00:00:00 ディスクへのスピルに関する講演の導入
00:00:34 小売業者のデータ処理とメモリの制約
00:02:13 永続ストレージのソリューションとコスト比較
00:04:07 ディスクとメモリの速度比較
00:05:10 パーティショニングとストリーミング技術の制限
00:06:16 順序付けされたデータと最適な読み込みサイズの重要性
00:07:40 データ読み込みの最悪ケースシナリオ
00:08:57 マシンのメモリがプログラムの実行に与える影響
00:10:49 ディスクへのスピル技術とメモリ使用量
00:12:59 コードセクションの説明および.NETでの実装
00:15:06 メモリ割り当ての制御とその結果
00:16:18 メモリマップドページとメモリマッピングファイル
00:18:24 読み書き可能なメモリマップとシステムパフォーマンスツール
00:20:04 仮想メモリとメモリマップドページの使用
00:22:08 大きなファイルと64ビットポインターへの対処
00:24:00 メモリマップドメモリからの読み込みにspanを使用
00:26:03 データコピーと整数を読み取るための構造体の使用
00:28:06 ポインターとメモリマネージャーからのspanの作成
00:30:27 メモリマネージャーのインスタンス作成
00:31:05 ディスクへのスピルプログラムとメモリマッピングの実装
00:33:34 パフォーマンス向上のためにメモリマップド版が望ましい
00:35:22 ファイルストリームのバッファリング戦略と制限
00:37:03 1つの大規模ファイルをマッピングする戦略
00:39:30 複数の大規模ファイルにメモリを分割する
00:40:21 結論と質疑応答への招待
概要
メモリに収まりきらないデータを処理するために、プログラムはNVMeドライブなどの、速度は遅いが容量の大きいストレージに一部のデータを退避することができます。あまり知られていない2つの.NET機能(メモリマップトファイルとメモリマネージャー)を組み合わせることで、C#からほとんどパフォーマンスへの影響なく実現できます。Warsaw IT Days 2023で行われたこの講演では、その仕組みの詳細に踏み込み、オープンソースのNuGetパッケージLokad.ScratchSpaceが多くの詳細を開発者から隠している方法について議論されます。
詳細な概要
包括的な講演において、LokadのCTOであるVictor Nicoletは、メモリ容量を超える大規模なデータセットの処理を可能にするための、.NETにおけるディスクへのスピル操作の複雑な仕組みに踏み込みます。Nicoletは、Lokadでの量的-供給-チェーン-マニフェストの経験を背景に、約10万点の商品を100店舗で取り扱う小売業者の実例を示します。これにより、過去3年間、毎日1データポイントを記録すると約1000日分となり、全体では100億エントリ(100億個のデータ項目)となり、各エントリに1つの浮動小数点値を保持するには37ギガバイトのメモリが必要となり、一般的なデスクトップコンピューターの容量を大きく上回ります。
Nicoletは、メモリの代替としてコスト効果の高いNVMe SSDなどの永続ストレージの使用を提案します。彼は、18ギガバイト分のメモリの価格で1テラバイトのSSDストレージを購入できる点を指摘し、メモリとSSDストレージのコスト比較を行います。また、ディスクからの読み込みがメモリからの読み込みよりも6倍遅いというパフォーマンストレードオフについても言及します。
彼は、ディスクスペースをメモリの代替として利用する技術として、パーティショニングとストリーミングを紹介します。パーティショニングは、メモリに収まる小さな単位でデータセットを処理することを可能にしますが、パーティション間での通信はできません。一方、ストリーミングは、異なる部分の処理間で状態を維持できるものの、最適なパフォーマンスのためにはディスク上のデータが順序付けまたは適切に整列されている必要があります。
Nicoletは、メモリ内に収める方法の限界を解決するため、ディスクへのスピル技術を導入します。これらの技術は、利用可能なメモリが多い場合はより高速に動作するために多くのメモリを使用し、メモリが不足している場合は使用量を減らすため、メモリと永続ストレージの間でデータを動的に分散させます。彼は、ディスクへのスピル技術が可能な限りメモリを活用し、メモリが枯渇した時点で初めてディスクにデータをダンプすることを説明し、この仕組みが初期想定より多いまたは少ないメモリに柔軟に対応できる理由であると述べます。
さらに彼は、ディスクへのスピル技術がデータセットを常にメモリ上にあるホットセクションと、必要に応じてその一部を永続ストレージに退避可能なコールドセクションの2つに分割することを説明します。プログラムは、通常NVMeの帯域幅を最大限に活用する大容量のバッチを伴うホット・コールド転送を実施し、コールドセクションにより可能な限り多くのメモリ使用を実現します。
Nicoletは、.NETにおけるこの実装方法についても議論します。ホットセクションでは通常の.NETオブジェクトを使用し、コールドセクションでは参照クラスを利用します。このクラスは、コールドストレージに格納される値への参照を保持し、値がメモリ上に存在しなくなった際にはnullに設定されます。プログラム内の中央システムがすべてのコールド参照を管理し、新たなコールド参照が作成されるたびにそれがメモリオーバーフローを引き起こすかを判断し、既存のコールド参照のスピル関数を呼び出してコールドストレージ用のメモリ予算内に収めます。
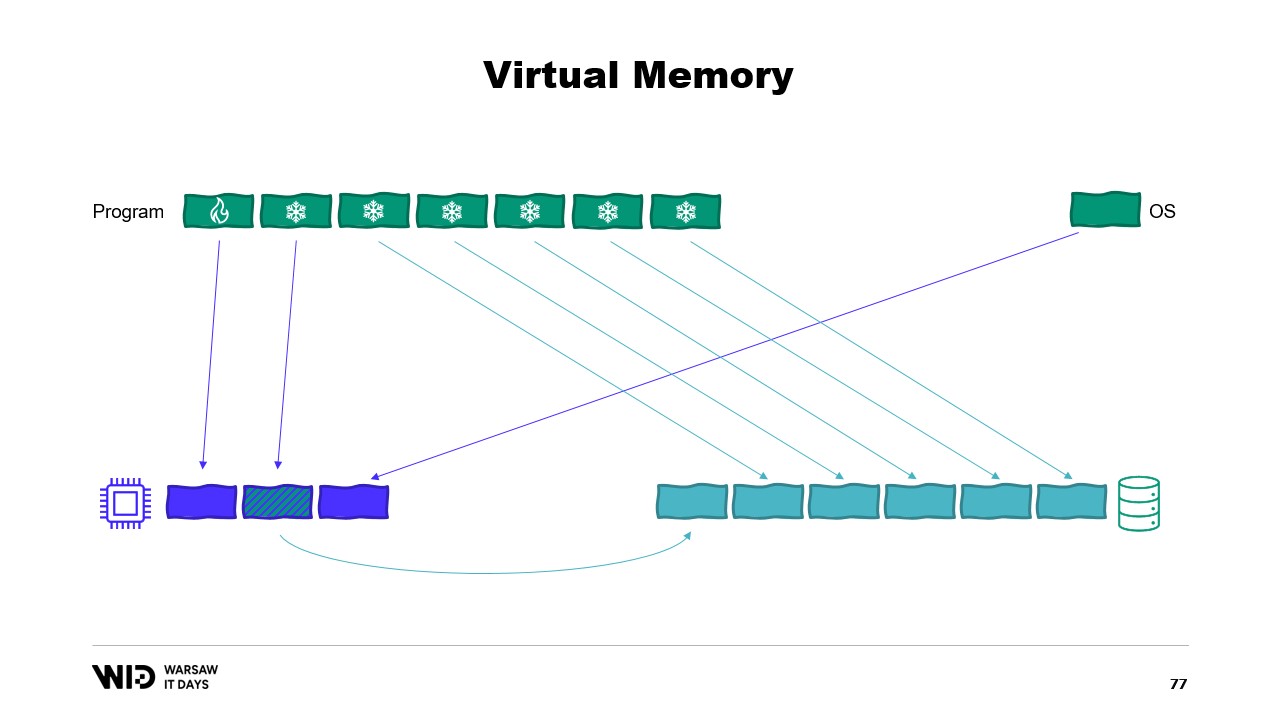
次に彼は、プログラムが物理メモリページに直接アクセスするのではなく、仮想メモリページにアクセスする仮想メモリの概念を導入します。メモリマップドページを作成することは、プログラムとメモリマッピングファイル間の通信を実装する一般的な方法です。メモリマッピングの主な目的は、各プログラムがメモリ内にDLLの独自コピーを持つことを防ぐためです。なぜなら、それらのコピーはすべて同一であるからです。
Nicoletは、現在の物理メモリ使用状況を示すシステムパフォーマンスツールについても議論します。緑色はプロセスに直接割り当てられたメモリ、青色はページキャッシュ、中央の変更されたページはディスクの正確なコピーであるはずがメモリ上で変更が加えられたものです。
続いて彼は、仮想メモリを利用した2回目の試みについて説明し、そこでコールドセクションは完全にメモリマップドページで構成されると述べます。オペレーティングシステムが突然メモリを必要とした場合、どのページがメモリマップドであるかを認識し、安全に破棄することが可能です。
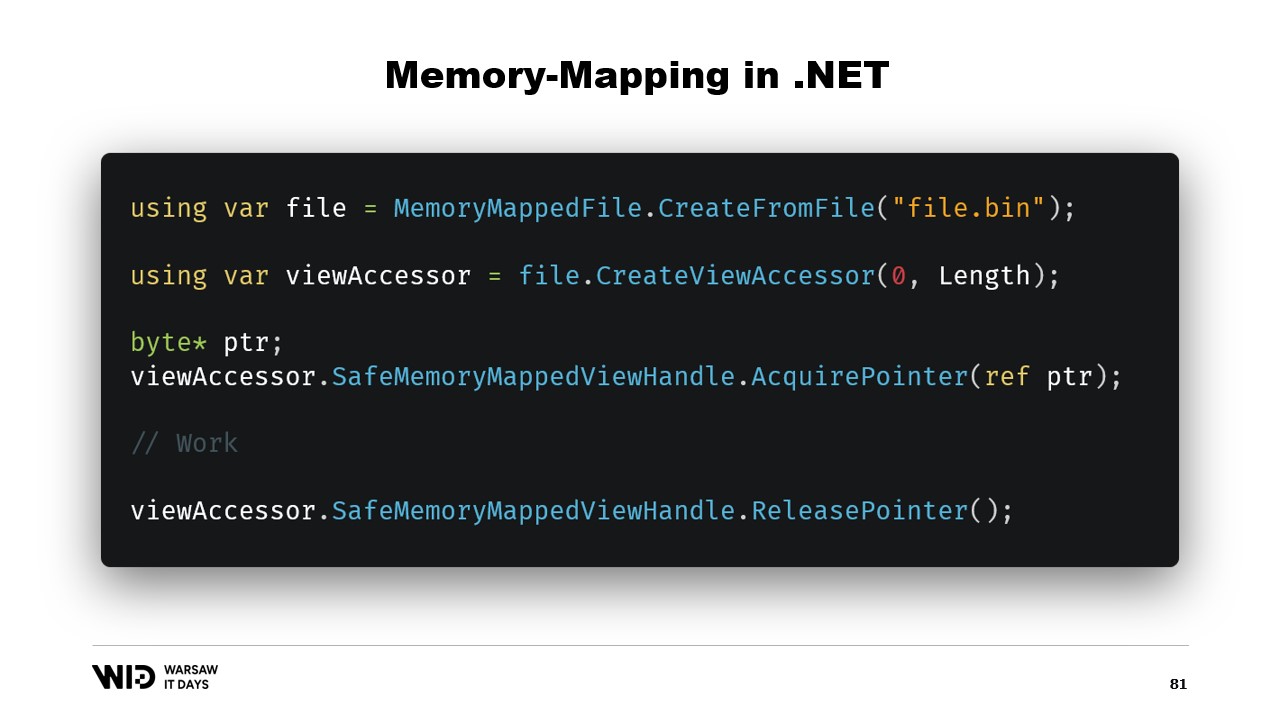
次にNicoletは、.NETでメモリマップドファイルを作成する基本手順について説明します。まず、ディスク上のファイルからメモリマップドファイルを作成し、その後ビューアクセサーを作成します。これらを分離しているのは、.NETが32ビットプロセスの場合にも対応する必要があるためであり、64ビットプロセスの場合はファイル全体を読み込む1つのビューアクセサーを作成できます。
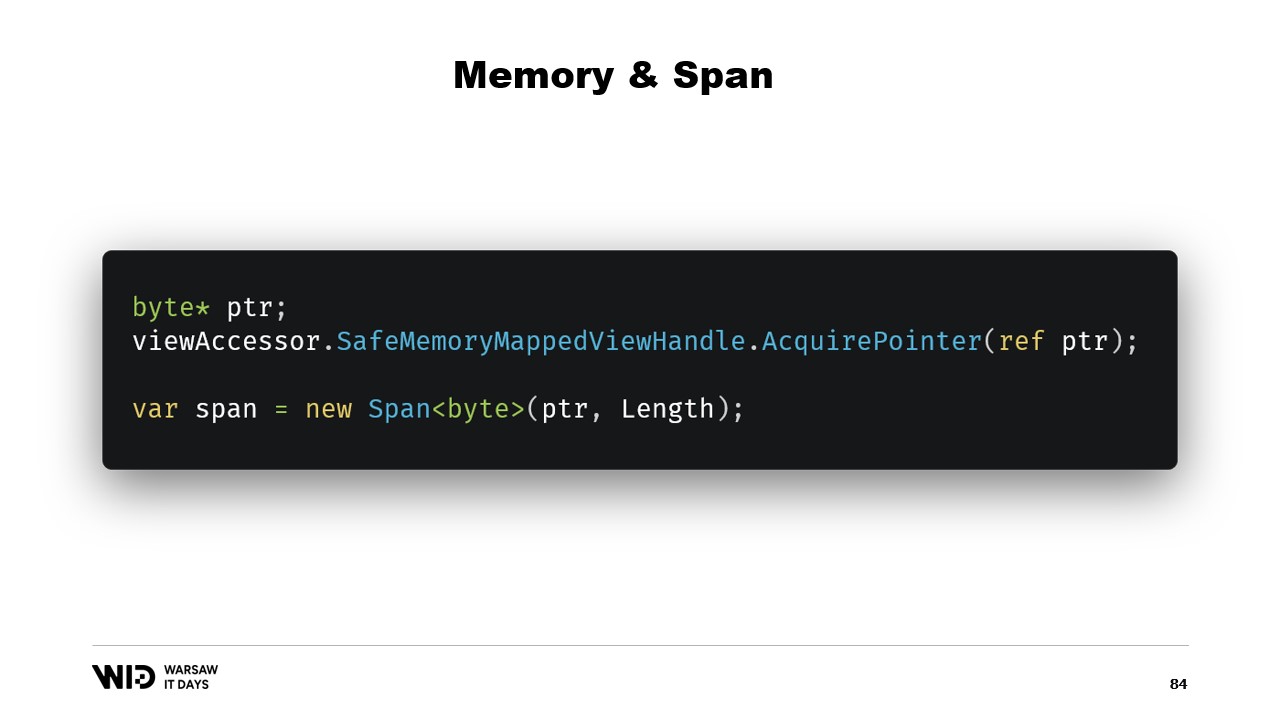
その後、Nicoletは5年前に導入されたmemoryとspanについて議論します。これらは、単なるポインターよりも安全にメモリの範囲を表現するための型です。基本的な考え方として、ポインターとバイト数が与えられれば、そのメモリ範囲を表す新たなspanを作成でき、一度spanが作成されれば、境界を超えての読み込みが試みられた場合にランタイムが例外を発生させるため、安全に読み込むことができます。
次にNicoletは、spanを用いてメモリマップドメモリから.NETマネージドメモリへデータを読み込む方法について説明します。例えば、文字列の読み込みが必要な場合、spanを中心とした多くのAPIが利用可能です。彼は、spanの先頭から整数を読み取るMemoryMarshal.ReadのようなAPIの使用方法や、バイトのspanから文字列に変換するEncoding.GetString関数についても解説します。
さらに彼は、これらの操作がディスク上にある可能性のあるデータの一部を表すspan上で実行されることを説明します。オペレーティングシステムは、データが初めてアクセスされた際にそれをメモリへ読み込む処理を行います。Nicoletは、float配列に読み込むべき浮動小数点値の連なりの例を示し、サイズを読み取るためのMemoryMarshal.Readの使用方法、該当サイズの浮動小数点値配列の確保、そしてMemoryMarshal.Castを用いてバイトのspanを浮動小数点値のspanに変換する方法を説明します。
また、彼はspanのCopyTo関数を用いて、メモリマップドファイルから配列へ高性能なデータコピーを行う手法についても論じます。ただし、この方法は全く新しいコピーを作成するため、やや非効率である可能性があると指摘します。Nicoletは、内部に2つの整数値を持つヘッダーを表す構造体を作成し、MemoryMarshalで読み取る方法を提案するとともに、データを解凍するための圧縮ライブラリの使用にも触れます。
Nicoletは、より長期間にわたるデータ範囲を表現するための型として、別の型であるMemoryの使用について議論します。彼は、ポインターからMemoryを作成する方法に関するドキュメントが不足していると述べ、GitHub上のgistを最良のリソースとして推奨します。また、配列の一部を指すだけでなく、より複雑な処理を行う際に内部的に利用されるMemoryManagerを作成する必要性についても解説します。
Nicoletは、ディスク上のデータにアクセスする際、明らかにFileStreamが利用されるべきであり、その使用方法が十分にドキュメント化されていることから、メモリマッピングとFileStreamの比較についても議論します。彼は、FileStreamのアプローチがスレッドセーフではなく、操作時にロックが必要なため、複数箇所からの並行読み込みが不可能になると指摘します。また、FileStreamの方式には、メモリマッピング方式には見られないオーバーヘッドが存在すると述べます。
彼は、可能な限り多くのメモリを利用し、メモリが不足した際にはデータセットの一部をディスクにスピルすることが可能なメモリマッピング版を使用すべきだと説明します。さらに、何個のファイルを割り当てるべきか、そのサイズや、メモリの割り当てと解放に伴ってそれらのファイルをどのように循環させるかという疑問も提起します。
彼は、複数の大規模ファイルにメモリを分割し、同じメモリに二度書き込むことを避け、可能な限り速やかにファイルを削除する方法を提案します。Nicoletは、Lokadの運用環境では、各ファイルが16ギガバイト、各ディスクに100ファイル、そして各L32VMが4枚のディスクを持ち、各VMに6テラバイト以上のスピルスペースを提供する特定の設定でLokad Scratch Spaceを使用していると締めくくります。
完全な書き起こし

