00:00:08 Introducción y antecedentes de Rob Hyndman en forecast.
00:01:31 Sostenibilidad de técnicas de forecast del mundo real y software.
00:04:08 Aplicación de técnicas de forecast en diversos campos con datos abundantes.
00:05:43 Desafíos de atender a diversas industrias en el supply chain.
00:07:30 Navegando por las complejidades del software empresarial y la recopilación de datos.
00:08:00 Forecast de series temporales y enfoques alternativos.
00:09:05 Desafíos enfrentados por Lokad en analítica predictiva.
00:11:29 Durabilidad y motivación en el desarrollo de software académico.
00:13:12 Cambio de forecast puntual a forecast probabilístico.
00:15:00 Deficiencias en los métodos académicos y su implementación en el mundo real.
00:16:01 El desempeño de un modelo simple en una competencia.
00:16:56 La importancia de métodos elegantes y concisos.
00:18:48 Equilibrando la precisión, la complejidad y el costo en los modelos.
00:19:25 Robustez y velocidad en paquetes R para forecast.
00:20:31 Equilibrando la robustez, la precisión y los costos de implementación en los negocios.
00:21:35 La importancia de métodos específicos para cada problema en forecast.
00:23:00 Predecir la durabilidad de las técnicas de forecast y las bibliotecas.
00:25:29 El compromiso de Rob con el mantenimiento de sus bibliotecas de forecast.
00:26:12 Introducción de Fable y su aplicación en el forecast de series temporales.
00:27:03 Apreciando el mundo open-source y su impacto en las herramientas de forecast.
Resumen
En una entrevista con Kieran Chandler, Joannes Vermorel, fundador de Lokad, y Rob Hyndman, Profesor de Estadística en la Monash University, discuten la sostenibilidad de las técnicas de forecast del mundo real. El software open-source de forecast de Hyndman, que ha sido descargado por millones de usuarios, resiste la prueba del tiempo y es capaz de resolver alrededor del 90% de los problemas de forecast de las empresas. Los invitados destacan los desafíos de atender a una audiencia amplia con necesidades diversas en la supply chain industry y la importancia de crear software fácil de usar que sea efectivo y accesible. También subrayan la importancia del software open-source y la colaboración en el desarrollo de métodos de forecast.
Resumen Extendido
En esta entrevista, Kieran Chandler discute la sostenibilidad de las técnicas de forecast del mundo real con Joannes Vermorel, fundador de Lokad, y Rob Hyndman, Profesor de Estadística en la Monash University. El software open-source de forecast de Hyndman ha sido descargado por millones de usuarios y resiste la prueba del tiempo, a diferencia de muchas otras herramientas de software.
Vermorel valora el trabajo de Hyndman por ir más allá del software académico típico al crear un conjunto integral de bibliotecas, embedding muchos de sus propios resultados y proporcionando un marco consistente basado en el popular lenguaje R para el análisis estadístico. Vermorel cree que hay pocos ejemplos de software científico que haya tenido tanta durabilidad y audiencia.
La investigación académica de Hyndman no se limita al forecast en supply chain; le interesa aplicar técnicas de forecast a cualquier área con grandes cantidades de datos. Su trabajo incluye forecast del consumo eléctrico, tasas de mortalidad, población, números de turistas y, recientemente, casos de COVID-19 para el gobierno australiano. Además del forecast, también trabaja en la detección de anomalías y el análisis exploratorio de análisis de datos.
Al discutir los desafíos de atender a una audiencia amplia con necesidades diversas en el supply chain, Vermorel explica que la forma en que se perciben y registran los datos por el enterprise software (ERPs, MRPs, WMS) es a menudo semi-accidental.
Abordan las complicaciones que surgen al utilizar datos que no fueron recolectados principalmente para fines de forecast y la transición de un sistema enterprise resource planning (ERP) a otro. También discuten la necesidad de técnicas de forecast que puedan adaptarse a diferentes entornos de TI y a accidentes históricos en el despliegue de software empresarial.
Vermorel destaca la importancia de los forecast en contextos que no se prestan al análisis de time series, como la moda, donde la ingeniería de la demanda y la introducción de new products influyen en el problema de forecast. Destaca la necesidad de que los modelos predictivos tengan en cuenta los bucles de retroalimentación y las acciones tomadas en base a los forecast, así como controlar diversos factores como el surtido de productos y las estrategias de promotion. Este enfoque multifacético es vital para que Lokad enfrente los complejos desafíos de analítica predictiva.
