00:00:08 Введение и предыстория Роба Хайндмана в прогнозировании.
00:01:31 Устойчивость реальных методов прогнозирования и программного обеспечения.
00:04:08 Применение методов прогнозирования в различных областях с обилием данных.
00:05:43 Проблемы удовлетворения потребностей различных отраслей в цепочке поставок.
00:07:30 Навигация по сложностям корпоративного программного обеспечения и сбора данных.
00:08:00 Прогнозирование временных рядов и альтернативные подходы.
00:09:05 Проблемы, с которыми сталкивается Lokad в предиктивной аналитике.
00:11:29 Долговечность и мотивация в разработке академического программного обеспечения.
00:13:12 Переход от точечного прогнозирования к вероятностному прогнозированию.
00:15:00 Недостатки академических методов и их применение в реальных условиях.
00:16:01 Производительность простой модели на соревнованиях.
00:16:56 Важность элегантных и сжатых методов.
00:18:48 Баланс точности, сложности и затрат в моделях.
00:19:25 Надежность и скорость в R-пакетах для прогнозирования.
00:20:31 Баланс между надежностью, точностью и затратами на внедрение в бизнесе.
00:21:35 Важность методов, специфичных для проблем прогнозирования.
00:23:00 Прогнозирование долговечности методов и библиотек прогнозирования.
00:25:29 Приверженность Роба поддержке его библиотек прогнозирования.
00:26:12 Представление Fable и его применение в прогнозировании временных рядов.
00:27:03 Признание вклада опенсорсного сообщества и его влияние на инструменты прогнозирования.
Резюме
В интервью с Кираном Чандлером, Жоанном Верморелем, основателем Lokad, и Робом Хайндманом, профессором статистики в Университете Монаша, обсуждается устойчивость реальных методов прогнозирования. Опенсорсное программное обеспечение для прогнозирования Роба Хайндмана, которое скачали миллионы пользователей, выдерживает испытание временем и способно решать около 90% проблем прогнозирования компаний. Гости подчеркивают проблемы обеспечения удовлетворения потребностей широкой аудитории с разными требованиями в индустрии цепей поставок и важность создания удобного для пользователя софта, который эффективен и доступен. Они также акцентируют внимание на значении опенсорсного программного обеспечения и сотрудничества в разработке высококачественных методов прогнозирования.
Расширенное резюме
В этом интервью Киран Чандлер обсуждает устойчивость реальных методов прогнозирования с Жоанном Верморелем, основателем Lokad, и Робом Хайндманом, профессором статистики в Университете Монаша. Опенсорсное программное обеспечение для прогнозирования Роба Хайндмана было скачано миллионами пользователей и выдерживает испытание временем, в отличие от многих других программных решений.
Верморель высоко оценивает работу Хайндмана за то, что он вышел за рамки типичного академического программного обеспечения, создав обширный набор библиотек, включающих многие его собственные результаты, и предоставил согласованную платформу, основанную на популярном языке R для статистического анализа. Верморель считает, что примеров научного софта, обладающего такой долговечностью и аудиторией, немного.
Академические исследования Хайндмана не ограничиваются прогнозированием для цепочек поставок; его интересует применение методов прогнозирования в любой области, где имеется большое количество данных. Его работа включает прогнозирование потребления электроэнергии, уровня смертности, численности населения, количества туристов и, недавно, случаев COVID-19 для австралийского правительства. Помимо прогнозирования, он также занимается обнаружением аномалий и исследовательским анализом данных.
Обсуждая проблемы удовлетворения потребностей широкой аудитории с разными требованиями в цепочке поставок, Верморель объясняет, что способ восприятия и записи данных корпоративным программным обеспечением (ERP, MRP, WMS) часто носит полуслучайный характер.
Они обсуждают сложности, возникающие при использовании данных, которые изначально не собирались для целей прогнозирования, а также переход от одной системы планирования ресурсов предприятия (ERP) к другой. Они также обсуждают необходимость методов прогнозирования, способных адаптироваться к различным ИТ-инфраструктурам и историческим особенностям внедрения корпоративного ПО.
Верморель подчеркивает важность прогнозов в контекстах, где неприменим анализ временных рядов, например, в модной индустрии, где прогнозированию влияют инженерия спроса и введение новых продуктов. Он акцентирует необходимость учета обратных связей и предпринимаемых на основе прогнозов действий в предиктивных моделях, а также контроля различных факторов, таких как ассортимент продукта и стратегии продвижения. Такой многогранный подход имеет решающее значение для Lokad в решении сложных задач предиктивной аналитики.
