00:00 Einführung
02:52 Hintergrund und Haftungsausschluss
07:39 Naiver Rationalismus
13:14 Bisherige Entwicklung
16:37 Wissenschaftler, wir brauchen euch!
18:25 Mensch + Maschine (das Problem 1/4)
23:16 Das Setup (das Problem 2/4)
26:44 Die Wartung (das Problem 3/4)
30:02 Der IT-Backlog (das Problem 4/4)
32:56 Die Mission (die Aufgabe des Wissenschaftlers 1/6)
35:58 Terminologie (die Aufgabe des Wissenschaftlers 2/6)
37:54 Ergebnisse (die Aufgabe des Wissenschaftlers 3/6)
41:11 Der Umfang (die Aufgabe des Wissenschaftlers 4/6)
44:59 Der Tagesablauf (die Aufgabe des Wissenschaftlers 5/6)
46:58 Verantwortung (die Aufgabe des Wissenschaftlers 6/6)
49:25 Eine supply chain Position (HR 1/6)
51:13 Einstellung eines Wissenschaftlers (HR 2/6)
53:58 Schulung des Wissenschaftlers (HR 3/6)
55:43 Bewertung des Wissenschaftlers (HR 4/6)
57:24 Bindung des Wissenschaftlers (HR 5/6)
59:37 Vom einen Wissenschaftler zum nächsten (HR 6/6)
01:01:17 Zum Thema IT (Unternehmensdynamik 1/3)
01:03:50 Zum Thema Finanzen (Unternehmensdynamik 2/3)
01:05:42 Zum Thema Führung (Unternehmensdynamik 3/3)
01:09:18 Altmodische Planung (Modernisierung 1/5)
01:11:56 Ende von S&OP (Modernisierung 2/5)
01:13:31 Altmodisches BI (Modernisierung 3/5)
01:15:24 Abschied von Data Science (Modernisierung 4/5)
01:17:28 Ein neuer Deal für IT (Modernisierung 5/5)
01:19:28 Fazit
01:22:05 7.3 Der Supply Chain Scientist - Fragen?
Beschreibung
Im Kern einer die Quantitative Supply Chain Initiative befindet sich der Supply Chain Scientist (SCS), der die Datenaufbereitung, die ökonomische Modellierung und das KPI-Reporting durchführt. Die intelligente Automatisierung der supply chain decisions ist das Endprodukt der vom SCS geleisteten Arbeit. Der SCS übernimmt die Verantwortung für die generierten Entscheidungen. Der SCS liefert menschliche Intelligenz, verstärkt durch maschinelle Rechenleistung.
Volles Transkript

Willkommen zu dieser Reihe von supply chain Vorlesungen. Ich bin Joannes Vermorel, und heute werde ich den supply chain scientist aus der Perspektive der die Quantitative Supply Chain vorstellen. Der supply chain scientist ist die Person oder möglicherweise eine kleine Gruppe von Personen, die die supply chain Initiative anführen. Diese Person überwacht das Erstellen und anschließende Pflegen der numerischen Rezepte, die die interessanten Entscheidungen generieren. Außerdem obliegt es dieser Person, dem restlichen Unternehmen alle notwendigen Belege zu liefern, die belegen, dass die generierten Entscheidungen fundiert sind.
Das Motto der quantifizierten supply chain ist es, das Beste aus moderner Hardware und moderner Software für supply chains herauszuholen. Allerdings ist der verkörperte Ansatz dieser Perspektive naiv. Menschliche Intelligenz bleibt ein Eckpfeiler des gesamten Unterfangens und kann aus vielfältigen Gründen bisher nicht optimal in Bezug auf supply chains verpackt werden. Ziel dieser Vorlesung ist es zu verstehen, warum und wie die Rolle des supply chain scientist in den letzten zehn Jahren zu einer bewährten Lösung geworden ist, um das Beste aus moderner Software für supply chain Zwecke zu nutzen.
Die Erreichung dieses Ziels beginnt mit dem Verständnis der großen Engpässe, mit denen moderne Software noch konfrontiert ist, wenn versucht wird, supply chain decisions zu automatisieren. Basierend auf diesem neu gewonnenen Verständnis werden wir die Rolle des supply chain scientist einführen, die, um es ganz auszudrücken, eine Antwort auf diese Engpässe darstellt. Schließlich werden wir sehen, wie diese Rolle das Unternehmen insgesamt, in kleinen und größeren Aspekten, neu gestaltet. Tatsächlich kann der supply chain scientist nicht als ein Silo innerhalb des Unternehmens operieren. So wie der Wissenschaftler mit dem Rest des Unternehmens kooperieren muss, um etwas zu erreichen, muss auch der Rest des Unternehmens mit dem Wissenschaftler zusammenarbeiten, damit dies gelingt.

Bevor wir weiter fortfahren, möchte ich einen Haftungsausschluss wiederholen, den ich in der allerersten Vorlesung dieser Reihe gegeben habe. Die vorliegende Vorlesung basiert nahezu vollständig auf einem etwas einzigartigen, jahrzehntelangen Experiment, das bei Lokad durchgeführt wurde, einem Anbieter von enterprise software, der sich auf supply chain optimization spezialisiert hat. All diese Vorlesungen wurden durch die Reise von Lokad geprägt, aber was die Rolle des supply chain scientist betrifft, ist die Verbindung noch stärker. Weitgehend lässt sich die Reise von Lokad selbst durch die Linse unserer schrittweisen Entdeckung der Rolle des supply chain scientist lesen.
Dieser Prozess ist noch im Gange. Zum Beispiel haben wir uns vor etwa fünf Jahren von der Mainstream-Perspektive des Data Scientist verabschiedet, als programming paradigms für Lern- und Optimierungszwecke eingeführt wurden. Lokad beschäftigt derzeit drei Dutzend supply chain scientists. Unsere fähigsten Wissenschaftler haben sich durch ihre Erfolgsbilanzen das Vertrauen für Entscheidungen in großem Maßstab verdient. Einige von ihnen sind individuell verantwortlich für Parameter, die einen Inventarwert von über einer halben Milliarde Dollar übersteigen. Dieses Vertrauen erstreckt sich auf eine Vielzahl von Entscheidungen, wie z. B. Bestellungen, Produktionsaufträge, inventory allocation Aufträge oder Preisgestaltung.
Wie man vermuten könnte, musste dieses Vertrauen erst verdient werden. Tatsächlich würden nur sehr wenige Unternehmen selbst ihren Mitarbeitern solch umfassende Befugnisse anvertrauen, geschweige denn einem Drittanbieter wie Lokad. Dieses Maß an Vertrauen zu gewinnen, ist ein Prozess, der in der Regel Jahre dauert, ungeachtet der technologischen Mittel. Dennoch wächst Lokad ein Jahrzehnt später schneller als in den Anfangsjahren, und ein beträchtlicher Teil dieses Wachstums stammt von unseren Bestandskunden, die den Umfang der an Lokad übertragenen Entscheidungen erweitern.
Das führt mich zurück zu meinem ursprünglichen Punkt: Diese Vorlesung ist fast zwangsläufig mit allerlei Vorurteilen behaftet. Ich habe versucht, diese Perspektive durch ähnliche Erfahrungen außerhalb von Lokad zu erweitern; jedoch gibt es in diesem Bereich nicht viel zu berichten. Soweit ich weiß, gibt es einige Tech-Giganten, genauer gesagt einige riesige E-Commerce-Unternehmen, die einen Automatisierungsgrad bei Entscheidungen erreichen, der mit dem von Lokad vergleichbar ist.
Diese Giganten setzen jedoch in der Regel zwei Größenordnungen mehr Ressourcen ein, als selbst große Unternehmen sich leisten können, mit Hunderten von Ingenieuren. Die Durchführbarkeit dieser Ansätze ist für mich unklar, da sie nur in äußerst profitablen Unternehmen funktionieren könnten. Andernfalls könnten die enormen Lohnkosten leicht die Vorteile einer besseren supply chain Ausführung übersteigen.
Darüber hinaus wird es zu einer eigenen Herausforderung, in solchem Ausmaß Ingenieurtalente anzuziehen. Einen talentierten Softwareingenieur einzustellen, ist bereits schwierig genug; 100 von ihnen einzustellen, erfordert eine durchaus bemerkenswerte Arbeitgebermarke. Glücklicherweise ist die heute vorgestellte Perspektive deutlich schlanker. Viele supply chain Initiativen, die von Lokad durchgeführt werden, erfolgen mit nur einem supply chain scientist, wobei ein zweiter als Vertretung fungiert. Abgesehen von den Einsparungen bei den Lohnkosten zeigt unsere Erfahrung, dass es beträchtliche supply chain Vorteile gibt, die mit einer kleineren Mitarbeiterzahl einhergehen.

