00:12 Einführung
02:23 Falsifizierbarkeit
08:25 Bisheriger Verlauf
09:38 Modellierungsansätze: Mathematische Optimierung (MO)
11:25 Überblick über die Mathematische Optimierung
14:04 Mainstream supply chain Theorie (Rückblick)
19:56 Umfang der Perspektive der Mathematischen Optimierung
23:29 Ablehnungsheuristiken
30:54 Der darauffolgende Tag
32:43 Erlösende Eigenschaften?
36:13 Modellierungsansätze: Experimentelle Optimierung (EO)
38:39 Überblick über die Experimentelle Optimierung
42:54 Ursachen des Irrsinns
51:28 Verrückte Entscheidungen identifizieren
58:51 Die Instrumentierung verbessern
01:01:13 Verbessern und wiederholen
01:04:40 Die Praxis der EO
01:11:16 Zusammenfassung
01:14:14 Fazit
01:16:39 Bevorstehende Vorlesung und Fragen des Publikums
Beschreibung
Weit entfernt von der naiven kartesischen Perspektive, in der Optimierung lediglich darin bestünde, einen Optimierer für eine gegebene Bewertungsfunktion einzusetzen, erfordert supply chain einen wesentlich iterativeren Prozess. Jede Iteration wird genutzt, um „verrückte“ Entscheidungen zu identifizieren, die untersucht werden sollen. Die Ursache liegt häufig in unangemessenen wirtschaftlichen Treibern, die im Hinblick auf ihre unbeabsichtigten Konsequenzen neu bewertet werden müssen. Die Iterationen enden, wenn die numerischen Rezepte keine verrückten Ergebnisse mehr liefern.
Gesamtes Transkript

Hallo zusammen, willkommen zu dieser Reihe von supply chain Vorlesungen. Ich bin Joannes Vermorel, und heute werde ich „Experimentelle Optimierung“ präsentieren, die als Optimierung von supply chain durch eine Reihe von Experimenten verstanden werden sollte. Für diejenigen unter euch, die die Vorlesung live verfolgen, besteht die Möglichkeit, jederzeit über den YouTube-Chat Fragen zu stellen. Allerdings werde ich den Chat während der Vorlesung nicht lesen; ich werde am Ende der Vorlesung auf den Chat zurückkommen, um die dort gestellten Fragen zu beantworten.
Das Ziel für uns heute ist die quantitative Verbesserung von supply chains, und wir möchten dies auf kontrollierte, zuverlässige und messbare Weise erreichen. Wir benötigen etwas Ähnliches wie die wissenschaftliche Methode, und eine der wichtigsten Eigenschaften der modernen Wissenschaft ist, dass sie tief in der Realität – bzw. genauer gesagt im Experiment – verwurzelt ist. In einer früheren Vorlesung habe ich kurz die Idee von supply chain Experimenten diskutiert und erwähnt, dass sie auf den ersten Blick langwierig und kostspielig erscheinen. Die Länge und die Kosten könnten sogar den eigentlichen Zweck, weshalb wir diese Experimente durchführen, untergraben, sodass es sich womöglich nicht einmal lohnt. Aber die Herausforderung besteht darin, dass wir einen besseren Ansatz für Experimente benötigen, und genau darum geht es bei der experimentellen Optimierung.
Experimentelle Optimierung ist grundsätzlich eine Praxis, die vor etwa einem Jahrzehnt bei Lokad entstanden ist. Sie bietet eine Methode, supply chain Experimente auf eine Weise durchzuführen, die tatsächlich funktioniert, bequem und profitabel ist, und wird das konkrete Thema der heutigen Vorlesung sein.

Aber zunächst wollen wir uns noch einen Moment mit diesem Begriff der Natur der Wissenschaft und ihrer Beziehung zur Realität auseinandersetzen.
Es gibt ein Buch, „Die Logik der wissenschaftlichen Entdeckung“, das 1934 von Karl Popper veröffentlicht wurde und als wegweisender Meilenstein in der Geschichte der Wissenschaft gilt. Es schlug eine völlig erstaunliche Idee vor, nämlich die Falsifizierbarkeit. Um zu verstehen, wie diese Idee der Falsifizierbarkeit entstanden ist und was sie bedeutet, ist es sehr interessant, die Reise von Karl Popper selbst noch einmal nachzuvollziehen.
Wisst ihr, in seiner Jugend war Popper mehreren Kreisen von Intellektuellen nahe. Unter diesen Kreisen waren zwei besonders interessant: Einerseits ein Kreis von Sozialökonomen, die damals typischerweise Befürworter der marxistischen Theorie waren, und andererseits ein Kreis von Physikern, zu denen vor allem Albert Einstein zählte. Popper erlebte, dass die Sozialökonomen eine Theorie hatten, mit dem Ziel, eine wissenschaftliche Theorie zu entwickeln, die die Entwicklung der Gesellschaft und ihrer Wirtschaft erklären könnte. Diese marxistische Theorie machte tatsächlich Vorhersagen darüber, was passieren würde. Die Theorie ging davon aus, dass es eine Revolution geben würde und dass diese in dem Land stattfinden würde, das am stärksten industrialisiert war und in dem die größte Anzahl an Fabrikarbeitern zu finden sei.
Es stellte sich heraus, dass die Revolution tatsächlich 1917 stattfand; sie ereignete sich jedoch in Russland, dem am wenigsten industrialisierten Land in Europa, und widersprach somit völlig den Vorhersagen der Theorie. Aus Poppers Sicht gab es eine wissenschaftliche Theorie, die Vorhersagen machte, und dann traten Ereignisse ein, die der Theorie widersprachen. Er erwartete, dass die Theorie widerlegt würde und man sich etwas anderem zuwenden würde. Stattdessen sah er etwas ganz anderes: Die Befürworter der marxistischen Theorie passten die Theorie im Nachhinein den tatsächlichen Ereignissen an. Dadurch wurde die Theorie allmählich unantastbar gegenüber der Realität. Was als wissenschaftliche Theorie begann, wurde schrittweise so modifiziert, dass nichts mehr in der realen Welt gegen sie sprechen konnte.
Dies stand in krassem Gegensatz zu dem, was in den Kreisen der Physiker geschah, wo Popper erlebte, wie Menschen wie Albert Einstein Theorien entwickelten und sich dann große Mühe gaben, Experimente zu konzipieren, die ihre eigenen Theorien widerlegen könnten. Die Physiker investierten ihre Energie nicht in den Beweis der Theorien, sondern in deren Widerlegung. Popper überlegte, welcher Ansatz der bessere Weg sei, Wissenschaft zu betreiben, und entwickelte das Konzept der Falsifizierbarkeit.
Popper schlug vor, dass Falsifizierbarkeit ein Kriterium dafür sei, ob eine Theorie als wissenschaftlich gelten kann. Er sagte, dass eine Theorie wissenschaftlich ist, wenn sie zwei Kriterien erfüllt. Das erste ist, dass die Theorie ein Risiko im Hinblick auf die Realität eingeht. Die Theorie muss so formuliert sein, dass es möglich ist, dass die Realität dem widerspricht, was behauptet wird. Wenn eine Theorie nicht widerlegt werden kann, geht es nicht darum, ob sie wahr oder falsch ist; sie liegt – zumindest aus wissenschaftlicher Sicht – jenseits dieser Frage. Damit eine Theorie als wissenschaftlich angesehen wird, muss sie ein gewisses Risiko in Bezug auf die Realität eingehen.
Das zweite Kriterium ist, dass das Vertrauen, das wir in eine Theorie setzen können, in gewissem Maße (und ich vereinfache hier) proportional zu der Arbeit sein sollte, die Wissenschaftler selbst investiert haben, um die Theorie zu widerlegen. Das wissenschaftliche Merkmal einer Theorie besteht darin, dass sie ein hohes Risiko eingeht und viele versuchen, diese Schwächen auszunutzen, um die Theorie zu widerlegen. Wenn sie wiederholt gescheitert sind, können wir der Theorie ein gewisses Maß an Glaubwürdigkeit zusprechen.
Diese Perspektive zeigt, dass es eine tiefgreifende Asymmetrie zwischen dem, was wahr, und dem, was falsch ist, gibt. Moderne wissenschaftliche Theorien sollten niemals als wahr oder bewiesen betrachtet werden, sondern immer als vorläufig gelten. Die Tatsache, dass viele versucht haben, sie zu widerlegen, ohne Erfolg, verleiht ihnen eine gewisse Glaubwürdigkeit. Diese Erkenntnis ist von entscheidender Bedeutung für die Welt der supply chain, und insbesondere hat das Konzept der Falsifizierbarkeit viele der beeindruckendsten Entwicklungen in der Wissenschaft, insbesondere in der modernen Physik, befeuert.
Bisher ist dies die dritte Vorlesung des zweiten Kapitels dieser Reihe über supply chain. Im ersten Kapitel des Prologs habe ich meine Ansichten über supply chain sowohl als Forschungsfeld als auch als Praxis dargestellt. Eine der zentralen Erkenntnisse war, dass supply chain eine Reihe von komplexen Problemen beinhaltet, im Gegensatz zu leicht lösbaren Problemen. Diese Probleme lassen sich von Natur aus nicht mit einer einfachen Lösung angehen. Daher müssen wir der Methodik, die wir sowohl zum Studium als auch zur praktischen Anwendung von supply chain verwenden, große Aufmerksamkeit schenken. Dieses zweite Kapitel handelt von diesen Methodiken.
In der ersten Vorlesung des zweiten Kapitels schlug ich eine qualitative Methode vor, um Wissen und später Verbesserungen in supply chain durch das Konzept der supply chain Personas zu vermitteln. Hier, in dieser dritten Vorlesung, schlage ich eine quantitative Methode vor: experimentelle Optimierung.

Wenn es darum geht, die quantitative Verbesserung von supply chains zu erreichen, benötigen wir ein quantitatives Modell, ein numerisches Modell. Es gibt mindestens zwei Ansätze, um dies zu erreichen: den Mainstream-Weg, mathematische Optimierung, und eine andere Perspektive, die experimentelle Optimierung.
Der Mainstream-Ansatz zur Erzielung quantitativer Verbesserungen in supply chain ist die mathematische Optimierung. Dieser Ansatz besteht im Wesentlichen darin, einen langen Katalog von Problem-Lösungs-Paaren zu erstellen. Ich bin jedoch der Meinung, dass diese Methode nicht besonders gut ist, und wir benötigen eine andere Perspektive, um die es bei der experimentellen Optimierung geht. Sie sollte als Optimierung von supply chains durch eine Reihe von Experimenten verstanden werden.
Die experimentelle Optimierung wurde nicht von Lokad erfunden. Sie entstand zunächst als Praxis bei Lokad und wurde Jahre später als solche konzeptualisiert. Was ich heute präsentiere, entspricht nicht dem Weg, wie sie sich allmählich bei Lokad entwickelt hat. Es war ein weitaus allmählicherer und undurchsichtiger Prozess. Jahre später habe ich diese aufkommende Praxis erneut aufgegriffen, um sie in Form einer Theorie zu festigen, die ich unter dem Titel experimentelle Optimierung präsentieren kann.

