00:00 Introduzione
03:39 L’automazione è sempre stata l’obiettivo
06:28 Gestione delle eccezioni e avvisi
10:27 La storia finora
14:33 Il nostro lancio in produzione oggi
15:59 Riepilogo: risultato, ambito e ruoli
19:01 Scoprire la forma della decisione
23:00 Risposta basata sul legacy
27:20 Iterare fino ad annullare completamente la follia
32:30 Metriche aspirazionali
36:27 Esecuzione duale: manuale + meccanica
39:19 Paralisi da analisi
43:21 Progressiva presa in carico dell’automazione
46:08 Sedimentazione del processo
48:57 Dal pianificatore al responsabile della rete
52:46 Il turista dei KPI
54:58 Leadership: da coach a product owner
58:46 Il capo supply chain analogico
01:02:25 Conclusione
01:04:44 7.2 Portare decisioni automatizzate in produzione - Domande?
Descrizione
Cerchiamo una ricetta numerica per guidare un’intera classe di decisioni banali, come i riapprovvigionamenti. L’automazione è essenziale per rendere la supply chain un’impresa capitalistica. Tuttavia, comporta rischi sostanziali di causare danni su larga scala se la ricetta numerica è difettosa. Fallire rapidamente e rompere le cose non è il giusto approccio per dare l’ok a una ricetta numerica in produzione. Tuttavia, molte alternative, come il modello waterfall, sono addirittura peggiori in quanto di solito danno l’illusione di razionalità e controllo. Un processo fortemente iterativo è la chiave per progettare quella ricetta numerica che si dimostri di livello industriale.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Johannes Vermorel e oggi presenterò “Bringing Automated Supply Chain Decisions to Production”. Negli ultimi due secoli, le nostre economie hanno subito una trasformazione massiccia attraverso la meccanizzazione. Le aziende che hanno raggiunto un grado superiore di meccanizzazione rispetto ai loro concorrenti hanno quasi sempre spinto sistematicamente tali concorrenti verso la bancarotta. La meccanizzazione ci permette di fare di più, meglio e più velocemente, riducendo i costi. Questo è vero per le attività fisiche, come spostare merci con un carrello elevatore invece di trasportare scatole a mano, ma lo è anche per le attività intellettuali, come calcolare quanto denaro vi rimane in banca.
Tuttavia, la nostra capacità di meccanizzare un compito dipende dalla tecnologia. Ci sono ancora molte attività fisiche che non possono ancora essere meccanizzate, per esempio fare un taglio di capelli o cambiare le lenzuola. Al contrario, ci sono ancora molte attività intellettuali che non possono ancora essere meccanizzate, come assumere la persona giusta o capire cosa desidera il cliente. Non c’è motivo di credere che tali compiti, siano essi intellettuali o meccanici, non potranno mai essere meccanizzati. Tuttavia, la tecnologia non è ancora al passo.
La maggior parte delle decisioni routinarie e banali della supply chain possono ora essere automatizzate. Questo è uno sviluppo relativamente recente. Un decennio fa, l’ambito delle decisioni della supply chain che potevano essere automatizzate con successo rappresentava solo una frazione dell’intero spettro delle decisioni. Oggi, la situazione è invertita e, con la giusta tecnologia, le decisioni ripetitive della supply chain che non possono essere automatizzate con successo sono poche e sporadiche. Per automazione di successo intendo un processo in cui le decisioni automatizzate sono superiori a quelle ottenute con un processo manuale, non la capacità di generare decisioni con un computer, cosa banale finché non ci si preoccupa della qualità delle decisioni generate.
Il nostro focus oggi non è sulla ricetta numerica - ovvero, il software che rende possibile tale automazione fin dall’inizio. Nel contesto dei processi decisionali della supply chain, gli ingredienti per elaborare una ricetta numerica sono stati trattati nei capitoli precedenti di questa serie di lezioni. Oggi ci concentriamo sulle parti dell’iniziativa della supply chain necessarie per portare tale ricetta numerica in produzione. L’obiettivo di questa lezione è delineare cosa occorre per passare da decisioni manuali della supply chain a decisioni automatizzate. Al termine di questa lezione, dovreste avere intuizioni sui dos e don’ts nel percorso verso l’automazione. Infatti, la pura difficoltà tecnica associata alla ricetta numerica tende ad oscurare gli aspetti organizzativi, che sono comunque altrettanto critici per il successo dell’iniziativa.

Quando ai professionisti della supply chain odierna viene presentata l’idea dell’automazione delle decisioni, la loro reazione immediata tende ad essere “Questa è un’idea così futuristica. Non siamo nemmeno lontanamente al punto.” Tuttavia, l’automazione completa delle decisioni banali e ripetitive della supply chain è stata letteralmente l’obiettivo fin dall’inizio dell’era digitale delle supply chain, oltre quattro decenni fa.
Non appena i computer divennero facilmente accessibili alle aziende, si capì che la maggior parte delle decisioni della supply chain erano candidati ovvi per l’automazione completa. Sullo schermo, ho selezionato una lista di pubblicazioni che illustrano questa ambizione. Negli anni ‘70 e ‘80, questo campo non veniva nemmeno chiamato supply chain. Il termine sarebbe diventato popolare solo negli anni ‘90. Tuttavia, l’intento era già chiaro. Questi sistemi informatici apparivano immediatamente adatti ad automatizzare le decisioni della supply chain più ripetitive, come i riapprovvigionamenti.
Ciò che mi sorprende di più è che questa comunità sembra essere in qualche modo inconsapevole delle sue ambizioni passate. Oggigiorno, per sembrare futuristici, il termine “autonomous supply chain” viene talvolta utilizzato da società di consulenza o aziende IT per trasmettere questa prospettiva di meccanizzazione delle decisioni banali della supply chain. Tuttavia, il termine “autonomous” mi sembra inappropriato. Non usiamo il termine “autonomous logistics” per riferirci a un nastro trasportatore dotato di un sistema di smistamento. Il nastro trasportatore è meccanizzato, non autonomo. Esso richiede ancora una supervisione tecnica, ma questa innovazione rappresenta solo una piccola frazione della manodopera che l’azienda altrimenti impiegherebbe per trasportare le merci senza il nastro trasportatore. Per quanto riguarda le decisioni della supply chain, l’obiettivo non è rimuovere completamente gli esseri umani dall’organizzazione, raggiungendo così una tecnologia veramente autonoma. L’obiettivo è semplicemente quello di escludere gli esseri umani dalla parte più dispendiosa in termini di tempo e più grezza del processo. Questa è esattamente la prospettiva adottata in quegli articoli pubblicati quattro decenni fa ed è la prospettiva che adotto anche in questa lezione.

Durante gli anni ‘90, sembra che i fornitori di software, sia quelli di ERP che gli specialisti nell’ottimizzazione degli inventari, abbiano in gran parte abbandonato l’idea di ottenere decisioni automatizzate per la supply chain. In retrospettiva, i modelli semplicistici degli anni ‘70, che ignoravano in larga misura molti fattori importanti come l’incertezza, erano la causa evidente per spiegare perché l’automazione non ebbe successo in quel periodo. Tuttavia, correggere questa causa radice si è rivelato al di là di ciò che la tecnologia poteva offrire in quel periodo. Invece, i fornitori di software hanno optato per sistemi di gestione delle eccezioni. Ci si aspettava che tali sistemi producessero avvisi di inventario basati su regole impostate dalla stessa azienda cliente. Il ragionamento era: lasciamo che l’automazione si occupi della maggior parte delle linee che possono essere elaborate automaticamente, per concentrare l’intervento umano sulle linee difficili, quelle che vanno al di là delle capacità della macchina.
Sottolineiamo subito che vendere un sistema di gestione delle eccezioni è un affare vantaggioso per il fornitore di software, ma molto meno per l’azienda cliente. In primo luogo, la gestione delle eccezioni sposta il peso della performance della supply chain dal fornitore al cliente. Una volta implementata la gestione delle eccezioni, se i risultati sono scadenti, la colpa è dell’azienda cliente. Avrebbero dovuto configurare avvisi migliori per prevenire situazioni dannose fin dall’inizio.
In secondo luogo, creare un sistema per gestire avvisi di inventario parametrizzati è facile per il fornitore di software, a condizione che il fornitore non debba fornire alcun valore di parametro che regoli gli avvisi di origine. Infatti, da una prospettiva analitica, essere in grado di produrre un buon avviso di inventario significa che si può progettare una regola in grado di identificare in modo affidabile le cattive decisioni sull’inventario. Se riesci a progettare una regola che identifichi in modo affidabile le cattive decisioni sull’inventario, allora per definizione la stessa regola può essere usata per produrre in modo affidabile buone decisioni sull’inventario. Infatti, la regola deve essere semplicemente usata come filtro per prevenire l’adozione di decisioni errate.
Terzo, la gestione delle eccezioni è una strategia alquanto astuta da parte del fornitore di software per sfruttare la psicologia umana. Infatti, quegli avvisi sfruttano un meccanismo noto come “commitment and consistency” dagli psicologi empirici. Questo meccanismo crea una forte, seppur in gran parte accidentale, dipendenza dal prodotto software. In breve, una volta che i dipendenti iniziano a modificare i numeri dell’inventario, non si tratta più di numeri arbitrari. Sono i loro numeri, il loro lavoro, e così i dipendenti si attaccano emotivamente al sistema, indipendentemente dal fatto che il sistema offra effettivamente una performance superiore della supply chain o meno.
Nel complesso, la gestione delle eccezioni rappresenta un vicolo cieco tecnologico perché, in generale, progettare eccezioni affidabili e avvisi affidabili è esattamente difficile quanto progettare un’automazione affidabile per le decisioni. Se non ti puoi fidare degli avvisi e delle eccezioni, allora devi comunque rivedere tutto manualmente, il che ti riporta al punto di partenza. Il processo decisionale rimane strettamente manuale.

