00:01 Introducción
02:44 Revisión de necesidades predictivas
05:57 Modelos vs. Modelado
12:26 La historia hasta ahora
15:50 Un poco de teoría y un poco de práctica
17:41 Programación diferenciable, SGD 1/6
24:56 Programación diferenciable, autodiff 2/6
31:07 Programación diferenciable, funciones 3/6
35:35 Programación diferenciable, meta-parámetros 4/6
37:59 Programación diferenciable, parámetros 5/6
40:55 Programación diferenciable, peculiaridades 6/6
43:41 Recorrido, previsión de la demanda minorista
45:49 Recorrido, ajuste de parámetros 1/6
53:14 Recorrido, compartición de parámetros 2/6
01:04:16 Recorrido, enmascaramiento de pérdidas 3/6
01:09:34 Recorrido, integración de covariables 4/6
01:14:09 Recorrido, descomposición esparsa 5/6
01:21:17 Recorrido, escalado libre 6/6
01:25:14 Caja blanca
01:33:22 Volviendo a la optimización experimental
01:39:53 Conclusión
01:44:40 Próxima lección y preguntas de la audiencia
Descripción
Programación diferenciable (DP) es un paradigma generativo utilizado para diseñar una amplia clase de modelos estadísticos, que resultan estar excelentemente adaptados para desafíos predictivos de supply chain. DP supera casi toda la literatura “clásica” de previsión basada en modelos paramétricos. DP es también superior a los algoritmos “clásicos” de machine learning - hasta finales de la década de 2010 - en prácticamente todas las dimensiones que importan para un uso práctico en supply chain, incluyendo la facilidad de adopción por parte de los profesionales.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy presentaré “Modelado predictivo estructurado con Programación diferenciable en Supply Chain.” Elegir el curso de acción correcto requiere una visión cuantitativa detallada del futuro. De hecho, cada decisión – comprar más, producir más – refleja una cierta anticipación del futuro. Invariablemente, la teoría dominante de supply chain hace énfasis en la noción de previsión para abordar este mismo asunto. Sin embargo, la perspectiva de la previsión, al menos en su forma clásica, adolece de dos carencias.
Primero, enfatiza una perspectiva estrecha de previsión de series temporales, que desafortunadamente no logra abordar la diversidad de desafíos tal como se presentan en las supply chain del mundo real. Segundo, enfatiza un enfoque limitado en la precisión de la previsión de series temporales, que también en gran medida pierde el punto. Ganar unos pocos puntos porcentuales extra de precisión no se traduce automáticamente en generar dólares adicionales de retorno para tu supply chain.
El objetivo de la presente lección es descubrir un enfoque alternativo a la previsión, que es en parte una tecnología y en parte una metodología. La tecnología será la programación diferenciable, y la metodología serán los modelos predictivos estructurados. Al final de esta lección, deberías ser capaz de aplicar este enfoque a una situación de supply chain. Este enfoque no es teórico; ha sido el enfoque predeterminado de Lokad durante un par de años. Además, si no has visto las lecciones anteriores, la presente lección no debería ser totalmente incomprensible. Sin embargo, en esta serie de lecciones, estamos llegando a un punto en el que realmente ayuda ver las lecciones en secuencia. En la presente lección, revisaremos bastantes elementos que han sido introducidos en lecciones previas.

La previsión de la demanda futura es el candidato obvio cuando se trata del análisis de las necesidades predictivas para nuestra supply chain. De hecho, una mejor anticipación de la demanda es un ingrediente crítico para decisiones muy básicas como comprar más y producir más. Sin embargo, a través de los principios de supply chain que hemos introducido en el transcurso del tercer capítulo de esta serie de lecciones, hemos visto que existe un conjunto bastante diverso de expectativas que se pueden tener en términos de requerimientos predictivos para impulsar tu supply chain.
En particular, por ejemplo, los tiempos de entrega varían y exhiben patrones estacionales. Prácticamente cada decisión relacionada con inventario requiere una anticipación tanto de la demanda futura como del tiempo de entrega futuro. Así, los tiempos de entrega deben ser previsión. Las devoluciones a veces representan hasta la mitad del flujo. Este es el caso, por ejemplo, del ecommerce de moda en Alemania. En esas situaciones, anticipar las devoluciones se vuelve crítico, y estas varían considerablemente de un producto a otro. Por lo tanto, en dichas situaciones, las devoluciones deben ser previsión.
En el lado de la oferta, la producción puede variar y no solo debido a retrasos adicionales o a los tiempos de entrega variables. Por ejemplo, la producción puede venir acompañada de cierto grado de incertidumbre. Esto ocurre en sectores de baja tecnología como la agricultura, pero también puede suceder en sectores de alta tecnología como la industria farmacéutica. Así, los rendimientos de producción también deben ser previsión. Finalmente, el comportamiento del cliente también importa mucho. Por ejemplo, impulsar la demanda a través de productos que generan adquisición es muy importante, y, inversamente, enfrentar faltantes de stock en productos que provocan una gran rotación cuando esos productos se encuentran ausentes precisamente debido a faltantes de stock, también es de gran importancia. Por lo tanto, esos comportamientos requieren análisis, predicción – en otras palabras, ser previsión. La conclusión clave es que la previsión de series temporales es solo una parte del rompecabezas. Necesitamos un enfoque predictivo que pueda abarcar todas esas situaciones y más, ya que es una necesidad si queremos tener un enfoque que tenga alguna posibilidad de tener éxito al enfrentar todas las situaciones que una supply chain del mundo real nos arroje.

El enfoque estándar cuando se trata del problema predictivo es presentar un modelo. Este enfoque ha dominado la literatura de previsión de series temporales durante décadas, y aún es, diría yo, el enfoque dominante en los círculos de machine learning hoy en día. Este enfoque centrado en el modelo, así es como me referiré a él, es tan omnipresente que resulta incluso difícil detenerse un momento a evaluar lo que realmente está sucediendo desde esta perspectiva centrada en el modelo.
Mi proposición para esta lección es que el supply chain requiere una técnica de modelado, una perspectiva centrada en el modelado, y que una serie de modelos, sin importar cuán extensa sea, nunca será suficiente para abordar todos nuestros requerimientos tal como se encuentran en las supply chain del mundo real. Aclararemos esta distinción entre el enfoque centrado en el modelo y el enfoque centrado en el modelado.
El enfoque centrado en el modelo enfatiza ante todo un modelo. El modelo se presenta como un paquete, un conjunto de recetas numéricas que típicamente vienen en forma de una pieza de software que puedes ejecutar. Incluso cuando dicho software no está disponible, se establece la expectativa de que si tienes un modelo pero no el software, se espera que el modelo se describa con precisión matemática, permitiendo una reimplementación completa del modelo. Se espera que este paquete, el software del modelo, sea el objetivo final.
Desde una perspectiva idealizada, se supone que este modelo se comporta exactamente como una función matemática: entradas a, salidas. Si queda alguna configurabilidad para el modelo, entonces esos elementos configurables se tratan como cabos sueltos, como problemas que aún deben ser completamente resueltos. De hecho, cada opción de configuración debilita el caso del modelo. Cuando tenemos configurabilidad y demasiadas opciones desde la perspectiva centrada en el modelo, el modelo tiende a disolverse en un conjunto de modelos, y de repente, ya no podemos comparar nada porque no existe tal cosa como un modelo único.
El enfoque de modelado adopta una visión completamente invertida respecto al ángulo de la configurabilidad. Maximizar la expresividad del modelo se convierte en el objetivo final. Esto no es un defecto; se convierte en una característica. La situación puede ser bastante confusa cuando observamos una perspectiva centrada en el modelado, porque si asistimos a una presentación desde dicha perspectiva, lo que veremos es una presentación de modelos. Sin embargo, esos modelos vienen con una intención muy diferente.
Si adoptas la perspectiva del modelado, el modelo que se presenta es solo una ilustración. No viene con la intención de ser completo ni de ser la solución final al problema. Es solo un paso en el camino para ilustrar la técnica de modelado en sí. El principal desafío con la técnica de modelado es que, de repente, se vuelve muy difícil evaluar el enfoque. De hecho, perdemos la opción ingenua de benchmarking, ya que, con esta perspectiva centrada en el modelado, tenemos potenciales de modelos. No nos enfocamos específicamente en un modelo versus otro; ni siquiera es la mentalidad correcta. Lo que tenemos es una opinión fundamentada.
Sin embargo, me gustaría señalar de inmediato que no es porque tengas un benchmark y números asociados a él que automáticamente califique como ciencia. Los números podrían ser simplemente sin sentido, y, a la inversa, no es porque sea solo una opinión fundamentada que sea menos científico. De alguna manera, es simplemente un enfoque diferente, y la realidad es que, entre diversas comunidades, ambos enfoques coexisten.
Por ejemplo, si miramos el artículo “Previsión at Scale,” publicado por un equipo de Facebook en 2017, tenemos algo que es prácticamente el arquetipo del enfoque centrado en el modelo. En este artículo, se presenta el modelo Facebook Prophet. Y en otro artículo, “Tensor Comprehension,” publicado en 2018 por otro equipo de Facebook, tenemos esencialmente una técnica de modelado. Este artículo puede verse como el arquetipo del enfoque de modelado. Así, se puede ver que incluso equipos de investigación que trabajan en la misma empresa, prácticamente al mismo tiempo, pueden abordar el problema desde un ángulo u otro, dependiendo de la situación.
Esta lección es parte de una serie de conferencias de supply chain. En el primer capítulo, presenté mis puntos de vista acerca de supply chain tanto como campo de estudio como práctica. Desde la primera lección, argumenté que la teoría dominante de supply chain no cumple con sus expectativas. Sucede que la teoría dominante de supply chain se apoya fuertemente en el enfoque centrado en el modelo, y creo que este único aspecto es una de las principales causas de fricción entre la teoría dominante de supply chain y las necesidades de las supply chain del mundo real.
En el segundo capítulo de esta serie de lecciones, introduje una serie de metodologías. De hecho, las metodologías ingenuas son típicamente superadas por la naturaleza episódica y, con frecuencia, adversarial de las situaciones de supply chain. En particular, la lección titulada “Optimización Experimental Empírica,” que formó parte del segundo capítulo, es el tipo de perspectiva que estoy adoptando hoy en esta lección.
En el tercer capítulo, introduje una serie de personae de supply chain. Las personae representan un enfoque exclusivo en los problemas que intentamos abordar, sin considerar en absoluto ninguna solución candidata. Estas personae son fundamentales para comprender la diversidad de los desafíos predictivos que enfrentan las supply chain del mundo real. Creo que estas personae son esenciales para evitar quedar atrapados en la estrecha perspectiva de series de tiempo, que es una característica de una teoría de supply chain que se ejerce prestando poca atención a los detalles minuciosos de las supply chain del mundo real.
En el cuarto capítulo, introduje una serie de ciencias auxiliares. Estas ciencias son distintas de supply chain, pero tener un dominio básico de estas disciplinas es esencial para la práctica moderna de supply chain. Ya hemos tocado brevemente el tema de la programación diferenciable en este cuarto capítulo, pero volveré a introducir este paradigma de programación con mucho más detalle en unos minutos.
Finalmente, en la primera lección de este quinto capítulo, hemos visto un modelo simple, algunos incluso dirían simplista, que alcanzó una precisión de previsión de vanguardia en una competencia de previsión a nivel mundial que tuvo lugar en 2020. Hoy, presento una serie de técnicas que pueden usarse para aprender los parámetros involucrados en este modelo que presenté en la lección anterior.
El resto de esta lección se dividirá ampliamente en dos bloques, seguidos de algunas reflexiones finales. El primer bloque está dedicado a la programación diferenciable. Ya hemos tocado este tema en el cuarto capítulo; sin embargo, hoy lo examinaremos mucho más de cerca. Al final de esta lección, deberías casi ser capaz de crear tu propia implementación de programación diferenciable. Digo “casi” porque los resultados pueden variar dependiendo del tech stack que estés utilizando. Además, la programación diferenciable es una habilidad menor por sí misma; se requiere algo de experiencia para lograr que funcione sin problemas en la práctica.
El segundo bloque de esta conferencia es una guía práctica para una situación de previsión de la demanda minorista. Esta guía es una continuación de la conferencia anterior, en la que presentamos el modelo que logró el primer lugar en la competición M5 de previsión en 2020. Sin embargo, en esa presentación anterior, no detallamos cómo se computaron efectivamente los parámetros del modelo. Esta guía entregará exactamente eso, y además abordaremos elementos importantes como los faltante de stock y promotions que quedaron sin tratar en la conferencia anterior. Finalmente, basado en todos estos elementos, discutiré mis puntos de vista sobre la idoneidad de la programación diferenciable para fines de supply chain.