Die vorherrschende Perspektive der supply chain basiert auf angewandter Mathematik. Methoden und Algorithmen werden so präsentiert, dass der menschliche Bediener völlig aus der Betrachtung herausgenommen wird. Zum Beispiel werden die safety stock Formel und die economic order quantity Formel als reine Angelegenheit der angewandten Mathematik dargestellt. Die Identität der Person, die diese Formeln anwendet, sowie deren Fähigkeiten oder Hintergrund spielen dabei nicht nur eine unbedeutende Rolle, sondern sind in der Darstellung überhaupt nicht Teil davon.
Generell wird diese Haltung in supply chain Lehrbüchern und folglich auch in supply chain Software weitgehend übernommen. Es erscheint zweifellos objektiver, die menschliche Komponente aus der Darstellung zu entfernen. Schließlich hängt die Gültigkeit eines Theorems nicht von der Person ab, die den Beweis vorträgt, und ebenso spielt die Leistung eines Algorithmus nicht die Rolle, wer letztlich die letzten Tastenanschläge bei seiner Implementierung ausführt. Dieser Ansatz zielt darauf ab, eine überlegene Form der Rationalität zu erreichen.
Ich behaupte jedoch, dass diese Haltung naiv ist und ein weiteres Beispiel für naiven Rationalismus darstellt. Meine These ist subtil, aber wichtig: Ich behaupte nicht, dass das Ergebnis eines numerischen Rezepts von der Person abhängt, die es letztlich ausführt, noch dass der Charakter eines Mathematikers etwas mit der Gültigkeit seiner Theoreme zu tun hat. Vielmehr ist meine These, dass die damit verbundene intellektuelle Haltung ungeeignet ist, supply chains anzugehen.
Ein realweltliches supply chain Rezept ist ein komplexes Handwerkskunststück, und der Autor des Rezepts ist alles andere als neutral oder unwesentlich, wie es scheinen mag. Lassen Sie uns diesen Punkt veranschaulichen, indem wir zwei identische numerische Rezepte betrachten, die sich nur in der Benennung ihrer Variablen unterscheiden. Auf numerischer Ebene liefern beide Rezepte identische Ergebnisse. Das erste Rezept verwendet jedoch wohlgewählte, aussagekräftige Variablennamen, während das zweite Rezept kryptische, inkonsistente Namen aufweist. In der Produktion ist das zweite Rezept (das mit den kryptischen, inkonsistenten Variablennamen) ein Desaster, das förmlich darauf wartet, zu passieren. Jede Änderung oder Fehlerbehebung am zweiten Rezept wird um Größenordnungen mehr Aufwand kosten als dieselbe Aufgabe am ersten Rezept. Tatsächlich sind Probleme bei der Benennung von Variablen so häufig und gravierend, dass vielen Lehrbüchern der Softwaretechnik ein ganzes Kapitel diesem einzelnen Aspekt gewidmet ist.
Weder Mathematik, Algorithmik noch Statistik sagt etwas über die Angemessenheit von Variablennamen aus. Die Angemessenheit dieser Namen liegt offen im Auge des Betrachters. Obwohl wir zwei numerisch identische Rezepte haben, wird eines aus scheinbar subjektiven Gründen als weitaus überlegen angesehen. Die These, die ich hier verteidige, ist, dass in diesen subjektiven Bedenken ebenfalls eine Rationalität zu finden ist. Diese Bedenken sollten keinesfalls von vornherein abgetan werden, nur weil sie von einem Subjekt oder einer Person abhängen. Im Gegenteil, die Erfahrung von Lokad zeigt, dass bei Verwendung derselben Software-Tools, mathematischer Instrumente und Algorithmensammlungen bestimmte supply chain scientists überlegene Ergebnisse erzielen. Tatsächlich ist die Identität des verantwortlichen Wissenschaftlers einer der besten Prädiktoren für den Erfolg der Initiative.
Wenn wir davon ausgehen, dass angeborenes Talent die Unterschiede im Erfolg von supply chains nicht vollständig erklären kann, sollten wir die Elemente annehmen, die zu erfolgreichen Initiativen beitragen – sei es objektiv oder subjektiv. Aus diesem Grund haben wir bei Lokad in den letzten Jahrzehnten viel Arbeit in die Verfeinerung unseres Ansatzes zur Rolle des supply chain scientist gesteckt, welches genau das Thema dieser Vorlesung ist. Die Nuancen, die mit der Position eines supply chain scientist verbunden sind, sollten nicht unterschätzt werden. Das Ausmaß der Verbesserungen, die durch diese subjektiven Elemente erzielt werden, ist vergleichbar mit unseren bemerkenswertesten technologischen Errungenschaften.
Diese Vorlesungsreihe ist als Trainingsmaterial für Lokads supply chain scientists gedacht. Ich hoffe jedoch auch, dass diese Vorlesungen für ein breiteres Publikum von supply chain Praktikern oder sogar supply chain Studenten von Interesse sein könnten. Am besten sieht man sich diese Vorlesungen in der Reihenfolge an, um ein umfassendes Verständnis dafür zu erlangen, womit supply chain scientists sich befassen.
Im ersten Kapitel haben wir gesehen, warum supply chains programmatisch werden müssen und warum es wünschenswert ist, ein numerisches Rezept in Produktion zu setzen. Die ständig zunehmende Komplexität von supply chains macht Automatisierung dringlicher denn je. Darüber hinaus gibt es einen finanziellen Imperativ, supply chain Praktiken kapitalistisch zu gestalten.
Das zweite Kapitel widmet sich den Methodologien. Supply chains sind wettbewerbsfähige Systeme, und diese Kombination entlarvt naive Methoden. Die Rolle der Wissenschaftler kann als Gegenmittel zum naiven Ansatz der angewandten Mathematik gesehen werden.
Das dritte Kapitel gibt einen Überblick über die Probleme, mit denen supply chain Mitarbeiter konfrontiert sind. Dieses Kapitel versucht, die Klassen von Entscheidungsherausforderungen zu charakterisieren, die angegangen werden müssen. Es zeigt, dass vereinfachte Perspektiven, wie die Wahl der richtigen Lagerbestandsmenge für jede SKU, nicht in reale Situationen passen; es gibt stets eine gewisse Tiefe in Form von Entscheidungsfindung.
Das vierte Kapitel beleuchtet die Elemente, die erforderlich sind, um eine moderne Praxis von supply chain zu erfassen, in der Softwarekomponenten allgegenwärtig sind. Diese Elemente sind grundlegend, um den breiteren Kontext zu verstehen, in dem die digitale supply chain operiert.
Die Kapitel 5 und 6 sind jeweils der prädiktiven Modellierung und der Entscheidungsfindung gewidmet. Diese Kapitel behandeln die „smarten“ Bestandteile des numerischen Rezepts und beinhalten machine learning sowie mathematische Optimierung. Bemerkenswerterweise fassen diese Kapitel Techniken zusammen, von denen sich gezeigt hat, dass sie in den Händen von supply chain scientists gut funktionieren.
Schließlich ist das siebte und vorliegende Kapitel der Umsetzung einer Initiative der die Quantitative Supply Chain gewidmet. Wir haben gesehen, was es braucht, um eine Initiative zu starten und dabei die richtigen Grundlagen zu legen. Wir haben gesehen, wie man die Ziellinie überquert und das numerische Rezept in Produktion bringt.

Heute werden wir sehen, welche Art von Person es braucht, um das Ganze zum Laufen zu bringen.
Die Rolle des Supply Chain Scientist zielt darauf ab, Probleme zu lösen, die in der akademischen Literatur zu finden sind. Wir werden den Job des Supply Chain Scientist überprüfen, einschließlich seiner Mission, seines Umfangs, seines Tagesablaufs und der Interessensgebiete. Diese Stellenbeschreibung spiegelt die heutige Praxis bei Lokad wider.
Eine neue Position innerhalb des Unternehmens ruft eine Reihe von Bedenken hervor, weshalb Supply Chain Scientists eingestellt, geschult, beurteilt und gehalten werden müssen. Wir werden diese Bedenken aus der Perspektive der Personalabteilung angehen. Vom Supply Chain Scientist wird erwartet, dass er mit anderen Abteilungen des Unternehmens jenseits seiner supply chain-Abteilung kooperiert. Wir werden sehen, welche Art von Interaktionen zwischen dem Supply Chain Scientist und IT, Finanzen und sogar der Unternehmensführung erwartet werden.
Der Supply Chain Scientist stellt auch eine Chance für das Unternehmen dar, seine Mitarbeiter und Abläufe zu modernisieren. Diese Modernisierung ist der schwierigste Teil der Reise, da es weitaus herausfordernder ist, eine Position zu entfernen, die nicht mehr relevant ist, als eine neue einzuführen.
Die Herausforderung, die wir uns in dieser Vorlesungsreihe gestellt haben, besteht in der systematischen Verbesserung von supply chains durch quantitative Methoden. Die Grundidee dieses Ansatzes besteht darin, das Beste aus dem modernen Rechnen und der Software herauszuholen, was supply chains zu bieten haben. Allerdings müssen wir klären, was noch in den Bereich menschlicher Intelligenz fällt und was erfolgreich automatisiert werden kann.
Die Grenze zwischen menschlicher Intelligenz und Automatisierung hängt nach wie vor stark von der Technologie ab. Überlegene Technologie soll ein breiteres Spektrum von Entscheidungen mechanisieren und bessere Ergebnisse liefern. Aus der supply chain-Perspektive bedeutet dies, vielfältigere Entscheidungen zu treffen, wie Preisentscheidungen zusätzlich zu Inventar-auffüllungsentscheidungen und bessere Entscheidungen zu treffen, die die Rentabilität des Unternehmens weiter verbessern.
Die Rolle des Supply Chain Scientist verkörpert diese Grenze zwischen menschlicher Intelligenz und Automatisierung. Während routinemäßige Ankündigungen über künstliche Intelligenz den Eindruck erwecken können, dass menschliche Intelligenz kurz davor steht, vollständig automatisiert zu werden, zeigt mein Verständnis des aktuellen Standes der Technik, dass allgemeine künstliche Intelligenz noch in weiter Ferne liegt. In der Tat werden menschliche Einsichten immer noch dringend benötigt, wenn es um die Gestaltung quantitativer Methoden von supply chain-Relevanz geht. Selbst die Etablierung einer grundlegenden supply chain-Strategie bleibt weitgehend jenseits dessen, was Software zu leisten vermag.
Allgemeiner gesagt verfügen wir noch nicht über Technologien, die in der Lage sind, schlecht definierte oder unerkannte Probleme anzugehen, wie sie in supply chains üblich sind. Sobald jedoch ein eng umrissenes, klar spezifiziertes Problem isoliert wurde, ist es denkbar, dass ein automatisierter Prozess dessen Lösung erlernt und diese sogar mit wenig oder keiner menschlichen Überwachung automatisiert.
Diese Perspektive ist nicht neu. So sind beispielsweise Anti-Spam-Filter weit verbreitet. Diese Filter bewältigen eine herausfordernde Aufgabe: Sie trennen das Relevante vom Irrelevanten. Dennoch wird das Design der nächsten Generation von Filtern weitgehend den Menschen überlassen, auch wenn neuere Daten zur Aktualisierung dieser Filter genutzt werden können. In der Tat erfinden Spammer, die Anti-Spam-Filter umgehen wollen, immer wieder neue Methoden, die einfache, datengesteuerte Aktualisierungen dieser Filter überlisten.
Daher, während menschliche Einsichten nach wie vor erforderlich sind, um die Automatisierung zu konzipieren, ist nicht klar, warum ein Softwareanbieter wie Lokad beispielsweise nicht eine grandiose supply chain-Engine entwickeln könnte, die all diese Herausforderungen bewältigt. Zweifellos sprechen die wirtschaftlichen Rahmenbedingungen der Softwareentwicklung sehr dafür, eine solch grandiose supply chain-Engine zu erstellen. Selbst wenn die Anfangsinvestition hoch ist, da Software zu vernachlässigbaren Kosten vervielfältigt werden kann, wird der Anbieter ein Vermögen an Lizenzgebühren verdienen, indem er diese grandiose Engine an eine Vielzahl von Unternehmen weiterverkauft.
Lokad startete bereits im Jahr 2008 eine Reise zur Entwicklung einer grandiosen Engine, die als ein verpacktes Softwareprodukt eingesetzt werden hätte können. Genauer gesagt, konzentrierte sich Lokad damals auf eine grandiose Forecasting-Engine anstelle einer grandiosen supply chain-Engine. Dennoch scheiterte Lokad an der Entwicklung einer solchen grandiosen Forecasting-Engine, obwohl Forecasting nur einen kleinen Teil der globalen supply chain-Herausforderung ausmacht. Die Quantitative Supply Chain-Perspektive, die in dieser Vorlesungsreihe vorgestellt wird, entstand aus den Trümmern dieser Ambition einer grandiosen Engine.
Bezüglich der supply chain stellte sich heraus, dass es drei große Flaschenhälse gibt, die angegangen werden müssen. Wir werden sehen, warum diese grandiose Engine von Anfang an zum Scheitern verurteilt war und warum wir höchstwahrscheinlich noch Jahrzehnte von einer derartigen ingenieurtechnischen Meisterleistung entfernt sind.
Die applikative Landschaft der typischen supply chain ist ein Dschungel, der sich in den letzten zwei oder drei Jahrzehnten wahllos entwickelt hat. Diese Landschaft ist kein französischer formaler Garten mit ordentlichen geometrischen Linien und gepflegten Sträuchern; es ist ein Dschungel, der sowohl lebendig als auch voller Dornen und feindlicher Fauna ist. Ernsthaft betrachtet sind supply chains das Produkt ihrer digitalen Geschichte. Es könnte mehrere semi-redundante ERPs, halbfertige hausgemachte Anpassungen, Batch-Integrationen – besonders mit Systemen, die von übernommenen Unternehmen stammen – und sich überschneidende Softwareplattformen geben, die um dieselben Funktionsbereiche konkurrieren.
Die Vorstellung, dass irgendeine grandiose Engine einfach angeschlossen werden könnte, ist angesichts des aktuellen Stands der Softwaretechnologien illusionär. Alle Systeme, die die supply chain betreiben, zusammenzuführen, ist ein beträchtliches Unterfangen, das vollständig von menschlichen Ingenieursleistungen abhängt.
Die Analyse der Gesamtausgaben zeigt, dass das Datenaufbereiten mindestens drei Viertel des gesamten technischen Aufwands einer supply chain-Initiative ausmacht. Im Gegensatz dazu entfallen auf die Ausarbeitung der intelligenten Aspekte des numerischen Rezepts, wie Forecasting und Optimierung, nicht mehr als ein paar Prozent des Gesamtaufwands. Folglich ist die Verfügbarkeit einer verpackten, grandiosen Engine weitgehend unerheblich in Bezug auf Kosten oder Verzögerungen. Es würde eine eingebaute, menschliche Intelligenz erfordern, damit sich diese Engine automatisch in die oft willkürliche IT-Landschaft integrieren kann, die in supply chains üblicherweise vorzufinden ist.
Zudem macht jede grandiose Engine dieses Vorhaben durch ihre bloße Existenz noch herausfordernder. Anstatt es mit einem komplexen System, der applikativen Landschaft, zu tun, haben wir nun zwei komplexe Systeme: die applikative Landschaft und die grandiose Engine. Die Komplexität der Integration dieser beiden Systeme ist nicht die Summe ihrer jeweiligen Komplexitäten, sondern vielmehr das Produkt dieser Komplexitäten.
Der Einfluss dieser Komplexität auf die Ingenieurskosten ist hochgradig nicht-linear, wie bereits im ersten Kapitel dieser Vorlesungsreihe dargelegt wurde. Der erste große Engpass für die supply chain-Optimierung ist die Einrichtung des numerischen Rezepts, die einen spezialisierten Ingenieursaufwand erfordert. Dieser Engpass schließt weitgehend die Vorteile aus, die man sich von irgendeiner Art verpackter grandioser supply chain-Engine erhoffen könnte.

