assunzione di supply chain scientists esperti non è ancora un’opzione.
In molti paesi, la durata media per gli ingegneri sotto i 30 anni nel settore del software e in campi affini è piuttosto bassa. Lokad ottiene una durata media più alta concentrandosi sul benessere dei dipendenti. Le aziende non possono portare felicità ai propri dipendenti, ma possono evitare di renderli infelici attraverso processi insensati. La sanità mentale gioca un ruolo fondamentale nella retention dei dipendenti.

Un Supply Chain Scientist competente ed esperto non può essere previsto per prendere rapidamente in carico una ricetta esistente, poiché la ricetta riflette la strategia unica dell’azienda e le stranezze della supply chain. Il passaggio da una supply chain a un’altra può richiedere circa un mese nelle migliori condizioni. Non è ragionevole per un’azienda di dimensioni considerevoli dipendere da un solo scientist; Lokad garantisce che due scientists siano esperti con qualsiasi ricetta utilizzata in produzione in ogni momento. La continuità è essenziale, e un modo per ottenerla è attraverso un manuale creato congiuntamente con i clienti, che può facilitare transizioni non pianificate tra scientists.

Il ruolo del Supply Chain Scientist richiede un livello insolito di cooperazione con diversi dipartimenti, in particolare con l’IT. L’esecuzione corretta della ricetta dipende dalla pipeline di estrazione dei dati, che è responsabilità dell’IT.
Esiste una fase relativamente intensa di interazione tra l’IT e il scientist all’inizio della prima iniziativa quantitativa della supply chain, che dura circa due o tre mesi. Successivamente, una volta implementata la pipeline di estrazione dei dati, l’interazione diventa meno frequente. Questo dialogo garantisce che il scientist rimanga aggiornato sulla roadmap IT e su eventuali aggiornamenti o cambiamenti software che potrebbero influire sulla supply chain.
Nella fase iniziale di un’iniziativa quantitativa della supply chain, c’è un’interazione relativamente intensa tra l’IT e i scientists. Durante i primi due o tre mesi, il scientist deve interagire con l’IT diverse volte a settimana. Successivamente, una volta implementata la pipeline di estrazione dei dati, l’interazione diventa molto meno frequente, circa una volta al mese o meno. Oltre a risolvere eventuali intoppi nella pipeline, questo dialogo garantisce che il scientist rimanga aggiornato sulla roadmap IT. Qualsiasi aggiornamento o sostituzione del software può richiedere giorni o addirittura settimane di lavoro per il scientist. Per evitare tempi di inattività, la ricetta deve essere modificata per adattarsi ai cambiamenti nell’ambiente applicativo.

La ricetta, così come implementata dal scientist, ottimizza i ritorni in dollari o euro. Abbiamo trattato questo aspetto nelle prime lezioni di questa serie. Tuttavia, non ci si dovrebbe aspettare che il scientist decida come modellare i costi e i profitti. Pur dovendo proporre modelli per riflettere i driver economici, spetta in definitiva alla finanza decidere se tali driver siano considerati corretti o meno. Molte pratiche della supply chain evitano il problema concentrandosi su percentuali, come i livelli di servizio e le accuratezze delle previsioni. Tuttavia, queste percentuali hanno quasi nessuna correlazione con la salute finanziaria dell’azienda. Pertanto, il scientist deve regolarmente confrontarsi con la finanza e fare in modo che questi contestino le scelte di modellazione e le assunzioni fatte nella ricetta numerica.
Le scelte di modellazione finanziaria sono transitorie, in quanto riflettono la strategia mutevole dell’azienda. Al scientist ci si aspetta anche che sviluppi qualche strumento collegato alla ricetta per il dipartimento di finanza, come l’ammontare massimo previsto di capitale circolante associato all’inventario per l’anno successivo. Per un’azienda di medie o grandi dimensioni, è ragionevole che un dirigente finanziario riveda trimestralmente il lavoro svolto dal Supply Chain Scientist.