Questa serie di lezioni sulla supply chain comprende due dozzine di episodi. A questo punto, in un certo senso, tutti gli elementi che abbiamo introdotto finora sono stati realizzati con l’esplicito scopo di arrivare al punto in cui siamo oggi: sull’orlo di mettere in produzione questa iniziativa di quantitative supply chain. Più specificamente, è la ricetta numerica che vogliamo mettere in previsione e questa impresa è il fulcro della lezione di oggi.
In queste lezioni, utilizzo il termine “ricetta numerica” per riferirmi alla sequenza di calcoli che prende in input i dati storici grezzi e produce in output le decisioni finali. Questa terminologia è intenzionalmente vaga, poiché riflette molti concetti, metodi e tecniche differenti che sono stati precisamente trattati nei capitoli precedenti. Nel primo capitolo, abbiamo visto perché la supply chain deve diventare programmatica e perché è altamente desiderabile poter mettere in produzione una tale ricetta numerica. L’aumento costante della complessità stessa delle supply chain rende l’automazione più urgente che mai. Esiste anche l’imperativo di rendere la supply chain practice un’impresa capitalistica.
Il secondo capitolo è dedicato alle metodologie. Infatti, le supply chain sono sistemi competitivi. Questa combinazione sconfigge le metodologie naïve. Tra le metodologie che abbiamo introdotto, le personae della supply chain e l’ottimizzazione sperimentale sono di primaria rilevanza per l’argomento di oggi. Le personae della supply chain sono la chiave per adottare la giusta forma decisionale. Rivedremo questo punto fra pochi minuti. L’ottimizzazione sperimentale è essenziale per fornire qualcosa che funzioni davvero. Ancora, rivedremo anche questo punto fra pochi minuti.
Il terzo capitolo esamina il problema, mettendo da parte la soluzione attraverso le personae della supply chain. Questo capitolo tenta di caratterizzare le classi di problemi decisionali che devono essere affrontati. Questo capitolo mostra che prospettive semplicistiche, come scegliere la giusta quantità per ogni SKU, non si adattano realmente alle situazioni del mondo reale. Esiste quasi invariabilmente una profondità nella forma delle decisioni.
Il quarto capitolo esamina gli elementi necessari per comprendere una pratica moderna della supply chain in cui gli elementi software sono ubiqui. Tali elementi sono fondamentali per comprendere il contesto più ampio in cui opera la ricetta numerica e, in realtà, la maggior parte dei processi della supply chain. Infatti, molti manuali sulla supply chain presumono implicitamente che le loro tecniche e formule operino in una sorta di vuoto. Non è così. Il panorama applicativo è importante.
I capitoli 5 e 6 sono dedicati rispettivamente alla modellazione predittiva e al processo decisionale. Questi capitoli coprono le parti intelligenti della ricetta numerica, che includono tecniche di machine learning e di ottimizzazione matematica. Infine, il settimo e presente capitolo è dedicato all’esecuzione di un’iniziativa di quantitative supply chain il cui scopo è proprio quello di mettere in produzione una ricetta numerica e mantenerla successivamente. Nella lezione precedente, abbiamo trattato cosa occorre per avviare l’iniziativa, gettando le basi appropriate a livello tecnico. Ciò significa l’installazione di un adeguato data pipeline. Oggi, vogliamo attraversare il traguardo e mettere in azione questa ricetta numerica.

Inizieremo con un breve riepilogo della lezione precedente e poi procederemo con tre aspetti importanti delle fasi successive dell’iniziativa. Il primo aspetto riguarda la progettazione della ricetta numerica. Tuttavia, non parlerò della progettazione degli elementi numerici della ricetta, ma della progettazione del processo ingegneristico stesso, che circonda la ricetta numerica. Vedremo come affrontare la sfida per dare all’iniziativa la possibilità di far emergere una soluzione soddisfacente.
Il secondo aspetto riguarda il corretto rollout della ricetta numerica. Infatti, l’azienda inizia con un processo manuale e terminerà con uno automatizzato. Un rollout adeguato può mitigare in larga misura il rischio associato a questa transizione o meglio mitigare il rischio associato a una ricetta numerica che si rivelerebbe difettosa, almeno inizialmente.
Il terzo aspetto riguarda il cambiamento che deve avvenire nell’azienda una volta implementata l’automazione. Vedremo che i ruoli e le missioni delle persone nella divisione supply chain dovrebbero subire un cambiamento sostanziale.
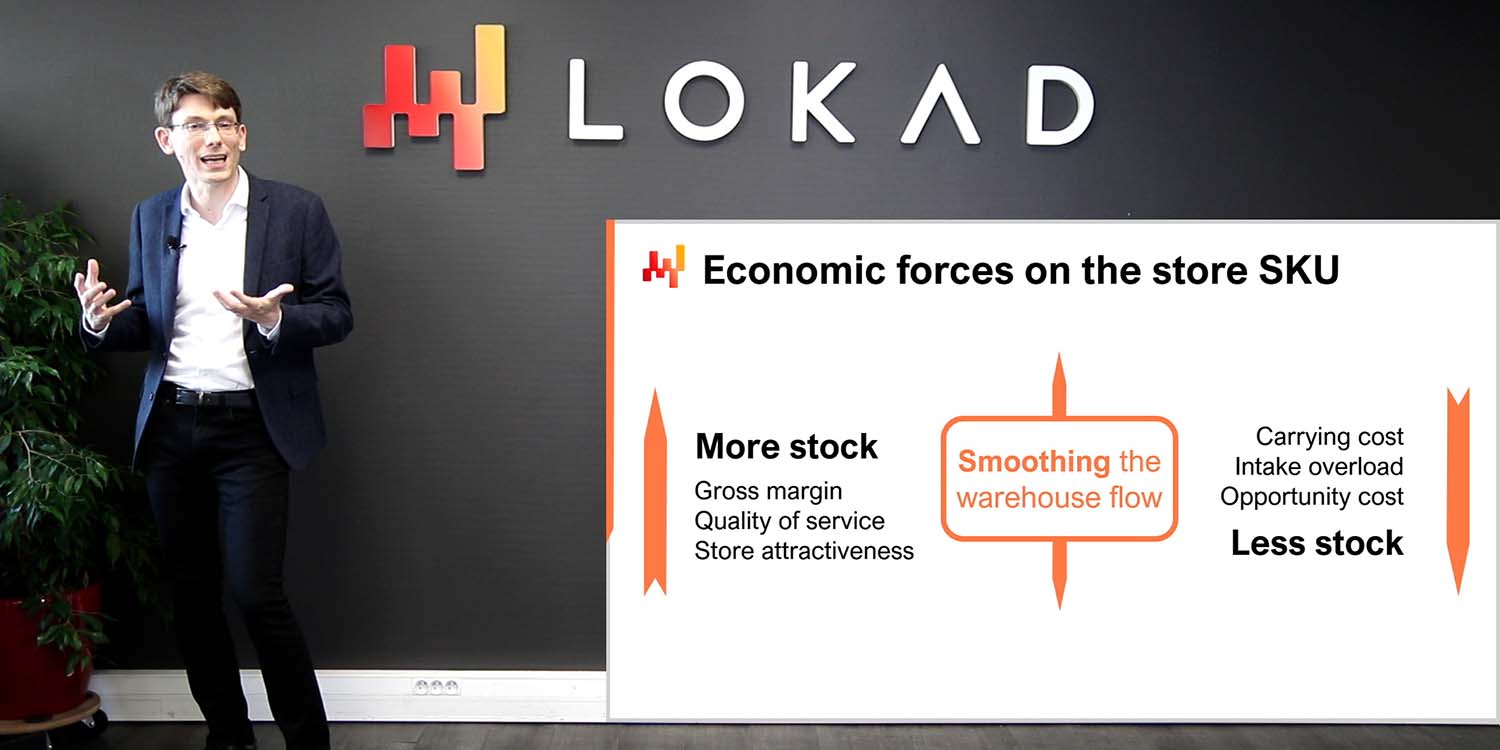
Nella lezione precedente, abbiamo visto come dare avvio a un’iniziativa quantitativa supply chain. Ripassiamo gli aspetti più importanti. Il deliverable è una ricetta numerica operativa, che è un pezzo di software capace di guidare una classe di decisioni supply chain, per esempio il reintegro delle scorte. Questa ricetta numerica, una volta messa in produzione, fornirà l’automazione che cerchiamo. Le decisioni non devono essere confuse con artefatti numerici come le previsioni della domanda, che sono semplicemente risultati intermedi che possono contribuire al calcolo delle decisioni stesse.
L’ambito dell’iniziativa deve essere allineato sia con la supply chain, intesa come sistema, sia con il suo paesaggio applicativo sottostante. Prestare attenzione alle proprietà sistemiche della supply chain è fondamentale per evitare di spostare i problemi anziché risolverli. Per esempio, se l’ottimizzazione dell’inventario di un negozio in una retail chain viene eseguita a discapito degli altri negozi, tale ottimizzazione perde di significato. Inoltre, prestare attenzione al paesaggio applicativo è importante perché dobbiamo minimizzare lo sforzo iniziale di data plumbing. Le risorse IT sono quasi sempre un collo di bottiglia, e dobbiamo fare attenzione a non esacerbare questa limitazione.
Infine, abbiamo individuato quattro ruoli per questa iniziativa, vale a dire il supply chain executive, il data officer, il supply chain scientist, e il supply chain practitioner. Il supply chain executive possiede la strategia, la conduzione del cambiamento e arbitrale le scelte di modellizzazione. Il data officer è responsabile dell’impostazione del data pipeline, che rende disponibili i dati transazionali rilevanti allo strato analitico. In questa lezione, assumiamo che il data pipeline sia già stato impostato. Il supply chain scientist ha il compito di implementare la ricetta numerica, che include molta strumentazione, non solo i componenti algoritmici intelligenti. Infine, il supply chain practitioner è una persona coinvolta nel processo decisionale manuale. Questa persona tipicamente ricopre il ruolo di supply and demand planner, sebbene la terminologia vari. All’inizio dell’iniziativa, ci si aspetta che transiti verso il ruolo di network manager entro la sua conclusione. Riprenderemo questo punto più avanti nella lezione.