Zunächst müssen wir den Begriff der mathematischen Optimierung klären. Wir haben zwei unterschiedliche Dinge, die wir unterscheiden müssen: die mathematische Optimierung als eigenständiges Forschungsfeld und die mathematische Optimierung als Perspektive für die quantitative Verbesserung von supply chain, welches das heutige Interessensgebiet darstellt. Lassen Sie uns die zweite Perspektive zunächst beiseitelegen und klären, worum es bei der mathematischen Optimierung als eigenständigem Forschungsfeld geht.
Es ist ein Forschungsfeld, das sich mit der Klasse mathematischer Probleme beschäftigt, die sich so präsentieren, wie sie auf dem Bildschirm beschrieben sind. Im Wesentlichen beginnt man mit einer Funktion, die von einer beliebigen Menge (Großbuchstabe A) in eine reelle Zahl führt. Diese Funktion, häufig als Verlustfunktion bezeichnet, wird mit f notiert. Wir suchen die optimale Lösung, die ein Punkt x sein wird, der zu der Menge A gehört und nicht weiter verbessert werden kann. Offensichtlich handelt es sich dabei um ein sehr breites Forschungsfeld mit unzähligen technischen Feinheiten. Manche Funktionen haben möglicherweise kein Minimum, während andere viele verschiedene Minima aufweisen. Als Forschungsfeld war die mathematische Optimierung äußerst produktiv und erfolgreich. Es gibt zahlreiche entwickelte Techniken und eingeführte Konzepte, die in vielen anderen Bereichen mit großem Erfolg eingesetzt wurden. Allerdings werde ich heute nicht auf all das eingehen, da es nicht Gegenstand dieser Vorlesung ist.
Der Punkt, den ich vermitteln möchte, ist, dass die mathematische Optimierung als Hilfswissenschaft in Bezug auf supply chain einen beträchtlichen Erfolg für sich beansprucht hat. Dies hat wiederum die quantitative Untersuchung von supply chains maßgeblich geprägt, worum es bei der mathematischen Optimierung der supply chain perspective geht.

Kehren wir zurück zu zwei Büchern, die ich in meiner allerersten supply chain Vorlesung eingeführt habe. Diese beiden Bücher repräsentieren, so glaube ich, die Mainstream die Quantitative Supply Chain Theorie, die die letzten fünf Jahrzehnte sowohl wissenschaftlicher Publikationen als auch Softwareentwicklung verkörpert. Es geht nicht nur um die veröffentlichten Arbeiten, sondern auch um die Software, die auf den Markt gebracht wurde. Was die quantitative Optimierung von supply chains betrifft, so wurde alles schon lange über Softwareinstrumente erledigt und wird es auch weiterhin.
Wenn man sich diese Bücher ansieht, kann jedes einzelne Kapitel als eine Anwendung der Perspektive der mathematischen Optimierung betrachtet werden. Es läuft immer auf eine Problemstellung mit verschiedenen Annahmen hinaus, gefolgt von der Präsentation einer Lösung. Die Korrektheit und manchmal auch die Optimalität der Lösung werden dann im Hinblick auf die Problemstellung bewiesen. Diese Bücher sind im Wesentlichen Kataloge von Problem-Lösungs-Paaren, die sich als mathematische Optimierungsprobleme präsentieren.
Beispielsweise kann Forecasting als ein Problem angesehen werden, bei dem man eine Verlustfunktion hat, die seinen Forecasting-Fehler darstellt, und ein Modell mit Parametern, die man abstimmen möchte. Anschließend möchte man den Optimierungsprozess, genauer gesagt numerisch, erlernen, der einem die optimalen Parameter liefert. Derselbe Ansatz gilt für eine inventory policy, bei der man Hypothesen über die Nachfrage aufstellen und anschließend beweisen kann, dass man eine Lösung hat, die sich als optimal in Bezug auf die getroffenen Annahmen herausstellt.
Wie ich bereits in der allerersten Vorlesung erläutert habe, habe ich große Bedenken gegenüber dieser Mainstream supply chain Theorie. Die von mir erwähnten Bücher sind keine zufälligen Auswahlen; ich glaube, sie spiegeln die letzten Jahrzehnte der supply chain Forschung zutreffend wider. Betrachtet man nun die von Karl Popper eingeführten Ideen zur Falsifizierbarkeit, wird klarer, worin das Problem besteht: Keines dieser Bücher ist tatsächlich Wissenschaft, da die Realität das, was präsentiert wird, nicht widerlegen kann. Diese Bücher sind im Wesentlichen völlig immun gegen reale supply chains. Wenn man ein Buch hat, das im Grunde eine Sammlung von Problem-Lösungs-Paaren ist, gibt es nichts zu widerlegen. Dies ist ein rein mathematisches Konstrukt. Die Tatsache, dass eine supply chain dies oder das tut, hat keine Relevanz dafür, etwas zu beweisen oder zu widerlegen, was in diesen Büchern dargestellt wird. Das ist wahrscheinlich meine größte Sorge in Bezug auf diese Theorien.
Dies ist nicht nur eine Frage der hier diskutierten Forschung. Wenn man sich anschaut, was es im Bereich Enterprise-Software gibt, um supply chains zu bedienen, ist die heute auf dem Markt vorhandene Software überwiegend ein Abbild dieser wissenschaftlichen Veröffentlichungen. Diese Software wurde nicht getrennt von diesen wissenschaftlichen Veröffentlichungen erfunden; in der Regel gehen sie Hand in Hand. Die meisten Bestandteile der Enterprise-Software, die auf dem Markt zu finden sind, um supply chain-Optimierungsprobleme anzugehen, sind Abbilder einer bestimmten Reihe von Papern oder Büchern, manchmal von denselben Personen verfasst, die sowohl die Software als auch die Bücher produziert haben.
Die Tatsache, dass die Realität keinerlei Einfluss auf die hier präsentierten Theorien hat, ist, denke ich, eine sehr plausible Erklärung dafür, warum von den in diesen Büchern vorgestellten Theorien tatsächlich so wenige in realen supply chains von Nutzen sind. Dies ist eine ziemlich subjektive Aussage, die ich treffe, aber in meiner Laufbahn hatte ich die Gelegenheit, mich mit mehreren hundert supply chain-Direktoren auszutauschen. Sie kennen diese Theorien, und falls sie selbst nicht sehr bewandert darin sind, haben sie Leute in ihrem Team, die es sind. Sehr häufig implementiert die von einem Unternehmen genutzte Software bereits eine Reihe von Lösungen, wie sie in diesen Büchern präsentiert werden, und dennoch werden sie nicht verwendet. Aus verschiedenen Gründen greifen die Menschen dann auf ihre eigenen Excel Spreadsheets zurück.
Also, das ist keine Unwissenheit. Wir haben dieses ganz reale Problem, und ich glaube, dass die Ursache buchstäblich darin liegt, dass es keine Wissenschaft ist. Man kann nichts der präsentierten widerlegen. Es ist nicht so, dass diese Theorien falsch sind – sie sind mathematisch korrekt – aber sie sind nicht wissenschaftlich im Sinne davon, dass sie nicht einmal die Qualifikation besitzen, als Wissenschaft zu gelten.

Nun stellt sich die Frage: Wie groß ist das Problem? Denn ich habe tatsächlich zwei Bücher ausgewählt, aber wie groß ist der tatsächliche Umfang dieser mathematischen Optimierungsperspektive in supply chain? Ich würde sagen, dass der Umfang dieser Perspektive absolut gewaltig ist. Als ein anekdotischer Beleg hierfür habe ich kürzlich Google Scholar genutzt, eine von Google bereitgestellte spezialisierte Suchmaschine, die ausschließlich Ergebnisse für wissenschaftliche Veröffentlichungen liefert. Wenn man allein für das Jahr 2020 nach “optimal inventory” sucht, erhält man über 30.000 Ergebnisse.
Diese Zahl sollte mit Vorsicht betrachtet werden. Offensichtlich gibt es in dieser Liste vermutlich zahlreiche Duplikate, und höchstwahrscheinlich auch Fehlalarme – Paper, in denen sowohl die Wörter “inventory” als auch “optimal” im Titel und Abstract erscheinen, das Paper jedoch überhaupt nicht um supply chain geht. Es ist einfach zufällig. Nichtsdestotrotz deutet ein flüchtiger Blick auf die Ergebnisse sehr stark darauf hin, dass es sich um mehrere tausend Paper handelt, die jährlich in diesem Bereich veröffentlicht werden. Als Basis ist diese Zahl sehr hoch, selbst im Vergleich zu Bereichen, die absolut massiv sind, wie deep learning. Deep learning ist wahrscheinlich eine der Theorien der Informatik, die in den letzten zwei oder drei Jahrzehnten den größten Erfolg genossen haben. Daher ist es tatsächlich erstaunlich, dass allein die Abfrage “optimal inventory” etwas zurückliefert, das etwa einem Fünftel von dem entspricht, was man für deep learning erhält. Optimal inventory ist offensichtlich nur ein Bruchteil dessen, worum es in den die Quantitative Supply Chain-Studien geht.
Diese einfache Abfrage zeigt, dass die mathematische Optimierungsperspektive wirklich massiv ist, und ich würde argumentieren – wenn auch vielleicht etwas subjektiv –, dass sie in Bezug auf quantitative Studien von supply chain tatsächlich dominiert. Wenn wir mehrere tausend Paper haben, die optimale Inventory-Richtlinien und optimale inventory management Modelle zur Unternehmensführung bereitstellen und jährlich publiziert werden, sollten doch die meisten Großunternehmen sicher auf Basis dieser Methoden arbeiten. Es geht hierbei nicht um nur ein paar Paper; es handelt sich um eine absolut enorme Menge an Veröffentlichungen.
Nach meiner Erfahrung, basierend auf einigen hundert supply chain-Datenpunkten, die ich kenne, ist das wirklich nicht der Fall. Diese Methoden sind fast nirgends zu finden. Es besteht eine absolut erstaunliche Diskrepanz zwischen dem Stand des Feldes, was die publizierten Paper betrifft – und übrigens auch die Software, da diese im Grunde ein Abbild dessen ist, was als wissenschaftliches Paper veröffentlicht wird – und der Art und Weise, wie supply chains tatsächlich funktionieren.

