00:05 Introducción
02:50 Dos ilusiones
09:09 Un pipeline de compilación
14:23 La historia hasta ahora
18:49 Conocimiento de embarque
19:40 Diseño del lenguaje
23:52 El futuro
30:35 El pasado
35:57 Eligiendo las batallas
39:45 Gramáticas 1/3
42:41 Gramáticas 2/3
49:02 Gramáticas 3/3
53:02 Análisis estático 1/2
58:50 Análisis estático 2/2
01:04:55 Sistema de tipos
01:11:59 Internos del compilador
01:27:48 Entorno de ejecución
01:33:57 Conclusión
01:36:33 Próxima conferencia y preguntas de la audiencia
Descripción
La mayoría de supply chains aún se gestionan a través de hojas de cálculo (i.e. Excel), mientras que los sistemas empresariales han estado en funcionamiento durante una, dos o incluso tres décadas - supuestamente para reemplazarlas. De hecho, las hojas de cálculo ofrecen una expresividad programática accesible, mientras que esos sistemas generalmente no lo hacen. Más en general, desde la década de 1960, ha existido un co-desarrollo constante de la industria del software en su conjunto y de sus lenguajes de programación. Hay evidencia de que la próxima etapa del rendimiento de supply chain estará mayormente impulsada por el desarrollo y la adopción de lenguajes de programación, o más bien de entornos programables.
Transcripción completa

Bienvenidos a esta serie de conferencias sobre supply chain. Soy Joannes Vermorel, y hoy presentaré “Languages and Compilers for Supply Chain.” No recuerdo haber visto alguna vez que se discutieran compiladores en algún libro de texto de supply chain, y sin embargo el tema es de suma importancia. Hemos visto en el primer capítulo de esta serie, en la conferencia titulada “Product-Oriented Delivery”, que la programación es la clave para capitalizar el tiempo invertido por los expertos en supply chain. Sin programación, no podemos capitalizar su tiempo, y tratamos a los expertos en supply chain como prescindibles.
Además, en este mismo cuarto capítulo, a través de las dos conferencias previas “Mathematical Optimization for Supply Chain” y “Machine Learning for Supply Chain,” hemos visto que estos dos campos - optimización y aprendizaje - han pasado a estar impulsados por programming paradigms durante la última década, en lugar de permanecer como un conjunto de algoritmos y modelos como solían ser en el pasado. Todos estos elementos señalan la importancia primordial de los lenguajes de programación, y por ello surge la pregunta sobre un lenguaje de programación y un compilador diseñados para abordar supply chain challenges.
El propósito de esta conferencia es desmitificar el diseño de un lenguaje de programación destinado a fines de supply chain. Es probable que su empresa nunca llegue a desarrollar por sí misma un lenguaje de programación de este tipo. No obstante, tener cierto conocimiento sobre el tema es fundamental para poder evaluar la adecuación de las herramientas que posee, y para evaluar la idoneidad de las herramientas que pretende adquirir para abordar los desafíos de supply chain que enfrenta su empresa. Además, esta conferencia también debería ayudarle a evitar algunos de los grandes errores que tienden a cometer las personas que no tienen ninguna comprensión sobre este tema.

Comencemos disipando dos ilusiones que han prevalecido en los círculos de enterprise software durante las últimas tres décadas aproximadamente. La primera es la ilusión de la “programación tipo Lego”, en la que se piensa que la programación es algo que se puede evitar por completo. De hecho, la programación es difícil, y siempre hay proveedores que prometen que, gracias a su producto y tecnología fantástica, la programación puede convertirse en una experiencia visual accesible para cualquiera, eliminando por completo toda la dificultad de programar, de modo que la experiencia se asemeje simplemente a armar Lego, algo que incluso un niño puede hacer.
Esto se ha intentado innumerables veces en las últimas dos décadas y siempre ha fallado de manera invariable. En el mejor de los casos, los productos que pretendían ofrecer una experiencia visual se convirtieron en lenguajes de programación comunes que no son especialmente más fáciles de dominar en comparación con otros lenguajes de programación. Esto es, por cierto, anecdóticamente la razón por la que, por ejemplo, en la serie de productos de Microsoft, existen las series “Visual”, como Visual Basic for Application y Visual Studio. Todos esos productos visuales se introdujeron en los años 90 con la esperanza de convertir la programación en una experiencia puramente visual con diseñadores, en la que solo se hiciera arrastrar y soltar. La realidad es que todas esas herramientas finalmente alcanzaron un grado de éxito muy significativo, pero hoy en día son simplemente lenguajes de programación bastante comunes. Queda muy poco de las partes visuales que existían en la concepción de esos productos.
El enfoque Lego falló porque, fundamentalmente, el cuello de botella no es la dificultad de la sintaxis de programación. Sí, es una dificultad, pero es mínima, especialmente en comparación con dominar los conceptos que están involucrados cada vez que se desea implementar algún tipo de automatización sofisticada. Su mente se convierte en el cuello de botella, y su comprensión de los conceptos en juego es mucho más significativa que la sintaxis.
La segunda ilusión es la ilusión de la “tecnología de Star Wars”, que consiste en pensar que es muy fácil conectar y utilizar piezas fantásticas de tecnología. Esta ilusión resulta muy atractiva tanto para los proveedores como para los proyectos internos. Esencialmente, se vuelve muy tentador decir que existe esta fantástica base de datos NoSQL que podemos simplemente incorporar, o que existe este fantástico stack de deep learning que podemos utilizar, o esta base de datos de grafos, o este framework activo distribuido, etc. El problema con este enfoque es que trata la tecnología como se hace en Star Wars. Cuando tienes una mano mecánica, el héroe puede simplemente obtener la mano mecánica, y funciona. Pero, en realidad, los problemas de integración dominan.
Star Wars pasa por alto el hecho de que habría una serie de problemas: primero, se necesitarían antibióticos, luego una larga reeducación de la mano para siquiera poder utilizarla. También se necesitaría un programa de mantenimiento para la mano porque es mecánica, y qué hay de la fuente de energía, etc. Todos estos problemas se ignoran. Simplemente conectas esa fantástica pieza de tecnología, y funciona. No es así en la realidad. Los problemas de integración dominan, y por ejemplo, en las grandes empresas de software, la mayoría de los ingenieros de software no trabajan en piezas de tecnología increíblemente geniales. La mayor parte de la plantilla de ingeniería de la gran mayoría de esos grandes proveedores de software se dedica únicamente a la integración de todas las partes.
Cuando tienes módulos, componentes o apps, necesitas un pequeño ejército de ingenieros únicamente para unir todas esas cosas y lidiar con todos los problemas que surgen al intentar integrarlas. Incluso una vez superados todos los obstáculos de la integración, aún se requiere una gran cantidad de fuerza de trabajo de ingeniería solo para afrontar el hecho de que cuando se modifica alguna parte del sistema, se tiende a generar problemas en otras partes del mismo. Por lo tanto, se necesita ese equipo de ingeniería para correr tras la solución de esos problemas.
Por cierto, como anécdota, otro problema que he observado con las piezas de tecnología geniales es el efecto Dunning-Kruger que se crea entre los ingenieros. Introduces una pieza de tecnología genial en tu stack, y de repente, los ingenieros, solo porque han comenzado a jugar con una pieza de tecnología que apenas entienden, piensan que de repente son expertos en IA o algo por el estilo. Ese es un caso típico del efecto Dunning-Kruger y está fuertemente relacionado con la cantidad de piezas tecnológicas geniales que incorporas en tu solución. En conclusión, con esas dos ilusiones, vemos que realmente no podemos sortear el problema de la programación. Tenemos que abordarlo de manera funcional, incluidas las partes difíciles.
Ahora bien, lo interesante de los lenguajes de programación es que los proveedores de enterprise software siguen reinventando, de manera accidental, los lenguajes de programación, y lo hacen todo el tiempo. De hecho, en supply chain, existe una necesidad feroz de configurabilidad. Como hemos visto en conferencias previas, el mundo de supply chain es diverso, y los problemas son numerosos y variados. Por lo tanto, cuando tienes un producto de software de supply chain, hay una necesidad extremadamente intensa de configurabilidad. Anecdóticamente, esta es la razón por la que configurar una pieza de software suele ser un proyecto de varios meses y, a veces, de varios años. Es porque hay una cantidad masiva de complejidad involucrada en esta configuración.
Las configuraciones suelen ser complejas, no se limitan a botones o casillas de verificación. Puedes tener disparadores, fórmulas, bucles y todo tipo de bloques asociados. Rápidamente se salen de control, y lo que obtienes a través de esas configuraciones es un lenguaje de programación emergente. Sin embargo, dado que es un lenguaje de programación emergente, tiende a ser un lenguaje muy deficiente.
Desarrollar un lenguaje de programación real es una tarea de ingeniería bien establecida. Existen docenas de libros sobre las prácticas de implementar un compilador de calidad para producción. Un compilador es un programa que convierte instrucciones, típicamente instrucciones en texto, en código de máquina o en una forma inferior de instrucciones. Siempre que existe un lenguaje de programación, hay un compilador involucrado. Por ejemplo, dentro de una hoja de cálculo de Excel, tienes fórmulas, y Excel tiene su propio compilador para compilar esas fórmulas y ejecutarlas. Lo más probable es que toda la audiencia haya estado utilizando compiladores durante toda su vida profesional sin saberlo.
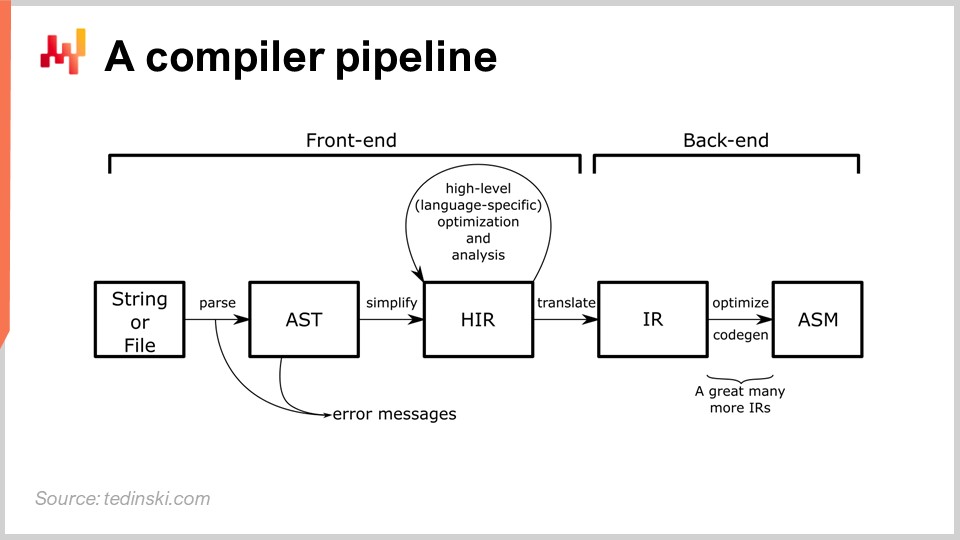
En el diagrama, puedes ver un pipeline típico, y este arquetipo se ajusta a la mayoría de los lenguajes de programación que probablemente hayas escuchado, como Python, JavaScript, Java y C#. Todos estos lenguajes tienen un pipeline esencialmente similar al que se describe aquí. En un pipeline de un compilador, tienes una serie de transformaciones, y en cada etapa del proceso, cuentas con una representación que abarca el programa completo. La forma en que se desarrolla un compilador es tener una serie de transformaciones bien definidas, y en cada etapa del proceso, se trabaja con el programa en su totalidad. Simplemente se representa de manera diferente.
La idea es que cada transformación es responsable de un conjunto bien definido de problemas. Se abordan esos problemas y luego se pasa a la siguiente transformación que se encargará de otro aspecto del proceso. Típicamente, en cada etapa, te acercas más al código a nivel de máquina. El compilador comienza con el script, y arranca con transformaciones que están muy cercanas a la sintaxis del lenguaje de programación en cuestión. Durante estas transformaciones iniciales, un compilador típico capturará errores sintácticos que impiden que el compilador convierta un script que ni siquiera representa un programa válido en algo ejecutable. Más adelante en esta conferencia volveremos a analizar más de cerca un pipeline de compilador.
Esta conferencia es la quinta conferencia del cuarto capítulo de esta serie. En el primer capítulo, presenté mis puntos de vista sobre supply chain tanto como campo de estudio como de práctica. En el segundo capítulo, revisé las metodologías apropiadas para tratar las situaciones encontradas en supply chain. Como hemos visto, la mayoría de las situaciones de supply chain son bastante adversariales por naturaleza, por lo que necesitamos estrategias y metodologías que sean resilientes frente a comportamientos adversariales tanto de las partes internas como externas de las empresas.
El tercer capítulo está dedicado al personal de supply chain, y se dedica íntegramente al estudio de los propios problemas de supply chain. Debemos tener mucho cuidado de no confundir el problema que estamos descubriendo con el tipo de solución que podemos imaginar para abordar ese problema. Se trata de dos cuestiones distintas: debemos separar el problema de la solución.
El cuarto y presente capítulo de esta serie de conferencias está dedicado a las ciencias auxiliares de supply chain. Estas ciencias auxiliares no son supply chain per se, pero son de gran ayuda para la práctica del supply chain moderno. Actualmente estamos avanzando en la escalera de abstracciones. Comenzamos este capítulo con la física de la computación, luego con los algoritmos, y pasamos al ámbito del software. Introdujimos la optimización matemática, que es de gran interés para supply chain y que, además, resulta ser la base del machine learning.
Hoy, estamos introduciendo lenguajes y compiladores, esenciales para implementar cualquier tipo de paradigma de programación. Si bien el tema de los lenguajes y compiladores puede resultar sorprendente para la audiencia, creo que a estas alturas no debería ser tan inesperado. Hemos visto que la optimización matemática y el machine learning deben abordarse hoy en día a través de paradigmas de programación, lo que plantea la interrogante de cómo implementar dichos paradigmas de programación. Eso nos lleva al diseño de un lenguaje de programación y su compilador de apoyo, que es precisamente el tema de hoy.

