00:00:00 Einführung in den Vortrag über das Auslagern auf die Festplatte
00:00:34 Datenverarbeitung von Einzelhändlern und Speicherbeschränkungen
00:02:13 Persistente Speicherlösung und Kostenvergleich
00:04:07 Geschwindigkeitsvergleich zwischen Festplatte und Speicher
00:05:10 Einschränkungen von Partitionierungs- und Streaming-Techniken
00:06:16 Bedeutung geordneter Daten und optimaler Lesegröße
00:07:40 Worst-Case-Szenario beim Datenlesen
00:08:57 Einfluss des Maschinenspeichers auf den Programmablauf
00:10:49 Auslagerungstechniken auf die Festplatte und Speichernutzung
00:12:59 Erklärung des Codeabschnitts und .NET-Implementierung
00:15:06 Kontrolle über die Speicherzuweisung und deren Konsequenzen
00:16:18 Memory-mapped Page und Memory-mapped Files
00:18:24 Lese-/Schreib-Memory-Maps und Systemleistungswerkzeuge
00:20:04 Verwendung von virtual memory und Memory-mapped Pages
00:22:08 Umgang mit großen Dateien und 64-Bit-Zeigern
00:24:00 Verwendung von span zum Laden aus Memory-mapped Memory
00:26:03 Datenkopie und Verwendung von Strukturen zum Einlesen von Ganzzahlen
00:28:06 Erstellen eines span aus einem Zeiger und Memory Manager
00:30:27 Erstellen einer Instanz von Memory Manager
00:31:05 Implementierung eines Programms zur Auslagerung auf die Festplatte und Memory Mapping
00:33:34 Memory-mapped Version ist leistungstechnisch vorzuziehen
00:35:22 File-Stream-Pufferstrategie und deren Einschränkungen
00:37:03 Strategie, eine große Datei zu mappen
00:39:30 Aufteilen des Speichers über mehrere große Dateien
00:40:21 Fazit und Einladung zu Fragen
Zusammenfassung
Um mehr Daten zu verarbeiten, als in den Hauptspeicher passen, können Programme einen Teil dieser Daten auf einen langsameren, aber größeren Speicher, wie NVMe-Laufwerke, auslagern. Durch eine Kombination von zwei eher obskuren .NET-Funktionen (Memory-mapped Files und Memory Managers) kann dies in C# mit wenig bis keiner Leistungseinbuße erfolgen. Dieser Vortrag, der bei den Warsaw IT Days 2023 gehalten wurde, taucht in die detaillierten Hintergründe ein, wie dies funktioniert, und diskutiert, wie das open source NuGet-Paket Lokad.ScratchSpace den Entwicklern die meisten dieser Details verbirgt.
Ausführliche Zusammenfassung
In einem umfassenden Vortrag geht Victor Nicolet, CTO von Lokad, auf die Feinheiten des Auslagerungsprozesses auf die Festplatte in .NET ein, eine Technik, die die Verarbeitung großer Datensätze ermöglicht, die die Speicherkapazität eines typischen Computers überschreiten. Nicolet greift auf seine umfangreiche Erfahrung im Umgang mit komplexen Datensätzen im Bereich der die Quantitative Supply Chainoptimierung bei Lokad zurück und liefert ein praktisches Beispiel eines Einzelhändlers mit hunderttausend Produkten an 100 Standorten. Dies führt zu einem Datensatz mit 10 Milliarden Einträgen, wenn man tägliche Datenpunkte über drei Jahre betrachtet, was 37 Gigabyte Speicher erfordert, um für jeden Eintrag einen Gleitkommawert zu speichern, was die Kapazität eines typischen Desktop-Computers bei weitem übersteigt.
Nicolet schlägt die Verwendung von persistentem Speicher, wie beispielsweise NVMe-SSD-Speicher, als kosteneffektive Alternative zum Arbeitsspeicher vor. Er vergleicht die Kosten von Arbeitsspeicher und SSD-Speicher und stellt fest, dass man für die Kosten von 18 Gigabyte Arbeitsspeicher einen Terabyte SSD-Speicher erwerben könnte. Er erörtert auch den Leistungskompromiss und weist darauf hin, dass das Lesen von der Festplatte sechs Mal langsamer ist als das Lesen aus dem Speicher.
Er führt Partitionierung und Streaming als Techniken ein, um den Festplattenspeicher als Alternative zum Arbeitsspeicher zu nutzen. Partitionierung ermöglicht die Verarbeitung von Datensätzen in kleineren Stücken, die in den Speicher passen, erlaubt jedoch keine Kommunikation zwischen den Partitionen. Streaming hingegen ermöglicht die Beibehaltung eines Zustands zwischen der Verarbeitung verschiedener Teile, erfordert jedoch, dass die auf der Festplatte gespeicherten Daten geordnet oder korrekt ausgerichtet sind, um eine optimale Leistung zu erzielen.
Nicolet führt dann die Auslagerungstechniken auf die Festplatte als Lösung für die Einschränkungen des Fits-in-Memory-Ansatzes ein. Diese Techniken verteilen Daten dynamisch zwischen Arbeitsspeicher und persistentem Speicher, indem sie mehr Arbeitsspeicher nutzen, wenn verfügbar, um schneller zu laufen, und bei weniger Verfügbarkeit langsamer werden, um weniger Arbeitsspeicher zu verbrauchen. Er erklärt, dass Auslagerungstechniken so viel Arbeitsspeicher wie möglich verwenden und erst dann beginnen, Daten auf die Festplatte zu schreiben, wenn der Speicher erschöpft ist. Dadurch können sie besser auf mehr oder weniger verfügbaren Speicher als anfänglich erwartet reagieren.
Er erläutert weiter, dass sich die Auslagerungstechniken auf die Festplatte in zwei Bereiche unterteilen: den Hot-Bereich, der stets im Speicher verbleibt, und den Cold-Bereich, der Teile seines Inhalts jederzeit in den persistenten Speicher auslagern kann. Das Programm verwendet Hot-Cold-Transfers, die üblicherweise große Chargen beinhalten, um die NVMe-Bandbreite maximal auszunutzen. Der Cold-Bereich ermöglicht es diesen Algorithmen, so viel Speicher wie möglich zu nutzen.
Nicolet erläutert anschließend, wie dies in .NET implementiert werden kann. Für den Hot-Bereich werden normale .NET-Objekte verwendet, während für den Cold-Bereich eine Referenzklasse genutzt wird. Diese Klasse hält eine Referenz auf den Wert, der in den Cold-Speicher ausgelagert wird, und dieser Wert kann auf null gesetzt werden, wenn er nicht mehr im Speicher vorhanden ist. Ein zentrales System im Programm verfolgt alle Cold-Referenzen, und immer wenn eine neue Cold-Referenz erstellt wird, wird überprüft, ob sie zu einem Überlauf des Speichers führt, und es wird die Spill-Funktion einer oder mehrerer bereits im System vorhandener Cold-Referenzen aufgerufen, um innerhalb des für den Cold-Speicher verfügbaren Speicherbudgets zu bleiben.
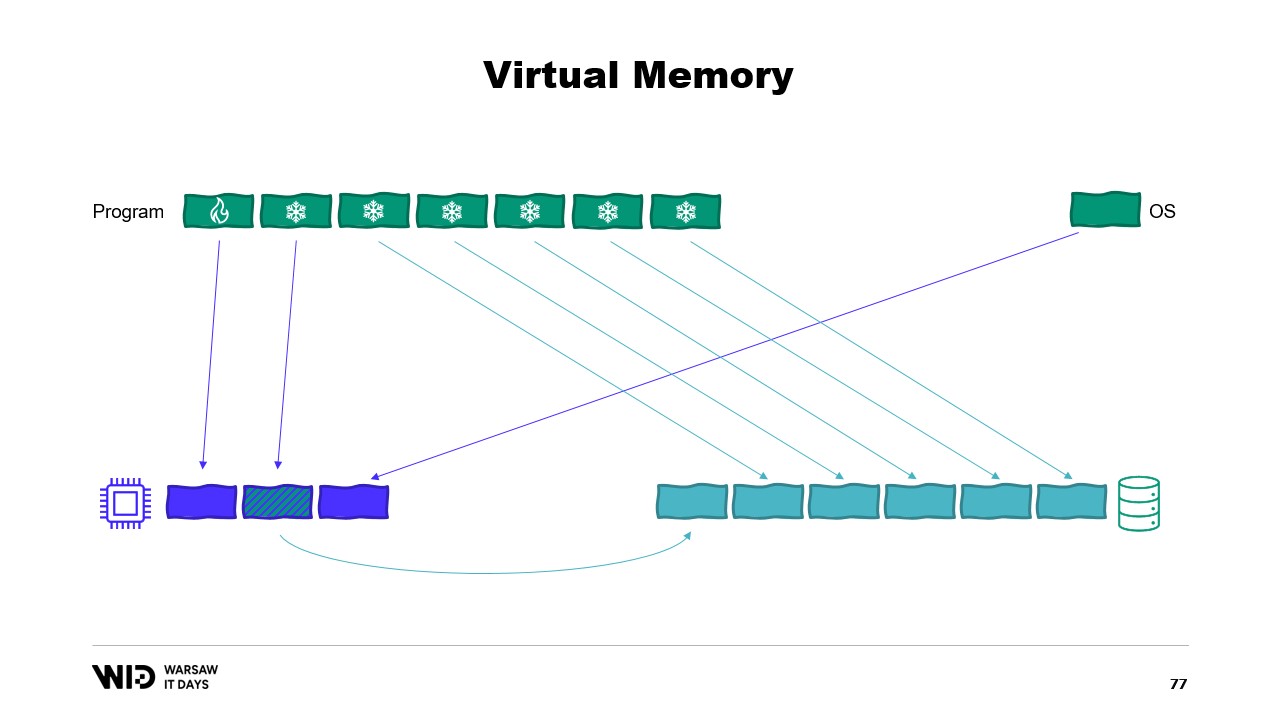
Anschließend führt er das Konzept des virtuellen Speichers ein, bei dem das Programm keinen direkten Zugriff auf physische Speicherseiten hat, sondern stattdessen auf virtuelle Speicherseiten zugreift. Es ist möglich, eine Memory-mapped Page zu erstellen, was eine übliche Methode ist, um die Kommunikation zwischen Programmen und Memory Mapping Files zu implementieren. Der Hauptzweck des Memory Mapping besteht darin, zu verhindern, dass jedes Programm eine eigene Kopie der DLL im Speicher besitzt, da all diese Kopien identisch sind.
Nicolet spricht anschließend über das System Performance Tool, das die aktuelle Nutzung des physischen Speichers anzeigt. In Grün ist der Speicher dargestellt, der direkt einem Prozess zugewiesen wurde, in Blau befindet sich der Page Cache, und die in der Mitte modifizierten Seiten sind jene, die eine exakte Kopie der Festplatte sein sollten, jedoch Änderungen im Speicher aufweisen.
Anschließend diskutiert er den zweiten Versuch unter Verwendung von virtuellem Speicher, bei dem der Cold-Bereich vollständig aus Memory-mapped Pages besteht. Falls das Betriebssystem plötzlich Speicher benötigt, weiß es, welche Seiten Memory-mapped sind und diese sicher verwerfen kann.
Nicolet erklärt daraufhin die grundlegenden Schritte zur Erstellung einer Memory-mapped File in .NET, nämlich zuerst eine Memory-mapped File aus einer Datei auf der Festplatte zu erstellen und anschließend einen View Accessor zu erzeugen. Diese beiden werden getrennt gehalten, da .NET den Fall eines 32-Bit-Prozesses berücksichtigen muss. Im Fall eines 64-Bit-Prozesses kann ein einzelner View Accessor erstellt werden, der die gesamte Datei lädt.
Nicolet spricht anschließend über die Einführung von Memory und span vor fünf Jahren, die Typen sind, die verwendet werden, um einen Speicherbereich auf eine sicherere Weise darzustellen als nur mit Zeigern. Die Grundidee hinter span und Memory ist, dass man, gegeben einen Zeiger und eine Anzahl von Bytes, einen neuen span erstellen kann, der diesen Speicherbereich repräsentiert. Sobald ein span erstellt wurde, kann er überall innerhalb des definierten Bereichs sicher ausgelesen werden, wobei im Falle eines Versuchs, über die Grenzen hinaus zu lesen, die Laufzeit den Fehler auffängt und eine Ausnahme ausgelöst wird, anstatt dass der Prozess einfach abbricht.
Nicolet erklärt anschließend, wie man span verwendet, um aus Memory-mapped Memory in den von .NET verwalteten Speicher zu laden. Zum Beispiel, wenn eine Zeichenkette gelesen werden muss, können zahlreiche APIs, die auf span basieren, genutzt werden. Nicolet erläutert die Verwendung von APIs wie MemoryMarshal.Read, die einen Integer vom Anfang des span auslesen kann. Er erwähnt auch die Funktion Encoding.GetString, die aus einem Byte-span eine Zeichenkette laden kann.
Er erklärt weiter, dass diese Operationen an span durchgeführt werden, die einen Datenabschnitt repräsentieren, der sich anstelle im Speicher auf der Festplatte befinden könnte. Das Betriebssystem übernimmt das Laden der Daten in den Speicher, sobald darauf zugegriffen wird. Nicolet gibt ein Beispiel für eine Folge von Gleitkommawerten, die in ein Float-Array geladen werden müssen. Er erläutert die Verwendung von MemoryMarshal.Read, um die Größe auszulesen, die Allokation eines Arrays mit Gleitkommawerten dieser Größe und die Verwendung von MemoryMarshal.Cast, um den Byte-span in einen Gleitkommawert-span umzuwandeln.
Er spricht auch über die Verwendung der CopyTo-Funktion von span, die eine Hochleistungs-Kopie der Daten von der Memory-mapped File in das Array durchführt. Er weist darauf hin, dass dieser Vorgang etwas verschwenderisch sein kann, da dabei eine völlig neue Kopie erstellt wird. Nicolet schlägt vor, eine Struktur zu erstellen, die den Header mit zwei Integer-Werten enthält, die von MemoryMarshal ausgelesen werden können. Außerdem erörtert er den Einsatz einer Kompressionsbibliothek, um die Daten zu dekomprimieren.
Nicolet spricht über die Verwendung eines anderen Typs, Memory, um einen länger lebenden Datenbereich darzustellen. Er erwähnt den Mangel an Dokumentation dazu, wie man aus einem Zeiger einen Memory erstellt, und empfiehlt einen Gist auf GitHub als die beste verfügbare Ressource. Er erklärt die Notwendigkeit, einen MemoryManager zu erstellen, der intern von einem Memory verwendet wird, sobald etwas Komplexeres als nur das Verweisen auf einen Teil eines Arrays erforderlich ist.
Nicolet erörtert den Einsatz von Memory Mapping im Vergleich zu FileStream und stellt fest, dass FileStream die naheliegende Wahl ist, wenn auf Daten auf der Festplatte zugegriffen wird, und dass dessen Verwendung gut dokumentiert ist. Er weist darauf hin, dass der FileStream-Ansatz nicht thread-safe ist und einen Lock um den Vorgang erfordert, was das parallele Auslesen von mehreren Stellen verhindert. Nicolet erwähnt außerdem, dass der FileStream-Ansatz einen Overhead mit sich bringt, der bei der Memory-mapped Version nicht auftritt.
Er erklärt, dass stattdessen die Memory-mapped Version verwendet werden sollte, da sie in der Lage ist, so viel Speicher wie möglich zu nutzen und bei Speichermangel Teile der Datensätze wieder auf die Festplatte auszulagern. Nicolet stellt die Frage, wie viele Dateien angelegt werden sollten, wie groß diese sein müssen und wie man diese Dateien zyklisch durchläuft, während der Speicher zugewiesen und freigegeben wird.
Er schlägt vor, den Speicher auf mehrere große Dateien aufzuteilen, niemals zweimal in denselben Speicher zu schreiben und Dateien so früh wie möglich zu löschen. Nicolet schließt seinen Vortrag mit der Information ab, dass in der Produktion bei Lokad der Lokad scratch space mit spezifischen Einstellungen genutzt wird: Die Dateien haben jeweils 16 Gigabyte, es gibt 100 Dateien pro Festplatte, und jede L32VM verfügt über vier Festplatten, was etwas mehr als 6 Terabyte Auslagerungsplatz für jede VM entspricht.
Vollständiges Transkript

Victor Nicolet: Hallo und herzlich willkommen zu diesem Vortrag über das Auslagern auf die Festplatte in .NET.
Auslagern auf die Festplatte ist eine Technik, um Datensätze zu verarbeiten, die nicht in den Speicher passen, indem nicht verwendete Teile des Datensatzes auf persistentem Speicher abgelegt werden.
Dieser Vortrag basiert auf meinen Erfahrungen bei Lokad. Wir betreiben quantitative supply chain Optimierung.
Der quantitative Teil bedeutet, dass wir mit großen Datensätzen arbeiten, und der supply chain Teil – nun, er ist Teil der realen Welt, weshalb sie unordentlich, überraschend und voller Randfälle innerhalb von Randfällen sind.
Daher führen wir eine Menge ziemlich komplexe Verarbeitung durch.
Schauen wir uns ein typisches Beispiel an. Ein Einzelhändler hätte in etwa hunderttausend Produkte.
Diese Produkte sind an bis zu 100 Standorten vertreten. Das können Geschäfte sein, sie können Lager sein, sie können sogar Bereiche von Lagern sein, die dem E-Commerce gewidmet sind.
Und wenn wir irgendeine echte Analyse dazu durchführen wollen, müssen wir das vergangene Verhalten betrachten, also was mit diesen Produkten und Standorten geschieht.
Wenn wir pro Tag nur einen Datenpunkt speichern und nur drei Jahre zurückblicken, ergibt das etwa 1000 Tage. Multipliziert man all dies, enthält unser Datensatz 10 Milliarden Einträge.
Wenn wir für jeden Eintrag nur einen Gleitkommawert speichern, nimmt der Datensatz bereits 37 Gigabyte Speicherplatz ein. Das liegt über dem, was ein typischer Desktop-Computer zur Verfügung hätte.

Und ein einzelner Gleitkommawert ist bei weitem nicht ausreichend, um irgendeine Art von Analyse durchzuführen.
Eine bessere Zahl wäre 20, und selbst dann unternehmen wir große Anstrengungen, den Speicherbedarf klein zu halten. Dennoch spricht man von etwa 745 Gigabyte Speichernutzung.
Dies passt in Cloud-Maschinen, wenn diese groß genug sind – etwa siebentausend Dollar pro Monat. Es ist also zwar erschwinglich, aber auch ziemlich verschwenderisch.