Le supply chain sono abbastanza favorevoli quando si tratta dell’automazione dei processi decisionali. Esistono numerose decisioni banali e altamente ripetitive di natura quantitativa. Sfortunatamente, la prospettiva modellistica offerta nella maggior parte dei manuali di supply chain è solitamente eccessivamente semplicistica. Non sto dicendo che le tecniche da manuale siano troppo semplici o riduttive. Tuttavia, sto semplicemente affermando che il tipo di problemi presentati in quei manuali tende ad essere semplicistico. Consideriamo, ad esempio, una situazione di reintegro dell’inventario. La prospettiva da manuale cerca la inventory policy ottimale per calcolare quante unità devono essere riordinate. Questo va bene, ma spesso si tratta di una risposta piuttosto incompleta.
Ad esempio, potremmo dover decidere se le merci saranno spedite via aerea o via marittima, con le due modalità di trasporto che rappresentano un compromesso tra lead time e costo del trasporto. Potremmo dover scegliere un fornitore tra molteplici fornitori eleggibili. Potremmo dover definire il piano di spedizione esatto, con diverse date di spedizione, se la quantità è sufficientemente elevata da giustificare più spedizioni.
Il terzo capitolo di questa serie, un capitolo dedicato alle personae della supply chain, ha presentato vedute dettagliate di situazioni reali in cui si osserva che quasi sempre ci sono sottigliezze oltre al semplice scegliere una singola quantità per un dato SKU. Pertanto, il supply chain scientist, con l’aiuto del supply chain practitioner e del supply chain executive, deve iniziare scoprendo la forma completa della decisione. La forma completa della decisione deve includere tutti gli elementi che contribuiscono a modellare l’operazione effettiva della supply chain. Scoprire la forma completa della decisione è difficile.
Innanzitutto, la divisione del lavoro, come viene attuata nella maggior parte delle aziende che gestiscono una grande supply chain, solitamente frammenta i vari aspetti della decisione tra diversi dipendenti e talvolta tra vari reparti. Per esempio, una persona sceglie la quantità da riordinare mentre un’altra decide quale fornitore riceve l’ordine di acquisto.
In secondo luogo, gli aspetti più sottili della decisione, come richiedere al fornitore di accelerare l’ordine in caso di un’impennata della domanda, tendono a essere trascurati perché i practitioner non si rendono conto che tali aspetti possono e devono essere automatizzati. Suggerisco di avere la descrizione di questa forma completa di decisione scritta, non come una serie di slide, ma come un vero e proprio testo. In particolare, il testo deve chiarire il “perché”. Cosa è esattamente in gioco per ciascun aspetto della decisione? Infatti, mentre alcuni aspetti della decisione potrebbero essere relativamente ovvi, come la quantità in un riordino, altri potrebbero essere trascurati o dimenticati. Per esempio, un fornitore potrebbe offrire, a un certo prezzo, l’opzione di restituire la merce entro sei mesi se i pacchi rimangono intatti. Esercitare o meno questa opzione dovrebbe far parte della decisione, ma può essere facilmente dimenticato.

Non riuscire a identificare la forma completa della decisione supply chain o, peggio, caratterizzare erroneamente la decisione nel suo insieme, è uno dei modi più sicuri per far fallire l’iniziativa. In particolare, la risposta guidata dal legacy è uno degli errori più frequenti che si verificano nelle grandi aziende. L’essenza della risposta guidata dal legacy consiste nell’adottare una forma di decisione che in realtà non ha senso per l’azienda e la sua supply chain, ma che viene comunque adottata perché la forma si adatta a un software transazionale esistente o a un processo preesistente all’interno dell’organizzazione.
Ad esempio, si può decidere che il reintegro dell’inventario debba essere controllato mediante il calcolo dei livelli di safety stock anziché calcolare direttamente le quantità effettive da riordinare. Calcolare gli safety stock può sembrare più semplice perché tali valori esistono già nell’ERP. Pertanto, se i valori degli safety stock venissero ricalcolati, potrebbero essere facilmente iniettati nell’ERP, sovrascrivendo qualsiasi formula effettivamente utilizzata nel DRP.
Tuttavia, gli safety stock presentano notevoli limiti. Anche qualcosa di basilare come una quantità minima d’ordine (MOQ) non rientra in una prospettiva di safety stock. Per lo meno, questa implementazione è favorita non per un pezzo di software, ma per processi preesistenti all’interno dell’organizzazione.
Ad esempio, una rete retail potrebbe avere due team di pianificazione: un team dedicato al reintegro dei negozi e un team dedicato ai livelli di personale dei centri di distribuzione. Tuttavia, questi due problemi sono fondamentalmente uno e lo stesso. Una volta stabilite le quantità da riordinare per i negozi, non resta margine per decidere quante risorse umane siano necessarie per i centri di distribuzione. Di conseguenza, i due team hanno missioni fondamentalmente sovrapposte. Questa divisione del lavoro funziona finché gli esseri umani sono coinvolti. Gli esseri umani sono bravi a gestire requisiti ambigui. Tuttavia, tale ambiguità rappresenta un ostacolo enorme per ogni tentativo di automatizzare sia il reintegro che le esigenze di personale.
Questo anti-pattern, la risposta guidata dal legacy, è molto allettante perché minimizza la quantità di cambiamenti da implementare. Tuttavia, l’automazione della decisione cambia il modo in cui essa stessa dovrebbe essere affrontata. Spesso, se il design legacy viene mantenuto, l’iniziativa quantitativa supply chain fallirà.
Innanzitutto, complica ulteriormente la progettazione della ricetta numerica, che è già un’impresa piuttosto complessa. Infatti, i modelli che erano adatti per una divisione del lavoro tra dipendenti umani non sono quelli adatti per un pezzo di software che è puramente meccanico.
In secondo luogo, la risposta guidata dal legacy annulla anche molti dei potenziali benefici associati all’automazione. Infatti, nella supply chain si trovano numerose inefficienze ai confini esistenti all’interno dell’azienda. L’automazione elimina la necessità della maggior parte di quei confini, introdotti solo a causa di un modo specifico di organizzare la divisione del lavoro che non avrebbe senso se un singolo computer si occupa dell’intera operazione. Non lasciare che decisioni prese due o tre decenni fa dettino il futuro della tua supply chain.
Una volta caratterizzata correttamente la forma della decisione, il supply chain scientist inizia a creare la ricetta numerica vera e propria, sfruttando i dati transazionali storici. In questa serie di lezioni, ci sono due capitoli dedicati ai dettagli delle tecniche algoritmiche che possono essere utilizzate per apprendere e ottimizzare. Non riprenderò quegli elementi oggi. Diciamo semplicemente che il supply chain scientist prende una serie di decisioni basate sul suo giudizio per elaborare una ricetta numerica iniziale, fondata sulla sua conoscenza, esperienza e sugli strumenti disponibili per i supply chain scientist.
Con gli strumenti e le tecniche adeguate, questa bozza iniziale può e deve essere implementata in pochi giorni, al massimo in alcune settimane. Infatti, non stiamo parlando di una ricerca avanzata per scoprire qualche tecnica innovativa, ma semplicemente di elaborare un adattamento di tecniche conosciute che abbracci le specificità della supply chain di interesse. Infatti, la ricetta numerica deve aderire in maniera molto rigorosa ai dettagli della decisione così come sono stati identificati nella loro forma completa.
Anche considerando un supply chain scientist estremamente competente che sfrutta i migliori strumenti che il denaro può comprare, è inutile aspettarsi che la ricetta numerica sia corretta al primo tentativo. Infatti, le supply chain sono troppo complesse e oscure, specialmente le loro rappresentazioni digitali, per ottenere una ricetta numerica perfetta al primo colpo. Metodi numerici introspezionali come quelli che prevedono metriche e benchmark non possono rilevare se il supply chain scientist ha frainteso un dato.
Per ogni colonna in ogni tabella ottenuta dal sistema transazionale che gestisce l’azienda, di solito ci sono diverse possibili interpretazioni di quei dati. Considerando che stiamo parlando di dozzine di colonne da integrare nella ricetta numerica, gli errori sono praticamente garantiti. L’unico modo per valutare la correttezza della ricetta numerica è metterla alla prova e ottenere un feedback dal mondo reale. Questo è stato discusso nel secondo capitolo di questa serie nella lezione intitolata “Experimental Optimization”.
Pertanto, il supply chain scientist deve collaborare con il supply chain practitioner per identificare le situazioni in cui la ricetta numerica, nella sua forma attuale, restituisce ancora risultati assurdi. In termini generali, il supply chain scientist implementa un dashboard che consolida la decisione come verrebbe presa oggi dalla ricetta numerica, e il supply chain practitioner cerca di individuare le voci che risultano assurde.
In base a questo feedback, i supply chain scientist aggiungono ulteriori strumenti alla ricetta numerica. Questi strumenti assumono la forma di indicators che cercano di rispondere alla domanda: perché è stata presa questa decisione apparentemente assurda in questo contesto? Grazie a questa strumentazione, diventa possibile decidere se la ricetta numerica necessita di correzioni, per esempio perché un driver economico è stato modellato in modo inappropriato, oppure se la decisione apparentemente assurda è in realtà corretta, sebbene differisca dal modo in cui sono state fatte le cose finora in azienda.
L’ottimizzazione sperimentale è un processo altamente iterativo. Come regola generale, con gli strumenti adeguati, un singolo supply chain scientist a tempo pieno dovrebbe essere in grado di presentare una nuova iterazione della ricetta numerica ogni giorno al supply chain practitioner. Se la ricetta numerica è correttamente strumentata, man mano che l’iniziativa procede, il practitioner non dovrebbe aver bisogno di più di due ore al giorno per fornire feedback sull’ultima iterazione.
L’iterazione si interrompe quando la ricetta numerica non genera più risultati assurdi, cioè quando il supply chain practitioner non riesce più a identificare decisioni dimostrabilmente dannose per l’azienda. L’assenza di decisioni assurde può sembrare un requisito minimo rispetto al nostro obiettivo complessivo di generare decisioni superiori rispetto al processo manuale. Tuttavia, ricordiamo che la ricetta numerica è stata progettata fin dall’inizio per eseguire esplicitamente un’ottimizzazione matematica dell’interesse economico a lungo termine dell’azienda. Se i risultati sono sensati, allora l’ottimizzazione funziona e, cosa ancora più importante, dimostra anche che il criterio di ottimizzazione è in qualche modo corretto.

