00:00:08 Introduzione e il background di Rob Hyndman nel campo delle previsioni.
00:01:31 Sostenibilità delle tecniche di forecasting nel mondo reale e dei software.
00:04:08 Applicazione delle tecniche di forecasting in diversi settori con dati abbondanti.
00:05:43 Le sfide di soddisfare le esigenze di vari settori nella supply chain.
00:07:30 Orientarsi nelle complessità del software aziendale e della raccolta dati.
00:08:00 Previsioni delle serie temporali e approcci alternativi.
00:09:05 Le sfide affrontate da Lokad nell’analisi predittiva.
00:11:29 Longevità e motivazione nello sviluppo di software accademici.
00:13:12 Il passaggio dalla previsione puntuale a quella probabilistica.
00:15:00 I difetti dei metodi accademici e la loro implementazione nel mondo reale.
00:16:01 La performance di un modello semplice in una competizione.
00:16:56 L’importanza di metodi eleganti e concisi.
00:18:48 Bilanciare accuratezza, complessità e costo nei modelli.
00:19:25 Robustezza e velocità nei pacchetti R per le previsioni.
00:20:31 Equilibrare robustezza, accuratezza e costi di implementazione in ambito aziendale.
00:21:35 L’importanza di metodi specifici per ogni problema nel forecasting.
00:23:00 Prevedere la longevità delle tecniche e delle librerie di forecasting.
00:25:29 L’impegno di Rob nel mantenere le sue librerie di forecasting.
00:26:12 Introduzione di Fable e la sua applicazione nelle previsioni delle serie temporali.
00:27:03 Apprezzare il mondo open source e il suo impatto sugli strumenti di forecasting.
Riepilogo
In un’intervista con Kieran Chandler, Joannes Vermorel, fondatore di Lokad, e Rob Hyndman, Professore di Statistica alla Monash University, discutono della sostenibilità delle tecniche di forecasting nel mondo reale. Il software open source di forecasting di Hyndman, scaricato da milioni di utenti, resiste alla prova del tempo ed è in grado di risolvere circa il 90% dei problemi di forecasting delle aziende. Gli ospiti evidenziano le sfide di rivolgersi a un pubblico ampio con esigenze diversificate nella supply chain industry e l’importanza di creare software user-friendly che sia efficace e accessibile. Sottolineano anche l’importanza del software open source e della collaborazione nello sviluppo di forecasting methods.
Riepilogo Esteso
In questa intervista, Kieran Chandler discute della sostenibilità delle tecniche di forecasting nel mondo reale con Joannes Vermorel, fondatore di Lokad, e Rob Hyndman, Professore di Statistica alla Monash University. Il software open source di forecasting di Hyndman è stato scaricato da milioni di utenti e resiste alla prova del tempo, a differenza di molti altri strumenti software.
Vermorel apprezza il lavoro di Hyndman per aver superato il tipico software accademico, creando un insieme completo di librerie, incorporando molti dei suoi risultati e fornendo un quadro coerente basato sul popolare linguaggio R per l’analisi statistica. Vermorel crede che ci siano pochi esempi di software scientifico che abbiano avuto una simile durabilità e seguito.
La ricerca accademica di Hyndman non si limita al forecasting nella supply chain; è interessato ad applicare le tecniche di forecasting in qualsiasi ambito con grandi quantità di dati. Il suo lavoro include la previsione del consumo elettrico, dei tassi di mortalità, della popolazione, del numero di turisti, e recentemente, dei casi di COVID-19 per il governo australiano. Oltre al forecasting, si occupa anche di rilevamento delle anomalie e di analisi dei dati.
Discutendo le sfide di rivolgersi a un pubblico ampio con esigenze diversificate nella supply chain, Vermorel spiega che il modo in cui i dati vengono percepiti e registrati dal enterprise software (ERP, MRP, WMS) è spesso semi-accidentale.
Affrontano le complicazioni derivanti dall’utilizzo di dati non raccolti principalmente per scopi di forecasting e il passaggio da un sistema di enterprise resource planning (ERP) all’altro. Discutono inoltre della necessità di tecniche di forecasting che possano adattarsi a diversi contesti IT e agli incidenti storici nell’implementazione del software aziendale.
Vermorel sottolinea l’importanza delle previsioni in contesti che non si prestano all’analisi delle time series, come la moda, dove l’ingegneria della domanda e l’introduzione di new products influenzano il problema del forecasting. Sottolinea la necessità che i modelli predittivi tengano conto dei cicli di feedback e delle azioni intraprese in base alle previsioni, oltre al controllo di vari fattori come l’assortimento dei prodotti e le strategie di promotion. Questo approccio multifaccettato è fondamentale per Lokad nell’affrontare le complesse sfide dell’analisi predittiva.