Wie man dem Titel dieses Vortrags entnehmen kann, besteht die Lösung darin, stattdessen persistenten Speicher zu verwenden, der zwar langsamer, aber günstiger als Arbeitsspeicher ist.
Heutzutage kann man NVMe-SSD-Speicher für etwa 5 Cent pro Gigabyte erwerben. Eine NVMe-SSD ist ungefähr die schnellste Art von persistentem Speicher, die man derzeit leicht bekommen kann.
Zum Vergleich kostet ein Gigabyte RAM 275 Dollar. Das entspricht ungefähr einem 55-fachen Unterschied.

Ein anderer Blickwinkel ist, dass man für das Budget, das zum Kauf von 18 Gigabyte Speicher benötigt wird, ausreichend Mittel hätte, um einen Terabyte SSD-Speicher zu bezahlen.

Wie sieht es mit Cloud-Angeboten aus? Nun, als Beispiel die Microsoft Cloud: Links befindet sich der L32s, Teil einer Reihe von virtuellen Maschinen, die für Speicher optimiert sind.
Für etwa zweitausend Dollar pro Monat erhält man fast 8 Terabyte persistenten Speicher.
Rechts befindet sich der M32ms, Teil einer Reihe, die für den Arbeitsspeicher optimiert ist, und für mehr als das Zweieinhalbfache der Kosten erhält man nur 875 Gigabyte RAM.
Wenn mein Programm auf der linken Maschine läuft und doppelt so lange zur Fertigstellung benötigt, bleibt es dennoch kosteneffizient.

Was ist mit der Leistung? Nun, das Lesen aus dem Speicher erfolgt mit etwa 21 Gigabyte pro Sekunde. Das Lesen von einem NVMe SSD läuft mit etwa 3,5 Gigabyte pro Sekunde.
Dies ist kein tatsächlicher Benchmark. Ich habe lediglich eine virtuelle Maschine erstellt und diese beiden Befehle ausgeführt, und es gibt viele Möglichkeiten, diese Werte sowohl zu erhöhen als auch zu verringern.
Der entscheidende Punkt hier ist einfach die Größenordnung des Unterschieds zwischen beiden. Das Lesen von der Platte ist sechsmal langsamer als das Lesen aus dem Speicher.
Die Festplatte ist also enttäuschend langsam, Sie möchten nicht ständig mit zufälligen Zugriffsmustern von der Festplatte lesen. Andererseits ist sie auch überraschend schnell. Wenn Ihre Verarbeitung hauptsächlich CPU-begrenzt ist, merken Sie vielleicht gar nicht, dass Sie von der Festplatte anstatt aus dem Speicher lesen.

Eine ziemlich bekannte Technik, den Festplattenspeicher als Alternative zum Arbeitsspeicher zu nutzen, ist die Partitionierung.
Die Idee hinter der Partitionierung besteht darin, eine der Dimensionen des Datensatzes auszuwählen und den Datensatz in kleinere Stücke zu zerteilen. Jedes Stück sollte klein genug sein, um in den Speicher zu passen.
Die Verarbeitung lädt dann jedes Stück einzeln, verarbeitet es und speichert es zurück auf die Festplatte, bevor das nächste Stück geladen wird.
In unserem Beispiel, wenn wir die Datensätze entlang der Standorte trennen und die Standorte nacheinander verarbeiten würden, würde jeder Standort nur 7,5 Gigabyte Arbeitsspeicher benötigen. Dies liegt gut im Rahmen dessen, was ein Desktop-Computer leisten kann.

Allerdings gibt es bei der Partitionierung keine Kommunikation zwischen den Partitionen. Wenn wir also Daten standortübergreifend verarbeiten müssen, können wir diese Technik nicht mehr verwenden.
Eine andere Technik ist das Streaming. Beim Streaming ist es in etwa wie bei der Partitionierung, dass wir zu jedem Zeitpunkt nur kleine Datenstücke in den Speicher laden.
Im Gegensatz zur Partitionierung dürfen wir einen gewissen Zustand zwischen der Verarbeitung der verschiedenen Teile beibehalten. Während der Verarbeitung des ersten Standorts würden wir also den Anfangszustand einrichten, und dann, bei der Verarbeitung des zweiten Standorts, dürfen wir alles verwenden, was zu diesem Zeitpunkt im Zustand vorhanden war, um am Ende der Verarbeitung des zweiten Standorts einen neuen Zustand zu erstellen.
Im Gegensatz zur Partitionierung eignet sich das Streaming nicht für eine parallele Ausführung. Aber es löst das Problem, etwas über den gesamten Datensatz hinweg zu berechnen, anstatt es in jedem Teil getrennt zu berechnen.
Allerdings hat das Streaming auch seine eigene Einschränkung. Damit es leistungsfähig ist, sollten die auf der Festplatte gespeicherten Daten geordnet oder korrekt ausgerichtet sein.
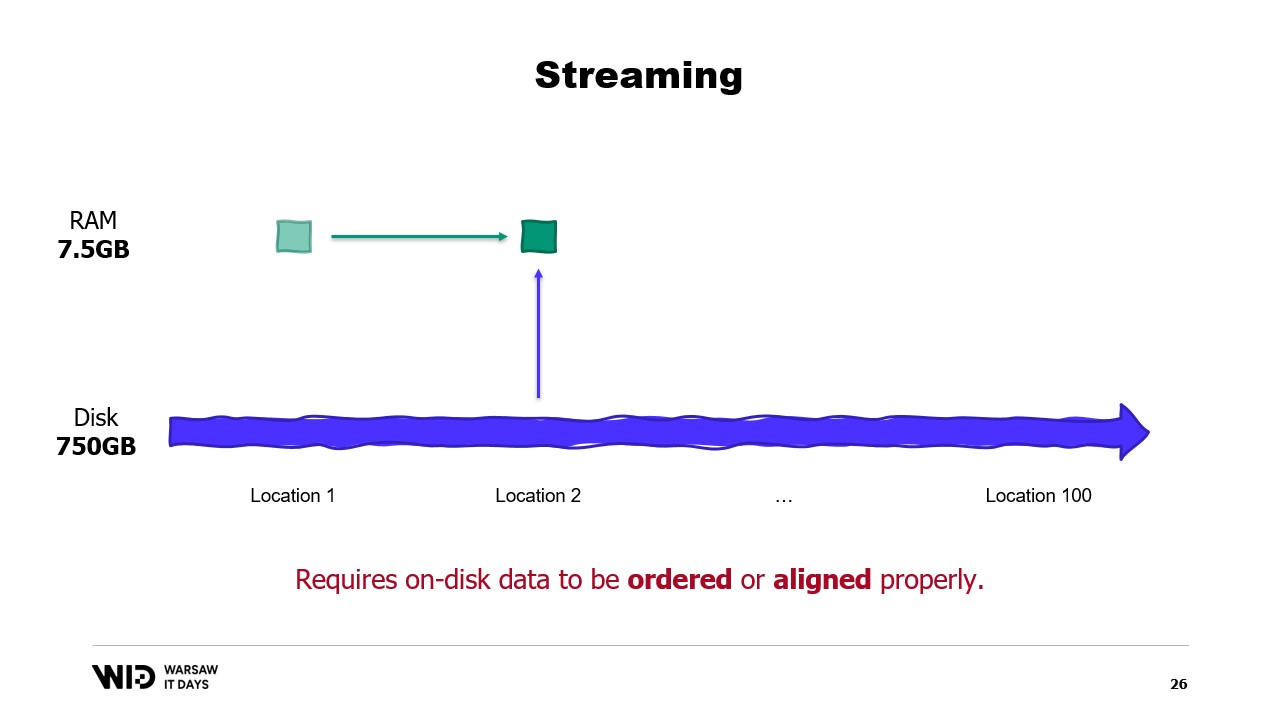
Um diese Anforderungen zu verstehen, muss man wissen, dass NVMe Daten in Sektoren von einem halben Kilobyte liest und schreibt und die früher genannten Leistungswerte, wie 3,5 Gigabyte pro Sekunde, davon ausgehen, dass Sektoren vollständig gelesen und genutzt werden.
Wenn wir nur einen Teil des Sektors nutzen, aber der gesamte Sektor gelesen werden muss, verschwenden wir Bandbreite und unsere Leistung wird um einen großen Faktor reduziert.

Daher ist es optimal, wenn die gelesenen Daten ein Vielfaches von einem halben Kilobyte betragen und an den Grenzen der Sektoren ausgerichtet sind.
Da wir heutzutage keine rotierenden Festplatten mehr verwenden, verursacht das Überspringen und Nichtlesen eines Sektors keine Kosten.

Falls es jedoch nicht möglich ist, die Daten an den Sektorengrenzen auszurichten, besteht eine andere Möglichkeit darin, sie in sequenzieller Reihenfolge zu laden.
Dies liegt daran, dass, sobald ein Sektor in den Speicher geladen wurde, das Lesen des zweiten Teils des Sektors keinen erneuten Ladevorgang von der Festplatte erfordert. Stattdessen kann das Betriebssystem Ihnen einfach die verbleibenden Bytes zur Verfügung stellen, die noch nicht verwendet wurden.
Wenn die Daten also aufeinanderfolgend geladen werden, geht keine Bandbreite verloren und Sie erhalten dennoch die volle Leistung.

Der schlimmste Fall ist, wenn Sie nur ein oder wenige Bytes aus jedem Sektor lesen. Wenn Sie beispielsweise aus jedem Sektor einen Gleitkommawert lesen, wird Ihre Leistung um den Faktor 128 reduziert.

Nog schlimmer ist, dass es eine weitere Einheit zur Gruppierung von Daten über den Sektoren gibt, nämlich die Betriebssystemseite, und das Betriebssystem in der Regel ganze Seiten von etwa 4 Kilobyte vollständig lädt.
Wenn Sie nun aus jeder Seite einen Gleitkommawert lesen, haben Sie Ihre Leistung um den Faktor 1024 reduziert.
Aus diesem Grund ist es wirklich wichtig sicherzustellen, dass Daten, die aus dem persistenten Speicher gelesen werden, in großen, aufeinanderfolgenden Blöcken gelesen werden.

