00:00 Introducción
03:39 La automatización siempre ha sido la meta
06:28 Gestión de excepciones y alertas
10:27 La historia hasta ahora
14:33 Nuestro despliegue en producción hoy
15:59 Resumen: entregable, alcance y roles
19:01 Descubriendo la forma de la decisión
23:00 Respuesta impulsada por legado
27:20 Iterando hasta un cero por ciento de locura
32:30 Métricas aspiracionales
36:27 Ejecución dual: manual + mecánica
39:19 Parálisis analítica
43:21 Transición gradual a la automatización
46:08 Sedimentación del proceso
48:57 De planificador a gestor de red
52:46 El turista de KPI
54:58 Liderazgo: de coach a product owner
58:46 El jefe analógico de supply chain
01:02:25 Conclusión
01:04:44 7.2 Llevando decisiones automatizadas a producción - ¿Preguntas?
Descripción
Buscamos una receta numérica para impulsar toda una clase de decisiones mundanas, tales como reabastecimientos de stock. La automatización es esencial para convertir supply chain en un emprendimiento capitalista. Sin embargo, conlleva riesgos sustanciales de causar daños a gran escala si la receta numérica es defectuosa. Fail fast and break things no es la mentalidad adecuada para aprobar una receta numérica para producción. Sin embargo, muchas alternativas, como el modelo en cascada, son incluso peores ya que usualmente dan la ilusión de racionalidad y control. Un proceso altamente iterativo es la clave para diseñar la receta numérica que demuestre ser de nivel de producción.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Johannes Vermorel y hoy presentaré “Llevando decisiones automatizadas de supply chain a producción”. Durante los últimos dos siglos, nuestras economías experimentaron una transformación masiva a través de la mecanización. Las empresas que lograron un grado superior de mecanización en comparación con sus competidores casi siempre llevaron sistemáticamente a esos competidores a la bancarrota. La mecanización nos permite hacer más, mejor y más rápido mientras se reduce el costo. Esto es cierto para tareas físicas como mover mercancías con una carretilla elevadora en lugar de transportar cajas a mano, pero también es cierto para tareas intelectuales como calcular cuánto dinero te queda en el banco.
Sin embargo, nuestra capacidad para mecanizar una tarea depende de la tecnología. Todavía hay muchas tareas físicas que aún no pueden ser mecanizadas, por ejemplo, cortar el cabello o cambiar las sábanas. Por el contrario, todavía existen muchas tareas intelectuales que aún no pueden ser mecanizadas, como contratar a la persona adecuada o descubrir lo que el cliente desea. No hay razón para creer que esas tareas, ya sean intelectuales o mecánicas, no puedan llegar a ser mecanizadas. Sin embargo, la tecnología aún no está del todo desarrollada.
La mayoría de las decisiones rutinarias y mundanas de supply chain ahora pueden ser automatizadas. Este es un desarrollo relativamente reciente. Hace una década, el alcance de las decisiones de supply chain que podían ser automatizadas con éxito era solo una fracción del espectro completo de decisiones de supply chain. Hoy en día, la situación se ha invertido y, con la tecnología adecuada, las decisiones repetitivas de supply chain que no pueden ser automatizadas con éxito son pocas y escasas. Por automatización exitosa, me refiero a un proceso en el que las decisiones automatizadas son superiores a aquellas obtenidas mediante un proceso manual, no a la capacidad de generar decisiones con una computadora, lo cual es trivial siempre y cuando no te preocupe la calidad de las decisiones generadas.
Nuestro enfoque hoy no está en la receta numérica – es decir, en el software que hace posible dicha automatización en primer lugar. En el contexto de los procesos de toma de decisiones de supply chain, los ingredientes para elaborar tal receta numérica se han cubierto en capítulos anteriores de esta serie de conferencias. Nuestro enfoque hoy está en las partes de la iniciativa de supply chain que son necesarias para llevar esa receta numérica a producción. El objetivo de esta conferencia es detallar lo que se necesita para hacer la transición de decisiones manuales de supply chain a decisiones automatizadas. Al final de esta conferencia, deberías tener ideas sobre lo que se debe y no se debe hacer al hacer la transición hacia la automatización. De hecho, la pura dificultad técnica asociada con la receta numérica tiende a eclipsar los aspectos organizativos que, sin embargo, son igualmente críticos para el éxito de la iniciativa.

Cuando a los profesionales actuales de supply chain se les presenta la idea de la automatización de la toma de decisiones, su reacción inmediata suele ser “Esta es una idea tan futurista. Aún estamos lejos de eso.” Sin embargo, la automatización completa de las decisiones mundanas y repetitivas de supply chain ha sido, literalmente, el objetivo desde el comienzo de la era digital de supply chain, hace más de cuatro décadas.
En cuanto las computadoras estuvieron disponibles para las empresas, la gente se dio cuenta de que la mayoría de las decisiones de supply chain eran candidatas obvias para la automatización completa. En la pantalla, he seleccionado una lista de publicaciones que ilustran esta ambición. En las décadas de 1970 y 1980, este campo ni siquiera se llamaba supply chain. El término solo se volvería popular en la década de 1990. Sin embargo, la intención ya estaba clara. Esos sistemas informáticos parecían inmediatamente adecuados para automatizar las decisiones de supply chain más repetitivas, tales como los reabastecimientos de inventario.
Lo que más me desconcierta es que esta comunidad parece estar algo ajena a sus antiguas ambiciones. Hoy en día, para sonar futurista, el término “autonomous supply chain” es utilizado a veces por firmas de consultoría o empresas de TI para transmitir esta perspectiva de mecanización de las decisiones mundanas de supply chain. Sin embargo, el término “autonomous” me parece inapropiado. No usamos el término “autonomous logistics” para referirnos a una cinta transportadora con un sistema de clasificación. La cinta transportadora está mecanizada, no es autónoma. La cinta transportadora aún requiere supervisión técnica, pero esta innovación representa solo una pequeña fracción de la mano de obra que, de otra manera, la empresa necesitaría para transportar las mercancías sin la cinta transportadora. En lo que respecta a las decisiones de supply chain, el objetivo no es eliminar completamente a los humanos de la organización, logrando así una tecnología verdaderamente autónoma. El objetivo es simplemente quitar a los humanos la parte del proceso que más tiempo consume y es la más rudimentaria. Esta es exactamente la perspectiva que se adoptó en aquellos artículos publicados hace cuatro décadas y es la perspectiva que yo adopto en esta conferencia también.

Durante la década de 1990, parece que los proveedores de software, tanto los proveedores de ERP como los especialistas en optimización de inventario, en gran medida abandonaron la idea de lograr decisiones automatizadas de supply chain. En retrospectiva, los modelos simplistas de los años 70, que en gran medida ignoraban muchos factores importantes como la incertidumbre, fueron la causa raíz obvia que explicó por qué la automatización no tuvo éxito en ese momento. Sin embargo, corregir esta causa raíz resultó estar fuera de lo que la tecnología podía ofrecer en ese período. En cambio, los proveedores de software optaron por sistemas de gestión de excepciones. Se espera que esos sistemas produzcan alertas de inventario basadas en reglas establecidas por la propia empresa cliente. La línea de razonamiento fue: dejemos que la automatización se encargue de la mayoría de las líneas que se pueden procesar automáticamente para mantener la intervención humana centrada en las líneas difíciles, aquellas que están más allá de la capacidad de la máquina.
Señalemos de inmediato que vender un sistema de gestión de excepciones es una muy buena oferta para el proveedor de software, pero mucho menos para la empresa cliente. Primero, la gestión de excepciones traslada la carga del rendimiento de supply chain del proveedor al cliente. Una vez que la gestión de excepciones está en funcionamiento, si los resultados son malos, es culpa del cliente. Deberían haber configurado alertas mejores para prevenir que situaciones dañinas ocurran en primer lugar.
En segundo lugar, crear un sistema para gestionar alertas de inventario parametrizadas es fácil para el proveedor de software siempre que éste no tenga que entregar ningún valor de parámetro que gobierne las alertas de origen. De hecho, desde una perspectiva analítica, ser capaz de producir una buena alerta de inventario significa que puedes diseñar una regla que identifique de manera fiable las malas decisiones de inventario. Si puedes diseñar una regla que identifique de manera fiable las malas decisiones de inventario, entonces, por definición, la misma regla también se puede utilizar para producir de manera fiable buenas decisiones de inventario. De hecho, la regla solo tiene que usarse como un filtro para evitar que se tomen malas decisiones.
En tercer lugar, la gestión de excepciones es una estrategia algo astuta para que el proveedor de software explote la psicología humana. De hecho, esas alertas explotan un mecanismo conocido como “commitment and consistency” por psicólogos empíricos. Este mecanismo crea una adicción fuerte, pero en gran medida accidental, al producto de software. En resumen, una vez que los empleados comienzan a modificar los números de inventario, ya no son números arbitrarios. Son sus números, su trabajo, y por ello los empleados se apegan emocionalmente al sistema, sin importar si el sistema realmente ofrece un rendimiento superior de supply chain o no.
En general, la gestión de excepciones es un callejón sin salida tecnológico, ya que, en el caso general, diseñar excepciones fiables y alertas fiables es tan difícil como diseñar una automatización fiable para las decisiones. Si no puedes confiar en tus alertas y si no puedes confiar en que tus excepciones sean fiables, entonces tienes que revisar todo manualmente de todos modos, lo que te devuelve al punto de partida. El proceso de toma de decisiones sigue siendo estrictamente manual.

