00:01 Введение
02:44 Обзор прогнозных потребностей
05:57 Модели против моделирования
12:26 История до сих пор
15:50 Немного теории и немного практики
17:41 Дифференцируемое программирование, SGD 1/6
24:56 Дифференцируемое программирование, автодифференцирование 2/6
31:07 Дифференцируемое программирование, функции 3/6
35:35 Дифференцируемое программирование, метапараметры 4/6
37:59 Дифференцируемое программирование, параметры 5/6
40:55 Дифференцируемое программирование, особенности 6/6
43:41 Обзор, прогнозирование спроса в розничной торговле
45:49 Обзор, подгонка параметров 1/6
53:14 Обзор, общие параметры 2/6
01:04:16 Обзор, маскирование потерь 3/6
01:09:34 Обзор, интеграция ковариативов 4/6
01:14:09 Обзор, разреженное разложение 5/6
01:21:17 Обзор, свободное масштабирование 6/6
01:25:14 Белый ящик
01:33:22 Возвращение к экспериментальной оптимизации
01:39:53 Заключение
01:44:40 Предстоящая лекция и вопросы аудитории
Описание
Дифференцируемое программирование (DP) - это генеративная парадигма, используемая для создания широкого класса статистических моделей, которые отлично подходят для прогнозирования вызовов в сфере поставок. DP превосходит практически всю “классическую” литературу по прогнозированию на основе параметрических моделей. DP также превосходит “классические” алгоритмы машинного обучения - почти до конца 2010-х годов - в практическом использовании для целей управления цепями поставок, включая простоту применения практикующими специалистами.
Полный текст

Добро пожаловать на эту серию лекций по цепи поставок. Я - Жоанн Верморель, и сегодня я буду представлять “Структурированное прогнозирование моделирования с использованием дифференцируемого программирования в цепи поставок”. Выбор правильного действия требует подробного количественного понимания будущего. Действительно, каждое решение - покупка большего количества, производство большего количества - отражает определенное предвидение будущего. Неизменно, основная теория цепи поставок подчеркивает понятие прогнозирования для решения этой проблемы. Однако, перспектива прогнозирования, по крайней мере в классической форме, недостаточна по двум фронтам.
Во-первых, она акцентирует внимание на узкой перспективе прогнозирования временных рядов, что, к сожалению, не учитывает разнообразие проблем, с которыми сталкиваются реальные цепи поставок. Во-вторых, она акцентирует внимание на узкой фокусировке на точности прогнозирования временных рядов, что также в значительной степени упускает суть. Получение нескольких дополнительных процентных пунктов точности не автоматически приводит к генерации дополнительных долларов прибыли для вашей цепи поставок.
Цель данной лекции - открыть альтернативный подход к прогнозированию, который является частично технологией и частично методологией. Технология будет представлена дифференцируемым программированием, а методология - структурированными прогностическими моделями. К концу этой лекции вы сможете применить этот подход к ситуации в цепи поставок. Этот подход не является теоретическим; он является основным подходом Lokad уже несколько лет. Кроме того, если вы не смотрели предыдущие лекции, эта лекция не должна быть совершенно непонятной. Однако в этой серии лекций мы подходим к моменту, когда будет очень полезно, если вы действительно смотрите лекции последовательно. В данной лекции мы вернемся к нескольким элементам, которые были введены в предыдущих лекциях.

Прогнозирование будущего спроса является очевидным кандидатом, когда речь идет о изучении прогностических потребностей нашей цепи поставок. Действительно, лучшее предвидение спроса является критическим компонентом для очень простых решений, таких как покупка большего количества товара и производство большего количества товара. Однако, благодаря принципам цепи поставок, которые мы представили в течение третьей главы этой серии лекций, мы видели, что существует довольно разнообразный набор ожиданий, которые вы можете иметь в отношении прогностических требований для управления вашей цепью поставок.
В частности, например, сроки поставки варьируются, и сроки поставки имеют сезонные закономерности. Практически каждое решение, связанное с запасами, требует предвидения будущего спроса, а также предвидения будущего срока поставки. Таким образом, сроки поставки должны быть прогнозируемыми. Возвраты иногда составляют до половины потока. Это так, например, в случае электронной коммерции модной одежды в Германии. В таких ситуациях предвидение возвратов становится критическим, и эти возвраты существенно различаются от одного продукта к другому. Таким образом, в таких ситуациях возвраты должны быть прогнозируемыми.
Со стороны поставщика само производство может варьироваться, и не только из-за дополнительных задержек или изменяющихся сроков поставки. Например, производство может сопровождаться определенной степенью неопределенности. Это происходит в низкотехнологичных отраслях, таких как сельское хозяйство, но может также происходить в высокотехнологичных отраслях, таких как фармацевтическая промышленность. Таким образом, также должны быть прогнозируемыми и результаты производства. Наконец, поведение клиента также имеет большое значение. Например, важно стимулировать спрос на продукты, которые генерируют привлечение, и, наоборот, сталкиваться с дефицитом товара, когда эти продукты отсутствуют именно из-за дефицита товара, также имеет большое значение. Таким образом, эти поведения требуют анализа, прогнозирования - другими словами, прогнозирования. Главный вывод здесь заключается в том, что прогнозирование временных рядов - это только часть головоломки. Нам нужен прогностический подход, который может охватить все эти ситуации и многое другое, так как это необходимо, если мы хотим иметь подход, который имеет хоть какие-то шансы на успех при столкновении со всеми ситуациями, с которыми сталкивается реальная цепь поставок.

Подход, который стал общепринятым при решении прогностической проблемы, - это представление модели. Этот подход определял литературу по прогнозированию временных рядов на протяжении десятилетий и до сих пор, я бы сказал, является основным подходом в кругах машинного обучения в наши дни. Этот подход, сосредоточенный на модели, так я назову этот подход, настолько распространен, что может быть даже трудно на время отойти в сторону, чтобы оценить, что на самом деле происходит с этой модельно-ориентированной перспективой.
Мое предложение для этой лекции заключается в том, что цепочка поставок требует техники моделирования, моделирования-ориентированной перспективы, и то, что серия моделей, как бы обширна она ни была, никогда не будет достаточной для решения всех наших требований, как они представлены в реальных цепях поставок. Давайте проясним эту разницу между модельно-ориентированным подходом и моделированием-ориентированным подходом.
Подход, сосредоточенный на модели, прежде всего подчеркивает модель. Модель поставляется в виде пакета, набора численных рецептов, которые обычно представлены в виде программного обеспечения, которое можно запустить. Даже если такого программного обеспечения нет, ожидается, что модель будет описана с математической точностью, позволяющей полностью повторить модель. Этот пакет, модель, сделанная программным обеспечением, должен быть конечной целью.
С идеализированной точки зрения эта модель должна вести себя точно так же, как математическая функция: входы внутрь, результаты на выходе. Если для модели остается какая-либо настраиваемость, то эти настраиваемые элементы рассматриваются как нерешенные проблемы. Действительно, каждая опция конфигурации ослабляет положение модели. Когда у нас есть настраиваемость и слишком много вариантов с точки зрения модели, модель начинает растворяться в пространстве моделей, и внезапно мы уже не можем сравнивать ничего, потому что не существует такой вещи, как единая модель.
Моделирование подходит к настраиваемости совершенно по-другому. Максимизация выразительности модели становится конечной целью. Это не ошибка; это становится особенностью. Ситуация может быть довольно запутанной, когда мы смотрим на моделирование-ориентированную перспективу, потому что если мы смотрим на представление моделирования-ориентированной перспективы, то мы увидим представление моделей. Однако эти модели имеют совершенно иное назначение.
Если вы принимаете моделирующую перспективу, то модель, которая представлена, является всего лишь иллюстрацией. Она не имеет намерения быть полной или окончательным решением проблемы. Это всего лишь шаг в путешествии, чтобы проиллюстрировать саму технику моделирования. Основной проблемой с техникой моделирования является то, что внезапно становится очень сложно оценить подход. Действительно, мы теряем наивную возможность сравнения, потому что с этой моделирующей перспективой у нас есть потенциальности моделей. Мы не сосредотачиваемся на одной модели по сравнению с другой; это даже не правильное мышление. У нас есть обоснованное мнение.
Однако я хотел бы сразу же указать, что не потому, что у вас есть бенчмарк и числа, прикрепленные к вашему бенчмарку, это автоматически квалифицируется как наука. Числа могут быть просто бессмысленными, и, наоборот, не потому, что это просто обоснованное мнение, это менее научно. В некотором смысле это просто другой подход, и реальность заключается в том, что среди различных сообществ эти два подхода сосуществуют.
Например, если мы посмотрим на статью “Прогнозирование в масштабе”, опубликованную командой Facebook в 2017 году, мы увидим нечто, что является практически архетипом модельно-ориентированного подхода. В этой статье представлена модель Facebook Prophet. И в другой статье, “Tensor Comprehension”, опубликованной в 2018 году другой командой Facebook, у нас есть, по сути, моделирующая техника. Эту статью можно рассматривать как архетип моделирующего подхода. Таким образом, вы можете видеть, что даже исследовательские команды, работающие в одной компании, практически в одно и то же время могут подходить к проблеме с разных сторон, в зависимости от ситуации.
Эта лекция является частью серии лекций по цепям поставок. В первой главе я представил свои взгляды на цепи поставок как на область исследования и практику. С самой первой лекции я утверждал, что основная теория цепей поставок не оправдывает своих ожиданий. Основная теория цепей поставок сильно опирается на модельно-центрический подход, и я считаю, что именно этот аспект является одной из основных причин трения между основной теорией цепей поставок и потребностями реальных цепей поставок.
Во второй главе этой серии лекций я представил ряд методологий. Наивные методологии обычно не справляются с эпизодическим и часто противоречивым характером ситуаций в цепях поставок. В частности, лекция под названием “Эмпирическая экспериментальная оптимизация”, которая была частью второй главы, является тем взглядом, который я принимаю сегодня в этой лекции.
В третьей главе я представил ряд персонажей цепей поставок. Эти персонажи представляют собой исключительное фокусирование на проблемах, которые мы пытаемся решить, полностью игнорируя любые кандидатские решения. Эти персонажи являются инструментом для понимания разнообразия прогностических вызовов, с которыми сталкиваются реальные цепи поставок. Я считаю, что эти персонажи необходимы, чтобы избежать попадания в узкую перспективу временных рядов, которая является отличительной чертой теории цепей поставок, которая применяется с малым вниманием к мелочам реальных цепей поставок.
В четвертой главе я представил ряд вспомогательных наук. Эти науки отличаются от цепей поставок, но базовое понимание этих дисциплин является необходимым для современной практики цепей поставок. Мы уже кратко затронули тему дифференцируемого программирования в этой четвертой главе, но я снова рассмотрю эту парадигму программирования более подробно через несколько минут.
Наконец, в первой лекции этой пятой главы мы увидели простую, можно сказать даже упрощенную модель, которая достигла передовой точности прогнозирования в мировом конкурсе по прогнозированию, который прошел в 2020 году. Сегодня я представляю ряд техник, которые могут быть использованы для изучения параметров, связанных с этой моделью, которую я представил в предыдущей лекции.
Остаток этой лекции будет разделен на два блока, за которыми последуют несколько заключительных мыслей. Первый блок посвящен дифференцируемому программированию. Мы уже затронули эту тему в четвертой главе; однако, сегодня мы рассмотрим ее более подробно. К концу этой лекции вы почти сможете создать свою собственную реализацию дифференцируемого программирования. Я говорю “почти”, потому что результат может зависеть от используемого вами набора технологий. Кроме того, дифференцируемое программирование - это своеобразное искусство, для успешной практики которого требуется определенный опыт.
Второй блок этой лекции - это обзор ситуации с прогнозированием спроса в розничной торговле. Этот обзор является продолжением предыдущей лекции, где мы представили модель, занявшую первое место в конкурсе прогнозирования M5 в 2020 году. Однако в предыдущей презентации мы не подробно рассмотрели, как эффективно вычислялись параметры модели. В этом обзоре мы рассмотрим именно это, а также важные элементы, такие как нехватка товара и акции, которые остались без внимания в предыдущей лекции. Наконец, на основе всех этих элементов я расскажу о своем мнении о пригодности дифференцируемого программирования для целей цепей поставок.