Obwohl die Einrichtung einen beträchtlichen Ingenieursaufwand erfordert, könnte es sich um eine einmalige Investition handeln, vergleichbar mit dem Kauf eines Eintrittstickets. Leider sind supply chains lebende Gebilde, die sich ständig weiterentwickeln. Der Tag, an dem sich eine supply chain nicht mehr ändert, ist der Tag, an dem das Unternehmen bankrottgeht. Veränderungen erfolgen sowohl intern als auch extern.
Intern verändert sich die applikative Landschaft ständig. Unternehmen können ihre applikative Landschaft nicht einfrieren, selbst wenn sie es wollten, da viele Upgrades von den Anbietern von Unternehmenssoftware vorgeschrieben werden. Das Ignorieren dieser Vorgaben würde die Anbieter von ihren vertraglichen Verpflichtungen entbinden, was ein inakzeptables Ergebnis wäre. Über rein technische Aktualisierungen hinaus ist jede bedeutende supply chain dazu gezwungen, Softwarekomponenten einzuführen und wieder aus dem Betrieb zu nehmen, während sich das Unternehmen selbst verändert.
Auch extern verändern sich Märkte stetig. Ständig tauchen neue Wettbewerber, Vertriebskanäle und potenzielle Lieferanten auf, während andere verschwinden. Vorschriften ändern sich fortlaufend. Während Algorithmen einige der einfachen Veränderungen, wie etwa das Nachfragewachstum für eine Produktklasse, automatisch erfassen können, verfügen wir noch nicht über Algorithmen, die Veränderungen im Markt hinsichtlich ihrer Art und nicht nur ihres Ausmaßes bewältigen können. Die Probleme, die die supply chain-Optimierung zu lösen versucht, verändern sich nämlich ständig.
Wenn die Software, die für die Optimierung der supply chain verantwortlich ist, es nicht schafft, mit diesen Veränderungen umzugehen, greifen die Mitarbeitenden auf Tabellenkalkulationen zurück. Tabellenkalkulationen mögen primitiv sein, aber immerhin können die Mitarbeitenden sie an die jeweilige Aufgabe anpassen. Anekdotisch betrachtet operiert die überwiegende Mehrheit der supply chains auf Entscheidungsebene immer noch über Tabellenkalkulationen und nicht auf Transaktionsebene. Dies ist der lebende Beweis dafür, dass die Softwarewartung gescheitert ist.
Seit den 1980er Jahren liefern Anbieter von Unternehmenssoftware Softwareprodukte, um supply chain-Entscheidungen zu automatisieren. Die meisten Unternehmen, die umfangreiche supply chains betreiben, haben in den letzten Jahrzehnten bereits mehrere dieser Lösungen implementiert. Dennoch greifen die Mitarbeitenden in der Regel wieder auf ihre Tabellenkalkulationen zurück, was beweist, dass, selbst wenn die Einrichtung ursprünglich als Erfolg gewertet wurde, etwas bei der Wartung schiefgelaufen ist.
Die Wartung ist der zweite große Engpass der supply chain-Optimierung. Das Rezept bedarf einer aktiven Wartung, auch wenn die Ausführung weitgehend unbeaufsichtigt erfolgen kann.

An diesem Punkt haben wir gezeigt, dass die supply chain-Optimierung nicht nur anfängliche Softwareentwicklungsressourcen, sondern auch fortlaufende Softwareentwicklungsressourcen erfordert. Wie bereits in dieser Vorlesungsreihe hervorgehoben, kann sich realistisch betrachtet nur ein programmatischer Ansatz der Vielfalt der Probleme von realen supply chains nähern. Tabellenkalkulationen zählen durchaus als programmierbare Werkzeuge, und ihre Ausdrucksstärke, im Gegensatz zu Buttons und Menüs, macht sie für supply chain-Praktiker so attraktiv.
Da in den meisten Unternehmen Softwareentwicklungsressourcen gesichert werden müssen, erscheint es naheliegend, auf die IT-Abteilung zurückzugreifen. Leider ist die supply chain nicht die einzige Abteilung, die in dieser Denkrichtung agiert. Jede einzelne Abteilung, einschließlich Vertrieb, Marketing und Finanzen, stellt fest, dass die Automatisierung ihrer jeweiligen Entscheidungsprozesse Softwareentwicklungsressourcen erfordert. Darüber hinaus müssen sie sich auch mit der Transaktionsebene und all ihrer zugrunde liegenden Infrastruktur auseinandersetzen.
Infolgedessen haben die IT-Abteilungen der meisten Unternehmen, die heute umfangreiche supply chains betreiben, einen jahrelangen Rückstand an Aufgaben. Somit verschlimmert sich der Rückstand nur noch, wenn von der IT-Abteilung erwartet wird, weitere fortlaufende Ressourcen für die supply chain bereitzustellen. Die Option, der IT-Abteilung mehr Ressourcen zuzuweisen, wurde bereits geprüft, und sie ist in der Regel nicht mehr realisierbar. Diese Unternehmen sehen sich bereits mit erheblichen Skalennachteilen in Bezug auf die IT-Abteilung konfrontiert. Der IT-Rückstand stellt den dritten großen Engpass der supply chain-Optimierung dar.
Fortlaufende Ingenieurressourcen werden benötigt, aber der Großteil dieser Ressourcen kann nicht von der IT stammen. Einige Unterstützungen seitens der IT sind zwar denkbar, jedoch muss dies etwas Unaufdringliches sein.
Diese drei großen Engpässe erläutern, warum eine spezifische Rolle benötigt wird: Der Supply Chain Scientist ist der Name, den wir für jene fortlaufenden Softwareentwicklungsressourcen verwenden, die nötig sind, um die alltäglichen und anspruchsvollen Entscheidungsprozesse der supply chain zu automatisieren.

