00:00:08 Introduction and Rob Hyndman’s background in forecasting.
00:01:31 Sustainability of real-world forecasting techniques and software.
00:04:08 Applying forecasting techniques in various fields with abundant data.
00:05:43 Challenges of catering to various industries in the supply chain.
00:07:30 Navigating the complexities of enterprise software and data collection.
00:08:00 Time series forecasting and alternative approaches.
00:09:05 Challenges faced by Lokad in predictive analytics.
00:11:29 Longevity and motivation in academic software development.
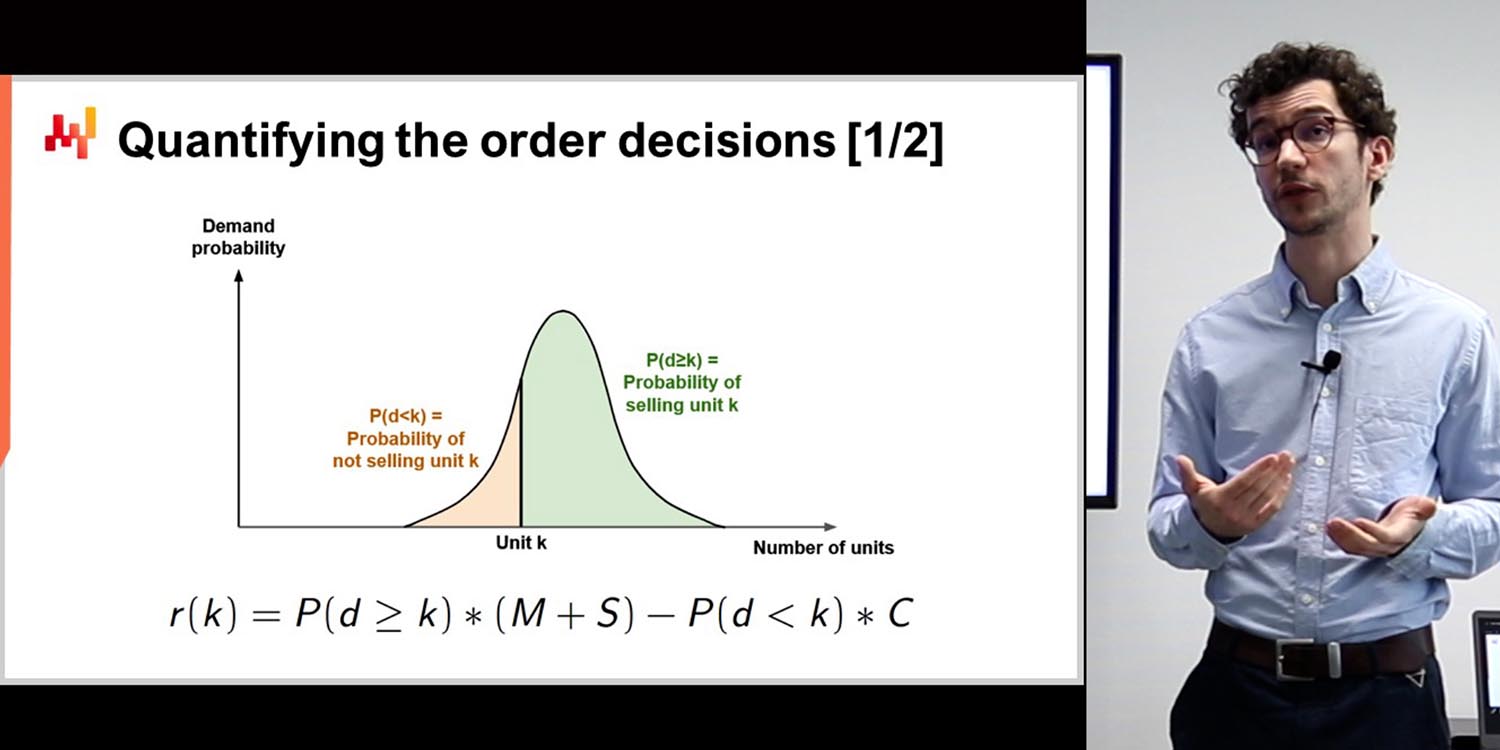
00:13:12 Shift from point forecasting to probabilistic forecasting.
