00:00 Introducción
02:52 Contexto y descargo de responsabilidad
07:39 Racionalismo ingenuo
13:14 La historia hasta ahora
16:37 ¡Científicos, os necesitamos!
18:25 Humano + Máquina (el problema 1/4)
23:16 La configuración (el problema 2/4)
26:44 El mantenimiento (el problema 3/4)
30:02 El backlog de TI (el problema 4/4)
32:56 La misión (el trabajo del científico 1/6)
35:58 Terminología (el trabajo del científico 2/6)
37:54 Entregables (el trabajo del científico 3/6)
41:11 El alcance (el trabajo del científico 4/6)
44:59 La rutina diaria (el trabajo del científico 5/6)
46:58 Responsabilidad (el trabajo del científico 6/6)
49:25 Una posición de supply chain (HR 1/6)
51:13 Contratando a un científico (HR 2/6)
53:58 Capacitando al científico (HR 3/6)
55:43 Revisando al científico (HR 4/6)
57:24 Reteniendo al científico (HR 5/6)
59:37 De un científico al siguiente (HR 6/6)
01:01:17 Sobre TI (dinámicas corporativas 1/3)
01:03:50 Sobre Finanzas (dinámicas corporativas 2/3)
01:05:42 Sobre Liderazgo (dinámicas corporativas 3/3)
01:09:18 Planificación a la antigua (modernización 1/5)
01:11:56 Fin de S&OP (modernización 2/5)
01:13:31 BI a la antigua (modernización 3/5)
01:15:24 Salida de Data Science (modernización 4/5)
01:17:28 Un nuevo acuerdo para TI (modernización 5/5)
01:19:28 Conclusión
01:22:05 7.3 The Supply Chain Scientist - ¿Preguntas?
Descripción
En el núcleo de una iniciativa de Supply Chain Quantitativa, se encuentra el Supply Chain Scientist (SCS) que ejecuta la preparación de datos, la modelización económica y el reporte de KPI. La automatización inteligente de las decisiones de supply chain es el producto final del trabajo realizado por el SCS. El SCS asume la responsabilidad de las decisiones generadas. El SCS entrega inteligencia humana amplificada mediante la potencia de procesamiento de las máquinas.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy presentaré al supply chain scientist desde la perspectiva de la Supply Chain Quantitativa. El supply chain scientist es la persona o, posiblemente, el pequeño grupo de personas encargado de liderar la iniciativa de supply chain. Esta persona supervisa la creación y el posterior mantenimiento de las recetas numéricas que generan las decisiones de interés. Esta persona también se encarga de proporcionar todas las evidencias necesarias al resto de la empresa, demostrando que las decisiones generadas son sólidas.
El lema de la Supply Chain Quantitativa es aprovechar al máximo lo que el hardware moderno y el software moderno tienen para ofrecer a las supply chain. Sin embargo, el matiz encarnado de esta perspectiva es ingenuo. La inteligencia humana sigue siendo una piedra angular de todo el emprendimiento y, por una variedad de razones, aún no puede ser empaquetada de manera adecuada en lo que respecta a una supply chain. El objetivo de esta conferencia es entender por qué y cómo el rol del supply chain scientist se ha convertido, durante la última década, en una solución probada para aprovechar al máximo el software moderno para fines de supply chain.
Alcanzar este objetivo comienza con entender los grandes cuellos de botella que el software moderno aún enfrenta al intentar automatizar las decisiones de supply chain. Basándonos en este nuevo entendimiento, introduciremos el rol del supply chain scientist, que es, a todos los efectos, una respuesta a esos cuellos de botella. Finalmente, veremos cómo este rol reconfigura, en formas pequeñas y grandes, a la empresa en su conjunto. De hecho, el supply chain scientist no puede operar como un silo dentro de la empresa. Así como el científico debe cooperar con el resto de la empresa para lograr algo, el resto de la empresa también debe cooperar con el científico para que esto suceda.

Antes de continuar, me gustaría reiterar un descargo de responsabilidad que hice en la primera conferencia de esta serie. La presente conferencia se basa casi en su totalidad en un experimento de una década de duración, algo único, llevado a cabo en Lokad, un enterprise software que se especializa en supply chain optimization. Todas estas conferencias han sido moldeadas por el camino de Lokad, pero cuando se trata del rol del supply chain scientist, el vínculo es aún más fuerte. En gran medida, el propio recorrido de Lokad puede ser interpretado a través de las lentes de nuestro gradual descubrimiento del rol del supply chain scientist.
Este proceso aún está en curso. Por ejemplo, hace aproximadamente cinco años abandonamos la perspectiva convencional del data scientist con la introducción de programming paradigms para fines de aprendizaje y optimización. Actualmente, Lokad emplea tres docenas de supply chain scientists. Nuestros científicos más capaces, gracias a sus historiales, han adquirido la confianza para tomar decisiones a gran escala. Algunos de ellos son responsables individualmente de parámetros que exceden los quinientos millones de dólares en inventario. Esta confianza se extiende a una amplia variedad de decisiones, como órdenes de compra, órdenes de producción, órdenes de inventory allocation o fijación de precios.
Como se podrá imaginar, esta confianza tuvo que ganarse. De hecho, muy pocas empresas confiarían siquiera a sus propios empleados con tales poderes, y mucho menos a un proveedor externo como Lokad. Ganar este grado de confianza es un proceso que típicamente lleva años, independientemente de los medios tecnológicos. Sin embargo, una década después, Lokad crece más rápido que nunca en sus primeros años, y una porción considerable de este crecimiento proviene de nuestros clientes existentes, quienes están ampliando el alcance de las decisiones confiadas a Lokad.
Esto me lleva de vuelta a mi punto inicial: esta conferencia casi con seguridad viene acompañada de todo tipo de sesgos. He intentado ampliar esta perspectiva a través de experiencias similares fuera de Lokad; sin embargo, no hay mucho que contar al respecto. Según tengo entendido, existen algunas gigantes de ecommerce que logran un grado de automatización de decisiones comparable al que alcanza Lokad.
Sin embargo, estos gigantes suelen asignar dos órdenes de magnitud más de recursos de lo que las empresas grandes regulares pueden costear, con plantillas de ingeniería que alcanzan los cientos. La viabilidad de estos enfoques me resulta poco clara, ya que pueden funcionar únicamente en empresas sumamente rentables. De lo contrario, los asombrosos costos de nómina podrían superar muy bien los beneficios que aporta una mejor ejecución de supply chain.
Además, atraer talento en ingeniería a tal escala se convierte en un desafío en sí mismo. Contratar a un ingeniero de software talentoso ya es suficientemente difícil; contratar a 100 de ellos requiere una marca empleadora bastante notable. Afortunadamente, la perspectiva presentada hoy es mucho más austera. Muchas iniciativas de supply chain llevadas a cabo por Lokad se realizan con un único supply chain scientist, con un segundo actuando como sustituto. Más allá de los ahorros en nómina, nuestra experiencia indica que existen beneficios sustanciales para la supply chain asociados con una plantilla más reducida.