Gehen wir nun mit einer präziseren Definition auf Basis der Lokad-Praxis vor. Die Mission des Supply Chain Scientist besteht darin, numerische Rezepte zu erstellen, die die alltäglichen, notwendigen Entscheidungen zur Steuerung der supply chain generieren. Die Arbeit des Supply Chain Scientist beginnt mit den aus der applikativen Landschaft gesammelten Datenbankauszügen. Vom Supply Chain Scientist wird erwartet, dass er das Rezept programmiert, das diese Datenbankauszüge verarbeitet und in Produktion bringt. Der Supply Chain Scientist übernimmt die volle Verantwortung für die Qualität der durch das Rezept generierten Entscheidungen. Diese Entscheidungen werden nicht von irgendeinem ambienten System erzeugt; sie sind der direkte Ausdruck der Einsichten des Supply Chain Scientist, die in einem Rezept festgehalten sind.
Dieser einzelne Aspekt ist eine entscheidende Abweichung von dem, was üblicherweise als die Rolle eines Data Scientist verstanden wird. Die Mission hört jedoch hier nicht auf. Vom Supply Chain Scientist wird erwartet, dass er in der Lage ist, für jede einzelne vom Rezept generierte Entscheidung Belege vorzulegen. Es ist nicht irgendein undurchsichtiges System, das für die Entscheidungen verantwortlich ist; es ist die Person, der Supply Chain Scientist. Dieser sollte in der Lage sein, sich mit dem Leiter der supply chain oder sogar dem CEO zu treffen und eine überzeugende Begründung für jede Entscheidung zu liefern, die durch das Rezept generiert wurde.
Wenn der Supply Chain Scientist nicht in der Lage ist, potenziell großen Schaden im Unternehmen anzurichten, dann stimmt etwas nicht. Ich befürworte nicht, jemandem – und schon gar nicht dem Supply Chain Scientist – große Befugnisse ohne Aufsicht oder Verantwortung zu übertragen. Ich möchte lediglich das Offensichtliche hervorheben: Wenn du nicht die Macht hast, dein Unternehmen negativ zu beeinflussen, egal wie schlecht du arbeitest, hast du auch nicht die Macht, es positiv zu beeinflussen, egal wie gut du arbeitest.
Große Unternehmen sind leider von Natur aus risikoscheu. Daher ist es sehr verlockend, den Supply Chain Scientist durch einen Analysten zu ersetzen. Im Gegensatz zum Supply Chain Scientist, der für die Entscheidungen selbst verantwortlich ist, ist der Analyst lediglich dafür zuständig, hier und da etwas Licht ins Dunkel zu bringen. Der Analyst ist größtenteils harmlos und kann nicht viel weiter tun, als seine eigene Zeit und einige Rechnerressourcen zu verschwenden. Harmlos zu sein, ist jedoch nicht das, worum es bei der Rolle des Supply Chain Scientist geht.

Lassen Sie uns kurz über den Begriff “supply chain scientist” sprechen. Diese Terminologie ist leider unvollkommen. Ich habe diesen Ausdruck ursprünglich vor etwa einem Jahrzehnt als Variante von “data scientist” geprägt, mit der Idee, diese Rolle als eine Variante des Data Scientist zu brandmarken, jedoch mit einer starken supply chain-Spezialisierung. Die Erkenntnis über die Spezialisierung war korrekt, diejenige über Data Science jedoch nicht. Ich werde diesen Punkt am Ende der Vorlesung noch einmal aufgreifen.
Ein “supply chain Ingenieur” wäre vielleicht eine bessere Formulierung gewesen, da sie den Wunsch unterstreicht, den Bereich zu beherrschen und zu kontrollieren, im Gegensatz zu reinem Verständnis. Allerdings wird von Ingenieuren, wie sie gemeinhin verstanden werden, nicht erwartet, dass sie an vorderster Front agieren. Der richtige Begriff wäre wahrscheinlich supply chain quant gewesen, im Sinne von Praktikern der die Quantitative Supply Chain.
Im Finanzwesen ist ein quant oder quantitative Trader ein Spezialist, der Algorithmen und quantitative Methoden einsetzt, um Handelsentscheidungen zu treffen. Quants können eine Bank enorm profitabel machen oder umgekehrt, extrem unrentabel. Menschliche Intelligenz wird durch Maschinen vergrößert, sowohl das Gute als auch das Schlechte.
Jedenfalls liegt es an der Gemeinschaft, die richtige Terminologie zu bestimmen: analyst, scientist, engineer, operative oder quant. Der Konsistenz halber werde ich im weiteren Verlauf dieser Vorlesung weiterhin den Begriff scientist verwenden.

Das primäre Lieferobjekt für den scientist ist ein Softwareprogramm, genauer gesagt, das numerische Rezept, das für die Generierung der täglichen supply chain Entscheidungen von Interesse verantwortlich ist. Dieses Rezept ist eine Sammlung all der Skripte, die von den frühesten Phasen der Datenaufbereitung bis zu den finalen Phasen der unternehmensinternen Validierung der Entscheidungen involviert sind. Dieses Rezept muss produktionsreif sein, das heißt, es muss unbeaufsichtigt laufen können und die von ihm generierten Entscheidungen werden standardmäßig vertraut. Natürlich musste dieses Vertrauen zunächst erworben werden, und eine fortlaufende Überwachung muss sicherstellen, dass dieses Vertrauensniveau über die Zeit hinweg gerechtfertigt bleibt.
Die Bereitstellung eines produktionsreifen Rezepts ist grundlegend, um die supply chain Praxis in ein produktives Asset zu verwandeln. Dieser Aspekt wurde bereits in der vorherigen Vorlesung über produktorientierte Auslieferung erörtert.
Über dieses Rezept hinaus gibt es zahlreiche sekundäre Lieferobjekte. Einige davon sind ebenfalls Software, auch wenn sie nicht direkt zur Generierung der Entscheidungen beitragen. Dies umfasst beispielsweise alle Instrumentierungen, die der scientist einführen muss, um das Rezept zu erstellen und später zu pflegen. Einige andere Komponenten sind für Kollegen innerhalb des Unternehmens bestimmt, einschließlich aller Dokumentationen der Initiative selbst und des Rezepts.
Der Quellcode des Rezepts beantwortet das “Wie” – wie wird es gemacht? Der Quellcode beantwortet jedoch nicht das “Warum” – warum wird es gemacht? Das “Warum” muss dokumentiert werden. Häufig beruht die Korrektheit des Rezepts auf einem feinsinnigen Verständnis der Intention. Die gelieferte Dokumentation muss den reibungslosen Übergang von einem scientist zum nächsten so weit wie möglich erleichtern, selbst wenn der vorherige scientist nicht zur Verfügung steht, um den Prozess zu unterstützen.
Bei Lokad besteht unser Standardverfahren darin, ein umfassendes Buch über die Initiative zu erstellen und zu pflegen, das als Joint Procedure Manual (JPM) bezeichnet wird. Dieses Handbuch ist nicht nur ein vollständiges Betriebshandbuch des Rezepts, sondern auch eine Sammlung aller strategischen Erkenntnisse, die den von den scientists getroffenen Modellierungsentscheidungen zugrunde liegen.
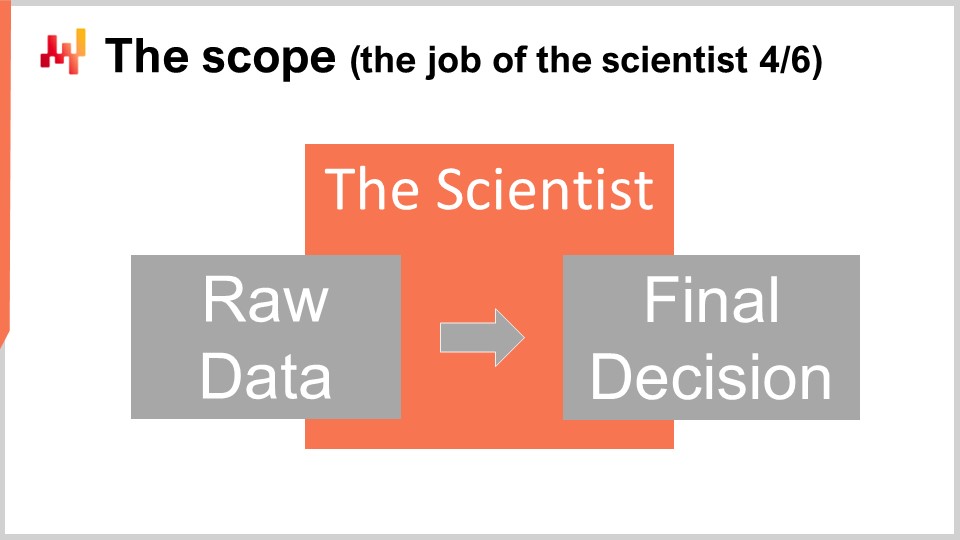
Auf technischer Ebene beginnt die Arbeit des scientist mit der Extraktion der Rohdaten und endet mit der Generierung der finalen supply chain Entscheidungen. Der scientist muss mit den Rohdaten arbeiten, wie sie aus den bestehenden Geschäftssystemen extrahiert wurden. Da jedes Geschäftssystem seinen eigenen technologischen Stack haben kann, ist die Extraktion in der Regel am besten IT-Spezialisten vorbehalten. Es ist nicht vernünftig zu erwarten, dass der scientist sich in ein halbes Dutzend SQL-Dialekten oder API-Technologien einarbeitet, nur um Zugang zu den Geschäftsdaten zu erhalten. Andererseits sollte von IT-Spezialisten nichts anderes erwartet werden als rohe Datenauszüge, weder Datenumwandlung noch Datenaufbereitung. Die dem scientist zugänglich gemachten extrahierten Daten müssen so nah wie möglich an den Daten bleiben, wie sie in den Geschäftssystemen vorliegen.
Am anderen Ende der Pipeline muss das vom scientist erstellte Rezept die finalen Entscheidungen generieren. Die Elemente, die mit der Umsetzung der Entscheidungen verbunden sind, fallen nicht in den Zuständigkeitsbereich des scientist. Sie sind zwar wichtig, aber weitgehend unabhängig von der Entscheidung selbst. Zum Beispiel gehört bei Bestellungen die Festlegung der endgültigen Mengen in den Aufgabenbereich des scientist, jedoch nicht das Erstellen der PDF-Datei – das vom Lieferanten erwartete Bestelldokument. Trotz dieser Grenzen ist der Aufgabenbereich ziemlich umfangreich. Daher ist es verlockend, aber falsch, den Umfang in eine Reihe von Unterbereichen zu fragmentieren. In größeren Unternehmen wird diese Versuchung sehr stark und muss widerstanden werden. Die Fragmentierung des Umfangs ist der sicherste Weg, um zahlreiche Probleme zu verursachen.
Im vorgelagerten Bereich, wenn jemand versucht, den scientists durch Aufbereitung der Eingabedaten zu helfen, endet dieser Versuch unweigerlich in “Garbage In, Garbage Out”-Problemen. Geschäftssysteme sind ohnehin komplex genug; die vorzeitige Transformation der Daten fügt nur eine zusätzliche unfreiwillige Komplexitätsebene hinzu. Im mittleren Bereich, wenn jemand versucht, den scientists zu helfen, indem er sich um einen herausfordernden Teil des Rezepts, wie etwa die Prognose, kümmert, stehen die scientists schließlich vor einer Black-Box inmitten ihres eigenen Rezepts. Eine solche Black-Box untergräbt die White-Box-Bemühungen der scientists. Und im nachgelagerten Bereich, wenn jemand versucht, dem scientist durch eine weitere Re-Optimierung der Entscheidungen zu helfen, führt dieser Versuch unweigerlich zu Verwirrung, und die zweischichtigen Optimierungslogiken können sogar gegeneinander arbeiten.
Dies impliziert nicht, dass der scientist alleine arbeiten muss. Ein Team von scientists kann gebildet werden, aber der Umfang bleibt bestehen. Wird ein Team gebildet, muss es eine kollektive Verantwortung für das Rezept geben. Das bedeutet zum Beispiel, dass, wenn ein Fehler im Rezept festgestellt wird, jedes Teammitglied in der Lage sein sollte, einzuspringen und ihn zu beheben.