Die Frage, die ich hatte, lautet: Gibt es bei tausenden von Papern überhaupt etwas Gutes zu finden? Ich hatte das Vergnügen, Hunderte quantitative supply chain Paper zu sichten, und ich kann Ihnen eine Reihe von Heuristiken nennen, die Ihnen nahezu Gewissheit darüber geben, dass das Paper keinerlei realen Mehrwert bietet. Diese Heuristiken sind nicht absolut, aber sie sind sehr präzise – man könnte sagen, zu über 99 % genau. Es ist nicht vollkommen exakt, aber es kommt fast an Perfektion heran.
Also, wie erkennen wir Paper, die einen realen Mehrwert bieten, oder andersherum, wie verwerfen wir Paper, die überhaupt keinen Wert hinzufügen? Ich habe eine kurze Reihe von Heuristiken aufgelistet. Die erste lautet: Wenn ein Paper irgendeinen Anspruch auf Optimalität erhebt, können Sie sicher sein, dass das Paper keinerlei Wert für reale supply chains hat. Erstens, weil dies zeigt, dass die Autoren nicht einmal im Ansatz verstehen, dass supply chains im Wesentlichen ein wicked problem sind. Die Tatsache, dass Sie behaupten, Sie hätten eine optimale Lösung – also, gehen wir zurück zur Definition einer optimalen Lösung: eine Lösung, die optimal ist, wenn sie nicht weiter verbessert werden kann. Zu sagen, dass Sie eine optimale supply chain-Lösung haben, gleicht sehr der Behauptung, es gäbe eine feste Grenze für menschliche Einfallsreichtum. Daran glaube ich keinen Moment. Ich halte das für einen völlig unzumutbaren Vorschlag. Wir sehen, dass es ein sehr großes Problem mit der Herangehensweise an supply chains gibt.
Ein weiteres Problem ist, dass immer, wenn ein Anspruch auf Optimalität erhoben wird, daraus unweigerlich folgt, dass eine Lösung vorliegt, die stark von Annahmen abhängt. Vielleicht haben Sie eine Lösung, die gemäß einer bestimmten Menge von Annahmen als optimal gilt, aber was, wenn diese Annahmen verletzt werden? Wird die Lösung dann noch brauchbar sein? Im Gegenteil, ich glaube, dass, wenn Sie eine Lösung haben, deren Optimalität Sie beweisen können, diese Lösung unglaublich abhängig von den getroffenen Annahmen ist, um auch nur annähernd korrekt zu sein. Wenn Sie die Annahmen verletzen, ist es sehr wahrscheinlich, dass die resultierende Lösung absolut katastrophal ist, weil sie niemals darauf ausgelegt wurde, robust gegenüber irgendetwas zu sein. Ansprüche auf Optimalität können quasi sofort verworfen werden.
Der zweite Punkt betrifft Normalverteilungen. Wann immer Sie ein Paper oder ein Stück Software sehen, das behauptet, Normalverteilungen zu verwenden, können Sie sicher sein, dass das Vorgeschlagene in realen supply chains nicht funktioniert. In einer früheren Vorlesung, in der ich quantitative Prinzipien für supply chain präsentierte, zeigte ich, dass alle interessierenden Populationen in supply chains Zipf-verteilt sind und nicht normalverteilt. Normalverteilungen finden sich in supply chains überhaupt nicht, und ich bin absolut überzeugt, dass dieses Ergebnis seit Jahrzehnten bekannt ist. Wenn Sie Paper oder Software finden, die auf dieser Annahme beruhen, ist es nahezu sicher, dass Sie eine Lösung haben, die aus Bequemlichkeit entwickelt wurde, um den mathematischen Beweis oder die Softwareerstellung zu erleichtern – und nicht, weil der Wunsch nach realer Leistungsfähigkeit bestand. Das Vorhandensein von Normalverteilungen zeugt schlichtweg von purer Faulheit oder bestenfalls von einem tiefgreifenden Unverständnis dessen, worum es in supply chains geht. Dies kann herangezogen werden, um diese Paper abzulehnen.
Dann, Stationarität – so etwas gibt es nicht. Es ist eine Annahme, die so aussieht, als wäre sie in Ordnung: Dinge sind stationär, immer dasselbe. Aber dem ist nicht so; es ist eine sehr starke Annahme. Im Grunde besagt sie, dass ein Prozess existiert, der zu Beginn der Zeit gestartet wurde und bis zum Ende andauern wird. Dies ist eine völlig unangemessene Perspektive für reale supply chains. In realen supply chains wurde jedes Produkt zu einem bestimmten Zeitpunkt eingeführt, und jedes Produkt wird irgendwann wieder vom Markt genommen. Selbst wenn man sich Produkte ansieht, die relativ langlebig sind, wie etwa in der Automobilindustrie, halten diese Prozesse bestenfalls ein Jahrzehnt an. Die betrachtete Lebensdauer, der relevante Zeitraum, ist endlich, sodass die stationäre Perspektive schlichtweg falsch ist.
Ein weiteres Merkmal, um eine quantitative Studie zu identifizieren, die nicht funktionieren wird, ist, wenn der Begriff der Substitution gänzlich fehlt. In realen supply chains sind Substitutionen allgegenwärtig. Wenn wir auf das supply chain-Beispiel zurückgehen, das ich vor zwei Wochen in einer früheren Vorlesung vorgestellt habe, konnte man mindestens ein halbes Dutzend Situationen entdecken, in denen Substitutionen im Spiel waren – auf der Angebotsseite, der Transformationsseite und der Nachfrageseite. Wenn Sie ein Modell haben, in dem konzeptionell überhaupt keine Substitution existiert, dann haben Sie etwas, das wirklich im Widerspruch zu realen supply chains steht.
Ähnlich ist das Fehlen von Globalität oder einer ganzheitlichen Perspektive auf supply chain ein deutliches Anzeichen dafür, dass etwas nicht stimmt. Wenn ich an die vorherige Vorlesung zurückdenke, in der ich die quantitativen Prinzipien für supply chain vorstellte, sagte ich, dass, wenn Sie etwas haben, das einem lokalen Optimierungsprozess ähnelt, Sie nichts optimieren werden; Sie werden lediglich die Probleme innerhalb Ihrer supply chain verlagern. Die supply chain ist ein System, ein Netzwerk, und daher können Sie keine Art von lokaler Optimierung anwenden und hoffen, dass dies dem Wohl der gesamten supply chain dient. Das ist schlichtweg nicht der Fall.
Mit diesen Heuristiken denke ich, dass man den Großteil der quantitativen supply chain Literatur nahezu eliminieren kann, was an sich ziemlich erstaunlich ist.

Die Sache ist die, dass wenn ich jedes einzelne Redaktionsgremium jeder supply chain-Konferenz und -Zeitschrift davon überzeugen würde, diese Heuristiken zu verwenden, um Beiträge von niedriger Qualität auszufiltern, es nicht funktionieren würde. Autoren würden sich einfach anpassen und den Prozess umgehen, selbst wenn wir diese Richtlinien für Veröffentlichungen in supply chain-Zeitschriften einführen würden. Wenn Marktanalysten diese in ihre Checklisten aufnehmen würden, käme es dazu, dass Autoren – sowohl von Papern als auch von Software – einfach reagieren. Sie würden das Problem verschleiern und kompliziertere Annahmen treffen, sodass man nicht mehr erkennt, dass es letztlich auf eine Normalverteilung oder eine stationäre Annahme hinausläuft. Es wird einfach in einer sehr undurchsichtigen Weise formuliert.
Diese Heuristiken sind nützlich, um Beiträge von niedriger Qualität zu identifizieren – sowohl Paper als auch Software –, aber man kann sie nicht einfach verwenden, um das Gute herauszufiltern. Wir brauchen eine tiefgreifendere Veränderung; wir müssen das gesamte Paradigma überdenken. An diesem Punkt mangelt es immer noch an Falsifizierbarkeit. Die Realität hat keine Möglichkeit, zurückzuschlagen und das Vorgelegte irgendwie zu widerlegen.

Als letzten Aspekt, um diesen Teil der Vorlesung über die mathematische Optimierungsperspektive abzuschließen, stellt sich die Frage, ob es überhaupt irgendeine erlösende Qualität in dieser enormen Produktion von Papern und Software gibt. Meine sehr subjektive Antwort auf diese Frage lautet absolut nein. Diese Paper – und ich habe sehr viele quantitative supply chain Paper gelesen – sind nicht interessant. Im Gegenteil, sie sind überaus langweilig, selbst die besten davon. Wenn man sich die Hilfswissenschaften anschaut, gibt es keine wirklich interessanten Erkenntnisse. Man kann sich all diese Paper ansehen, und ich habe Tausende von ihnen erfasst. Aus mathematischer Sicht ist es sehr eintönig. Es werden keine großartigen mathematischen Ideen präsentiert. Aus algorithmischer Sicht ist es nur eine direkte Anwendung dessen, was in der Welt der Algorithmen schon lange bekannt ist. Dasselbe gilt für statistische Modellierung und Methodik, die überaus dürftig ist. In puncto Methodik reduziert sich alles auf die mathematische Optimierungsperspektive, bei der man ein Modell präsentiert, etwas optimiert, die Lösung bereitstellt und nachweist, dass diese Lösung gewisse mathematische Eigenschaften in Bezug auf die Problemstellung aufweist.
Wir müssen wirklich mehr als nur oberflächliche Änderungen vornehmen. Ich kritisiere den Ansatz nicht. Es gibt historische Präzedenzfälle dafür. Es mag völlig erstaunlich klingen, dass ich behaupte, wir hätten zehntausende Paper, die vollkommen steril sind, aber das ist historisch vorgekommen. Wenn Sie sich das Leben von Isaac Newton, einem der Väter der modernen Physik, ansehen, werden Sie feststellen, dass er etwa die Hälfte seiner Zeit in der Physik mit einem gewaltigen Erbe verbrachte und die andere Hälfte in der Alchemie. Er war ein brillanter Physiker und ein sehr schlechter Alchemist. Historische Aufzeichnungen zeigen tendenziell, dass Isaac Newton in seiner Arbeit an der Alchemie genauso brillant, engagiert und ernsthaft war wie in seiner Arbeit an der Physik. Da die alchemistische Perspektive schlicht schlecht gerahmt war, erwies sich all die Arbeit und Intelligenz, die Newton in diesen Bereich investierte, als völlig steril, ohne jegliches nachhaltiges Erbe. Meine Kritik ist nicht, dass tausende Menschen idiotische Dinge veröffentlichen – die meisten dieser Autoren sind sehr intelligent. Das Problem liegt darin, dass der Rahmen selbst steril ist. Das ist der Punkt, den ich machen möchte.

Nun wollen wir zum zweiten Modellierungsansatz übergehen, den ich heute vorstellen möchte. In den frühen Jahren war Lokads Methodik tief in der mathematischen Optimierungsperspektive verwurzelt. In dieser Hinsicht waren wir sehr Mainstream, und es funktionierte für uns sehr schlecht. Eine Sache, die an Lokad sehr spezifisch war – fast zufällig – ist, dass ich irgendwann entschied, dass Lokad nicht Enterprise-Software verkaufen würde, sondern direkt End-Game supply chain Entscheidungen. Ich meine damit wirklich die exakten Mengen, die ein bestimmtes Unternehmen kaufen muss, die Mengen, die ein Unternehmen produzieren muss, und wie viele Einheiten von Ort A nach Ort B verschoben werden müssen – egal, ob ein einzelner Preis sinken sollte – Lokad war im Geschäft damit, End-Game supply chain Entscheidungen zu verkaufen. Aufgrund dieser halbzufälligen Entscheidung meinerseits wurden wir brutal mit unseren eigenen Unzulänglichkeiten konfrontiert. Wir wurden geprüft, und es gab einen sehr harten Realitätscheck. Wenn wir supply chain Entscheidungen produzierten, die sich als schlecht herausstellten, waren die Kunden sofort an mir und schrien empört, weil Lokad nichts Liefertaugliches bot.
Gewissermaßen entstand die experimentelle Optimierung bei Lokad. Sie wurde nicht bei Lokad erfunden; sie war eine emergente Praxis, die als Reaktion auf den enormen Druck unserer Kundenbasis entstand, etwas gegen die anfänglich allgegenwärtigen Mängel zu unternehmen. Wir mussten irgendeinen Überlebensmechanismus entwickeln und haben dazu vieles ausprobiert, manchmal ziemlich zufällig. Was dabei herauskam, ist das, was man als experimentelle Optimierung bezeichnet.