La perspectiva dominante de supply chain adopta el enfoque de las matemáticas aplicadas. Los métodos y algoritmos se presentan de manera que se elimina por completo al operador humano de la ecuación. Por ejemplo, la fórmula de safety stock y la fórmula de economic order quantity se presentan como mera cuestión de matemáticas aplicadas. La identidad de la persona que utiliza estas fórmulas, sus habilidades o su trayectoria, por ejemplo, no solo es irrelevante, sino que ni siquiera forma parte de la presentación.
Más en general, este enfoque es ampliamente adoptado en los libros de texto de supply chain y, en consecuencia, en el software de supply chain. Sin duda, resulta más objetivo eliminar el componente humano de la ecuación. Al fin y al cabo, la validez de un teorema no depende de la persona que enuncia la demostración, y de igual manera, el rendimiento de un algoritmo no depende de la persona que termina de presionar la última tecla en su implementación. Este enfoque tiene como objetivo alcanzar una forma superior de racionalidad.
Sin embargo, sostengo que este enfoque es ingenuo y representa, una vez más, un ejemplo de racionalismo ingenuo. Mi propuesta es sutil pero importante: no estoy argumentando que el resultado de una receta numérica dependa de la persona que finalmente la ejecuta, ni que el carácter de un matemático tenga algo que ver con la validez de sus teoremas. En cambio, mi propuesta es que la postura intelectual asociada con esta perspectiva es inapropiada para abordar las supply chain.
Una receta de supply chain en el mundo real es una pieza compleja de artesanía, y el autor de la receta no es ni de lejos tan neutral o irrelevante como podría parecer. Ilustremos este punto considerando dos recetas numéricas idénticas que solo difieren en la denominación de sus variables. A nivel numérico, ambas recetas entregan salidas idénticas. Sin embargo, la primera receta tiene nombres de variables bien elegidos y significativos, mientras que la segunda receta tiene nombres crípticos e inconsistentes. En producción, la segunda receta (la que tiene nombres de variables crípticos e inconsistentes) es un desastre esperando a suceder. Cada evolución o corrección de errores aplicada a la segunda receta costará órdenes de magnitud más esfuerzo en comparación con la misma tarea realizada en la primera receta. De hecho, los problemas de nomenclatura de variables son tan frecuentes y graves que muchos libros de texto de ingeniería de software dedican un capítulo entero a esta única cuestión.
Ni las matemáticas, ni la algoritmia, ni la estadística dicen nada sobre la adecuación de los nombres de las variables. La adecuación de esos nombres reside, obviamente, en el ojo del observador. Aunque tenemos dos recetas numéricas idénticas, una se considera muy superior a la otra por razones aparentemente subjetivas. La proposición que defiendo aquí es que también hay racionalidad en esas preocupaciones subjetivas. Estas preocupaciones no deben ser descartadas de plano por depender de un sujeto o persona. Al contrario, la experiencia de Lokad indica que, dado el mismo conjunto de herramientas de software, instrumentos matemáticos y biblioteca de algoritmos, ciertos supply chain scientists logran resultados superiores. De hecho, la identidad del científico a cargo es uno de los mejores predictores que tenemos para el éxito de la iniciativa.
Suponiendo que el talento innato no puede explicar por completo las discrepancias en el éxito de supply chain, debemos abrazar los elementos que contribuyen a iniciativas exitosas, sean objetivas o subjetivas. Por eso, en Lokad, hemos dedicado mucho esfuerzo durante las últimas décadas a perfeccionar nuestro enfoque del rol del supply chain scientist, que es precisamente el tema de esta conferencia. Los matices asociados con la posición de un supply chain scientist no deben ser subestimados. La magnitud de las mejoras aportadas por estos elementos subjetivos es comparable a nuestros logros tecnológicos más notables.
Esta serie de conferencias está destinada como material de formación para los supply chain scientists de Lokad. Sin embargo, también espero que estas conferencias puedan ser de interés para un público más amplio de profesionales de supply chain o incluso estudiantes de supply chain. Es mejor ver estas conferencias en secuencia para una comprensión completa de con qué se enfrentan los supply chain scientists.
En el primer capítulo, hemos visto por qué las supply chain deben volverse programáticas y por qué es altamente deseable poder poner una receta numérica en producción. La complejidad cada vez mayor de las supply chain hace que la automatización sea más urgente que nunca. Además, existe un imperativo financiero para hacer que las prácticas de supply chain sean capitalistas.
El segundo capítulo está dedicado a las metodologías. Las supply chain son sistemas competitivos, y esta combinación derrota las metodologías ingenuas. El rol de los científicos puede verse como un antídoto a la metodología ingenua de las matemáticas aplicadas.
El tercer capítulo repasa los problemas que enfrenta el personal de supply chain. Este capítulo intenta caracterizar las clases de desafíos en la toma de decisiones que deben abordarse. Muestra que perspectivas simplistas como escoger la cantidad de stock adecuada para cada SKU no se ajustan a situaciones del mundo real; invariablemente hay profundidad en la forma en que se toman las decisiones.
El cuarto capítulo repasa los elementos necesarios para comprender una práctica moderna de supply chain, donde los elementos de software son omnipresentes. Estos elementos son fundamentales para entender el contexto más amplio en el que opera la supply chain digital.
Los capítulos 5 y 6 están dedicados al modelado predictivo y la toma de decisiones, respectivamente. Estos capítulos abarcan las partes “inteligentes” de la receta numérica, contando con machine learning y optimización matemática. Cabe destacar que estos capítulos recopilan técnicas que se ha demostrado funcionan bien en manos de supply chain scientists.
Finalmente, el séptimo y presente capítulo está dedicado a la ejecución de una iniciativa de Supply Chain Quantitativa. Hemos visto lo que se requiere para iniciar una iniciativa mientras se establecen las bases adecuadas. Hemos visto cómo cruzar la meta y poner la receta numérica en producción.

Hoy, veremos qué tipo de persona se necesita para hacer que todo esto suceda.
El rol del científico tiene como objetivo resolver problemas encontrados en la literatura académica. Revisaremos el trabajo del Supply Chain Scientist, incluyendo su misión, alcance, rutina diaria y puntos de interés. Esta descripción de puesto refleja la práctica actual en Lokad.
Una nueva posición dentro de la empresa genera una serie de inquietudes, por lo que se necesita contratar, capacitar, evaluar y retener a los científicos. Abordaremos estas inquietudes desde una perspectiva de recursos humanos. Se espera que el científico colabore con otros departamentos dentro de la empresa, más allá de su departamento de supply chain. Veremos qué tipo de interacciones se esperan entre los científicos y TI, finanzas e incluso la dirección de la empresa.
El científico también representa una oportunidad para que la empresa modernice su personal y sus operaciones. Esta modernización es la parte más difícil del camino, ya que es mucho más desafiante eliminar un puesto que ha dejado de ser relevante que introducir uno nuevo.
El desafío que nos hemos propuesto en esta serie de conferencias es la mejora sistemática de los supply chain mediante métodos cuantitativos. La idea general de este enfoque es aprovechar al máximo lo que la computación moderna y el software tienen para ofrecer a los supply chain. Sin embargo, necesitamos aclarar qué sigue perteneciendo al ámbito de la inteligencia humana y qué puede automatizarse con éxito.
La línea de demarcación entre la inteligencia humana y la automatización sigue dependiendo en gran medida de la tecnología. Se espera que la tecnología superior mecanice un espectro más amplio de decisiones y entregue mejores resultados. Desde la perspectiva del supply chain, esto significa tomar decisiones más diversas, como decisiones de precios además de las decisiones de reabastecimiento de existencias, y producir mejores decisiones que mejoren aún más la rentabilidad de la empresa.
El rol del científico es la personificación de esta frontera entre la inteligencia humana y la automatización. Mientras los anuncios rutinarios sobre inteligencia artificial pueden dar la impresión de que la inteligencia humana está a punto de ser automatizada, mi comprensión del estado del arte indica que la inteligencia artificial general sigue siendo lejana. De hecho, aún se necesitan en gran medida los conocimientos humanos cuando se trata del diseño de métodos cuantitativos de relevancia para el supply chain. Establecer siquiera una estrategia básica de supply chain sigue estando, en gran medida, fuera del ámbito de lo que el software puede ofrecer.
Más en general, aún no contamos con tecnologías capaces de abordar problemas mal planteados o problemas no identificados, que son comunes en el supply chain. Sin embargo, una vez que se ha aislado un problema estrecho y bien definido, es concebible que un proceso automatizado aprenda su resolución e incluso automatice dicha resolución con poca o ninguna supervisión humana.
Esta perspectiva no es novedosa. Por ejemplo, los filtros anti-spam se han adoptado ampliamente. Esos filtros realizan una tarea desafiante: separar lo relevante de lo irrelevante. Sin embargo, el diseño de la próxima generación de filtros sigue siendo, en gran medida, responsabilidad de los humanos, incluso si se pueden usar datos más recientes para actualizar esos filtros. De hecho, los spammers que quieren eludir los filtros anti-spam siguen inventando nuevos métodos que vencen las simples actualizaciones basadas en datos de dichos filtros.
Así, aunque aún se necesitan conocimientos humanos para diseñar la automatización, no está claro por qué un proveedor de software como Lokad, por ejemplo, no podría diseñar un gran motor de supply chain que aborde todos estos desafíos. Ciertamente, la economía del software está muy a favor de diseñar dicho gran motor de supply chain. Incluso si la inversión inicial es elevada, puesto que el software puede replicarse a un costo insignificante, el proveedor obtendrá una fortuna en tarifas de licencia al revender este gran motor a un gran número de empresas.
Lokad, allá por 2008, sí emprendió el camino de crear un gran motor que podría haberse implementado como un producto de software empaquetado. Más precisamente, en ese momento Lokad se concentraba en un gran motor de forecast en lugar de un gran motor de supply chain. Sin embargo, a pesar de estas ambiciones comparativamente más modestas, ya que el forecast es solo una pequeña parte del desafío global del supply chain, Lokad fracasó en la creación de dicho gran motor de forecast. La perspectiva de Supply Chain Quantitativa presentada en esta serie de conferencias surgió de las cenizas de esta ambición del gran motor.
En lo que respecta al supply chain, resultó que hay tres grandes cuellos de botella que deben abordarse. Veremos por qué este gran motor estaba condenado desde el primer día y por qué, muy probablemente, aún estamos a décadas de lograr tal hazaña de ingeniería.
El paisaje aplicativo del supply chain típico es una jungla que ha crecido de manera desordenada durante las últimas dos o tres décadas. Este paisaje no es un jardín formal francés con líneas geométricas ordenadas y setos bien recortados; es una jungla, vibrante pero también llena de espinas y fauna hostil. Más seriamente, los supply chain son el producto de su historia digital. Podría haber múltiples ERPs semirredundantes, personalizaciones caseras a medio terminar, integraciones por lotes –especialmente con sistemas provenientes de empresas adquiridas– y plataformas de software superpuestas que compiten por las mismas áreas funcionales.
La idea de que se pueda simplemente conectar algún gran motor es ilusoria, considerando el estado actual de las tecnologías de software. Unir todos los sistemas que operan el supply chain es una tarea sustancial que depende enteramente de los esfuerzos de ingeniería humana.
El análisis de los gastos colectivos indica que la preparación y manejo de datos representa al menos las tres cuartas partes del esfuerzo técnico global asociado a una iniciativa de supply chain. En contraste, diseñar los aspectos inteligentes de la receta numérica, tales como el forecast y la optimización, representa no más de unos pocos por ciento del esfuerzo total. Así, la disponibilidad de un gran motor empaquetado es, en gran medida, insignificante en términos de costo o retrasos. Requeriría tener incorporada inteligencia a nivel humano para que este motor se integrara automáticamente en el, a menudo, desordenado paisaje de TI que se encuentra comúnmente en los supply chain.
Además, cualquier gran motor hace que esta tarea sea aún más desafiante debido a su existencia. En lugar de lidiar con un sistema complejo, el paisaje aplicativo, ahora tenemos dos sistemas complejos: el paisaje aplicativo y el gran motor. La complejidad de integrar estos dos sistemas no es la suma de sus respectivas complejidades, sino el producto de dichas complejidades.
El impacto de esta complejidad en el costo de ingeniería es altamente no lineal, un punto que ya se mencionó en el primer capítulo de esta serie de conferencias. El primer gran cuello de botella para la optimización del supply chain es la configuración de la receta numérica, la cual requiere un esfuerzo de ingeniería dedicado. Este cuello de botella elimina en gran medida los beneficios que, en teoría, podrían asociarse con cualquier tipo de gran motor de supply chain empaquetado.