Hyndman spiega che il suo software per le serie temporali è in grado di risolvere circa il 90% dei problemi di forecasting delle aziende, mentre il restante 10% richiede approcci differenti. Affronta anche il problema dei software accademici di breve durata, attribuendolo alla focalizzazione sulla pubblicazione di articoli e alla mancanza di incentivi per mantenere il software a lungo termine. Ciò si traduce in una scarsa attenzione alla collaborazione con i professionisti e a garantire che i metodi siano ben documentati e duraturi.
L’intervista evidenzia le sfide e le complessità dell’ottimizzazione e del forecasting nella supply chain, inclusa la necessità di tecniche adattabili, l’importanza di considerare contesti non legati alle time series e l’influenza dei cicli di feedback e del decision-making sui modelli predittivi. Inoltre, sottolinea il divario tra la ricerca accademica e l’applicazione pratica nel campo del forecasting.
Entrambi gli ospiti sottolineano l’importanza di creare software user-friendly che sia al contempo efficace e accessibile per fare la differenza nel mondo.
Hyndman menziona il passaggio dalla previsione puntuale al probabilistic forecasting nella letteratura accademica negli ultimi 15 anni. Lokad è stata una delle prime aziende di forecasting nella supply chain a incorporare questo cambiamento nel loro software. Poiché il software iniziale di Hyndman si concentrava sulle previsioni puntuali, i suoi pacchetti più recenti danno priorità alle previsioni probabilistiche.
Vermorel evidenzia le criticità nascoste in molte pubblicazioni accademiche, come l’instabilità numerica, i tempi computazionali eccessivi o l’implementazione complessa. Sottolinea inoltre l’importanza di bilanciare l>accuracy< con la semplicità, poiché modelli troppo complicati potrebbero non essere pratici o necessari. Vermorel fornisce un esempio dalla competizione M5, dove Lokad ha raggiunto un’elevata accuratezza utilizzando un modello relativamente semplice.
Hyndman concorda sul fatto che è essenziale bilanciare i costi di produzione del software, il calcolo e l’accuratezza. Entrambi gli ospiti apprezzano metodi di forecasting concisi ed eleganti, con ampia applicabilità, come quelli presenti nelle librerie di Hyndman.
La conversazione solleva domande sui trade-offs tra accuratezza e complessità nei modelli di forecasting. Vermorel mette in discussione l’idea di cercare un leggero miglioramento dell’accuratezza a scapito di una complessità molto maggiore, come si vede nei modelli di deep learning. Sia Vermorel che Hyndman sottolineano l’importanza di concentrarsi sull’essenza di buone previsioni senza perdersi in miglioramenti minimi che potrebbero non giustificare la complessità aggiuntiva.
Hyndman sottolinea l’importanza di considerare sia l’accuratezza che il costo computazionale nello sviluppo dei metodi di forecasting. Attribuisce la robustezza dei suoi pacchetti di forecasting alle loro origini in progetti di consulenza, dove dovevano essere rapidi, affidabili e applicabili a vari contesti.
Vermorel evidenzia l’importanza di considerare il valore aggiunto che un metodo di forecasting può apportare a un problema. Confronta modelli parametrici semplici con metodi più complessi come gli alberi di gradient boosting, osservando che in alcuni casi i modelli più semplici possono essere sufficienti. Vermorel discute anche le sfide uniche del forecasting in settori come la moda e l’automotive aftermarket, dove i fattori di sostituzione e compatibilità giocano un ruolo significativo.
Gli intervistati sottolineano l’importanza di non lasciarsi distrarre dalla sofisticazione, poiché non equivale necessariamente a risultati scientifici o a una maggiore accuratezza. Vermorel prevede che le tecniche fondamentali di forecasting delle serie temporali saranno ancora rilevanti tra 20 anni, mentre metodi complessi basati sull’hardware attuale potrebbero diventare obsoleti.
Rob Hyndman discute del suo lavoro sul forecasting, in particolare dello sviluppo del pacchetto software open source “Fable”, che semplifica il processo di forecasting per migliaia di serie temporali simultaneamente. Sottolinea il suo impegno a mantenere il pacchetto per almeno 10 anni e evidenzia i benefici del software open source, inclusa la collaborazione e l’accessibilità.
Sia Vermorel che Hyndman evidenziano l’importanza del software open source nel loro lavoro e il potenziale della collaborazione nello sviluppo di metodi di forecasting di alta qualità. Hyndman menziona anche la sua dedizione nel mantenere le librerie pubbliche, presenti fin dal 2005, e il ruolo che esse svolgono nel rendere l’analisi dei dati accessibile al pubblico.