Хайндман объясняет, что его программное обеспечение для анализа временных рядов способно решать около 90% проблем прогнозирования компаний, но оставшиеся 10% требуют иных подходов. Он также затрагивает проблему кратковременного академического ПО, объясняя это акцентом на публикации статей и отсутствием стимула для долгосрочной поддержки программ. Это приводит к недостаточному вниманию к сотрудничеству с практиками и обеспечению того, чтобы методы были хорошо документированы и долговечны.
Интервью подчеркивает проблемы и сложности оптимизации цепочек поставок и прогнозирования, включая необходимость гибких методов, важность учета контекстов, не связанных с анализом временных рядов, и влияние обратных связей и принятия решений на предиктивные модели. Кроме того, оно отмечает расхождение между академическими исследованиями и практическим применением в области прогнозирования.
Оба гостя подчеркивают важность создания удобного для пользователя программного обеспечения, которое является эффективным и доступным, чтобы изменить мир к лучшему.
Хайндман отмечает переход от точечного прогнозирования к вероятностному прогнозированию в академической литературе за последние 15 лет. Lokad была одной из первых компаний в области прогнозирования цепочек поставок, внедривших это изменение в свое программное обеспечение. Поскольку первоначальный софт Хайндмана был ориентирован на точечные прогнозы, его новые пакеты отдают приоритет вероятностным прогнозам.
Верморель указывает на скрытые недостатки во многих академических публикациях, такие как числовая нестабильность, чрезмерное время вычислений или сложная реализация. Он также подчеркивает важность баланса между точностью и простотой, поскольку чрезмерно сложные модели могут оказаться непрактичными или излишними. Верморель приводит пример с соревнования M5, где Lokad добилась высокой точности, используя сравнительно простую модель.
Хайндман соглашается, что балансировка затрат на разработку софта, вычислительные расходы и точность является необходимой. Оба гостя ценят лаконичные, элегантные методы прогнозирования с широкой применимостью, подобные тем, что используются в библиотеках Хайндмана.
Беседа поднимает вопросы о компромиссах между точностью и сложностью в моделях прогнозирования. Верморель ставит под сомнение целесообразность стремления к незначительному улучшению точности за счет значительно большей сложности, как это наблюдается в моделях глубокого обучения. И Верморель, и Хайндман подчеркивают важность сосредоточения на сущности хорошего прогноза, не забиваясь мелкими улучшениями, которые могут не оправдать дополнительной сложности.
Хайндман подчеркивает важность учета как точности, так и затрат на вычисления при разработке методов прогнозирования. Он объясняет надежность своих пакетов для прогнозирования их происхождением из консалтинговых проектов, где требовалась скорость, надежность и универсальность.
Верморель подчеркивает важность учета дополнительной ценности, которую метод прогнозирования приносит решаемой задаче. Он сопоставляет простые параметрические модели с более сложными методами, такими как градиентный бустинг, отмечая, что в некоторых случаях более простые модели могут быть достаточными. Верморель также обсуждает уникальные проблемы прогнозирования в таких отраслях, как модная индустрия и автомобильный рынок послепродажного обслуживания, где факторы замещения и совместимости играют значительную роль.
Участники интервью подчеркивают важность не отвлекаться на излишнюю сложность, так как она не всегда приводит к более высоким научным или точным результатам. Верморель прогнозирует, что фундаментальные методы прогнозирования временных рядов останутся актуальными через 20 лет, в то время как сложные методы, зависящие от современного оборудования, могут устареть.
Роб Хайндман рассказывает о своей работе в области прогнозирования, особенно о разработке опенсорсного пакета программ «Fable», который упрощает процесс прогнозирования для тысяч временных рядов одновременно. Он подчеркивает свою приверженность поддержке пакета минимум на 10 лет и отмечает преимущества опенсорсного софта, включая сотрудничество и доступность.
Оба Верморель и Хайндман подчеркивают важность опенсорсного программного обеспечения в своей работе и потенциал сотрудничества в разработке высококачественных методов прогнозирования. Хайндман также упоминает свою приверженность поддержке публичных библиотек, существующих с 2005 года, и роль, которую они играют в обеспечении доступности анализа данных для широкой публики.
