Programación diferenciable para optimizar sobre datos relacionales a gran escala
En el intrincado mundo de la gestión de supply chain, los datos relacionales son el rey. ERPs, WMS, PMS y otras herramientas de software omnipresentes en supply chain operan sobre bases de datos relacionales que rastrean desde los niveles de inventario hasta las relaciones con proveedores. Los datos relacionales consisten en una serie de tablas interconectadas, cada una rica en columnas de información. Sin embargo, cuando se trata de machine learning y optimización matemática, los datos relacionales a menudo son opacados por formas más simples como vectores, secuencias y grafos.
Los datos relacionales -gracias a su rica complejidad- ofrecen una visión más profunda y matizada de las operaciones que sus contrapartes más simples (los vectores, secuencias y grafos antes mencionados). Sin embargo, la mayoría del software empresarial lucha por utilizar de manera efectiva los datos en su forma relacional. ¿El resultado? Una adaptación forzada de clavijas cuadradas en agujeros redondos, intentando desesperadamente comprimir los datos relacionales en herramientas diseñadas para modelos más simples. Este desajuste perjudica a las empresas, similar a usar un palo de hockey en el golf: teóricamente factible, pero muy lejos del matrimonio óptimo entre herramienta y propósito.
Decidido a investigar este punto ciego, hace unos años, Paul Peseux inició un doctorado en Lokad con el propósito de transformar los datos relacionales en ciudadanos de primera clase tanto para propósitos de aprendizaje como de optimización. Sus esfuerzos de investigación condujeron a una serie de mejoras notables para nuestro respaldo de programación diferenciable dentro de Envision – el DSL de Lokad (lenguaje de programación de dominio específico) dedicado a la optimización de supply chain. Los impresionantes hallazgos de Paul ya están en producción, típicamente enterrados en las capacidades de autodiff del DSL.
Autor: Paul Peseux
Fecha: Septiembre 2023
Resumen:
Esta tesis doctoral, titulada, presenta tres contribuciones al campo de la programación diferenciable con un enfoque en datos relacionales. Los datos relacionales son prevalentes en industrias como la salud y supply chain, donde a menudo se organizan en tablas o bases de datos estructuradas. Los enfoques tradicionales de machine learning tienen dificultades para manejar los datos relacionales, mientras que los modelos de machine learning de caja blanca son más adecuados, pero desafiantes de desarrollar.