Victor Nicolet: こんにちは。これより、.NETにおけるディスクへのスピル操作に関する講演へようこそ。
ディスクへのスピルは、使用中でないデータセットの一部を永続ストレージに保持することで、メモリに収まりきらないデータセットを処理する技術です。
この講演は、Lokadでの私の経験に基づいています。私たちは定量的サプライチェーンの取り組みを行っています。
「定量的」というのは大規模なデータセットを扱うことを意味し、サプライチェーンの側面は実世界の一部であるため、複雑で予測不可能、そして無数の例外が潜んでいます。
そのため、非常に複雑な処理を多数行っています。
例えば、典型的な例を見てみましょう。小売業者は約10万点の商品を取り扱っています。
これらの商品は最大で100の拠点に存在します。これらは店舗であったり、倉庫であったり、さらにはeコマース専用の倉庫の一部であったりします。
そして、これらに関する実際の分析を行うためには、過去の動向、つまりそれらの商品や拠点で何が起こっているのかを調べる必要があります。
毎日1つのデータポイントを保持し、過去3年間のみを対象とすると約1000日分となり、これらを全て掛け合わせるとデータセットは100億エントリになります。
各エントリに1つの浮動小数点値を保持するだけで、データセットはすでに37ギガバイトのメモリ容量を必要とし、これは一般的なデスクトップコンピューターの容量を上回ります。

また、1つの浮動小数点値では実際の分析を行うには全く不十分です。
より適切な数値は20であり、それでもメモリフットプリントを小さく保つために非常に工夫しています。それでも約745ギガバイトのメモリ使用量となります。
大規模なクラウドマシンであれば収まりますが、月額約7000ドルが必要となるため、手頃である一方で、かなりの無駄も伴います。

この講演のタイトルから想像できるように、解決策はメモリよりも遅いが安価な永続ストレージを使用することです。
近年では、1ギガバイトあたり約5セントでNVMe SSDストレージを購入できます。NVMe SSDは、現代で容易に手に入る永続ストレージの中でも最速の部類に入ります。
これに対し、1ギガバイトのRAMは275ドルもするため、約55倍の価格差があります。

別の見方として、18ギガバイトのメモリを購入する予算があれば、1テラバイトのSSDストレージを購入できる計算になります。

クラウドの提供についてはどうでしょうか? Microsoftのクラウドを例に取ると、左側にあるのはストレージ最適化された仮想マシンシリーズの一部であるL32sです。
月額約2000ドルで、ほぼ8テラバイトの永続ストレージが提供されます。
右側にはメモリ最適化されたシリーズのM32msがあり、コストの2.5倍以上を支払っても、875ギガバイトのRAMしか得られません。
もし私のプログラムが左側のマシンで実行され、完了にかかる時間が倍になったとしても、コスト面では依然として有利です。

パフォーマンスはどうでしょうか?メモリからの読み込みは約21ギガバイト/秒で動作します。一方、NVMe SSDからの読み込みは約3.5ギガバイト/秒です。
これは実際のベンチマークではありません。単に仮想マシンを作成してその二つのコマンドを実行しただけであり、これらの数値を増加または減少させる方法は数多く存在します。
ここで重要なのは、両者の差の桁数に過ぎないという点です。ディスクからの読み込みはメモリからの読み込みの6倍遅いのです。
つまり、ディスクは残念ながら遅いので、常にランダムアクセスパターンでディスクから読み込むのは望ましくありません。しかし一方で、意外にも速いのです。もし処理が主にCPUに依存しているなら、メモリからではなくディスクから読み込んでいることに気づかないかもしれません。

ディスクスペースをメモリの代替として利用するための、よく知られた手法の一つにパーティショニングがあります。
パーティショニングの考え方は、データセットの次元の一つを選び、データセットをより小さな部分に分割することです。各部分はメモリに収まるほど小さくなければなりません。
その後、処理は各部分を個別に読み込み、処理を行い、その部分をディスクに保存してから次の部分を読み込みます。
例えば、データセットを場所ごとに分割して一度に一つの場所を処理すると、各場所はわずか7.5ギガバイトのメモリしか必要とせず、これはデスクトップコンピュータで対応可能な範囲です。

しかし、パーティショニングではパーティション間の通信が行われません。そのため、場所をまたいだデータ処理が必要な場合、この手法は使えなくなります。
もう一つの手法はストリーミングです。ストリーミングは、任意の時点でメモリに小さなデータの塊のみを読み込む点でパーティショニングに似ています。
パーティショニングとは異なり、ストリーミングでは異なる部分の処理間で状態を保持することが許されます。つまり、最初の場所を処理する際に初期状態を設定し、次の場所を処理する際にその時点の状態を利用して新たな状態を構築することが可能です。
また、パーティショニングとは違い、ストリーミングは並列実行に適していません。しかし、データセット全体にわたる計算という点では、各部分ごとに分断される問題を解決します。
ただし、ストリーミングには独自の制限があります。パフォーマンスを発揮するためには、オンディスクのデータが適切に整列または並び替えられている必要があります。
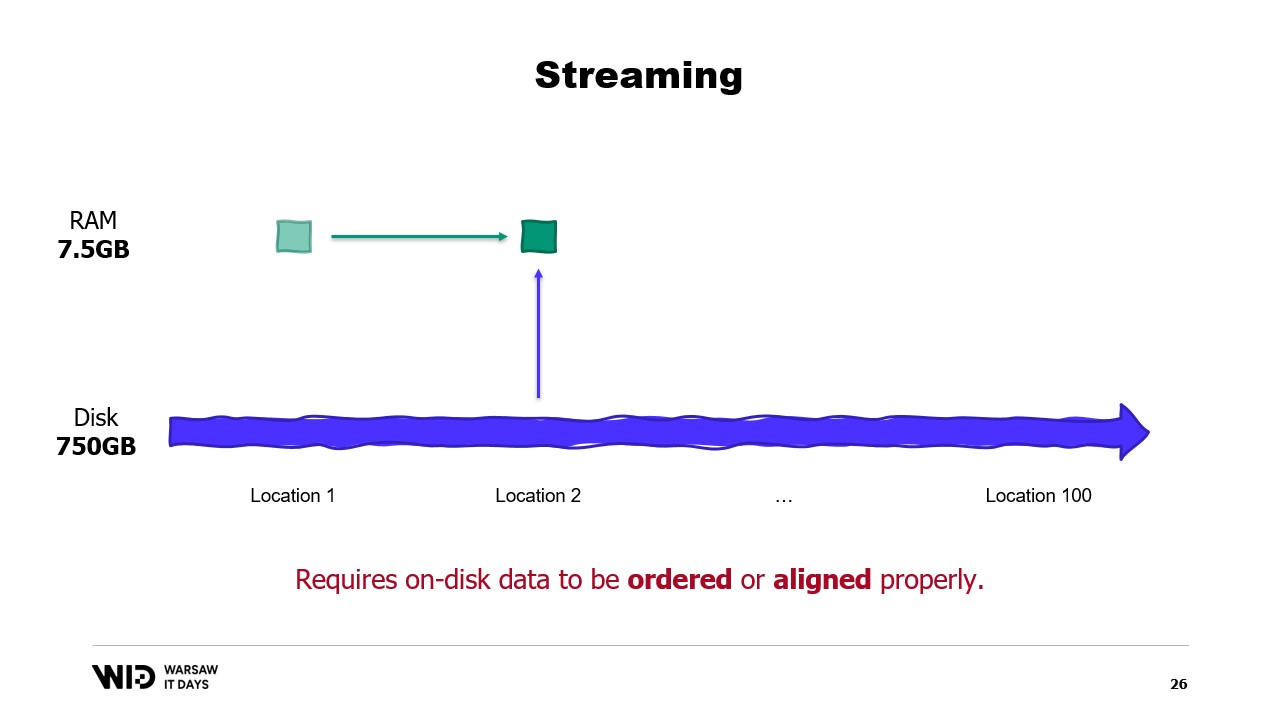
これらの要件を理解するには、NVMeが0.5キロバイト(512バイト)のセクター単位でデータを読み書きしており、前述の3.5ギガバイト/秒のパフォーマンス値は、セクターが完全に読み込まれて使用されることを前提にしていると知る必要があります。
もしセクターの一部だけを使用するにもかかわらず、セクター全体を読み込まなければならない場合、帯域幅が無駄になり、パフォーマンスが大幅に低下します。

したがって、読み込むデータが0.5キロバイトの倍数であり、セクターの境界に沿って整列されている場合が最適なのです。
今では回転ディスクは使用していないので、先読みをスキップしてセクターを読み込まない場合でも余分なコストはかかりません。

しかし、データをセクターの境界に整列させることが不可能な場合、別の方法として連続して読み込むという手法があります。
これは、一度セクターがメモリに読み込まれると、そのセクターの後半部分の読み込みには再度ディスクからの読み込みが不要になるためです。代わりに、オペレーティングシステムがまだ使用されていない残りのバイトを提供してくれます。
このように、データが連続して読み込まれる場合、帯域幅の無駄がなく、フルパフォーマンスを発揮できます。

最悪の場合は、各セクターから1バイトまたはわずか数バイトだけを読み込む場合です。例えば、各セクターから浮動小数点数を一つずつ読み込むと、パフォーマンスは128分の1になります。

さらに悪いのは、セクターよりも大きなデータのまとまりの単位としてオペレーティングシステムのページがあり、通常は約4キロバイトの全ページが一括で読み込まれることです。
つまり、各ページから1つの浮動小数点数を読み込むと、パフォーマンスは1024分の1に低下します。
このため、永続ストレージからのデータ読み込みは大きな連続したバッチで行われることを保証することが非常に重要です。

