00:21 Einführung
01:53 Vom Prognostizieren zum Lernen
05:32 Maschinelles Lernen 101
09:51 Die bisherige Geschichte
11:49 Meine Vorhersagen für heute
13:54 Genau auf Daten, die wir nicht haben 1/4
16:30 Genau auf Daten, die wir nicht haben 2/4
20:03 Genau auf Daten, die wir nicht haben 3/4
25:11 Genau auf Daten, die wir nicht haben 4/4
31:49 Ruhm dem Template Matcher
35:36 Eine Tiefe im Lernen 1/4
39:11 Eine Tiefe im Lernen 2/4
44:27 Eine Tiefe im Lernen 3/4
47:29 Eine Tiefe im Lernen 4/4
51:59 Alles geben oder nach Hause gehen
56:45 Jenseits des Verlusts 1/2
01:00:17 Jenseits des Verlusts 2/2
01:04:22 Jenseits des Labels
01:10:24 Jenseits der Beobachtung
01:14:43 Fazit
01:16:36 Nächste Vorlesung und Fragen des Publikums
Beschreibung
Prognosen sind in der supply chain unverkürzbar, da jede Entscheidung (Einkauf, Produktion, Lagerhaltung usw.) eine Erwartung zukünftiger Ereignisse widerspiegelt. Statistisches Lernen und machine learning haben das klassische ‚Forecasting‘-Feld weitgehend abgelöst, sowohl aus theoretischer als auch aus praktischer Sicht. Wir werden versuchen zu verstehen, was eine datengetriebene Vorwegnahme der Zukunft überhaupt aus einer modernen ‚Lern‘-Perspektive bedeutet.
Komplettes Transkript

Willkommen zur Reihe der supply chain-Vorlesungen. Ich bin Joannes Vermorel, und heute werde ich „Maschinelles Lernen für supply chain“ präsentieren. Wir können Güter nicht in Echtzeit 3D drucken, und wir können sie auch nicht teleportieren, um sie dorthin zu liefern, wo sie hin sollen. Tatsächlich müssen nahezu alle supply chain decisions vorausschauend getroffen werden, indem entweder die future demand oder Preisentwicklungen antizipiert werden, was implizit oder explizit eine erwartete zukünftige Marktsituation entweder auf der Nachfrageseite oder auf der Angebotsseite widerspiegelt. Folglich ist Forecasting ein integraler und unverkürzbarer Bestandteil der supply chain. Wir wissen nie mit Sicherheit, was die Zukunft bringt; wir können nur mit unterschiedlicher Sicherheit über die Zukunft spekulieren. Ziel dieser Vorlesung ist es zu verstehen, was machine learning im Hinblick auf die Erfassung der Zukunft leistet.

In dieser Vorlesung werden wir sehen, dass die Bereitstellung von accurate forecasts im Großen und Ganzen eine relativ sekundäre Rolle spielt. Tatsächlich bedeutet Forecasting in der supply chain heutzutage time series Forecasting. Historisch gesehen wurden Zeitreihenprognosen zu Beginn des 20. Jahrhunderts in den USA populär. Tatsächlich waren die USA das erste Land, in dem Millionen von Arbeitnehmern der Mittelschicht auch Aktien besaßen. Da die Menschen kluge Investoren sein wollten, wollten sie Einblicke in ihre Investitionen haben, und es stellte sich heraus, dass Zeitreihen und Zeitreihenprognosen eine intuitive und effektive Möglichkeit boten, diese Einblicke zu vermitteln. Man konnte Zeitreihenprognosen zu zukünftigen Marktpreisen, zukünftigen Dividenden und zukünftigen Marktanteilen erstellen.
In den 80er und 90er Jahren, als die supply chain im Wesentlichen digitalisiert wurde, profitierte auch die enterprise software der supply chain von Zeitreihenprognosen. Tatsächlich wurden Zeitreihenprognosen in jener Art von Unternehmenssoftware allgegenwärtig. Wenn man sich dieses Bild ansieht, erkennt man jedoch, dass Zeitreihenprognosen eine sehr vereinfachte und naive Art sind, in die Zukunft zu blicken.
Sehen Sie, wenn ich dieses Bild betrachte, kann ich bereits sagen, was als Nächstes passieren wird: Höchstwahrscheinlich wird eine Crew eintreffen, diesen Schlamassel beseitigen und sehr wahrscheinlich anschließend die Gabelstapler aus Sicherheitsgründen überprüfen. Möglicherweise führen sie sogar leichte Reparaturen durch, und mit hoher Wahrscheinlichkeit kann ich sagen, dass dieser Gabelstapler bald wieder in Betrieb genommen wird. Schon allein anhand dieses Bildes können wir auch vorhersagen, welche Umstände zu dieser Situation geführt haben. Nichts davon passt in die Perspektive von Zeitreihenprognosen, und dennoch sind all diese Vorhersagen sehr relevant.
Diese Vorhersagen beziehen sich nicht direkt auf die Zukunft, denn dieses Bild wurde vor einiger Zeit aufgenommen, und selbst die Ereignisse, die nach der Aufnahme dieses Bildes folgten, gehören inzwischen der Vergangenheit an. Dennoch sind es Vorhersagen im Sinne davon, dass wir Aussagen über Dinge treffen, über die wir uns nicht sicher sein können. Wir haben keine direkte Messung. Das Wesentliche ist also, wie ich überhaupt in der Lage bin, diese Vorhersagen zu erstellen und diese Aussagen zu treffen?
Es stellt sich heraus, dass ich als Mensch gelebt habe, Ereignisse miterlebt habe und daraus gelernt habe. So kann ich diese Aussagen tatsächlich treffen. Und es stellt sich heraus, dass machine learning genau das ist: Es ist der Anspruch, diese Lerngfähigkeit mit Maschinen nachbilden zu können, wobei heutzutage vorzugsweise Computer zum Einsatz kommen. An diesem Punkt fragen Sie sich vielleicht, wie sich machine learning überhaupt von anderen Begriffen wie künstlicher Intelligenz, kognitiven Technologien oder statistischem Lernen unterscheidet. Nun, es stellt sich heraus, dass diese Begriffe mehr über die Personen aussagen, die sie verwenden, als über das eigentliche Problem. Was das Problem betrifft, sind die Grenzen zwischen all diesen Bereichen sehr unscharf.

Nun tauchen wir ein in einen Überblick über das Archetyp der machine learning Rahmenwerke und behandeln eine kurze Reihe zentraler machine learning Konzepte. Die meisten wissenschaftlichen Arbeiten und Software, die in diesem Bereich des machine learning produziert werden, nutzen diesen Rahmen in erheblichem Maße. Das Feature repräsentiert ein Stück Daten, das zur Durchführung der Vorhersageaufgabe zur Verfügung gestellt wird. Die Idee ist, dass Sie eine Vorhersageaufgabe haben, die Sie ausführen möchten, und ein Feature (oder mehrere Features) repräsentiert, was zur Ausführung dieser Aufgabe bereitgestellt wird. Im Kontext von Zeitreihenprognosen würde das Feature den vergangenen Teil der Zeitreihe darstellen, und Sie hätten einen Vektor von Features, der alle bisherigen Datenpunkte repräsentiert.
Das Label repräsentiert die Antwort auf die Vorhersageaufgabe. Im Falle einer Zeitreihenprognose repräsentiert es typischerweise den Teil der Zeitreihe, den Sie nicht kennen, also den zukünftigen Abschnitt. Wenn Sie eine Menge von Features plus ein Label haben, spricht man von einer Beobachtung. Das typische machine learning Setup geht davon aus, dass Sie einen Datensatz haben, der sowohl Features als auch Labels enthält, was Ihr training data Set darstellt.
Das Ziel ist es, ein Programm namens Modell zu erstellen, das die Features als Eingabe nimmt und das gewünschte, vorhergesagte Label berechnet. Dieses Modell wird in der Regel durch einen Lernprozess entwickelt, der den gesamten Trainingsdatensatz durchläuft und das Modell aufbaut. Das Lernen im machine learning ist der Teil, in dem Sie tatsächlich das Programm konstruieren, das die Vorhersagen trifft.
Schließlich gibt es den Loss. Der Loss ist im Wesentlichen die Differenz zwischen dem echten Label und dem vorhergesagten. Ziel des Lernprozesses ist es, ein Modell zu erzeugen, das Vorhersagen trifft, die so nah wie möglich an den wahren Labels liegen. Man möchte ein Modell, das die vorhergesagten Labels so nah wie möglich an den wahren Labels hält.
Machine learning kann als eine weite generalization der Zeitreihenprognose angesehen werden. Aus der Perspektive von machine learning können Features alles Mögliche sein, nicht nur ein vergangener Abschnitt einer Zeitreihe. Labels können ebenfalls alles Mögliche sein, nicht nur der zukünftige Abschnitt einer Zeitreihe. Das Modell kann alles Mögliche sein, und selbst der Loss kann so ziemlich alles sein. Wir haben also einen Rahmen, der weitaus ausdrucksstärker ist als Zeitreihenprognosen. Wie wir jedoch sehen werden, stammen die meisten der wesentlichen Errungenschaften von machine learning als Forschungs- und Praxisfeld aus den Entdeckungen von Elementen, die uns zwingen, die Liste der Konzepte, die ich gerade kurz vorgestellt habe, zu überdenken und in Frage zu stellen.
Diese Vorlesung ist die vierte Vorlesung in der Reihe der supply chain-Vorlesungen. Hilfswissenschaften stellen Elemente dar, die nicht supply chain per se sind, aber von grundlegender Bedeutung für die supply chain sind. Im ersten Kapitel habe ich meine Ansichten zur supply chain sowohl als physische Studie als auch als Praxis vorgestellt. Im zweiten Kapitel haben wir eine Reihe von Methoden durchgesehen, die erforderlich sind, um ein Gebiet wie die supply chain zu bewältigen, das viele gegensätzliche Verhaltensweisen aufweist und nicht leicht zu isolieren ist. Das dritte Kapitel ist vollständig den personas der supply chain gewidmet, was ein Weg ist, sich auf die Probleme zu konzentrieren, die wir zu lösen versuchen.
In diesem vierten Kapitel bin ich allmählich die Abstraktionsleiter hinaufgegangen, beginnend mit Computern, dann Algorithmen, und der vorangegangenen Vorlesung zur mathematischen Optimierung, die als Basisschicht des modernen machine learning angesehen werden kann. Heute begeben wir uns in das Gebiet des machine learning, das entscheidend dafür ist, die Zukunft zu erfassen, die in allen supply chain-Entscheidungen, die wir täglich treffen, präsent ist.

Also, was ist der Plan für diese Vorlesung? Machine learning ist ein riesiges Forschungsfeld, und diese Vorlesung wird von einer kurzen Reihe von Fragen geleitet, die sich auf die Konzepte und Ideen beziehen, die ich zuvor vorgestellt habe. Wir werden sehen, wie die Antworten auf diese Fragen uns zwingen, den Begriff des Lernens und unseren Umgang mit den Daten neu zu überdenken. Eines der spektakulärsten Ergebnisse von machine learning ist, dass es uns zur Erkenntnis verholfen hat, dass in der Tat so viel mehr im Spiel ist als ursprünglich von den Forschern erhofft wurde, die dachten, wir könnten die menschliche Intelligenz innerhalb eines Jahrzehnts nachbilden.
Insbesondere werden wir einen Blick auf deep learning werfen, das wahrscheinlich der beste Kandidat ist, den wir derzeit haben, um ein höheres Maß an Intelligenz zu emulieren. Obwohl deep learning sich als eine unglaublich empirische Praxis erwiesen hat, werfen die Fortschritte und Errungenschaften, die durch deep learning erzielt wurden, ein neues Licht auf die grundlegende Perspektive des Lernens aus beobachteten Phänomenen.
