00:00:08 Introduction et parcours de Rob Hyndman en prévision.
00:01:31 Durabilité des techniques de prévision appliquées dans le monde réel et des logiciels.
00:04:08 Application des techniques de prévision dans divers domaines avec des données abondantes.
00:05:43 Les défis de répondre aux besoins de diverses industries dans le supply chain.
00:07:30 Naviguer à travers les complexités des logiciels d’entreprise et de la collecte de données.
00:08:00 Prévision des séries temporelles et approches alternatives.
00:09:05 Défis rencontrés par Lokad dans l’analyse prédictive.
00:11:29 Durabilité et motivation dans le développement de logiciels académiques.
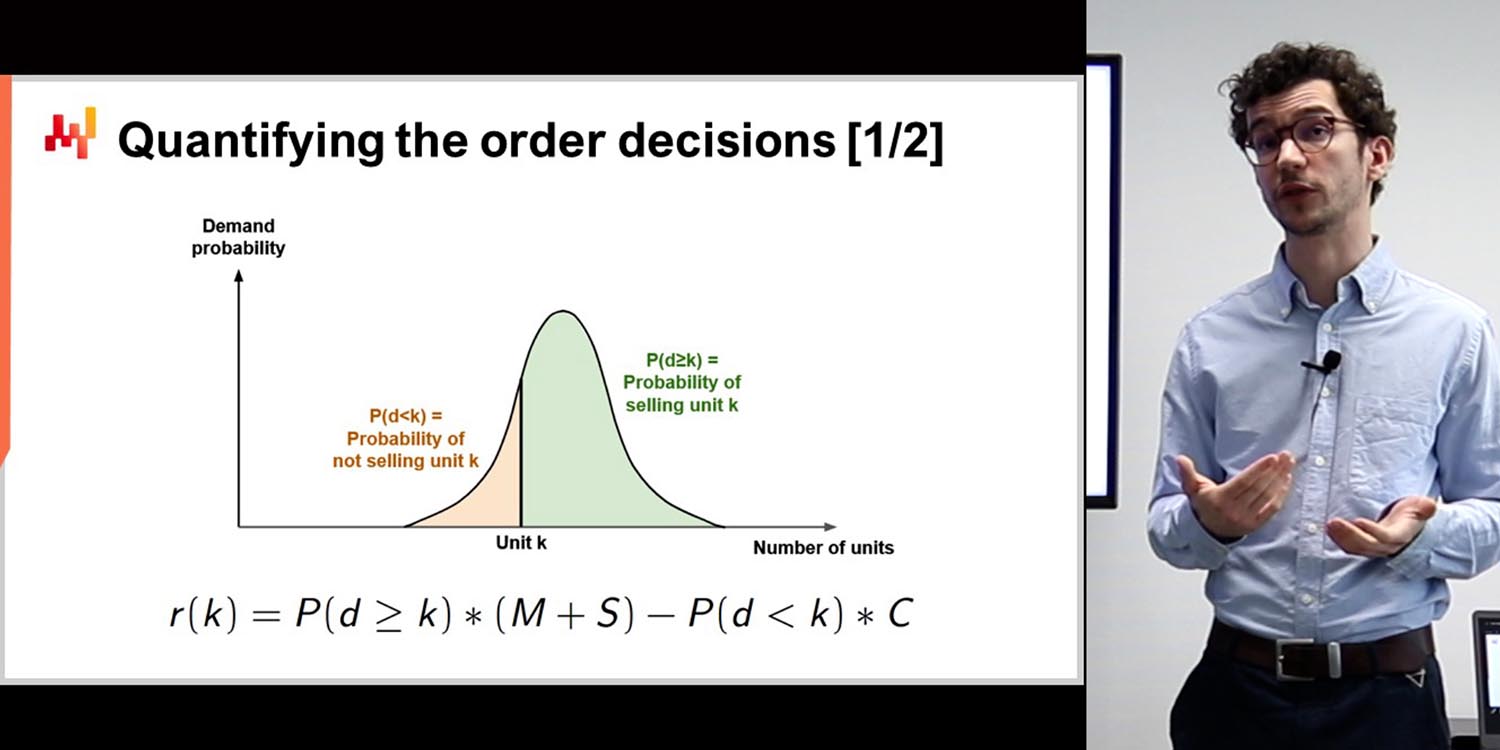
00:13:12 Passage de la prévision ponctuelle à la prévision probabiliste.
00:15:00 Défauts des méthodes académiques et leur mise en œuvre dans le monde réel.
00:16:01 Performance d’un modèle simple lors d’une compétition.
00:16:56 L’importance de méthodes élégantes et concises.
00:18:48 Équilibrer précision, complexité et coût dans les modèles.