Una delle minacce più grandi alla validità della ricetta è tradire accidentalmente l’intento strategico dell’azienda. Troppe pratiche della supply chain evitano la strategia nascondendosi dietro percentuali utilizzate come indicatori. Gonfiare o sgonfiare le previsioni attraverso lo sales and operations planning (S&OP) non sostituisce la chiarificazione dell’intento strategico. Il scientist non è responsabile della strategia aziendale, ma la ricetta sarà errata se non la comprende. L’allineamento della ricetta con la strategia deve essere progettato.
Il modo più diretto per valutare se il scientist comprende la strategia è fargliela re-spiegare alla leadership. Questo permette di individuare più facilmente eventuali fraintendimenti. In teoria, questa comprensione è già documentata dal scientist nel manuale dell’iniziativa. Tuttavia, l’esperienza indica che i dirigenti raramente dispongono del tempo necessario per rivedere in dettaglio la documentazione operativa. Una semplice conversazione velocizza il processo per entrambe le parti.
Questo incontro non ha lo scopo di far spiegare al scientist tutto quello che c’è da sapere sui modelli della supply chain o sui risultati finanziari. L’unico obiettivo è garantire una corretta comprensione da parte della persona che tiene la penna digitale. Anche in una grande azienda, è ragionevole che il scientist incontri almeno una volta l’amministratore delegato o il dirigente competente. I benefici di una ricetta più in sintonia con l’intento della leadership sono vasti e spesso sottovalutati.

I miglioramenti nella supply chain fanno parte della modernizzazione digitale in corso. Ciò richiede una certa riorganizzazione dell’azienda stessa. Anche se i cambiamenti potrebbero non essere drastici, eliminare le pratiche obsolete è una lotta in salita. Quando eseguito correttamente, la produttività di un Supply Chain Scientist è significativamente superiore a quella di un pianificatore tradizionale. Non è raro che un singolo scientist sia responsabile di un inventario superiore a mezzo miliardo di dollari o euro.
È possibile una drastica riduzione del personale della supply chain. Alcune aziende clienti di Lokad, che storicamente erano sottoposte a un’enorme pressione competitiva, hanno adottato questo approccio e sono sopravvissute in parte grazie a tali risparmi. Tuttavia, la maggior parte dei nostri clienti sta optando per una riduzione più graduale del personale, poiché i pianificatori passano naturalmente ad altre posizioni.
I pianificatori che rimangono riorientano i loro sforzi verso clienti e fornitori. Il feedback che raccolgono si rivela molto utile per i Supply Chain Scientists. In effetti, il lavoro del scientist è per sua natura rivolto all’interno. Operano sui dati dell’azienda, e risulta difficile capire cosa sia semplicemente assente.
Molte voci nel mondo degli affari da tempo sostengono la necessità di creare legami più stretti sia con i clienti sia con i fornitori. Tuttavia, è più facile a dirsi che a farsi, specialmente se gli sforzi vengono regolarmente neutralizzati a causa di crisi continue, rassicurazioni ai clienti e pressioni sui fornitori. I Supply Chain Scientists possono fornire un sollievo tanto necessario su entrambe le fronti.

Lo S&OP (Sales and Operations Planning) è una pratica diffusa destinata a favorire l’allineamento a livello aziendale attraverso una previsione della domanda condivisa. Tuttavia, per quanto ambiziose possano essere state le intenzioni iniziali, i processi S&OP che ho potuto osservare sono stati al meglio caratterizzati da una serie infinita di riunioni improduttive. Ad eccezione delle implementazioni ERP e della conformità, non riesco a pensare a nessuna pratica aziendale così demoralizzante come lo S&OP. L’Unione Sovietica può essere scomparsa, ma lo spirito del Gosplan vive attraverso lo S&OP.
Una critica approfondita dello S&OP meriterebbe una lezione a sé stante. Tuttavia, per brevità, dirò semplicemente che un Supply Chain Scientist è un’alternativa superiore allo S&OP in ogni dimensione che conta. Diversamente dallo S&OP, il Supply Chain Scientist è radicato in decisioni reali. L’unica cosa che impedisce a un scientist di diventare un ulteriore agente di una burocrazia aziendale ingombrante non è il suo carattere o la sua competenza, ma il fatto di avere la pelle nel gioco attraverso quelle decisioni reali.