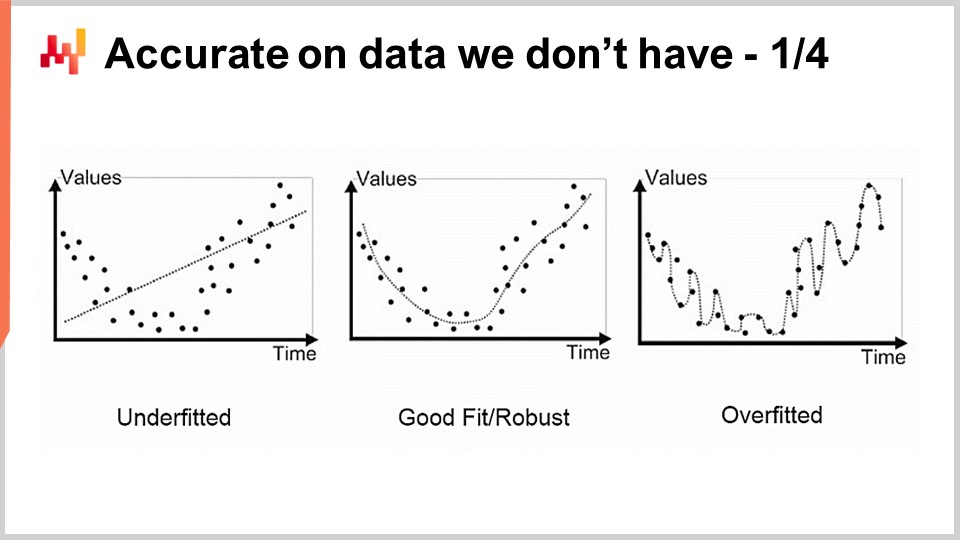
Das erste Problem, das wir bei der Modellierung, sei es statistisch oder anders, haben, ist die Genauigkeit von Daten, die wir nicht haben. Aus supply chain perspective ist dies von entscheidender Bedeutung, weil unser Interesse darin liegt, die Zukunft erfassen zu können. Per Definition stellt die Zukunft einen Satz von Daten dar, die wir noch nicht besitzen. Es gibt Techniken, wie backtesting oder Kreuzvalidierung, die uns einige empirische Messwerte darüber liefern können, was wir von der Genauigkeit der Daten, die uns nicht vorliegen, erwarten sollten. Warum diese Methoden überhaupt funktionieren, ist jedoch ein relativ faszinierendes und schwieriges Problem. Das Problem besteht nicht darin, ein Modell zu haben, das zu den Daten passt, die wir haben; es ist einfach, ein Modell zu erstellen, das zu den Daten passt, indem man ein Polynom mit einem ausreichenden Grad verwendet. Dennoch ist dieses Modell wenig zufriedenstellend, weil es nicht das erfasst, was wir erfassen möchten.
Der klassische Ansatz zur Lösung dieses Problems ist als Bias-Variance-Tradeoff bekannt. Rechts haben wir ein Modell mit sehr wenigen Parametern, das das Problem unteranpasst, was wir als zu viel Bias bezeichnen. Links haben wir ein Modell mit zu vielen Parametern, das überanpasst und zu viel Varianz aufweist. In der Mitte haben wir ein Modell, das ein gutes Gleichgewicht zwischen Bias und Varianz findet, was wir als gute Passung bezeichnen. Bis zum Ende des 20. Jahrhunderts war es ziemlich unklar, wie man dieses Problem über den Bias-Variance-Tradeoff hinaus angehen sollte.

Der erste wirkliche Einblick in die Genauigkeit von Daten, die wir nicht haben, stammt aus den Theorien der Lernfähigkeit, die 1984 von Valiant veröffentlicht wurden. Valiant führte die PAC-Theorie – Probably Approximately Correct – ein. In dieser PAC-Theorie bezieht sich der Teil „probably“ auf ein Modell mit einer gegebenen Wahrscheinlichkeit, hinreichend gute Antworten zu liefern. Der Teil „approximately“ bedeutet, dass die Antwort nicht allzu weit davon entfernt ist, was als gut oder gültig angesehen wird.
Valiant zeigte, dass es in vielen Situationen einfach nicht möglich ist, etwas zu lernen oder, genauer gesagt, dass wir, um lernen zu können, eine Anzahl von Stichproben benötigen würden, die so extravagant groß wäre, dass sie nicht praktikabel wäre. Dies war bereits ein sehr interessantes Ergebnis. Die angezeigte Formel stammt aus der PAC-Theorie, und es handelt sich um eine Ungleichung, die aussagt, dass wenn man ein Modell erzeugen möchte, das wahrscheinlich annähernd korrekt ist, man eine Anzahl von Beobachtungen, n, benötigt, die größer ist als eine bestimmte Größe. Dieser Wert hängt von zwei Faktoren ab: epsilon, der Fehlerquote (dem approximately correct Teil), und eta, der Ausfallwahrscheinlichkeit (eins minus eta ist die Wahrscheinlichkeit, nicht zu scheitern).
Was wir sehen, ist, dass wenn wir eine geringere Ausfallwahrscheinlichkeit oder ein kleineres Epsilon (einen hinreichend guten Bereich) haben wollen, wir mehr Stichproben benötigen. Diese Formel hängt auch von der Kardinalität des Hypothesenraums ab. Die Idee ist, dass je zahlreicher die konkurrierenden Hypothesen sind, desto mehr Beobachtungen wir benötigen, um sie zu sortieren. Das ist sehr interessant, denn im Wesentlichen, obwohl die PAC-Theorie uns hauptsächlich negative Ergebnisse liefert, sagt sie uns, was wir nicht tun können, nämlich ein beweisbar Probably Approximately Correct Modell mit weniger Stichproben zu erstellen. Die Theorie sagt uns nicht wirklich, wie man irgendetwas macht; sie ist nicht sehr vorschreibend, wenn es darum geht, tatsächlich besser darin zu werden, irgendeine Art von Vorhersageaufgabe zu lösen. Dennoch war es ein Meilenstein, weil sie die Idee kristallisierte, dass es möglich war, dieses Problem der Genauigkeit und der nicht vorhandenen Daten auf robustere Weise anzugehen, als nur einige sehr empirische Messungen mit zum Beispiel Kreuzvalidierung oder Backtesting durchzuführen.
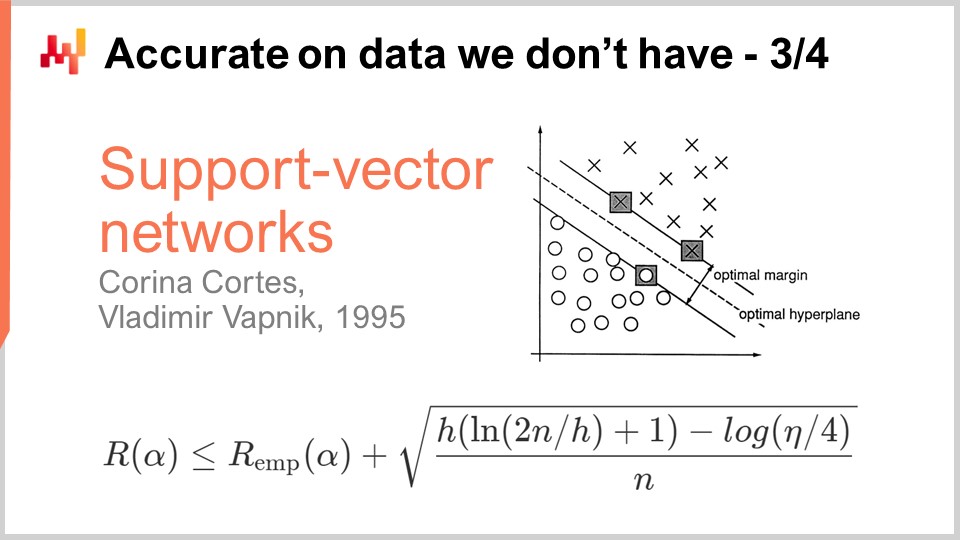
Ein Jahrzehnt später kam der erste operationelle Durchbruch, als Vapnik und einige andere das etablierten, was heute als die Vapnik-Chervonenkis (VC)-Theorie bekannt ist. Diese Theorie zeigt, dass es möglich ist, den realen Verlust – als Risiko bezeichnet – zu erfassen, also den Verlust, den man bei den Daten beobachten wird, die man nicht hat. Es war möglich, mathematisch zu beweisen, dass man die Fähigkeit besitzt, irgendetwas über den realen Fehler zu wissen, den man definitionsgemäß niemals messen kann. Dies ist ein sehr verwirrendes Ergebnis.
Im Wesentlichen besagt diese Formel, direkt aus der VC-Theorie, dass das reale Risiko durch das empirische Risiko, also das Risiko, das wir an den vorliegenden Daten messen können, plus einem weiteren Term, der häufig als strukturelles Risiko bezeichnet wird, nach oben beschränkt ist. Wir haben die Anzahl der Beobachtungen, n, und eta, welches die Ausfallwahrscheinlichkeit ist, genauso wie in der PAC-Theorie. Wir haben auch h, welches ein Maß für die VC-Dimension des Modells ist. Die VC-Dimension spiegelt die Lernkapazität des Modells wider; je größer die Kapazität des Modells zu lernen, desto größer ist die VC-Dimension.
Mit diesen Ergebnissen sehen wir, dass wir für Modelle, die alles lernen können, zumindest mathematisch nichts Aussagekräftiges sagen können. Das ist sehr verwirrend. Wenn Ihr Modell alles lernen kann, dann kann man zumindest mathematisch nichts über es aussagen.
Der Durchbruch im Jahr 1995 erfolgte durch eine Implementierung von Cortes und Vapnik dessen, was später als Support Vector Machines (SVM) bekannt wurde. Diese SVMs sind buchstäblich die direkte Umsetzung dieser mathematischen Theorie. Die Erkenntnis ist, dass wir, weil wir eine Theorie haben, die uns diese Ungleichung liefert, ein Modell implementieren können, das den Fehler, den wir an den Daten machen (das empirische Risiko), und die VC-Dimension in Einklang bringt. Wir können direkt ein mathematisches Modell erstellen, das diese beiden Faktoren exakt ausbalanciert, um die Gleichung so eng und so niedrig wie möglich zu halten. Genau darum geht es bei Support Vector Machines (SVMs). Diese Ergebnisse waren im operativen Einsatz so beeindruckend, dass sie sehr gute Resultate lieferten und einen erheblichen Einfluss auf die Machine-Learning-Community hatten. Zum ersten Mal war die Genauigkeit bei den Daten, die wir nicht haben, kein nachträglicher Gedanke; sie wurde direkt durch das sehr mathematische Design der Methode selbst erzielt. Das war so beeindruckend und kraftvoll, dass die gesamte Machine-Learning-Community ein Jahrzehnt lang auf diesem Weg verharrte. Wie wir sehen werden, stellte sich dieser Weg als weitgehend eine Sackgasse heraus, aber es gab gute Gründe dafür: Es war ein absolut beeindruckendes Ergebnis.
Betrieblich gesehen, aufgrund der Tatsache, dass SVMs größtenteils aus einer mathematischen Theorie hervorgingen, besaßen sie nur sehr wenig mechanisches Einfühlungsvermögen. Sie passten nicht gut zur vorhandenen Computerhardware. Genauer gesagt, bringt die naive Implementierung von SVMs einen quadratischen Kostenfaktor in Bezug auf den Speicherbedarf in Abhängigkeit von der Anzahl der Beobachtungen mit sich. Das ist viel, und folglich machen SVMs dadurch sehr langsam. Es gab spätere Verbesserungen mit einigen Online-Varianten von SVMs, die den Speicherbedarf erheblich senkten, aber dennoch wurden SVMs nie wirklich als ein wahrhaft skalierbarer Ansatz für Machine Learning betrachtet.