Esta serie de conferencias de supply chain incluye dos docenas de episodios. En este punto, de alguna manera, todos los elementos que hemos introducido hasta ahora se han presentado con el propósito explícito de llegar al punto en el que nos encontramos hoy: al borde de poner en producción esta iniciativa de Supply Chain Quantitativa. Más específicamente, es la receta numérica que queremos poner en predicción y este empeño es el foco de la conferencia de hoy.
En estas conferencias, utilizo el término “receta numérica” para referirme a la secuencia de cálculos que toma datos históricos sin procesar como entrada y produce las decisiones finales. Esta terminología es intencionadamente vaga porque refleja muchos conceptos, métodos y técnicas diferentes que ya se han tratado en detalle en los capítulos anteriores. En el primer capítulo, hemos visto por qué el supply chain debe volverse programático y por qué es altamente deseable poder poner esa receta numérica en producción. La complejidad creciente de los propios supply chain hace que la automatización sea más urgente que nunca. También existe un imperativo de convertir la práctica de supply chain en un emprendimiento capitalista.
El segundo capítulo está dedicado a las metodologías. De hecho, los supply chain son sistemas competitivos. Esta combinación vence a las metodologías ingenuas. Entre las metodologías que hemos introducido, los personae de supply chain y la optimización experimental son de suma relevancia para el tema de hoy. Los personae de supply chain son la clave para adoptar la forma correcta de tomar decisiones. Revisitaremos este punto en unos minutos. La optimización experimental es esencial para entregar algo que realmente funcione. Nuevamente, reiteraremos este punto en unos minutos.
El tercer capítulo examina el problema, dejando de lado la solución mediante los personae de supply chain. Este capítulo intenta caracterizar las clases de problemas de toma de decisiones que deben abordarse. Este capítulo muestra que perspectivas simplistas, como simplemente tener que elegir la cantidad correcta para cada SKU, realmente no encajan en situaciones del mundo real. Casi invariablemente, hay una profundidad en la forma de las decisiones.
El cuarto capítulo examina los elementos que se requieren para comprender una práctica moderna de supply chain donde los elementos de software son omnipresentes. Esos elementos son fundamentales para entender el contexto más amplio en el que opera la receta numérica y, de hecho, la mayor parte de los procesos de supply chain. De hecho, muchos libros de texto de supply chain asumen implícitamente que sus técnicas y fórmulas operan en algún tipo de vacío. Este no es el caso. El paisaje aplicativo es importante.
Los capítulos 5 y 6 están dedicados respectivamente al modelado predictivo y a la toma de decisiones. Esos capítulos abarcan las partes inteligentes de la receta numérica, que cuentan con técnicas de machine learning y técnicas de optimización matemática. Finalmente, el séptimo y actual capítulo está dedicado a la ejecución de una iniciativa de Supply Chain Quantitativa cuyo propósito es precisamente poner una receta numérica en producción y mantenerla posteriormente. En la conferencia anterior, hemos cubierto lo que se necesita para iniciar la iniciativa, estableciendo los fundamentos adecuados a nivel técnico. Esto implica la configuración de una tubería de extracción de datos. Hoy, queremos cruzar la línea de meta y poner esta receta numérica en acción.

Comenzaremos con un breve resumen de la conferencia anterior y luego procederemos con tres aspectos importantes de las etapas finales de la iniciativa. El primer aspecto se trata del diseño de la receta numérica. Sin embargo, no hablaré del diseño de los componentes numéricos de la receta, sino del diseño del proceso de ingeniería en sí, que rodea la receta numérica. Veremos cómo abordar el desafío para darle a la iniciativa la oportunidad de que emerja una solución satisfactoria.
El segundo aspecto se refiere al correcto despliegue de la receta numérica. De hecho, la empresa comienza con un proceso manual y terminará con uno automatizado. Un despliegue adecuado puede mitigar en gran medida el riesgo asociado con esta transición o, mejor dicho, mitigar el riesgo asociado a una receta numérica que resultara defectuosa, al menos inicialmente.
El tercer aspecto se refiere al cambio que debe ocurrir en la empresa una vez que se implemente la automatización. Veremos que los roles y las misiones de las personas en la división de supply chain deben experimentar un cambio sustancial.
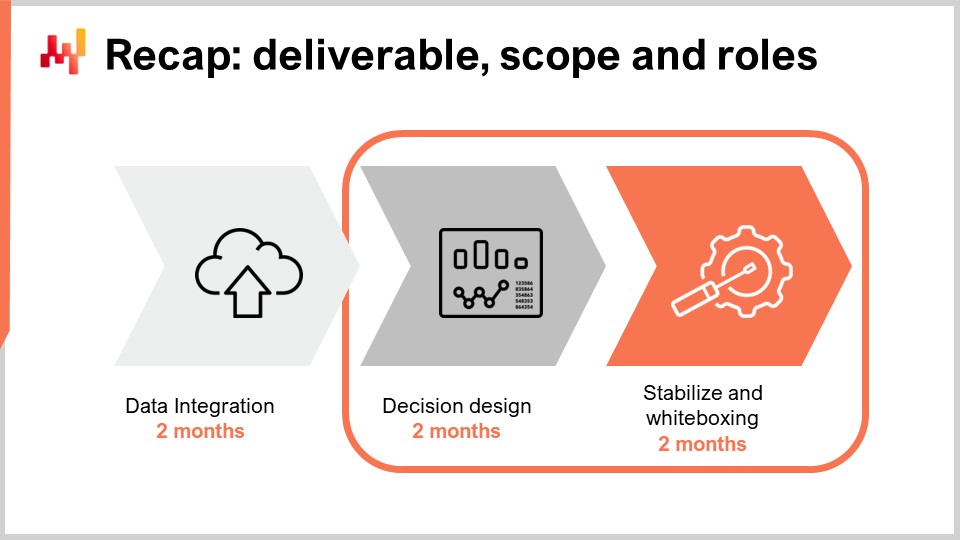
En la conferencia anterior, hemos visto cómo iniciar una iniciativa de Supply Chain Quantitativa. Repasemos los aspectos más importantes. El entregable es una receta numérica operativa, que es un software que impulsa una clase de decisiones de supply chain, por ejemplo, la reposición de inventario. Esta receta numérica, una vez puesta en producción, proporcionará la automatización que buscamos. Las decisiones no deben confundirse con artefactos numéricos como los forecast de demanda, que son meros resultados intermedios que pueden contribuir al cálculo de las propias decisiones.
El alcance de la iniciativa debe estar alineado tanto con la supply chain, entendida como un sistema, como con su paisaje aplicativo subyacente. Prestar atención a las propiedades del sistema de la supply chain es fundamental para evitar desplazar problemas en lugar de resolverlos. Por ejemplo, si la optimización de inventario de una tienda en una retail chain se realiza en detrimento de las otras tiendas, entonces dicha optimización carece de sentido. Además, prestar atención al paisaje aplicativo es importante porque debemos minimizar la cantidad inicial de esfuerzos en el manejo de datos. Los recursos de IT son casi siempre un cuello de botella, y debemos tener cuidado de no agravar esta limitación.
Finalmente, hemos identificado cuatro roles para esta iniciativa, a saber: el supply chain executive, el data officer, el supply chain scientist, y el supply chain practitioner. El supply chain executive es el responsable de la estrategia, la conducción del cambio y arbitra las decisiones de modelado. El data officer se encarga de configurar la tubería de datos, que pone a disposición de la capa analítica los datos transaccionales relevantes. En esta conferencia, asumimos que la tubería de datos ya ha sido configurada. El supply chain scientist está a cargo de la implementación de la receta numérica, que incluye mucha instrumentación, no solo los aspectos algorítmicos inteligentes. Por último, el supply chain practitioner es una persona involucrada en el proceso manual de toma de decisiones. Esta persona típicamente desempeña un rol de supply and demand planner, aunque la terminología varía. Al inicio de la iniciativa, se espera que transicione hacia el rol de network manager para el final de la iniciativa. Repasaremos este punto más adelante en la conferencia.