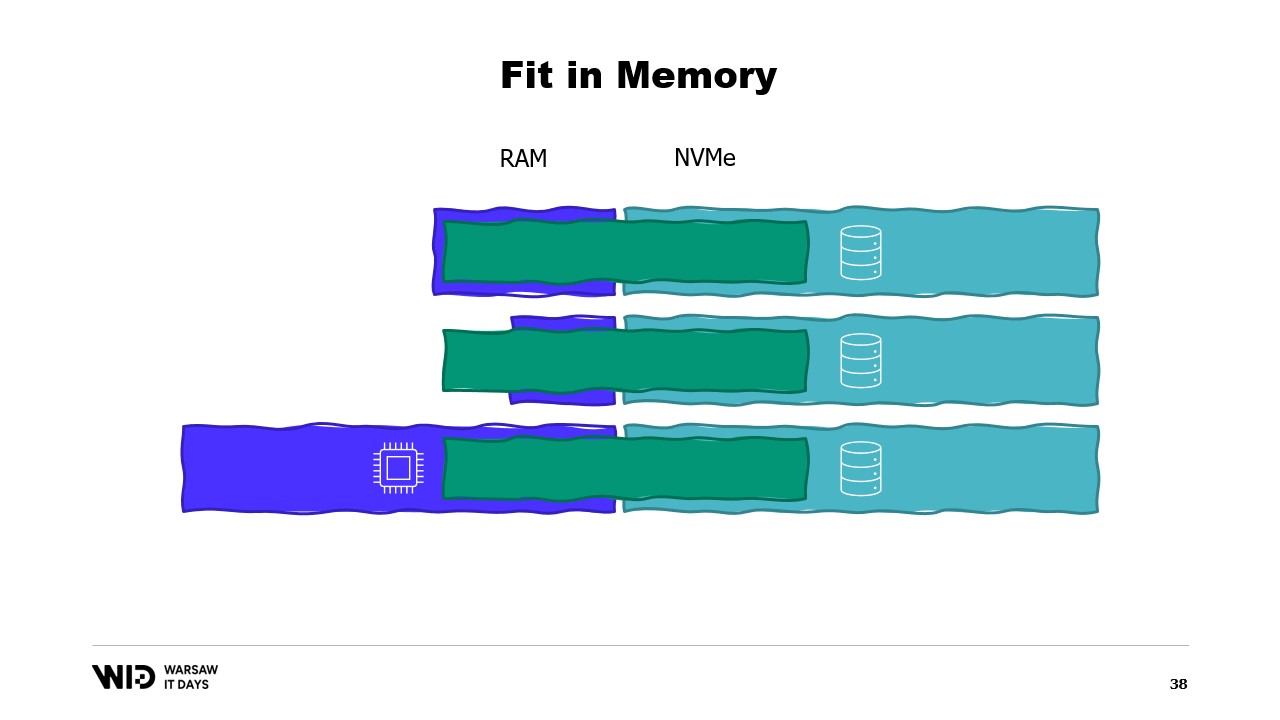
Mit diesen Techniken ist es möglich, das Programm in einen kleineren Speicherbereich zu bringen. Diese Techniken behandeln den Arbeitsspeicher und die Festplatte nun als zwei getrennte Speicherbereiche, die unabhängig voneinander sind.
Somit wird die Verteilung des Datensatzes zwischen Arbeitsspeicher und Festplatte vollständig durch den Algorithmus und die Struktur des Datensatzes bestimmt.
Wenn wir das Programm auf einer Maschine ausführen, die genau über die richtige Menge an Arbeitsspeicher verfügt, passt das Programm genau und es wird in der Lage sein, zu laufen.
Wenn wir eine Maschine bereitstellen, die weniger als die erforderliche Menge an Arbeitsspeicher hat, wird das Programm nicht in den Speicher passen und kann nicht ausgeführt werden.
Schließlich, wenn wir eine Maschine bereitstellen, die mehr als die notwendige Menge an Arbeitsspeicher hat, wird das Programm das tun, was Programme normalerweise tun: Es wird den zusätzlichen Speicher nicht nutzen und dennoch mit der gleichen Geschwindigkeit laufen.
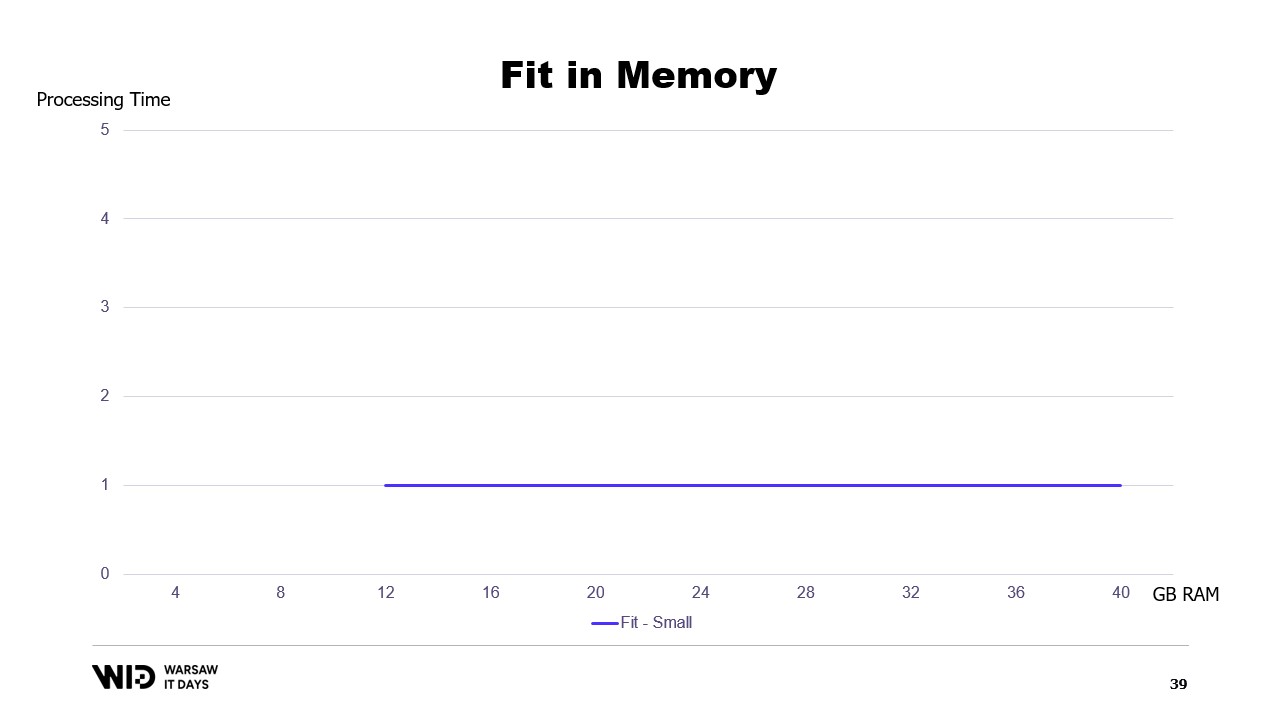
Wenn wir ein Diagramm der Ausführungszeit in Abhängigkeit vom verfügbaren Speicher erstellen würden, sähe es so aus. Unterhalb der Speichergrenze erfolgt keine Ausführung, also gibt es keine Verarbeitungszeit. Oberhalb der Grenze ist die Verarbeitungszeit konstant, da das Programm den zusätzlichen Speicher nicht nutzen kann, um schneller zu laufen.
Und was passiert, wenn der Datensatz wächst? Nun, je nachdem, in welcher Dimension, wenn der Datensatz so wächst, dass sich die Anzahl der Partitionen erhöht, bleibt der Speicherbedarf gleich, es gibt einfach mehr Partitionen.
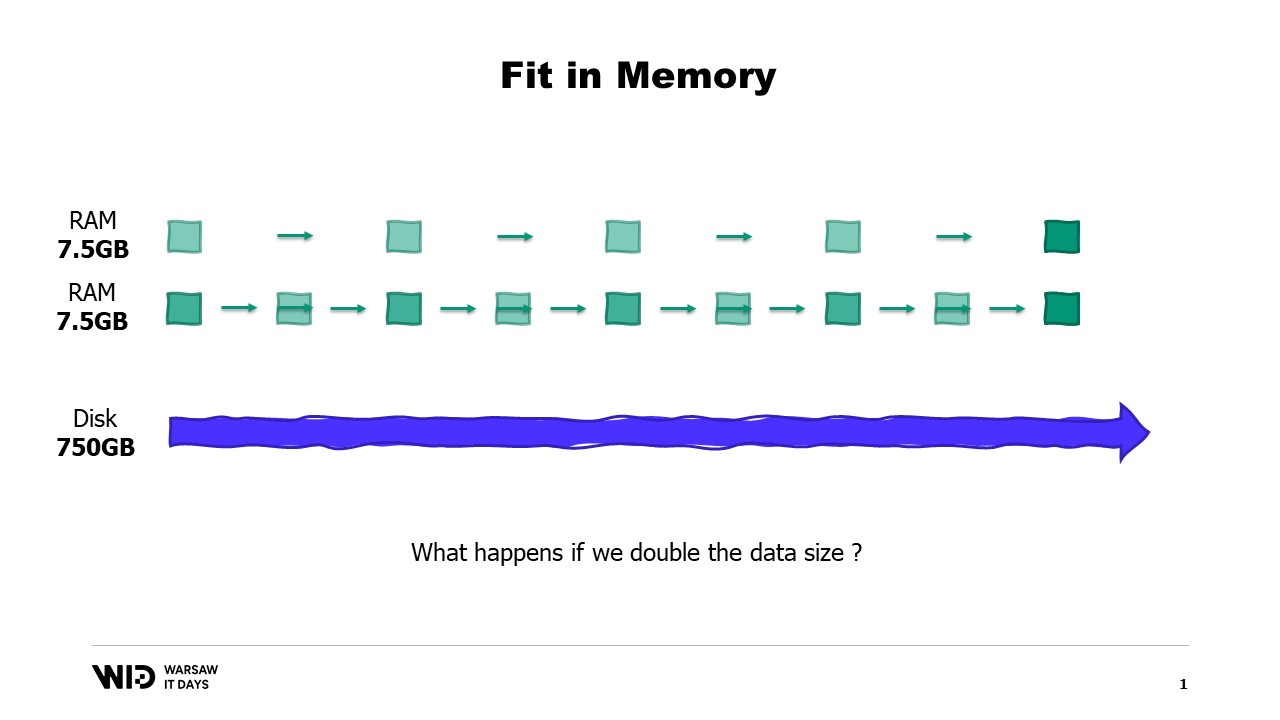
Auf der anderen Seite, wenn die einzelnen Partitionen wachsen, wird auch der Speicherbedarf zunehmen, was die minimale Menge an Arbeitsspeicher erhöht, die das Programm zum Ausführen benötigt.
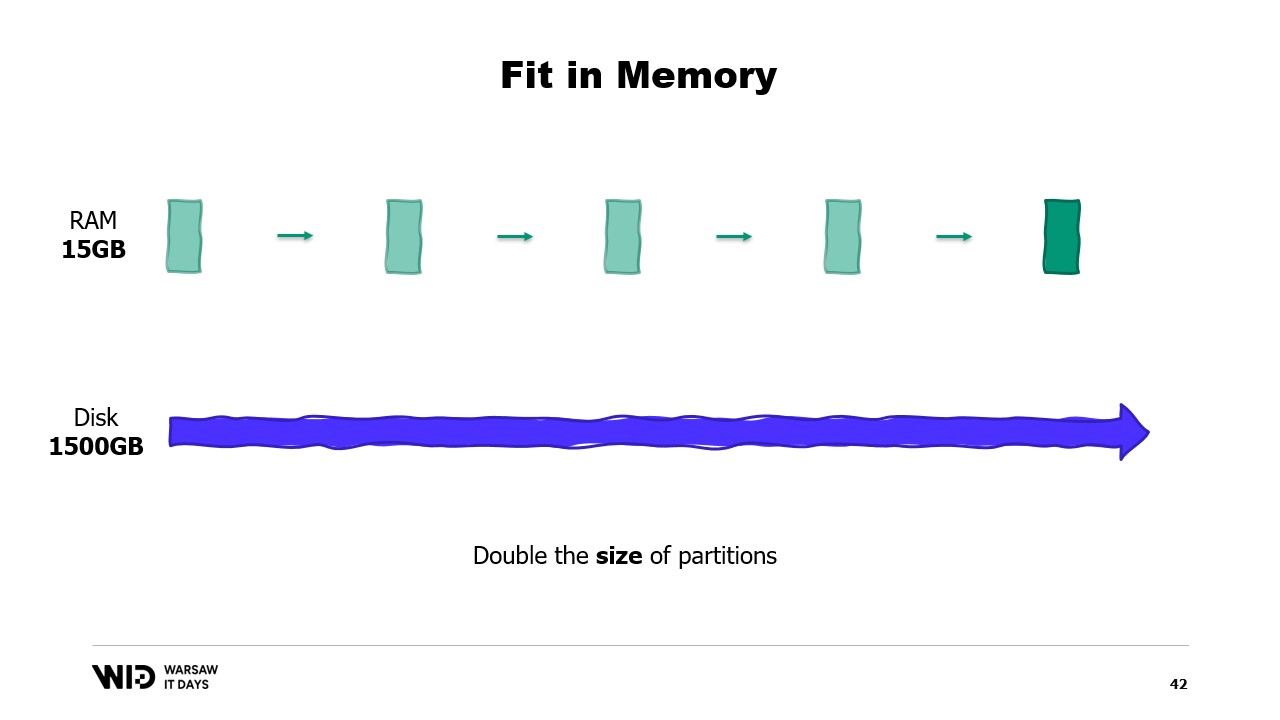
Anders ausgedrückt, wenn ich einen größeren Datensatz habe, den ich verarbeiten muss, dauert es nicht nur länger, sondern er hat auch einen größeren Speicherbedarf.
Dies führt zu einer unangenehmen Situation, in der ich mehr Arbeitsspeicher hinzufügen muss, um große Datensätze unterzubringen, wenn sie auftauchen, aber das Hinzufügen von mehr Speicher verbessert nichts an den kleineren Datensätzen.
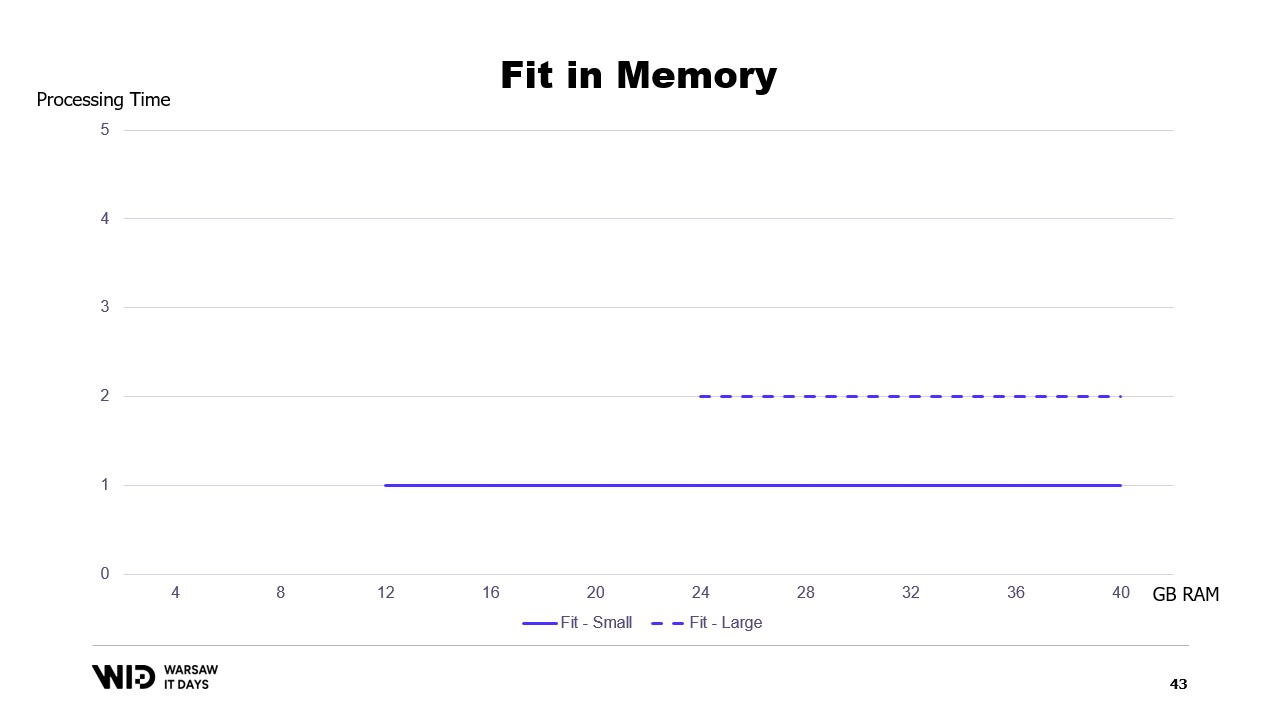
Dies ist eine Einschränkung des Fits-in-Memory-Ansatzes, bei dem die Verteilung des Datensatzes zwischen Arbeitsspeicher und persistentem Speicher vollständig durch die Struktur des Datensatzes und den Algorithmus selbst bestimmt wird.
Dabei wird die tatsächlich verfügbare Speichermenge nicht berücksichtigt. Was Spill-to-Disk-Techniken machen, ist, dass sie diese Verteilung dynamisch vornehmen. Wenn also mehr Speicher verfügbar ist, nutzen sie mehr Speicher, um schneller zu laufen.
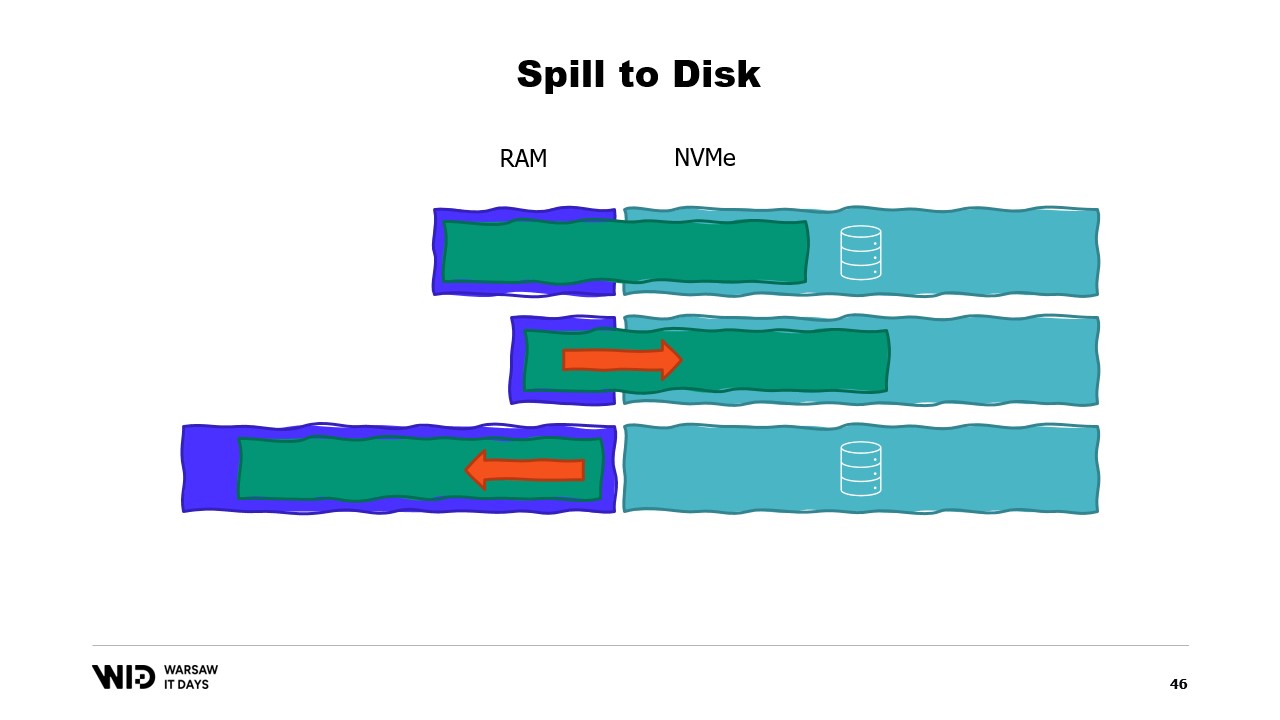
Im Gegensatz dazu, wenn weniger Speicher verfügbar ist, werden sie sich bis zu einem gewissen Punkt verlangsamen, um weniger Speicher zu verbrauchen. In diesem Fall sehen die Kurven viel besser aus. Der minimale Speicherbedarf ist kleiner und bei beiden Datensätzen gleich.
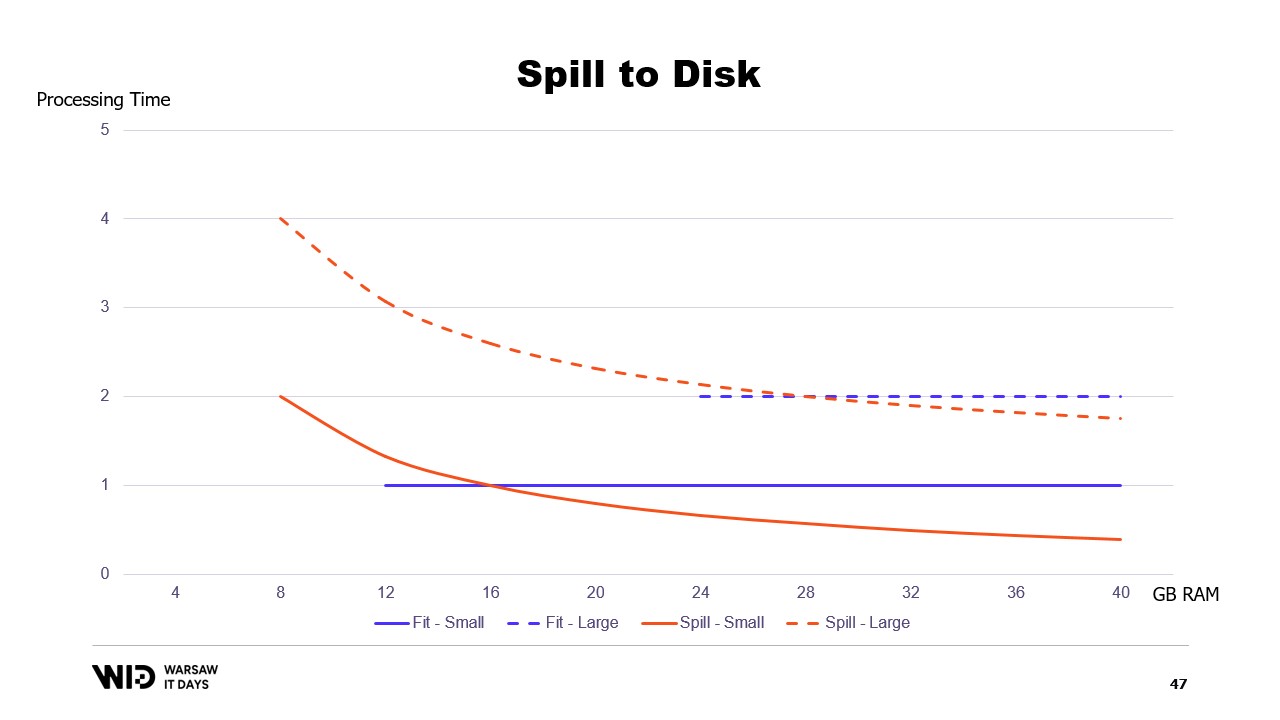
Die Leistung steigt in allen Fällen, wenn mehr Speicher hinzugefügt wird. Fit-to-Memory-Techniken werden proaktiv einige Daten auf die Festplatte auslagern, um den Speicherbedarf zu reduzieren. Im Gegensatz dazu werden Spill-to-Disk-Techniken so viel Speicher wie möglich nutzen und erst dann beginnen, Daten auf der Festplatte auszulagern, wenn der Speicher knapp wird, um Platz zu schaffen.
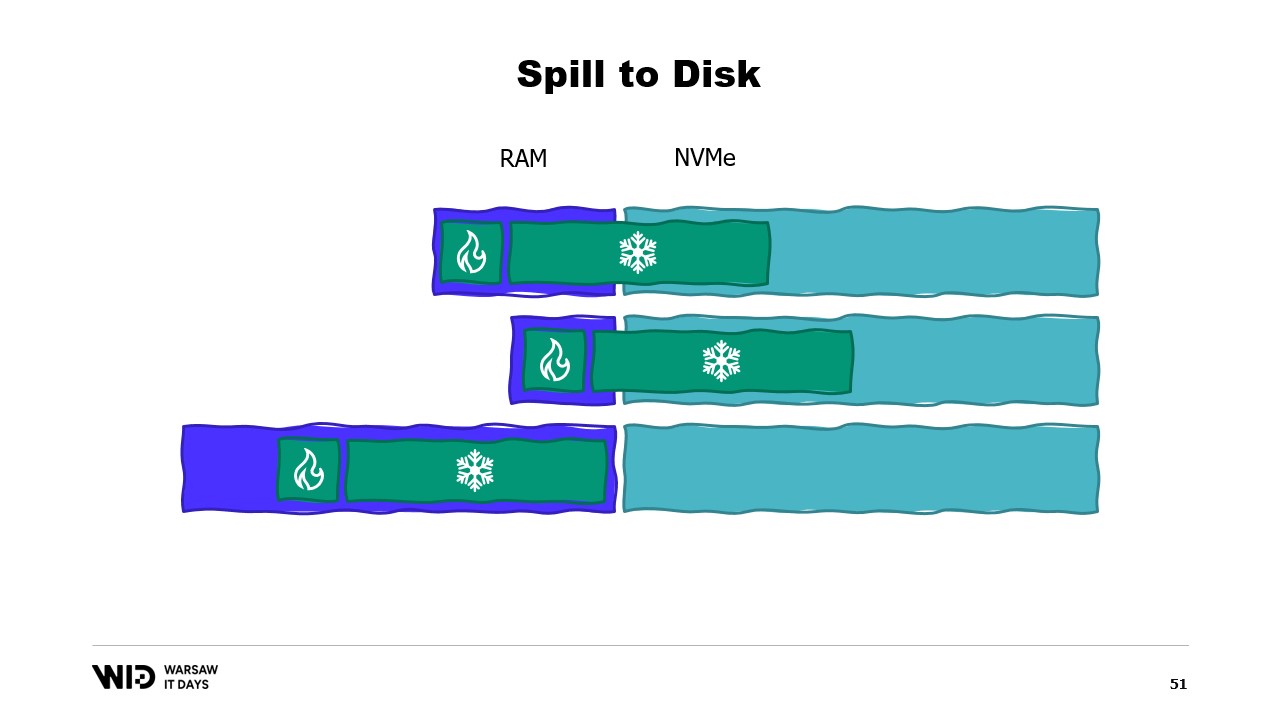
Das macht sie wesentlich besser darin, auf mehr oder weniger Speicher als ursprünglich erwartet zu reagieren. Spill-to-Disk-Techniken teilen den Datensatz in zwei Bereiche auf. Es wird angenommen, dass der Hot-Bereich immer im Speicher ist, sodass er in Bezug auf die Leistung stets sicher mit zufälligen Zugriffsmustern verwendet werden kann. Natürlich hat er ein maximales Budget, möglicherweise etwa 8 Gigabyte pro CPU auf einer typischen Cloud-Maschine.
Auf der anderen Seite darf der Cold-Bereich zu jedem Zeitpunkt Teile seines Inhalts in den persistenten Speicher auslagern. Es gibt kein maximales Budget, außer dem, was verfügbar ist. Und natürlich ist es in Bezug auf die Leistung nicht sicher möglich, vom Cold-Bereich zu lesen.
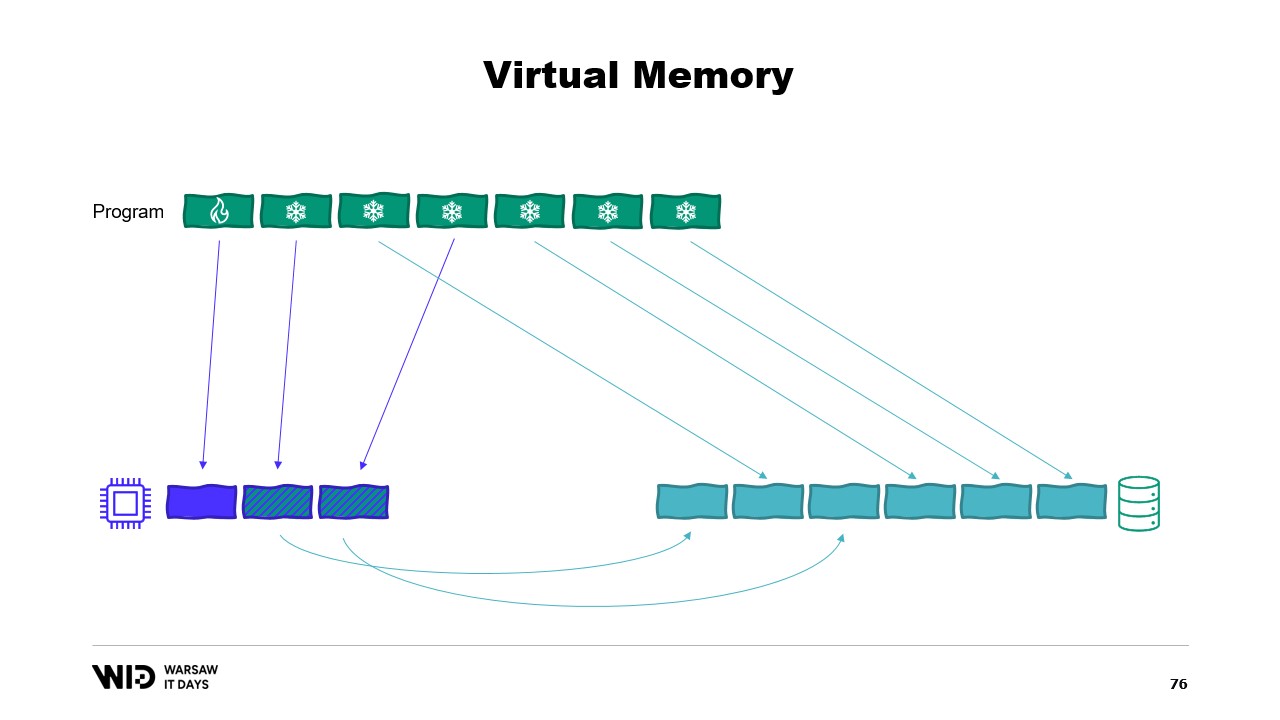
Das Programm wird also Hot-Cold-Transfers nutzen. Diese beinhalten in der Regel große Chargen, um die Nutzung der NVMe-Bandbreite zu maximieren. Und da die Chargen ziemlich groß sind, werden sie auch in einer relativ geringen Frequenz durchgeführt. Somit ist es der Cold-Bereich, der es diesen Algorithmen ermöglicht, so viel Speicher wie möglich zu nutzen.