Die Erfahrung von Lokad zeigt, dass ein gesundes Verhältnis für einen Supply Chain Scientist darin besteht, 40% ihrer Zeit mit Codierung, 30% mit dem Dialog mit dem Rest des Unternehmens und 30% mit dem Verfassen von Dokumenten, Schulungsmaterialien und dem Austausch mit anderen supply chain Praktikern oder anderen Supply Chain Scientists zu verbringen.
Die Codierung ist offensichtlich notwendig, um das Rezept selbst umzusetzen. Sobald das Rezept jedoch in Produktion ist, richten sich die meisten Codierungsbemühungen nicht auf das Rezept selbst, sondern auf seine Instrumentierung. Um das Rezept zu verbessern, benötigt der scientist weitere Erkenntnisse, und diese Erkenntnisse erfordern wiederum eine eigene Instrumentierung, die implementiert werden muss.
Der Dialog mit dem Rest des Unternehmens ist grundlegend. Anders als bei S&OP besteht der Zweck dieser Gespräche nicht darin, die Prognose nach oben oder unten zu lenken. Es geht darum sicherzustellen, dass die im Rezept verankerten Modellierungsentscheidungen weiterhin getreu die Unternehmensstrategie sowie alle operativen Einschränkungen widerspiegeln.
Schließlich ist es entscheidend, das institutionelle Wissen, das das Unternehmen über supply chain Optimierung besitzt, entweder durch direkte Schulung der scientists selbst oder durch die Erstellung von Dokumenten für Kollegen zu fördern. Die Leistung des Rezepts spiegelt weitgehend die Kompetenz des scientist wider. Der Zugang zu Kollegen und das Einholen von Feedback sind wenig überraschend eines der effizientesten Mittel, um die Kompetenz der scientists zu verbessern.

Der größte Unterschied zwischen einem supply chain scientist, wie er von Lokad konzipiert wurde, und einem herkömmlichen Data Scientist besteht im persönlichen Engagement für realweltliche Ergebnisse. Es mag wie eine kleine, unbedeutende Sache erscheinen, doch die Erfahrung lehrt etwas anderes. Vor einem Jahrzehnt musste Lokad auf die harte Tour lernen, dass das Engagement für die Lieferung eines produktionsreifen Rezepts keine Selbstverständlichkeit ist. Im Gegenteil, die Grundeinstellung von als Data Scientist ausgebildeten Personen scheint darin zu bestehen, die Produktion als sekundär zu betrachten. Der herkömmliche Data Scientist erwartet, sich um die cleveren Teile, wie maschinelles Lernen und mathematische Optimierung, zu kümmern, während die Bewältigung all der zufälligen Kleinigkeiten, die mit der realen supply chain einhergehen, allzu häufig als unter ihrer Würde angesehen wird.
Das Engagement für ein produktionsreifes Rezept bedeutet jedoch, sich mit den zufälligsten Dingen auseinandersetzen zu müssen. Beispielsweise erlitten im Juli 2021 viele europäische Länder katastrophale Überschwemmungen. Ein in Deutschland ansässiger Kunde von Lokad hatte die Hälfte seiner warehouses überflutet. Der für diesen Account verantwortliche supply chain scientist musste das Rezept nahezu über Nacht neu konzipieren, um das Beste aus dieser stark verschlechterten Situation herauszuholen. Die Lösung war kein grandioser Machine-Learning-Algorithmus, sondern vielmehr eine Reihe entschlüsselter Heuristiken. Umgekehrt, wenn der supply chain scientist die Entscheidung nicht besitzt, wird diese Person nicht in der Lage sein, ein produktionsreifes Rezept zu entwickeln. Es ist eine Frage der Psychologie. Die Bereitstellung eines produktionsreifen Rezepts erfordert enormen intellektuellen Einsatz, und die Herausforderungen müssen real sein, um das notwendige Maß an Fokus bei einem Mitarbeiter zu erreichen.
Nachdem die Aufgabe eines supply chain scientist geklärt wurde, lassen Sie uns erörtern, wie das aus der Perspektive der Personalabteilung funktioniert. Zunächst muss der scientist, was unternehmenspolitisch von Bedeutung ist, dem Leiter der supply chain oder zumindest einer Person, die als leitende supply chain Führungskraft qualifiziert ist, unterstellt sein. Es spielt keine Rolle, ob der scientist intern oder extern ist, wie es bei Lokad häufig der Fall ist. Entscheidend ist, dass der scientist unter der direkten Aufsicht einer Person steht, die die Befugnisse eines supply chain Executives innehat.
Ein häufiger Fehler besteht darin, den scientist dem IT-Leiter oder dem Leiter der Data Analytics zu unterstellen. Da das Erstellen eines Rezepts eine Codierungsaufgabe ist, fühlt sich die supply chain Führung möglicherweise nicht vollständig wohl dabei, ein solches Unterfangen zu beaufsichtigen. Dies ist jedoch falsch. Der scientist benötigt die Aufsicht durch jemanden, der genehmigen kann, ob die generierten Entscheidungen akzeptabel sind oder nicht, oder der zumindest diese Genehmigung veranlassen kann. Den scientist irgendwo anders als unter der direkten Aufsicht der supply chain Führung zu platzieren, ist ein Rezept dafür, endlos über Prototypen zu operieren, die niemals in die Produktion übergehen. In diesem Fall wandelt sich die Rolle unweigerlich in die eines Analysten, und die ursprünglichen Ambitionen der die Quantitative Supply Chain Initiative werden aufgegeben.

Die allerbesten supply chain scientists erzielen überdurchschnittliche Renditen im Vergleich zu durchschnittlichen. Dies war Lokads Erfahrung und spiegelt ein Muster wider, das vor Jahrzehnten in der Softwareindustrie identifiziert wurde. Softwareunternehmen haben lange beobachtet, dass die allerbesten Software-Ingenieure mindestens das Zehnfache der Produktivität durchschnittlicher Ingenieure aufweisen, und mittelmäßige Ingenieure können sogar eine negative Produktivität haben, wodurch die Software bei jeder für den Code aufgewendeten Stunde schlechter wird.
Im Falle der supply chain scientists verbessert überlegene Kompetenz nicht nur die Produktivität, sondern vor allem auch das Endergebnis der supply chain performance. Bei Verwendung derselben Software-Tools und mathematischen Instrumente erzielen zwei scientists nicht das gleiche Ergebnis. Daher ist es von größter Bedeutung, jemanden einzustellen, der das Potenzial hat, einer der besten scientists zu werden.
Die Erfahrung von Lokad, basierend auf der Einstellung von über 50 scientists, zeigt, dass unspezialisierte Ingenieurprofile in der Regel durchaus gut sind. So kontraintuitiv es erscheinen mag, sind Personen mit formaler Ausbildung in Data Science, Statistik oder Informatik typischerweise nicht die beste Wahl für Positionen als supply chain scientist. Diese Personen verkomplizieren das Rezept allzu häufig übermäßig und schenken den alltäglichen, aber kritischen Aspekten der supply chain nicht annähernd genug Aufmerksamkeit. Die Fähigkeit, auf eine Vielzahl von Details zu achten, und die Fähigkeit, endlos auszuharren, während man randständige numerische Artefakte verfolgt, scheinen die führenden Eigenschaften der besten scientists zu sein.
Anekdotisch lässt sich berichten, dass Lokad gute Erfahrungen mit jungen Ingenieuren gemacht hat, die einige Jahre als Wirtschaftsprüfer tätig waren. Zusätzlich zur Vertrautheit mit der Unternehmensfinanzierung scheint es, dass talentierte Wirtschaftsprüfer die Fähigkeit entwickeln, sich durch einen Ozean von Unternehmensunterlagen zu kämpfen, was mit der täglichen Realität eines supply chain scientist übereinstimmt.

Auch wenn die Einstellung sicherstellt, dass die Neueinstellungen das richtige Potenzial besitzen, ist der nächste Schritt, sicherzustellen, dass sie angemessen geschult werden. Die Standardhaltung von Lokad ist, dass nicht erwartet wird, dass die Personen bereits vorab etwas über supply chain wissen. Vorwissen über supply chain ist ein Plus, aber die akademische Ausbildung lässt in dieser Hinsicht oft zu wünschen übrig. Die meisten Studiengänge im Bereich supply chain konzentrieren sich auf Management und Führung, aber für junge Absolventen ist es unerlässlich, ein solides Grundwissen in Themen zu haben, wie sie in den zweiten, dritten oder vierten Kapiteln dieser Vorlesungsreihe behandelt werden. Leider ist dies oft nicht der Fall, und die quantitativen Teile dieser Studiengänge können enttäuschend sein. Infolgedessen müssen supply chain scientists von ihren Arbeitgebern geschult werden. Diese Vorlesungsreihe spiegelt die Art von Schulungsmaterialien wider, die bei Lokad verwendet werden.

Mitarbeiterbewertungen für supply chain scientists sind aus verschiedenen Gründen wichtig, etwa um sicherzustellen, dass das Geld des Unternehmens gut investiert wird, und um Beförderungen zu bestimmen. Es gelten die üblichen Kriterien: Einstellung, Fleiß, Kompetenz usw. Allerdings gibt es einen kontraintuitiven Aspekt: Die besten scientists erzielen Ergebnisse, die supply chain Herausforderungen nahezu unsichtbar erscheinen lassen, mit minimalem Drama.

Einen scientist darin zu schulen, bestehende Rezepte zu pflegen und gleichzeitig das bisherige Niveau der supply chain performance beizubehalten, dauert etwa sechs Monate, während die Schulung eines scientists, der ein prognosefähiges Rezept von Grund auf implementiert, ungefähr zwei Jahre in Anspruch nimmt. Die Bindung von Talenten ist entscheidend, insbesondere da die Einstellung erfahrener supply chain scientists noch keine Option ist.
In vielen Ländern ist die durchschnittliche Betriebszugehörigkeit von Ingenieuren unter 30 in der Software- und angrenzenden Branchen ziemlich gering. Lokad erreicht eine höhere durchschnittliche Betriebszugehörigkeit, indem es sich auf das Wohlbefinden der Mitarbeiter konzentriert. Unternehmen können ihren Mitarbeitern kein Glück bescheren, aber sie können verhindern, dass ihre Mitarbeiter durch unsinnige Prozesse unglücklich werden. Vernunft trägt wesentlich zur Mitarbeiterbindung bei.