Mentre il processo di ingegnerizzazione altamente iterativo della ricetta numerica può risolvere numerosi problemi presenti nell’implementazione iniziale, le sole iterazioni non sono sufficienti se la prospettiva su cui si basa l’ottimizzazione è errata. In questa serie di lezioni, ho già affermato che l’ottimizzazione deve essere eseguita secondo una metrica finanziaria, cioè una metrica espressa in euro o dollari. Tuttavia, permettetemi di chiarire questa affermazione: non utilizzare una metrica finanziaria è un errore che mette in pericolo l’intera iniziativa.
Purtroppo, le grandi organizzazioni solitamente evitano le metriche finanziarie. Invece, preferiscono le metriche aspirazionali, che sono espresse in percentuale e rappresentano una sorta di perfezione che verrebbe raggiunta se, a seconda del caso, si arrivasse allo zero percento o al 100 percento. Naturalmente, la perfezione non è di questo mondo, e questa situazione limite non verrà mai raggiunta. Livelli di servizio sono, per esempio, l’archetipo della metrica aspirazionale. Il livello di servizio al 100% è impossibile da raggiungere, poiché richiederebbe una quantità irragionevole di scorte.
Alcuni manager nelle grandi aziende amano queste metriche aspirazionali. I team si incontrano di routine per discutere cosa si possa fare per migliorarle ulteriormente. Poiché queste metriche dipendono invariabilmente da fattori al di fuori del controllo dell’azienda, possono essere rivisitate all’infinito. Ad esempio, i livelli di servizio dipendono dal volume di domanda espresso dai clienti e dai tempi di consegna offerti dai fornitori. Né la domanda né i tempi di consegna sono completamente sotto il controllo dell’azienda.
Queste metriche aspirazionali funzionano in qualche modo come obiettivi aziendali quando le persone rimangono parte del processo decisionale, perché inizialmente non prestano troppa attenzione a tali metriche. Ad esempio, anche se tutti concordano che il livello di servizio dovrebbe essere aumentato, i planner manterranno comunque molte eccezioni non documentate. Il livello di servizio verrà sistematicamente aumentato, tranne se il rischio di inventario è troppo elevato, se la quantità minima d’ordine è troppo alta, se il prodotto è in procinto di essere dismesso, o se non rimane budget per il prodotto, ecc.
Purtroppo, quelle metriche aspirazionali diventano veleno quando si implementa un processo automatizzato. Infatti, tali metriche sono incomplete e non riflettono ciò che è realmente auspicabile per l’azienda. Ad esempio, raggiungere un livello di servizio al 100% non è auspicabile perché creerebbe enormi eccedenze di scorte. È possibile – non sconsiderato, ma possibile – tentare di reimplementare tutti quei vincoli, tutte quelle eccezioni sopra le metriche aspirazionali. Intendo avere una ricetta numerica che miri alle metriche aspirazionali imponendo numerosi vincoli che riproducono ciò che potrebbe avvenire nella mente di un planner. Ad esempio, potremmo definire la regola secondo cui il livello di servizio dovrebbe essere aumentato finché l’inventario rimane al di sotto di una quantità pari a quattro mesi di scorte. Tuttavia, questa strategia per la progettazione e l’implementazione della ricetta numerica risulta estremamente fragile. L’ottimizzazione finanziaria diretta è una via notevolmente più sicura e superiore.

Per ottenere una collaborazione efficiente tra il supply chain practitioner – o, più probabilmente, i supply chain practitioners – e il Supply Chain Scientist, raccomando di adottare sin da subito una strategia a doppia esecuzione. La ricetta numerica dovrebbe essere eseguita quotidianamente accanto al processo manuale preesistente. Con la doppia esecuzione, l’azienda genera effettivamente la decisione due volte attraverso due processi concorrenti. Tuttavia, nonostante l’attrito, una doppia esecuzione offre benefici sostanziali. In primo luogo, il supply chain practitioner ha bisogno di decisioni fresche che riflettano la situazione attuale per poter formulare una valutazione. Altrimenti, il practitioner non riesce nemmeno a dare un senso alla decisione automatizzata, né a identificare le parti che risultano assurde. Infatti, dalla prospettiva del practitioner, decisioni che riflettono la situazione della supply chain di tre settimane fa sono storia antica. Non c’è molto da guadagnare trascorrendo ore a rivedere i livelli di scorte passati.
Al contrario, se le decisioni automatizzate sono aggiornate e riflettono la situazione attuale, esse competono con quelle che il practitioner sta per prendere manualmente. Tali decisioni automatizzate possono, nel frattempo, essere considerate semplici suggerimenti.
In secondo luogo, l’esecuzione quotidiana della ricetta numerica garantisce che l’intera pipeline dei dati venga sottoposta ogni giorno a un test funzionale completo. Infatti, la ricetta numerica non deve soltanto restituire risultati sensati, ma deve operare in maniera impeccabile dal punto di vista dell’infrastruttura IT. Già le supply chain sono sufficientemente caotiche; la ricetta numerica non deve aggiungere un ulteriore strato di caos. Mettere la ricetta in condizioni equivalenti a quelle di produzione il prima possibile garantisce che problemi poco frequenti si manifestino in anticipo e, di conseguenza, che il data officer e i Supply Chain Scientists abbiano la possibilità di risolverli tempestivamente. Come regola empirica, entro la fine del primo terzo – ovvero entro la fine del terzo mese dall’avvio di un’iniziativa di approvvigionamento quantitativo – la doppia esecuzione dovrebbe essere in atto, anche se la ricetta numerica non è ancora pronta per essere immessa in produzione.
Inoltre, entro la fine del primo mese della doppia esecuzione, se il Supply Chain Scientist fa un buon lavoro, il supply chain practitioner dovrebbe iniziare a notare dei pattern nella lista delle decisioni automatizzate che altrimenti sarebbero stati trascurati, anche se esistono ancora alcune righe assurde che richiedono ulteriori miglioramenti della ricetta numerica.