00:19:25 Robustesse et rapidité dans les packages R pour la prévision.
00:20:31 Équilibrer robustesse, précision et coûts de mise en œuvre dans le monde des affaires.
00:21:35 Importance des méthodes spécifiques au problème dans la prévision.
00:23:00 Prédire la durabilité des techniques de prévision et des bibliothèques.
00:25:29 L’engagement de Rob à maintenir ses bibliothèques de prévision.
00:26:12 Présentation de Fable et son application dans la prévision des séries temporelles.
00:27:03 Apprécier le monde open source et son impact sur les outils de prévision.
Résumé
Dans une interview avec Kieran Chandler, Joannes Vermorel, fondateur de Lokad, et Rob Hyndman, professeur de statistiques à l’Université Monash, discutent de la durabilité des techniques de prévision appliquées dans le monde réel. Le logiciel de prévision open source de Hyndman, qui a été téléchargé par des millions d’utilisateurs, résiste à l’épreuve du temps et est capable de résoudre environ 90 % des problèmes de prévision des entreprises. Les invités soulignent les défis que représente la satisfaction d’un large public aux besoins divers dans l’industrie supply chain et l’importance de créer des logiciels conviviaux, efficaces et accessibles. Ils insistent également sur l’importance du logiciel open source et de la collaboration dans le développement de méthodes de prévision.
Résumé étendu
Dans cette interview, Kieran Chandler aborde la durabilité des techniques de prévision appliquées dans le monde réel avec Joannes Vermorel, fondateur de Lokad, et Rob Hyndman, professeur de statistiques à l’Université Monash. Le logiciel de prévision open source de Hyndman a été téléchargé par des millions d’utilisateurs et résiste à l’épreuve du temps, contrairement à de nombreux autres outils logiciels.
Vermorel apprécie le travail de Hyndman qui va au-delà des logiciels académiques typiques en créant un ensemble complet de bibliothèques, intégrant bon nombre de ses propres résultats et offrant un cadre cohérent basé sur le langage R, très populaire pour l’analyse statistique. Vermorel estime qu’il y a peu d’exemples de logiciels scientifiques ayant une telle durabilité et un tel public.
La recherche académique de Hyndman ne se limite pas à la prévision dans le supply chain ; il s’intéresse à l’application des techniques de prévision dans tout domaine disposant de grandes quantités de données. Son travail comprend la prévision de la consommation d’électricité, des taux de mortalité, de la population, du nombre de touristes et, plus récemment, des cas de COVID-19 pour le gouvernement australien. En plus de la prévision, il travaille également sur la détection d’anomalies et l’analyse exploratoire de données.
En abordant les défis liés à la satisfaction d’un large public aux besoins divers dans le supply chain, Vermorel explique que la manière dont les données sont perçues et enregistrées par les logiciels d’entreprise (ERP, MRP, WMS) est souvent en partie fortuite.
Ils abordent les complications résultant de l’utilisation de données qui n’ont pas été principalement collectées à des fins de prévision et la transition d’un système d’enterprise resource planning (ERP) à un autre. Ils discutent également de la nécessité de disposer de techniques de prévision pouvant s’adapter à différents environnements informatiques et aux accidents historiques liés au déploiement des logiciels d’entreprise.
Vermorel souligne l’importance des prévisions dans des contextes qui ne se prêtent pas à l’analyse des séries temporelles, comme la mode, où l’ingénierie de la demande et l’introduction de nouveaux produits influencent le problème de prévision. Il insiste sur la nécessité pour les modèles prédictifs de prendre en compte les boucles de rétroaction et les actions entreprises sur la base des prévisions, ainsi que de contrôler divers facteurs tels que l’assortiment de produits et les stratégies de promotion. Cette approche multifacette est essentielle pour que Lokad puisse relever les défis complexes de l’analyse prédictive auxquels ils sont confrontés.
Hyndman explique que son logiciel de séries temporelles est capable de résoudre environ 90 % des problèmes de prévision des entreprises, mais que les 10 % restants nécessitent des approches différentes. Il aborde également la question des logiciels académiques éphémères, en l’attribuant à la focalisation sur la publication d’articles et au manque de reconnaissance pour le maintien des logiciels sur le long terme. Cela se traduit par un manque de collaboration avec les praticiens et par l’absence de documentation adéquate sur les méthodes afin d’assurer leur longévité.
L’interview met en lumière les défis et les complexités de l’optimisation et de la prévision dans le supply chain, notamment la nécessité de disposer de techniques adaptables, l’importance de prendre en compte des contextes non liés aux séries temporelles, ainsi que l’influence des boucles de rétroaction et de la prise de décision sur les modèles prédictifs. De plus, elle souligne le fossé entre la recherche académique et l’application pratique dans le domaine de la prévision.