これらの手法を用いれば、プログラムをより少ないメモリに収めることが可能です。なお、これらの手法はメモリとディスクを相互に独立した二つの記憶領域として扱います。
したがって、データセットのメモリとディスク間の分布は、アルゴリズムとデータセットの構造によって完全に決まります。
つまり、必要なメモリ量が正確に備わったマシンでプログラムを実行すれば、プログラムはぴったり収まり、正常に動作するでしょう。
必要なメモリ量が不足しているマシンを使えば、プログラムはメモリに収まらず、実行できなくなります。
最後に、必要以上のメモリがあるマシンを使った場合、プログラムは通常どおり、追加のメモリを使わず同じ速度で動作し続けます。
利用可能なメモリに基づいて実行時間のグラフを描くと、このようになります。メモリ使用率の下限では実行が行われず、処理時間も発生しません。使用率を超えると、プログラムが追加のメモリを利用して高速化できないため、処理時間は一定となります。
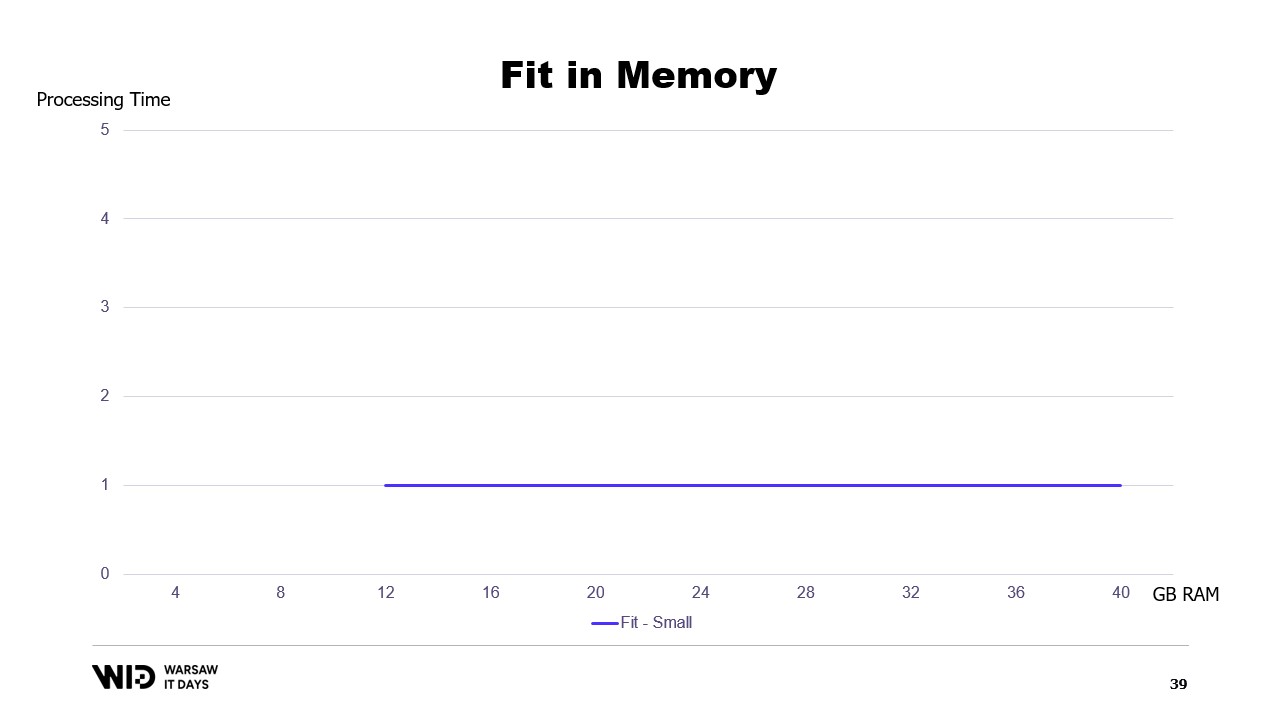
さらに、データセットが大きくなった場合はどうなるでしょうか?次元によりますが、データセットがパーティション数を増加させる形で成長すれば、メモリ使用率は同じままで、単にパーティションが多くなるだけです。
一方、各パーティション自体が大きくなると、メモリ使用率も増加し、プログラムの実行に必要な最小メモリ量も増えてしまいます。
つまり、より大きなデータセットを処理する必要がある場合、処理時間が長くなるだけでなく、メモリ使用率も大きくなるのです。
これは、大きなデータセットを収めるために追加のメモリを投入する必要がある一方、追加メモリは小さなデータセットに対しては何の改善ももたらさないという厄介な状況を招きます。
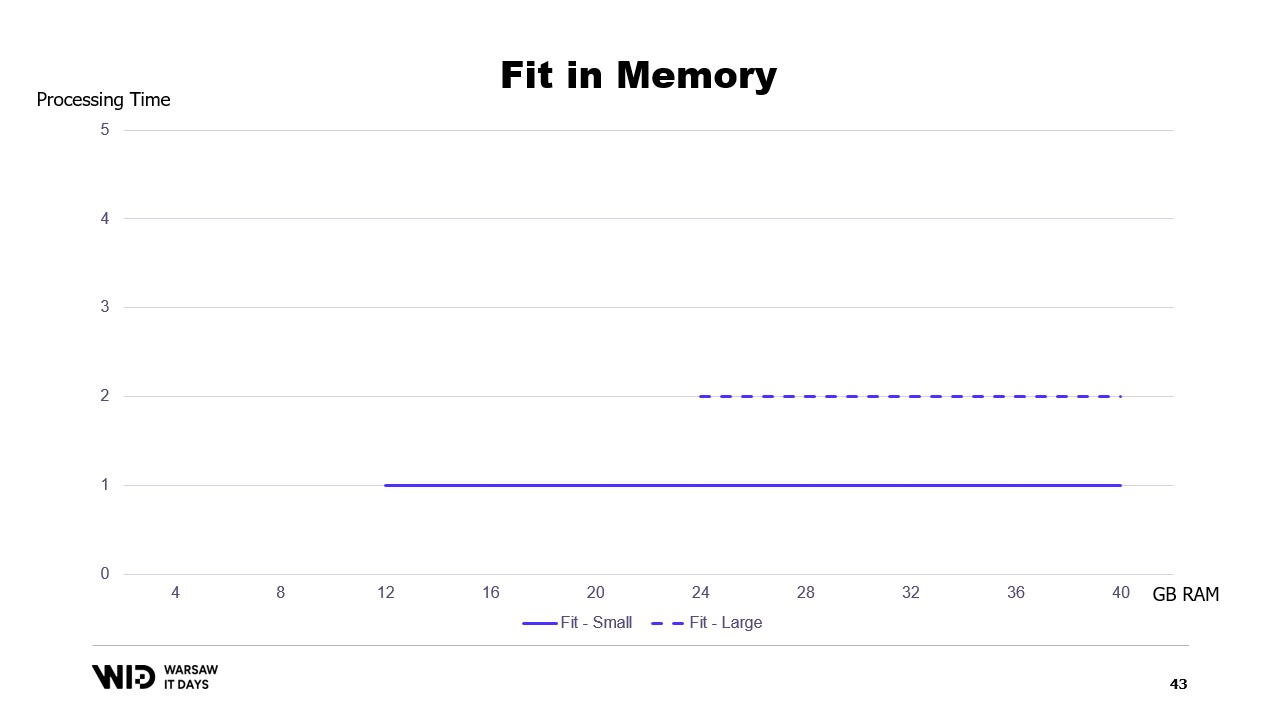
これは、データセットをメモリと永続ストレージに収める際のアプローチの制約であり、分布がデータセットの構造とアルゴリズム自体によって完全に決定されるための限界です。
実際に利用可能なメモリ量は考慮されません。spill to disk 技法は、この分布を動的に行います。つまり、利用可能なメモリが多ければ、より多くのメモリを使用して高速に実行します。
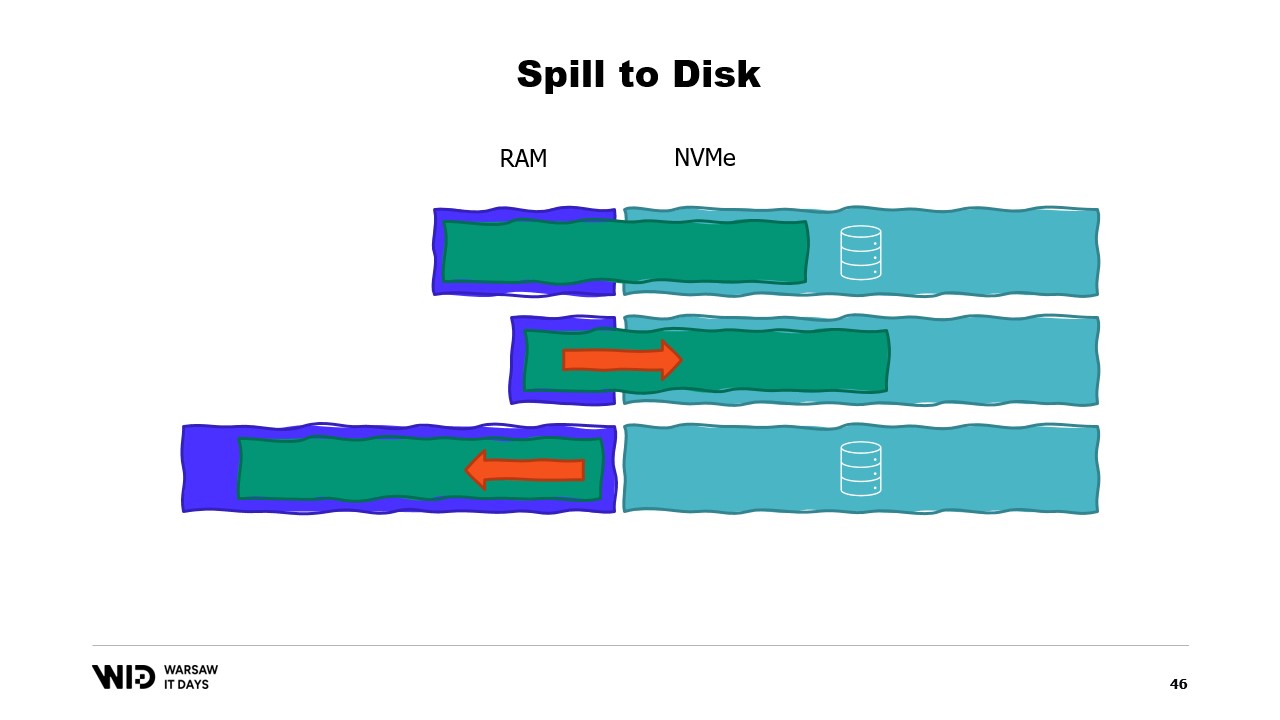
これに対し、利用可能なメモリが少ない場合は、必要な範囲内で処理を遅くしてメモリ使用量を抑えることができます。その結果、グラフの曲線は大幅に改善され、最小メモリ使用量も小さく、両方のデータセットで同じになります。
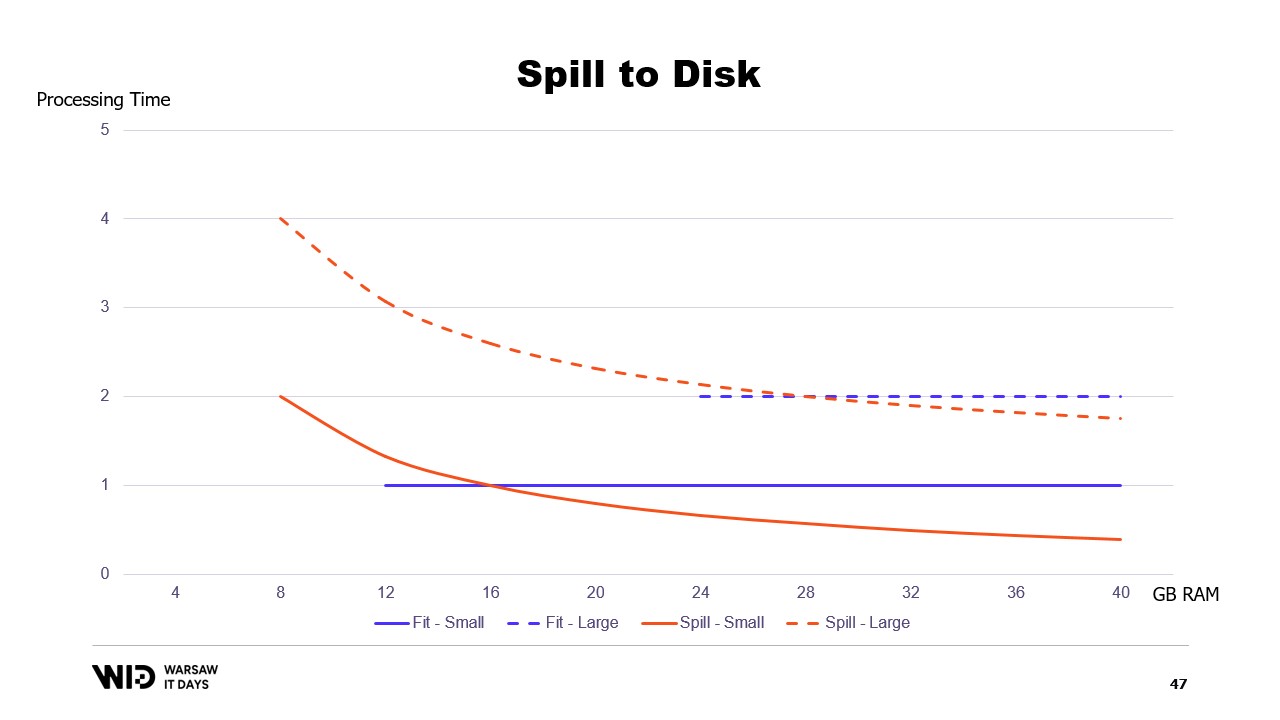
すべての場合において、メモリが増えるとパフォーマンスは向上します。fit to memory 技法では、メモリ使用率を下げるためにあらかじめ一部のデータをディスクにダンプします。一方、spill to disk 技法は可能な限り多くのメモリを利用し、メモリが不足したときのみディスクにデータをダンプして領域を確保します。
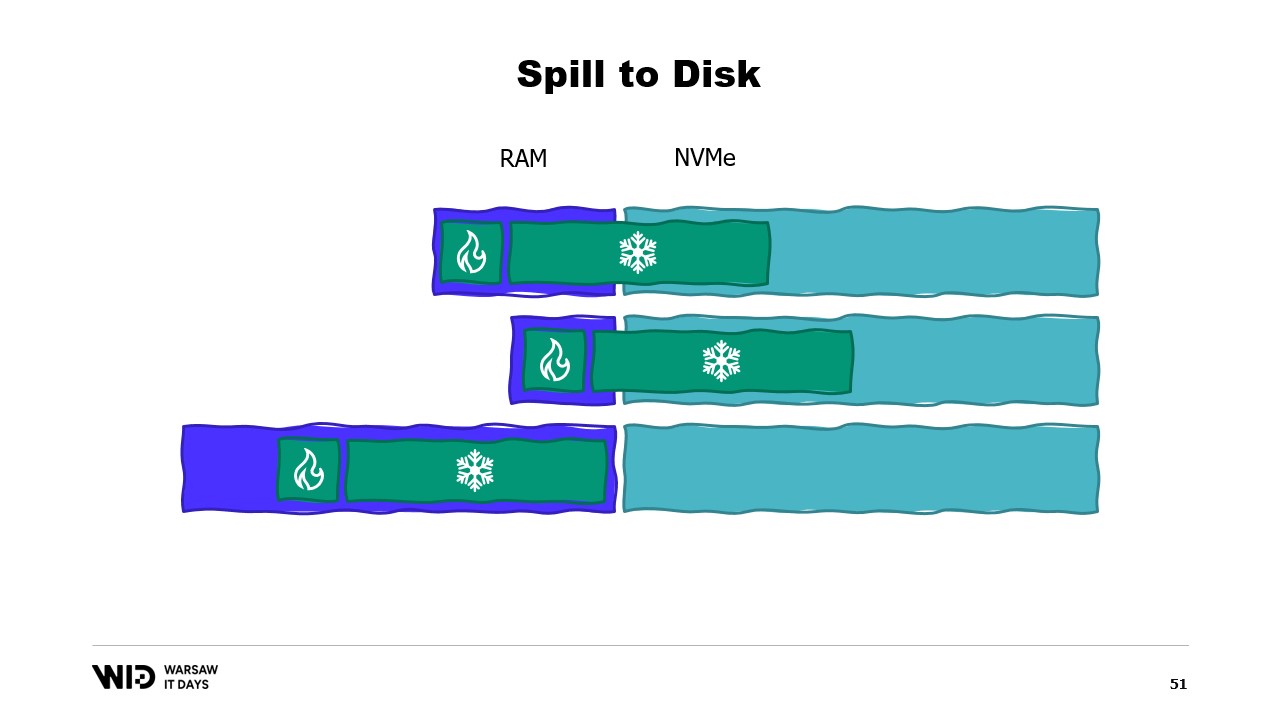
これにより、想定よりメモリが多かったり少なかったりする状況に柔軟に対応できます。spill to disk 技法はデータセットをホットセクションとコールドセクションの二つに分割します。ホットセクションは常にメモリ内に存在すると想定され、ランダムアクセスしてもパフォーマンス上安全です。もちろん、典型的なクラウドマシンではCPUあたり約8ギガバイト程度の最大予算が設定されるでしょう。
一方、コールドセクションは、いつでもその一部を永続ストレージにスピルすることが許されています。利用可能な容量以外に最大予算の制限はなく、もちろんコールドセクションから安全にデータを読み込むことはパフォーマンス上できません。
したがって、プログラムはホット・コールド転送を使用します。これらは通常、NVMeの帯域幅を最大限に活用するために大きなバッチで行われ、バッチサイズが大きいため実行頻度は低くなります。結果として、これらのアルゴリズムが可能な限り多くのメモリを使用できるのはコールドセクションのおかげなのです。

コールドセクションは利用可能なRAMをできるだけ埋め、その残りを永続ストレージにスピルします。では、これを.NETでどのように動作させるのでしょうか?最初の試みと呼ぶ理由は、うまくいかないことが予想されるからです。事前に問題点を見極めてください。
ホットセクションには通常の.NETオブジェクトを使用し、問題として普通の.NETプログラムを扱います。コールドセクションには「reference class」と呼ばれるものを使用します。このクラスは、コールドストレージに格納される値への参照を保持し、値がメモリ上に存在しなくなった場合にはnullに設定されます。また、spill関数を持ち、メモリ上の値を取り出してストレージに書き込み、その後参照をnullにして、.NETガベージコレクタが必要に応じてそのメモリを回収できるようにします。
最後に、valueプロパティがあります。このプロパティにアクセスすると、メモリ上に値が存在すればそれを返し、存在しなければディスクからメモリへ再ロードして返します。さらに、プログラム内で全てのコールド参照を追跡する中央システムを構築すれば、新たなコールド参照が生成されるたびに、それがメモリオーバーフローを引き起こすかどうかを判定し、利用可能なコールドストレージのメモリ予算内に収めるために、既存のコールド参照のspill関数を呼び出すことができます。