Denn der Cold-Bereich wird so viel RAM füllen, wie verfügbar ist, und den Rest in den persistenten Speicher auslagern. Wie können wir das also in .NET zum Laufen bringen? Da ich dies den ersten Versuch nenne, können Sie sich denken, dass es nicht funktionieren wird. Versuchen Sie also im Voraus herauszufinden, was das Problem sein wird.
Für den Hot-Bereich werde ich normale .NET-Objekte verwenden, und das Problem werden wir uns anhand eines normalen .NET-Programms ansehen. Für den Cold-Bereich werde ich eine sogenannte Referenzklasse verwenden. Diese Klasse hält eine Referenz auf den Wert, der in den Cold-Speicher abgelegt wird, und dieser Wert kann auf null gesetzt werden, wenn er nicht mehr im Speicher ist. Sie verfügt über eine Spill-Funktion, die den Wert aus dem Speicher nimmt, ihn in den Speicher schreibt und anschließend die Referenz auf null setzt, wodurch der .NET-Garbage-Collector diesen Speicher freigeben kann, wenn er unter Druck steht.
Und schließlich besitzt sie eine Value-Eigenschaft. Auf diese Eigenschaft zurückgegriffen wird, um den Wert aus dem Speicher zurückzugeben, falls vorhanden, und falls nicht, wird er von der Festplatte wieder in den Speicher geladen, bevor er zurückgegeben wird. Wenn ich nun ein zentrales System in meinem Programm einrichte, das alle Cold-Referenzen verfolgt, kann ich jedes Mal, wenn eine neue Cold-Referenz erstellt wird, feststellen, ob dadurch der Speicher überläuft, und die Spill-Funktion von einer oder mehreren der bereits im System vorhandenen Cold-Referenzen aufrufen, um innerhalb des verfügbaren Speicherbudgets für den Cold-Speicher zu bleiben.

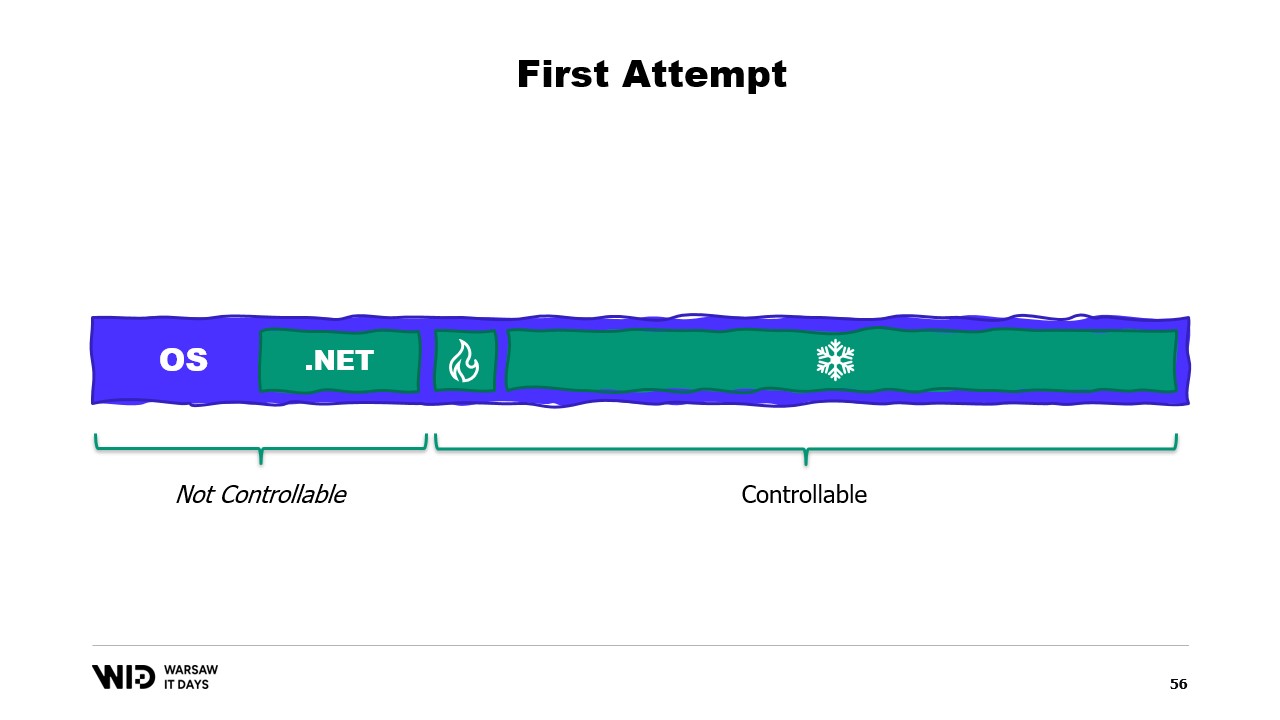
Also, was wird das Problem sein? Nun, wenn ich den Inhalt des Speichers einer Maschine betrachte, die unser Programm ausführt, wird es im Idealfall so aussehen: Zuerst links befindet sich der Speicher des Betriebssystems, den es für seine eigenen Zwecke verwendet. Dann folgt der interne Speicher, den .NET für Dinge wie geladene Assemblies oder den Overhead des Garbage Collectors usw. nutzt. Danach folgt der Speicher des Hot-Bereichs und schließlich beansprucht der Cold-Bereich den restlichen Speicher.
Mit einigem Aufwand können wir alles auf der rechten Seite kontrollieren, da das das ist, was wir zuweisen und für die Sammlung durch den Garbage Collector freigeben. Was jedoch auf der linken Seite liegt, liegt außerhalb unserer Kontrolle. Und was passiert, wenn das Betriebssystem plötzlich zusätzlichen Speicher benötigt und feststellt, dass alles von dem belegt wird, was der .NET-Prozess erstellt hat?
In einem solchen Fall wird die typische Reaktion, sagen wir, des Linux-Kernels darin bestehen, das Programm zu beenden, das am meisten Speicher verwendet, und es gibt keine Möglichkeit, schnell genug zu reagieren, um etwas Speicher an den Kernel zurückzugeben, sodass er uns nicht tötet. Also, was ist die Lösung?

Moderne Betriebssysteme verfügen über das Konzept des virtuellen Speichers. Das Programm hat keinen direkten Zugriff auf physische Speicherseiten. Stattdessen hat es Zugriff auf virtuelle Speicherseiten, und es gibt eine Zuordnung zwischen diesen Seiten und den tatsächlichen Seiten im physischen Speicher. Wenn ein anderes Programm auf demselben Computer läuft, kann es nicht eigenständig auf die Seiten des ersten Programms zugreifen. Es gibt jedoch Möglichkeiten zum Teilen.
Es ist möglich, eine speicherabbildete Seite zu erstellen. In diesem Fall wird alles, was das erste Programm in die freigegebene Seite schreibt, sofort vom anderen Teil sichtbar sein. Dies ist eine häufige Methode, um die Kommunikation zwischen Programmen zu implementieren, aber der Hauptzweck besteht darin, Dateien speicherzuordnend zu behandeln. Hier weiß das Betriebssystem, dass diese Seite eine exakte Kopie einer Seite im persistenten Speicher ist, üblicherweise Teile einer Shared-Library-Datei.
Der Hauptzweck besteht darin, zu verhindern, dass jedes Programm seine eigene Kopie der DLL im Speicher hat, da all diese Kopien identisch sind und es daher keinen Grund gibt, Speicherplatz für diese Kopien zu verschwenden. Hier haben wir beispielsweise zwei Programme, die insgesamt vier Seiten Speicher belegen, während im physischen Speicher nur Platz für drei Seiten ist. Was passiert nun, wenn wir im ersten Programm eine weitere Seite zuweisen wollen? Es ist kein Platz verfügbar, aber der Kernel weiß, dass die speicherabbildete Seite vorübergehend verworfen werden kann und bei Bedarf identisch aus dem persistenten Speicher neu geladen werden kann.
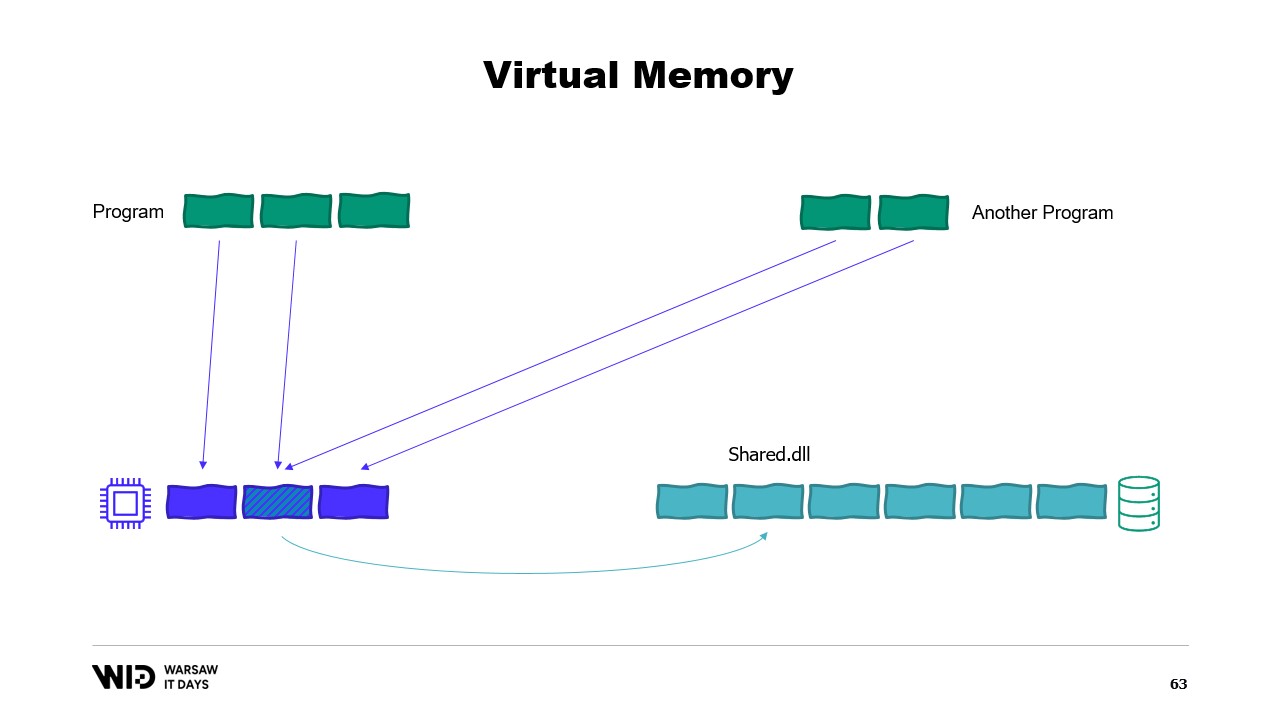
Und so wird es genau das tun. Die beiden freigegebenen Seiten werden nun auf die Festplatte zeigen anstatt auf den Speicher. Der Speicher wird vom Betriebssystem gelöscht, auf null gesetzt und dann dem ersten Programm für seine dritte logische Seite zugewiesen. Nun ist der Speicher vollständig belegt, und wenn eines der Programme versucht, auf die freigegebene Seite zuzugreifen, gibt es keinen Platz mehr, um sie wieder in den Speicher zu laden, da Seiten, die Programmen zugewiesen wurden, vom Betriebssystem nicht zurückgeholt werden können.
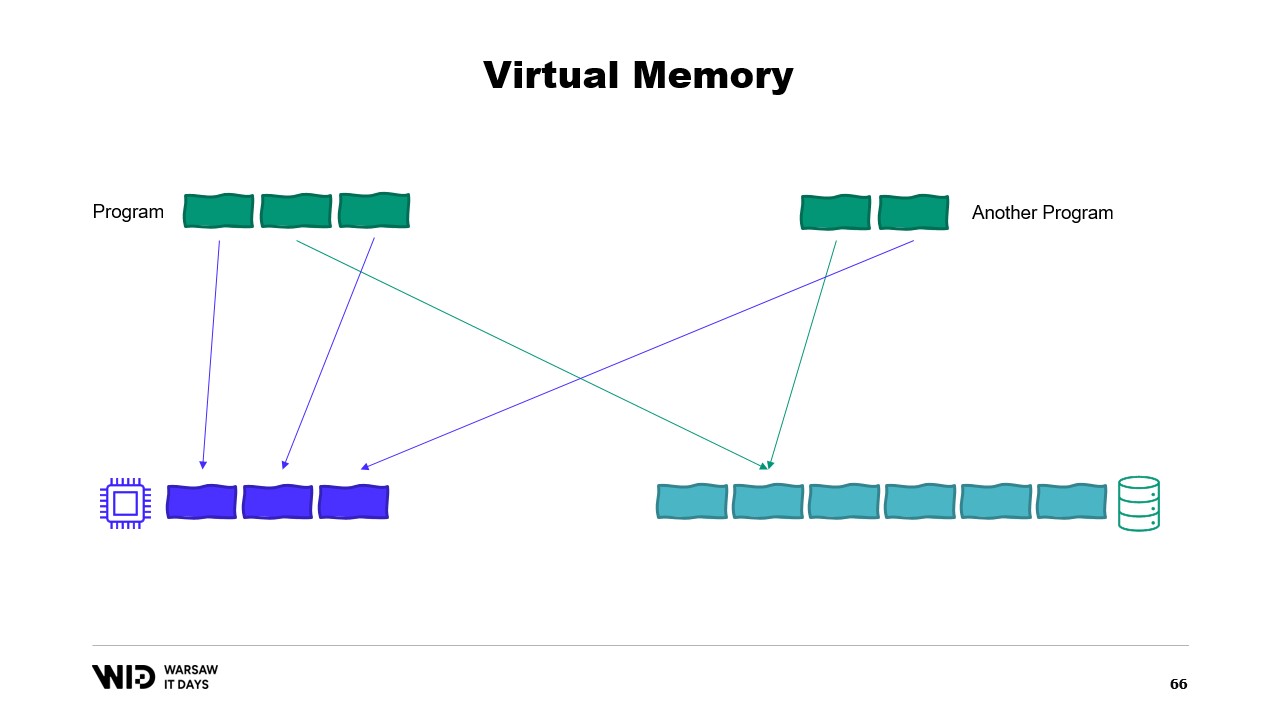
Also, es wird hier zu einem Out-of-Memory-Fehler kommen. Eines der Programme wird beendet, der Speicher wird freigegeben und dann neu zugewiesen, um die speicherabbildete Datei wieder in den Speicher zu laden. Obwohl die meisten Speicherabbildungen schreibgeschützt sind, ist es auch möglich, welche zu erstellen, die Lese-/Schreibzugriff erlauben.
Ein Programm ändert den Inhalt des Speichers auf der abgebildeten Seite, und dann wird das Betriebssystem zu einem späteren Zeitpunkt den Inhalt dieser Seite wieder auf die Festplatte speichern. Natürlich ist es möglich, dies zu einem bestimmten Zeitpunkt anzufordern, indem man Funktionen wie flush unter Windows verwendet. Das System Performance Tool verfügt über ein schönes Fenster, das die aktuelle Nutzung des physischen Speichers anzeigt.
Grün dargestellt ist der Speicher, der einem Prozess direkt zugewiesen wurde. Er kann nicht freigegeben werden, ohne den Prozess zu beenden. Blau zeigt den Seiten-Cache. Das sind Seiten, von denen bekannt ist, dass sie identische Kopien einer Seite auf der Festplatte sind, sodass, wenn ein Prozess von der Festplatte eine Seite lesen muss, die bereits im Cache vorhanden ist, kein Festplattenzugriff erfolgt und der Wert direkt aus dem Speicher zurückgegeben wird.
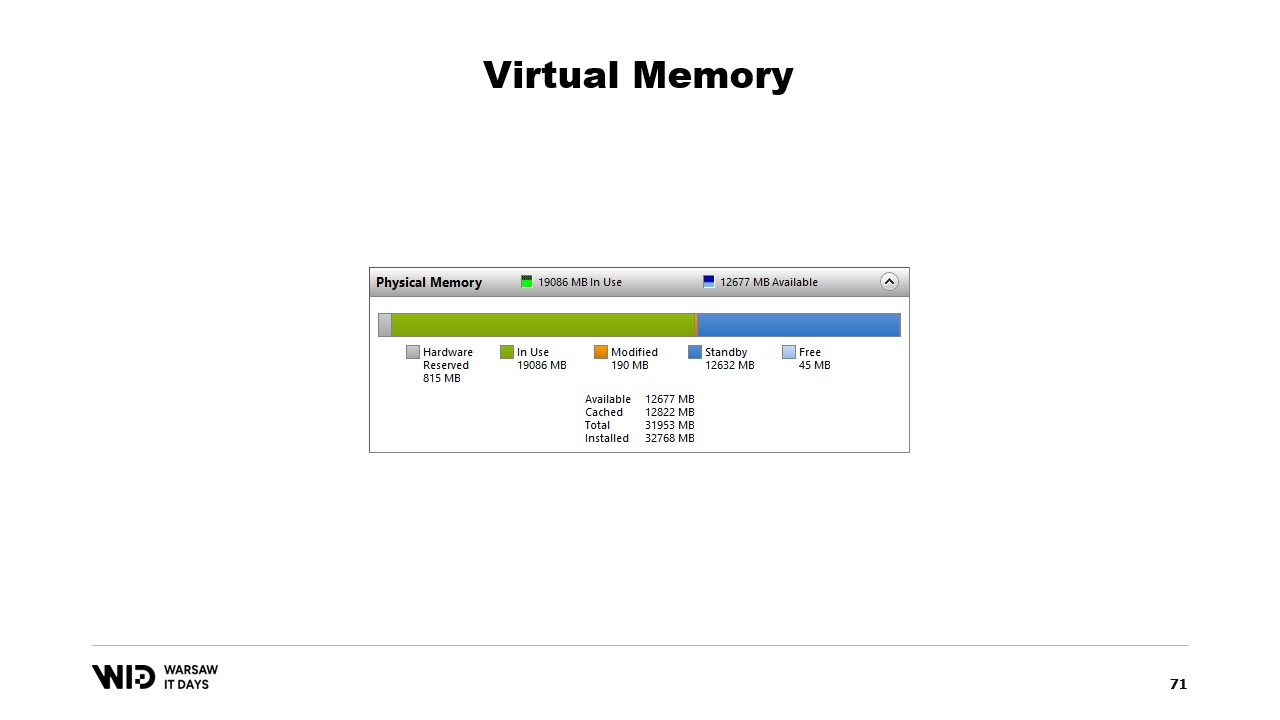
Schließlich befinden sich in der Mitte die modifizierten Seiten, die eine exakte Kopie der Festplatte sein sollten, jedoch Änderungen im Speicher enthalten. Diese Änderungen wurden noch nicht zurück auf die Festplatte übertragen, werden es aber in ziemlich kurzer Zeit. Unter Linux zeigt das h-stop-Tool ein ähnliches Diagramm. Links sind die Seiten, die direkt Prozessen zugewiesen wurden und ohne deren Beenden nicht freigegeben werden können, und rechts in Gelb befindet sich der Seiten-Cache.