Experimentelle Optimierung ist eine sehr einfache Methode. Das Ziel ist es, supply chain Entscheidungen zu erzeugen, indem man ein Rezept schreibt, das softwaregesteuert supply chain Entscheidungen generiert. Die Methode beginnt wie folgt: Schritt null, man schreibt einfach Rezepte, die Entscheidungen generieren. Es gibt eine Menge an Fachwissen, Technologien und Werkzeugen, die hier von Interesse sind. Dies ist nicht das Thema dieser Vorlesung; es wird in späteren Vorlesungen ausführlich behandelt. Also, Schritt eins, man schreibt einfach ein Rezept, und höchstwahrscheinlich wird es nicht sehr gut sein.
Anschließend beginnst du mit einer unbestimmten Iterationspraxis, bei der du zunächst das Rezept ausführst. Mit „ausführen“ meine ich, dass das Rezept in einer produktionsreifen Umgebung laufen können sollte. Es geht nicht nur darum, einen Algorithmus im data science Labor zu haben, den man ausführen kann. Es geht darum, ein Rezept zu haben, das alle Qualitäten besitzt, sodass, wenn du entscheidest, dass diese Entscheidungen gut genug sind, um in Produktion zu gehen, du dies mit einem Klick tun kannst. Die gesamte Umgebung muss produktionsreif sein; darum geht es beim Ausführen des Rezepts.
Als Nächstes musst du die verrückten Entscheidungen identifizieren, was in einer meiner vorherigen Vorlesungen über produktorientierte Auslieferung für supply chain behandelt wurde. Für diejenigen unter euch, die diese Vorlesung nicht besucht haben: Kurz gesagt, wir wollen, dass Investitionen in supply chain kapitalistisch und akkretiv sind, und um das zu erreichen, müssen wir sicherstellen, dass die Personen, die in dieser supply chain-Abteilung arbeiten, nicht nur im Feuerlöschen beschäftigt sind. Die Standardlage in der überwiegenden Mehrheit der Unternehmen zur Zeit ist, dass supply chain Entscheidungen von Software generiert werden – die meisten modernen Unternehmen verwenden bereits umfangreich Teile von Enterprise-Software, um ihre supply chain zu betreiben, und alle Entscheidungen werden durch Software erzeugt. Allerdings sind ein sehr großer Teil dieser Entscheidungen einfach völlig verrückt. Was die meisten supply chain Teams tun, ist, all diese verrückten Entscheidungen manuell zu überprüfen und fortlaufende Feuerlöschmaßnahmen zu ergreifen, um sie zu eliminieren. Somit werden alle Anstrengungen letztendlich durch den operativen Betrieb des Unternehmens aufgezehrt. Du bereinigst alle deine Ausnahmen an einem Tag, und am nächsten Tag kommst du mit einer ganz neuen Reihe von Ausnahmen zurück, die es zu behandeln gilt, und der Zyklus wiederholt sich. Du kannst nicht Kapital bilden; du verzehrst einfach die Zeit deiner supply chain Experten. Daher ist die Idee von Lokad, dass wir diese verrückten Entscheidungen als Softwarefehler behandeln und vollständig eliminieren müssen, sodass wir einen kapitalistischen Prozess und eine kapitalistische Praxis der supply chain selbst haben können.
Sobald wir das haben, müssen wir die Instrumentierung verbessern und folglich das numerische Rezept selbst optimieren. All diese Arbeit wird durchgeführt vom Supply Chain Scientist, einem Konzept, das ich in meiner zweiten Vorlesung des ersten Kapitels, “Die Quantitative Supply Chain Perspektive,” wie von Lokad gesehen, eingeführt habe. Die Instrumentierung ist von zentralem Interesse, denn durch eine bessere Instrumentierung kannst du besser verstehen, was in deiner supply chain vor sich geht, was in deinem Rezept passiert und wie du es weiter verbessern kannst, um jene verrückten Entscheidungen zu adressieren, die immer wieder auftauchen.

Lassen Sie uns einen Moment in die Ursachen der Verrücktheit eintauchen, die diese verrückten Entscheidungen erklären. Häufig, wenn ich supply chain Direktoren frage, warum sie denken, dass ihre Enterprise-Software-Systeme, die ihre supply chain Operationen steuern, immer wieder diese verrückten Entscheidungen hervorbringen, erhalte ich oft die, wenn auch fehlgeleitete Antwort: “Oh, es liegt einfach daran, dass wir schlechte Prognosen haben.” Ich glaube, diese Antwort ist auf mindestens zwei Ebenen fehlgeleitet. Erstens, wenn man von der Genauigkeit ausgeht, die man von einem sehr simplen gleitenden Durchschnittsmodell zu einem hochmodernen Machine-Learning-Modell gewinnen kann, gibt es vielleicht eine Steigerung der Genauigkeit um etwa 20 %. Also ja, es ist signifikant, aber es kann nicht den Unterschied zwischen einer sehr guten Entscheidung und einer völlig verrückten Entscheidung ausmachen. Zweitens besteht das größte Problem bei Prognosen darin, dass sie nicht alle Alternativen sehen; sie sind nicht probabilistisch. Aber ich schweife ab; das wäre ein Thema für eine weitere Vorlesung.
Wenn wir zur Wurzel der Verrücktheit zurückkehren, glaube ich, dass, obwohl Prognosefehler ein Problem darstellen, sie keineswegs das Hauptanliegen sind. Aus einem Jahrzehnt Erfahrung bei Lokad kann ich sagen, dass dies bestenfalls ein sekundäres Anliegen ist. Das primäre Anliegen, das größte Problem, das verrückte Entscheidungen hervorruft, sind die Datensemantiken. Denke daran, dass du eine supply chain nicht direkt beobachten kannst; das ist nicht möglich. Du kannst eine supply chain nur als Reflexion über die elektronischen Aufzeichnungen beobachten, die du durch Enterprise-Software sammelst. Die Beobachtung, die du über deine supply chain machst, ist ein sehr indirekter Prozess durch das Prisma der Software.
Hier sprechen wir von Hunderten von relationalen Tabellen und Tausenden von Feldern, und die Semantik jedes einzelnen dieser Felder ist wirklich entscheidend. Aber wie weißt du, dass du das richtige Verständnis und die richtige Denkweise hast? Der einzige Weg, um sicherzugehen, dass du wirklich verstehst, was eine bestimmte Spalte bedeutet, ist, sie dem Experiment zu unterziehen. In der experimentellen Optimierung ist der experimentelle Test die Erzeugung von Entscheidungen. Du gehst davon aus, dass diese Spalte etwas bedeutet; das ist in gewisser Weise deine wissenschaftliche Theorie. Dann erzeugst du eine Entscheidung basierend auf diesem Verständnis, und wenn die Entscheidung gut ist, dann ist dein Verständnis korrekt. Im Grunde genommen kannst du nur beobachten, ob dein Verständnis zu verrückten Entscheidungen führt oder nicht. Hier schlägt die Realität zurück.
Das ist kein kleines Problem; es ist ein sehr großes. Enterprise-Software ist, gelinde gesagt, komplex, und es gibt Bugs. Das Problem aus der Sicht der mathematischen Optimierung besteht darin, dass man das Problem betrachtet, als handele es sich um eine einfache Reihe von Annahmen, und dann eine relativ einfache, mathematisch elegante Lösung ausrollen könnte. Aber die Realität ist, dass wir Schichten von Enterprise-Software übereinander haben, und Probleme können überall auftreten. Einige dieser Probleme sind sehr banal, wie fehlerhaftes Kopieren, falsches Binden zwischen Variablen oder Systeme, die synchron sein sollten, die aus der Synchronität geraten. Es kann Versionsupgrades für Software geben, die Bugs erzeugen, und so weiter. Diese Bugs sind überall, und der einzige Weg, herauszufinden, ob du Bugs hast oder nicht, ist, erneut, die Entscheidungen zu betrachten. Wenn die Entscheidungen korrekt sind, dann gibt es entweder keine Bugs oder die vorhandenen Bugs sind unbedeutend und es ist uns egal.
Bezüglich wirtschaftlicher Treiber ergibt sich ein weiterer unkorrekter Ansatz, wenn man mit supply chain Direktoren spricht. Sie bitten mich oft, zu beweisen, dass es eine gewisse wirtschaftliche Rendite für ihr Unternehmen geben wird. Meine Antwort darauf ist, dass wir die wirtschaftlichen Treiber noch gar nicht kennen. Meine Erfahrung bei Lokad hat mir gezeigt, dass der einzige Weg, um definitiv zu wissen, was die wirtschaftlichen Treiber sind – und diese Treiber werden verwendet, um die Verlustfunktion zu erstellen, die wiederum für die tatsächliche Optimierung im numerischen Rezept verwendet wird – darin besteht, sie erneut dem Test zu unterziehen, nämlich durch die Erfahrung, Entscheidungen zu generieren und zu beobachten, ob diese Entscheidungen verrückt sind oder nicht. Diese wirtschaftlichen Treiber müssen durch Erfahrung entdeckt und validiert werden. Bestenfalls hat man nur eine Intuition davon, was korrekt ist, aber nur Erfahrung und Experimente können dir sagen, ob dein Verständnis tatsächlich korrekt ist.
Dann gibt es auch all die Unpraktikabilitäten. Du hast ein numerisches Rezept, das Entscheidungen generiert, und diese Entscheidungen scheinen allen von dir festgelegten Regeln zu entsprechen. Zum Beispiel, wenn Mindestbestellmengen (MOQs) existieren, generierst du Bestellungen, die mit deinen MOQs konform sind. Aber was, wenn ein Lieferant zurückkommt und dir sagt, dass die MOQ etwas anderes ist? Durch diesen Prozess könntest du viele Unpraktikabilitäten und scheinbar machbare Entscheidungen entdecken, die, wenn du versuchst, sie in der realen Welt zu testen, sich als undurchführbar herausstellen. Du entdeckst allerlei Randfälle und Einschränkungen, manchmal welche, an die du nicht einmal gedacht hast, bei denen die Welt zurückschlägt und du das ebenfalls beheben musst.
Dann ist da noch deine Strategie. Du denkst vielleicht, dass du eine übergreifende, hochrangige Strategie für deine supply chain hast, aber ist sie richtig? Um dir einen Eindruck zu geben, nehmen wir Amazon als Beispiel. Du könntest sagen, dass du kundenorientiert sein möchtest. Beispielsweise sollten Kunden, die online etwas kaufen und es nicht mögen, die Möglichkeit haben, es sehr einfach zurückzugeben. Du möchtest bei Rücksendungen sehr großzügig sein. Aber was passiert, wenn du Gegner oder schlechte Kunden hast, die das System ausnutzen? Sie bestellen vielleicht online ein teures 500-Dollar-Smartphone, erhalten es, ersetzen das echte Smartphone durch ein gefälschtes im Wert von nur 50 Dollar und senden es dann zurück. Amazon landet dadurch mit Fälschungen in ihrem Inventar, ohne es überhaupt zu merken. Dies ist ein sehr reales Problem, das online oft diskutiert wurde.
Vielleicht hast du eine Strategie, die besagt, dass du kundenorientiert sein möchtest, aber vielleicht sollte deine Strategie lauten, nur für ehrliche Kunden kundenorientiert zu sein. Es geht also nicht um alle Kunden; es ist nur ein Teil der Kunden. Selbst wenn deine Strategie annähernd richtig ist, liegt der Teufel im Detail. Wiederum ist der einzige Weg, um zu sehen, ob das Kleingedruckte deiner Strategie korrekt ist, durch Experimente, bei denen du die Details betrachten kannst.