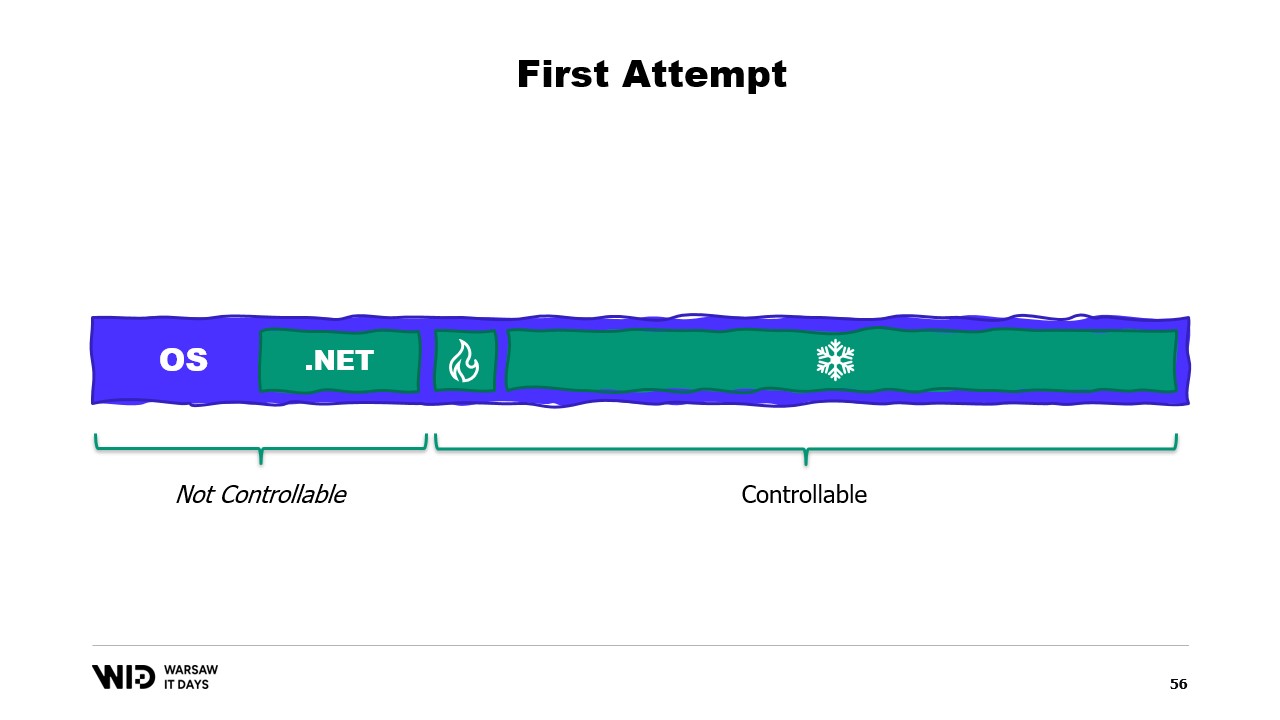
さて、問題は何でしょうか?理想的な状態で当該プログラムを実行するマシンのメモリ内容を見ると、まず左側にオペレーティングシステムが自身の用途のために使用するメモリがあり、次に読み込まれたアセンブリやガベージコレクションのオーバーヘッドなどに使用される.NET内部メモリ、そしてホットセクションのメモリ、最後に残り全てとしてコールドセクションに割り当てられたメモリが存在します。
私たちが割り当て、ガベージコレクタに回収を委ねる部分、つまり右側の部分はある程度制御できますが、左側の部分は私たちの制御外です。そして、もし突然オペレーティングシステムが追加のメモリを必要とし、.NETプロセスが生成したものすべてで占有されていると判明した場合、どうなるでしょうか?
この場合、例えばLinuxカーネルの一般的な反応は、最も多くメモリを使用しているプログラムを終了させることであり、カーネルに対して迅速にメモリを解放する術がないため、我々は強制終了されてしまいます。では、解決策は何でしょうか?

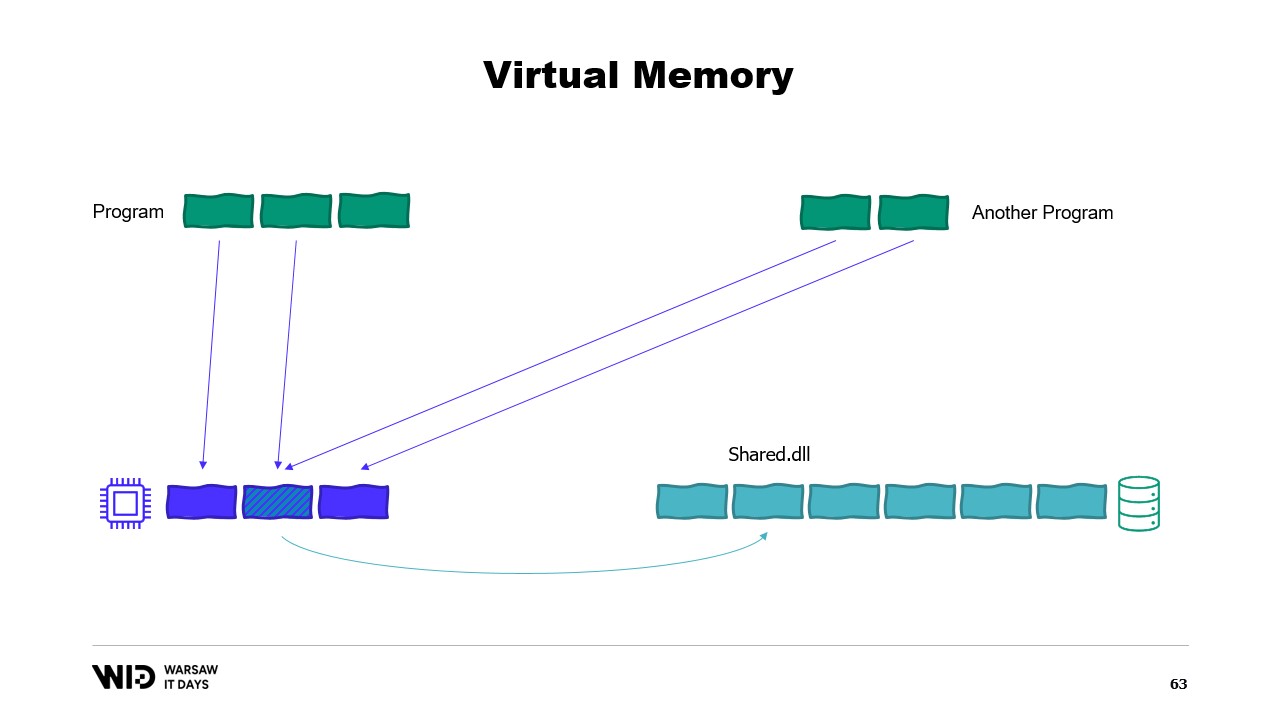
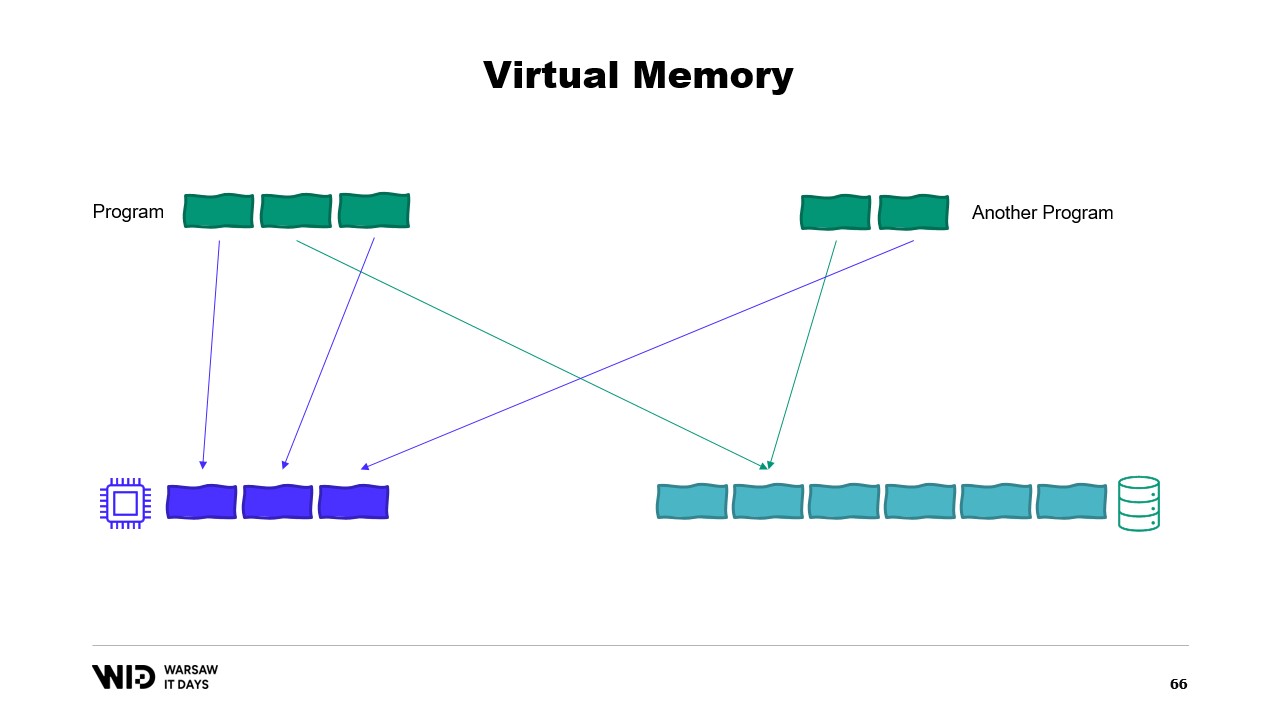
現代のオペレーティングシステムは仮想メモリの概念を採用しています。プログラムは物理メモリページに直接アクセスできず、代わりに仮想メモリページにアクセスし、これらのページと実際の物理メモリページとの間にマッピングがあります。同一コンピュータ上で別のプログラムが実行されていても、独自に最初のプログラムのページにアクセスすることはできません。ただし、共有する方法は存在します。
メモリマッピングされたページを作成することが可能です。その場合、最初のプログラムが共有ページに書き込んだ内容は、すぐに他の側でも見えるようになります。これはプログラム間の通信を実装する一般的な方法ですが、主な目的はファイルのメモリマッピングです。ここで、オペレーティングシステムはこのページが永続ストレージ上のページ(通常は共有ライブラリファイルの一部)の正確なコピーであると認識します。
ここでの主な目的は、各プログラムがDLLの独自コピーをメモリ上に保持しないようにすることです。なぜなら、すべてのコピーは同一であるため、無駄にメモリを消費する理由がないからです。例えば、物理メモリが3ページ分しかない状況で、2つのプログラムが合計4ページを使用しているとします。では、最初のプログラムでさらに1ページ割り当てようとすると、空きがありません。しかし、カーネルはメモリマッピングされたページが一時的に破棄され、必要に応じて永続ストレージから同一に再読み込みできることを認識しています。
つまり、まさにそのように動作します。二つの共有ページは、メモリの代わりにディスクを指すようになり、オペレーティングシステムによってメモリはクリアされゼロに設定され、その後、第一のプログラムに第三の論理ページとして割り当てられます。こうしてメモリが完全に満杯になると、いずれかのプログラムが共有ページにアクセスしようとしても、プログラムに割り当てられたページはオペレーティングシステムによって回収されないため、再びメモリに読み込む余地がなくなります。
この結果、メモリ不足エラーが発生します。どちらかのプログラムが終了し、メモリが解放され、そのメモリは再びメモリマッピングファイルをメモリに読み込むために再利用されます。なお、ほとんどのメモリマップは読み取り専用ですが、読み書き可能なものを作成することも可能です。
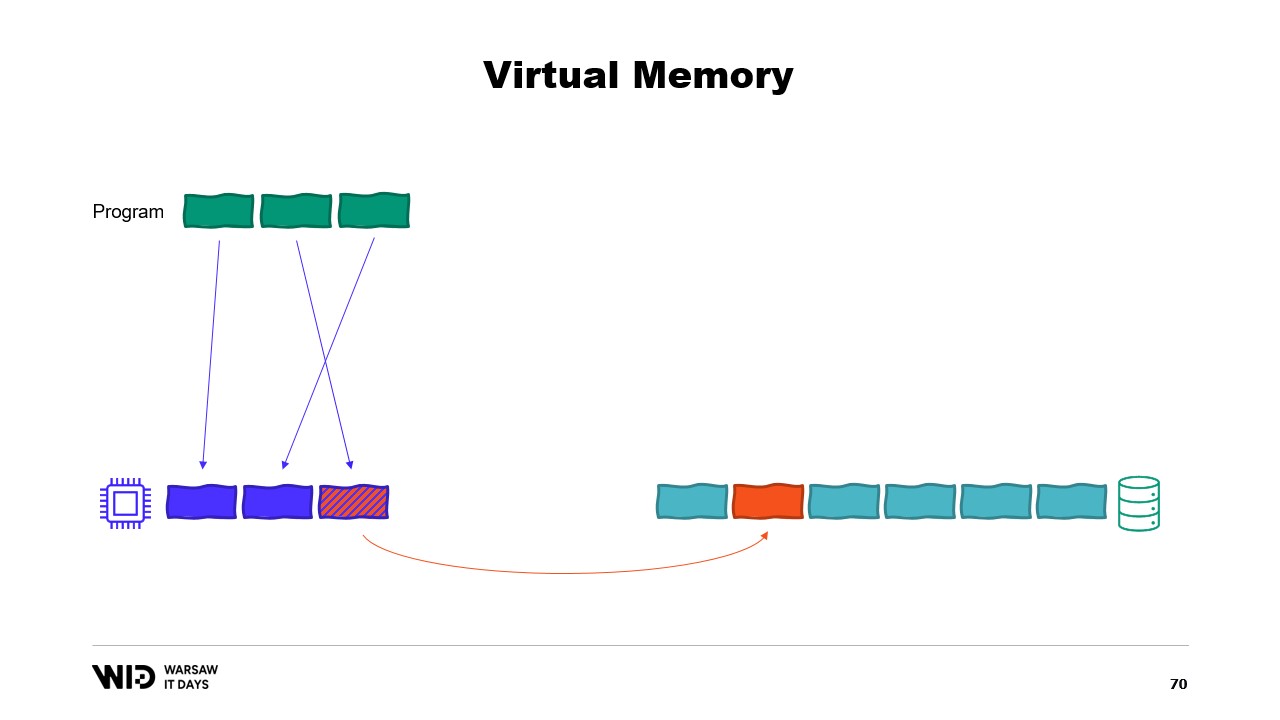
プログラムがマッピングされたページ内のメモリに変更を加えると、オペレーティングシステムは将来的にそのページの内容をディスクに保存します。そしてもちろん、Windowsのflushといった関数を使用することで、特定のタイミングでこれを実行させることも可能です。System Performance Toolには、現在の物理メモリ使用状況を示す優れたウィンドウがあります。
緑色はプロセスに直接割り当てられたメモリです。このメモリはプロセスを終了させない限り再利用できません。青色はページキャッシュを示しています。これらはディスク上のページと同一であることが確認されているページであり、そのためプロセスがディスクから既にキャッシュ内にあるページを読み込もうとすると、ディスクからの読み込みは発生せず、値は直接メモリから返されます。
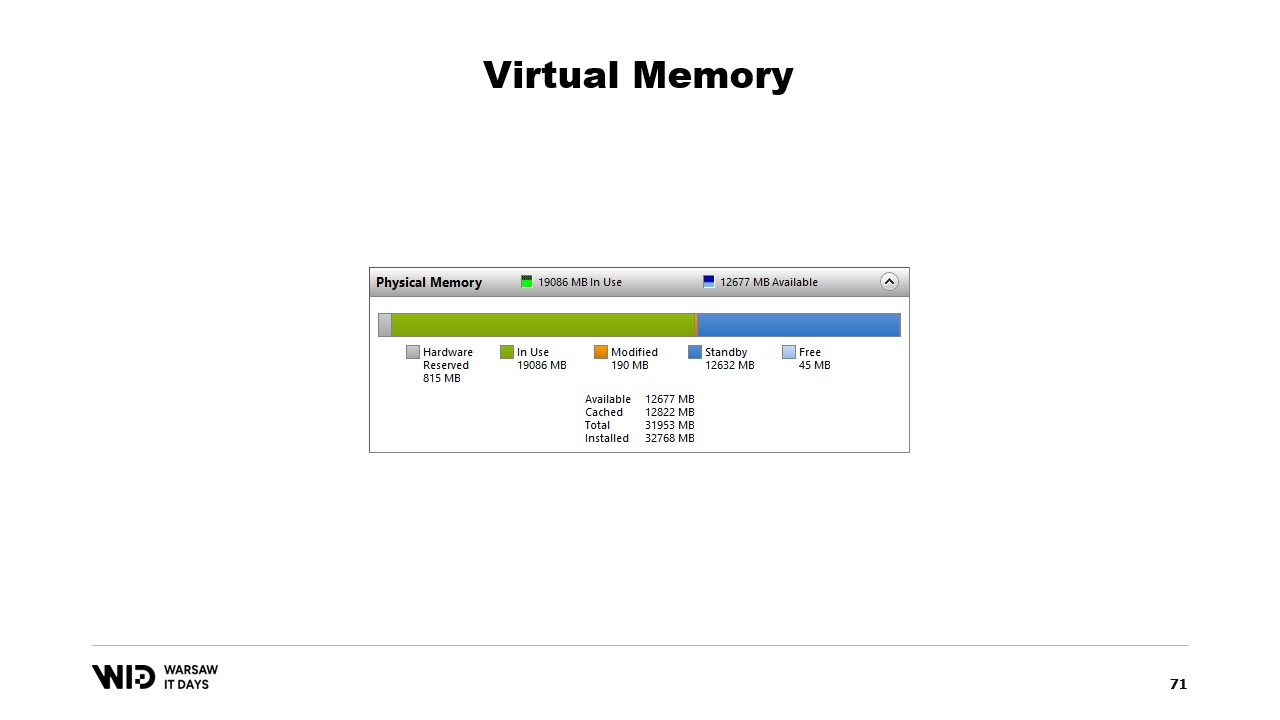
最後に、中間にある変更済みのページは、本来ディスク上の正確なコピーであるはずですが、メモリ上で変更が加えられています。これらの変更はまだディスクに反映されていませんが、非常に短い時間で適用されるでしょう。Linuxでは、h-stopツールが同様のグラフを表示します。左側はプロセスに直接割り当てられ、プロセスを終了させない限り再利用できないページで、右側の黄色はページキャッシュを示しています。