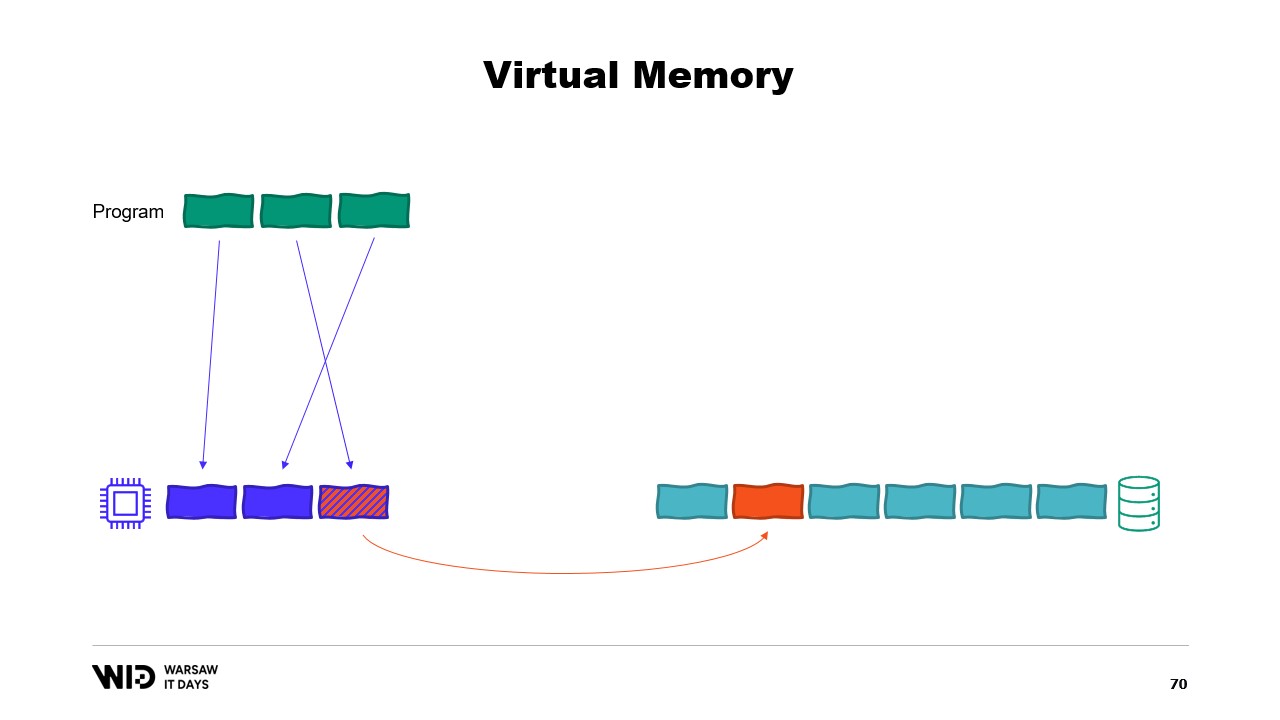
Falls Sie interessiert sind, gibt es eine ausgezeichnete Ressource von Vyacheslav Biryukov darüber, was im Linux-Seiten-Cache vor sich geht. Unter Verwendung von virtuellem Speicher versuchen wir einen zweiten Anlauf. Wird es diesmal funktionieren? Nun entscheiden wir, dass der kalte Abschnitt ausschließlich aus speicherabbildgemappten Seiten besteht. Daher wird erwartet, dass alle zunächst auf der Festplatte vorhanden sind.
Das Programm hat keine Kontrolle mehr darüber, welche Seiten im Speicher sind und welche ausschließlich auf der Festplatte vorhanden sind. Das Betriebssystem erledigt das transparent. Wenn das Programm also versucht, beispielsweise auf die dritte Seite im kalten Abschnitt zuzugreifen, erkennt das Betriebssystem, dass sie nicht im Speicher vorhanden ist, entlädt eine der vorhandenen Seiten – sagen wir die zweite – und lädt anschließend die dritte Seite in den Speicher.
Aus der Sicht des Prozesses selbst war dies völlig transparent. Das Warten auf das Lesen aus dem Speicher dauerte nur ein wenig länger als üblich. Und was passiert, wenn das Betriebssystem plötzlich etwas Speicher benötigt, um eigene Aufgaben zu erfüllen? Nun, es weiß, welche Seiten speicherabbildgemappt sind und gefahrlos verworfen werden können. Daher wird es einfach eine der Seiten verwerfen, sie für eigene Zwecke nutzen und sie nach Abschluss wieder freigeben.
All diese Techniken gelten für .NET und sind im Open-Source-Projekt Lokad Scratch Space enthalten. Der Großteil des folgenden Codes basiert darauf, wie dieses NuGet-Paket die Dinge handhabt.

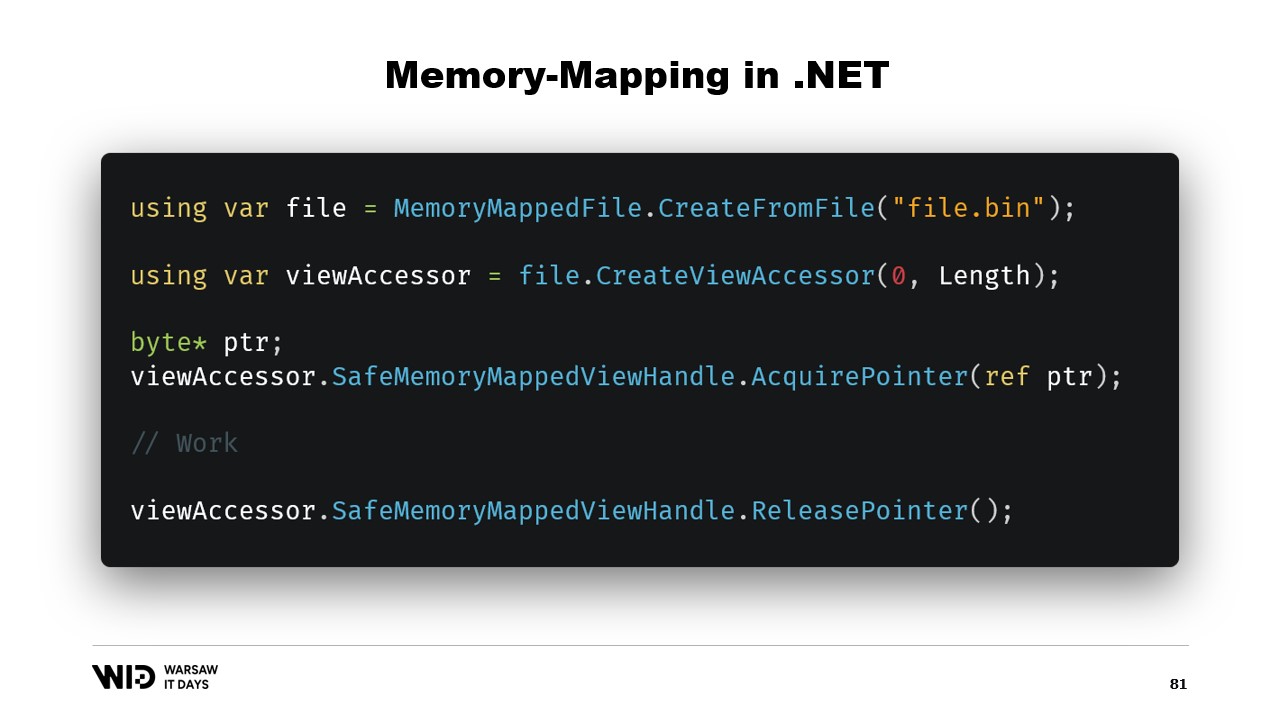
Zuerst, wie würden wir eine speicherabbildgemappte Datei in .NET erstellen? Memory Mapping gibt es seit dem .NET Framework 4, also seit etwa 13 Jahren. Es ist recht gut im Internet dokumentiert und der Quellcode ist vollständig auf GitHub verfügbar.

Die grundlegenden Schritte bestehen darin, zuerst eine speicherabbildgemappte Datei aus einer Datei auf der Festplatte zu erstellen und anschließend einen View Accessor zu erzeugen. Diese beiden Typen werden getrennt gehalten, da sie unterschiedliche Bedeutungen haben. Die speicherabbildgemappte Datei teilt dem Betriebssystem lediglich mit, dass bestimmte Bereiche dieser Datei in den Speicher des Prozesses abgebildet werden. Der View Accessor selbst repräsentiert diese Abbildungen.
Die beiden werden getrennt gehalten, da .NET mit dem Fall eines 32-Bit-Prozesses umgehen muss. Eine sehr große Datei, also eine, die größer als vier Gigabyte ist, kann nicht in den Adressraum eines 32-Bit-Prozesses abgebildet werden, da sie zu groß ist. Der Adressraum ist nicht groß genug, um sie darzustellen. Stattdessen ist es möglich, nur kleine Abschnitte der Datei jeweils so abzubilden, dass sie passen.
In unserem Fall arbeiten wir mit 64-Bit-Zeigern. Daher können wir einfach einen einzigen View Accessor erstellen, der die gesamte Datei lädt. Nun benutze ich AcquirePointer, um den Zeiger auf die ersten Bytes dieses speicherabbildgemappten Speicherbereichs zu erhalten. Sobald ich mit dem Zeiger fertig bin, kann ich ihn einfach freigeben. Die Arbeit mit Zeigern in .NET ist unsicher. Es erfordert, dass überall das Schlüsselwort unsafe verwendet wird, und es kann zu Abstürzen kommen, wenn versucht wird, auf Speicher außerhalb des erlaubten Bereichs zuzugreifen.
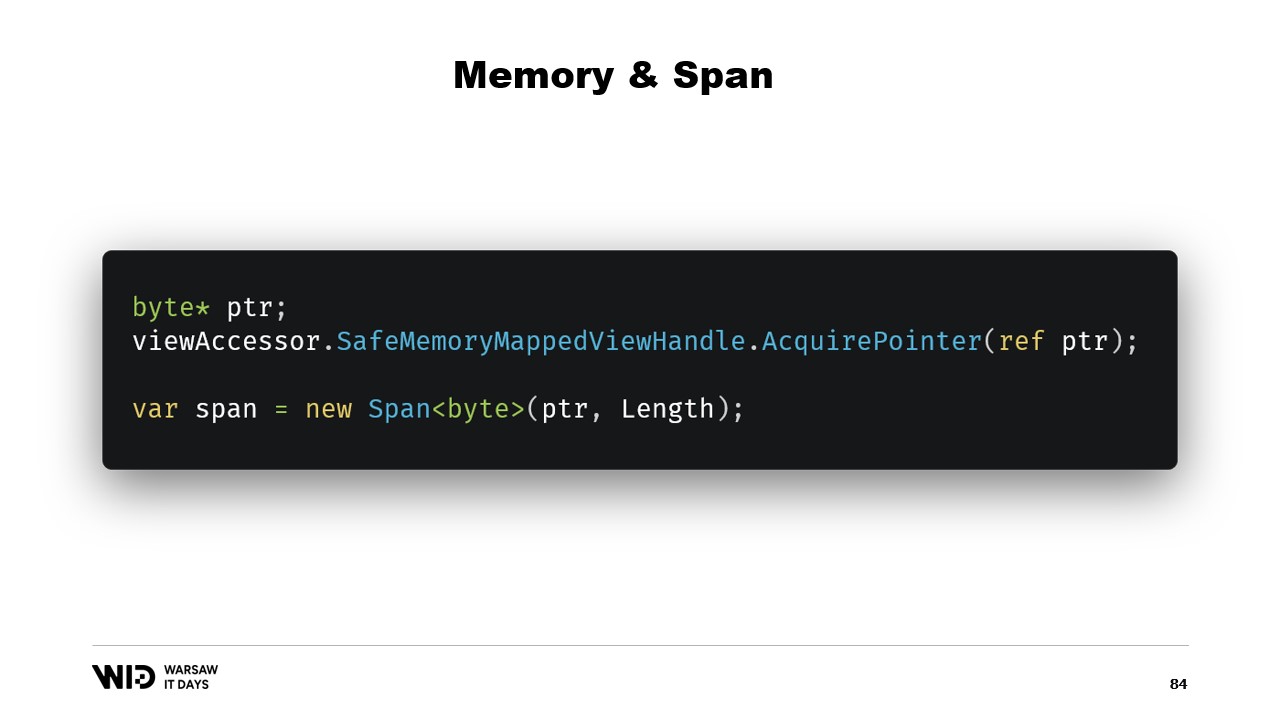
Glücklicherweise gibt es einen Weg, dies zu umgehen. Vor fünf Jahren führte .NET die Typen Memory und Span ein. Diese werden verwendet, um einen Speicherbereich auf eine sicherere Weise als mit reinen Zeigern darzustellen. Es ist recht gut dokumentiert und der Großteil des Codes ist an dieser Stelle auf GitHub zu finden.