Hyndman explica que su software de series temporales es capaz de resolver alrededor del 90% de los problemas de forecast de las empresas, pero el 10% restante requiere enfoques diferentes. También aborda el tema del software académico de corta vida, atribuyéndolo al enfoque en la publicación de artículos y a la falta de reconocimiento por mantener el software a largo plazo. Esto resulta en una falta de colaboración con los profesionales y en asegurar que los métodos estén bien documentados y tengan durabilidad.
La entrevista resalta los desafíos y las complejidades de la optimización y el forecast en supply chain, incluyendo la necesidad de técnicas adaptables, la importancia de considerar contextos que no son de series temporales, y la influencia de los bucles de retroalimentación y la decision-making en los modelos predictivos. Además, subraya la desconexión entre la investigación académica y la aplicación práctica en el campo del forecast.
Ambos invitados enfatizan la importancia de crear un software fácil de usar que sea tanto efectivo como accesible para marcar la diferencia en el mundo.
Hyndman menciona el cambio de forecast puntual a forecast probabilístico en la literatura académica durante los últimos 15 años. Lokad fue una de las primeras empresas de forecast en supply chain en incorporar este cambio en su software. Dado que el software inicial de Hyndman se centraba en forecast puntuales, sus paquetes más recientes priorizan los forecast probabilísticos.
Vermorel señala las fallas ocultas en muchas publicaciones académicas, tales como la inestabilidad numérica, el tiempo computacional excesivo o la compleja implementación. También destaca la importancia de equilibrar la accuracy con la simplicidad, ya que los modelos excesivamente complicados pueden no ser prácticos o necesarios. Vermorel proporciona un ejemplo de la competencia M5, en la que Lokad logró una alta accuracy utilizando un modelo relativamente simple.
Hyndman está de acuerdo en que equilibrar los costos de producción del software, la computación y la accuracy es esencial. Ambos invitados aprecian métodos de forecast concisos y elegantes con amplia aplicabilidad, como los de las bibliotecas de Hyndman.
La conversación plantea preguntas sobre los trade-offs entre la accuracy y la complejidad en los modelos de forecast. Vermorel cuestiona la sensatez de buscar una leve mejora en la accuracy a expensas de una complejidad mucho mayor, como se observa en los modelos de deep learning. Tanto Vermorel como Hyndman enfatizan la importancia de centrarse en la esencia de los buenos forecast sin distraerse con mejoras mínimas que pueden no justificar la complejidad añadida.
Hyndman enfatiza la importancia de considerar tanto la accuracy como el costo de la computación al desarrollar métodos de forecast. Atribuye la robustez de sus paquetes de forecast a sus orígenes en proyectos de consultoría, donde necesitaban ser rápidos, confiables y aplicables a diversos contextos.
Vermorel subraya la importancia de considerar el valor agregado que un método de forecast aporta a un problema. Contrasta los modelos paramétricos simples con métodos más complejos como los gradient boosting trees, señalando que en algunos casos, los modelos más simples pueden ser suficientes. Vermorel también discute los desafíos únicos del forecast en industrias como la moda y el mercado de posventa automotriz, donde los factores de sustitución y compatibilidad juegan roles significativos.
Los entrevistados enfatizan la importancia de no dejarse distraer por la sofisticación, ya que no necesariamente equivale a resultados científicos o de accuracy superiores. Vermorel predice que las técnicas fundamentales de forecast de series temporales seguirán siendo relevantes dentro de 20 años, mientras que los métodos complejos que dependen del hardware actual podrían quedar obsoletos.
Rob Hyndman habla sobre su trabajo en forecast, en particular sobre su desarrollo del paquete de software open-source “Fable,” que simplifica el proceso de forecast para miles de series temporales simultáneamente. Enfatiza su compromiso de mantener el paquete durante al menos 10 años y destaca los beneficios del software open-source, incluida la colaboración y la accesibilidad.
Tanto Vermorel como Hyndman destacan la importancia del software open-source en su trabajo y el potencial de colaboración en el desarrollo de métodos de forecast de alta calidad. Hyndman también menciona su dedicación a mantener bibliotecas públicas, que existen desde 2005, y el papel que desempeñan en hacer que el análisis de datos sea accesible para el público.
En general, la entrevista resalta los desafíos del forecast en un mundo complejo y en constante cambio y la importancia del software y la colaboración en el desarrollo de soluciones efectivas. El enfoque en el software open-source y el acceso público subraya el valor de hacer que el análisis de datos y el forecast estén disponibles para una audiencia más amplia.