Les deux invités soulignent l’importance de créer des logiciels conviviaux, à la fois efficaces et accessibles, pour faire une différence dans le monde.
Hyndman mentionne le passage de la prévision ponctuelle à la prévision probabiliste dans la littérature académique au cours des 15 dernières années. Lokad a été l’une des premières entreprises de prévision dans le supply chain à intégrer ce changement dans ses logiciels. Comme le logiciel initial de Hyndman se concentrait sur les prévisions ponctuelles, ses nouveaux packages privilégient les prévisions probabilistes.
Vermorel souligne les défauts cachés dans de nombreuses publications académiques, tels que l’instabilité numérique, le temps de calcul excessif ou une implémentation complexe. Il met également en avant l’importance d’équilibrer la précision avec la simplicité, car des modèles trop compliqués peuvent s’avérer peu pratiques ou superflus. Vermorel donne l’exemple de la compétition M5, où Lokad a atteint une grande précision en utilisant un modèle relativement simple.
Hyndman convient que l’équilibre entre les coûts de production des logiciels, le temps de calcul et la précision est essentiel. Les deux invités apprécient les méthodes de prévision concises et élégantes, applicables de manière large, telles que celles présentes dans les bibliothèques de Hyndman.
La conversation soulève des questions sur les compromis entre précision et complexité dans les modèles de prévision. Vermorel remet en question la pertinence de rechercher une légère amélioration de la précision aux dépens d’une complexité bien plus importante, comme on le voit dans les modèles de deep learning. Vermorel et Hyndman insistent tous deux sur l’importance de se concentrer sur l’essence de bonnes prévisions sans se perdre dans des améliorations mineures qui ne justifieraient pas la complexité supplémentaire.
Hyndman souligne l’importance de prendre en compte à la fois la précision et le coût de calcul lors du développement des méthodes de prévision. Il attribue la robustesse de ses packages de prévision à leurs origines dans des projets de conseil, où ils devaient être rapides, fiables et applicables à divers contextes.
Vermorel souligne l’importance de considérer la valeur ajoutée qu’une méthode de prévision apporte à un problème. Il compare les modèles paramétriques simples avec des méthodes plus complexes telles que les arbres de gradient boosting, notant que dans certains cas, des modèles plus simples peuvent être suffisants. Vermorel aborde également les défis spécifiques de la prévision dans des industries telles que la mode et l’après-vente automobile, où les facteurs de substitution et de compatibilité jouent un rôle important.
Les interviewés insistent sur l’importance de ne pas se laisser distraire par la sophistication, car elle n’équivaut pas nécessairement à de meilleurs résultats scientifiques ou à une meilleure précision. Vermorel prédit que les techniques fondamentales de prévision des séries temporelles resteront pertinentes dans 20 ans, tandis que les méthodes complexes reposant sur le matériel actuel pourraient devenir obsolètes.
Rob Hyndman évoque son travail sur la prévision, notamment le développement du package logiciel open source “Fable,” qui simplifie le processus de prévision pour des milliers de séries temporelles simultanément. Il souligne son engagement à maintenir ce package pendant au moins 10 ans et met en avant les avantages du logiciel open source, tels que la collaboration et l’accessibilité.
Vermorel et Hyndman insistent sur l’importance du logiciel open source dans leur travail et sur le potentiel de collaboration pour développer des méthodes de prévision de haute qualité. Hyndman mentionne également son dévouement à maintenir des bibliothèques publiques, qui existent depuis 2005, et le rôle qu’elles jouent pour rendre l’analyse de données accessible au grand public.
Dans l’ensemble, l’interview met en lumière les défis de la prévision dans un monde complexe et en évolution rapide, ainsi que l’importance des logiciels et de la collaboration pour développer des solutions efficaces. L’accent mis sur le logiciel open source et l’accès public souligne la valeur de rendre l’analyse de données et la prévision accessibles à un public plus large.
Les deux interviewés apprécient la nature open source de leur travail, qui permet un accès large et une collaboration pour développer des méthodes de prévision de haute qualité.
Transcription intégrale
Kieran Chandler: La prévision est une pratique ancienne qui évolue constamment, et en conséquence, de nombreux logiciels ne résistent pas à l’épreuve du temps. Une personne qui a défié cette tendance est notre invité aujourd’hui, Rob Hyndman, qui a mis en œuvre un logiciel open source ayant été téléchargé par des millions d’utilisateurs. Ainsi, aujourd’hui, nous allons discuter avec lui de la durabilité des techniques de prévision appliquées dans le monde réel. Alors, Rob, merci beaucoup de nous rejoindre en direct depuis l’Australie. Je sais qu’il se fait un peu tard chez vous. Comme toujours, nous aimons commencer par en apprendre un peu plus sur nos invités, alors peut-être pourriez-vous commencer par nous parler un peu de vous.