I pianificatori, i responsabili di magazzino e i responsabili di produzione sono spesso grandi utilizzatori di ogni tipo di report aziendale. Questi report sono solitamente prodotti da software gestionali comunemente definiti strumenti di business intelligence. La pratica tipica della supply chain consiste nell’esportare una serie di report in fogli di calcolo e poi usare una raccolta di formule per fondere tutte queste informazioni per generare in modo semi-manuale le decisioni di interesse. Eppure, come abbiamo visto, la ricetta del scientist sostituisce questa combinazione di business intelligence e fogli di calcolo.
Inoltre, né la business intelligence né i fogli di calcolo sono adatti a supportare l’implementazione di una ricetta. La business intelligence manca di espressività, poiché i calcoli rilevanti non possono essere espressi tramite questo tipo di strumenti. I fogli di calcolo mancano di manutenibilità e talvolta di scalabilità, ma soprattutto di manutenibilità. Il design dei fogli di calcolo è in gran parte incompatibile con qualsiasi tipo di correttezza per design, cosa molto necessaria per scopi di supply chain.
In pratica, l’instrumentation di una ricetta così come implementata dal scientist include numerosi report aziendali. Questi report sostituiscono quelli che venivano generati finora tramite la business intelligence. Questa evoluzione non implica necessariamente la fine della business intelligence, poiché altri dipartimenti possono ancora beneficiare di questo tipo di strumenti. Tuttavia, per quanto riguarda la supply chain, l’introduzione del Supply Chain Scientist annuncia la fine dell’era della business intelligence.

Mettendo da parte alcuni giganti della tecnologia che possono permettersi di impiegare centinaia, se non migliaia, di ingegneri per ogni problema software, l’esito tipico dei team di data science nelle aziende comuni è pessimo. Di solito, quei team non riescono a realizzare nulla di sostanziale. Tuttavia, la data science, come pratica aziendale, è solo l’ultima iterazione di una serie di mode aziendali.
Negli anni ‘70, la ricerca operativa era la moda. Negli anni ‘80, i motori di regole e gli esperti di conoscenza erano popolari. Alla fine del secolo, il data mining e i data miner erano richiesti. Dal 2010, la data science e i data scientists sono stati considerati la prossima grande novità. Tutte queste tendenze aziendali seguono lo stesso schema: si verifica una genuina innovazione software, le persone ne si entusiasmano e decidono di incorporare forzatamente questa innovazione nell’azienda attraverso la creazione di un nuovo dipartimento dedicato. Questo perché è sempre molto più facile aggiungere divisioni a un’organizzazione piuttosto che modificare o eliminare quelle esistenti.
Tuttavia, la data science come pratica aziendale fallisce perché non è saldamente radicata nell’azione. Questo fa tutta la differenza tra un Supply Chain Scientist, che fin dal primo giorno si impegna a essere responsabile della generazione di decisioni reali, e il dipartimento IT.

Se possiamo mettere da parte ego e feudi, il Supply Chain Scientist rappresenta un affare molto migliore rispetto al precedente status quo. Il tipico dipartimento IT è sommerso da anni di arretrato, e chiedere ulteriori risorse non è una proposta ragionevole, in quanto ritorce contro aumentando le aspettative degli altri dipartimenti e incrementando ulteriormente l’arretrato.
Al contrario, il Supply Chain Scientist apre la strada a una diminuzione delle aspettative. Il scientist si aspetta solo che vengano messi a disposizione estratti di dati grezzi, e la responsabilità di elaborarli ricade su di lui. Non si aspetta nulla dal dipartimento IT in questo senso. Il Supply Chain Scientist non dovrebbe essere visto come una versione corporativa del shadow IT. Si tratta di rendere il dipartimento della supply chain responsabile e responsabile della propria competenza centrale. Il dipartimento IT gestisce l’infrastruttura di basso livello e il layer transazionale, mentre il livello decisionale della supply chain dovrebbe appartenere interamente al dipartimento della supply chain.
Il dipartimento IT deve essere un facilitatore, non un decision maker, ad eccezione delle parti veramente incentrate sull’IT del business. Molti dipartimenti IT sono consapevoli del loro arretrato e abbracciano questo nuovo accordo. Tuttavia, se l’istinto di proteggere ciò che viene percepito come il loro territorio è troppo forte, potrebbero rifiutare di lasciare andare il livello decisionale della supply chain. Queste situazioni sono dolorose e possono essere risolte solo attraverso l’intervento diretto del CEO.