Ambos entrevistados aprecian la naturaleza open-source de su trabajo, que permite un acceso amplio y la colaboración en el desarrollo de métodos de forecast de alta calidad.
Transcripción Completa
Kieran Chandler: Forecasting es una práctica antigua que está en constante evolución, y como tal, muchos programas de software no resisten la prueba del tiempo. Una persona que ha desafiado esta tendencia es nuestro invitado de hoy, Rob Hyndman, quien ha implementado software open-source que ha sido descargado por millones de usuarios. Así que, hoy vamos a discutir con él la sostenibilidad de las técnicas de forecast del mundo real. Entonces, Rob, muchísimas gracias por acompañarnos en vivo desde Australia. Sé que es un poco tarde en tu localidad. Como siempre, nos gusta comenzar conociendo un poco a nuestros invitados, por lo que tal vez podrías empezar contándonos un poco sobre ti mismo.
Rob Hyndman: Gracias, Kieran, y es un placer unirme a ustedes. Sí, son las 8 de la noche aquí en Australia, así que no es tan tarde. Soy Profesor de Estadística y Jefe del Departamento de Econometría y Estadística Empresarial en la Monash University. He estado allí durante 26 años. Durante la mayor parte de ese tiempo, también fui Editor en Jefe del International Journal of Forecasting y Director del International Institute of Forecasters, desde 2005 hasta 2018. Soy académico; escribo muchos artículos, y he escrito algunos libros, incluyendo tres sobre forecast. Si no estoy haciendo eso, normalmente estoy jugando al tenis.
Kieran Chandler: Genial, a mí también me gusta un poco el tenis en los meses de verano. Quizás algún día podamos verte para jugar. Joannes, hoy nuestro tema es la sostenibilidad de las técnicas de forecast del mundo real y la idea de que un piece of software sea sostenible y perdure en el tiempo. ¿Cuál es la idea detrás de eso?
Joannes Vermorel: La mayoría del software tiende a deteriorarse con el tiempo por diversas razones. Cuando se trata de software científico, hay que pensar en cómo se produce este software. Usualmente, se crea para apoyar la publicación de un artículo, por lo que es esencialmente software desechable. Lo que encontré realmente notable en el trabajo del Profesor Hyndman es que fue más allá de lo que normalmente se hace en los círculos académicos, que es producir software desechable, publicar el artículo, dejarlo y pasar al siguiente. En realidad, construyó un vasto conjunto de bibliotecas que no solo incorporaban muchos de sus propios resultados y muchos de los resultados de sus colegas, sino que también proporcionaban un marco muy consistente basado en un lenguaje que se volvió muy popular, que es R, un entorno para el análisis estadístico. Esto ha demostrado su valor a lo largo de varias décadas, y eso es todo un logro. La mayoría del software que vemos hoy es antiguo, con muy pocos fundamentos que surgen de Unix y otras cosas más sofisticadas. En términos de data science, no hay tantos ejemplos de cosas que resistan la prueba del tiempo, aparte de los bloques básicos para el álgebra lineal y campos similares.
Kieran Chandler: … análisis, pero cuando realmente lo piensas, probablemente podría mencionar una docena de ejemplos de software que logró tener tal audiencia y durabilidad. Sin embargo, en realidad no son tantos. Creo que hay algo realmente notable aquí que va más allá de lo que normalmente se hace en la investigación académica. Rob, hablemos un poco más sobre tu investigación académica entonces. Obviamente, no te enfocas solo en el mundo del supply chain como lo hacemos nosotros. Entonces, ¿en qué otras áreas te interesa aplicar técnicas de forecast?
Rob Hyndman: Me interesa cualquier cosa donde pueda obtener muchos datos. Hago forecast sobre el consumo de electricidad, por ejemplo, donde hay muchos datos realmente buenos que se remontan a décadas. Realizo forecast de tasas de mortalidad, población y, últimamente, he estado trabajando en los números de turistas, lo cual es algo bastante difícil de forecast en medio de una pandemia. He estado ayudando al gobierno australiano a entender cómo funciona eso. Otro trabajo que realizo para el gobierno australiano es forecast de casos de COVID-19. Es mi primer esfuerzo por hacer algo en el mundo epidemiológico y he tenido que aprender bastante sobre el enfoque epidemiológico para el modelado e incorporarlo a algunos ensemble de forecast. Ha sido interesante. Esencialmente, si hay muchos datos, me interesa intentar modelarlos. También hago cosas como la detección de anomalías y el análisis exploratorio de datos cuando existen grandes colecciones de datos. He trabajado con muchas empresas y organizaciones gubernamentales, y si me abordan con un problema que involucra bastantes datos, me interesa pensar en cómo hacer better forecasting mejor de lo que sucede actualmente.