SVMs ebneten den Weg für eine andere, bessere Klasse von Modellen, die vermutlich auch nicht überanpassen. Überanpassung bedeutet im Grunde, sehr ungenau bei den Daten zu sein, die man nicht hat. Die bekanntesten Beispiele sind wahrscheinlich Random Forests und Gradient Boosted Trees, die fast unmittelbare Nachkommen davon sind. Im Kern steht hier das Boosting, ein Meta-Algorithmus, der schwache Modelle in stärkere verwandelt. Boosting entstand aus Fragen, die gegen Ende der 80er Jahre zwischen Kearns und Valiant aufkamen, die wir zuvor in diesem Vortrag erwähnt haben.
Um zu verstehen, wie ein Random Forest funktioniert, ist es relativ einfach: Nehmen Sie Ihren Trainingsdatensatz und wählen Sie eine Stichprobe aus diesem Datensatz. Auf dieser Stichprobe erstellen Sie einen Entscheidungsbaum. Wiederholen Sie diesen Vorgang, indem Sie eine weitere Stichprobe aus dem ursprünglichen Trainingsdatensatz ziehen und einen weiteren Entscheidungsbaum bauen. Wiederholen Sie diesen Prozess, und am Ende haben Sie viele Entscheidungsbäume. Entscheidungsbäume sind als Machine-Learning-Modelle relativ schwach, da sie sehr komplexe Muster nicht erfassen können. Werden jedoch all diese Bäume zusammengefügt und die Ergebnisse gemittelt, erhält man einen Wald – einen Random Forest –, da jeder Baum auf einer zufällig gezogenen Untermusterung des ursprünglichen Trainingsdatensatzes basiert. Das Ergebnis eines Random Forests ist ein wesentlich stärkeres, besseres Machine-Learning-Modell.
Gradient Boosted Trees sind nur eine geringfügige Variation dieser Erkenntnis. Die Hauptvariation besteht darin, dass anstatt eine zufällige Stichprobe aus Ihrem Trainingsdatensatz zu ziehen und einen Baum unabhängig zu erstellen, bei Gradient Boosted Trees zunächst der Wald aufgebaut wird und dann der nächste Baum entsteht, indem man die Residuen des bereits bestehenden Waldes betrachtet. Die Idee ist, dass Sie begonnen haben, ein Modell aus vielen Bäumen zu konstruieren, und dass Ihre Vorhersagen von der Realität abweichen. Sie erhalten diese Deltas, also die Unterschiede zwischen den realen und den prognostizierten Werten, die als Residuen bezeichnet werden. Die Idee ist, dass der nächste Baum nicht gegen den ursprünglichen Datensatz, sondern gegen eine Stichprobe der Residuen trainiert wird. Gradient Boosted Trees funktionieren sogar noch besser als Random Forests. In der Praxis überanpassen Random Forests zwar, aber nur ein wenig. Es gibt einige Beweise, die zeigen, dass Random Forests unter bestimmten Bedingungen nicht überanpassen sollten.
Interessanterweise dominieren Gradient Boosted Trees seit anderthalb Jahrzehnten nahezu alle Machine-Learning-Wettbewerbe. Betrachtet man etwa 80–90 % der Kaggle-Wettbewerbe, stellt man fest, dass im Wesentlichen ein Gradient Boosted Tree den ersten Platz erreicht. Dennoch gab es trotz dieser unglaublichen Dominanz in Machine-Learning-Wettbewerben nur wenige Durchbrüche bei der Anwendung von Gradient Boosted Trees auf supply chain Probleme in der Praxis. Der Hauptgrund ist, dass Gradient Boosted Trees nur sehr wenig mechanisches Einfühlungsvermögen besitzen; ihr Design ist überhaupt nicht freundlich gegenüber der vorhandenen Computerhardware.
Es ist leicht zu verstehen, warum: Man baut ein Modell mit einer Reihe von Bäumen, und das Modell erweist sich datenmäßig als größer als ein Bruchteil des ursprünglichen Datensatzes. In vielen Situationen endet man mit einem Modell, das, was die Datenmenge betrifft, größer ist als der Datensatz, mit dem man begonnen hat. Wenn Ihr Datensatz also bereits sehr groß ist, wird Ihr Modell gigantisch, und das ist ein sehr problematisches Problem.
In der Geschichte der Gradient Boosted Trees gab es eine Reihe von Implementierungen, beginnend mit GBM (Gradient Boosted Machines) im Jahr 2007, die diesen Ansatz in einem R-Paket wirklich populär machten. Von Anfang an gab es Probleme mit der Skalierbarkeit. Die Leute begannen schnell, die Ausführung mit PGBRT (Parallel Gradient Boosted Regression Trees) zu parallelisieren, doch es war immer noch sehr langsam. XGBoost war ein Meilenstein, weil es eine Größenordnung an Skalierbarkeit gewann. Die Schlüsselidee bei XGBoost war, ein spaltenorientiertes Design in den Daten zu übernehmen, um die Baumkonstruktion zu beschleunigen. Später recycelte LightGBM alle Erkenntnisse von XGBoost, änderte jedoch die Strategie, wie die Bäume aufgebaut werden. XGBoost ließ den Baum ebenenweise wachsen, während LightGBM sich dazu entschied, den Baum blattweise wachsen zu lassen. Das Endergebnis ist, dass LightGBM, bei gleicher Computerhardware, nun um mehrere Größenordnungen schneller ist als GBM es jemals war. Doch aus praktischer supply chain Perspektive ist der Einsatz von Gradient Boosted Trees in der Regel unpraktikabel langsam. Es ist nicht unmöglich, sie zu verwenden; es ist nur so eine Hürde, dass es sich meistens nicht lohnt.

Das Merkwürdige ist, dass Gradient Boosted Trees so leistungsfähig sind, dass sie fast alle Machine-Learning-Wettbewerbe gewinnen, und dennoch, meiner bescheidenen Meinung nach, stellen diese Modelle einen technologischen Irrweg dar. Support Vector Machines, Random Forests und Gradient Boosted Trees haben alle gemeinsam, dass sie nichts weiter als Musterabgleiche sind. Sie sind – bedenken Sie – sehr gute Musterabgleiche, aber letztlich nicht mehr. Was sie außergewöhnlich gut beherrschen, ist im Wesentlichen die Variablenselektion, und darin sind sie sehr gut, aber mehr gibt es nicht. Insbesondere fehlt ihnen Ausdruckskraft in ihrer Fähigkeit, die Eingabe in etwas anderes als eine direkte Auswahl oder Filterung der Eingabe umzuwandeln.
Wenn wir auf das Gabelstaplerbild zurückblicken, das ich zu Beginn dieses Vortrags gezeigt habe, besteht keinerlei Hoffnung, dass eines dieser Modelle in der Lage wäre, die Art von Aussagen zu treffen, die ich gerade gemacht habe – ganz gleich, wie groß der Bilddatensatz ist. Man könnte diesen Modellen buchstäblich Millionen von Bildern, die aus Lagerhäusern weltweit stammen, zuführen, und sie wären dennoch nicht in der Lage zu sagen: “Oh, ich habe in dieser Situation einen Gabelstapler gesehen; ein Team wird erscheinen und Reparaturen durchführen.” Wirklich nicht.
In der Praxis haben wir festgestellt, dass die Tatsache, dass diese Modelle Machine-Learning-Wettbewerbe gewinnen, trügerisch ist, weil Faktoren in solchen Situationen zu ihren Gunsten wirken. Erstens sind reale Datensätze sehr komplex, was sich von Machine-Learning-Wettbewerben unterscheidet, bei denen Sie bestenfalls kleine Datensätze haben, die nur einen Bruchteil der Komplexität realer Einsatzszenarien repräsentieren. Zweitens, um einen Machine-Learning-Wettbewerb mit Modellen wie Gradient Boosted Trees zu gewinnen, ist ein umfangreiches Feature Engineering erforderlich. Da diese Modelle verherrlichte Musterabgleiche sind, müssen Sie die richtigen Features einbringen, sodass allein die Auswahl der Variablen das Modell hervorragend funktionieren lässt. Es muss eine hohe Dosis menschlicher Intelligenz in die Datenaufbereitung einfließen, damit es funktioniert. Dies ist ein großes Problem, denn in der realen Welt, wenn Sie versuchen, ein Problem für echte supply chain zu lösen, sind die Ingenieursstunden, die Sie dafür aufbringen können, begrenzt. Man kann nicht sechs Monate an einem winzigen, zeitlich begrenzten, Spielzeugproblem-Aspekt seiner supply chain arbeiten.
Das dritte Problem ist, dass sich Datensätze in supply chains ständig ändern. Es ändert sich nicht nur die Datenlage, sondern auch das Problem verändert sich allmählich. Dies verschärft die Probleme, die mit Feature Engineering einhergehen. Im Grunde bleiben uns Modelle, die Machine-Learning- und Forecasting-Wettbewerbe gewinnen, aber wenn wir einen Blick ein Jahrzehnt in die Zukunft werfen, sehen wir, dass diese Modelle nicht die Zukunft des Machine Learning sind; sie gehören der Vergangenheit an.

Deep Learning war die Antwort auf diese oberflächlichen Musterabgleiche. Deep Learning wird oft als der Nachkomme der künstlichen neuronalen Netzwerke präsentiert, doch die Realität ist, dass Deep Learning erst an dem Tag richtig durchstartete, als die Forscher beschlossen, biologische Metaphern aufzugeben und sich stattdessen auf mechanisches Einfühlungsvermögen zu konzentrieren. Nochmals, mechanisches Einfühlungsvermögen – also gut mit der vorhandenen Computerhardware zusammenzuarbeiten – ist entscheidend. Das Problem bei künstlichen neuronalen Netzwerken war, dass wir versuchten, die Biologie nachzuahmen, aber die Computer, die uns zur Verfügung stehen, unterscheiden sich völlig von den biologischen Substraten, die unser Gehirn unterstützen. Diese Situation erinnert an die frühen Luftfahrt-geschichtlichen Entwicklungen, bei denen zahlreiche Erfinder versuchten, Flugmaschinen zu bauen, indem sie Vögel imitierten. Heutzutage haben wir Fluggeräte, die um ein Vielfaches schneller fliegen als die schnellsten Vögel, jedoch hat die Art und Weise, wie diese Maschinen fliegen, fast nichts mit dem Fliegen von Vögeln gemeinsam.
Der erste Erkenntnisgewinn im Deep Learning war das Bedürfnis nach etwas Tiefem und Ausdrucksstarkem, das in der Lage ist, jede beliebige Transformation der Eingabedaten anzuwenden, sodass ein intelligentes, prädiktives Verhalten aus dem Modell entstehen kann. Gleichzeitig musste es aber auch gut mit der vorhandenen Computerhardware harmonieren. Die Idee war, dass wenn wir komplexe Modelle hätten, die sehr gut mit der Hardware zusammenarbeiten, wir höchstwahrscheinlich Funktionen erlernen könnten, die – bei sonst gleichen Bedingungen – um mehrere Größenordnungen komplexer sind als jede Methode, die nicht über denselben Grad an mechanischem Einfühlungsvermögen verfügt.
Differenzierbares Programmieren, das in der vorherigen Vorlesung vorgestellt wurde, kann als Basisschicht des Deep Learning betrachtet werden. Ich werde in dieser Vorlesung nicht auf differentielles Programmieren zurückkommen, aber ich lade das Publikum ein, sich die vorherige Vorlesung anzusehen, falls Sie diese noch nicht gesehen haben. Sie sollten in der Lage sein, das Folgende zu verstehen, auch wenn Sie die vorherige Vorlesung nicht gesehen haben. Die vorige Vorlesung sollte einige der kniffligen Details des Lernprozesses selbst klären. Zusammenfassend ist differentielles Programmieren nur ein Weg, wenn wir eine spezifische Modellform wählen, die optimalen Werte für die Parameter zu identifizieren, die in diesem Modell existieren.