00:15:00 Flaws in academic methods and their real-world implementation.
00:16:01 Simple model’s performance in a competition.
00:16:56 The importance of elegant and concise methods.
00:18:48 Balancing accuracy, complexity, and cost in models.
00:19:25 Robustness and speed in R packages for forecasting.
00:20:31 Balancing robustness, accuracy, and implementation costs in business.
00:21:35 Importance of problem-specific methods in forecasting.
00:23:00 Predicting the longevity of forecasting techniques and libraries.
00:25:29 Rob’s commitment to maintaining his forecasting libraries.
00:26:12 Introduction of Fable and its application in time series forecasting.
00:27:03 Appreciating the open-source world and its impact on forecasting tools.
Summary
In an interview with Kieran Chandler, Joannes Vermorel, founder of Lokad, and Rob Hyndman, Professor of Statistics at Monash University, discuss the sustainability of real-world forecasting techniques. Hyndman’s open-source forecasting software, which has been downloaded by millions of users, stands the test of time and is capable of solving around 90% of companies’ forecasting problems. The guests highlight the challenges of catering to a wide audience with diverse needs in the supply chain industry and the importance of creating user-friendly software that is effective and accessible. They also stress the significance of open-source software and collaboration in developing high-quality forecasting methods.
Extended Summary
In this interview, Kieran Chandler discusses the sustainability of real-world forecasting techniques with Joannes Vermorel, founder of Lokad, and Rob Hyndman, Professor of Statistics at Monash University. Hyndman’s open-source forecasting software has been downloaded by millions of users and stands the test of time, unlike many other software tools.
Vermorel appreciates Hyndman’s work for going beyond typical academic software by creating a comprehensive set of libraries, embedding many of his own results and providing a consistent framework based on the popular R language for statistical analysis. Vermorel believes there are few examples of scientific software that has had such durability and audience.
Hyndman’s academic research is not limited to supply chain forecasting; he’s interested in applying forecasting techniques to any area with large amounts of data. His work includes forecasting electricity consumption, mortality rates, population, tourist numbers, and recently, COVID-19 cases for the Australian government. In addition to forecasting, he also works on anomaly detection and exploratory data analysis.
Discussing the challenges of catering to a wide audience with diverse needs in the supply chain industry, Vermorel explains that the way data is perceived and recorded by enterprise software (ERPs, MRPs, WMS) is often semi-accidental.
They address the complications arising from using data that is not primarily collected for forecasting purposes and the transition from one enterprise resource planning (ERP) system to another. They also discuss the need for forecasting techniques that can adapt to different IT landscapes and historical accidents in enterprise software deployment.
Vermorel highlights the importance of forecasts in contexts that do not lend themselves to time series analysis, such as fashion, where demand engineering and the introduction of new products influence the forecasting problem. He emphasizes the need for predictive models to account for feedback loops and actions taken based on forecasts, as well as controlling various factors like product assortment and promotion strategies. This multifaceted approach is vital for Lokad to address the complex predictive analytics challenges they face.
Hyndman explains that his time series software is capable of solving around 90% of companies’ forecasting problems, but the remaining 10% require different approaches. He also addresses the issue of short-lived academic software, attributing it to the focus on publishing papers and the lack of reward for maintaining software long-term. This results in a lack of focus on collaboration with practitioners and ensuring that methods are well-documented and have longevity.
The interview highlights the challenges and complexities of supply chain optimization and forecasting, including the need for adaptable techniques, the importance of considering non-time series contexts, and the influence of feedback loops and decision-making on predictive models. Additionally, it underscores the disconnect between academic research and practical application in the field of forecasting.
Both guests emphasize the importance of creating user-friendly software that is both effective and accessible to make a difference in the world.