Стохастический градиентный спуск (SGD) является одним из двух основных принципов дифференцируемого программирования. SGD обманчиво прост, и все же до конца не ясно, почему он работает так хорошо. Понятно, почему он работает; что не очень ясно, так это почему он работает так хорошо.
История стохастического градиентного спуска уходит корнями в 1950-е годы, поэтому у него довольно долгая история. Однако эта техника стала широко признанной только в последнее десятилетие с появлением глубокого обучения. Стохастический градиентный спуск тесно связан с математической оптимизацией. У нас есть функция потерь Q, которую мы хотим минимизировать, и у нас есть набор реальных параметров, обозначенных как W, которые представляют все возможные решения. Мы хотим найти комбинацию параметров W, которая минимизирует функцию потерь Q.
Предполагается, что функция потерь Q должна иметь одно фундаментальное свойство: ее можно аддитивно разложить на ряд терминов. Именно наличие этого аддитивного разложения позволяет стохастическому градиентному спуску работать. Если ваша функция потерь не может быть разложена аддитивно, то стохастический градиентный спуск не применим как техника. В этой перспективе X представляет собой набор всех терминов, которые вносят вклад в функцию потерь, и Qx представляет собой частичную потерю, которая представляет потерю для одного из терминов в этой перспективе, где функция потерь является суммой частичных терминов.
Хотя стохастический градиентный спуск не является специфичным для ситуаций обучения, он отлично подходит для всех случаев обучения, и когда я говорю об обучении, я имею в виду обучение в контексте машинного обучения. Действительно, если у нас есть набор данных для обучения, этот набор данных будет представлять собой список наблюдений, при этом каждое наблюдение будет представлять собой пару признаков, которые представляют вход модели, и метки, которые представляют выходы. В основном, то, что мы хотим с точки зрения обучения, это создать модель, которая лучше всего выполняет эмпирическую ошибку и другие вещи, наблюдаемые из этого набора данных для обучения. С точки зрения обучения, X на самом деле будет списком наблюдений, а параметры будут параметрами модели машинного обучения, которые мы пытаемся оптимизировать, чтобы лучше соответствовать этому набору данных.
Стохастический градиентный спуск является фундаментальным итерационным процессом, который случайным образом проходит через наблюдения, одно наблюдение за раз. Мы выбираем одно наблюдение, небольшое X, за раз, и для этого наблюдения мы вычисляем локальный градиент, представленный как набла Qx. Это просто локальный градиент, который применяется только к одному термину функции потерь. Это не градиент полной функции потерь, а локальный градиент, который применяется только к одному термину функции потерь - вы можете рассматривать это как частичный градиент.
Шаг стохастического градиентного спуска состоит в том, чтобы взять этот локальный градиент и немного изменить параметры W на основе этого частичного наблюдения градиента. Вот что происходит здесь, с обновлением W с помощью W минус эта умножить на набла QxW. Это просто означает, в очень краткой форме, сдвинуть параметр W в направлении очень локального градиента, полученного с помощью X, где X - это просто одно из наблюдений вашего набора данных, если мы решаем проблему с точки зрения обучения. Затем мы продолжаем случайным образом, применяя этот локальный градиент и итерируя.
Интуитивно стохастический градиентный спуск работает очень хорошо, потому что он демонстрирует компромисс между более быстрой и шумной итерацией и более детализированной и, следовательно, более быстрой итерацией. Суть стохастического градиентного спуска заключается в том, что нам не важно иметь очень неточные измерения для наших градиентов, пока мы можем получить эти неточные измерения очень быстро. Если мы можем сместить компромисс в сторону более быстрой итерации, даже в ущерб более шумным градиентам, давайте это сделаем. Вот почему стохастический градиентный спуск настолько эффективен в минимизации количества вычислительных ресурсов, необходимых для достижения определенного качества решения для параметра W.
Наконец, у нас есть переменная eta, которая называется скоростью обучения. На практике скорость обучения не является постоянной; эта переменная изменяется во время выполнения стохастического градиентного спуска. В Lokad мы используем алгоритм Adam для контроля эволюции этого параметра eta для скорости обучения. Adam - это метод, опубликованный в 2014 году, и он очень популярен в кругах машинного обучения, когда используется стохастический градиентный спуск.

Второй основой дифференцируемого программирования является автоматическое дифференцирование. Мы уже видели эту концепцию на предыдущей лекции. Давайте еще раз рассмотрим этот концепт, посмотрев на фрагмент кода. Этот код написан на Envision, специализированном языке программирования, разработанном Lokad для целей предиктивной оптимизации цепей поставок. Я выбираю Envision, потому что, как вы увидите, примеры гораздо более лаконичны и, надеюсь, намного понятнее по сравнению с альтернативными презентациями, если бы я использовал Python, Java или C#. Однако я хотел бы отметить, что даже если я использую Envision, здесь нет никакого секретного соуса. Вы можете полностью реализовать все эти примеры на других языках программирования. Скорее всего, это увеличит количество строк кода в десять раз, но в общем плане это детали. Здесь, для лекции, Envision дает нам очень четкую и лаконичную презентацию.
Давайте посмотрим, как дифференцируемое программирование может быть использовано для решения задачи линейной регрессии. Это игрушечная проблема; нам не нужно дифференцируемое программирование для выполнения линейной регрессии. Целью является просто ознакомиться с синтаксисом дифференцируемого программирования. Строки с 1 по 6 объявляют таблицу T, которая представляет собой таблицу наблюдений. Когда я говорю о таблице наблюдений, просто помните множество стохастического градиентного спуска, которое называлось X. Это то же самое. Эта таблица имеет два столбца: один столбец с признаком, обозначенный X, и один столбец с меткой, обозначенный Y. Мы хотим взять X в качестве входных данных и быть в состоянии предсказывать Y с помощью линейной модели, или точнее, аффинной модели. Очевидно, в этой таблице T всего четыре точки данных. Это смешно маленький набор данных; это просто для ясности изложения.
В строке 8 мы вводим блок autodiff. Блок autodiff можно рассматривать как цикл в Envision. Это цикл, который перебирает таблицу, в данном случае таблицу T. Эти итерации отражают шаги стохастического градиентного спуска. Таким образом, когда выполнение Envision входит в этот блок autodiff, у нас есть серия повторяющихся выполнений, где мы выбираем строки из таблицы наблюдений, а затем применяем шаги стохастического градиентного спуска. Для этого нам нужны градиенты.
Откуда берутся градиенты? Здесь мы написали программу, небольшое выражение нашей модели, Ax + B. Мы вводим функцию потерь, которая является среднеквадратичной ошибкой. Мы хотим получить градиент. Для такой простой ситуации мы могли бы написать градиент вручную. Однако автоматическое дифференцирование - это техника, которая позволяет компилировать программу в двух формах: первая форма - это прямое выполнение программы, а вторая форма - это обратная форма выполнения, которая вычисляет градиенты, связанные со всеми параметрами, присутствующими в программе.
В строках 9 и 10 у нас есть объявление двух параметров, A и B, с ключевым словом “auto”, которое говорит Envision выполнить автоматическую инициализацию значений этих двух параметров. A и B - это скалярные значения. Автоматическое дифференцирование происходит для всех программ, содержащихся в этом блоке autodiff. По сути, это техника на уровне компилятора, которая компилирует эту программу дважды: один раз для прямого прохода и второй раз для программы, которая будет предоставлять значения градиентов. Красота техники автоматического дифференцирования заключается в том, что она гарантирует, что количество используемого процессорного времени для вычисления обычной программы соответствует количеству используемого процессорного времени для вычисления градиента при выполнении обратного прохода. Это очень важное свойство. Наконец, в строке 14 мы выводим параметры, которые мы только что изучили с помощью блока autodiff выше.