Aunque la configuración requiere un esfuerzo de ingeniería sustancial, podría tratarse de una inversión única, similar a pagar una entrada. Desafortunadamente, los supply chain son entidades vivas en constante evolución. El día en que un supply chain deje de cambiar es el día en que la empresa se declare en quiebra. Los cambios son tanto internos como externos.
Internamente, el paisaje aplicativo está en constante cambio. Las empresas no pueden congelar su paisaje aplicativo, incluso si quisieran, ya que muchas actualizaciones son mandatadas por los proveedores de software empresarial. Ignorar estos mandatos eximiría a dichos proveedores de sus obligaciones contractuales, lo cual no es un resultado aceptable. Más allá de las actualizaciones puramente técnicas, cualquier supply chain de gran envergadura está destinado a incorporar y eliminar piezas de software a medida que la empresa misma cambia.
Externamente, los mercados también están cambiando de forma continua. Constantemente surgen nuevos competidores, canales de venta y proveedores potenciales, mientras que algunos desaparecen. Las regulaciones siguen cambiando. Aunque los algoritmos pueden capturar automáticamente algunos de los cambios sencillos, como el crecimiento de la demanda para una clase de productos, aún no contamos con algoritmos para enfrentar cambios en el mercado en tipo, en lugar de solo en magnitud. Los mismos problemas que la optimización del supply chain intenta abordar están en constante cambio.
Si el software encargado de optimizar el supply chain no logra enfrentar estos cambios, los empleados recurren a las hojas de cálculo. Las hojas de cálculo pueden ser rudimentarias, pero al menos los empleados pueden mantenerlas relevantes para la tarea en cuestión. De manera anecdótica, la gran mayoría de los supply chain aún operan utilizando hojas de cálculo a nivel de toma de decisiones y no a nivel transaccional. Esta es la prueba viviente de que el mantenimiento del software ha fallado.
Desde los años 80, los proveedores de software empresarial han estado ofreciendo productos para automatizar las decisiones del supply chain. La mayoría de las empresas que operan grandes supply chain ya han implementado varias de estas soluciones en las últimas décadas. Sin embargo, los empleados invariablemente vuelven a sus hojas de cálculo, demostrando que, incluso si la configuración fue considerada un éxito originalmente, algo salió mal con el mantenimiento.
El mantenimiento es el segundo gran cuello de botella en la optimización del supply chain. La receta requiere un mantenimiento activo, incluso si la ejecución puede dejarse, en gran medida, sin supervisión.

En este punto, hemos demostrado que la optimización del supply chain requiere no solo recursos iniciales de ingeniería de software, sino también recursos continuos de ingeniería de software. Como se señaló anteriormente en esta serie de conferencias, nada menos que capacidades programáticas puede acercarse de manera realista a la diversidad de problemas que enfrentan los supply chain en el mundo real. Las hojas de cálculo sí cuentan como herramientas programables, y su expresividad –en contraposición a botones y menús– es lo que las hace tan atractivas para los profesionales del supply chain.
Como en la mayoría de las empresas se deben asegurar recursos de ingeniería de software, resulta natural recurrir al departamento de TI. Lamentablemente, el supply chain no es el único departamento con este pensamiento. Cada departamento, incluyendo ventas, marketing y finanzas, termina dándose cuenta de que automatizar sus respectivos procesos de toma de decisiones requiere recursos de ingeniería de software. Además, también deben lidiar con la capa transaccional y toda su infraestructura subyacente.

Como resultado, la mayoría de las empresas que operan grandes supply chain hoy en día tienen sus departamentos de TI abrumados por años de retrasos acumulados. Por lo tanto, esperar que el departamento de TI asigne más recursos continuos al supply chain solo empeora dicho retraso. La opción de asignar más recursos al departamento de TI ya se ha explorado, y generalmente ya no es viable. Estas empresas ya enfrentan graves deseconomías de escala en lo que respecta al departamento de TI. El acumulado de retrasos en TI representa el tercer gran cuello de botella para la optimización del supply chain.
Se requieren recursos de ingeniería continuos, pero la mayor parte de esos recursos no puede provenir de TI. Se puede prever cierto apoyo por parte de TI, pero debe tratarse de una colaboración discreta.
Procedamos con una definición más precisa basada en la práctica de Lokad. La misión del Supply Chain Scientist es diseñar recetas numéricas que generen las decisiones rutinarias necesarias a diario para operar el supply chain. El trabajo del científico comienza con los extractos de bases de datos recolectados de todo el paisaje aplicativo. Se espera que el científico programe la receta que procese dichos extractos y lleve las recetas a producción. El científico asume la responsabilidad total por la calidad de las decisiones generadas por la receta. Las decisiones no son producto de algún tipo de sistema ambiental; son la expresión directa de los conocimientos del científico transmitidos a través de una receta.
Este único aspecto es una desviación crítica de lo que usualmente se entiende como el rol de un científico de datos. Sin embargo, la misión no termina ahí. Se espera que el Supply Chain Scientist sea capaz de presentar evidencia que respalde cada decisión generada por la receta. No se trata de un sistema opaco responsable de las decisiones; es la persona, el científico. El científico debería poder reunirse con el responsable del supply chain o incluso con el CEO y proporcionar una justificación convincente para cualquier decisión que haya sido generada por la receta.
Si el científico no está en una posición de poder causar potencialmente mucho daño a la empresa, entonces algo está mal. No estoy abogando por otorgar a nadie –y ciertamente no al científico– grandes poderes sin supervisión o rendición de cuentas. Simplemente estoy señalando lo obvio: si no tienes el poder de impactar negativamente a tu empresa, sin importar lo mal que desempeñes, tampoco tienes el poder de impactarla positivamente, sin importar lo bien que lo hagas.
Desafortunadamente, las grandes empresas son, por naturaleza, adversas al riesgo. Por lo tanto, es muy tentador reemplazar al científico por un analista. A diferencia del científico, que se encarga de las decisiones en sí mismas, el analista solo es responsable de arrojar algo de luz aquí y allá. El analista es, en su mayoría, inofensivo y no puede hacer mucho más que perder su propio tiempo y algunos recursos de computación. Sin embargo, ser inofensivo no es de lo que se trata el rol del Supply Chain Scientist.

