L'exploration de données en temps réel avec slices
Il y a deux mois, nous avons lancé une nouvelle fonctionnalité majeure pour Lokad : notre premier volet d’exploration de données en temps réel. Cette fonctionnalité est appelée en interne dashboard slicing, et elle nous a obligé à une refonte complète du back-end de traitement de données bas niveau qui alimente Envision. Avec les dashboard slices, chaque tableau de bord devient un véritable dictionnaire de vues de tableau de bord, pouvant être exploré en temps réel grâce à une barre de recherche.
Par exemple, en découpant un tableau de bord destiné à servir d’inspecteur de produit, qui centralise toutes les informations concernant un produit - y compris les prévisions probabilistes de la demande et de lead time par exemple - il est désormais possible de passer en temps réel d’un produit à l’autre.
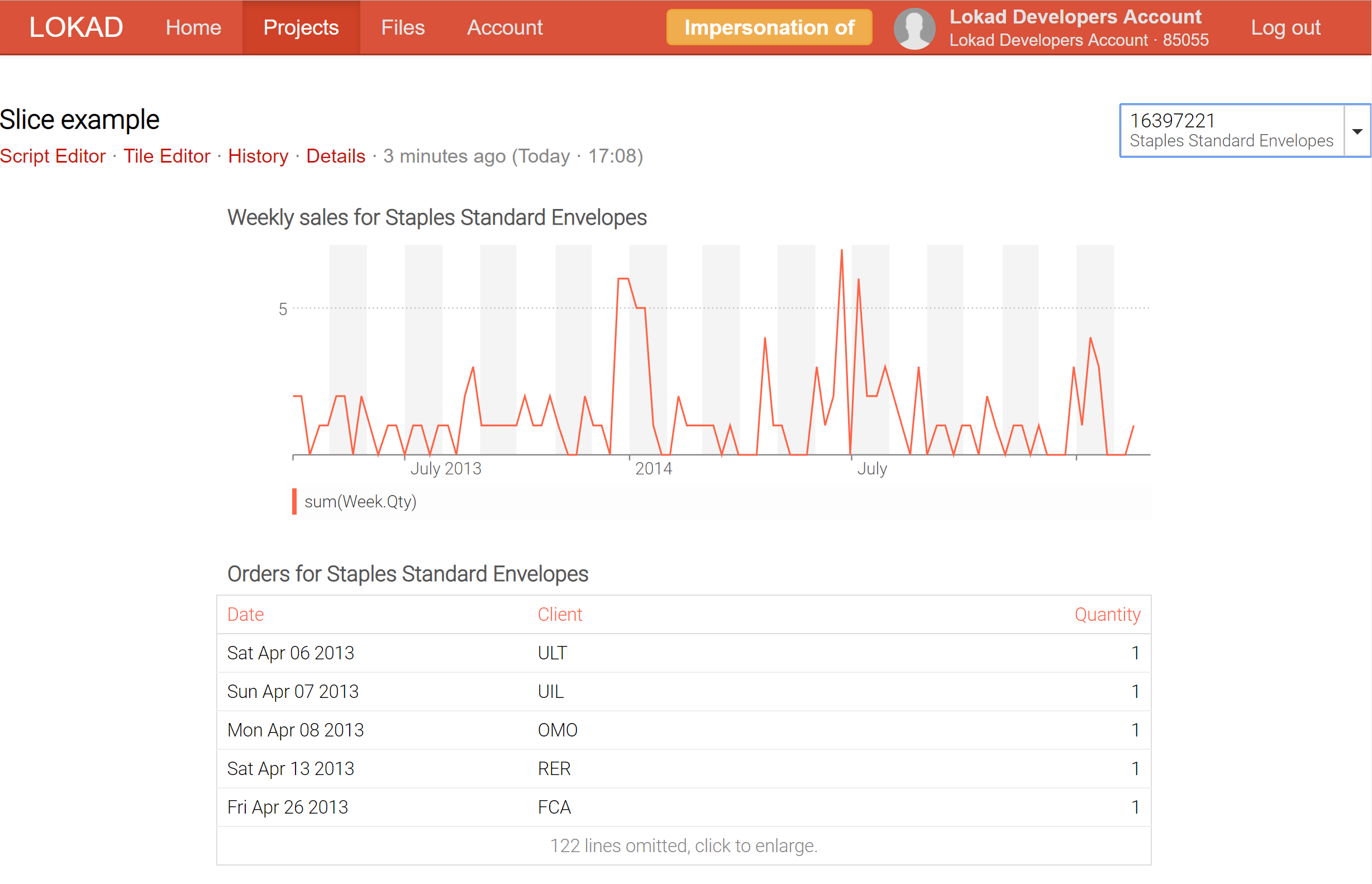
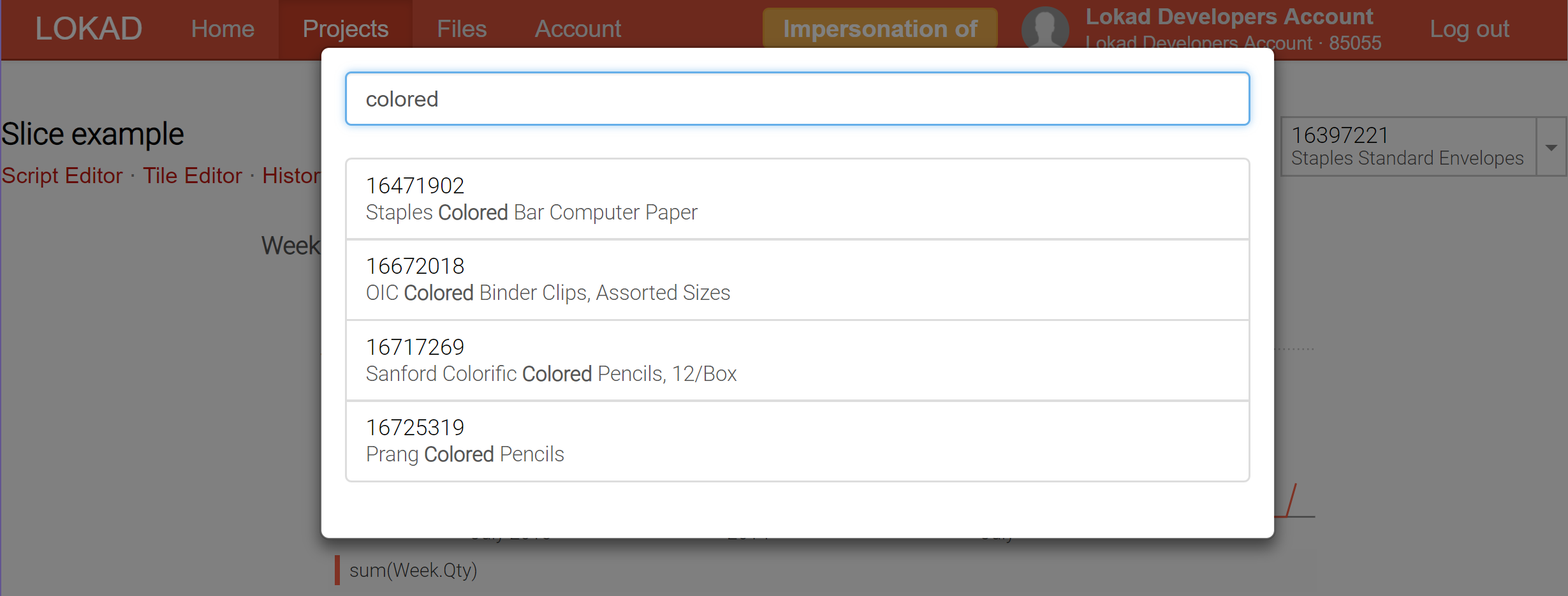
Actuellement, Lokad peut produire jusqu’à 200,000 slices (alias vues de tableau de bord) pour un seul tableau de bord ; et ces slices peuvent être affichées en temps réel via le sélecteur, qui est doté d’une fonctionnalité de recherche en temps réel afin de faciliter l’exploration des données. Contrairement aux outils de business intelligence (BI), ces slices peuvent contenir des calculs extrêmement complexes, et pas seulement des opérations de slice-and-dice sur un cube OLAP.
Quand il s’agit de traiter les données et de réaliser des rapports, il existe généralement deux camps : le traitement en ligne et le traitement par lots. Le traitement en ligne prend un flux de données, et il est généralement attendu que tout ce qui est affiché par le système soit toujours à jour : le système n’a pas plus de quelques minutes, voire parfois seulement