El Descenso de Gradiente Estocástico (SGD) es uno de los dos pilares de la programación diferenciable. El SGD es engañosamente simple, y sin embargo, aún no está completamente claro por qué funciona tan bien. Es absolutamente claro por qué funciona; lo que no resulta muy claro es por qué funciona tan bien.
La historia del Descenso de Gradiente Estocástico se remonta a la década de 1950, por lo que tiene una historia bastante larga. Sin embargo, esta técnica solo alcanzó el reconocimiento generalizado durante la última década con la llegada del deep learning. El Descenso de Gradiente Estocástico está profundamente arraigado en la perspectiva de la optimización matemática. Tenemos una función de pérdida Q que queremos minimizar, y contamos con un conjunto de parámetros reales, denotado W, que representan todas las posibles soluciones. Lo que queremos encontrar es la combinación de parámetros W que minimice la función de pérdida Q.
Se supone que la función de pérdida Q debe cumplir una propiedad fundamental: puede descomponerse de manera aditiva en una serie de términos. La existencia de esta descomposición aditiva es lo que hace posible que el Descenso de Gradiente Estocástico funcione. Si tu función de pérdida no se puede descomponer aditivamente de esta manera, entonces el Descenso de Gradiente Estocástico no es aplicable como técnica. En esta perspectiva, X representa el conjunto de todos los términos que contribuyen a la función de pérdida, y Qx representa una pérdida parcial que equivale a la pérdida de uno de los términos en esta visión de la función de pérdida como la suma de términos parciales.
Aunque el Descenso de Gradiente Estocástico no es específico de situaciones de aprendizaje, se adapta muy bien a todos los casos de uso de aprendizaje, y cuando digo aprendizaje, me refiero al aprendizaje en el sentido de los casos de uso de machine learning. De hecho, si tenemos un training dataset, este conjunto de datos tendrá la forma de una lista de observaciones, donde cada observación es un par de características que representan la entrada del modelo y etiquetas que representan las salidas. Esencialmente, lo que queremos desde una perspectiva de aprendizaje es desarrollar un modelo que tenga el mejor desempeño en el error empírico y otras métricas observadas a partir de este training dataset. Desde la perspectiva de aprendizaje, X sería en realidad la lista de observaciones, y los parámetros serían los parámetros de un modelo de machine learning que tratamos de optimizar para que se ajuste lo mejor posible a este conjunto de datos.
El Descenso de Gradiente Estocástico es fundamentalmente un proceso iterativo que recorre aleatoriamente las observaciones, una a la vez. Elegimos una observación, un pequeño X, a la vez, y para esta observación, calculamos un gradiente local, representado como nabla de Qx. Es simplemente un gradiente local que solo se aplica a un término de la función de pérdida. No es el gradiente de la función de pérdida completa, sino un gradiente local que sólo se aplica a un término de la función de pérdida; se puede ver como un gradiente parcial.
Un paso del Descenso de Gradiente Estocástico consiste en tomar este gradiente local y ajustar ligeramente los parámetros W en función de esta observación parcial del gradiente. Eso es exactamente lo que sucede aquí, con W siendo actualizado con W menos eta por nabla QxW. Esto simplemente indica, de manera muy concisa, ajustar el parámetro W en la dirección del gradiente muy local obtenido con X, donde X es sólo una de las observaciones de tu conjunto de datos, si estamos abordando un problema desde una perspectiva de aprendizaje. Luego, procedemos al azar, aplicando este gradiente local e iterando.
Intuitivamente, el Descenso de Gradiente Estocástico funciona muy bien porque presenta un trade-off entre iteraciones más rápidas y gradientes más ruidosos, hasta llegar a iteraciones más granulares y, por lo tanto, más rápidas. La esencia del Descenso de Gradiente Estocástico es que no nos importa tener mediciones muy imperfectas para nuestros gradientes mientras podamos obtener esas mediciones imperfectas de forma super rápida. Si podemos desplazar el trade-off hacia iteraciones más rápidas, incluso a expensas de gradientes más ruidosos, hagámoslo. Por eso el Descenso de Gradiente Estocástico es tan efectivo en minimizar la cantidad de recursos informáticos necesarios para alcanzar una cierta calidad de solución para el parámetro W.
Finalmente, tenemos la variable eta, que se conoce como la tasa de aprendizaje. En la práctica, la tasa de aprendizaje no es una constante; esta variable varía mientras el Descenso de Gradiente Estocástico está en curso. En Lokad, usamos el algoritmo Adam para controlar la evolución de este parámetro eta para la tasa de aprendizaje. Adam es un método publicado en 2014, y es muy popular en los círculos de machine learning cada vez que se utiliza el Descenso de Gradiente Estocástico.