Las supply chains son bastante favorables en lo que respecta a la automatización de los procesos de toma de decisiones. Existen numerosas decisiones mundanas y altamente repetitivas que son de naturaleza cuantitativa. Desafortunadamente, la perspectiva de modelado ofrecida en la mayoría de los libros de texto de supply chain suele ser demasiado simplista. No estoy diciendo que las técnicas de los libros de texto sean demasiado simples o simplistas. Sin embargo, solo quiero decir que el tipo de problemas presentados en esos libros tiende a ser simplista. Consideremos, por ejemplo, una situación de reposición de inventario. La perspectiva de los libros de texto busca la política de inventario óptima para calcular cuántas unidades deben reordenarse. Esto está bien, pero con frecuencia es una respuesta bastante incompleta.
Por ejemplo, puede que tengamos que decidir si las mercancías se enviarán por aire o por mar, siendo ambos modos de transporte un compromiso entre el lead time y el costo de transporte. Puede que tengamos que elegir un proveedor entre varios proveedores elegibles. Puede que tengamos que determinar el plan de envío exacto con varias fechas de envío si la cantidad es lo suficientemente grande como para justificar varios envíos.
El tercer capítulo de esta serie, un capítulo dedicado a las personae de supply chain, presentó vistas detalladas de situaciones reales de supply chain en las que vemos que casi siempre existen sutilezas más allá de escoger una única cantidad para un determinado SKU. Así, el supply chain scientist, con la ayuda del supply chain practitioner y el supply chain executive, debe comenzar descubriendo la forma completa de la decisión. La forma completa de la decisión debe incluir todos los elementos que contribuyen a moldear la operación real de la supply chain. Descubrir la forma completa de la decisión es difícil.
Primero, la división del trabajo, tal como se implementa en la mayoría de las empresas que operan una gran supply chain, usualmente fragmenta los diversos aspectos de la decisión entre varios empleados y, a veces, entre varios departamentos. Por ejemplo, una persona elige la cantidad a reordenar, mientras que otra persona decide qué proveedor recibe la orden de compra.
En segundo lugar, los aspectos más sutiles de la decisión, como solicitar al proveedor que agilice el pedido cuando ha habido un aumento en la demanda, tienden a pasarse por alto porque los supply chain practitioner no se dan cuenta de que esos aspectos también pueden y deben automatizarse. Sugiero que la descripción de esta forma completa de la decisión se escriba, no como una serie de diapositivas, sino como un texto en sí mismo. En particular, el texto debe aclarar el “por qué”. ¿Qué está en juego exactamente con cada aspecto de la decisión? De hecho, mientras que algunos aspectos de la decisión pueden ser relativamente obvios, como la cantidad en un reorden, otros aspectos pueden ser pasados por alto u olvidados. Por ejemplo, un proveedor podría ofrecer, por un precio, la opción de devolver las mercancías dentro de los seis meses si los paquetes permanecen intactos. Ejercer o no esta opción debería ser parte de la decisión, pero puede olvidarse fácilmente.

No identificar la forma completa de la decisión de supply chain o, peor aún, caracterizarla erróneamente, es una de las maneras más seguras de hacer fracasar la iniciativa. En particular, la respuesta impulsada por el legado es uno de los errores más frecuentes que ocurre en las grandes empresas. La esencia de la respuesta impulsada por el legado es adoptar una forma de decisión que en realidad no tiene sentido para la empresa y su supply chain, pero que se adopta de todos modos porque la forma se ajusta a un software transaccional existente o a un proceso existente dentro de la organización.
Por ejemplo, se puede decidir que la reposición de inventario se controle mediante el cálculo de niveles de safety stock en lugar de calcular directamente las cantidades reales a reordenar. Calcular los safety stocks puede parecer más fácil porque esos safety stocks ya existen dentro del ERP. Así, si los valores de safety stock se volvieran a calcular, dichos valores podrían ser fácilmente inyectados en el ERP, sobrescribiendo cualquier fórmula que se utilizara en el DRP.
Sin embargo, los safety stocks tienen importantes deficiencias. Incluso algo tan básico como una cantidad mínima de pedido (MOQ) no encaja en una perspectiva de safety stock. Al menos, esta implementación se favorece no por un software, sino por procesos preexistentes en la organización.
Por ejemplo, una red de retail puede tener dos equipos de planificación: un equipo dedicado a la reposición de las tiendas y otro equipo dedicado a los niveles de personal de los centros de distribución. Sin embargo, esos dos problemas son fundamentalmente uno y el mismo. Una vez que se han elegido las cantidades de reorden para las tiendas, ya no hay margen para decidir cuántos empleados se necesitan para los centros de distribución. Así, ambos equipos tienen misiones fundamentalmente superpuestas. Esta división del trabajo funciona mientras los humanos participen. Los humanos son buenos para tratar con requisitos ambiguos. Sin embargo, esa ambigüedad representa un obstáculo masivo para cualquier intento de automatizar la reposición o los requerimientos de personal.
Este anti-patrón, la respuesta impulsada por el legado, es muy tentador porque minimiza la cantidad de cambio a implementar. Sin embargo, la automatización de la decisión cambia la forma en que la decisión debe abordarse. Con frecuencia, si se mantiene el diseño basado en el legado, la iniciativa de Supply Chain Quantitativa fracasará.
Primero, complica aún más el diseño de la receta numérica, que ya es una empresa bastante compleja. De hecho, los patrones que eran adecuados para una división del trabajo entre empleados humanos no son los adecuados para un software que es puramente mecánico.
Segundo, la respuesta impulsada por el legado también anula muchos de los beneficios potenciales asociados con la automatización. De hecho, en la supply chain se encuentran muchas ineficiencias en los límites existentes dentro de la empresa. La automatización elimina la necesidad de la mayoría de esos límites, que fueron introducidos debido a una forma específica de organizar la división del trabajo que no tiene sentido si se tiene una computadora que se encarga de todo. No permitas que decisiones tomadas hace dos o tres décadas dicten el futuro de tu supply chain.
Una vez que se ha caracterizado adecuadamente la forma de la decisión, el supply chain scientist comienza a elaborar la receta numérica propiamente dicha, aprovechando los datos transaccionales históricos. En esta serie de conferencias, hay dos capítulos dedicados a los detalles de las técnicas algorítmicas que pueden usarse para aprender y optimizar. No volveré a revisar esos elementos hoy. Basta con decir que el supply chain scientist toma una serie de decisiones basadas en su juicio para crear una receta numérica inicial basada en su conocimiento y experiencia y también en las herramientas que están disponibles para los supply chain scientists.
Con las herramientas y técnicas adecuadas, este borrador inicial puede y debe implementarse en cuestión de días, a lo sumo unas pocas semanas. De hecho, no estamos hablando de investigación avanzada tratando de descubrir algún tipo de técnica novedosa, sino simplemente de elaborar una adaptación de técnicas conocidas que abarquen las especificidades de la supply chain en cuestión. En efecto, la receta numérica debe abarcar de manera muy estricta los detalles de la decisión tal como han sido identificados en su forma completa.
Incluso considerando a un supply chain scientist muy competente que utilice las mejores herramientas que el money can buy, es inútil esperar que la receta numérica sea correcta en el primer intento. En efecto, las supply chains son demasiado complejas y oscuras, especialmente en sus representaciones digitales, para acertar con una receta numérica en el primer intento. Los métodos numéricos introspectivos, como tener métricas y benchmarks, no pueden detectar una mala interpretación por parte del supply chain scientist de un dato.
Para cada columna en cada tabla obtenida del sistema transaccional que opera la empresa, usualmente hay varias maneras posibles de interpretar esos datos. Considerando que estamos hablando de decenas de columnas que deben integrarse en la receta numérica, es seguro que ocurran errores. La única forma de evaluar la corrección de la receta numérica es ponerla a prueba y obtener retroalimentación del mundo real. Esto se discutió en el segundo capítulo de esta serie en la conferencia titulada “Experimental Optimization”.
Así, el supply chain scientist debe colaborar con el supply chain practitioner para identificar situaciones en las que la receta numérica en su forma actual aún arroje resultados insensatos. En términos generales, el supply chain scientist implementa un dashboard que consolida la decisión tal como sería tomada hoy por la receta numérica, y el supply chain practitioner intenta identificar puntos que parecen insensatos.
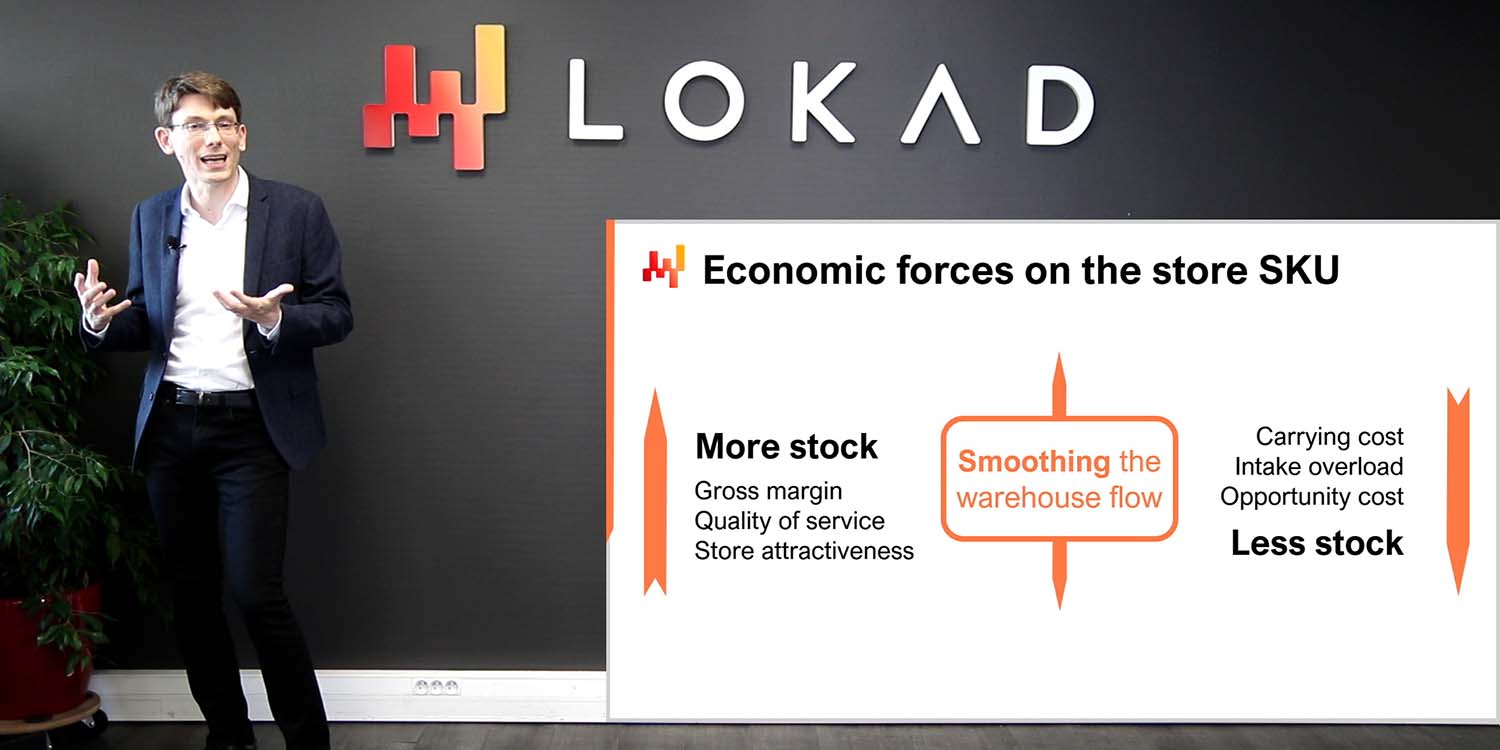
Basándose en esta retroalimentación, los supply chain scientist instrumentan aún más la receta numérica. La instrumentación toma la forma de indicadores que intentan responder a la pregunta: ¿por qué se tomó esta decisión aparentemente insensata en este contexto? Con base en esta instrumentación, se hace posible decidir si la receta numérica necesita ser corregida, por ejemplo, porque un impulsor económico está modelado de manera incorrecta, o si la decisión aparentemente insensata es en realidad correcta, solo que diferente a la forma en que se hacía en la empresa hasta ahora.
La optimización experimental es un proceso altamente iterativo. Como regla general, con las herramientas adecuadas, un único supply chain scientist a tiempo completo debe ser capaz de presentar una nueva iteración de la receta numérica cada día al supply chain practitioner. Si la receta numérica está debidamente instrumentada, a medida que avanza la iniciativa, el supply chain practitioner no debería necesitar más de dos horas al día para proporcionar retroalimentación sobre la última iteración de la receta numérica.
La iteración se detiene cuando la receta numérica ya no genera resultados insensatos, es decir, cuando el supply chain practitioner no puede identificar decisiones que sean demostrablemente perjudiciales para la empresa. La ausencia de decisiones insensatas puede parecer un estándar bajo en comparación con nuestro objetivo global de generar decisiones superiores en comparación con el proceso manual. Sin embargo, recordemos que la receta numérica ha sido diseñada desde el principio para realizar explícitamente una optimización matemática del interés económico a largo plazo de la empresa. Si los resultados son sensatos, entonces la optimización está funcionando, y lo más importante, también demuestra que el criterio de optimización es, en cierto modo, correcto.