Este es un resumen del resto de la conferencia. Comenzaremos con observaciones de alto nivel sobre la historia y el mercado de los lenguajes de programación. Revisaremos industrias que representan, creo, tanto el futuro como el pasado de supply chain. Luego, profundizaremos gradualmente en el diseño de lenguajes de programación y compiladores, avanzando hacia preocupaciones de nivel inferior y las particularidades técnicas involucradas en el diseño de un compilador.

Desde la década de 1950, se han puesto en producción miles de lenguajes de programación. Las estimaciones varían, pero el número de lenguajes de programación que se han utilizado con fines de producción probablemente oscila entre mil y diez mil. Muchos de esos lenguajes son simplemente variaciones o primos entre sí, a veces incluso solo la base de código del compilador bifurcada en una dirección ligeramente distinta. Es notable que varias compañías de software empresarial muy grandes se expandieron considerablemente mediante la introducción de lenguajes de programación de su propia creación. Por ejemplo, SAP introdujo ABAP en 1983, Salesforce introdujo Apex en 2006, e incluso Microsoft comenzó antes de Windows al desarrollar Altair BASIC en 1975.
Históricamente, aquellos de ustedes en la audiencia que tienen la edad suficiente para recordar los años 90 podrían recordar que en ese entonces los proveedores comercializaban lenguajes de programación de tercera y cuarta generación. La realidad es que existía una serie bien identificada de generaciones—primera, segunda, tercera, cuarta, etc.—que conducían a la quinta, donde esencialmente la comunidad dejó de contar en términos de generaciones. Durante las primeras tres o cuatro décadas, todos esos lenguajes de programación seguían una bonita progresión hacia niveles superiores de abstracción. Sin embargo, a finales de los 90, ya existían muchas más direcciones, además de alcanzar un mayor grado de abstracción, dependiendo del caso de uso.
Crear un nuevo lenguaje de programación se ha hecho muchas veces. Es un campo de la ingeniería bien establecido, y existen libros enteros dedicados al tema desde un ángulo muy práctico. La ingeniería de un nuevo lenguaje de programación es una práctica mucho más fundamentada y predecible que, digamos, llevar a cabo un experimento de data science. Hay casi certeza de que obtendrás el resultado que deseas si realizas la ingeniería adecuada, considerando lo que se conoce hoy y lo que está disponible como conocimiento.
Todo eso realmente plantea la pregunta: ¿qué hay de un lenguaje de programación específicamente diseñado para fines de supply chain? De hecho, puede haber una mejora significativa en términos de productividad, fiabilidad e incluso en el rendimiento de supply chain.