El segundo pilar de la programación diferenciable es la diferenciación automática. Ya hemos visto este concepto en una conferencia anterior. Revisemos este concepto observando un fragmento de código. Este código está escrito en Envision, un lenguaje de programación específico de dominio desarrollado por Lokad con el propósito de la optimización predictiva de supply chains. Elijo Envision porque, como verás, los ejemplos son mucho más concisos y, con suerte, mucho más claros también, en comparación con presentaciones alternativas si usara Python, Java o C#. Sin embargo, me gustaría señalar que, aunque estoy utilizando Envision, no hay ninguna receta secreta involucrada. Podrías reimplementar por completo todos estos ejemplos en otros lenguajes de programación. Lo más probable es que se multiplique el número de líneas de código por un factor de 10, pero en el gran esquema de las cosas, esto es un detalle. Aquí, para una conferencia, Envision nos ofrece una presentación muy clara y concisa.
Veamos cómo se puede utilizar la programación diferenciable para abordar una regresión lineal. Este es un problema de juguete; no necesitamos la programación diferenciable para hacer una regresión lineal. El objetivo es simplemente familiarizarnos con la sintaxis de la programación diferenciable. Desde las líneas 1 a 6, se declara la tabla T, que representa la tabla de observaciones. Cuando digo tabla de observaciones, recuerda el conjunto de Descenso de Gradiente Estocástico que se llamó X. Esto es exactamente lo mismo. Esta tabla tiene dos columnas, una característica denotada X y una etiqueta denotada Y. Lo que queremos es tomar X como entrada y poder predecir Y con un modelo lineal, o más precisamente, un modelo afín. Obviamente, solo tenemos cuatro puntos de datos en esta tabla T. Este es un conjunto de datos ridículamente pequeño; es solo por el bien de la claridad de la exposición.
En la línea 8, introducimos el bloque autodiff. El bloque autodiff se puede ver como un bucle en Envision. Es un bucle que itera sobre una tabla, en este caso, la tabla T. Estas iteraciones reflejan los pasos del Descenso de Gradiente Estocástico. Así, lo que ocurre cuando la ejecución de Envision entra en este bloque autodiff es que tenemos una serie de ejecuciones repetidas en las que se seleccionan líneas de la tabla de observaciones y luego se aplican pasos del Descenso de Gradiente Estocástico. Para ello, necesitamos los gradientes.
¿De dónde provienen los gradientes? Aquí, hemos escrito un programa, una pequeña expresión de nuestro modelo, Ax + B. Introducimos la función de pérdida, que es el error cuadrático medio. Queremos obtener el gradiente. Para una situación tan simple como esta, podríamos escribir el gradiente manualmente. Sin embargo, la diferenciación automática es una técnica que te permite compilar un programa en dos formas: la primera forma es la ejecución hacia adelante del programa, y la segunda es la forma inversa de ejecución que calcula los gradientes asociados a todos los parámetros presentes en el programa.
En las líneas 9 y 10, tenemos la declaración de dos parámetros, A y B, con la palabra clave “auto” que indica a Envision realizar una inicialización automática de los valores de estos dos parámetros. A y B son valores escalares. La diferenciación automática ocurre para todos los programas que están contenidos en este bloque autodiff. Esencialmente, es una técnica a nivel de compilador para compilar este programa dos veces: una para la pasada hacia adelante y otra para un programa que proporcionará los valores de los gradientes. La belleza de la técnica de diferenciación automática es que garantiza que la cantidad de CPU necesaria para calcular el programa regular se alinee con la cantidad de CPU necesaria para calcular el gradiente cuando se realiza la pasada inversa. Esa es una propiedad muy importante. Finalmente, en la línea 14, imprimimos los parámetros que acabamos de aprender con el bloque autodiff anterior.

La programación diferenciable realmente brilla como paradigma de programación. Es posible componer un programa arbitrariamente complejo y obtener la diferenciación automática de este programa. Este programa puede incluir ramas y llamadas a funciones, por ejemplo. Este ejemplo de código retoma la pinball función de pérdida que introdujimos en la conferencia anterior. La función de pérdida pinball se puede usar para derivar estimaciones de quantiles cuando observamos desviaciones de una distribución de probabilidad empírica. Si minimizas el error cuadrático medio con tu estimación, obtienes una estimación de la media de tu distribución empírica. Si minimizas la función de pérdida pinball, obtienes una estimación de un objetivo de quantil. Si apuntas a un quantil del 90, significa que es el valor en tu distribución de probabilidad en el que el valor futuro a observar tiene un 90% de probabilidad de estar por debajo de tu estimación si apuntas a un objetivo del 90, o un 10% de probabilidad de estar por encima. Esto recuerda al análisis de niveles de servicio que existe en supply chain.
En las líneas 1 y 2, estamos introduciendo una tabla de observaciones poblada con desviaciones muestreadas aleatoriamente de una distribución de Poisson. Los valores de la distribución de Poisson se muestrean con una media de 3, y obtenemos 10,000 desviaciones. En las líneas 4 y 5, implementamos a medida nuestra implementación de la función de pérdida pinball. Esta implementación es casi idéntica al código que presenté en la conferencia anterior. Sin embargo, la palabra clave “autodiff” se ha añadido ahora a la declaración de la función. Esta palabra clave, cuando se adjunta a la declaración de la función, garantiza que el compilador de Envision pueda diferenciar automáticamente esta función. Aunque, en teoría, la diferenciación automática se puede aplicar a cualquier programa, en la práctica hay muchos programas en los que no tiene sentido diferenciar o muchas funciones en las que no tendría sentido. Por ejemplo, considera una función que toma dos valores de texto y los concatena. Desde la perspectiva de la diferenciación automática, no tiene sentido aplicar la diferenciación automática a este tipo de operaciones. La diferenciación automática requiere que haya números presentes en la entrada y salida de las funciones que se intentan diferenciar.
En las líneas 7 a 9, tenemos el bloque autodiff, que calcula la estimación del objetivo de quantil para la distribución empírica obtenida a través de la tabla de observaciones. Bajo el capó, en realidad es una distribución de Poisson. La estimación del quantil se declara como un parámetro llamado “quantile” en la línea 8, y en la línea 9, hacemos una llamada a nuestra propia implementación de la función de pérdida pinball. El objetivo del quantil se fija en 0.5, por lo que en realidad estamos buscando una estimación de la mediana de la distribución. Finalmente, en la línea 11, imprimimos los resultados del valor que hemos aprendido a través de la ejecución del bloque autodiff. Este fragmento de código ilustra cómo un programa que vamos a diferenciar automáticamente puede incluir tanto una llamada a una función como una rama, y todo esto puede suceder de forma completamente automática.

He dicho que los bloques autodiff se pueden interpretar como un bucle que realiza una serie de pasos de Descenso de Gradiente Estocástico (SGD) sobre la tabla de observaciones, seleccionando una línea de dicha tabla a la vez. Sin embargo, he sido bastante elusivo acerca de la condición de paro para esta situación. ¿Cuándo se detiene el Descenso de Gradiente Estocástico en Envision? Por defecto, el Descenso de Gradiente Estocástico se detiene después de 10 épocas. Una época, en la terminología de machine learning, representa un ciclo completo a través de la tabla de observaciones. En la línea 7, se puede adjuntar un atributo llamado “epochs” a los bloques autodiff. Este atributo es opcional; por defecto, el valor es 10, pero si especificas este atributo, puedes elegir un conteo diferente. Aquí, estamos especificando 100 épocas. Ten en cuenta que el tiempo total para el cálculo es casi lineal en función del número de épocas. Por lo tanto, si tienes el doble de épocas, el tiempo de cómputo se duplicará.
Aún, en la línea 7, también introducimos un segundo atributo llamado “learning_rate”. Este atributo también es opcional y, por defecto, tiene el valor 0.01, adjunto al bloque autodiff. Esta tasa de aprendizaje es un factor utilizado para inicializar el algoritmo Adam que controla la evolución de la tasa de aprendizaje. Este es el parámetro eta que hemos visto en el paso del Descenso de Gradiente Estocástico. Controla el algoritmo Adam. Esencialmente, este es un parámetro que no necesitas modificar con frecuencia, pero a veces ajustarlo puede ahorrar una parte significativa de la potencia de procesamiento. No es sorprendente que, afinando esta tasa de aprendizaje, puedas ahorrar alrededor del 20% del tiempo total de cómputo de tu Descenso de Gradiente Estocástico.

La inicialización de los parámetros que se aprenden en el bloque autodiff también requiere un examen más minucioso. Hasta ahora, hemos usado la palabra clave “auto,” y en Envision, esto simplemente significa que éste inicializará el parámetro extrayendo aleatoriamente un valor de una distribución gaussiana con media 1 y desviación estándar 0.1. Esta inicialización se aparta de la práctica habitual en deep learning, donde los parámetros se inicializan aleatoriamente con gaussianas centradas en cero. La razón por la que Lokad adoptó este enfoque diferente se aclarará más adelante en esta conferencia cuando procedamos con una situación real de previsión de la demanda minorista.
En Envision, es posible sobreescribir y controlar la inicialización de los parámetros. El parámetro “quantile,” por ejemplo, se declara en la línea 9 pero no necesita ser inicializado. De hecho, en la línea 7, justo por encima del bloque de autodiff, tenemos una variable “quantile” a la que se le asigna el valor 4.2, y por lo tanto la variable ya está inicializada con un valor determinado. No es necesaria la inicialización automática. También es posible imponer un rango de valores permitidos para los parámetros, y esto se hace con la palabra clave “in” en la línea 9. Esencialmente, estamos definiendo que “quantile” debe estar entre 1 y 10, inclusive. Con esos límites establecidos, si se obtiene una actualización del algoritmo Adam que empuja el valor del parámetro fuera del rango aceptable, limitamos el cambio proveniente de Adam para que se mantenga dentro de este rango. Además, también ponemos a cero los valores de momentum que normalmente se adjuntan al algoritmo Adam internamente. Imponer límites a los parámetros se desvía de la práctica clásica de deep learning; sin embargo, los beneficios de esta característica se harán evidentes una vez que empecemos a discutir un ejemplo real de retail demand previsión.