La programación diferenciable ofrece una solución potencial al tratar las consultas en bases de datos relacionales como programas diferenciables, lo que permite desarrollar modelos de machine learning de caja blanca que puedan razonar directamente sobre los datos relacionales. El objetivo principal de esta investigación es explorar la aplicación de machine learning a los datos relacionales utilizando técnicas de programación diferenciable.
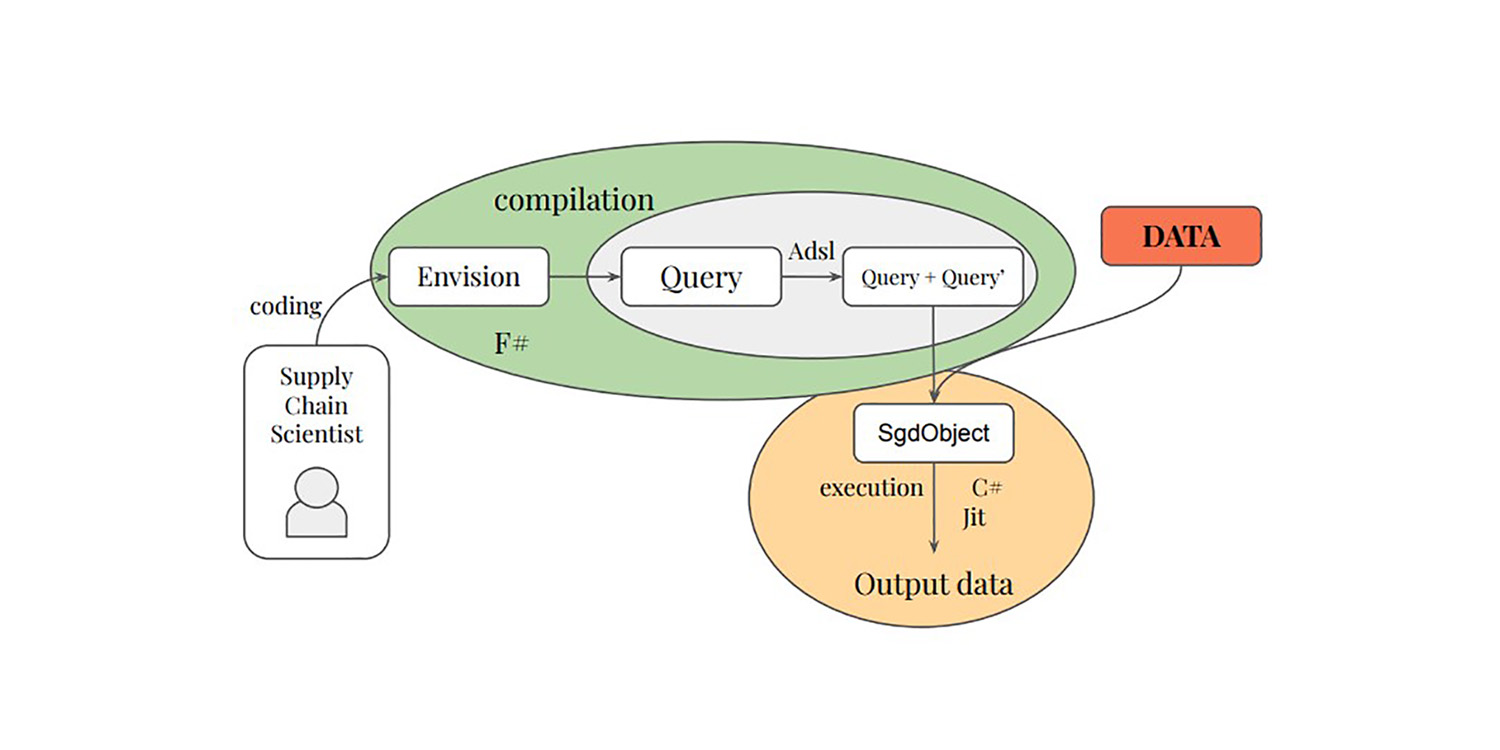
La primera contribución de la tesis introduce una capa diferenciable en los lenguajes de programación relacional, tanto teórica como prácticamente. Se creó el lenguaje de programación Adsl para realizar diferenciación y transcribir operaciones relacionales de una consulta. El lenguaje de dominio específico Envision ha sido ampliado con capacidades de programación diferenciable, permitiendo el desarrollo de modelos que aprovechan los datos relacionales en un entorno nativo de lenguajes de programación relacional.
La segunda contribución desarrolla un novedoso estimador de gradiente llamado GCE, diseñado para características categóricas representadas en datos relacionales. Se demuestra que GCE es útil en diversos conjuntos de datos y modelos categóricos y se ha implementado para modelos de deep learning. GCE también está integrado como el estimador de gradiente nativo en la capa de programación diferenciable de Envision, facilitado por la primera contribución de esta tesis.
La tercera contribución desarrolla un estimador de gradiente generalizado llamado Stochastic Path Automatic Differentiation (SPAD), que deriva su estocasticidad de la descomposición del código. SPAD introduce la idea de retropropagar una fracción del gradiente para reducir el consumo de memoria durante las actualizaciones de parámetros. La implementación de este enfoque de estimación de gradiente es posible gracias a las decisiones de diseño durante la diferenciación de Adsl.
Esta investigación tiene importantes implicaciones para las industrias que dependen de los datos relacionales, desbloqueando nuevos conocimientos y mejorando la toma de decisiones al aplicar modelos de machine learning de caja blanca a los datos relacionales mediante técnicas de programación diferenciable.
Jurado:
La defensa tuvo lugar frente a un jurado compuesto por:
- Thierry Paquet, Profesor universitario (University of Rouen Normandy), director de tesis.
- Maxime Berar, Profesor adjunto (University of Rouen Normandy), co-supervisor de la tesis.
- Romain Raveaux, Profesor adjunto (University of Tours), relator.
- Thierry Artières, Profesor universitario (ECM / LIS – AMU – CNRS), relator.
- Cécilia Zanni-Merk, Profesora universitaria (INSA Rouen Normandie), examinadora.
- Laurent Wendling, Profesor universitario (Paris Cité University), examinador.
- Victor Nicolet, CTO de Lokad, asesor.