В целом, интервью подчеркивает проблемы прогнозирования в сложном и быстро меняющемся мире, а также важность программного обеспечения и сотрудничества в разработке эффективных решений. Ориентация на опенсорсное ПО и доступность для общественности подчеркивает ценность предоставления анализа данных и прогнозирования более широкой аудитории.
Оба участника интервью высоко ценят опенсорсную природу своей работы, которая обеспечивает широкий доступ и возможность сотрудничества в разработке высококачественных методов прогнозирования.
Полная расшифровка
Kieran Chandler: Прогнозирование — это древняя практика, которая постоянно развивается, и поэтому многие программные продукты не выдерживают испытания временем. Один из тех, кто сумел изменить эту тенденцию — наш сегодняшний гость, Роб Хайндман, который разработал опенсорсный софт, скачанный миллионами пользователей. Поэтому сегодня мы обсудим с ним устойчивость реальных методов прогнозирования. Роб, большое спасибо, что присоединились к нам из Австралии. Я знаю, что у вас уже довольно поздно. Как всегда, мы начинаем с того, что узнаем немного о наших гостях, так что, возможно, вы могли бы начать с рассказа о себе.
Rob Hyndman: Спасибо, Киран, рад присоединиться. Да, здесь в Австралии 8 часов вечера, так что не слишком поздно. Я профессор статистики и заведующий кафедрой эконометрики и бизнес-статистики в Университете Монаша. Я работаю здесь уже 26 лет. Большую часть этого времени я также был главным редактором International Journal of Forecasting и директором Международного института прогнозистов с 2005 по 2018 год. Я академик; я пишу много статей, а также несколько книг, включая три о прогнозировании. Если я не занят этим, обычно играю в теннис.
Kieran Chandler: Отлично, я сам люблю немного поиграть в теннис летом. Возможно, однажды мы сможем сыграть вместе. Жоаннес, сегодня наша тема — устойчивость реальных методов прогнозирования и идея о программном обеспечении, которое является устойчивым и долговечным. Какова суть этой идеи?
Joannes Vermorel: Большинство программного обеспечения со временем устаревает по разным причинам. Когда речь идет о научном программном обеспечении, нужно учитывать, как оно создается. Обычно оно разрабатывается для поддержки публикации статьи, поэтому по сути является временным решением. Что мне показалось по-настоящему примечательным в работе профессора Хайндмана, так это то, что он вышел за рамки обычной академической практики, заключающейся в создании временного ПО, публикации статьи, затем завершении работы и переходе к следующей. Он на самом деле создал обширный набор библиотек, который не только включал многие его собственные результаты и результаты его коллег, но и предоставлял очень согласованную структуру, основанную на языке, ставшем чрезвычайно популярным — R, среде для статистического анализа. Это подтвердило свою ценность на протяжении нескольких десятилетий, и это действительно достижение. Большинство программного обеспечения, которое мы видим сегодня, устарело, и основную его часть составляют несколько фундаментов, возникших из Unix и более сложных вещей. Что касается data science, примеров того, что выдержало испытание временем, существует не так много, за исключением базовых строительных блоков для линейной алгебры и подобных областей.
Kieran Chandler: … анализ, но если задуматься, я могу назвать дюжину примеров программного обеспечения, которому удалось сохранить такую аудиторию и долговечность. Однако таких примеров не так много. Я считаю, что здесь есть нечто по-настоящему примечательное, выходящее за рамки типичных академических исследований. Роб, давайте поговорим немного подробнее о ваших академических исследованиях. Вы, очевидно, не ограничиваетесь только миром цепочек поставок, как мы здесь. Так в каких еще областях вы интересуетесь применением методов прогнозирования?
Rob Hyndman: Меня интересует всё, где можно получить огромное количество данных. Например, я делаю прогнозирование потребления электроэнергии, где есть масса действительно хороших данных, насчитывающих десятки лет. Я прогнозирую уровень смертности, численность населения, а в последнее время работаю с туристическими потоками, что является довольно сложной задачей во время пандемии. Я помогаю австралийскому правительству разобраться, как это работает. Ещё одна моя задача для австралийского правительства — прогнозирование случаев COVID-19. Это мой первый опыт в эпидемиологическом направлении, и мне пришлось изучить довольно много методов эпидемиологического моделирования и встроить их в ансамбли прогнозов. Это было интересно. По сути, если данных достаточно, мне интересно попытаться их смоделировать. Я также занимаюсь обнаружением аномалий и исследовательским анализом данных, когда имеется большой объём информации. Я работал со множеством компаний и государственных организаций, и если ко мне обращаются с проблемой, связанной с большим объёмом данных, мне интересно подумать о том, как сделать лучше прогнозирование, чем то, что происходит в настоящее время.