Aunque el proceso de ingeniería altamente iterativo de la receta numérica puede solucionar numerosos problemas presentes en la implementación inicial, las iteraciones por sí solas no son suficientes si la perspectiva en la que se basa la optimización es incorrecta. En esta serie de conferencias, ya he dicho que la optimización debe realizarse según una métrica financiera, es decir, una métrica expresada en euros o dólares. Sin embargo, permítanme aclarar esta afirmación: no utilizar una métrica financiera es un error que pone en peligro toda la iniciativa.
Desafortunadamente, las grandes organizaciones suelen alejarse de los indicadores financieros. En cambio, prefieren los indicadores aspiracionales, que se expresan como un porcentaje y representan una especie de perfección que se lograría si se alcanzara, según el caso, cero por ciento o 100 por ciento. Naturalmente, la perfección no es de este mundo, y esta situación límite nunca se alcanzará. Service levels son, por ejemplo, el arquetipo del indicador aspiracional. El 100% service level es imposible de alcanzar, ya que requeriría una cantidad irrazonable de stock.
Algunos directivos en las grandes empresas adoran estos indicadores aspiracionales. Los equipos se reúnen rutinariamente para discutir qué se puede hacer para mejorar aún más dichos indicadores. Como estos indicadores dependen invariablemente de factores que están fuera del control de la empresa, pueden ser revisados interminablemente. Por ejemplo, los niveles de servicio dependen del volumen de demanda expresado por los clientes y de los tiempos de entrega ofrecidos por los proveedores. Ni la demanda ni los tiempos de entrega están bajo el control total de la empresa.
Esos indicadores aspiracionales funcionan, en cierta medida, como objetivos corporativos cuando los humanos permanecen en el proceso de toma de decisiones, ya que, en primer lugar, no prestan demasiada atención a dichos indicadores. Por ejemplo, incluso si todos están de acuerdo en que se debe aumentar el nivel de servicio, los planificadores seguirán manteniendo muchas excepciones no documentadas. El nivel de servicio se incrementará sistemáticamente, excepto si el inventory risk es demasiado alto, si la minimum order quantity es demasiado alta, si el producto está a punto de ser descontinuado o si no queda presupuesto para el producto, etc.
Desafortunadamente, esos indicadores aspiracionales se vuelven veneno al implementar un proceso automatizado. De hecho, dichos indicadores son incompletos y no reflejan lo que en realidad es deseable para la empresa. Por ejemplo, alcanzar un nivel de servicio del 100% no es deseable porque crearía excesos de stock masivos para la empresa. Es posible —no imprudente, sino posible— tratar de reimplementar todas esas restricciones, todas esas excepciones sobre los indicadores aspiracionales. Es decir, tener la receta numérica orientada a los indicadores aspiracionales con muchas restricciones que imitan lo que podría estar ocurriendo en la mente de un planificador. Por ejemplo, podríamos definir la regla que establece que se debe aumentar el nivel de servicio siempre que mantengamos el inventario por debajo de lo equivalente a cuatro meses de stock. Sin embargo, esta estrategia para el diseño y la implementación real de la receta numérica es sumamente frágil. La optimización financiera directa es un camino mucho más seguro y superior.

Para lograr una colaboración eficiente entre el supply chain practitioner — o, más probablemente, practitioners (en plural) — y el Supply Chain Scientist, recomiendo adoptar desde el principio una estrategia de ejecución dual. La receta numérica debe ejecutarse diariamente junto al proceso manual preexistente. Con la ejecución dual, la empresa genera efectivamente la decisión dos veces mediante dos procesos en competencia. Sin embargo, a pesar de la fricción, una ejecución dual ofrece beneficios sustanciales. Primero, el supply chain practitioner necesita decisiones recién generadas que se correspondan con la situación actual para poder hacer su evaluación. De lo contrario, el practitioner ni siquiera podría entender la decisión automatizada, ni identificar las partes que son absurdas. De hecho, desde la perspectiva del practitioner, las decisiones que reflejan la situación del supply chain de hace tres semanas son historia antigua. Se gana poco al pasar horas revisitando los niveles de stock anteriores.
Por el contrario, si las decisiones automatizadas son frescas y reflejan la situación actual, entonces dichas decisiones compiten con las que el practitioner está a punto de tomar manualmente. Estas decisiones automatizadas pueden considerarse como sugerencias por el momento.
En segundo lugar, la ejecución diaria de la receta numérica garantiza que toda la canalización de datos reciba una prueba funcional completa cada día. De hecho, la receta numérica no solo debe arrojar resultados sensatos; también debe operar sin fallos desde la perspectiva de la infraestructura de IT. En efecto, los supply chain son lo suficientemente caóticos; la receta numérica no debe añadir su propia capa de caos encima. Poner la receta en lo que equivale a condiciones de producción lo antes posible asegura que problemas poco frecuentes se manifiesten temprano y, de ese modo, el responsable de datos y los Supply Chain Scientist tengan la oportunidad de solucionarlos de inmediato. Como regla general, al final del primer tercio —es decir, al finalizar el tercer mes tras comenzar una iniciativa Supply Chain Quantitativa— la ejecución dual debería estar en marcha, incluso si la receta numérica aún no está lista para ser puesta en producción.
Asimismo, al final del primer mes de la ejecución dual, si el Supply Chain Scientist hace un trabajo adecuado, entonces el practitioner debería comenzar a observar patrones en la lista de decisiones automatizadas que, de otro modo, se habrían pasado por alto, incluso si aún existen algunas líneas absurdas que requieren mayor mejora de la receta numérica.

