Technologie
Zurück zum Blog ›
Probabilistisches exponentielles Glätten für Explainable AI im supply chain-Bereich
Lies Antonio Cifonelli's Doktorarbeit über Probabilistisches exponentielles Glätten für Explainable AI im supply chain-Bereich—eine weitere großartige Studie, die zeigt, dass ein halbes Dutzend ausgeklügelter Tricks ein Modell, das so simpel wie exponentielles Glätten ist, in einen Rennwagen verwandeln kann, der den modernsten Deep Learning Modellen überlegen ist.
Verkaufsanalyse mit Envision - Workshop #2
Dieser zweite Envision Workshop bietet Studierenden und supply chain specialists eine geführte Schulung zur Analyse von Einzelhandelskunden aus Lokads probabilistischem, risikomanagementorientiertem Blickwinkel.

Selektive Pfad-Automatische Differenzierung: Jenseits gleichmäßiger Verteilung beim Backpropagation-Dropout
Die Methode der Selektiven Pfad-Automatischen Differenzierung (SPAD) verbessert den stochastischen Gradientenabstieg (SGD), indem sie eine Teildatenpunktperspektive einsetzt. Diese Technik, die auf Compiler-Ebene implementiert wurde, tauscht Gradientenqualität gegen Gradientenquantität und ergänzt herkömmliche SGD-Methoden um einen differenzierteren Blick.

Eine meinungsstarke Bewertung von Deep Inventory Management