Discutamos por un momento el término “supply chain scientist”. Esta terminología es, lamentablemente, imperfecta. Originalmente acuñé esta expresión como una variación de “científico de datos” hace aproximadamente una década, con la idea de marcar este rol como una variación del científico de datos pero con una fuerte especialización en supply chain. La idea sobre la especialización fue correcta, pero la de ciencia de datos no lo fue. Revisitaré este punto al final de la conferencia.
Un “supply chain engineer” podría haber sido una mejor redacción, ya que enfatiza el deseo de dominar y controlar el dominio, en lugar de una mera comprensión. Sin embargo, no se espera que los ingenieros, tal como se entienden comúnmente, estén a la vanguardia de la acción. El término correcto probablemente habría sido supply chain quant, como en los practicantes de Supply Chain Quantitativa.
En finanzas, un quant o quantitative trader es un especialista que aprovecha algoritmos y métodos cuantitativos para tomar decisiones de trading. Los quants pueden hacer que un banco sea extremadamente rentable o, por el contrario, extremadamente no rentable. La inteligencia humana se magnifica a través de las máquinas, tanto lo bueno como lo malo.
En cualquier caso, corresponderá a la comunidad en general decidir sobre la terminología adecuada: analista, scientist, ingeniero, operativo o quant. Por coherencia, seguiré usando el término scientist en el resto de esta conferencia.

El entregable principal para el scientist es una pieza de software, más precisamente, la receta numérica responsable de generar las decisiones diarias de supply chain de interés. Esta receta es una colección de todos los scripts involucrados desde las etapas iniciales de la preparación de datos hasta las etapas finales de validación corporativa de las decisiones en sí. Esta receta debe ser de calidad de producción, es decir, debe poder ejecutarse sin supervisión y las decisiones que genere deben ser confiables por defecto. Naturalmente, esta confianza tuvo que ganarse en primer lugar, y la supervisión continua debe asegurar que este nivel de confianza se mantenga justificado con el tiempo.
Entregar una receta de calidad de producción es fundamental para convertir la práctica de supply chain en un activo productivo. Este enfoque ya se ha discutido en la conferencia anterior sobre entrega orientada al producto.
Más allá de esta receta, existen numerosos entregables secundarios. Algunos de ellos también son software, aunque no contribuyan directamente a la generación de las decisiones. Esto incluye, por ejemplo, toda la instrumentación que el scientist necesita introducir para elaborar y luego mantener la receta en sí. Otros elementos están destinados a los colegas dentro de la empresa, incluyendo toda la documentación de la iniciativa en sí y de la receta.
El código fuente de la receta responde al “cómo” – ¿cómo se hace? Sin embargo, el código fuente no responde al “por qué” – ¿por qué se hace? El “por qué” debe ser documentado. Con frecuencia, la corrección de la receta depende de una sutil comprensión de la intención. La documentación entregada debe facilitar tanto como sea posible la transición suave de un scientist a otro, incluso si el anterior scientist no está disponible para apoyar el proceso.
En Lokad, nuestro procedimiento estándar consiste en producir y mantener un gran libro de la iniciativa, conocido como el Joint Procedure Manual (JPM). Este manual no es solo un manual operativo completo de la receta, sino también una colección de todas las ideas estratégicas que subyacen a las decisiones de modelado tomadas por los scientists.
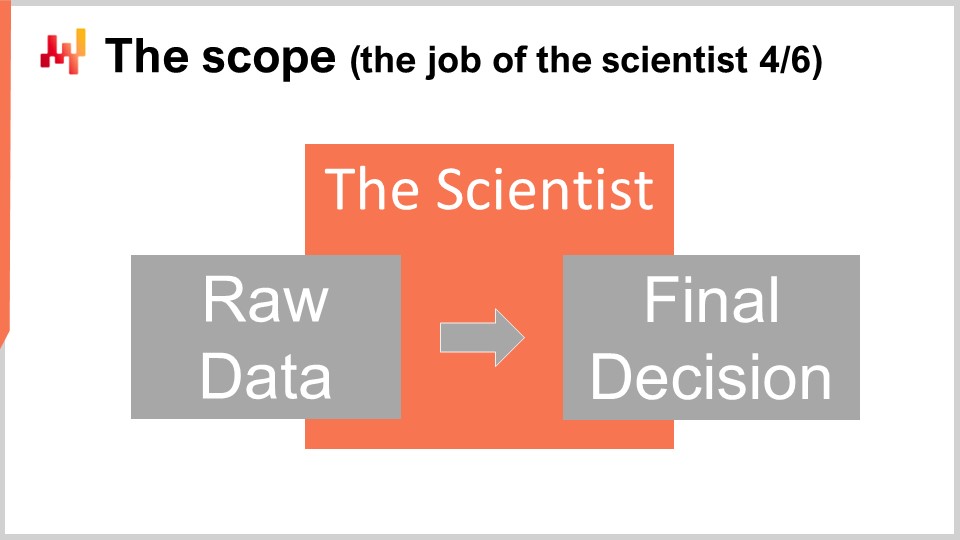
A nivel técnico, el trabajo del scientist comienza en el punto de extracción de los datos crudos y termina con la generación de las decisiones finales de supply chain. El scientist debe operar a partir de los datos crudos extraídos de los sistemas empresariales existentes. Dado que cada sistema empresarial tiende a tener su propio stack tecnológico, la extracción en sí generalmente se dedica mejor a los especialistas de IT. No es razonable esperar que el scientist se vuelva experto en media docena de dialectos SQL o media docena de tecnologías API únicamente para acceder a los datos empresariales. Por otro lado, no se debe esperar de los especialistas de IT más que extractos de datos crudos, ni transformación de datos ni preparación de datos. Los datos extraídos y puestos a disposición del scientist deben estar lo más cerca posible de los datos tal como se presentan en los sistemas empresariales.
En el otro extremo del proceso, la receta elaborada por el scientist debe generar las decisiones finales. Los elementos asociados al despliegue de las decisiones no están bajo el alcance del scientist. Son importantes, pero también en gran medida independientes de la decisión en sí. Por ejemplo, al considerar órdenes de compra, establecer las cantidades finales entra en el ámbito del scientist, pero generar el archivo PDF – el documento de orden que espera el proveedor – no. A pesar de estos límites, el alcance es algo amplio. Como resultado, es tentador pero equivocado fragmentar el alcance en una serie de subalcances. En empresas más grandes, esta tentación se vuelve muy fuerte y debe ser resistida. Fragmentar el alcance es la manera más segura de crear numerosos problemas.
En la parte aguas arriba, si alguien intenta ayudar a los scientists manipulando la entrada, este intento invariablemente termina en problemas de “garbage in, garbage out”. Los sistemas empresariales son lo suficientemente complejos; transformar los datos de antemano no hace otra cosa que añadir una capa accidental extra de complejidad. En la parte intermedia, si alguien intenta ayudar a los scientists encargándose de una pieza desafiante de la receta, como el forecast, entonces los scientists terminan enfrentándose a una caja negra en medio de su propia receta. Dicho “black box” socava los esfuerzos de “white-boxing” de los scientists. Y en la parte aguas abajo, si alguien intenta ayudar al scientist reoptimizando aún más las decisiones, este intento inevitablemente crea confusión, y las lógicas de optimización de dos capas incluso podrían trabajar en objetivos opuestos.
Esto no implica que el scientist tenga que trabajar solo. Se puede formar un equipo de scientists, pero el alcance sigue siendo el mismo. Si se forma un equipo, debe haber una propiedad colectiva de la receta. Esto implica, por ejemplo, que si se identifica un defecto en la receta, cualquier miembro del equipo debería poder intervenir y arreglarlo.