Программирование с дифференцированием действительно является парадигмой программирования. Можно составить произвольно сложную программу и получить автоматическое дифференцирование этой программы. Эта программа может включать ветвления и вызовы функций, например. В этом примере кода мы возвращаемся к функции потерь pinball, которую мы ввели в предыдущей лекции. Функцию потерь pinball можно использовать для получения оценок квантилей, когда мы наблюдаем отклонения от эмпирического распределения вероятностей. Если минимизировать среднеквадратичную ошибку с помощью вашей оценки, вы получите оценку среднего вашего эмпирического распределения. Если минимизировать функцию потерь pinball, вы получите оценку целевого квантиля. Если вы стремитесь к 90-му квантилю, это означает, что это значение в вашем распределении вероятностей, где будущее значение, которое будет наблюдаться, имеет 90% шанс быть ниже вашей оценки, если у вас есть цель на 90-й квантиль, или 10% шанс быть выше. Это напоминает анализ уровней обслуживания, который существует в цепи поставок.
В строках 1 и 2 мы вводим таблицу наблюдений, заполненную случайными отклонениями, выбранными случайным образом из распределения Пуассона. Значения распределения Пуассона выбираются средним значением 3, и мы получаем 10 000 отклонений. В строках 4 и 5 мы выполняем нашу собственную реализацию функции потерь pinball. Эта реализация практически идентична коду, который я представил в предыдущей лекции. Однако ключевое слово “autodiff” теперь добавлено к объявлению функции. Это ключевое слово, когда оно присоединяется к объявлению функции, гарантирует, что компилятор Envision может автоматически дифференцировать эту функцию. Хотя в теории автоматическое дифференцирование может быть применено к любой программе, на практике существует множество программ, для которых не имеет смысла их дифференцировать или множество функций, для которых это не имеет смысла. Например, рассмотрим функцию, которая принимает два текстовых значения и объединяет их. С точки зрения автоматического дифференцирования, не имеет смысла применять автоматическое дифференцирование к этому типу операции. Автоматическое дифференцирование требует наличия чисел во входных и выходных данных для функций, которые вы пытаетесь дифференцировать.
В строках с 7 по 9 у нас есть блок autodiff, который вычисляет оценку целевого квантиля для эмпирического распределения, полученного через таблицу наблюдений. Под капотом это на самом деле распределение Пуассона. Оценка квантиля объявляется как параметр с именем “quantile” в строке 8, и в строке 9 мы вызываем нашу собственную реализацию функции потерь pinball. Целевой квантиль установлен на 0,5, поэтому мы фактически ищем медианную оценку распределения. Наконец, в строке 11 мы выводим результаты для значения, которое мы узнали в результате выполнения блока autodiff. Этот код иллюстрирует, как программа, которую мы собираемся автоматически дифференцировать, может включать как вызов функции, так и ветвление, и все это может происходить полностью автоматически.

Я сказал, что блоки autodiff можно интерпретировать как цикл, выполняющий серию шагов стохастического градиентного спуска (SGD) по таблице наблюдений, выбирая одну строку из этой таблицы наблюдений за раз. Однако я остался довольно неопределенным относительно условия остановки для этой ситуации. Когда останавливается стохастический градиентный спуск в Envision? По умолчанию стохастический градиентный спуск останавливается после 10 эпох. Эпоха в терминологии машинного обучения представляет собой полный проход по таблице наблюдений. В строке 7 к блокам autodiff может быть добавлен атрибут с именем “epochs”. Этот атрибут является необязательным; по умолчанию значение равно 10, но если вы указываете этот атрибут, вы можете выбрать другое значение. Здесь мы указываем 100 эпох. Имейте в виду, что общее время вычисления практически строго линейно зависит от количества эпох. Таким образом, если у вас вдвое больше эпох, время вычисления будет вдвое дольше.
Все еще, на строке 7, мы также вводим второй атрибут с именем “learning_rate”. Этот атрибут также является необязательным и по умолчанию имеет значение 0.01, присоединенное к блоку autodiff. Эта скорость обучения является фактором, используемым для инициализации алгоритма Adam, который контролирует эволюцию скорости обучения. Это параметр eta, который мы видели на шаге стохастического градиентного спуска. Он контролирует алгоритм Adam. По сути, это параметр, который вам не часто приходится трогать, но иногда настройка этого параметра может сэкономить значительную часть вычислительной мощности. Неудивительно, что, подкрутив эту скорость обучения, вы можете сэкономить около 20% от общего времени вычислений для вашего стохастического градиентного спуска.

Инициализация параметров, которые изучаются в блоке autodiff, также требует более пристального рассмотрения. До сих пор мы использовали ключевое слово “auto”, и в Envision это просто означает, что Envision инициализирует параметр, случайным образом выбирая значение из гауссовского распределения с математическим ожиданием 1 и стандартным отклонением 0.1. Эта инициализация отличается от обычной практики в глубоком обучении, где параметры случайно инициализируются с гауссовскими распределениями, сосредоточенными вокруг нуля. Причина, по которой Lokad выбрал этот другой подход, станет яснее позже в этой лекции, когда мы продолжим с реальной ситуацией прогнозирования спроса в розничной торговле.
В Envision возможно переопределить и контролировать инициализацию параметров. Например, параметр “quantile” объявлен на строке 9, но его не нужно инициализировать. На самом деле, на строке 7, прямо над блоком autodiff, у нас есть переменная “quantile”, которой присваивается значение 4.2, и, следовательно, переменная уже инициализирована с заданным значением. Больше нет необходимости в автоматической инициализации. Также возможно задать диапазон допустимых значений для параметров, и это делается с помощью ключевого слова “in” на строке 9. По сути, мы определяем, что “quantile” должен быть между 1 и 10 включительно. С учетом этих границ, если обновление, полученное из алгоритма Adam, выталкивает значение параметра за пределы допустимого диапазона, мы ограничиваем изменение от Adam, чтобы оно оставалось в этом диапазоне. Кроме того, мы также устанавливаем в ноль значения импульса, которые обычно присоединены к алгоритму Adam внутри. Принудительное ограничение параметров отличается от классической практики глубокого обучения; однако преимущества этой функции станут очевидными, когда мы начнем обсуждать реальный пример прогнозирования спроса в розничной торговле.