Para abordar esta pregunta, necesitamos echar un vistazo al futuro. Afortunadamente para nosotros, la manera más simple de ver el futuro es examinar una industria que ha estado consistentemente una década por delante de todos los demás durante las últimas tres décadas aproximadamente, y esa es la industria de los videojuegos. Esta es una industria muy grande hoy en día, y solo para darte una idea de la escala, la industria de los videojuegos es ahora dos tercios de la industria aeroespacial en todo el mundo en términos de tamaño comparativo, y está creciendo mucho más rápido que la aeroespacial. Dentro de una década, los videojuegos podrían ser realmente más grandes que la aeroespacial.
Lo interesante de la industria de los videojuegos es que tiene una estructura muy bien establecida. Primero, tenemos motores de juego, siendo los dos líderes Unity y Unreal. Estos motores de juego ofrecen los componentes de bajo nivel que son de interés para gráficos 3D refinados e intensivos, y definen el paisaje para el nivel de infraestructura de tu código. Hay algunas compañías que desarrollan productos muy complejos llamados motores de juego, y estos motores son utilizados por toda la industria.
A continuación, tenemos estudios de videojuegos, que desarrollan el código de cada juego. El código del juego será una base de código que, típicamente, es específico para el juego que se está desarrollando. El motor de juego requiere ingenieros de software muy dedicados, con un alto nivel técnico, pero que no necesariamente saben mucho sobre videojuegos. El desarrollo del código del juego no es tan intensivo en términos de habilidades técnicas puras. Sin embargo, los ingenieros de software que desarrollan el código del juego necesitan comprender el juego en el que están trabajando. El código del juego establece la plataforma para las mecánicas del juego, pero no especifica los pormenores.
Esta tarea es típicamente gestionada por diseñadores de juegos, quienes no son ingenieros de software, pero escriben código en los lenguajes de scripting que les proporciona el equipo de ingeniería encargado del código del juego. Tenemos estas tres etapas: motores de juego, que involucran a ingenieros de software súper técnicos y dedicados creando bloques básicos centrales; estudios, que cuentan con equipos de ingeniería, típicamente uno por juego, desarrollando el juego como una plataforma para las mecánicas del juego; y finalmente, diseñadores de juegos, que no son ingenieros de software pero son especialistas en juegos, implementando el comportamiento que hará felices a los jugadores, los clientes al final del proceso.
Hoy en día, el código del juego se hace frecuentemente accesible a la comunidad de fans, lo que significa que los diseñadores de juegos pueden escribir reglas y potencialmente modificar el juego, pero los fans, que son simplemente consumidores regulares de los juegos, también pueden hacerlo. Existen algunas anécdotas interesantes en la industria. Por ejemplo, el juego Dota 2, que es increíblemente exitoso, comenzó como una modificación de un juego existente. La primera versión, simplemente llamada Dota, fue una modificación puramente de la comunidad de fans del juego World of Warcraft 3. Se puede observar que este grado de configurabilidad y programabilidad a nivel de las reglas del juego es muy extenso, ya que fue posible, a partir de un juego comercial existente, World of Warcraft 3, crear un juego completamente nuevo, que luego se convirtió en un enorme éxito comercial propio mediante una segunda versión. Ahora, esto es interesante, y podemos empezar a pensar, al mirar la industria de los videojuegos, ¿qué significa esto para la industria de supply chain?
Bueno, podríamos pensar en qué tipo de paralelo podríamos trazar. Podríamos tener un motor de supply chain que se encargue de las partes algorítmicas muy difíciles, de la infraestructura de bajo nivel y de los bloques tecnológicos centrales, tales como la optimización matemática y el machine learning. La idea es que, para cada supply chain, se necesitaría un equipo de ingeniería para reunir todos los datos relevantes e integrar todo el panorama aplicativo.
Como primera etapa, necesitaríamos el equivalente de diseñadores de juegos, que serían especialistas en supply chain. Estos especialistas no son ingenieros de software, sino que son las personas que escribirán, mediante un código simplificado, todas las reglas y mecánicas necesarias para implementar la optimización predictiva de interés para el supply chain. La industria de los videojuegos proporciona un ejemplo vívido de lo que es probable que suceda en el ámbito de supply chain en la próxima década.

Hasta ahora, el enfoque de la industria de los videojuegos en el supply chain sigue siendo ciencia ficción, salvo para unas pocas empresas. Creo que la mayoría de esas empresas resultan ser clientes de Lokad. Volviendo al tema de hoy, hemos visto en conferencias anteriores que Excel sigue siendo el lenguaje de programación número uno en esta industria. Por cierto, en términos de lenguajes de programación, Excel es un lenguaje de programación funcional reactivo, por lo que es incluso una clase en sí mismo.
Hoy en día podrías estar escuchando a proveedores que proponen actualizar supply chains utilizando algún tipo de configuración de data science. Sin embargo, mi observación casual durante la última década es que la gran mayoría de estas iniciativas han fracasado. Esto ya es cosa del pasado, y para entender por qué, necesitamos empezar a mirar la lista de lenguajes de programación involucrados. Si observamos Excel, vemos que involucra esencialmente dos lenguajes de programación: las fórmulas de Excel y VBA. VBA ni siquiera es un requisito; se puede llegar lejos solo con VLOOKUPs en Excel. Típicamente, se trata de un solo lenguaje de programación, y es accesible para quienes no son ingenieros de software.
Por otro lado, la lista de lenguajes de programación necesarios para replicar las capacidades de Excel con una configuración de data science es bastante extensa. Necesitaremos SQL, y potencialmente varios dialectos de SQL, para acceder a los datos. Necesitaremos Python para implementar la lógica central. Sin embargo, Python por sí solo tiende a ser lento, por lo que podrías necesitar un sub-lenguaje como NumPy. En este punto, aún no estás haciendo nada en términos de machine learning o optimización matemática, así que para un análisis numérico realmente intenso, necesitarás algo más, otro lenguaje de programación propio, como PyTorch, por ejemplo. Ahora que tienes todos estos elementos, ya cuentas con bastantes partes móviles, por lo que la configuración de la propia aplicación será bastante compleja. Necesitarás una configuración, y esta configuración se escribirá con otro lenguaje de programación, como JSON o XML. A decir verdad, estos no son lenguajes de programación super complejos, pero se suman a la pila.
Lo que sucede cuando tienes tantas partes móviles es que, típicamente, necesitas un sistema de construcción, algo que pueda ejecutar todos los compiladores y recetas mundanas necesarias para producir el software. Los sistemas de construcción tienen sus propios lenguajes. El enfoque tradicional es un lenguaje llamado Make, pero existen muchos otros. Además, dado que Excel es capaz de mostrar resultados, necesitas una forma de mostrar información al usuario y visualizarla. Esto se realizará con una combinación de JavaScript, HTML y CSS, añadiendo más lenguajes a la lista.
En este punto, tenemos una larga lista de lenguajes de programación, y una configuración de producción real podría ser aún más compleja. Esto explica por qué la mayoría de las empresas que intentaron optar por esta cadena de data science durante la última década han fracasado de manera abrumadora y, en la práctica, se han quedado con Excel. La razón es que implica dominar casi una docena de lenguajes de programación en lugar de solo uno, como es el caso con Excel. Ni siquiera hemos empezado a abordar ninguno de los problemas reales de supply chain; solo hemos estado discutiendo las tecnicalidades que se interponen en el camino para comenzar a hacer algo.

Ahora, comencemos a pensar en cómo sería un lenguaje de programación para supply chain. Primero, tenemos que decidir qué está dentro del lenguaje y qué pertenece al lenguaje como ciudadano de primera clase y qué pertenece a las librerías. De hecho, con los lenguajes de programación siempre es posible delegar capacidades a las librerías. Por ejemplo, veamos el lenguaje de programación C. Se considera un lenguaje de programación bastante de bajo nivel, y C no tiene un recolector de basura. Sin embargo, es factible usar un recolector de basura de terceros como una librería en un programa en C. Debido a que la recolección de basura no es un ciudadano de primera clase en el lenguaje de programación C, la sintaxis tiende a ser relativamente verbosa y tediosa.
Para fines de supply chain, existen aspectos como la optimización matemática y el machine learning que suelen tratarse como librerías. Entonces, tenemos un lenguaje de programación, y todos esos aspectos se delegan esencialmente a librerías de terceros. Sin embargo, si fuéramos a diseñar un lenguaje de programación para supply chain, tendría mucho sentido que esos aspectos se integraran como ciudadanos de primera clase en el propio lenguaje. Además, tendría sentido tener datos relacionales como parte del lenguaje como ciudadano de primera clase. En supply chain, el panorama aplicativo, que incluye muchas piezas de software empresarial, presenta datos relacionales en forma de bases de datos relacionales, como las bases de datos SQL, por doquier. Prácticamente todos los productos de software empresarial que existen hoy en día tienen en su núcleo una base de datos relacional, lo que significa que, para fines de supply chain, tan pronto como queramos tocar los datos, la realidad es que interactuaremos con datos que son de naturaleza relacional. Los datos se presentan como una lista de tablas extraídas de todas esas bases de datos que impulsan diversas aplicaciones, y cada tabla tiene una lista de columnas o campos.
Realmente tiene sentido tener datos relacionales dentro del lenguaje. Además, ¿qué pasa con la interfaz de usuario (UI) y la experiencia de usuario (UX)? Uno de los puntos fuertes de Excel es que todo eso está completamente integrado en el lenguaje, por lo que no tienes un lenguaje de programación y luego todo tipo de librerías de terceros para tratar la presentación, el renderizado y la interacción con el usuario. Todo esto es parte del lenguaje. Hacer de todo eso un ciudadano de primera clase también sería de muy relevante interés en lo concerniente a supply chain, al menos si queremos ser tan buenos como Excel puede ser para supply chains.