La experiencia de Lokad indica que una combinación saludable para un supply chain scientist implica dedicar el 40% de su tiempo a programar, el 30% a dialogar con el resto de la empresa, y el 30% a redactar documentos, materiales de capacitación e intercambiar con colegas supply chain practitioners o con otros supply chain scientists.
Evidentemente se necesita programar para implementar la receta en sí. Sin embargo, una vez que la receta está en producción, la mayor parte de los esfuerzos de codificación se dirigen no a la receta en sí, sino a su instrumentación. Para mejorar la receta, el scientist necesita ideas adicionales y, a su vez, esas ideas requieren una instrumentación dedicada que debe implementarse.
Dialogar con el resto de la empresa es fundamental. A diferencia de S&OP, el propósito de estas discusiones no es orientar el forecast al alza o a la baja. Se trata de asegurarse de que las decisiones de modelado incorporadas en la receta sigan reflejando fielmente tanto la estrategia de la empresa como todas sus restricciones operativas.
Finalmente, fomentar el conocimiento institucional que la empresa posee sobre la optimización de supply chain, ya sea mediante la capacitación directa de los scientists o la producción de documentos destinados a los colegas, es crucial. El desempeño de la receta es, en gran medida, un reflejo de la competencia del scientist. Tener acceso a compañeros y buscar retroalimentación es, sorprendentemente, uno de los medios más eficientes para mejorar la competencia de los scientists.

La mayor diferencia entre un supply chain scientist, tal como lo concibe Lokad, y un data scientist convencional es el compromiso personal con los resultados en el mundo real. Puede parecer algo pequeño e insignificante, pero la experiencia dice lo contrario. Hace una década, Lokad aprendió de la manera difícil que el compromiso con la entrega de una receta de calidad de producción no era algo garantizado. Por el contrario, la actitud predeterminada de las personas formadas como data scientists parece ser tratar la producción como una preocupación secundaria. El data scientist convencional espera gestionar las partes inteligentes, como el machine learning y la optimización matemática, mientras que lidiar con todas las trivialidades aleatorias que conlleva el supply chain del mundo real es, con demasiada frecuencia, percibido como algo inferior.
Sin embargo, el compromiso con una receta de calidad de producción implica lidiar con las cosas más aleatorias. Por ejemplo, en julio de 2021, muchos países europeos sufrieron inundaciones catastróficas. Un cliente de Lokad con sede en Alemania tuvo inundados la mitad de sus warehouses. El supply chain scientist a cargo de esta cuenta tuvo que reingeniar la receta casi de la noche a la mañana para aprovechar al máximo esta situación severamente degradada. La solución no fue algún tipo de gran algoritmo de machine learning, sino más bien un conjunto de heurísticas decodificadas. Por el contrario, si el supply chain scientist no es dueño de la decisión, esa persona no podrá elaborar una receta de calidad de producción. Se trata de una cuestión de psicología. Entregar una receta de calidad de producción requiere un esfuerzo intelectual inmenso, y las apuestas deben ser reales para lograr el nivel de concentración necesario por parte de un empleado.
Habiendo aclarado el trabajo de un supply chain scientist, discutamos cómo funciona desde la perspectiva de los recursos humanos. Primero, entre las preocupaciones corporativas, el scientist debe reportar al jefe de supply chain o al menos a alguien que califique como liderazgo senior de supply chain. No importa si el scientist es interno o externo, como suele ser el caso en Lokad. Lo importante es que el scientist debe estar bajo la supervisión directa de alguien que ostente el poder de un ejecutivo de supply chain.
Un error común es hacer que el scientist reporte al jefe de IT o al jefe de análisis de datos. Dado que elaborar una receta es un ejercicio de programación, el liderazgo de supply chain podría no sentirse completamente cómodo supervisando tal empresa. Sin embargo, esto es incorrecto. El scientist necesita la supervisión de alguien que pueda aprobar si las decisiones generadas son aceptables o no, o al menos que pueda hacer que esta aprobación se lleve a cabo. Colocar al scientist en cualquier lugar que no sea bajo la supervisión directa del liderazgo de supply chain es una receta para operar interminablemente con prototipos que nunca llegan a producción. En esta situación, el rol inevitablemente se relega a un analista, y las ambiciones iniciales de la iniciativa de Supply Chain Quantitativa son abandonadas.

Los mejores supply chain scientists generan retornos desproporcionados en comparación con los promedio. Esta ha sido la experiencia de Lokad y refleja el patrón identificado hace décadas en la industria del software. Las empresas de software han observado desde hace mucho que los mejores ingenieros de software tienen al menos 10 veces más productividad que los promedio, e incluso los ingenieros mediocres pueden tener productividad negativa, empeorando el software por cada hora invertida en la base de código.
En el caso de los supply chain scientists, una competencia superior no solo mejora la productividad, sino que, lo que es más importante, mejora el desempeño final de supply chain performance. Dadas las mismas herramientas de software e instrumentos matemáticos, dos scientists no logran el mismo resultado. Por lo tanto, contratar a alguien con el potencial de convertirse en uno de los mejores scientists es de suma importancia.
La experiencia de Lokad, basada en la contratación de más de 50 scientists, indica que los perfiles de ingeniería no especializados suelen ser bastante buenos. Aunque es contraintuitivo, las personas con formación formal en data science, estadística o informática, por lo general, no son las más adecuadas para los puestos de supply chain scientist. Estos individuos con demasiada frecuencia complican en exceso la receta y no prestan suficiente atención a los aspectos mundanos pero críticos del supply chain. La capacidad de prestar atención a una multitud de detalles y la habilidad de perseverar sin cesar mientras se persiguen artefactos numéricos marginales parecen ser las cualidades principales de los mejores scientists.
De manera anecdótica, en Lokad, se ha observado un buen historial con jóvenes ingenieros que han pasado algunos años como auditores. Además de la familiaridad con las finanzas corporativas, parece que los auditores talentosos desarrollan la capacidad de zambullirse en un océano de registros corporativos, lo cual se alinea con la realidad cotidiana de un supply chain scientist.

Si bien la contratación asegura que los reclutas tienen el potencial adecuado, el siguiente paso es asegurarse de que estén debidamente capacitados. La posición por defecto de Lokad es que no se espera que las personas sepan nada sobre supply chain de antemano. Conocer el supply chain es una ventaja, pero la academia sigue siendo algo deficiente en este aspecto. La mayoría de las carreras en supply chain se centran en la gestión y el liderazgo, pero para los jóvenes graduados es esencial tener un conocimiento fundamental adecuado en temas como los abordados en el segundo, tercer o cuarto capítulos de esta serie de conferencias. Lamentablemente, este no suele ser el caso, y las partes cuantitativas de estas carreras pueden ser poco impresionantes. Como resultado, los supply chain scientists deben ser capacitados por sus empleadores. Esta serie de conferencias refleja el tipo de materiales de capacitación utilizados en Lokad.

Las evaluaciones de desempeño para los supply chain scientists son importantes por una variedad de razones, como asegurar que el dinero de la empresa se gaste bien y determinar promotions. Se aplican los criterios habituales: actitud, diligencia, competencia, etc. Sin embargo, hay un aspecto contraintuitivo: los mejores scientists logran resultados que hacen que los desafíos del supply chain parezcan casi invisibles, con un drama mínimo.

Capacitar a un scientist para mantener recetas existentes mientras se conserva el nivel previo de desempeño del supply chain lleva aproximadamente seis meses, mientras que capacitar a un scientist para implementar una receta de calidad de predicción desde cero lleva alrededor de dos años. La retención del talento es crítica, especialmente dado que la contratación de supply chain scientists experimentados aún no es una opción.
En muchos países, la permanencia media de los ingenieros menores de 30 años en el software y campos adyacentes es bastante baja. Lokad logra una permanencia media más alta al enfocarse en el bienestar de los empleados. Las empresas no pueden brindar felicidad a sus empleados, pero sí pueden evitar hacerlos miserables a través de procesos absurdos. La cordura es fundamental para la retención de empleados.