Ein kompetenter, erfahrener Supply Chain Scientist kann nicht erwarten, ein bestehendes Rezept schnell zu übernehmen, da das Rezept die einzigartige Strategie des Unternehmens und die Besonderheiten der supply chain widerspiegelt. Der Übergang von einer supply chain zur anderen kann unter besten Bedingungen etwa einen Monat dauern. Es ist nicht vernünftig, dass ein großes Unternehmen von einem einzelnen Scientist abhängt; Lokad stellt sicher, dass zwei Scientists zu jeder Zeit mit jedem in der Produktion eingesetzten Rezept vertraut sind. Kontinuität ist wesentlich, und ein Weg, dies zu erreichen, ist ein gemeinsam mit den Kunden erstelltes Handbuch, das ungeplante Übergänge zwischen den Scientists erleichtern kann.

Die Rolle des Supply Chain Scientist erfordert ein ungewöhnlich hohes Maß an Kooperation mit mehreren Abteilungen, insbesondere der IT. Die ordnungsgemäße Ausführung des Rezepts hängt von der Datenextraktions-Pipeline ab, die in der Verantwortung der IT liegt.
Es gibt eine relativ intensive Phase der Interaktion zwischen IT und dem Supply Chain Scientist zu Beginn der ersten die Quantitative Supply Chain-Initiative, die etwa zwei bis drei Monate dauert. Anschließend, sobald die Datenextraktions-Pipeline einsatzbereit ist, wird die Interaktion seltener. Dieser Dialog stellt sicher, dass der Supply Chain Scientist über die IT-Roadmap und etwaige Software-Upgrades oder Änderungen, die die supply chain betreffen, informiert bleibt.
In der Anfangsphase einer die Quantitative Supply Chain-Initiative findet eine relativ intensive Interaktion zwischen IT und den Supply Chain Scientists statt. Während der ersten zwei bis drei Monate muss der Supply Chain Scientist mehrmals pro Woche mit der IT interagieren. Anschließend, sobald die Datenextraktions-Pipeline eingerichtet ist, wird die Interaktion viel seltener, etwa einmal im Monat oder weniger. Neben der Behebung gelegentlicher Fehler in der Pipeline stellt dieser Dialog sicher, dass der Supply Chain Scientist über die IT-Roadmap informiert bleibt. Jedes Software-Upgrade oder jeder Austausch kann Tage oder sogar Wochen an Arbeit für den Supply Chain Scientist erfordern. Um Ausfallzeiten zu vermeiden, muss das Rezept angepasst werden, um Veränderungen in der Anwendungslandschaft Rechnung zu tragen.

Das Rezept, wie es vom Supply Chain Scientist implementiert wurde, optimiert Rückflüsse in Dollar oder Euro. Wir haben diesen Aspekt bereits in den allerersten Vorträgen dieser Reihe behandelt. Allerdings sollte nicht erwartet werden, dass der Supply Chain Scientist entscheidet, wie Kosten und Gewinne modelliert werden. Zwar sollte er Modelle vorschlagen, um die wirtschaftlichen Treiber abzubilden, letztlich obliegt es jedoch der Finanzabteilung zu entscheiden, ob diese Treiber als korrekt angesehen werden. Viele supply chain Praktiken umgehen das Problem, indem sie sich auf Prozentsätze konzentrieren, wie beispielsweise service levels und Prognosegenauigkeiten. Diese Prozentsätze korrelieren jedoch kaum mit der finanziellen Gesundheit des Unternehmens. Daher muss der Supply Chain Scientist routinemäßig mit der Finanzabteilung zusammenarbeiten und diese die Modellierungsentscheidungen und Annahmen im numerischen Rezept hinterfragen lassen.
Finanzmodellierungsentscheidungen sind vorübergehend, da sie die sich ändernde Strategie des Unternehmens widerspiegeln. Vom Supply Chain Scientist wird außerdem erwartet, dass er Instrumente entwickelt, die dem Rezept für die Finanzabteilung zugeordnet sind, wie beispielsweise den maximal prognostizierten Betrag an Working Capital, der mit dem Lagerbestand für das kommende Jahr verbunden ist. Für ein mittelständisches oder großes Unternehmen ist es sinnvoll, eine vierteljährliche Überprüfung der vom Supply Chain Scientist geleisteten Arbeit durch einen Finanzverantwortlichen durchzuführen.

Eine der größten Gefahren für die Gültigkeit des Rezepts besteht darin, unabsichtlich die strategische Ausrichtung des Unternehmens zu verraten. Zu viele supply chain Praktiken umschiffen die Strategie, indem sie sich hinter Prozentsätzen verstecken, die als Leistungs-indikatoren verwendet werden. Das Aufblasen oder Absenken der Prognose durch Sales and Operations Planning (S&OP) ersetzt nicht die Klärung der strategischen Ausrichtung. Der Supply Chain Scientist ist zwar nicht für die Unternehmensstrategie zuständig, aber das Rezept wird falsch sein, wenn er sie nicht versteht. Die Abstimmung des Rezepts mit der Strategie muss gezielt herbeigeführt werden.
Der direkteste Weg, um festzustellen, ob der Supply Chain Scientist die Strategie versteht, besteht darin, ihn diese erneut dem Führungsteam zu erklären. So können Missverständnisse leichter erkannt werden. Theoretisch ist dieses Verständnis bereits vom Supply Chain Scientist im Initiativ-Handbuch dokumentiert. Allerdings zeigt die Erfahrung, dass Führungskräfte selten die Zeit haben, operative Dokumentationen im Detail zu prüfen. Ein einfaches Gespräch beschleunigt den Prozess für beide Seiten.
Dieses Treffen ist nicht dafür gedacht, dass der Supply Chain Scientist alles über supply chain Modelle oder Finanzergebnisse erklärt. Der alleinige Zweck besteht darin, ein angemessenes Verständnis der Person, die den digitalen Stift führt, sicherzustellen. Selbst in einem großen Unternehmen ist es sinnvoll, dass der Supply Chain Scientist sich mindestens einmal im Jahr mit dem CEO oder einem relevanten Führungskraft trifft. Die Vorteile eines Rezepts, das stärker auf die Intentionen der Führung ausgerichtet ist, sind enorm und werden oft unterschätzt.

Verbesserungen in der supply chain sind Teil der fortlaufenden digitalen Modernisierung. Dies erfordert eine gewisse Reorganisation des Unternehmens selbst. Auch wenn die Veränderungen womöglich nicht drastisch sind, ist das Ausmerzen veralteter Praktiken ein steiniger Weg. Wird dies richtig umgesetzt, ist die Produktivität eines Supply Chain Scientist erheblich höher als die eines traditionellen Planers. Es ist nicht ungewöhnlich, dass ein einzelner Scientist für Lagerbestände im Wert von mehr als einer halben Milliarde Dollar oder Euro verantwortlich ist.
Eine drastische Reduzierung der Anzahl an Mitarbeitenden in der supply chain ist möglich. Einige Kundinnen und Kunden von Lokad, die historisch unter immensem Wettbewerbsdruck standen, haben diesen Ansatz verfolgt und sind teilweise aufgrund dieser Einsparungen überlebt. Die meisten unserer Kunden entscheiden sich jedoch für eine schrittweise Reduzierung der Belegschaft, da Planer natürlicherweise in andere Positionen wechseln.
Die verbleibenden Planer richten ihre Bemühungen vermehrt auf Kunden und Lieferanten aus. Das Feedback, das sie sammeln, erweist sich als sehr nützlich für die Supply Chain Scientists. Tatsächlich ist die Arbeit des Scientists naturgemäß nach innen gerichtet. Sie arbeiten mit den Unternehmensdaten, und es ist schwer zu erkennen, was einfach fehlt.
Viele Wirtschaftsvertreter plädieren seit langem dafür, stärkere Verbindungen sowohl zu Kunden als auch zu Lieferanten zu knüpfen. Dies ist jedoch leichter gesagt als getan, insbesondere wenn Bemühungen routinemäßig durch andauernde Problembekämpfung, das Beruhigen von Kunden und den Druck auf Lieferanten neutralisiert werden. Die Supply Chain Scientists können auf beiden Seiten dringend benötigte Entlastung bieten.