Während differentielles Programmieren sich darauf konzentriert, die besten Parameter zu identifizieren, liegt der Fokus des Machine Learning darauf, die überlegenen Modellformen zu finden, die die höchste Kapazität besitzen, aus Daten zu lernen.

Also, wie erstellen wir eine Vorlage für eine beliebig komplexe Funktion, die jede beliebig komplexe Transformation der Eingabedaten widerspiegeln kann? Beginnen wir mit einem Schaltkreis aus Fließkommazahlen. Warum Fließkommazahlen? Nun, es liegt daran, dass es die Art von Zahlen sind, bei denen wir den Gradientenabstieg anwenden können, der, wie wir in der vorherigen Vorlesung gesehen haben, sehr skalierbar ist. Also bleiben wir bei Fließkommazahlen. Wir werden eine Sequenz von Fließkommazahlen haben, was Fließkommazahlen als Eingabe und Fließkommazahlen als Ausgabe bedeutet.
Nun, was tun wir in der Mitte? Lassen Sie uns lineare Algebra einsetzen – genauer gesagt, Matrizenmultiplikation. Warum? Die Antwort darauf, warum Matrizenmultiplikation, wurde in der allerersten Vorlesung dieses vierten Kapitels gegeben. Es hängt mit der Art und Weise zusammen, wie moderne Computer konstruiert sind; im Wesentlichen ist es möglich, einen relativ dramatischen Geschwindigkeitszuwachs in Bezug auf die Verarbeitungsleistung zu erzielen, wenn man sich ausschließlich auf lineare Algebra stützt. Also, lineare Algebra it is. Wenn ich nun meine Eingaben nehme und eine lineare Transformation anwende – was einfach eine Matrizenmultiplikation mit einer Matrix namens W ist (diese Matrix enthält die Parameter, die wir später lernen wollen) – wie können wir das komplexer gestalten? Wir können eine zweite Matrizenmultiplikation hinzufügen. Wenn Sie sich jedoch an Ihre Kurse in linearer Algebra erinnern, erhalten Sie, wenn Sie eine lineare Funktion mit einer anderen linearen Funktion multiplizieren, wiederum eine lineare Funktion. Wenn wir also einfach die Matrizenmultiplikation hintereinander schalten, erhalten wir immer noch eine lineare Funktion.
Was wir tun werden, ist, Nichtlinearitäten zwischen die linearen Operationen einzufügen. Genau das habe ich auf diesem Bildschirm gemacht. Ich habe eine Funktion eingefügt, die in der Deep-Learning-Literatur typischerweise als Rectified Linear Unit (ReLU) bekannt ist. Dieser Name, der im Vergleich zu dem, was sie tut, fantastischerweise kompliziert klingt, ist nur eine sehr einfache Funktion, die besagt: Wenn ich eine Zahl nehme und diese Zahl positiv ist, gebe ich exakt dieselbe Zahl zurück (also handelt es sich um eine Identitätsfunktion), aber wenn die Zahl negativ ist, gebe ich 0 zurück. Man kann sie auch als das Maximum aus dem Wert und Null schreiben. Dies ist eine sehr triviale Nichtlinearität.
Wir könnten wesentlich ausgefeiltere nichtlineare Funktionen verwenden. Historisch gesehen, als man neuronale Netzwerke entwickelte, wollte man ausgeklügelte Sigmoidfunktionen verwenden, weil man annahm, dass dies der Arbeitsweise unserer Neuronen entsprach. Aber die Realität ist: Warum sollten wir Rechenleistung verschwenden, um Dinge zu berechnen, die irrelevant sind? Die zentrale Erkenntnis ist, dass wir etwas Nichtlineares einführen müssen, und es ist eigentlich egal, welche nichtlineare Funktion wir nutzen. Das Einzige, was zählt, ist, dass sie sehr schnell ist. Wir wollen das Ganze so schnell wie möglich halten.
Was ich hier aufbaue, nennt sich dichte Schichten. Eine dichte Schicht ist im Wesentlichen eine Matrixmultiplikation mit einer Nichtlinearität (der Rectified Linear Unit). Wir können sie stapeln. Auf dem Bildschirm siehst du ein Netzwerk, das typischerweise als Multi-Layer Perceptron bezeichnet wird, und wir haben drei Schichten. Man könnte sie weiter stapeln, und man könnte 20 oder 2.000 davon haben; es spielt wirklich keine Rolle. Die Realität ist, so simpel es auch erscheinen mag: Wenn du ein solches Netzwerk mit nur ein paar Schichten nimmst und es in dein differenzierbares Programmierframework eingibst, das dir die Parameter liefert, wird das differenzierbare Programmieren als Basisschicht in der Lage sein, die Parameter zu trainieren, die anfänglich zufällig gewählt wurden. Wenn du es initialisieren möchtest, initialisiere einfach alle Parameter zufällig. Du wirst ziemlich gute Ergebnisse für eine sehr große Vielfalt von Problemen erzielen.
Das ist sehr interessant, denn an diesem Punkt hast du nahezu alle grundlegenden Zutaten des Deep Learnings. Also, an das Publikum: Glückwunsch! Du kannst wahrscheinlich schon „Deep Learning Specialist“ in deinen Lebenslauf aufnehmen, denn das ist fast alles, was dazu gehört. Nun, nicht ganz, aber sagen wir, es ist ein guter Ausgangspunkt.

Die Realität ist, dass Deep Learning abgesehen von Tensoralgebra, die im Grunde computerisierte lineare Algebra darstellt, sehr wenig Theorie beinhaltet. Aber Deep Learning umfasst jede Menge Tricks. Zum Beispiel müssen wir die Eingaben normalisieren und die Gradienten stabilisieren. Wenn wir beginnen, viele derartige Operationen zu stapeln, können die Gradienten exponentiell anwachsen, wenn wir im Netzwerk rückwärtsgehen, und irgendwann wird die Kapazität, diese Zahlen darzustellen, überfordert. Wir haben reale Computer, und sie können nicht beliebig große Zahlen darstellen. Irgendwann sprengst du einfach die Kapazität, die Zahl mit einem 32-Bit- oder 16-Bit-Gleitkommawert darzustellen. Es gibt jede Menge Tricks zur Stabilisierung der Gradienten. Zum Beispiel ist der Trick typischerweise die Batch-Normalisierung, aber es gibt auch andere Methoden dafür.
Wenn deine Eingaben eine geometrische Struktur haben, beispielsweise eindimensional wie eine Zeitreihe (historische Verkaufszahlen, wie wir im supply chain sehen), die auch zweidimensional (als Bild zu verstehen), dreidimensional (wie ein Film) oder vierdimensional sein können, etc., dann gibt es spezielle Schichten, die diese geometrische Struktur erfassen können. Die bekanntesten davon werden wahrscheinlich als convolutional layers bezeichnet.
Dann gibt es auch Techniken und Tricks, um mit kategorialen Eingaben umzugehen. Im Deep Learning sind all deine Eingaben Gleitkommawerte, also wie geht man mit kategorialen Variablen um? Die Antwort lautet: embeddings. Du hast sogenannte Stellvertreter-Verluste, die alternative Verlustfunktionen sind, welche sehr steile Gradienten aufweisen und den Konvergenzprozess erleichtern, wodurch letztlich verstärkt wird, was du aus den Daten lernen kannst. Es gibt jede Menge Tricks, und all diese Tricks können typischerweise in das Programm eingebaut werden, das du zusammenstellst, da wir differenzierbares Programmieren als Basisschicht einsetzen.
Deep Learning dreht sich im Grunde darum, wie wir ein Programm zusammensetzen, das, sobald es den Trainingsprozess des differenzierbaren Programmierens durchlaufen hat, über eine sehr hohe Lernkapazität verfügt. Die meisten der Punkte, die ich gerade auf dem Bildschirm aufgelistet habe, haben auch einen programmatischen Charakter, was sehr praktisch ist, da uns differenzierbares Programmieren als Programmierparadigma all dies unterstützt.
An diesem Punkt sollte klarer werden, warum Deep Learning sich vom klassischen Machine Learning unterscheidet. Deep Learning dreht sich nicht um Modelle. Tatsächlich beinhalten die meisten Open-Source Deep Learning-Bibliotheken nicht einmal irgendwelche Modelle. Beim Deep Learning zählen tatsächlich die Modellarchitekturen, die man sich als Vorlagen vorstellen kann, die stark angepasst werden müssen, wenn man eine spezifische Situation abbilden will. Wenn du jedoch eine passende Architektur wählst, kannst du erwarten, dass deine Anpassung dennoch das Wesentliche der Lernkapazität deines Modells bewahrt. Beim Deep Learning verlagern wir das Interesse vom finalen Modell, das relativ uninteressant wird, hin zur Architektur, die zum eigentlichen Forschungsgegenstand wird.
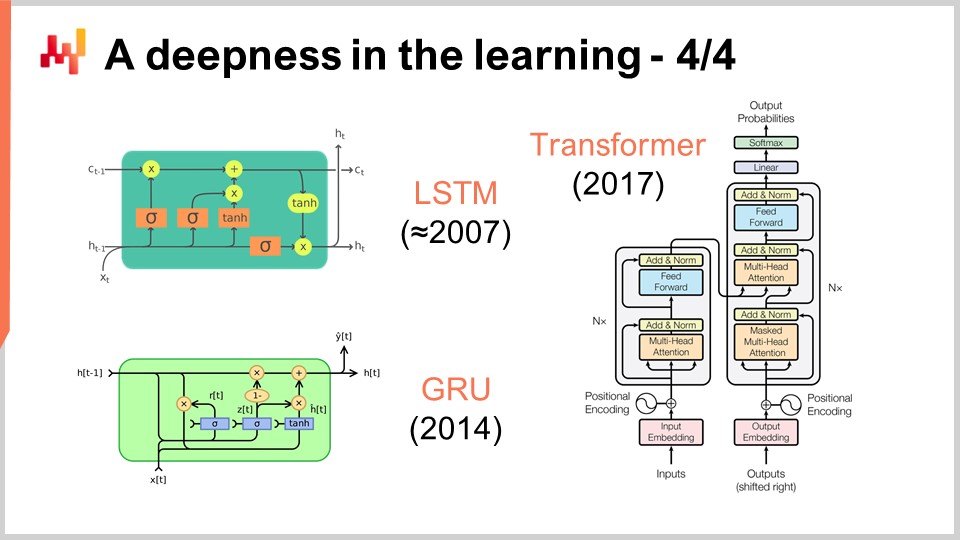
Auf dem Bildschirm siehst du eine Reihe bemerkenswerter Architekturbeispiele. Zunächst LSTM, was für Long Short-Term Memory steht, begann um 2007 zu arbeiten. Die Publikationsgeschichte von LSTM ist etwas komplizierter, aber im Grunde nahm es um 2007 Deep-Learning-Stil seinen Anfang. Es wurde von Gated Recurrent Units (GRU) abgelöst, die im Wesentlichen dasselbe wie LSTM sind, nur einfacher und eleganter. Im Grunde genommen rührt ein Großteil der LSTM-Komplexität von den biologischen Metaphern her. Es stellte sich heraus, dass man die biologischen Metaphern weglassen kann und man erhält etwas Einfacheres, das im Wesentlichen genauso funktioniert. Das sind die Gated Recurrent Units (GRU). Später kamen Transformers, die im Grunde sowohl LSTM als auch GRU obsolet machten. Transformers waren ein Durchbruch, da sie viel schneller, sparsamer in Bezug auf benötigte Rechenressourcen waren und eine noch höhere Lernkapazität besaßen.