No se puede esperar que un supply chain scientist competente y experimentado asuma rápidamente una receta existente, ya que la receta refleja la estrategia única de la empresa y las peculiaridades del supply chain. La transición de un supply chain a otro puede llevar alrededor de un mes en las mejores condiciones. No es razonable que una empresa de gran tamaño dependa de un único scientist; Lokad se asegura de que dos scientists dominen cualquier receta utilizada en la producción en cualquier momento. La continuidad es esencial, y una forma de lograrlo es mediante un manual creado conjuntamente con los clientes, que puede facilitar las transiciones imprevistas entre scientists.

El rol del supply chain scientist requiere un nivel inusual de cooperación con múltiples departamentos, especialmente IT. La correcta ejecución de la receta depende de la canalización de extracción de datos, que es responsabilidad de IT.
Existe una fase relativamente intensa de interacción entre IT y el scientist al inicio de la primera iniciativa de Supply Chain Quantitativa, que dura aproximadamente dos a tres meses. Posteriormente, una vez establecida la canalización de extracción de datos, la interacción se vuelve menos frecuente. Este diálogo asegura que el scientist se mantenga al tanto de la hoja de ruta de IT y de cualquier actualización o cambio en el software que pueda impactar el supply chain.
En la fase inicial de una iniciativa de Supply Chain Quantitativa, existe una interacción relativamente intensa entre IT y los scientists. Durante los primeros dos o tres meses, el scientist necesita interactuar con IT varias veces por semana. Posteriormente, una vez que se establece la canalización de extracción de datos, la interacción se vuelve mucho menos frecuente, aproximadamente una vez al mes o menos. Además de solucionar algún fallo ocasional en la canalización, este diálogo asegura que el scientist se mantenga al tanto de la hoja de ruta de IT. Cualquier actualización o sustitución del software puede requerir días o incluso semanas de trabajo para el scientist. Para evitar tiempos de inactividad, la receta debe modificarse para adaptarse a los cambios en el paisaje aplicativo.

La receta, tal como es implementada por el scientist, optimiza los dólares o euros de retorno. Cubrimos este aspecto en las primeras conferencias de esta serie. Sin embargo, no se debe esperar que el scientist decida cómo modelar los costos y las ganancias. Si bien debería proponer modelos que reflejen los impulsores económicos, en última instancia, es tarea de finanzas decidir si dichos impulsores se consideran correctos o no. Muchas prácticas del supply chain eluden el problema al centrarse en porcentajes, tales como niveles de servicio y precisiones de forecast. Sin embargo, estos porcentajes tienen casi ninguna correlación con la salud financiera de la empresa. Por ello, el scientist debe interactuar rutinariamente con finanzas y permitir que estos cuestionen las opciones de modelado y las asunciones hechas en la receta numérica.
Las elecciones en el modelado financiero son transitorias, ya que reflejan la estrategia cambiante de la empresa. Además, se espera que el scientist elabore alguna instrumentación adjunta a la receta para el departamento de finanzas, como la cantidad máxima proyectada de capital de trabajo asociada con el inventario para el próximo año. Para una empresa mediana o grande, es razonable contar con una revisión trimestral por parte de un ejecutivo de finanzas del trabajo realizado por el supply chain scientist.

Una de las mayores amenazas para la validez de la receta es traicionar accidentalmente la intención estratégica de la empresa. Demasiadas prácticas del supply chain eluden la estrategia escondiéndose detrás de porcentajes utilizados como indicadores. Inflar o deflactar el forecast a través de la planificación de ventas y operaciones (S&OP) no sustituye la clarificación de la intención estratégica. El scientist no está a cargo de la estrategia de la empresa, pero la receta será incorrecta si no la comprende. La alineación de la receta con la estrategia debe ser diseñada.
La forma más directa de evaluar si el scientist entiende la estrategia es hacer que la reexponga ante la dirección. Esto permite detectar malentendidos con mayor facilidad. En teoría, este entendimiento ya está documentado por el scientist en el manual de la iniciativa. Sin embargo, la experiencia indica que los ejecutivos rara vez tienen tiempo para revisar en detalle la documentación operativa. Una simple conversación agiliza el proceso para ambas partes.
Esta reunión no está diseñada para que el scientist explique todo sobre los modelos del supply chain o los resultados financieros. El único propósito es garantizar una comprensión adecuada por parte de la persona que sostiene la pluma digital. Incluso en una empresa grande, es razonable que el scientist se reúna con el CEO o con el ejecutivo pertinente al menos una vez al año. Los beneficios de una receta más en sintonía con la intención del liderazgo son vastos y a menudo subestimados.

Las mejoras en el supply chain forman parte de la modernización digital continua. Esto requiere cierta reorganización de la propia empresa. Aunque los cambios pueden no ser drásticos, eliminar prácticas obsoletas es una tarea difícil. Cuando se ejecuta correctamente, la productividad de un supply chain scientist es significativamente mayor que la de un planificador tradicional. No es raro que un solo scientist sea responsable de un inventario valorado en más de quinientos millones de dólares o euros.
Es posible una reducción drástica del personal del supply chain. Algunas empresas clientes de Lokad, que históricamente han estado bajo una inmensa presión competitiva, adoptaron este enfoque y sobrevivieron en parte gracias a esos ahorros. La mayoría de nuestros clientes, sin embargo, opta por una reducción más gradual del personal, ya que los planificadores pasan naturalmente a otros puestos.
Los planificadores que permanecen reorientan sus esfuerzos hacia clientes y proveedores. La retroalimentación que recogen resulta muy útil para los supply chain scientists. De hecho, el trabajo del scientist es, por naturaleza, introspectivo. Operan sobre los datos de la empresa, y es difícil notar lo que simplemente falta.
Muchos actores empresariales han abogado durante mucho tiempo por forjar vínculos más fuertes tanto con clientes como con proveedores. Sin embargo, es más fácil decirlo que hacerlo, especialmente si los esfuerzos se neutralizan de manera rutinaria debido a la lucha constante contra emergencias, la necesidad de tranquilizar a los clientes y la presión sobre los proveedores. Los supply chain scientists pueden brindar el tan necesario alivio en ambos frentes.