Дифференцируемое программирование тесно связано со стохастическим градиентным спуском. Стохастический аспект буквально делает спуск очень быстрым. Это двухгранный меч; шум, получаемый через частичные потери, не только является ошибкой, но и особенностью. Благодаря небольшому количеству шума спуск может избежать застревания в зонах с очень плоскими градиентами. Таким образом, наличие этого шумного градиента не только делает итерацию намного быстрее, но также помогает вывести итерацию из областей, где градиент очень плоский и вызывает замедление спуска. Однако следует иметь в виду, что при использовании стохастического градиентного спуска сумма градиента не является градиентом суммы. В результате стохастический градиентный спуск имеет незначительные статистические смещения, особенно когда речь идет о хвостовых распределениях. Однако, когда возникают такие проблемы, относительно просто можно скорректировать численные методы, даже если теория остается немного неясной.
Дифференцируемое программирование (DP) не следует путать с произвольным математическим оптимизационным решателем. Градиент должен протекать через программу, чтобы дифференцируемое программирование вообще работало. Дифференцируемое программирование может работать с произвольно сложными программами, но эти программы должны быть разработаны с учетом дифференцируемого программирования. Кроме того, дифференцируемое программирование - это культура; это набор советов и трюков, которые хорошо сочетаются со стохастическим градиентным спуском. В целом, дифференцируемое программирование находится на легкой стороне спектра машинного обучения. Это очень доступная техника. Тем не менее, для овладения этим подходом и его плавной эксплуатации в производстве требуется некоторое мастерство.
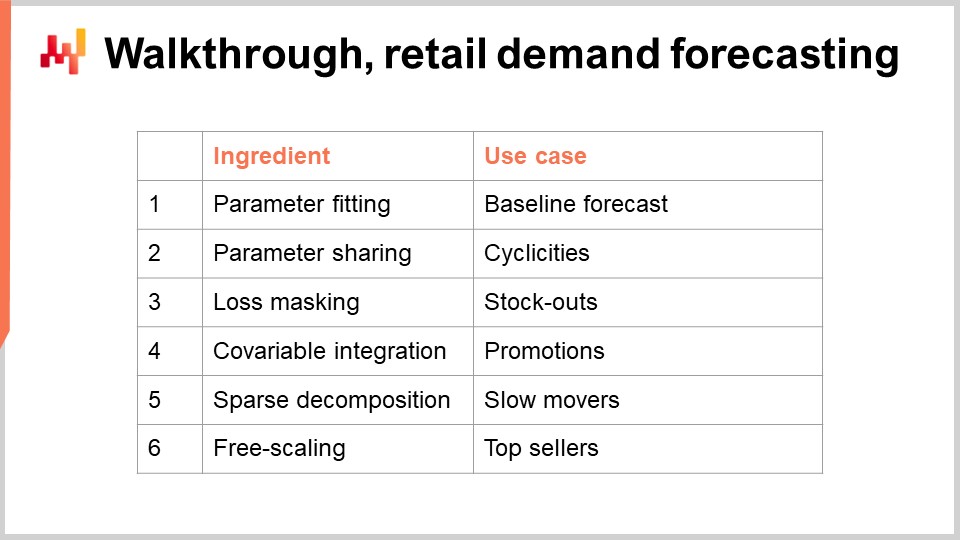
Мы готовы приступить ко второму блоку этой лекции: прогулке. У нас будет прогулка для нашей задачи прогнозирования спроса в рознице. Это моделирующее упражнение соответствует вызову прогнозирования, который мы представили в предыдущей лекции. Вкратце, мы хотим прогнозировать ежедневный спрос на уровне SKU в розничной сети. SKU, или единица складского учета, технически является декартовым произведением между продуктами и магазинами, отфильтрованными по записям ассортимента. Например, если у нас есть 100 магазинов и 10 000 продуктов, и если каждый продукт присутствует в каждом магазине, мы получаем 1 миллион SKU.
Есть инструменты для преобразования детерминированной оценки в вероятностную. Мы видели один из таких инструментов в предыдущей лекции с помощью техники ESSM. Мы еще раз рассмотрим эту конкретную проблему - превращение оценок в вероятностные оценки - более подробно на следующей лекции. Однако сегодня нас интересуют только оценки средних значений, и все остальные типы оценок (квантили, вероятностные) будут рассмотрены позже как естественное расширение основного примера, который я представлю сегодня. В этой прогулке мы собираемся изучить параметры простой модели прогнозирования спроса. Простота этой модели обманчива, потому что эта модель достигает передового уровня прогнозирования, как это показано в конкурсе прогнозирования M5 в 2020 году.

Для нашей параметрической модели спроса давайте введем один параметр для каждого SKU. Это абсолютно упрощенная форма модели; спрос моделируется как постоянный для каждого SKU. Однако это не одно и то же постоянное значение для каждого SKU. Как только у нас есть это постоянное среднее значение на каждый день всего жизненного цикла SKU, оно будет одинаковым для всех дней всего жизненного цикла SKU.
Давайте посмотрим, как это делается с помощью дифференцируемого программирования. Со строк 1 по 4 мы вводим блок мок-данных. На практике эта модель и все ее варианты зависели бы от входных данных, полученных из бизнес-систем: ERP, WMS, TMS и т. д. Представление лекции, в которой я бы подключал математическую модель к реалистичному представлению данных, таких, как они получаются из ERP, привело бы к множеству случайных осложнений, которые не имеют отношения к текущей теме лекции. Поэтому то, что я делаю здесь, - это введение блока мок-данных, который даже не притворяется реалистичным ни в каком виде или в виде данных, которые можно наблюдать в реальной розничной ситуации. Единственная цель этого мок-данных - представить таблицы и связи внутри таблиц и убедиться, что приведенный пример кода является полным, может быть скомпилирован и выполнен. Все приведенные вами примеры кода полностью автономны; нет скрытых фрагментов до или после. Единственная цель блока мок-данных - убедиться, что у нас есть автономный код.
В каждом примере в этой прогулке мы начинаем с этого блока мок-данных. В строке 1 мы вводим таблицу дат с “dates” в качестве первичного ключа. Здесь у нас есть диапазон дат, который в основном составляет два года и один месяц. Затем, в строке 2, мы вводим таблицу SKU, которая является списком SKU. В этом минималистическом примере у нас всего три SKU. В реальной розничной ситуации для крупной розничной сети у нас было бы миллионы, если не десятки миллионов, SKU. Но здесь, ради примера, я беру очень маленькое число. В строке 3 у нас есть таблица “T”, которая является декартовым произведением между SKU и датой. По сути, то, что вы получаете через эту таблицу “T”, - это матрица, в которой у вас есть каждый отдельный SKU и каждый отдельный день. У нее два измерения.
На строке 6 мы вводим наш фактический блок автодифференциации. Таблица наблюдений - это таблица SKU, а стохастический градиентный спуск будет выбирать один SKU за раз. На строке 7 мы вводим “уровень”, который будет нашим единственным параметром. Это векторный параметр, и до сих пор в наших блоках автодифференциации мы только вводили скалярные параметры. Предыдущие параметры были просто числом; здесь “SKU.level” на самом деле является вектором. Это вектор, который имеет одно значение для каждого SKU, и это буквально наша постоянная потребность, моделируемая на уровне SKU. Мы указываем диапазон, и мы увидим, почему это важно через минуту. Он должен быть не менее 0,01, и мы устанавливаем 1 000 в качестве верхней границы среднесуточного спроса для этого параметра. Этот параметр автоматически инициализируется значением, близким к единице, что является разумной отправной точкой. В этой модели у нас есть только одна степень свободы на SKU. Наконец, на строках 8 и 9 мы фактически реализуем саму модель. На строке 8 мы вычисляем “dot.delta”, который представляет собой спрос, предсказанный моделью, минус наблюдаемый, который является “T.sold”. Модель представляет собой всего одно слагаемое, константу, а затем у нас есть наблюдение, которое является “T.sold”.
Чтобы понять, что здесь происходит, у нас есть некоторые происходящие вещи с вещанием. Таблица “T” является перекрестной таблицей между SKU и датой. Блок автодифференциации - это итерация, которая проходит по строкам таблицы наблюдений. На строке 9 мы находимся внутри блока автодифференциации, поэтому мы выбрали строку для таблицы SKU. Значение “SKUs.level” здесь не является вектором; это просто скалярное значение, только одно значение, потому что мы выбрали только одну строку таблицы наблюдений. Затем “T.sold” больше не является матрицей, потому что мы уже выбрали один SKU. Остается только то, что “T.sold” на самом деле является вектором, вектором, который имеет размерность, равную дате. Когда мы делаем это вычитание, “SKUs.level - T.sold”, мы получаем вектор, который выровнен с таблицей дат, и присваиваем его “D.delta”, который является вектором с одной строкой на день, два года и один месяц. Наконец, на строке 9 мы вычисляем функцию потерь, которая является просто среднеквадратичной ошибкой. Эта модель очень упрощенная. Давайте посмотрим, что можно сделать с календарными паттернами.