Una volta che la doppia esecuzione è in atto, ci si aspetta che il supply chain practitioner dedichi un po’ di tempo – una o due ore al giorno – a esaminare le decisioni generate dalla ricetta numerica, cercando di identificare le parti che non siano ancora del tutto sensate. Tuttavia, a volte la situazione risulterà semplicemente poco chiara. Una decisione sorprende – magari la ricetta numerica è lenta, magari no. Il practitioner si sente incerto e, in questo caso, dovrebbe chiedere al Supply Chain Scientist di aggiungere ulteriore strumentazione per fare chiarezza sulla vicenda. Questo processo è esattamente ciò a cui si fa riferimento in questa serie di lezioni come white-boxing della ricetta numerica. Il white-boxing è un processo in cui la ricetta numerica viene resa il più trasparente possibile per gli stakeholder. Il white-boxing è una cosa buona – anzi, essenziale – per costruire fiducia nella ricetta numerica.
Supponendo che le decisioni automatizzate siano raccolte in una tabella sul dashboard, la forma più tipica di strumentazione sarà rappresentata da colonne aggiuntive accanto a quelle delle decisioni. Ad esempio, se si considerano le quantità di riordino, si possono prevedere evidenti colonne di strumentazione quali la quantità di scorte disponibili, il tempo medio di consegna previsto e la domanda media giornaliera attesa, ecc. Questa strumentazione è fondamentale per consentire al supply chain practitioner di effettuare valutazioni rapide sulla validità delle decisioni automatizzate. Tuttavia, occorre prestare attenzione alla quantità di strumentazione che si accumula sopra la ricetta numerica. Ogni singolo indicatore introdotto per arricchire la decisione automatizzata nell’ambito del processo di white-boxing ingombra ulteriormente la visione complessiva delle stesse decisioni. Troppo di una cosa buona può trasformarsi in qualcosa di negativo. Se, dopo due mesi di esecuzione, il supply chain practitioner continua abitualmente a richiedere ulteriore strumentazione mentre la pipeline dei dati è già stata stabilizzata, allora potremmo avere un problema.
La causa principale del problema può essere attribuita a elementi troppo sofisticati della ricetta numerica. Nei capitoli 5 e 6 di questa serie abbiamo visto che non tutte le tecniche e i modelli nascono uguali in termini di interpretabilità. Molti modelli sono, per loro natura, molto opachi, anche per i data scientist che li utilizzano. Non intendo oggi riprendere le classi di modelli che soddisfano il requisito dell’interpretabilità. Ai fini di questa discussione, presumerò semplicemente che i modelli integrati nella ricetta numerica siano adeguatamente interpretabili da un punto di vista della supply chain. In questo contesto, quando l’iniziativa sembra bloccarsi a causa di una richiesta infinita di ulteriore strumentazione, la causa più probabile è la paralisi da analisi. Il supply chain practitioner sta sovrainterpretando la propria valutazione della ricetta numerica. Questa è l’essenza della paralisi da analisi. Il practitioner sottopone la ricetta numerica a un livello di scrutinio che supera quello riservato al processo manuale. È compito del dirigente della supply chain assicurarsi che l’iniziativa non rimanga bloccata nella paralisi da analisi. E, se ciò dovesse succedere – e può succedere – spetta anche al dirigente della supply chain ricordare gentilmente al team che le decisioni basate sull’intervento umano sono anch’esse imperfette. Stiamo cercando un miglioramento rispetto al processo manuale, non la perfezione.

Una volta che la ricetta numerica non genera più decisioni assurde e che queste ultime sono accompagnate da un livello di strumentazione ritenuto adeguato, è giunto il momento di una transizione graduale dal processo manuale a quello automatizzato. Come regola empirica, questo stadio dovrebbe essere raggiunto entro due o quattro mesi dall’inizio della doppia esecuzione. Fin dal primo giorno di doppia esecuzione, la ricetta numerica dovrebbe operare su tutto l’ambito dell’iniziativa. Così, in teoria, la transizione dalle decisioni manuali a quelle automatizzate potrebbe avvenire praticamente da un giorno all’altro.
Tuttavia, la pratica spesso diverge dalla teoria. Se si parla di un’azienda di grandi dimensioni, è importante passare tutte le decisioni da un processo all’altro da un giorno all’altro. Le supply chain sono molto complesse e bisogna aspettarsi l’imprevisto. Perciò, è più saggio iniziare con un ambito operativo ridotto, come una singola categoria di prodotto, e poi espandersi. Nelle fasi iniziali della transizione, è opportuno dedicare una o due settimane per ogni iterazione. Sia il supply chain practitioner che i Supply Chain Scientists devono esaminare attentamente come vengono attuate le decisioni automatizzate. E se, in questo ambito operativo ridotto, non dovesse verificarsi nulla di imprevisto, anzi, anche se la ricetta numerica non dovesse generare ulteriori decisioni apparentemente assurde a questo punto, potrebbero comunque sorgere problemi nel modo in cui le decisioni automatizzate vengono integrate nei sistemi transazionali. Una volta che la ricetta numerica ha guidato la produzione per alcune settimane, anche se l’ambito era relativamente piccolo, è opportuno accelerare le iterazioni.
La transizione può prevedere incrementi più sostanziali ad ogni iterazione e la durata delle stesse iterazioni può essere compressa, possibilmente fino a due iterazioni a settimana. Infatti, l’intero arco temporale della transizione verso il processo automatizzato dovrebbe essere mantenuto ragionevolmente breve. Altrimenti, il ritardo nella transizione introduce ulteriori tipologie di rischio. La supply chain continua a cambiare, così come il suo contesto applicativo. Come regola empirica, la transizione non dovrebbe superare i due o quattro mesi, a seconda della scala e della complessità dell’azienda.

Quando la supply chain passa da un processo manuale a uno automatizzato, è necessario che avvengano una serie di cambiamenti anche all’interno dell’organizzazione. Le grandi aziende sono notoriamente difficili da cambiare, ma esistono due direzioni distinte per il cambiamento. L’organizzazione può aggiungere un processo oppure può rimuoverne uno.
Rimuovere un processo è molto più difficile che aggiungerne uno. Aggiungere un processo significa assumere persone, e l’unica opposizione a questo verrà dal vertice dell’azienda, poiché implica una spesa extra di bilancio. Rimuovere un processo significa licenziare persone o, quantomeno, eliminare le loro mansioni, pur mantenendo e riqualificando i dipendenti. In questo caso, la situazione si inverte: ci si può aspettare opposizione da tutta l’organizzazione, ad eccezione del vertice.
Il modo più semplice per portare una ricetta numerica in produzione consiste nel mantenere indefinitamente la doppia esecuzione. Il processo manuale esistente viene preservato e sfrutta ora le decisioni automatizzate come semplici suggerimenti. Questo approccio risulta sicuro e può anche garantire guadagni marginali, poiché i suggerimenti automatici aiutano i practitioner a identificare alcuni dei peggiori errori associati al processo manuale. Tuttavia, mantenere la doppia esecuzione indefinitamente porta a una sedimentazione del processo, in cui l’organizzazione non riesce a eliminare ciò che non serve.
Affinché le pratiche della supply chain diventino un’impresa capitalistica – un asset produttivo – l’organizzazione deve lasciar perdere il processo manuale. Quest’ultimo è una strada senza uscita e non migliorerà ulteriormente col tempo. L’organizzazione deve reindirizzare tutto il tempo e l’energia spesi nel processo manuale verso il continuo miglioramento di quello automatizzato. Mantenere il processo manuale ostacola soltanto la capacità di sfruttare appieno l’automazione e le sue potenzialità. In particolare, fintantoché continuano a verificarsi interventi manuali, nulla sarà veramente riproducibile e, di conseguenza, nulla potrà essere ottimizzato in senso reale, poiché l’ottimizzazione richiede riproducibilità.

L’automazione delle decisioni, anche quelle banali e ripetitive, rappresenta un cambiamento di paradigma nel modo in cui le supply chain vengono gestite. Il cambiamento è così significativo da far venir voglia di liquidarlo del tutto. Tuttavia, il cambiamento è in arrivo. Due secoli di meccanizzazione progressiva della nostra economia hanno reso chiaro un punto: una volta che qualcosa può essere automatizzato, lo viene. Col tempo non si torna più allo stato delle cose precedente. Lokad gestisce circa 100 supply chain in configurazioni altamente automatizzate, fornendo una prova tangibile che l’automazione della supply chain è già realtà; è solo che non è ancora diffusa.
Uno dei maggiori cambiamenti da implementare dai nostri clienti riguarda il ruolo del supply and demand planner. La forma più comune di questi ruoli, che viene identificata con vari nomi nel settore – come inventory managers, category managers o supply managers – prevede che un dipendente gestisca una lista ristretta di SKU, che può variare da 50 a 5.000 SKU a seconda del volume di flusso. Il planner è responsabile della disponibilità continua degli SKU nella lista, sia tramite il riordino dell’inventario che mediante l’attivazione di lotti di produzione, o entrambi. La divisione del lavoro è semplice: all’aumentare del numero di SKU, aumenta anche il numero di planner.
Il focus del planner è rivolto all’interno. Questa persona trascorre molto tempo a rivedere i numeri, sia consolidati in un foglio di calcolo che mostrati su dashboard. I planner potrebbero sfruttare strumenti software aziendali, ma quasi sempre concludono le loro decisioni all’interno di fogli di calcolo che mantengono personalmente. Lo scopo del foglio di calcolo è fornire un contesto numerico accessibile e totalmente personalizzabile per supportare le decisioni prese dal planner. La routine del planner consiste nel rivedere l’intera lista ristretta di SKU ogni settimana, possibilmente ogni giorno.
Tuttavia, una volta che la ricetta numerica è in produzione, non ha senso mantenere questo calendario di revisione manuale della lista ristretta degli SKU da parte del planner. Il planner dovrebbe passare al ruolo di responsabile della rete. In gran parte liberato dalle routine legate ai dati, il responsabile della rete può investire il proprio tempo comunicando con la network, sia a monte con i fornitori sia a valle con i clienti, e rivedendo le ipotesi che supportano il design della ricetta numerica. Il pericolo principale che minaccia la ricetta numerica non è perdere la sua accuratezza; è perdere la sua rilevanza. Il responsabile della rete cerca di identificare ciò che non può essere visto attraverso le lenti dei dati, almeno non ancora. Non si tratta di microgestire la ricetta numerica o di apportare aggiustamenti numerici alle decisioni stesse; si tratta di identificare fattori che rimangono ignorati o fraintesi dalla ricetta numerica.
Il responsabile della rete consolida le intuizioni destinate sia ai Supply Chain Scientists sia agli supply chain executives. Sulla base di queste intuizioni, gli scientists possono aggiustare o rifattorizzare la ricetta numerica per riflettere una comprensione rinnovata della situazione.