ご興味がある方には、Linuxのページキャッシュで何が起こっているのかについて、Vyacheslav Biryukovによる優れた資料があります。仮想メモリを使用して、2度目の試みを行いましょう。今回はうまくいくでしょうか? 今回はコールドセクションを完全にメモリマップされたページで構成することに決めました。したがって、すべてのページは最初にディスク上に存在することが期待されます。
プログラムは、どのページがメモリ上にあり、どのページがディスク上にのみ存在するかを制御できなくなりました。この処理はオペレーティングシステムによって透過的に行われます。例えば、プログラムがコールドセクションの3番目のページにアクセスしようとすると、オペレーティングシステムはそのページがメモリ上に存在しないことを検知し、既存のページのうちの1つ、例えば2番目のページをアンロードしてから、3番目のページをメモリにロードします。
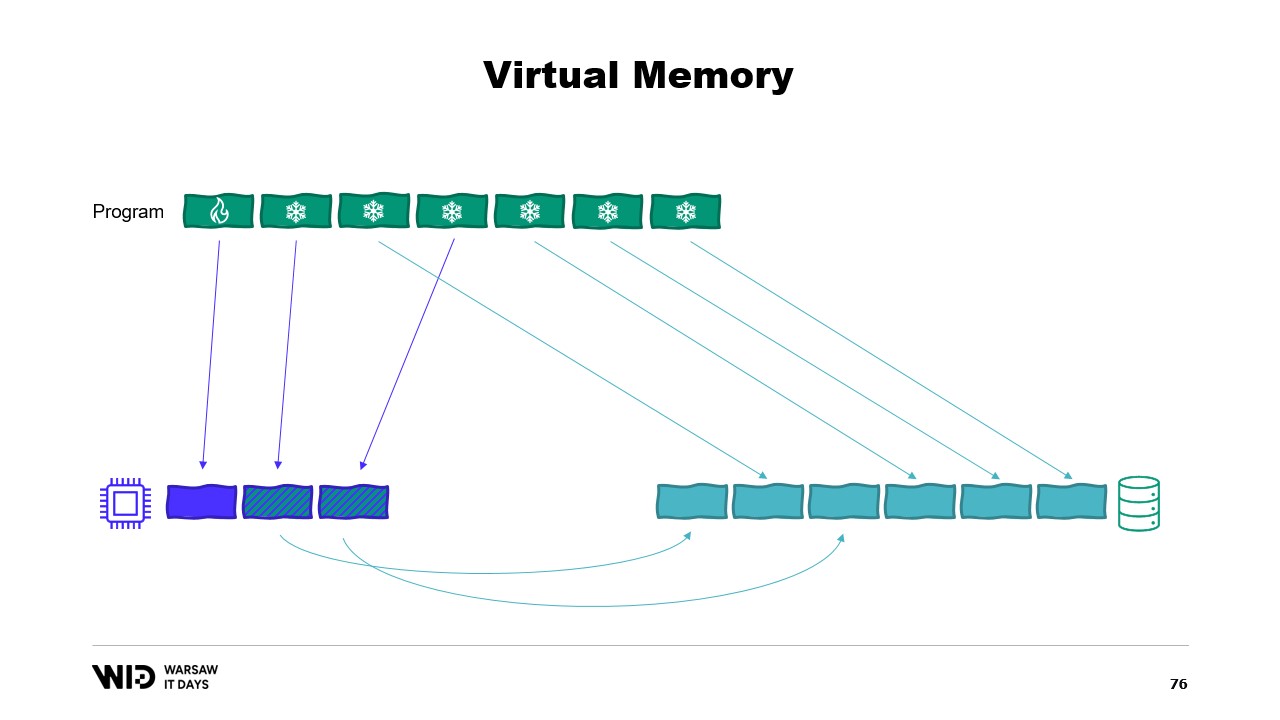
プロセス自身の観点からすると、これは完全に透過的でした。メモリからの読み込み待ちは通常よりもほんの少し長くなるだけです。そして、オペレーティングシステムが突然自身の処理のためにメモリを必要とした場合はどうなるでしょうか? その場合、どのページがメモリマップされていて安全に破棄できるかを把握しているため、単にそのページの1つを落とし、自身の目的のために使用し、処理が完了したら再び解放します。
これらすべての技術は.NETにも適用され、Lokad Scratch Spaceオープンソースプロジェクトにも実装されています。そして、以下に示すほとんどのコードは、このNuGetパッケージの実装方法に基づいています。

まず、.NETでメモリマップファイルをどのように作成するかですが、メモリマッピングは約13年前の.NET Framework 4から存在しています。インターネット上で十分にドキュメント化されており、そのソースコードはGitHubで完全に公開されています。

基本的な手順は、まずディスク上のファイルからメモリマップファイルを作成し、次にビューアクセッサを作成することです。これらの2つの型は、それぞれ異なる意味を持つため別々に管理されます。メモリマップファイルは、このファイルの一部のセクションがプロセスのメモリにマップされることをオペレーティングシステムに通知するだけです。一方、ビューアクセッサはそのマッピングを表現します。
.NETが32ビットプロセスのケースに対応する必要があるため、これらは分離されています。4ギガバイトを超える非常に大きなファイルは、32ビットプロセスのメモリ空間にマッピングすることはできません。サイズが大きすぎるため、一度にファイル全体をマッピングするのではなく、適合するように小さなセクションのみを一度にマッピングすることが可能となります。
今回は64ビットポインターを使用するため、ファイル全体をロードする1つのビューアクセッサを作成するだけで済みます。そして、AcquirePointerを使って、このメモリマップされた領域の先頭バイトへのポインターを取得します。作業が終われば、単にそれを解放します。.NETでポインターを扱うのは危険であり、どこでもunsafeキーワードを追加する必要があり、許可された範囲外へアクセスしようとするとクラッシュする可能性があります。
幸いにも、その問題を回避する方法があります。5年前、.NETはmemoryとspanを導入しました。これらは、単なるポインターよりも安全にメモリの範囲を表現するための型です。十分にドキュメント化されており、ほとんどのコードはGitHub上で確認できます。