El S&OP (Planificación de Ventas y Operaciones) es una práctica extendida que pretende fomentar la alineación en toda la empresa mediante un forecast de demanda compartido. Sin embargo, sin importar cuáles hayan sido las ambiciones originales, los procesos de S&OP que he presenciado se caracterizaron por una interminable serie de reuniones improductivas. Salvo las implementaciones de ERP y el cumplimiento normativo, no se me ocurre ninguna práctica corporativa tan desmoralizadora como el S&OP. La Unión Soviética pudo haber desaparecido, pero el espíritu del Gosplan vive a través del S&OP.
Una crítica en profundidad del S&OP merecería una conferencia propia. Sin embargo, para ser breve, simplemente diré que un supply chain scientist es una alternativa superior al S&OP en cada dimensión que importa. A diferencia del S&OP, el supply chain scientist está basado en decisiones del mundo real. Lo único que impide que un scientist sea otro agente de una burocracia corporativa inflada no es su carácter o competencia; es tener skin in the game a través de esas decisiones del mundo real.
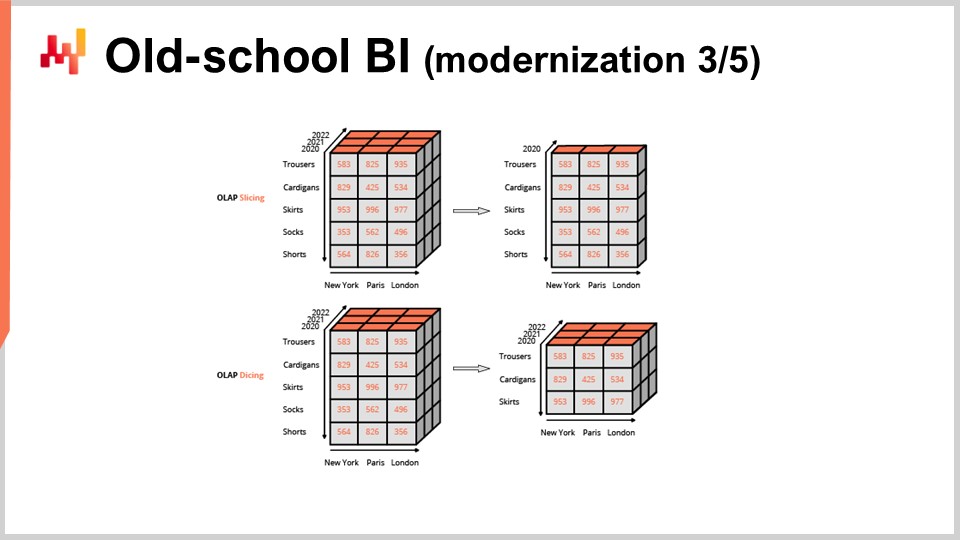
Los planificadores, gerentes de inventario y gerentes de producción son frecuentemente grandes consumidores de todo tipo de reportes empresariales. Esos reportes son usualmente producidos por productos de software empresarial comúnmente referidos como herramientas de business intelligence. La práctica típica del supply chain consiste en exportar una serie de reportes a hojas de cálculo y luego utilizar una colección de fórmulas de hojas de cálculo para combinar toda esta información y generar de forma semi-manual las decisiones de interés. Sin embargo, como hemos visto, la receta del scientist reemplaza esta combinación de business intelligence y hojas de cálculo.
Además, ni el business intelligence ni las hojas de cálculo son adecuados para apoyar la implementación de una receta. El business intelligence carece de expresividad, ya que los cálculos relevantes no pueden expresarse mediante esta clase de herramientas. Las hojas de cálculo carecen de capacidad de mantenimiento y, en ocasiones, de escalabilidad, pero sobre todo de mantenibilidad. El diseño de las hojas de cálculo es en gran medida incompatible con cualquier tipo de corrección por diseño, lo cual es muy necesario para fines del supply chain.
En la práctica, la instrumentación de una receta tal como la implementa el scientist incluye numerosos reportes empresariales. Esos reportes reemplazan a los que se generaban hasta ahora mediante el business intelligence. Esta evolución no implica necesariamente el fin del business intelligence, ya que otros departamentos aún pueden beneficiarse de esta clase de herramientas. Sin embargo, en lo que respecta al supply chain, la introducción del supply chain scientist anuncia el fin de la era del business intelligence.

Si dejamos a un lado a algunos gigantes tecnológicos que pueden permitirse asignar cientos, si no miles, de ingenieros a cada problema de software, el resultado típico de los equipos de data science en empresas comunes es desalentador. Usualmente, nada sustancial se logra por esos equipos. Sin embargo, el data science, como práctica corporativa, es solo la última iteración de una serie de modas corporativas.
En la década de 1970, la investigación operativa estaba de moda. En la década de 1980, los motores de reglas y los expertos en conocimiento eran populares. Al cambio de siglo, el data mining y los data miners eran muy solicitados. Desde la década de 2010, el data science y los data scientists han sido considerados lo próximo grande. Todas estas tendencias corporativas siguen el mismo patrón: ocurre una innovación genuina en software, la gente se entusiasma en exceso y decide integrar forzosamente esta innovación en la empresa mediante la creación de un nuevo departamento dedicado. Esto se debe a que siempre es mucho más fácil añadir divisiones a una organización que modificar o eliminar las existentes.
Sin embargo, el data science como práctica corporativa fracasa porque no está firmemente arraigado en la acción. Esto marca la diferencia entre un supply chain scientist, que se compromete desde el primer día a ser responsable de generar decisiones del mundo real, y el departamento de IT.

Si podemos dejar de lado los egos y feudos, el supply chain scientist representa una propuesta mucho mejor que el antiguo status quo. El departamento de IT típico está enterrado bajo años de acumulación, y buscar más recursos no es una propuesta razonable, ya que resulta contraproducente al inflar las expectativas de otros departamentos y aumentar aún más la acumulación de tareas pendientes.
Por el contrario, el supply chain scientist allana el camino para una disminución de las expectativas. El scientist solo espera que se dispongan de extractos de datos crudos, y sus batallas de procesamiento son su responsabilidad. No espera nada del departamento de IT en este sentido. El supply chain scientist no debe ser visto como una versión corporativizada del shadow IT. Se trata de hacer que el departamento del supply chain sea responsable y rinda cuentas de su propia competencia central. El departamento de IT gestiona la infraestructura de bajo nivel y la capa transaccional, mientras que la capa de decisiones del supply chain debería quedar completamente a cargo del departamento del supply chain.
El departamento de IT debe ser un facilitador, no un tomador de decisiones, salvo en las partes verdaderamente centradas en IT del negocio. Muchos departamentos de IT son conscientes de su acumulación y adoptan este nuevo enfoque. Sin embargo, si el instinto de proteger lo que se percibe como su territorio es demasiado fuerte, pueden negarse a ceder la capa de decisiones del supply chain. Estas situaciones son dolorosas y solo pueden resolverse mediante la intervención directa del CEO.

A lo lejos, nuestra conclusión podría ser que el rol del supply chain scientist puede verse como una variación más especializada del data scientist. Históricamente, así fue como Lokad intentó resolver los problemas asociados con la práctica corporativa del data science. Sin embargo, nos dimos cuenta hace una década de que esto era insuficiente. Nos tomó años descubrir gradualmente todos los elementos que se han presentado hoy.
El supply chain scientist no es un complemento al supply chain de la empresa; es una clarificación sobre la propiedad de las decisiones cotidianas y mundanas del supply chain. Para aprovechar al máximo este enfoque, el supply chain, o al menos su componente de planificación, debe ser remodelado. Departamentos adyacentes como finanzas y operaciones también deben adaptarse a ciertos cambios, aunque en un grado mucho menor.
Fomentar un equipo de supply chain scientists es un compromiso considerable para una empresa, pero cuando se hace correctamente, la productividad es alta. En la práctica, cada scientist termina reemplazando de 10 a 100 planificadores, forecasters o gerentes de inventario, generando enormes ahorros en nómina, incluso si los scientists perciben salarios más altos. El supply chain scientist ilustra un nuevo enfoque con IT, reposicionando a IT como un facilitador en lugar de un proveedor de soluciones, eliminando muchos, si no la mayoría, de los cuellos de botella relacionados con IT.
Más en general, este enfoque puede replicarse en todos los demás departamentos no relacionados con IT de la empresa, como marketing, ventas y finanzas. Cada departamento tiene sus propias decisiones diarias y mundanas que abordar, y que también se beneficiarían ampliamente del mismo tipo de automatización. Sin embargo, al igual que el supply chain scientist es, ante todo, un experto en supply chain
Sin embargo, al igual que un supply chain scientist es, ante todo, un experto en supply chain, un marketing scientist o marketing quant debería ser un experto en marketing. La perspectiva del scientist allana el camino para aprovechar al máximo la combinación de la inteligencia de máquina y humana en este temprano siglo XXI.
La próxima conferencia será el 10 de mayo, un miércoles, a la misma hora del día, 3 pm hora de París. La conferencia de hoy fue no técnica, pero la siguiente será en gran medida técnica. Presentaré técnicas para la optimización de precios. Los libros de texto convencionales de supply chain usualmente no incluyen la fijación de precios como un elemento de supply chain; sin embargo, la fijación de precios contribuye sustancialmente al equilibrio entre la oferta y la demanda. Además, los precios tienden a ser altamente específicos del dominio, ya que es demasiado fácil abordar el desafío de manera incorrecta cuando se piensa en términos abstractos. Así, limitaremos nuestras investigaciones al mercado posventa automotriz. Esta será la ocasión para revisar los elementos presentados en Stuttgart, una de las supply chain personas que introduje en el tercer capítulo de esta serie de conferencias.