Kieran Chandler: Genial, puedo imaginar que la industria turística es una de las que resulta bastante interesante en este momento. Es una verdadera anomalía desde la perspectiva de forecast. Johannes, nuestro enfoque está obviamente en la supply chain industry, pero la idea es que no nos centramos en una sola industria dentro de ella. Atendemos a una audiencia muy amplia, así que, ¿qué tipo de desafíos puedes encontrar al intentar atender a tanta gente con tantas necesidades diferentes?
Joannes Vermorel: Primero, es simplemente la manera en que percibimos el mundo. No disponemos de algo que se asemeje a una medición científica, como estadísticas establecidas para mortalidad u otras cosas. Lo que tienes es software empresarial, como ERPs, MRPs y WMS, que producen o registran datos de forma casi semi-accidental. La recolección de datos no fue la razón por la que se implementaron todos esos softwares, así que terminas con registros, pero éstos no fueron diseñados como herramientas para realizar mediciones a lo largo del tiempo que pudieras forecast. Es casi un subproducto accidental, y eso crea toneladas de complicaciones. Uno de los desafíos que tienes es si puedes hacer, en términos de técnicas de forecast e investigación enfocada, algo que sobreviva al pasar de un ERP a otro. Si cambias el sistema, que es muy desordenado y accidental, tienes que considerar cómo afectará al proceso de forecast.
Kieran Chandler: Entonces, el siguiente tema que me gustaría discutir es el diverso panorama de TI y los accidentes históricos en términos de despliegue de varias herramientas de software empresarial. Si tienes que cambiar completamente el método, obviamente no se está construyendo ningún conjunto de conocimientos o técnicas. Uno de los desafíos es, ¿puedes hacer algo en esta área? Y desde nuestra perspectiva en Lokad, el tipo de forecast que más nos interesa son, por lo general, aquellos que no se presentan naturalmente como series temporales. ¿Qué pasa si tienes un problema que no se presta a ser encuadrado convenientemente como una serie temporal? Aún necesitas algo que se asemeje a un forecast, pero se presenta de formas muy diferentes. Rob, ¿cuáles son tus pensamientos sobre el uso de alternativas a los forecast de series temporales?
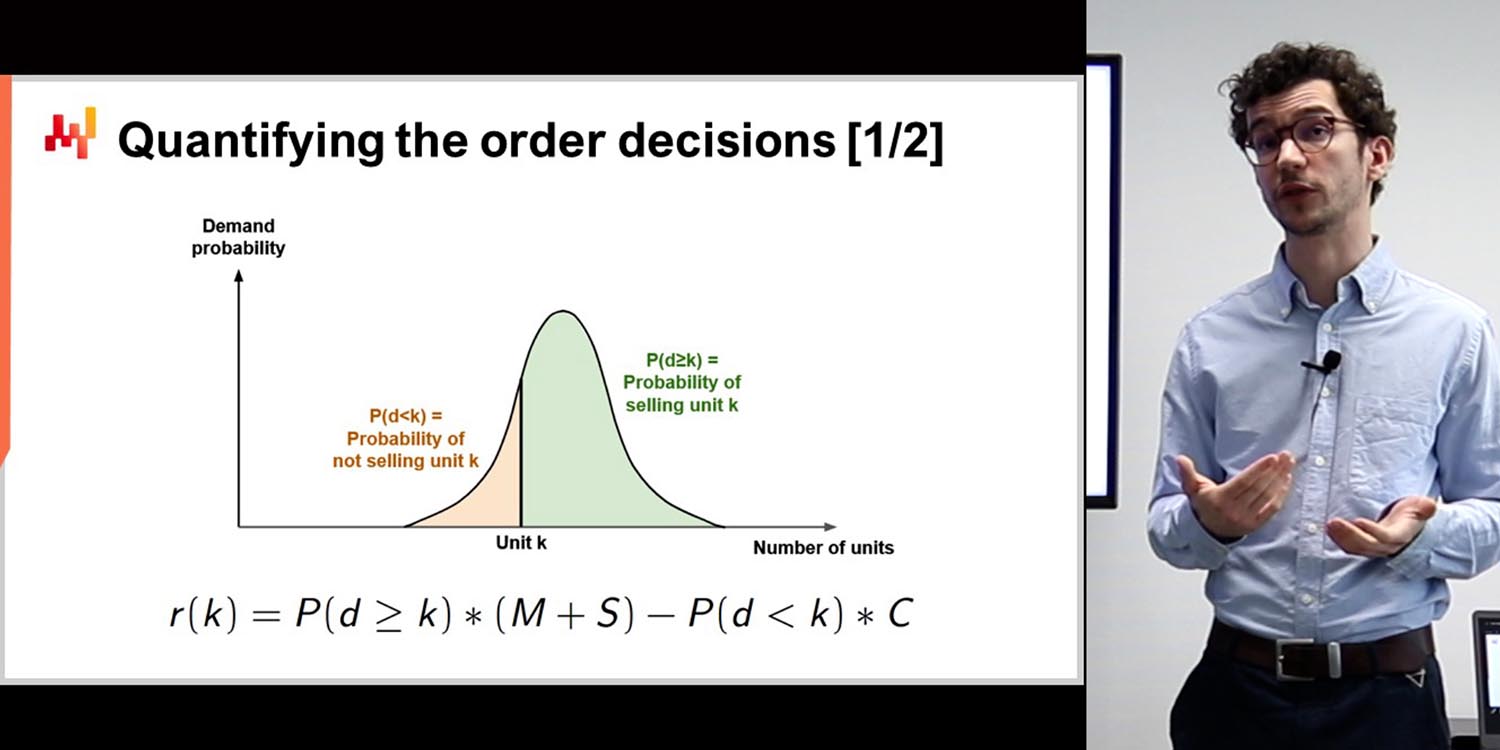
Rob Hyndman: Bueno, depende mucho de los datos, como dijo Joannes, para determinar qué tipo de modelo va a ser necesario construir para ese problema en particular. Mi software de series temporales maneja muchos problemas, pero no todos. Algunas empresas tendrán un conjunto de datos configurado o registrado de tal manera que tendrán que modificarlo o buscar una solución diferente. El software que he escrito y que es más popular resuelve el 90% de los problemas de forecast de las empresas; es en el otro 10% donde hay que hacer cosas diferentes.