Nel complesso, l’intervista evidenzia le sfide del forecasting in un mondo complesso e in rapida evoluzione e l’importanza del software e della collaborazione nello sviluppo di soluzioni efficaci. L’attenzione al software open source e all’accesso pubblico sottolinea il valore nel rendere l’analisi dei dati e il forecasting disponibili a un pubblico più ampio.
Entrambi gli intervistati apprezzano la natura open source del loro lavoro, che consente un accesso diffuso e la collaborazione nello sviluppo di metodi di forecasting di alta qualità.
Trascrizione Completa
Kieran Chandler: Il forecasting è una pratica antica in costante evoluzione, e di conseguenza, molti software non resistono alla prova del tempo. Una persona che ha sfidato questa tendenza è il nostro ospite di oggi, Rob Hyndman, che ha implementato un software open source scaricato da milioni di utenti. Perciò, oggi discuteremo con lui della sostenibilità delle tecniche di forecasting nel mondo reale. Quindi, Rob, grazie mille per esserti unito a noi in diretta dall’Australia. So che per te è un po’ tardi. Come sempre, ci piace iniziare conoscendo un po’ i nostri ospiti, quindi forse potresti iniziare raccontandoci qualcosa di te stesso.
Rob Hyndman: Grazie, Kieran, è un piacere essere qui. Sì, qui in Australia sono le 20:00, quindi non è così tardi. Sono Professore di Statistica e Capo del Dipartimento di Econometria e Statistica Aziendale alla Monash University. Ci sono da 26 anni. Per la maggior parte di questo periodo, sono stato anche Editor-in-Chief dell’International Journal of Forecasting e Direttore dell’International Institute of Forecasters, dal 2005 al 2018. Sono un accademico; scrivo molti articoli, e ho scritto alcuni libri, tra cui tre sul forecasting. Se non sto facendo questo, di solito gioco a tennis.
Kieran Chandler: Bello, anche a me piace giocare a tennis in estate. Forse un giorno potremo vederti per una partita. Joannes, oggi il nostro argomento è la sostenibilità delle tecniche di forecasting nel mondo reale e l’idea che un piece of software possa essere sostenibile e durare a lungo. Qual è l’idea alla base di ciò?
Joannes Vermorel: La maggior parte dei software tende a decadere nel tempo per vari motivi. Quando si tratta di software scientifico, bisogna considerare come viene prodotto. Di solito, viene creato per supportare la pubblicazione di un articolo, quindi è sostanzialmente un software usa e getta. Ciò che ho trovato notevole nel lavoro del Professor Hyndman è che ha superato ciò che di solito avviene nei circoli accademici, ovvero produrre software usa e getta, pubblicare l’articolo, finire e passare al successivo. Ha infatti costruito un vasto insieme di librerie che non solo incorporavano molti dei suoi risultati e quelli dei suoi colleghi, ma fornivano anche un quadro molto coerente basato su un linguaggio divenuto molto popolare, ovvero R, un ambiente per l’analisi statistica. Questo ha dimostrato il suo valore nel corso di decenni, ed è davvero un risultato notevole. La maggior parte dei software che vediamo oggi è vecchia, con pochissime fondamenta che emergono da Unix e da concetti più sofisticati. In termini di data science, non ci sono molti esempi di cose che resistono alla prova del tempo, a parte i blocchi elementari per l’algebra lineare e campi simili.
Kieran Chandler: … analisi, ma se ci si pensa davvero, potrei probabilmente elencare una dozzina di esempi di software che sono riusciti ad avere un tale seguito e durabilità. Tuttavia, in realtà non ce ne sono molti. Credo che ci sia qualcosa di veramente notevole qui che va oltre ciò che solitamente si fa nella ricerca accademica. Rob, parliamo un po’ di più della tua ricerca accademica. Ovviamente non ti concentri solo sul mondo della supply chain come noi qui. Quindi, in quali altri ambiti sei interessato ad applicare le tecniche di forecasting?