Kieran Chandler: Отлично, могу представить, что туристическая отрасль сейчас находится в весьма интересном состоянии. С точки зрения прогнозирования это настоящая аномалия. Йоханнес, наш фокус, безусловно, на логистической цепочке, но идея в том, что мы не ограничиваемся одной только отраслью. Мы работаем с очень широкой аудиторией, так что с какими вызовами вы сталкиваетесь, пытаясь удовлетворить потребности стольких разных людей с разными запросами?
Joannes Vermorel: Во-первых, это просто способ восприятия мира. У нас нет чего-то, что можно было бы сравнить с научной мерой, например, с уже установленной статистикой смертности или чего-то подобного. Есть корпоративное программное обеспечение, такое как ERP, MRP и WMS, которое генерирует или записывает данные почти случайным образом. Сбор данных не был целью внедрения всего этого ПО, поэтому в итоге у вас появляются записи, которые не были задуманы как инструменты для измерения во времени, на основе которых можно было бы делать прогнозы. Это почти случайный побочный эффект, что создаёт массу осложнений. Одна из проблем заключается в том, сможете ли вы, с точки зрения методов прогнозирования и целенаправленных исследований, создать нечто, что выдержит переход от одной ERP-системы к другой. Если вы меняете систему, которая и так очень запутана и случайна, вам приходится учитывать, как это повлияет на процесс прогнозирования.
Kieran Chandler: Так, следующая тема, которую я хотел бы обсудить — это различный IT-ландшафт и исторические случайности при внедрении различных инструментов корпоративного ПО. Если вам приходится полностью менять метод, очевидно, что вы не накапливаете набор знаний или техник. Одним из вызовов является: можно ли вообще что-то сделать в этой области? И с нашей точки зрения в Lokad, прогнозы, которые нас больше всего интересуют, обычно не являются естественными временными рядами. Что делать, если у вас есть проблема, которую неудобно оформить в виде временного ряда? Вам всё равно нужно что-то, похожее на прогноз, но представляемое очень по-разному. Роб, что ты думаешь насчёт использования альтернатив традиционным прогнозам по временным рядам?
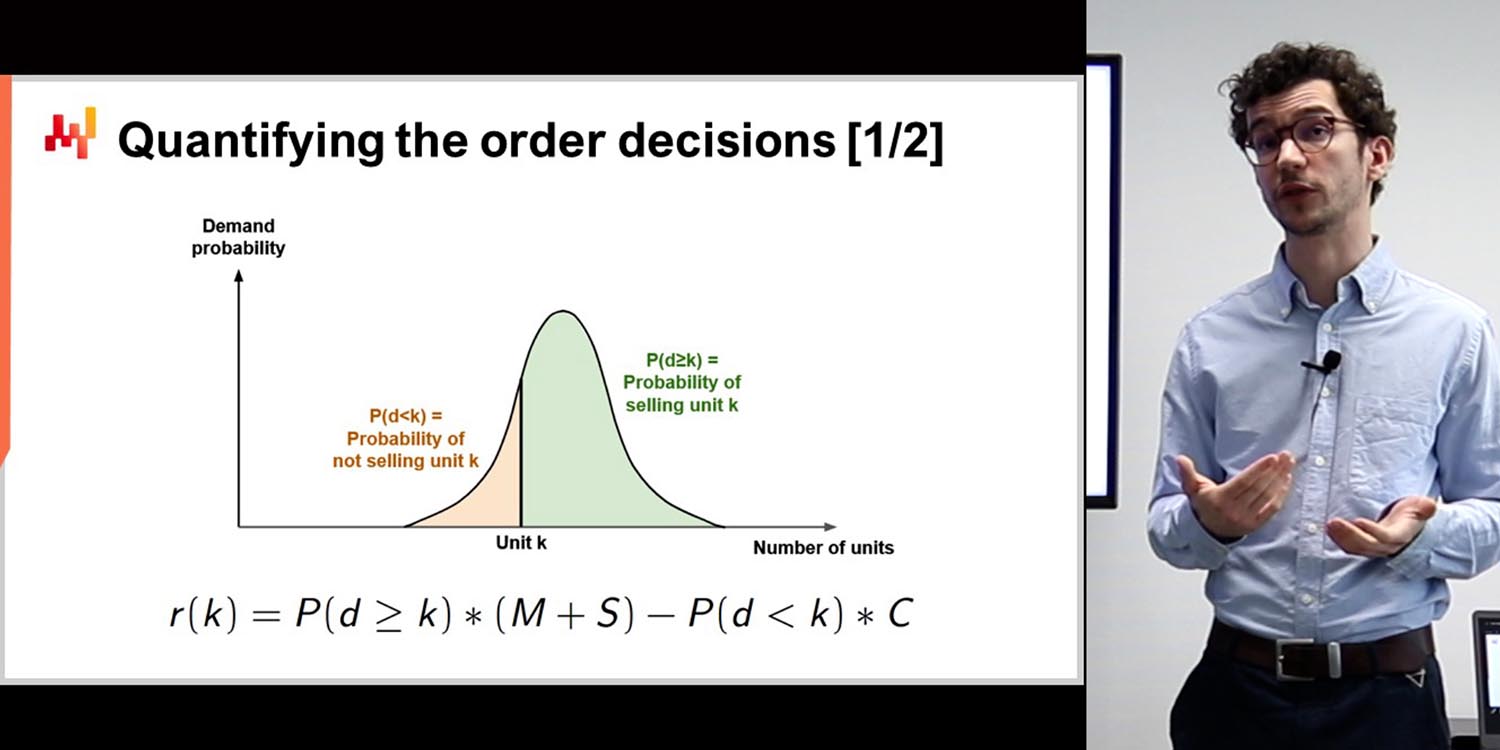