quelques secondes de retard sur la réalité. Les cubes OLAP, ainsi que la plupart des outils qualifiés de business intelligence, appartiennent à cette catégorie. Bien que les analyses en temps réel 1 soient très désirables, non seulement d’un point de vue commercial (les données fraîches sont meilleures que des données obsolètes), mais aussi du point de vue de l’utilisateur final (performance is a feature), elles comportent également des limitations strictes. En d’autres termes, il est extrêmement difficile de fournir des analyses intelligentes2 en temps réel. Par conséquent, tous les systèmes analytiques en ligne présentent de sévères limitations quant au type d’analyses qu’ils peuvent réaliser.
D’un autre côté, le traitement par lots est généralement exécuté selon un calendrier prédéfini (par exemple des exécutions quotidiennes) lors de l’entrée de l’ensemble des données historiques (ou d’une partie significative de celles-ci). La fraîcheur des résultats est limitée par la fréquence d’exécution : un traitement par lots quotidien vous donne toujours des résultats reflétant la situation d’hier, et non celle d’aujourd’hui. Comme toutes les données sont disponibles dès le départ, le traitement par lots est idéal pour réaliser toutes sortes d’optimisations informatiques capables d’augmenter considérablement la performance globale du processus. En conséquence, grâce au traitement par lots, il est possible d’exécuter des classes entières de calculs complexes qui restent hors de portée en considérant le traitement en ligne. Par ailleurs, d’un point de vue informatique, le traitement par lots tend à être beaucoup plus simple à mettre en œuvre et à exploiter 3. Le principal inconvénient du traitement par lots réside dans le délai imposé par la nature groupée du processus.