Rob Hyndman: Mi interessa qualsiasi cosa che mi permetta di ottenere tanti dati. Ad esempio, faccio previsioni sul consumo di elettricità, dove ci sono molti dati davvero buoni che risalgono a decenni fa. Prevedo i tassi di mortalità, la popolazione e, ultimamente, ho lavorato sui numeri dei turisti, che è una cosa piuttosto difficile da prevedere nel bel mezzo di una pandemia. Ho aiutato il governo australiano a riflettere su come funziona. Un altro incarico che sto svolgendo per il governo australiano è prevedere i casi di COVID-19. È il mio primo tentativo di fare qualcosa nel campo epidemiologico, e ho dovuto imparare parecchio dell’approccio epidemiologico alla modellizzazione e integrarlo in alcuni ensemble di previsioni. È stato interessante. Fondamentalmente, se ci sono abbondanti dati, sono interessato a cercare di modellizzarli. Mi occupo anche di rilevamento delle anomalie e di analisi esplorativa dei dati quando si tratta di grandi raccolte di dati. Ho collaborato con molte aziende e organizzazioni governative, e se mi si presenta un problema che coinvolge un bel po’ di dati, mi interessa pensare a come fare previsioni migliori rispetto a quanto sta accadendo attualmente.
Kieran Chandler: Ottimo, posso immaginare che l’industria turistica in questo momento sia piuttosto interessante. È una vera anomalia dal punto di vista delle previsioni. Johannes, il nostro focus è ovviamente sull’industria della supply chain, ma l’idea è che non ci limitiamo a un solo settore. Ci rivolgiamo a un pubblico molto ampio, quindi quali tipi di sfide si possono presentare quando si cerca di soddisfare così tante persone con esigenze così diverse?
Joannes Vermorel: Innanzitutto, è semplicemente il modo in cui percepiamo il mondo. Non possediamo qualcosa che somigli a una misurazione scientifica, come le statistiche stabilite per le mortalità o altre cose. Quello che esiste è il software aziendale, come ERP, MRP e WMS, che producono o registrano dati in modo quasi semi-accidentale. La raccolta dei dati non era il motivo per cui tutti quei software sono stati implementati, così ci si ritrova con dei record che non sono stati concepiti come strumenti per effettuare misurazioni nel tempo da cui poter fare previsioni. Si tratta di un sottoprodotto quasi accidentale, e questo crea un sacco di complicazioni. Una delle sfide è capire se, in termini di tecniche di previsione e ricerca mirata, si riesce a creare qualcosa che sopravviva al passaggio da un ERP all’altro. Se cambi il sistema, che è molto disordinato e accidentale, devi considerare come ciò influenzerà il processo di previsione.