Sfortunatamente, opporsi all’implementazione della ricetta numerica non è l’unico modo per il planner di mantenere lo status quo. Un’altra strategia consiste nel proseguire la stessa routine lavorativa: continuare a rivedere la lista ristretta degli SKU ma, invece di sovrascrivere le decisioni, limitarsi a riportare eventuali riscontri al Supply Chain Scientist. Le persone amano le loro abitudini, e i dipendenti delle grandi aziende ancor di più.
Il problema di questo approccio è che, una volta che l’automazione è in atto, i Supply Chain Scientists possono osservare direttamente gli esiti del processo automatizzato, sia quelli positivi che quelli negativi. Il planner e gli scientists hanno accesso agli stessi dati; tuttavia, lo scientist, per definizione, dispone di strumenti analitici più potenti rispetto al planner. Pertanto, una volta implementata l’automazione, il valore aggiunto del feedback del planner diminuisce rapidamente quando si tratta del miglioramento continuo della ricetta numerica.
Poiché il planner ora ha più tempo per analizzare, è probabile che richieda la creazione di ulteriori indicatori e dashboard da parte dello scientist. Questo porta al “KPI tourism”: aumentare il numero di indicatori da esaminare fino a che il semplice esaminarli diventa un lavoro a tempo pieno. Questo carico di lavoro diventa anche una distrazione per gli scientists. In questa fase, post-deployment, migliorare la ricetta numerica richiede una buona comprensione delle debolezze dell’implementazione attuale. Lo scientist è idealmente posizionato per svolgere questo lavoro, mentre il planner è molto meno adatto. Per essere d’aiuto, il planner dovrebbe diventare un responsabile della rete e, come già evidenziato, iniziare a guardare verso l’esterno. Altrimenti, la posizione del planner si trasforma in KPI tourism.

Il lavoro del supply chain executive è in gran parte definito dall’organizzazione e dai suoi processi. Finché decisioni banali rimangono il risultato di un processo manuale, l’organizzazione non ha altra scelta che adottare una divisione del lavoro in cui ogni planner gestisce la propria lista ristretta di SKU. Pertanto, il supply chain executive è innanzitutto il responsabile di un team di planner. Se l’azienda è abbastanza grande da giustificare uno strato di middle management, l’executive potrebbe gestire i planner solo indirettamente. Tuttavia, la divisione della supply chain rimane la stessa: una piramide con i planner alla base. Per necessità, essere un buon supply chain executive significa essere un buon coach per quei planner. L’executive non guida le decisioni della supply chain; sono i planner a prendere tali decisioni. Migliorare le decisioni dipende principalmente dal far svolgere un lavoro migliore ai planner.
I fornitori di software per la supply chain sostengono che i loro strumenti possano fare la differenza. Tuttavia, come abbiamo già sottolineato, i fogli di calcolo vengono quasi sempre utilizzati per prendere quelle decisioni, indipendentemente da quanti strumenti siano stati implementati all’interno dell’azienda. Quindi, alla fine, tutto si riduce a ciò che i planner fanno con i propri fogli di calcolo.
Una volta che una tipologia di decisione per la supply chain viene automatizzata, il ruolo del supply chain executive cambia in modo sostanziale. Il compito non consiste più nel fare da coach a un grande team di planner che eseguono variazioni dello stesso lavoro. Ora il compito del supply chain executive è fare tutto il necessario affinché l’azienda sfrutti al massimo l’automazione della supply chain. L’executive deve diventare il proprietario del prodotto software che guida efficacemente le decisioni della supply chain.
Infatti, il focus e il contributo dei Supply Chain Scientists sono rivolti all’interno, proprio come lo erano in precedenza i contributi dei planner. Gli scientists possono migliorare la ricetta numerica solo dall’interno. Non ci si può aspettare che rifattorizzino il panorama applicativo o i processi aziendali più ampi. È compito del supply chain executive far sì che ciò accada. In particolare, l’executive diventa responsabile dell’elaborazione di una roadmap per il miglioramento continuo dell’automazione.
Finché le decisioni erano guidate dai planner, la roadmap era in gran parte ovvia. I planner continuavano a fare ciò che facevano, e la missione per il trimestre successivo era in gran parte simile a quella del trimestre precedente. Tuttavia, una volta implementata l’automazione, migliorare la ricetta numerica comporta quasi sempre il fare qualcosa che non è mai stato fatto prima. Quando si sviluppa software, se lo fai bene, non ti ripeti: si va avanti. Una volta acquisita un’intuizione, bisogna cercarne una nuova. La missione delle persone che lavorano sotto un software product owner cambia continuamente per design.
Le nuove direzioni e obiettivi non cadono dal cielo. È responsabilità del supply chain executive indirizzare lo sviluppo del prodotto software per la supply chain in direzioni favorevoli.

La maggior parte dei problemi quotidiani affrontati dalle supply chain sono problemi software. Questo è da oltre un decennio il caso nei paesi sviluppati, anche in aziende dove tutte le decisioni vengono derivate manualmente da fogli di calcolo. Questa situazione è una conseguenza diretta del fatto che le supply chain si trovano all’incrocio di molti sistemi: ERP, CRM, WMS, OMS, PIM e dozzine di acronimi a tre lettere tanto amati dai fornitori di software aziendale, che descrivono i vari componenti del software aziendale contenenti tutti i dati di interesse per la supply chain. Le supply chain richiedono una visione end-to-end del business e, di conseguenza, finiscono per connettere gran parte del panorama applicativo dell’azienda. Tuttavia, la maggior parte delle aziende sembra ancora scegliere leader della supply chain che sanno pochissimo di software. Ancor peggio, alcuni di questi leader non hanno alcuna intenzione di apprendere nulla sul software. Questa situazione rappresenta l’anti-pattern del “analytics supply chain bus”. Quando dico software, intendo quel genere di argomento che ho trattato nel quarto capitolo di questa serie di lezioni, con temi che spaziano dall’hardware informatico all’ingegneria del software.
Al giorno d’oggi, l’illetteratezza software nel top management della supply chain annuncia enormi problemi per l’azienda. O il management crede di poter cavarsela senza competenze software, oppure ritiene di poter cavarsela con competenze software esterne. In ogni caso, le conseguenze non sono buone.
Se il top management crede di poter cavarsela senza competenze software, l’azienda perderà terreno su tutti i canali elettronici, sia nel lato delle vendite che in quello degli acquisti. Eppure, poiché molti dipendenti comprendono l’importanza di questi canali elettronici, che piaccia o meno al top management, il fenomeno dello shadow IT diligherà. Inoltre, state certi che per la prossima grande transizione software all’interno dell’azienda, questa transizione sarà gestita in modo estremamente inadeguato, con lunghi periodi di bassa qualità del servizio a causa di problemi software che avrebbero dovuto essere evitati sin dall’inizio.
Se il management ritiene di poter cavarsela con competenze software di terze parti, la situazione è marginalmente migliore rispetto al caso precedente, ma non di molto. Affidarsi a esperti esterni va bene se si ha un problema ristretto e autonomo, come garantire che il processo di selezione del personale sia conforme a una certa regolamentazione. Tuttavia, le sfide della supply chain non sono autonome; si diffondono in tutta l’azienda e molto spesso anche al di là di essa. Il tranello più comune legato al pensare che le competenze possano essere esternalizzate consiste nel spendere somme irragionevoli per grandi fornitori di software, sperando che risolvano i problemi. Sorpresa—non lo faranno. L’unica soluzione a questi problemi è un minimo di alfabetizzazione software da parte del top management.
Oggi abbiamo illustrato come portare in produzione decisioni automatizzate per la supply chain. Il processo è un mix di design, ingegneria e gestione del cambiamento. È un percorso difficile, con numerosi sentieri apparentemente facili o rassicuranti che conducono direttamente al fallimento dell’iniziativa. Per avere successo, l’iniziativa richiede un’evoluzione sostanziale dei ruoli e delle missioni sia del top management della supply chain che dei suoi dipendenti.
Per le aziende profondamente radicate nei loro processi manuali, portare avanti un’iniziativa del genere può sembrare insormontabile, e quindi mantenere lo status quo potrebbe apparire come l’unica opzione. Tuttavia, non sono d’accordo con questa conclusione per due motivi. In primo luogo, sebbene il percorso sia arduo, è economico, almeno rispetto alla maggior parte degli investimenti aziendali. Reinventendo il costo annuo di cinque demand planners, l’azienda può automatizzare il carico di lavoro di 50 demand planners. Naturalmente, i grandi fornitori di software aziendale sosterranno che ci vogliono decine di milioni di dollari solo per iniziare, ma esistono alternative molto più snelle. In secondo luogo, il percorso potrebbe essere arduo, ma non è realmente facoltativo. Le aziende che impiegano eserciti di impiegati per prendere decisioni ripetitive e banali relative alla supply chain soffrono anche di lunghi tempi di attesa autoimposti a causa dei propri processi interni. Queste aziende non rimarranno competitive contro quelle che hanno automatizzato i loro processi decisionali di routine. Il vantaggio competitivo derivante dall’automazione è sempre modesto all’inizio; tuttavia, poiché l’automazione può essere migliorata nel tempo mentre un processo manuale no, il vantaggio competitivo diventa esponenzialmente maggiore col passare del tempo. A questo punto, le decisioni automatizzate per la supply chain possono ancora essere percepite come futuristiche, ma fra due decenni il vero opposto sarà vero. I processi manuali saranno percepiti come reliquie antiquate di un’era passata.