spanとmemoryの基本的な考え方は、ポインターとバイト数が与えられた場合、そのメモリ範囲を表す新しいspanを作成できるということです。
一度このspanを得れば、境界を超えて読み込もうとするとランタイムがそれを検知して例外を発生させるため、span内のどこからでも安全に読み込むことができます。
spanを使って、メモリマップされたメモリから.NETの管理メモリへどのようにロードするかを見てみましょう。パフォーマンス上の理由から、コールドセクションに直接アクセスするのではなく、一度に大量のデータをロードするコールドからホットへの転送を行いたいのです。
例えば、読み込みたい文字列があるとします。それは、サイズとUTF-8でエンコードされたバイトのペイロードとしてメモリマップファイルに配置され、そこから.NETの文字列をロードしたいとします。
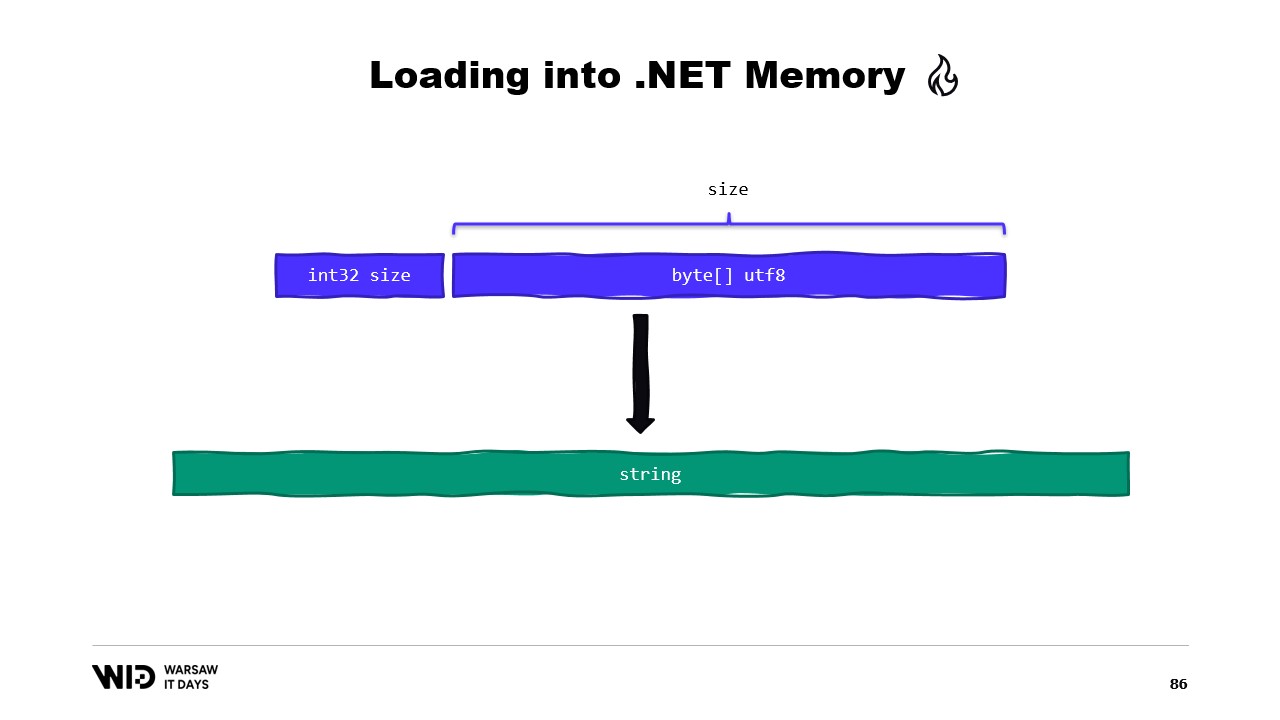
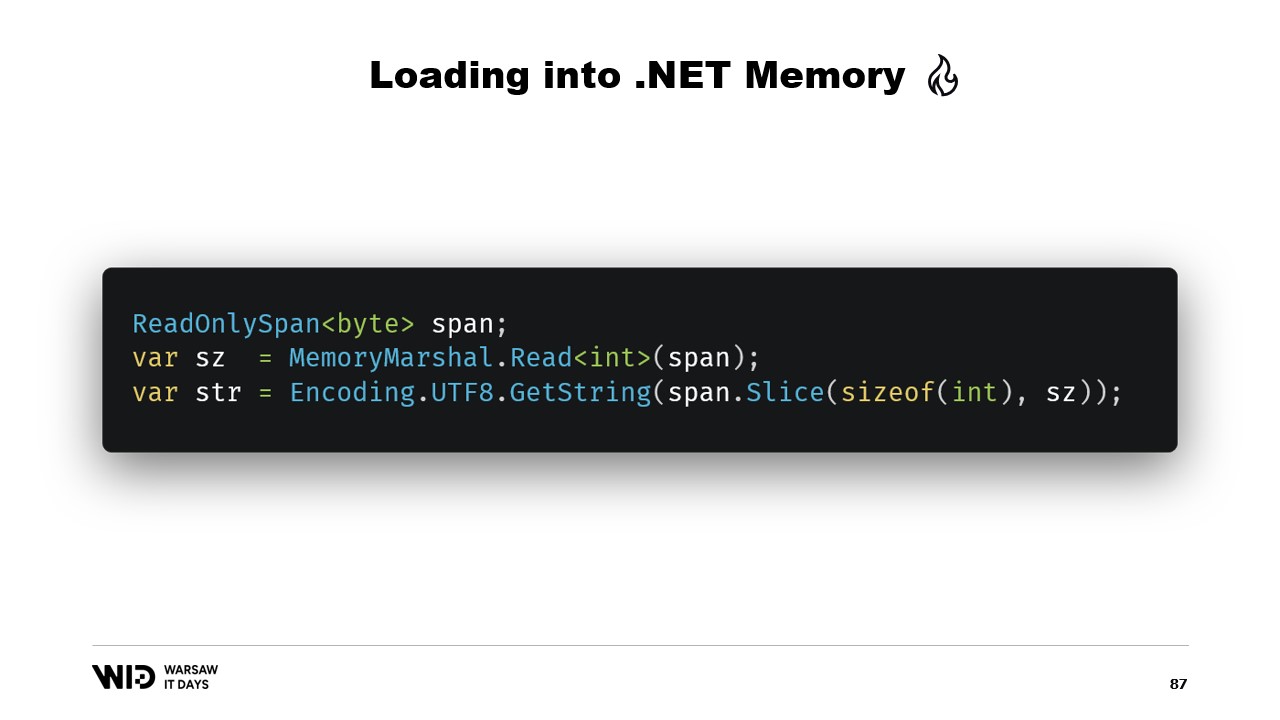
さて、spanを中心とした多くのAPIが利用可能です。例えば、MemoryMarshal.Readはspanの先頭から整数を読み取ることができます。その後、そのサイズを使って、Encoding.GetString関数にspanから文字列に変換するよう依頼できます。
これらはすべてspan上で操作を行います。たとえspanがメモリ上ではなくディスク上に存在するデータの一部を示していたとしても、最初にアクセスされた時にオペレーティングシステムが透過的にデータをメモリにロードしてくれます。
もう一つの例として、float配列にロードしたい一連の浮動小数点数があります。
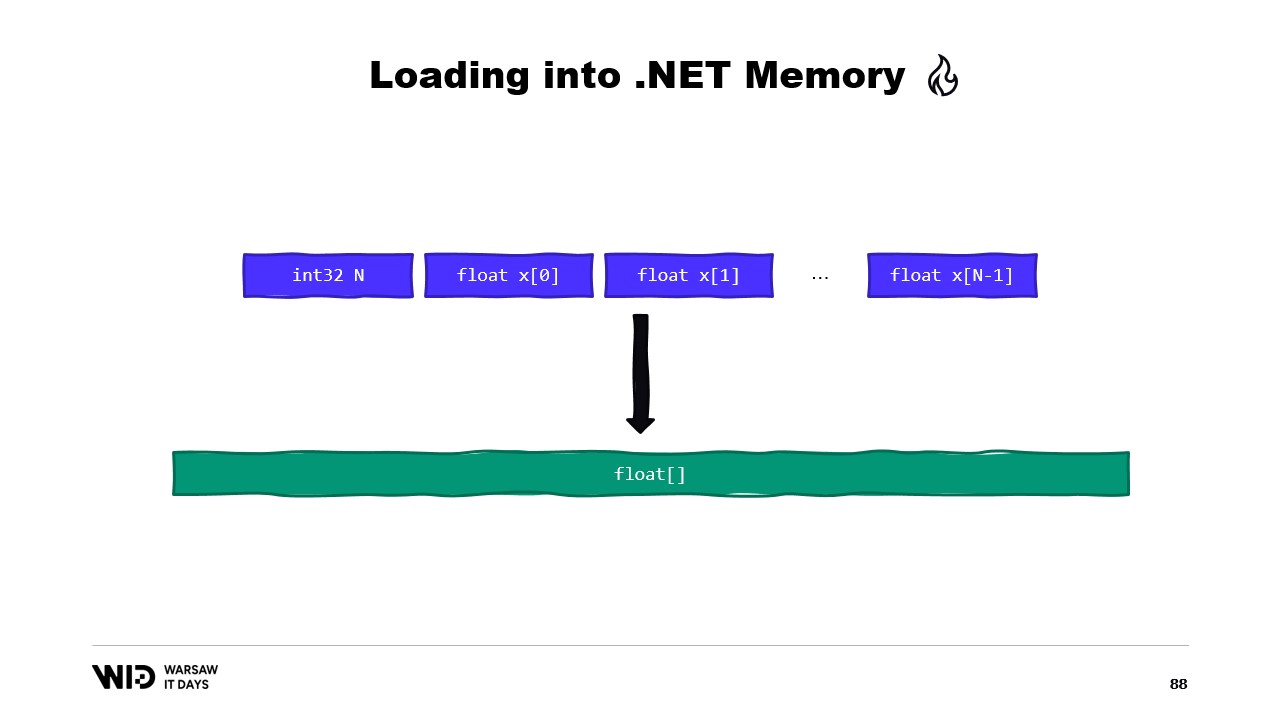
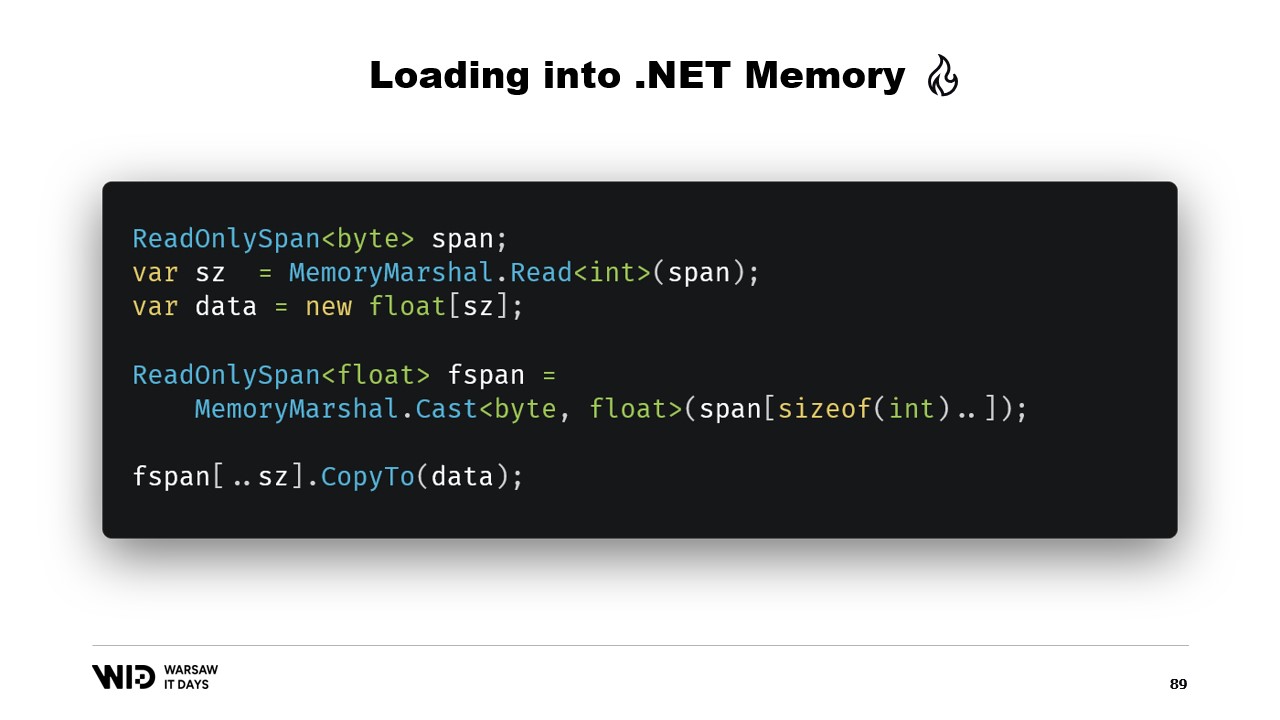
再び、MemoryMarshal.Readを使用してサイズを読み取り、そのサイズの浮動小数点数の配列を割り当て、次にMemoryMarshal.Castを使ってバイトのspanを浮動小数点数のspanに変換します。これは、span内にあるデータを単なるバイトではなく、浮動小数点数として再解釈するだけです。
最後に、spanのCopyTo関数を使用して、メモリマップファイルから配列へ高性能なコピーを実行します。これはある意味で少し無駄で、全く新しいコピーを行っていることになります。
これを回避できるかもしれません。通常、ディスクに保存されるのは生の浮動小数点数ではなく、圧縮されたバージョンです。ここでは、圧縮されたサイズを保存しており、これは読み取る必要があるバイト数を示します。さらに、出力サイズ、すなわち展開後のサイズを保存します。これは管理メモリに割り当てる必要がある浮動小数点数の数を示し、最後に圧縮されたペイロードそのものを保存します。
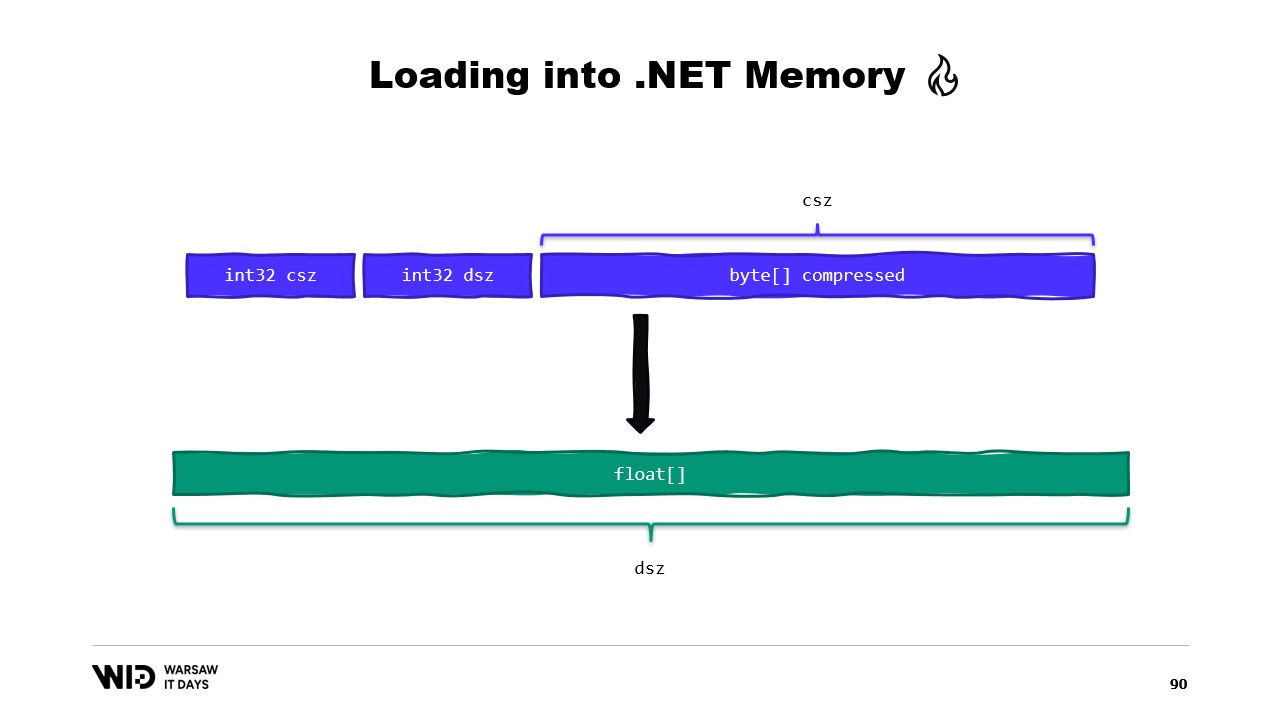
これをロードするには、2つの整数を個別に読み取るのではなく、内部に2つの整数値を持つヘッダーを表す構造体を作成する方が良いでしょう。

MemoryMarshalは、その構造体のインスタンスを読み取り、2つのフィールドを同時にロードすることができます。浮動小数点数の配列を割り当て、次に多くの圧縮ライブラリが、入力として読み取り専用のバイトのspan、出力としてバイトのspanを受け取るデコンプレッション関数のいずれかのバージョンを持っているはずです。再びMemoryMarshal.Castを使用して、浮動小数点数の配列をバイトのspanに変換し、目的地として使用します。
これにより、コピーは発生しません。代わりに、圧縮アルゴリズムが通常、ページキャッシュを経由してディスクから直接、目的の浮動小数点数の配列へ読み込みます。

ただし、spanには大きな制限が1つあります。それは、クラスメンバーとしては使用できず、拡張的に言えばasyncメソッドのローカル変数としても使用できないという点です。
幸いなことに、より長期間使用するデータ範囲を表現するために使用すべき別の型、Memoryがあります。
残念ながら、これを実現する方法についてのドキュメントは非常に乏しいです。ポインターからspanを作成するのは容易ですが、ポインターからMemoryを作成する方法は十分にドキュメント化されておらず、現時点で最良の情報源はGitHub上のgistです。ぜひ一読することをお勧めします。
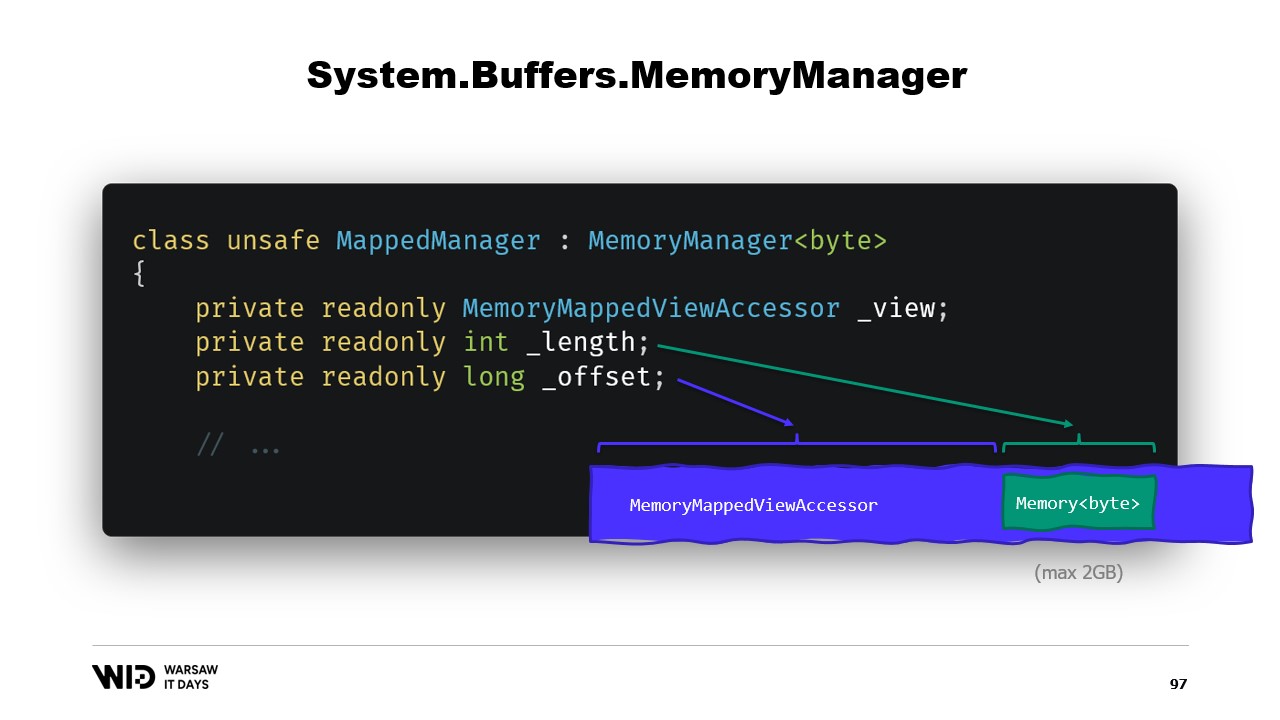
要するに、必要なのはMemoryManagerを作成することです。MemoryManagerは、配列の一部を指すだけでなく、より複雑な操作を行う必要がある場合に、Memoryによって内部的に使用されます。
今回の場合、参照すべきはメモリマップされたビューアクセッサです。参照可能な長さを把握し、さらにオフセットが必要になります。これは、バイトのMemoryが設計上2ギガバイト以上を表現できず、ファイル自体も2ギガバイトを超える可能性が高いからです。したがって、オフセットはより広いビューアクセッサ内でメモリが開始する位置を示します。
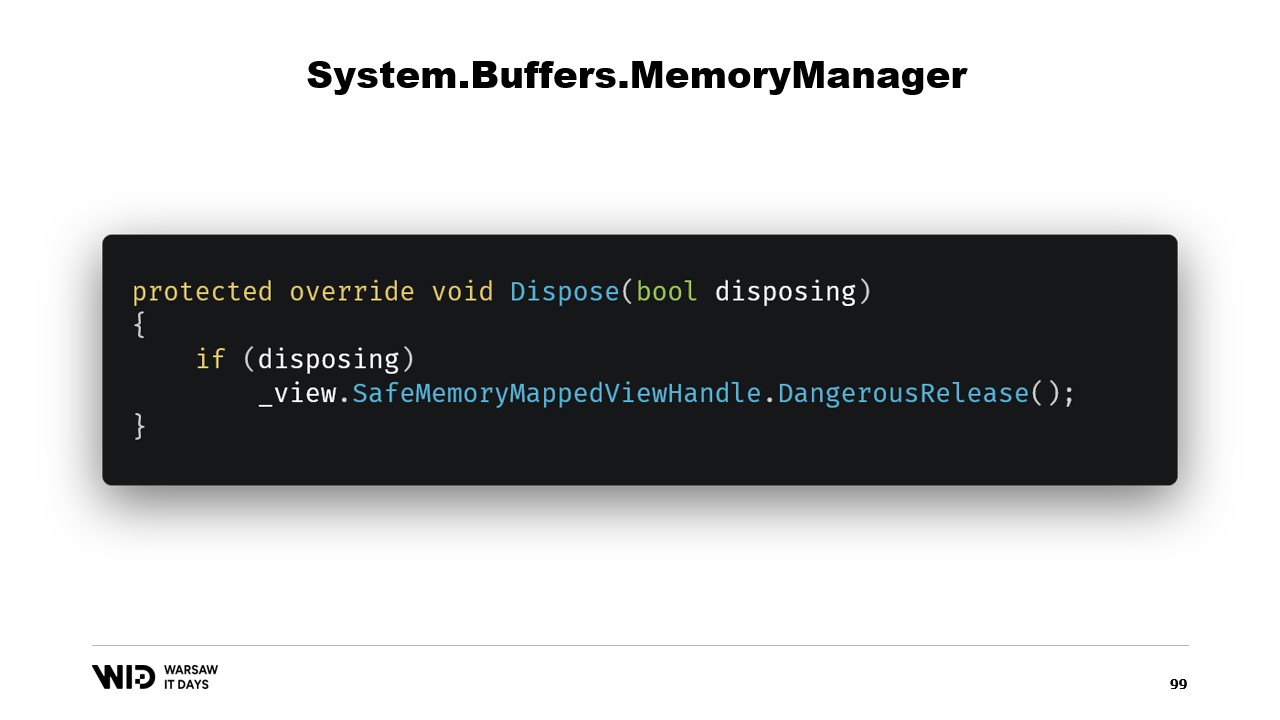
クラスのコンストラクタは非常にシンプルです。