Nun wollen wir besprechen, wie wir verrückte Entscheidungen identifizieren. Wie unterscheiden wir gesunde von verrückten Entscheidungen? Mit „verrückter Entscheidung“ meine ich eine Entscheidung, die für dein Unternehmen nicht vernünftig ist. Dies ist eine Art von Problem, das wirklich allgemeine menschliche Intelligenz erfordert. Es besteht keinerlei Hoffnung, dass du dieses Problem durch einen Algorithmus lösen kannst. Es mag paradox klingen, aber es ist genau die Art von Problem, die Intelligenz auf menschlichem Niveau erfordert, jedoch nicht unbedingt einen extrem klugen Menschen.
Es gibt viele andere Probleme dieser Art in der realen Welt. Ein Beispiel zur Veranschaulichung sind Filmfehler. Wenn du Hollywood-Studios nach einem Algorithmus fragen würdest, der alle Fehler in irgendeinem Film identifizieren kann, würden sie wahrscheinlich sagen, dass sie keine Ahnung haben, wie man einen solchen Algorithmus konzipiert, da es sich um eine Aufgabe handelt, die menschliche Intelligenz erfordert. Wenn du das Problem jedoch in eines verwandelst, bei dem du einfach Leute haben möchtest, die darauf trainiert werden können, Filmfehler sehr gut zu erkennen, wird die Aufgabe wesentlich einfacher. Es ist sehr leicht vorstellbar, dass man ein Handbuch mit allen Tricks zur Identifizierung von Filmfehlern zusammenstellen kann. Du brauchst keine Menschen, die außergewöhnlich intelligent sind, um diese Arbeit zu leisten; du brauchst nur Personen, die vernünftig intelligent und engagiert sind. Genau darum geht es.
Wie sieht die Situation also aus der Perspektive der supply chain aus? Wenn wir das Problem konkret untersuchen wollen, suchen wir im Wesentlichen nach Ausreißern. Wir müssen einfach mit einem Blickwinkel beginnen. Nehmen wir zum Beispiel die Paris-Persona, die ich vor zwei Wochen vorgestellt habe. Das ist ein Modeunternehmen, das ein großes Einzelhandelsnetzwerk von Modegeschäften betreibt. Nehmen wir als Beispiel an, dass wir uns um die Servicequalität sorgen.
Beginnen wir mit den Stockouts. Wenn wir einfach eine Abfrage über alle Produkte und alle Geschäfte durchführen, werden wir sehen, dass wir Tausende von Stockouts im gesamten Netzwerk haben. Das hilft also nicht wirklich; es gibt Tausende davon, und die Antwort lautet: “Na und?” Vielleicht sind es nicht nur die Stockouts; was wirklich von Interesse ist, sind die Stockouts in den Hauptgeschäften, den Stores, die viel verkaufen. Dort zählt es, und nicht die Stockouts bei irgendwelchen Produkten, sondern bei den Topsellern. Lassen Sie uns die Suche nach Stockouts in den Hauptgeschäften für die Topseller eingrenzen.
Anschließend können wir einen SKU untersuchen, bei dem der Bestand zufällig bei null liegt. Bei näherer Betrachtung werden wir jedoch feststellen, dass vielleicht zu Beginn des Tages tatsächlich drei Einheiten vorhanden waren und die letzte Einheit erst 30 Minuten vor Ladenschluss verkauft wurde. Wenn wir genauer hinschauen, sehen wir, dass am nächsten Tag drei Einheiten wieder aufgefüllt werden. Somit haben wir hier eine Situation, in der wir einen Stockout feststellen, aber ist das wirklich von Bedeutung? Es stellt sich heraus, dass es nicht so wichtig ist, da die letzte Einheit kurz vor dem Ladenschluss am Abend verkauft wurde und die Menge wieder aufgefüllt wird. Außerdem, wenn wir weiter hinschauen, sehen wir, dass möglicherweise nicht genügend Platz im Geschäft ist, um mehr als drei Einheiten unterzubringen, sodass wir hier begrenzt sind.
Das ist also nicht wirklich ein erhebliches Problem. Vielleicht sollten wir die Suche auf Stockouts eingrenzen, bei denen die Möglichkeit bestand, aufzufüllen – Top-Geschäft, Top-Produkt – aber dies nicht geschehen ist. Wir finden ein Beispiel für einen solchen gegebenen SKU, und dann sehen wir, dass im Distributionszentrum kein Bestand mehr vorhanden ist. Ist das in diesem Fall wirklich ein Problem? Man könnte nein sagen, aber warte einen Moment. Wir haben keinen Bestand im Distributionszentrum, aber für dasselbe Produkt werfen wir einen Blick auf das Gesamt-Netzwerk. Haben wir irgendwo noch Bestand?
Nehmen wir an, dass wir für dieses Produkt – Top-Produkt, Top-Geschäft – viele schwache Geschäfte haben, die noch reichlich Inventar für dasselbe Produkt haben, aber es wird einfach nicht rotiert. Hier sehen wir, dass wir tatsächlich ein Problem haben. Das Problem bestand nicht darin, dass dem Top-Geschäft zu wenig Bestand zugewiesen wurde; vielmehr war das Problem, dass zu viel Bestand zugewiesen wurde – vermutlich während der anfänglichen Zuteilung an die Geschäfte für die neue Kollektion – an sehr schwache Geschäfte. Also gehen wir Schritt für Schritt vor, um die Grundursache des Problems zu identifizieren. Wir können es zurückführen auf ein Servicequalitätsproblem, das nicht durch zu wenig, sondern vielmehr durch zu viel Versand verursacht wurde und letztlich eine systemweite Auswirkung auf die Servicequalität dieser power stores hat.
Was ich hier gemacht habe, ist das genaue Gegenteil von Statistik, und das ist etwas Wichtiges, wenn wir nach “verrückten” Entscheidungen suchen. Man möchte die Daten nicht aggregieren; im Gegenteil, man möchte mit vollständig disaggregierten Daten arbeiten, sodass sich alle Probleme manifestieren. Sobald man jedoch anfängt, die Daten zu aggregieren, verschwinden in der Regel diese feinen Verhaltensweisen. Der Trick besteht normalerweise darin, auf der am wenigsten aggregierten Ebene zu beginnen und sich durch das Netzwerk zu arbeiten, um genau herauszufinden, was vor sich geht – nicht auf statistischer Ebene, sondern auf einer sehr grundlegenden, elementaren Ebene, die man verstehen kann.
Diese Methode eignet sich auch sehr gut für die Perspektive, die ich in der die Quantitative Supply Chain eingeführt habe, wo ich sage, dass man wirtschaftliche Treiber benötigt. Es geht um alle möglichen Zukünfte, alle möglichen Entscheidungen, und dann bewerten Sie alle Entscheidungen nach den wirtschaftlichen Treibern. Es stellt sich heraus, dass diese wirtschaftlichen Treiber sehr nützlich sind, wenn es darum geht, all diese SKUs, Entscheidungen und Ereignisse, die in der supply chain passieren, zu sortieren. Man kann sie nach abnehmendem Dollar-Einfluss ordnen, und das ist ein sehr mächtiger Mechanismus, selbst wenn die wirtschaftlichen Treiber teilweise inkorrekt oder unvollständig sind. Es erweist sich als eine sehr effektive Methode, um mit hoher Produktivität zu untersuchen und zu diagnostizieren, was in einer bestimmten supply chain vor sich geht.
Wenn Sie im Verlauf der Initiativen, in denen Sie diese experimentelle Optimierungsmethode einsetzen, “verrückte” Entscheidungen untersuchen, gibt es eine allmähliche Verschiebung von wirklich verrückten, dysfunktionalen Entscheidungen hin zu einfach nur schlechten Entscheidungen. Sie werden Ihr Unternehmen nicht sprengen, aber sie sind einfach nicht sehr gut.

Hier zeigt sich der tiefgreifende Unterschied zur mathematischen Optimierungsperspektive für supply chain.
Bei der experimentellen Optimierung hat die Verlustfunktion selbst – weil die experimentelle Optimierung intern mathematische Optimierungswerkzeuge verwendet, üblicherweise im Kern der numerischen Rezepte, die die Entscheidung generieren – eine Komponente der mathematischen Optimierung. Aber es ist nur ein Mittel, kein Selbstzweck, das Ihren Prozess unterstützt. Anstatt die mathematische Optimierungsperspektive zu verfolgen, bei der Sie Ihr Problem formulieren und es dann optimieren, stellen Sie hier wiederholt in Frage, was Sie überhaupt über das Problem selbst verstehen, und modifizieren direkt die Verlustfunktion.
Um ein tieferes Verständnis zu erlangen, müssen Sie so ziemlich alles instrumentieren. Sie müssen Ihren Optimierungsprozess selbst, Ihr numerisches Rezept und alle möglichen Eigenschaften der Daten, mit denen Sie arbeiten, instrumentieren. Es ist sehr interessant, denn aus historischer Perspektive – wenn man sich viele der größten wissenschaftlichen Fortschritte anschaut, bei denen bedeutende Entdeckungen gemacht wurden – gab es in der Regel einige Jahrzehnte vor diesen Entdeckungen einen Durchbruch im Bereich der Instrumentierung. Wenn es darum geht, Wissen zu entdecken, findet man normalerweise zuerst einen neuen Weg, das Universum zu beobachten, erzielt einen Durchbruch auf der Ebene der Instrumentierung, und dann kann man tatsächlich den Durchbruch in dem erzielen, was in der Welt von Interesse ist. Genau das geschieht hier. Übrigens machte Galileo die meisten seiner Entdeckungen, weil er der erste Mensch war, der ein selbstgebautes Teleskop zur Verfügung hatte, und so entdeckte er beispielsweise die Monde des Jupiter. All diese Metriken sind die Instrumente, die Ihren Fortschritt wirklich vorantreiben.