En tant que plateforme logicielle, Lokad se positionne résolument dans le camp du traitement par lots. En effet, bien que la Supply Chain Quantitative nécessite un haut degré de réactivité, il existe de nombreuses décisions qui ne requièrent pas une réactivité instantanée, par exemple décider s’il faut produire une palette supplémentaire de produits ou déterminer s’il est temps de baisser le prix afin de liquider un stock. Pour ces décisions, la préoccupation principale est de prendre la meilleure décision possible, et si celle-ci peut être améliorée de manière mesurable en consacrant une heure de calcul supplémentaire, il est presque garanti que cette heure additionnelle sera un bon investissement 4.
Ainsi, Envision est conçu autour d’une approche de traitement par lots. Nous avons pas mal d’astuces dans notre manche pour rendre Envision très rapide, même lorsqu’il s’agit de traiter des téraoctets de données ; mais à cette échelle, nous parlons d’obtenir des résultats en quelques minutes, et non en moins d’une seconde. En réalité, en raison de la nature fortement distribuée du modèle de calcul d’Envision, il est difficile pour Lokad de compléter l’exécution de n’importe quel script Envision en moins de 5 secondes environ - même lorsqu’il ne s’agit que de quelques mégaoctets de données. Plus un système est distribué, plus l’inertie interne nécessaire à la synchronisation de toutes ses parties se fait sentir. Une plus grande scalabilité est l’ennemie d’une latence réduite.
Il y a quelques années, nous avons introduit la notion de entry forms dans Envision : une fonctionnalité qui vous permet d’ajouter un formulaire configurable sur le tableau de bord, lequel devient une entrée accessible depuis le script Envision. Par exemple, grâce à cette fonctionnalité, il a été simple de concevoir un tableau de bord destiné à servir d’inspecteur de produit, affichant toutes les informations pertinentes relatives aux produits spécifiés. Malheureusement, afin d’aligner le tableau de bord avec la nouvelle valeur saisie dans le formulaire, le script Envision devait être réexécuté, entraînant plusieurs secondes de délai pour obtenir les résultats actualisés ; une durée inacceptablement longue pour l’exploration des données.
Les slices de tableau de bord (consultez notre documentation technique) représentent notre tentative d’obtenir le meilleur des deux mondes : le traitement en ligne et par lots. L’astuce est que Lokad peut désormais calculer par batch un nombre considérable de slices (chaque slice peut représenter un produit, un emplacement, un scenario, ou une combinaison de tous ces éléments) et vous permettre de passer de l’une à l’autre en temps réel, ce qui est possible parce que tout a été pré-calculé. Naturellement, le pré-calcul d’un grand nombre de slices est plus coûteux en termes de calcul, mais pas autant qu’on pourrait le penser. Il est généralement moins cher pour Lokad de calculer 10,000 slices en une seule fois, plutôt que d’effectuer 100 exécutions indépendantes, chacune dédiée à une slice unique.
Grâce aux slices, Lokad acquiert des capacités de business intelligence on steroid : non seulement il est possible d’explorer de nombreuses vues différentes (par ex. produits, emplacements, périodes) en temps réel, mais ce, sans aucune des restrictions habituelles des architectures de traitement en ligne.
-
Dans un système distribué, il n’existe pas de véritable “temps réel”. La vitesse de la lumière impose elle-même des limites strictes au degré de synchronisation d’un système s’étendant sur plusieurs continents. Ainsi, cette terminologie est quelque peu abusive. Pourtant, si la latence globale est inférieure à une seconde environ, il est généralement acceptable de qualifier une application de traitement de données comme “temps réel”. ↩︎
-
Même les systèmes avancés de traitement de données en temps réel, tels que ceux utilisés pour la conduite autonome, évitent soigneusement toute opération d"apprentissage" lorsqu’ils fonctionnent en temps réel. Tous les modèles de machine learning sont pré-calculés et statiques. ↩︎
-
La mise en œuvre typique d’un processus par lots consiste à déplacer des fichiers plats, ce qui est une fonctionnalité de base supportée par pratiquement tous les systèmes de nos jours. Ensuite, d’un point de vue opérationnel, si un composant du processus par lots subit une panne transitoire, une simple stratégie de nouvelle tentative résout généralement le problème. En revanche, les systèmes en ligne ont tendance à mal se comporter lorsqu’un composant tombe en panne. ↩︎
-
À l’heure actuelle, une heure de calcul sur un CPU moderne coûte généralement moins de 0.02 $ lorsqu’on utilise le modèle pay-as-you-go sur les principales plateformes de cloud computing. Ainsi, tant que les bénéfices générés par une meilleure décision supply chain individuelle valent bien plus que 0.02 $, il est raisonnable d’investir cette heure de calcul. ↩︎