Kieran Chandler: Quindi, il prossimo argomento di cui vorrei discutere è il diverso panorama IT e gli incidenti storici in termini di implementazione di vari strumenti di software aziendale. Se devi cambiare completamente il metodo, ovviamente non stai accumulando nessun insieme di conoscenze o tecniche. Una delle sfide è: puoi fare qualcosa in quest’area? E, dal nostro punto di vista in Lokad, le previsioni che ci interessano maggiormente sono tipicamente quelle che non si presentano naturalmente come serie temporali. E se hai un problema che non si presta ad essere inquadrato comodamente come una serie temporale? Hai comunque bisogno di qualcosa che somigli a una previsione, ma che si presenti in modi molto differenti. Rob, quali sono i tuoi pensieri sull’uso di alternative alle previsioni basate su serie temporali?
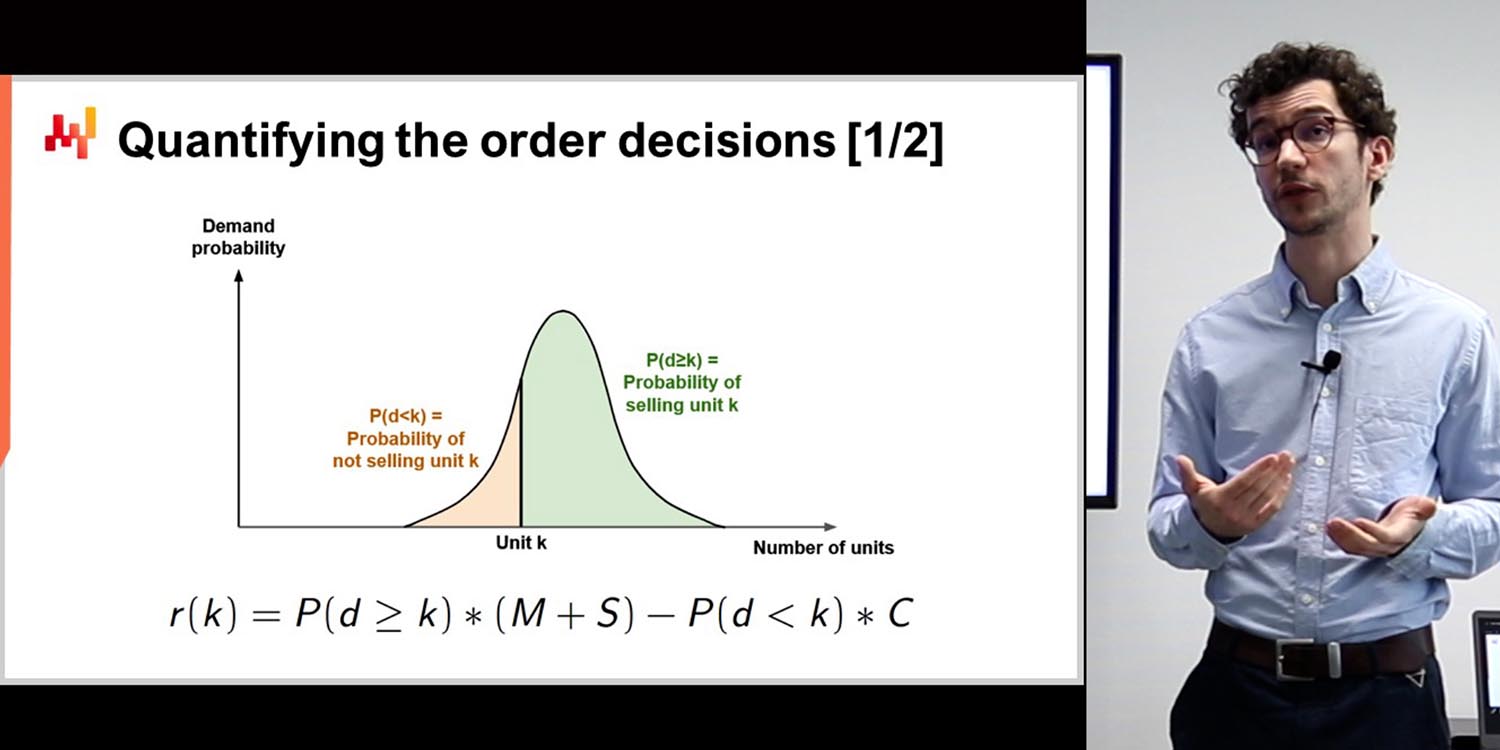
Rob Hyndman: Beh, dipende molto dai dati, come ha detto Joannes, per determinare quale tipo di modello sarà necessario costruire per quel particolare problema. Il mio software per serie temporali gestisce molti problemi, ma non tutti. Alcune aziende avranno un dataset strutturato o registrato in un modo tale che dovranno modificarlo o trovare una soluzione diversa. Il software che ho scritto, e che è il più popolare, risolve il 90% dei problemi di previsione delle aziende; è il restante 10% per cui bisogna fare altre cose.
Kieran Chandler: Quanto spesso diresti che c’è quel tipo di 10% nella tua esperienza, Joannes?
Joannes Vermorel: È un problema molto sottile. Il mio percorso nel mondo delle previsioni in Lokad mi ha fatto comprendere quanta profondità ci sia. Prima, siamo passati dalle previsioni puntuali a quelle probabilistiche, cambiando il modo in cui affrontiamo il problema. Ma è ancora più profondo di così. Ad esempio, se consideriamo la moda, il problema è che vuoi prevedere la domanda per sapere cosa produrre. Tuttavia, quando decidi cosa produrre, hai la flessibilità di introdurre più o meno prodotti. Quindi, l’idea stessa di avere serie temporali da prevedere dipende dalle tue decisioni. Nella moda, ad esempio, il fatto di introdurre un prodotto in più nel tuo assortimento fa parte del problema predittivo. Vuoi non solo prevedere la domanda, ma anche influenzarla. Nel nostro percorso, ci siamo resi conto che esistono incertezze irriducibili che ci offrono una prospettiva completamente ortogonale rispetto alla classica visione delle previsioni puntuali. Ma dobbiamo anche gestire tutti i loop di feedback.
Kieran Chandler: Quindi, Joannes, puoi dirci come i modelli predittivi influenzano l’ottimizzazione della supply chain?
Joannes Vermorel: Quando facciamo una previsione, compiamo un’azione più informata. Questo ha un’influenza profonda sul modo in cui vogliamo costruire i nostri modelli predittivi. Poi possiamo aggiungere altre variabili, come il controllo del grado di prodotti, i prezzi, il messaggio e persino la promozione dei prodotti. Se continuo con l’esempio della moda, prevedi le quantità che desideri avere e poi decidi che, nei tuoi negozi, alcuni prodotti saranno esposti in modo molto più permanente rispetto ad altri. Ciò ha un impatto profondo su ciò che osserverai. La sfida che Lokad ha affrontato nell’ambito dell’analisi predittiva è stata quella di abbracciare problemi osservando i numerosi angoli da cui si presentano, complicando la pura prospettiva delle serie temporali.