Hyndman mentions the shift from point forecasting to probabilistic forecasting in academic literature over the past 15 years. Lokad was one of the first supply chain forecasting companies to incorporate this change into their software. As Hyndman’s initial software focused on point forecasts, his newer packages prioritize probabilistic forecasts.
Vermorel points out the hidden flaws in many academic publications, such as numerical instability, excessive computational time, or complex implementation. He also highlights the importance of balancing accuracy with simplicity, as overly complicated models may not be practical or necessary. Vermorel provides an example from the M5 competition, where Lokad achieved high accuracy using a relatively simple model.
Hyndman agrees that balancing the costs of producing software, computation, and accuracy is essential. Both guests appreciate concise, elegant forecasting methods with broad applicability, such as those in Hyndman’s libraries.
The conversation raises questions about the trade-offs between accuracy and complexity in forecasting models. Vermorel challenges the wisdom of pursuing a slight improvement in accuracy at the expense of much higher complexity, as seen in deep learning models. Both Vermorel and Hyndman emphasize the importance of focusing on the essence of good forecasts without getting lost in minute improvements that may not justify the added complexity.
Hyndman emphasizes the importance of considering both accuracy and the cost of computation when developing forecasting methods. He attributes the robustness of his forecasting packages to their origins in consulting projects, where they needed to be fast, reliable, and applicable to various contexts.
Vermorel highlights the importance of considering the added value a forecasting method brings to a problem. He contrasts simple parametric models with more complex methods like gradient boosting trees, noting that in some cases, simpler models may be sufficient. Vermorel also discusses the unique challenges of forecasting in industries like fashion and automotive aftermarket, where substitution and compatibility factors play significant roles.
The interviewees emphasize the importance of not being distracted by sophistication, as it doesn’t necessarily equate to better scientific or accurate results. Vermorel predicts that fundamental time series forecasting techniques will still be relevant in 20 years, while complex methods relying on current hardware may become obsolete.
Rob Hyndman discusses his work on forecasting, particularly his development of the open-source software package “Fable,” which simplifies the forecasting process for thousands of time series simultaneously. He emphasizes his commitment to maintaining the package for at least 10 years and highlights the benefits of open-source software, including collaboration and accessibility.
Both Vermorel and Hyndman stress the importance of open-source software in their work and the potential for collaboration in developing high-quality forecasting methods. Hyndman also mentions his dedication to maintaining public libraries, which have been around since 2005, and the role they play in making data analysis accessible to the public.
Overall, the interview highlights the challenges of forecasting in a complex and rapidly changing world and the importance of software and collaboration in developing effective solutions. The focus on open-source software and public access underscores the value of making data analysis and forecasting available to a wider audience.
Both interviewees appreciate the open-source nature of their work, which allows widespread access and collaboration in developing high-quality forecasting methods.
Full Transcript
Kieran Chandler: Forecasting is an ancient practice which is constantly evolving, and as such, many pieces of software fail to stand the test of time. One person who has bucked this trend is our guest today, Rob Hyndman, who has implemented open source software which has been downloaded by millions of users. As such, today we’re going to discuss with him the sustainability of real-world forecasting techniques. So, Rob, thanks very much for joining us live from Australia. I know it’s a bit late in the day at your end. As always, we like to start off by learning a bit about our guests, so perhaps you could just start off by telling us a bit about yourself.
Rob Hyndman: Thanks, Kieran, and lovely to join you. Yeah, it’s 8 in the evening here in Australia, so not so late. I’m Professor of Statistics and Head of the Department of Econometrics and Business Statistics at Monash University. I’ve been there for 26 years. For most of that period, I was also Editor-in-Chief of the International Journal of Forecasting and a Director of the International Institute of Forecasters, from 2005 to 2018. I’m an academic; I write lots of papers, and I’ve written a few books, including three on forecasting. If I’m not doing that, I’m usually playing tennis.