Rob Hyndman: Merci, Kieran, et ravi de vous rejoindre. Oui, il est 20 heures ici en Australie, donc pas trop tard. Je suis professeur de statistiques et chef du département d’économétrie et de statistiques commerciales à l’Université Monash. J’y suis depuis 26 ans. Pendant la majeure partie de cette période, j’ai également été rédacteur en chef de l’International Journal of Forecasting et directeur de l’International Institute of Forecasters, de 2005 à 2018. Je suis un universitaire ; j’écris de nombreux articles, et j’ai écrit quelques livres, dont trois sur la prévision. Si je ne fais pas cela, je joue généralement au tennis.
Kieran Chandler: Sympa, j’apprécie moi-même un peu le tennis durant les mois d’été. Peut-être qu’un jour nous pourrons vous voir pour une partie. Joannes, aujourd’hui, notre sujet est la durabilité des techniques de prévision appliquées dans le monde réel et l’idée qu’un logiciel puisse être durable et perdurer sur une longue période. Quelle est l’idée derrière cela ?
Joannes Vermorel: La plupart des logiciels ont tendance à se dégrader avec le temps pour diverses raisons. Lorsqu’il s’agit de logiciels scientifiques, il faut réfléchir à la manière dont ces logiciels sont produits. En général, ils sont créés pour soutenir la publication d’un article, de sorte qu’il s’agit essentiellement de logiciels à usage unique. Ce que j’ai trouvé particulièrement remarquable dans le travail du professeur Hyndman, c’est qu’il est allé au-delà de ce qui se fait habituellement dans les cercles académiques, qui consiste à produire un logiciel destiné à être jeté après la publication, à publier l’article, puis à passer au suivant. Il a en fait construit un vaste ensemble de bibliothèques qui non seulement intègrent bon nombre de ses propres résultats et ceux de ses pairs, mais fournissent également un cadre très cohérent basé sur un langage devenu très populaire, à savoir R, un environnement pour l’analyse statistique. Cela a prouvé sa valeur au fil de plusieurs décennies, et c’est tout à fait un exploit. La plupart des logiciels que nous voyons aujourd’hui sont anciens, avec très peu de fondations issues d’Unix ou de technologies plus sophistiquées. En ce qui concerne la data science, il n’existe pas tant d’exemples de choses qui résistent à l’épreuve du temps, à part les éléments de base de l’algèbre linéaire et des domaines similaires.
Kieran Chandler: … analyse, mais quand on y réfléchit vraiment, je pourrais probablement citer une douzaine d’exemples de logiciels qui ont réussi à avoir un public et une durabilité tels. Cependant, il n’y en a pas tant, en réalité. Je crois qu’il y a quelque chose de vraiment remarquable ici qui va au-delà de ce qui se fait habituellement en recherche académique. Rob, parlons un peu plus de votre recherche académique alors. Vous ne vous concentrez évidemment pas uniquement sur le monde du supply chain comme nous ici. Alors, dans quels autres domaines souhaitez-vous appliquer les techniques de prévision ?
Rob Hyndman : Je m’intéresse à tout ce qui me permet d’obtenir énormément de données. Je réalise des prévisions sur la consommation d’électricité, par exemple, où il existe de très bonnes données remontant sur plusieurs décennies. Je prévois les taux de mortalité, la population, et dernièrement, je travaille sur le nombre de touristes, ce qui est assez difficile à prévoir en pleine pandémie. J’aide le gouvernement australien à réfléchir à la manière dont cela fonctionne. Une autre mission que j’effectue pour le gouvernement australien consiste à prévoir les cas de COVID-19. C’est ma première incursion dans le domaine épidémiologique, et j’ai dû apprendre pas mal l’approche épidémiologique de la modélisation pour l’intégrer dans certains ensembles de prévisions. Cela a été intéressant. Essentiellement, s’il y a beaucoup de données, je suis intéressé par leur modélisation. Je fais également des choses comme la détection d’anomalies et l’analyse exploratoire de données, lorsqu’il s’agit de grandes collections de données. J’ai travaillé avec de nombreuses entreprises et organisations gouvernementales, et si elles viennent me voir avec un problème impliquant énormément de données, je m’intéresse à réfléchir à comment réaliser de meilleures prévisions que ce qui se fait actuellement.
Kieran Chandler : Génial, j’imagine que l’industrie du tourisme est particulièrement intéressante en ce moment. C’est une véritable anomalie d’un point de vue de la prévision. Johannes, notre focus est évidemment sur l’industrie de la supply chain, mais l’idée est que nous ne nous concentrons pas uniquement sur un secteur. Nous nous adressons à un public très large, alors quels types de défis peut-on rencontrer lorsqu’on essaie de satisfaire autant de personnes aux besoins si divers ?