Rob Hyndman: Всё во многом зависит от данных, как сказал Йоханнес, чтобы определить, какую именно модель необходимо построить для решения данной задачи. Мое программное обеспечение для временных рядов решает множество проблем, но не все. У некоторых компаний набор данных организован или записывается таким образом, что приходится его модифицировать или искать другое решение. Программа, которую я написал и которая пользуется наибольшей популярностью, решает 90% задач прогнозирования в компаниях; а вот для оставшихся 10% приходится применять иные подходы.
Kieran Chandler: Как часто, по твоему опыту, встречается эта 10% ситуация, Йоханнес?
Joannes Vermorel: Это очень тонкая проблема. Мой собственный путь в мире прогнозирования в Lokad состоял в понимании глубины этой области. Сначала мы перешли от поэлементных прогнозов к вероятностным, что изменило наше восприятие задачи. Но это ещё глубже. Например, если взглянуть на моду, проблема в том, что вы хотите прогнозировать спрос, чтобы знать, что производить. Однако, когда вы решаете, что именно будете производить, у вас появляется возможность вводить больше или меньше продуктов. Так что сама идея о том, что у вас есть временные ряды, которые можно прогнозировать, зависит от ваших решений. В моде, например, тот факт, что вы добавляете еще один продукт в ассортимент, является частью вашей прогностической задачи. Вы хотите не только прогнозировать спрос, но и формировать его. В своём пути мы поняли, что существуют неустранимые неопределенности, которые дают нам взгляд, полностью ортогональный классическому поэлементному подходу к прогнозированию. Но нам также приходится иметь дело со всеми обратными связями.
Kieran Chandler: Так, Йоханнес, можешь рассказать, как прогностические модели влияют на оптимизацию цепочек поставок?
Joannes Vermorel: Когда мы делаем прогноз, мы принимаем решение, основанное на лучшей информации. Это оказывает глубокое влияние на то, как мы строим наши модели. Затем мы можем добавить дополнительные переменные, такие как регулирование ассортимента продуктов, ценовые категории, месседжинг и даже продвижение продуктов. Если продолжить на примере моды, вы прогнозируете количества, которые вам нужны, а затем решаете, что в магазинах некоторые товары будут представлены на постоянной основе, а другие — временно. Это сильно влияет на то, что вы будете наблюдать. Задача, с которой столкнулась Lokad в области предиктивной аналитики, заключалась в том, чтобы охватить проблему с разных сторон, что усложняет чисто временной подход.