La programación diferenciable se basa en gran medida en el descenso por gradiente estocástico. El ángulo estocástico es literalmente lo que hace que el descenso funcione muy rápido. Es una espada de doble filo; el ruido obtenido a través de las pérdidas parciales no es simplemente un defecto, sino también una característica. Al tener un poco de ruido, el descenso puede evitar quedarse atascado en zonas con gradientes muy planos. Así, disponer de este gradiente ruidoso no solo hace que la iteración sea mucho más rápida, sino que también ayuda a impulsar la iteración para salir de áreas donde el gradiente es muy plano y provoca que el descenso se desacelere. Sin embargo, algo a tener en cuenta es que, cuando se utiliza el descenso por gradiente estocástico, la suma de los gradientes no equivale al gradiente de la suma. Como resultado, el descenso por gradiente estocástico presenta pequeños sesgos estadísticos, especialmente cuando se trata de distribuciones de cola. No obstante, cuando surgen estas preocupaciones, es relativamente sencillo parchear las recetas numéricas, incluso si la teoría sigue siendo un tanto confusa.
La programación diferenciable (DP) no debe confundirse con un solucionador arbitrario de optimización matemática. El gradiente debe fluir a través del programa para que la programación diferenciable funcione en absoluto. La programación diferenciable puede trabajar con programas arbitrariamente complejos, pero esos programas deben ser diseñados pensando en la programación diferenciable. Además, la programación diferenciable es una cultura; es un conjunto de consejos y trucos que funcionan bien con el descenso por gradiente estocástico. Considerándolo todo, la programación diferenciable se encuentra en el lado fácil del espectro del machine learning. Es una técnica muy accesible. No obstante, se requiere cierta habilidad para dominar este paradigma y operarlo sin inconvenientes en producción.
Ahora estamos listos para embarcarnos en el segundo bloque de esta conferencia: la demostración. Tendremos una demostración para nuestra tarea de retail demand previsión. Este ejercicio de modelado está alineado con el desafío de previsión que presentamos en la conferencia anterior. En resumen, queremos previsión la demanda diaria a nivel de SKU en una red minorista. Un SKU, o stock-keeping unit, es técnicamente el producto cartesiano entre productos y tiendas, filtrado a lo largo de las entradas del surtido. Por ejemplo, si tenemos 100 tiendas y 10,000 productos, y si cada producto está presente en todas las tiendas, terminamos con 1 millón de SKUs.
Existen herramientas para transformar una estimación determinista en una estimación probabilística. Hemos visto una de esas herramientas en la conferencia anterior a través de la técnica ESSM. Revisaremos esta preocupación específica —convertir estimaciones en estimaciones probabilísticas— con mayor detalle en la próxima conferencia. Sin embargo, hoy solo nos dedicamos a estimar promedios, y todos los demás tipos de estimaciones (quantiles, probabilistic) llegarán más adelante como extensiones naturales del ejemplo central que presentaré hoy. En esta demostración, vamos a aprender los parámetros de un modelo sencillo de retail demand previsión. La simplicidad de este modelo es engañosa, ya que esta clase de modelo sí alcanza un estado del arte en previsión, como se ilustra en la competencia M5 de previsión en 2020.

Para nuestro modelo paramétrico de demanda, introduzcamos un único parámetro para cada SKU. Esta es una forma absolutamente simplista de modelo; la demanda se modela como una constante para cada SKU. Sin embargo, no es la misma constante para todos los SKUs. Una vez que tenemos este promedio diario constante, será el mismo valor para todos los días del ciclo de vida completo del SKU.
Veamos cómo se hace con la programación diferenciable. De las líneas 1 a 4, estamos introduciendo el bloque de datos simulados. En la práctica, este modelo y todas sus variantes dependerían de entradas obtenidas de los sistemas de negocio: el ERP, WMS, TMS, etc. Presentar una conferencia en la que conectara un modelo matemático a una representación realista de datos, tal como se obtiene del ERP, introduciría toneladas de complicaciones accidentales que son irrelevantes para el tema actual de la conferencia. Así que, lo que hago aquí es introducir un bloque de datos simulados que ni siquiera pretende ser realista de ninguna manera, o del tipo de datos que se puede observar en una situación minorista real. El único objetivo de este bloque de datos simulados es introducir las tablas y las relaciones dentro de las tablas, y asegurar que el ejemplo de código proporcionado es completo, se puede compilar y se puede ejecutar. Todos los ejemplos de código que has visto hasta ahora son completamente independientes; no hay partes ocultas antes o después. El único propósito del bloque de datos simulados es asegurarse de que tenemos un trozo de código autónomo.
En cada ejemplo de esta demostración, comenzamos con este bloque de datos simulados. En la línea 1, introducimos la tabla de fechas con “dates” como su clave primaria. Aquí, tenemos un rango de fechas que es básicamente de dos años y un mes. Luego, en la línea 2, introducimos la tabla de SKUs, que es la lista de SKUs. En este ejemplo minimalista, tenemos solo tres SKUs. En una situación minorista real para una red minorista de gran tamaño, tendríamos millones, si no decenas de millones, de SKUs. Pero aquí, para el ejemplo, tomo un número muy pequeño. En la línea 3, tenemos la tabla “T,” que es un producto cartesiano entre los SKUs y la fecha. Esencialmente, lo que obtienes a través de esta tabla “T” es una matriz donde tienes cada SKU y cada día. Tiene dos dimensiones.
En la línea 6, introducimos nuestro bloque real de autodiff. La tabla de observación es la tabla de SKUs, y el descenso por gradiente estocástico aquí seleccionará un SKU a la vez. En la línea 7, introducimos el “level”, que será nuestro único parámetro. Es un parámetro vectorial, y hasta ahora, en nuestros bloques de autodiff, solo hemos introducido parámetros escalares. Los parámetros anteriores eran solo un número; aquí, “SKU.level” es en realidad un vector. Es un vector que tiene un valor por SKU, y ese es literalmente nuestro modelado de la demanda constante a nivel de SKU. Especificamos un rango, y veremos por qué es importante en un momento. Tiene que ser al menos 0.01, y fijamos 1,000 como el límite superior para el promedio diario de la demanda de este parámetro. Este parámetro se inicializa automáticamente con un valor cercano a uno, lo cual es un punto de partida razonable. En este modelo, lo que tenemos es solo un grado de libertad por SKU. Finalmente, en las líneas 8 y 9, estamos implementando el modelo en sí. En la línea 8, estamos calculando “dot.delta,” que es la demanda tal como la predice el modelo menos la observada, que es “T.sold.” El modelo es solo un término, una constante, y luego tenemos la observación, que es “T.sold.”
Para entender lo que está sucediendo aquí, se dan algunos comportamientos de broadcasting. La tabla “T” es una tabla cruzada entre SKU y fecha. El bloque de autodiff es una iteración que recorre las líneas de la tabla de observación. En la línea 9, estamos dentro del bloque de autodiff, por lo que hemos seleccionado una línea de la tabla de SKUs. El valor “SKUs.level” no es un vector aquí; es solo un escalar, un solo valor, ya que hemos seleccionado solo una línea de la tabla de observación. Luego, “T.sold” ya no es una matriz porque ya se ha seleccionado un SKU. Lo que queda es que “T.sold” es en realidad un vector, un vector cuya dimensión es igual a la de la fecha. Cuando hacemos esta resta, “SKUs.level - T.sold”, obtenemos un vector que está alineado con la tabla de fechas, y lo asignamos a “D.delta,” que es un vector con una línea por día, de dos años y un mes. Finalmente, en la línea 9, calculamos la función de pérdida, que es simplemente el error cuadrático medio. Este modelo es súper simplista. Veamos qué se puede hacer respecto a los patrones del calendario.

El compartir parámetros es probablemente una de las técnicas de programación diferenciable más simples y útiles. Se dice que un parámetro es compartido si contribuye a múltiples líneas de observación. Al compartir parámetros entre observaciones, podemos estabilizar el descenso por gradiente y mitigar problemas de overfitting. Consideremos el patrón del día de la semana. Podríamos introducir siete parámetros que representen los diversos pesos para cada SKU. Hasta ahora, un SKU tiene solo un parámetro, que es simplemente la demanda constante. Si queremos enriquecer esta percepción de la demanda, podríamos decir que cada día de la semana viene con su propio peso, y dado que tenemos siete días en la semana, podemos tener siete pesos y aplicarlos de manera multiplicativa.
Sin embargo, es poco probable que cada SKU tenga su propio patrón único del día de la semana. La realidad es que resulta mucho más razonable asumir que existe una categoría o algún tipo de jerarquía, como una familia de productos, categoría de producto, subcategoría de producto o incluso un departamento en la tienda, que capture correctamente este patrón del día de la semana. La idea es que no queremos introducir siete parámetros por SKU; lo que queremos es introducir siete parámetros por categoría, ese nivel de agrupación en el que se asume que hay un comportamiento homogéneo en términos de patrones del día de la semana.
Si decidimos introducir esos siete parámetros con un efecto multiplicativo sobre el level, este es exactamente el enfoque que se adoptó en la conferencia anterior para este modelo, que terminó siendo el número uno a nivel de SKU en la competencia M5. Tenemos un level y un efecto multiplicativo con el patrón del día de la semana.
En el código, en las líneas 1 a 5, tenemos el bloque de datos simulados tal como antes, e introducimos una tabla extra llamada “category.” Esta tabla es una tabla de agrupación de los SKUs, y conceptualmente, para cada línea en la tabla de SKUs, hay una y solo una línea que coincide en la tabla de categoría. En el lenguaje Envision, decimos que la categoría está aguas arriba de la tabla SKUs. La línea 7 introduce la tabla del día de la semana. Esta tabla es instrumental, y la introducimos con una forma específica que refleja el patrón cíclico que queremos capturar. En la línea 7, creamos la tabla del día de la semana agrupando las fechas de acuerdo con su valor módulo siete. Estamos creando una tabla que tendrá exactamente siete líneas, y esas siete líneas representarán cada uno de los siete días de la semana. Para cada línea en la tabla de fechas, existe una y solo una línea correspondiente en la tabla del día de la semana. Así, siguiendo el lenguaje Envision, la tabla del día de la semana está aguas arriba de la tabla “date.”
Ahora tenemos la tabla “CD,” que es un producto cartesiano entre categoría y día de la semana. En términos del número de líneas, esta tabla tendrá tantas líneas como categorías multiplicado por siete, ya que la tabla del día de la semana tiene siete líneas. En la línea 12, introducimos un nuevo parámetro llamado “CD.DOW” (DOW significa day of the week), que es otro parámetro vectorial perteneciente a la tabla CD. En términos de grados de libertad, tendremos exactamente siete valores de parámetro por el número de categorías, que es lo que buscamos. Queremos un modelo que sea capaz de capturar este patrón del día de la semana, pero con solo un patrón por categoría, y no un patrón por SKU.
Declaramos este parámetro, y usamos la palabra clave “in” para especificar que el valor para “CD.DOW” debe estar entre 0.1 y 100. En la línea 13, escribimos la demanda tal como la expresa el modelo. La demanda es “SKUs.level * CD.DOW,” lo que representa la demanda. Tomamos la demanda menos lo observado “T.sold,” y eso nos da un delta. Luego, calculamos el error cuadrático medio.
En la línea 13, ocurre bastante magia de broadcasting. “CD.DOW” es una tabla cruzada entre categoría y día de la semana. Debido a que estamos dentro del bloque de autodiff, la tabla CD es una tabla cruzada entre categoría y día de la semana. Dado que estamos dentro del bloque de autodiff, el bloque está iterando sobre la tabla de SKUs. Esencialmente, cuando seleccionamos un SKU, hemos seleccionado efectivamente una categoría, ya que la tabla de categoría está aguas arriba. Esto significa que CD.DOW ya no es una matriz, sino un vector de dimensión siete. Sin embargo, está aguas arriba de la tabla “date,” por lo que esas siete líneas pueden difundirse en la tabla de fechas. Solo hay una forma de realizar este broadcast, ya que cada línea de la tabla del día de la semana guarda afinidad con líneas específicas de la tabla de fechas. Se produce un doble broadcasting, y al final se obtiene una demanda que es una serie de valores cíclicos a nivel del día de la semana para el SKU. Ese es nuestro modelo en este momento, y el resto de la función de pérdida permanece sin cambios.
Observamos una forma muy elegante de abordar las ciclicidades combinando los comportamientos de broadcasting obtenidos de la naturaleza relacional de Envision con sus capacidades de programación diferenciable. Podemos expresar las ciclicidades del calendario en solo tres líneas de código. Este enfoque funciona bien incluso si estamos tratando con datos muy dispersos. Funcionaría perfectamente incluso si estuviéramos analizando productos que se venden, en promedio, solo una unidad por mes. En tales casos, el enfoque prudente sería tener una categoría que incluya decenas, si no cientos, de productos. Esta técnica también se puede utilizar para reflejar otros patrones cíclicos, como el mes del año o el día del mes.
El modelo introducido en la conferencia anterior, que logró resultados de última generación en la competencia M5, fue una combinación multiplicativa de tres ciclicidades: día de la semana, mes del año y día del mes. Todos estos patrones se encadenaron como una multiplicación. Implementar las otras dos variantes se deja a la audiencia atenta, pero es solo cuestión de un par de líneas de código por patrón cíclico, lo que lo hace muy conciso.