Una vez que la ejecución dual esté en marcha, se espera que el supply chain practitioner dedique algo de tiempo —una o dos horas al día— a revisar las decisiones generadas por la receta numérica, e intente identificar las partes que aún no son del todo sensatas. Sin embargo, a veces la situación simplemente no estará clara. Una decisión resulta sorprendente —quizás la receta numérica sea lenta, o quizás no lo sea. El practitioner se siente inseguro y, en ese caso, debería pedir al Supply Chain Scientist que añada más instrumentación para arrojar luz sobre el caso. Este proceso es exactamente lo que se denomina en esta serie de conferencias como white-boxing de la receta numérica. White-boxing es un proceso mediante el cual se hace la receta numérica lo más transparente posible para los accionistas. White-boxing es algo bueno —incluso esencial— para generar confianza en la receta numérica.
Asumiendo que las decisiones automatizadas se recogen en una tabla en el dashboard, la forma más típica de instrumentación será agregar columnas adicionales junto a las columnas de decisión. Por ejemplo, si estamos considerando las cantidades de reorden, existen columnas de instrumentación evidentes que se pueden considerar, tales como la cantidad de stock disponible, el tiempo de entrega promedio esperado, la demanda promedio esperada en términos diarios, etc. Esta instrumentación es crítica para que el practitioner pueda hacer evaluaciones rápidas sobre la sensatez de las decisiones automatizadas. Sin embargo, debemos ser conscientes de la cantidad de instrumentación que se está acumulando sobre la receta numérica. Cada indicador que se introduce para adornar la decisión automatizada como parte del proceso de white-boxing sobrecarga un poco más la visión de las propias decisiones. Demasiado de algo bueno puede volverse malo. Si, después de dos meses de ejecución, el practitioner sigue solicitando rutinariamente más instrumentación mientras la canalización de datos ya se ha estabilizado, entonces podríamos tener un problema.
La causa raíz del problema puede estar asociada a los componentes inteligentes de la receta numérica. En los capítulos 5 y 6 de esta serie, hemos visto que no todas las técnicas y modelos nacen iguales en términos de interpretabilidad. Muchos modelos son muy opacos por diseño, incluso para los data scientists que los manejan. No voy a retomar hoy las clases de modelos que cumplen con los requisitos en cuanto a interpretabilidad se refiere. Para efectos de esta discusión, asumiré simplemente que los modelos incorporados en la receta numérica son adecuadamente interpretables desde una perspectiva de supply chain. En este contexto, cuando la iniciativa parece estancarse debido a una avalancha interminable de solicitudes de más instrumentación, la causa raíz más probable es la parálisis por análisis. El supply chain practitioner está sobreanalizando su evaluación de la receta numérica. Esa es la esencia de la parálisis por análisis. El practitioner está sometiendo la receta numérica a un grado de escrutinio que excede lo que se hace en el proceso manual. Es responsabilidad del ejecutivo de supply chain asegurarse de que la iniciativa no se quede atrapada en la parálisis por análisis. Y, si llegara a ocurrir —y es posible—, también es responsabilidad del ejecutivo de supply chain recordar amablemente al equipo que las decisiones impulsadas por humanos también son imperfectas. Buscamos una mejora respecto al proceso manual, no la perfección.

Una vez que la receta numérica ya no genere decisiones absurdas y que las propias decisiones cuenten con lo que se percibe como un nivel adecuado de instrumentación, es momento de asumir progresivamente el control del proceso automatizado en reemplazo del proceso manual. Como regla general, este punto debería alcanzarse entre dos y cuatro meses después del inicio de la ejecución dual. Desde el primer día de la ejecución dual, la receta numérica debería haber estado operando en todo el alcance de la iniciativa. Así, en teoría, la transición de decisiones manuales a automatizadas podría ocurrir prácticamente de la noche a la mañana.
Sin embargo, la práctica frecuentemente difiere de la teoría. Si hablamos de una empresa de gran tamaño, es importante trasladar todas las decisiones de un proceso a otro de la noche a la mañana. Los supply chain son muy complejos y debemos esperar lo inesperado. Por ello, es más prudente comenzar con un alcance operativo pequeño, como una sola categoría de producto, y expandirse a partir de ahí. Para las primeras etapas de la toma, es apropiado dedicar una o quizás dos semanas para cada iteración. Tanto el supply chain practitioner como los Supply Chain Scientist deben inspeccionar cuidadosamente cómo se implementan las decisiones automatizadas. Y si, dentro de este pequeño alcance operativo, no sucede nada inesperado —incluso si la receta numérica ya no genera más decisiones aparentemente absurdas en este punto—, aún podrían presentarse problemas en la forma en que las decisiones automatizadas se integran en los sistemas transaccionales. Una vez que la receta numérica haya estado impulsando la producción durante unas semanas, incluso si el alcance era relativamente pequeño, es apropiado acelerar las iteraciones.
La toma del control puede experimentar incrementos más sustanciales en cada iteración y la duración de las iteraciones en sí mismas puede comprimirse, posiblemente hasta llegar a dos iteraciones por semana. De hecho, el marco temporal total de la transición hacia el proceso automatizado debe mantenerse razonablemente corto. De lo contrario, la demora en la toma introduce otras clases de riesgo. El supply chain sigue cambiando, así como su panorama aplicativo. Como regla general, la toma no debería superar los dos a cuatro meses, dependiendo de la escala y complejidad de la empresa.

A medida que el supply chain transita de un proceso manual a uno automatizado, es necesario que ocurran también una serie de cambios dentro de la organización. Las grandes organizaciones son notoriamente difíciles de cambiar, pero existen dos direcciones distintas para el cambio. La organización puede añadir un proceso o puede eliminar uno.
Eliminar un proceso es mucho más complicado que añadir uno. Añadir un proceso implica contratar personas, y la única oposición a esto provendrá de la cúpula de la empresa, ya que representa una línea de presupuesto adicional. Eliminar un proceso significa despedir personas o, al menos, eliminar sus puestos de trabajo, manteniendo y reciclando a los empleados. Al eliminar un proceso, la situación se invierte. Se puede esperar oposición de toda la organización, excepto de sus máximos directivos.
La forma más sencilla de poner en producción una receta numérica implica mantener una ejecución dual de forma indefinida. Se preserva el proceso manual existente, y ahora se aprovechan las decisiones automatizadas como simples sugerencias. Este enfoque resulta seguro e incluso puede proporcionar ganancias marginales, ya que las sugerencias automáticas ofrecen algunos beneficios al ayudar a los practitioners a identificar algunos de los peores errores asociados con el proceso manual. Sin embargo, mantener la ejecución dual de forma indefinida resulta en una sedimentación del proceso, donde la organización fracasa en eliminar algo.
Para que las prácticas del supply chain se conviertan en un emprendimiento capitalista —un activo productivo— la organización debe dejar atrás el proceso manual. El proceso manual es un callejón sin salida; no mejorará con el tiempo. La organización debe redirigir todo el tiempo y la energía dedicados al proceso manual hacia la mejora continua del proceso automatizado. Mantener el proceso manual únicamente obstaculiza la capacidad de aprovechar al máximo la automatización y lo que ésta tiene para ofrecer. En particular, mientras sigan ocurriendo intervenciones manuales, nada es verdaderamente reproducible y, por lo tanto, nada se puede optimizar de verdad, ya que la optimización requiere reproducibilidad.