Die meisten dieser Architekturen kommen mit Metaphern. LSTM verfügt über eine kognitive Metapher – das Long Short-Term Memory –, während Transformers mit einer Informationsabruf-Metapher daherkommen. Diese Metaphern haben jedoch sehr wenig prädiktive Kraft und könnten tatsächlich eher eine Quelle der Verwirrung und Ablenkung sein, was diese Architekturen wirklich zum Funktionieren bringt, was zu diesem Zeitpunkt noch nicht vollständig verstanden wird.
Transformers sind von großem Interesse für die supply chain, weil sie eine der vielseitigsten Architekturen darstellen. Heutzutage werden sie nahezu überall eingesetzt, vom autonomen Fahren über automatisierte Übersetzungen bis hin zu vielen anderen schwierigen Problemen. Das zeugt von der Macht, die richtige Architektur zu wählen, die dann verwendet werden kann, um eine enorme Vielfalt von Problemen zu bewältigen. Was die supply chain betrifft, so ist eine der größten Herausforderungen bei jedem Machine-Learning-Vorhaben, dass wir es mit einer so unglaublichen Vielfalt an Problemen zu tun haben. Wir können es uns nicht leisten, ein Team zu haben, das fünf Jahre an Forschungsarbeit für jedes einzelne Teilproblem investiert. Wir brauchen etwas, mit dem wir schnell vorankommen und nicht bei jedem neuen Problem die Hälfte des Machine Learnings neu erfinden müssen.
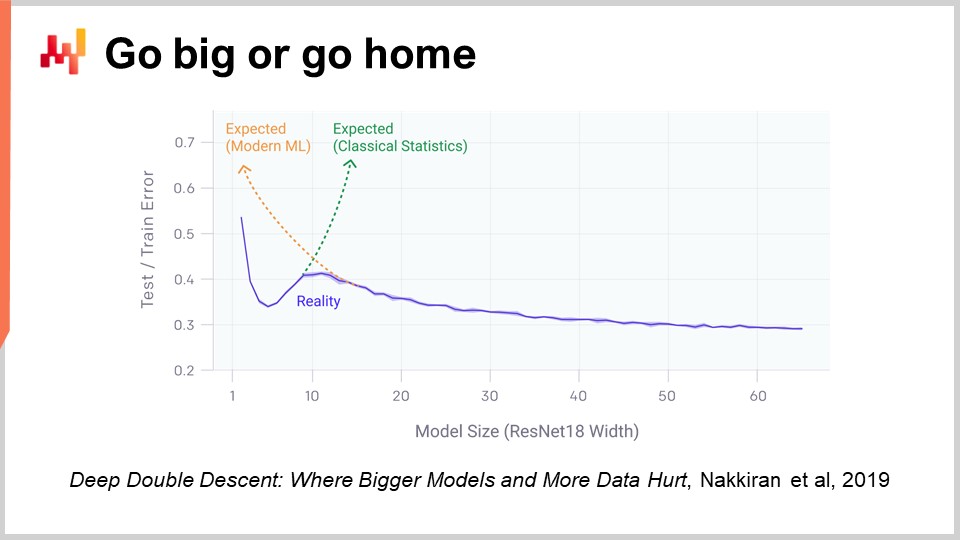
Ein Aspekt des Deep Learnings, der wirklich schockierend ist, wenn man darüber nachdenkt, ist die enorme Anzahl von Parametern. In dem Multi-Layer Perceptron, das ich vor ein paar Minuten vorgestellt habe und das dichte Schichten mit Matrixmultiplikationen beinhaltet, können sich in diesen Matrizen sehr viele Parameter befinden. Tatsächlich ist es nicht sehr schwierig, genauso viele Parameter zu haben wie Datenpunkte oder Beobachtungen in unseren Trainingsdatensätzen. Wie wir zu Beginn unserer Vorlesung gesehen haben, sollte ein Modell mit so vielen Parametern dramatisch unter Overfitting leiden.
Die Realität beim Deep Learning ist sogar noch rätselhafter. Es gibt viele Situationen, in denen wir weitaus mehr Parameter haben als Beobachtungen, und dennoch erleben wir keine dramatischen Overfitting-Probleme. Noch erstaunlicher ist, dass Deep-Learning-Modelle dazu neigen, den Trainingsdatensatz vollständig anzupassen, sodass du praktisch einen Fehler von Null auf deinem Trainingsdatensatz hast, und sie trotzdem ihre Vorhersagekraft für Daten beibehalten, die wir nicht besitzen.
Vor zwei Jahren hat das Deep Double Descent-Paper, veröffentlicht von OpenAI, ein sehr interessantes Licht auf diese Situation geworfen. Das Team zeigte, dass wir im Grunde ein „uncanny valley“ im Bereich des Machine Learnings haben. Die Idee ist, dass, wenn du ein Modell mit nur wenigen Parametern hast, ein hoher Bias entsteht und die Qualität deiner Ergebnisse bei ungesehenen Daten nicht gut ist. Dies entspricht der klassischen Machine-Learning-Vorstellung sowie der klassischen statistischen Sichtweise. Wenn du die Anzahl der Parameter erhöhst, verbesserst du zwar die Qualität deines Modells, aber ab einem gewissen Punkt wirst du beginnen zu overfitten. Genau das haben wir in der früheren Diskussion über Underfitting und Overfitting gesehen. Es gilt, ein Gleichgewicht zu finden.
Allerdings haben sie gezeigt, dass, wenn du die Anzahl der Parameter weiter erhöhst, etwas sehr Seltsames geschieht: Du wirst immer weniger overfitten, was genau das Gegenteil von dem ist, was die klassische Theorie des statistischen Lernens vorhersagen würde. Dieses Verhalten ist nicht zufällig. Die Autoren zeigten, dass dieses Verhalten sehr robust und weit verbreitet auftritt. Es passiert so ziemlich immer in einer großen Vielfalt von Situationen. Es ist noch nicht gut verstanden, warum das so ist, aber was derzeit sehr gut verstanden wird, ist, dass das Deep Double Descent Phänomen sehr real und weit verbreitet ist.
Das hilft auch zu verstehen, warum Deep Learning relativ spät zur Machine-Learning-Party kam. Damit Deep Learning erfolgreich sein konnte, mussten wir zunächst Modelle entwickeln, die Zehntausende oder sogar Hunderttausende von Parametern verarbeiten konnten, um dieses „uncanny valley“ zu überwinden. In den 80er und 90er Jahren wäre es schlichtweg nicht möglich gewesen, einen Deep-Learning-Durchbruch zu erzielen, weil die Hardware-Ressourcen nicht in der Lage waren, über dieses „uncanny valley“ hinwegzuspringen.
Glücklicherweise ist es mit der heutigen Computerhardware möglich, Modelle ohne großen Aufwand zu trainieren, die Millionen oder sogar Milliarden von Parametern besitzen. Wie wir in den vorherigen Vorlesungen festgestellt haben, gibt es mittlerweile Unternehmen wie Facebook, die Modelle mit über einer Billion Parametern trainieren. Also, wir können sehr weit gehen.

Bisher haben wir angenommen, dass die Verlustfunktion bekannt ist. Aber warum sollte das so sein? Betrachten wir einmal die Situation eines Fashion Stores aus supply chain-Perspektive. Ein Fashion Store hat Lagerbestände für jede einzelne SKU, und wir möchten die zukünftige Nachfrage prognostizieren. Wir wollen ein mögliches Szenario erstellen, das für die zukünftige Nachfrage dieses einen Stores glaubhaft ist. Was passieren wird, ist, dass, wenn bestimmte SKUs ausverkauft sind, wir Kannibalisierung und Substitution beobachten sollten. Sobald eine bestimmte SKU einen stockout erreicht, sollte die Nachfrage normalerweise teilweise auf ähnliche Produkte zurückfallen.
Aber wenn wir versuchen, einen solchen Ansatz mit klassischen Prognosemetriken wie Mean Absolute Percentage Error (MAPE), Mean Absolute Error (MAE), Mean Square Error (MSE) oder anderen Metriken, die SKU für SKU, Tag für Tag oder Woche für Woche agieren, anzugehen, werden wir keines dieser Verhaltensweisen erfassen. Was wir wirklich wollen, ist eine Metrik, die erfasst, ob wir sehr gut darin sind, all diese Kannibalisierungs- und Substitutionseffekte abzubilden. Aber wie sollte diese Verlustfunktion aussehen? Das ist sehr unklar und scheint ein recht ausgeklügeltes Verhalten zu erfordern. Einer der entscheidenden Durchbrüche im Deep Learning war letztlich die Erkenntnis, dass die Verlustfunktion gelernt werden sollte. So wurde genau das Bild auf dem Bildschirm erzeugt. Dies ist ein vollständig maschinell erzeugtes Bild; keine dieser Personen ist echt. Sie wurden generiert, und das Problem war: Wie baut man eine Verlustfunktion oder Metrik, die dir sagt, ob ein Bild ein gutes, fotorealistisches Porträt eines Menschen ist oder nicht?
Die Realität ist, dass, wenn du in Begriffen von Mean Absolute Percentage Error (MAPE) denkst, du letztlich mit einer Metrik landest, die Pixel für Pixel operiert. Das Problem ist, dass eine Metrik, die Pixel für Pixel arbeitet, dir nichts darüber verrät, ob das Bild als Ganzes wie ein menschliches Gesicht aussieht. Dasselbe Problem haben wir im Fashion Store bei SKUs und der Nachfrageprognose. Es ist sehr einfach, eine Metrik auf SKU-Ebene zu haben, aber das liefert keine Aussage über das große Ganze des Stores. Doch aus supply chain-Perspektive sind wir nicht an der Genauigkeit auf SKU-Ebene interessiert; wir interessieren uns für die Genauigkeit auf Store-Ebene. Wir wollen wissen, ob die Lagerbestände in ihrer Gesamtheit gut sind, und nicht, ob sie für eine einzelne SKU und dann für die nächste SKU gut sind. Wie hat also die Deep-Learning-Community dieses Problem angegangen?
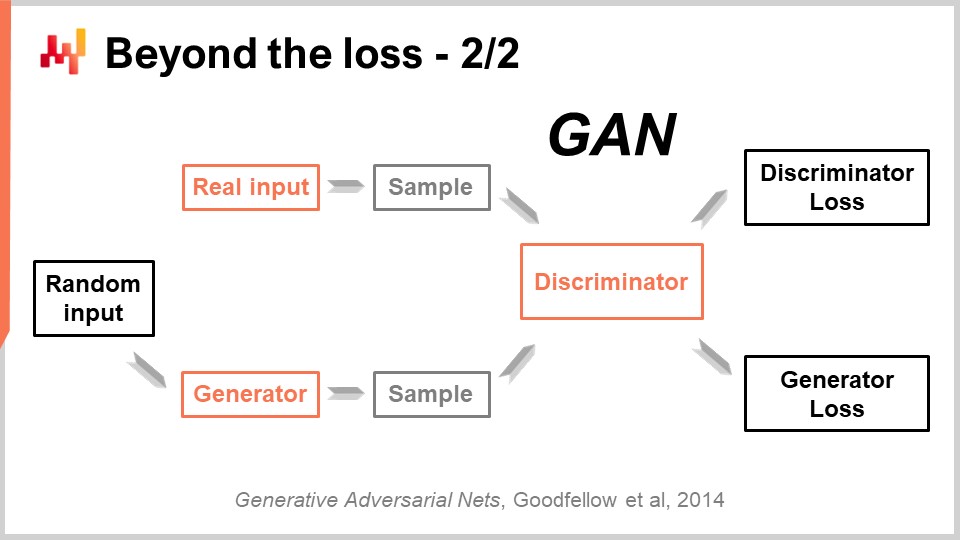
Dieser beeindruckende Erfolg wurde mit einer wunderschön einfachen Technik erzielt, die als Generative Adversarial Networks (GANs) bezeichnet wird. In den Medien hast du vielleicht schon von diesen Techniken als Deepfakes gehört. Deepfakes sind Bilder, die mit dieser GAN-Technik erzeugt wurden. Wie funktioniert das?