En la conferencia anterior, presentamos un modelo de previsión de ventas. Sin embargo, no son las ventas lo que nos interesa, sino la demanda. No debemos confundir ventas cero con demanda cero. Si no quedó stock para que el cliente lo compre en la tienda en un día determinado, se utiliza en Lokad la técnica de enmascaramiento de pérdidas para hacer frente a faltante de stock. Esta es la técnica más simple utilizada para hacer frente a faltante de stock, pero no es la única. Hasta donde yo sé, contamos al menos con otras dos técnicas que se usan en producción, cada una con sus propios pros y contras. Esas otras técnicas no se cubrirán hoy, pero se abordarán en conferencias posteriores.
Volviendo al ejemplo de código, las líneas 1 a 3 permanecen sin cambios. Examinemos lo que sigue. En la línea 6, estamos enriqueciendo los datos simulados con la bandera booleana in-stock. Para cada SKU y para cada día, tenemos un valor booleano que indica si hubo un faltante de stock al final del día para la tienda. En la línea 15, estamos modificando la función de pérdida para excluir, poniéndolos a cero, los días en los que se observó un faltante de stock al final del día. Al poner esos días a cero, nos aseguramos de que ningún gradiente se retropropague en situaciones que presentan un sesgo debido a la ocurrencia del faltante de stock.
El aspecto más desconcertante de la técnica de enmascaramiento de pérdidas es que ni siquiera cambia el modelo. De hecho, si observamos el modelo expresado en la línea 14, es exactamente el mismo; no ha sido modificado. Es únicamente la función de pérdida la que se modifica. Esta técnica puede ser simple, pero diverge profundamente de una perspectiva centrada en el modelo. Es, en esencia, una técnica centrada en la modelización. Estamos mejorando la situación al reconocer el sesgo causado por faltante de stock, reflejándolo en nuestros esfuerzos de modelización. Sin embargo, lo hacemos cambiando la métrica de precisión, no el modelo en sí. En otras palabras, estamos cambiando la pérdida que optimizamos, haciendo que este modelo no sea comparable con otros modelos en términos de error numérico puro.
Para una situación como Walmart, tal como se discutió en la conferencia anterior, la técnica de enmascaramiento de pérdidas es adecuada para la mayoría de los productos. Como regla general, esta técnica funciona bien si la demanda no es tan escasa que solo se tiene una unidad en stock la mayor parte del tiempo. Además, se deben evitar productos en los que faltante de stock sea muy frecuente, ya que es la estrategia explícita del minorista terminar con un faltante de stock al final del día. Esto suele suceder con algunos productos ultra-frescos donde el minorista apunta a una situación de faltante de stock al final del día. Técnicas alternativas remedian estas limitaciones, pero no tenemos tiempo para cubrirlas hoy.

Las promociones son un aspecto importante del retail. Más en general, existen muchas maneras para que el minorista influya y moldee la demanda, tales como la fijación de precios o el traslado de mercancías a una góndola. Las variables que proporcionan información extra con fines predictivos se conocen típicamente como covariables en los círculos de supply chain. Hay muchas ilusiones sobre covariables complejas como los datos meteorológicos o los datos de redes sociales. Sin embargo, antes de profundizar en temas avanzados, debemos abordar el elefante en la habitación, como la información de precios, que obviamente tiene un impacto significativo en la demanda que se observará. Así, en la línea 7 de este ejemplo de código, introducimos para cada día en la línea 14, “category.ed”, donde “ed” significa elasticidad de la demanda. Este es un parámetro vectorial compartido con un grado de libertad por categoría, destinado a ser una representación de la elasticidad de la demanda. En la línea 16, introducimos una forma exponencial de price elasticity como la exponencial de (-category.ed * t.price). Intuitivamente, con esta forma, cuando el precio aumenta, la demanda converge rápidamente a cero debido a la presencia de la función exponencial. Por el contrario, cuando el precio converge a cero, la demanda aumenta explosivamente.
Esta forma exponencial de respuesta a los precios es simplista, y compartir los parámetros asegura un alto grado de estabilidad numérica incluso con esta función exponencial en el modelo. En entornos del mundo real, especialmente para situaciones como Walmart, tendríamos varias informaciones de precios, tales como descuentos, la diferencia respecto al precio normal, covariables que representan impulsos de marketing ejecutados por el proveedor, o variables categóricas que introducen elementos como góndolas. Con la programación diferenciable, es sencillo diseñar respuestas de precios arbitrariamente complejas que se ajusten de cerca a la situación. Integrar covariables de casi cualquier tipo es muy sencillo con la programación diferenciable.