Общий параметр - это, вероятно, одна из самых простых и полезных техник дифференцируемого программирования. Параметр считается общим, если он вносит вклад в несколько строк наблюдения. Объединяя параметры для разных наблюдений, мы можем стабилизировать градиентный спуск и устранить проблемы переобучения. Рассмотрим паттерн дня недели. Мы могли бы ввести семь параметров, представляющих различные веса для каждого отдельного SKU. До сих пор у одного SKU был только один параметр, который представляет собой просто постоянный спрос. Если мы хотим обогатить это восприятие спроса, мы можем сказать, что каждый день недели имеет свой собственный вес, и поскольку у нас есть семь дней недели, мы можем иметь семь весов и применять эти веса умножительно.
Однако маловероятно, что у каждого отдельного SKU будет свой собственный уникальный паттерн дня недели. Реальность заключается в том, что гораздо более разумно предположить, что существует категория или некоторый вид иерархии, такой как семейство продуктов, категория продукта, подкатегория продукта или даже отдел в магазине, который правильно отражает этот паттерн дня недели. Идея заключается в том, что мы не хотим вводить семь параметров на SKU; то, что мы хотим, это ввести семь параметров на категорию, на уровень группировки, где мы предполагаем, что есть однородное поведение в терминах паттернов дня недели.
Если мы решим ввести эти семь параметров с мультипликативным эффектом на уровне, это именно тот подход, который был выбран в предыдущей лекции для этой модели, которая заняла первое место на уровне SKU в конкурсе M5. У нас есть уровень и мультипликативный эффект с паттерном дня недели.
В коде, в строках с 1 по 5, у нас есть блок фиктивных данных, как и раньше, и мы вводим дополнительную таблицу с названием “category”. Эта таблица является группирующей таблицей SKU, и концептуально, для каждой строки в таблице SKU существует одна и только одна строка, которая соответствует в таблице “category”. В языке Envision мы говорим, что категория находится выше таблицы SKU. В строке 7 вводится таблица дня недели. Эта таблица является инструментальной, и мы вводим ее с определенной структурой, которая отражает циклический паттерн, который мы хотим уловить. В строке 7 мы создаем таблицу дня недели, агрегируя даты в соответствии с их значением по модулю семь. Мы создаем таблицу, которая будет состоять из ровно семи строк, и эти семь строк будут представлять каждый из семи дней недели. Для каждой строки в таблице дат каждая строка в базе данных имеет одну и только одну пару в таблице дня недели. Таким образом, следуя языку Envision, таблица дня недели находится выше таблицы “date”.
Теперь у нас есть таблица “CD”, которая является декартовым произведением между категорией и днем недели. Что касается количества строк, эта таблица будет иметь столько же строк, сколько есть категорий, умноженное на семь, потому что день недели имеет семь строк. В строке 12 мы вводим новый параметр с названием “CD.DOW” (DOW означает день недели), который является еще одним векторным параметром, принадлежащим таблице CD. Что касается степеней свободы, у нас будет ровно семь значений параметра, умноженных на количество категорий, именно то, что мы ищем. Мы хотим модель, которая способна уловить этот паттерн дня недели, но только с одним паттерном на каждую категорию, а не с одним паттерном на каждый SKU.
Мы объявляем этот параметр и используем ключевое слово “in”, чтобы указать, что значение для “CD.DOW” должно быть между 0.1 и 100. В строке 13 мы записываем спрос, выраженный моделью. Спрос составляет “SKUs.level * CD.DOW”, представляя спрос. У нас есть спрос минус наблюдаемое значение “T.sold”, и это дает нам дельту. Затем мы вычисляем среднеквадратичную ошибку.
В строке 13 происходит некоторая магия с вещанием. “CD.DOW” - это перекрестная таблица между категорией и днем недели. Поскольку мы находимся в блоке автодифференцирования, таблица CD является перекрестной таблицей между категорией и днем недели. Поскольку мы находимся в блоке автодифференцирования, блок итерируется по таблице SKU. По сути, когда мы выбираем один SKU, мы фактически выбираем одну категорию, так как таблица категорий находится выше. Это означает, что CD.DOW больше не является матрицей, а является вектором размерности семь. Однако он находится выше таблицы “date”, поэтому эти семь строк могут быть вещаны в таблице даты. Есть только один способ сделать это вещание, потому что каждая строка таблицы дня недели имеет связь с определенными строками таблицы даты. У нас происходит двойное вещание, и в конце мы получаем спрос, который является серией значений, которая циклична на уровне дня недели для SKU. Это наша модель на данный момент, и остальная часть функции потерь остается неизменной.
Мы видим очень элегантный способ подхода к цикличности, объединяя поведение вещания, полученное из реляционной природы Envision, с его возможностями дифференцируемого программирования. Мы можем выразить календарные цикличности всего в трех строках кода. Этот подход хорошо работает даже при работе с очень разреженными данными. Он бы работал прекрасно даже если бы мы рассматривали продукты, которые в среднем продавались только одной единицей в месяц. В таких случаях разумным подходом было бы иметь категорию, включающую десятки, если не сотни продуктов. Эта техника также может использоваться для отражения других циклических паттернов, таких как месяц года или день месяца.
Модель, представленная в предыдущей лекции, которая достигла передовых результатов на конкурсе M5, была мультипликативной комбинацией трех цикличностей: день недели, месяц года и день месяца. Все эти паттерны были объединены в виде умножения. Реализация двух других вариантов остается на внимательном слушателе, но это всего лишь вопрос пары строк кода на каждый циклический паттерн, что делает его очень лаконичным.

В предыдущей лекции мы представили модель прогнозирования продаж. Однако нас не интересуют продажи, а спрос. Мы не должны путать отсутствие продаж с отсутствием спроса. Если на определенный день в магазине не осталось товара для покупки, в Lokad используется техника маскировки потерь для справления с отсутствием товара на складе. Это самая простая техника, используемая для справления с отсутствием товара на складе, но это не единственная техника. Насколько мне известно, у нас есть как минимум еще две техники, которые используются в производстве, каждая со своими плюсами и минусами. Эти другие техники не будут рассмотрены сегодня, но о них будет рассказано в последующих лекциях.
Вернемся к примеру кода, строки с 1 по 3 остаются неизменными. Давайте рассмотрим, что следует за ними. В строке 6 мы обогащаем мок-данные флагом in-stock. Для каждого отдельного SKU и каждого отдельного дня у нас есть булевое значение, которое указывает, был ли отсутствие товара в конце дня в магазине. В строке 15 мы изменяем функцию потерь, чтобы исключить, обнулив их, дни, когда было зафиксировано отсутствие товара в конце дня. Обнуляя эти дни, мы гарантируем, что градиент не будет обратно распространяться в ситуациях, которые имеют смещение из-за возникновения отсутствия товара.
Самым загадочным аспектом техники маскировки потерь является то, что она даже не изменяет модель. Действительно, если мы посмотрим на модель, выраженную в строке 14, она точно такая же; она не была изменена. Изменяется только сама функция потерь. Эта техника может быть простой, но она глубоко отличается от модельно-центрической перспективы. Она является, в своей сущности, техникой, ориентированной на моделирование. Мы улучшаем ситуацию, признавая смещение, вызванное отсутствием товара, отражая это в наших усилиях по моделированию. Однако мы делаем это, изменив метрику точности, а не саму модель. Другими словами, мы изменяем потерю, которую мы оптимизируем, делая эту модель непригодной для сравнения с другими моделями с точки зрения чистой числовой ошибки.
Для ситуации, подобной Walmart, о которой говорилось в предыдущей лекции, техника маскировки потерь является адекватной для большинства товаров. Как правило, эта техника работает хорошо, если спрос не настолько разрежен, что у вас большую часть времени есть только одна единица товара на складе. Кроме того, следует избегать товаров, где отсутствие товара весьма часто, потому что это является явной стратегией розничного торговца, чтобы закончить день с отсутствием товара. Это обычно происходит с некоторыми свежими продуктами, где розничный торговец стремится к ситуации отсутствия товара к концу дня. Альтернативные техники устраняют эти ограничения, но у нас нет времени, чтобы рассмотреть их сегодня.

Промо-акции являются важным аспектом розничной торговли. Более общо, существует множество способов для розничного торговца влиять и формировать спрос, таких как ценообразование или перемещение товаров на гондолу. Переменные, которые предоставляют дополнительную информацию для прогнозирования, обычно называются ковариатами в сфере цепей поставок. Существует много мечтаний о сложных ковариатах, таких как погодные данные или данные социальных сетей. Однако, прежде чем углубляться в продвинутые темы, нам нужно рассмотреть сложности, такие как информация о ценообразовании, которая, очевидно, оказывает значительное влияние на спрос, который будет наблюдаться. Таким образом, в строке 7 в этом примере кода мы вводим для каждого отдельного дня в строке 14 “category.ed”, где “ed” означает эластичность спроса. Это общий векторный параметр с одной степенью свободы на категорию, предназначенный в качестве представления эластичности спроса. В строке 16 мы вводим экспоненциальную форму ценовой эластичности в виде экспоненты (-category.ed * t.price). Интуитивно, с этой формой, когда цена увеличивается, спрос быстро сходится к нулю из-за присутствия экспоненциальной функции. Напротив, когда цена сходится к нулю, спрос взрывно возрастает.
Эта экспоненциальная форма реакции на ценообразование является упрощенной, и совместное использование параметров обеспечивает высокую степень численной стабильности даже с этой экспоненциальной функцией в модели. В реальных условиях, особенно для ситуаций, подобных Walmart, у нас было бы несколько информации о ценообразовании, таких как скидки, разница по сравнению с обычной ценой, ковариаты, представляющие маркетинговые усилия, выполненные поставщиком, или категориальные переменные, которые вводят такие вещи, как гондолы. С помощью дифференцируемого программирования легко создавать произвольно сложные реакции на цену, которые тесно соответствуют ситуации. Интеграция ковариатов практически любого вида очень проста с помощью дифференцируемого программирования.