Kieran Chandler: ¿Con qué frecuencia dirías que existe ese tipo de 10% en tu experiencia, Joannes?
Joannes Vermorel: Es un problema muy sutil. Mi propio recorrido por el mundo del forecast en Lokad fue darme cuenta de la profundidad que existe. Primero, pasamos de forecast puntuales a forecast probabilísticos, lo que cambió la forma en que miramos el problema. Pero es aún más profundo que eso. Por ejemplo, si observamos la moda, el problema es que quieres forecast de la demanda para saber qué producir. Sin embargo, cuando decides lo que estás a punto de producir, tienes la flexibilidad de introducir más o menos productos. Así que, la idea misma de que tienes series temporales que podrías forecast depende de tus decisiones. En la moda, por ejemplo, el hecho de que introduzcas un producto más en tu surtido es parte de tu problema predictivo. No solo quieres forecast de la demanda, sino también ingeniar la demanda. En nuestro recorrido, nos dimos cuenta de que teníamos incertidumbres irreducibles que nos brindan un ángulo completamente ortogonal a la perspectiva clásica de forecast puntuales. Pero también tenemos que lidiar con todos los bucles de retroalimentación.
Kieran Chandler: Entonces, Joannes, ¿puedes decirnos cómo impactan los modelos predictivos en la optimización de la supply chain?
Joannes Vermorel: Cuando realizamos un forecast, tomamos una acción que está mejor informada. Eso tiene una influencia profunda en la manera en que queremos construir nuestros modelos predictivos. Luego podemos añadir más variables, tales como controlar el grado de productos, los puntos de precio, el mensaje e incluso la promoción de productos. Si continúo con el ejemplo de la moda, predices las cantidades que deseas tener y luego decides que en tus tiendas, algunos productos se colocarán de forma mucho más permanente que otros. Eso tiene un impacto profundo en lo que vas a observar. El desafío que ha enfrentado Lokad en términos de analítica predictiva fue poder abordar problemas desde los numerosos ángulos que se presentan y que complican la perspectiva pura de series temporales.
Kieran Chandler: Bien, Rob, quizá pasemos ahora a hablar desde un punto de vista académico. Mucha gente crea piezas de software únicamente para un artículo y luego se desechan casi de inmediato. ¿Por qué crees que no hay la suficiente longevidad en algunas de las piezas de software que la gente está creando?