Los productos de lenta rotación son una realidad en el retail y en muchos otros sectores. El modelo introducido hasta ahora tiene un parámetro, un grado de libertad por SKU, y más si se cuentan los parámetros compartidos. Sin embargo, esto ya puede ser demasiado, especialmente para SKUs que solo rotan una vez al año o pocas veces al año. En tales situaciones, ni siquiera podemos permitirnos un grado de libertad por SKU, por lo que la solución es confiar únicamente en parámetros compartidos y eliminar todos los parámetros con grados de libertad a nivel de SKU.
En las líneas 2 y 4, introducimos dos tablas denominadas “products” y “stores”, y la tabla “SKUs” se construye como una subtabla filtrada del producto cartesiano entre products y stores, que es la propia definición de surtido. En las líneas 15 y 16, introdujimos dos parámetros vectoriales compartidos: un nivel con afinidad con la tabla products y otro nivel que tiene afinidad con las tablas stores. Estos parámetros también están definidos dentro de un rango específico, de 0.01 a 100, que es el valor máximo.
Ahora, en la línea 18, el nivel por SKU se compone como la multiplicación del nivel del producto y el nivel de la tienda. El resto del script permanece sin cambios. Entonces, ¿cómo funciona? En la línea 19, SKU.level es un escalar. Tenemos el bloque autodesk que itera sobre la tabla SKUs, que es la tabla de observación. Así, SKUs.level en la línea 18 es simplemente un valor escalar. Luego tenemos products.level. Dado que la tabla products está aguas arriba de la tabla SKUs, para cada SKU hay una y solo una tabla de producto. Por lo tanto, products.level es simplemente un número escalar. Lo mismo se aplica a la tabla stores, que también está aguas arriba de la tabla SKUs. En la línea 18, solo hay una tienda asociada a este SKU específico. Por lo tanto, lo que tenemos es la multiplicación de dos valores escalares, lo que nos da el SKU.level. El resto del modelo permanece sin cambios.
Estas técnicas ponen una luz completamente nueva sobre la afirmación de que a veces no hay suficientes datos o que a veces los datos son demasiado escasos. De hecho, desde la perspectiva diferenciable, esas afirmaciones ni siquiera tienen mucho sentido. No existe algo como datos insuficientes o que los datos sean demasiado escasos, al menos no en términos absolutos. Solo existen modelos que pueden modificarse hacia la escasez y posiblemente hacia una escasez extrema. La estructura impuesta es como rieles guía que hacen que el proceso de aprendizaje sea no solo posible sino también numéricamente estable.
En comparación con otras técnicas de machine learning que intentan que el modelo de machine learning descubra todos los patrones ex nihilo, este enfoque estructurado establece la propia estructura que debemos aprender. Así, el mecanismo estadístico en juego aquí tiene una libertad limitada en cuanto a lo que debe aprender. En consecuencia, en términos de eficiencia de datos, puede ser increíblemente eficiente. Naturalmente, todo esto depende del hecho de que hayamos elegido la estructura correcta.
Como puedes ver, realizar experimentos es muy sencillo. Ya estamos haciendo algo muy complicado, y en menos de 50 líneas, podríamos manejar una situación bastante compleja similar a la de Walmart. Esto es todo un logro. Hay un poco de proceso empírico, pero la realidad es que no es tanto. Estamos hablando de unas pocas docenas de líneas. Ten en cuenta que un ERP como el que dirige una empresa, una gran red de retail, típicamente tiene mil tablas y 100 campos por tabla. Así que, claramente, la complejidad de los sistemas empresariales es absolutamente gigantesca en comparación con la complejidad de este modelo predictivo estructurado. Si tenemos que dedicar un poco de tiempo iterando, es casi nada.
Además, como se demostró en la competencia M5 de previsión, la realidad es que los profesionales de supply chain ya conocen los patrones. Cuando el equipo M5 usó tres patrones de calendario, que eran el día de la semana, el mes del año y el día del mes, todos estos patrones eran evidentes para cualquier profesional de supply chain con experiencia. La realidad en supply chain es que no estamos tratando de descubrir algún patrón oculto. El hecho de que, por ejemplo, si bajas masivamente el precio, la demanda aumentará masivamente, no sorprenderá a nadie. La única pregunta que queda es cuál es exactamente la magnitud del efecto y cuál es la forma exacta de la respuesta. Estos son detalles relativamente técnicos, y si te permites la oportunidad de realizar algunos experimentos, puedes abordar estos problemas con relativa facilidad.
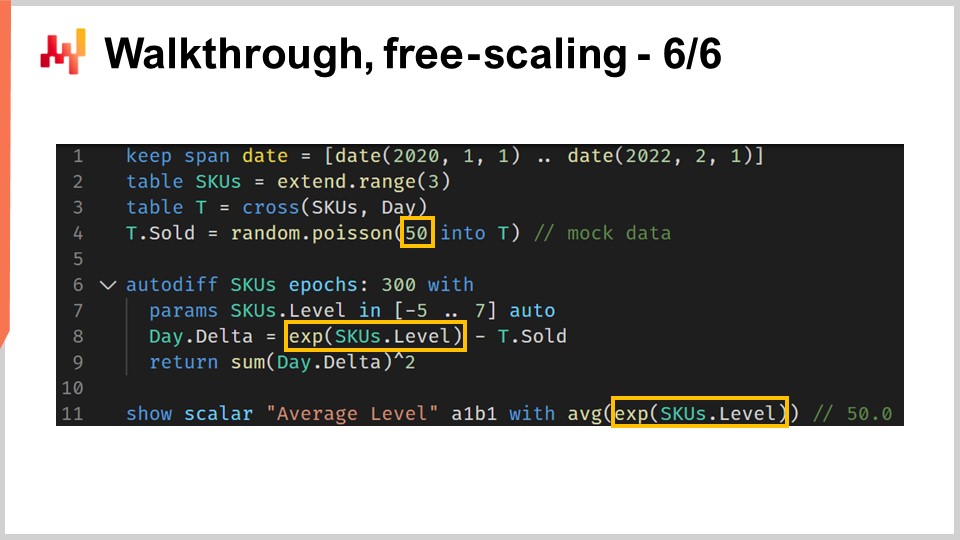
Como último paso de este recorrido, me gustaría señalar un pequeño detalle peculiar de la programación diferenciable. La programación diferenciable no debe confundirse con un solucionador genérico de optimización matemática. Debemos tener en cuenta que hay un descenso por gradiente en marcha. Más específicamente, el algoritmo utilizado para optimizar y actualizar los parámetros tiene una velocidad máxima de descenso que es igual a la tasa de aprendizaje que viene con el algoritmo ADAM. En Envision, la tasa de aprendizaje predeterminada es 0.01.
Si miramos el código, en la línea 4, introdujimos una inicialización donde las cantidades que se venden se muestrean de una distribución de Poisson con una media de 50. Si queremos aprender un nivel, técnicamente, necesitaríamos tener un nivel del orden de 50. Sin embargo, cuando realizamos una inicialización automática del parámetro, comenzamos con un valor que está alrededor de uno, y solo podemos avanzar en incrementos de 0.01. Se necesitarían algo así como 5,000 epochs para alcanzar realmente este valor de 50. Dado que tenemos un parámetro no compartido, SKU.level, este parámetro se toca solo una vez por epoch. Por lo tanto, se necesitarían 5,000 epochs, lo que ralentizaría innecesariamente el cómputo.
Podríamos aumentar la tasa de aprendizaje para acelerar el descenso, lo cual sería una solución. Sin embargo, no aconsejaría inflar la tasa de aprendizaje, ya que típicamente no es la manera correcta de abordar el problema. En una situación real, tendríamos parámetros compartidos además de este parámetro no compartido. Esos parámetros compartidos serán tocados por el descenso por gradiente estocástico muchas veces a lo largo de cada epoch. Si incrementas enormemente la tasa de aprendizaje, corres el riesgo de crear inestabilidades numéricas en tus parámetros compartidos. Podrías aumentar la velocidad de cambio del nivel de SKU pero crear problemas de estabilidad numérica para los otros parámetros.
Una técnica mejor sería usar un truco de reescalado y envolver el parámetro en una función exponencial, que es exactamente lo que se hace en la línea 8. Con este envoltorio, ahora podemos alcanzar valores de parámetro para el nivel que pueden ser tanto muy bajos como muy altos con un número mucho menor de epochs. Esta peculiaridad es básicamente la única peculiaridad que necesitaría introducir para tener un ejemplo realista para este recorrido de la situación de previsión de la demanda en retail. Considerándolo todo, es una peculiaridad menor. No obstante, es un recordatorio de que la programación diferenciable requiere prestar atención al flujo de gradientes. La programación diferenciable ofrece una experiencia de diseño fluida en general, pero no es magia.
Algunas reflexiones finales: los modelos estructurados sí logran una precisión de previsión de última generación. Este punto se expuso extensamente en la conferencia anterior. Sin embargo, basado en los elementos presentados hoy, argumentaría que la precisión ni siquiera es el factor decisivo a favor de la programación diferenciable con un modelo paramétrico estructurado. Lo que obtenemos es entendimiento; no solo conseguimos un software capaz de realizar predicciones, sino que también obtenemos conocimientos directos sobre los propios patrones que intentamos capturar. Por ejemplo, el modelo introducido hoy nos daría directamente una previsión de la demanda que viene con pesos explícitos para el día de la semana y una elasticidad explícita de la demanda. Si extendiéramos esta demanda, por ejemplo, para introducir un impulso asociado al Black Friday, un evento quasi-estacional que no ocurre en la misma época cada año, podríamos hacerlo. Solo agregaríamos un factor, y luego tendríamos una estimación del impulso del Black Friday en aislamiento de todos los otros patrones, como el patrón del día de la semana. Esto es de suma importancia.
Lo que obtenemos a través del enfoque estructurado es entendimiento, y es mucho más que solo el modelo crudo. Por ejemplo, si terminamos con una elasticidad negativa, una situación en la que el modelo te indica que cuando aumentas el precio, aumentas la demanda, en una situación similar a la de Walmart, este es un resultado muy dudoso. Lo más probable es que refleje que la implementación de tu modelo es defectuosa, o que hay problemas profundos en marcha. No importa lo que la métrica de precisión te indique, si terminas en una situación de Walmart con algo que te dice que al encarecer un producto, la gente compra más, realmente deberías cuestionar toda tu canal de datos, porque lo más probable es que algo esté muy mal. Eso es a lo que se refiere el entendimiento.
Además, el modelo está abierto al cambio. La programación diferenciable es increíblemente expresiva. El modelo que tenemos es solo una iteración en un viaje. Si el mercado se transforma o si la propia empresa se transforma, podemos tener la seguridad de que el modelo que tenemos podrá capturar esta evolución de manera natural. No existe tal cosa como una evolución automática; se requerirá el esfuerzo de un Supply Chain Scientist para capturar esta evolución. Sin embargo, se puede esperar que este esfuerzo sea relativamente mínimo. Todo se reduce al hecho de que si tienes un modelo muy pequeño y ordenado, entonces cuando necesites revisitar este modelo más adelante para ajustar su estructura, será una tarea relativamente pequeña en comparación con una situación en la que tu modelo fuera una bestia de la ingeniería.
Cuando se diseñan cuidadosamente, los modelos producidos con programación diferenciable son muy estables. La estabilidad se reduce a la elección de la estructura. La estabilidad no es algo garantizado para ningún programa que optimices mediante programación diferenciable; es el tipo de característica que obtienes cuando tienes una estructura muy clara en la que los parámetros tienen una semántica específica. Por ejemplo, si tienes un modelo en el que, cada vez que lo reentrenas, terminas con pesos completamente distintos para el día de la semana, entonces la realidad en tu negocio no está cambiando tan rápido. Si ejecutas tu modelo dos veces, deberías obtener valores para el día de la semana que sean bastante estables. Si no es así, entonces hay algo muy mal en la forma en que has modelado tu demanda. Por lo tanto, si haces una elección inteligente para la estructura de tu modelo, puedes obtener resultados numéricos increíblemente estables. Al hacer esto, evitamos escollos que tienden a afectar a los complejos modelos de machine learning cuando intentamos utilizarlos en un contexto de supply chain. De hecho, desde una perspectiva de supply chain, las inestabilidades numéricas son mortales porque tenemos efectos de trinquete por todas partes. Si tienes una estimación de la demanda que fluctúa, significa que, al azar, vas a generar una orden de compra o una orden de producción sin motivo alguno. Una vez que has generado tu orden de producción, no puedes decidir la próxima semana que fue un error y que no deberías haberlo hecho. Estás atado a la decisión que acabas de tomar. Si tienes un estimador de demanda futura que sigue fluctuando, terminarás con replenishment inflado y órdenes de producción infladas. Este problema puede resolverse asegurando la estabilidad, lo cual es una cuestión de diseño.
Uno de los mayores obstáculos para llevar machine learning a producción es la confianza. Cuando operas con millones de euros o dólares, entender lo que está ocurriendo en tu receta numérica es fundamental. Los errores en supply chain pueden ser sumamente costosos, y hay muchos ejemplos de disasters de supply chain impulsados por una mala aplicación de algoritmos poco entendidos. Aunque la programación diferenciable es muy poderosa, los modelos que se pueden diseñar son increíblemente simples. Estos modelos podrían, de hecho, ejecutarse en una spreadsheet de Excel, ya que generalmente son modelos multiplicativos sencillos con ramas y funciones. El único aspecto que no podría ejecutarse en una spreadsheet de Excel es la diferenciación automática, y obviamente, si tienes millones de SKUs, no intentes hacerlo en una spreadsheet. Sin embargo, en cuanto a simplicidad, es totalmente compatible con algo que pondrías en una spreadsheet. Esa simplicidad es fundamental para generar confianza y llevar machine learning a producción, en lugar de mantenerlos como prototipos elegantes en los que la gente nunca llega a confiar completamente.
Finalmente, cuando reunimos todas estas propiedades, obtenemos una pieza de tecnología muy precisa. Este enfoque se discutió en el primer capítulo de esta serie de conferencias. Queremos convertir todos los esfuerzos invertidos en supply chain en inversiones capitalistas, en lugar de tratar a los expertos y profesionales de supply chain como consumibles que deben hacer lo mismo una y otra vez. Con este enfoque, podemos tratar todos estos esfuerzos como inversiones que generarán y seguirán generando retorno de inversión a lo largo del tiempo. La programación diferenciable encaja muy bien con esta perspectiva capitalista para supply chain.