Y ahora, procederé con las preguntas.
Question: A la academia le tomó casi una década descubrir que el campo de data science había emergido y que debían enseñarlo en la escuela secundaria. ¿Ya ves que lo mismo sucede en los círculos académicos de supply chain al adoptar la perspectiva de supply chain sciences?
Primero, no tengo conocimiento de que se enseñe data science en las escuelas secundarias en Francia. Apenas se enseña algo relacionado con la computación en la escuela secundaria, y mucho menos data science. No estoy muy seguro de dónde encontrarían a los profesores o docentes para hacerlo. Pero puedo entender que quieras que los estudiantes de secundaria adquieran cierta competencia digital. Creo que familiarizarse con la programación es algo muy bueno, y se puede hacer incluso desde temprana edad, según mi propia experiencia, a partir de los siete u ocho años, dependiendo de la madurez del niño. Se puede hacer incluso en la escuela primaria, pero hablamos de conceptos básicos de programación: variables, listas de instrucciones y esas cosas. Creo que data science excede en gran medida lo que se debería enseñar en la escuela secundaria, a menos que se tenga un prodigio o algo similar. Para mí, es claramente algo destinado a personas a nivel universitario, ya sean de pregrado o posgrado.
De hecho, a la academia le tomó una década impulsar data science, pero detengámonos un momento. Describí data science como una práctica corporativa, que es prácticamente la versión especular de lo que hace la academia al enseñar data science. Así que, debemos pensar en el problema, y aquí creo que uno de los problemas es que es increíblemente difícil enseñar algo que no practicas. Al menos a nivel universitario, si no antes. Lo que veo es que ya tenemos un problema con data science, ya que las personas que enseñan data science no son las que realmente hacen data science en lugares importantes, como Microsoft, Google, Facebook, OpenAI y demás.
Para supply chain, tenemos un problema similar, y tener acceso a personas con la experiencia adecuada es simplemente increíblemente difícil. Espero, y esto es una autopromoción sin vergüenza de mi parte, que Lokad comience, en las próximas semanas, a intentar proporcionar algunos materiales destinados a titulaciones de supply chain. Comenzaremos a impulsar algunos materiales que están empaquetados de una manera que debería hacerlos apropiados para profesores en la academia, para que ellos puedan transmitir esos conocimientos. Obviamente, tendrán que usar su propio juicio para evaluar si esos materiales que Lokad está impulsando realmente valen la pena ser enseñados a los estudiantes.
Question: ¿No se utiliza el lenguaje específico de dominio de Lokad en otros lugares? Más allá de Lokad, ¿cómo motivas a los posibles nuevos contratados a aprender algo que probablemente nunca vuelvan a usar en su próximo trabajo?
Ese es exactamente el punto que estaba señalando sobre el problema que tenía con los data scientists. Las personas literalmente se postulaban, diciendo: “Quiero hacer TensorFlow, soy un tipo de TensorFlow” o “Soy un tipo de PyTorch.” Esta no es la actitud correcta. Si confundes tu identidad con un conjunto de herramientas técnicas, te estás perdiendo el punto. El desafío es entender los problemas de supply chain y cómo abordarlos cuantitativamente para generar decisiones de producción de calidad.
En esta conferencia, mencioné que le toma seis meses a un Supply Chain Scientist volverse competente para mantener una receta y dos años para diseñar una receta desde cero. ¿Cuánto tiempo se necesita para ser completamente competente con Envision, nuestro lenguaje de programación propietario? Según nuestra experiencia, se necesitan tres semanas. Envision es un pequeño detalle en comparación con el desafío global, pero es importante. Si tus herramientas son deficientes, enfrentarás problemas accidentales inmensos. Sin embargo, seamos realistas: es una pequeña parte del rompecabezas en general.
Las personas que pasan tiempo en Lokad aprenden muchísimo sobre los problemas de supply chain. El lenguaje de programación podría ser reescrito en otros lenguajes, pero podría requerir más líneas de código. Lo que las personas, especialmente los jóvenes ingenieros, a menudo no se dan cuenta es cuán transitorias son muchas tecnologías. No duran mucho, generalmente solo un par de años antes de ser reemplazadas por otra cosa.
Hemos visto una serie interminable de tecnologías que van y vienen. Si un candidato dice, “Realmente me importan los detalles técnicos,” probablemente no sea un buen candidato. Ese era mi problema con los data scientists: querían lo lujoso, lo más puntero. Los supply chain son sistemas inmensamente complejos, y cuando cometes un error, puede costar millones. Necesitas herramientas de calidad de producción, no el paquete más nuevo y no probado.
Los mejores candidatos tienen un interés genuino en convertirse en profesionales de supply chain. La parte importante es el supply chain, no los detalles del lenguaje de programación.
Question: Estoy cursando una licenciatura en supply chain, transporte y gestión logística. ¿Cómo puedo convertirme en un Supply Chain Scientist?
Primero, te animo a postularte en Lokad. Tenemos posiciones abiertas todo el tiempo. Pero, más en serio, la clave para convertirse en un Supply Chain Scientist es tener una oportunidad en una empresa que esté dispuesta a automatizar sus decisiones de supply chain. El aspecto más importante es tener la propiedad de las decisiones. Si encuentras una empresa dispuesta a intentarlo, eso te ayudará enormemente a convertirte en un scientist.
A medida que enfrentes los desafíos de la toma de decisiones de calidad de producción, te darás cuenta de la importancia de los temas que estoy discutiendo en esta serie de conferencias. Cuando estés lidiando con predicciones que moverán inventarios, órdenes y movimientos de stock por millones de dólares, entenderás la inmensa responsabilidad y la necesidad de la corrección por diseño. Estoy bastante seguro de que otras empresas crecerán y adquirirán muchas más oportunidades. Pero, incluso en mis sueños más salvajes, no creo que pueda esperar que cada empresa en la Tierra esté aprovechando Lokad. Habrá muchas empresas que siempre decidirán hacerlo a su manera, y estarán perfectamente bien.
Question: Dado que el 40% de la rutina diaria de un Supply Chain Scientist consiste en programar, ¿qué lenguaje de programación sugerirías que aprendan primero los estudiantes de pregrado, especialmente aquellos que estudian administración?
Yo diría que lo que sea fácilmente accesible. Python es un buen comienzo. Mi sugerencia es probar varios lenguajes de programación. Lo que se espera de un ingeniero de supply chain es prácticamente lo opuesto a lo que se espera de los ingenieros de software. Para los ingenieros de software, mi consejo por defecto es elegir un lenguaje y profundizar al máximo, entendiendo realmente todos los matices. Pero para las personas que en última instancia son generalistas, diría que hagan lo contrario. Prueben un poco de SQL, un poco de Python, un poco de R. Presten atención a la sintaxis de Excel, y quizá echen un vistazo a lenguajes como Rust, solo para ver cómo se ven. Así que, elijan lo que tengan a la mano. Por cierto, Lokad tiene planes para hacer que Envision esté fácilmente accesible para los estudiantes de forma gratuita, así que estén atentos.
Question: ¿Ves que las bases de datos de grafos tengan un impacto significativo en los forecast de supply chain?
Absolutamente no. Las bases de datos de grafos han existido por más de dos décadas, y aunque son interesantes, no son tan poderosas como las bases de datos relacionales como PostgreSQL y MariaDB. Para los forecast de supply chain, tener operadores similares a los de grafos no es lo que se necesita. En forecasting competitions, ninguno de los 100 mejores participantes ha estado usando una base de datos de grafos. Sin embargo, hay cosas que se pueden hacer con deep learning aplicado a grafos, lo cual ilustraré en mi próxima conferencia sobre precios.
Respecto a la cuestión de si los Supply Chain Scientists deberían estar involucrados en la definición de objetivos en proyectos de customer data science, creo que existe un problema con la premisa subyacente de enfocarse en data science antes de entender el problema que estamos tratando de resolver. Sin embargo, reformulando la pregunta, ¿deberían los Supply Chain Scientists estar involucrados en la definición de objetivos de la optimización de supply chain? Sí, absolutamente. Hacer que el scientist descubra lo que realmente queremos es difícil y requiere una estrecha colaboración con las partes interesadas para asegurar que se persigan los objetivos correctos. Entonces, ¿deben los científicos participar en ello? Absolutamente, es fundamental.
Sin embargo, aclaremos que esto no es una iniciativa de data science; es una iniciativa de supply chain que resulta poder usar los datos como un ingrediente adecuado. Realmente necesitamos empezar desde los problemas y ambiciones de supply chain y, luego, como queremos aprovechar al máximo el software moderno, necesitamos a estos científicos. Ellos ayudarán a pulir aún más tu entendimiento del problema, ya que la línea de demarcación entre lo que es factible en el software y lo que sigue siendo estrictamente dominio de la inteligencia humana es algo difusa. Necesitas a los científicos para navegar por esa línea de demarcación.
Espero verlos dentro de dos meses, el 10 de mayo, en la próxima conferencia, donde estaremos discutiendo precios. Nos vemos entonces.