La automatización de decisiones, incluso cuando se trata de decisiones mundanas y repetitivas, representa un cambio de paradigma en la manera de gestionar los supply chain. El cambio es tan significativo que resulta tentador descartarlo por completo. Sin embargo, el cambio está en camino. Dos siglos de mecanización progresiva de nuestra economía han dejado muy claro: una vez que algo se puede automatizar, se automatiza. Con el tiempo, no hay vuelta atrás a la situación anterior. Lokad opera cerca de 100 supply chain en configuraciones altamente automatizadas, brindando la prueba viviente de que la automatización de supply chain ya está aquí; sólo que aún no está generalizada.
Uno de los mayores cambios que deben implementar nuestros clientes concierne al rol del planificador de supply and demand. La forma convencional de estos roles, que recibe diversos nombres en la industria —como inventory managers, category managers o supply managers—, implica que un empleado se haga cargo de una lista reducida de SKUs, la cual puede variar de 50 a 5,000 SKUs dependiendo del volumen de flujo. El planificador es responsable de la disponibilidad continua de los SKUs en la lista, ya sea activando la reposición de inventario o las tandas de producción, o ambos. La división del trabajo es sencilla: a medida que aumenta el número de SKUs, también aumenta el número de planificadores.
El enfoque del planificador es interno. Esta persona dedica mucho tiempo a revisar números, ya sea consolidados en un spreadsheet o mostrados en dashboards. Los planificadores podrían estar aprovechando herramientas de software empresarial, pero casi invariablemente finalizan sus decisiones dentro de hojas de cálculo que ellos mismos mantienen. El propósito de la hoja de cálculo es proporcionar un contexto numérico accesible y totalmente personalizable para apoyar las decisiones tomadas por el planificador. La rutina del planificador consiste en revisar toda la lista corta de SKUs cada semana, posiblemente cada día.
Sin embargo, una vez que la receta numérica esté en producción, no tiene sentido mantener este calendario de revisión manual de la lista corta de SKUs por parte del planificador. El planificador debería transformarse en un network manager. Liberado en gran medida de las rutinas relacionadas con los datos, el network manager puede invertir su tiempo en comunicarse con la red, tanto aguas arriba con los proveedores como aguas abajo con los clientes, y en revisar los supuestos que respaldan el diseño de la receta numérica. El peligro principal que amenaza la receta numérica no es perder su accuracy; es perder su relevancia. El network manager intenta identificar aquello que no se puede ver a través de los lentes de los datos, al menos aún no. No se trata de microgestionar la receta numérica ni de hacer ajustes numéricos a las decisiones mismas; se trata de identificar factores que permanecen ignorados o malinterpretados por la receta numérica.
El network manager consolida conocimientos destinados tanto a los Supply Chain Scientist como a los ejecutivos de supply chain. Basándose en estos conocimientos, los Supply Chain Scientist pueden ajustar o refactorizar la receta numérica para reflejar una comprensión renovada de la situación.

Desafortunadamente, oponerse a la implementación de la receta numérica no es la única forma en que el planificador puede mantener el status quo. Otra estrategia consiste en continuar con la misma rutina laboral: seguir revisando la lista corta de SKUs pero, en lugar de anular las decisiones, simplemente informar de todos los hallazgos, si los hubiera, al Supply Chain Scientist. A la gente le encantan sus hábitos, y a los empleados de las grandes empresas, aún más.
El problema con este enfoque es que, una vez que la automatización está en marcha, los Supply Chain Scientist pueden observar directamente los resultados del proceso automatizado, tanto los buenos como los malos. El planificador y los scientists tienen acceso a los mismos datos; sin embargo, el scientist, por definición, tiene acceso a herramientas analíticas más potentes en comparación con el planificador. Así, una vez que se implementa la automatización, el valor añadido de los comentarios del planificador disminuye rápidamente en lo que respecta a la mejora continua de la receta numérica.
Dado que el planificador ahora tiene más tiempo para analizar, es probable que solicite que el scientist elabore más indicadores y dashboards. Esto conduce al “KPI tourism”: aumentar el número de indicadores a revisar hasta que el mero hecho de examinarlos se convierte en un trabajo a tiempo completo. Esta carga de trabajo también se vuelve una distracción para los scientists. En esta etapa, tras la implementación, mejorar la receta numérica requiere una buena comprensión de las debilidades de la implementación real. El scientist está idealmente posicionado para realizar este trabajo, mientras que el planificador es mucho menos adecuado. Para ser de ayuda, el planificador debería convertirse en un network manager y, como se señaló anteriormente, comenzar a mirar hacia el exterior. De lo contrario, la posición del planificador se degrada a KPI tourism.

El trabajo del ejecutivo de supply chain está definido en gran medida por la organización y sus procesos. Mientras que las decisiones mundanas sigan siendo el resultado de un proceso manual, no hay alternativa para la organización más que adoptar una división del trabajo en la que cada planificador opere sobre su propia lista corta de SKUs. Así, el ejecutivo de supply chain es, ante todo, el gerente de un equipo de planificadores. Si la empresa es lo suficientemente grande como para justificar una capa de mandos intermedios, entonces el ejecutivo podría estar gestionando a los planificadores de forma indirecta. Sin embargo, la división de supply chain sigue siendo la misma: una pirámide con planificadores en la base. Por necesidad, ser un buen ejecutivo de supply chain significa ser un buen coach para esos planificadores. El ejecutivo no está impulsando las decisiones de supply chain; son los planificadores quienes toman dichas decisiones. Mejorar las decisiones es, fundamentalmente, una cuestión de que se realice un mejor trabajo por parte de los planificadores.
Los proveedores de software de supply chain argumentan que sus herramientas pueden marcar la diferencia. Sin embargo, como ya se ha señalado, las hojas de cálculo se utilizan casi siempre para tomar esas decisiones, sin importar cuántas herramientas se hayan implementado en la empresa. Por lo tanto, en última instancia, todo se reduce a lo que los planificadores hacen con sus propias hojas de cálculo.
Una vez que una clase de decisión de supply chain ha sido automatizada, el trabajo del ejecutivo de supply chain cambia sustancialmente. El trabajo ya no consiste en entrenar a un gran equipo de planificadores que todos realizan variaciones del mismo trabajo. Ahora, el trabajo del ejecutivo de supply chain es hacer lo que sea necesario para que la empresa aproveche al máximo su automatización de supply chain. El ejecutivo debe convertirse en el propietario del producto de software que impulsa efectivamente las decisiones de supply chain.
De hecho, el enfoque y la contribución de los Supply Chain Scientist son internos, al igual que las contribuciones anteriores de los planificadores. Los scientists solo pueden mejorar la receta numérica desde adentro. No se les puede esperar que refactoreen el panorama aplicativo o los procesos generales de la empresa. Es tarea del ejecutivo de supply chain hacer que esto suceda. En particular, el ejecutivo se vuelve responsable de establecer una hoja de ruta para la mejora continua de la automatización.
Mientras que las decisiones fueran impulsadas por planificadores, la hoja de ruta era en gran medida evidente por sí misma. Los planificadores continuarían haciendo lo que hacen, y la misión para el próximo trimestre sería, en gran medida, similar a la misión que tuvieron durante el trimestre anterior. Sin embargo, una vez que la automatización está en marcha, mejorar la receta numérica casi siempre implica hacer algo que nunca se había hecho antes. Al desarrollar software, si lo haces bien, no te repites: avanzas. Una vez que se ha adquirido una perspectiva, se debe buscar un nuevo tipo de perspectiva. La misión de las personas que trabajan bajo un dueño de producto de software cambia continuamente por diseño.
Las nuevas direcciones y objetivos no caen del cielo. Es responsabilidad del ejecutivo de supply chain dirigir el desarrollo del producto de software de supply chain en direcciones favorables.

La mayoría de los problemas cotidianos que enfrentan las supply chain son problemas de software. Este ha sido el caso por más de una década en los países desarrollados, incluso en empresas donde todas las decisiones se derivan manualmente de hojas de cálculo. Esta situación es una consecuencia directa de que las supply chain se encuentran en la encrucijada de muchos sistemas: el ERP, CRM, WMS, OMS, PIM y docenas de acrónimos de tres letras que adoran los proveedores de software empresarial para describir las diversas piezas de software empresarial que contienen todos los datos de interés para fines de supply chain. Las supply chain exigen una perspectiva de extremo a extremo del negocio y, como resultado, terminan conectando la mayor parte del panorama aplicativo de la empresa. Sin embargo, la mayoría de las empresas parecen seguir eligiendo líderes de supply chain que saben muy poco sobre software. Aún peor, algunos de esos líderes no tienen intención de aprender nunca nada sobre software. Esta situación es el anti-patrón del “analytics supply chain bus”. Cuando digo software, se debe entender como el tipo de tema que cubrí en el cuarto capítulo de esta serie de conferencias, con temas que van desde hardware de computación hasta ingeniería de software.
Hoy en día, la falta de conocimientos de software en la alta dirección de la supply chain significa enormes problemas para la empresa. O bien, la dirección cree que puede funcionar perfectamente sin experiencia en software, o bien, cree que puede hacerlo perfectamente con experiencia externa en software. En cualquier caso, las consecuencias no son buenas.
Si la alta dirección cree que puede funcionar perfectamente sin experiencia en software, entonces la empresa perderá terreno en todos los canales electrónicos, tanto en el lado de la venta como en el de la compra. Sin embargo, dado que muchos empleados se dan cuenta de que esos canales electrónicos importan, guste o no a la alta dirección, el shadow IT será rampante. Además, ten la seguridad de que, para la próxima gran transición de software dentro de la empresa, esta transición estará sumamente mal gestionada, lo que resultará en extensos períodos de baja calidad de servicio debido a problemas relacionados con el software que se deberían haber evitado por completo desde el principio.
Si la dirección cree que puede funcionar perfectamente con la experiencia en software de terceros, es marginalmente mejor que el caso anterior, pero no por mucho. Confiar en expertos externos está bien si se tiene un problema estrecho y autocontenido, como asegurar que el proceso de contratación cumpla con alguna regulación. Sin embargo, los desafíos de supply chain no son autocontenidos; se extienden por toda la empresa e, incluso, con mucha frecuencia, más allá de ella. La trampa más frecuente asociada a pensar que la experiencia se puede externalizar consiste en empujar cantidades irrazonables de dinero a grandes proveedores de software, esperando que ellos resuelvan los problemas por ti. Sorpresa: no lo harán. La única cura para estos problemas es un mínimo de alfabetización en software por parte de la alta dirección.
Hoy hemos esbozado cómo llevar las decisiones automatizadas de supply chain a producción. El proceso es una mezcla de diseño, ingeniería y gestión del cambio. Es un camino difícil, con numerosos senderos aparentemente fáciles o tranquilizadores que conducen directamente al fracaso de la iniciativa. Para tener éxito, la iniciativa requiere una evolución sustancial de los roles y las misiones tanto de la alta dirección de supply chain como de sus empleados.
Para las empresas que están profundamente arraigadas en sus procesos manuales, llevar a cabo una iniciativa de este tipo puede parecer insuperable, y por lo tanto, mantener el status quo puede parecer la única opción. Sin embargo, no estoy de acuerdo con esta conclusión en dos aspectos. Primero, aunque el camino es arduo, es barato, al menos en comparación con la mayoría de las inversiones empresariales. Al reinvertir el costo anual de cinco planificadores de demanda, la empresa puede automatizar la carga de trabajo de 50 planificadores de demanda. Naturalmente, se puede confiar en que los grandes proveedores de software empresarial afirmen que se necesitan decenas de millones de dólares solo para comenzar, pero existen alternativas mucho más esbeltas. Segundo, el camino puede ser arduo, pero tampoco es realmente opcional. Las empresas que emplean ejércitos de oficinistas para tomar sus decisiones mundanas y repetitivas de supply chain también sufren largos tiempos de espera autoimpuestos debido a sus propios procesos internos. Esas empresas no se mantendrán competitivas frente a aquellas que han automatizado sus procesos rutinarios de toma de decisiones. La ventaja competitiva que se gana con la automatización siempre es modesta al principio; sin embargo, a medida que la automatización puede mejorarse con el tiempo, mientras que un proceso manual no puede, la ventaja competitiva se vuelve exponencialmente más fuerte con el tiempo. En este momento, las decisiones automatizadas de supply chain aún pueden percibirse como futuristas, pero dentro de dos décadas, lo contrario será cierto. Los procesos manuales se percibirán como restos anticuados de una era pasada.