Ahora, en el diseño de lenguajes, la gramática representa la representación formal de las reglas que definen un programa válido de acuerdo con el nuevo lenguaje de programación que has introducido. Esencialmente, comienzas con un fragmento de texto, y primero aplicarás un lexer, que es una clase específica de algoritmos o un pequeño programa. El lexer descompone tu fragmento de texto, el programa que acabas de escribir, en una secuencia de tokens. El lexer aísla todas las variables y símbolos en juego en tu lenguaje de programación. La gramática ayuda a convertir la secuencia de tokens en la semántica real del programa, definiendo lo que significa el programa y el conjunto exacto, no ambiguo, de operaciones que deben realizarse para ejecutarlo.
La gramática en sí se aborda típicamente como un trade-off entre las preocupaciones que deseas internalizar dentro de tu lenguaje y los conceptos que quieres externalizar. Por ejemplo, si abordamos los datos relacionales como una preocupación externa, el programador tendría que introducir muchas estructuras de datos especializadas, como diccionarios, búsquedas y tablas hash, para realizar manualmente dentro del lenguaje de programación todas esas operaciones. Si la gramática quiere internalizar el álgebra relacional, significa que el programador puede escribir típicamente toda la lógica relacional directamente en su forma relacional. Sin embargo, eso implica que, de repente, todas esas restricciones relacionales y todo ese álgebra relacional se convierten en parte de la carga que la gramática tiene que soportar.
Desde una perspectiva de supply chain, dado que los datos relacionales son sumamente prevalentes en el software empresarial, tiene mucho sentido que una gramática se encargue de todas las preocupaciones relacionales directamente a nivel de la gramática en el lenguaje.

Las gramáticas en ciencias de la computación son un tema enormemente estudiado. Han existido durante décadas, y sin embargo, probablemente es el único ámbito en el que los proveedores de software empresarial fracasan de manera más rotunda. De hecho, invariablemente terminan creando lenguajes de programación accidentales que surgen de forma natural cada vez que hay configuraciones complejas en juego. Cuando tienes condiciones, disparadores, bucles y respuestas, típicamente necesitas encargarte de ese lenguaje en lugar de dejar que simplemente surja por sí solo.

Lo que sucede es que cuando no se tiene una gramática, cada vez que introduces cambios en la aplicación, acabarás con consecuencias desordenadas en el comportamiento real del sistema. Por cierto, esto también explica por qué actualizar de una versión de un software empresarial a otra suele ser muy complejo. Se supone que la configuración es la misma, pero cuando realmente intentas ejecutar la misma configuración en la siguiente versión del software, obtienes resultados completamente diferentes. La causa raíz de estos problemas es la falta de una gramática y de unas semánticas formalizadas establecidas para lo que la configuración va a significar.
La forma típica de representar una gramática es utilizando formalmente la Forma de Backus-Naur (BNF), que es una notación especial. En la pantalla, lo que puedes ver es un mini lenguaje de programación que representa direcciones postales de EE.UU. Cada línea con un signo igual representa una regla de producción. Lo que tienes a la izquierda es un símbolo no terminal, y a la derecha del signo igual hay una secuencia de símbolos terminales y no terminales. Los símbolos terminales están en rojo y representan símbolos que no se pueden derivar más. Los símbolos no terminales están entre corchetes y se pueden derivar más. Esta gramática no está completa; habría muchas más reglas de producción para una gramática completa. Solo quería mantener esta diapositiva razonablemente concisa.
Una gramática es algo muy sencillo de definir en términos de sintaxis para tu lenguaje de programación, y además garantiza que será no ambigua. Sin embargo, no es porque esté escrita con la Forma de Backus-Naur que vaya a ser una gramática válida o incluso una buena gramática. Para tener una buena gramática, necesitamos hacer un poco más que eso. La forma matemática de caracterizar una buena gramática es tener una gramática libre de contexto. Se dice que una gramática es libre de contexto si las reglas de producción se pueden aplicar para cualquier símbolo no terminal, sin importar los símbolos que encuentres a la derecha y a la izquierda. La idea es que una gramática libre de contexto es algo en lo que puedes aplicar las reglas de producción en cualquier orden, y tan pronto como ves una coincidencia o derivación, simplemente la aplicas.
Lo que obtienes de una gramática libre de contexto es una gramática que, si cambias algo en ella y este cambio crea una ambigüedad, el compilador no podrá compilar el programa donde ocurre la ambigüedad. Esto es de interés primario cuando se pretende mantener una configuración durante un largo período de tiempo. En supply chain, la mayor parte del software empresarial tiene una vida muy larga. No es infrecuente ver piezas de software empresarial operando durante dos o tres décadas. En Lokad, atendemos a más de 100+ empresas, y es bastante común que extraigamos datos de sistemas que han estado implementados por más de tres décadas, especialmente en grandes empresas.
Con una gramática libre de contexto, obtienes la garantía de que, si se introduce un cambio en este lenguaje (y recuerda, cuando digo “lenguaje”, puedo referirme a algo tan básico como la configuración), podrás identificar las ambigüedades que surgen cuando aplicas este cambio. Esto es en lugar de que esas ambigüedades ocurran sin que te des cuenta de que tienes un problema, lo que puede conducir a dificultades al actualizar de un sistema a otro.
Lo que sucede cuando las personas no saben nada sobre gramáticas es que escriben manualmente un analizador. Si nunca has oído hablar de una gramática, un ingeniero de software escribiría un analizador, que es un programa que crea de forma desordenada una especie de árbol que representa la versión analizada de tu programa. El problema con eso es que terminas con una semántica para tu programa que es increíblemente específica para la única versión del programa que tienes. Así que, si cambias este programa, cambias la semántica y obtendrás resultados diferentes, lo que significa que puedes tener la misma configuración pero un comportamiento diferente para tu supply chain.
Afortunadamente, en 2004, se produjo un pequeño avance introducido por Brian Ford con un artículo titulado “Parsing Expression Grammars: A Recognition-Based Syntactic Foundation.” Con este trabajo, Ford proporcionó a la comunidad una forma de formalizar ese tipo de analizador ad hoc accidental que existe en el campo. Por ejemplo, a estas gramáticas se les llama Parsing Expression Grammars (PEGs), y con las PEGs, puedes convertir esos analizadores empíricos semi-accidentales en gramáticas formales reales de algún tipo.
Python, por ejemplo, no tiene exactamente una gramática libre de contexto, sino que tiene una PEG. Las PEGs están bastante bien si cuentas con un conjunto extenso de pruebas automatizadas, ya que, en este caso, puedes lidiar con la preservación de la semántica a lo largo del tiempo. De hecho, con las PEGs, dispones de una formalización de tu gramática, por lo que te encuentras en una situación mejor en comparación con no tener ninguna gramática y solo contar con un analizador. Sin embargo, en términos de evolución de la semántica, con una PEG, no detectarás automáticamente que hay un cambio semántico si modificas la gramática en sí. Por lo tanto, necesitas tener una suite extensa de pruebas automatizadas sobre tu PEG, lo cual, por cierto, es exactamente lo que tiene la comunidad de Python. Tienen un conjunto de pruebas automatizadas muy robusto y extenso. Ahora, desde la perspectiva de supply chain, creo que las gramáticas no solo tienen el interés de hacerte notar su importancia, sino que también constituyen una prueba decisiva. Puedes realmente evaluar a los proveedores de software empresarial al discutir un software de gran complejidad. Debes preguntar al proveedor sobre la gramática que utiliza para la configuración compleja. Si el proveedor responde con “¿qué es una gramática?”, entonces sabes que estás en problemas, y el mantenimiento probablemente será lento y costoso.