Kieran Chandler: Nice, I enjoy a bit of tennis myself in the summer months. Maybe one day we can see you for a game. Joannes, today our topic is the sustainability of real-world forecasting techniques and the idea of a piece of software being sustainable and lasting a long period of time. What’s the idea behind that?
Joannes Vermorel: Most software tends to decay over time for various reasons. When it comes to scientific software, you have to think about how this software is produced. Usually, it’s created to support the publication of a paper, so it’s essentially throwaway software. What I found quite remarkable in Professor Hyndman’s work is that he went beyond what is usually done in academic circles, which is to produce throwaway software, publish the paper, get done, and move on to the next paper. He actually built a vast set of libraries that not only embedded many of his own results and many results of his peers but also provided a very consistent framework based on a language that became very popular, which is R, an environment for statistical analysis. This has proved its value over several decades, and that’s quite an achievement. Most of the software that we see today is old, with very few foundations emerging from Unix and more sophisticated things. In terms of data science, there are not that many examples of things that stand the test of time, aside from basic building blocks for linear algebra and similar fields.
Kieran Chandler: … analysis, but when you really think about it, I could probably come up with a dozen examples of software that managed to have such an audience and durability. However, there are not that many, actually. I believe that there is something quite remarkable here that goes beyond what is usually done in academic research. Rob, let’s talk a little bit more about your academic research then. You’re obviously not focused just on the world of supply chain like we are at this end. So, what other kind of areas are you interested in applying forecasting techniques for?
Rob Hyndman: I’m interested in anything where I can get a lot of data. I do forecasting around electricity consumption, for example, where there’s lots of really good data going back decades. I forecast mortality rates, population, and lately, I’ve been working on tourist numbers, which is a pretty difficult thing to forecast in the middle of a pandemic. I’ve been helping the Australian government think through how that works. Another job I’m doing for the Australian government is forecasting COVID-19 cases. It’s my first effort to do anything in the epidemiological world, and I’ve had to learn quite a bit of the epidemiological approach to modeling and build that into some forecasting ensembles. That’s been interesting. Essentially, if there’s plenty of data, I’m interested in trying to model it. I also do things like anomaly detection and exploratory data analysis where there are large collections of data. I’ve worked with a lot of companies and government organizations, and if they come to me with a problem that involves quite a lot of data, I’m interested in thinking about how to do better forecasting than what’s currently happening.
Kieran Chandler: Great, I can imagine the tourist industry is one that’s pretty interesting at the minute. It’s a real anomaly from a forecasting perspective. Johannes, our focus is obviously on the supply chain industry, but the idea is that we’re not focused on just one industry within that. We cater to a very wide audience, so what kind of challenges can you come across when you’re trying to cater for so many different people with so many different needs?
Joannes Vermorel: First, it’s just the way we perceive the world. We do not have something that would be akin to a scientific measurement, such as statistics established for mortalities or other things. What you have is enterprise software, like ERPs, MRPs, and WMS, which produce or record data almost in a semi-accidental manner. Collecting data was not the reason why all those software were put in place, so you end up with records, but those were not designed as tools to perform measurements over time that you could forecast. It is a nearly accidental byproduct, and that creates tons of complications. One of the challenges that you have is whether you can do, in terms of forecasting techniques and focused research, something that survives going from one ERP to the next. If you change the system, which is very messy and accidental, you have to consider how that will affect the forecasting process.
Kieran Chandler: So, the next topic I’d like to discuss is the different IT landscape and historical accidents in terms of deployment of various enterprise software tools. If you have to completely change the method, it’s obviously not building up any set of knowledge or techniques. One of the challenges is, can you do anything in this area? And from our perspective at Lokad, the sort of forecasts that are of most interest to us are typically things that do not present themselves naturally as time series. What if you have a problem that does not lend itself to be framed conveniently as a time series? You still need something that is akin to a forecast, but it presents itself in very different ways. Rob, what are your thoughts on using alternatives to time series forecasts?