Nun, so funktioniert es: Zuerst startest du mit einem Generator. Der Generator nimmt ein wenig Rauschen als Eingabe – das sind einfach zufällige Werte – und wird in diesem Fall ein Bild erzeugen. Wenn wir zurück zum supply chain-Fall gehen, würde er Trajektorien für alle beobachteten Nachfragepunkte für jede einzelne SKU für, sagen wir, die nächsten drei Monate in diesem Fashion Store erzeugen. Dieser Generator ist selbst ein Deep-Learning-Netzwerk.
Jetzt setzen wir einen Discriminator ein. Ein Discriminator ist ebenfalls ein Deep-Learning-Netzwerk, und das Ziel des Discriminators ist es zu lernen, ob vorhersagen kann, ob das, was gerade erzeugt wurde, echt oder synthetisch ist. Der Discriminator ist ein binärer Klassifikator, der lediglich sagen muss, ob es echt ist oder nicht. Wenn der Discriminator in der Lage ist, korrekt vorherzusagen, dass ein Sample gefälscht ist – also synthetisch – leiten wir die Gradienten zurück zum Generator und lassen den Generator daraus lernen.
Was bei diesem Setup passiert, ist, dass der Generator lernt, Muster zu erzeugen, die den Diskriminator tatsächlich täuschen und verwirren. Gleichzeitig lernt der Diskriminator, immer besser zwischen den echten Mustern und den synthetischen zu unterscheiden. Nimmt man diesen Prozess, konvergiert er hoffentlich zu einem Zustand, in dem man sowohl einen sehr hochwertigen Generator, der Muster erzeugt, die unglaublich realistisch sind, als auch einen sehr guten Diskriminator hat, der feststellen kann, ob etwas echt ist oder nicht. Genau das wird bei GANs durchgeführt, um diese fotorealistischen Bilder zu generieren. Wenn wir auf die supply chain zurückgehen, werden Sie Experten in supply chain-Kreisen finden, die sagen, dass für eine bestimmte Situation die beste Metrik MAPE, oder gewichteter MAPE, oder was auch immer ist. Sie werden mit Rezepten daherkommen, die einem sagen, dass man in bestimmten Situationen diese oder jene Metrik verwenden muss. Die Realität ist, dass Deep Learning zeigt, dass eine Prognosemetrik ein veraltetes Konzept ist. Wenn man eine hochdimensionale Genauigkeit erreichen will, nicht nur punktweise Genauigkeit, muss man die Metrik erlernen. Obwohl ich im Moment vermute, dass es nahezu keine supply chain gibt, die diese Techniken nutzt, werden es zukünftig irgendwann tun. Es wird zur Norm werden, die Prognosemetrik mittels generativer adversarialer Netzwerke oder deren Nachfahren zu erlernen, da dies ein Weg ist, um das feine, hochdimensionale Verhalten zu erfassen, das wirklich von Interesse ist, anstatt nur punktweise Genauigkeit zu haben.

Bisher kam jede einzelne Beobachtung mit einem Label, und das Label war der Output, den wir vorhersagen wollen. Allerdings gibt es Situationen, die nicht als Input-Output-Probleme formuliert werden können. Labels sind einfach nicht verfügbar. Wenn wir ein Beispiel aus der supply chain nehmen wollen, wäre das ein Hypermarkt. In Hypermärkten sind die Lagerbestände nicht perfekt genau. Waren können beschädigt, gestohlen oder abgelaufen sein, und es gibt viele Gründe, warum die electronic records in Ihrem System nicht wirklich widerspiegeln, was im Regal verfügbar ist, so wie es von den Kunden wahrgenommen wird. Inventur ist zu teuer, um eine Echtzeit-Datenquelle für accurate inventory zu sein. Man kann Inventur durchführen, aber man kann nicht jeden Tag den gesamten Hypermarkt abgehen. Am Ende hat man eine große Menge leicht ungenauer Bestände. Es gibt davon tonnenweise, aber man kann nicht wirklich sagen, welche davon genau sind und welche nicht.
Dies ist im Grunde die Art von Situation, in der unüberwachtes Lernen wirklich sinnvoll ist. Wir wollen etwas lernen; wir haben Daten, aber uns fehlen die richtigen Antworten. Wir besitzen diese Labels nicht. Was wir haben, ist schiere Masse an Daten. Unüberwachtes Lernen wurde von der Machine-Learning-Community über Jahrzehnte hinweg als der Heilige Gral betrachtet. Lange Zeit war es die Zukunft, wenngleich eine ferne Zukunft. In letzter Zeit gab es jedoch einige unglaubliche Durchbrüche in diesem Bereich. Einer dieser Durchbrüche wurde beispielsweise von einem Facebook-Team mit einem Paper mit dem Titel “Unsupervised Machine Translation Using Monolingual Corpora Only” erzielt.
Was das Facebook-Team in diesem Paper gemacht hat, war der Aufbau eines Übersetzungssystems, das ausschließlich einen Korpus englischer Texte und einen Korpus französischer Texte verwendete. Diese beiden Korpora haben nichts gemeinsam – es handelt sich nicht einmal um denselben Text. Es ist einfach Text in Englisch und Text in Französisch. Dann, ohne dem System eine tatsächliche Übersetzung vorzugeben, lernten sie ein System, das von Englisch ins Französische übersetzt. Dies ist ein absolut beeindruckendes Ergebnis. Übrigens, die Methode, wie dies erreicht wurde, beruht auf einer Technik, die den zuvor vorgestellten generativen adversarialen Netzwerken unglaublich ähnlich ist. Ähnlich veröffentlichte ein Team bei Google vor zwei Jahren BERT (Bidirectional Encoder Representations from Transformers). BERT ist ein Modell, das in einer weitgehend unüberwachten Weise trainiert wird. Wir sprechen wieder über Text. Bei BERT geschieht dies, indem man enorme Textdatenbanken nimmt und Wörter zufällig maskiert. Anschließend trainiert man das Modell darauf, diese Wörter vorherzusagen, und wiederholt diesen Prozess für das gesamte Korpus. Einige Leute bezeichnen diese Technik als self-supervised, aber was an BERT sehr interessant ist und wo es für die supply chain relevant wird, ist, dass man plötzlich seine Daten dahingehend behandelt, dass man eine Maschine baut, in der man Teile der Daten verbergen kann, und die Maschine dennoch in der Lage ist, die Daten zu vervollständigen.
Der Grund, warum dies für die supply chain von herausragender Bedeutung ist, liegt darin, dass das, was mit BERT im Kontext der natürlichen Sprachverarbeitung gemacht wird, grundsätzlich auf viele andere Bereiche übertragbar ist. Es ist die ultimative „Was-wäre-wenn“-Antwortmaschine. Zum Beispiel: Was wäre, wenn ich noch einen weiteren Laden hätte? Diese „Was-wäre-wenn“-Frage kann beantwortet werden, da man einfach seine Daten modifiziert, den Laden hinzufügt und das gerade erstellte Machine-Learning-Modell abfragt. Was wäre, wenn ich ein zusätzliches Produkt hätte? Was wäre, wenn ich einen zusätzlichen Kunden hätte? Was wäre, wenn ich einen anderen Preis für dieses Produkt ansetze? Und so weiter. Unüberwachtes Lernen ist von zentralem Interesse, weil man beginnt, seine Daten als Ganzes zu betrachten und nicht nur als eine Liste von Paaren. Man erhält letztlich einen Mechanismus, der völlig allgemein ist und Vorhersagen über jeden Aspekt machen kann, der in den Daten in irgendeiner Form vorhanden ist. Das ist sehr mächtig.
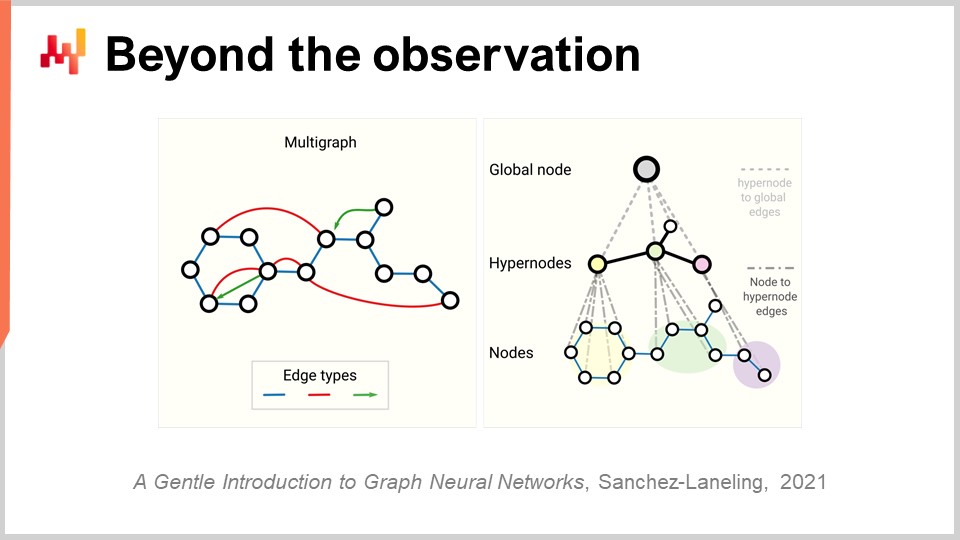
Nun, endlich müssen wir das gesamte Konzept der Beobachtung erneut betrachten. Zunächst sagten wir, dass eine Beobachtung ein Paar aus Merkmalen und einem Label sei. Wir haben gesehen, wie man das Label entfernen kann, aber was ist mit den Merkmalen selbst und der Beobachtung? Das Problem in der supply chain ist, dass wir eigentlich keine Beobachtungen haben. Es ist nicht einmal klar, dass man eine supply chain in eine Liste unabhängiger oder homogener Beobachtungen zerlegen kann. Wie in einer vorherigen Vorlesung erörtert, handelt es sich bei der Beobachtung einer supply chain nicht um eine direkte wissenschaftliche Beobachtung der supply chain selbst. Was wir haben, ist eine Reihe von Unternehmenssoftware-Komponenten, und der einzige Weg, eine supply chain zu beobachten, erfolgt indirekt über die in diesen Komponenten gesammelten Aufzeichnungen. Das kann das ERP sein, das WMS, der Point of Sales usw. Aber das Fazit ist, dass uns im Wesentlichen elektronische Aufzeichnungen zur Verfügung stehen, die transaktionaler Natur sind, da all diese Systeme typischerweise auf transaktionalen Datenbanken implementiert sind. Somit sind die Beobachtungen nicht unabhängig. Die Aufzeichnungen, die wir haben, sind wortwörtlich relational, weil sie in einer relationalen Datenbank gespeichert sind. Wenn ich sage, dass sie Beziehungen haben, meine ich, dass, wenn man einen Kunden mit einer loyalty Karte betrachtet, dieser beispielsweise mit allen Produkten verbunden ist, die er gekauft hat. Jedes einzelne Produkt ist mit all den Geschäften verknüpft, in denen das Produkt Teil des Sortiments ist. Jedes Geschäft ist mit allen Lagern verbunden, die in der Lage sind, das jeweilige Geschäft zu bedienen. Also haben wir keine unabhängigen Beobachtungen; wir haben Daten mit einer Fülle überlagerter relationaler Strukturen, und keines dieser Elemente ist tatsächlich unabhängig von den anderen.