Die Grundidee hinter Span und Memory lautet, dass man, gegeben einen Zeiger und eine Anzahl von Bytes, einen neuen Span erstellen kann, der diesen Speicherbereich repräsentiert.
Sobald man diesen Span hat, kann man sicher innerhalb dieses Bereichs lesen, in dem Wissen, dass, wenn man versucht, über die Grenzen hinaus zu lesen, die Laufzeit den Verstoß auffängt und statt einfach den Prozess zu beenden, eine Ausnahme ausgelöst wird.
Schauen wir mal, wie wir Span verwenden können, um aus speicherabbildgemapptem Speicher in den verwalteten .NET-Speicher zu laden. Denken Sie daran, dass wir aus Leistungsgründen nicht direkt auf den kalten Abschnitt zugreifen möchten. Stattdessen wollen wir Transfers von kalt zu heiß durchführen, die große Mengen an Daten gleichzeitig laden.
Zum Beispiel nehmen wir an, wir haben einen String, den wir lesen möchten. Er wird in der speicherabbildgemappten Datei als eine Größe, gefolgt von einer UTF-8-kodierten Bytes-Nutzlast, abgelegt, und wir möchten daraus einen .NET-String laden.
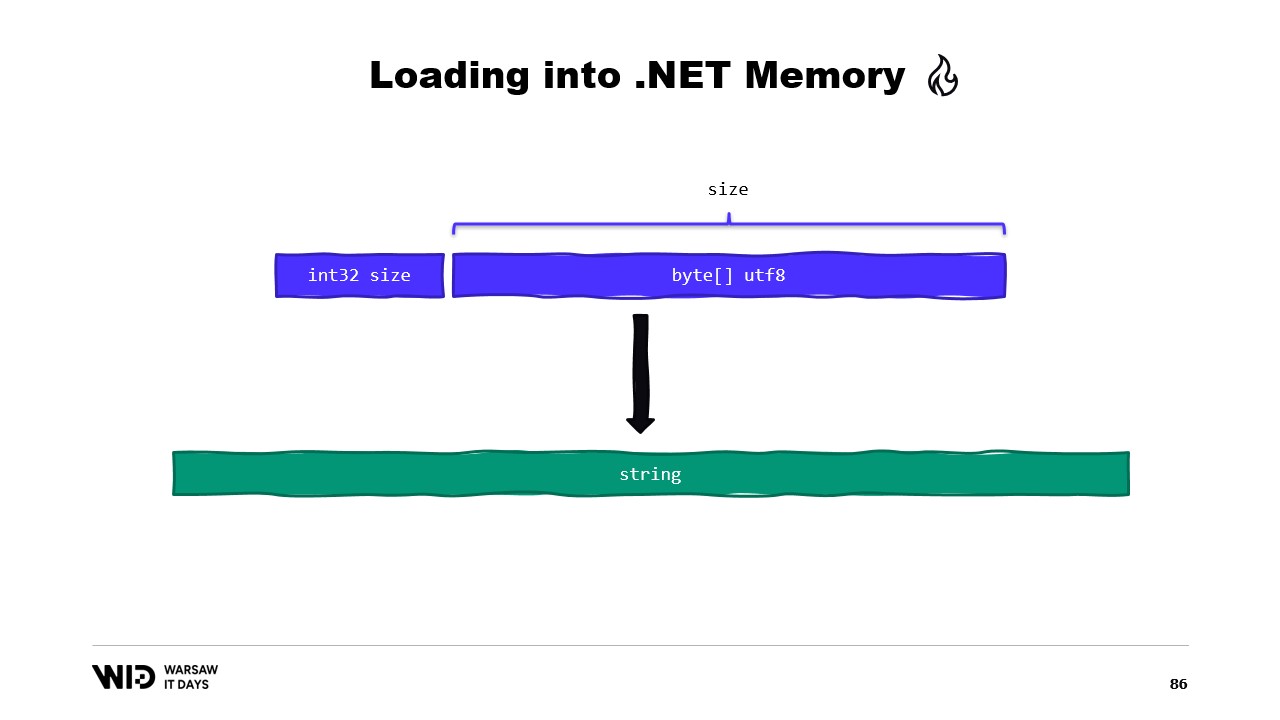
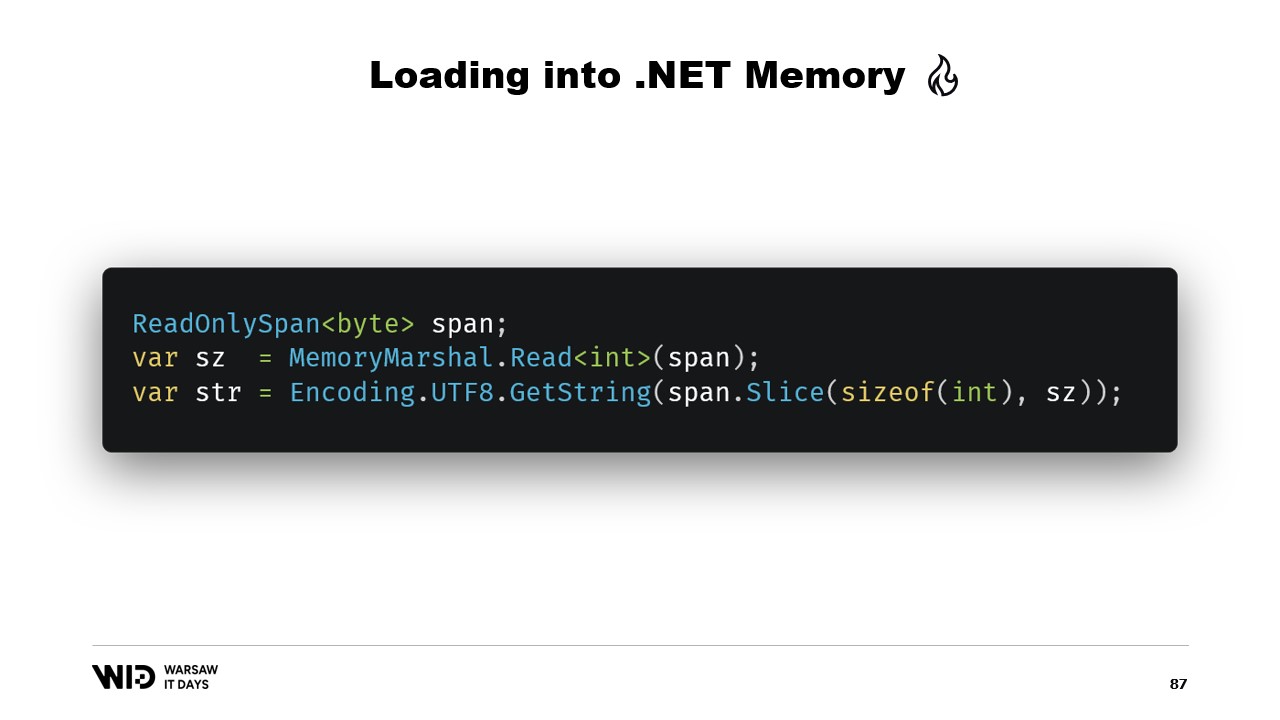
Nun, es gibt viele APIs, die auf Spans basieren und die wir verwenden können. Beispielsweise kann MemoryMarshal.Read einen Integer vom Beginn des Spans lesen. Anschließend kann ich mit dieser Größe die Funktion Encoding.GetString aufrufen, um aus einem Bytes-Span einen String zu laden.
All diese arbeiten mit Spans, und auch wenn der Span einen Datenabschnitt repräsentiert, der möglicherweise auf der Festplatte anstelle von im Speicher vorhanden ist, sorgt das Betriebssystem dafür, dass die Daten beim ersten Zugriff transparent in den Speicher geladen werden.
Ein weiteres Beispiel wäre eine Folge von Gleitkommazahlen, die wir in ein Float-Array laden möchten.
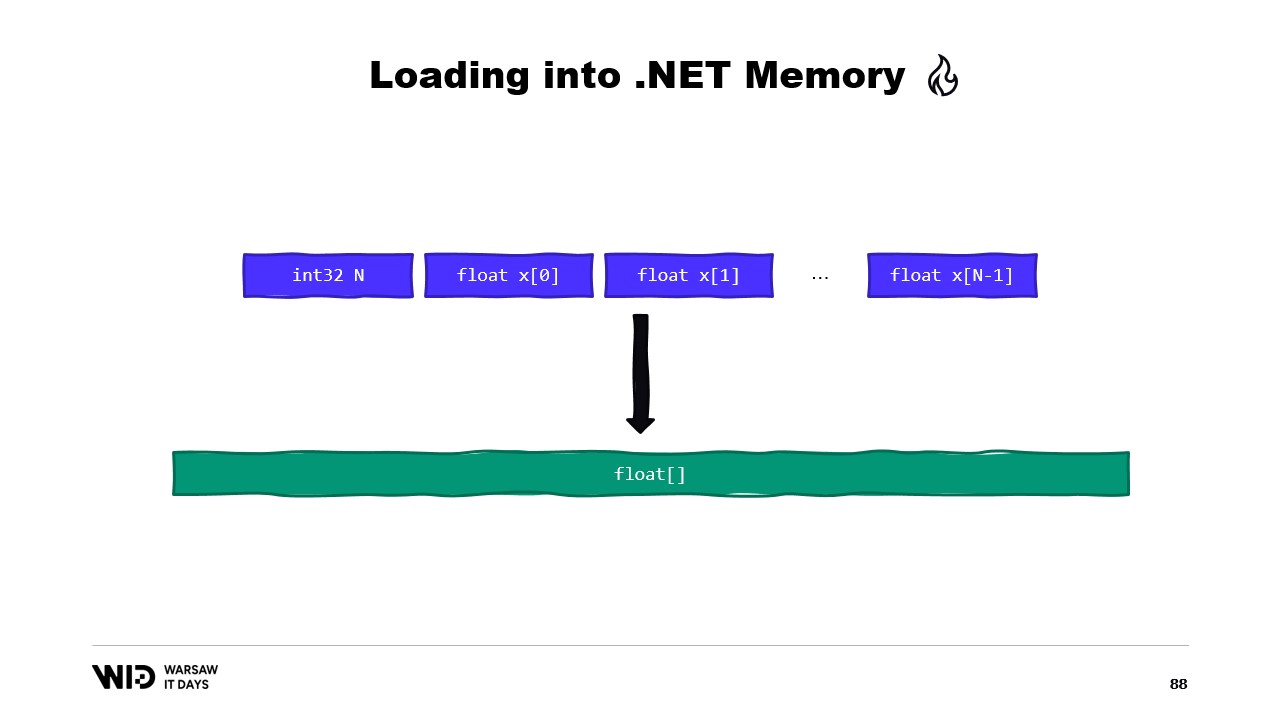
Auch hier verwenden wir MemoryMarshal.Read, um die Größe zu lesen. Wir allozieren ein Array von Gleitkommazahlen dieser Größe und nutzen dann MemoryMarshal.Cast, um den Bytes-Span in einen Span von Gleitkommazahlen umzuwandeln. Damit werden die im Span vorhandenen Daten tatsächlich als Gleitkommazahlen interpretiert, statt als einfache Bytes.
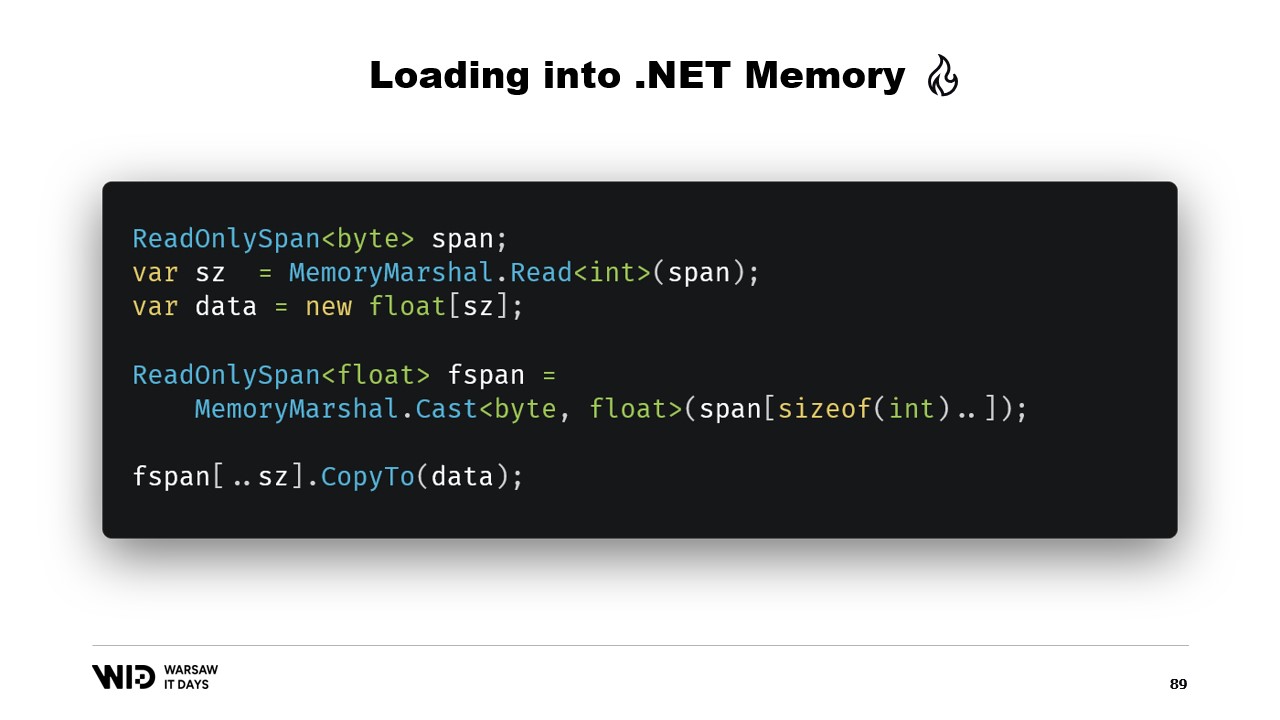
Schließlich verwenden wir die CopyTo-Funktion von Spans, die eine Hochleistungskopie der Daten von der speicherabbildgemappten Datei in das Array selbst durchführt. Dies ist in gewisser Weise etwas verschwenderisch, da wir eine völlig neue Kopie erstellen.
Vielleicht könnten wir das vermeiden. Normalerweise speichern wir auf der Festplatte nicht die rohen Gleitkommazahlen, sondern eine komprimierte Version davon. Hier speichern wir die komprimierte Größe, die angibt, wie viele Bytes gelesen werden müssen. Wir speichern die Zielfeldgröße beziehungsweise die dekomprimierte Größe, was uns mitteilt, wie viele Gleitkommazahlen wir im verwalteten Speicher allozieren müssen. Und schließlich speichern wir die komprimierte Nutzlast selbst.
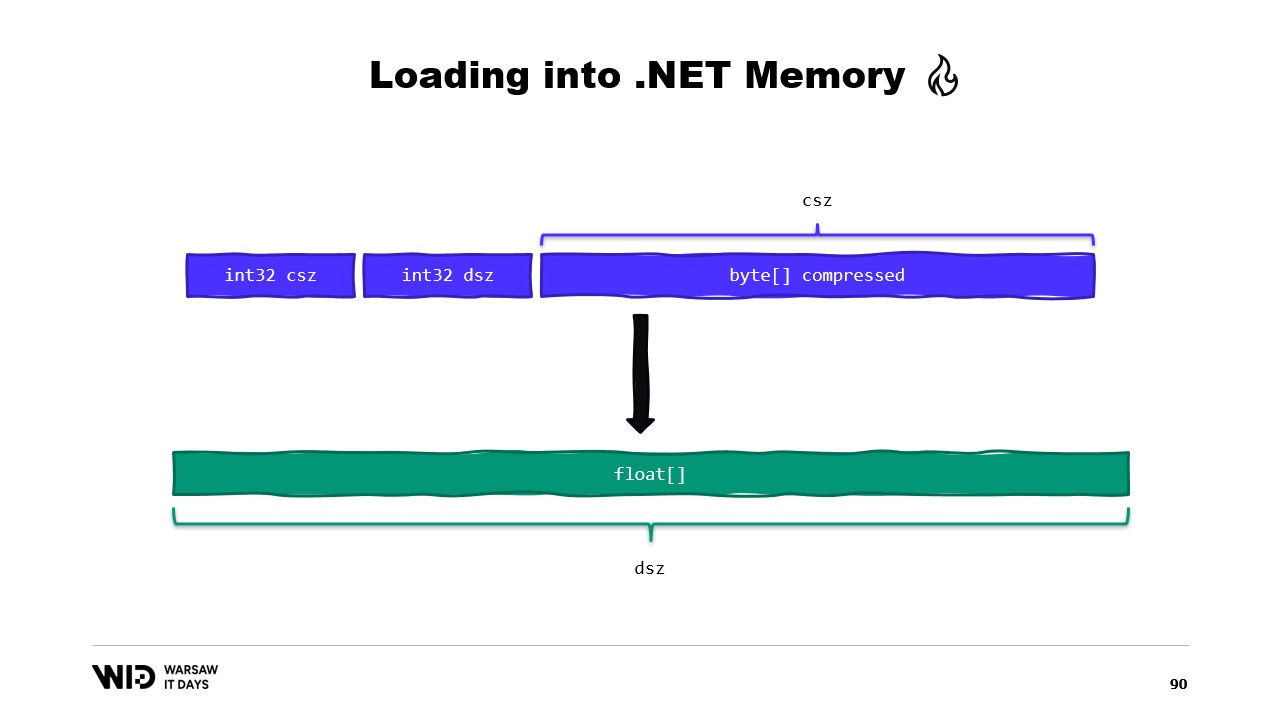
Um dies zu laden, ist es besser, anstatt zwei Integer zu lesen, eine Struktur zu erstellen, die diesen Header mit zwei Ganzzahlwerten darin repräsentiert.

MemoryMarshal kann eine Instanz dieser Struktur lesen und dabei beide Felder gleichzeitig laden. Wir allozieren ein Array von Gleitkommazahlen, und dann hat unsere Kompressionsbibliothek fast sicher eine Variante einer Dekompressionsfunktion, die einen read-only Bytes-Span als Eingabe und einen Bytes-Span als Ausgabe verwendet. Wiederum können wir MemoryMarshal.Cast einsetzen, um das Array von Gleitkommazahlen in einen Bytes-Span umzuwandeln, der als Ziel dient.
Nun ist keine Kopie involviert. Stattdessen liest der Kompressionsalgorithmus direkt von der Festplatte – in der Regel über den Seiten-Cache – in das Ziel-Array von Fließkommazahlen.