Медленно движущиеся товары - это факт жизни в розничной торговле и многих других отраслях. Введенная до сих пор модель имеет один параметр, одну степень свободы на SKU, с большим количеством, если учитывать общие параметры. Однако это может быть уже слишком много, особенно для SKU, которые вращаются только один раз в год или всего несколько раз в год. В таких ситуациях мы даже не можем позволить себе одну степень свободы на SKU, поэтому решение заключается в полном использовании общих параметров и удалении всех параметров со степенями свободы на уровне SKU.
В строках 2 и 4 мы вводим две таблицы с названиями “products” и “stores”, а таблица “SKUs” создается как отфильтрованная подтаблица декартова произведения между products и stores, что является определением ассортимента. В строках 15 и 16 мы вводим два общих векторных параметра: один уровень с привязкой к таблице products и другой уровень с привязкой к таблице stores. Эти параметры также определены в определенном диапазоне от 0,01 до 100, что является максимальным значением.
Теперь, в строке 18, уровень на SKU составляется как произведение уровня продукта и уровня магазина. Остальная часть скрипта остается неизменной. Как это работает? В строке 19 SKU.level является скаляром. У нас есть блок autodesk, который выполняет итерацию по таблице SKUs, которая является таблицей наблюдений. Таким образом, SKUs.level в строке 18 является просто скалярным значением. Затем у нас есть products.level. Поскольку таблица products находится выше таблицы SKUs, для каждого отдельного SKU есть только одна таблица products. Таким образом, products.level является просто скалярным числом. То же самое относится и к таблице stores, которая также находится выше таблицы SKUs. В строке 18 есть только один магазин, привязанный к этому конкретному SKU. Поэтому у нас есть произведение двух скалярных значений, которое дает нам SKU.level. Остальная часть модели остается неизменной.
Эти техники полностью меняют представление о том, что иногда данных недостаточно или что данные слишком разрежены. На самом деле, с дифференцируемой точки зрения эти утверждения даже не имеют особого смысла. Нет такой вещи, как слишком мало данных или данные, слишком разреженные, по крайней мере, не в абсолютных значениях. Есть только модели, которые могут быть изменены в сторону разреженности и, возможно, к крайней разреженности. Навязанная структура подобна направляющим рельсам, которые делают процесс обучения не только возможным, но и численно стабильным.
По сравнению с другими методами машинного обучения, которые пытаются позволить модели машинного обучения открывать все шаблоны ex nihilo, этот структурированный подход устанавливает саму структуру, которую мы должны изучить. Таким образом, статистический механизм, действующий здесь, имеет ограниченную свободу в том, что он должен изучить. Следовательно, с точки зрения эффективности использования данных, он может быть невероятно эффективным. Естественно, все это зависит от того, что мы выбрали правильную структуру.
Как видите, проведение экспериментов очень просто. Мы уже делаем нечто очень сложное, и за меньше чем 50 строк мы можем справиться с довольно сложной ситуацией, подобной Walmart. Это довольно значительное достижение. Здесь есть некоторый эмпирический процесс, но на самом деле его не так много. Речь идет о нескольких десятках строк. Имейте в виду, что ERP-система, которая управляет компанией, крупной розничной сетью, обычно имеет тысячи таблиц и 100 полей на таблицу. Таким образом, сложность бизнес-систем абсолютно гигантская по сравнению с сложностью этой структурированной прогностической модели. Если нам приходится немного времени тратить на итерацию, это почти ничто.
Кроме того, как показано в конкурсе прогнозирования M5, реальность заключается в том, что практики в сфере цепей поставок уже знают эти закономерности. Когда команда M5 использовала три календарных закономерности - день недели, месяц года и день месяца, все эти закономерности были очевидны для любого опытного практика в сфере цепей поставок. Реальность в цепях поставок заключается в том, что мы не пытаемся обнаружить скрытые закономерности. Факт того, что, например, если вы сильно снизите цену, спрос значительно увеличится, никого не удивит. Единственный вопрос, который остается, - это какова именно величина эффекта и какова точная форма реакции. Это относительно технические детали, и если вы позволите себе возможность провести небольшой эксперимент, вы сможете относительно легко решить эти проблемы.
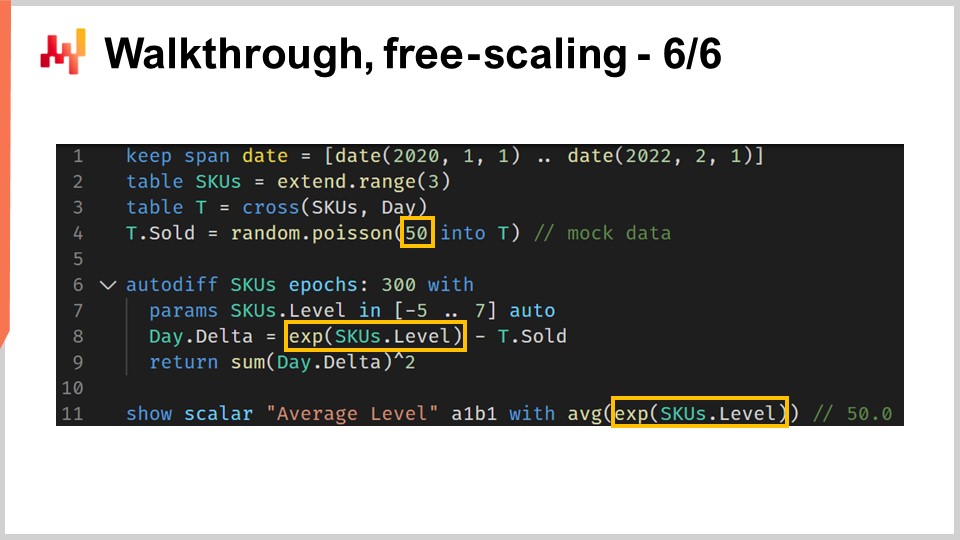
В качестве последнего шага этого обзора я хотел бы указать на небольшую особенность дифференцируемого программирования. Дифференцируемое программирование не следует путать с обычным математическим оптимизационным решателем. Мы должны помнить, что здесь происходит градиентный спуск. Более конкретно, алгоритм, используемый для оптимизации и обновления параметров, имеет максимальную скорость спуска, равную скорости обучения, которая поставляется с алгоритмом ADAM. В Envision значение скорости обучения по умолчанию составляет 0,01.
Если мы посмотрим на код, на строке 4 мы вводим инициализацию, при которой количество продаваемых товаров выбирается из распределения Пуассона с средним значением 50. Если мы хотим изучить уровень, технически нам нужно иметь уровень, который будет порядка 50. Однако, когда мы выполняем автоматическую инициализацию параметра, мы начинаем с значения, которое около единицы, и мы можем изменять его только с шагом 0,01. Нам потребуется около 5 000 эпох, чтобы действительно достичь этого значения 50. Поскольку у нас есть неподеленный параметр SKU.level, этот параметр за эпоху изменяется только один раз. Таким образом, нам потребуется 5 000 эпох, что бессмысленно замедлит вычисления.
Мы могли бы увеличить скорость обучения, чтобы ускорить спуск, это было бы одно решение. Однако я бы не советовал увеличивать скорость обучения, так как это обычно не является правильным подходом к проблеме. В реальной ситуации у нас были бы общие параметры в дополнение к этому неподеленному параметру. Эти общие параметры будут изменяться стохастическим градиентным спуском много раз в каждую эпоху. Если вы сильно увеличите скорость обучения, вы рискуете создать численные неустойчивости для ваших общих параметров. Вы можете увеличить скорость изменения уровня SKU, но создать проблемы с численной устойчивостью для других параметров.
Более правильным подходом было бы использование трюка с масштабированием и обертыванием параметра в экспоненциальную функцию, что и делается на строке 8. С помощью этой обертки мы теперь можем достигать значений параметра для уровня, которые могут быть очень низкими или очень высокими с гораздо меньшим количеством эпох. Эта особенность фактически единственная особенность, которую мне нужно ввести, чтобы иметь реалистичный пример для этого обзора ситуации прогнозирования спроса в розничной торговле. При всем этом это незначительная особенность. Тем не менее, это напоминает о том, что дифференцируемое программирование требует внимания к потоку градиентов. Дифференцируемое программирование в целом предлагает гибкий опыт проектирования, но это не волшебство.
Несколько заключительных мыслей: структурированные модели действительно достигают передовой точности прогнозирования. Этот момент был подробно рассмотрен в предыдущей лекции. Однако, исходя из представленных сегодня элементов, я бы утверждал, что точность даже не является решающим фактором в пользу дифференцируемого программирования с структурированной параметрической моделью. Мы получаем понимание; мы не только получаем программное обеспечение, способное делать прогнозы, но также получаем прямые представления о тех самых закономерностях, которые мы пытаемся уловить. Например, введенная сегодня модель непосредственно дает нам прогноз спроса, который сопровождается явными весами дня недели и явной эластичностью спроса. Если бы мы хотели расширить этот спрос, например, чтобы ввести увеличение, связанное с Черной пятницей, квази-сезонное событие, которое не происходит в одно и то же время каждый год, мы могли бы это сделать. Мы просто добавим фактор, и затем у нас будет оценка для увеличения Черной пятницы в изоляции от всех остальных закономерностей, таких как закономерность дня недели. Это представляет особый интерес.
Что мы получаем с помощью структурированного подхода - это понимание, и это гораздо больше, чем просто сырая модель. Например, если мы получаем отрицательную эластичность, ситуацию, когда модель говорит вам, что при увеличении цены вы увеличиваете спрос, в ситуации, подобной Walmart, это очень сомнительный результат. Скорее всего, это отражает то, что ваша реализация модели неправильна или что происходят серьезные проблемы. Независимо от того, что говорит вам метрика точности, если вы оказываетесь в ситуации Walmart с чем-то, что говорит вам, что сделав продукт дороже, люди покупают больше, вам следует серьезно задать вопрос всей вашей системе обработки данных, потому что, скорее всего, что-то очень не так. В этом и заключается понимание.
Кроме того, модель открыта для изменений. Дифференцируемое программирование невероятно выразительно. Модель, которую мы имеем, является всего лишь одной итерацией в путешествии. Если рынок преобразуется или сама компания преобразуется, мы можем быть уверены, что модель, которую мы имеем, сможет естественным образом уловить эту эволюцию. Нет такого понятия, как автоматическая эволюция; для захвата этой эволюции потребуется усилие со стороны специалиста по цепям поставок. Однако можно ожидать, что это усилие будет относительно минимальным. Это сводится к тому, что если у вас есть очень маленькая, аккуратная модель, то когда вам понадобится пересмотреть эту модель позже, чтобы изменить ее структуру, это будет относительно небольшая задача по сравнению с ситуацией, когда ваша модель была бы громадиной инженерии.
При тщательной разработке модели, созданные с помощью дифференцируемого программирования, очень стабильны. Стабильность сводится к выбору структуры. Стабильность не является данностью для любой программы, которую вы оптимизируете с помощью дифференцируемого программирования; это то, что вы получаете, когда у вас есть очень четкая структура, в которой параметры имеют определенную семантику. Например, если у вас есть модель, в которой каждый раз, когда вы повторно обучаете модель, у вас получаются совершенно разные веса для дня недели, то реальность в вашем бизнесе не меняется так быстро. Если вы запускаете свою модель дважды, вы должны получить значения для дня недели, которые достаточно стабильны. Если это не так, то в том, как вы смоделировали спрос, что-то очень не так. Таким образом, если вы сделаете мудрый выбор структуры вашей модели, вы можете получить невероятно стабильные числовые результаты. Таким образом, мы избегаем проблем, которые часто возникают у сложных моделей машинного обучения, когда мы пытаемся использовать их в контексте цепи поставок. Действительно, с точки зрения цепи поставок, численные неустойчивости являются смертельными, потому что у нас повсюду есть эффекты рачка. Если у вас есть оценка спроса, которая колеблется, это означает, что случайно вы будете запускать заказ на закупку или заказ на производство просто так. Как только вы запустили заказ на производство, вы не можете решить на следующей неделе, что это была ошибка и вам не следовало делать этого. Вы застряли с принятой вами решением. Если у вас есть оценка будущего спроса, которая продолжает колебаться, вы получите завышенное пополнение и завышенные заказы на производство. Эту проблему можно решить, обеспечив стабильность, что является вопросом дизайна.
Одной из самых больших преград для внедрения машинного обучения в производство является доверие. Когда вы работаете с миллионами евро или долларов, понимание того, что происходит в вашем числовом рецепте, критически важно. Ошибки в цепочке поставок могут быть чрезвычайно дорогими, и есть множество примеров катастроф в цепочке поставок, вызванных плохим применением плохо понятных алгоритмов. Хотя дифференцируемое программирование очень мощно, модели, которые можно создать, невероятно просты. Эти модели могут быть запущены в электронной таблице Excel, так как они обычно представляют собой простые мультипликативные модели с ветвями и функциями. Единственный аспект, который не может быть запущен в электронной таблице Excel, - это автоматическое дифференцирование, и, очевидно, если у вас есть миллионы SKU, не пытайтесь делать это в электронной таблице. Однако, с точки зрения простоты, это очень совместимо с тем, что вы бы поместили в электронную таблицу. Эта простота идет долгим путем в установлении доверия и внедрении машинного обучения в производство, вместо того, чтобы оставлять их в качестве модных прототипов, которым люди никогда не могут полностью доверять.
Наконец, объединив все эти свойства, мы получаем очень точную технологию. Этот аспект был обсужден в самой первой главе этой серии лекций. Мы хотим превратить все усилия, вложенные в цепочку поставок, в капиталистические инвестиции, вместо того, чтобы рассматривать экспертов и практиков в области цепочки поставок как расходные материалы, которые должны делать одно и то же снова и снова. С таким подходом мы можем рассматривать все эти усилия как инвестиции, которые будут генерировать и продолжать генерировать прибыль со временем. Дифференцируемое программирование очень хорошо сочетается с этой капиталистической перспективой для цепочки поставок.