Der relevante Durchbruch im Deep Learning, um mit dieser Art von miteinander verknüpften Daten umzugehen, ist als Graph Learning bekannt. Graph Learning ist genau das, was man braucht, um Verhaltensweisen wie Substitution und Kannibalisierung in der Modebranche anzugehen. Der beste Weg, Kannibalisierung zu verstehen, besteht darin, sich vorzustellen, dass alle Produkte um dieselben Kunden konkurrieren, und durch die Analyse der Daten, die Kunden und Produkte verbinden, kann man Kannibalisierung untersuchen. Achtung: Graph Learning hat nichts mit Graph-Datenbanken zu tun, die etwas völlig Anderes sind. Graph-Datenbanken sind im Wesentlichen lediglich Datenbanken, die zum Abfragen von Graphen verwendet werden, ohne dass dabei Lernen stattfindet. Graph Learning dreht sich darum, zusätzliche Eigenschaften der Graphen selbst zu erlernen. Es geht darum, Beziehungen zu lernen, die nur teilweise oder gar nicht beobachtet werden können, oder die Art der Beziehung, die wir haben, mit einer Schicht umsetzbaren Wissens zu verfeinern.
Meiner Meinung nach, da die supply chain per Design ein System ist, in dem alle Teile miteinander verbunden sind – das ist der Fluch der supply chain, bei dem man nichts lokal optimieren kann, ohne Probleme zu verlagern – wird Graph Learning zunehmend als Ansatz an Bedeutung gewinnen, um diese Probleme in der supply chain und im Machine Learning zu bewältigen. Im Wesentlichen sind Graph Neural Networks Deep-Learning-Techniken, die speziell dafür entwickelt wurden, um mit Graphen umzugehen.
Zusammenfassend ist die Annahme, dass Machine Learning lediglich dazu dient, genauere Prognosen zu liefern, gelinde gesagt ziemlich naiv. Es ist, als würde man sagen, der Hauptzweck eines Automobils bestehe darin, an ein schnelleres Pferd zu gelangen. Ja, es stimmt, dass wir höchstwahrscheinlich durch Machine Learning genauere Prognosen erzielen können. Allerdings ist dies nur ein kleiner Teil eines sehr großen Bildes, das mit den Durchbrüchen in der Machine-Learning-Community ständig größer wird. Wir begannen mit Machine-Learning-Frameworks, die eine Reihe von Konzepten beinhalteten: Feature, Label, Observation, Model und Loss. Dieses kleine, elementare Framework war bereits weitaus allgemeiner als die Sichtweise der Zeitreihenprognose. Mit der jüngsten Entwicklung im Machine Learning stellen wir fest, dass selbst diese Konzepte langsam und allmählich an Relevanz verlieren, weil wir Wege finden, sie zu überwinden. Für die supply chain ist dieser Paradigmenwechsel von entscheidender Bedeutung, da er bedeutet, dass wir denselben Paradigmenwechsel auch bei der Prognose anwenden müssen. Machine Learning zwingt uns, unsere Herangehensweise an Daten und den Umgang mit ihnen völlig neu zu überdenken. Machine Learning öffnet Türen, die bis vor Kurzem noch fest verschlossen waren.

Schauen wir uns nun einige Fragen an.
Question: Nutzen Random Forests nicht Bagging?
Mein Punkt ist, dass sie ja eine Erweiterung davon sind und mehr zu bieten haben als nur Bagging. Bagging ist eine interessante Technik, aber wann immer man eine Machine-Learning-Technik sieht, muss man sich fragen: Wird diese Technik meinen Fortschritt in Bezug auf die Fähigkeit fördern, wirklich schwierige Probleme wie Kannibalisierung oder Substitution zu bewältigen? Und wird diese Technik gut mit der vorhandenen Rechenhardware harmonieren? Das ist eine der wichtigsten Erkenntnisse, die Sie aus dieser Vorlesung mitnehmen sollten.
Question: Mit dem Bestreben der Unternehmen, alles mithilfe von Robotik zu automatisieren, wie sieht die Zukunft der Logistik-Lagerarbeiter aus? Werden sie in naher Zukunft durch Roboter ersetzt werden?
Diese Frage steht nicht direkt im Zusammenhang mit Machine Learning, ist aber eine sehr gute Frage. Fabriken haben sich massiv in Richtung umfangreicher robotization transformiert, wobei diese Transformation Roboter einsetzen kann oder auch nicht. Die Produktivität der Fabriken hat zugenommen, und selbst in China sind Fabriken größtenteils stark automatisiert. Lagerhäuser kamen zu spät zur Party. Was ich heutzutage jedoch sehe, ist die Entwicklung von Lagerhäusern, die zunehmend mechanisch und automatisiert werden. Ich würde nicht sagen, dass es unbedingt Roboter sind; es gibt viele konkurrierende Technologien, um ein Lager so zu gestalten, dass ein höherer Automatisierungsgrad erreicht wird. Das Fazit ist, dass der Trend klar ist. Lagerhäuser und Logistikzentren werden insgesamt dieselbe Art von massiven Produktivitätssteigerungen durchlaufen, die wir bereits in der Produktion erlebt haben.
Um Ihre Frage zu beantworten: Ich behaupte nicht, dass Menschen durch Roboter ersetzt werden; sie werden durch Automatisierung ersetzt. Automatisierung wird manchmal in Form von etwas wie einem Roboter auftreten, kann aber auch viele andere Gestalten annehmen. Einige dieser Formen sind einfach clevere Aufbauten, die die Produktivität enorm verbessern, ohne dass dabei die Technologie zum Einsatz kommt, die wir intuitiv mit Robotern in Verbindung bringen. Allerdings glaube ich, dass der logistische Teil der supply chain insgesamt schrumpfen wird. Das Einzige, was diesen Bereich derzeit wachsen lässt, ist die Tatsache, dass wir mit dem Aufstieg des E-Commerce die sogenannte Last Mile bedienen müssen. Die Last Mile nimmt zunehmend den Großteil der Arbeitskräfte in Anspruch, die sich mit Logistik befassen. Selbst die Last Mile wird in nicht allzu ferner Zukunft automatisiert werden. Autonome Fahrzeuge stehen kurz bevor; sie wurden für dieses Jahrzehnt versprochen und, obwohl sie vielleicht etwas spät eintreffen, kommen sie.
Question: Halten Sie es für sinnvoll, Zeit in das Erlernen von Machine Learning zu investieren, um in der supply chain zu arbeiten?
Absolut. Meiner Meinung nach ist Machine Learning eine Hilfswissenschaft der supply chain. Betrachten Sie die Beziehung, die ein Arzt zur Chemie hat. Wenn Sie ein moderner Arzt sind, erwartet niemand, dass Sie Chemiker sind. Wenn Sie Ihrem Patienten jedoch sagen, dass Sie absolut nichts über Chemie wissen, würden die Leute denken, dass Sie nicht das Zeug dazu haben, ein moderner Arzt zu sein. Man sollte Machine Learning genauso angehen, wie Medizinstudierende die Chemie angehen. Es ist kein Selbstzweck, sondern ein Mittel. Wenn Sie ernsthafte Arbeit in der supply chain leisten möchten, müssen Sie solide Grundlagen in Machine Learning haben.
Question: Können Sie Beispiele nennen, bei denen Sie Machine Learning angewendet haben? Wurde das Tool operational eingesetzt?
Aus meiner Sicht als Joannes Vermorel, Unternehmer und CEO von Lokad, haben wir derzeit über 100 Unternehmen in Produktion, die Machine Learning für vielfältige Aufgaben einsetzen. Diese Aufgaben umfassen die Prognose von lead times, die Erstellung probabilistischer Nachfrageprognosen, die Vorhersage von Retouren, die Prognose von Qualitätsproblemen, die Überarbeitung von Schätzungen zur mittleren Zeit zwischen ungeplanten Reparaturen sowie die Erkennung, ob wettbewerbliche Preise korrekt sind oder nicht. Es gibt viele Anwendungen, wie zum Beispiel die Neubewertung von Kompatibilitätsmatrizen zwischen Autos und Teilen im Aftermarket der Automobilbranche. Mit Machine Learning kann man einen großen Teil von Datenbankfehlern automatisch beheben. Bei Lokad haben wir diese 100 Unternehmen nicht nur in Produktion, sondern das ist schon seit fast einem Jahrzehnt der Fall. Die Zukunft ist bereits da – sie ist nur nicht gleichmäßig verteilt.
Question: Was ist der beste Weg, Machine Learning in der Freizeit zu erlernen? Würden Sie Seiten wie Udemy, Coursera oder etwas anderes empfehlen?
Mein Vorschlag wäre eine Kombination aus Wikipedia und dem Lesen von Fachartikeln. Wie Sie in diesem Vortrag gesehen haben, ist es wichtig, die Grundlagen zu verstehen und stets über die neuesten Entwicklungen im Bereich auf dem Laufenden zu bleiben. Wie Sie in diesen Vorträgen gesehen haben, zitiere ich tatsächlich veröffentlichte Forschungspapiere. Vertrauen Sie nicht auf Informationen aus zweiter Hand; greifen Sie direkt auf das Veröffentlichte zu. All diese Dinge sind direkt online verfügbar. Es gibt im Bereich des Machine Learning Arbeiten, die schlecht geschrieben und unverständlich sind, aber es gibt auch Arbeiten, die brillant verfasst wurden und kristallklare Einblicke in das Geschehen bieten. Mein Vorschlag ist es, Wikipedia für einen Überblick auf hohem Niveau zu nutzen, damit Sie das große Ganze erfassen, und dann mit dem Lesen von Fachartikeln zu beginnen. Anfangs mag es undurchsichtig erscheinen, aber nach einer Weile wird man sich daran gewöhnen. Sie können Udemy oder Coursera nutzen, aber persönlich habe ich das nie gemacht. Mein Ziel bei diesen Vorträgen ist es, Ihnen einige intuitive Einsichten zu vermitteln, damit Sie das große Ganze erfassen. Wenn Sie in die Details einsteigen möchten, lesen Sie einfach das eigentliche Papier, das vor Jahren oder Jahrzehnten veröffentlicht wurde. Greifen Sie auf Informationen aus erster Hand zurück und vertrauen Sie auf Ihre eigene Intelligenz.
Deep Learning ist ein sehr empirisches Forschungsfeld. Das meiste, was in diesem Bereich gemacht wird, ist mathematisch betrachtet nicht extrem komplex. Es geht in der Regel nicht über das hinaus, was man am Ende der High School lernt, sodass es ziemlich zugänglich ist.
Frage: Mit dem Aufkommen von No-Code-Tools wie CodeX und Co-Pilot von OpenAI, sehen Sie, dass supply chain Praktiker irgendwann Modelle in einfachem Englisch erstellen?
Die kurze Antwort lautet: nein, überhaupt nicht. Die Idee, dass man das Programmieren umgehen könnte, gibt es schon lange. Zum Beispiel war Microsofts Visual Basic als ein visuelles Tool gedacht, damit die Menschen nicht mehr programmieren mussten; sie konnten einfach Dinge visuell wie Legosteine zusammensetzen. Aber heutzutage hat sich dieser Ansatz als unwirksam erwiesen, und der nächste Trend ist, Dinge verbal auszudrücken.
Der Grund, warum ich in diesen Vorträgen mathematische Formeln verwende, liegt darin, dass es viele Situationen gibt, in denen die Verwendung einer mathematischen Formel der einzige Weg ist, um klar zu vermitteln, was man sagen möchte. Das Problem mit der englischen Sprache oder jeder natürlichen Sprache ist, dass sie oft ungenau und anfällig für Fehlinterpretationen ist. Im Gegensatz dazu sind mathematische Formeln präzise und eindeutig. Das Problem mit der einfachen Sprache ist, dass sie unglaublich unscharf ist, und obwohl sie ihre Verwendung hat, setzen wir Formeln ein, um dem Gesagten eine eindeutige Bedeutung zu verleihen. Ich versuche, den Einsatz von Formeln zu beschränken, aber wenn ich eine einfüge, dann, weil ich das Gefühl habe, dass es der einzige Weg ist, die Idee klar zu vermitteln – mit einem Maß an Klarheit, das das, was ich verbal ausdrücken kann, übertrifft.