Questo conclude la lezione di oggi. Procederemo tra un minuto con le domande. La prossima lezione sarà la prima settimana di novembre, mercoledì, alle 15:00, ora di Parigi, come di consueto. Torneremo al terzo capitolo con una supply chain persona. Si parlerà di un’azienda fittizia chiamata Stuttgart, che opera nel mercato aftermarket automobilistico. Vedremo che l’automotive è l’industria delle industrie e presenta una serie di sfide piuttosto specifiche che, ancora una volta, non sono adeguatamente riflesse nei manuali di supply chain.
Diamo un’occhiata alle domande.
Domanda: La supply chain quantitativa richiede un proprio modo ideale di divisione del lavoro?
Sì, può trattarsi di una transizione graduale, ma l’idea è che la divisione del lavoro che si aveva con un processo manuale era definita dal fatto che un planner può gestire solo un numero limitato di SKU. Più SKU, più planner. Si tratta di una divisione del lavoro molto semplicistica. Quando si ha una grande azienda e si desidera un processo automatizzato, l’idea è che si avrà personale specializzato. Ad esempio, un network manager potrebbe specializzarsi nella qualità del servizio così come percepita dal cliente. La percezione conta; non si tratta della qualità astratta del servizio, come i livelli di servizio. Forse i clienti hanno una loro prospettiva in merito, per cui qualcuno potrebbe specializzarsi proprio in questo. Un altro network manager potrebbe concentrarsi su un ambito specifico in cui una maggiore coordinazione e integrazione con alcuni fornitori potrebbe, ad esempio, ridurre i tempi di consegna e portare nuove opzioni sul tavolo. Improvvisamente, la divisione del lavoro diventa più focalizzata sui numerosi aspetti che devono essere studiati, rivisitati e re-analizzati da una prospettiva analitica. Puoi avere diverse persone a lavorarci sopra. Ma ancora una volta, non si tratta di avere qualcosa di definito come una lista di SKU. È anche l’essenza del migliorare qualcosa. Forse bastano più persone per poter fare brainstorming insieme, cercare di identificare le idee migliori e ordinarle.
Domanda: L’utilizzo di percentuali invece di metriche finanziarie aiuta a nascondere le inefficienze del processo legacy. In tal caso, quanto è probabile che l’iniziativa possa avere successo?
È una domanda molto carica. Uno dei motivi per cui le grandi aziende, e così tanti manager al loro interno, amano quelle metriche aspirazionali è che non vi è alcuna attribuzione di colpa. Una volta che hai un indicatore espresso in percentuale, nessuno si rende conto che rappresenta milioni di dollari persi a causa di un errore specifico commesso da una determinata divisione guidata da una certa persona solo nell’ultimo trimestre. Queste percentuali sono incredibilmente opache e rappresentano una vera sfida far sì che quelle iniziative abbiano successo, perché, molto frequentemente, una volta che si passa a dollari o euro, si scopre l’effettiva entità delle inefficienze, che può essere assolutamente massiccia.
In base all’esperienza di Lokad, per le società pubbliche che divulgavano tutti i numeri sui mercati pubblici con oltre 200 revisori che certificavano il valore dell’inventario, abbiamo riscontrato che i valori dell’inventario risultavano errati del 20% a favore dell’azienda. Stiamo parlando di un’azienda con oltre un milione di euro di inventario registrato nei libri contabili. La cosa folle era che l’inventario era stato revisionato da oltre 200 persone per letteralmente decenni, e tutto era digitalizzato da decenni.
Quando si scoprono questo genere di cose, è difficile, ma credo che il modo di affrontarle sia essere severi sui problemi e indulgenti con le persone. Le aziende devono imparare a essere indulgenti con le persone e veramente severe sui problemi, invece di ignorare il problema e licenziare le persone.
Question: Le grandi aziende usano molti più KPI di quanti ne abbiano bisogno. Quando lanciate l’iniziativa, come mettete in discussione tutti i KPI?
Molto buona domanda. Tutti quei KPI sono una grande distrazione che supporta il lavoro svolto manualmente dai pianificatori. Una volta che hai una ricetta numerica, perché dovresti preoccuparti di tutti quei KPI? Tutto ciò che ottimizzi dovrebbe essere incorporato nei tuoi criteri finanziari. Dovresti avere una metrica che ti dica, per ogni decisione potenziale, quanti soldi sono in gioco, quanto vincerai o perderai a seconda dell’esito della decisione. Invece di accumulare una serie infinita di indicatori, se vuoi affinare la tua metrica finanziaria, puoi aggiungere un fattore. Ma ciò non significa che aggiungi una colonna extra nel rapporto; significa semplicemente che apporti un piccolo aggiustamento attribuendo un fattore extra che, in modo additivo, aggiunge o sottrae qualche euro o dollaro ai valori che assegni a una determinata decisione.
In sostanza, tutto ciò che è al di fuori di questi obiettivi finanziari viene ignorato dalla ricetta numerica. La ricetta numerica esegue un processo di ottimizzazione matematica che ottimizza rigorosamente un obiettivo finanziario. Questo è tutto. Tutti quegli altri indicatori vengono ignorati. Un setup automatizzato rende molto più evidente che quegli indicatori sono inutili. Non vengono inclusi nella ricetta, non sono considerati dalla ricetta numerica e non fanno nemmeno parte del processo decisionale. Inoltre, chiarisce che metriche aspirazionali, come i livelli di servizio, sono negative. Non puoi semplicemente portare la tua qualità di servizio a un livello di servizio del 100% perché non è un risultato desiderabile per l’azienda. Se fatto correttamente, l’automazione chiarisce ciò che è effettivamente necessario in termini di indicatori, e ti rendi conto che non ce ne sono così tanti. Inoltre, poiché coinvolgi meno persone nel processo, la pressione di aggiungere costantemente indicatori è minore. Un altro aspetto di avere grandi team di pianificatori è che ogni singola persona tende ad avere uno o due indicatori preferiti. Se hai 200 persone e ognuna vuole che venga aggiunto un indicatore per la propria comodità, finisci con 200 indicatori, il che è decisamente troppo. Ma se hai solo un decimo di quel personale, la pressione di accumulare indicatori è molto minore.
Question: Come fanno i fornitori di software per demand planning a comprendere gli ecosistemi dei loro potenziali clienti, come le esigenze di safety stock, mentre effettuano personalizzazioni prima del deployment presso il cliente? Voglio dire, una volta che avviene il deployment, non ci sono insidie in termini di errori di previsione.
La prospettiva classica, che credo abbia fallito nel portare l’automazione alle decisioni della supply chain negli anni ‘70, si basava sull’assunzione che una soluzione software preconfezionata potesse risolvere i problemi delle aziende. Credo fermamente che non sia così. Un software preconfezionato non può adattarsi a nessuna supply chain non banale. Quello che succede è che un fornitore di software aziendale con un modulo di ottimizzazione dell’inventario e di previsione cerca di vendere il prodotto a un’azienda, e man mano che mancano funzionalità, le continua ad aggiungere. In un arco di 10 anni o più, finiscono per avere un prodotto software mostruoso e gonfiato, con centinaia di schermate e migliaia di valori di parametro.
Il problema è che più il prodotto software è complesso, più le tue aspettative in termini di dati e di ciò che l’azienda dovrebbe avere sono specifiche. Più il prodotto è complesso, più diventa difficile integrarlo nell’azienda cliente, perché hai una supply chain complessa con molti sistemi già in essere e un prodotto di ottimizzazione della supply chain super complesso. Ci sono lacune e discrepanze ovunque.
La realtà è che la maggior parte delle grandi aziende con cui ho parlato ha operato supply chain digitali nei paesi sviluppati per due o tre decenni, e hanno già implementato mezza dozzina di soluzioni software per demand planning, ottimizzazione dell’inventario e design della supply chain negli ultimi due o tre decenni. Quindi, ci sono già state e l’hanno fatto, non solo una volta, ma mezza dozzina di volte. Di solito, le persone non sono in azienda da abbastanza tempo da rendersi conto che questi processi si ripetono da due o tre decenni. Eppure, i processi sono ancora completamente manuali e spesso si affidano a strumenti come Excel. Il problema non è l’errore di previsione; credo che sia una diagnosi errata del problema, perché l’idea che si possa avere una previsione perfetta con un sistema o un altro è ridicola. Non è possibile generare una previsione perfetta, e gli esseri umani che gestiscono manualmente una supply chain non hanno accesso a informazioni perfette. Non è perché sei un demand planner umano che puoi prevedere perfettamente la domanda.