Kieran Chandler: Ладно, Роб, давай теперь перейдём к обсуждению с академической точки зрения. Многие создают программное обеспечение исключительно для статьи, а затем оно практически выбрасывается. Почему, по-твоему, не хватает долговечности в некоторых из этих решений?
Rob Hyndman: Ну, нужно подумать о мотивации большинства академиков. Им платят за написание статей и преподавание. Как только статья написана, их могут немного подтолкнуть к выпуску программного обеспечения для её реализации. Но за это академики практически не получают вознаграждения, и уж тем более нет стимула поддерживать это ПО в течение длительного времени. Любой, кто этим занимается, делает это потому, что ему небезразлично или потому что это дело любви. Это вовсе не то, за что им платят. Это не их основное дело. Думаю, это проблема академического мира. Слишком сильно сосредоточены на создании новых методов и публикации, а недостаточно внимания уделяется связи с практиками, тщательной документации методов и созданию удобного в использовании ПО, которое существует долгосрочно. Это вопрос мотивации в академическом мире. Моя мотивация заключается в том, что когда я разрабатываю новую методологию, я хочу, чтобы люди её использовали. Я не хочу просто опубликовать статью, которую прочитают десяток людей или, если повезёт, 100. Я действительно хочу, чтобы мои методы имели значение в мире. Помимо того, за что мне платят, я делаю это, потому что получаю огромное удовлетворение, когда вижу, что мои методы используются на практике.
Joannes Vermorel: Прогностические модели стали сложнее, и сделать их надёжными не так-то просто. В Lokad нам приходится поддерживать много старого кода, чтобы наши модели функционировали. Проблема в том, что нельзя просто придумать шикарную модель и оставить её так. Нужно иметь возможность объяснить, что делает модель и почему она это делает. Необходимо обеспечить хорошую документацию модели, чтобы люди могли использовать её на практике. Это непростая задача, но она важна, если вы хотите, чтобы ваши модели принимались.
Rob Hyndman: Я также нахожу интересным, что по мере изменений во времени разрабатываются новые методы, и поэтому нужно предоставлять новое ПО или новые инструменты, учитывающие развитие прогнозирования. Один из методов, о котором сказал Йоханнес — переход от точечного прогнозирования к вероятностному, который произошёл в академической литературе за последние 15 лет, и Lokad очень быстро подхватил эту идею, представив вероятностные прогнозы. Думаю, мы были одними из первых компаний в сфере цепочек поставок, кто это сделал. Моё первоначальное ПО, хотя и генерировало вероятностные прогнозы, всегда делало акцент на точечных прогнозах,
Kieran Chandler: За последние несколько лет всё изменилось: сначала получаются вероятностные прогнозы, а точечные уже на втором плане.
Joannes Vermorel: Одной из моих критических замечаний в отношении многих академических публикаций является то, что в итоге в методах оказывается множество скрытых недостатков. У вас может быть метод, который, как вы знаете, покажет лучшие результаты на тестовой выборке, но когда вы пытаетесь внедрить его на практике, оказывается, что, например, он численно крайне нестабилен или время расчётов настолько велико, что даже на игрушечном наборе данных требуется несколько дней вычислений. А если использовать какой-либо реальный набор данных, это займет, возможно, годы вычислений.
И могут возникать всевозможные проблемы, например, метод оказывается чертовски сложным в реализации, и даже если теоретически его можно настроить правильно, на практике всегда будет какая-то глупая ошибка, которая помешает достичь результата. Или же метод может иметь невероятно тонкие зависимости от множества метапараметров, так что это становится чем-то вроде чёрного искусства, поскольку у вас есть около 20 туманных параметров, которые нужно подгонять способами, совершенно не задокументированными и обычно известными только исследователям, создавшим этот метод.
Rob Hyndman: Это очень интересно, потому что когда я смотрю на методы, выдерживающие испытание временем, многие классические методы, созданные, например, для Hyndman, показывают удивительно хорошие результаты по сравнению с очень сложными методами. Во время соревнования M5 в прошлом году Lokad заняла шестое место среди 909 команд по точности точечного прогноза. Но мы сделали это с помощью модели, которая была супер простой, почти как учебная параметрическая модель прогнозирования, и использовали небольшой трюк с ETS-моделированием на её основе, чтобы в принципе получить «эффект дробовика» и вероятностное распределение.