Rob Hyndman: Well, it very much depends on the data, as Joannes said, to determine what sort of model is going to be necessary to build for that particular problem. My time series software handles many problems but not all of them. Some companies will have a dataset set up in such a way, or recorded in such a way, that they’ll have to modify it or come up with a different solution. The software that I’ve written that’s most popular solves 90% of companies’ forecasting problems; it’s the other 10% that you’ve got to do different things with.
Kieran Chandler: How often would you say that there’s that kind of 10% in your experience, Joannes?
Joannes Vermorel: It’s a very subtle problem. My own journey through the world of forecasting at Lokad was realizing how much depth there is. First, we went from pointwise forecasts to probabilistic forecasts, which changed the way we look at the problem. But it’s even more profound than that. For example, if we look at fashion, the problem is that you want to forecast demand so that you know what to produce. However, when you decide what you’re about to produce, you have the flexibility to introduce more or fewer products. So, the very idea that you have time series that you could forecast depends on your decisions. In fashion, for example, the fact that you introduce one more product in your assortment is part of your predictive problem. You want not only to forecast the demand but also to engineer the demand. On our journey, we realized that we had irreducible uncertainties that give us one angle that is fully orthogonal to the classic pointwise forecasting perspective. But we also have to deal with all the feedback loops.
Kieran Chandler: So, Joannes, can you tell us how predictive models impact supply chain optimization?
Joannes Vermorel: When we make a forecast, we take an action that is better informed. That has a profound influence on the way we want to build our predictive models. Then we can add more variables, such as controlling the degree of products, price points, message, and even promotion of products. If I continue on the example of fashion, you predict the quantities that you want to have and then decide that in your stores, some products will be put much more permanently than others. That has a profound impact on what you’re going to observe. The challenge that Lokad has faced in terms of predictive analytics was to be able to embrace problems looking at the numerous angles that present themselves that complicates the pure time series perspective.
Kieran Chandler: Okay, Rob, let’s maybe move things now to talk things from an academic point of view. Lots of people create pieces of software purely for a paper and then it’s almost kind of thrown away. Why do you think there’s not enough kind of longevity in some of the pieces of software that people are creating?
Rob Hyndman: Well, you have to think about the motivation of most academics. They’re paid to write papers and to teach classes. Once the paper’s written, there might be some encouragement to put out some software to implement it. But there’s no real reward for most academics in doing that, and there’s certainly no reward in maintaining that software over a long period of time. Anyone who does it does it because they care or that it’s a labor of love. It’s not really what they’re paid to do. It’s not their core business. I think that’s a problem actually in the academic world. There’s so much focus on getting new methods out and getting them published and not enough focus on the liaison with the practitioner community and making sure your methods are well-documented and have user-friendly software that’s available long-term. It’s a problem of motivation in the academic world. My motivation is that when I develop a new methodology, I want people to use it. I don’t want to just publish a paper and have it read by a dozen people or maybe 100 people, if I’m lucky. I actually want my methods to make a difference in the world. Quite apart from what I’m paid to do, that’s what I do because I get a lot of satisfaction out of seeing my methods actually used in practice.
Joannes Vermorel: Predictive models have become more complicated, and it’s not easy to make them robust. At Lokad, we have to maintain a lot of old code to keep our models running. The challenge is that you can’t just come up with a fancy model and leave it at that. You need to have a way to explain what the model does and why it does it. You need to make sure that the model is well-documented, and that people can use it in practice. That’s not an easy thing to do, but it’s important if you want your models to be adopted.
Rob Hyndman: I think it’s also interesting that as things have changed over time, new methods get developed, and so you need to provide new software or new tools that take into account the developments in forecasting. One that Joannes mentioned is the move from point forecasting to probabilistic forecasting, which happened in the academic literature in the last 15 years maybe, and Lokad was very quick at picking that up and putting out probabilistic forecasts. I think probably one of the first supply chain forecasting companies in the world to do that. My initial software, although it did produce probabilistic forecasts, the emphasis was always on the point forecasts,
Kieran Chandler: Developing over the last few years, the emphasis is the other way around. They get probabilistic forecasts first and point forecasts second.