Ein Team bei Amazon hat Ende 2022 Deep Inventory Management (DIM) veröffentlicht. Dieses Paper präsentiert eine DIM-Inventuroptimierungstechnik, die sowohl Reinforcement Learning als auch Deep Learning beinhaltet. Da Lokad in der Vergangenheit einen ähnlichen Weg gegangen ist, liefert sein CEO und Gründer Joannes Vermorel seine kritische Einschätzung der vorgeschlagenen Technik.
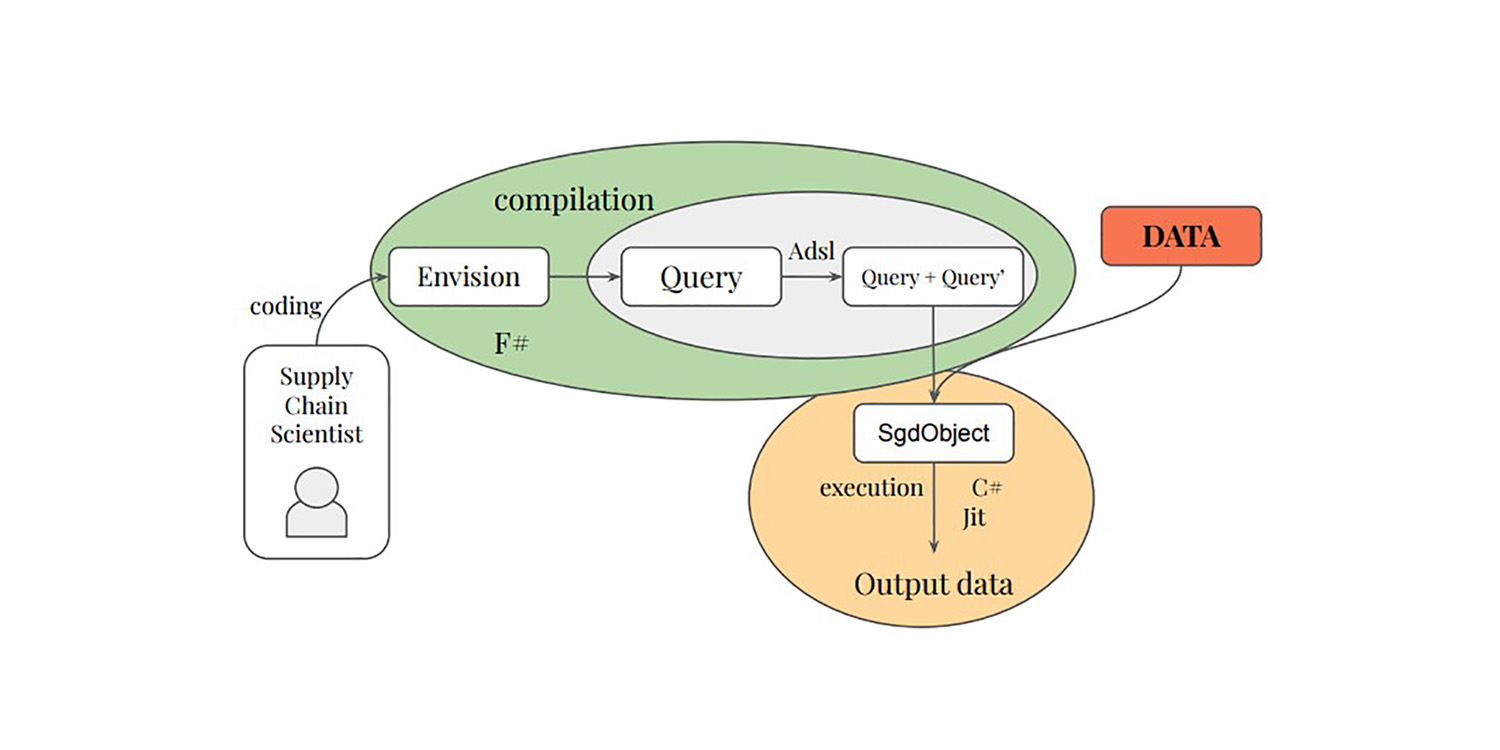
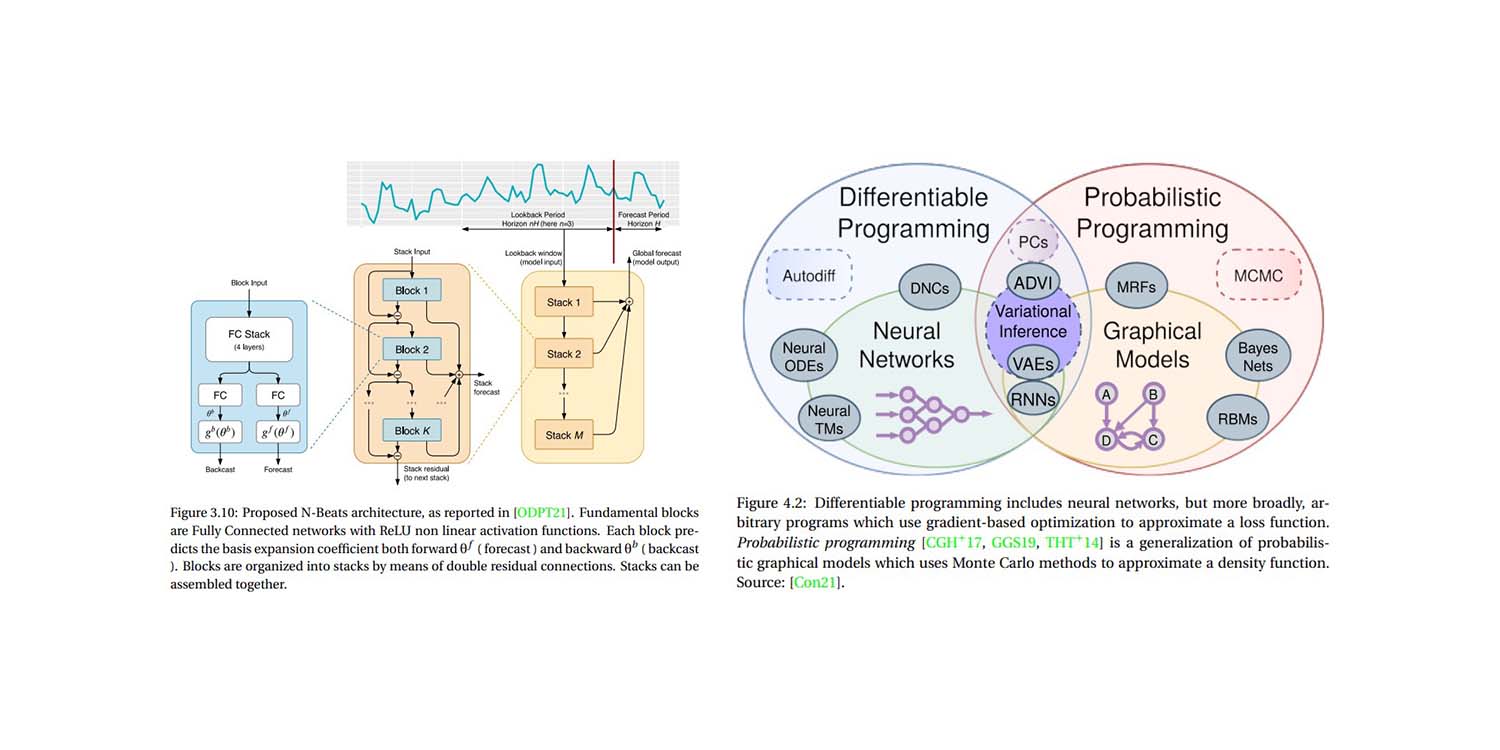
Differenzierbares Programmieren zur Optimierung großskaliger relationaler Daten
Paul Peseux' Promotion zur Differenzierung relationaler Abfragen – ein weiteres untererforschtes Gebiet der supply chain – führte den TOTAL JOIN-Operator, Polystar und eine Mini-Sprache ADSL ein, um relationale Abfragen zu differenzieren, die alle von Lokad in sein DSL Envision im Rahmen von autodiff zur Optimierung der täglichen Bestandsentscheidungen integriert wurden.
Lieferantenanalyse durch Envision - Workshop #1
Lokad startet seinen ersten Envision Workshop, in dem Studenten (und supply chain specialists) lernen, wie man Einzelhandelslieferanten mithilfe von Lokads probabilistischer, risikomanagementorientierter Perspektive analysiert.
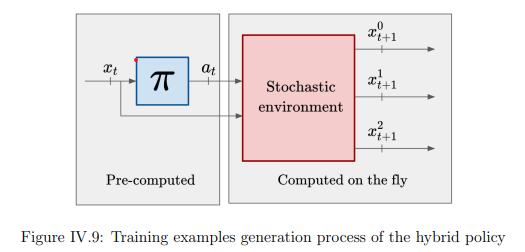
Bestandsmanagement unter der Einschränkung von Multi-Referenz-Mindestbestellmengen
Gaetan Delétoilles Doktorarbeit über MOQs - ein überraschend untererforschter Bereich des supply chain - führte zur Einführung der w-Policy, die von Lokad in seine Lösung zur täglichen Bestandsentscheidungsfindung integriert wurde.