La programación es muy difícil, y la gente cometerá muchos errores. Si fuera fácil, ni siquiera necesitaríamos programación en primer lugar. Un buen lenguaje de programación minimiza el tiempo que toma identificar un error y corregirlo. Este es uno de los aspectos más críticos de un lenguaje de programación, garantizando una productividad decente para quien esté escribiendo código.
Consideremos la siguiente situación: mientras escribes código, si el error puede ser detectado a medida que escribes, como un error tipográfico con un subrayado rojo en Microsoft Word, entonces el ciclo de retroalimentación para corregir el error puede ser tan corto como 10 segundos, lo cual es ideal. Si el error solo puede detectarse cuando comienzas a ejecutar el programa, el ciclo de retroalimentación durará al menos 10 minutos. En supply chain, a menudo tenemos grandes conjuntos de datos para procesar, y no podemos esperar que el programa empiece a recorrer todos los datos en cuestión de segundos. Como resultado, si el problema ocurre solo en tiempo de ejecución, el ciclo de retroalimentación será de 10 minutos o más.
Si el error solo puede detectarse después de que el script se complete, es decir, el programa tiene un error pero no falla, el ciclo de retroalimentación tomará alrededor de 10 horas o más. Pasamos de 10 segundos de retroalimentación en tiempo real a 10 minutos si tenemos que ejecutar el programa y luego a 10 horas si tenemos que inspeccionar los resultados numéricos y KPIs producidos por el programa.
Existe un escenario aún peor: si la plataforma en la que operas no es estrictamente determinista, es decir, que con la misma entrada y datos, puede darte resultados diferentes. Esto no es tan extraño como puede parecer, ya que en supply chain, podríamos tener cosas como simulaciones Monte Carlo en marcha. Si existe alguna aleatoriedad en los resultados, podemos tener algo que falla solo de vez en cuando, y en esta situación, el ciclo de retroalimentación suele ser superior a 10 días. Así que, pasamos de 10 segundos a 10 días, y hay riesgos enormes en estrechar este ciclo de retroalimentación. El análisis estático representa un conjunto de técnicas que se pueden aplicar para detectar problemas, errores o fallos sin siquiera ejecutar el programa. Con el análisis estático, la idea es que ni siquiera ejecutes el programa, lo que significa que puedes reportar el error en tiempo real mientras la gente escribe, al igual que un subrayado rojo para errores tipográficos en Microsoft Word. Más en general, existe un fuerte interés en transformar cada problema para que se traslade a una categoría de retroalimentación más temprana, cambiando problemas que llevarían días en identificarse a minutos o minutos a segundos, y así sucesivamente.
Desde la perspectiva de supply chain, hemos visto en una de las conferencias anteriores que las supply chains pueden esperar mucho caos. No podemos tener ciclos de lanzamiento clásicos donde esperas a que se entregue la siguiente versión de tu software. A veces ocurren eventos extraordinarios, como un cambio de tarifa, un buque portacontenedores varado en un canal o una pandemia. Estas situaciones de emergencia requieren correcciones de emergencia, y la cantidad de análisis estático que puedes hacer sobre tu lenguaje de programación define prácticamente cuánto caos tendrás en producción debido a errores no capturados en tiempo real mientras se escribe el código. Los eventos extraordinarios pueden parecer raros, pero en la práctica, las sorpresas en supply chain son bastante comunes.

Existen pruebas matemáticas de que no es posible detectar todos los errores con un lenguaje de programación general en una situación general. Por ejemplo, ni siquiera es posible probar que el programa se completará, lo que significa que no es posible garantizar que lo que has escrito no seguirá ejecutándose indefinidamente.
Con el análisis estático, típicamente obtienes tres categorías: algunas partes del código probablemente son buenas, otras partes probablemente son malas, y para muchas cosas intermedias, simplemente no se sabe. La idea es que, cuanto más te desplaces de “no saber” a “código malo”, mayor será el esfuerzo que necesitarás en términos de diseño del lenguaje para convencer al compilador de que tu programa es válido. Así que, tenemos que encontrar un equilibrio entre cuánto esfuerzo deseas invertir para convencer al lenguaje de programación de que tu código es correcto versus cuántas garantías deseas tener sobre el programa en tiempo de compilación, incluso antes de que el programa se ejecute. Esto es cuestión de productividad.
Ahora, una lista rápida de errores típicos detectados con el análisis estático incluye errores de sintaxis, como comas o paréntesis olvidados. Algunos lenguajes de programación ni siquiera pueden señalar errores de sintaxis antes de tiempo de ejecución, como Bash, el lenguaje de shell en Linux. El análisis estático también puede detectar errores de tipo, que ocurren cuando tienes el tipo incorrecto o un número incorrecto de argumentos para una función que estás llamando.
También se puede detectar código inalcanzable, lo que significa que el código está bien, pero nunca se ejecutará porque el programa entero puede ejecutarse sin llegar jamás a esa parte del código. Es como código muerto o una conexión lógica olvidada. El código inconsecuente es otro problema que se puede identificar, donde el código se ejecuta pero no tiene impacto en el resultado final. Es una variante del código inalcanzable.
También se puede detectar código que consume recursos en exceso, lo cual se refiere a código que se ejecutaría, excepto que la cantidad de recursos computacionales necesarios excede ampliamente lo que puedes permitir para tu programa. Un programa consume recursos computacionales como memoria, almacenamiento y CPU. A través del análisis estático, puedes demostrar que un bloque de código consume muchos más recursos de los que puedes permitir, considerando tus limitaciones, como completar el cálculo dentro de un plazo específico. Preferirías que esto falle en tiempo de compilación en lugar de ejecutar tu programa durante una hora y luego que falle debido a un timeout, lo que llevaría a una productividad muy baja.
Sin embargo, hay un giro cuando se trata del análisis estático. Mientras escribes, estás lidiando con un programa que es inválido todo el tiempo. A medida que pulsas tecla tras tecla, estás transformando un programa válido en uno inválido. Una solución de nivel industrial para esta situación se llama Language Server Protocol. Esta herramienta viene con un lenguaje de programación y es lo más avanzado en lo que respecta a la retroalimentación de errores en tiempo real para los programas que escribes.
A través de un Language Server Protocol, puedes acceder a funciones como “ir a la definición” cuando haces clic en una variable. El Language Server Protocol es fundamentalmente con estado, recordando la última versión de tu programa que era correcta, junto con las anotaciones y semánticas disponibles. Conserva estas anotaciones y detalles adicionales al lidiar con tu programa dañado simplemente porque has presionado una tecla extra, y ya no es un programa válido. Es un cambio radical en términos de productividad, y siempre que hay algún grado de urgencia, marca una gran diferencia para los propósitos de supply chain.