Kieran Chandler: Va bene, Rob, forse passiamo ora a discutere da un punto di vista accademico. Molte persone creano software esclusivamente per un articolo e poi lo abbandonano quasi. Perché pensi che non ci sia abbastanza longevità in alcuni dei software che le persone stanno creando?
Rob Hyndman: Beh, devi considerare la motivazione della maggior parte degli accademici. Vengono pagati per scrivere articoli e insegnare corsi. Una volta scritto l’articolo, potrebbe esserci qualche incentivo a rilasciare del software per implementarlo. Ma per la maggior parte degli accademici non c’è una vera ricompensa nel farlo, e sicuramente non c’è una ricompensa nel mantenere quel software per un lungo periodo. Chi lo fa lo fa perché ci tiene o perché è un lavoro di passione. Non è davvero ciò per cui vengono pagati. Non è il loro core business. Penso che questo sia un problema nel mondo accademico. C’è così tanto concentramento sull’uscita di nuovi metodi e sulla loro pubblicazione, e non abbastanza sull’interazione con la comunità dei professionisti e sull’assicurarsi che i metodi siano ben documentati e che esista un software user-friendly disponibile a lungo termine. È un problema di motivazione nel mondo accademico. La mia motivazione è che, quando sviluppo una nuova metodologia, voglio che le persone la usino. Non voglio semplicemente pubblicare un articolo e che venga letto da una dozzina di persone o magari da 100, se sono fortunato. Voglio che i miei metodi facciano veramente la differenza nel mondo.
Joannes Vermorel: I modelli predittivi sono diventati più complicati, e non è facile renderli robusti. In Lokad, dobbiamo mantenere molto codice vecchio per far funzionare i nostri modelli. La sfida è che non puoi semplicemente ideare un modello sofisticato e lasciarlo così com’è. Devi avere un modo per spiegare cosa fa il modello e perché lo fa. Devi assicurarti che il modello sia ben documentato e che le persone possano utilizzarlo praticamente. Non è una cosa semplice da fare, ma è importante se vuoi che i tuoi modelli vengano adottati.
Rob Hyndman: Penso sia anche interessante che, con il passare del tempo, vengono sviluppati nuovi metodi, e quindi bisogna fornire nuovo software o nuovi strumenti che tengano conto degli sviluppi nelle previsioni. Uno di questi, menzionato da Joannes, è il passaggio dalle previsioni puntuali a quelle probabilistiche, che si è verificato nella letteratura accademica negli ultimi 15 anni, forse, e Lokad è stato molto veloce nell’adottarlo e nel rilasciare previsioni probabilistiche. Credo sia probabilmente una delle prime aziende di previsioni della supply chain al mondo a farlo. Il mio software iniziale, sebbene producesse previsioni probabilistiche, poneva sempre l’accento sulle previsioni puntuali,
Kieran Chandler: Negli ultimi anni, l’enfasi si è invertita. Prima si ottengono le previsioni probabilistiche e poi quelle puntuali.
Joannes Vermorel: Una delle mie critiche a molte pubblicazioni accademiche è che solitamente si finisce per avere una miriade di difetti nascosti nei metodi. Quindi hai un metodo di cui sai che supererà i benchmark, ma quando vuoi implementarlo realmente, scopri che, per esempio, è numericamente estremamente instabile o che i tempi di calcolo sono ridicolosamente lunghi al punto che, se usi un dataset di prova, ci vorranno già giorni di calcolo. E se vuoi utilizzare un dataset reale, si parlerebbe addirittura di anni di calcolo.
E puoi avere ogni sorta di problemi, come il fatto che il metodo sia diavolosamente complicato da implementare e quindi, anche se in teoria riesci a farlo funzionare, in pratica avrai sempre qualche stupido bug che ti impedirà di ottenere risultati. Oppure il metodo può avere dipendenze incredibilmente sottili su una lunga serie di meta-parametri, tanto che diventa quasi un’arte oscura farlo funzionare, perché hai tipo 20 parametri oscuri che devi regolare in modi completamente non documentati e normalmente noti solo ai ricercatori che hanno elaborato il metodo.
Rob Hyndman: È molto interessante, perché quando guardo ai metodi che resistono alla prova del tempo, molti metodi super classici che sono stati prodotti, ad esempio per Hyndman, danno risultati sorprendentemente buoni rispetto a metodi molto sofisticati. Durante la competizione M5 dello scorso anno, Lokad si è classificata sesta tra 909 team in termini di accuratezza delle previsioni puntuali. Ma lo abbiamo fatto con un modello estremamente semplice, quasi il modello parametrico da manuale, e abbiamo usato un piccolo trucco di modellazione ETS sopra di esso per ottenere fondamentalmente l’effetto “shotgun” e la distribuzione probabilistica.