Da una prospettiva esterna, la nostra conclusione potrebbe essere che il ruolo del Supply Chain Scientist può essere visto come una variazione più specializzata del data scientist. Storicamente, è così che Lokad ha cercato di risolvere i problemi associati alla pratica aziendale della data science. Tuttavia, ci siamo resi conto già un decennio fa che ciò non era sufficiente. Ci sono voluti anni per scoprire gradualmente tutti gli elementi che sono stati presentati oggi.
Il Supply Chain Scientist non è un’aggiunta alla supply chain dell’azienda; è una chiarificazione sulla proprietà delle decisioni quotidiane banali della supply chain. Per ottenere il massimo da questo approccio, la supply chain, o almeno la sua componente di pianificazione, deve essere rimodellata. Anche i dipartimenti adiacenti, come la finanza e le operazioni, devono accomodare dei cambiamenti, sebbene in misura molto minore.
Nutrire un team di Supply Chain Scientists rappresenta un impegno notevole per un’azienda, ma se fatto correttamente, la produttività è elevata. In pratica, ogni scientist finisce per sostituire da 10 a 100 pianificatori, previsori o responsabili di magazzino, generando enormi risparmi sul libro paga, anche se i scientists percepiscono salari più alti. Il Supply Chain Scientist illustra un nuovo accordo con l’IT, riposizionando l’IT come facilitatore piuttosto che come fornitore di soluzioni, eliminando molti, se non la maggior parte, dei colli di bottiglia legati all’IT.
Più in generale, questo approccio può essere specchiato in tutti gli altri dipartimenti non IT dell’azienda, come marketing, vendite e finanza. Ogni dipartimento ha le proprie decisioni quotidiane banali da affrontare, che trarrebbero ampiamente beneficio dallo stesso tipo di automazione. Tuttavia, proprio come il Supply Chain Scientist è prima di tutto un esperto di supply chain
Tuttavia, proprio come il Supply Chain Scientist è prima di tutto un esperto di supply chain, un marketing scientist o un marketing quant dovrebbe essere un esperto di marketing. La prospettiva del scientist apre la strada per sfruttare al meglio la combinazione di intelligenza artificiale e umana in questo primo XXI secolo.
La prossima lezione si terrà il 10 maggio, un mercoledì, alla stessa ora, le 15:00 ora di Parigi. La lezione di oggi non era tecnica, ma la prossima sarà in gran parte tecnica. Presenterò tecniche per l’ottimizzazione dei prezzi. I manuali mainstream di supply chain solitamente non includono il pricing come elemento della supply chain; tuttavia, il pricing contribuisce in modo sostanziale all’equilibrio tra domanda e offerta. Inoltre, il pricing tende ad essere altamente specifico del dominio, poiché è fin troppo facile affrontare erroneamente la sfida pensando in termini astratti. Pertanto, restringeremo le nostre indagini all’aftermarket automobilistico. Questa sarà l’occasione per rivedere gli elementi presentati con Stoccarda, una delle supply chain personas che ho introdotto nel terzo capitolo di questa serie di lezioni.

E adesso, procederò con le domande.
Domanda: All’accademia ci è voluto quasi un decennio per rendersi conto che il campo della data science era emerso e che doveva essere insegnato alle scuole superiori. Vedi già che lo stesso sta accadendo nei circoli accademici della supply chain adottando la prospettiva delle supply chain sciences?