メモリ領域を表す安全ハンドルへの参照を追加するだけで、この参照はdispose関数で解放されます。
次に、addressプロパティがあります。これは単なる付加情報ではなく、有用なものです。DangerousGetHandleを使用してポインターを取得し、オフセットを加えることで、アドレスが目的のメモリ領域の最初のバイトを指すようにします。
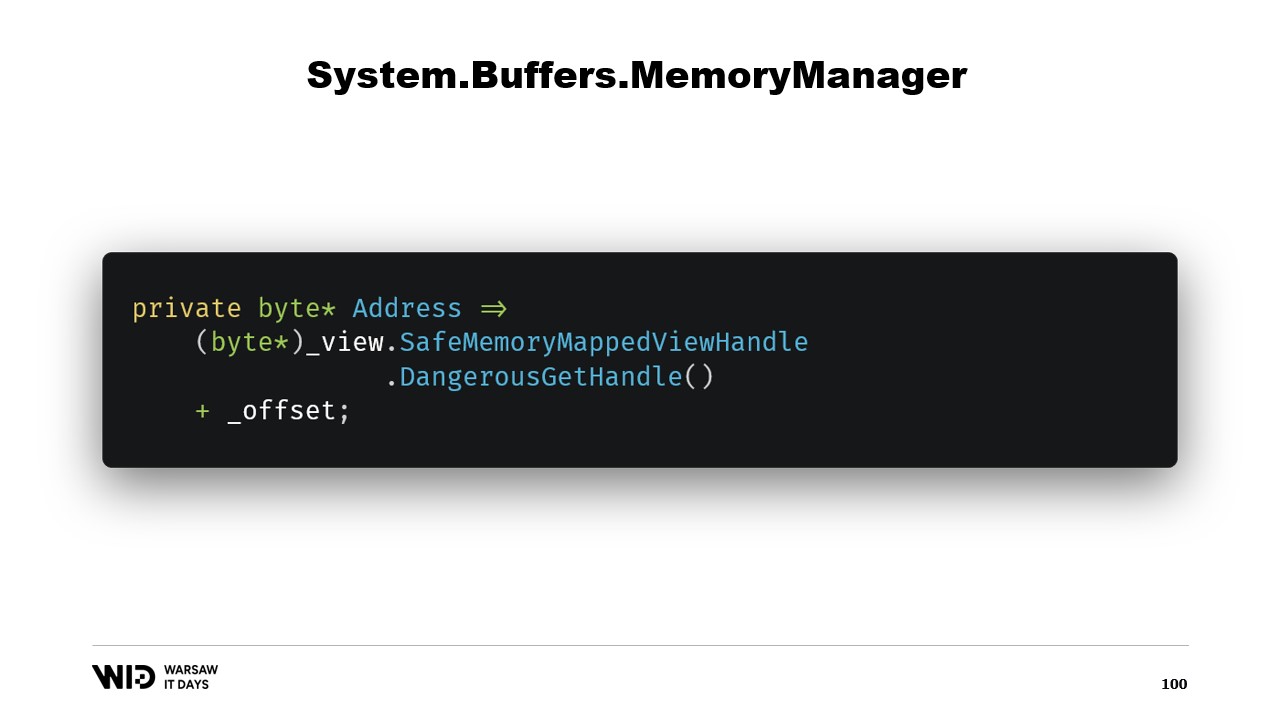
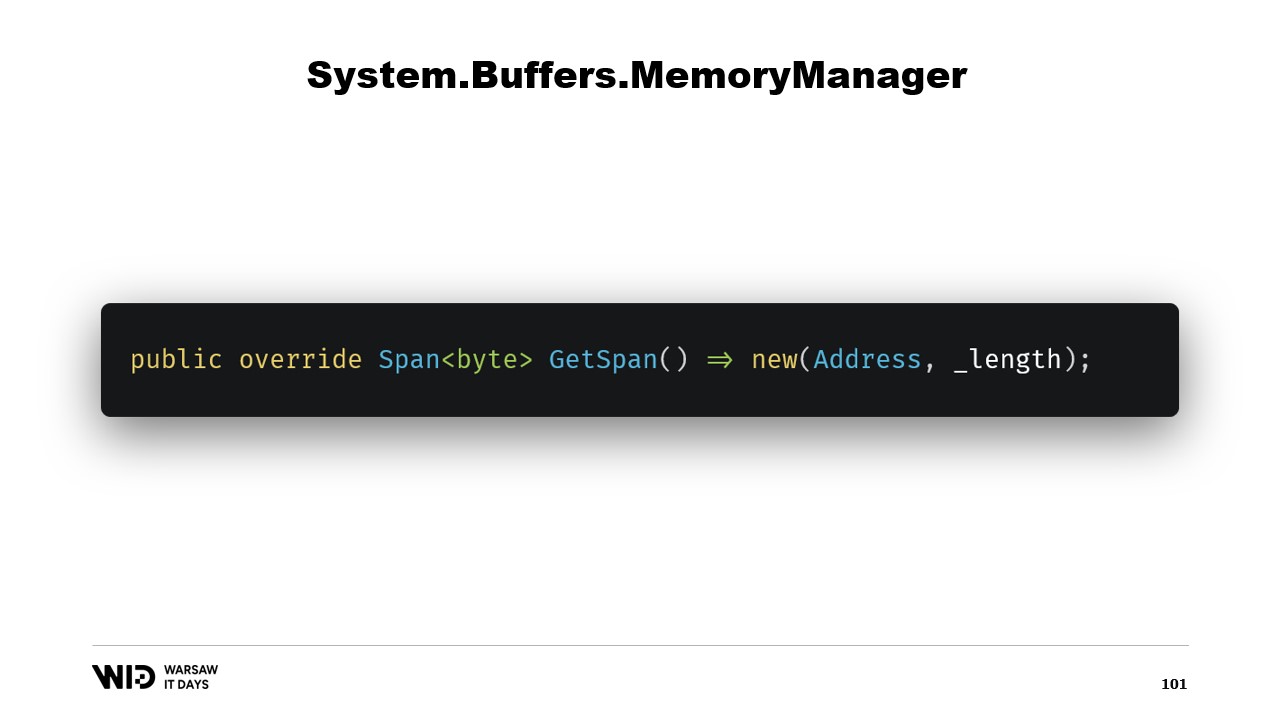
GetSpan関数をオーバーライドして、アドレスと長さを用いてspanを作成するという全ての魔法を実現しています。
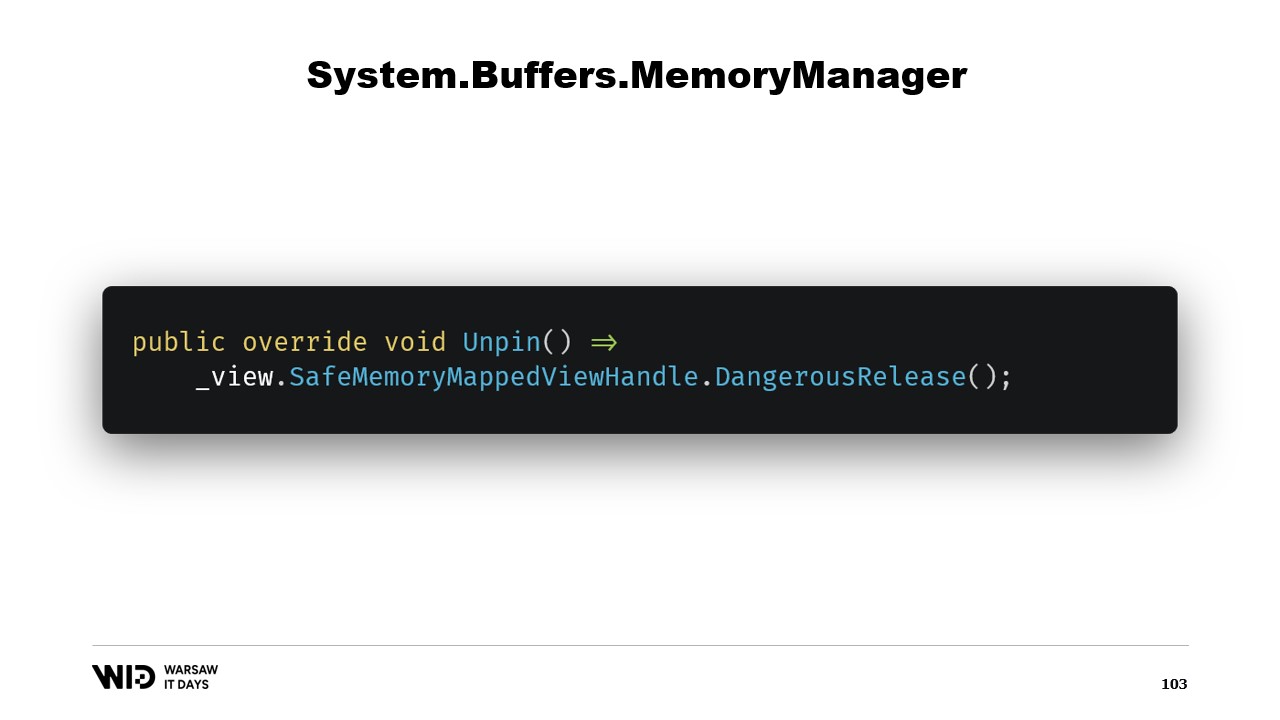
MemoryManagerで実装すべきもう2つのメソッドがあります。そのうちの1つがPinです。これは、メモリを短期間同じ位置に固定する必要がある場合に、ランタイムによって使用されます。参照を追加し、正しい位置を指し、かつ現在のオブジェクトをピン可能なものとして参照するMemoryHandleを返します。