Во второй главе мы представили важную лекцию под названием “Экспериментальная оптимизация”, которая дала один из возможных ответов на простой, но фундаментальный вопрос: что на самом деле означает улучшение или достижение лучших результатов в цепочке поставок? Перспектива дифференцируемого программирования предоставляет очень конкретное понимание многих проблем, с которыми сталкиваются практики в области цепочки поставок. Поставщики корпоративного программного обеспечения часто винят плохие данные в своих неудачах в цепочке поставок. Однако я считаю, что это просто неправильный подход к проблеме. Данные - это просто то, что они есть. Ваша ERP-система никогда не была разработана для науки о данных, но она работала без сбоев в течение многих лет, если не десятилетий, и люди в компании смогли управлять цепочкой поставок. Даже если ваша ERP-система, которая собирает данные о вашей цепочке поставок, не идеальна, это нормально. Если вы ожидаете, что будут предоставлены идеальные данные, это просто мечтательное мышление. Мы говорим о цепочках поставок; мир очень сложен, поэтому системы несовершенны. Реалистично говоря, у вас нет одной бизнес-системы; у вас есть, как минимум, полдюжины, и они не полностью согласованы друг с другом. Это просто факт жизни. Однако, когда поставщики корпоративного программного обеспечения винят плохие данные, реальность заключается в том, что вендор использует очень конкретную модель прогнозирования, и эта модель была разработана с определенным набором предположений о компании. Проблема заключается в том, что если ваша компания нарушает хотя бы одно из этих предположений, технология полностью разрушается. В этой ситуации у вас есть модель прогнозирования, которая основана на нереалистичных предположениях, вы подаете данные, они не идеальны, и поэтому технология разрушается. Совершенно неразумно говорить, что виновата компания. Виновна технология, которую продвигает поставщик, и которая делает совершенно нереалистичные предположения о том, какие данные могут быть в контексте цепочки поставок.
Сегодня я не представлял никаких показателей точности. Однако моя предпосылка заключается в том, что эти показатели точности в основном незначительны. Предиктивная модель - это инструмент для принятия решений. Важно, являются ли эти решения - что купить, что произвести, повысить или понизить цену - хорошими или плохими. Плохие решения могут быть прослежены до предиктивной модели, это верно. Однако большую часть времени это не проблема точности. Например, у нас была модель прогнозирования продаж, и мы исправили угол нехватки товара, который не был должным образом управляем. Однако, когда мы исправили угол нехватки товара, мы фактически исправили сам показатель точности. Таким образом, исправление предиктивной модели не означает улучшение точности; очень часто это означает буквально пересмотр самой проблемы и перспективы, в которой вы работаете, и, следовательно, изменение показателя точности или даже чего-то более глубокого. Проблема с классической перспективой заключается в том, что она предполагает, что показатель точности является достойной целью. Это не совсем так.
Цепи поставок функционируют в реальном мире, и здесь происходит множество неожиданных и даже экстраординарных событий. Например, может произойти блокировка Суэцкого канала из-за судна; это полностью экстраординарное событие. В такой ситуации все существующие модели прогнозирования времени доставки становятся недействительными. Очевидно, что раньше такого не происходило, поэтому мы не можем провести обратное тестирование в такой ситуации. Однако, даже если у нас есть такая совершенно исключительная ситуация, как блокировка Суэцкого канала, мы все равно можем исправить модель, по крайней мере, если у нас есть такой подход, как я предлагаю сегодня. Это исправление будет включать степень догадки, что вполне допустимо. Лучше быть приблизительно правым, чем точно неправым. Например, если мы смотрим на блокировку Суэцкого канала, можно просто сказать: “добавим один месяц к сроку поставки для всех поставок, которые должны были пройти через этот маршрут”. Это очень приблизительно, но лучше предположить, что задержки не будет, хотя у вас уже есть информация об этом. Кроме того, изменения часто происходят изнутри. Например, рассмотрим розничную сеть, в которой есть один старый центр распределения и новый центр распределения, обеспечивающий несколько десятков магазинов. Предположим, что происходит миграция, при которой поставки для магазинов переносятся из старого центра распределения в новый. Такая ситуация происходит почти единожды в истории этого конкретного ритейлера и не может быть подвергнута обратному тестированию. Однако с помощью подхода, основанного на дифференцируемом программировании, совершенно легко реализовать модель, которая будет соответствовать этой постепенной миграции.

В заключение, дифференцируемое программирование - это технология, которая дает нам подход к структурированию наших представлений о будущем. Дифференцируемое программирование позволяет нам буквально формировать наше представление о будущем. Дифференцируемое программирование находится на стороне восприятия в этой картине. Исходя из этого восприятия, мы можем принимать лучшие решения для цепей поставок, и эти решения определяют действия, которые находятся на другой стороне картинки. Одно из самых больших недоразумений основной теории цепей поставок заключается в том, что вы можете рассматривать восприятие и действие как изолированные компоненты. Это принимает форму, например, когда одна команда отвечает за планирование (это восприятие), а другая независимая команда отвечает за пополнение запасов (это действие).
Однако обратная связь между восприятием и действием очень важна; она является первостепенной важностью. Это буквально механизм, который направляет вас к правильному виду восприятия. Если у вас нет этого механизма обратной связи, даже неясно, смотрите ли вы на правильную вещь или является ли то, на что вы смотрите, действительно тем, за что вы его принимаете. Вам нужен этот механизм обратной связи, и именно через этот цикл обратной связи вы можете действительно направлять свои модели к правильной количественной оценке будущего, которая является релевантной для принятия решений в вашей цепи поставок. Основные подходы к управлению цепями поставок почти полностью отвергают этот случай, потому что, по сути, я считаю, что они застряли в очень жесткой форме прогнозирования. Эта модельно-центричная форма прогнозирования может быть старой моделью, например, моделью прогнозирования Хольта-Винтерса, или недавней, например, Facebook Prophet. Ситуация одинакова: если вы застряли с одной моделью прогнозирования, то вся обратная связь, которую вы можете получить со стороны действия, не имеет значения, потому что вы не можете ничего сделать с этой обратной связью, кроме полного ее игнорирования.
Если вы застряли с определенной моделью прогнозирования, вы не можете изменить или переструктурировать свою модель по мере получения информации с действующей стороны. С другой стороны, дифференцируемое программирование с его структурированным подходом к моделированию предлагает совершенно другую парадигму. Прогностическая модель полностью подлежит утилизации - полностью. Если обратная связь, которую вы получаете от ваших действий, требует радикальных изменений в вашей прогностической перспективе, просто внедрите эти радикальные изменения. Нет никакой специфической привязки к определенной итерации модели. Очень простая модель позволяет сохранить возможность изменять эту модель после ввода в эксплуатацию. Потому что, снова, если то, что вы создали, похоже на зверя, инженерное чудовище, то после ввода в эксплуатацию его очень сложно изменить. Один из ключевых аспектов заключается в том, что если вы хотите иметь возможность продолжать меняться, вам нужна модель, которая очень экономна в терминах количества строк кода и внутренней сложности. В этом отличие дифференцируемого программирования. Речь не идет о достижении более высокой точности, а о достижении более высокой релевантности. Без релевантности все метрики точности абсолютно бессмысленны. Дифференцируемое программирование и структурированное моделирование предлагают вам путь к достижению релевантности и поддержанию ее со временем.