In primo luogo, non sono a conoscenza che la data science venga insegnata nelle scuole superiori in Francia. Nelle scuole superiori si insegna a malapena qualcosa di correlato all’informatica, per non parlare della data science. Non sono molto sicuro di dove troverebbero i professori o gli insegnanti per farlo. Però posso capire che tu voglia che gli studenti delle scuole superiori acquisiscano una certa competenza digitale. Credo che familiarizzare con la programmazione sia una cosa molto positiva, e si può iniziare anche prima, secondo la mia esperienza, a partire dai sette o otto anni, a seconda della maturità del bambino. Si può fare anche nella scuola primaria, ma stiamo parlando solo dei concetti base della programmazione: variabili, liste di istruzioni e simili. Credo che la data science superi di gran lunga ciò che dovrebbe essere insegnato alle scuole superiori, a meno che non si abbiano dei prodigi o qualcosa del genere. Per me, è chiaramente qualcosa per persone a livello universitario, sia undergraduate che graduate. Infatti, all’accademia ci è voluto un decennio per dare risalto alla data science, ma fermiamoci un attimo. Ho descritto la data science come una pratica aziendale, che è praticamente la versione speculare di ciò che fa l’accademia insegnando la data science. Quindi, dobbiamo riflettere sul problema, e qui penso che uno dei problemi sia che è incredibilmente difficile insegnare qualcosa che non si pratica. Almeno a livello universitario, se non anche a livelli inferiori. Quello che vedo è che abbiamo già un problema con la data science, poiché le persone che la insegnano non sono quelle che effettivamente la praticano in contesti importanti, come Microsoft, Google, Facebook, OpenAI e simili. Per la supply chain, abbiamo un problema simile, e avere accesso a persone con l’esperienza giusta è semplicemente incredibilmente difficile. Spero, e questo è un plug senza vergogna da parte mia, che Lokad inizi, nelle prossime settimane, a fornire alcuni materiali destinati ai corsi di laurea in supply chain. Inizieremo a proporre alcuni materiali confezionati in modo tale da renderli adatti ai professori dell’accademia, affinché possano diffondere tali intuizioni. Ovviamente, dovranno usare il proprio giudizio per valutare se quei materiali che Lokad propone valgono davvero la pena di essere insegnati agli studenti.
Domanda: Il linguaggio specifico per dominio di Lokad non viene utilizzato altrove? Al di fuori di Lokad, come motivi i potenziali nuovi assunti a imparare qualcosa che probabilmente non utilizzeranno mai più nel loro prossimo lavoro? È esattamente il punto che stavo facendo notare riguardo al problema che avevo con i data scientist. Le persone applicavano letteralmente, dicendo “Voglio usare TensorFlow, sono un tipo da TensorFlow” oppure “Sono un tipo da PyTorch”. Questo non è l’atteggiamento giusto. Se confondi la tua identità con una serie di strumenti tecnici, perdi di vista l’essenza. La sfida è comprendere i problemi della supply chain e come affrontarli in modo quantitativo per generare decisioni di livello produttivo. In questa lezione, ho menzionato che ci vogliono sei mesi perché un Supply Chain Scientist acquisisca la competenza per mantenere una ricetta e due anni per ingegnerizzarla da zero. Quanto tempo ci vuole per essere completamente proficienti con Envision, il nostro linguaggio di programmazione proprietario? Nella nostra esperienza, ci vogliono tre settimane. Envision è un piccolo dettaglio rispetto alla sfida complessiva, ma è importante. Se i tuoi strumenti sono scadenti, affronterai enormi problemi accidentali. Tuttavia, per essere realistici: è una piccola parte dell’insieme. Le persone che trascorrono del tempo da Lokad imparano immensamente sui problemi della supply chain. Il linguaggio di programmazione potrebbe essere riscritto in altri linguaggi, ma potrebbe richiedere più righe di codice. Quello che le persone, soprattutto i giovani ingegneri, spesso non si rendono conto è quanto siano effimere molte tecnologie. Non durano a lungo, solitamente solo un paio d’anni prima di essere sostituite da qualcos’altro. Abbiamo visto una serie infinita di tecnologie andare e venire. Se un candidato dice “Mi interessano davvero i dettagli tecnici”, probabilmente non è un buon candidato. Questo era il mio problema con i data scientist – volevano roba ostentata e all’avanguardia. Le supply chain sono sistemi immensamente complessi, e quando commetti un errore, può costare milioni. Hai bisogno di strumenti di livello produttivo, non dell’ultimo pacchetto non testato. I migliori candidati hanno un genuino interesse a diventare professionisti della supply chain. L’importante è la supply chain, non i dettagli del linguaggio di programmazione. Domanda: Sto conseguendo una laurea in supply chain, trasporti e gestione della logistica. Come posso diventare un Supply Chain Scientist? Prima di tutto, ti incoraggio a candidarti da Lokad. Abbiamo posizioni aperte continuamente. Ma, più seriamente, la chiave per diventare un Supply Chain Scientist è avere l’opportunità in un’azienda disposta ad automatizzare le proprie decisioni relative alla supply chain. L’aspetto più importante è la proprietà delle decisioni. Se riesci a trovare un’azienda disposta a provarlo, questo ti aiuterà notevolmente a diventare uno scientist. Affrontando le sfide delle decisioni di livello produttivo, ti renderai conto dell’importanza degli argomenti di cui sto parlando in questa serie di lezioni. Quando ti troverai a gestire previsioni che guideranno milioni di dollari in inventario, ordini e movimenti di magazzino, comprenderai l’enorme responsabilità e la necessità di una correttezza per progettazione. Sono abbastanza certo che altre aziende cresceranno e acquisiranno molte più opportunità. Ma neanche nei miei sogni più sfrenati penso di poter sperare che ogni singola azienda sulla Terra sfrutterà Lokad. Ci saranno molte aziende che decideranno sempre di fare a modo loro, e andranno benissimo.