Klassifikationsalgorithmen, die in der Cloud verteilt werden
Matthieu Durut, zweiter Mitarbeiter bei Lokad, verteidigte 2012 seine Promotion für seine bei Lokad geleistete Forschungsarbeit. Diese Promotion ebnete den Weg für den Übergang von Lokad hin zu cloud-nativen verteilten Computing-Architekturen, die heutzutage entscheidend sind, um mit großskaligen supply chains umzugehen.

Großskalenlernen: ein Beitrag zu verteilten asynchronen Clustering-Algorithmen
Benoit Patra, erster Mitarbeiter bei Lokad, verteidigte 2012 seine Doktorarbeit für die bei Lokad durchgeführte Forschung. Diese Doktorarbeit brachte radikal neuartige Elemente in die supply chain Theorie und ebnete den Weg für die zukünftige Entwicklung von Lokad's probabilistischem Prognoseansatz.

Stochastischer Gradientenabstieg mit Gradienten-Schätzer für kategoriale Merkmale
Das breite Feld des maschinellen Lernens (ML) bietet eine Vielzahl von Techniken und Methoden, die zahlreiche Situationen abdecken. supply chain hingegen bringt seine eigenen spezifischen Herausforderungen im Umgang mit Daten mit sich, und manchmal profitieren Aspekte, die von supply chain-Praktikern als „grundlegend“ angesehen werden könnten, nicht von zufriedenstellenden ML-Instrumenten – zumindest nach unseren Maßstäben.