Это завершает лекцию на сегодня. В следующий раз, во вторник, второго марта, в то же время, в 15:00 по парижскому времени, я буду представлять вероятностное моделирование для цепей поставок. Мы ближе рассмотрим технические аспекты рассмотрения всех возможных будущих сценариев, а не просто выбора одного будущего и объявления его правильным. Действительно, рассмотрение всех возможных будущих сценариев очень важно, если вы хотите, чтобы ваша цепь поставок была эффективно устойчивой к риску. Если вы просто выбираете одно будущее, это рецепт для получения чего-то, что будет крайне хрупким, если ваш прогноз окажется не совершенно точным. И догадайтесь, прогноз никогда не бывает полностью точным. Поэтому очень важно принять идею о том, что вам нужно рассмотреть все возможные будущие сценарии, и мы рассмотрим, как это сделать с помощью современных численных методов.
Вопрос: Стохастический шум добавляется для избежания локальных минимумов, но как он используется или масштабируется, чтобы избежать больших отклонений, чтобы градиентный спуск не уводил далеко от своей цели?
Это очень интересный вопрос, и на него есть две части ответа.
Во-первых, вот почему алгоритм Адам очень консервативен в терминах величины движений. Градиент фундаментально неограничен; у вас может быть градиент, который стоит тысячи или миллионы. Однако с Адамом максимальный шаг фактически ограничивается скоростью обучения. Таким образом, Адам по сути поставляет численный рецепт, который буквально обеспечивает максимальный шаг, и, надеюсь, это избегает массовой численной нестабильности.
Теперь, если случайным образом, несмотря на то, что у нас есть эта скорость обучения, мы могли бы сказать, что просто из-за чистой флуктуации мы будем двигаться итеративно, по одному шагу за раз, но много раз в неправильном направлении, это возможно. Вот почему я говорю, что стохастический градиентный спуск все еще не полностью понятен. Он работает невероятно хорошо на практике, но почему он работает так хорошо, и почему он сходится так быстро, и почему у нас не возникает больше проблем, которые могут возникнуть, не полностью понятно, особенно если учесть, что стохастический градиентный спуск происходит в высоких измерениях. Обычно вы имеете буквально десятки, а то и сотни параметров, которые касаются на каждом шаге. То представление, которое вы можете иметь в двух или трех измерениях, очень вводящее в заблуждение; вещи ведут себя совершенно иначе, когда вы смотрите на более высокие измерения.
Итак, основная идея для этого вопроса: это очень актуально. Есть одна часть, где это волшебство Адама, которое очень консервативно относится к масштабу ваших шагов градиента, и другая часть, которая плохо понимается, но все равно в практике работает очень хорошо. Кстати, я считаю, что тот факт, что стохастический градиентный спуск не является полностью интуитивным, также является причиной того, что в течение почти 70 лет эта техника была известна, но не признавалась эффективной. Почти 70 лет люди знали, что она существует, но они были крайне скептически настроены. Для того, чтобы сообщество признало и признало, что она действительно работает очень хорошо, даже если мы не понимаем, почему, понадобился огромный успех глубокого обучения.
Вопрос: Как понять, когда определенный шаблон является слабым и поэтому должен быть удален из модели?
Опять-таки, очень хороший вопрос. Здесь нет строгих критериев; это буквально суждение со стороны ученого по цепям поставок. Причина в том, что если введенный вами шаблон приносит вам минимальные преимущества, но с точки зрения моделирования это всего лишь две строки кода, и его влияние на объем вычислений незначительно, и если вы когда-нибудь захотите удалить шаблон позже, это будет полу-тривиально, вы можете сказать: “Ну, я могу просто оставить его. Кажется, он не вредит, он не делает много пользы. Я могу представить ситуации, когда этот слабый шаблон на самом деле может стать сильным”. С точки зрения поддержки, это нормально.
Однако вы также можете увидеть другую сторону медали, когда у вас есть шаблон, который не захватывает многое, и он добавляет много вычислений в модель. Так что это не бесплатно; каждый раз, когда вы добавляете параметр или логику, вы увеличиваете объем вычислительных ресурсов, необходимых для вашей модели, делая ее медленнее и более неуклюжей. Если вы думаете, что этот слабый шаблон на самом деле может стать сильным, но в плохом смысле, вызывая нестабильность и создавая хаос в вашем прогностическом моделировании, это обычно та ситуация, когда вы подумаете: “Нет, я, наверное, должен его удалить”.
Вы видите, это действительно вопрос суждения. Дифференцируемое программирование - это культура; вы не одиноки. У вас есть коллеги и товарищи, которые, возможно, попробовали разные вещи в Lokad. Это та культура, которую мы пытаемся выращивать. Я знаю, что это может быть немного разочарованием по сравнению с перспективой всеобъемлющего искусственного интеллекта, идеей, что мы могли бы иметь всеобъемлющий искусственный интеллект, решающий все эти проблемы за нас. Но реальность в том, что цепи поставок настолько сложны, а наши методы искусственного интеллекта настолько грубы, что у нас нет реалистичной замены для человеческого интеллекта. Когда я говорю о суждении, я просто имею в виду, что вам нужна здоровая доза прикладного, очень человеческого интеллекта в данном случае, потому что все алгоритмические трюки далеки от того, чтобы дать удовлетворительный ответ.
Тем не менее, это не означает, что нельзя разработать некоторые инструменты. Это будет другая тема; я посмотрю, действительно ли я расскажу о таких инструментах, которые мы предоставляем в Lokad для облегчения проектирования. Побочным шаблоном было бы, если нам пришлось бы принимать решение, давайте попробуем предоставить всю инструментацию, чтобы это решение можно было принять очень быстро, минимизируя количество боли, связанной с этим видом нерешительности, когда ученый по цепям поставок должен принять решение о судьбе текущего состояния модели.
Вопрос: Какой порог сложности цепи поставок, после которого машинное обучение и дифференцируемое программирование приводят к значительно лучшим результатам?
В Lokad мы обычно достигаем значительных результатов для компаний с оборотом от 10 миллионов долларов в год и выше. Я бы сказал, что это действительно начинает сиять, если у вас есть компания с годовым оборотом от 50 миллионов долларов и выше.
Причина в том, что фундаментально вам нужно установить очень надежный поток данных. Вам нужно иметь возможность извлекать все необходимые данные из ERP ежедневно. Я не имею в виду, что это будут хорошие данные или плохие данные, просто данные, которые у вас есть, могут иметь много дефектов. Тем не менее, это означает, что для того, чтобы иметь возможность извлекать самые основные транзакции ежедневно, требуется довольно много “сантехники”. Если компания слишком маленькая, то обычно у них даже нет отдельного IT-отдела, и им не удается обеспечить надежное ежедневное извлечение, что действительно подрывает результаты.
Теперь, что касается отраслей или сложности, дело в том, что в большинстве компаний и большинстве цепей поставок, по моему мнению, они даже не начали оптимизировать еще. Как я уже сказал, основная теория цепей поставок подчеркивает, что вы должны стремиться к более точным прогнозам. Уменьшение процента ошибки прогнозирования - это цель, и многие компании, например, занимаются этим, имея команду планирования или команду прогнозирования. По моему мнению, все это не добавляет ничего ценного для бизнеса, потому что это фундаментально предоставляет очень сложные ответы на неправильный набор вопросов.
Может показаться неожиданным, но дифференцируемое программирование действительно блестит не потому, что оно фундаментально супермощное - оно такое - но потому, что это обычно первый раз, когда в компании появляется что-то, что действительно имеет отношение к бизнесу. Если вы хотите пример, то большая часть того, что реализовано в цепи поставок, обычно является моделями, такими как модель резервного запаса, которые абсолютно не имеют никакого отношения к реальной цепи поставок. Например, в модели резервного запаса предполагается, что возможно иметь отрицательное время выполнения заказа, что означает, что вы заказываете сейчас, а вам доставили вчера. Это не имеет никакого смысла, и в результате операционные результаты для резервных запасов обычно неудовлетворительны.
Дифференцируемое программирование блестит, достигая актуальности, а не какой-то великой численной превосходности или тем, что оно лучше других альтернативных методов машинного обучения. Суть заключается в достижении актуальности в мире, который очень сложен, хаотичен, враждебен, постоянно меняется, и где вам приходится иметь дело с полукошмарным прикладным ландшафтом, который представляет данные, которые вам нужно обработать.
Кажется, больше нет вопросов. В таком случае, я предполагаю, что увидимся в следующем месяце на лекции по вероятностному моделированию для цепи поставок.