Ahora, profundicemos en el sistema de tipos. Como una primera aproximación, un sistema de tipos es un conjunto de reglas que aprovecha la categorización de los objetos en tu programa, o la categorización de los elementos que manipulas, para aclarar si ciertas interacciones están permitidas o no. Por ejemplo, los tipos típicos incluyen cadenas de caracteres, enteros y números de punto flotante, todos los cuales son tipos muy básicos. Definirá que sumar dos enteros es válido, pero sumar una cadena y un entero no es válido, excepto en JavaScript, porque las semánticas son diferentes allí.
Los sistemas de tipos, en general, son un problema de investigación abierto y pueden volverse increíblemente abstractos. Para arrojar algo de luz, debemos aclarar que hay dos tipos de tipos, que a menudo se confunden. Primero, están los tipos de valores, que solo existen en tiempo de ejecución cuando el programa realmente se está ejecutando. Por ejemplo, en Python, si consideramos una función que devuelve el primer elemento de un arreglo de enteros, entonces el tipo del valor devuelto por esta función será un entero. Desde esta perspectiva, todos los lenguajes de programación tienen tipos: todos están tipados.
Segundo, están los tipos de variables, que solo existen en tiempo de compilación mientras el programa se está compilando y aún no se ejecuta. El desafío con los tipos de variables es extraer la mayor cantidad de información posible sobre esas variables en tiempo de compilación. Si volvemos al ejemplo anterior, en Python, puede o no ser posible identificar el tipo del valor devuelto por la función, porque Python no es completamente fuertemente tipado en tiempo de compilación.
Desde una perspectiva de supply chain, buscamos un sistema de tipos que soporte lo que pretendemos hacer en beneficio de la supply chain. Queremos ser lo más restrictivos posible para detectar problemas y errores tempranamente, pero también lo más flexibles posible para permitir todas las operaciones que pudieran ser de interés. Por ejemplo, considere la suma de una fecha y un entero. En un lenguaje de programación regular, probablemente dirías que no es legítimo, pero desde una perspectiva de supply chain, si tenemos una fecha y queremos sumar siete días, tendría sentido escribir “date + 7”.
En cuanto a los tipos, ¿queremos permitir sumar una fecha a otra? Probablemente no. Sin embargo, ¿queremos permitir la resta entre dos fechas? ¿Por qué no? Si restamos una fecha de otra que ocurre antes, obtenemos la diferencia, que podría expresarse en días. Esto tiene mucho sentido para los cálculos involucrados en la planificación.
Continuando con el tema de las fechas, también existen características que podrían ser de interés al pensar en lo que un sistema de tipos debería hacer por nosotros en términos de supply chain. Por ejemplo, ¿qué hay de restringir el rango de tiempo aceptable? Podríamos decir que las fechas fuera del alcance de 20 años en el pasado y 20 años en el futuro simplemente no son válidas. Lo más probable es que, si estamos realizando una operación de planificación y en algún punto del programa manipulamos una fecha que es más de 20 años en el futuro, las probabilidades son abrumadoras de que no sea un scenario de planificación válido para la mayoría de las industrias. En la mayoría de los casos, no planificarías operaciones diarias con más de 20 años de antelación. Por lo tanto, no solo podemos tomar los tipos usuales, sino redefinirlos de maneras que sean más restrictivas y más apropiadas para fines de supply chain.
Además, está todo el aspecto de la incertidumbre. En la gestión de supply chain, siempre estamos mirando hacia el futuro, pero desafortunadamente, el futuro siempre es incierto. La manera matemática de abrazar la incertidumbre es a través de variables aleatorias. Tendría sentido incorporar variables aleatorias en el lenguaje para representar la demanda futura incierta, lead times, y las devoluciones de clientes, entre otras cosas.
En Lokad, hemos desarrollado Envision, un lenguaje de programación dedicado a la optimización predictiva de supply chains. Envision es una mezcla de SQL, Python, optimización matemática, machine learning y capacidades de big data, todo integrado como ciudadanos de primera clase dentro del lenguaje. Este lenguaje viene con un Entorno de Desarrollo Integrado (IDE) basado en la web, lo que significa que puedes escribir un script desde la web y contar con todas las características modernas de edición de código. Estos scripts operan sobre un sistema de archivos distribuido integrado que viene con el entorno de Lokad, por lo que la capa de datos está completamente integrada en el lenguaje de programación.
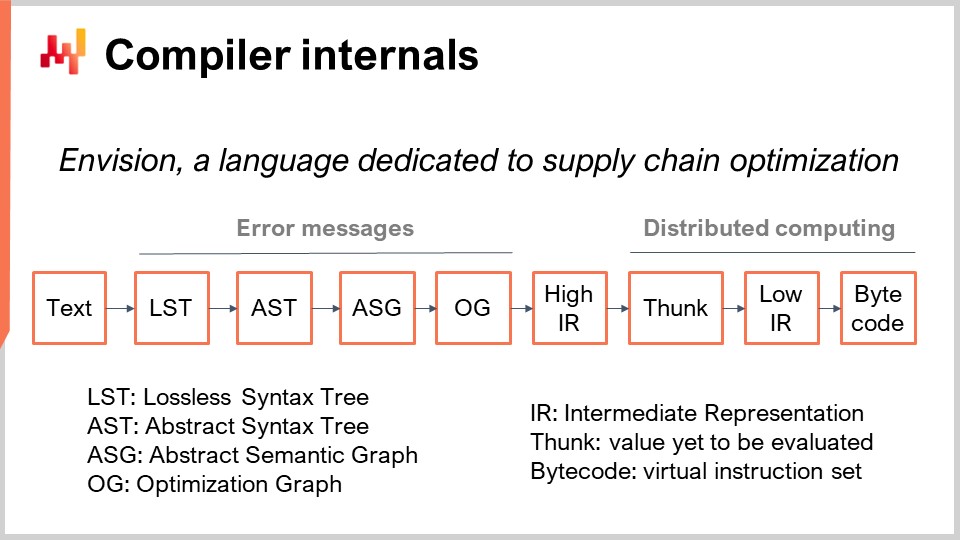
Los scripts de Envision se ejecutan en una flota de máquinas, diseñadas para aprovechar toda la nube. Cuando se ejecuta el script, se distribuye en muchas máquinas para ejecutarse más rápido. En la pantalla, puedes ver la cadena de compilación utilizada por Envision. Hoy, no vamos a discutir este lenguaje de programación; simplemente vamos a discutir su cadena de compilación porque es el tema de interés para la conferencia de hoy.
Primero, empezamos con un fragmento de texto que contiene el script de Envision. Representa un programa que ha sido escrito por un experto en supply chain, no por un ingeniero de software, para abordar un desafío específico de supply chain. Este desafío podría ser decidir qué producir, qué reponer, qué mover, o si se debe ajustar un precio al alza o a la baja. Estos casos de uso implican decisiones acerca de qué producir, reponer, mover, o si se deben ajustar los precios al alza o a la baja. El texto del script contiene las instrucciones, y la idea es procesar este script y obtener el Árbol de Sintaxis sin Pérdidas (LST). El LST es de interés porque es una representación muy específica que no descarta ni un solo carácter. Incluso los espacios en blanco no significativos se preservan. La razón de esto es asegurar que cualquier reescritura automatizada del programa no altere el código existente. Este enfoque evita situaciones en las que las herramientas reorganizan el código, mueven las indentaciones, o provocan otras alteraciones que dificultan reconocer el código.
Una operación básica de refactorización, por ejemplo, podría implicar renombrar una variable y todas sus ocurrencias en el programa sin alterar nada más. Desde el LST, pasamos al Árbol de Sintaxis Abstracta (AST), donde simplificamos el árbol. No se necesitan paréntesis en esta etapa porque la estructura del árbol define las prioridades de todas las operaciones. Además, realizamos una serie de operaciones de eliminación de azúcar sintáctica para eliminar cualquier sintaxis provista en beneficio del programador final.
Pasando del AST al Grafo de Sintaxis Abstracta (ASG), aplanamos el árbol. Este proceso implica descomponer sentencias complejas con expresiones altamente anidadas en una secuencia de sentencias elementales. Por ejemplo, una sentencia como “a = b + c + d” se dividiría en dos sentencias, cada una con una sola suma. Esto es precisamente lo que sucede durante la transición del AST al ASG.
Desde el ASG, pasamos al Grafo de Optimización (OG), donde realizamos el moldeado de tipos y el broadcasting, particularmente en relación con el álgebra relacional. Como se mencionó anteriormente, Envision integra un álgebra relacional dentro del lenguaje. Como se ha insinuado muchas veces antes, Envision integra un álgebra relacional, al igual que en las bases de datos relacionales o en las bases de datos SQL, como ciudadano de primera clase. Existen numerosas operaciones relacionales, y verificamos que estas operaciones sean válidas de acuerdo con el esquema de las tablas con las que operamos al pasar del ASG al OG. El Grafo de Optimización (OG) representa el último paso del front-end de nuestro compilador y consta de operaciones relacionales elementales y puras que se aplican al programa, representando pequeñas porciones de lógica. Al igual que en SQL, estos elementos son de naturaleza relacional.
El grafo de optimización se llama “optimización” porque hay numerosas transformaciones que ocurren de OG a OG. Estas transformaciones se producen porque, al tratar con álgebra relacional, organizar las operaciones de ciertas maneras puede hacer que el programa se ejecute mucho más rápido. Por ejemplo, en SQL, si tienes un filtro y luego una operación, o una operación primero y luego un filtro, es mucho mejor filtrar primero los datos y luego aplicar la operación. Esto asegura que las operaciones se apliquen únicamente a los datos necesarios, mejorando la eficiencia.
En Lokad, el último paso del compilador front-end es la Representación Intermedia Alta (HIR). El HIR es una frontera limpia, estable y documentada entre el front-end y el back-end de la cadena de compilación. A diferencia del Grafo de Optimización (OG), que cambia constantemente debido a heurísticas, el HIR es estable y proporciona una entrada consistente para el back-end del compilador. Además, el HIR es serializable, lo que significa que puede transformarse fácilmente en un paquete de bytes para ser trasladado de una máquina a otra. Esta propiedad es esencial para distribuir cálculos entre múltiples máquinas.
Desde la Representación Intermedia Alta, pasamos a los “funcs”. Los funcs son valores que aún no han sido evaluados y representan los bloques atómicos de cálculo dentro de una ejecución distribuida. Por ejemplo, al sumar dos vectores gigantes de una tabla con miles de millones de líneas, habrá una serie de funcs que representan diversas porciones de estos vectores. Cada func es responsable de sumar una porción de los dos vectores y se ejecuta en una máquina. Los cálculos grandes se dividen en muchos funcs para distribuir la carga de trabajo entre múltiples CPUs y múltiples máquinas, si el cálculo es lo suficientemente grande como para justificar este grado de distribución. Los funcs se denominan “lazy” porque no se evalúan de entrada; se evalúan cuando es necesario. Muchos cálculos pueden ocurrir antes de que algunos funcs sean efectivamente computados, y una vez que un func es computado, el propio func es reemplazado por su resultado.
Dentro del func, encontrarás la representación intermedia baja, que representa la lógica imperativa de bajo nivel que se ejecuta dentro del func. Puede, por ejemplo, incluir bucles y accesos a diccionarios. Finalmente, esta representación intermedia de bajo nivel se compila en bytecode, que representa el objetivo final de nuestra cadena de compilación. En Lokad, apuntamos al bytecode .NET, técnicamente conocido como MSIL.
Desde la perspectiva de supply chain, lo realmente interesante es que, mediante esta cadena de compilación —que podría parecer compleja— estamos reproduciendo el grado de integración que se encuentra en Microsoft Excel. El lenguaje está integrado con la capa de datos y la capa de UI/UX, permitiendo a los usuarios ver e interactuar con los resultados del programa, tal como lo harían con una hoja de cálculo de Excel. Sin embargo, a diferencia de Excel, nos adentramos en territorios mucho más interesantes para la gestión de supply chain al abrazar conceptos relacionales como ciudadanos de primera clase, así como optimización matemática y machine learning.
Tanto la optimización matemática como el machine learning en esta cadena pasan por toda la cadena, en lugar de simplemente llamar a una biblioteca que se encuentre en algún lugar. Tener machine learning como ciudadano de primera clase en la cadena permite mensajes de error más inteligibles, lo cual marca una gran diferencia en términos de productividad para los expertos en supply chain.