Joannes Vermorel : D’abord, c’est simplement notre manière de percevoir le monde. Nous ne disposons pas d’une mesure scientifique, comme des statistiques établies pour les mortalités ou autre. Ce que vous avez, ce sont des logiciels d’entreprise, tels que les ERPs, MRPs et WMS, qui produisent ou enregistrent des données de manière quasi accidentelle. La collecte de données n’était pas la raison pour laquelle tous ces logiciels ont été mis en place, si bien que vous vous retrouvez avec des enregistrements qui n’ont pas été conçus comme des outils pour effectuer des mesures dans le temps que l’on pourrait prévoir. C’est un sous-produit quasiment accidentel, et cela engendre une multitude de complications. L’un des défis est de savoir si, en termes de techniques de prévision et de recherche ciblée, il est possible de développer quelque chose qui puisse survivre au passage d’un ERP à un autre. Si vous changez de système, qui est très désordonné et accidentel, vous devez envisager comment cela affectera le processus de prévision.
Kieran Chandler : Le sujet suivant que j’aimerais aborder concerne le paysage informatique différent et les accidents historiques en matière de déploiement de divers outils logiciels d’entreprise. Si vous devez complètement changer de méthode, vous ne bâtissez évidemment pas un ensemble de connaissances ou de techniques. L’un des défis est de savoir si l’on peut agir dans ce domaine. Et, de notre point de vue chez Lokad, les prévisions qui nous intéressent le plus concernent généralement des éléments qui ne se présentent pas naturellement sous forme de séries temporelles. Que faire si vous avez un problème qui ne se prête pas à être encadré commodément comme une série temporelle ? Vous avez quand même besoin de quelque chose qui s’apparente à une prévision, mais cela se présente sous des formes très différentes. Rob, que pensez-vous de l’utilisation d’alternatives aux prévisions de séries temporelles ?
Rob Hyndman : Eh bien, cela dépend beaucoup des données, comme l’a dit Joannes, pour déterminer quel type de modèle sera nécessaire pour ce problème particulier. Mon logiciel de séries temporelles gère de nombreux problèmes, mais pas tous. Certaines entreprises disposent d’un jeu de données structuré ou enregistré de telle manière qu’elles devront le modifier ou trouver une solution différente. Le logiciel que j’ai développé et qui est le plus populaire résout 90 % des problèmes de prévision des entreprises ; ce sont les 10 % restants pour lesquels il faut adopter des approches différentes. Kieran Chandler : À quelle fréquence diriez-vous qu’il existe ce genre de 10 % dans votre expérience, Joannes ? Joannes Vermorel : C’est un problème très subtil. Mon propre parcours dans le domaine des prévisions chez Lokad a consisté à réaliser toute l’ampleur du sujet. D’abord, nous sommes passés des prévisions ponctuelles aux prévisions probabilistes, ce qui a transformé notre manière d’aborder le problème. Mais c’est encore plus profond que cela. Par exemple, dans le secteur de la mode, le problème est que vous voulez prévoir la demande pour savoir quoi produire. Cependant, lorsque vous décidez de ce que vous allez produire, vous avez la flexibilité d’introduire davantage ou moins de produits. Donc, l’idée même d’avoir des séries temporelles à prévoir dépend de vos décisions. Dans la mode, par exemple, le fait d’ajouter un produit de plus à votre assortiment fait partie intégrante de votre problème prédictif. Vous souhaitez non seulement prévoir la demande, mais aussi la modeler.
Kieran Chandler : Alors, Joannes, pouvez-vous nous expliquer comment les modèles prédictifs influent sur l’optimisation de la supply chain ?
Joannes Vermorel : Lorsque nous établissons une prévision, nous prenons une décision mieux informée. Cela influence profondément la façon dont nous construisons nos modèles prédictifs. Ensuite, nous pouvons ajouter davantage de variables, telles que le contrôle du degré de produits, les points de tarification, le message, et même la promotion des produits. Si je poursuis l’exemple de la mode, vous prévoyez les quantités dont vous avez besoin, puis décidez que, dans vos magasins, certains produits seront présents de manière bien plus permanente que d’autres. Cela a un impact considérable sur ce que vous allez observer. Le défi auquel Lokad a été confronté en matière d’analytique prédictive était de pouvoir appréhender les problèmes sous les nombreux angles qui se présentent, ce qui complique la perspective pure des séries temporelles.
Kieran Chandler : D’accord, Rob, passons maintenant à une discussion d’un point de vue académique. Beaucoup de personnes créent des logiciels uniquement pour accompagner un article, puis ils sont pratiquement oubliés. Pourquoi pensez-vous qu’il n’y a pas assez de pérennité dans certains logiciels que les gens développent ?