En el segundo capítulo, introdujimos una conferencia importante titulada “Optimización Experimental,” la cual proporcionó una posible respuesta a la pregunta simple pero fundamental: ¿Qué significa realmente mejorar o desempeñarse mejor en un supply chain? La perspectiva de la programación diferenciable proporciona una visión muy específica sobre muchas de las dificultades que enfrentan los profesionales de supply chain. Los software vendors empresariales frecuentemente culpan a los datos malos por sus fallas en supply chain. Sin embargo, creo que esta es simplemente la manera equivocada de ver el problema. Los datos son simplemente lo que son. Tu ERP nunca ha sido diseñado para la ciencia de datos, pero ha estado operando sin problemas durante años, si no décadas, y la gente en la empresa logra administrar el supply chain de todas formas. Incluso si tu ERP que captura datos sobre tu supply chain no es perfecto, está bien. Si esperas que se disponga de datos perfectos, esto es solo un deseo ilusorio. Estamos hablando de supply chains; el mundo es muy complejo, por lo que los sistemas son imperfectos. Realísticamente, no tienes un único sistema de negocio; tienes como media docena, y no son completamente consistentes entre sí. Esto es simplemente un hecho de la vida. Sin embargo, cuando los software vendors empresariales culpan a los malos datos, la realidad es que el vendor utiliza un modelo de previsión muy específico, y este modelo ha sido diseñado con un conjunto específico de suposiciones sobre la empresa. El problema es que si tu empresa llega a violar cualquiera de esas suposiciones, la tecnología se desmorona por completo. En esta situación, tienes un modelo de previsión que viene con suposiciones poco razonables, le proporcionas los datos, no son perfectos, y por lo tanto la tecnología se desmorona. Es completamente irrazonable decir que la culpa es de la empresa. La tecnología en falta es aquella que impulsa el vendor y que hace suposiciones completamente poco realistas sobre lo que los datos pueden ser incluso en un contexto de supply chain.
No he presentado ningún benchmark para ninguna métrica de exactitud hoy. Sin embargo, mi proposición es que esas métricas de exactitud son en su mayoría inconsecuentes. Un modelo predictivo es una herramienta para impulsar decisiones. Lo que importa es si esas decisiones—qué comprar, qué producir, si subir o bajar tu precio—son buenas o malas. Es cierto que las malas decisiones se pueden rastrear hasta el modelo predictivo. Sin embargo, la mayoría de las veces, no se trata de un problema de exactitud. Por ejemplo, teníamos un modelo de sales previsión, y solucionamos el ángulo del faltante de stock que no se gestionaba adecuadamente. Sin embargo, al solucionar el ángulo del faltante de stock, lo que hicimos fue arreglar la métrica de exactitud en sí. Entonces, arreglar el modelo predictivo no significa mejorar la exactitud; muy frecuentemente, significa literalmente revisar el mismo problema y la perspectiva en la que operas, y por lo tanto modificar la métrica de exactitud o algo incluso más profundo. El problema con la perspectiva clásica es que asume que la métrica de exactitud es un objetivo valioso. Esto no es del todo así.
Los supply chains operan en un mundo real, y existen numerosos eventos inesperados e incluso insólitos. Por ejemplo, puedes tener una obstrucción del Canal de Suez debido a un barco; se trata de un evento completamente insólito. En tal situación, se invalidarían inmediatamente todos los modelos de previsión de tiempo de entrega existentes que observaban esta parte del mundo. Obviamente, esto era algo que realmente no había ocurrido antes, por lo que no podemos retroprobar nada en tal situación. Sin embargo, incluso si tenemos esta situación completamente excepcional con un barco bloqueando el Canal de Suez, aún podemos arreglar el modelo, al menos si contamos con este tipo de enfoque white-box que propongo hoy. Esta solución va a implicar un grado de conjetura, lo cual está bien. Es mejor estar aproximadamente en lo correcto que exactamente equivocado. Por ejemplo, si consideramos que el Canal de Suez está bloqueado, simplemente se puede decir: “agreguemos un mes al tiempo de entrega para todos los suministros que se suponía debían pasar por esta ruta.” Esto es muy aproximado, pero es mejor asumir que no habrá demora alguna, aunque ya dispongas de la información. Además, el cambio frecuentemente proviene desde dentro. Por ejemplo, consideremos una red de retail que tiene un centro de distribución antiguo y un centro de distribución nuevo que abastece a unas pocas docenas de tiendas. Digamos que se está llevando a cabo una migración, donde esencialmente los suministros para las tiendas están siendo trasladados del centro de distribución antiguo al nuevo. Esta situación ocurre casi solo una vez en la historia de este minorista en particular, y realmente no se puede retroprobar. Sin embargo, con un enfoque como la programación diferenciable, es completamente sencillo implementar un modelo que se adapte a esta migración gradual.

En conclusión, la programación diferenciable es una tecnología que nos brinda un enfoque para estructurar nuestras visiones sobre el futuro. La programación diferenciable nos permite moldear, literalmente, la forma en que miramos el futuro. La programación diferenciable se sitúa en el lado de la percepción de este panorama. Con base en esta percepción, podemos tomar mejores decisiones para supply chains, y esas decisiones impulsan las acciones que se encuentran en el otro lado del panorama. Uno de los mayores malentendidos de la teoría dominante de supply chain es que se puede tratar la percepción y la acción en aislamiento como componentes estrictamente separados. Esto toma la forma, por ejemplo, de tener un equipo a cargo de la planificación (esa es la percepción) y un equipo independiente a cargo de [replenishment] (esa es la acción).
Sin embargo, el bucle de retroalimentación acción-percepción es muy importante; es de importancia primordial. Este es, literalmente, el mecanismo que te guía hacia una forma correcta de percepción. Si no tienes este bucle de retroalimentación, ni siquiera está claro si estás observando lo correcto, o si lo que estás observando es realmente lo que crees que es. Necesitas este mecanismo de retroalimentación, y es a través de este bucle que puedes dirigir tus modelos hacia una evaluación cuantitativa correcta del futuro que sea relevante para el curso de acción de tu supply chain. Los enfoques convencionales de supply chain están descartando este caso casi por completo porque, esencialmente, creo que están atrapados con una forma muy rígida de previsión. Esta forma de previsión centrada en el modelo puede ser un modelo antiguo, como el modelo Holt-Winters de previsión, o uno reciente como Facebook Prophet. La situación es la misma: si estás atrapado con un único modelo de previsión, entonces toda la retroalimentación que puedas obtener del lado de la acción carece de sentido, porque no puedes hacer nada respecto a dicha retroalimentación excepto ignorarla por completo.
Si estás atrapado con un modelo de previsión dado, no puedes reformatear o reestructurar tu modelo a medida que recibes información desde el lado de la acción. Por otro lado, la programación diferenciable, con su enfoque de modelado estructurado, te ofrece un paradigma completamente diferente. El modelo predictivo es completamente desechable—en su totalidad. Si la retroalimentación que recibes de la acción requiere cambios radicales en tu perspectiva predictiva, simplemente implementa esos cambios radicales. No existe un apego específico a una iteración dada del modelo. Mantener el modelo muy simple es fundamental para asegurarte de que, una vez en producción, conserves la opción de seguir cambiándolo. Porque, de nuevo, si lo que has diseñado es como una bestia, un monstruo de la ingeniería, entonces una vez en producción, se vuelve increíblemente difícil de cambiar. Uno de los aspectos clave es que, si quieres poder seguir cambiando, necesitas tener un modelo que sea muy parsimonioso en términos de líneas de código y complejidad interna. Aquí es donde brilla la programación diferenciable. No se trata de lograr una mayor exactitud; se trata de lograr una mayor relevancia. Sin relevancia, todas las métricas de exactitud carecen de sentido. La programación diferenciable y el modelado estructurado te ofrecen el camino para lograr relevancia y luego mantenerla con el tiempo.