Joannes Vermorel: One of my own critiques with many academic publications is that usually, you end up with tons of hidden flaws in the methods. So you have a method that you know will outperform on the benchmark, but when you want to put that in an actual implementation, you will see that, for example, it’s numerically super unstable or that the compute times are ridiculously long to the point that if you use a toy dataset, it will already take days of computation. And if you want to have any kind of real-world dataset, that would be counting like years of compute.
And you can have all sorts of problems, such as the method being devilishly complicated to implement and thus, even if in theory you can get it right, in practice you will always have some stupid bug that will prevent you from achieving anything. Or maybe the method can have incredibly subtle dependencies on a long series of meta-parameters, so it’s a bit like a dark art to make it work because you have like 20 obscure parameters that you need to tweak in ways that are completely undocumented and usually only in the mind of the researchers that produced the method.
Rob Hyndman: That’s very interesting because when I look at methods that stand up to the test of time, many super classic methods that you did produce for Hyndman, for example, are giving surprisingly good results against very sophisticated methods. During the M5 competition last year, Lokad landed number six among 909 teams in terms of forecasting accuracy for the point forecast. But we did that with a model that was super simple, almost the textbook parametric forecasting model, and we used a tiny trick of ETS modeling on top of that to basically get the shotgun effect and the probabilistic distribution.
But all in all, it was probably a model that we could have summarized on one page with a few coefficients for the seasonalities, day of the week, week of the month, week of the year, and that was it. So, literally, we came up one percent away from the most accurate model that was using gradient boosted trees, and I suspect that in terms of code complexity, model complexity, and overall opacity, we are talking about something that is like two orders of magnitude, if not three, more complex.
Joannes Vermorel: That’s something that I believe in the success of your libraries. What I really like about the methods is that most of them have an elegant implementation and they’re concise. So, indeed, in terms of applicability, there is something that is profoundly true and valid about it, where you get the accuracy with the minimum amount of effort and fuss as opposed to, I would say, on the other side of the camp, the deep learning camp. I have nothing against deep learning when you want to tackle incredibly tough problems like, let’s say, for example…
Kieran Chandler: Welcome to the episode. Today, we have Joannes Vermorel, the founder of Lokad, and Rob Hyndman, Professor of Statistics and Head of the Department of Econometrics and Business Statistics at Monash University. Let’s discuss machine translation and model accuracy.
Joannes Vermorel: I challenge the wisdom of having a model that is one percent more accurate, but takes millions of parameters, and is incredibly complex and opaque. Is it truly better from a scientific perspective? Maybe we shouldn’t be distracted by achieving one percent more accuracy at the expense of something 1000 times more complex. There is a danger of getting completely lost. Good science, especially in forecasting, should focus on the essence of what makes a good forecast, putting aside distractions that bring a tiny bit of extra accuracy but maybe at the expense of a great deal of extra confusion.
Rob Hyndman: You have to balance the two costs: the cost of producing the software and doing the actual computation, and the cost of accuracy. In the academic world, the focus is usually on accuracy without considering the cost of computation or code development. I agree with you, Joannes, that we need to take both into account. Sometimes you don’t necessarily want the most accurate method if it’s going to take too much time to both maintain the code and to do the computation. My forecasting packages are robust because they were developed through consulting projects. These functions were applied in various contexts, so they had to be relatively robust. I didn’t want companies coming back to me saying it’s broken or it doesn’t work on their dataset. The fact that I’ve done a lot of consulting means that those functions have seen a lot of data before being released to the general public. They also have to be relatively fast because most companies don’t want to wait days for some MCMC computation to happen on a fancy Bayesian model; they want the forecast in a reasonable amount of time.
Kieran Chandler: How do you balance robustness, accuracy, and the cost of implementing the model from a business perspective, Joannes?
Joannes Vermorel: It really boils down to what you’re adding to the table. For example, if we have a super simplistic parametric model like the one we used for the M5 competition and we get to one percent of the accuracy of a very fancy gradient booster tree method, which was the winner, is it worth the added complexity? The winning method used gradient booster trees with a very fancy data augmentation scheme, which was basically a way to vastly inflate your dataset.