Rob Hyndman: Bueno, hay que pensar en la motivación de la mayoría de los académicos. Se les paga por escribir artículos y enseñar clases. Una vez que el artículo está escrito, puede haber cierto incentivo para sacar algún software que lo implemente. Pero no existe una verdadera recompensa para la mayoría de los académicos por hacer eso, y ciertamente no hay recompensa por mantener ese software durante un largo período. Quien lo hace, lo hace porque le importa o porque es una labor de amor. No es realmente lo que se les paga hacer. No es su negocio principal. Creo que ese es un problema, de hecho, en el mundo académico. Hay tanto énfasis en sacar nuevos métodos y publicarlos, y no suficiente enfoque en la conexión con la comunidad de practicantes y en asegurarse de que tus métodos estén bien documentados y cuenten con software fácil de usar que esté disponible a largo plazo. Es un problema de motivación en el mundo académico. Mi motivación es que, cuando desarrollo una nueva metodología, quiero que la gente la use. No quiero simplemente publicar un artículo y que lo lean una docena de personas o tal vez 100, si tengo suerte. Realmente quiero que mis métodos marquen la diferencia en el mundo.
Joannes Vermorel: Los modelos predictivos se han vuelto más complicados, y no es fácil hacerlos robustos. En Lokad, tenemos que mantener mucho código antiguo para que nuestros modelos sigan funcionando. El desafío es que no puedes simplemente idear un modelo sofisticado y dejarlo ahí. Necesitas tener una forma de explicar lo que hace el modelo y por qué lo hace. Es necesario asegurarse de que el modelo esté bien documentado y que las personas puedan utilizarlo en la práctica. No es algo sencillo de hacer, pero es importante si quieres que tus modelos sean adoptados.
Rob Hyndman: También me parece interesante que, a medida que las cosas han cambiado con el tiempo, se han desarrollado nuevos métodos, por lo que necesitas proporcionar nuevo software o nuevas herramientas que tengan en cuenta los avances en forecast. Uno que Joannes mencionó es el paso del forecast puntual al forecast probabilístico, que ocurrió en la literatura académica en los últimos 15 años, quizá, y Lokad fue muy rápido en adoptarlo y poner a disposición forecast probabilísticos. Creo que probablemente fue una de las primeras empresas de forecast de supply chain en el mundo en hacerlo. Mi software inicial, aunque producía forecast probabilísticos, siempre se enfatizaba en los forecast puntuales,
Kieran Chandler: Desarrollándose en los últimos años, el énfasis es al revés. Primero obtienen forecast probabilísticos y luego forecast puntuales.
Joannes Vermorel: Una de mis propias críticas a muchas publicaciones académicas es que, usualmente, terminas con toneladas de fallos ocultos en los métodos. Tienes un método que sabes que superará en el benchmark, pero cuando quieres implementarlo en la práctica, verás que, por ejemplo, es numéricamente súper inestable o que los tiempos de cómputo son ridículamente largos, hasta el punto de que si usas un conjunto de datos de juguete, ya tomaría días de cómputo. Y si deseas trabajar con cualquier tipo de conjunto de datos real, eso implicaría años de cómputo.
Y puedes tener todo tipo de problemas, como que el método sea endiabladamente complicado de implementar y, por lo tanto, aunque en teoría puedas hacerlo bien, en la práctica siempre tendrás algún error estúpido que te impedirá lograr algo. O quizá el método tenga dependencias increíblemente sutiles en una larga serie de meta-parámetros, de modo que resulta casi un arte oscuro hacerlo funcionar porque tienes como 20 parámetros oscuros que necesitas ajustar de formas completamente desdocumentadas y que, por lo general, solo existen en la mente de los investigadores que produjeron el método.
Rob Hyndman: Eso es muy interesante porque, cuando miro métodos que han resistido la prueba del tiempo, muchos métodos súper clásicos –que, por ejemplo, produjiste para Hyndman– están dando resultados sorprendentemente buenos frente a métodos muy sofisticados. Durante la competencia M5 del año pasado, Lokad ocupó el sexto lugar entre 909 equipos en términos de exactitud de forecast para el forecast puntual. Pero lo hicimos con un modelo que era súper simple, casi el modelo paramétrico de forecast de libro, y utilizamos un pequeño truco de modelado ETS encima de eso para básicamente conseguir el efecto dispersión y la distribución probabilística.