Span hat jedoch eine wesentliche Einschränkung, nämlich dass es nicht als Klassenmitglied verwendet werden kann und folglich auch nicht als lokale Variable in einer async-Methode.
Glücklicherweise gibt es einen anderen Typ, Memory, der verwendet werden sollte, um einen längerlebigen Datenbereich darzustellen.
Leider gibt es enttäuschend wenig Dokumentation darüber, wie man dies umsetzt. Einen Span aus einem Zeiger zu erstellen, ist einfach, aber das Erstellen eines Memory aus einem Zeiger ist so wenig dokumentiert, dass die beste verfügbare Dokumentation ein Gist auf GitHub ist, das ich Ihnen dringend empfehle zu lesen.
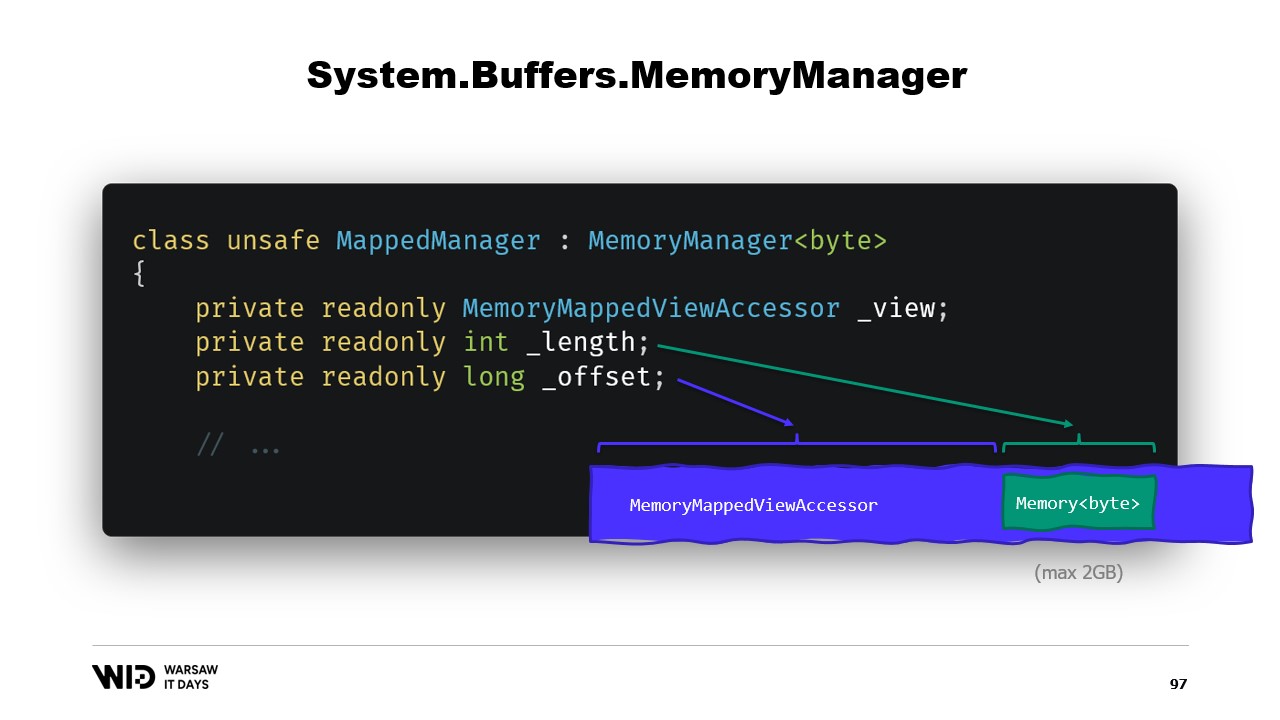
Kurz gesagt, was wir tun müssen, ist einen MemoryManager zu erstellen. Der MemoryManager wird intern von einem Memory verwendet, sobald etwas Komplexeres als das einfache Zeigen auf einen Abschnitt eines Arrays erforderlich ist.
In unserem Fall müssen wir auf den speicherabbildgemappten View Accessor verweisen, in den wir hineinschauen. Wir müssen die Länge kennen, die wir betrachten dürfen, und schließlich benötigen wir einen Offset. Dies liegt daran, dass ein Memory von Bytes per Design nicht mehr als zwei Gigabyte repräsentieren kann und die Datei selbst wahrscheinlich länger als zwei Gigabyte ist. Der Offset gibt uns somit den Startpunkt des Speichers innerhalb des größeren View Accessor an.
Der Konstruktor der Klasse ist ziemlich einfach.

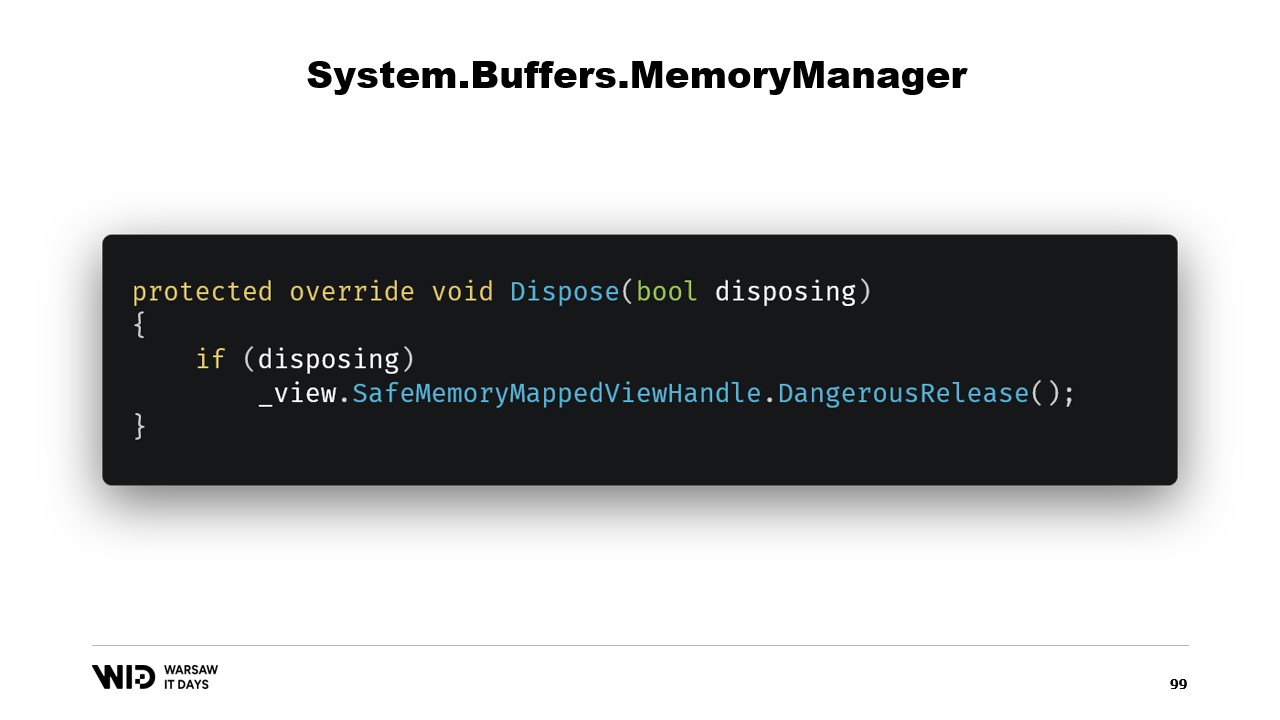
Wir müssen lediglich eine Referenz auf den Safe Handle hinzufügen, der den Speicherbereich repräsentiert, und diese Referenz wird in der Dispose-Funktion freigegeben.
Als Nächstes haben wir eine Address-Eigenschaft, die zwar nicht besonders aufregend ist, aber nützlich für uns ist. Wir verwenden DangerousGetHandle, um einen Zeiger zu erhalten, und addieren den Offset, sodass die Adresse auf die ersten Bytes des Bereichs zeigt, den unser Memory repräsentieren soll.
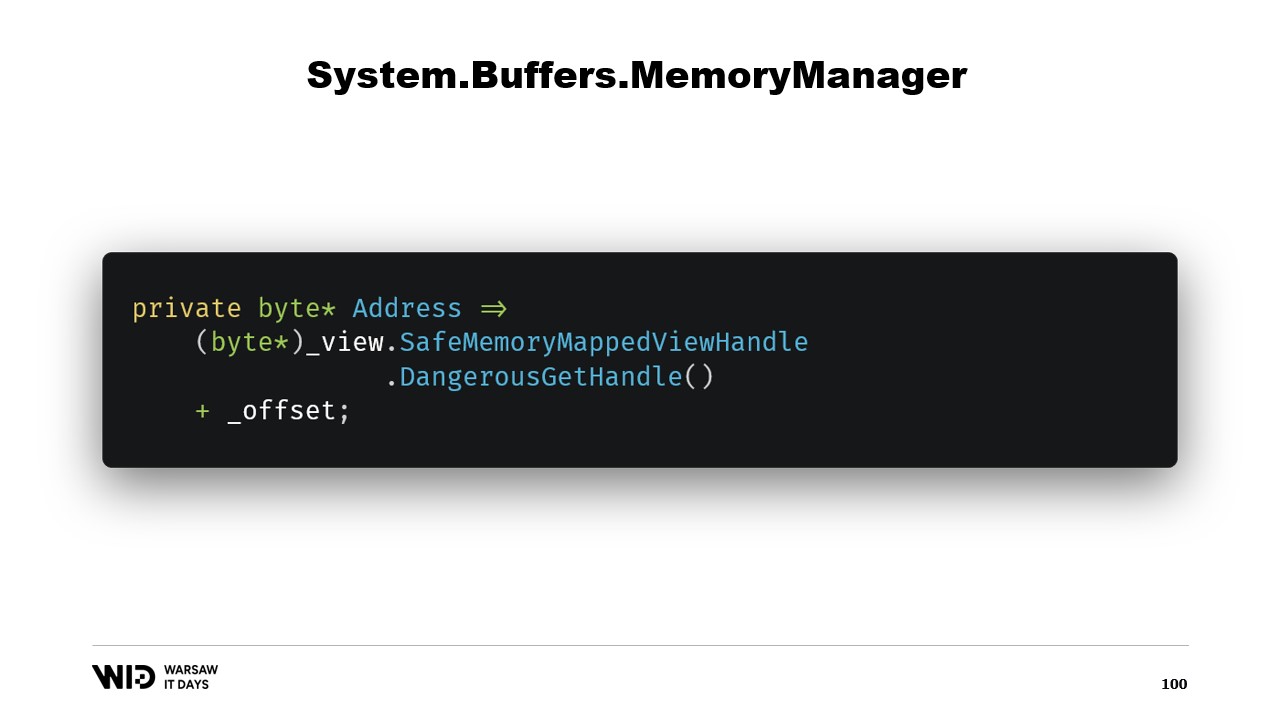
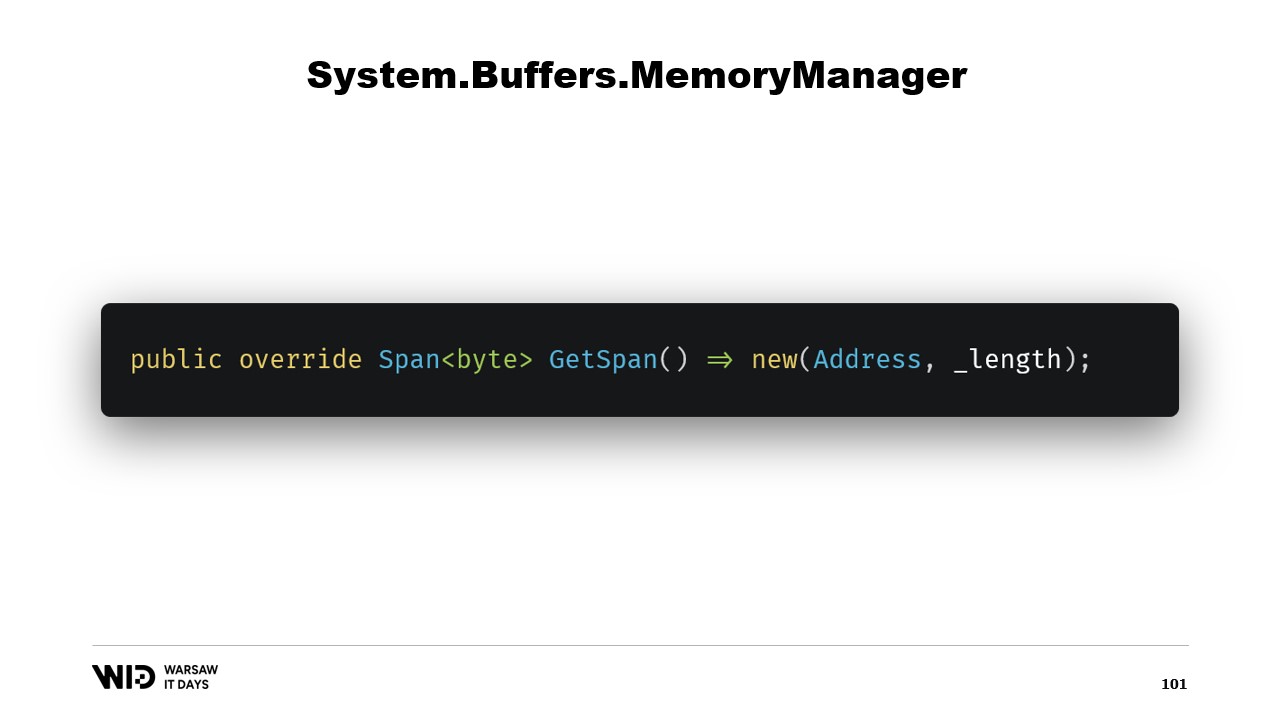
Wir überschreiben die GetSpan-Funktion, die die ganze Magie bewirkt. Sie erstellt einfach einen Span unter Verwendung der Adresse und der Länge.
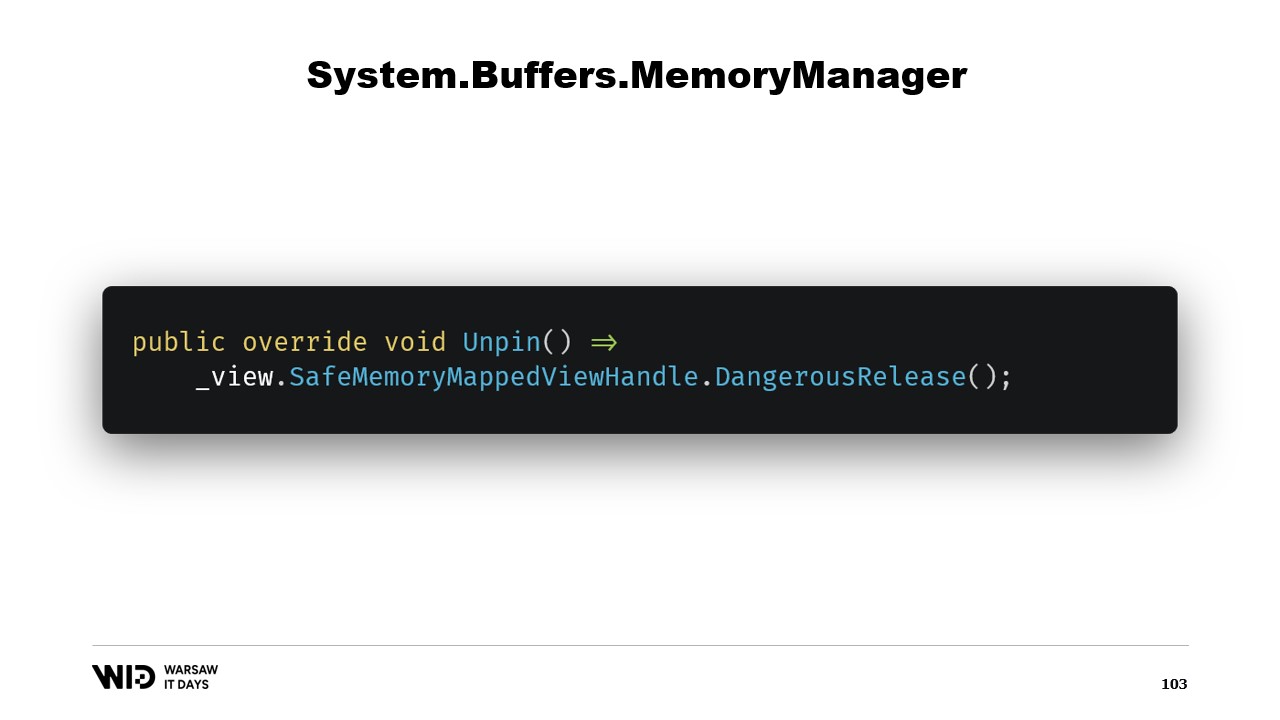
Es gibt zwei weitere Methoden, die im MemoryManager implementiert werden müssen. Eine davon ist Pin. Sie wird von der Laufzeit in Fällen verwendet, in denen der Speicher für eine kurze Zeit an derselben Stelle verbleiben muss. Wir fügen eine Referenz hinzu und geben einen MemoryHandle zurück, der auf die korrekte Position zeigt und zudem das aktuelle Objekt als pinnable referenziert.