Esto concluirá la conferencia de hoy. La próxima vez, el dos de marzo, a la misma hora del día, 3 PM hora de París, presentaré modelado probabilístico para supply chain. Examinaremos más de cerca las implicaciones técnicas de considerar todos los posibles futuros en lugar de simplemente elegir uno y declararlo el correcto. De hecho, considerar todos los posibles futuros es muy importante si deseas que tu supply chain sea verdaderamente resiliente ante el riesgo. Si simplemente eliges un futuro, es una receta para terminar con algo que es increíblemente frágil si tu previsión no resulta ser perfectamente correcto. Y adivina qué, la previsión nunca es completamente correcto. Por eso es muy importante adoptar la idea de que necesitas considerar todos los posibles futuros, y veremos cómo hacerlo con modernas recetas numéricas.
Question: Se añade ruido estocástico para evitar mínimos locales, pero ¿cómo se aprovecha o escala para evitar grandes desviaciones de manera que el descenso de gradiente no se aleje demasiado de su objetivo?
Esa es una pregunta muy interesante, y hay dos partes en esta respuesta.
Primero, por esto el algoritmo Adam es muy conservador en cuanto a la magnitud de los movimientos. El gradiente es fundamentalmente ilimitado; puedes tener un gradiente que valga miles o millones. Sin embargo, con Adam, el paso máximo está realmente acotado por la tasa de aprendizaje. Así que, efectivamente, Adam viene con una receta numérica que literalmente impone un paso máximo, y con suerte, eso evita una inestabilidad numérica masiva.
Ahora, si al azar, a pesar de que tenemos esta tasa de aprendizaje, se podría decir que, simplemente por pura fluctuación, vamos a movernos de manera iterativa, un paso a la vez, pero muchas veces en una dirección incorrecta, es una posibilidad. Por eso digo que el descenso de gradiente estocástico aún no se comprende completamente. Funciona increíblemente bien en la práctica, pero por qué funciona tan bien, y por qué converge tan rápido, y por qué no se presentan más de los problemas que pueden ocurrir, no se entiende del todo, especialmente si consideras que el descenso de gradiente estocástico ocurre en altas dimensiones. Así que, típicamente, tienes literalmente decenas, si no cientos, de parámetros que se tocan en cada paso. La intuición que puedes tener en dos o tres dimensiones es muy engañosa; las cosas se comportan de manera muy diferente cuando observas dimensiones superiores.
En resumen, para esta pregunta: es muy relevante. Hay una parte en la que se destaca la magia de Adam al ser muy conservador con la escala de tus pasos de gradiente, y otra parte, que es poco comprendida pero, sin embargo, funciona muy bien en la práctica. Por cierto, creo que el hecho de que el descenso de gradiente estocástico no sea completamente intuitivo es también la razón por la que durante casi 70 años esta técnica fue conocida pero no reconocida como efectiva. Durante casi 70 años, la gente supo que existía, pero era muy escéptica. Se necesitó el éxito masivo del deep learning para que la comunidad reconociera y admitiera que en realidad está funcionando muy bien, incluso si realmente no entendemos por qué.
Pregunta: ¿Cómo se entiende cuándo un cierto patrón es débil y, por lo tanto, debe ser eliminado del modelo?
De nuevo, una muy buena pregunta. No hay criterios estrictos; es literalmente una decisión de juicio del Supply Chain Scientist. La razón es que si el patrón que introduces te brinda beneficios mínimos, pero en términos de modelado son solo dos líneas de código y el impacto en términos de tiempo de cómputo es insignificante, y si alguna vez quieres eliminar el patrón más adelante es semi-trivial, podrías decir: “Bueno, puedo simplemente dejarlo. No parece perjudicar, no hace mucho bien. Puedo ver situaciones donde este patrón, que es débil ahora, podría llegar a ser fuerte.” En términos de mantenibilidad, eso está bien.
Sin embargo, también puedes ver el otro lado de la moneda, donde tienes un patrón que no capta mucho, y añade mucha carga computacional al modelo. Así que no es gratis; cada vez que agregas un parámetro o lógica, vas a inflar la cantidad de recursos de cómputo necesarios para tu modelo, haciéndolo más lento y pesado. Si crees que este patrón débil podría llegar a volverse fuerte, pero de una manera negativa, generando inestabilidad y causando estragos en tu modelado predictivo, esta es típicamente la clase de situación en la que pensarías, “No, probablemente debería eliminarlo.”
Verás, en realidad se trata de una cuestión de juicio. La programación diferenciable es una cultura; no estás solo. Tienes colegas y compañeros que tal vez hayan intentado diferentes cosas en Lokad. Este es el tipo de cultura que intentamos cultivar. Sé que puede ser algo decepcionante en comparación con la perspectiva de una IA todopoderosa, la idea de que podríamos tener una inteligencia artificial todopoderosa resolviendo todos esos problemas por nosotros. Pero la realidad es que las supply chains son tan complejas, y nuestras técnicas de inteligencia artificial son tan rudimentarias, que no tenemos ningún sustituto realista para la inteligencia humana. Cuando digo juicio, simplemente me refiero a que necesitas una saludable dosis de inteligencia aplicada, muy humana, al caso, porque todos los trucos algorítmicos ni siquiera se acercan a ofrecer una respuesta satisfactoria.
No obstante, eso no significa que no puedas diseñar algún tipo de herramienta. Ese sería otro tema; veré si realmente cubro el tipo de herramientas que proporcionamos en Lokad para facilitar el diseño. Un patrón tangencial sería, si tenemos que tomar una decisión de juicio, intentemos proporcionar toda la instrumentación para que esta decisión pueda tomarse de manera muy rápida, minimizando el dolor que conlleva este tipo de indecisión en la que el Supply Chain Scientist necesita decidir algo sobre el destino del estado actual del modelo.
Pregunta: ¿Cuál es el umbral de complejidad de una supply chain a partir del cual el machine learning y la programación diferenciable aportan resultados considerablemente mejores?
En Lokad, típicamente logramos aportar resultados sustanciales para empresas que tienen una facturación de $10 millones por año o más. Diría que realmente empieza a brillar si tienes una empresa con una facturación anual de $50 millones o más.
La razón es que, fundamentalmente, necesitas establecer una tubería de datos muy confiable. Necesitas poder extraer todos los datos relevantes del ERP a diario. No quiero decir que sean datos buenos o malos, simplemente los datos que tienes pueden tener muchos defectos. No obstante, esto significa que hay bastantes conexiones solo para poder extraer las transacciones más básicas a diario. Si la empresa es demasiado pequeña, entonces usualmente ni siquiera tienen un departamento de TI, y no pueden lograr una extracción diaria confiable, lo cual compromete realmente los resultados.
Ahora, en términos de verticales o complejidad, la cuestión es que, en la mayoría de las empresas y supply chains, en mi opinión, ni siquiera han empezado a optimizar aún. Como dije, la teoría principal de supply chain enfatiza que deberías perseguir previsiones más precisas. Tener un porcentaje reducido de error en la previsión es una meta, y muchas empresas, por ejemplo, lo abordarían formando un equipo de planificación o un equipo de previsión. En mi opinión, todo eso no añade nada de valor al negocio porque fundamentalmente está proporcionando respuestas muy sofisticadas al conjunto equivocado de preguntas.
Puede parecer sorprendente, pero la programación diferenciable realmente brilla no porque sea fundamentalmente súper poderosa – lo es – sino que brilla porque generalmente es la primera vez que se implementa algo que es verdaderamente relevante para el negocio en la empresa. Si solo quieres tener un ejemplo, la mayoría de lo que se implementa en supply chain son típicamente modelos como el safety stock model, que tienen absolutamente cero relevancia para cualquier supply chain del mundo real. Por ejemplo, en el modelo de safety stock, asumes que es posible tener un tiempo de entrega negativo, lo que significa que ordenas ahora y te entregan ayer. No tiene ningún sentido, y como consecuencia, los resultados operativos de los stocks de seguridad suelen ser insatisfactorios.
La programación diferenciable brilla al lograr relevancia, no al alcanzar algún tipo de gran superioridad numérica o por ser mejor que otras técnicas alternativas de machine learning. La clave es realmente lograr relevancia en un mundo que es muy complejo, caótico, adversarial, que cambia constantemente, y en el que tienes que lidiar con un panorama aplicativo semi-caótico que representa los datos que debes procesar.
Parece que no hay más preguntas. En este caso, supongo que nos veremos el próximo mes para la conferencia de modelado probabilístico para la supply chain.