Pero en definitiva, probablemente fue un modelo que podríamos haber resumido en una sola página con unos pocos coeficientes para las estacionalidades, el día de la semana, la semana del mes, la semana del año, y eso fue todo. Así que, literalmente, estuvimos a un uno por ciento de distancia del modelo más exacto que utilizaba gradient boosted trees, y sospecho que, en términos de complejidad del código, complejidad del modelo y opacidad general, estamos hablando de algo que es como dos órdenes de magnitud, si no tres, más complejo.
Joannes Vermorel: Eso es algo en lo que creo para el éxito de tus bibliotecas. Lo que realmente me gusta de los métodos es que la mayoría tiene una implementación elegante y es concisa. Así que, en términos de aplicabilidad, hay algo que es profundamente cierto y válido, donde obtienes la exactitud con el mínimo esfuerzo y complicaciones, en contraposición, diría yo, al otro lado del campo, el campo del deep learning. No tengo nada en contra del deep learning cuando quieres abordar problemas increíblemente difíciles, como, por ejemplo…
Kieran Chandler: Bienvenidos al episodio. Hoy tenemos a Joannes Vermorel, el fundador de Lokad, y a Rob Hyndman, Profesor de Estadística y Jefe del Departamento de Econometría y Estadísticas Empresariales de Monash University. Discutamos la traducción automática y la exactitud del modelo.
Joannes Vermorel: Desafío la sabiduría de tener un modelo que es un uno por ciento más exacto, pero que utiliza millones de parámetros y es increíblemente complejo y opaco. ¿Es realmente mejor desde una perspectiva científica? Tal vez no deberíamos distraernos por lograr un uno por ciento más de exactitud a costa de algo 1000 veces más complejo. Existe el peligro de perderse completamente. La buena ciencia, especialmente en forecast, debería centrarse en la esencia de lo que hace un buen forecast, dejando de lado distracciones que aportan un poco de exactitud extra pero tal vez a costa de muchísima confusión.
Rob Hyndman: Hay que equilibrar dos costos: el de producir el software y realizar el cómputo real, y el de la exactitud. En el mundo académico, el enfoque suele estar en la exactitud sin considerar el costo de cómputo o el desarrollo del código. Estoy de acuerdo contigo, Joannes, en que debemos tener en cuenta ambos. A veces no necesariamente deseas el método más exacto si va a tomar demasiado tiempo mantener el código y realizar el cómputo. Mis paquetes de forecast son robustos porque se desarrollaron a través de proyectos de consultoría. Estas funciones se aplicaron en diversos contextos, por lo que tuvieron que ser relativamente robustas. No quería que las empresas volvieran a mí diciendo que estaba roto o que no funcionaba en su conjunto de datos. El hecho de haber hecho mucha consultoría significa que esas funciones han manejado muchos datos antes de ser publicadas para el gran público. Además, tienen que ser relativamente rápidas, ya que la mayoría de las empresas no quieren esperar días para que ocurra algún cómputo MCMC en un modelo bayesiano sofisticado; quieren el forecast en un plazo razonable.
Kieran Chandler: ¿Cómo equilibras la robustez, la exactitud y el costo de implementar el modelo desde una perspectiva empresarial, Joannes?
Joannes Vermorel: Todo se reduce a lo que estás aportando. Por ejemplo, si tenemos un modelo paramétrico súper simplista, como el que usamos para la competencia M5, y logramos alcanzar un uno por ciento de la exactitud de un método de gradient booster trees muy sofisticado –que fue el ganador–, ¿vale la pena la complejidad añadida? El método ganador utilizó gradient booster trees con un esquema de aumento de datos muy sofisticado, que básicamente era una forma de inflar enormemente tu conjunto de datos.
Kieran Chandler: Eso es bastante grande y ahora terminas con un conjunto de datos que es como 20 veces mayor. Y luego aplicas un modelo súper pesado y complejo sobre eso. Entonces, la pregunta es, ¿estás aportando algo fundamentalmente nuevo y profundo? ¿Y cómo equilibras eso?