Domanda: Dato che il 40% della routine quotidiana di un Supply Chain Scientist consiste nel coding, quale linguaggio di programmazione suggeriresti agli studenti universitari di apprendere per primi, in particolare a quelli che studiano management? Direi di prendere qualunque cosa sia facilmente accessibile. Python è un buon punto di partenza. Il mio suggerimento è di provare effettivamente diversi linguaggi di programmazione. Quello che ti aspetti da un ingegnere della supply chain è praticamente l’opposto di ciò che ti aspetti da un ingegnere del software. Per gli ingegneri del software, il mio consiglio predefinito è di scegliere un linguaggio e approfondirlo in maniera super profonda, comprendendone davvero tutte le sfumature. Ma per le persone che, in definitiva, sono generaliste, direi di fare il contrario. Prova un po’ di SQL, un po’ di Python, un po’ di R. Presta attenzione alla sintassi di Excel, e magari dai un’occhiata a linguaggi come Rust, solo per vedere come sono fatti. Quindi, scegli qualunque cosa tu abbia a disposizione. A proposito, Lokad ha in programma di rendere Envision facilmente accessibile agli studenti gratuitamente, quindi rimanete sintonizzati. Domanda: Vedi che i database a grafo avranno un impatto significativo sulle previsioni della supply chain? Assolutamente no. I database a grafo esistono da più di due decenni, e sebbene siano interessanti, non sono potenti quanto i database relazionali come PostgreSQL e MariaDB. Per le previsioni della supply chain, avere operatori simili ai grafi non è ciò che basta. Nei concorsi di forecasting, nessuno dei primi 100 partecipanti ha utilizzato un database a grafo. Tuttavia, ci sono cose che possono essere fatte con il deep learning applicato ai grafi, che illustrerò nella mia prossima lezione sui prezzi. Per quanto riguarda la domanda se i Supply Chain Scientist debbano essere coinvolti nella definizione degli obiettivi nei progetti di customer data science, credo che ci sia un problema nell’assunto di base di concentrarsi sulla data science prima di comprendere il problema che stiamo cercando di risolvere. Tuttavia, riformulando la domanda, i Supply Chain Scientist dovrebbero essere coinvolti nella definizione degli obiettivi dell’ottimizzazione della supply chain? Sì, assolutamente. Far sì che lo scientist scopra ciò che realmente desideriamo è difficile e richiede una stretta collaborazione con gli stakeholder per garantire il perseguimento degli obiettivi giusti. Quindi, gli scientist dovrebbero essere coinvolti? Assolutamente, è fondamentale. Tuttavia, lasciatemi chiarire che questa non è un’iniziativa di data science; è un’iniziativa di supply chain che per caso può utilizzare i dati come ingrediente adatto. Dobbiamo davvero partire dai problemi e dalle ambizioni della supply chain e, poi, poiché vogliamo sfruttare al massimo il software moderno, abbiamo bisogno di questi scientist. Essi aiuteranno a perfezionare ulteriormente la tua comprensione del problema, perché il confine tra ciò che è realizzabile nel software e ciò che rimane strettamente nel dominio dell’intelligenza umana è alquanto sfocato. Hai bisogno degli scientist per navigare questo confine. I hope to see you two months from now, on May 10th, for the next lecture, where we will be discussing pricing. See you then.