Como tema final, hoy en día los compiladores casi siempre tienen como destino una máquina virtual, pero estas máquinas virtuales, a su vez, se compilan hacia otra máquina virtual. En la pantalla, las capas típicas de VM que se encuentran en una configuración basada en servidor son muy similares a lo que tenemos con un script de Envision. Acabo de presentar la cadena de compilación, pero fundamentalmente, sería prácticamente la misma pila si estuviéramos pensando en un script de Python o una hoja de cálculo de Excel operada desde un servidor. Al diseñar un compilador, esencialmente eliges la capa en la que vas a inyectar el código. Cuanto más profunda sea la capa, más tecnicismos tendrás que abordar. Para elegir la capa, hay una serie de preocupaciones que deben ser abordadas.
Primero, está la seguridad. ¿Cómo proteges tu memoria y qué debería o no debería acceder el programa? Si tienes un lenguaje de programación genérico, tus opciones son limitadas. Podrías necesitar operar a nivel del sistema operativo huésped, aunque incluso eso podría no ser muy seguro. Existen formas de crear entornos aislados (sandbox), pero es muy complicado, por lo que incluso podrías tener que ir más bajo que eso.
En segundo lugar, está la preocupación por las características de bajo nivel que te interesan. Por ejemplo, esto podría ser importante si deseas lograr una ejecución más eficiente, reduciendo la cantidad de recursos informáticos necesarios para completar tu programa. Puedes decidir bajar lo suficiente para gestionar la memoria y los hilos. Sin embargo, con este poder viene la responsabilidad de gestionar efectivamente la memoria y los hilos.
En tercer lugar, existen características de conveniencia como la recolección de basura, el seguimiento de pila (stack trace), el depurador y el profiler. Típicamente, toda la instrumentación en torno al compilador es más compleja que el propio compilador. La cantidad de características de conveniencia de las que te beneficias no debe subestimarse.
En cuarto lugar, existen preocupaciones sobre la asignación de recursos. Si operas con una hoja de cálculo de Excel en tu escritorio, Excel puede consumir todos los recursos informáticos de tu estación de trabajo. Sin embargo, con Envision o SQL, tienes múltiples usuarios a los que atender, y debes decidir cómo asignar los recursos. Además, con Envision, no se trata solo de múltiples usuarios, sino de múltiples empresas a atender, ya que Lokad es multi-tenant. Esto tiene sentido en supply chain porque la necesidad de recursos computacionales es muy intermitente para la mayoría de las supply chains.
Típicamente, solo necesitas un estallido muy intenso de computación durante algo así como media hora o quizás una hora, y luego nada durante las siguientes 23 horas. Luego, se repite a diario. Si asignaras recursos de hardware computacional a una empresa, esos recursos permanecerían sin usar el 90% del tiempo o incluso más. Por lo tanto, deseas poder distribuir la carga de trabajo entre muchas máquinas y a lo largo de muchas empresas, potencialmente empresas que operan en diversas zonas horarias.
Por último, está la preocupación del ecosistema. La idea es que cuando decides una capa específica y una VM específica como objetivo para tu compilador, será bastante conveniente integrar e interconectar tu compilador con lo que también tenga como destino las mismas máquinas virtuales. Esto plantea la cuestión del ecosistema: ¿qué puedes encontrar al mismo nivel que lo que tienes como objetivo, para no reinventar la rueda para cada pequeño detalle involucrado en toda tu pila? Esta es la última y crucial preocupación.

En conclusión, felicitaciones a los pocos afortunados que han llegado tan lejos en esta serie de conferencias de supply chain. Probablemente, esta sea una de las conferencias más técnicas hasta ahora. Los compiladores son, indudablemente, un componente muy técnico; sin embargo, la realidad de las supply chains modernas es que todo se mediatiza a través de un lenguaje de programación. Ya no existe lo que se podría llamar una supply chain cruda y directamente observable. La única manera de observar una supply chain es a través de la mediación de los registros electrónicos producidos por todas las piezas de software empresarial que constituyen el paisaje aplicativo. Por lo tanto, se necesita un lenguaje de programación, y por defecto, este lenguaje de programación resulta ser Excel.
Sin embargo, si queremos algo mejor que Excel, necesitamos reflexionar seriamente sobre lo que “mejor” significa desde una perspectiva de supply chain y lo que implica en términos de lenguajes de programación. Si una empresa no tiene la estrategia o la cultura adecuada, ninguna tecnología la salvará. Sin embargo, si la estrategia y la cultura son sólidas, entonces las herramientas realmente importan. Las herramientas, incluyendo los lenguajes de programación, definirán tu capacidad de ejecución, la productividad que puedes esperar de tus expertos en supply chain, y el rendimiento que obtendrás de tu supply chain al convertir la macro estrategia en las miles de decisiones diarias mundanas que tu supply chain necesita tomar. Poder evaluar la adecuación de las herramientas, incluidos los lenguajes de programación que pretendes usar para abordar desafíos de supply chain, es de primordial importancia. Si no eres capaz de evaluar, entonces es simplemente un completo cargo cult.