Joannes Vermorel: La forma en que equilibro eso es pensando si me falta un elefante en la habitación que realmente necesito tener en cuenta. Por ejemplo, si hablo de moda, obviamente la cannibalización y la sustitución son muy fuertes. La gente no entra a una tienda de moda pensando que quiere ese código de barras exacto. Ni siquiera es la forma adecuada de considerar el problema. La cannibalización y la sustitución están presentes por todas partes, y necesitas algo que abarque esa visión. Si me remito al sector automotriz, por ejemplo, y examino el mercado de repuestos automotrices, el problema es que la gente no compra repuestos porque le gustan los repuestos. Los compra porque su vehículo tiene un problema y quieren repararlo, punto final. Resulta que existe una matriz de compatibilidad súper compleja entre vehículos y repuestos. En Europa, hay más de 1 millón de repuestos distintos y más de 100,000 vehículos distintos. Y, generalmente, para cualquier problema que tengas, hay como una docena de repuestos diferentes compatibles, por lo que hay sustitución, pero a diferencia de la moda, se presenta de una forma completamente determinista. Las sustituciones son casi perfectamente conocidas y estructuradas, y se desea contar con un método que realmente aproveche el hecho de que no existe incertidumbre sobre ello.
Entonces, problema por problema, la forma en que equilibro eso es asegurándome de que, si queremos pagar por mayor sofisticación, realmente valga la pena. Por ejemplo, si tomo las librerías del Profesor Hyndman frente, digamos, a TensorFlow, solo para dar una idea, para la mayoría de tus modelos hablamos de probablemente kilobytes de código. Si observamos TensorFlow, solo una librería compilada tiene 800 megabytes y, en cuanto incluyes TensorFlow versión uno, casi estás incluyendo miles de millones de líneas de código.
A veces, la gente puede pensar que estamos discutiendo algo que es meramente una cuestión de matices de gris, y que no hay una respuesta correcta o incorrecta. Es simplemente una cuestión de gusto, si se puede tener de manera ligeramente más simple o un poco más complicada. Pero la realidad de lo que he observado es que, usualmente, no se trata solo de matices de gris. Estamos hablando de métodos con varios órdenes de magnitud de complejidad. Y así, si quiero hacer un forecast propio, por ejemplo, ¿cuáles son las probabilidades de que las librerías del Profesor Hyndman sigan vigentes dentro de 20 años, y cuáles son las probabilidades de que TensorFlow versión uno siga existiendo dentro de 20 años? Apostaría bastante dinero a que los métodos fundamentales de series temporales seguirán siendo relevantes.
Kieran Chandler: ¿Crees que la técnica de forecast seguirá existiendo dentro de 20 años?
Joannes Vermorel: Las cosas que incorporan literalmente miles de millones de líneas de complejidad accidental sobre las especificidades de las tarjetas gráficas que se han producido en los últimos cinco años desaparecerán. No estoy negando el hecho de que ha habido algunos avances absolutamente sorprendentes en deep learning. Lo que estoy diciendo es que realmente necesitamos entender el valor agregado, que varía bastante dependiendo de los problemas que estemos analizando. No deberíamos distraernos con la sofisticación. No es porque algo sea sofisticado que sea intrínsecamente más científico, preciso o válido. Puede ser más impresionante y al estilo de una charla TED, pero tenemos que tener mucho cuidado con eso.
Kieran Chandler: Rob, te dejaré la pregunta final a ti. En cuanto a lo que Joannes mencionó, con las cosas aún presentes en 10 a 20 años, ¿puedes ver que tus librerías sigan existiendo? ¿En qué estás trabajando hoy que crees que será útil en los próximos años?
Rob Hyndman: Mi primera librería pública fue alrededor de 2005, así que han durado 15 años hasta ahora. Estoy ciertamente comprometido a mantenerlas todas, incluso aquellas que considero han sido reemplazadas por otras. No requiere un gran esfuerzo hacerlo. Los paquetes más nuevos en los que estoy trabajando son este paquete llamado Fable, que implementa la mayoría de las mismas técnicas, pero de una forma diferente para facilitar a los usuarios el forecast de miles de series temporales simultáneamente. Fable y algunos paquetes asociados han estado disponibles durante un par de años, y mi libro de texto más reciente los utiliza. Espero que sean ampliamente utilizados al menos durante 10 años, y mientras yo sea capaz, los mantendré y me aseguraré de que sigan existiendo. Tengo la suerte de contar con un asistente muy bueno que me ayuda con el mantenimiento de los paquetes. Él también está comprometido con el mundo open-source y con sacar software de alta calidad en desarrollo de código abierto.
Kieran Chandler: Eso es genial, y el mundo open-source permite que todos tengan acceso a ello. Muchas gracias a ambos por su tiempo. Tendremos que dejarlo aquí, y gracias por sintonizar. Nos veremos de nuevo en el próximo episodio.