S&OP (Sales and Operations Planning) ist eine weit verbreitete Praxis, die darauf abzielt, durch eine gemeinsame Bedarfsprognose eine unternehmensweite Ausrichtung zu fördern. Unabhängig von den ursprünglichen Ambitionen waren die S&OP-Prozesse, die ich je erlebt habe, am besten durch eine endlose Reihe unproduktiver Meetings zu charakterisieren. Abgesehen von ERP-Implementierungen und Compliance fällt mir keine Unternehmenspraxis ein, die so seelenzerstörend wie S&OP ist. Die Sowjetunion mag verschwunden sein, aber der Geist des Gosplan lebt durch S&OP weiter.
Eine ausführliche Kritik von S&OP würde einen eigenen Vortrag verdienen. Der Kürze halber sei jedoch gesagt, dass ein Supply Chain Scientist in jeder relevanten Dimension eine überlegene Alternative zu S&OP darstellt. Im Gegensatz zu S&OP basiert der Supply Chain Scientist auf realen Entscheidungen. Das Einzige, was einen Scientist daran hindert, ein weiterer Agent einer aufgeblähten Unternehmensbürokratie zu werden, ist nicht sein Charakter oder seine Kompetenz, sondern dass er bei diesen realen Entscheidungen auch unmittelbare Verantwortung trägt.
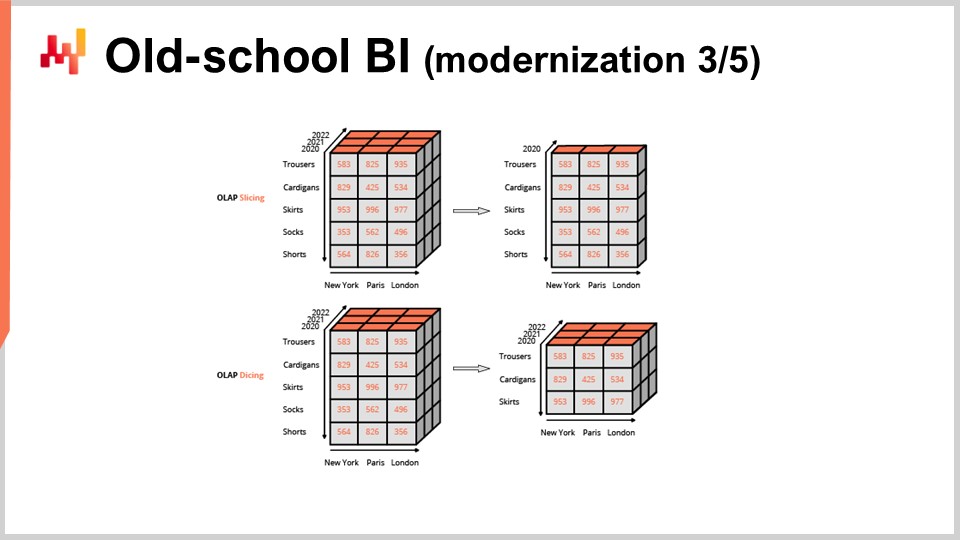
Planer, Inventarverwalter und Produktionsleiter sind häufig große Nutzer verschiedener Geschäftsberichte. Diese Berichte werden in der Regel von unternehmensweiter Software produziert, die gemeinhin als Business Intelligence Tools bezeichnet wird. Die typische supply chain Praxis besteht darin, eine Reihe von Berichten in Tabellenkalkulationen zu exportieren und dann eine Sammlung von Tabellenkalkulationsformeln zu verwenden, um all diese Informationen zu vermischen und so halbmanuell die interessierenden Entscheidungen zu generieren. Doch wie wir gesehen haben, ersetzt das Rezept des Supply Chain Scientist diese Kombination aus Business Intelligence und Tabellenkalkulationen.
Zudem sind weder Business Intelligence noch Tabellenkalkulationen geeignet, die Implementierung eines Rezepts zu unterstützen. Business Intelligence fehlt es an Ausdruckskraft, da die relevanten Berechnungen mit dieser Art von Tools nicht ausgedrückt werden können. Tabellenkalkulationen mangelt es an Wartbarkeit und manchmal an Skalierbarkeit, vor allem aber an Wartbarkeit. Das Design von Tabellenkalkulationen ist weitgehend unvereinbar mit einer Art von Korrektheit durch Design, die für die supply chain Zwecke dringend benötigt wird.
In der Praxis umfasst die Instrumentierung eines Rezepts, wie sie vom Supply Chain Scientist umgesetzt wird, zahlreiche Geschäftsberichte. Diese Berichte ersetzen diejenigen, die bisher durch Business Intelligence erstellt wurden. Diese Entwicklung impliziert nicht zwangsläufig das Ende von Business Intelligence, da auch andere Abteilungen noch von dieser Tool-Kategorie profitieren können. Was jedoch die supply chain betrifft, läutet die Einführung des Supply Chain Scientist das Ende des Business-Intelligence-Zeitalters ein.

Wenn wir einige Tech-Giganten außer Acht lassen, die es sich leisten können, Hunderte, wenn nicht Tausende von Ingenieuren für jedes Softwareproblem einzusetzen, ist das typische Ergebnis von Data-Science-Teams in normalen Unternehmen trostlos. In der Regel wird von diesen Teams nichts Substanzielles erreicht. Data Science als Unternehmenspraxis ist jedoch nur die neueste Iteration einer Reihe von Unternehmenskuren.
In den 1970er Jahren war Operations Research in Mode. In den 1980er Jahren waren Regel-Engines und Knowledge Experts beliebt. Um die Jahrhundertwende waren Data Mining und Data Miner gefragt. Seit den 2010er Jahren gelten Data Science und Data Scientists als das nächste große Ding. All diese Unternehmenskuren folgen demselben Muster: Eine echte Software-Innovation tritt auf, die Menschen sind übermäßig enthusiastisch darüber, und sie beschließen, diese Innovation gewaltsam durch die Gründung einer neuen, speziellen Abteilung im Unternehmen zu verankern. Denn es ist immer viel einfacher, einer Organisation neue Abteilungen hinzuzufügen, als bestehende zu modifizieren oder abzuschaffen.
Data Science als Unternehmenspraxis scheitert jedoch, weil sie nicht fest in Handlung verankert ist. Das ist der entscheidende Unterschied zwischen einem Supply Chain Scientist, der von Anfang an dafür verantwortlich ist, reale Entscheidungen zu treffen, und der IT-Abteilung.

Wenn wir Egos und Herrschaftsdenken außer Acht lassen, stellt der Supply Chain Scientist eine viel bessere Lösung dar als der bisherige Status quo. Die typische IT-Abteilung ist unter jahrelangem Rückstand begraben, und der Versuch, mehr Ressourcen zu erhalten, ist keine vernünftige Option, da dies dazu führt, dass die Erwartungen anderer Abteilungen in die Höhe getrieben und der Rückstand weiter vergrößert wird.
Im Gegenteil ebnet der Supply Chain Scientist den Weg zu geringeren Erwartungen. Der Scientist erwartet lediglich, dass Rohdatenextrakte verfügbar gemacht werden, und seine Rechenarbeit liegt in seiner Verantwortung. Er erwartet in dieser Hinsicht nichts von der IT-Abteilung. Der Supply Chain Scientist sollte nicht als eine von der Unternehmensführung sanktionierte Version von Shadow IT betrachtet werden. Es geht darum, die supply chain Abteilung für ihre eigene Kernkompetenz verantwortlich und rechenschaftspflichtig zu machen. Die IT-Abteilung verwaltet die grundlegende Infrastruktur und die Transaktionsschicht, während die supply chain Entscheidungsfindung vollständig der supply chain Abteilung überlassen sein sollte.
Die IT-Abteilung muss ein Enabler sein, kein Entscheider, abgesehen von den wirklich IT-zentrierten Teilen des Geschäfts. Viele IT-Abteilungen sind sich ihres Rückstands bewusst und begrüßen diesen neuen Ansatz. Sollte jedoch der Instinkt, das, was als ihr Territorium wahrgenommen wird, zu stark zu schützen, vorhanden sein, könnten sie sich weigern, die supply chain Entscheidungsebene loszulassen. Diese Situationen sind schmerzhaft und können nur durch das direkte Eingreifen des CEO gelöst werden.

Aus der Ferne mag unsere Schlussfolgerung lauten, dass die Rolle des Supply Chain Scientist als eine spezialisiertere Variante des Data Scientist betrachtet werden kann. Historisch gesehen war dies der Ansatz, mit dem Lokad versuchte, Probleme im Zusammenhang mit der Unternehmenspraxis der Data Science zu beheben. Wir erkannten jedoch vor einem Jahrzehnt, dass dies unzureichend war. Es hat Jahre gedauert, um all die Elemente, die heute vorgestellt wurden, nach und nach zu erschließen.
Der Supply Chain Scientist ist kein Zusatz zur supply chain des Unternehmens; er klärt vielmehr die Zuständigkeit für die alltäglichen, banalen Entscheidungen in der supply chain. Um das Beste aus diesem Ansatz herauszuholen, muss die supply chain, oder zumindest ihre Planungskomponente, umgestaltet werden. Auch angrenzende Abteilungen wie Finanzen und Betrieb müssen sich – wenn auch in geringerem Maße – anpassen.
Die Förderung eines Teams von Supply Chain Scientists ist für ein Unternehmen ein beachtliches Unterfangen, aber wenn es richtig durchgeführt wird, ist die Produktivität hoch. In der Praxis ersetzt jeder Scientist letztlich 10 bis 100 Planer, Prognostiker oder Lagerverwalter, was zu enormen Einsparungen bei der Gehaltsabrechnung führt, selbst wenn die Scientists höhere Gehälter verlangen. Der Supply Chain Scientist veranschaulicht einen neuen Ansatz im Umgang mit IT, indem die IT als Enabler und nicht als Lösungsanbieter neu positioniert wird und damit viele, wenn nicht gar die meisten IT-bezogenen Engpässe beseitigt.
Allgemeiner kann dieser Ansatz in allen anderen nicht-IT-Abteilungen des Unternehmens widerspiegelt werden, wie beispielsweise Marketing, Vertrieb und Finanzen. Jede Abteilung hat ihre eigenen alltäglichen, banalen Entscheidungen zu treffen, von denen ebenfalls in hohem Maße eine Automatisierung profitieren würde. Allerdings, so wie der Supply Chain Scientist in erster Linie ein Experte in der supply chain ist
ebenso sollte ein Marketing Scientist oder Marketing Quant, ähnlich wie der Supply Chain Scientist in erster Linie ein Experte in der supply chain ist, ein Experte im Marketing sein. Die Perspektive des Scientist ebnet den Weg, um die Vorteile der Kombination aus maschineller und menschlicher Intelligenz im frühen 21. Jahrhundert optimal zu nutzen.
Die nächste Vorlesung findet am 10. Mai, einem Mittwoch, zur selben Tageszeit um 15 Uhr Pariser Zeit statt. Die heutige Vorlesung war nicht-technisch, aber die nächste wird weitgehend technisch sein. Ich werde Techniken zur Preisoptimierung vorstellen. In gängigen supply chain Lehrbüchern wird Preisgestaltung typischerweise nicht als Bestandteil der supply chain behandelt; dennoch trägt die Preisgestaltung wesentlich zur Balance von Angebot und Nachfrage bei. Außerdem neigt die Preisgestaltung dazu, hochdomänenspezifisch zu sein, da es allzu leicht ist, die Herausforderung in abstrakten Begriffen völlig falsch anzugehen. Daher werden wir unsere Untersuchungen auf den automobilen Aftermarket eingrenzen. Dies wird die Gelegenheit sein, die in Stuttgart vorgestellten Elemente erneut aufzugreifen, eine der supply chain Personas, die ich im dritten Kapitel dieser Vorlesungsreihe eingeführt habe.