Mentre affronti le sfide delle decisioni di livello produttivo, ti renderai conto dell’importanza degli argomenti di cui sto parlando in questa serie di lezioni. Quando ti troverai a gestire previsioni che guideranno milioni di dollari in inventario, ordini e movimenti di magazzino, comprenderai l’enorme responsabilità e la necessità di una correttezza per progettazione. Sono abbastanza certo che altre aziende cresceranno e acquisiranno molte più opportunità. Ma anche nei miei sogni più sfrenati, non credo di poter sperare che ogni singola azienda sulla Terra sfrutterà Lokad. Ci saranno molte aziende che decidono sempre di fare a modo loro, e andranno benissimo.
Domanda: Dato che il 40% della routine quotidiana di un Supply Chain Scientist consiste nel coding, quale linguaggio di programmazione suggeriresti agli studenti universitari di apprendere per primi, in particolare a quelli che studiano management?
Direi di prendere qualunque cosa sia facilmente accessibile. Python è un buon punto di partenza. Il mio suggerimento è di provare effettivamente diversi linguaggi di programmazione. Quello che ti aspetti da un ingegnere della supply chain è praticamente l’opposto di ciò che ti aspetti da un ingegnere del software. Per gli ingegneri del software, il mio consiglio predefinito è di scegliere un linguaggio e approfondirlo in maniera super profonda, comprendendone davvero tutte le sfumature. Ma per le persone che, in definitiva, sono generaliste, direi di fare il contrario. Prova un po’ di SQL, un po’ di Python, un po’ di R. Presta attenzione alla sintassi di Excel, e magari dai un’occhiata a linguaggi come Rust, solo per vedere come sono fatti. Quindi, scegli qualunque cosa tu abbia a disposizione. A proposito, Lokad ha in programma di rendere Envision facilmente accessibile agli studenti gratuitamente, quindi rimanete sintonizzati.
Domanda: Vedi che i database a grafo avranno un impatto significativo sulle previsioni della supply chain?
Assolutamente no. I database a grafo esistono da più di due decenni, e sebbene siano interessanti, non sono potenti quanto i database relazionali come PostgreSQL e MariaDB. Per le previsioni della supply chain, avere operatori simili ai grafi non è ciò che basta. Nei concorsi di forecasting, nessuno dei primi 100 partecipanti ha utilizzato un database a grafo. Tuttavia, ci sono cose che possono essere fatte con il deep learning applicato ai grafi, che illustrerò nella mia prossima lezione sui prezzi.
Per quanto riguarda la domanda se i Supply Chain Scientist debbano essere coinvolti nella definizione degli obiettivi nei progetti di customer data science, credo che ci sia un problema nell’assunto di base di concentrarsi sulla data science prima di comprendere il problema che stiamo cercando di risolvere. Tuttavia, riformulando la domanda, i Supply Chain Scientist dovrebbero essere coinvolti nella definizione degli obiettivi dell’ottimizzazione della supply chain? Sì, assolutamente. Far sì che lo scientist scopra ciò che realmente desideriamo è difficile e richiede una stretta collaborazione con gli stakeholder per garantire il perseguimento degli obiettivi giusti. Quindi, gli scientist dovrebbero essere coinvolti? Assolutamente, è fondamentale.
Tuttavia, lasciatemi chiarire che questa non è un’iniziativa di data science; è un’iniziativa di supply chain che per caso può utilizzare i dati come ingrediente adatto. Dobbiamo davvero partire dai problemi e dalle ambizioni della supply chain e, poi, poiché vogliamo sfruttare al massimo il software moderno, abbiamo bisogno di questi scientist. Essi aiuteranno a perfezionare ulteriormente la tua comprensione del problema, perché il confine tra ciò che è realizzabile nel software e ciò che rimane strettamente nel dominio dell’intelligenza umana è alquanto sfocato. Hai bisogno degli scientist per navigare questo confine.
Spero di vedervi tra due mesi, il 10 maggio, per la prossima lezione, in cui discuteremo dei prezzi. A presto.