Ma, in definitiva, probabilmente era un modello che avremmo potuto riassumere in una pagina con qualche coefficiente per le stagionalità, il giorno della settimana, la settimana del mese, la settimana dell’anno, e basta. Quindi, letteralmente, siamo scesi a solo un uno per cento di distanza dal modello più accurato che utilizzava gradient boosted trees, e sospetto che, in termini di complessità del codice, complessità del modello e opacità complessiva, stiamo parlando di qualcosa di circa due ordini di grandezza, se non tre, più complesso.
Joannes Vermorel: Questo è qualcosa in cui credo per il successo delle vostre librerie. Quello che mi piace veramente dei metodi è che la maggior parte di essi ha un’implementazione elegante ed è concisa. Quindi, in termini di applicabilità, c’è qualcosa di profondamente vero e valido, in cui si ottiene l’accuratezza con il minimo sforzo e complicazioni, al contrario, direi, del campo del deep learning. Non ho niente contro il deep learning quando si vuole affrontare problemi incredibilmente difficili, come, diciamo per esempio…
Kieran Chandler: Benvenuti all’episodio. Oggi abbiamo Joannes Vermorel, il fondatore di Lokad, e Rob Hyndman, Professore di Statistica e Capo del Dipartimento di Econometria e Statistica Aziendale presso la Monash University. Discutiamo di traduzione automatica e dell’accuratezza dei modelli.
Joannes Vermorel: Metto in discussione la saggezza di avere un modello che sia dell’uno per cento più accurato, ma che richieda milioni di parametri, ed è incredibilmente complesso e opaco. È veramente migliore da un punto di vista scientifico? Forse non dovremmo distrarci cercando di ottenere un uno per cento di accuratezza in più a scapito di qualcosa di 1000 volte più complesso. C’è il rischio di perdersi completamente. La buona scienza, specialmente nelle previsioni, dovrebbe concentrarsi sull’essenza di ciò che rende una buona previsione, lasciando da parte le distrazioni che apportano un minimo in più di accuratezza ma magari a costo di molta confusione.
Rob Hyndman: Devi bilanciare i due costi: il costo di produrre il software e di eseguire il calcolo vero e proprio, e il costo dell’accuratezza. Nel mondo accademico, l’attenzione è solitamente rivolta all’accuratezza, senza considerare il costo del calcolo o dello sviluppo del codice. Sono d’accordo con te, Joannes, sul fatto che dobbiamo tenerne conto entrambi. A volte non vuoi necessariamente il metodo più accurato se questo richiede troppo tempo sia per mantenere il codice sia per eseguire i calcoli. I miei pacchetti di previsione sono robusti perché sono stati sviluppati attraverso progetti di consulenza. Queste funzioni sono state applicate in vari contesti, quindi dovevano essere relativamente robuste. Non volevo che le aziende tornassero da me dicendo che era rotto o che non funzionava sul loro dataset. Il fatto che abbia fatto molta consulenza significa che quelle funzioni hanno già avuto a che fare con un sacco di dati prima di essere rilasciate al pubblico. Devono anche essere relativamente veloci, perché la maggior parte delle aziende non vuole aspettare giorni affinché avvenga un calcolo MCMC su un modello bayesiano sofisticato; vogliono la previsione in un tempo ragionevole.
Kieran Chandler: Come bilanci robustezza, accuratezza e il costo di implementare il modello da un punto di vista aziendale, Joannes?
Joannes Vermorel: Alla fine, tutto si riduce a ciò che stai aggiungendo. Ad esempio, se abbiamo un modello parametrico super semplice come quello che abbiamo usato per la competizione M5 e raggiungiamo un uno per cento dell’accuratezza di un metodo a gradient booster trees molto sofisticato, che era il vincitore, vale la pena della complessità aggiuntiva? Il metodo vincente ha utilizzato gradient booster trees con uno schema di data augmentation molto elaborato, che era fondamentalmente un modo per espandere enormemente il tuo dataset.
Kieran Chandler: Questo è piuttosto grande e alla fine ti ritrovi con un dataset che è circa 20 volte più grande. E poi applichi un modello super pesante e complesso sopra a quello. Quindi, la domanda è: stai portando qualcosa di fondamentalmente nuovo e profondo? E come bilanci tutto ciò?