Und nun werde ich mit den Fragen fortfahren.
Frage: Es hat der Akademie fast ein Jahrzehnt gedauert, um herauszufinden, dass das Feld der Datenwissenschaft entstanden ist und dass man es an der Schule lehren sollte. Siehst du bereits, dass in den akademischen supply chain Kreisen die supply chain sciences Perspektive übernommen wird?
Zunächst bin ich mir nicht bewusst, dass Datenwissenschaft in französischen Schulen gelehrt wird. Man unterrichtet in der Sekundarstufe kaum etwas Computerbezogenes, geschweige denn Datenwissenschaft. Ich bin mir nicht sicher, wo sie überhaupt die Professoren oder Lehrer finden würden, die das übernehmen könnten. Aber ich verstehe, dass du möchtest, dass Schüler über digitale Kompetenz verfügen. Meiner Meinung nach ist es sehr gut, sich mit Programmierung vertraut zu machen, und man kann damit sogar früher beginnen – nach meiner eigenen Erfahrung ab einem Alter von sieben oder acht, je nach Reife des Kindes. Das geht sogar in der Grundschule, aber wir sprechen hier nur von grundlegenden Programmierkonzepten: Variablen, Listen von Anweisungen und dergleichen. Ich glaube, dass Datenwissenschaft weit über das hinausgeht, was an Schulen gelehrt werden sollte, es sei denn, man hat Wunderkinder oder Ähnliches. Für mich ist es eindeutig etwas, das für Leute auf Universitätsniveau gedacht ist, sei es im Bachelor- oder im Masterstudium.
In der Tat hat es der Akademie ein Jahrzehnt gekostet, data science voranzubringen, aber lassen Sie uns einen Moment innehalten. Ich habe data science als eine unternehmerische Praxis beschrieben, was im Grunde die Spiegelversion dessen ist, was die Akademia beim Unterrichten von data science macht. Daher müssen wir über das Problem nachdenken, und hier denke ich, dass eines der Probleme darin besteht, etwas zu lehren, das man nicht selbst praktiziert. Zumindest auf Universitätsniveau, wenn nicht sogar darunter. Was ich sehe, ist, dass wir bereits ein Problem mit data science haben, denn die Personen, die data science unterrichten, sind nicht dieselben, die tatsächlich data science in relevanten Unternehmen wie Microsoft, Google, Facebook, OpenAI und so weiter praktizieren.
Für die supply chain haben wir ein ähnliches Problem, und es ist einfach unglaublich schwierig, Zugang zu Personen mit der richtigen Erfahrung zu erhalten. Ich hoffe – und das ist ein herrenloser Eigenplug von mir – dass Lokad in den kommenden Wochen beginnen wird, Materialien bereitzustellen, die für supply chain Studiengänge gedacht sind. Wir werden Materialien herausbringen, die so aufbereitet sind, dass sie für Professoren in der Akademia geeignet sind, sodass diese die Erkenntnisse weitervermitteln können. Offensichtlich müssen sie ihr eigenes Urteil darüber fällen, ob die von Lokad bereitgestellten Materialien tatsächlich für den Unterricht geeignet sind.
Frage: Wird Lokads domänenspezifische Sprache nicht auch anderswo verwendet? Abgesehen von Lokad, wie motiviert man potenzielle Neueinstellungen dazu, etwas zu lernen, das sie in ihrem nächsten Job wahrscheinlich nie wieder anwenden werden?
Genau das war mein Punkt in Bezug auf das Problem, das ich mit data scientists hatte. Die Leute bewarben sich buchstäblich mit Aussagen wie: “Ich will TensorFlow einsetzen, ich bin ein TensorFlow-Typ” oder “Ich bin ein PyTorch-Typ.” Das ist nicht die richtige Einstellung. Wenn du deine Identität mit einem Satz technischer Werkzeuge verwechselst, verfehlst du das Wesentliche. Die Herausforderung besteht darin, supply chain Probleme zu verstehen und sie quantitativ anzugehen, um Entscheidungen auf Produktionsniveau zu generieren.
In dieser Vorlesung habe ich erwähnt, dass es sechs Monate dauert, bis ein Supply Chain Scientist die Fähigkeit erlangt, ein Rezept zu pflegen, und zwei Jahre, um ein Rezept von Grund auf zu entwickeln. Wie viel Zeit benötigt man, um Envision, unsere proprietäre Programmiersprache, vollständig zu beherrschen? Nach unserer Erfahrung dauert es drei Wochen. Envision ist ein kleines Detail im Vergleich zur Gesamtaufgabe, aber ein wichtiges. Wenn deine Werkzeuge mangelhaft sind, wirst du auf immense zufällige Probleme stoßen. Aber seien wir realistisch: Es ist nur ein kleines Puzzleteil des Gesamtkonzepts.
Diejenigen, die Zeit bei Lokad verbringen, lernen enorm viel über supply chain Probleme. Die Programmiersprache könnte in anderen Sprachen neu geschrieben werden, aber es würde möglicherweise mehr Codezeilen erfordern. Was besonders junge Ingenieure oft nicht erkennen, ist, wie vergänglich viele Technologien sind. Sie halten nicht lange, in der Regel nur ein paar Jahre, bevor sie durch etwas anderes ersetzt werden.
Wir haben eine endlose Reihe von Technologien kommen und gehen sehen. Wenn ein Bewerber sagt, “Mir sind die technischen Details wirklich wichtig”, ist er wahrscheinlich kein guter Kandidat. Das war mein Problem mit data scientists – sie wollten das schicke, hochmoderne Zeug. Supply chains sind enorm komplexe Systeme, und wenn man einen Fehler macht, kann das Millionen kosten. Man braucht Werkzeuge auf Produktionsniveau, nicht das neueste, ungetestete Paket.
Die besten Kandidaten haben ein aufrichtiges Interesse daran, supply chain Professionals zu werden. Der entscheidende Aspekt ist die supply chain, nicht die Details der Programmiersprache.
Frage: Ich studiere Supply Chain, Transport- und Logistikmanagement im Bachelor. Wie kann ich ein Supply Chain Scientist werden?
Zunächst ermutige ich dich, dich bei Lokad zu bewerben. Wir haben ständig offene Stellen. Aber ernsthaft, der Schlüssel dazu, ein Supply Chain Scientist zu werden, liegt darin, in einem Unternehmen die Chance zu bekommen, supply chain Entscheidungen zu automatisieren. Der wichtigste Aspekt ist die Verantwortung für die Entscheidungen. Wenn du ein Unternehmen findest, das bereit ist, dies auszuprobieren, wird dir das sehr dabei helfen, ein Scientist zu werden.
Wenn du dich den Herausforderungen von Entscheidungen auf Produktionsniveau stellst, wirst du die Bedeutung der Themen erkennen, die ich in dieser Vorlesungsreihe bespreche. Wenn du mit Vorhersagen zu tun hast, die Millionen von Dollar an Lagerbeständen, Bestellungen und Bestandsbewegungen steuern, wirst du die immense Verantwortung und die Notwendigkeit der Korrektheit durch Design verstehen. Ich bin mir ziemlich sicher, dass andere Unternehmen wachsen und viele weitere Chancen erhalten werden. Aber selbst in meinen kühnsten Träumen glaube ich nicht, dass jedes einzelne Unternehmen auf der Welt Lokad nutzen wird. Es wird viele Unternehmen geben, die sich immer dafür entscheiden, es auf ihre Art zu machen, und das wird in Ordnung sein.
Frage: Da 40 % der täglichen Routine eines Supply Chain Scientist aus Codierung besteht, welche Programmiersprache würdest du Studierenden im Grundstudium, insbesondere denen im Management, als ersten Lernschritt empfehlen?
Ich würde sagen, greife auf das zu, was leicht zugänglich ist. Python ist ein guter Anfang. Mein Vorschlag ist, tatsächlich mehrere Programmiersprachen auszuprobieren. Was man von einem Supply Chain Engineer erwartet, ist ziemlich genau das Gegenteil von dem, was man von Softwareingenieuren erwartet. Für Softwareingenieure lautet mein Standardrat, sich auf eine Sprache zu konzentrieren und diese intensiv zu erlernen, um sämtliche Feinheiten zu verstehen. Aber für Menschen, die letztlich Generalisten sind, würde ich dazu raten, das Gegenteil zu tun. Probiere ein wenig SQL, ein wenig Python, ein wenig R aus. Achte auf die Syntax von Excel, und vielleicht wirf einen Blick auf Sprachen wie Rust, nur um zu sehen, wie sie aussehen. Also, greife auf das zurück, was dir zugänglich ist. Übrigens plant Lokad, Envision Studierenden kostenlos zugänglich zu machen, also bleibt dran.
Frage: Siehst du, dass Graph-Datenbanken einen signifikanten Einfluss auf supply chain Vorhersagen haben?
Auf keinen Fall. Graph-Datenbanken gibt es seit mehr als zwei Jahrzehnten, und obwohl sie interessant sind, sind sie nicht so leistungsfähig wie relationale Datenbanken wie PostgreSQL und MariaDB. Für supply chain Vorhersagen sind graph-ähnliche Operatoren nicht das, was zählt. Bei Forecasting-Wettbewerben hat keiner der Top 100 Teilnehmer eine Graph-Datenbank verwendet. Es gibt jedoch Dinge, die mit Deep Learning in Verbindung mit Graphen gemacht werden können, was ich in meiner nächsten Vorlesung über Preisgestaltung erläutern werde.
Bezüglich der Frage, ob Supply Chain Scientists in die Zielfestlegung bei Kundenprojekten der Datenwissenschaft einbezogen werden sollten, glaube ich, dass es ein Problem mit der zugrunde liegenden Annahme gibt, sich zuerst auf data science zu konzentrieren, bevor man das eigentliche Problem versteht, das es zu lösen gilt. Um die Frage umzuformulieren: Sollten Supply Chain Scientists in die Zielfestlegung der supply chain Optimierung einbezogen werden? Ja, absolut. Es ist schwierig, den Scientist herausfinden zu lassen, was wir wirklich wollen, und es erfordert eine enge Zusammenarbeit mit den Stakeholdern, um sicherzustellen, dass die richtigen Ziele verfolgt werden. Also, sollten die Scientists dafür an Bord sein? Absolut, das ist entscheidend.
Allerdings wollen wir klarstellen, dass dies keine Datenwissenschafts-Initiative ist; es handelt sich um eine supply chain Initiative, die zufällig Daten als geeignetes Element nutzen kann. Wir müssen wirklich bei den supply chain Problemen und Ambitionen anfangen, und dann, wenn wir das Beste aus moderner Software herausholen wollen, benötigen wir diese Scientists. Sie werden dir helfen, dein Verständnis des Problems weiter zu verfeinern, denn die Grenze zwischen dem, was in der Software machbar ist, und dem, was strikt im Bereich menschlicher Intelligenz verbleibt, ist irgendwie unscharf. Du brauchst die Scientists, um diese Grenze zu navigieren.
Ich hoffe, euch in zwei Monaten, am 10. Mai, zur nächsten Vorlesung zu sehen, in der wir über Preisgestaltung sprechen werden. Bis dann.