これにより、ランタイムはメモリのピン留めが解除される際に、このオブジェクトのUnpinメソッドを呼び出し、安全ハンドルが再び解放されることを認識します。
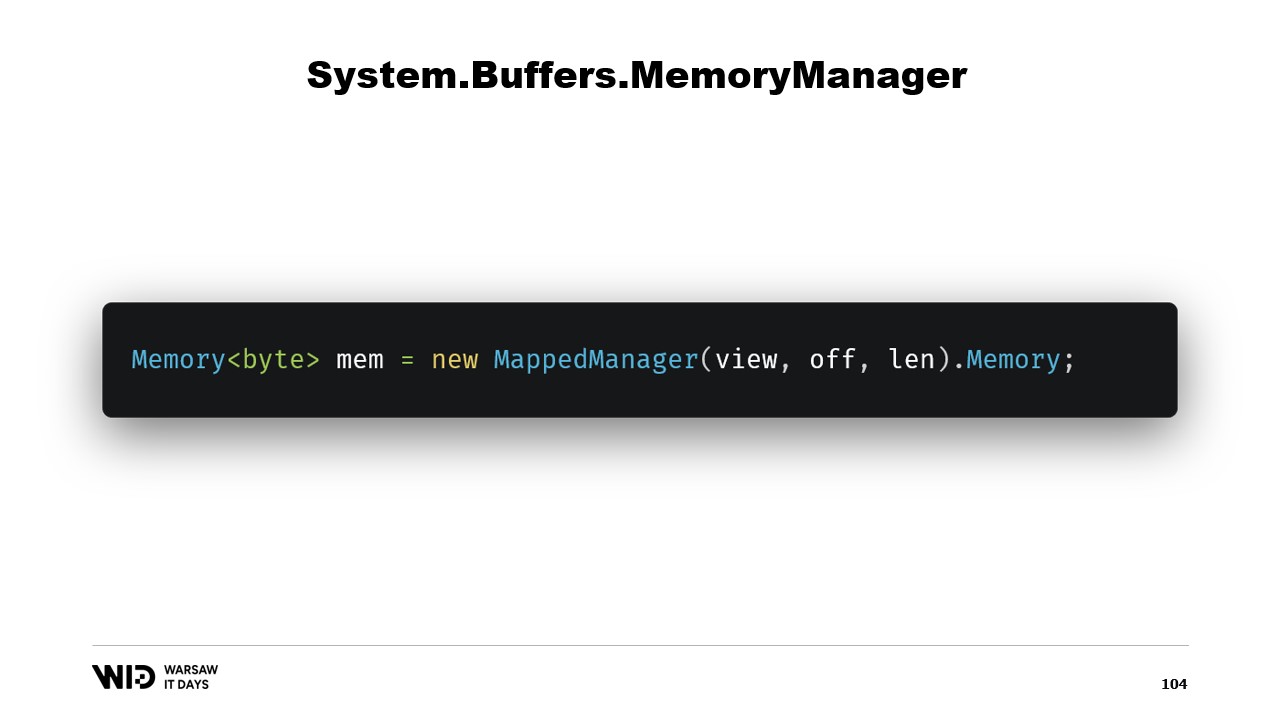
このクラスを作成すれば、そのインスタンスを生成し、そのMemoryプロパティにアクセスするだけで、内部的に作成されたMemoryManagerを参照するバイトのMemoryが返されます。これで、メモリの一部が手に入りました。書き込みを行うと、必要に応じて自動的にディスクにアンロードされ、アクセスされると、必要なときに透過的にディスクから再ロードされます。
これで、ディスクへのスピルプログラムを実装するには十分です。もう一つの疑問として、FileStreamを使用できるのに、なぜメモリマッピングを使うのでしょうか? 結局のところ、ディスク上のデータにアクセスする際にはFileStreamが明らかな選択肢であり、その使用方法も十分にドキュメント化されています。例えば、浮動小数点数の配列を読み込むには、FileStreamとそれをラップするBinaryReaderが必要です。FileStreamの位置をデータが存在するオフセットに設定し、リーダーでInt32を読み取ってサイズを得た後、浮動小数点数の配列を割り当て、MemoryMarshal.Castを使ってバイトのspanに変換します。
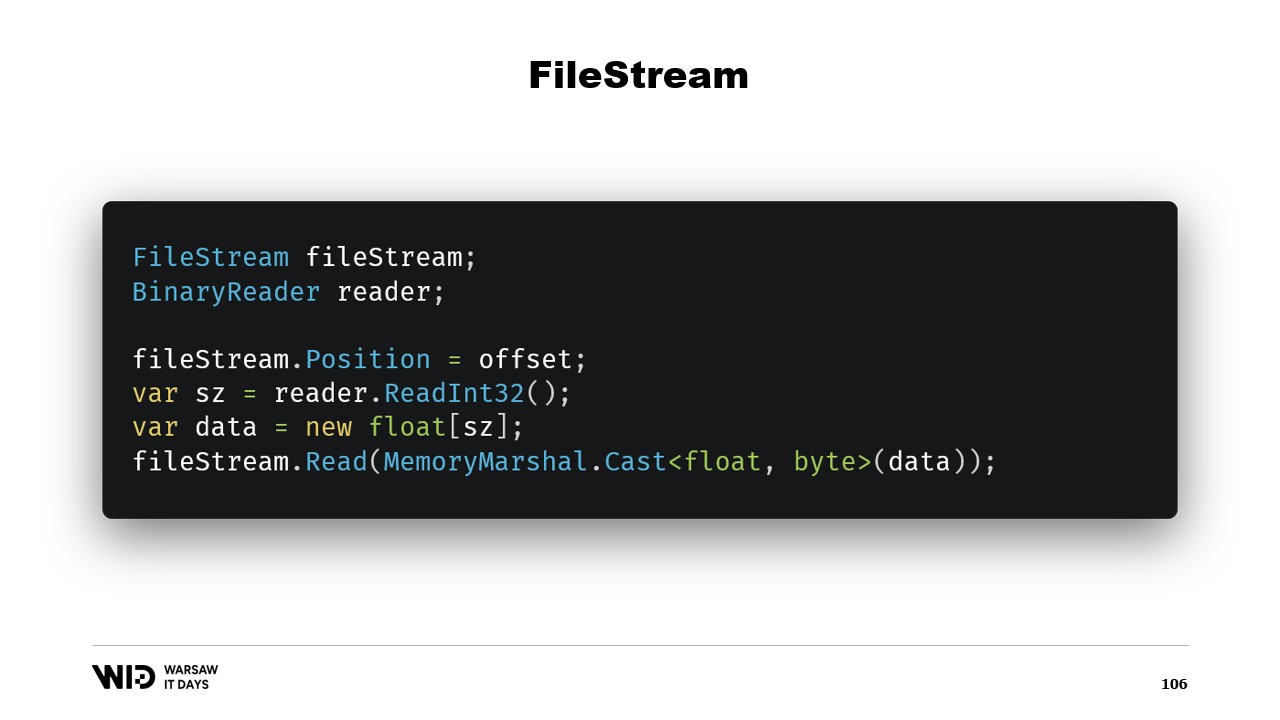
現在、FileStream.Readには宛先としてバイトのspanを受け取るオーバーロードが存在します。これは実際、ページキャッシュも利用しています。ページをプロセスのアドレス空間にメモリマッピングする代わりに、オペレーティングシステムはそれらを保持し、値を読み込む際にディスクからメモリへロードし、そのページから提供された宛先spanへコピーします。したがって、性能および動作の点でメモリマッピング版と同等です。
しかし、2つの大きな違いがあります。まず、これはスレッドセーフではありません。ある行で位置を設定し、次の文でその位置がそのままであると仮定するため、この操作の周りにロックが必要になり、メモリマップファイルでは可能であっても複数の場所から並行して読み込むことはできません。
もう一つの問題は、FileStreamで採用される戦略によっては、Int32の読み取りとspanへの読み取りのために2回の読み込みが行われる点です。各々が1回のシステムコールを実行し、オペレーティングシステムを呼び出して、そのメモリ内のデータをプロセスメモリへコピーするため、オーバーヘッドが発生します。もしくは、ストリームがバッファリングされている場合、最初に4バイトを読み込むとおそらく1ページのコピーが作成され、そのコピーが後にread関数による実際のコピーに上乗せされるため、メモリマッピング版にはないオーバーヘッドが発生します。
このため、性能面ではメモリマッピング版の使用が望ましいです。結局、ディスク上のデータにアクセスする際にはFileStreamは明らかな選択肢であり、その使い方も非常に良くドキュメント化されています。例えば、浮動小数点数の配列を読み込むには、FileStream、BinaryReaderが必要です。FileStreamの位置をデータの存在するオフセットに設定し、Int32を読み取ってサイズを得た後、浮動小数点数の配列を割り当て、MemoryMarshal.Castでバイトのspanに変換し、読み込みのためのバイトのspanを受け取るFileStream.Readのオーバーロードに渡します。そして、これもページキャッシュを利用します。ページがプロセスに関連付けられるのではなく、オペレーティングシステム自体が保持し、ディスクからページキャッシュへ、さらにページキャッシュからプロセスメモリへとコピーされるのです。
The FileStreamアプローチには、しかしながら大きな欠点が二つあります。第一に、このコードはマルチスレッド環境で安全に使えるものではありません。結局のところ、ある文で位置が設定され、その後の文でその位置が使用されるため、これらの読み込み操作の周りにロックが必要になるのです。メモリマップ版ではロックは不要で、実際にディスク上の複数の場所から並行してロードすることができます。SSDでは、これがキューの深さを増大させ、性能向上につながるため、通常は望ましいとされています。もう一つの問題は、FileStreamが二度の読み込みを行う必要があることです.
ストリーム内部で採用される戦略によっては、オペレーティングシステムを起こす必要がある二回のシステムコールが発生する可能性があります。まず、ストリーム自身のメモリからプロセスメモリへいくらかのデータがコピーされ、その後すべてをクリアしてプロセスに制御を返さなければなりません。これにはいくらかのオーバーヘッドが伴います。もう一つの可能な戦略は、FileStreamにバッファを用いる方法です。その場合、システムコールは一度だけ行われますが、オペレーティングシステムのメモリからFileStreamの内部バッファへコピーされ、さらに読み込み操作で内部バッファから浮動小数点数の配列へ再びコピーされることになります。つまり、メモリマップ版では発生しない無駄なコピーが生じるのです.
FileStreamは扱いやすい反面、いくつかの制限が存在します。そのため、代わりにメモリマップ版を使用すべきです。こうして、可能な限り多くのメモリを活用し、メモリが不足した場合にはデータセットの一部をディスクに退避させるシステムが完成しました。このプロセスは完全に透過的であり、オペレーティングシステムと協調して動作します。頻繁にアクセスされるデータ部分は常にメモリ上に保持されるため、最大限のパフォーマンスが実現されます.
しかし、最後に答えるべき疑問が一つ残ります。結局のところ、メモリマッピングを行う際には、ディスク全体をマッピングするのではなく、ディスク上のファイルをマッピングするのです。さて、問題は、いくつのファイルを割り当てるのか、ファイルの大きさはどの程度にするのか、そしてメモリの割り当てや解放を行う際に、それらのファイルをどのように循環させるのか、ということです.
一見の選択肢は、プログラム開始時に一つの大きなファイルをマッピングし、その上で動作し、使用されなくなった部分は上書きするというものです。しかし、これはあまりにも単純すぎるため、正しくありません.

この手法の第一の問題は、メモリページを上書きするためには、個別のアルゴリズムが必要であるという点です.
アルゴリズムは次の通りです。まず、ページを即座にメモリに読み込みます。次に、メモリ上でページの内容を変更します。オペレーティングシステムは、ステップ2でページ内のすべてを消去して置き換えることを予測できないため、変更されない部分がそのまま保持されるように、ページを再度ロードする必要があります。最後に、そのページを将来的にディスクへ書き戻すようスケジュールします.
さて、新しいファイル内の特定のページに初めて書き込む際、ロードすべきデータは存在しません。オペレーティングシステムはすべてのページがゼロであると認識しているため、ロードは無料です。単にゼロのページを取り出して使用するだけです。しかし、一度ページが変更され、メモリ上に存在しなくなると、オペレーティングシステムはそれをディスクから再ロードしなければなりません.

第二の問題は、ページキャッシュのページが最も最近使われていない順に追い出されるため、オペレーティングシステムは二度と使用されないメモリの不要な部分を削除すべきであることを認識していない点にあります。そのため、必要ないデータセットの一部がメモリに保持され、逆に必要な部分が排除される可能性があります。不要なセクションを無視するようにオペレーティングシステムに指示する方法はありません.
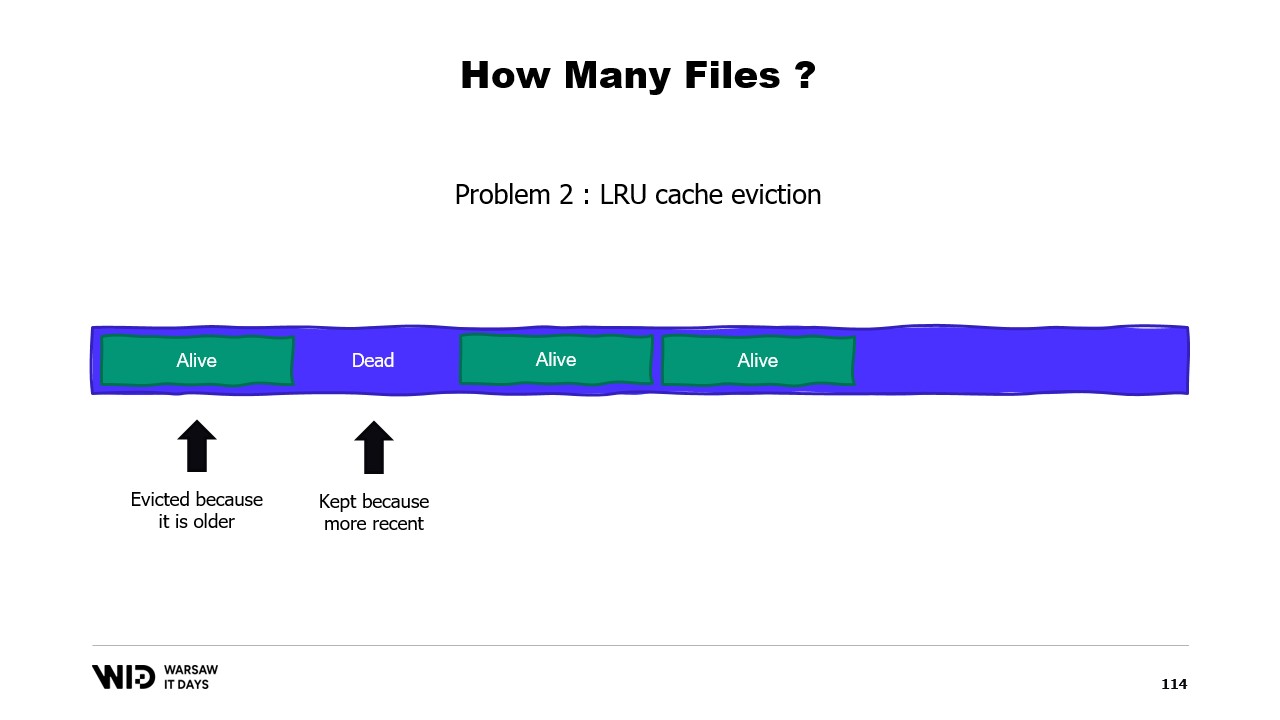
第三の問題は関連しており、データのディスクへの書き込みが常にメモリへの書き込みに遅れていることです。そして、もしページがもはや必要ないことがわかっていても、まだディスクに書き込まれていない場合、オペレーティングシステムにはその情報が伝わりません。結果として、二度と使用されないバイトを書き込むための時間が費やされ、全体の処理速度が低下してしまいます.
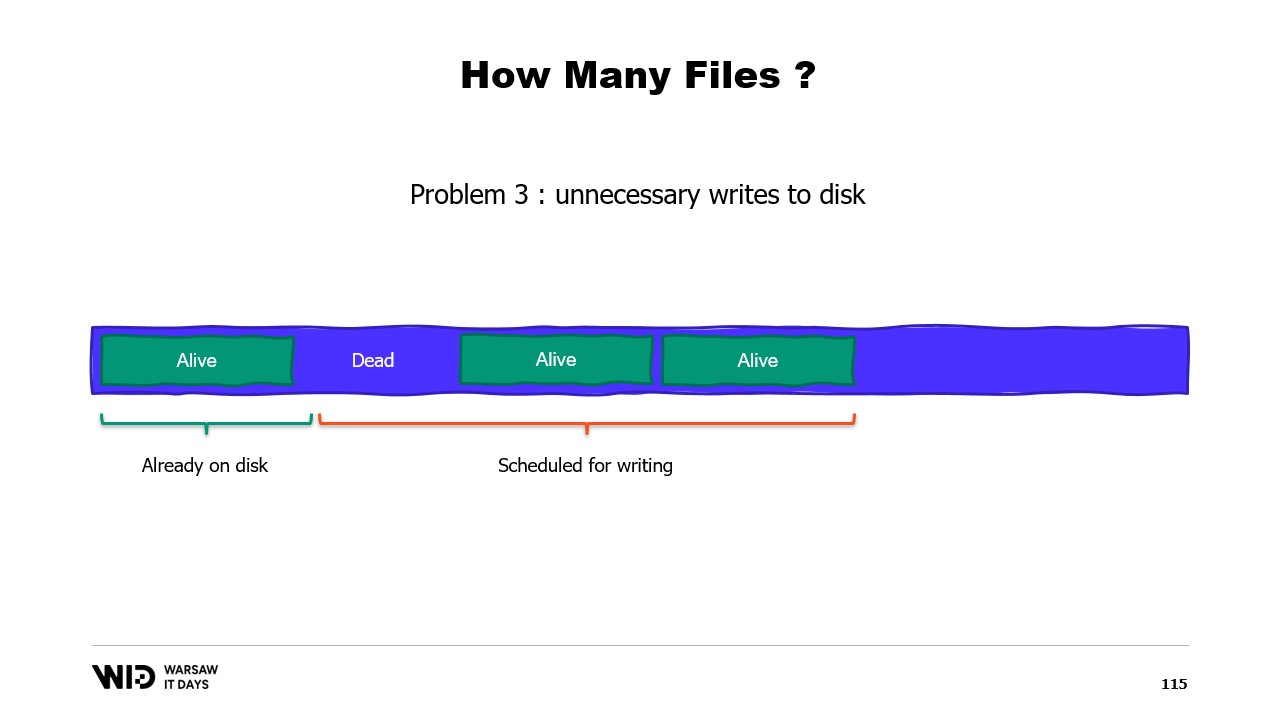
その代わりに、メモリは複数の大きなファイルに分割すべきです。同じメモリ領域に二度書き込むことはありません。これにより、すべての書き込みがオペレーティングシステムによってゼロであると認識されるページに対して行われ、ディスクからのロードを伴いません。また、ファイルは可能な限り速やかに削除されます。これにより、オペレーティングシステムに対して、それらがもはや不要であり、ページキャッシュから削除でき、既にディスクへ書かれていなければ書き込む必要がないことが伝えられます.

Lokadの実運用環境では、一般的な生産用VM上で、以下の設定でLokadスクラッチスペースを利用しています。各ファイルは16ギガバイトのサイズで、各ディスクには100ファイル、そして各L32VMには4つのディスクが搭載されています。合計すると、各VMに対して6テラバイト以上のスピルスペースが確保されていることになります.

本日はこれで終了です。ご質問やご意見がございましたら、お気軽にお知らせください。また、ご視聴いただきありがとうございました.