Rob Hyndman : Eh bien, il faut penser à la motivation de la plupart des universitaires. Ils sont payés pour rédiger des articles et enseigner. Une fois l’article publié, il peut y avoir une incitation à développer un logiciel pour l’implémenter. Mais il n’y a aucune réelle récompense pour la plupart des universitaires dans ce domaine, et il n’existe certainement aucune récompense à maintenir ce logiciel sur le long terme. Quiconque le fait, le fait parce qu’il y tient, ou que c’est un travail de passion. Ce n’est pas vraiment ce pour quoi ils sont payés. Ce n’est pas leur cœur de métier. Je pense que c’est un problème dans le monde académique. On se concentre tellement sur la sortie de nouvelles méthodes et leur publication, au détriment de la liaison avec la communauté des praticiens et de la garantie que vos méthodes soient bien documentées et que des logiciels conviviaux à long terme soient disponibles. C’est une question de motivation dans le monde académique. Ma motivation, c’est que lorsque je développe une nouvelle méthodologie, je veux qu’elle soit utilisée. Je ne veux pas simplement publier un article et qu’il ne soit lu que par une douzaine, voire 100 personnes, si j’ai de la chance. Je veux réellement que mes méthodes fassent une différence dans le monde.
Joannes Vermorel : Les modèles prédictifs sont devenus plus compliqués, et il n’est pas facile de les rendre robustes. Chez Lokad, nous devons maintenir beaucoup de vieux codes pour garder nos modèles opérationnels. Le défi, c’est que vous ne pouvez pas simplement proposer un modèle sophistiqué et laisser faire. Vous devez être en mesure d’expliquer ce que fait le modèle et pourquoi il le fait. Vous devez vous assurer que le modèle est bien documenté et que les gens peuvent l’utiliser concrètement. Ce n’est pas une tâche facile, mais c’est essentiel si vous voulez que vos modèles soient adoptés.
Rob Hyndman : Je trouve également intéressant que, avec le temps, de nouvelles méthodes se développent, et qu’il faille donc proposer de nouveaux logiciels ou outils prenant en compte les évolutions en matière de prévision. L’un des éléments mentionnés par Joannes est la transition des prévisions ponctuelles aux prévisions probabilistes, qui a eu lieu dans la littérature académique ces 15 dernières années environ, et Lokad a été très rapide à s’adapter en proposant des prévisions probabilistes. Je pense que nous avons probablement été l’une des premières entreprises de prévision en supply chain au monde à le faire. Mon logiciel initial, bien qu’il produisît des prévisions probabilistes, mettait toujours l’accent sur les prévisions ponctuelles,
Kieran Chandler : Au cours des dernières années, l’accent s’est inversé. On obtient d’abord des prévisions probabilistes et ensuite des prévisions ponctuelles.
Joannes Vermorel : L’une de mes critiques à l’égard de nombreuses publications académiques est qu’on se retrouve généralement avec une multitude de défauts cachés dans les méthodes. Vous obtenez une méthode que vous savez plus performante sur un benchmark, mais lorsque vous voulez l’implémenter concrètement, vous constatez, par exemple, qu’elle est numériquement très instable ou que les temps de calcul sont ridiculement longs, au point que l’utilisation d’un jeu de données d’exemple prendrait déjà des jours de calcul. Et si vous voulez utiliser un jeu de données réel, cela représenterait des années de calcul.
Et vous pouvez rencontrer toutes sortes de problèmes, par exemple la méthode étant diaboliquement compliquée à implémenter, et même si, en théorie, vous pouvez y parvenir, en pratique, un bug stupide viendra toujours tout compromettre. Ou alors la méthode peut présenter des dépendances incroyablement subtiles sur une longue série de méta-paramètres, si bien que la faire fonctionner relève presque d’un art occulte, car vous devez ajuster une vingtaine de paramètres obscurs de manière complètement non documentée et généralement seulement connue des chercheurs qui ont conçu la méthode.
Rob Hyndman : C’est très intéressant, car lorsque j’examine les méthodes qui résistent à l’épreuve du temps, de nombreuses méthodes classiques – comme celles développées pour Hyndman, par exemple – produisent des résultats étonnamment bons face à des techniques très sophistiquées. Lors de la compétition M5 de l’année dernière, Lokad s’est classé sixième parmi 909 équipes en termes de précision des prévisions ponctuelles. Mais nous avons réalisé cela avec un modèle extrêmement simple, presque le modèle paramétrique de référence, et nous avons utilisé une petite astuce de modélisation ETS pour obtenir essentiellement l’effet “shotgun” et la distribution probabiliste.