Esto concluye la conferencia de hoy. Procederemos en un minuto con las preguntas. La próxima conferencia será la primera semana de noviembre, el miércoles, a las 3 p.m., hora de París, como de costumbre. Regresaremos al tercer capítulo con una persona de supply chain. Se tratará de una empresa ficticia llamada Stuttgart, que es una compañía del mercado de accesorios automotrices. Veremos que lo automotriz es la industria de las industrias, y presenta una serie de desafíos bastante específicos que, una vez más, no se reflejan adecuadamente en los libros de texto de supply chain.
Echemos un vistazo a las preguntas.
Pregunta: ¿Requiere Supply Chain Quantitativa su propia forma ideal de división del trabajo?
Sí, puede ser una transición gradual, pero la idea es que la división del trabajo que tenías con un proceso manual se definía por el hecho de que un planificador solo puede gestionar cierta cantidad de SKUs. A más SKUs, más planificadores. Esta es una división del trabajo muy simplista. Cuando tienes una empresa grande y quieres tener un proceso automatizado, la idea es que contarás con personas que se especialicen. Por ejemplo, un network manager puede convertirse en un especialista en la calidad del servicio tal como lo percibe el cliente. La percepción importa; no es la calidad abstracta del servicio, como los niveles de servicio. Quizás los clientes tengan su propia perspectiva al respecto, por lo que alguien puede especializarse en ello. Otro network manager puede especializarse en un ángulo específico en el que una coordinación e integración más estrechas con algunos proveedores podrían, por ejemplo, acortar los lead times y aportar nuevas opciones a la mesa. De repente, la división del trabajo se centra más en los muchos ángulos que deben estudiarse, revisarse y reanalizarse desde una perspectiva analítica. Puedes tener a varias personas trabajando en ello. Pero, de nuevo, no se trata de tener algo tan definido como una lista de SKUs. Es, además, la esencia de mejorar algo. Tal vez se necesite que haya varias personas para que puedan hacer brainstorming juntas e intentar identificar las mejores ideas y ordenarlas.
Pregunta: ¿El uso de porcentajes en lugar de métricas financieras ayuda a ocultar las ineficiencias del proceso legado? En ese caso, ¿qué tan probable es que la iniciativa tenga éxito?
Esa es una pregunta muy cargada. Una de las razones por las que las grandes empresas, y tantos gerentes dentro de ellas, aman esas métricas aspiracionales es que no se les asigna culpa. Una vez que tienes un indicador expresado como un porcentaje, nadie se da cuenta de que representa millones de dólares que se han perdido debido a un error específico cometido por una división particular dirigida por cierta persona, solo en el último trimestre. Estos porcentajes son increíblemente opacos, y es un verdadero desafío hacer que esas iniciativas tengan éxito porque, muy frecuentemente, una vez que se expresan en dólares o euros, se descubre el verdadero alcance de las ineficiencias, que puede ser absolutamente masivo.
En la experiencia de Lokad, para las empresas públicas que divulgaban todos los números al mercado, con más de 200 auditores certificando el valor del inventario, encontramos que los valores del inventario estaban desfasados en un 20% a favor de la empresa. Estamos hablando de una compañía con más de un millón de euros en inventario en sus libros. Lo increíble era que el inventario había sido auditado por más de 200 personas durante literalmente décadas, y todo había sido digitalizado también durante décadas.
Cuando descubres este tipo de cosas, es difícil, pero creo que la manera de abordarlo es ser firme con los problemas e indulgente con las personas. Las empresas tienen que aprender a ser suaves con las personas y realmente firmes con los problemas, en lugar de ignorar el problema y despedir a la gente.
Pregunta: Las grandes empresas utilizan muchos más KPIs de los que necesitan. Cuando implementas la iniciativa, ¿cómo cuestionas todos los KPIs?
Muy buena pregunta. Todos esos KPIs son una gran distracción que respalda el trabajo realizado manualmente por los planificadores. Una vez que tienes una receta numérica, ¿por qué te importarían todos esos KPIs? Todo lo que optimizas debería estar integrado en tus criterios financieros. Deberías tener una métrica que te indique, para cada decisión potencial, cuánto dinero está en juego, cuánto ganarás o perderás dependiendo del resultado de la decisión. En lugar de acumular una serie interminable de indicadores, si deseas refinar tu métrica financiera, puedes agregar un factor. Pero eso no significa que añadas una columna extra en el informe; simplemente significa que ajustas un poco atribuyendo un factor extra que suma o resta, de manera aditiva, unos pocos euros o dólares a los valores que asignas a una decisión determinada.
Fundamentalmente, todo lo que está fuera de estos objetivos financieros es ignorado por la receta numérica. La receta numérica está realizando un proceso de optimización matemática que optimiza de forma estricta un objetivo financiero. Eso es todo. Todos esos otros indicadores son ignorados. Una configuración automatizada deja mucho más claro que esos indicadores son inútiles. No se incorporan en la receta, no son considerados por la receta numérica, e incluso no forman parte del proceso de toma de decisiones. También se aclara que las métricas aspiracionales, como los niveles de servicio, son adversas. No puedes simplemente llevar tu calidad de servicio a un nivel de servicio del 100% porque no es un resultado deseable para la empresa. Cuando se hace correctamente, la automatización aclara lo que realmente se necesita en términos de indicadores, y te das cuenta de que no se requieren tantos. Además, debido a que hay menos personas involucradas en el proceso, la presión para seguir añadiendo indicadores es mucho menor. Otro aspecto de tener grandes equipos de planificadores es que cada persona tiende a tener uno o dos indicadores favoritos. Si tienes 200 personas y cada una desea que se añada un indicador para su conveniencia personal, terminas con 200 indicadores, lo cual es demasiado. Pero si solo cuentas con una décima parte de ese personal, la presión para acumular indicadores es mucho menor.
Pregunta: ¿Cómo entienden los proveedores de software de planificación de la demanda los ecosistemas de sus potenciales clientes, tales como los requerimientos de stock de seguridad, mientras realizan una personalización antes del despliegue en el cliente? Quiero decir, una vez que se implementa, no hay inconvenientes en términos de error de forecast.
La perspectiva clásica, que creo que fracasó en llevar la automatización a las decisiones de supply chain en los años 70, se basaba en la suposición de que una solución de software empaquetada podía abordar los problemas de las empresas. Creo firmemente que ese no es el caso. Una pieza de software empaquetada no puede adaptarse a ningún supply chain no trivial. Lo que sucede es que un proveedor de software empresarial, con algún tipo de módulo de optimización de inventario y forecast, intenta vender el producto a una empresa y, a medida que faltan características, las sigue añadiendo. Después de 10 años o más, terminan con un producto de software monstruoso y sobrecargado con cientos de pantallas y miles de valores de parámetros.
El problema es que, cuanto más complejo es el producto de software, más específicas son tus expectativas en términos de datos y de lo que la empresa debería tener. Cuanto más complejo es el producto de software, se vuelve más difícil integrarlo en la empresa cliente porque tienes un supply chain complejo con una gran cantidad de sistemas ya implementados y un producto de optimización de supply chain super complejo. Hay brechas y desajustes por todas partes.
La realidad es que la mayoría de las grandes empresas con las que he hablado han estado operando supply chains digitales en países desarrollados durante dos o tres décadas, y ya han implementado media docena de soluciones de software de planificación de la demanda, optimización de inventario y diseño de supply chain en las últimas dos o tres décadas. Así que, ya han estado allí y lo han hecho, no solo una vez, sino media docena de veces. Usualmente, las personas no han estado en la empresa el tiempo suficiente para darse cuenta de que estos procesos han ocurrido una y otra vez durante las últimas dos o tres décadas. Y, sin embargo, los procesos siguen siendo completamente manuales y a menudo dependen de herramientas como Excel. El problema no es el error de forecast; creo que es un diagnóstico erróneo del problema, ya que la idea de que puedas tener un forecast perfecto con un sistema u otro es ridícula. No es posible generar un forecast perfecto, y los humanos que manejan un supply chain manualmente tampoco disponen de información perfecta. No es porque seas un planificador de demanda humano que puedas forecastear perfectamente la demanda.