Но в общем и целом, это, вероятно, была модель, которую можно было бы описать на одной странице с несколькими коэффициентами для сезонности, дни недели, недели месяца, недели года, и всё. То есть, буквально, мы оказались всего на один процент уступающими самой точной модели, использующей градиентный бустинг деревьев, и я подозреваю, что с точки зрения сложности кода, сложности модели и общей непрозрачности, речь идёт о решении, которое в два, если не три раза, сложнее.
Joannes Vermorel: Это то, во что я верю в успехе ваших библиотек. Мне действительно нравится в этих методах то, что большинство из них имеет элегантную реализацию и лаконичны. Таким образом, с точки зрения применимости, в них есть нечто глубоко истинное и верное: вы получаете точность с минимальными затратами усилий и суеты, в отличие, я бы сказал, от подхода глубокого обучения. У меня нет ничего против глубокого обучения, когда речь идёт о решении невероятно сложных задач, например…
Kieran Chandler: Добро пожаловать в выпуск. Сегодня у нас в гостях Йоханнес Верморель, основатель Lokad, и Роб Хайндман, профессор статистики и заведующий кафедрой эконометрики и бизнес-статистики в Университете Монэш. Давайте обсудим машинный перевод и точность моделей.
Joannes Vermorel: Я ставлю под сомнение здравомыслие использования модели, которая на один процент точнее, но требует миллионов параметров и является невероятно сложной и непрозрачной. Действительно ли она лучше с научной точки зрения? Возможно, нас не должно отвлекать стремление набрать на один процент больше точности за счёт чего-то в 1000 раз более сложного. Существует опасность полностью заблудиться. Хорошая наука, особенно в прогнозировании, должна сосредотачиваться на сути того, что делает прогноз качественным, отбрасывая отвлекающие факторы, которые дают немного лишней точности, но, возможно, приводят к огромной путанице.
Rob Hyndman: Нужно уметь балансировать две стоимости: стоимость разработки программного обеспечения и вычислений, а также стоимость точности. В академическом мире акцент обычно делается на точности, не учитывая затраты на вычисления или разработку кода. Согласен с тобой, Йоханнес, что нужно учитывать оба аспекта. Иногда не стоит выбирать самый точный метод, если он занимает слишком много времени для поддержки кода и осуществления вычислений. Мои пакеты для прогнозирования надёжны, потому что они были разработаны в рамках консалтинговых проектов. Эти функции применялись в различных контекстах, так что им приходилось быть достаточно устойчивыми. Я не хотел, чтобы компании возвращались ко мне с жалобами, что что-то не работает или сломалось на их данных. То, что я занимался консалтингом, означает, что эти функции видели много данных до того, как их выпустили для широкой публики. Они также должны быть достаточно быстрыми, потому что большинство компаний не хотят ждать дни, пока какое-то вычисление MCMC произойдёт на сложной байесовской модели; им нужен прогноз в разумные сроки.
Kieran Chandler: Как ты балансируешь между надёжностью, точностью и затратами на внедрение модели с бизнес-позиции, Йоханнес?
Joannes Vermorel: Всё сводится к тому, что вы вносите в процесс. Например, если у нас есть суперпростая параметрическая модель, как та, что мы использовали для соревнования M5, и она обеспечивает точность на один процент уступающую очень сложному методу на основе градиентного бустинга деревьев, который победил, стоит ли усложнять систему? Победивший метод использовал градиентный бустинг деревьев с очень изощрённой схемой увеличения объёма данных, что по сути было способом значительно увеличить ваш набор данных.
Kieran Chandler: Это довольно объёмно, и в итоге у вас получается набор данных примерно в 20 раз больше. А затем вы применяете к нему супернагруженную и сложную модель. Так в чём же суть? Привносите ли вы по-настоящему нечто новое и существенное, и как вы это балансируете?