Joannes Vermorel: Il modo in cui bilancio tutto ciò è pensando se mi manca un elefante nella stanza che devo davvero prendere in considerazione. Ad esempio, se parlo di moda, ovviamente cannibalizzazione e sostituzione sono estremamente forti. Le persone non entrano in un negozio di moda pensando di voler esattamente quel codice a barre. Non è nemmeno il modo giusto di affrontare il problema. Cannibalizzazione e sostituzione sono ovunque, e serve qualcosa che abbracci questa visione. Se passo all’automotive, per esempio, e guardo ai mercati aftermarket dell’automotive, il problema è che le persone non acquistano pezzi di ricambio perché amano i pezzi di ricambio. Li acquistano perché il loro veicolo ha un problema e vogliono ripararlo, fine della storia. Si scopre che esiste una matrice di compatibilità super complessa tra veicoli e pezzi di ricambio. In Europa, ci sono oltre 1 milione di pezzi di ricambio distinti e oltre 100.000 veicoli distinti. E di solito, per ogni problema che si presenta, ci sono una dozzina di pezzi di ricambio compatibili, quindi c’è la sostituzione, ma a differenza della moda, si presenta in maniera completamente deterministica. Le sostituzioni sono quasi perfettamente note e strutturate, e si desidera un metodo che sfrutti davvero il fatto che non c’è alcuna incertezza a riguardo.
Quindi, problema per problema, il modo in cui bilancio ciò consiste nel fare in modo che, se vogliamo pagare per una sofisticazione extra, ne valga davvero la pena. Ad esempio, se prendo le librerie del Professor Hyndman rispetto, per esempio, a TensorFlow, solo per dare un’idea, per la maggior parte dei modelli di cui parliamo, si tratta probabilmente di kilobyte di codice. Se osserviamo TensorFlow, solo una libreria compilata pesa 800 megabyte, e appena includi TensorFlow versione uno, stai quasi includendo miliardi di righe di codice.
A volte, le persone potrebbero pensare che stiamo discutendo di qualcosa che è solo una questione di sfumature di grigio, e che non esista una risposta giusta o sbagliata. È solo una questione di gusto, se può essere leggermente più semplice o leggermente più complicato. Ma la realtà di ciò che ho osservato è che, di solito, non si tratta solo di sfumature di grigio. Stiamo parlando di metodi con diversi ordini di grandezza di complessità. E quindi, se volessi fare una mia previsione, per esempio, quali sono le probabilità che le librerie del Professor Hyndman siano ancora attuali tra 20 anni, e quali sono le probabilità che TensorFlow versione uno esista ancora tra 20 anni? Scommetterei parecchio sull’idea che i metodi fondamentali delle serie temporali rimarranno rilevanti.
Kieran Chandler: Pensi che la tecnica di previsione sarà ancora in uso tra 20 anni?
Joannes Vermorel: Le cose che inglobano letteralmente miliardi di righe di complessità accidentale riguardo alle specificità delle schede grafiche prodotte negli ultimi cinque anni spariranno. Non nego il fatto che ci siano stati alcuni sviluppi assolutamente stupefacenti nel deep learning. Quello che sto dicendo è che dobbiamo davvero comprendere il valore aggiunto, che varia notevolmente a seconda dei problemi esaminati. Non dovremmo essere distratti dalla sofisticazione. Non è perché qualcosa è sofisticato che è intrinsecamente più scientifico, accurato o valido. Può essere più impressionante e in stile TED talk, ma dobbiamo esserne molto cauti.
Kieran Chandler: Rob, lascio a te l’ultima domanda. In termini di ciò di cui ha parlato Joannes, di cose che saranno ancora presenti tra 10 o 20 anni, vedi che le tue librerie saranno ancora lì? Su cosa stai lavorando oggi che pensi sarà utile negli anni a venire?
Rob Hyndman: La mia prima libreria pubblica risale al 2005, quindi sono passati ormai 15 anni. Sono sicuramente impegnato a mantenerle tutte, anche quelle che considero essere state superate da altre. Non richiede uno sforzo enorme farlo. I pacchetti più recenti su cui sto lavorando sono quel pacchetto chiamato Fable, che implementa la maggior parte delle stesse tecniche ma in modo diverso per rendere più facile agli utenti prevedere migliaia di serie temporali simultaneamente. Fable e alcuni pacchetti associati sono in circolazione da un paio d’anni, e il mio nuovo libro di testo li utilizza. Mi aspetto che saranno ampiamente usati per almeno 10 anni, e finché sarò in grado, li manterrò e mi assicurerò che rimangano disponibili. Sono fortunato ad avere un assistente molto valido che mi aiuta con la manutenzione dei pacchetti. È anche impegnato nel mondo open-source e nel rilasciare software di alta qualità in sviluppo open-source.
Kieran Chandler: È fantastico, e il mondo open-source permette a tutti di avere accesso a esso. Grazie mille a entrambi per il vostro tempo. Dovremo lasciarlo qui, e grazie per averci seguito. Ci vediamo nel prossimo episodio.