Dies teilt der Laufzeit mit, dass, wenn der Speicher entpinnt wird, die Unpin-Methode dieses Objekts aufgerufen wird, was erneut zur Freigabe des Safe Handles führt.
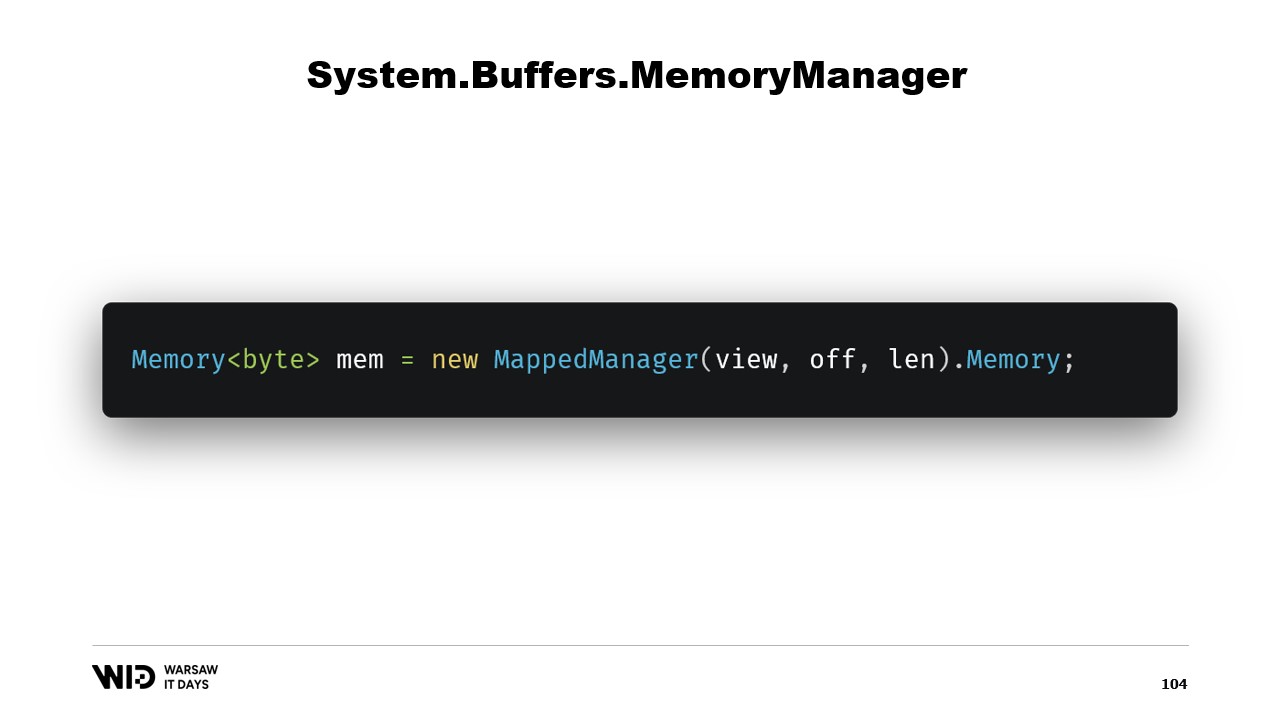
Sobald diese Klasse erstellt wurde, genügt es, eine Instanz davon zu erzeugen und auf ihre Memory-Eigenschaft zuzugreifen, die ein Memory von Bytes zurückgibt, welches intern auf den gerade erstellten MemoryManager verweist. Und da haben Sie es – nun haben Sie ein Stück Speicher. Wenn Sie darauf schreiben, wird er automatisch auf die Festplatte ausgelagert, wenn Platz benötigt wird, und beim Zugriff transparent von der Festplatte wieder eingelesen.
Das genügt, um unser Spill-to-Disk-Programm zu implementieren. Es stellt sich jedoch noch die Frage, warum Memory Mapping verwendet werden sollte, wenn stattdessen FileStream eingesetzt werden könnte? Schließlich ist FileStream die naheliegende Wahl, um auf Daten zuzugreifen, die auf der Festplatte liegen, und seine Verwendung ist sehr gut dokumentiert. Um beispielsweise ein Array von Gleitkommazahlen zu lesen, benötigt man einen FileStream und einen BinaryReader, der um den FileStream gewickelt ist. Sie setzen die Position des FileStream auf den Offset, an dem die Daten in der Datei vorhanden sind, lesen mit dem Reader ein Int32, allozieren das Array von Gleitkommazahlen und wandeln es mithilfe von MemoryMarshal.Cast in einen Bytes-Span um.
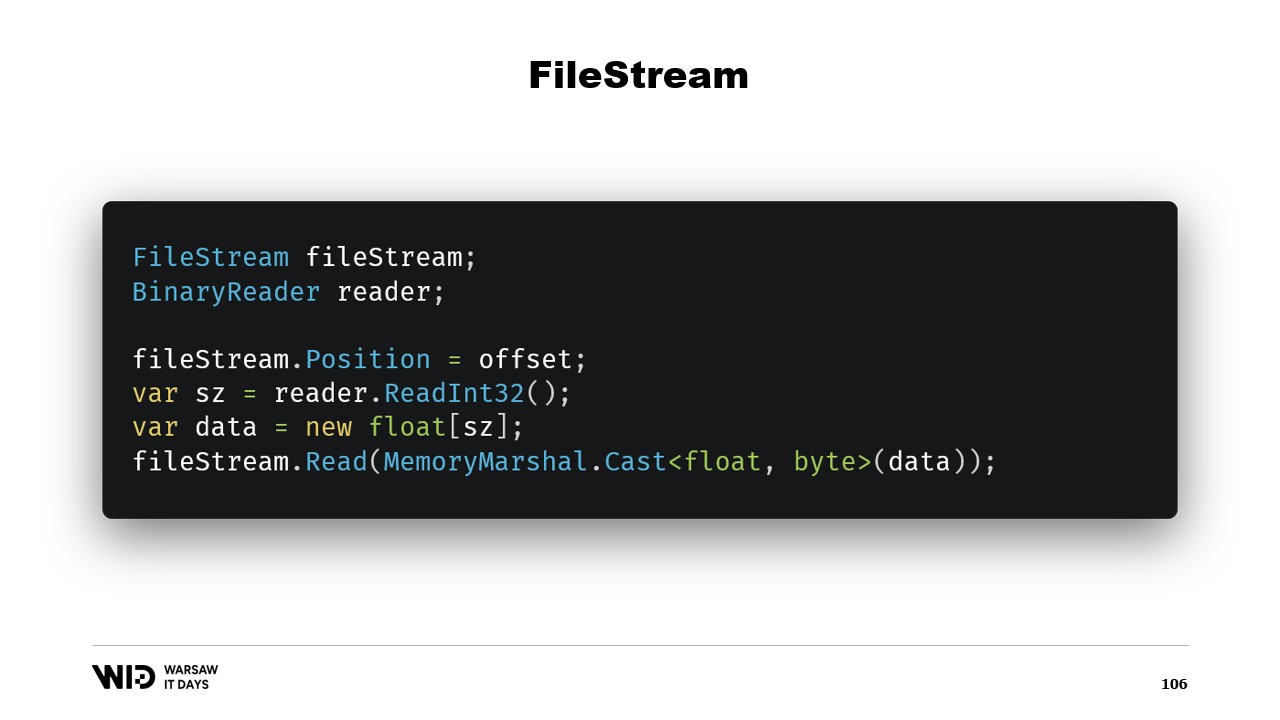
FileStream.Read verfügt nun über eine Überladung, die einen Bytes-Span als Ziel akzeptiert. Dies nutzt ebenfalls den Seiten-Cache. Anstatt diese Seiten in den Adressraum Ihres Prozesses zu memory mappen, behält das Betriebssystem sie einfach, und um die Werte zu lesen, lädt es sie von der Festplatte in den Speicher und kopiert dann von dieser Seite in den von Ihnen bereitgestellten Ziel-Span. In Bezug auf Leistung und Verhalten ist dies also gleichwertig zu dem, was in der speicherabbildgemappten Version geschah.
Es gibt jedoch zwei wesentliche Unterschiede. Erstens ist dies nicht threadsicher. Sie setzen die Position in einer Zeile, und in einer anderen Anweisung verlassen Sie sich darauf, dass diese Position unverändert bleibt. Das bedeutet, dass Sie einen Lock um diese Operation benötigen und somit nicht von mehreren Stellen parallel lesen können, obwohl dies bei Memory Map Files möglich ist.
Ein weiteres Problem ist, dass je nach der vom FileStream verwendeten Strategie zwei Lesevorgänge durchgeführt werden – einer für das Int32 und einer für das Lesen in den Span. Eine Möglichkeit ist, dass jeder von ihnen einen Systemaufruf tätigt. Dabei ruft er das Betriebssystem auf, und das Betriebssystem kopiert einige Daten aus seinem eigenen Speicher in den Speicher des Prozesses. Das verursacht einen gewissen Overhead. Die andere Möglichkeit ist, dass der Stream gepuffert ist. In diesem Fall würde das initiale Lesen von vier Bytes wahrscheinlich eine Kopie einer Seite erzeugen, zusätzlich zu der eigentlichen Kopie, die später von der Lese-Funktion durchgeführt wird. Dadurch entsteht ein Overhead, der bei der speicherabbildgemappten Version nicht vorhanden ist.
Aus diesem Grund ist die speicherabbildgemappte Version in Bezug auf die Leistung vorzuziehen. Schließlich ist FileStream die naheliegende Wahl, um auf Daten zuzugreifen, die auf der Festplatte liegen, und seine Verwendung ist sehr gut dokumentiert. Um beispielsweise ein Array von Gleitkommazahlen zu lesen, benötigen Sie einen FileStream, einen BinaryReader. Sie setzen die Position des FileStream auf den Offset, an dem die Daten in der Datei vorhanden sind, lesen ein Int32, um die Größe zu ermitteln, allozieren das Array von Gleitkommazahlen, wandeln es mithilfe von MemoryMarshal.Cast in einen Bytes-Span um und übergeben es an die Überladung von FileStream.Read, die einen Bytes-Span als Ziel für das Lesen erwartet. Auch dies nutzt den Seiten-Cache. Anstatt dass die Seiten mit dem Prozess assoziiert sind, werden sie vom Betriebssystem selbst behalten, das sie einfach von der Festplatte in den Seiten-Cache lädt und von dort in den Speicher des Prozesses kopiert – genau wie wir es bei der speicherabbildgemappten Version gemacht haben.
Der FileStream-Ansatz hat jedoch zwei große Nachteile. Der erste besteht darin, dass dieser Code nicht threadsicher ist. Schließlich wird die Position in einer Anweisung festgelegt und dann in den folgenden Anweisungen verwendet. Deshalb benötigen wir einen Lock für diese Lesevorgänge. Die speicherabbildete Version benötigt keine Locks und kann tatsächlich von mehreren Stellen auf der Festplatte parallel laden. Bei SSDs erhöht dies die Warteschlangentiefe, was die Leistung steigert und somit in der Regel erwünscht ist. Das andere Problem besteht darin, dass der FileStream zwei Lesevorgänge durchführt.
Je nach der intern vom Stream verwendeten Strategie kann dies zu zwei Systemaufrufen führen, die das Betriebssystem aktivieren müssen. Es kopiert einige Daten aus seinem eigenen Speicher in den Prozessspeicher und muss dann alles bereinigen und die Kontrolle an den Prozess zurückgeben. Dies verursacht einen gewissen Overhead. Die andere mögliche Strategie besteht darin, dass der FileStream gepuffert ist. In diesem Fall würde nur ein Systemaufruf durchgeführt, allerdings würde dies einen Kopiervorgang vom Betriebssystemspeicher in den internen Puffer des FileStream beinhalten, und dann müsste die Leseanweisung erneut aus dem internen Puffer des FileStream in das Gleitkomma-Array kopieren. Dadurch entsteht eine verschwenderische Kopie, die bei der speicherabbildeten Version nicht auftritt.
Der FileStream, obwohl etwas einfacher zu handhaben, hat einige Einschränkungen. Stattdessen sollte die speicherabbildete Version verwendet werden. So haben wir nun ein System, das so viel Speicher wie möglich nutzt und, wenn der Speicher ausgeht, Teile der Datensätze wieder auf die Festplatte auslagert. Dieser Prozess ist völlig transparent und arbeitet mit dem Betriebssystem zusammen. Er läuft mit maximaler Leistung, da die Teile des Datensatzes, auf die häufig zugegriffen wird, stets im Speicher gehalten werden.
Es gibt jedoch noch eine letzte Frage, die wir beantworten müssen. Schließlich memory-mappen Sie nicht die Festplatte, sondern Dateien auf der Festplatte. Nun stellt sich die Frage, wie viele Dateien wir zuweisen werden? Wie groß werden sie sein? Und wie werden wir diese Dateien zyklisch nutzen, während wir Speicher zuweisen und freigeben?
Die naheliegende Wahl wäre, einfach eine große Datei zu mappen, dies beim Programmstart zu tun und ständig über sie zu laufen. Wenn ein Teil nicht mehr verwendet wird, einfach überschreiben. Das erscheint offensichtlich und ist daher falsch.

Das erste Problem bei diesem Ansatz ist, dass das Überschreiben einer Speicherseite einen diskreten Algorithmus erfordert.
Der Algorithmus lautet wie folgt: Zuerst laden Sie die Seite sofort in den Speicher. Dann ändern Sie den Inhalt der Seite im Speicher. Das Betriebssystem hat keine Möglichkeit zu wissen, dass in Schritt zwei alles gelöscht und ersetzt wird, sodass es die Seite dennoch laden muss, damit die Teile, die Sie nicht ändern, gleich bleiben. Schließlich planen Sie, die Seite zu einem späteren Zeitpunkt zurück auf die Festplatte zu schreiben.
Beim ersten Schreibvorgang auf eine bestimmte Seite in einer nagelneuen Datei gibt es keine Daten, die geladen werden müssen. Das Betriebssystem weiß, dass alle Seiten null sind, sodass das Laden kostenlos ist. Es nimmt einfach eine Nullseite und verwendet sie. Aber wenn die Seite bereits modifiziert wurde und nicht mehr im Speicher ist, muss das Betriebssystem sie erneut von der Festplatte laden.

Ein zweites Problem besteht darin, dass die Seiten aus dem Page Cache nach dem Prinzip “am wenigsten kürzlich verwendet” ausgelagert werden, und das Betriebssystem weiß nicht, dass ein ungenutzter Abschnitt Ihres Speichers, der nie wieder verwendet wird, entfernt werden muss. So könnte es passieren, dass Teile des Datensatzes, die nicht benötigt werden, im Speicher verbleiben, während Teile ausgelagert werden, die benötigt werden. Es gibt keine Möglichkeit, dem Betriebssystem mitzuteilen, dass es die veralteten Bereiche einfach ignorieren soll.
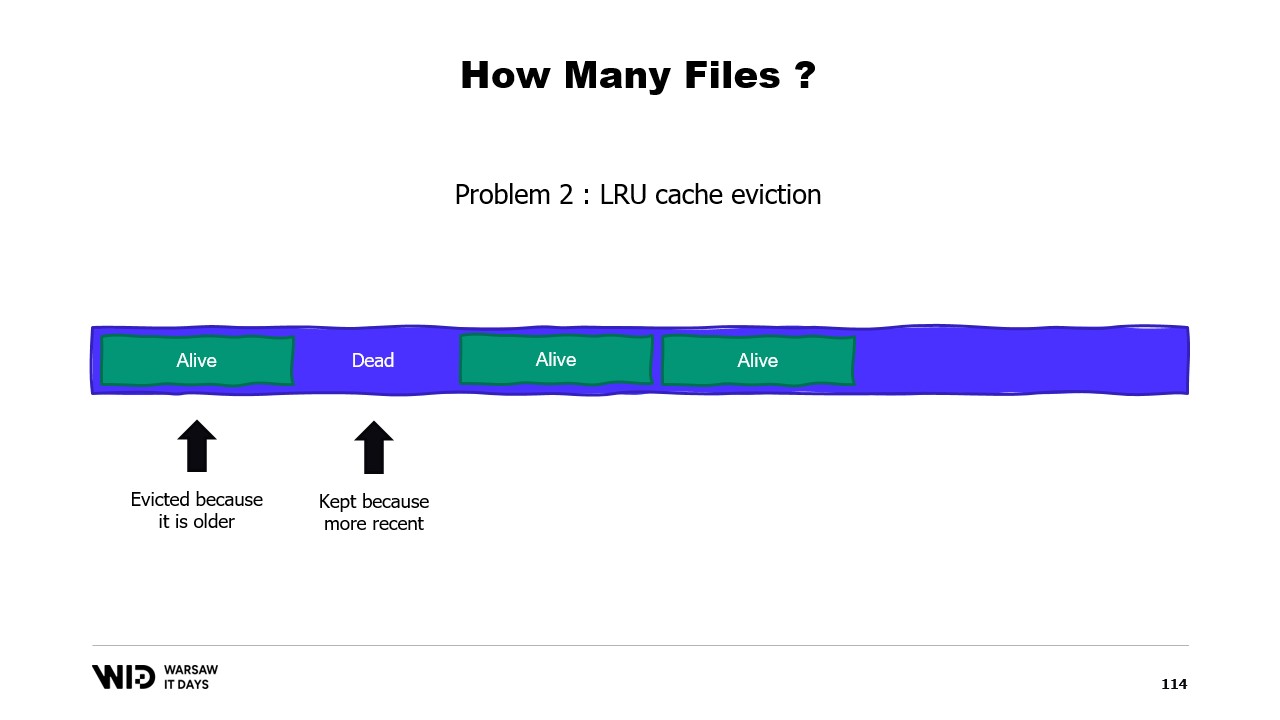
Ein drittes Problem hängt ebenfalls damit zusammen, dass das Schreiben der Daten auf die Festplatte immer hinter dem Schreiben der Daten in den Speicher zurückbleibt. Und wenn Sie wissen, dass eine Seite nicht mehr notwendig ist und sie noch nicht auf die Festplatte geschrieben wurde, weiß das Betriebssystem das nicht. Somit verbringt es dennoch Zeit damit, diese Bytes auf die Festplatte zu schreiben, die nie wieder verwendet werden, was alles verlangsamt.
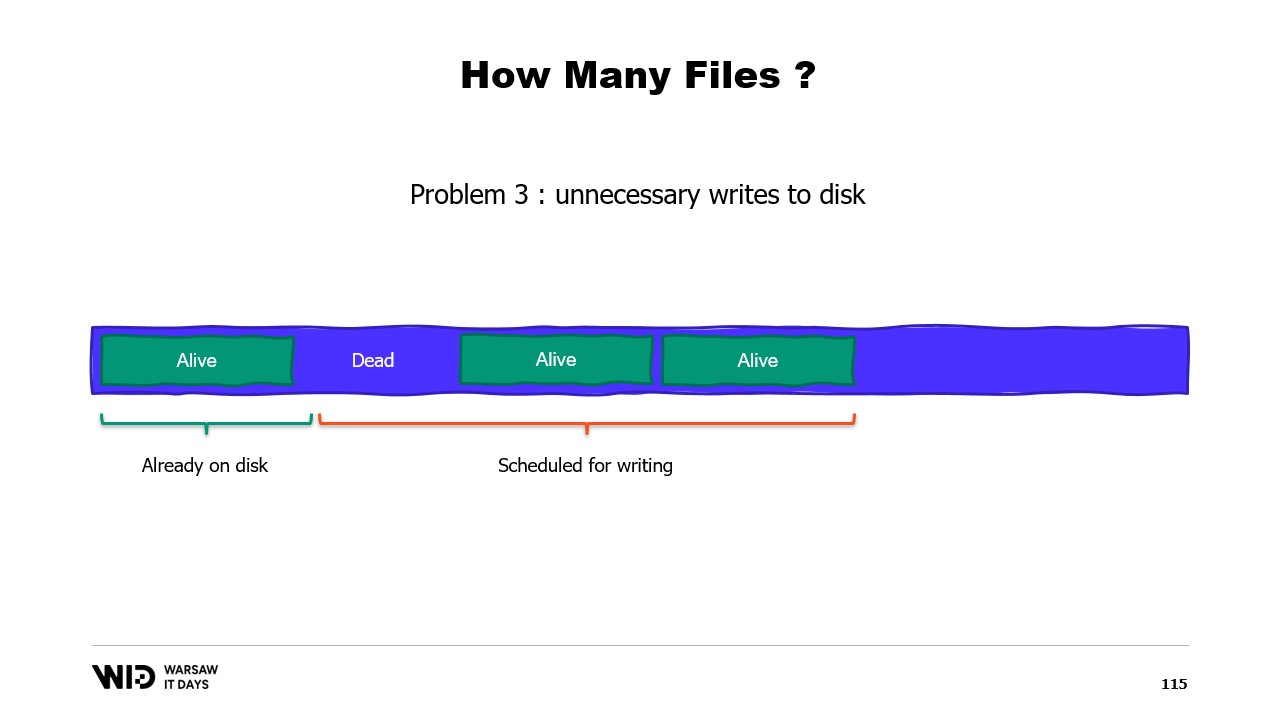
Stattdessen sollten wir den Speicher auf mehrere große Dateien verteilen. Wir schreiben niemals zweimal in denselben Speicherbereich. Dies stellt sicher, dass jeder Schreibvorgang auf eine Seite trifft, von der das Betriebssystem weiß, dass sie komplett null ist und kein Laden von der Festplatte erfordert. Und wir löschen Dateien so bald wie möglich. Dadurch wird dem Betriebssystem mitgeteilt, dass diese nicht mehr benötigt werden, sie aus dem Page Cache entfernt werden können und, falls sie noch nicht geschrieben wurden, nicht auf die Festplatte geschrieben werden müssen.

Im Produktionseinsatz bei Lokad, auf einer typischen Produktions-VM, verwenden wir den Lokad scratch space mit folgenden Einstellungen: Die Dateien haben jeweils 16 Gigabyte, es gibt 100 Dateien pro Festplatte, und jede L32VM verfügt über vier Festplatten. Insgesamt entspricht dies etwas mehr als 6 Terabyte Auslagerungsplatz pro VM.

Das war’s für heute. Bitte melden Sie sich, wenn Sie Fragen oder Anmerkungen haben, und vielen Dank fürs Zuschauen.