Nun besteht die Herausforderung darin, dass – wie bereits gesagt – experimentelle Optimierung ein iterativer Prozess ist. Die hier sehr wichtige Frage ist, ob wir eine Bürokratie gegen eine andere eintauschen. Eine meiner größten Kritiken am herkömmlichen supply chain management ist, dass wir am Ende mit einer Bürokratie von Menschen dastehen, die nur Brandbekämpfung leisten, täglich durch all diese Ausnahmen waten, und deren Arbeit nicht kapitalistisch ist. Ich stellte die kontrastierende Perspektive des Supply Chain Scientist vor, bei der deren Arbeit kapitalistisch akkretiv sein soll. Letztlich läuft es jedoch darauf hinaus, welche Produktivität mit Supply Chain Scientists erreicht werden kann, und diese Menschen müssen sehr produktiv sein.
Hier gebe ich Ihnen eine kurze Liste von KPIs dafür, was diese Produktivität mit sich bringt. Zuerst möchten Sie wirklich in der Lage sein, die Datenpipelines in weniger als einer Stunde von Anfang bis Ende durchzugehen. Wie bereits gesagt, ist eine der Ursachen für Wahnsinn die Datensemantik. Wenn Sie feststellen, dass Sie ein Problem auf semantischer Ebene haben, möchten Sie es testen, und Sie müssen die gesamte Datenpipeline neu ausführen. Ihr supply chain Team oder Supply Chain Scientist muss in der Lage sein, dies mehrmals am Tag zu tun.
Wenn es um das numerische Rezept geht, das die Optimierung selbst vornimmt, sind die Daten an diesem Punkt bereits vorbereitet und konsolidiert, sodass es sich um einen Teil der gesamten Datenpipeline handelt. Sie werden eine sehr große Anzahl von Iterationen benötigen, daher möchten Sie in der Lage sein, täglich Dutzende von Iterationen durchzuführen. Echtzeit wäre fantastisch, aber in der Realität verlagert lokale Optimierung in supply chain lediglich Probleme. Sie müssen eine ganzheitliche Perspektive einnehmen, und das Problem mit naiven oder trivialen Modellen Ihrer supply chain ist, dass sie in puncto ihrer Fähigkeit, all die in supply chains vorkommenden Komplexitäten zu erfassen, nicht sehr gut sind. Es besteht ein Kompromiss zwischen der Ausdruckskraft und Kapazität des numerischen Rezepts und der Zeit, die es benötigt, um aktualisiert zu werden. Typischerweise ist dieses Gleichgewicht gut, solange Sie die Berechnungszeit auf wenige Minuten beschränken.
Abschließend – und dieser Punkt wurde auch in der Vorlesung über produktorientierte Softwarebereitstellung für supply chain behandelt – müssen Sie in der Lage sein, jeden einzelnen Tag ein neues Rezept in Produktion zu nehmen. Es ist nicht so, dass ich dazu rate, sondern vielmehr, dass Sie dazu in der Lage sein müssen, weil unerwartete Ereignisse eintreten werden. Es könnte eine Pandemie sein, oder manchmal ist es nicht so extravagant. Es besteht immer die Möglichkeit, dass ein warehouse überschwemmt wird, dass es einen Produktionsvorfall gibt oder dass Sie eine große Überraschung in Form einer promotion von einem Konkurrenten erleben. Alle möglichen Dinge können geschehen und Ihren Betrieb stören, weshalb Sie in der Lage sein müssen, sehr rasch Korrekturmaßnahmen zu ergreifen. Das bedeutet, dass Sie eine Umgebung benötigen, in der es möglich ist, jeden einzelnen Tag mit einer neuen Iteration Ihres supply chain Rezepts live zu gehen.

Die Praxis der experimentellen Optimierung ist interessant. Lokads Ansatz war eine emergente Praxis, und sie hat sich über ein Jahrzehnt allmählich in den Arbeitsalltag eingeschlichen. In den frühen Jahren hatten wir so etwas wie einen proto-experimentellen Optimierungsprozess im Einsatz. Der Hauptunterschied war, dass wir noch iterierten, jedoch mathematische supply chain Modelle aus der supply chain Literatur verwendeten. Es stellte sich heraus, dass diese Modelle in der Regel monolithisch sind und sich nicht für den sehr iterativen Prozess eignen, den ich mit experimenteller Optimierung beschreibe. Infolgedessen iterierten wir, waren jedoch weit davon entfernt, jeden einzelnen Tag ein neues Rezept in Produktion zu nehmen. Es dauerte eher mehrere Monate, um ein neues Rezept zu entwickeln. Wenn man sich Lokads Website und den Weg, den wir eingeschlagen haben, ansieht, spiegelten die aufeinanderfolgenden Iterationen unserer Prognose-Engine diesen Ansatz wider. Im Grunde nahm es 18 Monate, um von einer Prognose-Engine zur nächsten Generation von Prognose-Engines zu gelangen, mit einer kurzen Serie von vielleicht einer großen Iteration pro Quartal oder so ähnlich.
Das war das, was zuvor der Fall war, und der Wendepunkt kam mit der Einführung von Programmierparadigmen. In meinem Prolog gibt es eine frühere Vorlesung, in der ich Programmierparadigmen für supply chain vorstellte. Mit dieser Vorlesung sollte nun klarer werden, warum uns diese Programmierparadigmen so wichtig sind. Sie sind es, die diese experimentelle Optimierungsmethode antreiben. Sie sind die Paradigmen, die Sie benötigen, um ein numerisches Rezept zu erstellen, mit dem Sie jeden einzelnen Tag effizient iterieren können, um all diese verrückten Entscheidungen loszuwerden und in Richtung von etwas zu steuern, das wirklich einen enormen Mehrwert für die supply chain schafft.
Was die experimentelle Optimierung in der Praxis betrifft, so bin ich der Überzeugung, dass sie etwas ist, das sich entwickelt hat. Sie wurde bei Lokad nicht wirklich erfunden; vielmehr hat sie sich dort herausgebildet, einfach weil wir immer wieder mit unseren eigenen Unzulänglichkeiten bei tatsächlichen supply chain Entscheidungen konfrontiert wurden. Ich vermute stark, dass auch andere Unternehmen, die ähnlichen Zwängen ausgesetzt sind, ihre eigenen experimentellen Optimierungsprozesse entwickelt haben – Varianten von dem, was ich Ihnen heute präsentiert habe.
Wenn Sie sich die Tech-Giganten wie GAFA anschauen, habe ich Kontakte dort, die – ohne irgendwelche Geschäftsgeheimnisse preiszugeben – andeuten, dass diese Art von Praxis unter verschiedenen Namen firmiert, aber bereits in diesen Tech-Giganten sehr präsent ist. Das erkennt man sogar als externer Beobachter daran, dass viele der Open-Source-Tools, die sie veröffentlichen, Werkzeuge sind, die wirklich Sinn ergeben, wenn man darüber nachdenkt, welche Art von Tools man gerne hätte, wenn man Initiativen nach dieser experimentellen Optimierungsmethode durchführt. Zum Beispiel ist PyTorch kein Modell; es ist eine Metasolution, ein Programmierparadigma für Machine Learning, und passt somit in diesen Rahmen.
Dann fragen Sie sich vielleicht, warum, wenn es so erfolgreich ist, es nicht als solches mehr anerkannt wird. Wenn es darum geht, experimentelle Optimierung in freier Wildbahn zu erkennen, ist das schwierig. Wenn Sie einen Schnappschuss eines Unternehmens zu einem bestimmten Zeitpunkt machen, sieht es genau aus wie die mathematische Optimierungsperspektive. Zum Beispiel, wenn Lokad einen Schnappschuss eines der Unternehmen macht, die wir betreuen, haben wir zu diesem Zeitpunkt eine Problemstellung und eine von uns vorgelegte Lösung. Damit sieht die Situation zu jenem Zeitpunkt genau so aus wie die mathematische Optimierungsperspektive. Dies ist jedoch nur die statische Perspektive. Sobald man jedoch die Zeitdimension und die Dynamik betrachtet, ist es radikal anders.
Außerdem ist es wichtig zu beachten, dass es zwar ein iterativer Prozess ist, aber nicht konvergiert. Das kann etwas beunruhigend sein. Die Vorstellung, dass man einen iterativen Prozess haben kann, der zu etwas Optimalem konvergiert, ist, als würde man behaupten, es gäbe eine feste Grenze für menschliche Einfallsreichtum. Ich halte das für ein übertriebenes Unterfangen. Supply chain Probleme sind unberechenbar, sodass es keine Konvergenz gibt – denn es gibt immer wieder Dinge, die das Spiel radikal verändern können. Es ist kein eng abgegrenztes Problem, bei dem man hoffen könnte, die optimale Lösung zu finden. Ein weiterer Grund, warum in der Praxis keine Konvergenz zu beobachten ist, liegt darin, dass sich die Welt ständig verändert. Ihre supply chain operiert nicht im Vakuum; Ihre Lieferanten, Kunden und das Umfeld ändern sich. Was auch immer für ein numerisches Rezept Sie zu einem bestimmten Zeitpunkt hatten, kann anfangen, verrückte Entscheidungen zu produzieren, nur weil sich die Marktbedingungen geändert haben und das, was einst vernünftig war, es nicht mehr ist. Sie müssen sich neu anpassen, um der aktuellen Situation gerecht zu werden. Schauen Sie nur, was 2020 mit der Pandemie geschah – es gab offensichtlich so viele Veränderungen, dass etwas Vernünftiges vor der Pandemie währenddessen nicht vernünftig bleiben konnte. Das Gleiche wird wieder geschehen.
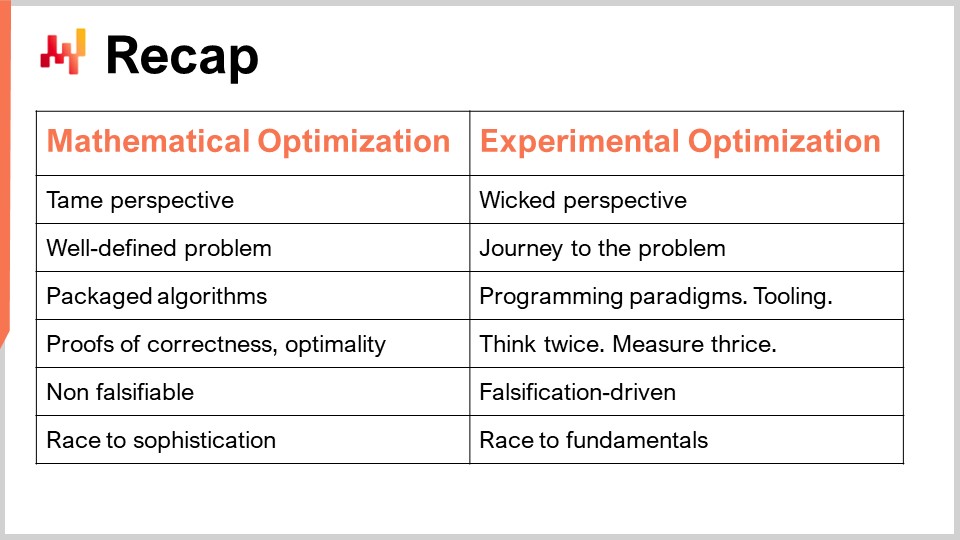
Um zusammenzufassen: Wir haben zwei verschiedene Perspektiven – die mathematische Optimierungsperspektive, bei der wir es mit klar definierten Problemen zu tun haben, und die experimentelle Optimierungsperspektive, bei der das Problem unberechenbar ist. Man kann das Problem nicht einmal klar definieren; man kann sich ihm nur annähern. Durch ein klar definiertes Problem innerhalb der mathematischen Optimierungsperspektive können Sie einen eindeutigen Algorithmus als Lösung bereitstellen und diesen in einer Software verpacken, um dessen Korrektheit und Optimalität zu beweisen. In der Welt der experimentellen Optimierung können Sie jedoch nicht alles verpacken, da es viel zu komplex ist. Was Sie haben können, sind Programmierparadigmen, Werkzeuge, Infrastrukturen – und danach ist es stets eine Frage menschlicher Intelligenz. Es geht darum, zweimal zu denken, dreimal zu messen und einen Schritt vorwärts zu machen. Nichts davon kann automatisiert werden; letztlich kommt es auf die menschliche Intelligenz des Supply Chain Scientist an.
In Bezug auf die Falsifizierbarkeit ist meine Hauptaussage, dass die mathematische Optimierungsperspektive keine Wissenschaft ist, weil man nichts, was sie produziert, falsifizieren kann. Am Ende führt das zu einem Wettlauf um Raffinesse – man will Modelle, die immer komplexer sind, aber es ist nicht so, dass sie aufgrund ihrer höheren Komplexität wissenschaftlicher sind oder mehr Wert für das Unternehmen erzeugen. Im krassen Gegensatz dazu ist die experimentelle Optimierung falsifizierungsgetrieben. Alle Iterationen beruhen darauf, dass Sie Ihre numerischen Rezepte unter realen Bedingungen testen, Entscheidungen generieren und die richtigen Entscheidungen identifizieren. Dieser experimentelle Test kann mehrmals am Tag durchgeführt werden, um Ihre Theorie in Frage zu stellen und sie immer wieder zu widerlegen – iterativ, und hoffentlich dabei einen großen Mehrwert zu liefern.
Es ist interessant, denn im Endeffekt ist experimentelle Optimierung kein Wettlauf um Raffinesse; es ist ein Wettlauf um die Grundlagen. Es geht darum zu verstehen, was Ihre supply chain antreibt, welche grundlegenden Elemente die supply chain bestimmen, und genau wie Sie nachvollziehen, was in Ihren numerischen Rezepten vor sich geht, damit sie nicht ständig diese verrückten Entscheidungen produzieren, die Ihrer supply chain schaden. Letztendlich möchten Sie etwas sehr Gutes für Ihre supply chain schaffen.