Mais dans l’ensemble, c’était probablement un modèle que nous pourrions résumer en une page, avec quelques coefficients pour les saisonnalités, le jour de la semaine, la semaine du mois, la semaine de l’année, et c’était tout. Donc, littéralement, nous étions à un pour cent près du modèle le plus précis utilisant des arbres de gradient boosted, et je soupçonne qu’en termes de complexité du code, de complexité du modèle et d’opacité générale, il s’agit de quelque chose de deux, voire trois ordres de grandeur plus complexe. Joannes Vermorel : C’est sans doute ce qui fait le succès de vos bibliothèques. Ce que j’apprécie vraiment dans ces méthodes, c’est que la plupart d’entre elles possèdent une mise en œuvre élégante et concise. En termes d’applicabilité, il y a quelque chose de fondamentalement vrai et valable : obtenir la précision avec le minimum d’effort et de tracas, contrairement, je dirais, à l’autre camp, celui du deep learning. Je n’ai rien contre le deep learning lorsqu’il s’agit d’aborder des problèmes incroyablement difficiles, comme, par exemple… Kieran Chandler : Bienvenue dans cet épisode. Aujourd’hui, nous accueillons Joannes Vermorel, le fondateur de Lokad, et Rob Hyndman, Professeur de Statistiques et Chef du Département d’Économétrie et de Statistiques d’Affaires à l’Université Monash. Discutons de traduction automatique et de la précision des modèles. Joannes Vermorel : Je remets en question la pertinence d’avoir un modèle qui est un pour cent plus précis, mais qui nécessite des millions de paramètres et est incroyablement complexe et opaque. Est-il vraiment meilleur d’un point de vue scientifique ? Peut-être ne devrions-nous pas être distraits par l’obtention d’un pour cent de précision supplémentaire au détriment de quelque chose de mille fois plus complexe. Il y a un risque de se perdre complètement. Une bonne science, surtout en prévision, devrait se concentrer sur l’essence de ce qui fait une bonne prévision, en mettant de côté les distractions qui apportent un petit surplus de précision mais peut-être au prix d’une grande confusion. Rob Hyndman : Il faut équilibrer ces deux coûts : celui de produire le logiciel et d’effectuer les calculs réels, et celui de la précision. Dans le monde académique, l’attention se porte généralement sur la précision sans tenir compte du coût du calcul ou du développement du code. Je suis d’accord, Joannes, il faut considérer les deux aspects. Parfois, on n’a pas forcément envie de choisir la méthode la plus précise si cela demande trop de temps pour maintenir le code et réaliser les calculs. Mes packages de prévision sont robustes parce qu’ils ont été développés dans le cadre de projets de conseil. Ces fonctions ont été appliquées dans divers contextes, elles devaient donc être relativement robustes. Je ne voulais pas que des entreprises reviennent vers moi en disant que ça ne fonctionne pas sur leur jeu de données. Le fait d’avoir réalisé beaucoup de missions de conseil signifie que ces fonctions ont déjà été soumises à une multitude de données avant d’être mises à la disposition du grand public. Elles doivent aussi être relativement rapides, car la plupart des entreprises ne veulent pas attendre des jours pour qu’un calcul MCMC soit effectué sur un modèle bayésien sophistiqué ; elles veulent obtenir la prévision dans un délai raisonnable. Kieran Chandler : Comment équilibrez-vous la robustesse, la précision et le coût de mise en œuvre du modèle du point de vue de l’entreprise, Joannes ? Joannes Vermorel : Tout se résume à ce que vous apportez concrètement. Par exemple, si nous avons un modèle paramétrique super simpliste – comme celui utilisé pour la compétition M5 – et que nous atteignons 1 % de la précision d’une méthode très sophistiquée basée sur des arbres de gradient boosted, la méthode gagnante, cela vaut-il la complexité supplémentaire ? La méthode gagnante utilisait des arbres de gradient boosted avec un schéma d’augmentation de données très élaboré, qui était essentiellement un moyen d’augmenter considérablement votre jeu de données. Kieran Chandler : Cela est assez considérable et vous vous retrouvez alors avec un jeu de données environ 20 fois plus volumineux. Ensuite, vous appliquez par-dessus un modèle super lourd et complexe. La question est donc : apportez-vous quelque chose de fondamentalement nouveau et profond, et comment équilibrez-vous cela ?