Kieran Chandler: That is quite large and now you end up with a data set that is like 20 times larger. And then you apply a super heavy and complex model on top of that. So the question is, are you bringing something fundamentally new and profound to the table? And how do you balance that?
Joannes Vermorel: The way I balance that is by thinking if I am missing an elephant in the room that I really need to take into account. For example, if I talk about fashion, obviously cannibalization and substitution are super strong. People don’t walk into a fashion store thinking they want this exact barcode. That’s not even the proper way to think about the problem. Cannibalization and substitution are all over the place, and you need something that embraces that vision. If I go for automotive, for example, and I look at automotive aftermarkets, the problem is people don’t buy car parts because they like car parts. They buy car parts because their vehicle has a problem, and they want to repair it, end of the story. It turns out that you have a super complex compatibility matrix between vehicles and car parts. In Europe, you have over 1 million distinct car parts and over 100,000 distinct vehicles. And usually, for any problem that you have, there is like a dozen different compatible car parts, so you have substitution, but unlike fashion, it presents itself in a completely deterministic fashion. The substitutions are almost perfectly known and perfectly structured, and you want to have a method that really takes advantage of the fact that there is zero uncertainty about that.
So, problem by problem, the way I balance that is by making sure that if we want to pay for extra sophistication, it’s really worth it. For example, if I take the libraries of Professor Hyndman versus, let’s say, TensorFlow, just to give an idea, for most of your models, we are talking about probably kilobytes of code. If we look at TensorFlow, just one library compiled is 800 megabytes large, and as soon as you include TensorFlow version one, you’re almost including billions of lines of code.
Sometimes, people may think we are arguing on something that is just a matter of shades of gray, and there is no right or wrong answer. It’s just a matter of taste, whether you can have it slightly simpler or slightly more complicated. But the reality of what I observed is that usually, it’s not just shades of gray. We are talking about methods with several orders of magnitude of complexity. And so, if I want to make a forecast of my own, for example, what are the odds that the libraries of Professor Hyndman are still around 20 years from now, and what are the odds that TensorFlow version one is still around 20 years from now? I would bet quite a lot of money on the idea that fundamental time series methods will still be relevant.
Kieran Chandler: Do you think the forecasting technique will still be around 20 years from now?
Joannes Vermorel: Things that embed literally billions of lines of accidental complexity about the specificities of the graphic cards that have been produced for the last five years will be gone. I’m not denying the fact that there have been some absolutely stunning breakthroughs in deep learning. What I’m saying is that we really need to understand the added value, which varies quite a lot depending on the problems we’re looking at. We should not be distracted by sophistication. It’s not because it’s sophisticated that it’s inherently more scientific, accurate, or valid. It may be more impressive and TED talk-ish, but we have to be quite careful about that.
Kieran Chandler: Rob, I’ll leave the final question to you. In terms of what Joannes spoke about, things still being around in 10 to 20 years, can you see your libraries still being there? What are you working on today that you think will be useful in the coming years?
Rob Hyndman: My first public library was around 2005, so they’ve lasted 15 years so far. I’m certainly committed to maintaining all of them, even the ones that I regard as having been superseded by others. It’s not a huge amount of effort to do that. The newer packages I’m working on are this package called Fable, which implements most of the same techniques but in a different way to make it easier for users to forecast thousands of time series simultaneously. Fable and some associated packages have been out for a couple of years, and my newest textbook uses them. I expect them to be widely used for at least 10 years, and as long as I’m capable, I’ll maintain them and make sure they’re around. I’m lucky to have a very good assistant who helps me with package maintenance. He’s also committed to the open-source world and to putting out high-quality software in open-source development.
Kieran Chandler: That’s great, and the open-source world allows everyone to have access to it. Thanks very much both for your time. We’ll have to leave it there, and thanks for tuning in. We’ll see you again in the next episode.