Das war eine lange Vorlesung, aber die Kernaussage sollte sein, dass mathematische Optimierung eine Illusion ist. Es ist eine verführerische, anspruchsvolle und attraktive Illusion – aber dennoch nur eine Illusion. Experimentelle Optimierung, soweit es mich betrifft, ist die reale Welt. Wir haben sie fast ein Jahrzehnt lang eingesetzt, um den Prozess für reale Unternehmen zu unterstützen. Lokad ist nur ein Datenpunkt, aber aus meiner Perspektive ist er ein sehr überzeugender Datenpunkt. Es geht wirklich darum, einen Vorgeschmack auf die reale Welt zu bekommen. Übrigens, dieser Ansatz ist grausam hart zu Ihnen, denn wenn Sie in der realen Welt agieren, schlägt die Realität zurück. Sie hatten Ihre schönen Theorien darüber, welches numerische Rezept funktionieren sollte, um die supply chain zu steuern und zu optimieren, und dann schlägt die Realität zurück. Das kann zeitweise unglaublich frustrierend sein, weil die Realität immer Wege findet, all die klugen Ideen zunichtemachen, auf die Sie gekommen sind. Dieser Prozess ist weitaus frustrierender, aber ich glaube, dass dies die Dosis Realität ist, die wir benötigen, um tatsächlich reale und profitable Renditen für Ihre supply chains zu erzielen. Meiner Ansicht nach wird es in Zukunft einen Punkt geben, an dem die experimentelle Optimierung – oder vielleicht ein Abkömmling dieser Methode – die mathematische Optimierungsperspektive bei Studien und Praktiken der supply chain völlig ablöst.