Los planificadores de la demanda son capaces de hacer su trabajo con forecasts que no son perfectos. Estas personas no son magos ni científicos super avanzados. Puede que no sean malos en lo que respecta al forecast, pero no hay razón para esperar que, en promedio, los planificadores de la demanda en esta industria, que emplea a cientos de miles de personas en todo el mundo, sean todos super talentosos y capaces de generar forecasts de demanda increíblemente precisos. Lo que hace que el sistema funcione es que estas personas tienen sus heurísticas y formas de manejar manualmente el supply chain que sobreviven a pesar de disponer de forecasts pobres.
El objetivo en tu configuración automatizada es tener un sistema que funcione perfectamente, incluso si los forecasts no son tan buenos en primer lugar. Esta es la esencia del enfoque de forecast probabilístico; no se trata de refinar la precisión, sino de reconocer y aceptar el hecho de que el forecast no es tan bueno. Si volvemos a esos proveedores, creo que la industria colectivamente ha fracasado en lograr un grado satisfactorio de automatización durante las últimas cuatro décadas, y el meollo del problema fue la perspectiva empaquetada, en la que se esperaba que las empresas simplemente integraran un módulo y ya estuviera. Esto no funciona. Los supply chains son demasiado variados, versátiles y cambiantes para que un enfoque tan mecánico sea exitoso.
Pregunta: Con la perspectiva presentada, ¿cómo abordas el problema de conciliar los diferentes forecasts de la empresa, como ventas, inventario y otros?
Mi pregunta es, ¿por qué hacen forecasts en primer lugar? Los forecasts son simplemente artefactos numéricos; no importan. Tu empresa no será más rentable porque existe un better forecast. Los forecasts son exactamente lo que llamé en los capítulos anteriores de esta serie de conferencias, un artefacto numérico. Es una abstracción que puede o no resultar útil para derivar ciertas clases de decisiones. Resulta que, dependiendo de la decisión que consideres, el tipo de forecast que necesitas puede ser muy diferente.
Desafío la idea de que puedas tener un forecast en la parte superior y luego orquestar todo el supply chain basado en esos forecasts. Estoy totalmente en desacuerdo con este enfoque, ya que no ha sido mi experiencia, y creo que no funciona tan bien. He visto un montón de empresas en las que existe un proceso de planificación sénior que produce forecasts en el área de ventas, lo cual es un ejercicio masivo de subestimación intencionada. Los vendedores a menudo infravaloran enormemente sus proyecciones porque, de esa manera, si superan esos números, pueden superar las expectativas más fácilmente más adelante. Las personas en las fábricas o en los warehouses ven estos números acercándose y pueden pensar que no pueden ser correctos, por lo que descartan el número y hacen algo completamente distinto. En mi opinión, los ejercicios de forecast llevados a cabo por la gran mayoría de las empresas son esfuerzos burocráticos sin sentido. No aportan valor añadido.
Desde una perspectiva de Supply Chain Quantitativa, es esencial centrarse en las decisiones que importan, en lugar de en los forecasts, que pueden ser solo tecnicismos. Algunas clases de decisiones pueden ni siquiera requerir que se haga un forecast, o si lo requieren, podrían necesitar un tipo de forecast muy diferente al que las empresas están considerando actualmente. Cuando hablamos de forecast, la mayoría de la gente se refiere a forecasts de series de tiempo. Sin embargo, si vuelves al tercer capítulo de esta serie de conferencias, que está dedicado a las personas de supply chain y a situaciones del mundo real, verás que los forecasts de series de tiempo a menudo no son la respuesta. La misma forma del forecast resulta inadecuada para captar los patrones que queremos identificar en el negocio.
Para concluir, sugeriría ni siquiera intentar conciliar esos forecasts. En su lugar, ignóralos y céntrate en las decisiones mismas. Observa lo que se necesita para diseñar recetas que generen buenas decisiones, y lo más probable es que todos esos forecasts puedan ser completamente ignorados.
En respuesta al comentario sobre comparar los aspectos financieros con los resultados de KPI en porcentaje, es cierto que se pueden hacer comparaciones intentando correlacionar los niveles de servicio o los fill rates con tus métricas financieras. Sin embargo, ¿esto realmente genera un retorno de la inversión para la empresa? Tomar mejores decisiones de inventario puede generar valor, pero dedicar tiempo a correlacionar KPIs no lo hace. Muchas empresas están adictas a estos KPIs expresados como porcentajes, pero a menudo son distracciones burocráticas sin sentido.
Los proveedores de software empresarial aman estos indicadores porque pueden venderlos a las empresas clientes, lo que lleva a que muchos proveedores impulsen la creación de más indicadores. En realidad, para una clase de decisiones de supply chain, tener diez números que valga la pena revisar a diario ya es bastante. Generalmente, es difícil incluso identificar diez números que merezcan ser consultados diariamente por un humano. A menudo, son incluso menos, y eso está bien. Las clases de problemas en los supply chains tienden a ser muy específicas de la empresa y del supply chain de interés, pero no son increíblemente complicadas. No estoy diciendo que las situaciones de supply chain requieran miles de impulsores económicos. Más bien, estoy diciendo que los supply chains varían mucho, y debes asegurarte de resolver el problema correcto que se ajuste a las sutilezas del supply chain en cuestión. Para un supply chain de interés, puede que tengas tres o cuatro impulsores básicos, como el costo del stock, el margen bruto y otros factores que se encuentran prácticamente en todas partes. Luego podrías tener cuatro o cinco indicadores, nuevamente métricas financieras, que sean muy específicos para un negocio de interés. En total, seguimos estando por debajo de diez números.
En respuesta a la pregunta sobre equilibrar la compensación entre los KPIs financieros y los KPIs de supply chain, diría que sí y no. Si crees que los KPIs financieros no son los que deberías optimizar, entonces hay un problema en la propia definición de tus KPIs financieros. En el primer capítulo de esta serie de conferencias, mencioné que, típicamente, hay dos círculos de impulsores a considerar al establecer una métrica financiera. El primer círculo involucra factores que las finanzas pueden leer directamente en los libros, como el margen bruto, el valor del stock y los costos de compra. El segundo círculo incluye impulsores como la buena voluntad del cliente y la penalización implícita cuando hay baja calidad de servicio. Todo esto necesita estar integrado.
La perspectiva financiera no se trata de tener KPIs en los que exista una compensación. Se trata de consolidar todo en una sola puntuación en dólares o euros para tu desempeño y toma de decisiones. No se trata de conciliar los KPIs de supply chain con los KPIs financieros. Más bien, se trata de establecer una gobernanza en la empresa para que las personas puedan ponerse de acuerdo sobre el costo real del stock, el costo real de faltante de stock, y si una decisión de reordenar es la mejor opción o no.
Desde esta nueva perspectiva de poseer el producto de software que impulsa el supply chain, el trabajo del ejecutivo de supply chain es facilitar el consenso dentro de la empresa. En lugar de conducir un proceso sin sentido de S&OP en el que la gente intenta revisar los números cada mes y ponerse de acuerdo sobre cifras de ventas sin sentido, se trata de implementar un S&OP 2.0 liderado por el director de supply chain. Contrario a lo que dicen los proveedores de S&OP, el CEO no tiene que ser el dueño del proceso de S&OP, ya que esto podría ser más una distracción para él. No es necesario involucrar al CEO en cada batalla.
La misión del director de supply chain es trabajar con el jefe de finanzas, el jefe de marketing y el jefe de ventas para ponerse de acuerdo sobre cómo medir el impacto financiero de factores como la calidad de servicio. Ese es su trabajo. No es necesaria una conciliación de diversas métricas, ya que ya están preunificadas gracias al trabajo realizado bajo el liderazgo del jefe del supply chain o del director de supply chain, según el título que tenga en la empresa.
Eso concluye la conferencia de hoy. Nos vemos la próxima vez durante la primera semana de noviembre.