I pianificatori della domanda sono in grado di svolgere il loro lavoro anche con previsioni non perfette. Queste persone non sono maghi o scienziati super-avanzati. Potrebbero non essere male nel fare previsioni, ma non c’è motivo di aspettarsi che, in media, i demand planner in questo settore, che impiega centinaia di migliaia di persone in tutto il mondo, siano tutti super talentuosi e capaci di previsioni incredibilmente accurate. Quello che fa funzionare il sistema è che queste persone hanno le loro euristiche e i loro modi di gestire manualmente la supply chain che sopravvivono nonostante dispongano di previsioni scarse.
L’obiettivo della vostra configurazione automatizzata è avere un sistema che funzioni bene anche se le previsioni non sono eccezionali fin dall’inizio. Questa è l’essenza dell’approccio alle previsioni probabilistiche; non si tratta di migliorare l’accuratezza, ma di riconoscere e accettare il fatto che la previsione non è così buona. Se torniamo a quei fornitori, credo che l’industria abbia collettivamente fallito nel portare un grado soddisfacente di automazione negli ultimi quattro decenni, e il nocciolo del problema era la prospettiva preconfezionata, in cui si prevedeva che le aziende si limitassero a inserire un modulo e il gioco era fatto. Questo non funziona. Le supply chain sono troppo diverse, versatili e in continuo mutamento perché un approccio così meccanico possa avere successo.
Question: Con la prospettiva presentata, come affronti il problema di conciliare le diverse previsioni dell’azienda, come quelle relative alle vendite, all’inventario e ad altre?
La mia domanda è: perché fate previsioni in primo luogo? Le previsioni sono solo artefatti numerici; non contano. La tua azienda non diventerà più redditizia perché esiste una previsione migliore. Le previsioni sono esattamente ciò che ho definito nei capitoli precedenti di questa serie di lezioni, un artefatto numerico. È un’astrazione che può o non può rivelarsi utile per derivare determinate classi di decisioni. Si scopre che, a seconda della decisione che si considera, il tipo di previsione necessario può essere molto diverso.
Metto in discussione l’idea che si possa avere una previsione iniziale e poi orchestrare l’intera supply chain basandosi su quelle previsioni. Sono fortemente in disaccordo con questo approccio, poiché non è stata la mia esperienza, e credo che non funzioni così bene. Ho visto un’infinità di aziende in cui esiste un processo di pianificazione senior che produce previsioni sul lato vendite, rappresentando un enorme esercizio di contenimento. I venditori spesso sottostimano enormemente le loro proiezioni perché così, se superano quei numeri, possono più facilmente superare le aspettative in seguito. Le persone nelle fabbriche o nei magazzini vedono questi numeri arrivare e possono pensare che non possano essere giusti, così scartano il numero e fanno qualcosa di completamente diverso. A mio parere, gli esercizi di previsione svolti dalla stragrande maggioranza delle aziende sono solo sforzi burocratici inutili. Non c’è alcun valore aggiunto in questo.
Da una prospettiva quantitativa della supply chain, è essenziale concentrarsi sulle decisioni che contano, piuttosto che sulle previsioni, che potrebbero essere solo tecnicismi. Alcune classi di decisioni potrebbero non richiedere affatto una previsione, oppure, se necessario, potrebbero richiedere un tipo di previsione molto diverso da quello attualmente considerato dalle aziende. Quando si parla di previsioni, la maggior parte delle persone intende le previsioni in serie temporali. Tuttavia, se torni al terzo capitolo di questa serie di lezioni, dedicato alle personas della supply chain e alle situazioni reali, scoprirai che le previsioni in serie temporali spesso non sono la risposta. La forma stessa della previsione non è adeguata a catturare i modelli che vogliamo individuare nel business.
Per concludere, suggerirei di non provare nemmeno a conciliare quelle previsioni. Invece, ignorale e concentrati sulle decisioni stesse. Scopri cosa serve per progettare ricette che generino buone decisioni, e molto probabilmente tutte quelle previsioni possono essere completamente ignorate.
In risposta al commento sul confronto tra dati finanziari e risultati KPI espressi in percentuali, è vero che si possono fare confronti cercando di correlare i livelli di servizio o i fill rate con le metriche finanziarie. Tuttavia, questo crea davvero un ritorno sull’investimento per l’azienda? Prendere decisioni migliori sull’inventario può creare valore per l’azienda, ma passare tempo a correlare i KPI non lo fa. Molte aziende sono dipendenti da questi KPI espressi in percentuali, ma sono spesso distrazioni burocratiche prive di significato.
I fornitori di software aziendale amano questi indicatori perché possono venderli alle aziende clienti, portando così molti fornitori a spingere per un maggior numero di indicatori. In realtà, per una classe di decisioni della supply chain, avere dieci numeri da osservare ogni giorno è già davvero tanto. Di solito, è difficile identificare anche dieci numeri che valgano la pena di essere esaminati quotidianamente da un essere umano. Spesso, sono addirittura meno, e va bene così. Le classi di problemi nelle supply chain tendono ad essere molto specifiche per l’azienda e per la supply chain di interesse, ma non sono complicate in maniera insormontabile. Non sto dicendo che le situazioni della supply chain richiedano migliaia di driver economici. Sto invece dicendo che le supply chain variano molto, e bisogna assicurarsi di risolvere il problema giusto che si adatta alle sottigliezze della supply chain di interesse. Per una supply chain di interesse, potresti avere tre o quattro driver di base, come il costo dello stock, il margine lordo e altri fattori che si riscontrano praticamente ovunque. Poi potresti avere quattro o cinque indicatori, ancora metriche finanziarie, che sono molto specifici per un determinato settore di interesse. In totale, siamo ancora al di sotto di dieci numeri.
In risposta alla domanda sul bilanciare il compromesso tra KPI finanziari e KPI della supply chain, direi sì e no. Se credi che i KPI finanziari non siano quelli che dovresti ottimizzare, allora c’è un problema nella definizione stessa dei tuoi KPI finanziari. Nel primo capitolo di questa serie di lezioni, ho menzionato che ci sono tipicamente due cerchi di driver da considerare quando si stabilisce una metrica finanziaria. Il primo cerchio comprende fattori che la finanza può leggere direttamente dai libri, come il margine lordo, il valore dello stock e i costi di acquisto. Il secondo cerchio include driver come il goodwill del cliente e la penalità implicita quando la qualità del servizio è bassa. Tutto questo deve essere integrato.
La prospettiva finanziaria non riguarda l’avere KPI in cui c’è un compromesso. Si tratta invece di consolidare tutto in un unico punteggio in dollari o euro per le performance e il processo decisionale. Non si tratta di riconciliare i KPI della supply chain con quelli finanziari. Piuttosto, si tratta di avere una governance in azienda in modo che le persone possano concordare il costo effettivo dello stock, il costo reale degli stockout e se la decisione di riordinare sia la scelta migliore o meno.
Da questa nuova prospettiva di possedere il prodotto software che guida la supply chain, il compito del dirigente della supply chain è facilitare il consenso all’interno dell’azienda. Invece di guidare un processo S&OP privo di senso in cui le persone cercano di rivedere i numeri ogni mese e concordare cifre di vendita prive di significato, si tratta di implementare un S&OP 2.0 guidato dal direttore della supply chain. Contrariamente a quanto affermato dai fornitori di S&OP, il CEO non deve essere il responsabile del processo S&OP, poiché ciò potrebbe rappresentare una distrazione per lui. Non c’è bisogno di coinvolgere il CEO in ogni singola battaglia.
La missione del direttore della supply chain è lavorare con il responsabile della finanza, il responsabile marketing e il responsabile vendite per concordare come misurare l’impatto finanziario di fattori come la qualità del servizio. Questo è il loro compito. Non c’è bisogno di riconciliare varie metriche, poiché esse sono già pre-unificate grazie al lavoro svolto sotto la guida del responsabile della supply chain o del direttore della supply chain, a seconda del titolo in uso nell’azienda.
Questo conclude la lezione di oggi. Ci vediamo la prossima volta durante la prima settimana di novembre.