Joannes Vermorel: La façon dont j’équilibre cela, c’est en me demandant si je passe à côté d’un éléphant dans la pièce que je dois vraiment prendre en compte. Par exemple, si je parle de mode, évidemment la cannibalisation et la substitution sont très fortes. Les gens n’entrent pas dans une boutique de mode en pensant qu’ils veulent exactement ce code-barres. Ce n’est même pas la bonne manière de concevoir le problème. La cannibalisation et la substitution sont omniprésentes, et il faut adopter une approche qui intègre cette vision. Si je m’oriente vers l’automobile, par exemple, et que j’observe l’après-vente automobile, le problème est que les gens n’achètent pas des pièces de voiture parce qu’ils aiment les pièces de voiture. Ils les achètent parce que leur véhicule a un problème et qu’ils veulent le réparer, point final. Il s’avère qu’il existe une matrice de compatibilité super complexe entre véhicules et pièces de voiture. En Europe, il y a plus d’un million de pièces de voiture distinctes et plus de 100 000 véhicules distincts. Et généralement, pour n’importe quel problème, il y a une dizaine de pièces de voiture compatibles, donc il y a substitution, mais contrairement à la mode, cela se présente de manière complètement déterministe. Les substitutions sont presque parfaitement connues et parfaitement structurées, et il faut avoir une méthode qui tire vraiment parti du fait qu’il n’y a aucune incertitude à ce sujet.
Donc, problème par problème, la manière dont j’équilibre cela, c’est en m’assurant que si nous voulons payer pour une sophistication supplémentaire, cela en vaut vraiment la peine. Par exemple, si je prends les bibliothèques du Professeur Hyndman par rapport, disons, à TensorFlow, juste pour donner une idée, pour la plupart de vos modèles, nous parlons probablement de quelques kilo-octets de code. Si l’on considère TensorFlow, une seule bibliothèque compilée pèse 800 mégaoctets, et dès que vous incluez TensorFlow version one, vous incluez presque des milliards de lignes de code.
Parfois, les gens pourraient penser que nous débattons sur quelque chose qui n’est qu’une question de nuances de gris, et qu’il n’y a ni bonne ni mauvaise réponse. C’est simplement une question de goût, qu’on puisse l’avoir légèrement plus simple ou légèrement plus compliqué. Mais la réalité, d’après ce que j’ai observé, est que, généralement, il ne s’agit pas seulement de nuances de gris. Nous parlons de méthodes avec plusieurs ordres de grandeur de complexité. Et donc, si je veux établir ma propre prévision, par exemple, quelles sont les chances que les bibliothèques du Professeur Hyndman soient toujours présentes dans 20 ans, et quelles sont les chances que TensorFlow version one existe encore dans 20 ans ? Je parierais pas mal d’argent sur l’idée que les méthodes fondamentales de séries temporelles resteront pertinentes.
Kieran Chandler: Pensez-vous que la technique de prévision sera toujours là dans 20 ans ?
Joannes Vermorel: Les choses qui intègrent littéralement des milliards de lignes d’une complexité accidentelle concernant les spécificités des cartes graphiques produites ces cinq dernières années disparaîtront. Je ne nie pas le fait qu’il y ait eu des percées absolument époustouflantes en deep learning. Ce que je dis, c’est que nous devons vraiment comprendre la valeur ajoutée, qui varie considérablement en fonction des problèmes que nous examinons. Nous ne devrions pas nous laisser distraire par la sophistication. Ce n’est pas parce que quelque chose est sophistiqué que c’est intrinsèquement plus scientifique, précis ou valide. Cela peut être plus impressionnant et digne d’un TED talk, mais nous devons être très prudents à ce sujet.
Kieran Chandler: Rob, je te laisse la question finale. En ce qui concerne ce dont Joannes a parlé, ces choses qui perdureront dans 10 à 20 ans, vois-tu tes bibliothèques être encore présentes ? Sur quoi travailles-tu aujourd’hui que tu penses être utile dans les années à venir ?
Rob Hyndman: Ma première bibliothèque publique date d’environ 2005, donc elles ont duré 15 ans jusqu’à présent. Je suis certainement engagé à les maintenir toutes, même celles que je considère comme ayant été dépassées par d’autres. Ce n’est pas un effort colossal à fournir. Les packages plus récents sur lesquels je travaille incluent notamment ce package appelé Fable, qui implémente la plupart des mêmes techniques, mais d’une manière différente pour faciliter la prévision simultanée de milliers de séries temporelles par les utilisateurs. Fable et quelques packages associés sont disponibles depuis quelques années, et mon dernier manuel les utilise. Je m’attends à ce qu’ils soient largement utilisés pendant au moins 10 ans, et tant que j’en serai capable, je les maintiendrai et veillerai à ce qu’ils demeurent disponibles. J’ai la chance d’avoir un très bon assistant qui m’aide avec la maintenance des packages. Il est également engagé dans le monde open-source et dans la diffusion de logiciels open-source de haute qualité.
Kieran Chandler: C’est génial, et le monde open-source permet à tout le monde d’y avoir accès. Merci beaucoup à vous deux pour votre temps. Nous devrons en rester là, et merci de nous avoir suivis. Nous nous reverrons dans le prochain épisode.