Joannes Vermorel: Способ, которым я уравновешиваю это, заключается в том, чтобы задуматься, не упускаю ли я “слона в комнате”, который действительно нужно принять во внимание. Например, если я говорю о моде, очевидно, что каннибализация и замена играют огромную роль. Люди не заходят в модный магазин, думая, что им нужен именно этот штрих-код. Это даже не самый правильный способ рассматривать проблему. Каннибализация и замена встречаются повсюду, и вам нужно нечто, что охватывает это видение. Если я говорю об автомобильной отрасли, например, и рассматриваю рынок послепродажных запчастей, проблема в том, что люди не покупают автозапчасти, потому что им нравятся автозапчасти. Они покупают автозапчасти, потому что у их транспортного средства возникла проблема, и они хотят её устранить, точка. Оказывается, существует суперсложная матрица совместимости между транспортными средствами и автозапчастями. В Европе у вас более 1 миллиона различных автозапчастей и более 100 000 различных транспортных средств. И, как правило, при любой возникшей проблеме существует около дюжины различных подходящих запчастей, значит, замена возможна, но в отличие от моды, это проявляется совершенно детерминированным образом. Замены почти идеально известны и структурированы, и вам нужен метод, который действительно использует тот факт, что неопределенности вообще нет.
Таким образом, решая проблему за проблемой, я стараюсь убедиться, что если мы хотим платить за дополнительную сложность, это действительно того стоит. Например, если я беру библиотеки профессора Хайндмана и сравниваю их, скажем, с TensorFlow, чтобы дать представление, для большинства ваших моделей речь идёт, вероятно, о килобайтах кода. Если мы посмотрим на TensorFlow, то одна скомпилированная только библиотека имеет размер 800 мегабайт, и как только вы добавляете TensorFlow версии один, вы почти подключаете миллиарды строк кода.
Иногда люди могут подумать, что мы спорим о чем-то, что является лишь вопросом оттенков серого, где нет правильного или неправильного ответа. Это всего лишь дело вкуса — можно сделать всё чуть проще или чуть сложнее. Но реальность того, что я наблюдал, такова, что обычно речь идёт не просто об оттенках серого. Мы говорим о методах с рядом порядков разницы в сложности. И поэтому, если я хочу создать свой собственный прогноз, например, каковы шансы, что библиотеки профессора Хайндмана будут востребованы через 20 лет, и каковы шансы, что TensorFlow версии один всё ещё будет существовать через 20 лет? Я бы поставил немалые деньги на то, что фундаментальные методы анализа временных рядов останутся актуальными.
Kieran Chandler: Считаете ли вы, что метод прогнозирования будет актуален через 20 лет?
Joannes Vermorel: Вещи, содержащие буквально миллиарды строк случайной сложности, связанные со спецификой графических карт, произведённых за последние пять лет, исчезнут. Я не отрицаю, что в области глубокого обучения произошли поистине ошеломляющие прорывы. Но я говорю, что нам действительно нужно понять добавленную ценность, которая существенно варьируется в зависимости от решаемых проблем. Мы не должны отвлекаться на изысканность. То, что что-то выглядит изысканным, не означает, что оно по своей сути более научно обосновано, точно или корректно. Это может быть более впечатляюще и напоминать TED talk, но с этим нужно быть очень осторожными.
Kieran Chandler: Роб, я оставлю тебе последний вопрос. Относительно того, о чём говорил Joannes, о том, что вещи будут существовать ещё через 10–20 лет, можешь ли ты представить, что твои библиотеки всё ещё будут актуальны? Над чем ты работаешь сегодня, что, по твоему мнению, будет полезно в ближайшие годы?
Rob Hyndman: Моя первая публичная библиотека появилась около 2005 года, так что они уже существуют 15 лет. Я определённо привержен поддержке всех них, даже тех, которые, на мой взгляд, были заменены другими. Это не требует огромных усилий. Новейшие пакеты, над которыми я работаю, — это пакет под названием Fable, который реализует большинство тех же техник, но по-другому, чтобы пользователям было проще прогнозировать одновременно тысячи временных рядов. Fable и несколько сопутствующих пакетов существуют уже пару лет, и мой самый новый учебник использует их. Я ожидаю, что они будут широко использоваться как минимум в течение 10 лет, и пока я в состоянии, я буду их поддерживать и обеспечивать их актуальность. Мне повезло, что у меня есть очень хороший ассистент, который помогает мне с поддержкой пакетов. Он также предан идеалам открытого программного обеспечения и созданию качественного ПО в рамках open-source разработки.
Kieran Chandler: Это здорово, и мир открытого программного обеспечения позволяет каждому иметь к нему доступ. Большое спасибо вам обоим за ваше время. Придётся на этом остановиться, и спасибо, что присоединились. Увидимся в следующем эпизоде.