Bezüglich Low-Code-Plattformen bin ich sehr skeptisch, da dieser Ansatz in der Vergangenheit oft versucht wurde, ohne großen Erfolg. Meine persönliche Ansicht ist, dass wir das Programmieren im supply chain Management angemessener gestalten sollten, indem wir identifizieren, warum Programmieren schwer ist, und die unbeabsichtigte Komplexität beseitigen. Was übrig bleibt, ist das richtig umgesetzte Programmieren für die supply chain, was Lokad anstrebt.
Frage: Macht maschinelles Lernen die Bedarfsprognose genauer für saisonale oder regelmäßige Verkaufsdaten?
Wie ich in dieser Präsentation erwähnt habe, macht maschinelles Lernen das Konzept der Genauigkeit obsolet. Wenn Sie sich den letzten groß angelegten Wettbewerb zur Zeitreihenprognose – den M5-Wettbewerb – ansehen, waren die Top-10-Modelle alle bis zu einem gewissen Grad maschinelle Lernmodelle. Also, macht maschinelles Lernen die Prognosen genauer? Faktisch gesehen, basierend auf dem Prognosewettbewerb, ja. Aber es ist nur marginal genauer im Vergleich zu anderen Techniken, und es liefert keinen bahnbrechenden Genauigkeitsvorteil.
Außerdem sollten Sie die Prognose nicht in einer eindimensionalen Perspektive betrachten. Wenn Sie nach der Genauigkeit für Saisonalität fragen, betrachten Sie ein Produkt nach dem anderen, was nicht der richtige Ansatz ist. Wahre Genauigkeit bedeutet, einzuschätzen, wie sich die Markteinführung eines neuen Produkts auf alle anderen Produkte auswirkt, da es in gewissem Maße zu Kannibalisierung kommen wird. Der Schlüssel liegt darin zu bewerten, ob die Art und Weise, wie Sie diese Kannibalisierung in Ihrem Modell abbilden, korrekt ist oder nicht. Plötzlich wird dies zu einem mehrdimensionalen Problem. Wie ich im Vortrag mit generativen Netzwerken gezeigt habe, muss die Metrik dessen, was Genauigkeit tatsächlich bedeutet, erlernt werden; sie kann nicht vorgegeben werden. Mathematische Formeln, wie der mittlere absolute Fehler, der mittlere absolute prozentuale Fehler und der mittlere quadratische Fehler, sind lediglich mathematische Kriterien. Sie sind nicht die Art von Metriken, die wir tatsächlich benötigen; sie sind einfach sehr naive Metriken.
Frage: Wird die alltägliche Arbeit von Prognostikern durch eine automatische Prognose ersetzt werden?
Ich würde sagen, die Zukunft ist bereits da, aber sie ist nicht gleichmäßig verteilt. Bei Lokad prognostizieren wir bereits täglich zig Millionen SKUs, und ich habe niemanden in der Gehaltsliste, der Prognosen anpasst. Also ja, es wird bereits praktiziert, aber das ist nur ein kleiner Teil des Ganzen. Wenn Sie Menschen benötigen, die Prognosen anpassen oder Prognosemodelle abstimmen, weist das auf einen dysfunktionalen Ansatz hin. Sie sollten den Bedarf, Prognosen anzupassen, als einen Fehler betrachten und diesen Teil des Prozesses durch Automatisierung beheben.
Noch einmal, basierend auf Lokads Erfahrung, werden diese Dinge vollständig eliminiert, da wir es bereits umgesetzt haben. Wir sind nicht die Einzigen, die es auf diese Weise tun, sodass es für uns seit fast einem Jahrzehnt fast antike Geschichte ist.
Frage: Wie weit wird maschinelles Lernen aktiv zur Entscheidungsfindung im supply chain eingesetzt?
Das hängt vom Unternehmen ab. Bei Lokad wird es überall eingesetzt, und wenn ich „bei Lokad“ sage, meine ich die Unternehmen, die von Lokad bedient werden. Allerdings nutzt der überwiegende Teil des Marktes im Grunde genommen immer noch Excel, ohne jeglichen Einsatz von maschinellem Lernen. Lokad verwaltet aktiv Inventare im Wert von Milliarden Euro oder Dollar, was bereits Realität ist und das schon seit geraumer Zeit. Aber Lokad macht nicht einmal 0,1 % des Marktes aus, sodass wir weiterhin ein Ausreißer sind. Wir wachsen schnell, ebenso wie einige Konkurrenten. Meine Vermutung ist, dass es im gesamten supply chain Markt immer noch ein Randphänomen ist, aber es verzeichnet ein zweistelliges Wachstum. Unterschätzen Sie niemals die Macht des exponentiellen Wachstums über einen langen Zeitraum. Letztendlich wird es sehr groß, hoffentlich auch mit Lokad, aber das ist eine andere Geschichte.
Frage: Bei vielen Unbekannten im supply chain, was ist eine Strategie, die es ermöglicht, Annahmen als Eingaben für ein Modell zu treffen?
Die Idee ist, dass es zwar jede Menge Unbekannte gibt, die Eingaben für Ihr Modell jedoch nicht frei wählbar sind. Es kommt darauf an, was in Ihren Unternehmenssystemen vorhanden ist, also welche Art von Daten in Ihrem ERP existiert. Wenn Ihr ERP historische Lagerbestände enthält, können Sie diese als Teil Ihres maschinellen Lernmodells verwenden. Falls Ihr ERP nur aktuelle Lagerbestände erfasst, sind diese Daten nicht verfügbar. Sie können beginnen, Momentaufnahmen Ihrer Lagerbestände zu erfassen, wenn Sie diese als zusätzliche Eingaben nutzen möchten, aber die Kernaussage ist, dass es sehr wenig Auswahlmöglichkeiten bei den Eingaben gibt – es ist buchstäblich das, was in Ihren Systemen existiert.
Mein typischer Ansatz ist, dass, wenn Sie neue Datenquellen erschließen müssen, dies schleppend und schmerzhaft verlaufen wird und wahrscheinlich nicht Ihr Ausgangspunkt für den Einsatz von maschinellem Lernen im supply chain ist. Größere Unternehmen sind seit Jahrzehnten digitalisiert, sodass das, was Sie in Ihren Transaktionssystemen, wie Ihrem ERP und WMS haben, bereits einen ausgezeichneten Ausgangspunkt darstellt. Wenn Sie später feststellen, dass Sie mehr benötigen, wie beispielsweise Wettbewerbsanalysen, genehmigte Lagerbestände oder von Ihren Lieferanten angegebene ETAs, werden diese würdige Ergänzungen sein, um sie als Eingaben für Ihre Modelle zu nutzen. In der Regel ist das, was Sie als Eingaben verwenden, etwas, von dem Sie intuitiv wissen, dass es mit dem, was Sie vorhersagen möchten, korreliert, und eine grobe Intuition ist in der Regel ausreichend. Der gesunde Menschenverstand, der schwer zu definieren ist, ist völlig ausreichend. Dies ist nicht der Flaschenhals in Bezug auf das Engineering.
Frage: Welche Auswirkungen haben Preisentscheidungen auf die Abschätzung der zukünftigen Nachfrage, selbst aus einer probabilistischen Perspektive, und wie geht man aus der Sicht des maschinellen Lernens damit um?
Das ist eine sehr gute Frage. Es gab eine Episode auf LokadTV, die genau dieses Problem behandelte. Die Idee ist, dass das, was Sie lernen, zu dem wird, was typischerweise als eine Policy bekannt ist – ein Objekt, das steuert, wie Sie auf verschiedene Ereignisse reagieren. Die Art der Prognose besteht darin, eine Art Landschaft im Monte-Carlo-Stil zu erzeugen. Sie werden eine Trajektorie erstellen, aber Ihre Prognose liefert nicht statische Datenpunkte. Es wird ein viel generativerer Prozess sein, bei dem Sie in jedem Stadium des Prognoseprozesses die Nachfrage generieren müssen, die Sie beobachten können, die Entscheidungen, die Sie treffen, erzeugen und anschließend die Marktreaktion auf das, was Sie gerade getan haben, neu erzeugen.
Es wird sehr kompliziert, die Genauigkeit Ihres Nachfrage-Reaktions erzeugenden Prozesses zu bewerten, und genau deshalb müssen Sie Ihre Prognosemetriken tatsächlich erlernen. Das ist sehr knifflig, aber deshalb können Sie Ihre Prognose- und Genauigkeitsmetriken nicht als ein eindimensionales Problem betrachten. Zusammengefasst wird die Bedarfsprognose zu einem Generator, also ist sie grundlegend dynamisch und nicht statisch. Es ist etwas, das generativ ist. Dieser Generator reagiert auf einen Agenten, einen Agenten, der als Policy implementiert wird. Sowohl der Generator als auch das policy-bildende System müssen erlernt werden. Sie müssen auch die Verlustfunktion erlernen. Es gibt viel zu lernen, aber glücklicherweise ist Deep Learning ein sehr modularer und programmatischer Ansatz, der sich gut für die Zusammensetzung all dieser Techniken eignet.
Frage: Ist es schwierig, Daten zu sammeln, insbesondere von KMU?
Ja, es ist sehr schwierig. Der Grund dafür ist, dass, wenn Sie es mit einem Unternehmen zu tun haben, das weniger als 10 Millionen Umsatz hat, es so gut wie keine IT-Abteilung gibt. Möglicherweise gibt es ein kleines ERP-System, aber selbst wenn die Werkzeuge gut, anständig und modern sind, existiert kein IT-Team. Wenn Sie nach den Daten fragen, gibt es in der Kundenfirma niemanden, der über die Kompetenz verfügt, eine SQL-Abfrage zur Datenextraktion auszuführen.
Ich bin mir nicht sicher, ob ich Ihre Frage richtig verstanden habe, aber das Problem liegt nicht primär im Sammeln der Daten. Das Sammeln der Daten erfolgt natürlich über die Buchhaltungssoftware oder das vorhandene ERP-System, und heutzutage sind ERPs auch für relativ kleine Unternehmen zugänglich. Das Problem ist die Extraktion der Daten aus diesen Unternehmungssoftwaresystemen. Wenn Sie in einem Unternehmen tätig sind, das weniger als 20 Millionen Dollar Umsatz hat und kein E-Commerce-Unternehmen ist, ist die IT-Abteilung höchstwahrscheinlich nicht existent. Selbst wenn es eine winzige IT-Abteilung gibt, ist diese in der Regel nur dafür zuständig, Maschinen und Windows-Desktops für alle einzurichten. Es ist nicht jemand, der sich mit Datenbanken und fortgeschritteneren administrativen IT-Aufgaben auskennt.
Okay, ich denke, das war’s. Die nächste Sitzung findet in ein paar Wochen statt. Es wird am Mittwoch, den 13. Oktober, sein. Bis zum nächsten Mal!
Referenzen
- A theory of the learnable, L. G. Valiant, November 1984
- Support-vector networks, Corinna Cortes, Vladimir Vapnik, September 1995
- Random Forests, Leo Breiman, October 2001
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree, Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu, 2017
- Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, last revised December 2017
- Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, December 2019
- Analyzing and Improving the Image Quality of StyleGAN, Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila, last revised March 2020
- Generative Adversarial Networks, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, June 2014
- Unsupervised Machine Translation Using Monolingual Corpora Only, Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, last revised April 2018
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, last revised May 2019
- A Gentle Introduction to Graph Neural Networks, Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko, September 2021