In den kommenden Vorlesungen werden wir die eigentlichen Methoden, numerischen Methoden und numerischen Werkzeuge besprechen, die wir nutzen können, um diese Praxis zu unterstützen. Die heutige Vorlesung befasste sich ausschließlich mit der Methode; später werden wir das Know-how und die Taktiken behandeln, die notwendig sind, um sie zum Funktionieren zu bringen. Die nächste Vorlesung findet in zwei Wochen am selben Tag und zur selben Zeit statt und wird sich mit negativem Wissen in der supply chain befassen.
Nun, lassen Sie mich einen Blick auf die Fragen werfen.
Frage: Wenn supply chain papers keine Chance haben, mit der Realität, auch nur entfernt, verbunden zu sein, und jeder reale Fall einer NDA unterliegt, was würden Sie denen empfehlen, die supply chain-Studien durchführen und ihre Ergebnisse veröffentlichen möchten?
Mein Vorschlag ist, dass Sie die Methode in Frage stellen müssen. Die Methoden, die uns zur Verfügung stehen, sind nicht geeignet, um die supply chain zu untersuchen. In dieser Vorlesungsreihe habe ich zwei Ansätze vorgestellt: das supply chain-Personal und die experimentelle Optimierung. Es gibt eine Menge zu tun, basierend auf diesen Methodologien. Das sind nur zwei Methodologien; ich bin ziemlich sicher, dass es noch viele weitere gibt, die noch entdeckt oder erfunden werden müssen. Mein Vorschlag wäre, im Kern zu hinterfragen, was eine Disziplin zu einer echten Wissenschaft macht.
Frage: Wenn mathematische Optimierung nicht die beste Abbildung davon ist, wie die supply chain in der realen Welt funktionieren sollte, warum wäre dann die Deep-Learning-Methode besser? Trifft Deep Learning nicht Entscheidungen basierend auf zuvor optimalen Entscheidungen?
In dieser Vorlesung habe ich eine klare Unterscheidung getroffen zwischen mathematischer Optimierung als eigenständigem Forschungsgebiet und Deep Learning als eigenständigem Forschungsgebiet sowie mathematischer Optimierung als Perspektive, die auf die supply chain angewendet wird. Ich kritisiere nicht, dass die mathematische Optimierung als Forschungsgebiet ungültig ist – ganz im Gegenteil. In der experimentellen Optimierungsmethode, die ich bespreche, finden Sie im Kern des numerischen Rezepts in der Regel einen mathematischen Optimierungsalgorithmus irgendeiner Art. Der Punkt ist die mathematische Optimierung als Perspektive; das ist es, was ich hier infrage stelle. Ich weiß, es ist subtil, aber das ist ein wesentlicher Unterschied, den ich betone. Deep Learning ist eine Hilfswissenschaft. Deep Learning ist ein separates Forschungsgebiet, genau wie die mathematische Optimierung ein separates Forschungsgebiet ist. Beide sind großartige Forschungsgebiete, aber sie sind völlig unabhängig und verschieden von supply chain-Studien. Was uns heute wirklich betrifft, ist die quantitative Verbesserung von supply chains. Darum geht es mir – um Methoden, die quantitative Verbesserungen in der supply chain auf eine kontrollierte, verlässliche und messbare Weise liefern.
Frage: Kann Reinforcement Learning der richtige Ansatz für das Supply Chain Management sein?
Zunächst würde ich sagen, dass es wahrscheinlich der richtige Ansatz für die supply chain-Optimierung ist. Das ist eine Unterscheidung, die ich in einer meiner früheren Vorlesungen gemacht habe – aus softwaretechnischer Perspektive gibt es die Management-Seite mit Enterprise Resource Management und dann die Optimierungsseite. Reinforcement Learning ist ein weiteres Forschungsgebiet, das auch Elemente aus Deep Learning und mathematischer Optimierung nutzen kann. Es ist die Art von Zutat, die Sie in dieser experimentellen Optimierungsmethode einsetzen können. Entscheidend wird sein, ob Sie über die Programmierparadigmen verfügen, um diese Reinforcement-Learning-Techniken so zu integrieren, dass Sie sehr flüssig und iterativ arbeiten können. Das ist eine große Herausforderung. Sie wollen in der Lage sein zu iterieren, und wenn Sie etwas Komplexes haben – ein monolithisches Reinforcement-Learning-Modell – dann werden Sie Schwierigkeiten haben, genau wie Lokad in den frühen Jahren, als wir versuchten, diese Art von monolithischen Modellen zu verwenden, bei denen unsere Iterationen sehr langsam waren. Eine Reihe technischer Durchbrüche war notwendig, um die Iteration zu einem wesentlich flüssigeren Prozess zu machen.
Frage: Ist mathematische Optimierung ein integraler Bestandteil von Reinforcement Learning?
Ja, Reinforcement Learning ist ein Teilbereich des Machine Learning, und Machine Learning kann gewissermaßen als Teilbereich der mathematischen Optimierung betrachtet werden. Allerdings liegt das Problem darin, dass in dieser Betrachtungsweise alles ineinander übergeht und was diese Bereiche wirklich unterscheidet, ist, dass sie nicht dieselbe Perspektive auf das Problem einnehmen. Alle diese Felder sind miteinander verbunden, aber üblicherweise unterscheidet sie vor allem die Intention, die Sie verfolgen.
Frage: Wie definieren Sie eine wahnsinnige Entscheidung im Kontext von Deep-Learning-Methoden, die oft viele Entscheidungen vorausdenken?
Eine wahnsinnige Entscheidung hängt von zukünftigen Entscheidungen ab. Genau das habe ich im Beispiel demonstriert, als ich sagte: “Ist ein Stockout ein Problem?” Nun ja, es ist kein Problem, wenn Sie erkennen, dass die nächste Entscheidung, die getroffen werden soll, eine Nachfüllung ist. Ob ich diese Situation nun als wahnsinnig qualifiziere oder nicht, hing tatsächlich von einer Entscheidung ab, die kurz bevorstand. Das erschwert die Untersuchung, aber genau darum geht es, wenn ich sage, dass Sie über eine sehr gute Instrumentierung verfügen müssen. Zum Beispiel bedeutet das, dass Sie, wenn Sie eine Out-of-Stock-Situation untersuchen, in der Lage sein müssen, die zukünftigen Entscheidungen zu prognostizieren, die Sie treffen werden – sodass Sie nicht nur die vorhandenen Daten sehen, sondern auch die Entscheidungen, von denen Sie ausgehen, dass sie gemäß Ihrem aktuellen numerischen Rezept getroffen werden. Sehen Sie, es geht darum, über geeignete Instrumente zu verfügen, und nochmal, das ist keine leichte Aufgabe. Es erfordert Intelligenz auf menschlichem Niveau; das kann man nicht einfach automatisieren.
Frage: Wie funktionieren experimentelle Optimierung, das Erkennen von Wahnsinn und das Finden von Lösungen in der Praxis? Ich kann es ja gar nicht erwarten, dass der Wahnsinn in der Realität eintritt, oder?
Absolut richtig. Wenn ich an den Anfang dieser Vorlesung zurückdenke, erwähnte ich zwei Gruppen von Menschen: moderne Physiker und Marxisten. Die Gruppe der Physiker, von der ich sagte, dass sie richtige Wissenschaft betreiben, waren nicht passiv und warteten darauf, dass ihre Theorien widerlegt würden. Sie gingen aktiv den extra Weg und entwarfen unglaublich clevere Experimente, die die Chance hatten, ihre Theorien zu widerlegen. Es war ein sehr proaktiver Mechanismus.
Wenn man sich anschaut, was Albert Einstein den größten Teil seines Lebens tat, so suchte er stets nach cleveren Wegen, die von ihm – zumindest teilweise – erfundenen physikalischen Theorien experimentell zu überprüfen. Also ja, man wartet nicht darauf, dass eine wahnsinnige Entscheidung eintritt. Deshalb müssen Sie in der Lage sein, Ihr Rezept immer wieder auszuführen und Zeit zu investieren, um nach der wahnsinnigen Entscheidung zu suchen. Offensichtlich gibt es einige Entscheidungen, wie diejenigen mit Unpraktikabilitäten, bei denen es keine Hoffnung gibt – man muss sie in der Produktion umsetzen, und dann schlägt die Welt zurück. Aber bei der überwiegenden Mehrheit lassen sich wahnsinnige Entscheidungen durch tägliche Experimente identifizieren. Allerdings benötigen Sie Daten und müssen den realen Prozess haben, der die echten Entscheidungen generiert, die in die Produktion überführt werden könnten.
Frage: Wenn ein Rezept aufgrund einer mathematischen Methode und/oder Perspektive fehlschlagen könnte und Sie diese andere Perspektive nicht kennen, wie können Sie herausfinden, dass es Ihnen nicht an der Methode, sondern an der Perspektive mangelt, und sich dazu anspornen, eine andere Perspektive zu entdecken, die besser zum Problem passt?
Das ist ein sehr großes Problem. Wie können Sie etwas erkennen, das nicht da ist? Wenn ich das Beispiel des supply chain-Personals eines Pariser Modeunternehmens, das Einzelhandelsgeschäfte betreibt, heranziehe, stellen Sie sich für einen Moment vor, dass Sie vergessen haben, an die langfristige Wirkung zu denken, die Ihre End-of-Season-Rabatte auf die Gewohnheiten Ihrer Kunden haben. Sie merken nicht, dass Sie damit eine Gewohnheit in Ihrer Kundenbasis erzeugen. Wie sollen Sie das jemals bemerken? Das ist ein Problem der allgemeinen Intelligenz. Es gibt keine magische Lösung.
Man muss brainstormen, und übrigens lautet die ganz konkrete Antwort von Lokad, dass das Unternehmen in Paris ansässig ist. Wir bedienen Kunden in zwanzig-sieben entfernten Ländern, darunter Australien, Russland, die USA und Kanada. Warum habe ich all meine Teams von Supply Chain Scientists in Paris zusammengebracht, obwohl es mit der Pandemie etwas komplizierter ist und viel Remote-Arbeit stattfindet? Weil ich diese Leute an einem Ort brauchte, damit sie miteinander sprechen, brainstormen und neue Ideen entwickeln können. Nochmals, das ist eine sehr Low-Tech-Lösung, aber ich kann wirklich keine bessere versprechen. Wenn es etwas gibt, das Sie nicht sehen können, wie beispielsweise das Bedürfnis, an die langfristigen Implikationen zu denken, und Sie das einfach vergessen haben oder nie daran gedacht haben, dann kann dieses Problem sehr offensichtlich und fehlend sein. In einer meiner früheren Vorlesungen gab ich das Beispiel des Koffers. Es dauerte 5.000 Jahre, bis man auf die Idee kam, dass es gut wäre, Koffern Räder zu verpassen. Die Räder wurden vor Tausenden von Jahren erfunden, und die verbesserte Version des Koffers wurde Jahrzehnte nach der Mondlandung entwickelt. So etwas zeigt, dass es etwas Offensichtliches geben kann, das man einfach nicht sieht. Dafür gibt es kein Rezept; es ist einfach menschliche Intelligenz. Man tut einfach, was man hat.
Frage: Ständig wechselnde Bedingungen werden die optimale Lösung für Ihre supply chain ständig obsolet machen, oder?
Ja und nein. Aus der Perspektive der experimentellen Optimierung gibt es keine optimale Lösung. Sie haben optimierte Lösungen, aber dieser Unterschied macht den entscheidenden Unterschied. Optimierte Lösungen sind bei weitem nicht optimal. Optimal zu sein bedeutet – und ich wiederhole mich – dass es eine harte Grenze der menschlichen Genialität gibt. Es gibt also nichts, das wirklich optimal ist; es ist lediglich optimiert. Und ja, mit jedem Tag, der vergeht, weicht der Markt von all den Experimenten ab, die Sie bisher durchgeführt haben. Die bloße Evolution der Welt verschlechtert einfach die Optimierung, die Sie erzielt haben. So ist die Welt nun einmal. Es gibt Tage, an denen beispielsweise eine Pandemie eintritt und die Divergenz drastisch zunimmt. Wiederum – so ist die Welt. Die Welt verändert sich, und so muss auch Ihr numerisches Rezept sich ändern. Das ist eine externe Kraft, daher gibt es kein Entkommen; die Lösung muss ständig neu überdacht werden.
Das ist einer der Gründe, warum Lokad ein Abonnement verkauft, und wir sagen zu unseren Kunden: “Nein, wir können Ihnen keinen Supply Chain Scientist nur für die Implementierungsphase verkaufen. Das ist Unsinn. Die Welt wird sich weiter verändern; dieser Supply Chain Scientist, der das numerische Rezept entwickelt hat, wird entweder bis ans Ende der Zeit oder bis Sie genug von uns haben, für Sie da sein.” So wird diese Person in der Lage sein, das numerische Rezept anzupassen. Es gibt kein Entkommen; das ist einfach die externe Welt, die sich ständig verändert.
Frage: Der Weg zum Problem, so richtig er auch sein mag, treibt obere Führungskräfte in den Wahnsinn. Sie können das einfach nicht verstehen; sie denken: “Wie kann man das Problem mehrfach im Lebenszyklus eines Projekts erneut aufgreifen?” Welche bekannten Analogien aus dem Leben würden Sie vorschlagen, um in solchen Gesprächen zu verdeutlichen, dass es sich um ein weit verbreitetes Problem handelt?
Zunächst einmal habe ich genau das in der letzten Folie gesagt, auf der ich den Screenshot aus The Matrix gezeigt habe. Irgendwann muss man sich entscheiden, ob man in einer Fantasie leben oder in der realen Welt. Das Management – hoffentlich, wenn Ihr oberes Management in Ihrem Unternehmen einfach ein Haufen Idioten ist, dann rate ich Ihnen, zu einem anderen Unternehmen zu wechseln, denn ich bezweifle, dass dieses Unternehmen noch lange bestehen wird – aber die Realität ist: Ich glaube nicht, dass Manager Dummköpfe sind. Sie wollen sich nicht mit eingebildeten Problemen auseinandersetzen. Wenn Sie Manager in einem großen Unternehmen sind, kommen täglich zehnmal Personen zu Ihnen mit einem “großen Problem”, das gar kein reales Problem ist. Die Reaktion des Managements, die korrekt ist, lautet: “Es gibt überhaupt kein Problem, machen Sie einfach weiter so, wie Sie es bisher getan haben. Entschuldigung, ich habe keine Zeit, die Welt mit Ihnen neu zu gestalten. Das ist einfach nicht der richtige Ansatz, um das Problem zu betrachten.” Sie haben das Richtige getan, denn durch jahrzehntelange Erfahrung können sie das klären. Sie verfügen über bessere Heuristiken als diejenigen, die weiter unten in der Hierarchie stehen.
Aber manchmal gibt es ein sehr reales Anliegen. Zum Beispiel lautet Ihre Frage: Wie überzeugt man das obere Management von vor zwei Jahrzehnten davon, dass E-Commerce in zwei Jahrzehnten eine dominierende Kraft sein wird? Irgendwann muss man einfach seine Schlachten sorgfältig auswählen. Wenn Ihr oberes Management kein Dummkopf ist und Sie gut vorbereitet zu einem Meeting erscheinen und sagen: “Chef, ich habe dieses Problem. Das ist kein Scherz. Es ist ein sehr zentrales Anliegen mit Millionen von Dollar im Spiel. Ich scherze nicht. Das ist Unmengen an Geld, das wir auf dem Tisch liegen lassen. Schlimmer noch, ich vermute, dass die meisten unserer Wettbewerber uns ablösen werden, wenn wir nichts tun. Das ist kein Nebenaspekt; das ist ein sehr reales Problem. Ich benötige 20 Minuten Ihrer Aufmerksamkeit.” Wiederum ist es in großen Unternehmen selten, dass das obere Management ein Haufen kompletter Idioten ist. Sie mögen beschäftigt sein, aber sie sind keine Idioten.
Frage: Was wäre die angemessene Tool-Landschaft für Fertigungsunternehmen: experimentelle Optimierung wie Lokad, plus ERP, plus Visualisierung? Und was ist mit der Rolle von simultanen Planungssystemen online?
Die überwiegende Mehrheit unserer Wettbewerber orientiert sich an der mathematischen Optimierungsperspektive auf supply chains. Sie haben das Problem definiert und Software implementiert, um das Problem zu lösen. Was ich sagen möchte, ist, dass, wenn sie die Software auf die Probe stellen und sie unweigerlich Tonnen von verrückten Entscheidungen hervorbringt, sie sagen: “Oh, es liegt daran, dass du die Software nicht richtig konfiguriert hast.” Das macht das Softwareprodukt immun gegen den Realitätscheck. Sie finden Wege, die Kritik abzulenken, anstatt sie anzugehen.
Bei Lokad entstand diese Methode nur, weil wir uns von unseren Wettbewerbern sehr unterschieden haben. Wir hatten nicht den Luxus, eine Entschuldigung zu haben. Wie man so schön sagt: “Man kann entweder Entschuldigungen oder Ergebnisse haben, aber nicht beides.” Bei Lokad hatten wir nicht die Option, Ausreden zu machen. Wir lieferten Entscheidungen, und es gab nichts, was vom Kundenseite aus konfiguriert oder angepasst werden konnte. Lokad trat ungeschminkt seinen eigenen Unzulänglichkeiten entgegen. Soweit ich weiß, sind alle unsere Wettbewerber fest in der mathematischen Optimierungsperspektive verankert und leiden unter dem Problem, in gewissem Maße immun gegen die Realität zu sein. Um ehrlich zu sein, sind sie nicht völlig immun gegen die Realität, aber sie haben letztlich ein sehr langsames Iterationstempo, wie ich es für Lokad in den frühen Jahren beschrieben habe. Sie sind nicht völlig immun gegen die Realität, aber ihr Verbesserungsprozess schreitet glazial langsam voran, und die Welt verändert sich ständig.
Was unweigerlich geschieht, ist, dass die Unternehmenssoftware nicht annähernd so schnell verändert wird, um mit der Welt im Allgemeinen Schritt zu halten, sodass man am Ende Software hat, die einfach altert. Sie wird nicht wirklich besser, denn jedes vergangene Jahr bringt zwar Verbesserungen in der Software, aber die Welt wird immer seltsamer und unterschiedlicher. Die Unternehmenssoftware gerät immer weiter hinter eine Welt, die zunehmend von ihrem Ursprungsort abgekoppelt ist.
Frage: Was wäre die richtige Landschaft von Werkzeugen für Fertigungsunternehmen?
Die richtige Landschaft sind Enterprise Resource Management Tools, die alle transaktionalen Aspekte verwalten können. Darüber hinaus ist es wirklich wichtig, eine Lösung zu haben, die in Bezug auf Ihre numerische Rezeptur sehr integriert ist. Man möchte keinen Tech-Stack für Visualisierung, einen anderen für Optimierung, einen weiteren für Untersuchung und noch einen weiteren für Datenvorbereitung. Wenn man am Ende mit einem halben Dutzend technologischer Stacks für all diese unterschiedlichen Dinge dasteht, benötigt man eine Armee von Softwareingenieuren, um sie alle miteinander zu verbinden, und man hat am Ende etwas, das das Gegenteil von agil ist.
Es wird so viel Software-Engineering-Kompetenz benötigt, dass kein Raum mehr für echte supply chain Kompetenz bleibt. Denken Sie daran, das war der Punkt meiner dritten Vorlesung über produktorientierte Softwarebereitstellung. Man benötigt etwas, das von einem supply chain specialist, nicht von einem Softwareingenieur, bedient werden kann.
Das ist alles. Wir sehen uns in zwei Wochen, am gleichen Tag und zur gleichen Stunde, zu “Negatives Wissen in supply chain.”
Referenzen
- Die Logik der wissenschaftlichen Entdeckung, Karl Popper, 1934