La siguiente conferencia tratará sobre ingeniería de software. Hoy, discutimos las herramientas; sin embargo, la próxima vez, discutiremos a las personas que usan las herramientas y qué tipo de trabajo en equipo se requiere para hacer bien el trabajo. La conferencia se realizará el mismo día de la semana, miércoles, a las 3 p.m., hora de París.
Ahora, voy a echar un vistazo a las preguntas.
Pregunta: Al seleccionar software para supply chains, ¿cómo pueden las empresas que no son expertas en tecnología evaluar si el compilador y la programación son adecuados para sus necesidades?
Bueno, estoy bastante seguro de que una empresa típica que opera una supply chain típica no tiene las calificaciones para diseñar un vehículo, sin embargo, logran comprar camiones que son adecuados para sus requerimientos de supply chain y transporte. No es porque no seas un experto y no seas capaz de reconstruir y reingeniar un camión que no puedas tener una opinión muy sólida sobre si es un buen camión para tus necesidades de transporte. Así que, no estoy diciendo que las empresas que no son expertas en tecnología deban dar un salto increíble y de repente convertirse en expertas en el diseño de compiladores. Sin embargo, creo que en tan solo una hora y media, cubrimos bastante terreno. Con 10 horas más de una introducción más detallada y a un ritmo más lento, aprenderías todo lo que necesitarías saber en términos de diseño de lenguajes para supply chain.
Existe una diferencia entre ser un experto y ser tan increíblemente ignorante que la gente te puede vender una scooter pretendiendo que es un camión. Si tradujéramos este tipo de ignorancia que he observado en términos de diseño de software empresarial a la industria automotriz, la gente diría que una scooter es una semi y viceversa, y se saldrían con la suya.
Esta serie de conferencias trata sobre ciencias auxiliares, por lo que no se espera que las personas que quieren ser practicantes de supply chain se conviertan en expertas en estos dominios. No obstante, al tener un conocimiento básico, puedes llegar muy lejos en la evaluación. La mayoría de las veces, solo necesitas tener el conocimiento justo para hacer preguntas difíciles. Si el proveedor te da una respuesta sin sentido, no se ve bien. Si ni siquiera sabes qué preguntas técnicas hacer, puedes ser engañado.
Mi sugerencia es que no necesitas volverte increíblemente experto en tecnología; solo necesitas ser lo suficientemente astuto como para ser un aficionado a nivel básico que pueda señalar fallas y evaluar si todo se desmorona o si hay sustancia real detrás. Lo mismo ocurre con la optimización matemática, deep learning, CPUs, y así sucesivamente. La idea es saber lo suficiente para diferenciar entre algo fraudulento y algo legítimo.
Pregunta: ¿Abordaste directamente el problema con los lenguajes de programación existentes que no están diseñados para supply chain?
Esta es una muy buena pregunta. Desarrollar un lenguaje de programación completamente nuevo puede parecer totalmente disparatado. ¿Por qué no optar por algo ya bien establecido, como Python, e incorporar las pequeñas modificaciones que necesitamos? Habría sido una opción. El problema es que la cuestión principal no es realmente lo que necesitamos agregar a esos lenguajes, sino lo que necesitamos eliminar.
Mi principal preocupación con Python no es que no tenga un álgebra probabilística o que no tenga un álgebra relacional incorporada. Mi crítica número uno es que es un lenguaje de programación genérico y totalmente capaz, y por lo tanto expone a la persona que va a escribir código a todo tipo de conceptos, como la programación orientada a objetos para Python, que son completamente irrelevantes en lo que concierne a supply chain. El problema no era tanto tomar un lenguaje y agregar algo, sino tomar un lenguaje e intentar eliminar montones de cosas. Sin embargo, el problema es que en cuanto quitas cosas de un lenguaje de programación existente, lo rompes todo.
Por ejemplo, la primera versión de Python fue en 1990, por lo que es un lenguaje de programación de 30 años. La cantidad de código en un stack popular como Python es absolutamente gigantesca, y por una buena razón. No lo estoy criticando; es un stack muy sólido, pero también es enorme. Así que, al final, evaluamos varias opciones: tomar un lenguaje de programación, restar montones de cosas hasta que estemos satisfechos con lo que tenemos, o considerar que todos esos lenguajes de programación tienen toneladas de legado propio.
Evaluamos cuánto esfuerzo requeriría crear un lenguaje completamente nuevo, y al final, estuvo muy a favor de crear un nuevo lenguaje. Desarrollar un lenguaje de programación nuevo es un campo muy establecido, así que, aunque pueda sonar increíble, no lo es. Hay cientos de libros que te dan recetas, y ahora incluso es accesible para los estudiantes de informática. Existen incluso profesores en departamentos de informática que asignan a sus estudiantes la tarea de crear un compilador para un nuevo lenguaje de programación en un semestre.
Al final, decidimos que las supply chains eran lo suficientemente masivas como para justificar un esfuerzo dedicado. Sí, siempre puedes reciclar cosas que no fueron diseñadas para supply chains, pero las supply chains son una industria y un conjunto de problemas masivos a nivel mundial. Por lo que pensamos, considerando la escala que estamos mirando, tiene sentido hacer lo correcto y crear algo directamente para supply chain en lugar de un reciclaje accidental.
Pregunta: Para la optimización de supply chain, Envision es apropiado ya que comprende SQL, Python, etc. Sin embargo, para WMS, ERP, donde el flujo de procesos es clave más que la optimización matemática, ¿cómo puedes evaluar su compilador y lenguaje de programación?
Esa es una muy buena pregunta. Personalmente, he estado jugueteando con la idea de que hay actores en esta industria que en realidad han desarrollado sus propios lenguajes de programación, solo por los beneficios de implementar algo puramente transaccional por naturaleza, orientado al flujo de trabajo. Supply chain, tal como lo veo, es esencialmente acerca de la optimización predictiva. Sin embargo, el señor Nannani tiene toda la razón; ¿qué pasa con toda la parte de gestión, como ERP, WMS, etc.?
Resulta que hay muchas empresas en este campo que han creado su propio lenguaje de programación. Mencioné a SAP, que tiene ABAP, diseñado solo para eso. Desafortunadamente, en mi opinión, ABAP no ha envejecido muy bien. Hay muchas cosas en ABAP que realmente no tienen sentido en el siglo XXI. Se nota realmente que este sistema fue diseñado en el ‘83, y se nota. Por ejemplo, en Microsoft Dynamics, el ERP tiene su propio lenguaje de programación. Dynamics AX tiene su propio lenguaje de programación, y hay muchos proyectos de ERP que, en gran medida, incorporan su propio lenguaje de programación. Así que, sí existe.
Ahora, ¿son realmente esos lenguajes el pináculo de lo que podemos hacer en términos de lenguajes de programación modernos y de última generación en 2021? No lo creo, y ese es también el problema que estaba mencionando: los proveedores de software empresarial siguen reinventando lenguajes de programación, pero usualmente hacen un trabajo muy pobre en ello. Es simplemente un diseño de ingeniería improvisado. Ni siquiera se toman el tiempo de leer los muchos libros disponibles en el mercado, y luego hay ingenieros deficientes que se quedan con un gran montón de desorden.
Volviendo a tu pregunta, he estado jugueteando con la idea de que Lokad incursionara en esta área y creara un lenguaje que no estuviera diseñado para la optimización, sino para apoyar el flujo de trabajo. Sin embargo, a este punto, el crecimiento de Lokad es tal que no podemos bifurcarnos y ocuparnos de los flujos de trabajo. Estoy absolutamente seguro de que esto es acertado, y que surgirán nuevos actores que harán un muy buen trabajo en la parte de gestión del problema. Lokad solo está abordando la parte de optimización de las supply chains; también existe la parte de gestión.
Pregunta: Python es actualmente visto como un lenguaje de programación estándar. ¿Existen evoluciones en curso en el mercado?
Esa es una muy buena pregunta. Verás, cuando la gente me dice “los estándares”, he estado lo suficientemente tiempo en esto como para ver estándares ir y venir. No soy muy viejo, pero cuando estaba en la secundaria, el estándar era C++. En los ‘90, C++ era el estándar. ¿Por qué harías las cosas de otra manera? Luego vino Java, alrededor del año 2000, y la combinación de Java y XML era el estándar.
Incluso se dijo que las universidades en ese momento se habían transformado en “escuelas de Java.” Literalmente, ese era el término de moda alrededor del año 2000; la gente decía, “Esta ya no es una universidad de ciencias de la computación; esto es solo una escuela de Java.” Unos años después, cuando fundé Lokad, el lenguaje de programación para cualquier cosa relevante a la estadística seguía siendo R. Python aún era muy marginal, y R dominaba absolutamente el campo en términos de análisis estadístico.
A medida que avanzamos en términos de lenguajes de programación, C++ fue quedando en el olvido. Microsoft introdujo C# en 2002 y la plataforma .NET, que canibalizó una parte significativa del ecosistema de C++. Una gran parte de los desarrolladores de C++ en todo el mundo estaban en Microsoft, una empresa muy masiva. La idea a la que quiero llegar es que ha habido una evolución continua completa, y cada año la gente mira esto como si existiera un estándar, pero este estándar cambia todo el tiempo.
JavaScript había existido durante 20 años, pero no era nada significativo. Luego, un libro publicado alrededor de 2009 o 2012 llamado “JavaScript: The Good Parts” reveló que JavaScript no era completamente loco. Podías usar JavaScript para un proyecto real sin perder la cordura; solo tenías que apegarte a las buenas partes. De repente, JavaScript se puso de moda, y la gente comenzó a usarlo del lado del servidor con un sistema llamado Node.js.
Python solo alcanzó prominencia hace unos pocos años, después de que la comunidad de Python sufriera una actualización agotadora de la versión 2.7 a la versión 3.x. Al final de esa actualización, el interés en Python se renovó. Sin embargo, hay muchos peligros que se avecinan para Python. No es un muy buen lenguaje según los estándares del siglo XXI. Es un lenguaje de 30 años, y se nota su edad. Si buscas algo mejor en cada dimensión excepto en la madurez, podrías considerar a Julia. Julia es superior en casi todos los aspectos a Python para la ciencia de datos, excepto en madurez, donde Julia aún está años detrás.
Hay montones de evoluciones en curso, y es fácil confundir el estado de la industria con algo que es un estándar que se supone debe durar. Por ejemplo, en el ecosistema de Apple, existía Objective-C, y luego Apple decidió producir Swift como reemplazo, el cual ahora está reemplazando a Objective-C. El panorama de lenguajes de programación sigue evolucionando, y aunque toma tiempo, si miramos el ecosistema dentro de diez años, probablemente habrá una cantidad significativa de evolución. Python puede que no emerja como el lenguaje de programación dominante, ya que existen muchas opciones rivales que ofrecen mejores respuestas.
Pregunta: Las empresas de alimentos y las startups de e-commerce a menudo piensan que pueden ganar la batalla con equipos de ciencia de datos y lenguajes de programación de propósito general. ¿Cuál sería tu principal argumento de venta para hacerles refinar este enfoque y hacerles darse cuenta de que necesitan algo más específico al problema?
Como dije, este es el problema con el efecto Dunning-Kruger. Le das a un ingeniero de software un sistema de programación lineal entera mixta para hacer programación entera, y una semana después, esta persona pensará que de repente se ha convertido en un experto en optimización discreta. Entonces, ¿cómo gano la batalla? A decir verdad, usualmente, no les ganamos. Lo que hago es describir la manera en que se desarrollarán las catástrofes.
Es sencillo cuando se utilizan bloques tecnológicos genéricos para crear prototipos fantásticos. Estos prototipos funcionan de maravilla debido a la ilusión de Star Wars – tienes solo tu pieza de tecnología en aislamiento. A medida que estas empresas comiencen a tratar de llevar esas cosas a producción, tendrán dificultades, la mayoría de las veces debido a problemas muy mundanos. Enfrentarán problemas de integración continuos, no como Google, Microsoft o Amazon, quienes pueden permitirse tener mil ingenieros para encargarse de toda la plomería.
TensorFlow, por ejemplo, es un desafío de integración. Google tiene los 1000 ingenieros necesarios para integrar TensorFlow en todas sus data pipelines y aplicaciones para sus propósitos. Pero la pregunta es, ¿pueden las startups o las empresas de e-commerce permitirse tener a tantas personas encargadas de toda la plomería? Generalmente, la respuesta es no. La gente imagina que solo al elegir estas herramientas, podrán seleccionar lo mejor de cada una y ensamblarlas, y mágicamente funcionará. Pero no es así. Requiere una enorme cantidad de ingeniería.
Por cierto, algunos proveedores de software empresarial están experimentando exactamente el mismo problema. Tienen demasiados componentes en su solución, y eso explica por qué implementar una solución, sin ninguna personalización, ya toma meses debido a que hay tantas partes inestables en el sistema que solo están integradas de manera laxa. Se vuelve muy difícil.
Supongo que esa fue la última pregunta. Nos vemos la próxima vez.


